REALIZZAZIONE DI UN MOTORE DI RICERCA PER IMMAGINI SU SISTEMA OPERATIVO ANDROID BASATO SUL RELEVANCE FEEDBACK
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Università degli studi di Cagliari Dipartimento di Ingegneria Elettrica ed Elettronica Corso di Laurea in Ingegneria Informatica TESI DI LAUREA REALIZZAZIONE DI UN MOTORE DI RICERCA PER IMMAGINI SU SISTEMA OPERATIVO ANDROID BASATO SUL RELEVANCE FEEDBACK FABIO PERRA Relatori: Prof. Giorgio Giacinto Dott. Luca Piras Dott. Lorenzo Putzu Anno accademico 2017-2018
SOMMARIO CAPITOLO 1 ........................................................................................................................................................ 3 INTRODUZIONE.............................................................................................................................................. 3 CAPITOLO 2 ........................................................................................................................................................ 5 CONTENT BASED IMAGE RETRIEVAL ............................................................................................................. 5 2.1 – INTRODUZIONE ................................................................................................................................. 6 2.2 – COSTRUZIONE DI UN MOTORE DI RICERCA BASATO SU CBIR .......................................................... 6 CAPITOLO 3 ...................................................................................................................................................... 12 IL RELEVANCE FEEDBACK ............................................................................................................................. 12 3.1 – INTRODUZIONE ............................................................................................................................... 13 3.2 – STIMA DELLA RILEVANZA TRAMITE NEAREST NEIGHBOR .............................................................. 13 3.3 – CALCOLO DEL RELEVANCE SCORE................................................................................................... 14 CAPITOLO 4 ...................................................................................................................................................... 16 IL SISTEMA OPERATIVO ANDROID ............................................................................................................... 16 4.1 – INTRODUZIONE ............................................................................................................................... 17 4.2 – ARCHITETTURA ............................................................................................................................... 17 4.3 – COMPONENTI DI UNA APP ............................................................................................................. 19 CAPITOLO 5 ...................................................................................................................................................... 23 LA LIBRERIA OPEN CV .................................................................................................................................. 23 5.1 – INTRODUZIONE ............................................................................................................................... 24 5.2 – IMPLEMENTAZIONE ........................................................................................................................ 24 5.3 – OPENCV MANAGER ........................................................................................................................ 24 5.4 – FUNZIONI E CLASSI UTILIZZATE....................................................................................................... 24 CAPITOLO 6 ...................................................................................................................................................... 27 IMPLEMENTAZIONE ..................................................................................................................................... 27 6.1 – INTRODUZIONE ............................................................................................................................... 28 6.2 – INTERFACCIA GRAFICA .................................................................................................................... 28 6.3 – ESTRAZIONE DELLE FEATURES ED INDICIZZAZIONE........................................................................ 31 6.4 – CALCOLO DELLE DISTANZE.............................................................................................................. 32 6.5 – MEMORIZZAZIONE DEL FEEDBACK ................................................................................................. 34 6.6 – CALCOLO DEL RELEVANCE SCORE................................................................................................... 34 6.7 – RISULTATI ........................................................................................................................................ 38 CAPITOLO 7 ...................................................................................................................................................... 48 CONCLUSIONI .............................................................................................................................................. 48 2
CAPITOLO 1 INTRODUZIONE 3
La seguente tesi si pone l’obiettivo di realizzare un motore di ricerca per immagini basato sul relevance feedback, incorporato in un’applicazione per sistema operativo Android. Per la rilevazione delle immagini viene utilizzato un sistema basato su metodologia CBIR (Content-Based Image Retrieval), ovvero un sistema di recupero di immagini digitali basato sulle caratteristiche visuali di ciascuna immagine. Per CBIR si intende l’insieme dei sistemi che si occupano di gestione e di ricerca delle immagini sulla base di un confronto di una o più caratteristiche che l’immagine possiede, come ad esempio il colore, la forma, la tessitura e numerose altre. Il funzionamento di un sistema basato sul CBIR può essere riassunto così: si prende innanzitutto una immagine di riferimento, detta query e scelta dall’utente. Tale immagine viene analizzata e comparata con ciascuna delle immagini presenti nella galleria foto del proprio dispositivo (tali foto costituiscono l’insieme dei dati chiamato dataset), eseguendo un confronto, detto feature matching, che si basa su una tipologia di descrittore scelto. Una volta eseguito il confronto, all’utente verrà mostrato un numero limitato di risultati che corrispondono alle immagini considerate dal sistema più vicine all’immagine di riferimento. Sarà quindi premura dell’utente verificare che i risultati ottenuti siano rilevanti rispetto all’immagine di query e, successivamente, tramite l’invio di un feedback, il sistema sarà in grado di fornire dei migliori risultati grazie al sistema detto Relevance Feedback. Quest’ultimo esegue un confronto tra tutte le immagini del dataset rispetto alle immagini catalogate dall’utente come rilevanti o non rilevanti, attribuendo un punteggio, detto Relevance Score o semplicemente score, a ciascuna immagine. Le immagini più vicine alle rilevanti avranno uno score vicino al massimo, ovvero unitario, mentre quelle più vicine alle non rilevanti avranno un valore molto piccolo, tanto vicino allo zero quanto distante dalle rilevanti. La realizzazione di sistema basato su CBIR sul sistema operativo Android è stata agevolata dalla presenza di numerose funzionalità presenti in una libreria open source denominata OpenCV, realizzata su più piattaforme e rilasciata secondo licenza BSD, che fornisce un insieme di classi e funzioni volte all’analisi delle immagini. OpenCV è stata progettata principalmente per un utilizzo su ambiente desktop, poiché in tale ambiente è presente una elevata potenza di calcolo fornita dai processori di ultima generazione. Al contrario, su ambiente mobile, fra cui Android, si devono affrontare numerose problematiche legate principalmente all’ottimizzazione, in quanto i dispositivi mobili odierni non offrono una potenza di calcolo tanto elevata quanto quella fornita da un computer fisso, oltre che una minor capacità di memorizzazione dei dati. Tali limitazioni hanno portato alla rimozione o alla semplificazione di alcune funzioni presenti nell’ambiente desktop affinché potessero essere utilizzate anche su ambiente mobile. Sarà infine necessario un lavoro di studio di un’interfaccia grafica in grado di essere fruibile e di facile comprensione da parte di un utente medio, tramite l’uso di una serie di componenti grafici familiari all’utente. L’elaborato si compone di due parti. La prima, introduttiva, presenterà i concetti necessari a comprendere il problema e la sua soluzione. Partendo dal riassumere la natura del sistema operativo Android, descritta nel secondo capitolo, e successivamente parlando del funzionamento della libreria OpenCV sul terzo capitolo, si passerà infine alla seconda parte dell’elaborato, che riassume l’implementazione del Relevance Feedback, oggetto principale di questa tesi, fino a terminare l’intero elaborato con i test eseguiti e le conclusioni raggiunte con l’intero lavoro svolto. 4
CAPITOLO 2 CONTENT BASED IMAGE RETRIEVAL 5
2.1 – INTRODUZIONE Ormai, sempre più spesso, la ricerca basata sulle immagini sta entrando fra le abitudini degli utenti. Esistono numerosi sistemi basati sulla ricerca delle immagini ed altrettanti motori di ricerca che consentono questa funzione, in primis Google. Più in dettaglio, esistono tre tipi di ricerca basata sulle immagini: • La ricerca tramite meta-data, ovvero ad ogni foto è associata una parola o un concetto, e in base a quello è possibile ricavarne delle immagini simili. Pertanto tale metodo di ricerca non va ad analizzare l’immagine di per sé. • La ricerca basata su esempi, ovvero data una immagine si vanno a ricercare quelle simili a seconda di uno o più criteri di somiglianza. Tale ricerca è tutt’oggi esente dalla perfezione, ed è pertanto molto probabile che i risultati forniti da tale ricerca siano prevalentemente falsi positivi, ovvero risultati che si reputano corretti ma in realtà sono errati. • La ricerca ibrida, basata sia sul meta-data che su un esempio. Si tratta di una ricerca più precisa, in quanto si hanno due metodi di comparazione. Ci focalizzeremo sul secondo tipo di ricerca, ovvero quello basato sugli esempi. Difatti, il Content-Based Image Retrieval (CBIR) è un motore di ricerca per immagini che quantifica il contenuto di un’immagine, per poi mostrare tutte quelle immagini con un contenuto simile. Il funzionamento di un CBIR si basa sull’estrazione di features (ovvero delle caratteristiche che l’immagine possiede, viste dal sistema come un array numerico), che avviene tramite uno strumento chiamato descriptor (descrittore). Ogni qualvolta che l’utente invia un’immagine da analizzare, detta query, il CBIR va ad estrarre le features dall’immagine e confronta tali features con quelle presenti in ciascuna immagine nel proprio database. Figura 1: principio di funzionamento per l'estrazione delle features. Una volta ottenuti tutti gli array di features, è necessario confrontarli tra loro. Possono essere comparati tramite un algoritmo basato sulla similarità oppure sulla distanza. Tale confronto produrrà un indice, ad esempio basato su scala da zero a uno, dove lo zero potrebbe indicare la più totale lontananza fra le due immagini, mentre l’uno indicherebbe invece l’uguaglianza fra le due immagini confrontate. Figura 2: il confronto tra due immagini fornisce un valore che indica la vicinanza fra tali immagini 2.2 – COSTRUZIONE DI UN MOTORE DI RICERCA BASATO SU CBIR Possiamo definire pertanto quattro passaggi per poter costruire un CBIR. 6

1. Definire l’Image Descriptor 2. Indicizzare il data set 3. Definire il metodo di comparazione per le immagini che si vogliono analizzare e confrontare 4. Eseguire la ricerca, fornendo una query. È importante analizzare ciascun punto, soffermandosi anche sulla terminologia di alcune delle parole utilizzate. PASSO 1: DEFINIZIONE DI UN IMAGE DESCRIPTOR Come già accennato pocanzi, è necessario definire un Image Descriptor affinché sia possibile estrarre delle features da una immagine. Mentre per un essere umano la rilevazione delle features, ovvero dei particolari dettagli che sono in grado di catturare l’attenzione, è una cosa relativamente semplice, naturale e familiare, per il computer non è invece facile eseguire questa analisi. Pertanto lo scopo dell’Image Descriptor è di fondamentale importanza per permettere al calcolatore di poter analizzare le immagini. Esistono vari Image Descriptor, ciascuno di essi andrà a restituire un Feature Vector diverso dagli altri a seconda del descrittore stesso utilizzato per l’estrazione. I descrittori possono essere raggruppati in tre categorie principali: • Descrittori cromatici, o di colore: ogni immagine analizzata andrà a restituire un array numerico contenente informazioni sulle tonalità di colore presenti nell’immagine stessa. • Descrittori tessiturali, o di texture: vengono in questo caso analizzati tutti i pattern che compongono un’immagine. • Descrittori di forma: l’analisi viene effettuata sulle forme di ciascun elemento che va a formare l’immagine. Di seguito verranno elencati i due descrittori utilizzati per la realizzazione dell’app e verranno esposti i principi di funzionamento. ISTOGRAMMA DI COLORE L’istogramma di colore è una delle possibili rappresentazioni della distribuzione dei colori di una immagine ed è usato come primo descrittore nell’app. Un istogramma viene costruito in base allo spazio colore e fornisce una rappresentazione dei dati attraverso un grafico. Figura 3: Esempio di un istogramma di colore applicato nello spazio tridimensionale RGB. Non ci occuperemo di rappresentare uno o più istogrammi graficamente ma di manipolare i dati contenuti all’interno di un istogramma per ottenere alcune importanti informazioni per il confronto fra immagini. 7

Per migliorare il funzionamento del descrittore, ciascuna immagine analizzata in viene suddivisa cinque aree distinte. Pertanto non si lavora sulla singola immagine in sé, ma sulla similarità delle cinque aree. In tal modo diventa importante, per la distinzione delle immagini, anche la posizione degli oggetti nell’immagine stessa. Figura 4: Suddivisione di un'immagine in cinque aree per l’estrazione di features basate su istogramma dei colori. Per l’estrazione delle features, pertanto, si è fatto uso, all’interno del progetto, di maschere in grado di considerare solamente una determinata porzione dell’immagine. Il numero di maschere e la loro forma corrispondono esattamente a ciascuna delle cinque aree indicate in figura 4. ORB L’ORB (Oriented FAST and Rotated BRIEF) è il secondo descrittore utilizzato nell’app. Lavora abbastanza bene in ambito mobile in quanto ha un tempo medio relativamente basso per l’individuazione dei punti chiave (KeyPoints) di una immagine rispetto ai suoi diretti concorrenti: i descrittori SIFT e SURF. Il descrittore lavora secondo due algoritmi: il FAST e il BRIEF. Il FAST lavora sull’individuazione dei punti chiave. Tale processo è basato sulla analisi della luminosità dell’immagine in un intorno di un presunto punto chiave, si dimostra essere tale solo se, disegnato un cerchio di 16 pixel attorno ad esso, si riesce a trovare un arco di punti contigui con lunghezza maggiore ai tre quarti del perimetro e con luminosità che differisce dal punto al centro. Figura 5: insieme di punti chiave (cerchi in verde) calcolati in un'immagine con l’algoritmo FAST. Tale algoritmo tuttavia ha un problema: non calcola l’orientamento del punto chiave in esame. Definire l’orientamento è un fattore non di poco conto, in quanto ruotando l’immagine (anche di pochi gradi) 8
potrebbe non essere possibile rilevare una similitudine fra due immagini. Ciò è stato risolto generando un array che parte dal centro del punto chiave individuato sino al suo baricentro. La direzione del vettore ci dà l’orientamento del punto chiave. L’algoritmo BRIEF, realizzato in versione semplificata, permette l’estrazione delle features. Tramite il calcolo di una stringa binaria, si vanno ad eseguire una serie di test con il fine di determinare le differenze di intensità luminosa tra coppie di pixel. Tale stringa, però, viene generata considerando solo le informazioni sulla coppia di pixel analizzata ed è molto sensibile al rumore. Per questo solitamente si preferisce effettuare una riduzione del rumore dell’immagine prima di eseguire il BRIEF, in tal modo è possibile aumentare la ripetibilità e la stabilità del descrittore stesso. Il confronto fra immagini analizzate con descrittore ORB avviene tramite degli algoritmi definiti come matcher. Nel progetto in questione, ciò avviene tramite un altro algoritmo detto Bruteforce Hamming. Si tratta di un Descriptor Matcher che opera con descrittori binari, ovvero l’insieme di descrittori che restituiscono una stringa di bit come risultato di un calcolo. Il confronto tra features estratte dalle due immagini avviene su ogni pixel della prima immagine: per ciascuno di essi viene trovato il matching migliore nella seconda immagine, usando come criterio la distanza di Hamming. Questa viene calcolata considerando due stringhe binarie di lunghezza identica e rappresenta il numero di sostituzioni necessarie per convertire una stringa nell’altra. Le due stringhe prese come riferimento saranno considerate identiche fra loro se la loro distanza è pari a zero. PASSO 2: INDICIZZAZIONE DEL DATASET Per la realizzazione di un CBIR è di interesse estrarre le features dalle immagini che intendiamo analizzare. Di fatto, poiché stiamo lavorando ad un motore di ricerca, il nostro scopo è quello di sfruttare l’Image Descriptor definito al punto 1 su tutte quelle immagini con le quali vogliamo eseguire un confronto, che vanno a rappresentare il nostro dataset. Si andrà quindi a salvare su una coppia chiave-valore tutti i vettori di features estratti, in modo che sia facile reperire, dato il percorso fisico di una particolare immagine, il suo Feature Vector. Tale processo, detto indicizzazione, permette una maggiore velocità durante la fase di confronto: infatti, anziché dover estrarre ogni qualvolta si esegue una comparazione i Feature Vector, si andrà a recuperarli semplicemente dalla memoria. Figura 6: schema riassuntivo del secondo passo, volto all'indicizzazione dei dati. PASSO 3: METODO DI COMPARAZIONE FRA IMMAGINI Una volta estratti ed indicizzati i Feature Vector è necessario definire un metro di paragone per il confronto delle immagini. Questo passaggio è indispensabile in quanto il CBIR dovrà essere in grado di distinguere ed ordinare le immagini confrontate a seconda di un criterio. Per far questo si va a generare e studiare una misura di distanza o di somiglianza fra Feature Vector. Le più importanti ed utilizzate funzioni di calcolo della distanza sono le seguenti: 9
• Distanza euclidea • Distanza chi-squared (test chi quadrato) • Coseno di similitudine DISTANZA EUCLIDEA La distanza euclidea è la trasposizione dei concetti della distanza in uno spazio bidimensionale su uno spazio n-dimensionale. La formula per calcolare tale distanza è la seguente: √∑( − )2 =1 [2.2.1] Più due vettori sono vicini tra loro, più il valore generato sarà basso, pertanto più le immagini saranno visivamente simili fra di loro. Se tali vettori dovessero risultare identici fra loro, tale espressione fornirebbe un risultato pari a zero. Tale formula viene usata per confronti eseguiti con gli Image Descriptor basati sulla tessitura. DISTANZA CHI-SQUARED La distanza Chi-Squared viene sfruttata nel caso in cui l’Image Descriptor usato si basa sul colore. Anche in tal caso la distanza fra due immagini identiche produrrà un valore nullo, quella fra due immagini visivamente simili produrrà un valore molto piccolo, mentre quelle distanti fra loro generanno un valore vicino all’uno. La formula per ottenere la distanza Chi-Squared è la seguente: 1 ( − )2 ∑ 2 + =1 [2.2.2] COSENO DI SIMILITUDINE Il coseno di similitudine è utilizzato per i descrittori che lavorano sulla forma, in quanto è una misura di similarità e non di distanza. A differenza delle formule precedenti, l’uguaglianza si ottiene nel momento in cui si ottiene un valore unitario, la somiglianza invece produrrà un valore tanto più vicino all’unità quanto più l’immagine è simile a quella presa come riferimento, mentre fornirà un valore vicino allo zero tanto più l’immagine è diversa da quella confrontata. La formula per calcolare il coseno di similitudine è la seguente: ∑ =1( ∗ ) √∑ =1 2 ∗ √∑ =1 2 [2.2.3] 10
Il confronto di due immagini fornirà un valore che poi, a seconda del metodo di comparazione utilizzato, ci darà indicazione su quanto un’immagine è più o meno vicina ad un’altra. PASSO 4: ESECUZIONE DELLA RICERCA Sfruttando tutti i precedenti passi è infine possibile realizzare il motore di ricerca, il cui schema è riassunto nella seguente figura. Figura 7: schema riassuntivo per effettuare la ricerca in un sistema CBIR. Si parte innanzitutto dal presupposto che tutti i Feature Vector siano già stati estratti da ciascuna delle immagini del dataset, avendo pertanto un database memorizzato ed indicizzato. Con tale premessa, l’algoritmo per eseguire una ricerca è il seguente: 1. L’utente sceglie un’immagine che sarà l’immagine di query. 2. Si estrae il Feature Vector dall’immagine secondo il descrittore scelto. 3. Vengono recuperati dalla memoria tutti i Feature Vector memorizzati. 4. Inizia ora la comparazione fra il Feature Vector dell’immagine di query e ciascun elemento del database memorizzato. 5. Tale confronto produrrà un risultato per ciascuna immagine comparata. Ciascun risultato verrà inserito all’interno di un array che successivamente verrà ordinato in ordine crescente. 6. Infine si prendono le immagini con i valori desiderati e vengono mostrate all’utente. 11
CAPITOLO 3 IL RELEVANCE FEEDBACK 12
3.1 – INTRODUZIONE Lo scopo principale della tesi è l’implementazione di un sistema di recupero delle informazioni (Information Retrieval, IR), basato su di un feedback richiesto all’utente in seguito alla visualizzazione dei risultati ritenuti più pertinenti. La necessità di usare un sistema basato sul feedback in un CBIR nasce in quanto esiste un netto divario fra il concetto di similarità per un essere umano e quello invece determinabile tramite una distanza calcolata con i Feature Vectors. Ciò che può essere numericamente simile non è detto che rappresenti un risultato rilevante per l’utente. L’approccio usato si pone come un ulteriore sistema in grado di migliorare, col tempo, i risultati forniti, e viene chiamato Relevance Feedback. Il suo funzionamento può essere riassunto in tre punti: 1. Il sistema fornisce i risultati più rilevanti basati su una determinata query. 2. Viene quindi richiesto un feedback all’utente riguardo la rilevanza dei risultati mostrati. Le informazioni che l’utente fornisce vengono raccolte e tenute in memoria. 3. Queste ultime informazioni vengono utilizzate per formulare una nuova query ed offrire pertanto risultati migliori in successive iterazioni. Figura 8: schema del funzionamento di un Relevance Feedback. Il feedback richiesto all’utente consiste nel catalogare le immagini in due tipologie: quelle considerate rilevanti, ovvero visivamente o concettualmente simili rispetto all’immagine scelta come query, oppure come non rilevanti, cioè non simili all’immagine selezionata. Tale processo genera un insieme di dati definito come training data e permette pertanto, ad un sottoinsieme dei risultati ottenuti, di essere contrassegnati come rilevanti e\o come non rilevanti. 3.2 – STIMA DELLA RILEVANZA TRAMITE NEAREST NEIGHBOR L’obiettivo principale che si vuole ottenere è la capacità, da parte del sistema, di predire i risultati rilevanti in base ad una determinata query. Per riuscire ad ottenere un risultato di questo tipo sono nate un insieme di tecniche che vengono denominate Nearest Neighbor. 13
Figura 9: esempio del funzionamento del Nearest Neighbor. In verde è indicata la query, in rosso gli elementi non rilevanti, in blu quelli rilevanti. Le tecniche Nearest Neighbor vengono usate in tutti quei casi dove è difficile produrre un alto livello di generalizzazione per una determinata “classe” di oggetti. L’apprendimento degli elementi rilevanti nel CBIR è un valido esempio dei casi precedentemente citati, in quanto è difficile generare un modello che può essere adattato per rappresentare diversi concetti di similarità. Oltretutto, il numero di esempi disponibili può risultare troppo piccolo per stimare correttamente un set di parametri per ciascun modello generale. Si dimostra pertanto più efficace usare ciascuna immagine catalogata come “rilevante”, così come ciascuna immagine catalogata come “non rilevante”, per eseguire tutte le comparazioni con l’immagine i-esima. Per tale motivo si può assumere che: • Un’immagine sarà tanto rilevante quando la sua dissimilarità con la rilevante più vicina è bassa. • Analogamente, un’immagine è tanto non rilevante quanto la dissimilarità con la non rilevante più vicina è piccola. 3.3 – CALCOLO DEL RELEVANCE SCORE Una volta ottenute le prime immagini catalogate come rilevanti o non rilevanti, è possibile procedere al calcolo di un punteggio che stima il grado di rilevanza. È possibile calcolare tale punteggio con tre requisiti: 1. Un dataset abbastanza ampio 2. Almeno un’immagine catalogata dall’utente come rilevante (rispetto ad una query) 3. Almeno un’immagine catalogata dall’utente come non rilevante (rispetto ad una query) A questo punto, è possibile eseguire il calcolo dello score tramite la seguente formula matematica: ‖ − ( )‖ = ‖ − ( )‖ + ‖ − ( )‖ [3.3.1] Dove: • I rappresenta l’immagine I-esima del dataset, in quanto il calcolo dello score viene eseguito per ciascuna immagine presente nel database. • ( ) rappresenta l’elemento non rilevante più vicino (la vicinanza è data dal calcolo della distanza basata sul descrittore scelto per l’analisi delle immagini) rispetto alla immagine i-esima presa in considerazione. • Analogamente, ( ) rappresenta l’elemento rilevante più vicino, in termini dello stesso descrittore, all’immagine i-esima. 14
Al numeratore, pertanto, con la dicitura ‖ − ( )‖, si va a calcolare la distanza (basata sempre sul descrittore scelto) fra l’immagine i-esima e la sua non rilevante più vicina, mente al denominatore si va a calcolare la distanza con la rilevante più vicina e la si somma alla distanza calcolata al numeratore. In questo modo, per ciascuna immagine, si può ottenere un punteggio che va da 0 ad 1. Più il risultato di tale score è vicino allo zero, più l’immagine è vicina alle non rilevanti. Sarà invece vicino ad uno se l’immagine presa in analisi è più vicina a quelle rilevanti rispetto a quelle non rilevanti. Quando il risultato è esattamente pari a zero, significa che l’immagine presa in esame è esattamente una fra quelle non rilevanti già precedentemente catalogate. Infatti, se l’immagine I-esima è una non rilevante, la distanza con la non rilevante più vicina (ovvero sé stessa) vale zero, quindi al numeratore avrò uno zero. Al denominatore avrò sicuramente un numero diverso da zero poiché sto considerando anche la distanza con la rilevante più vicina. Il risultato quindi sarà pari a zero. Invece, se l’immagine i-esima è presente fra quelle contrassegnate come rilevanti, produrrà uno score esattamente uguale ad uno. Con un ragionamento simile al precedente, al denominatore la distanza fra la rilevante più vicina e l’immagine i-esima darà zero in quanto le due immagini sono identiche fra loro. Rimane pertanto un rapporto fra due numeri uguali, che non sono altro che la distanza con la non rilevante più vicina: tale rapporto sarà quindi unitario. Ordinando quindi in modo discendente la lista degli score ottenuti, ovvero dal numero più alto al numero più basso, avrò un insieme di immagini ordinate in termini di rilevanza. Tale formula si dimostra tanto più efficace quanti più elementi sono stati catalogati dall’utente come rilevanti e come non rilevanti, data una determinata query. I risultati ottenuti dall’utilizzo di questo score verranno esposti nel penultimo capitolo. 15
CAPITOLO 4 IL SISTEMA OPERATIVO ANDROID 16
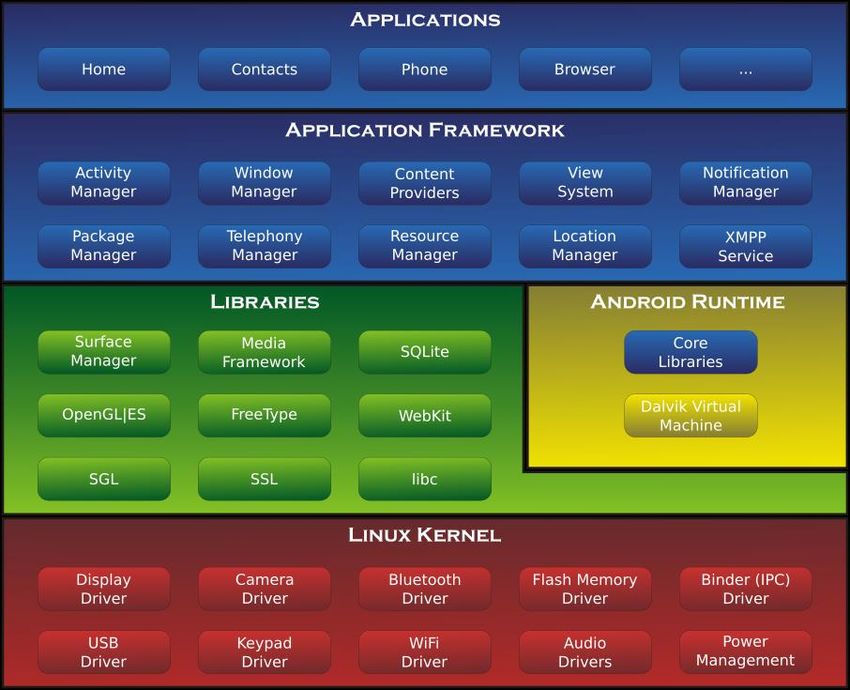
4.1 – INTRODUZIONE Android è un sistema operativo sviluppato dalla Google nel 2008 e ad oggi in continua evoluzione. Inizialmente concepito come sistema operativo (OS) per gli smartphone touch-screen, oggi è il sistema operativo più diffuso al mondo, con oltre il 60% di fetta di mercato. Tale OS, basato su kernel Linux, è un sistema embedded, progettato pertanto per funzionare su svariati dispositivi, fra cui Tablet, Smartphone, TV, orologi, dispositivi preinstallati su automobili (Android Auto) e molti altri. L’ultima versione rilasciata del sistema operativo è la 8.1, il cui nome in codice è Oreo. 4.2 – ARCHITETTURA L’architettura del sistema operativo può essere vista come strutturata su vari livelli (detti layer), ognuno dei quali non è altro che un’astrazione del livello sottostante. Possiamo catalogare cinque livelli principali. Figura 10: Suddivisione in livelli del sistema operativo Android. Si parte quindi dal livello più basso, ovvero il Linux Kernel, dove è previsto un interfacciamento con tutti i moduli hardware di cui il dispositivo è provvisto, fino ad arrivare in cima, ovvero il livello delle applicazioni, che si occupano di semplificare ed offrire la comunicazione fra l’utente finale e il sistema operativo stesso, comunicando con i livelli sottostanti. 17
LINUX KERNEL Il livello più basso è rappresentato dal kernel Linux, scelto in quanto esiste da tempo ed è un kernel oramai consolidato e stabile. Lo scopo del kernel è di offrire una comunicazione fra componenti hardware e software, ad esempio è affidato a lui il compito di offrire la comunicazione con il Bluetooth, il Wi-Fi, la fotocamera e tutti gli altri componenti di cui è provvisto il telefono. Grazie al kernel, tutte le aziende che decidono di implementare Android come sistema operativo per il proprio smartphone dovranno implementare esclusivamente i driver. LIBRARIES In tale livello sono incluse un insieme di librerie scritte in C++ e il C utilizzate dal sistema operativo per svolgere numerose funzioni. Ad esempio, il Surface Manager è il responsabile della gestione delle View, strumento con il quale è possibile realizzare un’interfaccia grafica. SQLite, invece, è un piccolo e performante database relazionale, messo a disposizione agli sviluppatori per poter salvare in modo permanente i dati di ciascuna app sviluppata. ANDROID RUNTIME Android Runtime (detto ART) è la macchina virtuale di Android, introdotta in seguito all’aggiornamento alla versione 5.0 di Android. Grazie ad essa, ogni applicazione avrà un processo univoco, con la sua istanza nella macchina virtuale, in grado di funzionare con un basso quantitativo di memoria utilizzata. L’Android Runtime sostituisce tutt’oggi la vecchia macchina virtuale denominata Dalvik, basata su tecnologia JIT (just-in-time). Tale tecnologia, dispendiosa in termini di risorse, obbligava a far compilare allo sviluppatore solo una parte dell’app, mentre la rimanente veniva eseguita e compilata in linguaggio macchina dall’interprete software (la Dalvik stessa) in tempo reale, ovvero ad ogni esecuzione dell’app. ART invece si basa sulla tecnologia AOT (Ahead-Of-Time), che esegue la compilazione completa del codice durante l’installazione dell’app, permettendo un gran vantaggio in termini prestazionali. L’unico svantaggio che si ha rispetto a prima è il tempo di installazione delle app, maggiore rispetto al passato, ma oramai poco osservabile in quanto l’hardware sempre più potente va ad appiattire queste differenze. APPLICATION FRAMEWORK L’application framework raggruppa tutti quei blocchi di funzioni utilizzate per lo sviluppo delle app. È pertanto un insieme di API (Application Programming Interface) scritte in Java e alcune di esse scritte nel nuovo linguaggio chiamato Kotlin. Alcuni dei moduli più utilizzati nello sviluppo sono: • Resource Manager: permette la gestione efficiente delle risorse grafiche e multimediali, oltre che dell’interfaccia grafica di una app. • Activity Manager: consente un controllo completo del ciclo di vita di una activity, ovvero l’entità associata ad una particolare schermata dell’app. Si può, attraverso tale modulo, gestirle in modo da farle apparire in ordine • Notification Manager: fornisce la possibilità di invio e ricezione di notifiche. 18
APPLICATIONS L’ultimo livello è rappresentato dalle app in sé. Le app sono archivi compressi in formato APK che hanno la caratteristica di essere auto-installanti. Contengono al loro interno il software in formato DEX, eventuali librerie, le risorse utilizzate e tutti i file XML del progetto. 4.3 – COMPONENTI DI UNA APP Possiamo vedere un’app come un insieme di tre componenti: 1. Un file chiamato manifest, in formato XML, che descrive l’insieme delle caratteristiche funzionali che compongono o vengono richieste da una particolare applicazione per funzionare. 2. Una cartella chiamata res (abbreviativo di resources) che contiene tutte le risorse proprietarie di una app, necessarie pertanto al corretto funzionamento della stessa. Le risorse sono a loro volta organizzate in sottocartelle, questo per facilitare la lettura e l’ottimizzazione. 3. Un’altra cartella, chiamata src (abbreviativo di source), che contiene il codice sorgente dell’app. ANDROID MANIFEST Il file AndroidManifest.xml è il primo indispensabile file necessario per il funzionamento di un’app. Senza di esso l’app non potrebbe essere avviata. Il manifest, scritto in un linguaggio di Mark-Up chiamato XML, ha lo scopo di indicare i seguenti parametri: • Tutte le Activity presenti in una app, con le loro proprietà (ad esempio il tema, la possibilità di essere eseguita in base ad una particolare rotazione del telefono, il titolo etc.). Sarà compito dello sviluppatore elencare tutte le Activity in questo file durante lo sviluppo, pena un malfunzionamento dell’app. • Tutti i servizi (ovvero i processi in grado di rimanere attivi in background, anche quando l’app è chiusa) che possono essere avviati dall’app. • I permessi (o autorizzazioni) che sono necessari per il corretto svolgimento di alcune delle funzioni dell’app (ad esempio il permesso di usare internet, il permesso di accedere alla rubrica, di attivare il Bluetooth, di leggere i dati dalla memoria etc.). Tali permessi verranno richiesti all’utente in fase di avvio dell’app, ed egli potrà decidere se concederli o meno. • Gli eventuali Content Providers, che servono a rendere condivisibili eventuali dati dell’applicazione. • Informazioni sull’app stessa (come il nome o l’icona usata) • Eventuali parametri sugli strumenti di build e sugli SDK (Software Development Kit) utilizzati. • Il nome del pacchetto dell’app, che solitamente è identico allo spazio dei nomi del codice. ACTIVITY Come già accennato precedentemente, una Activity è una importante entità di un’app e può essere riassunta come una singola e mirata azione che un utente può eseguire. Quasi tutte le Activity offrono la possibilità all’utente di interagire con esse, e ciascuna Activity è associata ad un particolare layout, ovvero una rappresentazione grafica anch’essa scritta in XML. Ogni Activity ha una serie di stati che compongono il suo ciclo di vita, ovvero un insieme di eventi che vengono invocati dalla generazione di essa sino alla sua distruzione. Nella figura 3 è possibile vedere riassunti tutti gli eventi del ciclo di vita di una Activity. Fra tutti quelli disponibili sicuramente i più usati sono due: 19
• onCreate() : viene invocato nel momento in cui una Activity viene appunto creata. In questo particolare evento, tramite la funzione setContentView(), è possibile associare il layout che rappresenta la parte di interfaccia grafica dell’app. • onResume(): evento richiamato nel momento in cui l’Activity, messa in background, torna ad essere messa in primo piano. Tale evento è utile, assieme all’evento onPause(), per gestire in modo efficiente la memoria utilizzata dal dispositivo, ed evitare pertanto l’utilizzo e lo spreco di risorse durante periodi di inattività. Figura 11: schema riassuntivo del ciclo di vita di una Activity Quando si parla di Activity è importante menzionare l’utilizzo dei Bundle. I Bundle sono dei contenitori che permettono il passaggio di dati tra diverse Activity, ma anche per mantenere invariati alcuni dati nel processo di rotazione dello schermo del dispositivo. INTENT Durante lo sviluppo di un’app composta da più Activity è necessario creare uno o più Intent. Un Intent, come è possibile intuire dal nome stesso, rappresenta l’intenzione di effettuare una particolare operazione, ed è principalmente utilizzato per passare da una Activity ad un’altra (non per forza della medesima app). Tramite gli Intent siamo inoltre in grado di passare dei dati (argomenti) dall’Activity precedente verso la nuova, se quest’ultima è predisposta a riceverli. Infine, l’Intent offre l’opportunità di avviare i servizi, ovvero i componenti forniti dal sistema operativo in grado di svolgere operazioni di lunga durata in background. 20
RESOURCES Le risorse (solitamente abbreviate in res) contengono tutto il materiale grafico e multimediale di una app. Tale cartella del sistema è strutturata gerarchicamente in varie sottocartelle, ognuna con una particolare funzione. Le principali sono le seguenti: • Anim: la seguente cartella raccoglie tutti i file che rappresentano un’animazione grafica. Tali file sono un insieme di file XML con proprietà specifiche per eseguire transizioni. • Drawable: tale cartella contiene tutte le risorse grafiche del sistema, quali icone dei menù o dei pulsanti, e le eventuali immagini. Dalla versione 5.0 di Android, tale cartella può esser riempita anche con dei Vector Drawables, ovvero delle immagini vettoriali espresse anch’esse in formato XML, in grado di ridimensionarsi attivamente in base alla risoluzione del dispositivo che si sta utilizzando. • Layout: contiene numerosi XML, ciascuno di questi non è altro che l’interfaccia grafica di una o più Activity. Vengono inseriti qui anche quegli XML che andranno a disegnare gli Adapters, ovvero un particolare elemento di una lista. • Mip-Map: contiene le icone del sistema. • Assets e Raw: entrambe contengono delle risorse in sola lettura che non rientrano fra quelle elencate in precedenza, come ad esempio video, documenti di testo, pdf, font ed elementi simili (anche elementi personalizzati). La differenza fra le due è che qualunque file inserito all’interno della cartella Raw è indicizzato, mentre questo non accade per i file inseriti negli Assets. VIEW Ogni file XML all’interno della cartella layout è composto da un insieme di View, che insieme andranno a formare la schermata finale che l’utente visualizzerà su schermo. Una View è un’area rettangolare dove vengono disegnati uno o più elementi grafici, in grado di catturare e di gestire qualsiasi evento di interazione tra dispositivo ed utente. In ciascuna View sarà possibile posizionare vari elementi, ovvero degli oggetti grafici comuni in grado di offrire una particolare interazione. È utile distinguere le View in tre gruppi: • ViewGroup: è una View in grado di contenerne altre. I principali ViewGroup sono i RelativeLayout, i ConstraintLayout e i LinearLayout, ma ne esistono molti altri. Ogni file di layout solitamente nasce con un ViewGroup che sarà successivamente il padre di altre View o ViewGroup. • Container: sono delle View particolare in grado di contenere indirettamente altre view al loro interno. Il loro funzionamento è direttamente collegato con gli Adapter, un insieme di oggetti graficamente identici fra loro che compongono una lista di elementi, differenziati fra loro per i dati contenuti al loro interno. Alcuni esempi di container sono le ListView, le GridView o il RecyclerView. • Elemento: una View che solitamente non è in grado di contenerne altre. Sono posizionabili all’interno di un ViewGroup. Un elemento può essere ad esempio il Button, la ProgressBar o la CheckBox. Con il tempo gli elementi sono diventati molto comuni e familiari per l’utente medio. 21
Figura 12: esempio di due comuni View, viste sia dal punto di vista grafico (destra) che tramite XML (sinistra). Figura 13: schema gerarchico di una porzione di View. 22
CAPITOLO 5 LA LIBRERIA OPEN CV 23
5.1 – INTRODUZIONE La libreria OpenCV (Open Source Computer Vision Library) è una libreria software che si occupa della elaborazione delle immagini. Nata come progetto di ricerca Intel nel 1999, ora è una libreria open source e cross-platform, ovvero in grado di funzionare su numerosi e diversi sistemi operativi. Scritta in C/C++, OpenCV sfrutta i processori dotati di più core e permette pertanto l’analisi in tempo reale di immagini e fornisce la possibilità di svolgere operazioni complesse, come il riconoscimento facciale e di oggetti, tracciamento di movimenti, interpolazione di immagini e tanto altro, superando un totale di 2500 algoritmi ottimizzati. 5.2 – IMPLEMENTAZIONE Per poter utilizzare la libreria di Open CV su Android è necessario innanzitutto avere due componenti installati all’interno del proprio ambiente di sviluppo: • NDK (Native Development Kit): gli strumenti di sviluppo che permettono ad uno sviluppatore di poter implementare una parte di codice scritto in C/C++. • JNI (Java Native Interface): il framework Java in grado di richiamare, o di esser richiamato dal, codice “nativo”, ovvero scritto in C\C++. Più semplicemente, permette l’interfacciamento del sistema operativo con un codice scritto in linguaggio differente, come appunto tale libreria. Come penultimo passo rimane da importare la libreria all’interno del proprio progetto Android, in modo che tutte le classi della libreria possano essere richiamate in qualunque parte del codice. Sarà infine necessario avere installato all’interno del proprio smartphone l’app chiamata OpenCV Manager, un’applicazione gratuita presente sul Play Store che permetterà al software scritto con tale libreria di funzionare sul dispositivo finale. 5.3 – OPENCV MANAGER Tale applicazione, sviluppata per sistemi operativi Android, permette l’interfacciamento dei file binari della libreria con le applicazioni che intendono usufruirne. Senza di questa importante app, le applicazioni che importano la libreria non saranno in grado di funzionare sul dispositivo. OpenCV Manager offre una gestione ottimizzata della memoria, nonché varie ottimizzazioni hardware e risoluzioni di eventuali bug. 5.4 – FUNZIONI E CLASSI UTILIZZATE Per la realizzazione di questo progetto sono state sfruttate alcune importanti funzioni, oggetti e classi di questa libreria di Computer Vision. Di seguito sono elencati e descritti i più importanti. MAT Ogni immagine, per il computer, non è altro che un insieme di pixel, ovvero un insieme di punti campione, disposti ordinatamente e pertanto in grado di comporre la rappresentazione di un’immagine bitmap. Per pixel si intende, nello specifico, il più piccolo componente che costituisce un’immagine. A ciascun pixel viene associato un numero che compone, ad esempio, il totale del bianco, in una scala da 1 a 255, presente in quel punto campione dell’immagine (nel caso di una immagine in bianco e nero). Nelle 24
immagini a colori, invece, ogni pixel avrà ben tre numeri associati ad esso, uno per ciascuno dei tre colori fondamentali, quali rosso, verde e blu. Poiché ciascuna immagine si sviluppa in due dimensioni, si può pensare di associare una matrice a ciascuna immagine, dove il numero di righe è pari al numero di pixel su schermo in lunghezza ed il numero di colonne pari al numero di pixel su schermo in larghezza. Con tale rappresentazione è stato ideato e realizzato il componente Mat della libreria di OpenCV, diminutivo di Matrix (matrice), che ha il compito di associare dei numeri a ciascun pixel dell’immagine. Figura 14: Esempio di un oggetto Mat associato ad un'immagine in bianco e nero. Grazie a tale rappresentazione, OpenCV riesce ad analizzare una qualsiasi immagine e a manipolarne il contenuto. In Java è possibile generare un oggetto Mat a partire dal percorso dell’immagine con la seguente istruzione: Mat mat = Imgcodecs.imread(String imagePath); In alternativa è possibile generare un elemento Mat vuoto definendo il numero di righe, il numero di colonne ed infine il formato, ovvero un codice che rappresenta le modalità di salvataggio dei dati dell’immagine. Il numero dei canali è un altro dato importante da tener conto. Come già accennato prima, ciascuna immagine può avere diverse informazioni associate a ciascun pixel. Un’immagine in bianco e nero avrà un solo dato associato ad ogni pixel, pertanto un unico canale, le immagini a colori possono averne tre (un numero intero che rappresenta il totale di rosso, di verde e di blu, se si lavora nello spazio tridimensionale RGB) o quattro (una informazione addizionale contenente la trasparenza dell’immagine). Dal punto di vista pratico saranno presenti tre (o quattro) matrici e, tramite un processo di sintesi additiva, si genererà una immagine a colori. ISTOGRAMMA DI COLORE Per poter calcolare l’istogramma di un’immagine è necessario richiamare la seguente funzione su Java: Imgproc.calcHist(List images, MatOfInt channels, Mat mask, Mat hist, MatOfInt hintSize, MatOfFloat ranges); La funzione prende numerosi parametri in ingresso. Tali parametri sono: • List images: l’insieme delle immagini di cui ci interessa calcolare l’istogramma di colore. • MatOfInt channels: parametro contenente il numero di canali (dims) dell’istogramma. • Mat mask: a volte può essere d’interesse applicare una maschera a ciascun’immagine, ovvero considerare solamente una porzione dell’area totale dell’immagine. La maschera è anch’essa rappresentata con un oggetto Mat, in quanto è a tutti gli effetti una matrice. • Mat hists: un altro oggetto Mat nel quale verranno memorizzate le informazioni sull’istogramma analizzato. • MatOfInt hintSize: oggetto contenente il numero di bins dell’istogramma.. • MatOfFloat ranges: conterrà il range dei valori dell’istogramma. 25
ORB Per quanto riguarda l’implementazione dell’algoritmo ORB sul software Android, a differenza del metodo descritto per l’istogramma di colore, il descrittore ORB lavora sull’intera immagine e semplifica in modo netto il lavoro dietro all’estrazione delle features. Tale semplificazione, tuttavia, è solo dal punto di vista teorico, in quanto il tempo per l’estrazione del Feature Vector con tale descrittore è nettamente maggiore rispetto al tempo impiegato dall’istogramma dei colori a causa del calcolo dei punti chiave. Il metodo con cui sono estratte le features tramite descrittore ORB sarà trattato nel prossimo capitolo. 26
CAPITOLO 6 IMPLEMENTAZIONE 27
6.1 – INTRODUZIONE Il seguente capitolo è incentrato sul lavoro svolto per implementare il Relevance Feedback, oggetto principale della tesi discusso nel precedente capitolo, in un’applicazione per sistema operativo Android basata su CBIR. Poiché tutti i dispositivi mobili hanno capacità computazionali decisamente limitate rispetto ai moderni computer desktop, ho lavorato all’ottimizzazione del codice per riuscire ad eseguire i calcoli necessari con la minore richiesta di risorse possibili. Il Relevance Feedback è stato applicato su due diversi tipi di descrittori: l’istogramma di colore, il migliore per l’analisi della distribuzione dei colori in un’immagine, e l’ORB, il più leggero nel suo genere per l’estrazione dei punti chiave dalle immagini. Nell’app l’utente ha possibilità di scegliere quale descrittore adottare per l’analisi delle immagini, nonché la possibilità di scegliere la visualizzazione più adatta dei risultati alla fine di ciascuna iterazione. Il processo di catalogazione delle immagini basato sul Relevance Feedback, come accennato pocanzi, è un processo iterativo, ovvero un procedimento per cui si arriva al risultato attraverso la ripetizione di una serie di operazioni. Un processo iterativo, fissate le condizioni iniziali, è in grado di ripetere le operazioni descritte nel suo algoritmo all’infinito se non si pongono certi limiti o si fissa un risultato desiderato. Ai fini della tesi, tale risultato è rappresentato dalla catalogazione di un numero minimo di immagini rilevanti. Una condizione soddisfacente può essere rappresentata da un insieme di dieci immagini rilevanti per ciascuna immagine scelta come query. 6.2 – INTERFACCIA GRAFICA All’avvio dell’app sarà visualizzata la seguente schermata, che rappresenta la Activity principale: Figura 15: Main Activity dell'applicazione CBIR 3. L’Activity principale (Main Activity) è pertanto suddivisa in quattro principali blocchi, come è possibile vedere nella figura 15. Nel primo blocco (indicato con la lettera A) viene proposto all’utente di scegliere il descrittore da usare per l’analisi delle immagini. A disposizione, come già accennato nell’introduzione, sono presenti due tipi di descrittori: l’istogramma di colore e l’ORB. Nell’app è stata implementata la possibilità di combinare tali 28
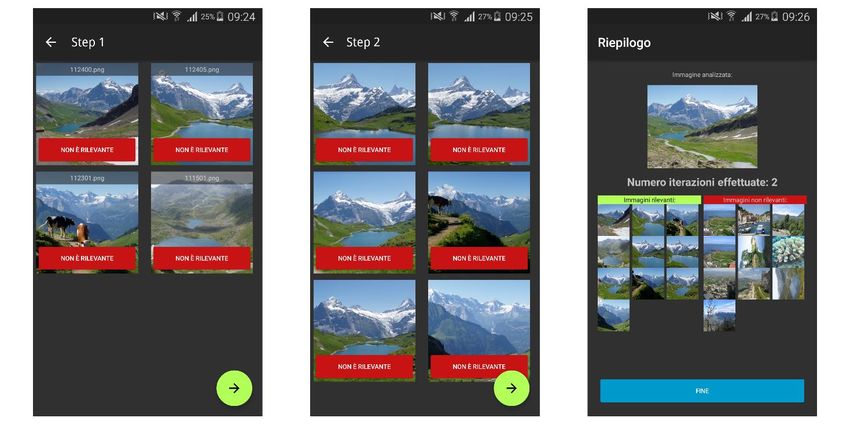
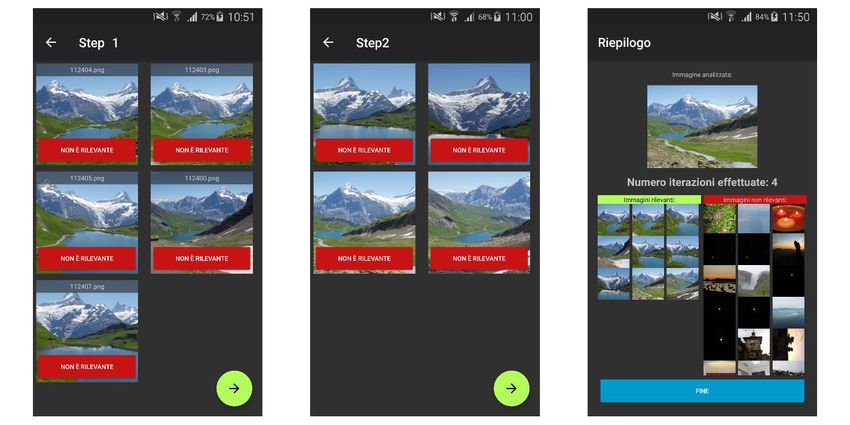
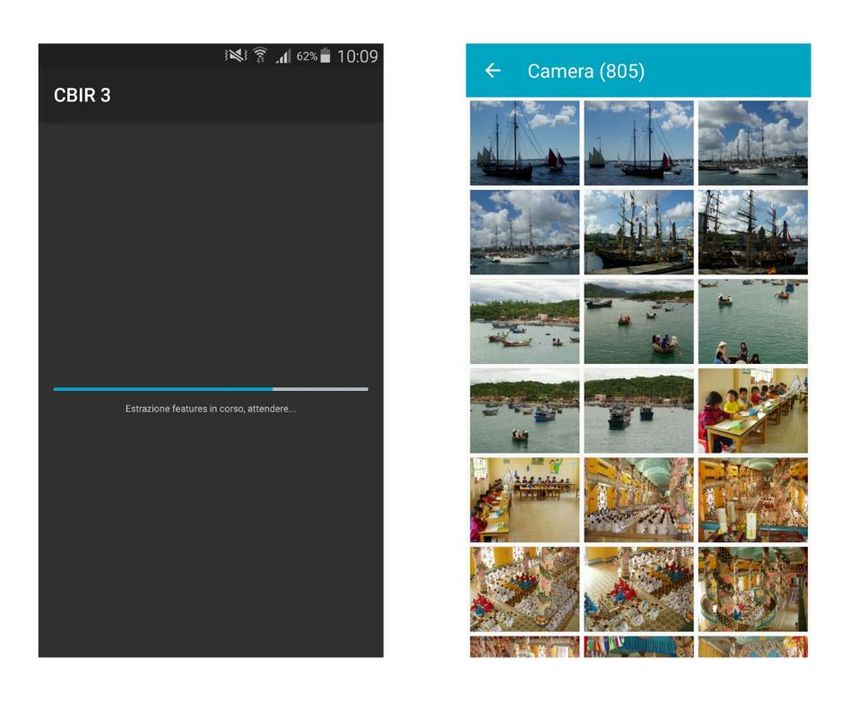
descrittori tramite un elemento grafico chiamato “SeekBar”. Trascinando il pallino è possibile regolare manualmente la percentuale di ciascun descrittore. Nel secondo blocco (B) è proposto il metodo di visualizzazione dei risultati. È possibile scegliere fra due diverse modalità: • Expert: tramite la seguente modalità verranno visualizzate esclusivamente le immagini non ancora catalogate. Le immagini già etichettate come rilevanti (e non rilevanti) vengono tenute in memoria e verranno mostrate solamente al raggiungimento del numero minimo di rilevanti prefissato. In questo modo il processo che permette la catalogazione risulta più rapido. • Friendly: In quest’altra modalità verranno visualizzati anche i risultati già inseriti fra quelli rilevanti, che saranno posti in cima (avranno infatti il massimo valore dello score, cioè pari ad uno). Tale modalità risulta più familiare all’utente, che riscontrerà sin da subito i risultati del Relevance Feedback, tuttavia saranno necessarie più iterazioni per riuscire a determinare un numero accettabile di immagini rilevanti. Infatti, il numero di immagini mostrate all’utente è fissato ed è pari a dieci. Per tale motivo il totale di immagini non ancora catalogate sarà limitato al numero delle precedenti non rilevanti. Il blocco C è un elemento descrittivo, detto TextView, posto all’interno di un elemento padre chiamato CardView, che ha il compito di spiegare all’utente il funzionamento delle due modalità. Tale blocco, al variare della modalità scelta, cambierà il testo contenuto all’interno del TextView. L’ultimo dei blocchi, ovvero il blocco D, avvierà l’estrazione delle features dal database secondo il descrittore scelto, per poi, al termine di quest’operazione, far selezionare all’utente una immagine, che verrà adottata come immagine di query. Figura 16: Schermata per l'estrazione delle features (a sinistra) e di scelta della query (a destra). 29
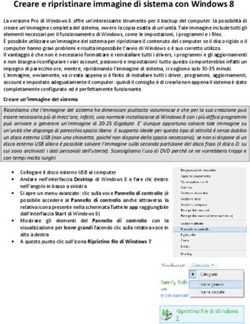
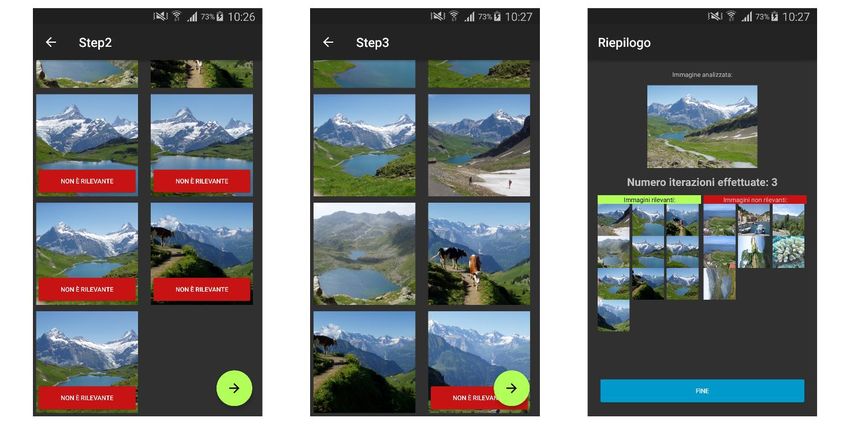
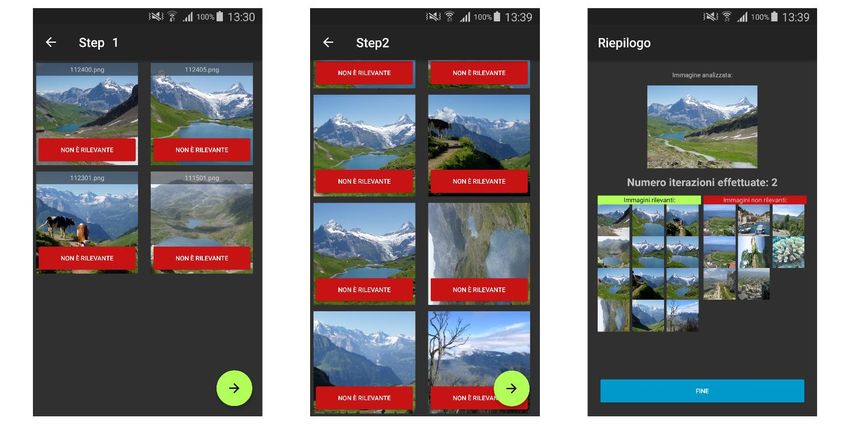
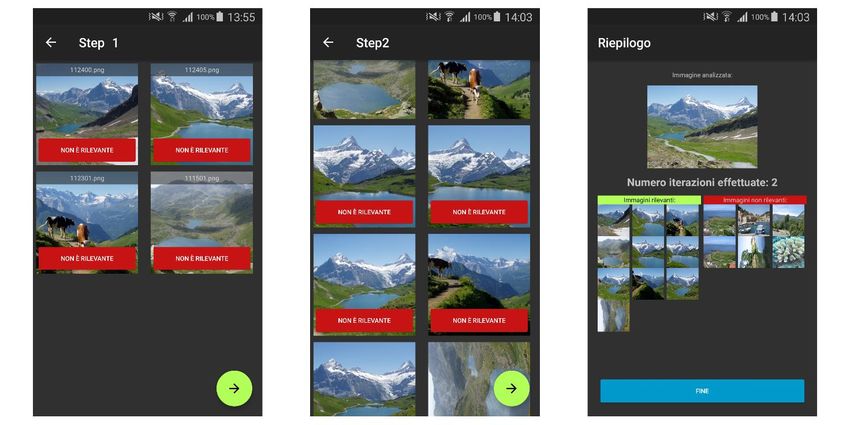
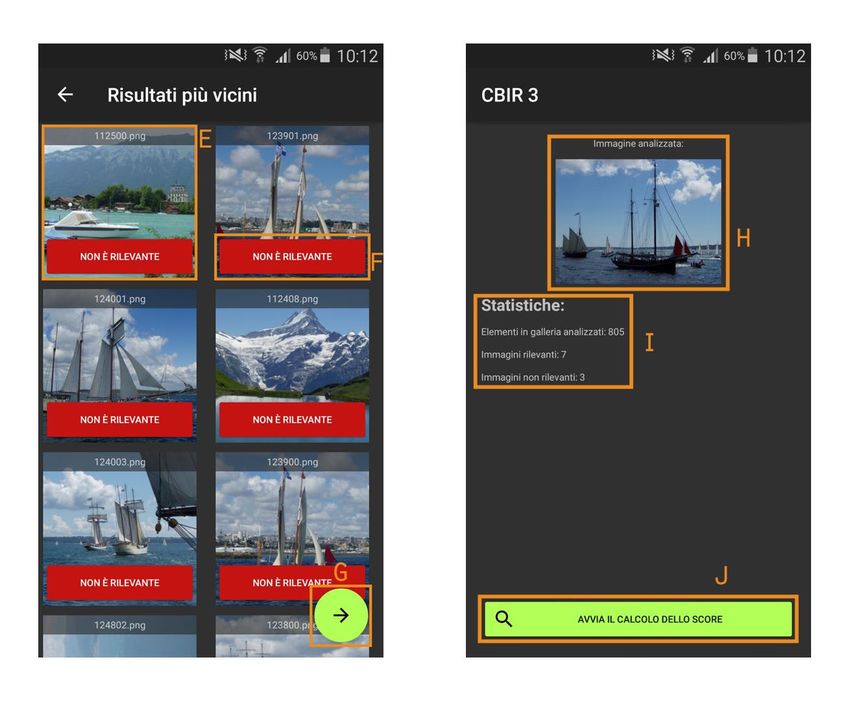
Successivamente alla scelta della query, l’app avvierà la comparazione delle features rispetto alla immagine selezionata precedentemente. Tale processo genererà un valore per ciascuna immagine analizzata che rappresenta la distanza di una specifica immagine del dataset rispetto all’immagine di query. I risultati di questo processo verranno riordinati in ordine ascendente (dal valore più piccolo al valore più grande), per poi mostrare all’utente i dieci risultati più vicini, in termini di distanza basata sul descrittore scelto, all’immagine scelta. A tal punto verrà visualizzata una nuova Activity, mostrata nella figura 16. Figura 17: Activity che mostra i risultati più vicini all’immagine di query (a sinistra) e schermata di riepilogo (a destra) In questa nuova Activity si inviterà l’utente a selezionare, tramite un apposito tasto rosso (elemento F della figura) presente in ciascuno dei risultati proposti (elemento E), quali immagini egli considera come non rilevanti. Tutte le immagini non catalogate come non rilevanti verranno automaticamente catalogate come rilevanti alla pressione del Button verde (elemento G). Prima di poter analizzare nuovamente le immagini basandosi sullo score, viene proposta all’utente una schermata di riepilogo che fornisce informazioni su quante immagini sono state catalogate (elemento I), sino a quel momento, come rilevanti e non rilevanti, nonché mostrare l’immagine scelta come query (elemento H). L’utente a questo punto potrà avviare il calcolo del Relevance Score tramite il Button posto in basso (elemento J). Verrà pertanto riproposto lo stesso meccanismo di visualizzazione dei risultati e di riepilogo (visto in Fig. 17) fino a che non saranno state etichettate un minimo di 10 immagini come “rilevanti”. 30
Puoi anche leggere