Neural Trader: utilizzo di reti neurali per il trading di scommesse
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Neural Trader:
utilizzo di reti neurali per il trading di scommesse
Mario Arrigoni Neri
A. Introduzione
Il trading di scommesse sportive è una attività relativamente nuova, che si presenta per la prima
volta nel 2003 quando una importante società del Regno Unito, The Sporting Exchange Limited,
sviluppa un portale che propone un sistema di scambio di quote di scommesse analogo ad una borsa
valori. Questo sito, www.betfair.com, assorbe ben presto la gran parte del colossale giro d’affari
che, nel Regno Unito e non solo, ruota intorno alle scommesse, sportive ma non solo, tanto che
nello stesso anno Betfair riceve il Queen’s Award for Enterprise dalla Regina d’Inghilterra.
Il mercato delle scommesse presenta numerose analogie con quello azionario, tuttavia, grazie al suo
collegamento esplicito con eventi reali ed oggettivi, risulta fortemente più “vincolato”, nel senso
che è possibile valutare facilmente ed in maniera affidabile il grado di pertinenza di un mercato
all’evento sottostante, nonché i livelli di convenienza delle quote disponibili.
Per questi ed altri motivi, l’attenzione di alcuni broker di borsa si è spostato sul ricco mercato
offerto da Betfair (ed altri sistemi paralleli nati successivamente).
Lo scopo di questo lavoro è valutare se le tecniche di soft computing, quali le reti neurali e gli
algoritmi genetici, possono essere proficuamente applicate al mercato delle scommesse.
Dopo una prima brevissima introduzione ai concetti fondamentali dello scambio di scommesse,
proverò ad addestrare una rete neurale a stimare le probabilità di vittoria in relazione ad una
determinata scommessa, sperando di ottenere una stima più accurata di quella che si riflette nelle
quote (o prezzi) disponibili sul mercato. In effetti, ottenere una rete siffatta significherebbe depurare
almeno parzialmente il modello degli eventi sottostanti (ad esempio quelli sportivi) dalle dinamiche
sociali, psicologiche e speculative che intervengono nella formulazione di una quota. Così facendo
sarebbe in linea di principio possibile utilizzare la stima del sistema per valutare se il prezzo
proposto è più o meno conveniente, con un evidente vantaggio economico.
Una volta ottenuta la rete per la predizione passerò ad implementare un trader automatico che ne
sfrutti l’accuratezza per operare sul mercato guidato da alcuni parametri operativi. Infine questi
parametri operativi, che in generale saranno indicati dall’utente, saranno oggetto di ottimizzazione
da parte di un algoritmo genetico, che cercherà di identificare la politica ottima e, quindi, il trader
più performante.
B. Concetti base del mercato scommesse
Caratteristiche delle scommesse
Una scommessa non è altro che un accordo tra due attori, detti giocatore e banco, sull’effettuare
una transazione economica sulla base del verificarsi o meno di un evento, solitamente successivo
alla stipula dell’accordo.
Il giocatore corrisponde al banco una somma di denaro concordata detta carico, in caso in cui
l’evento si verifichi il banco corrisponderà al giocatore una somma concordata detta premio. In
sostanza, il giocatore, pagando il carico, acquista il diritto a ricevere dal banco il premio
condizionatamente al verificarsi dell’evento.
L’elemento caratteristico della scommessa è la quota (o prezzo), definito come:premio
quota =
carico
Ovviamente, a parità di tutte le altre condizioni, più alta è la quota, maggiore è il vantaggio del
giocatore rispetto al banco. I livelli di rischio degli attori prende il nome di esposizione o
responsabilità ed indica la massima perdita a cui ciascuno degli attori si espone partecipando alla
scommessa. Il giocatore si espone, in caso l’evento non si verifichi, ad una perdita pari al carico,
mentre il banco si espone in caso l’evento si verifichi ad una perdita pari al premio decurtato del
carico che comunque riceve dal giocatore. Quindi:
exp G = carico
exp B = premio − carico = ( quota − 1) ⋅ carico
Esistono diversi schemi di scommesse, i due principali si distinguono sulla base dei meccanismi che
portano al calcolo della quota:
a quota fissa E’ il sistema più diffuso. Il banco propone una scommessa ad
una platea di potenziali giocatori. La scommessa è
caratterizzata da una quota, decisa unilateralmente dal banco
e da un carico massimo che il banco stesso è disposto a
coprire.
Il giocatore può decidere liberamente se accettare la quota
proposta dal banco.
a totalizzatore E’ il sistema utilizzato da alcuni sistemi di scommesse
statali, tra cui i sistemi italiani (SNAI, SiSal, Tris, ecc..).
Il banco accetta scommesse da una platea di giocatori,
riservandosi di decidere successivamente la quota delle
singole scommesse. I giocatori, quindi, indicano solo il
carico che intendono scommettere. Al termine della raccolta
il banco calcola le quote a cui accettare ogni scommessa. In
questo caso la quota è nota solo dopo la chiusura delle
scommesse ed è calcolata in modo inversamente
proporzionale al carico totale collezionato su ogni possibile
esito. E’ chiaro che se gli eventi sono mutuamente esclusivi
(come ad esempio i risultati di una partita) il banco può
bilanciare le quote in modo da non rischiare mai di perdere
del denaro.
Il mercato
Il mercato scommesse raccoglie un insieme di utenti, che possono operare contemporaneamente
come banco e come giocatore. Il mercato è organizzato in un albero di eventi reali (intesi come
eventi sportivi o meno nel mondo reale, come una partita, una corsa, una votazione politica, ecc..).
Per ogni evento sono disponibili uno o più mercati, ogni mercato si occupa di un particolare aspetto
dell’evento ed e caratterizzato dai possibili esiti di tale aspetto, detti anche selezioni.
Ad esempio, considerando come evento naturale una partita di calcio Milan-Inter, esisterà
quantomeno il mercato sul vincente, che permette di scambiare scommesse su quale sarà il risultato
di schedina. Questo mercato proporrà come possibili selezioni Milan, Inter e Pareggio.Sullo stesso evento reale possono essere definiti mercati differenti, come il numero di reti, il
risultato finale, ecc.., ciascuno con una serie di selezioni che esauriscono i possibili esiti del
mercato.
Per ogni selezione di ogni mercato un utente può operare sia come banco che come giocatore, in
ogni momento può inserire nel sistema l’offerta di una scommessa indicando il carico e la quota a
cui è interessato.
Per ogni selezione il sistema mantiene una lista delle offerte e le propone agli utenti in un book a tre
livelli non dissimile da quello a cui si è abituati sul mercato borsistico organizzate sui due lati
dell’offerta:
• Lato del back: raccoglie tutte le proposte dei banchi, quindi ogni utente può decidere se
abbinare una scommessa inserendo, di fatto, una richiesta di gioco. E’ l’analogo della lista
delle offerte di vendita di un titolo
• Lato del lay: raccoglie le proposte dei giocatori. Ogni utente può decidere se abbinare una
scommessa inserendo una richiesta di banco. E’ analogo alla lista delle offerte di acquisto
Se una richiesta in back non è interamente soddisfacibile al prezzo richiesto, la frazione di carico
residua rimarrà disponibile in lay per ulteriori abbinamenti; dualmente i carichi non abbinati in lay
rimarranno disponibili in back.
Nell’analogia con i termini borsistici diremo che “acquistare” un evento ad un determinato prezzo
corrisponde a scommettere sulla sua realizzazione ad una data quota.
In termini operativi, conviene evidenziare subito il fatto che, contrariamente a quanto avviene in
borsa, il miglior acquisto è quello al prezzo massimo, così che un trader (o un bookmaker in questo
caso) ha come obiettivo acquistare eventi a prezzi elevati e rivenderli a prezzi inferiori, così da
poter tratte un utile indipendentemente dal verificarsi o meno dell’evento (e cioè effettuando quello
che in gergo prende il nome di arbitrato).
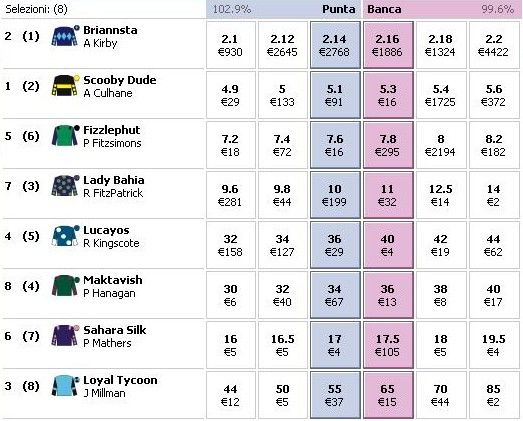
In Figura 1 è riportata una schermata del book a tre livelli su un mercato “vincente” di una corsa
ippica, per ogni selezione e per ogni livello di quota è riportato il carico disponibile per
l’abbinamento.Figura 1 esempio di book a tre livelli
Ovviamente in ogni istante e per ogni selezione il massimo prezzo disponibile in back è inferiore al
minimo prezzo disponibile in lay. Mettendo in competizione sullo stesso mercato non solo giocatori
differenti, ma anche e soprattutto banchi differenti fa sì che le quote disponibili sul mercato siano
mediamente molto più convenienti delle quote fisse dei bookmaker tradizionali. Si valuta che
questo vantaggio sia nell’ordine del 25%.
Il margine di banco
Differentemente dal mercato valori, a prescindere dalle valutazioni tecniche in merito alla
convenienza dell’una o dell’altra selezione, è sempre e comunque possibile valutare la bontà e
concorrenzialità del mercato tenendo presente che una ed una sola delle selezioni sarà pagata dal
banco, mentre le altre si tradurranno in una perdita per il giocatore.
Il margine di banco è l’indice primario per stimare la bontà del mercato e misura il vantaggio che
si riserva il banco che propone tutte le selezioni al miglior prezzo disponibile. Chiaramente nel caso
di un mercato scommesse questo è un banco virtuale, nel senso che solitamente non esiste un unico
utente che propone i prezzi migliori su tutte le selezioni di un mercato. Assumendo un mercato
perfetto, ogni selezione dovrebbe avere una quota determinata unicamente dalla probabilità che
l’evento si verifichi. Il banco remunera il rischio dello scommettitore, garantendo un rapporto tra
vincita e carico inversamente proporzionale alla probabilità di vittoria. In formule:
1
P=
prezzo
Ad esempio é evidente che se si scommette su un evento con probabilità P=1/2, uno scommettitore
onesto accetterà una quota pari a due, in modo da avere una esposizione pari alla vincita.Dato che le selezioni di un mercato M sono una partizione dell’evento certo (sono incompatibili tra
di loro e la loro ed una di esse deve necessariamente verificarsi), la somma delle loro probabilità
deve essere pari ad uno:
1
Q = ∑ Psel = ∑ =1
sel∈ M sel∈ M prezzo sel
Sotto l’ipotesi di mercato perfetto (Q=1) è possibile costruire un book di scommesse neutro, infatti
è possibile giocare (o bancare) tutte le selezioni alle quote disponibili garantendosi un utile nullo a
prescindere dall’esito dell’evento scegliendo i carichi da collocare su ogni selezione sulla base della
quota. Occorre quindi garantire che:
∀ S ∈ M : prezzo S ⋅ carico S − ∑ carico S 2 = 0
S 2∈ M
In un mercato perfetto l’equazione ammette la soluzione:
∑ carico S 2
∀ S ∈ M : carico S = S 2∈ M
prezzo S
In realtà, in ogni istante, il mercato presenta due livelli di quote, uno in back ed uno in lay, che
approssimano solamente il mercato perfetto. Dal lato del back troviamo le offerte di banco non
ancora abbinate ed è quindi naturale che tali quote diano un vantaggio al banco, quindi avremo
Q>1. Al contrario nel lato del lay avremo Q1) o negativo (QInoltre è possibile valutare lo starting price su intervalli successivi di tempo per stimare le
dinamiche di medio periodo di una selezione, utilizzando di fatto lo starting price come un
indicatore più robusto ed affidabile dei semplici prezzi disponibili.
C. Logging dei dati
Mercati di riferimento
Da un punto di vista tecnico, Betfair mette a disposizione, a pagamento, un accesso al proprio
mercato tramite WebService. In ogni istante è quindi possibile monitorare le quote disponibili e
consultare lo storico delle transazioni, ricavando utili indicazioni per le operazioni di trading.
Per sperare di ottenere uno stimatore delle probabilità di vittoria di una selezione occorre garantire
una certa uniformità tra gli eventi considerati. Nel mio lavoro ho scelto di concentrarmi sulle
scommesse sportive sui mercati “vincente” delle corse ippiche inglesi ed irlandesi.
Questa scelta è stata dovuta a due fattori:
• Il volume di gioco su questi eventi è notevole. Indicativamente si ha una media di 25-30
corse al giorno e su ciascuna di queste vengono transati diversi milioni di euro. L’alto
volume di gioco è da un lato indice di un possibile guadagno e dall’altro un indicatore di
concorrenzialità del mercato stesso (che ha in genere un Q molto prossimo ad 1). In un
mercato concorrenziale i prezzi e gli indicatori tecnici sono di norma più indicativi della
reale probabilità di vittoria e possono quindi essere verosimilmente utilizzati da un
predittore neurale
• I mercati “vincente” delle corse inglesi ed irlandesi sono aperti anche durante lo svolgersi
della corsa. In gergo si dice che il mercato è live. La possibilità di scommettere durante la
gara fa si che ci siano delle fasi molto concitate, dove grandi volumi di denaro vengono
scambiati su mercati molto volatili e con prezzi in rapida oscillazione. Questo fornisce
solitamente ottime opportunità di trading all’operatore umano e, verosimilmente, è un
indicatore di possibile successo anche per un trader artificiale.
Il logger
Una volta scelti i mercati di riferimento, il primo passo del mio lavoro è stata l’implementazione di
un client per il webservice di Betfair che fosse in grado di memorizzare tutte le transazioni. In realtà
Betfair stesso fornisce ai propri clienti delle statistiche sui mercati e sugli sport più popolari (tra cui
per prime troviamo proprio le corse inglesi). Tuttavia, queste non sono sufficienti per ricostruire le
dinamiche dei prezzi e delle transazioni: informazioni fondamentali in quanto sono le uniche
disponibili a runtime durante l’attività di trading.
Il logger è un semplice tool sviluppato in Java. Utilizza Axis per interfacciarsi al webservice di
Betfair ed è pensato per operare autonomamente per lunghi periodi.
Ogni giorno l’albero degli eventi viene aggiornato per contenere gli eventi giornalieri, le corse di
interesse si svolgono normalmente dall’una di pomeriggio fino a sera e la lista dei mercati viene
aggiornata entro le 10 di mattina.
Il logger, quindi, opera su base giornaliera. Alle 10 di mattina aggiorna la lista dei mercati,
navigando lungo le directory degli eventi fino alle corse di cavalli. A questo punto estrae le sole
corse inglesi ed irlandesi che prevedono una parte in live ed infine si mette in ascolto su tali eventi.
Già in fase di log è necessario effettuare alcune scelte sia sulle informazioni da considerare che
sulle modalità e le risoluzioni con cui osservarle:
• Intervallo di osservazione: solitamente, per gli eventi sportivi si osserva una
concentrazione dell’attività di compravendita a partire dagli ultimi minuti prima dell’evento
reale. Nell’ambiente ippico è detto effetto tondino; nella prima parte della giornata, i varibookmaker si propongono per bancare le selezioni sulla base di analisi tecniche di
periziatori ed i giocatori piazzano scommesse sulla base di fattori esogeni rispetto all’evento
vero e proprio. Il risultato sono scarsissime transazioni e quote di fatto slegate dalle
probabilità reali di vincita. 5 o 10 minuti prima dell’inizio della corsa i concorrenti si
presentano sul campo di gara e gli scommettitori possono visionare effettivamente cavallo e
fantino e valutarne le qualità e la forma. Questo è il momento in cui, trascinati dalle
scommesse inviate direttamente dall’ippodromo, i mercati incominciano a muovere i capitali
maggiori. Per queste considerazioni il logger analizza i mercati a partire da dieci minuti
prima della partenza.
• Intervallo di campionamento: è una variabile fondamentale per ottenere dei campioni
numerosi, ma contemporaneamente significativi. Visto che alcune informazioni si
riferiscono all’intero intervallo di osservazione, non conviene spingere gli aggiornamenti
oltre una certa frequenza per evitare di campionare del rumore. Vista la volatilità dei mercati
e valutata la dinamica degli scambi, ho impostato l’intervallo tra due campioni a cinque
secondi. Empiricamente i tempi di comunicazione con il server ed i ritardi dovuti alla
scrittura dei dati hanno comportato un aumento di circa un secondo.
Figura 2 il tool per il log dei mercati
Il programma visualizza in una lista i riferimenti di tutti gli eventi monitorati, indicando
cromaticamente la fase in cui si trova il mercato:
• Grigio: mercato in attesa, non è ancora iniziata la fase di logging
• Giallo: logging pre-live, il sistema sta memorizzando lo storico del mercato, ma l’evento
reale non è ancora iniziato
• Verde: logging in-live, il sistema sta memorizzando lo storico del mercato e l’evento reale è
in corso. La distinzione rispetto al logging pre-live permetterà di specializzare la rete in una
delle due fasi, qualora emergano differenze sostanziali nei rispettivi comportamenti
• Rosso: logging terminato, il mercato è stato chiuso e si sta attendendo la regolazione delle
scommese abbinate; nessun gol viene creato in questa faseDurante la fase di logging occorre estrarre dai dati grezzi forniti dalla piattaforma quelle
informazioni che permetteranno, di costruire i campioni di addestramento della rete. In particolare è
necessario calcolare lo starting price ed i volumi scambiati partendo dallo storico di tutte le
transazioni. L’impossibilità di accedere direttamente a questi valori richiede di accedere ad ogni
campione a tutte le quote abbinate ed è la principale causa dell’overhead in fase di logging.
Per ogni campione e per ogni selezione vengono quindi salvati:
• Il miglior prezzo in back
• Il miglior prezzo in lay
• Il carico disponibile al miglior prezzo in back
• Il carico disponibile al miglior prezzo in lay
• Lo starting price della selezione
• Il volume totale scambiato per la selezione
I file di log
Il frutto del logger viene salvato in una serie di file XML. Ogni file contiene i dati di un particolare
mercato ed i file sono organizzati in directory, una per ogni giornata.
Figura 3 DTD del linguaggio di log
L’elemento radice di ogni file contiene il nome del mercato (che corrisponde al nome del file), il
numero di rilevazioni eseguite e riporta la lista dei singoli campioni. Ogni campione è classificato a
seconda che sia stato o meno raccolto durante la fase live del mercato; inoltre si memorizza il
tempo, in secondi, che manca all’inizio ufficiale della gara. Questo può essere importante per
valutare in che misura i prezzi disponibili sul mercato sono legati al reale valore della selezione.
Ogni campione riporta poi i dati delle singole selezioni secondo le misure indicate nel paragrafo
precedente.
La Figura 3 riporta il DTD del linguaggi dei log, mentre la Figura 4 mostra il frammento iniziale del
log di una corsa.
Il logger è stato mantenuto in linea a partire dal 10 giugno fino al 27 novembre 2006, per un totale
di 3351 eventi reali a cui corrispondono ben 3790707 campioni.Figura 4 frammento di un file di log
D. La rete neurale
Nello sviluppo della rete ho utilizzato il tool open sorse Joone (http://www.jooneworld.com/).
La rete implementata è una rete feedforward con:
• Uno strato lineare in ingresso
• Uno strato nascosto sigmoidale
• Un neurone di uscita sigmoidale
L’idea di base è addestrare la rete per riconoscere i campioni che si riferiscono a selezioni vincenti
da quelli che si riferiscono a selezioni perdenti. In questo modo il valore restituito dalla rete (che è
limitato tra zero ed uno a causa del neurone di uscita) può essere convenientemente interpretato
come la probabilità di vittoria.
Figura 5 rete neurale di baseIn Errore: sorgente del riferimento non trovata viene mostrata la rete di partenza all’interno
dell’editor di Joone. Sono indicati i tre livelli della rete e le strutture necessarie all’addestramento ed
alla valutazione della rete stessa.
Tra queste troviamo:
• vari connettori a file, che permettono di leggere i campioni e gli esiti noti per
l’addestramento supervisionato
• il componente di apprendimento (teacher) che misura l’errore della rete ed implementa
l’algoritmo di addestramento scelto
• il componente grafico che si occupa di disegnare l’andamento dell’errore durante
l’addestramento.
Costruzione del training set
Il sistema di addestramento prevede che i campioni siano inseriti in un file testuale con i singoli
elementi divisi da caratteri di interpunzione (;). E’ quindi necessario sviluppare un secondo
programma di traduzione che:
• ricava dai dati dei log delle informazioni significative da fornire in ingresso alla rete.
Questa fase di preprocesso permette di ridurre lo spazio dei parametri (cioè la dimensione
dei campioni in ingresso) ed è finalizzata ad una migliore convergenza della rete, dato che
parte dell’elaborazione che questa dovrebbe apprendere è di fatto fornita dall’esperto del
dominio. Joone fornisce una libreria di plugin per il proprocessing dei campioni, tuttavia
l’elaborazione richiesta è fortemente dipendente dall’applicazione e mal si presta ad essere
demandata ai plugin della piattaforma
• seleziona un sottoinsieme di campioni dall’enorme mole di dati raccolta, mantenendone la
rappresentatività. Contestualmente esegue un resampling dei dati in modo da renderli più
efficaci per la classificazione.
Per sua natura, l’analisi dei prezzi e degli scambi trae vantaggio dall’elaborazione congiunta di una
serie di campioni letti in intervalli temporali contigui. L’approccio è molto vicino all’analisi di
sequenze temporali, ma rispetto alla semplice giustapposizione di campioni diversi successivi è
opportuno calcolare alcune grandezze di processo quali gli scambi nell’ultimo intervallo di
osservazione.
Ogni campione sottoposto alla rete riporta informazioni sui prezzi della selezione di interesse
relative agli ultimi tre istanti di osservazione. Per evitare un aumento insostenibile dello spazio in
ingresso ho scelto di utilizzare le sole informazioni sui migliori prezzi disponibili, riducendo di
fatto il book ad un unico livello. Queste informazioni sono integrate da informazioni sulle
transazioni della selezione, che rendono conto dell’effettivo interesse suscitato dall’evento ed
alcune informazioni generali sul mercato, che permettono di caratterizzare il tipo di evento e la
situazione in cui avviene il trading. Infine, è utile poter confrontare la selezione attuale con il suo
diretto antagonista, cioè con la selezione sullo stesso mercato che appare favorita dalle quote attuali;
a tale scopo il campione in ingresso viene integrato da alcuni dati sulla selezione antagonista.
Infatti spesso, e soprattutto in live, le stime sulle possibilità di vittoria di un corridore dipendono dal
raffronto delle dinamiche con selezioni differenti.
Complessivamente, ogni campione è costituito da 34 valori, a cui si aggiunge il valore dell’output
desiderato che nella fattispecie è la funzione indicatrice della vittoria. Dato che i dati dei log non
riportano esplicitamente il vincitore di una corsa è necessario estrarre questa informazione. Ciò è
possibile se si considera che al termine dell’evento, cioè appena prima della chiusura di un mercato,
il concorrente con quota minima è quasi certamente il vincitore.
La tabella seguente mostra i singoli campi di ogni campione, raggruppati per tipologia ed indicando
ove necessario il metodo di calcolo a partire dai dati nei log.# nome descrizione
Prezzi della selezione corrente
1 B(t) Miglior prezzo in back all’istante corrente
2 L(t) Miglior prezzo in lay all’istante corrente
3 BS(t) Stake (o carico) disponibile al miglior prezzo in back
4 LS(t) Stake (o carico) disponibile al miglior prezzo in lay
5 B(t-1) Miglior prezzo in back all’istante precedente
6 L(t-1) Miglior prezzo in lay all’istante predente
7 BS(t-1) Stake (o carico) disponibile al miglior prezzo in back
8 LS(t-1) Stake (o carico) disponibile al miglior prezzo in lay
9 B(t-2) Miglior prezzo in back a due istanti precedenti
10 L(t-2) Miglior prezzo in lay a due istanti precedenti
11 BS(t-2) Stake (o carico) disponibile al miglior prezzo in back
12 LS(t-2) Stake (o carico) disponibile al miglior prezzo in lay
Scambi sulla selezione corrente
13 MODD(t) Starting price attuale della selezione
14 MS(t) Carico scambiato sulla selezione
15 DODD(t) E’ il prezzo medio scambiato nell’ultimo intervallo temporale. Visto che non
è fornito direttamente dai file di log è necessario calcolarlo come:
MODD(t ) ⋅ MS (t ) − MODD(t − 1) ⋅ MS (t − 1)
DODD( t ) =
DS (t )
16 DS(t) Volume scambiato nell’ultimo intervallo di tempo, calcolabile come:
DS (t ) = MS (t ) − MS (t − 1)
17 DODD(t-1) Prezzo medio scambiato nel penultimo intervallo temporale. E’ di fatto la
versione traslata di un istante di DOSS(t)
18 DS(t-1) Volume scambiato nel penultimo intervallo temporale
19 MODD(t-2) Starting price calcolato due istanti prima dell’attuale, raccoglie
l’informazione sul comportamento medio prima delle ultime rilevazioni
20 MS(t-2) Volume scambiato dall’apertura del mercato al terzultimo campione
Prezzi della selezione antagonista
21 BA(t) Miglior prezzo in back all’istante corrente della selezione antagonista. La
selezione antagonista è quella con il prezzo di Back minore tra le atre
selezioni. Quindi è solitamente il concorrente favorito, salvo nel caso in cui il
favorito sia la selezione corrente
22 LA(t) Miglior prezzo in lay all’istante corrente della selezione antagonista
23 BAS(t) Stake (o carico) disponibile al miglior prezzo in back della selezione
antagonista
24 LAS(t) Stake (o carico) disponibile al miglior prezzo in lay della selezione
antagonista
25 BA(t-1) Miglior prezzo in back all’istante precedente della selezione antagonista
26 LA(t-1) Miglior prezzo in lay all’istante predente della selezione antagonista
27 BAS(t-1) Stake (o carico) disponibile al miglior prezzo in back della selezione
antagonista
28 LAS(t-1) Stake (o carico) disponibile al miglior prezzo in lay della selezione
antagonista
29 BA(t-2) Miglior prezzo in back a due istanti precedenti della selezione antagonista
30 LA(t-2) Miglior prezzo in lay a due istanti precedenti della selezione antagonista
31 BAS(t-2) Stake (o carico) disponibile al miglior prezzo in back della selezioneantagonista
32 LAS(t-2) Stake (o carico) disponibile al miglior prezzo in lay della selezione
antagonista
Informazioni generali sul mercato
33 Togo Secondi che mancano alla partenza ufficiale della gara
34 Runners Numero di selezioni disponibili per il mercato
Uscita desiderata
35 wins Funzione indicatrice della vittoria
Selezione dei campioni
La selezione dei campioni da inserire nel training set è fondamentale per garantire la
rappresentatività del campione stesso. La mole di dati raccolti fornisce una buona libertà nella scelta
dei criteri di ammissibilità dei campioni:
• omogeneità dei campioni: quando l’evento reale inizia, il mercato passa dalla fase di
trading a quella “live”. In questo passaggio tutte le scommesse non abbinate vengono
rimosse ed inizia una nuova contrattazione. Al fine di avere campioni temporali significativi
è quindi importante che i tre istanti che concorrono alla definizione di un campione
(nominalmente t, t-1 e t-2) appartengano alla stessa fase di contrattazione. Se così non fosse
si otterrebbero delle discontinuità sui prezzi di mercato artificiosi, dovuti ad un evento
singolare che interrompe la sequenza
• ammissibilità per prezzo: la significatività dei prezzi osservati varia enormemente a
seconda del livello di quota. A prezzi molto piccoli (al di sotto di 1.1) corrisponde una
vittoria quasi certa; al contrario livelli di prezzo molto alti (al di sopra di 1:50) sono molto
poco significativi in quanto sono determinati quasi unicamente da quote residue
abbandonate dal banco o da azioni speculative. E’ pertanto opportuno limitarsi a campioni
con prezzi di mercato (userò il back per maggiore significatività) compresi in un opportuno
intervallo.
• ricampionamento: il ricampionamento dei dati in ingresso permette di manipolare la
proporzione tra diverse classi di campioni. Uno dei problemi del fenomeno osservato è la
bassa incidenza statistica delle selezioni vincenti. Infatti, un mercato ha mediamente 10-12
selezioni a cui corrisponde una probabilità a priori di vittoria intorno al 5%. In letteratura è
noto che questo sbilanciamento tra le cardinalità delle due classi può rendere difficoltoso
l’apprendimento. Tuttavia il ricampionamento pone due problematiche:
• la probabilità a priori è di per sé un’informazione: ricampionare eccessivamente il
dataset può distruggere completamente questa informazione. Visto che l’obiettivo è
stimare le probabilità di vittoria e di sconfitta conviene mantenere il ricampionamento
entro termini accettabili
• ricampionare il training set vuole spesso dire replicare alcuni campioni della classe meno
numerosa. Questo solleva evidenti problemi sul filtraggio del rumore e sulla capacità di
generalizzazione della rete ottenuta e ripropone problematiche di overfitting. Nel nostro
caso il ricampionamento può essere effettuato senza replicare alcun campione. Dato il
grande numero di rilevamenti è infatti sufficiente campionare la classe dei vincitori con
una distribuzione di probabilità diversa per ottenere un aumento di dati senza
duplicazione degli stessi.Nella costruzione del dataset ho scelto i seguenti parametri:
parametro valore commenti
Prezzo minimo 1.3 Equivale ad una probabilità stimata di vittoria di circa
il 30%, al di sotto di questo valore già si vedono gli
effetti della speculazione
Prezzo massimo 50 Al di sopra del 50% i prezzi appaiono decisamente
poco significativi
% perdenti 5% Per i campioni che soddisfano gli altri criteri si applica
una probabilità di selezione del 5%. Questo permette
di ottenere un numero comunque molto alto di
campioni che spaziano su tutti gli eventi registrati.
Mediamente un evento viene osservato per 13-14
minuti (10 di trading + 3-4 di durata del live), quindi
campionando ogni 5-7 secondi si hanno circa 140
campioni per evento; ricampionando se ne hanno 7-8.
% vincenti 15% Selezionando i vincenti con una probabilità tripla
rispetto ai perdenti si innalza la percentuale dei
vincenti a circa il triplo dell’incidenza originaria,
mantenendola comunque di gran lunga inferiore al
50%
Applicando questi parametri ai campioni reali ottenuti dalla fase di logging, composta da circa 3300
eventi, si filtrano gli oltre 3 milioni e mezzo di campioni fino ad ottenerne “solo” 186175,
innalzando contemporaneamente la percentuale di campioni vincenti dal 5 al 15%E. Addestramento
Una volta estratto il training set si passa alla fase di addestramento. Come primo tentativo usiamo la
rete di Figura 5 ed un algoritmo di backpropagation con learning rate pari a 0.8 ed un momento di
0.6. il risultato, utilizzando i primi 5000 campioni del dataset, è riportato in Figura 6. Come appare
evidente, la rete parte già con delle performance interessanti, caratterizzate da un errore medio
intorno a 0.3 (che, come mostrerò, è già comparabile con l’errore medio delle stime basate sui
prezzi). Tuttavia, con l’avanzare delle epoche di addestramento, l’errore non diminuisce
significativamente, tanto da attestarsi dopo 200 epoche intorno a 0.28. E’ da evidenziare che anche
una riduzione modesta dell’errore di previsione può essere sfruttata per ottenere utili, seppur su una
grande mole di eventi.
Figura 6 RMSE del training di base
L’obiettivo è di modificare questa dinamica dell’errore per ottenere una riduzione constante, anche
se limitata, dell’errore stesso. A questo scopo è possibile attuare due interventi, il primo frutto di
considerazioni generali sulla dinamica dell’errore, il secondo specifico per le caratteristiche del
particolare problema in analisi.
Innanzitutto pare che la mancata dinamica decrescente dell’errore sia dovuta ad oscillazioni che
statizzano l’RMSE intorno ad un valore prossimo a quello iniziale. La soluzione tipica in questi casi
è una qualche forma di annealing. In questo caso ho scelto un annealing dinamico al 15%, questo
significa che ogni qualvolta l’errore aumenta il learning rate viene diminuito del 15%.
Inoltre, valutando il dataset, appare evidente una certa di sproporzione tra gli ordini di grandezza
delle singole componenti di ogni campione. Infatti, in ogni campione troviamo campi che
rappresentano prezzi (vuoi prezzi di mercato che starting price), altri che rappresentano carichi
(stake disponibile o volumi scambiati) ed infine altri che rappresentano intervalli temporali e
numero di partecipanti. Le tre classi di componenti assumono ovviamente valori ben differenti, a
volte distanti ordini di grandezza tra di loro. Questa considerazione, unitamente ad alcune
valutazioni sul significato di valori particolari, introduce la tematica del condizionamento tramite
preprocessing dei dati. Analizziamo queste operazioni per le tre classi di componenti:• valori di prezzo: i prezzi vengono distorti utilizzando una scala logaritmica. Man mano che
il prezzo aumenta, la differenza tra due prezzi diventa sempre meno significativa. Inoltre il
prezzo pari a 2 assume un significato particolare, dato che è il prezzo che, almeno
idealmente, dovrebbe indicare un evento puramente casuale; per questo motivi ho scelto di
utilizzare il prezzo 2 come punto per il cambio di segno del logaritmo. Riassumendo, i
prezzi vengono preelaborati attraverso la formula:
price = ln( p − 1)
• valori di flussi: le componenti che rappresentano flussi di denaro assumono solitamente
valori maggiori dei prezzi, mentre anche per queste componenti rimane valicala
considerazione generale sulla significatività delle variazioni rispetto al valore assunto.
Inoltre in questo caso occorre gestire l’eventualità di un carico nullo. Per questi motivi ho
utilizzato un logaritmo in base dieci con una preventiva traslazione di una unità del volume
scambiato (o disponibile):
volume = log10 ( v + 1)
• valori generici: le componenti che indicano i secondi mancanti all’inizio della corsa ed il
numero di partecipanti non vengono preelaborati, essendo per loro natura limitati ad un
range piuttosto contenuto.
Figura 7 andamento dell'RMSE con preprocessing
Per valutare l’effetto del condizionamento dei campioni è stato necessario aggiungere il
condizionatore al programma di elaborazione dei log. Aggiungendo l’annealing ed il preprocessing
dei campioni si ottiene il risultato di Figura 7. In effetti in questo caso le oscillazioni dell’errore
vengono smorzate entro le prime epoche di addestramento e l’errore assume il tipico andamento
decrescente, tendendo ad un valore prossimo a 0.24.
Si conclude quindi che le modifiche apportate hanno da un lato risotto l’errore finale della rete, e
dall’altro ne hanno stabilizzato il comportamento.F. Generalizzazione della rete
Una volta compreso quale forma dare ai dati di training e che tipo di rete utilizzare occorre
dimensionare correttamente la rete medesima e scegliere i valori da assegnare ai parametri di
apprendimento (learning rate e momento).
A tal fine occorre confrontare tra di loro diverse opzioni sulla base dell’errore di validazione e per
fare ciò è opportuno utilizzare una tecnica di cross-validazione, in cui l’intero campione in ingresso
viene partizionato in K frammenti. La valutazione della rete avviene in K turni, in ciascuno dei
quali la rete viene reinizializzata, addestrata con i campioni provenienti da tutti i frammenti meno
uno, ed infine valicata sul frammento non usato nella fase di addestramento. Ad ogni turno si
sceglie un frammento diverso per la validazione ed alla fine si calcola la media degli errori di
validazione. La media calcolata è un indice delle capacità di generalizzazione della rete con
riferimento al particolare dataset, ma utilizzando porzioni diverse dello stesso dataset in fase di
addestramento e di validazione questo diventa un indicatore della generalizzazione della rete
rispetto al problema ed è quindi utile per scegliere i parametri tipici della rete.
Per usare la K-fold crossvalidation per selezionare la rete da utilizzare è possibile, banalmente,
misurare la generalizzazione di diverse configurazioni e scegliere quella che garantisce l’errore di
generalizzazione minimo.
Nel nostro caso i parametri che determinano maggiormente la capacità di generalizzazione della
rete sono il numero di nodi nello strato nascosto, il coefficiente di apprendimento ed il momento.
Nell’esperimento sono stati combinati tre valori per la dimensione del livello nascosto (15, 7 e 35)
con due livelli per il learning rate (0.8 e 0.6) e due per il momento (0.6 e 0.4), ottenendo un totale di
12 differenti configurazioni.
Il campione è stato diviso in cinque frammenti di 20000 campioni ciascuno. Viste alcune difficoltà
implementative di Joone si è scelto di memorizzare i singoli frammenti in file fisicamente distinti e
di usarli per una closs validation con K=5; ad ogni iterazione, quindi, la rete è stata addestrata con
80000 campioni e valicata con i restanti 20000. Per ogni configurazione provata e per ogni
combinazione dei blocchi di training si è eseguito l’addestramento per 100 epoche.
I risultati della valutazione comparativa, ottenuti dopo qualche ora di computazione, sono riportati
nella tabella seguente:
Mean
Mean Training
# hidden level Learning rate Momentum Generalizzation
error
error
15 0.8 0.6 0.356758 0.3763
15 0.8 0.4 0.340779 0.35604
15 0.6 0.6 0.34712 0.36362
15 0.6 0.4 0.339618 0.35328
7 0.8 0.6 0.34353 0.36024
7 0.8 0.4 0.33582 0.34997
7 0.6 0.6 0.33775 0.3513
7 0.6 0.4 0.33428 0.34871
35 0.8 0.6 0.38539 0.37
35 0.8 0.4 0.36564 0.39274
35 0.6 0.6 0.36835 0.4035
35 0.6 0.4 0.35199 0.36768
Come si può notare gli errori di training e di validazione sono molto vicini tra di loro, questo indica
che il campione raccolto è in effetti significativo e si può ben sperare in risultati analoghi
utilizzando campioni al di fuori dei log.Anche se di poco, la configurazione più efficiente sia in termini di apprendimento che in termini di
generalizzazione è quella con 7 neuroni nello strato nascosto, un learning rate iniziale (ridotto
dall’annealing) pari a 0.6 ed un momento di 0.4.
A questo punto è necessario chiedersi se questi risultati sono o meno sufficienti a fornire un trader
efficace. In particolare occorre confrontare l’errore medio di generalizzazione della rete con quello
che si otterrebbe con dei predittori elementari. Il modo più semplice per stimare la probabilità del
verificarsi di un evento è tramite l’inverso del numero di eventi disgiunti ed incompatibili. Nella
fattispecie si tratta di considerare, a priori, ogni corridore ugualmente capace di vincere la corsa, in
questo caso la proprietà viene stimata come:
1
P=
# partenti
In realtà, superare la precisione di una stima a priori non è sufficiente per ottenere un vantaggio
rispetto al mercato, quello che occorre è invece ottenere una stima più precisa di quella “fatta” dal
mercato stesso.
La stima del mercato può essere calcolata sia utilizzando le quote in back che quelle in lay:
1 1
P= P=
Backprice Layprice
Il calcolo delle stime di mercato viene eseguito contestualmente all’estrazione dei campioni dai log
ed è quindi pertinente ai campioni effettivamente utilizzati e resi disponibili al predittore. Gli errori
calcolati in questi tra modi sono riportati di seguito:
• RSME base = 0.512707392186992
• RSME back = 0.45659080492446985
• RSME lay = 0.4597434753711496
Effettivamente gli errori delle stime di back e di lay sono più precise di quelle del predittore di base;
questo sta a significare che i prezzi sono, come ovvio, correlati all’effettiva probabilità di vittoria.
Il confronto con il migliore dei predittori di base, quello basato sui prezzi in back, mostra una
precisione nettamente superiore, quantificabile con una riduzione dell’errore medio pari al 24%.
G. Trading automatico
Fino ad ora abbiamo ottenuto uno stimatore che appare nettamente migliore rispetto alle stime delle
quote di mercato. Questo significa che la rete ottenuta è effettivamente in grado di fornire un
vantaggio competitivo, vuoi fornendo indicazioni all’utente, vuoi fungendo da fonte informativa per
un sistema di trading automatico.
Resta ora da capire come si possa sfruttare questo predittore per automatizzare alcune operazioni sui
mercati. In questo lavoro mi limiterò all’uso più semplice, che consiste nell’adoperare la predizione
della rete per valutare quando i prezzi di mercato sono convenienti (alti in back o bassi in lay) e,
sotto alcune condizioni di ammissibilità e con qualche indicazione sulle tattiche operative, operare
di conseguenza degli acquisti di quote libere sul mercato.
Il trader opera con la seguente modalità:
• In ogni istante di campionamento osserva il mercato, registrando le quote disponibili ed i
carichi corrispondenti
o Per ogni corridore
Utilizzando una memoria per gli stati del mercato ai due istanti precedenti
calcola in tempo reale i 34 ingressi del predittore neurale
Passa gli ingressi alla rete ottenendo una stima della probabilità di vittoria di
ogni selezione
Se la probabilità di vittoria desunta dal prezzo in back è sufficientemente
più bassa di quella ottenuta dalla rete e la selezione non è stata ancoragiocata in back, gioca la selezione al prezzo di mercato ed un carico
compreso in un intervallo predefinito compatibilmente con il mercato
Se la probabilità di vittoria desunta dal prezzo in lay è sufficientemente più
alta di quella ottenuta dalla rete e la selezione non è stata ancora giocata in
lay, banca la selezione al prezzo di mercato ed un carico compreso in un
intervallo predefinito compatibilmente con il mercato
o Se hai raggiunto l’esposizione massima accettabile termina
Per poter simulare l’attività del trader sui mi dadi inseriti nel log è necessario introdurre dei
controlli per evitare che la stessa selezione venga giocata (o bancata) più di una volta. Questo è
importante perché, dato che si stanno usando dei log, in realtà le operazioni eseguite dal trader non
interferiscono con le quote di mercato. Questo vuol dire che se una selezione rimane costantemente
ad un prezzo considerato conveniente il trader continuerebbe a giocarla ogni 5 secondi; questo
comportamento, oltre ad essere particolarmente pericoloso, non riflette ciò che accadrebbe in un uso
reale sul campo, in cui invece la transazione farebbe quantomeno diminuire il carico disponibile, ed
è pertanto poco indicativa dell’effettivo potenziale del trading.
Il funzionamento del trader è parametrico rispetto a nove parametri:
Parametro Descrizione
Vantaggio minimo stimato per cui conviene operare sul mercato.
Una volta calcolata la probabilità di vittoria dal mercato (vuoi in
back, vuoi in lay) questa viene confrontata con la previsione della
rete, ottenendo il vantaggio della rete in percentuale rispetto alla
probabilità di mercato.
In back questo diventa:
previsione
minAdv adv = − 1 ⋅ 100
mercato
Mentre in lay abbiamo
previsione
adv = 1 − ⋅ 100
mercato
Vengono valutate solo le operazioni per cui
adv ≥ min Adv
Anche vantaggi troppo eclatanti possono indicare operazioni troppo
rischioso. Infatti può essere sintomo di fattori esogeni particolari
che incidono sulla probabilità di vittoria del corridore, ma che per
loro natura non possono essere stati presi in considerazione durante
maxAdv
la fase di addestramento della rete.
Per questo motivo vengono valutate solo le operazioni con
adv ≤ max Adv
Indica il livello minimo di prezzo a cui si è disposti operare. Oer
minPrice motivi di semplicità lo stesso valore viene usato sia in back che in
lay
maxPrice Indica il livello massimo di prezzo a cui si è disposti operare
E’ il carico minimo che si vuole puntare, se il mercato non offre il
minStake
carico minimo l’operazione viene ignorata
E’ il carico massimo che si vuole puntare. Se il mercato offre un
maxStake carico maggiore l’operazione sarà comunque eseguita con il carico
massimoEsposizione massima sul singolo evento. Quando il trader ha
collocato o bancato scommesse per una responsabilità pari
Exposure all’esposizione (il carico in back e carico * (prezzo-1) in lay)
termina le operazioni e passa al prossimo mercato.
Questo evita di esporsi eccessivamente durante la fase di trading.
E’ anche possibile decidere da che parte del banco giocare, in back,
Back in lay o in entrambi. Questo parametro booleano indica se operare
in back
Lay Indica se operare in lay
H. Ottimizzazione dei parametri
Sebbene il lavoro di apprendimento del mercato possa dirsi concluso con successo, è opportuno
valutare le potenzialità di guadagno offerte dal predittore. Per fare questo occorre cercare una
particolare configurazione dei parametri operativi che, in una simulazione di mercato, garantisca il
massimo guadagno.
In questo frangente ci si può affidare a tecniche genetiche, che ottimizzino l’insieme dei parametri
rispetto al guadagno.
Il sistema opera con un crossover ad un punto ed una probabilità di mutazione uniforme.
Tecnologicamente, la scelta è caduta sulla libreria JGAP che, rispetto ad altre soluzioni, permette di
operare con cromosomi eterogenei, cioè composti da geni di tipo diverso.
Campioni per l’addestramento
Il simulatore del trading è a tutti gli effetti il trader definitivo, fatto salvo il fatto che opera su dati
simulati invece che in linea con il mercato reale. Per farlo funzionare, quindi, servono i parametri
operativi ed i dati provenienti dal mercato.
Questi ultimi sono di fatto analoghi a quelli usati nella fase di addestramento della rete: i 34
campioni in ingresso vengono usati per stimare la probabilità di vittoria, mentre l’informazione sul
vincente viene usata per calcolare le vincite. Tuttavia, non è possibile riutilizzare i log per
l’addestramento della rete dato che questi non hanno alcuna caratteristica di località e sono anzi
prodotti volutamente scegliendo campioni da mercati diversi ed evitando di campionare troppo
spesso lo stesso mercato.
Per una corretta simulazione, al contrario, è necessario avere log completi di alcuni mercati, pur
operando un campionamento anche rado all’interno del set di mercati. Per questo motivo è
necessario eseguire una seconda estrazione dai log. In questo caso ho campionato i mercati con una
probabilità del 5% estraendo, per motivi di efficienza, solo 20 mercati (corrispondenti all’incirca ad
una giornata di attività). L’estrazione genera il log completo del mercato nella forma idonea ad
essere processata dalla rete neurale; per ogni corridore estrae le tuple che lo riguardano e le combina
con quelle del rispettivo antagonista. L’effetto è la creazione di uno storico di circa cento campioni
(ciascuno composto da 35 valori) per ogni corridore di ciascun mercato selezionato.
Evoluzione
I cromosomi, come detto, contengono un gene per ogni parametro operativo, cioè nove geni.
Innanzitutto ogni gene ha un tipo e degli intervalli ammissibili differenti; questo non crea problemi
durante la fase di addestramento, dato che si è scelto un crossover ad un punto e quindi le posizioni
all’interno del cromosoma vengono preservate durante la fase di evoluzione.
Fortunatamente la libreria utilizzata, JGAP, supporta cromosomi eterogenei.Scegliendo convenientemente i limiti ammissibili per ogni gene si può indirizzare l’evoluzione
verso valori ritenuti semanticamente accettabili e velocizzare pertanto la convergenza della
popolazione anche utilizzando un numero tuttosommato esiguo di individui.
Nella fattispecie, i tipi ed i range ammissibili di ogni gene sono indicati di seguito:
Gene Tipo Min Max
minAdv Int 1 100
maxAdv Int 30 300
minPrice Double 1 4
maxPrice Double 3 30
minStake Int 1 400
maxStake Int 200 1000
Exposure Double 300 3000
Back Boolean - -
Lay Boolean - -
Anche all’interno dei range proposti esistono dei cromosomi che in realtà non ammettono alcuna
politica di trading diversa dalla politica nulla (cioè dall’assenza di operazioni sul mercato), ad
esempio è perfettamente lecito generare un cromosoma con minPrice>maxPrice, visto che i due
range ammissibili non sono disgiunti. Un siffatto cromosoma non accetterebbe di piazzare o
ricevere scommesse ad alcun prezzo. Lo stesso si dica per le restanti coppie di geni. Inoltre, anche
un cromosoma che disabiliti contemporaneamente le operazioni in back e quelle in lay sarebbe di
fatto inattivo e pertanto da scartare a priori.
Le dipendenze funzionali tra geni hanno caratteristiche locali, nel senso che coinvolgono al
massimo due geni. E’ pertanto conveniente definire dei cosiddetti supergeni:
“Un supergene è un gruppo di geni vicini in un cromosoma che sono ereditati insieme a
causa del forte legame genetico e sono funzionalmente correlati in senso evolutivo,
sebbene siano raramente co-regolati geneticamente” – Wikipedia
Da un punto di vista tecnico, un multigene è una collezione di geni contigui che:
• Non vengono spezzati dall’operazione di crossover
• Se vengono mutati vengono mutati insieme
• Sono co-vincolati da un vincolo di integrità che deve essere rispettato durante la mutazione
Il principale vantaggio nell’uso dei supergeni è che, invece di produrre un intero cromosoma e
valutarne l’ammissibilità prima di introdurlo nella popolazione, è possibile mutare ogni supergene
indipendentemente e valutarne indipendentemente l’ammissibilità, con un sostanziale
miglioramento dell’efficienza dell’algoritmo e dei tempi di convergenza dello stesso.
Nel caso specifico ho definito due tipi di supergeni:
• Un supergene ordinale, che impone l’ordinamento dei geni (interi o double) che lo
costituiscono. Viene usato per garantire che gli intervalli operativi dei diversi parametri non
siano vuoti. Questo ovviamente non garantisce che la politica non sia nulla, ma elimina una
grande moltitudine di cromosomi evidentemente inattivi
• Un supergene booleano, che impone che i costituenti (booleani) non siano entrambi falsi.
Viene usato per garantire che le due modalità operative back e lay non vengano mai
disabilitate contemporaneamenteminAdv maxAdv minPrice maxPrice minStake maxStake exposure back lay
< < < exposure ∨
Figura 8 partizionamento del cromosoma in supergeni
La fitness usata dall’algoritmo di apprendimento non è altro che il guadagno netto prodotto dalla
politica rappresentata dal cromosoma ottenuto dal simulatore sui mercati estratti casualmente dal
campione di log. In realtà, visto che la si richiede una fitness definita positiva, il profitto o perdita
della politica deve essere postprocessato.
La funzione di postprocessing dovrebbe:
• Evidenziare i miglioramenti in terreno positivo
• Penalizzare le politiche che generano perdite
La scelta è caduta su una funzione continua e monotona crescente, che è lineare per le vincite ed
esponenziale per le perdite:
x
+1 x≥ 0
fitness (c) = 1000
e x x < 1
fitness
1 1/1000
P/L
Le restanti caratteristiche dell’algoritmo sono:
• Popolazione di venti campioni, mantenuta costante tramite una selezione pesata sulla fitness
• Elitismo del solo primo elemento: mantenere il miglior esemplare nella generazione
seguente impedisce di perdere una soluzione pseudo-ottima o comunque ad alta efficienza
• Crossover ad un punto con probabilità costante del 10%
• Mutazione con probabilità costante del 5% sul cromosoma
Nonostante la ridotta dimensione della popolazione, dopo sole dieci generazioni viene selezionato
un gruppo di soluzioni molto efficaci, la migliore delle quali è:adv [36-110]
price[3.37-7.87]
stake[372-525]
exposure = 2067
back: false
lay: true
Questa soluzione produce un utile netto su 20 mercati pari a 3546 euro. Considerando che il
campione considerato, seppur sparso in mesi di log, equivale come durata ad una giornata di
attività, è evidente l’efficacia della politica individuata.
In realtà la soluzione appare robusta e dotata di buone caratteristiche di generalità. Infatti:
• La scelta di operare unicamente in lay è supportata dal fatto che, mediamente, il denaro
disponibile in lay è fornito da giocatori meno esperti di quello disponibile in back, che è
invece gestito da bookmaker professionisti. E’ pertanto plausibile che su questo frangente si
presentino le migliori occasioni e ci sia una maggiore probabilità di avere prezzi che si
discostino dai reali valori di mercato
• Gli intervalli di ammissibilità di prezzi e carichi e l’esposizione massima consentita sul
singolo mercato sono più che ragionevoli, ed anzi sono sorprendentemente conformi
all’operatività media di un buon trader.
• L’intervallo del vantaggio fornito dalla rete appare anche molto adeguato. Vantaggi
superiori al 100% corrispondono ad una probabilità di vittoria pari alla metà di quella posta
sul mercato (operando in lay) e sono pertanto da valutare con cautela
I. Conclusioni
In questo lavoro ho mostrato come sia possibile utilizzare combinatamene le tecniche neurali e
genetiche per sintetizzare una politica di acquisto e vendita di quote di scommesse sportive
producendo un utile. Il trader ottenuto opera senza bisogno dell’intervento umano, estrae
dall’osservazione del mercato alcuni indici e coefficienti che caratterizzano la fase di contrattazione
e li fa elaborare da una rete neurale appositamente addestrata per stimare la probabilità di vittoria di
ogni partecipante.
La fase preliminare di trading della rete ha permesso di ottenere un predittore più preciso del
mercato stesso; il trader può pertanto utilizzare la rete per valutare quanto le quote di mercato siano
disallineate dall’effettivo valore di ogni concorrente ed operare di conseguenza alcune scelte
tattiche sulla posizione da assumere rispetto ad ogni selezione.
Per ottenere la rete sono state necessarie diverse fasi:
• Innanzitutto è stato sviluppato un tool in grado di accedere al mercato ed estrarre le
informazioni salienti delle con trattazioni in tempo reale e di memorizzarle in appositi file
XML
• Sono stati estratti diversi campioni, con diverse politiche, per la fase di addestramento della
rete e di successiva ottimizzazione dei parametri operativi
• E’ stato valutato un sistema di preprocessing dei dati in grado di mettere in evidenza
grandezze semanticamente rilevanti quali i prezzi medi scambiati e si è arrivati a definire gli
input della rete
• E’ stato implementato un sistema genetico che, sfruttando la tecnica dei supergeni, ha
portato entro poche generazioni ad identificare una politica vincente
L’insieme delle operazioni svolte, degli artefatti e dei dati prodotti è riportato nella figura seguente:Puoi anche leggere

















































