Facebook: privacy e sicurezza
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
UNIVERSITA’ DEGLI STUDI DI CATANIA
Facoltà in Scienze Matematiche, Fisiche e Naturali
Corso di Laurea in Informatica Applicata
______________________________________________________
Sicurezza dei sistemi informatici 1
Prof. Giuseppe Scollo
Facebook:
privacy e sicurezza
Giovanni Alescio
Carmelo Patti
Antonio Roccuzzo
Anno accademico 2008/2009
Introduzione Si è scelto di stilare una relazione a nostro avviso di estrema attualità e di non meno interesse per le generazioni a noi vicine e perché no anche passate e sicuramente future. Tratteremo qui di seguito di uno dei fenomeni di massa ormai consolidati e conosciuti, Facebook, il social network con più utenti iscritti al mondo. La nostra trattazione verterà in una presentazione breve e generale del portale, per poi dedicarci interamente a quanto concerne la sicurezza, perno centrale del corso seguito, e perché no fonte di informazione per tutti coloro che vorrebbero saperne di più circa i sistemi di sicurezza adottati dal social network in questione. Nonostante il grande successo riscosso non tutti o meglio quasi nessuno sa cosa sia effettivamente Facebook, come sia stato sviluppato e soprattutto quali garanzie, e di che livello, offre ai propri utenti. Cercheremo quindi di far meglio conoscere questo fenomeno ormai di dominio pubblico magari cercando di dare anche qualche consiglio per un uso oculato del portale aiutando magari l'utente alle prime armi a guardarsi bene da truffe o raggiri. Il fenomeno ha visto evolversi con una rapidità impressionante e come tale ha avuto più e più rivisitazioni modifiche e miglioramenti e questo anche grazie all'aiuto di meticolosi user che hanno fatto presente ai gestori del social network qualche piccola falla che nella maggior parte dei casi è stata risanata più o meno rapidamente. Quello che noi ci auguriamo è che alla fine della trattazione anche i nostri cinque o sei lettori (di manzoniana memoria) possano essere stuzzicati dalla voglia di esplorare meglio il fenomeno e perchè no trovare qualche piccolo miglioramento che di sicuro potrà non danneggiare il sistema. Sperando che le pagine a seguire possano quindi servire a qualcosa e non essere archiviate e dimenticate rimandiamo i lettori al nostro lavoro sperando possa essere gradito.
Sommario Cap.1 Cosa è Facebook 1.1Cosa è Facebook 1.2 Come nasce 1.3 A cosa è dovuto il suo successo 1.4 Infrastrutture Cap.2 Sicurezza 2.1 Sicurezza su Facebook 2.2 Come diventare un utente 2.3 Sicurezza nelle autenticazioni 2.3.1 Phishing scam con il sito Areps.at 2.3.2 Facebook implementa OpenID 2.4 Furti d'identità 2.4.1 Introduzione 2.4.2 Url personalizzato: allarme per i furti d'identità. 2.4.3 Cybersquatting 2.5 Privacy 2.5.1 Introduzione 2.5.2 Rubare informazioni dagli utenti 2.5.3 Facebook e Google 2.5.4 Spam

2.6 Garanzie per gli utenti
2.6.1 Il worm Koobface
2.6.2 Quattro mesi per rimediare una falla
2.6.3 Cross Site Scripting
2.6.4 I pericoli del Cross Site Scripting
2.6.5 Cancellazione di un profilo o di dati
2.6.6 Cosa effettivamente cancelliamo e cosa no
Cap. 3 Applicazioni
3.1 La Facebook Platform
3.2 Cosa serve per iniziare
3.3 Struttura e funzionamento di una applicazione
3.4 Creare una nuova applicazione
3.5 Primi passi nell'implementazione.
3.6 Il codice PHP di una prima applicazione
3.7 Considerazioni
3.8 Applicazioni e sicurezza
3.9 Esempi
- il caso “Secret Crush”
- “The Error Check System” e “Facebook closing down“
- altri esempi
3.10 Qualche semplice consiglio
Cap. 4 Notizie dal mondo
4.1 Il capo degli 007 bruciato da Facebook
4.2 Iran: di nuovo censurato Facebook
4.3 Il capo ufficio?Su Facebook meglio non averlo come amico!
4.4 Agrigentoweb Licenzia Giornalista perchè Pubblica su
F acebook un link di Repubblica.it
Conclusioni e Riferimenti
Cap.1 Cosa è Facebook
1.1 Cos'è Facebook Con la nascita e la diffusione di internet nelle case e la possibilità di comunicare attraverso questo mezzo dalle incredibili potenzialità è cresciuta di pari passo la voglia e il bisogno che la gente ha percepito sempre più di comunicare "virtualmente".Venne così il boom delle chat rooms, siti dove la gente aveva la possibilità di chattare con centinaia di persone in contemporanea, poi si è assistito al diffondersi di software più diretti in questo campo, da c6 a MIRC, per poi arrivare a MSN messenger, uno dei client di messaggistica istantanea più utilizzato. Il 2008 si può descrivere significativamente come l’anno del definitivo boom dei Social Network, migliaia di persone, infatti, aderiscono ogni giorno a questa nuova forma di comunicazione in rete. Questo fenomeno, nato in origine negli USA, si basa principalmente su tre tematiche fondamentali: relazioni professionali, d’amicizia e amorose. I primi social network furono messi online tra il 2003 e il 2004: Tribe.net, LinkedIn, Friendster,al giorno d’oggi i padroni incontrastati dell’universo della net-comunication sono i due colossi MySpace e Facebook. 1.2 Come nasce Facebook, di più giovane creazione, viene fondato il 4 febbraio 2004 dal giovanissimo Mark Zuckerberg, all’epoca 19enne e studente dell’università di Harvard. Comincia a diffondersi nei primi tempi nelle università di tutto il mondo, per poi estendersi nel 2007 anche nelle scuole superiori e nelle grandi aziende, permettendo a chiunque di entrare a far parte di una community che abbracciava ormai la maggior parte degli utenti di internet. Con facebook è possibile configurare il proprio profilo personale, inserire materiale multimediale di vario genere e lasciare messaggi privati o pubblici agli utenti che fanno parte della sezione “amici”; la visione più dettagliata dei propri dati è permessa solo alle persone facenti parte proprio di quest’ultima sezione. Dati statistici affermano che il 60% degli iscritti si logga quotidianamente, circa l’85% almeno una volta a settimana ed il 93% almeno una volta al mese, per una media di circa 19 minuti al giorno spesi davanti a facebook. Il tasso di crescita per MySpace in Italia è stato invece di circa 4.500 nuovi profili al giorno, più o meno uno ogni 5 secondi. Entrambi questi giganti del sistema di online-comunication traggono profitto dalle pubblicità, inclusi i banner che appaiono sulle pagine: alcuni rumors nel 2006 parlarono di circa 1,5 milioni $ di entrate a settimana per la creatura del giovane Zuckerberg. Secondo gli ultimi dati dell’agenzia comScore, che monitora il numero di accessi ai principali siti, nel mese di giugno Facebook ha ufficialmente superato nel numero di visite MySpace, conquistandosi la medaglia d’oro nella classifica dei Social Network, con un totale di ben 132 milioni di visite uniche, contro le “misere” 117 milioni del suo rivale. Tutto merito di una crescita record del 150% in un anno e dello sviluppo anche nel mercato estero, con il rilascio delle versioni in spagnolo, tedesco, francese e italiano. Non tutti sanno che il nome “Facebook” è riferito agli annuari con le foto di ogni studente che alcuni college e scuole statunitensi pubblicano all’inizio di ogni anno accademico. Facebook è stato nominato come la seconda cosa più “in” tra gli studenti universitari, condividendo il podio con la birra, il sesso e l’iPod. 1.3 A cosa è dovuto il suo successo Quale è il motivo del successo di Facebook? Stando alle statistiche sembra proprio la fotografia. Circa il 69% dei visitatori e degli utenti su Facebook carica e commenta fotografie, e recentemente più di 10 miliardi di foto sono state caricate sul celebre social network.
Altri due importanti fattori alla base del suo successo sono i seguenti: Motore di Ricerca di amici e colleghi: consente di trovare vecchi amici e colleghi gratis Blog-community: consente agli utenti di scrivere un diario o un album fotografico della propria vita in modo partecipato Il primo fattore è molto semplice. Facebook nasce come motore di ricerca per trovare vecchi amici. L'idea di per sé non è comunque originale o così determinante per giustificare il suo successo. Anche prima dell'escalation di Facebook esistevano servizi che consentivano di trovare i vecchi compagni di banco. Erano però servizi per lo più a pagamento, la cui iscrizione limitava di molto l'entità del database in cui ricercare. Anche Facebook ha iniziato così, fornendo però il medesimo servizio gratuitamente. In pochi mesi ha conquistato il mondo delle università americane per poi estendersi al mondo delle imprese e del lavoro. Il servizio erogato da Facebook era anche caratterizzato dalla possibilità di caricare una propria foto, di piccole dimensioni, per agevolare la propria riconoscibilità ed evitare le omonimie. Questa caratteristica è stata considerata portante all'inizio del progetto, al punto da costituire parte integrante del nome di dominio del sito: Face Book ossia libro dei volti, prendendo in prestito la prassi delle scuole americane di conservare un album fotografico storico dei vecchi studenti. Il secondo fattore è molto più complesso. Il decollo iniziale di Facebook è stato gestito con saggezza, reinvestendo gran parte dei ricavi per migliorare il servizio e per aggiungere nuove funzioni, come ad esempio la possibilità di caricare foto, aprire discussioni, scrivere vere e proprie pagine di diario. Questa evoluzione di Facebook l'ha reso un servizio di blog-community del tutto imparagonabile con altre case history precedenti. Ogni utente ha iniziato a ricomporre i ricordi della propria vita come in un puzzle, caricando foto e brevi commenti sul proprio passato. A quale scopo? Molto semplice. Se si vuole ritrovare i vecchi amici del passato è necessario essere sinceri su sé stessi e fornire dati veritieri per essere rintracciati o perlomeno riconosciuti. In questo modo, milioni e milioni di persone hanno cominciato a scrivere la propria vita su Facebook. Questi diari digitali hanno la grandiosa caratteristica d'essere linkati tra gli utenti, sotto forma di tag, creando un diario ancora più grande di storie personali ed eventi. Ogni uomo ha di per sé migliaia di fatti da raccontare della propria vita e spesso non basterebbe un libro per farlo. Su Facebook queste storie non restano chiuse nel cassetto. Può quindi capitare di assistere allo stesso evento del passato visto da persone diverse, ad esempio un matrimonio che si rompe commentato da entrambi gli ex sposti e dagli amici, una promozione sul lavoro, il voto di un esame ecc. Storie di tutti i giorni intrecciate tra loro in qualcosa che vale molto più di un semplice diario o di un semplice servizio per trovare amici. Questo è Facebook. In questo settore Facebook sembra aver sbaragliato i concorrenti: Photobucket e Flickr hanno subito un calo delle visite e un calo anche nel caricamento delle foto. Il divario con gli altri siti è salito sempre di più. Quale è il vantaggio delle fotografie per Facebook? Innanzi tutto il caricamento delle foto è la funzione predefinita di tutti i più grandi social network del mondo. E il sistema scelto da Facebook ha un aspetto virale: ogni volta che si tagga una foto ogni amico segnalato riceve un’email. Una caratteristica che ha tutte le funzioni di una catena che passa da utente a utente. I servizi di social networking sono ormai in mano a MySpace, Bebo, Facebook. Dalla sua nascita Facebook ha fatto passi da gigante. Agli esordi era utilizzato soprattutto da un pubblico di adolescenti e studenti. Facebook inizia a distinguersi dagli altri social networking non solamente dalla tipologia di utenti e dal design ma soprattutto dalle caratteristiche, grazie alle sue API che vengono rilasciate a sviluppatori esterni, dando la possibilità di avere molte funzionalità in più. Proprio grazie alle nuove funzioni cresce il suo successo. Gli utenti non sono più gli adolescenti e il numero di registrazioni si moltiplicano.
Ora Facebook ha il layout e la navigazione più pulita e lineare, permette di realizzare network con i propri amici, fare aggiornamenti al proprio status (sia attraverso servizi proprietari che attraverso Twitter) che verranno immediatamente comunicati a propri contatti, telefonare tramite Skype, intrattenersi in live chat, costruire album fotografici e slideshow, importare e condividere video, esportare sia contenuti che funzionalità da un profilo ad un altro. 1.4 Infrastrutture Facebook ha tre datacenter, due sulla west coast (San Francisco, Santa Clara) e uno sulla east (Northern Virginia). I server utilizzati sono x86. Il datacenter principale è quello di Santa Clara, dove ha sede la società. Il livello più alto, quello web, è costituito da applicazioni scritte in Php. Il cuore del sistema invece è scritto in C++, Java, Python e Ruby. Facebook, tempo fa, ha aperto il codice dell’IDL(Interface Description Language), il quale è un linguaggio con cui descrivere interfacce; che usa Thrift al suo interno. Thrift è quindi un linguaggio con cui definire interfacce: tipi semplici e complessi, tipi strutturati e operazioni con parametri di input e di output. Con il compilatore che include, si genera poi, a partire dalle interfacce così descritte, data-bindings e stubs, lato server e client. Thrift è indipendente da trasporto, protocollo e serializzazione: non ne impone di specifici ma ne stabilisce l’interfaccia in modo da poter essere adattato o esteso. Di alcuni trasporti (file, memoria, socket e pochi altri) ne include l’implementazione. Thrift nasce da esigenze ben precise: l’interoperabilità tra un certo numero di linguaggi (Java, C++, PHP, Python e altri) a vantaggio dell'intero sistema, la generazione automatica del codice di “traduzione” tra formati d’interscambio e nativi, il volersi sottrarre all’aggiornamento contemporaneo di tutti i sistemi e il desiderio di concentrarsi sulla logica di business piuttosto che sui dettagli d’infrastruttura. Facebook impiega Thrift in un elevato numero di sistemi, tra cui: ricerca, logging, gestione degli annunci pubblicitari e applicazioni mobili. L'interfaccia che Facebook mette a disposizione per consentire alle nostre applicazioni di dialogare con il cuore del sistema si basa su un'architettura di tipo REST, Representational State Transfer, ossia un'architettura software le cui idee rappresentano un approccio abbastanza comune nella costruzione di un Web Service. Questa tecnica prevede un semplice scambio di informazioni tra server e client tramite protocollo HTTP, senza l'utilizzo di tecniche più evolute per lo scambio di messaggi (come ad esempio SOAP) o per tenere traccia della sessione (come ad esempio l'uso di cookie). Più nel dettaglio, da parte di Facebook viene messo a disposizione un API REST Server, che rimane in ascolto attendendo richieste HTTP di tipo POST e rispondendo con stringhe in formato XML che possono quindi essere interpretate dal client. Da questo punto di vista, le nostre applicazioni svolgono quindi il ruolo di client. Per quanto riguarda i database, Facebook utilizza server Mysql (8-core, come quelli web su cui viene eseguito Apache). Il popolare database opensource riesce tranquillamente a lavorare con 40 TB di dati, grazie all'aiuto di 800 macchine che lavorano contemporaneamente. Dato che però le richieste ricevute sono 15 milioni al secondo, 800 database server non sono sufficienti. Per questo Facebook si avvale di un consistente sistema di caching (memcache, molto diffuso anche in Italia) che permette di rispondere in tempi rapidissmi al 95% delle richieste. “Solo”
le rimanenti 500000 vengono inoltrate ai database server (Mysql) veri e propri. Sempre in California, come abbiamo accennato sopra, c’è un datacenter a San Francisco, che si limita a replicare i servizi web e di caching, ma utilizza gli stessi database di Santa Clara (le località sono vicine, e quindi questo è possibile). Non è possibile fare la stessa cosa per i server in Virginia, troppo lontani per potere inviare query Mysql quando necessario. La soluzione? Replicare completamente anche i database server.
Cap. 2 Sicurezza
2.1 Sicurezza su Facebook
E' formidabile come Facebook possa mettere in contatto e comunicazione innumerevoli amici e
conoscenti. Tuttavia ogni essere umano ha diritto alla propria privacy. Con grande rammarico però,
si può affermare che Facebook non la custodisce in modo ottimale. Diventa esattamente come noi
custode dei nostri dati e siccome nessuno da nulla per nulla in qualche modo dai nostri dati deve pur
guadagnare qualcosa visto che il social network è gratuito. E' cosi infatti che nulla si può fare se ci
si ritrova con una nostra foto in un banner pubblicitario, infatti Facebook da contratto prevede anche
l'utilizzo di tutto ciò che noi pubblichiamo sul nostro profilo. Tutto ciò non piace molto agli user
che passano davanti al pc giornate intere ed infatti l'amministrazione sta cercando di ridimensionare
al quanto la cosa.
2.2 Come diventare un utente
La registrazione è gratuita ed i dati di base sono essenzialmente pochi. Se non si ha già un account
ci si reca nella home-page di facebook.com e si seleziona la lingua italiana.
Home page di Facebook
I dati obbligatori per l'iscrizione su Facebook. Nella home page è disponibile il modulo per
registrare un account su Facebook. E' necessario fornire e compilare i seguenti dati:
•Nome e cognome
•Email
•Password per accedere in Facebook
•Sesso
•Data di nascita
Nella pagina di conferma è visualizzato un codice di sicurezza composto da numeri e caratteri. Si
copia nel campo sottostante. E' un controllo indispensabile per evitare la registrazione automatica
da parte degli spider. In pratica, così facendo si dimostra d'essere una persona. Gli spider, di fatto,
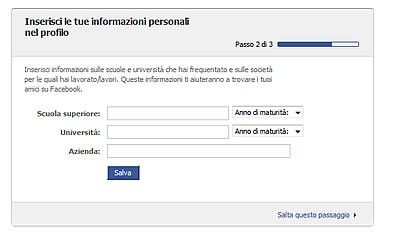
non sono perfettamente in grado di leggere e riprodurre i caratteri da una foto.Pagina di conferma Una volta verificata la pagina di sicurezza, Facebook invia all'indirizzo di posta elettronica, che si è indicato nella fase di registrazione, una email di conferma. Si clicca sul link di conferma, posto all'interno della email inviata da Facebook, per attivare il proprio account A questo punto si è pronti per poter accedere. Al primo ingresso sono chieste alcune informazioni facoltative sulle scuole frequentate e le aziende in cui si è lavorato. Queste informazioni possono infatti essere documentate anche in un secondo momento. Il primo accesso in Facebook. 2.3 Sicurezza nelle autenticazioni: 2.3.1 Phishing scam con il sito Areps.at Non sempre a comparire è la pagina iniziale e di autenticazione di Facebook infatti negli ultimi tempi con l'avanzare della popolarità del suddetto, anche i cyber-criminali non hanno perso tempo a trovare un modo per organizzare vere e proprie truffe ai danni degli utenti. Uno dei metodi più noti è quello di consigliare agli utenti dei vari siti internet da visitare. L'ultima frontiera criminale si chiama “areps.at”. Nient'altro che una pagina praticamente verosimile l'home page di Facebook all'interno del quale il poco accorto utente immette il proprio nome utente e password per l'accesso al portale. I suoi dati ovviamente non lo faranno entrare ma bensì verranno raccolti dai malintenzionati gestori della truffa e servirà poco tempo per vedere la propria password modificata e quindi sarà impossibile accedere al caro Facebook. Naturalmente come se non bastasse in seguito, a tutti gli amici presenti nella propria lista verranno inviati gli stessi messaggi privati con il suggerimento di visitare il suddetto sito, mettendo cosi in moto una lunga catena difficile da
spezzare. Questo è ciò che oggi appare digitando su Mozilla “www.areps.at” 2.3.2 Facebook implementa OpenID Il più noto tra i social network ha deciso di incorporare il sistema di autenticazione utilizzando, OpenID, un meccanismo di autenticazione distribuito e decentralizzato dove la propria identità è l'URL. In particolare è un sistema di identificazione che permette di utilizzare un unico login per più servizi Web, basandosi su una identità on-line. Il sistema è già stato adottato da diversi servizi internet. La scelta di Facebook, però, appare oggi un po' in contraddizione: Facebook ha già un suo servizio di identificazione, chiamato Facebook Connect (in poche parole un passepartout che consente di accedere ad altri mondi senza la necessità di accreditarsi ogni volta facendo una nuova iscrizione. Molti servizi e piattaforme USA si stanno organizzando per unirsi al programma Facebook Connect. I più famosi tanto per fare un esempio sono Vimeo, Drop.io e Twitter ), nato inizialmente proprio per contrastare OpenID. Eppure negli ultimi mesi Facebook ha compiuto enormi passi in avanti verso gli standard aperti, e recentemente ha anche rilasciato le Stream API del suo sito. Oltre ad estendere le possibilità di interoperabilità, l'uso di OpenID snellisce il processo di registrazione e di login, abbassando le barriere di ingresso per nuovi utenti. Come ogni cosa ci sono i pro e i contro ovviamente il fatto di non dover inserire ogni volta il proprio nome utente e password è un grande passo avanti specie per gli informatici amanti delle ottimizzazioni ma ci chiediamo se una tale centralizzazione non possa nuocere alla sicurezza stessa, perno della nostra discussione. 2.4 Furti d'identità 2.4.1 Introduzione Nei social network come Facebook, MySpace, Linkedin milioni di persone consegnano a un universo di interlocutori sconosciuti la propria radiografia anagrafica. Chiunque può appropriarsi della vita di chiunque. Una volta creato il profilo vanno impostati i livelli di sicurezza. L'utente deve scegliere chi può vedere le sue foto (solo gli amici, o tutto il resto del mondo) chi può leggere il suo status (solo chi è in connessione o anche gli amici degli amici). Basta leggere nella home di Facebook per scoprire due cose non rassicuranti. e poi un comodo e altrettanto illegale La possibilità che il network possa usare i nostri dati a scopi pubblicitari non è comunque molto lontana dalla realtà visto che solo in energia elettrica spende un milione di dollari al mese.
2.4.2 Url personalizzato: allarme per i furti d'identità. Caratteristica piuttosto rara tra i social network, Facebook fino ad oggi non ha fornito un indirizzo web personalizzabile per le pagine dei suoi utenti, bensì ha automaticamente generato una lunga e anonima stringa numerica che ha reso di fatto impossibile identificare qualcuno dal semplice Url del suo profilo. L'originale scelta del sito, diversa da quella di altre popolari piattaforme quali MySpace e Twitter, ha permesso a tanti utenti omonimi di registrarsi senza dover accettare curiose ed improbabili abbreviazioni o accostamenti con date di nascite, scelte ormai obbligatorie per l'iscrizione ai più popolari fornitori di posta elettronica. Secondo il comunicato pubblicato sul blog ufficiale, la decisione è arrivata per facilitare il riconoscimento di un utente tra gli altri, approfittando magari della migliore ottimizzazione sui motori di ricerca che questa modifica porterà. Se oggi per trovare un amico bisognava scandagliare il social network con il suo motore interno, con il rischio di dover spulciare tra decine di omonimi, questa ulteriore aggiunta dovrebbe facilitare un po' le cose. Alle motivazioni indicate dall'amministrazione si deve però aggiungere come la mossa di Facebook sia l'ultimo passaggio nella lunga battaglia per l'identità digitale che vede il social network confrontarsi con Google e i suoi neonati profili. Il cambiamento del proprio Url è stato possibile in Italia a partire dalle 6 e 1 minuto di sabato 13 giugno 2009. A partire dall'ora X, gli utenti che lo desiderano hanno potuto modificare l'indirizzo web del profilo, seguendo i canoni classici della rete (nomecognome, nome.cognome ecc) oppure introducendo un nickname. A differenza dei dati personali che sono continuamente aggiornabili, l'Url non si può più cambiare, quindi è meglio stare attenti a non digitare errori. Passare da un sistema di indirizzi generato automaticamente a uno personalizzabile porta con se diversi problemi. Una prima difficoltà è la presenza di diversi omonimi che, se interessati a un "Vanity url" (come ribattezzato dai blog americani), hanno dovuto fare a gara per accaparrarsi le combinazioni disponibili (gli url infatti devono necessariamente essere diversi gli uni dagli altri). Immaginarsi centinaia di persone davanti al computer alle 6 di mattina per registrare il proprio nome è un'ipotesi non remota. La combinazione finale di certi url farà capire chi ha puntato meglio la sveglia o ha il click più veloce. Lasciando da parte le suggestioni vanitose, un problema di certo più sentito è la possibile ripetizione anche su Facebook del fenomeno del cybersquatting, ovvero la registrazione e lo sfruttamento di marchi altrui sulla rete. Se proprio ieri il social network ha vinto la sua battaglia per avere il dominio facebook. it, fino ad ora in mano ad un cybersquatter internazionale, paradossalmente la nascita dei domini personalizzati creerà una nuova dimensione del fenomeno. Per evitare che qualcuno si impossessi di marchi celebri, il sito permette ai detentori legali di un logo di pre- registrare la richiesta ed ha bloccato la possibilità di creare url personalizzati agli utenti iscrittisi dopo il 9 giugno. 2.4.3 Cybersquatting La parola Cybersquatting è composta dalla parola inglese cyber - che, a sua volta è l’abbreviazione di cybernetics,- (ovvero cibernetica) e dall’altra parola inglese squatter che significa occupante abusivo. Lo squatter è alla disperata ricerca di spazi necessari per perseguire sue determinate finalità di varia natura: trovare una casa, realizzare uno spazio sociale, ricavare un covo per compiere attività criminali, etc. La pratica dello squatting segue un principio molto semplice: dove vedi un edificio abbandonato appropriatene. La pratica del cybersquatting è differente dallo squatting per molteplici motivi, ma è accomunata da una caratteristica: si tratta sempre di un’occupazione, presumibilmente, abusiva di uno spazio lasciato vuoto dal legittimo proprietario. Ma quali “spazi vuoti” vengono occupati dai cybersquatter? Quelli relativi ai nomi a dominio di siti non ancora registrati, ma che appartengono comunque a determinate persone fisiche o giuridiche. Il cybersquatting consiste nel registrare nomi a dominio identici a quei nomi famosi. Creare siti che
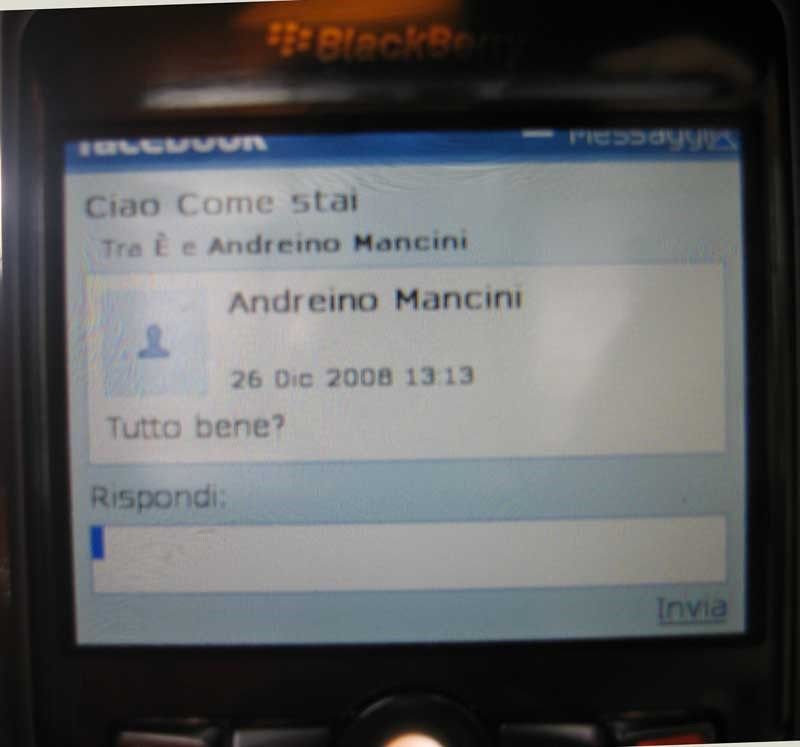
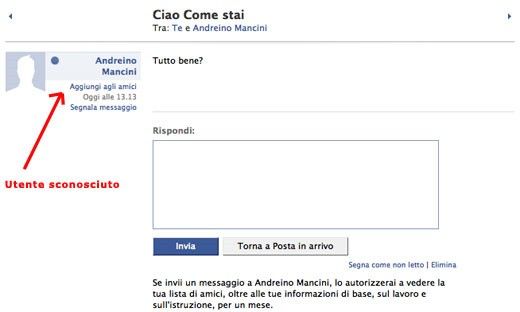
abbiano un nome molto diffuso, che richiami alla mente qualcosa di molto popolare è il fine del cybersquatter. Tipo www.telegiornale.it, www.banca.it, www.italia.it. Oggi sembra quasi paradossale che alcune grandi imprese possano subire cybersquatting perché quasi tutte le aziende di dimensioni medio-grandi registrano un proprio sito internet. Tuttavia questa tecnica di occupazione abusiva di nomi a dominio continua a prendere piede, ed è finalizzata alla realizzazione di tecniche di concorrenza sleale fra aziende. Com’è possibile che venga sottratto un nome a dominio ad un legittimo titolare? In realtà è molto più semplice di quanto non si immagini. Non esiste un diritto di proprietà di un nome a dominio, in quanto esso altro non è che una stringa alfanumerica che ci consente di memorizzare facilmente l’indirizzo IP di un sito (che è costituito da un codice numerico). 2.5 Privacy 2.5.1 Introduzione Aperto a tutti, gratis. Ma il prezzo da pagare è un altro. La propria privacy. Iscriversi è un attimo: mail, password, nome (vero o meno), sesso. A scelta: numero di cellulare, data di nascita, le scuole frequentate, le preferenze musicali, politiche e religiose. Il numero di carta di credito! Poi si caricano gli scatti del proprio compleanno,matrimonio, delle vacanze, si “taggano” (nominano) gli amici sulle foto altrui, si commenta. E, non per ultimo, su Facebook c'è anche chi aggiunge immagini di figli e nipoti. Un piatto troppo succulento per truffatori, ladri di identità e perchè no anche pedofili alla ricerca di immagini da scaricare e ragazzini da adescare. Tuttavia i minori possono iscriversi senza alcun problema. 2.5.2 Rubare informazioni dagli utenti Bisogna essere dei veri patiti di Facebook per notare un'altra piccola stranezza o pecca se vogliamo in questo ormai noto sistema di networking. In questo caso particolare il problema risiede nell'uso di FB da Blackberry e quindi da dispositivo mobili da cui sembra molto semplice essere ingannati. La messaggistica interna di Facebook, le mail per capirsi, non si appoggia a nessun servizio pubblico (non è possibile, mandare mail con la nostra Gmail o Hotmail) ma il tutto è gestito unicamente all’interno del Network. Cosa distingue quindi una mail rispetto ad un’ altra? Semplicemente il nome della persona che ce lo invia. Bene, sappiamo tutti che su Facebook non c’è un vero e proprio controllo d' identità. Ognuno può essere chi vuole e che cosa vuole, saranno gli utenti a dire se dietro c’è realmente la persona o l’attività commerciale che noi sappiamo esistere realmente. Il suo comportamento, e la cerchia di amicizie che saprà generare dicono poi la verità. Ma è altrettanto semplice registrare infiniti utenti, con nomi e cognomi di persone conosciute. E non si parla di personaggi pubblici, ma cose molto più spicciole, come il nome di un ex-fidanzato per capire cosa sta combinando, o il nome di colleghi che non ci stanno particolarmente simpatici per scoprire qualche loro strana abitudine nascosta. Non è molto difficile, registrarsi con il nome di un nostro “Amico” che sappiamo essere amico dell’ amico, cliccare sul profilo, ed inviare una mail, anche se questo non è tra i nostri contatti. Ecco come diventa il messaggio di un perfetto sconosciuto su Blackberry che però ha un nome familiare.
Ora, c’è da dire che la magagna è veramente palese sulla versione mobile del portale, la controparte web ha una scritta (piccolissima però) che indica che il contatto a cui stiamo rispondendo non è inserito tra nostri amici. Però le persone più sbadate potrebbero non notare la cosa, soprattutto se il profilo del furbetto è accompagnato dalla foto “rubata” alla controparte reale. Rubare la foto è infatti semplice, basta un semplice print screen (su Mac c’è l’applicazione Istantanea, su windows basta usare programmi dedicati o semplicemente cliccare su print da tastiera ed incollare l’immagine su un software di grafica, basta anche Paint) ed il furto di identità è iniziato. Una cosa del genere è davvero pericolosa, soprattutto alla luce del fatto che su Facebook ci sono utenti giovanissimi, molti ma davvero molti adolescenti che potrebbero facilmente cadere nel tranello. Ma siamo convinti che molti “grandi” non eccessivamente smaliziati potrebbero fare lo stesso. 2.5.3 Facebook e Google Questo pullulare di piazze virtuali ha messo in pericolo la privacy degli utenti che, con una semplice ricerca su Google, potevano fino a ieri scoprire in pochi secondi i dati personali degli iscritti ai social network. Secondo i Garanti Europei della Privacy l’indicizzazione delle pagine personali ledeva i diritti degli utenti ed ha emanato quindi una direttiva per rendere privati i dati pubblicati dagli utenti. A farne le spese, almeno per ora, c’è soprattutto Facebook che ha dovuto rendere inaccessibili ai motori di ricerca i dati dei propri utenti. La decisione è stata presa a seguito della conferenza “Proteggere la privacy in un mondo senza confini” tenutasi a Strasburgo, i temi trattati sono stati, appunto, quelli legati alla sicurezza dei dati personali con l’obiettivo di ratificare le linee guida in materia. In poche parole, 11 milioni di profili utente dei maggiori social network non saranno più rintracciabili tramite motori di ricerca, fatta eccezione per gli utenti che acconsentiranno espressamente l’indicizzazione del proprio profilo. Siamo sicuri, però, che questo provvedimento, una volta tanto, non nuocerà alla libertà della rete poiché chiunque voglia continuare a effettuare queste ricerche potrà farlo mediante gli strumenti messi a disposizione dai vari social network in maniera più limpida a seguito di registrazione. Insomma, un provvedimento che impedirà ai ficcanaso di farsi gli affari degli altri, niente di più.
2.5.4 Spam Facebook usa le informazioni che i propri utenti accettano di fornire spontaneamente per poter usufruire di alcune funzionalità del social network per generare spam mascherato da richieste generate dai suoi utenti. Il social network possiede un’apposita funzionalità che dietro l’autorizzazione esplicita, accede all’account dell’email dell’utente per estrarne gli indirizzi email presenti nella rubrica e confrontarli con quelli usati dagli utenti come user id, in teoria soltanto per rintracciare velocemente all’interno di Facebook le persone che conosciamo. Ora si scopre che gli indirizzi email non abbinati ad account registrati, non solo vengono conservati, ma vengono anche riutilizzati per inviare spam (e chissà per che altro). Non abbiamo motivo di dubitare dell’autenticità del mittente: la presenza di un elenco di nominativi che vengono proposti come persone che il destinatario del messaggio potrebbe conoscere, con una modalità del tutto simile alla pagina “persone che potresti conoscere” che tutti gli utenti di Facebook conoscono, mostra che il mittente ha accesso ai dati che tracciano le relazioni che intercorrono tra gli utenti registrati. Nella pagina c’è un link con la dicitura “maggiori informazioni” che però sembrerebbe riguardare soltanto l’uso che il sito fa della nostra password. Non è presente alcuna spiegazione o alcun
rimando esplicito alle modalità di trattamento dei dati raccolti. Seguendo però il link si scopre a sorpresa che Facebook memorizza gli indirizzi raccolti “per poterti connettere con i tuoi amici, inoltre possiamo utilizzare queste informazioni per creare suggerimenti per te e i tuoi contatti di Facebook” Tale disclaimer non è mostrato agli utenti in modo sufficientemente chiaro e trasparente, ma anche nel caso che lo fosse, non vediamo come possa autorizzare il social network a esprimere proprie volontà senza esplicito consenso e senza che l'utente ne sia a conoscenza. 2.6 Garanzie per gli utenti 2.6.1 Il worm Koobface Il 5 dicembre 2008 sono stati in 120 milioni gli utenti potenziali vittime del worm «Koobface», che prende di mira il sistema di messaggistica del social network per infettare i Pc degli iscritti e successivamente appropriarsi di dati sensibili come i numeri delle carte di credito. Koobface sfrutta l'ingegneria sociale (social engineering) per propagarsi. Arriva alla vittima sotto forma di un messaggio apparentemente proveniente da un amico di Facebook della vittima. Il messaggio è in inglese, e già questo dovrebbe mettere sul chi vive l'utente: dice cose del tipo "sembri buffo in questo nuovo video" oppure "sei eccezionale in questo nuovo video". Se la vittima clicca sul link presente nel messaggio, viene portata a un sito che sembra essere Youtube e ha un nome che inizia per http://youtube, ma è in realtà un sito-trappola. Qui le viene proposto di vedere il video, ma la visualizzazione non funziona e viene proposto di installare un aggiornamento del player Flash. Se la vittima accetta, il suo computer viene infettato e a partire dal successivo riavvio tutti i dati delle sue navigazioni (siti visitati, cookie, login, password, numeri di carta di credito, messaggi personali) vengono trasmessi di nascosto ai padroni del virus. Il virus colpisce esclusivamente gli utenti di Windows (tutte le versioni) ed è contrastabile con una sana vigilanza e con un antivirus aggiornato. Ancora una volta, il grimaldello preferito dagli untori della Rete per scardinare le difese informatiche delle vittime è la psicologia: si crea una situazione emotivamente coinvolgente (in questo caso si fa leva su curiosità e/o imbarazzo) e si approfitta della fiducia che inevitabilmente tendiamo a porre nei messaggi che ci arrivano, almeno in apparenza, da persone che conosciamo. 2.6.2 Quattro mesi per rimediare una falla Se è indubbio il suo successo in termini di pubblico, Facebook sembra soffrire dal punto di vista della sicurezza. Un altro incidente di percorso di cui si ha notizia ha però a che fare con il codice del portale: si tratta di una falla cross-site scripting (XSS) con cui è possibile fare di tutto e anche di peggio. La vulnerabilità, appartenente a un genere che da tempo va per la maggiore come vettore di attacco sul web, è stata dimostrata e dà la possibilità teorica a chi ne fosse a conoscenza di far credere all'utente di stare visitando Facebook mentre la maggioranza del contenuto e del codice della pagina proviene da tutt'altra parte. Si tratta di una falla piuttosto pericolosa: chi l'ha scoperta ha informato gli admin di Facebook già lo scorso agosto 2008. Il risultato è stato disarmante: la falla ha continuato indisturbata ad attendere che qualche malware writer o ingegnere software votato al lato oscuro della forza ne usufruisse per i suoi nefasti affari. La falla, il cui funzionamento sarebbe stato verificato con tutti i maggiori browser in circolazione, è stata chiusa solo dopo quattro mesi.
2.6.3 Cross Site Scripting La grande diffusione dei siti a contenuto dinamico che utilizzano linguaggi lato server (come ASP e PHP) ha favorito lo sviluppo di particolari tecniche di hacking ideate per colpire gli utilizzatori delle applicazioni web. Una delle tecniche più conosciute prende il nome di Cross Site Scripting, spesso abbreviata con CSS (oppure XSS, per non confondere la sigla con quella dei fogli di stile nelle pagine web). Il CSS permette ad un aggressore di inserire codice arbitrario come input di una web application, così da modificarne il comportamento per perseguire i propri fini illeciti. Se uno script consente questo tipo di attacco, è facile confezionare un URL ad hoc e inviarlo all'utente che sarà vittima del sotterfugio. All'utente, ignaro di questa modifica, sembrerà di utilizzare il normale servizio offerto dal sito web vulnerabile. Pagine web o e-mail sono i mezzi ideali per portare a termine l'attacco. 2.6.4 I pericoli del Cross Site Scripting Quando utilizziamo un servizio che richiede l'inserimento di username e password, spesso questi dati vengono registrati sul nostro computer sotto forma di Cookie (un file di testo) per non doverli digitare ogni volta. Per ovvi motivi di sicurezza, i dati contenuti nel cookie sono accessibili solo dal sito web che li ha creati. Ma supponiamo che il sito in questione utilizzi una applicazione vulnerabile al CSS: l'aggressore potrà iniettare un semplice JavaScript che legge il cookie dell'utente e lo riferisce. Il browser dell'utente permetterà la lettura, perchè in effetti il JavaScript viene eseguito da un sito autorizzato a leggere il cookie! Il risultato immediato è evidente: l'aggressore avrà accesso al cookie e, a seconda delle informazioni contenute, sarà in grado di leggere la nostra posta, oppure di utilizzare il nostro nickname nel forum che frequentiamo (e i nostri privilegi, se ad esempio siamo amministratori), e così via. Oltre al danno, la beffa: il Cross Site Scripting solitamente richiede un intervento attivo da parte della vittima per poter funzionare: anche il click su un link in una pagina web o in un messaggio di posta elettronica può nascondere insidie di questo tipo. 2.6.5 Cancellazione di un profilo o di dati E' un dato di fatto: il numero degli iscritti a Facebook, in Italia e non solo, è cresciuto in maniera esponenziale nell'ultimo anno. Eppure, se da una parte ci sono tanti utenti che entrano a far parte di questo network, dall'altra c'è chi decide di uscirne. A chi volesse cancellare il proprio profilo su Facebook e non sapesse come fare, suggeriamo di seguire i passaggi seguenti: - Cliccare in alto a destra su "Impostazioni" - Individuare l'opzione "Disattiva Account" - Cliccare su "Disattiva" - Durante la cancellazione viene chiesta una motivazione, potrete scrivete qualcosa ma non siete obbligati a dare una risposta effettiva. In questo modo tutti i dati, le foto e quanto faceva parte del profilo verranno prontamente eliminati da Facebook. 2.6.6 Cosa effettivamente cancelliamo e cosa no Analizziamo una duplice preoccupante curiosità nel trattamento dei dati personali da parte del colosso del social network in relazione all'archiviazione, la conservazione e la cancellazione delle immagini caricate dagli utenti. Le immagini, all'atto dell'upload vengono caricate su un server diverso da quelli sui quali gira la piattaforma e, ad esse, viene assegnato un autonomo IP che le rende raggiungibili senza l'esigenza di passare per la piattaforma stessa. Con una prima, importante, conseguenza: chiunque conosca la "codifica" dell'URL assegnato ad ogni immagine all'atto dell'upload - si tratta, peraltro, di una
codifica che risponde ad un preciso schema matematico e, dunque, agevolmente decodificabile - è in condizione, quali che siano le scelte in materia di privacy del titolare delle immagini - di accedervi, visualizzarle ed appropriarsene per qualsiasi genere di uso. Piuttosto grave, se si considera che le condizioni generali sul trattamento dei dati personali dell'utente pubblicate su Facebook inducono quest'ultimo a ritenere - in conformità peraltro alla disciplina vigente - di essere in grado di autodeterminare l'ambito di "pubblicità" dei dati e delle informazioni immesse nella piattaforma. Ma c'è di più. Le stesse condizioni generali chiariscono all'utente che, in qualsiasi momento, può rimuovere i contenuti che ha caricato online, revocando - da un punto di vista giuridico - il consenso prestato alla diffusione al pubblico delle proprie immagini. Se proviamo infatti a caricare una immagine nel nostro profilo e ad eliminarla in seguito,questa sarà ancora lì, non più raggiungibile attraverso il profilo personale ma facilmente accessibile da chiunque abbia conservato l'URL di pubblicazione o, addirittura, casualmente. La sostanza è questa: pare che Facebook, a seguito della richiesta di rimozione di un contenuto dalla propria piattaforma (e dunque della revoca del consenso all'utilizzo dei dati personali di un utente) si limiti a sospendere l'indicizzazione del contenuto medesimo in abbinamento al profilo dell'utente ma conservi i relativi dati o informazioni. Volendo fare un ulteriore esperimento si può creare un profilo utente ed eliminarlo in seguito. Qualcosa accade realmente, ovvero non è possibile più accedere alla pagina personale,ma sfortunatamente, le immagini caricate nel periodo di utilizzo del profilo sono ancora al loro posto e, quindi, raggiungibili da chiunque. È grave, gravissimo promettere ad un utente la cancellazione di un dato e continuarlo, invece, ad utilizzare. Si tratta - prima che di una violazione di legge - di una manifestazione di scarso rispetto che rischia di compromettere ogni possibilità di dialettica e confronto tra i protagonisti della Rete e le istituzioni ed è un peccato che per gli errori di pochi debbano pagare in molti, assistendo impotenti al proliferare di una politica legislativa di repressione rispetto ad una tecnologia che, se usata con rispetto, equilibrio e buon senso, può essere il più fedele alleato dei cittadini del XXI secolo e non già il loro nemico giurato come troppo spesso viene rappresentata.
Cap. 3 Applicazioni
3.1 La Facebook platform
Nel maggio del 2007 è stata lanciata Facebook Platform, un framework che mette gli sviluppatori in
grado di creare applicazioni che interagiscono con il nucleo di Facebook. Contemporaneamente, lo
stesso Facebook ha proposto le prime applicazioni, ad esempio Events, per condividere
informazioni sugli eventi a cui gli utenti sono invitati a partecipare, oppure Video, per la
condivisione di filmati. Ad oggi, le applicazioni segnalate sono migliaia e le loro funzionalità sono
le più disparate, dai giochi alle utility.
3.2 Cosa serve per iniziare
Per lo sviluppo di un'applicazione Facebook, questi sono gli ingredienti assolutamente necessari:
• un account su Facebook: potrebbe sembrare una banalità, ma la creazione di applicazioni
richiede che lo sviluppatore sia registrato al servizio;
• un proprio spazio web che supporti un linguaggio lato server, ed eventualmente un database:
Facebook non fornisce hosting per le applicazioni di terzi, ma si limita ad integrarle nel
proprio servizio (vedi il prossimo paragrafo);
• la conoscenza dell'API messa a disposizione da Facebook: quest'ultimo punto non è
strettamente necessario se si sfrutta una libreria ad hoc, come ad esempio PHP Facebook
Client Library, che faccia il lavoro sporco per noi.
3.3 Struttura e funzionamento di un'applicazione
Prima di analizzare nel dettaglio l'anatomia di un'applicazione, introduciamo in questo paragrafo
alcuni particolari che ci servono per comprendere come Facebook vada ad integrare le nostre
applicazioni all'interno del suo servizio.
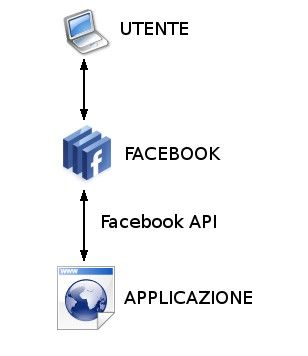
Ogni applicazione viene identificata dagli utenti con un indirizzo chiamato Canvas Page URL.
Tale indirizzo è sempre nella forma apps.facebook.com/mia- applicazione dove "mia-applicazione"
è una stringa dai 7 ai 20 caratteri (alfanumerici, underscore o il segno meno). Questo indirizzo fa da
tramite tra Facebook e la nostra applicazione: quando un utente richiama la Canvas Page di
un'applicazione, la richiesta viene girata alla Callback URL, che sarà l'indirizzo, sul nostro spazio
web, dove l'applicazione effettivamente risiede, ad esempio www.html.it/mia-applicazione. Teniamo
presente che l'applicazione può essere formata da più pagine, per cui se ad esempio l'utente
richiama la pagina apps.facebook.com/mia- applicazione/pippo.php, la richiesta verrà girata alla
corrispondente pagina www.html.it/mia-applicazione/ pippo.php. La "homepage" dell'applicazione è
la classica pagina index.
In Figura viene sintetizzato quanto appena descritto.Il dialogo tra Facebook e la nostra applicazione avviene mediante un approccio REST-based,
secondo quanto descritto dall'API del servizio. In sostanza, Facebook mette in moto la nostra
applicazione, la quale invia delle richieste HTTP allo stesso Facebook aspettando le relative
risposte, per fornire infine l'output che Facebook servirà all'utente. La conoscenza dell'API non è
necessaria se si decide di appoggiarsi ad una libreria che ne implementa le funzionalità. Nel nostro
caso sfrutteremo la PHP Facebook Client Library, libreria in PHP 5 fornita dallo stesso Facebook.
3.4 Creare una nuova applicazione
Assumendo di aver già installato le applicazioni Developers e Translations, procediamo con la
registrazione della nuova applicazione come descritto. Questo primo passo ci consente di ottenere i
due codici API Key e Secret (nella versione in italiano: Chiave API e Invisibile) necessari per
interfacciarsi con la Facebook Platform. I parametri importanti da specificare sono i seguenti:
• Nome dell'applicazione: HTML.it Goal;
• Callback URL: il nostro spazio web dove risiede l'applicazione;
• Canvas Page URL: l'indirizzo per identificare l'applicazione su Facebook, nel nostro caso
http://apps.facebook.com/htmlit-goal;
• Can your application be added on Facebook? Yes: parametro fondamentale per consentire
agli utenti di aggiungere l'applicazione nel proprio profilo;
• Nome e indirizzo Tab: l'etichetta e la relativa pagina web da associare alla scheda che un
utente può aggiungere al proprio profilo. Nel nostro caso, utilizziamo Goal come nome e
tab.php come indirizzo: ci serviranno per approfondire l'integrazione dell'applicazione con
gli account dei nostri futuri utenti;
Per quanto riguarda gli aspetti di internazionalizzazione, è bene partire utilizzando la lingua inglese,
English (US), ed andare a tradurre successivamente le varie stringhe con l'applicazione
Translations. Anche nella descrizione dell'applicazione, utilizziamo inizialmente la lingua inglese.
Teniamo presente che l'applicazione Developers ci consente di correggere in un secondo momento i
dati che abbiamo inserito. A questo punto, una volta registrata l'applicazione saremo in possesso dei
due codici API Key e Secret.
3.5 Primi passi nell'implementazionePrima di procedere con l'implementazione del cuore della nostra applicazione, assicuriamoci di
creare la cartella specificata come Callback URL nel nostro spazio web, e di copiarci tutti i sorgenti
della PHP Facebook Client Library.
Per quanto riguarda gli obiettivi che i nostri utenti gestiranno, le informazioni verranno
memorizzate nella seguente tabella MySQL:
CREATE TABLE goal (
goal_id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT UNSIGNED,
goal_date DATE ,
goal_deadline DATE,
goal_title VARCHAR(250),
goal_status INT
);
• goal_id è la chiave primaria;
• user_id è una chiave esterna per memorizzare l'ID dell'utente, il campo BIGINT in MySQL
è necessario in quanto Facebook utilizza interi a 64 bit;
• goal_date è la data in cui l'obiettivo viene inserito;
• goal_deadline è la data di scadenza entro cui si vuole raggiungere l'obiettivo. Se il campo
viene lasciato nullo, assumiamo che non ci siano scadenze;
• goal_title descrive l'obiettivo;
• goal_status rappresenta lo stato dell'obiettivo (per ora: 1 = Raggiunto, -1 = Fallito, 0 = In
svolgimento); in questo caso potrebbe essere sufficiente anche un TINYINT come tipo di
dato.
3.6 Il codice PHP di una prima applicazione
Il file index.php mostrato di seguito comprende tutto il codice di un eventuale primo programma
che chiameremo “Hello World”.}
echo '';
// Dump dell'oggetto $facebook
// echo ''; var_dump($facebook); echo '';
?>
Codice e commenti sono abbastanza autoesplicativi, ma vediamo ora di spendere qualche parola in
più per fugare eventuali dubbi.
Tutti i sorgenti della PHP Facebook Client Library sono stati copiati nella stessa cartella in cui
risiede index.php, dal quale includiamo facebook.php che è il file principale della libreria.
$app_apikey e $app_secret sono le due variabili dedicate a contenere i codici forniti da
Facebook quando abbiamo creato la nuova applicazione. Questi sono necessari per creare l'oggetto
$facebook che sarà il punto centrale del nostro codice.
Dopo la creazione dell'oggetto Facebook, è fondamentale verificare l'autenticazione dell'utente,
sfruttando il metodo require_login() che restituisce l'ID numerico dell'utente stesso
all'interno del servizio.
Il messaggio di benvenuto sfrutta l'utilizzo di codice FBML, un insieme di tag che possono essere
immersi nel normale HTML e che vengono poi trasformati da Facebook. Nel nostro caso, il tag
fb:name mostra il nome dell'utente sotto forma di link al suo profilo. L'attributo uid serve per
specificare il suo ID numerico, mentre l'attributo useyou, se impostato a true, mostra la dicitura
you invece del nome.
Il passo successivo è recuperare la lista degli amici: l'oggetto $facebook contiene una proprietà
$api_client, a sua volta un oggetto, la quale funge appunto da client per l'API di Facebook. Il
suo metodo friends_get() restituisce un array con tutti gli ID numerici degli amici. Decidiamo
quindi di stampare tre nomi casuali (mescolando l'array con shuffle() ) sfruttando ancora le
funzionalità di FBML.
Per un'occhiata più dettagliata all'interno dell'oggetto $facebook, basta togliere il commento sulla
riga relativa al dump della variabile.
In Figura vediamo l'output del nostro Hello World.
3.7 Considerazioni
Facebook suggerisce delle linee guida per lo sviluppo di applicazioni di qualità. Secondo queste
linee guida, un'applicazione dovrebbe essere:
• significativa, ossia essere utile, espressiva, e sociale (coinvolge il grafo degli amici,
consente all'utente di esprimere qualcosa di se stesso, invoglia l'utente ad utilizzarla ancora).
• fidata, ossia deve rispettare la privacy, deve rispettare i bisogni degli utenti e deve essere
assolutamente trasparente, mostrando quello che fa e come lo fa.
• ben disegnata, ossia intuitiva, semplice, senza errori, ma anche scalabile e robusta,
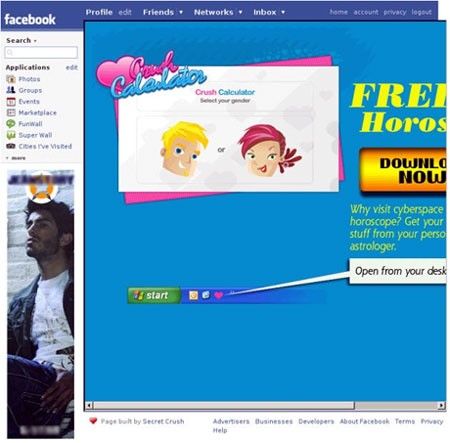
garantendo un buon uptime (questo può dipendere anche dalla qualità dal vostro hosting).3.8 Applicazioni e sicurezza È facile capire quindi che ogni applicazione sviluppata ha un potenziale bacino di utenza vastissimo: quale migliore strumento per veicolare codice nocivo? Purtroppo questa riflessione è stata fatta già da una moltitudine di persone, che hanno sviluppato diversi tipi i applicazioni dannose. Come abbiamo visto, Facebook non ospita codice di terze parti, ma semplicemente permette di integrare un software a piacimento. Non può quindi eseguire alcun controllo sulle applicazioni se non quello esercitato a monte nei permessi di programmazione. Potenzialmente pericolosa quindi, su Facebook, è la possibilità di creare applicazioni pubblicabili liberamente all'interno del network. In questa categoria rientrano tutti quei giochi, sondaggi, quiz e programmi che tutti gli iscritti conoscono bene, e che si presentano normalmente sotto forma di invito a partecipare da parte degli amici. Praticamente chiunque, con un account e un po' di abilità nella programmazione può crearle e metterle a disposizione di tutti, servendosi di un servizio di hosting (ce ne sono tanti, gratuiti) che possa ospitarle. Le applicazioni si diffondono su Facebook perché chi le riceve, nel momento in cui le accetta, viene sollecitato ad invitare a sua volta all'utilizzo alcuni amici della sua lista personale. Questo meccanismo, aiutato dal fatto che Facebook ha poco controllo sulle applicazioni che diffonde, ha fatto sì che potessero presto trasformarsi in veicolo di adware e malware. Questa situazione potrebbe diventare veramente pericolosa se il pc in questione fa parte di una rete aziendale, perché in questo modo si espongono a rischio non solo i propri dati personali, ma anche informazioni riservate dell'azienda (password, coordinate bancarie, numeri di carte di credito, ecc.). 3.9 Esempi –il caso “Secret Crush” Una delle prime ad essere utilizzata a fini dannosi è Secret Crush. L'esca viene lanciata inviando alla vittima una richiesta in cui si indica l'esistenza di un fantomatico "ammiratore segreto". Secret Crush Per visualizzare l'identità di questo ammiratore, l'utente, dopo aver accettato la richiesta, deve selezionare cinque dei suoi amici per invitarli ad usare l'applicazione. A differenza del phishing questa minaccia fa uso del social engineering per propagarsi, ovvero l'abilità di spingere la vittima ad eseguire le operazioni desiderate. A questo punto l'utente viene invitato a scaricare ed installare un file contenente l'adware chiamato Zango.
Puoi anche leggere

















































