Studio delle principali Tecnologie No-SQL - Elaborato finale in Basi di Dati Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Facoltà di Ingegneria
Corso di Studi in Ingegneria Informatica
Elaborato finale in Basi di Dati
Studio delle principali Tecnologie No-SQL
Anno Accademico 2010/2011
Candidato:
Giovanni Trotta
matr. N46/000047
I
Indice
Introduzione 1
Capitolo 1. Confronto con il modello relazionale 3
1.1 Normalizzazione 3
1.2 Scalabilità 4
Capitolo 2. Text Database 8
2.1 Criteri di Valutazione 9
2.2 Sistemi di Information Retrival 10
2.3 Rappresentazione di documenti tetuali 11
2.4 Estrazione delle Feature di testo 11
Capitolo 3. MongoDB 13
3.1 Introduzione 13
2.2 Document-Oriented Storage 14
2.3 Supporto agli indici 15
2.4 Replicazione 16
2.5 Sharding 16
2.6 Query 17
Capitolo 4. Apache CouchDB 18
3.1 Introduzione 18
2.2 Il modello Map-Reduce 19
2.3 M.V.C.C 20
2.4 Query 21
2.5 Confronto con MongoDB 21
Capitolo 5. Apache Cassandra 23
3.1 Introduzione 23
2.2 Data Model 24
II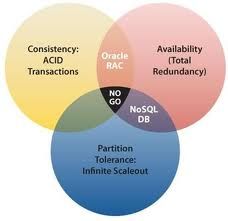
2.3 Keyspace 25
2.4 Confronto con MongoDBe CouchDB 25
Bibliografia 26
III
Studio delle principali tecnologie No-SQL
Introduzione
La richiesta sempre maggiore di database di enormi dimensioni, la crescente richiesta del
mercato di sistemi cloud e l’eterogeneità delle applicazioni ha messo in risalto alcuni
svantaggi del modello relazionale.
La soluzione proposta dalle principali aziende di
Information Tecnology è il movimento No-SQL,
acronimo di “Not Only SQL”, che sta ad indicare
un modello basato su database non relazionali. In
questo elaborato si presenterà il modello facendo
attenzione ai vantaggi che questo offre, si studieranno più nel dettaglio due delle principali
tecnologie MongoDB , CouchDB e Cassandra.
Perché No-SQL?
Il principale obiettivo del No-SQL è quello di creare un supporto per particolari esigenze
rispetto al modello relazionale. Quest’ultimo non viene sostituito, infatti in molti campi,
ancora oggi, il sistema relazionale rappresenta la migliore soluzione possibile, come per
sistemi transazionali ad esempio sistemi bancari.
Il concetto di No-SQL non è nuovo, infatti fu usato per la prima volta nel 1998 per indicare
una basi dati relazionale open-source che non usava una interfaccia SQL, ma non
particolarmente richiesto in passato.
1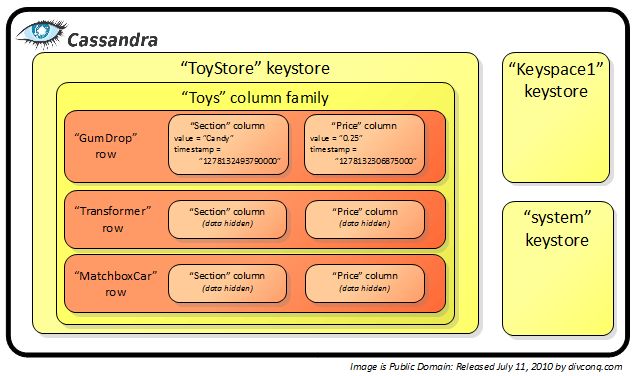
Studio delle principali tecnologie No-SQL
Il mercato però negli ultimi anni, anche grazie all’avvento di Social Network e del cloud
computing, ha richiesto l’utilizzo di sistemi non legati basati su relazioni.
Le cause possono essere:
Big Data Si è assistito a un incremento
esponenziale della richiesta di archiviazione.
In pratica aumentando linearmente la
quantità di dati in modelli relazionali, si
incrementa esponenzialmente il tempo di
risposta del sistema.
Diversity Uno dei principali obbiettivi di questa tecnica è quello di creare un
supporto per l’eterogeneità dei sistemi software. Un modello relazionale è rigidamente
progettato su una struttura relazionale, l’esigenza è quella di uno schema-free cioè
memorizzare su uno spazio libero i dati.
Connectivity Il modello relazionale rende molto oneroso la
comunicazione e la suddivisione su più nodi della base di dati,
non presenta neanche notevoli vantaggi al P2P Knowledge.
Cloud Computing Nel Cloud Computing i nodi possono essere
veramente molti, gestire un RDBMS diventa davvero molto
complicato e la potenza computazione si riduce notevolmente.
Cuncurrency Il mercato ha imposto quindi di ridurre il time-to-market, ovvero il tempo
che intercorre tra l’ideazione e la commercializzazione di un progetto, strutture always on-
line, sicure, affidabili.
2
Capitolo 1
Confronti con Il modello Relazionale
1.1 Normalizzazione
Una delle tecniche più usate nei modelli relazionali è la Normalizzazione, ossia la
creazione e la definizione di nuove tabelle per risolvere due problemi legati alla ridondanza
dei dati e alla dipendenza incoerente.
La ridondanza dei dati comporta notevoli svantaggi come lo spreco di risorse e per
esempio in caso di modifica di un campo di una tabella, questa deve essere replicata su
tutti i dati.
La dipendenza incoerente invece può rendere difficile l’accesso ai dati, in quanto il
percorso per la ricerca dei dati può risultare mancante o danneggiato.
Ci sono varie fasi di Normalizzazione chiamate Forme Normali che ne certificano la
qualità. Nel caso più comune le forme normali sono tre.
Prima forma normale
Eliminare i gruppi ripetuti in singole tabelle.
Creare una tabella separata per ciascun insieme di dati correlati.
Identificare ciascun insieme di dati correlati associandovi una chiave primaria.
Non utilizzare campi multipli in una singola tabella per memorizzare dati simili.
3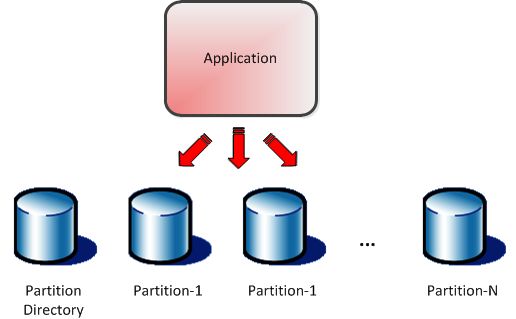
Seconda forma normale
Creare tabelle separate per insiemi di valori validi per più record.
Correlare queste tabelle a una chiave esterna.
I record devono dipendere solo dalla chiave primaria della tabella, se necessario una chiave
composta.
Terza forma normale
Eliminare i campi che dipendono dalla chiave.
Si capisce che la terza forma normale non è sempre praticabile anche se teoricamente
auspicabile. L’utilizzo elevato di tabelle compromette la reattività del sistema richiede infatti
capacità di apertura dei file superiori a quelli disponibili.
1.2 Scalabilità
La modifica alle strutture delle tabella comporta un overhead notevole e una difficoltà
nella modifica della struttura delle tabelle.
In questo caso la possibile soluzione è la scalabilità, che può essere di due tipi: orizzontale
e verticale.
Scalabilità Orizzontale
Significa partizionare le enormi tabelle su databese e server differenti. Può essere definito
come uno schema di partizionamento “shared-noting” e costituisce una soluzione
economica alla latenza. Questo però introduce anche degli svantaggi per esempio le tabelle
sono consultabili solo tramite join.
Occorre un’ attenta analisi durante il partizionamento per organizzare in modo adeguato le
query. Una volta analizzato il problema occorre implementare tutta la parte software per lo
4smistamento delle query in modo da evitare che la stessa query venga sottoposta ad ogni
entità. Le funzioni disponibili saranno quindi limitate.
Per i database No-SQL questo problema non si riscontra in quanto non esistono tabelle ne
tantomeno operazioni di aggregazione.
Ogni elemento è da considerarsi come oggetto a se stante, questo presenta molti vantaggi
come l’auto-sharding, cioè scalare orizzontalmente in maniera automatica. Ovviamente
quindi presenta svantaggi legati alla ridondanza dei dati e allo spreco di risorse di
archiviazione.
Per effettuare lo sharding si devono valutare una serie di caratteristiche che il sistema deve
soddisfare.
Affidabilità Il sistema deve sempre essere consultabile e deve garantire la possibilità di
ripristinarsi in caso di errori.
• Ogni shard deve essere sottoposto a backup automatici
• Avere come minimo due copie di ogni shard
• Hardware ridondati
• Procedura di ripristino
Query distribuite Un approccio molto importate è quello di distribuire le query su tutti i
shard e in seguito consolidare tutti i risultati e restituirli all’applicativo. Questa tecnica
aumenta di 10 volte le prestazioni rispetto al modello relazionale.
5Evitare Cross-Shard joins Le richieste di join di solito, nei sistemi distribuiti sono molto
inefficienti e difficili da realizzare. Per risolvere questo problema esistono vari approcci
come replicare le tabelle globali richiamate nei join e prevedere un meccanismo
automatico di sincronizzazione per mantenerle aggiornate.
Auto incremento delle chiavi primarie Ogni volta che si crea una nuova riga tipicamente
si fornisce una nuova chiave primaria. Per il database partizionato questo non è sufficiente
a garantire l’unicità, occorre quindi creare un meccanismo che crea chiavi uniche in tutto il
sistema.
Supporto shard a schemi multipli Per ottimizzare le prestazioni si prevede una serie di
reti di shard a cui indirizzare la richiesta. Molto spesso le applicazioni utilizzano più
configurazioni di reti per ottenere il risultato ottimo.
• Session-based sharding Ogni utente o processo interagisce con uno specifico
shard per tutta la durata della sessione dell’utente o del processo. Questo è
l’approccio più semplice e si sviluppa per applicazioni del tipo customer-
centric, ove tutte le informazioni che un utente può richiedere e tutte le
informazioni di quello stesso utente sono contenute in un unico shard.
• Transaction-based sharding La decisione dello shard da utilizzare è basato
sulla prima richiesta. Tutte le altre sono indirizzate al primo shard.
Statement-based sharding Ad ogni query si sceglie lo shard più appropriato.
6Determinare il miglior metodo di sharding Il metodo di suddivisione deve tener presente
l’applicazione che gestisce il database, come devono essere distribuite le chiavi e il numero
di transizioni che si devono effettuare e la grandezza delle tabelle.
Le stategie sono:
• Shard per chiave primaria su una tabella, è il metodo più semplice da
implementare ma efficace alla condizione che i dati siano ben distribuiti, è+se
ad esempio si sceglie di attribuire una chiave primaria sequenziale il
vantaggio risulterebbe nullo, mentre per una chiave opportunamente
distribuita i vantaggi sono notevoli.
• Usare una tabella di riferimento in uno shard a cui fanno riferimento tutti gli
altri shard. Richiede una ulteriore query e causa un peggioramento delle
prestazioni.
• Shard per data, Ogni shard conserva dati appartenenti ad un certo intervallo
di tempo o date.
Scalabilità verticale
La scalabilità verticale invece consiste in un incremento delle risorse del sistema che
gestisce il database sia per incremento della memoria che della Potenza di calcolo. Questo
approccio non richiede la modifica delle applicazioni ma comporta un notevole aumento dei
costi e per questo motivo non molto spesso usato.
7Capitolo 2
Text Database
Un particolare esempio di No-SQL è un database in grado di gestire, memorizzare ed
interrogare documenti testuali non strutturati. Bisogna minimizzare il tempo necessario per
la ricerca delle informazioni ed assicurare che i risultati siano ordinati per rilevanza.
Lo scopo principale del Natural Language Processing, ovvero sistemi in grado di processare
il linguaggio umano, è quello di rendere le conoscenze linguistiche necessarie a
comprendere il significato e la struttura del testo, a un calcolatore.
Con lo sviluppo del web si è cambiata la metodologia e l’approccio delle basi di dati
multimediali. Sono poi state introdotte nuove problematiche quali la bassa qualità dei dati
pervenuti, dati ridondati ma anche deadlinks.
Esistono due tipi di approcci per l’accesso alla base dati che sono il Retrival e il Browsing,
nel primo caso c’è una query basata su keywords, nel secondo caso invece si può partire da
documenti di interesse, seguire gli hyperlinks per arrivare a specificare la query sul
documento.
82.1 Criteri di Valutazione
I criteri di valutazione hanno come scopo di reperire solo e tutti i documenti interessanti per
l’utente. Un sistema di questo tipo è ideale per questo si valuta la precision (precisione)e il
recall (richiamo).
Il recall valuta la capacità di escludere documenti non rilevanti e rappresenta la percentuale
di documenti rilevanti presenti nel database. Il suo valore ideale è uno ma non può mai avere
questo valore perché significa che ogni documento presente nel database è rilevante.
La precision, valuta la capacità di trovare documenti rilevanti all’interno del database e
rappresenta la percenutale dei documenti rilevanti sul totale dei documenti recuperati.
92.2 Sistemi di Information Retrival
I database di testi sfruttano tecniche sviluppate per i sistemi di Information Retrival (IR).
L’ambito di questi sistemi ha introdotto molti modelli per la rappresentazione di documenti,
architetture e linguaggi, interfacce e metodi di visualizzazione.
L’ IR è un insieme di tecniche che permettono di estrapolare informazioni rilevanti, usando
dei criteri di valutazione, da documenti non strutturati secondo schemi come il testo;
Devono essere estratte semantica e parole chiavi, questo però molto spesso produce notevoli
cambiamenti dal contenuto informativo.
L’ambiguità dei testi rende il Retrival molto complicato e richiede un’ attenta analisi e
particolari elaborazioni. Le interrogazioni, spesso non si riferiscono al semplice dato, ma a
particolari esigenze.
Per questo si analizza in principio il testo sottomesso per la ricerca, per valutarne il
contenuto e rendere la restituzione dei documenti di interesse quanto più precisa possibile.
Anche i documenti restituiti devono essere di una quantità limitata rispetto alla grande
quantità di dati presenti del database. Si cercano pertanto quelle “informazioni” che sono di
interesse per il topic.
Tra tutti i risultati restituiti bisogna fare una classificazione in base alla pertinenza del
documento rispetto alla query inserita. Per questo si sfruttano tecniche di “ranking” ovvero
si attribuisce ad ogni documento la sua rilevanza rispetto a quella query.
Tutti questi valori vengono poi restituiti del document-query matching.
In questo documento è mantenuta quindi una classificazione basata sul contenuto
informativo del documento. Nasce quindi l’esigenza di definire una misura del contenuto
informativo. Distinguere quindi ì documenti in: elite e non elite. Si valuta la frequenza delle
parole chiavi di interesse, ma anche la quantità del contenuto informativo del documento in
base alla frequenza di parole chiave.
102.3 Rappresentazione documenti testuali
Si sfruttano dei modelli per rappresentare dei testi, i più usati sono il modello booleano, il
modello vettoriale o algebrico e il modello probabilistico.
La rappresentazione, poi, si suddivide in cinque fasi.
• Structure struttura interna del documento (capitoli, sottocapitoli)
• Stopwords articoli e congiunzioni
• Noun groups si eliminano aggettivi e verbi
• Stemming si riduce a radice comune (plurale, singloare)
2.4 Estrazione delle Features di testo
L’ estrazione delle feature di testo avviene in quattro fasi.
Analisi Lessicale del testo
Ha il compito di eliminare la punteggiatura e convertire in maiuscolo e minuscolo per creare
una sequenza di parole partendo da una sequenza di caratteri.
Eliminare le stopwords
Le stopwords sono parole con un’ elevata ricorrenza nel testo che non portano informazione
utile all’ estrazione semantica. Statisticamente le dimensioni del documento vengono ridotte
del 20-30% . L’eliminazione diminuisce il potere di recall. Solitamente sono congiunzioni,
articoli e proposizioni.
11Normalizzazione
La normalizzazione consiste nel condurre tutte le parole alla radice morfologica cosi com’ è
sul vocabolario, eliminando flessi, coniugazioni.
La sua utilità presenta pareri tuttora discordanti, per esempio è stato dimostrato che nelle
lingue anglosassoni è di scarsa utilità.
Selezioni dei termini caratterizzanti (indicizzazione)
Bisogna distinguere i metodi di rappresentazione dei documenti e i criteri di recupero per
soddisfare una specifica richiesta.
I metodi si suddividono in metodi di rappresentazione diretta e indiretta. Per quanto riguarda
la rappresentazione diretta, il documento è rappresentato dalle parole in esso contenute in
sequenza. Però questa rappresentazione non è adeguata sempre perché si possono cercare
documenti che non hanno parole chiavi in comune con il testo di ricerca.
La rappresentazione indiretta, è realizzata con un’ indicizzazione, derivati manualmente o
automaticamente che descrivono in modo sintetico il contenuto. Vengono associati ai testi
delle parole chiavi (keywords), semplici o composte. E’ di solito fatta manualmente da
esperti ma sono state studiate tecniche automatiche. Il fine ultimo dell’indicizzazione è
rappresentare il contenuto in modo sintetico tenendo presente due obiettivi: esaustività (
numero elevato di indici assegnati) e specificità ( recuperare pochi documenti e specifici).
Gli indici o tag possono essere radici di parole, frasi estratte, metadati ecc.
La fase di indicizzazione serve al recupero e alla restituzione del documento, può essere
Manuale e automatico. L’indicizzazione manuale è affidata a una persona con competenze
su quella materia la quale sceglie termini che meglio caratterizzano il contenuto. Quello
Automatico è eseguito da un programma, statisticamente peggiore ma in proporzione molto
più economico. Tramite un’ analisi in base a degli algoritmi vengono generati degli index
terms. Quest’ analisi è fatta in modo statistico usando la frequenza delle parole chiave.
12Capitolo 3
MongoDB
3.1 Introduzione
MongoDB è un Database management System, orientato alla gestione dei testi, è sviluppato
in C++ è ha come obiettivo quello di strutturare delle basi di dati testuali, in particolare con
dati poco strutturati.
13E’ possibile realizzare un database orientato alla gestione dei documenti creando uno strato
software superiore al database o sfruttare i meccanismi di un database orientato agli oggetti.
I database relazionali sono sviluppati sul modello ACID (Atomicity, Consistency, Isolation,
Durability), il MongoDB invece sfrutta un modello CAP(Consistency, Aviability and
Partition Tollerance) che descrive alcune strategie per distribuire la “application logic”
attraverso le reti. Applica la replicazione per prorogare gli “application changes” attraverso i
nodi della rete.
La coerenza è mantenuta in tutti i nodi che visualizzano gli stessi dati agendo con modifiche
simultanee. La disponibilità è mantenuta su tutti i client dato che il servizio risulta sempre
attivo e funzionante. Tolleranza e partizionamento sono parametri indispensabili perché
molto spesso il database è partizionato su più server.
Non è possibile ottenere tutte queste caratteristiche insieme ma solo due alla volta.
Pertanto se si sceglie di non avere un Partition Tollerance avremo problemi sulla scalarità
verticale che è sicuramente più costosa. Se si rinuncia all’ Aviability dobbiamo attendere
che vengano risolte alcune richieste a discapito delle prestazioni. Se si rinuncia alla
Consistency si avrà per un periodo un disallineamento dei dati sui nodi. Questi ultimi due
problemi sono quelli più noti e permettono di superare il problema della scalabilità.
3.2 Document-Oriented storage
Questo DBMS eredita il meccanismo di storage dal paradigma doc-oriented che consiste nel
memorizzare ogni record come documento che possiede caratteristiche predeterminate. Si
14può aggiungere qualsiasi numero di campi con una qualsiasi lunghezza. Nei doc-oriented si
segue una metodologia differente rispetto al modello relazionale: si accorpano quanto più
possibile gli oggetti, creando delle macro entità dal massimo contenuto informativo. Questi
oggetti incorporano tutte le notizie di cui necessitano per una determinata semantica.
Pertanto MongoDB non possiede uno schema e ogni documento non è strutturato, ha solo
due chiavi obbligatorie:
_id Serve per ideò+ntificare univocamente il documento (è comparabile, semanticamente,
alla chiave primaria dei database relazionali)
_rev Viene utilizzata per la gestione delle revisioni, ad ogni operazione di modifica infatti la
chiave rev viene aggiornata.
Pertanto si può interrogare il DBMS anche per versioni del documento non recenti perché
mantiene in memoria tutte le verisoni.
3.2 Supporto agli Indici
In MongoDB sono presenti tecniche di indicizzazione:
• Il campo _id è indicizzato automaticamente
• I campi sui quali è tipico eseguire ricerche o accaduti di frequenze andrebbero
indicizzati
• I campi su cui sono definiti ordinamenti generalmente andrebbero indicizzati.
MongoDB fornisce strumenti in grado di suggerire su quali campi sia opportuno definire
indici. Conviene privilegiare applicazioni read-intensitive, ovvero collezioni con un alto
rapporto letture/scritture per incrementare le letture. Un indice viene inteso come una
struttura dati che cataloga le informazioni con una struttura B-tree.
E’ possibile definire chiavi semplici, composte, documento e array.
Le chiavi semplici indicano il campo collection come indice, quelle composte per due o più
collection, mentre le chiavi documento sono indici che contengono oggetti. Le chiavi array
15invece sono realizzare da come lascia intuire il nome con degli array. In mongoDB si
memorizzano anche indici geospaziali bidimensionali che ci permettono di interrogare il
sistema con query basate sulla posizione.
3.3 Replicazione
La replicazione introduce la ridondanza dei dati per rimediare a malfunzionamenti. Ci sono
due tipi differenti di replicazione, quella Master-slave semplice e l’insieme di replicazione.
La prima come si intuisce dal nome presenta un’ unità centrale master che è sempre
aggiornata e che modifica periodicamente tutti gli altri nodi dipendenti ad essa. In caso di
malfunzionamento di un nodo, deve essere eseguito manualmente.
La tecnica di insieme di replicazione invece aggiunge il ripristino automatico alla tecnica del
master-slave.
3.4 Sharding
MongoDB presenta tecniche di Sharding per partizionare orizzontalmente il database in
tuple da inserire in tabelle. Ogni shard in MongoDB ha la caratteristica di essere
completamente slegato dagli altri, infatti non dipendono dal sistema fisico sottostante e
logico. Questo DBMS prevede un servizio automatico di sharding. Si generano delle shard
key ovvero delle chiavi di
frammentazione, partendo dai chunk creati
dai cluster che contengono i dati. Tutti i
metadati si memorizzano in un server di
configurazione e si creano dei nodi router
che propagano le richieste ai nodi. Quando
ci sarà una richiesta si interroga un nodo
che possiede una tabella con una mappa
del sistema.
163.6 Query
In questo DBMS è presente il supporto a query dinamiche (ad hoc). Per le interrogazioni, si
utilizza un sistema che non richiede indici speciali e la migrazione da query SQL a
MongoDB sarà molto semplice. Infatti come per l’SQL c’è un selettore di campo
corrispondente nel modello relazionale alla SELECT e presenta anche un campo di selezione
di documenti (WHERE). E’ possibile creare anche degli ordinamenti dei risultati (ORDER
BY in SQL).
MongoDB usa tecniche di cursori, questi solo usati per recuperare iterativamente tutti i
documenti ritornati dalla query eseguita.
Il processo di selezione potrebbe causare un overhead per la ricerca di documenti nel
database, per questo utilizza due funzioni: ”Map /Reduce”.
Prima di tutto per ogni elemento viene invocata la funzione “Map” che produce delle coppie
chiave-valore da passare alla successiva funzione e in seguito invoca la funzione “Reduce”,
che aggrega i risultati ricevuti e restituisce il risultato.
17Capitolo 4
Apache CouchDB
4.1 Introduzione
CouchDB è anche esso un database non relazionale, orientato ai testi, l’obbiettivo è quello di
facilitare l’organizzazione delle base di dati testuali. E’ pensato per sostituire gli strumenti
classici come MySQL che necessitano aggiustamenti alla struttura delle applicazioni Web.
Ha un’ interfaccia intuitiva http-based REST API, richiede inoltre tramite httpRequest i dati.
Il formato di restituzione è XML JSON. Questo tipo di DBMS si basa su API http di tipo
18REST quindi implementa dei metodi di accesso alla risorsa molto simili a quelli di HTTP
(come il metodo get, post, put).
E’ scritto in un linguaggio di programmazione Earling, che lo rende rapido, scalabile e facile
da distribuire e si può sfruttare opportunamente anche su architetture multi-core.
CouchDb è molto resistente ai guasti e a sovraccarico di richieste di accesso. Infatti l’errore
non viene propagato su tutto il database e distribuisce le richieste sui nodi.
Aumenta anche la scalabilità e il supporto a strumenti ancora in fase di implementazione e
futuri, incrementa anche il supporto a dispositivi mobili e l’approccio molto simile ad http
rende molto semplice l’implementazione.
Questo è anche molto performante anche per l’aggregazione di documenti semi strutturati e
li organizza come documenti JSON. In CouchDB non esistono tabelle, ma tutto è
organizzato in database di documenti. Ogni documento è organizzato con delle coppie
chiave-valore, e ognuno di essi può essere organizzato in maniera differente.
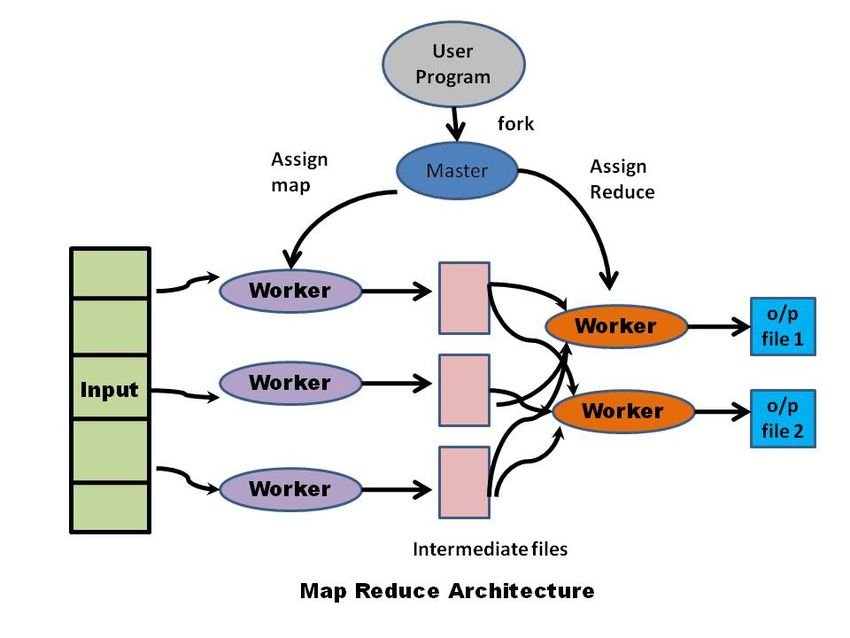
4.2 Il modello Map/Reduce
La grande quantità ed eterogeneità dei documenti rende molto complicata la gestione e la
selezione di essi per questo si introducono tecniche di Map e Reduce. Queste producono una
coppia chiave-valore che vengono poi organizzate secondo un schema Btree archiviandole
in ordine di chiave. Una funzione Map
trasforma ogni documento contenuto
nel database in un altro insieme di
coppie chiave/valore e associa un’unica
chiave. Il risultato di questa fase sarà un
array associativo composto dalle coppie
chiave/valore notificate dalla funzione
emit (dove la chiave è il primo
parametro del secondo).
194.3 M.V.C.C.
Quando si vuole modificare un’ entità relazionale bisogna rendere consistenti i dati in ogni
momento. Per questo bisogna sempre tenere presente il problema della concorrenza sulla
risorsa. Come per i sistemi operativi con i semafori, si è introdotto uno stato della tabella che
può essere lock e unlock. Ma questo causa uno spreco di risorse notevoli.
CouchDB utilizza Multi Verison Concurrency Control (MVCC) per gestire l’accesso
simultaneo al database. Sui documenti da modificare si fa un controllo versione, in pratica si
crea una nuova verisone del documento che verrà salvata sulla vecchia versione.
Questo riduce notevolmente i tempi di accesso/modifica della risorsa, e ogni volta che si
necessita una nuova istanza si otterrà sempre un’ istantanea del sistema più aggiornata
possibile. Ogni volta che si prova a modificare un documento, CouchDB passerà alla
funzione “validazione” una copia del documento esistente, una copia del nuovo documento
ed una raccolta di informazioni aggiuntive, ad esempio l’utente e i dettagli
dell’autenticazione.
Quando si tenta di mantenere la coerenza tra un database distribuito su più server si possono
riscontrare alcuni problemi, sono stati quindi sviluppati molti approcci di risoluzione come
multi-master e master-slave.
La risoluzione di questo problema aumenta la scalabilità e rappresenta un punto notevole di
forza di CouchDB.
204.4 Query
A differenza del modello relazionale, con le query scritte in SQL in couchDB si utilizzano
degli indici interni e le proprie relazioni per costruire in tempo reale una tabella di risultato.
Questa soluzione è molto performante in quanto i dati sono sviluppati per questo scopo.
Le views sono il principale strumento d’esecuzione delle query in CouchDB. Esistono due
tipi di views come quelle permanenti, che sono memorizzate all’interno di speciali
documenti chiamati “design document”. Ci sono poi le views temporanee che non sono
memorizzate ma eseguite su richiesta, ancora in fase di sviluppo.
Le views sono definite da una funzione JavaScript la quale usa la funzione “Map” per le
views archiviate secondo lo schema key/value.
4.4 Confronto con MongoDB
La prima sostanziale differenza tra i due DBMS è
di sciuro il MVCC che classifica i dati, MongoDB
invece usa “l’update in place”. Il primo quindi è
performante per una maggiore libertà di design,
ma introduce il problema della compattazione.
Il secondo offre una velocità notevole in scrittura
e un enorme risparmio di memoria di archiviazione ma non tiene memoria delle versioni.
Anche la scalabilità nei due sistemi sfrutta due meccanismi differenti in MongoDB si ha
l’auto Sharding, mentre su CouchDB la replicazione multi-master.
MongoDB consente query dinamiche e offre uno strumento per ottimizzare le query
consigliando creazioni di indici dove necessario, a differenza di CouchDB che invece usa un
particolare sistema per generare indici ed ottimizzare particolari query che devono essere
predefinite necessariamente.
21CouchDB presenta una affidabilità maggiore, robusto sugli stop, e un’ interfaccia utente
molto semplice a differenza di MongoDB che usa una shell con interprete javascript.
In conclusione questi due DBMS presentano numerosi vantaggi e rispondono a esigenze
diverse.
Ovviemente non si può scegliere, come descritto nel teorema CAP, un DBMS performante
su tutte le esigenze di Consistency, Aviability e partition Tollerance, ma solo su due di esse,
per cui bisogna trovare dei compromessi tecnici.
22Capitolo 5
Apache Cassandra
5.1 Introduzione
Successivamente all’avvento del web 2.0, le case produttrici di DBMS hanno orientato le
proprie “forze” progettuali verso sistemi NO-SQL. Apache Cassandra è uno degli esempi di
maggiore rilievo, infatti anche grazie all’avvento di social network (come Facebook, ove si
usavano DBMS usava Mysql, in modo non troppo ortodosso) si è migrato verso il sitema
open sorce Cassandra.
Come per CouchDB anche Cassandra è un DBMS “fault tolerant”, elastico e con
consistenza dei dati sia per processi di lettura che di scrittura. I dati sono duplicati in modo
automatico su più nodi, e infrastrutturalmente identici per cui questo tipo di DBMS è molto
tollerante a crash e il sistema non è mai inoperabile.
Durante read/write si possono specificare i livelli di consistenza delle funzioni, passando due
parametri che indicano il comportamento atteso. Per esempio la funzione di write, può
23decidere di eseguire tutte le funzioni in asincrono o verificare la scrittura su un determinato
numero di nodi. Invece la funzione Read consente di scegliere da quanti nodi effettuare la
lettura e quale sia il dato più aggiornato.
Aumentare il numero di nodi per la verifica della scrittura e la lettura aumenta linearmente la
consistenza a discapito delle performance.
5.2 Data Model
Bisogna fare nota del modello dati di Cassandra che è formato da un insieme di Hash e
Array, che però a seconda della posizione rivestono ruoli distinti.
Le colonne sono i costrutti più semplici, è un hash formato da tre chiavi: name, value e
timestamp che sono stabilite a priori. La colonna nel modello relazionale è una cella
all’interno di un record che a sua volta è contenuto in una tabella. I name e value sono
considerati da Cassandra come array di bite e possono contenere qualsiasi cosa.
Le Supercolumn o gruppo di colonne invece sono delle colonne, nel cui value vi si trova un
array di colonne. In questo caso non si può fare un corrispondente nel modello relazionale.
Le coulomn e supercolumn vengono raggruppate in strutture dati chiamate Coulumn family
e supercolumnfamily che corrispondono nel modello relazionale a delle tabelle. La prima è
contraddistinta da un nome che la identifica e da un array di coppia chiave-valore. La
24seconda ha una chiave che identifica le row mentre i valori sono i campi attributi alle
column o supercolumn nel caso di supercolumn family.
In Cassandra non esiste nessuno schema predefinito per le singole row; non è possibile
creare a runtime column family e supercolumn family ma è necessario inserirle in un file di
documentazione.
5.3 KeySpace
Il keyspace come nel modello relazionale è all’ultimo gradino gerarchico. Ogni keyspace
comunemente contiene il set di column family specifico di un’ applicazione, che deve essere
specificato nel file di configurazione. E’ presente un attributo (Comparewith) che predeve il
mentro di ordinamento delle chiavi delle column all’interno delle row.
Anche in questo DBMS non è presente il concetto classico di query SQL ma ha un generico
set di API che agiscono direttamente sul database con operazioni molto simili (per esempio
di selezione).
Il lavoro di ordinamento deve essere effettuato in fase di scrittura, sia per modifica che per
inserimento, perché questa funzione deve mantenere l’ordine.
5.3 Confronto con CouchDB e MongoDB
A differenza di MongoDB e CouchDB Cassandra è usato più per le scritture che per le letture
(logging). E’ spesso usato per usi finanziari, dove le scritture devono essere veloci e performanti
anche a discapito delle letture. Presenta inoltre una consistenza e una resistenza ai guasti notevole.
A differenza di CouchDB però non ha un’ interfaccia intuitiva, metre è stato introdotto un
linguaggio di Query SQL like come CouchDB. Anche in questo caso bisogna far riferimento al
teorema del CAP, infatti in questo è notevole Consistency e Partion Tollerance a discapito
dell’Aviability.
25Bibliografia
[1] Angelo Chianese, Vincenzo Moscato, Antonio Picariello, Lucio Sansone “Basi di
dati per la gestione dell’informazione”
[2] www.economist.org
[3] www.wikipedia.org
[5] www.nosql.org
[6] www.mongodb.org
[7] couchdb.apasche.org
[8] cassandra.apache.org
[9] http://it.wikipedia.org/wiki/MongoDB
[10] http://blog.html.it/11/02/2010/mongodb-un-database-senza-sql/
[11] http://en.wikipedia.org/wiki/CouchDB
[12] http://guide.couchdb.org/
[13] http://www.ossblog.it/post/4794/couchdb-il-database-non-relazionale
[14] http://it.wikipedia.org/wiki/Cassandra_(database)
[15] http://en.wikipedia.org/wiki/Apache_Cassandra
[16] http://database.html.it/articoli/leggi/3321/introduzione-a-apache-cassandra/
[17] http://www.unixmen.com/install-nosql-cassandra-db-in-ubuntu-via-ppa-repository/
[18] “MongoDB, the Definitive Guide”, Kristina Chodorow, Michael Dirolf, O’Reilly,
2010
[19] http://database.html.it/articoli/leggi/3321/introduzione-a-apache-cassandra/
[20] http://www.unixmen.com/install-nosql-cassandra-db-in-ubuntu-via-ppa-repository/
26Puoi anche leggere

















































