Sistemi Operativi - robertomana.it
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Sistemi Operativi
Rev. Digitale 1.0 del 01/09/2016
Architettura dei Sistemi Operativi ……………………………..………... 2
Introduzione ……………………….………………………………..……… 2
Classificazione ed evoluzione dei Sistemi Operativi ……..…………………. 3
Il Kernel di un SO : il modello Onion Skin ……..……………..……………. 4
Interrupt e System Call ……..……………..…………………………………. 6
SO monolitici e microkernel ……..……....…………………………………. 7
La Gestione delle Memorie di Massa : il File System ……….………... 9
Formattazione Fsica ………….……….…………………………………. 9
Codici di Rilevazione e Correzione degli errori .…………………………. 9
Partizionamento………………………………….…………………………. 11
Formattazione Logica: il File System ……………………………………. 12
Il File System Manager …………………………………….……...……… 13
La Gestione dei volumi …………………………………….……...……… 14
La Gestione fisica dei files ………………………………….……...……… 16
FAT ………………………………………………..……….……...……… 17
EXT2 / EXT3 ………………..……………………..……….……...……… 20
NTFS …………..…………………………………..……….……...……… 22
ISO 9660 …………..………………………………..……….……...……… 23
La Gestione dei Processi …………………….…………………..………... 24
Gli Stati di un processo …………....………………………………..……… 25
Le tre tipologie di scheduler ……....………………………………..……… 26
Algoritmi di scheduling dei processi …...…………………………..……… 28
Thread ……....………..………………………..…………………..……… 31
Cenni sugli schedulatori nei principali SO ………………………………… 32
Inter Process Comunication ……………….…………………..………... 33
Sezioni critiche e Mutua Esclusione ……..……………….………..……… 33
Semafori e Primitive semaforiche ……....…………………..……..……… 35
La Sincronizzazione fra processi …………..……….……………..……… 37
Shared Memory ……....………..……………....…………………..……… 38
Deadlock ……....………..……………....…………………………..……… 40
La Gestione della Memoria ……………….…………………..…………... 41
Tecniche di allocazione contigua ……..…………………………...……… 42
Allocazione non contigua: paginazione ……..……………………...……… 43
Allocazione non contigua Segmentazione paginata …...…………….…… 44
Paginazione dinamica …....………………………………………………… 45
Strategie di paginazione dinamica …...……………………………….…… 46
Gestione delle memorie cache ……………………………………………... 49
Gestione della memoria nell‟architettura IA32 ……..…………..………... 50
La Gestione delle Periferiche …………….…………………..…………... 53
Accesso diretto e accesso tramite Device Driver ……..…………...……… 54
Device Driver di tipo concorrente ………………………………………….. 56
La comunicazione seriale ………………………………………………….. 58
Gestione della porta seriale in dot Net …………………………………….. 60
pag 1Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Architettura dei Sistemi Operativi
Definizione di Processo
Si definisce processo l’istanza di un programma caricato in memoria centrale e in esecuzione su un certo
insieme di dati. Ogni programma può generare più processi indipendenti (tramite le funzione fork o spawn).
Istanza significa allocazione dinamica (in continua evoluzione) di un programma, che viceversa è una entità statica.
Due istanze di word aperte su file differenti possono essere viste come due processi separati.
I termini task e job sono sinonimi di processo. Il processore è il dispositivo che esegue il processo.
Definizione di File
Archivio elettronico, cioè archivio di dati memorizzati su un supporto elettronico (memoria di massa).
Definizione di Risorsa
Si definisce risorsa di un computer un qualunque componente hardware e software che può essere utilizzato da un
processo in esecuzione e che ne condiziona l‟avanzamento (CPU, memoria, dispositivi di IO e relativi driver, ma
anche, ad esempio, i files di un disco).
Definizione di Sistema Operativo (SO)
Il SO un software di base mirato alla gestione delle risorse hw e sw presenti un personal computer, facendo in
modo che un utente possa utilizzare la macchina nel modo più semplice ed efficiente possibile.
Il SO, mediante un vasto insieme di funzioni e procedure, esegue una virtualizzazione della macchina, mostrando
all‟utente una machina virtuale “più bella” e molto più semplice, i cui componenti sono simulati sulla base del
calcolatore reale. Più in dettaglio si possono individuare i seguenti obiettivi fondamentali:
Gestione delle risorse hardware della macchina mostrando all‟utente un’immagine astratta delle risorse
disponibili, nascondendo i dettagli dell‟hardware ed esponendo un insieme di funzioni dette primitive (es le
API di Windows) che il programmatore può utilizzare nei suoi programmi. Grazie all‟astrazione realizzata dal
SO, due macchine utilizzanti hardware differenti ma lo stesso SO sono viste dall‟utente allo stesso modo.
Questo costituisce il primo passo verso la portabilità dei programmi. Modifiche o upgrade sull‟hardware
(cambio di monitor, stampante, modem, HD) vengono “assorbite” dal SO senza modifica delle applicazioni.
Gestione delle applicazioni utente : dal caricamento dei programmi in memoria alla loro esecuzione, evitando
che un processo possa accedere ad aree di memorie esterne rispetto a quelle di sua competenza, ed evitando
eventuali conflitti fra processi che tentano di utilizzare una medesima risorsa (ad esempio devono entrambi
accedere alla stampante o ad uno stesso file).
Implementazione di una interfaccia utente semplice e funzionale, attraverso la quale l‟utente possa interagire
con il SO (e quindi con la macchina) ed inviare i propri comandi all’interprete dei comandi del SO (in
inglese shell). L‟interfaccia utente può essere
- di tipo CLI (Command Line Interface) cioè a linea di comando, es DOS, sessioni TTY di Linux)
- di tipo GUI (Graphical User Interface) cioè tale da consentire l‟accesso al sistema tramite un insieme di
elementi grafici (finestre, icone e menù) con il puntamento mediante mouse. Sono oggi sempre più ricche di
funzionalità e user friendly, cioè facili da usare, anche da parte di personale non specializzato.
Realizzazione di un meccanismo di protezione e sicurezza nell‟accesso ai dati. Ogni utente deve poter
accedere ai propri dati con la possibilità di concedere/ negare l‟accesso anche agli altri.
Poiché un SO non può conoscere a priori i dettagli hardware di ogni possibile dispositivo presente sul mercato, è
indispensabile che ogni dispositivo sia dotato di un apposito software denominato “device driver” (pilota del
dispositivo) e che il SO, in qualunque momento, possa essere “ampliato” con l‟installazione di un nuovo driver. Il SO
deve essere in grado di installare correttamente il driver in modo tale che non si creino conflitti con dispositivi
preesistenti, assegnandogli ad esempio un numero di interrupt libero ed aggiornando la propria Interrupt Vector Table
pag 2Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Portabilità di un programma
Un software si dice portabile quando può essere compilato ed eseguito indipendentemente sia dalla
piattaforma hardware sottostante, sia dal SO stesso.
L‟indipendenza dell‟hardware viene assicurata dal SO: i software applicativi non comunicano con l‟hardware
ma con il SO
L‟indipendenza del SO è più difficile da realizzare. Occorre che i vari SO mettano a disposizione delle
applicazioni client le stesse chiamate di sistema (detta System Call), realizzate internamente in modo
differente, ma che presentano al programma sorgente (testuale) la stessa firma. Il primo esempio di software
portabile è stato JAVA che ha introdotto il concetto di un ulteriore substrato di interfacciamento fra
Applicazione utente e SO, cioè la Virtual Java Machine. Per poter eseguire un programma JAVA su una
certa macchina occorre installare sulla macchina la Virtual Java Machine relativa al SO in uso e che con esso
si interfaccia. Dopo di che l‟applicazione finale non comunica più con il SO, ma soltanto con la Virtual Java
Machine, che gli espone le stesse primitive di interfacciamento in modo indipendente dal SO sottostante
Classificazione ed evoluzione dei SO
Sistemi Dedicati
I sistemi di elaborazione, nella loro struttura iniziale, erano in grado di gestire un solo processo per volta,
completamente residente in memoria a cui erano destinate tutte le risorse a disposizione. Il SO ha lo scopo di gestire
caricamento, inizializzazione e terminazione del programma, oltre che fornire supporto base per l‟accesso
all‟hardware. Anche i primi Personal Computer erano sistemi dedicati (ms DOS), mono utente e single task.
Sistemi Batch Sequenziali
Fin dagli anni 60 apparve evidente che era inaccettabile che un sistema di elaborazione dal costo estremamente
elevato fosse a disposizione di un unico utilizzatore che occupava tempo macchina con lunghe e onerose procedure di
caricamento del programma. Nacquero così i primi sistemi batch, cioè sistemi di elaborazione a lotti, in cui i vari
lavori (job) caricati tramite schede da utenti diversi (ciascuno con il proprio UID), venivano poi uno alla volta
caricati in memoria centrale dal SO ed eseguiti in rigida sequenza.
Se un job andava in errore veniva terminato e si passava immediatamente al job successivo. L‟utente non ha
interazione con l‟elaboratore. Pur essendo i sistemi batch ormai caduti in disuso, il termine batch è ancora oggi
utilizzato per indicare una qualunque sequenza di comandi da eseguire uno dopo l‟altro (file .BAT del DOS).
Sistemi Batch Multiprogrammati (multitask non preemptive)
In un sistema di elaborazione la risorsa più importante, sia come capacità di elaborazione sia come costo, è la CPU.
Nei sistemi batch il processore risultava decisamente sottoutilizzato in quanto doveva spesso fermarsi per attendere
l‟esecuzione delle operazioni di IO, infinitamente più lente rispetto ai tempi di elaborazione di CPU. Nacque così
molto presto il concetto di multiprogrammazione che consiste nel caricare simultaneamente più programmi in
memoria centrale, ciascuno all‟interno di una sua ben precisa zona di competenza. Quando un processo si arresta per
eseguire una operazione di IO viene avviato il processo successivo. Il processo sospeso potrà riprendere la propria
attività nel momento in cui il nuovo processo termina o richiede a sua volta una operazione di IO.
A livello di terminologia il termine task sostituisce il termine job. Pur essendo sostanzialmente dei sinonimi,
il termine job indica stretta sequenzialità, mentre task indica parallelismo.
Il termine non preemptive significa che i sistemi batch multiprogrammati erano non prelazionali, nel senso
che il SO non aveva la prelazione, cioè la facoltà, (il diritto) di interrompere un processo a meno che questo
non decidesse spontaneamente di fermarsi per eseguire una operazione di IO.
pag 3Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Sistemi multitask time sharing
Si tratta di sistemi in grado di eseguire più task in parallelo, assegnando alternativamente ad ognuno di essi
una porzione di tempo detta TIME SLICE (quanto di tempo): Un task può sospendere la propria attività
Di sua volontà, perché deve eseguire una operazione di IO
Contro la propria volontà, perché è scaduto il suo time slice.
Si tratta appunto di un sistema preemptive, in quanto il SO ha la prelazione (facoltà , diritto) di interrompere un
processo dopo un certo tempo di esecuzione, anche contro la volontà del processo stesso.
Grazie al time sharing, è come se ogni processo avesse una macchina virtuale completamente dedicata.
Il Time Sharing nasce con i grandi mainframe degli anni 70 (VAX) in cui gli utenti erano collegati all‟elaboratore
centrale tramite semplici terminali utente. Poiché gli utenti operano con tempi molto più lunghi rispetto ai tempi di
CPU, si crea nell‟utente l‟illusione di avere tutto il sistema a propria disposizione.
Notevole appesantimento del SO, che deve continuamente eseguire dei Context Switch da un processo all‟altro, cioè
Memorizzare lo stato del processo corrente (in modo da poterlo poi riprendere da dove era arrivato)
Caricare in CPU lo stato del nuovo processo, aggiornando le pipiline
Occorre inoltre gestire i problemi di condivisione delle risorse disponibili, gestendo eventuali conflitti che possono
sorgere per l‟assegnazione di una risorsa a diversi processi in esecuzione parallela
Concetto di System Overhead
Nel time sharing il tempo di CPU non è più interamente utilizzato per l‟esecuzione dei programmi utente, ma viene
ripartito fra questi e le routine del SO. Cioè parte del tempo di CPU viene “sprecato” per l‟esecuzione del sistema
operativo anziché dedicato all‟esecuzione dei programmi utente, diminuendo l’efficienza del processore.. Il System
Overhead rappresenta appunto la percentuale di tempo di CPU utilizzato per l‟esecuzione del SO rispetto al tempo
utilizzato per l‟esecuzione dei processi utente.
Sistemi multi user
Fin dai primi sistemi batch era già presente il concetto di sistema multiuser, in cui job eseguiti sequenzialmente
potevano comunque appartenere proprietari diversi. Anche i sistemi time sharing tipo VAX erano multiuser.
Per quanto riguarda invece i Personal Computer, DOS è single user. Anche Windows è tipicamente single user,
tranne che nelle ultime versioni XP e Vista. UNIX e LINUX sono invece per loro natura sistemi multi user, in cui più
utenti possono aprire sessioni parallele ed eseguire parallelamente processi differenti.
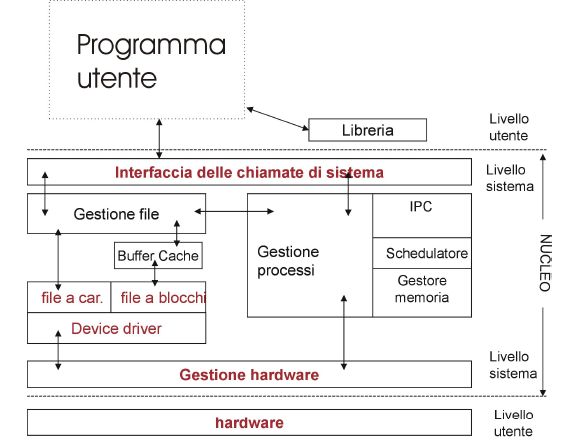
Il Kernel di un SO
Un SO in prima analisi può essere suddiviso in due parti principali:
Il kernel (nocciolo), che costituisce il cuore del SO. Esso comunica direttamente con l‟hardware e si occupa della
gestione dei processi fornendo loro un accesso sicuro e controllato alle risorse hardware della macchina.
Il kernel viene caricato in memoria centrale al momento dello start up della macchina e vi risiede per tutta la
durata del funzionamento del PC.
La shell dei comandi, che funge da interfaccia tra kernel e utente, consentendo all‟utente di poter lanciare in
esecuzione allo stesso modo qualsiasi tipo di programma, anche programmi molto differenti fra loro.
La shell può essere di due tipi: CLI o GUI. Nel caso del CLI il SO presenta un semplice PROMPT in
corrispondenza del quale l‟utente digita i comandi in modalità testuale. Nel caso della GUI l‟utente interagisce
tipicamente con icone e immagini visualizzate sullo schermo. Molto più amichevole. La maggior parte dei SO
mettono a disposizione entrambe queste interfacce. Nel caso di Linux l‟interfaccia GUI è detta Desktop
Manager (es Gnome, KDE, OpenBox). UNIX è stato il primo SO a introdurre il concetto di interfaccia utente
(shell) come processo esterno al kernel, con la possibilità di cambiare shell senza dover ricompilare il kernel.
Insieme alla shell, il SO rende di solito disponibili anche un insieme di utility aggiuntive come un editor di testi
(es vi nel CLI o gedit nella GUI). Nei sistemi Unix / Linux anche il compilatore C fa parte delle Utilità del SO
pag 4Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Il modello Onion Skin
Modello proposto nel 1983 da H. Deitel. Fornisce una rappresentazione modulare gerarchica (Onion Skin, cioè a
buccia di cipolla) su come dovrebbe essere strutturato il kernel di un SO, cioè suddiviso in 4 moduli che
rappresentano le quattro principali funzionalità del SO :
Gestore dei Processi
Gestore della Memoria
Gestore delle Periferiche
Gestore del File System
Gestore Gestore delle
Gestore periferiche di File Shell e
dei della
memoria IO System Utility
processi
kernel
Nella gerarchia onion skin il centro è costituito dall‟hardware ed ogni livello comunica soltanto con i livelli adiacenti.
Compito di ogni livello è quello di fornire servizi al livello superiore ed è visibile dal livello superiore soltanto
attraverso un insieme ben definito di funzioni dette primitive.
Primitive di un kernel
Sono dette primitive tutte quelle funzioni che costituiscono il kernel di un SO e che ogni modulo del kernel espone
ai livelli superiori (che possono essere altri moduli del kernel, la shell o direttamente i processi utente).
Sono normalmente scritte in linguaggio C o nel linguaggio macchina specifico del processore in uso.
Il Gestore dei Processi si occupa di creare e cancellare i processi utente e i processi di sistema; mantenere
aggiornato lo stato dei vari processi e del processore; decidere a quale processo assegnare il processore e per quanto
tempo. Gestisce inoltre la comunicazione fra i vari processi. Al sopra di questo livello i processi vedranno ciascuno
un proprio processore virtuale completamente dedicato.
Il Gestore della Memoria si occupa di mantenere uno stato della memoria; assegnare ai vari processi un apposito
spazio in memoria (assicurandosi che i vari processi non possano, per errore o per volontà, andare ad operare nelle
aree di memoria dedicate ad altri processi o al SO); liberare spazio in memoria quando è piena. Al di sopra di questo
livello gli altri livelli vedranno una unica area di memoria completamente dedicata al processo. Se un processo
tenta di accedere ad un‟area esterna a quella di sua competenza viene generato un interrupt di sistema (trap)
Il Gestore delle Periferiche si occupa di mantenere aggiornato lo stato di tutte le periferiche e dei dispositivi di
controllo; virtualizzare le risorse, facendo in modo che ogni processo veda la risorsa tutta per se; gestire il mapping
tra risorsa reale e risorsa fisica. In realtà il processo dispone di risorse virtuali che il SO simula servendosi delle
risorse del calcolatore reale. Ad esempio la tecnica di spool (Simultaneus Peripheral Operations On-line) consente al
SO di scaricare temporaneamente su disco i dati destinati alla stampa, gestendo così una coda di stampa condivisibile
fra più processi. Un apposito modulo si occupa di inoltrare progressivamente la coda di stampa alla stampante.
Il Gestore del File System si occupa della gestione dei dischi. Deve mantenere traccia di tutti i file e diretory
memorizzati, cioè la loro dislocazione, la loro lunghezza, nonché i diritti di accesso su di essi; gestire l‟assegnazione
degli archivi ai vari processi; supportare primitive per la manipolazione di file e cartelle.
pag 5Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Pregi del modello Onion Skin Il pregio fondamentale è quello di individuare i 4 moduli fondamentali di un SO.
L‟elevata modularità del modello Onion Skin garantisce una notevole robustezza al SO che potrebbe facilmente
essere portato su macchine differenti sostituendo soltanto i moduli più interni che operano sull‟hw
Difetti del modello Onion Skin Il modello Onion Skin risulta estremamente carente dal punto di vista delle
prestazioni. Se ad es la shell necessita di servizi forniti dal Gestore dei Processi deve passare diversi confini.
L'attraversamento dei vari confini si traduce ovviamente in elevati tempi di risposta, in contrasto con il fatto che
il SO dovrebbe offrire un ambiente per l'esecuzione delle applicazioni il più efficiente e rapido possibile. Tutto
ciò che si contrappone a questa esigenza è detto sovraccarico (overhead). In una struttura onion skin l‟overhead
è massimizzato. Elevato overhead significa bassa efficienza.
Interrupt e System Call
Nei SO più datati non esisteva il concetto di System Call. I processi comunicavano con il SO soltanto attraverso i
cosiddetti Interrupt Software. Nei SO più moderni gli Interrupt Software entrano a far parte di un più ampio gruppo
di procedure messe a disposizione dal SO denominate System Call, cioè chiamate di sistema, che il processo utente
può utilizzare per richiamare una primitiva del kernel.
Le system call rappresentano lo strumento principale attraverso cui un processo utente comunica col kernel il quale a
sua volta comunica con l‟hardware (virtualizzazione dell‟hardware).
Ad esempio se si vuole stampare un file, invece che inviare i comandi fisici al gestore dell‟HD per la ricerca del file
e poi i relativi comandi fisici alla stampante, è sufficiente fare una System Call ad una apposita primitiva del SO
indicandogli quale file stampare e su quale stampante.
Il termine Interrupt è ora riservato soltanto più per gli interrupt hardware, generati dai dispositivi esterni per
avvisare la CPU riguardo alla terminazione di una certa operazione. In corrispondenza del sopraggiungere
dell‟interrupt, il SO avvia la Routine di Riposta all‟Interrupt (RRI), detta normalmente interrupt handler
Gli stati di un processore: Kernel Mode e User Mode
Tutti i processori Intel con architettura IA32 (a partire dal 80386 fino ai processori attuali) sono in grado gestire 4
livelli di protezione delle istruzioni (Kernel Mode, System Services, OS Extension, User Mode), cioè in sostanza ad
ogni istruzione è assegnato un livello di protezione e può essere eseguita soltanto da processi aventi un livello di
protezione uguale o superiore a quello dell‟istruzione. Scopo di queste protezioni è quello di impedire o consentire
l‟accesso a particolari aree di memoria in base allo stato del processore.
A tal fine le istruzioni del processore sono state suddiviso in due categorie: le istruzioni standard, eseguibili da
chiunque in ogni momento, e le istruzioni privilegiate che interagiscono con il sistema (ad es le istruzioni IN e
OUT) che possono essere eseguite soltanto in particolari condizioni. In corrispondenza si possono individuare 2 stati
del processore: uno stato utente (user mode) in cui è consentita soltanto l‟esecuzione delle istruzioni standard, ed
uno stato supervisore (kernel mode) con diversi livelli di privilegio in cui è consentita qualunque istruzione.
Un processo utente, normalmente, viene avviato con un livello di protezione pari a “user mode”. Nel momento in cui
il processo esegue una System Call al SO, il SO provvede ad eseguire un Mode Switch (cambio di modo) del
processore elevandolo dal livello user mode al livello kernel mode (modalità privilegiata), avviando il processo di
sistema richiesto. Terminato il processo di sistema, il SO provvede a riportare il processore in stato utente e
rassegnarlo al process utente In questo modo solo i processi di sistema possono utilizzare le istruzioni privilegiate
Esempio tipico di istruzioni privilegiate sono le istruzioni IN e OUT che possono essere eseguite soltanto in kernel
mode in modo da evitare che il programma utente possa eseguire un accesso diretto e incontrollato all‟hardware della
macchina. Per cui, per poter eseguire le istruzioni IN e OUT, il programma utente dovrà necessariamente eseguire
una System Call ai driver del SO i quali, soltanto loro, potranno eseguire le istruzioni IN e OUT sui registri di IO.
Per comunicare con dispositivi del quali non si dispone del driver occorre scriverselo o reperirlo su Internet.
Ad esempio i SO attuali non contengono più il driver relativo alla porta parallela, ritenuta ormai obsoleta. Per cui,
volendo comunicare con la parallela in ambiente Windows occorre necessariamente realizzare un apposito driver.
pag 6Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Sistemi Operativi monolitici
Un SO monolitico è composto da un insieme di moduli e procedure tutte compilati insieme e caricate all‟interno dello
stesso spazio di memoria. Ogni funzione ha una ben definita interfaccia (in termini di parametri e risultati) e può
indifferentemente chiamare tutte le altre in qualsiasi momento ne abbia bisogno.
Per costruire un sistema operativo monolitico occorre compilare tutti i vari moduli e poi collegarli insieme mediante
il linker in un unico file eseguibile di sistema. Anche se ogni modulo è normalmente separato dal resto
(programmazione modulare), l'integrazione del codice è comunque molto stretta.
Il programma utente può accedere ai servizi forniti dal SO tramite speciali istruzione di trap, le System Call, che
cambiano la modalità della macchina da user mode a kernel mode trasferendo il controllo al sistema operativo.
I parametri da passare al SO vengono posizionati in locazioni ben definite (tipicamente i registri di CPU o lo stack).
Pregi: Quando l'implementazione del sistema è completa e sicura, la stretta integrazione interna dei componenti
rende un buon kernel monolitico estremamente efficiente e veloce.
Difetti: 1) Siccome tutti i moduli operano nello stesso spazio di memoria, un bug in uno di essi può bloccare
l'intero sistema. 2) Ma lo svantaggio principale dei kernel monolitici è tuttavia che non è possibile aggiungere
un nuovo dispositivo hardware senza aggiungere il relativo modulo al kernel, operazione che richiede la
ricompilazione del kernel. I kernel monolitici contengono solitamente al loro interno i driver relativi a tutti
i principali dispositivi hardware presenti sul mercato.
Esempio di sistema monolitico: il kernel di Unix
In figura è riportato uno schema a blocchi semplificato del kernel monolitico di Unix.
Quello che un utente vede del kernel è la system call interface, interfaccia che traduce le richieste esterne (ovvero le
invocazioni alle system call) in opportune procedure di sistema. La fig suddivide le System Call in due gruppi: quelle
che interagiscono con il modulo di gestione dei file e quelle che interagiscono con il modulo di gestione dei processi.
Un punto di forza di Unix è che gran parte dei comandi sono realizzati a livello utente per mezzo di applicazioni
che usano le chiamate di sistema e che non fanno parte del SO. Trattandosi di programmi estremamente efficienti,
diventa abbastanza semplice scrivere applicazioni interpretate (script di shell) come estensione dei comandi del SO.
pag 7Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Microkernel e Modello client-server
L'approccio microkernel consiste nel definire delle macchine virtuali molto semplici sopra l'hardware, con un set di
primitive per implementare servizi minimali quali semafori, gestione dei thread, spazi di indirizzamento o
comunicazione interprocesso, spostando quanto più possibile il codice di sistema verso i livelli superiori con un
kernel minimale. L'approccio consueto consiste nell'implementare molti servizi di sistema all'interno di processi
esterni al kernel. Per richiedere un servizio, come la lettura di un blocco di un file, un processo utente (chiamato ora
processo client) invia la richiesta a un processo server esterno al kernel che effettua il lavoro e ritorna la risposta.
In questo modello il kernel, dovendo solo gestire la comunicazione tra processi client e server, diventa estremamente
leggero e si limita a svolgere la funzione di Gestore dei Processi, demandando gran parte delle altre
funzionalità a moduli esterni che vengono caricati in memoria soltanto al momento della necessità (soprattutto i
driver). Inoltre un servizio non funzionante non provoca il blocco dell'intero sistema, ma il singolo servizio può
essere riavviato indipendentemente dal resto
Nota: Un altro vantaggio del modello client-server è la sua adattabilità all'utilizzo in sistemi distribuiti. Se un client
comunica con un server inviandogli messaggi, il client non ha bisogno di sapere se il suo messaggio viene gestito
localmente sulla macchina o se viene inviato ad un processo server su una macchina remota. I processi server
possono girare anche su macchine con altri SO dal client. Unica differenza è che nei sistemi distribuiti il kernel non
può occuparsi solo del traffico dei messaggi ma deve saper gestire la comunicazione con altri nodi della rete
Monolitico o microkernel ?
Sia Unix che Linux utilizzano sostanzialmente un kernel monolitico, molto più modulare nel caso di Linux, scritti
entrambi prima che fosso dimostrato che i microkernel puri potevano comunque avere performance elevate
confrontabili con quelle dei kernel monolitici. Comunque è tutt‟ora aperta la disputa sul fatto che sia migliore il
sistema monolitico o il microkernel. Il progetto di Linux nato come kernel monolitico anziché come microkernel è
stato uno degli argomenti della famosa guerra di religione fra Linus Torvalds (creatore di Linux) e Andrew
Tanenbaum (celebre docente di SO, autore di Minix).
In ogni caso i kernel monolitici più moderni come il Kernel Linux e FreeBSD possono caricare dei moduli in fase di
esecuzione, a patto che questi fossero previsti in fase di compilazione, permettendo così l'estensione del kernel
quando richiesto e mantenendo al contempo le dimensioni del codice nello spazio del kernel al minimo
indispensabile. Non si tratta più di un kernel monolitici puri ma sostanzialmente di kernel ibridi.
Kernel ibridi
I kernel ibridi sono essenzialmente dei microkernel che hanno del codice "non essenziale" al livello di spazio del
kernel in modo che questo codice possa girare più rapidamente che se fosse implementato ad alto livello.
Compromesso adottato da molti sviluppatori di SO, in particolar modo Windows che introduce il concetto di DLL.
pag 8Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Gestione delle Memorie di Massa
Formattazione Fisica e Partizionamento
Struttura di un HD
L‟HD è costituito da un insieme di dischi rotanti su uno stesso asse e ricoperti di materiale magnetico.
Ogni faccia del disco contiene un insieme di tracce circolari concentriche e una apposta testina di lettura.
Le tracce corrispondenti sulle diverse facce costituiscono un cilindro
Le tracce sono suddivise in settori di dimensione fissa (typ 512 bytes) numerati sequenzialmente all‟interno della
traccia. I settori sono suddivisi da piccoli intervalli non magnetizzati detti gap
Formattazione Fisica
La Formattazione Fisica di un HD può essere ese4guita mediante formattatori di basso livello quali fdisk o Partition
Magic. Consiste essenzialmente nella creazione fisica di tracce e settori sul disco.
La Formattazione Fisica provvede a creare, per ogni settore :
una intestazione contenente indirizzo fisico del settore(numero d‟ordine del settore all‟interno della traccia)
e dimensione del settore stesso
una coda in cui verrà memorizzato un Controllo di Parità per le rilevazione e correzione degli errori.
La formattazione fisica determina univocamente la capacità del disco.
Ad es un disco con 6 Testine (cioè 3 dischi a doppia faccia), 1024 cilindri (cioè 1024 tracce per facciata), 36 settori
per traccia (da 512 bytes), ha una capacità fisica pari a 6 x 1024 x 36 x 512 = 113.246.108 bytes, cioè 108 MBytes.
Codici di Rilevazione e Correzione degli Errori
Controllo di Parità Semplice (Redundancy Check)
Si consideri un settore grande 512 bytes che può essere visto come una matrice di bit con 8 colonne e 512 righe.
Il metodo più semplice per controllare la presenza di errori all‟interno del settore è quello di aggiungere al fondo
della matrice un byte di parità verticale in cui viene scritto un 1 oppure uno 0 in modo da rendere pari il numero
complessivo di uni su ogni colonna.
Ogni volta che il settore viene aggiornato, viene aggiornato anche il byte di parità. Ogni volta che il settore viene
letto viene ricalcolato anche il byte di parità che viene confrontato con quello memorizzato al fondo del settore.
Se le due informazioni coincidono, i dati contenuti nel settore sono considerati validi,
altrimenti significa che i dati sono corrotti ed il sistema provvede a visualizzare un messaggio di errore.
Un sistema di questo tipo (con distanza 2 secondo la codifica di Hamming) :
è in grado di:Rilevare errori singoli ( o comunque un numero dispari di errori)
non è in grado di Applicare nessuna correzione
Controllo di Parità Incrociato
Il controllo incrociato consiste nell‟applicare 2 controlli di parità, uno in verticale ed uno in orizzontale. Cioè oltre al
byte di parità verticale viene aggiunta in coda anche una sequenza di 512 bit di parità orizzontale che controllano la
cortezza di ogni singolo byte. In questo modo, in caso di errore singolo, facendo l‟intersezione tra riga e colonna in
cui si riscontra l‟errore, è possibile eseguire una correzione automatica dell‟errore.
pag 9Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Un sistema di questo tipo (con distanza 4 secondo la codifica di Hamming) :
è in grado di:Rilevare con certezza fini a 3 error
è in grado di Correggere automaticamente 1 singolo errore
Controllo Polinomiale CRC (Cyclic Redundancy Check)
Gli N bit di un intero settore o pacchetto dati vengono considerati come i coefficienti di un polinomio P(x) da
dividere per un polinomio G(x), detto Polinomio Generatore, formato da una sequenza prestabilita di M bit:
agli N bit del pacchetto vengono aggiunti M-1 zeri;
il polinomio ottenuto viene diviso per il polinomio generatore
gli M-1 bit del resto così ottenuto sono accodati agli N bit del pacchetto (codice CRC).
In fase di lettura viene eseguita la divisione del pacchetto completo (lungo N + M bit) per G(x): se il resto è
nullo, presume che non vi siano stati errori, viceversa c'è qualche bit alterato e il pacchetto è rifiutato.
Scegliendo opportunamente il polinomio generatore, il metodo risulta molto affidabile, (l‟errore dovrebbe essere
esattamente multiplo di G(x)) e molto veloce in quanto il calcolo viene eseguito via hardware. Non è autocorrettivo.
Codici di Hamming
I vari codici di Hamming aggiungono più bit ridondanti ad ogni singolo byte, trasformando un codice di (n) bit, con
distanza uno, in un codice di (n + c) bit (dove c sono i bit aggiunti) con distanza superiore, in modo da poter
verificare e correggere più errori sul singolo byte. La rilevazione e l‟autocorrezione degli errori sarà tanto più
efficienti quanto maggiore è il numero di bit di ridondanza aggiuntii. Ovviamente la migliorata efficienza nel
controllo degli errori si paga con un notevole rallentamento nella lettura e trasmissione delle informazioni.
Indirizzamento fisico dei settori
L‟indirizzamento fisico dei settori può essere effettuato in due modi.
a) Mediante una terna C H S (cilindro, testina, settore). I cilindri sono numerati dall‟esterno verso l‟interno; le
testine dall‟alto verso il basso; i settori in verso orario, tutti a partire da 0. Storicamente nella letteratura
informatica la numerazione dei settori è fatta partire da 1, ma operativamente poi la partenza è riferita allo 0.
b) Mediante in numero progressivo crescente, detto LBA (Linear Base Address), che parte da 0 e segue le regole
precedenti (il primo settore LBA coincide con il primo settore CHS del cilindro più esterno sul disco più alto).
Nei dischetti da 3 ½ che hanno 80 * 2 * 18 = 2880 settori, gli indirizzi LBA vanno da 0 a 2779
Calcolo dell’indirizzo LBA a partire dalla terna CHS:
La numerazione lineare LBA è ottenuta partendo dalla traccia più esterna della prima faccia (su cui vengono
conteggiati tutti i settori), proseguendo poi sulla traccia più esterna della seconda faccia e così via fino al completo
scorrimento dell‟intero cilindro. Si passa quindi a considerare il secondo cilindro, scorrendo di nuovo tutte le tracce
dalla prima all’ultima faccia, e così via fino all‟ultimo cilindro più interno. La formula da utilizzare è la seguente:
LBA = ((C * NTESTINE + H) * NSETTORIxTRACCIA ) + S
Supponendo che il disco abbia 80 tracce per faccia (da 0 a 79), 2 testine (cioè due facce 0 e 1), 18 settori per traccia
(da 0 a 17) (dischetto da 3 1/2 ), l‟indirizzo lineare LBA del settore 16 del disco 0 del cilindro 3 può essere così
ottenuta :
LBA = ((3 * 2+ 0) * 18) + 16 = 124
Calcolo della terna CHS a partire dall’indirizzo LBA
Algoritmo noto come ASSISTED LBA, utilizzato dalle procedure di bootstrap per interpretare il contenuto del MBR
C = LBA / (NTESTINE * NSETTORIxTRACCIA ) = 124 /(2*18) = 3
resto = LBA % (NTESTINE * NSETTORIxTRACCIA ) = 124 % 36 = 16
H = resto / NSETTORIxTRACCIA = 16 / 18 = 0
S = resto % NSETTORIxTRACCIA = 16 % 18 = 16
pag 10Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Tempi di accesso ad un settore fisico
L‟accesso ai vari settori avviene facendo ruotare il disco e spostando radialmente le testine di lettura.
Il movimento di tutte le testine è controllato mediante un unico braccio meccanico ad altissima precisione.
Il tempo di posizionamento radiale delle testine sulla traccia è detto tempo di seek, e presenta oggi un valore medio
di 8 – 10 msec (inteso come metà del tempo massimo di spostamento fra i due estremi). Durante la lettura il disco è
in rotazione a velocità costante. Ad ogni passaggio la testina legge normalmente un singolo settore completo,
Il tempo medio per il posizionamento della testina su un settore (metà del tempo di rotazione completa) è detto
tempo di latenza che è comunque un tempo trascurabile rispetto al tempo di seek di posizionamento delle testine.
Partizionamento
Il partizionamento di un disco fisico consiste nella sua suddivisione in più unità logiche, dette volumi. I singoli
volumi sono visti come unità separate su cui è possibile applicare formattazioni logiche indipendenti. Due obiettivi:
Poter installare ed eseguire SO differenti su una stessa macchina
Creare partizioni dati separate, di facile backup ed accessibili anche in seguito ad eventuali “disastri” sul SO
MBR - Master Boot Record
Il primo settore fisico di un disco (cilindro 0, testina 0, settore 0) è detto MBR o Settore di Avvio. MBR non
appartiene a nessuna partizione ed è il settore che il BIOS, terminata la fase di POST ed eventuali istruzioni base,
provvede a leggere per caricare il SO dal volume indicato nella sequenza di boot. MBR contiene 2 informazioni :
Il Master Boot Program MBP che può avviare direttamente il SO oppure avviare una interfaccia utente
che consenta all‟utente di scegliere un SO (sistemi attuali sia Linux e Windows Vista, mentre XP avvia
direttamente se stesso, dunque deve essere installato per primo modificando poi MBP).
Una Tabella delle Partizioni articolata in 4 record contenenti una descrizione di ciascuna partizione
Le partizioni si suddividono in 2 gruppi:
Partizioni Primarie, referenziate direttamente nella Partition Table e in grado di avviare un SO
Partizione Estesa in grado di contenere fino a 24 partizioni logiche non avviabili.
Ogni disco può contenere al massimo 4 partizioni primarie oppure tre partizioni primarie ed una partizione estesa
suddivisibile (al massimo) in 24 sottopartizioni non avviabili.
Ogni partizione, primaria o estesa, (volume) contiene a sua volta uno speciale settore detto VBR Volume Boot
Record, costituito dal primo settore della partizione, creato in fase di partizione logica di alto livello e contenente
Nel caso delle partizioni primarie il codice di boot del SO
Una descrizione della struttura interna della partizione
Questa doppia struttura permette al BIOS di caricare qualunque SO indipendentemente dalla sua posizione sul disco.
Struttura di MBR (nel formato ereditato da FAT)
Primi 446 Bytes Master Boot Program (di cui i primi 30 relativi ai BIOS Parameters)
Successivi 66 Bytes Partition Table suddivisa in 4 record da 16 bytes ciascuno, contenenti rispettivamente le
informazioni relative alle varie partizioni
Gli ultimi 2 byte sono un identificativo di riconoscimento della fine del MBR e contengono il
valore AA55H (memorizzati secondo la convenzione little endian).
Il Master Boot Program effettua uno scan della tabella delle partizioni e localizza la prima partizione primaria
marcata con il flag di partizione avviabile (bootable - codice 80). Appena il codice dell'MBR trova una partizione
così marcata, viene letto in memoria il primo settore di tale partizione ed eseguito il codice presente in questo settore
che costituisce il vero e proprio boot sector, quello che in definitiva provvede ad avviare il SO presente.
Utilizzando come Master Boot Program un loader quale GRUB si può richiedere all‟utente quale SO avviare.
GRUB provvede a caricare in memoria il primo settore della partizione selezionata.
pag 11Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Struttura delle entry della Partition Table
Byte Contenuto
0 Indicatore di boot (contiene il valore 80H per le partizioni bootable, 0 per le altre partizioni)
1-3 Cilindro, Testina, Settore del primo blocco della partizione
4 Identificatore del filesystem contenuto nella partizione. 17=NTFS; 0B=FAT32 primaria; 0F=FAT32 estesa
5-7 Cilindro, Testina, Settore dell’ultimo blocco della partizione
8-11 Numero LBA del primo settore della partizione
12-15 Numero di settori che costituiscono la partizione
Per quanto concerne i campi Testina, Settore e Cilindro, si hanno a disposizione 3 byte suddivisi in 8 bit per le testine
(max 256), 6 bit per i settori (max 64) e 10 bit per i cilindri (max 1024). Indipendentemente dalla suddivisione, i 3
byte limitano comunque la dimensione max del disco a 16 Milioni di settori da 512 cioè 8 GB.
Al posto della terna CHS si possono utilizzare gli identificatori LBA contenuti negli ultimi 2 campi da 4 byte. I valori
LBA vengono poi convertiti dal SO nella terna CHS dall‟algoritmo ASSISTED LBA.
Gli identificatori LBA consentono una capacità massima del disco pari a 232 settori cioè 4 G settori cioè 2 TBytes.
che rappresenta il limite massimo della capacità di un HD gestito tramite il formato standard del MBR.
Formattazione Logica : il File System
La Formattazione Logica di un volume consiste nel definire il formato di memorizzazione dei file sul volume
stesso, cioè nel creare sul disco uno specifico File System (sistema di files).
Con il termine File System si intende l’organizzazione dei Dati su un certo volume. Definire un File System
significa definire l‟organizzazione dei dati sul volume.
Con il termine File System Manager si intende il modulo del SO che gestisce il File System,
In dettaglio definire un File System significa definire:
La dimensione dei blocchi logici, detti cluster, (grappolo), insieme di settori contigui il cui numero dipende
dal file system in uso. Il cluster rappresenta l’unità minima di allocazione logica su disco. Esso può
raggruppare un numero generico di settori (tipicamente 1, 2, 4 8). La dimensione del cluster è omogenea su
un certo volume, ma può variare fra volumi diversi utilizzati in uno stesso sistema.
Nota: Il raggruppamento in cluster viene di solito applicato soltanto al Blocco Dati e non ai settori iniziali
Una Tabella di Descrittori in cui vengono memorizzate le posizioni su disco di tutti i blocchi che
compongono ogni file.
Il File System Manager, tramite la Tabella dei Descrittori, gestisce l‟organizzazione del file all‟interno del disco,
mostrando all‟utente i vari file come un vettore continuo e lineare, esattamente come la memoria centrale. Fornisce
cioè un livello di astrazione nascondendo all‟utente sia la posizione fisica dei files su disco, sia i dettagli di lettura /
scrittura. La Tabella dei Descrittori consente al File System Manager di passare dalla rappresentazione logica
virtuale di un file (mostrato all‟utente come una sequenza continua di byte) ad alla rappresentazione fisica del file
su disco (cioè la reale posizione sul disco di tutti i vari blocchi che compongono il file) e viceversa.
Tra gli scopi del File System Manager
Tradurre gli indirizzi logici in indirizzi fisici (tramite l’apposita Tabella dei Descrittori)
Gestire lo stato di allocazione / deallocazione di tutti i vari cluster che costituiscono il volume
Gestire i diritti dei vari utenti sui vari file
Tipica Struttura di un File System
Tabella dei
VBR Root Directory Blocchi Dati .
Descrittori
pag 12Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
Il VBR è posizionato sul primo settore della partizione e contiene di solito le seguenti informazioni::
il Boot Program. Al momento dell'accensione della macchina un piccolo programma posto nella ROM
carica e manda in esecuzione il boot program relativo al volume di avvio, il quale carica il SO in RAM
Il tipo di File System utilizzato
La dimensione dei cluster
Il settore di inizio del blocco dati (posizione della Root Directory)
La Tabella dei Descrittori contiene i descrittori di tutti i files del volume. Ogni descrittore contiene i seguenti campi:
nome e tipo di file (testo, eseguibile, etc)
dimensione
uno o più puntatori ai cluster che compongono il files
data di creazione, data dell‟ultimo accesso, data dell‟ultima modifica
identificatore del proprietario (UID)
criteri di protezione del file (lettura / scrittura /esecuzione per proprietario, gruppo e altri)
Criteri di Dimensionamento dei cluster
Un qualsiasi file, per piccolo che sia, occupa sull‟HD sempre almeno un cluster. La dimensione del cluster può essere
impostata in fase di formattazione logica del disco. Spesso è decisa dal File System che si sta utilizzando.
Utilizzando cluster di grandi dimensioni (ad esempio 8 settori, cioè 4 kBytes) vengono migliorati i tempi di
IO in quanto ogni blocco trasferisce più informazioni, ma viene aumentata la cosiddetta frammentazione
interna del disco. Ogni file infatti occuperà sempre almeno 4 kBytes. Anche nei file di grandi dimensioni,
l‟ultimo cluster sarà sempre mediamente mezzo vuoto, con notevole spreco di spazio disco.
Utilizzando cluster di piccole dimensioni, i file “grandi” vengono spezzettati su un numero elevatissimo di
cluster, appesantendo enormemente le gestione e peggiorando i tempi di IO. Nei Floppy 1 cluster = 1 settore
Il File System Manager
File regolari e Stream
Un file è visto dall‟utente come una sequenza di byte registrata su memoria di massa (dischi, nastri,pen drive). Si
parla in questo caso di file regolari. Un file può essere visto anche come una sequenza di byte non necessariamente
statica. Ad esempio un flusso, continuo o meno, di dati che arrivano da Internet, o vengono inviati a una scheda
audio, o scambiati, attraverso delle code, da due programmi in esecuzione. Si parla in questo caso di Stream.
Tipi di files Regolari
Testuale Ascii
Formattato tramite opportuni algoritmi (Word, Excel, JPG, etc.)
File Dati cioè inizialmente file di record oggi database
Binario, contenente tipicamente l‟immagine di un processo.
Files Speciali : Directory e Collegamenti
- = file regolare, cioè un file nel senso classico del termine
d = file directory, il cui contenuto non può essere editato dall‟utente. Sono visualizzati in blu
l = file link, cioè collegamento ad un file / directory esterni rispetto alla directory corrente. Meccanismo di
condivisione dei files. I link sono visualizzati in cyano
Ad ogni file (file regolare, file directory o link) corrisponde un Descrittore che in EXT3 è detto i-node (index node)
che contiene varie informazioni relative al file, prima fra tutte la posizione del file su disco.
Directory
I file directory (in Windows CARTELLE) rappresentano l‟elemento centrale nell'organizzazione di un file
system. Sono “file di servizio” modificabili soltanto dal SO e contenenti un elenco testuale di file che, a loro
volta, possono essere file regolari, directory o link Un file directory contiene di solito un elenco testuale di coppie:
nome file (assegnato dall‟utente) - numero di descrittore corrispondente (assegnato dal SO). I nomi dei file
sono nomi ASCII con lunghezza max 255 caratteri con esclusione dei caratteri / e NULL.
pag 13Sistemi - Classe Quarta robertomana.it
Sistemi Operativi
I file directory sono di solito organizzati mediante una struttura gerarchica a più livelli articolata ad albero.
Il nodo principale dell‟albero è detto root (radice) o master directory identificata dal nome / (slash o barra).
La root directory deve essere collocata in una posizione precisa del volume, nota a priori, in modo che il SO possa
accedere ad essa in qualunque momento senza bisogno di informazioni aggiuntive. La root directory contiene un
certo numero di file e directory di primo livello, le quali a loro volta contengono altri file e directory.
Ogni directory rappresenta un nodo dell‟albero, mentre i file rappresentano le foglie.
Ogni directory contiene sempre almeno due elementi, cioè
. single dot che rappresenta un link all‟i-node della directory corrente
.. double dot che rappresenta un link all‟i-node della directory genitore rispetto alla directory corrente
Collegamenti
Anziché ripetere i file / directory in più posti, i link consentono di creare riferimenti multipli (detti alias) ad uno
stesso file. Il link è sostanzialmente un nuovo nome riferito ad un Descrittore già esistente. Ogni volta che si
crea un link ad un file, all‟interno del Descrittore viene incrementato un contatore dei riferimenti al file.
Cancellando il link non si cancella il file associato, ma viene semplicemente decrementato il contatore dei
riferimenti. Se l‟utente cerca di cancellare un file che ha dei link attivi, il SO segnala un warning. Il comando per
creare un link è ln. L‟introduzione dei link trasforma la struttura del File System da un albero ad un grafo.
Home Directory
Per ogni utente viene automaticamente montata all‟interno di /home una directory personale detta Home Directory.
Working Directory
Per ogni sessione di lavoro esiste una working directory che all'inizio della sessione coincide con la Home Directory
dell'utente. Il comando pwd mostra la Working Directory corrente. Il comando cd modifica il valore della Working
Directory. In Eclipse la Working Directory corrente è costituita dalla directory del progetto all'interno del Workspace
Pathname
Il pathname di un file rappresenta il percorso che il SO deve seguire per individuare l‟i-node del file. Può essere:
Assoluto, cioè a partire da root es /home/miaCartella/mioFile
Relativo, rispetto alla Working Directory corrente es ./mioFile
Relativo, rispetto alla Home Directory es ~/miaCartella/mioFile
La lunghezza massima di un pathname è di solito 256 caratteri. Notare che il pathname di un certo file non è
memorizzato da nessuna parte, ma viene costruito navigando l’albero delle directory.
Nel momento in cui l‟utente “apre” una directory (es clickando sopra oppure tramite un comando cd), il file directory
viene caricato in memoria centrale all‟interno di una struttura ad albero che :
consente di effettuare rapidamente operazioni di aggiunta / cancellazione di elementi
ben si presta a supportare meccanismi di protezione legati agli utenti, associando specifici diritti di accesso ai
vari file e sottodirectory contenute. Ogni utente può essere proprietario di una porzione di albero, all‟interno
della quale può creare sottocartelle annidate e file a suo piacimento (home directory)
Gestione dei volumi all’interno del File System
Windows
In Windows i volumi vengono identificati da una lettera progressiva a partire da C: Le lettere A e B sono storicamente
riservate per i floppy disk. Ogni volume ha un suo albero indipendente. Questo crea non pochi problemi nella
portabilità delle applicazioni. A livello di interfaccia grafica i vari alberi vengono raggruppati in un unico albero
denominato Risorse del Computer all’interno della quale vengono “montati”, con lettere crescenti, tutti i volumi
individuati in fase di avvio (disco fisso e relative partizioni, lettore floppy, CD ROM, HD esterni, pen drive USB).
Anche i device aggiunti “a caldo” vengono montati automaticamente sempre nella cartella “Risorse del Computer”.
pag 14Puoi anche leggere

















































