Manuale per l'installazione e l'utilizzo di R-php - Angelo M. Mineo & Alfredo Pontillo
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Manuale per l’installazione e l’utilizzo di R-php
Versione n. 0.99a
Angelo M. Mineo & Alfredo Pontillo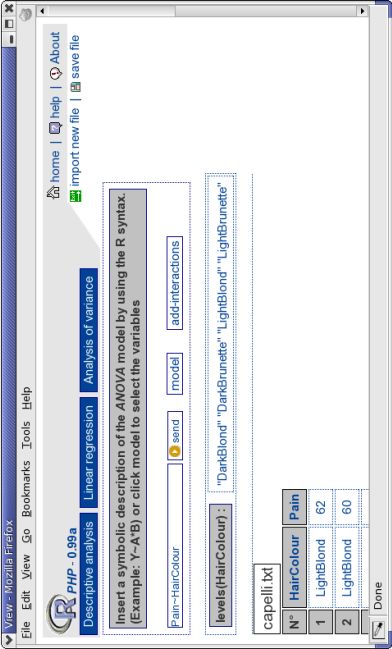
1 Presentazione R-php è un progetto sviluppato nell’ambito del Dipartimento di Scienze Statistiche e Matemetiche “Silvio Vianelli” dell’Università degli Studi di Palermo e si pone come obiettivo la realizzazione di un software statistico web-oriented, cioè un software a cui l’utilizzatore finale accede attraverso Internet e per il cui funzionamento è richiesta solamente l’installazione di un browser, cioè di un programma per la visualizzazione di hypertesti (esempi di browser sono: Explorer, Mozilla, Firefox, Opera, ecc...). R-php è un progetto open-source con il codice rilasciato dagli autori e può essere liberamente installato (vedi paragrafo 1.1) L’idea di progettare un software statistico che potesse essere utilizzato attraverso internet nasce dalle seguenti considerazioni: è un fatto accertato che la crescente diffusione di Internet e la richiesta di nuovi servizi da parte dei suoi utenti ha e sta, tuttora, cambiando radicalmente le modalità di accesso alle strutture di uso quotidiano (lavoro, studio, ecc...); ormai la maggior parte delle informazioni e dei servizi fruiscono attraverso il web e nella stessa direzione si sta muovendo la filosofia del software: un esempio in questo senso si ha nell’ambito del software per la gestione di database con l’applicativo PhpMyAdmin che costituisce un’interfaccia grafica via web di MySQL, che è il database piu utilizzato per applicazioni web-oriented; altro esempio è dato, da un punto di vista commerciale dell’utilizzo della rete, dallo sviluppo che ha avuto l’home-banking. Per quanto riguarda, in generale, l’utilizzo del software, la tendenza a produrre software che vanno installati sul proprio computer sta lentamente scemando a favore proprio di software utilizzabili attraverso l’ausilio di una connessione ad internet e di un browser. Una caratteristica fondamentale di R-php è il fatto che tutte le elaborazioni stati- stiche sfruttano come “motore” l’ambiente statistico di programmazione open-source R, che sempre più viene utilizzato non solo dal mondo accademico, ma anche da ditte di consulting (Marc Scwatz, 2004, The Decision to Use R: a cosulting business per- spective, R News, Vol. 4(1), pp. 2-5). R-php è quindi classificabile tra i progetti web dedicati ad R. Oltre a questo progetto ne esistono altri quali: R-web, R-PHP, ecc..
2 (vedi pagina web http://http://franklin.imgen.bcm.tmc.edu/R.web.servers). In breve, la differenza sostanziale tra R-php e gli altri progetti citati in precedenza consiste nel fatto che R-php presenta un modulo interattivo (R-php point-and-click ) che consente di effettuare alcune delle principali analisi statistiche senza che l’utente debba avere necessariamente una conoscenza approfondita dell’ambiente statistico R. Diversi sono i potenziali fruitori di R-php: si pensi, per esempio, all’utilizzo da parte di studenti o all’interno di strutture didattiche, quali aule di informatica, o da casa attraverso un semplice collegamento ad Internet, oppure un utilizzatore che non conoscendo e non volendo imparare ambienti di programmazione, qual è R, vuole eseguire semplici analisi statistiche, senza dover ricorrere all’acquisto della licenza di un software statistico commerciale.

Capitolo 1
Caratteristiche fondamentali di
R-php
1.1 Guida all’installazione per la creazione di un
server con R-php
In questa sezione tratteremo l’argomento relativo all’installazione di R-php su un
server Apache, rinviando ai paragrafi successivi per una descrizione più dettaglia-
ta dei software necessari per un corretto funzionameto di R-php. Per semplicità
senza perdere di generalità, per indicare i passi necessari per l’installazione fare-
mo riferimento a un sistema LAMP (Linux, Apache, MySQL, PHP), cioè una
macchina con sistema operativo Linux, con installato il webserver Apache, il data-
base MySQL e il linguaggio PHP1 . Scaricato il sorgente R-php-xxx.tar.gz dal sito
http://dssm.unipa.it/R-php oppure da http://r-php.homelinux.net, bisogna
seguire i seguenti passi:
1. acquisire i privilegi di superutente (root) con il comando su.
2. Copiare il sorgente nella root di Apache: ad esempio, aprendo un terminale e
1
PHP è un linguaggio di scripting, lato server, per la creazione di pagine web con contenuto
dinamico.
3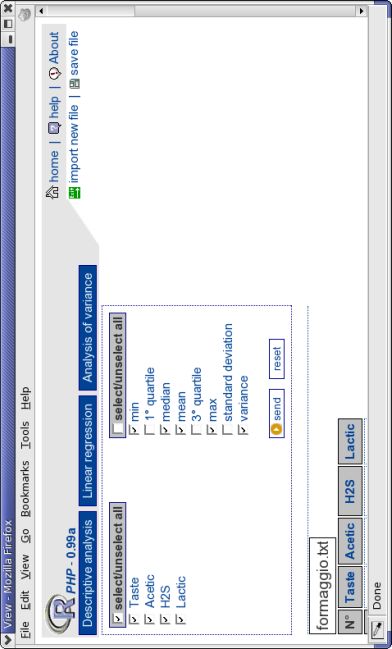
CAPITOLO 1. CARATTERISTICHE FONDAMENTALI DI R-PHP 4
posizionandoci nella directory dove si trova il file R-php-xxx.tar.gz scaricato in
precedenza, basta digitare il seguente comando:
• per una distribuzione Redhat based
]\# cp R-php-xxx.tar.tgz /var/www/html/
• per una distribuzione Debian
]\# cp R-php-xxx.tar.tgz /var/www/
3. Decomprimere il file R-php-xxx.tar.gz, ad esempio con il seguente comando:
]\# tar xvzf R-php-xxx.tar.gz
A questo punto l’utente troverà, a partire dalla radice del server Apache, la
directory R-php-xxx che contiene tutto il software.
4. Entrare nella directory R-php-xxx con il seguente comando:
]\# cd R-php-xxx
La cartella conterrà i seguenti file e le seguenti directory:
• COPYNG (file che contiene la lincenza d’uso);
• Doc (directory che contiene la documentazione);
• include (directory che contiene i file di configurazione);
• index.html (pagina principale);
• R (Modulo base di R-php);
• README (file che contiene alcune informazioni iniziali sul software);
• R-gui (Modulo Point and Click di R-php);
5. Entrare nella directory include con il seguente comando:
]\# cd include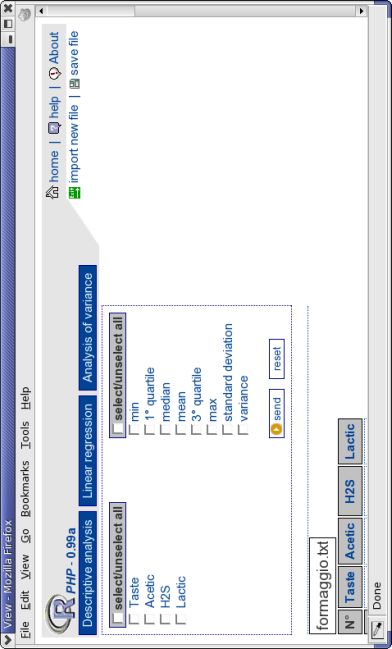
CAPITOLO 1. CARATTERISTICHE FONDAMENTALI DI R-PHP 5
6. Editare (con un qualsiasi editor, ad esempio vi) il file conn.php e modificare i
campi con i dati necessari per l’accesso a MySQL (user e password).
]\# vi conn.php
A questo punto basterà puntare col proprio browser all’indirizzo http://localhost/
R-php-xxx/, oppure all’indirizzo http://tuo-dominio/R-php-xxx, per accedere ad
R-php.
1.2 Descrizione di R-php
In questo paragrafo illustreremo il software che è necessario per l’implementazione di
un server R-php e il codice utilizzato per il funzionamento dei due moduli previsti.
Si sottolinea che tutto il software utilizzato è open-source.
1.2.1 Software richiesto
Per un corretto funzionamento di R-php è necessario installare sul server i seguenti
software:
• Apache:
Il server Httpd Apache:
– è un Web server potente, flessibile HTTP/1.1 compatibile;
– implementa i più recenti protocolli;
– è altamente configurabile e integrabile con altri moduli appartenenti ad
altri software;
– può essere configurato scrivendo moduli che utilizzano un modulo API
dello stesso Apache.
– fornisce gli interi codici sorgente ed è rilasciato con una licenza non restrit-
tiva;
CAPITOLO 1. CARATTERISTICHE FONDAMENTALI DI R-PHP 6
– può essere eseguito su Windows NT/9X, su Netware 5.X e superiori,
su OS/2 e sulla maggior parte delle versioni di UNIX, cosı̀ come su diversi
altri sistemi operativi;
– è altamente sviluppabile;
– implementa molte caratteristiche richieste frequentemente, le cui principali
sono:
∗ database DBM per l’autenticazione, che permette di configurare fa-
cilmente pagine protette da password con numeri elevati di utenti
autorizzati senza che il server collassi.
∗ personalizzazione dei messaggi di errore; permette, infatti, di confi-
gurare file o anche script CGI che vengono ritornati dal server come
risposta a errori e problemi;
∗ gestione indipendente per le direttive da assegnare alle directory, che
permette anche di indicare al server quale file aprire di default quando
una directory url è richiesta, qualunque sia il suo contenuto;
∗ virtual host, che è una caratteristica molto richiesta, conosciuta anche
come “multi-homed-servers”; questa caratteristica permette al server
di distinguere tra richieste effettuate a differenti indirizzi IP o nomi
“mappati” sulla stessa macchina;
∗ possibilità di configurare e personalizzare la gestione dei log.
Oggi Apache è ritenuto il Web server più veloce, efficente e più funzionale
che esista; non a caso in base, ad esempio, ai dati forniti dal Netcraft Web
Server Survay (http://news.netcraft.com/archives/web_server_survey.
html) Apache risulta il Web server più utilizzato con una percentuale di utilizzo
pari a 68.43 % (dato riferito al gennaio 2005). Per un confronto sulla diffusione
dei più comuni Web server vedi figura 1.1.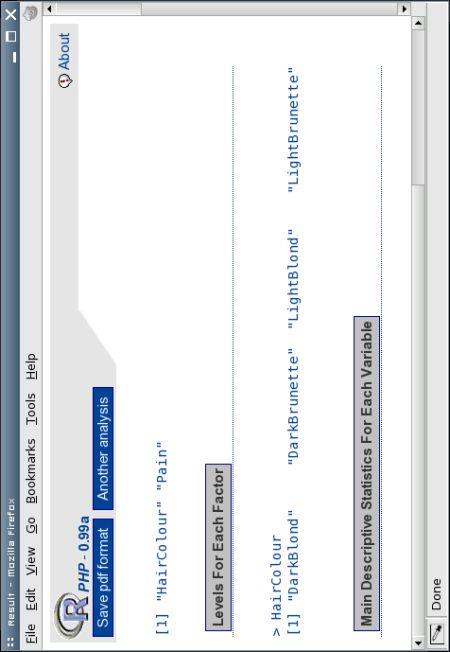
CAPITOLO 1. CARATTERISTICHE FONDAMENTALI DI R-PHP 7 Figura 1.1: Statistiche relative all’andamento nel tempo della frequenza di utilizzo dei principali Web server.
CAPITOLO 1. CARATTERISTICHE FONDAMENTALI DI R-PHP 8
• R
R è un linguaggio e un ambiente per il calcolo e la grafica statistica; è un pro-
getto GNU simile al linguaggio S, sviluppato ai BELL Laboratories, diventato
successivamente AT&T e ora Lucent Technologies, da John Chambers e alcuni
colleghi. R può essere considerato come una differente implementazione di S.
Ci sono alcune significative differenze tra i due ambienti, ma molto codice scrit-
to per S si esegue inalterato sotto R. R fornisce un’ampia varietà di tecniche
statistiche (modellizzazione lineare e non lineare, test statistici classici, analisi
di serie storica, classificazione, etc...) e grafica ed è altamente estensibile. Il
linguaggio S è spesso lo strumento scelto per la ricerca nella metodologia stati-
stica ed R fornisce un’alternativa open-source a tale attività. Uno dei punti di
forza di R è la facilità con cui possono essere prodotti grafici di alta qualità che
includono simboli e formule matematiche, dov’è necessario. R si compila e si
esegue su una grande varietà di piattaforme UNIX e sistemi similari (incluso
FreeBSD e Linux), Windows e MacOS. R è un insieme di utilità software
integrate per la manipolazione dei dati, il calcolo e la visualizzazione grafica e
include tra l’altro:
– un efficace manipolatore di dati e un altrettanto efficace dispositivo di
memorizzazione;
– un insieme di operatori per i calcoli su array, in particolare matrici;
– una grande, coerente, integrata raccolta di strumenti intermedi per l’analisi
dei dati;
– risorse grafiche per l’analisi dei dati con visualizzazione direttamente sul
computer o su carta attraverso stampante;
– un ben sviluppato, semplice ed efficace linguaggio di programmazione che
include istruzioni condizionali, loop, funzioni ricorsive definite dall’utente
e strumenti di input/output.
Il termine “ambiente” caratterizza un sistema pienamente pianificato e coerente,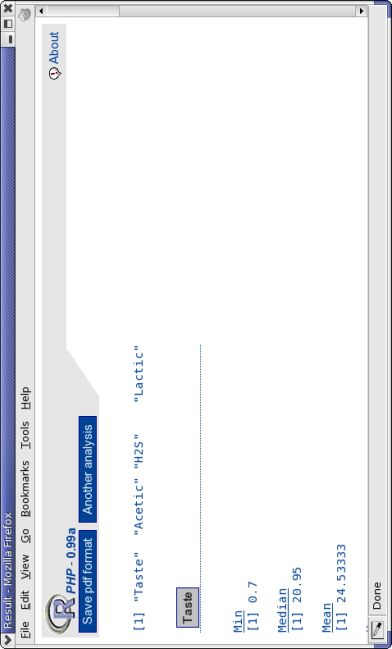
CAPITOLO 1. CARATTERISTICHE FONDAMENTALI DI R-PHP 9
piuttosto che un sistema che si incrementa attraverso parti molto specifiche e
poco flessibili, come accade frequentemente con altri software statistici.
• PHP
PHP è un linguaggio di scripting HTML-embedded, cioè un linguaggio che per-
mette di inserire codice eseguibile all’interno di pagine HTML. Molta parte
della sua sintassi è presa in prestito da C, Java e Perl con l’inserimento di
alcune caratteristiche proprie del linguaggio. L’obiettivo di PHP è permettere
agli sviluppatori di pagine Web di scrivere velocemente pagine generate dina-
micamente. PHP sta per PHP Hypertext Preprocessor e il suo nome è quindi
un acronimo cosiddetto ricorsivo.
• MySQL
MySQL è un sistema di amministrazione per database relazionali. La carat-
teristica principale di un database relazionale consiste nel memorizzare i dati
in strutture separate, chiamate tabelle, piuttosto che mettere tutti i dati in
un’unica zona. La parte SQL presente nel nome MySQL è acronimo di Struc-
ture Query Language, che è il più comune linguaggio utilizzato per l’accesso
ai database. MySQL database server è il più popolare database open-source
al mondo; la sua fortuna è dovuta alla sua estrema velocità e flessibilità, ed è
proprio la velocità di accesso ai dati che lo rende particolarmente indicato per
l’implementazione di applicazioni web.
• ImageMagick
ImageMagick è una collezione di strumenti e librerie per la manipolazione
di immagini. ImageMagick è in grado di gestire, convertire e manipolare i
più popolari formati, inclusi .gif, .jpeg, .png e .pdf; inoltre si possono creare
dinamicamente grafici in formato .gif per applicazioni web. Di seguito sono
riportati alcuni esempi di operazioni che ImageMagick può svolgere:
– Convertire un’immagine da un formato ad un altro;
– Ridimensionare, ruotare, modificare colori o aggiungere effetti;CAPITOLO 1. CARATTERISTICHE FONDAMENTALI DI R-PHP 10
– Creare thumbnails;
– Montare un gruppo di immagini in un’unica sequenza per la realizzazione
di una sequenza animata in formato .gif.
– Aggiungere ad un’immagine elementi quali testo o parti di altre immagini;
– Decorare un’immagine con bordi;
– Descrivere il formato e le caratteristiche di un’immagine.
La caratteristica principale di ImageMagick, che lo rende strumento indispen-
sabile per la gestione di immagini anche per applicazoni web, è la possibilità
di effettuare le operazioni prima citate (e non solo) da riga di comando (con
l’utilizzo di una qualsiasi shell, ad esempio la BASH 2 ).
Come è noto, all’interno di R sono disponibili una serie di comandi per la gestio-
ne di immagini di vari formati (.png, .jpeg, .ps, etc...), ma nel modulo base di
R-php l’utilizzo di ImageMagick è risultato più facilmente gestibile. Inoltre,
sotto UNIX il device png di R usa il driver X11, il che costituisce un proble-
ma quando si effettuano operazioni in “batch mode” o in remoto. L’utilizzo di
ImageMagick nel modulo base è stato esteso anche al modulo point-and-click
di R-php. R invocato in “batch mode” produce i grafici in un unico file in
formato .ps; di seguito è riportato il codice in PHP per manipolare e convertire
il file .ps in formati “web-compatible” attraverso l’ausilio di ImageMagick:
exec("convert ./pages/tmp/$temp/Rplots.ps ./pages/tmp/$temp/R.png");
exec("convert -antialias -rotate 90 $fn ./pages/tmp/$temp/$nn.png");
• htmldoc
htmldoc è un programma che genera file in formato .html indicizzato, Adobe
Postscript e .pdf da file sorgenti .html. htmldoc include una semplice interfac-
cia GUI (Grafical User Interface) per trattare file .html e generare automatica-
mente file da visualizzare e/o stampare. htmldoc può anche essere utilizzato
su un Web server per generare file “on-the-fly”.
2
Bourn Again SHellCAPITOLO 1. CARATTERISTICHE FONDAMENTALI DI R-PHP 11
Per i software prima descritti è consigliabile disporre delle ultime versioni ed è co-
munque indispensabile avere installato: per il software PHP una versione a partire
dalla 4.3.0., per R una versione a partire dalla 2.0.0.
1.2.2 Descrizione del primo modulo (R-php base)
Quando l’utente entra nella pagina iniziale di questo modulo viene creata una direc-
tory temporanea; il nome di questa directory è generato dalla seguente porzione di
codice:
$unico = substr(uniqid("5555"),-5);
$time = time();
$max = mktime(6, 0, 0, 1, 1, 1970);
$temp = $unico."_".$time;
In base a questo codice implementato, viene inizialmente generata in maniera pseudo-
casuale una stringa di caratteri alfa-numerici, cui viene associato il timestamp unix.
All’interno di questa directory temporanea si troveranno tutti i file generati dall’utente
collegato e relativi alla corrente sessione di lavoro; questo garantisce la multi-utenza,
cioè l’utilizzo concorrente di più utenti, senza determinare confusione tra i file creati
durante le diverse sessioni conteporanee. Questa caratteristica di R-php non sembra
essere implementata in altri sistemi similari. Il numero massimo di utenti concorrenti
non dipende da R-php, ma dalle impostazioni del server Apache che lo ospita. Di
seguito si riporta il codice PHP che confronta il timestamp unix corrente con quello
presente nel nome delle directory temporanee ed elimina quelle presenti sul server da
almeno sei ore: questo permette di evitare di avere all’interno del server un numero
eccessivo di directory:
foreach(glob("./pages/tmp/*") as $dir){
$time_scad_temp = explode("_", $dir);
$control = $time - $time_scad_temp[1];
if($control>=$max){CAPITOLO 1. CARATTERISTICHE FONDAMENTALI DI R-PHP 12
delfile("$dir/*");
rmdir("$dir");
}
}
mkdir("pages/tmp/$temp", 777);
chmod("pages/tmp/$temp", 0777);
Il primo modulo di R-php permette di immettere in una textarea porzioni di
codice R che viene trascritto in un file di testo. Di seguito è riportata la sequenza di
istruzioni in PHP che permettono di eseguire questa operazione:
$nomefile = "codice.txt";
$fp = fopen("./pages/tmp/$temp/$nomefile", "w")
or die("impossibile aprire file");
fputs ( $fp, "$codice") or die("impossibile scrivere");
fclose($fp);
Come è noto, R contiene comandi che permettono l’interazione col sistema ope-
rativo della macchina utilizzata; questo potrebbe risultare pericoloso in un ambiente
come questo, perchè un utente esterno potrebbe immettere (volontariemente e non)
comandi dannosi. Per evitare questo incoveniente si è deciso di implementare una
struttura di controllo che non consente l’utilizzo di un insieme di comandi che si
ritengono pericolosi per la sicurezza del server. Tali comandi sono contenuti in un
database MySQL, che contiente anche una breve descrizione di quello che farebbe il
comando vietato. È chiaro che l’utente, interessato ad installare su un proprio server
R-php, può modificare in qualunque momento questa lista di comandi. Per mag-
giore sicurezza questa struttura di controllo viene effettuata dapprima “lato-client”
in javascript e successivamente (solo se si riesce ad eludere tale controllo) anche
“lato-server” in PHP.
Per quanto riguarda l’immissione dei dati, oltre a poterli inserire in maniera ma-
nuale attraverso gli opportuni comandi di R, vi è la possibilità di poter leggere i dati
da un file di testo contenuto all’interno della macchina dell’utente. Da un punto diCAPITOLO 1. CARATTERISTICHE FONDAMENTALI DI R-PHP 13
vista tecnico questa operazione coincide con un “upload” sul server, per il quale viene
utilizzata la seguente sequenza di comandi PHP:
if(isset($HTTP_POST_VARS[upFile]) and $HTTP_POST_VARS[upFile] = "yes"){
include("./include/temp.php");
$nomeFile = pulisci($HTTP_POST_FILES[’file’][’name’]);
move_uploaded_file($HTTP_POST_FILES[’file’][’tmp_name’],
"./pages/tmp/$_SESSION[temp]/$nomeFile");
}
I comandi R, contenuti nel file creato precedentemente, vengono processati da
R che nel frattempo è stato invocato in “batch mode” da PHP. Il comando che
permette di effettuare questa operazione è il seguente:
exec(R --no-save -q < codice.txt > output 2>&1);
R, invocato in “batch mode”, restituisce l’output in due formati: uno puramente
testuale con l’analisi richiesta, uno in formato .ps che contiene eventuali grafici. A
questo punto i due file vengono trattati in due modi differenti:
• il file di testo viene semplicemente formattato (utilizzando gli style-sheet) per
renderlo più leggibile;
• il file in formato .ps viene diviso per ottenere un file per ogni immagine; ogni
immagine viene poi convertita in un formato più idoneo per la visualizazzione
web (in formato .png); queste operazioni sono effettuate con l’ausilio del software
ImageMagick, descritto precedentemente.
Nella fase finale l’output, completo di eventuali grafici, viene visualizzato in una
nuova finestra. In questa finestra vi è la possibilità per l’utente di salvare l’output
in formato .pdf attraverso il software htmldoc, oppure si può decidere di salvare
separatamente, qualora siano stati generati, uno o più grafici prodotti durante la
sessione.CAPITOLO 1. CARATTERISTICHE FONDAMENTALI DI R-PHP 14
1.2.3 Descrizione del secondo modulo (R-php point-and-click)
Il modulo di R-php che descriviamo in questo paragrafo non è una semplice interfac-
cia web di R, ma presenta a tutti gli effetti le caratteristche di un GUI; questa parte
fa sı̀ che R-php presenti caratteri di novità rispetto a progetti similari.
L’organizzazione delle sessioni concorrenti relative a questo modulo è analoga a
quella descritta nel paragrafo precedente per il modulo R-php base.
Per quanto riguarda l’immissione dei dati, che costituisce il primo passo nell’uti-
lizzo di R-php point-and-click, viene effettuata caricando un file ASCII dal computer
dell’utilizzatore. Successivamente, il contenuto del file viene visualizzato in una nuova
pagina sotto forma di uno “spreadsheet”; questo insieme di dati è gestito da My-
SQL: questo permette di poter effettuare alcune operazioni interattive direttamente
sui dati; ad esempio, è possibile modificare il nome delle variabili o i valori di ogni
singola cella dello “spreadsheet”; di seguito è riportato il codice in PHP e MySQL
per la modifica del valore di una cella:
$sql = "UPDATE $temp SET var$v = ’$val’ where id=’$r’";
mysql_query ($sql, $conn);
Caricato l’insieme di dati, è possibile scegliere che tipo di analisi effettuare tra
quelle proposte. Ciascuna di queste analisi può essere effettuata attraverso l’ausilio
di un GUI; nel GUI vengono scelte le opzioni di analisi che l’utente vuole utilizzare;
tali opzioni verranno tradotte in codice R che viene inviato per essere processato
dall’ambiente di programmazione R. In maggiore dettaglio questa fase comporta i
seguenti passi:
1. il codice viene trascritto in un file ASCII che sarà l’input di R; questa operazione
ricalca quella descritta per il modulo base;
2. viene esportato il database contenente i dati in un file ASCII; di seguito ripor-
tiamo il codice utilizzato:
exec("mysqldump -T ./pages/tmp/$temp --fields-terminated-by=’ ’
R $temp -u’$user’ -p’$pass’");CAPITOLO 1. CARATTERISTICHE FONDAMENTALI DI R-PHP 15
3. R, invocato in “batch mode”, processa il codice contenuto nel file creato prece-
dentemente;
4. R restituisce l’output che si presenta in due file, uno (in formato ASCII) che
contiene la parte testuale dell’analisi e l’altro (in formato .ps) che contiene i
grafici;
5. il file ASCII viene formattato per essere compatibile con gli standard WEB;
6. il file .ps viene dapprima diviso in più file e poi manipolato e convertito con
l’ausilio di ImageMagick in .png; questa operazione ricalca quella descritta
per il modulo base;
A questo punto viene generata una pagina web che contiene il testo e i grafici
dell’analisi effettuata. La pagina contenente l’output consente, inoltre, altre opera-
zioni interessanti, quali il salvataggio dell’output, completo di grafici, in formato .pdf
(Portable Document Format) ed il salvataggio delle singole immagini attraverso un
semplice click.
Non ci soffermiamo sulla descrizione di ciascuno dei GUI presenti per le diverse
analisi che è possibile effettuare con R-php point-and-click, perchè dal punto di vista
della progettazione il codice implementato è formalmente analogo per ciascuno dei
GUI.Capitolo 2
Guida all’utilizzo
2.1 Utilizzo di R-php base
Questa interfaccia permette il semplice inserimento del codice R in una text-area. Le
componenti della pagina utilizzabili dall’utente sono:
• La text-area per l’inserimento del codice R
In questa parte della pagina l’utente deve digitare il codice R necessario per l’a-
nalisi da effettuare. Non è consentito utilizzare comandi in R che interagiscono
con il sistema operativo; quando un utente digita uno di questi comandi, non
viene eseguita alcuna parte di codice e contestualmente appare una finestra di
“alert” che avvisa l’utente che nel codice immesso c’è un comando vietato; la
stessa finestra consente all’utente di visualizzare la lista dei comandi “banna-
ti” con una breve descrizione di ciascuno di essi. Il codice può essere digitato
direttamente, ma naturalmente si potrebbe anche copiarlo da altre fonti ed
“incollarlo”;
• Il tasto send
Quando l’utente ha finito di immettere tutto il codice R che vuole eseguire nella
text-area, basta cliccare su questo tasto e il codice inserito sarà inviato ad R
per essere processato.
16CAPITOLO 2. GUIDA ALL’UTILIZZO 17
• Il tasto reset
Se l’utente decide di immettere nuovo codice nella text-area, il tasto reset gli
consente all’inizio di pulire l’area di immissine del codice.
• Il campo di testo
Nel caso l’utente voglia utilizzare per la propria analisi un dataset in formato
ASCII presente nel proprio computer, può immettere direttamente il percor-
so del file in questo campo, oppure più semplicemente può cliccare sul tasto
sfoglia (browse) e selezionare dalla finestra di caricamento-file del browser il
file desiderato; una volta inserito il dataset, verrà riprodotto nella text-area il
codice R necessario per il caricamento del dataset prescelto.
A questo punto l’utente deve solamente cliccare sul tasto send per ottenere l’out-
put del codice immesso in una nuova finestra; in questa finestra saranno compresi
anche gli eventuali grafici generati.
Nella finestra di output vi è la possibilità di salvare il risultato dell’analisi in
formato .pdf cliccando sull’apposito link (vedi 2.3).
2.2 Utilizzo di R-php point-and-click
In questo tipo di interfaccia i dati non possono essere digitati direttamente, ma è
necessario preparare, eventualmente con un editor, un file di testo che viene selezio-
nato dal proprio computer, cliccando sul tasto sfoglia (browse). Per l’utilizzo di
questo modulo non è necessaria da parte dell’utente la conoscenza dell’ambiente di
programmazione R, ma tutte le analisi consentite possono essere effettuate solo con
l’ausilio del mouse.
Per poter effettuare analisi con questo modulo è necessario caricare un file di dati
dal proprio computer; la procedura per il caricamento di un dataset è esattamente
analoga a quella vista per il modulo R-php base. L’import del file di testo non presenta
grossi problemi; si possono usare vari delimitatori di campo (virgola, tabulazione,
spazio, ecc.) e a meno di alcuni caratteri non alfa-numerici utilizzati da alcuni editor,
i dati saranno importati correttamente (si consiglia eventualmente di effettuare piùCAPITOLO 2. GUIDA ALL’UTILIZZO 18
Figura 2.1: R-php base.CAPITOLO 2. GUIDA ALL’UTILIZZO 19
Figura 2.2: R-php base: codice per l’import del dataset.CAPITOLO 2. GUIDA ALL’UTILIZZO 20
Figura 2.3: R-php base: output.CAPITOLO 2. GUIDA ALL’UTILIZZO 21
prove, rieditando il file ed eliminando i caratteri che dovessero dare problemi). È
inoltre necessario indicare, spuntando la casella relativa a Header, con yes o no la
presenza o meno dei nomi delle variabili nella prima riga del dataset.
Nella fase successiva i dati si presentano ordinati in una tabella come nei più
classici “spreadsheet”, quale ad esempio Excel.
Una caratteristica molto interessante riguarda la possibilità di poter modificare il
contenuto di ogni singola cella dello “spreadsheet”, compreso il nome delle variabili,
direttamente dalla pagina che visualizza i dati, attraverso un “popup” che permette
tali modifiche.
Nel menu in alto sono disponibili i tasti per effettuare vari tipi di analisi1 . Se
nell’insieme dei dati vengono apportate modifiche, è possibile salvare nel proprio
computer il nuovo insieme di dati in formato testo.
Scelto il dataset, è possibile effettuare le analisi a disposizione; se l’utente volesse
effettuare analisi su un nuovo dataset, non è possibile utilizzare le opzioni fornite dal
browser, ma è necessario utilizzare l’opportuno link progettato proprio per l’import
di nuovi insiemi di dati. Nel caso in cui un utente dovesse innavvertitamente utiliz-
zare il tasto indietro del browser, non otterrà l’effetto sperato, ma quello che verrà
comunque visualizzato sarà l’insieme di dati importato precedentemente.
A questo punto, importato il dataset, è possibile effettuare le seguenti analisi.
2.2.1 Descriptive analysis
Scegliendo il GUI relativo all’analisi descrittiva, oltre all’insieme di dati precedente-
mente caricato, che anche in questa fase può essere comunque modificato, compare
una finestra dove è possibile selezionare:
• le variabili del dataset su cui si vogliono calcolare le statistiche;
• l’elenco delle statistiche descrittive a disposizione.
1
Per ora i tipi di analisi disponibili sono limitati in numero, ma si prevede in un prossimo futuro
di arricchire le funzionalità di questo software.CAPITOLO 2. GUIDA ALL’UTILIZZO 22
In questa versione è possibile calcolare le seguenti statistiche descrittive: minimo,
massimo, media aritmetica, mediana, quartili, scarto quadratico medio e varianza.
Cliccando sul tasto send comparirà una nuova finestra contenente le statistiche
descrittive calcolate per ciascuna delle variabili selezionate. Se l’utente non dovesse
selezionare alcuna variabile, oppure nessuna statistica descrittiva, cliccando sul tasto
send comparirà un messaggio di errore che invita l’utente a selezionare almeno una
variabile ed una statistica descrittiva.
Anche in questo caso, come d’altronde avviene per gli altri moduli, è possibile
salvare la finestra dell’output in fomato .pdf.
2.2.2 Linear regression
Scegliendo il GUI relativo all’analisi di regressione lineare, oltre all’insieme di dati
precedentemente caricato, che anche in questa fase può essere comunque modificato,
appare un campo di testo dove è possibile inserire l’espressione del modello, uti-
lizzando la sintassi propria di R. In realtà, non è necessario che l’utente immetta
direttamente la formula del modello, ma può scegliere di cliccare sul tasto model che
aprirà una nuova finestra dove è possibile scegliere, tra le variabili del dataset, la va-
riabile di risposta e le variabili esplicative. In questa finestra sono stati implementati
dei controlli per cui:
• non è possibile scegliere nessuna o più di una variabile di risposta;
• è necessario scegliere almeno una variabile esplicativa;
• una stessa variabile non può essere scelta contemporaneamente come variabile
di risposta ed esplicativa.
Scelte la variabile di risposta e le variabili esplicative, cliccando sul tasto insert
questa finestra scomparirà e nel campo di testo della finestra iniziale del GUI com-
parirà, in sintassi R, il modello corrispondente alle scelte fatte. Se un utente volesse
immettere attraverso il campo di testo dei comandi potenzialmente pericolosi, anche
in questo caso i comandi non verrebbero eseguiti e comparirebbe un messaggio diCAPITOLO 2. GUIDA ALL’UTILIZZO 23
errore, attraverso il quale si può anche visionare la lista dei comandi non autorizzati.
A questo punto cliccando sul tasto send viene eseguita la corrispondente analisi di
regressione. I risultati dell’analisi verranno visualizzati in una finestra di output che
contiene:
• le principali statistiche descrittive calcolate sulle variabili presenti nel modello;
• la matrice di varianza e covarianza;
• la matrice di correlazione;
• i risultati dell’analisi di regressione che comprendono:
– la formula utilizzata per il modello;
– alcune statistiche descrittive sui residui;
– i valori dei coefficenti stimati, compresi l’errore standard e il valore del test
t;
– il coefficiente di determinazione R2 ;
– la statistica F per saggiare l’ipotesi nulla di coefficenti di regressione tutti
pari a zero, contro l’ipotesi alternativa che almeno uno sia diverso da zero.
– tavola dell’analisi della varianza.
• il grafico che contiene la matrice dei diagrammi di punto per ciascuna delle
variabili coinvolte nel modello;
• i grafici relativi all’analisi dei residui necessari per verificare le ipotesi di ba-
se sull’adeguatezza del modello, sulla normalità della parte stocastica del mo-
dello, l’omoscedasticità e il diagramma delle distanze di Cook per individuare
eventuali valori anomali.
In questa finestra sono inoltre presenti dei tasti per il salvataggio dell’output:
• tutto l’output in fomato .pdf;
• ogni singola immagine in formato .png.CAPITOLO 2. GUIDA ALL’UTILIZZO 24
2.2.3 Analysis of variance
La finestra grafica di questo GUI si presenta in maniera molto simile a quanto visto
per il GUI di regressione lineare; anche in questo caso, oltre all’insieme di dati prece-
dentemente caricato, appare un campo di testo dove è possibile inserire l’espressione
del modello, utilizzando la sintassi propria di R. Per quanto riguarda l’insieme di
dati si raccomanda all’utilizzatore di immettere insiemi di dati bilanciati per ottenere
risultati facilmente interpretabili, come è noto. Anche in questo GUI, se un utente
volesse immettere attraverso il campo di testo dei comandi potenzialmente pericolosi,
i comandi non verrebbero eseguiti e comparirebbe un messaggio di errore, attraverso
il quale si può anche visionare la lista dei comandi non autorizzati. In realtà, non è
necessario che l’utente immetta direttamente la formula del modello, ma può scegliere
di cliccare sul tasto model, che aprirà una nuova finestra dove è possibile scegliere,
tra le variabili del dataset, la variabile di risposta e le variabili esplicative. Nel caso
in cui le variabili esplicative siano codificate attraverso valori numerici, il codice im-
plementato forza queste variabili a fattori. In questa finestra sono stati implementati
dei controlli per cui:
• non è possibile scegliere nessuna o più di una variabile di risposta;
• è necessario scegliere almeno una variabile esplicativa;
• una stessa variabile non può essere scelta contemporaneamente come variabile
di risposta ed esplicativa.
Inserito il modello, si chiude la finestra di scelta del modello ed apparirà la finestra
principale leggermente modificata. In particolare, sotto il campo di immissione del
modello verranno visualizzati i livelli delle variabili esplicative scelte. Accanto al
tasto model comparirà, inoltre, un nuovo tasto che permettere all’utente di inserire
nel modello le eventuali interazioni.
A questo punto l’utente può effettuare l’analisi della varianza del modello prescelto
cliccando sul tasto send. Apparirà quindi la finestra di output che conterrà le seguenti
informazioni:CAPITOLO 2. GUIDA ALL’UTILIZZO 25 • le variabili coinvolte nel modello; • i livelli di ogni fattore; • le principali statistiche descrittive per ogni variabile inclusa nel modello; • la tavola di analisi della varianza; • i grafici relativi all’analisi dei residui. Quando si effettua un’analisi della varianza a più di una via e si ha un’unica osservazione per cella, inserendo tutte le possibili interazioni si ha la somma dei quadrati del residuo pari a zero con una conseguente perdita di validità dei test F . In questi casi R-php, dopo la tabella di analisi della varianza, ferma l’esecuzione del codice e restituisce un messaggio di errore che evidenzia all’utente il fatto di essere incorso in una situazione di questo tipo. A questo punto si consiglia di tornare nella finestra principale del GUI reimmettendo il modello senza interazioni. Nella finestra di output sono inoltre presenti dei tasti per il salvataggio dell’output: • tutto l’output in formato .pdf; • ogni singola immagine in formato .png. 2.3 Esempi di utilizzo di R-php point-and-click In questa sezione vedremo alcuni esempi di utilizzo per ciascuno dei GUI finora svi- luppati per R-php point-and-click. Questa che segue vuole essere solamente un’in- dicazione fornita all’utente su come è possibile utilizzare R-php point-and-click ; se problemi dovessero sorgere nell’analisi di altri insiemi di dati, gli utenti sono invitati a segnalare tali problemi agli autori. 2.3.1 Statistiche descrittive In questa sezione verrà utilizzato l’insieme di dati contenuto nel file “formaggio.txt”. Questo file contiene dati relativi alle concentrazione di varie sostanze chimiche in
CAPITOLO 2. GUIDA ALL’UTILIZZO 26
30 campioni di formaggio Cheddar prodotto nella zona La Trobe Valley dello stato
Victoria in Australia e una misura soggettiva del gusto per ogni campione (Moore e
McCabe, 2002, Introduction to the practice of Statistics, Freeman and Co.). È noto,
infatti, che man mano che il formaggio matura hanno luogo diversi processi chimici
che determinano il sapore del prodotto finale. In particolare, le variabili prese in
considerazione sono:
• Taste: punteggio soggettivo del test sul gusto, ottenuto combinando i punteggi
dati da diversi assaggiatori.
• Acetic: logaritmo naturale della concentrazione di acido acetico.
• H2S: logaritmo naturale della concentrazione di acido solfidrico.
• Lactic: concentrazione di acido lattico.
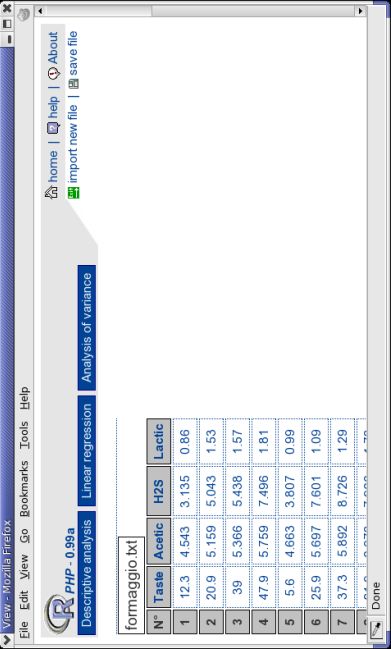
Caricato l’insieme di dati, selezionando il file “formaggio.txt” da una directory del
computer locale e indicando l’opzione Yes di Header, il risultato ottenuto è quello
mostrato in figura 2.4.
Selezionando il GUI della statistica descrittiva verrà visualizzata la schermata
presente in figura 2.5.
Supponiamo di voler calcolare per tutte le 4 variabili presenti nel file importato le
seguenti statistiche descrittive: minimo, massimo, media, mediana e varianza (vedi
fig 2.6).
A questo punto si eseguono i calcoli richiesti cliccando sul tasto send. La finestra
di output avrà la forma riportata in figura 2.7.
Come già descritto in precedenza, è possibile salvare l’output in formato .pdf; per
l’output ottenuto in questo caso il file .pdf è riportato in appendice.
2.3.2 Regressione Lineare
Per mostrare come utilizzare il GUI di regressione lineare di R-php point-and-click,
consideriamo lo stesso file, “formaggio.txt”, utilizzato nella sezione precedente. Im-
portato il file e scelto il GUI di regressione lineare (vedi figura 2.8) si vuole stimare ilCAPITOLO 2. GUIDA ALL’UTILIZZO 27
Figura 2.4: Import del file di dati.CAPITOLO 2. GUIDA ALL’UTILIZZO 28
Figura 2.5: Schermata iniziale del GUI di Statistica descrittiva.CAPITOLO 2. GUIDA ALL’UTILIZZO 29
Figura 2.6: Selezione delle analisi del GUI di statistica descrittiva.CAPITOLO 2. GUIDA ALL’UTILIZZO 30
Figura 2.7: Output del GUI di statistica descrittiva.CAPITOLO 2. GUIDA ALL’UTILIZZO 31 modello di regressione con Taste variabile di risposta e le rimanenti tre come variabili esplicative. Cliccando sul tasto model comparirà la finestra per la scelta delle variabili di risposta ed esplicative; nel nostro caso clicchiamo sul punto incrocio tra Taste e Response, mentre selezioniamo le rimanenti variabili come esplicative (vedi figura 2.9). Cliccando sul tasto insert si ritorna alla finestra iniziale del GUI di Regressione lineare e nel campo di testo apparirà l’espressione del modello scelto. A questo punto basta cliccare sul tasto send per ottenere i risultati relativi al modello scelto (vedi figura 2.10). Come già descritto in precedenza, è possibile salvare l’output in formato .pdf; per l’output ottenuto in questo caso il file .pdf è riportato in appendice. 2.3.3 Analisi della varianza Per quanto riguarda l’analisi della varianza vedremo un primo esempio di analisi della varianza ad una via. Si consideri l’insieme di dati contenuto nel file “capelli.txt”. I dati contenuti in questo file sono relativi ad uno studio condotto dalla University of Melbourne per stabilire se vi sono differenze nella soglia del dolore in tipi dai capelli biondi o bruni (McClave e Dietrich, 1991, Statistics, Dellen Pubblishing). In particolare, uomini e donne di varie età sono stati divisi in quattro gruppi secondo il colore dei capelli: LightBlond, DarkBlonde, LightBrunette, DarkBrunette. Lo scopo dell’esperimento è stato quello di vedere se il colore dei capelli è legato al dolore prodotto da comuni tipi di traumi. Ad ogni persona facente parte dell’esperimento è stato dato un punteggio per la soglia del dolore basato sulla sua performance in un test di sensibilità al dolore (più alto era il punteggio, più elevata era la tolleranza al dolore). Le variabili sono: HairColor e Pain. Come prima cosa importiamo il file come già descritto in precedenza. Scegliendo il GUI di Analisi della Varianza apparirà il relativo tool. A questo punto cliccando sul tasto model apparirà la finestra che consente all’utente di scegliere la variabile di risposta e i fattori; nel nostro caso
CAPITOLO 2. GUIDA ALL’UTILIZZO 32
Figura 2.8: Schermata iniziale del GUI di Regressione lineare.CAPITOLO 2. GUIDA ALL’UTILIZZO 33
Figura 2.9: Finestra per la selezione delle variabili.
clicchiamo sul punto incrocio tra HairColor ed Explanatory e sul punto incrocio tra
Pain e Response (vedi figura 2.11).
Cliccando sul tasto insert si ritorna alla finestra iniziale del GUI di Analisi della
Varianza che apparirà leggermente diversa rispetto all’inizio. Nel campo di testo
apparirà l’espressione del modello scelto e, sotto, i livelli dei fattori precedentemente
scelti (vedi figura 2.12).
A questo punto basta cliccare sul tasto send per ottenere i risultati relativi al
modello scelto (vedi figura 2.13).
Come già descritto in precedenza, è possibile salvare l’output in formato .pdf; perCAPITOLO 2. GUIDA ALL’UTILIZZO 34 l’output ottenuto in questo caso il file .pdf è riportato in appendice. Vedremo adesso due esempi di Analisi della Varianza a due vie, il primo in cui abbiamo un’unica osservazione per cella e quindi dobbiamo supporre un effetto di interazione nullo, il secondo in cui abbiamo un piano bilanciato con più di un’osser- vazione per cella e quindi considereremo anche l’effetto di interazione. Per quanto riguarda il primo caso utilizzeremo il file “lunapiena.txt”. I dati contenuti in questo file si riferiscono ai tassi di ammissione a camere di emergenza di una clinica per la sa- lute mentale delle Virginia, prima, durante e dopo le 12 lune piene dall’Agosto 1971 al Luglio 1972. Questi dati sono stati rilevati per verificare se ha un qualche fondamento la credenza popolare che la luna piena sia portatrice di qualcosa di sinistro (Larsen & Marx, 1986, An Introduction to Mathematical Statistics and Its Applications, 3a edizione, Prentice Hall). Le variabili prese in considerazione sono Admission, che tiene conto del tasso di ammissione giornaliero; Month, che tiene conto del mese; Moon, che tiene conto del periodo di luna piena. Come prima cosa importiamo il file di dati come già descritto in precedenza. Scegliendo il GUI di Analisi della Varianza apparirà il relativo tool. A questo punto cliccando sul tasto model apparirà la finestra che consente all’utente di scegliere la variabile di risposta e i fattori; nel nostro caso, clicchiamo sul punto incrocio tra Month ed Explanatory, sul punto incrocio tra Moon ed Explanatory e sul punto incrocio tra Admission e Response (vedi figura 2.14). A questo punto si ritornerà alla precedente schermata e comparirà il tasto per immettere nel modello le eventuali interazioni add-interactions; nel nostro caso, non utilizzeremo questo tasto e procediamo con l’analisi cliccando sul tasto send. Sarà quindi visualizzato l’output in una nuova finestra (vedi figura 2.15). Come già descritto in precedenza è possibile salvare l’output in formato .pdf; per l’output ottenuto in questo caso il file .pdf è riportato in appendice. Vedremo adesso un esempio di Analisi della Varianza a due vie con effetto di interazione; per questo esempio utilizzeremo il file “insulate.txt”. Questo insieme di dati è costituito da tre variabili: la variabile di risposta Strength relativa alla forza di impatto di un particolare materiale isolante, espressa in piedi/libbre, con variabili esplicative Lot, che tiene conto del lotto del materiale isolante e Cut che tiene conto del tipo di taglio effettuato (Ostle & Malone, 1987, Statistics in Research: Basic
CAPITOLO 2. GUIDA ALL’UTILIZZO 35 Concepts and Techniques for Research Workers , 4a edizione, Blackwell Pubblishing). Come prima cosa importiamo il file di dati, come già descritto in precedenza. Scegliendo il GUI di Analisi della Varianza apparirà il relativo tool. A questo punto cliccando sul tasto model apparirà la finestra che consente all’utente di scegliere la variabile di risposta e i fattori; nel nostro caso, clicchiamo sul punto incrocio tra Cut ed Explanatory, sul punto incrocio tra Lot ed Explanatory e sul punto incrocio tra Strength e Response (vedi figura 2.16). Cliccando sul tasto insert si tornerà alla precedente schermata e comparirà il tasto add-interactions che consente all’utente di aggiungere al modello le eventuali interazioni; nel nostro caso selezioniamo le due variabili di cui vogliamo studiare l’effetto di interazione (vedi figura 2.17) Cliccando su insert verrà inserito il modello, completo delle interazioni scelte, nel campo apposito e cliccando sul tasto send verrà visualizzato l’output in una nuova finestra (vedi figura 2.18). Come già descritto in precedenza è possibile salvare l’output in formato .pdf; per l’output ottenuto in questo caso il file .pdf è riportato in appendice.
CAPITOLO 2. GUIDA ALL’UTILIZZO 36
Figura 2.10: Output del GUI di Regressione lineareCAPITOLO 2. GUIDA ALL’UTILIZZO 37
Figura 2.11: Finestra per la selezione delle variabili.CAPITOLO 2. GUIDA ALL’UTILIZZO 38
Figura 2.12: Schermata del GUI di Analisi della Varianza.CAPITOLO 2. GUIDA ALL’UTILIZZO 39
Figura 2.13: Output del GUI di Analisi della VarianzaCAPITOLO 2. GUIDA ALL’UTILIZZO 40
Figura 2.14: Finestra per la selezione delle variabili.CAPITOLO 2. GUIDA ALL’UTILIZZO 41
Figura 2.15: Output del GUI di Analisi della varianza.CAPITOLO 2. GUIDA ALL’UTILIZZO 42
Figura 2.16: Finestra per la selezione delle variabili.CAPITOLO 2. GUIDA ALL’UTILIZZO 43
Figura 2.17: Finestra per la selezione delle interazioni.CAPITOLO 2. GUIDA ALL’UTILIZZO 44
Figura 2.18: Output del GUI di Analisi della varianza.APPENDICE
output R−PHP − http://r−php.homelinux.net
[1] "Taste" "Acetic" "H2S" "Lactic"
Taste
Min
[1] 0.7
Median
[1] 20.95
Mean
[1] 24.53333
Max
[1] 57.2
Variance
[1] 264.2375
Acetic
Min
[1] 4.477
Median
[1] 5.425
Mean
[1] 5.498033
Max
[1] 6.458
Variance
[1] 0.3259021
H2S
Min
[1] 2.996
1output R−PHP − http://r−php.homelinux.net
Median
[1] 5.329
Mean
[1] 5.941767
Max
[1] 10.199
Variance
[1] 4.523615
Lactic
Min
[1] 0.86
Median
[1] 1.45
Mean
[1] 1.442
Max
[1] 2.01
Variance
[1] 0.0921062
2output R−PHP − http://r−php.homelinux.net
[1] "Taste" "Acetic" "H2S" "Lactic"
Taste Acetic H2S Lactic
Min. : 0.70 Min. :4.477 Min. : 2.996 Min. :0.860
1st Qu.:13.55 1st Qu.:5.237 1st Qu.: 3.978 1st Qu.:1.250
Median :20.95 Median :5.425 Median : 5.329 Median :1.450
Mean :24.53 Mean :5.498 Mean : 5.942 Mean :1.442
3rd Qu.:36.70 3rd Qu.:5.883 3rd Qu.: 7.575 3rd Qu.:1.667
Max. :57.20 Max. :6.458 Max. :10.199 Max. :2.010
Taste Acetic H2S Lactic
Taste 264.237471 5.0996402 26.1288011 3.4742414
Acetic 5.099640 0.3259021 0.7503155 0.1046089
H2S 26.128801 0.7503155 4.5236150 0.4162177
Lactic 3.474241 0.1046089 0.4162177 0.0921062
Taste Acetic H2S Lactic
Taste 1.0000000 0.5495393 0.7557523 0.7042362
Acetic 0.5495393 1.0000000 0.6179559 0.6037826
H2S 0.7557523 0.6179559 1.0000000 0.6448123
Lactic 0.7042362 0.6037826 0.6448123 1.0000000
Call:
lm(formula = Taste ~ Acetic + H2S + Lactic)
Residuals:
1output R−PHP − http://r−php.homelinux.net
Min 1Q Median 3Q Max
−17.391 −6.612 −1.009 4.908 25.449
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) −28.8768 19.7354 −1.463 0.15540
Acetic 0.3277 4.4598 0.073 0.94198
H2S 3.9118 1.2484 3.133 0.00425 **
Lactic 19.6705 8.6291 2.280 0.03108 *
−−−
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
Residual standard error: 10.13 on 26 degrees of freedom
Multiple R−Squared: 0.6518, Adjusted R−squared: 0.6116
F−statistic: 16.22 on 3 and 26 DF, p−value: 3.81e−06
Analysis of Variance Table
Response: Taste
Df Sum Sq Mean Sq F value Pr(>F)
Acetic 1 2314.14 2314.14 22.5481 6.528e−05 ***
H2S 1 2147.02 2147.02 20.9197 0.0001035 ***
Lactic 1 533.32 533.32 5.1964 0.0310795 *
Residuals 26 2668.41 102.63
−−−
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
2output R−PHP − http://r−php.homelinux.net
3output R−PHP − http://r−php.homelinux.net
[1] "HairColour" "Pain"
> HairColour
[1] "DarkBlond" "DarkBrunette" "LightBlond" "LightBrunette"
Pain HairColour
Min. :30.00 DarkBlond :5
1st Qu.:40.00 DarkBrunette :5
Median :48.00 LightBlond :5
Mean :47.84 LightBrunette:4
3rd Qu.:56.00
Max. :71.00
Analysis of Variance Table
Response: Pain
Df Sum Sq Mean Sq F value Pr(>F)
HairColour 3 1360.73 453.58 6.7914 0.004114 **
Residuals 15 1001.80 66.79
−−−
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
1output R−PHP − http://r−php.homelinux.net
2output R−PHP − http://r−php.homelinux.net
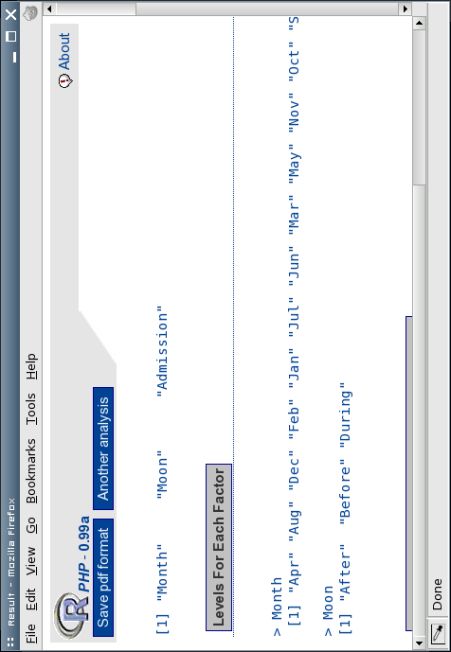
[1] "Month" "Moon" "Admission"
> Month
[1] "Apr" "Aug" "Dec" "Feb" "Jan" "Jul" "Jun" "Mar" "May" "Nov" "Oct" "Sep"
> Moon
[1] "After" "Before" "During"
Admission Month Moon
Min. : 5.000 Apr : 3 After :12
1st Qu.: 8.475 Aug : 3 Before:12
Median :12.850 Dec : 3 During:12
Mean :11.931 Feb : 3
3rd Qu.:14.000 Jan : 3
Max. :25.000 Jul : 3
(Other):18
Analysis of Variance Table
Response: Admission
Df Sum Sq Mean Sq F value Pr(>F)
Month 11 455.58 41.42 7.1285 5.076e−05 ***
Moon 2 41.51 20.76 3.5726 0.04533 *
Residuals 22 127.82 5.81
−−−
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
1output R−PHP − http://r−php.homelinux.net
2output R−PHP − http://r−php.homelinux.net
[1] "Lot" "Cut" "Strength"
> Lot
[1] "1" "2" "3" "4" "5"
> Cut
[1] "Cross" "Length"
Strength Lot Cut Lot.Cut
Min. :0.4400 1:20 Cross :50 1:Cross :10
1st Qu.:0.6250 2:20 Length:50 1:Length:10
Median :0.8050 3:20 2:Cross :10
Mean :0.7841 4:20 2:Length:10
3rd Qu.:0.9025 5:20 3:Cross :10
Max. :1.3200 3:Length:10
(Other) :40
Analysis of Variance Table
Response: Strength
Df Sum Sq Mean Sq F value Pr(>F)
Lot 4 2.79117 0.69779 70.2689output R−PHP − http://r−php.homelinux.net
2Puoi anche leggere

















































