INTELLIGENZA ARTIFICIALE: il futuro è già presente RELATORE
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Dipartimento di Impresa e Management Cattedra di Informatica INTELLIGENZA ARTIFICIALE: il futuro è già presente RELATORE: CANDIDATO: Prof. Laura Luigi Pompili Alessio Matr. 233271 Anno Accademico 2020-2021
Indice INTRODUZIONE .................................................................................................................................................................. 3 1. INTELLIGENZA ARTIFICIALE ........................................................................................................................................ 4 1.1 Storia, Turing e i primi sviluppi: ......................................................................................................................... 4 1.2 Intelligenza: cos’è, è possibile definirla? ........................................................................................................... 7 1.3 Le basi dell’Intelligenza Artificiale: .................................................................................................................... 9 1.4 Paradigmi dell’Intelligenza Artificiale: ............................................................................................................. 13 2. MACHINE LEARNING E DEEP LEARNING .................................................................................................................. 18 2.1 Machine Learning: ........................................................................................................................................... 18 2.2 Funzionamento: ............................................................................................................................................... 19 2.3 Capire il problema e lavorare con i dati: ......................................................................................................... 19 2.4 Tipi di apprendimento: .................................................................................................................................... 24 2.5 Training, validazione e ottimizzazione:............................................................................................................ 27 2.6 Categorie di soluzioni: ..................................................................................................................................... 31 2.7 Deep Learning: ................................................................................................................................................. 33 2.8 Cervello umano:............................................................................................................................................... 37 3. DOVE SIAMO E DOVE VOGLIAMO ARRIVARE .......................................................................................................... 41 3.1 Applicazioni, dove siamo oggi: ........................................................................................................................ 41 3.2 Big Data:........................................................................................................................................................... 53 3.3 Privacy:............................................................................................................................................................. 58 3.4 Etica, fino a dove si vuole arrivare:.................................................................................................................. 62 3.5 Lavoro: ............................................................................................................................................................. 68 3.6 Uno sguardo al futuro:..................................................................................................................................... 71 4. ADDESTRAMENTO DI UNA RETE NEURALE.............................................................................................................. 77 4.1 Introduzione: ................................................................................................................................................... 77 4.2 Codice: ............................................................................................................................................................. 77 4.3 Risultati: ........................................................................................................................................................... 80 CONCLUSIONI .................................................................................................................................................................. 85 BIBLIOGRAFIA .................................................................................................................................................................. 86 2
INTRODUZIONE Il tema dell’Intelligenza Artificiale è stato molto dibattuto, e continua ad esserlo sempre più. Da un lato c’è chi pensa che l’Intelligenza Artificiale sia la cosa migliore che potesse inventare l’essere umano, dall’altro lato c’è chi pensa che sia la cosa peggiore. Secondo la visione più ottimistica, l’Intelligenza Artificiale porterà l’essere umano ad uno stato superiore rendendo la sua vita migliore sotto tutti i punti di vista ed eliminando le disuguaglianze tra le persone. Al contrario, secondo la visione pessimistica, l’Intelligenza Artificiale porterà la razza umana all’estinzione. Probabilmente entrambe le visioni sono troppo estreme per verificarsi. Tuttavia, nonostante non si riesca (ancora) a giungere ad una conclusione condivisa sul fatto che l’Intelligenza Artificiale sia o meno favorevole per lo sviluppo della qualità della vita dell’essere umano, è bene che esista e che si sviluppi questo dibattito. Nel dibattito sull’Intelligenza Artificiale non viene sempre data la giusta importanza al funzionamento degli algoritmi. Comprendere il funzionamento di questa tecnologia è fondamentale per capire in che modo potrebbe evolversi e realmente a che punto è il suo sviluppo. Dopo che si è compreso il suo funzionamento, e le sue reali applicazioni, è possibile instaurare un dibattito sugli effettivi sviluppi che potrebbe avere in futuro. Nella prima parte di quest’elaborato viene descritta la storia di quest’affascinante materia, andando anche a cercare di capire che cosa sia effettivamente l’Intelligenza Artificiale e se possa essere definita intelligente, fornendo anche dei paragoni su come viene intesa l’intelligenza degli esseri umani e degli animali. Sempre nella prima parte vengono analizzate le basi sulle quali si fondano gli algoritmi di Intelligenza Artificiale e vengono descritti alcuni dei paradigmi più importanti. Spesso, quando si parla di algoritmi di Intelligenza Artificiale si pensa subito al Machine Learning. Questa tecnica è sicuramente molto utilizzata, ma non è certo l’unica e non è sempre la migliore. Nella seconda parte viene descritto il funzionamento del Machine Learning e della sottocategoria del Deep Learning, andando anche analizzare il processo alla base che permette a questi algoritmi di funzionare. Quando si sviluppando algoritmi di Intelligenza Artificiale è necessario comprender e il problema che si vuole andare a risolvere in modo tale da selezionare l’approccio più accurato. In questa sezione non mancano alcuni consigli pratici per poter implementare gli algoritmi in maniera più accurata, per ridurre i costi e per migliorare l’efficienza al fine di ottenere risultati più adatti al problema da risolvere. Nella terza parte, compreso il funzionamento di alcuni tipi di algoritmi di Intelligenza Artificiale si passa all’esplorazione delle applicazioni di questi algoritmi. Sono presenti sia applicazioni robotiche, che sono in grado di interagire con lo spazio circostante, sia applicazioni meramente computazionali che permettono l’analisi di dati e lo svolgimento di determinate previsioni. In questa sezione vengono analizzati i Big Data e vengono approfondite le tematiche legate alla privacy. Oltre a questo viene descritto come dovrebbero essere programmati gli algoritmi per tenere comportamenti etici, ma anche che etica dovrebbero seguire i programmatori al fine di non creare algoritmi pericolosi per gli esseri viventi. Alla fine vengono analizzate le posizioni degli esperti in merito a quale sia il futuro dell’intelligenza artificiale, sia in ambito lavorativo che in un ambito più generale. Nell’ultima parte viene descritto un algoritmo di Intelligenza Artificiale che è in grado di prendere in input 2 immagini, una di contenuto e una di stile, e dare come output il contenuto della prima immagine con lo stile della seconda. 3
1. INTELLIGENZA ARTIFICIALE 1.1 Storia, Turing e i primi sviluppi: L’Intelligenza Artificiale ha un enorme legame con lo sviluppo dei computer, che iniziarono a diffondersi negli anni 40’ con i lavori di McColloch e Pitts. Nel 1943 elaborarono dei modelli matematici formati da neuroni sulla base dell’analisi dei neuroni biologici originali. Questi lavori riuscirono a spiegare approssimativamente l’accensione e lo spegnimento dei neuroni, operando in un sistema binario, e dimostrando che gli stessi possono apprendere e di conseguenza possono modificare le loro azioni nel tempo. Negli anni 50’ Alan Turing1 si chiese se una macchina potesse pensare ed elaborò un test, famoso con il nome di “Test di Turing”, intuendo che per assegnare un livello di intelligenza ad un altro essere umano siamo soliti rivolgergli delle domande, quindi dovremmo fare lo stesso con le macchine. Questo metodo fu accettato perché non prevedeva di definire tutte le caratteristiche di intelligenza ma testava il grado di indistinguibilità di una macchina da un essere umano in una conversazione con un altro essere umano. Il test di Turing originale prevedeva un interrogatore con una tastiera e un monitor diviso in due parti per mostrare le diverse risposte del computer e dell’altro essere umano. Venivano previsti 5 minuti per discutere di qualsiasi argomento deciso dall’interrogatore e alla scadenza si doveva decidere quale delle due chat era stata eseguita con una macchina. Se il computer fosse riuscito ad ingannare il 30% degli interrogatori medi2, facendosi votare come essere umano, allora avrebbe superato il test. Il test non è impeccabile perché se fosse svolto da due persone di diversa intelligenza, una delle due persone esaminate potrebbe ottenere meno del 30% dei voti e quindi fallire il test. Il test certifica solo il fatto che la macchina possa o meno simulare il pensiero umano e non affronta la questione della consapevolezza di sé del computer. Turing quando elaborò il test previse che in circa 50 anni, quindi approssimativamente negli anni 2000, qualche macchina avrebbe superato il test. Ad oggi ancora nessuna macchina ha superato il test. Negli ultimi anni sono state riportate notizie del superamento del test ma analizzando il modo in cui era stato svolto il test e le premesse si è notato un tentativo di porre delle restrizioni alla giuria, andando quindi ad infrangere la regola della totale libertà di giudizio. Un esempio di questo falso superamento è il chatbot Eugene Goostman che nel 2014 ottenne il 33% dei voti, ma essendosi presentato come un tredicenne ucraino che non parlava frequentemente l’inglese ha, probabilmente, indotto alcuni valutatori a giudicare alcune sue risposte in maniera meno critica date le sue difficoltà linguistiche e questo potrebbe aver compromesso la loro valutazione, spiegandone il superamento del test di Turing. Ogni anno viene assegnato il premio Loebner, finanziato da Hugh Loebner, il quale si propone di riconoscere la migliore macchina da conversazione. In questa competizione ci sono alcuni aspetti diversi dal test di Turing originale perché si ha una conversazione di 25 minuti e non è consentito l’accesso alla rete, andando quindi a sfavorire la macchina. Nelle edizioni passate l’andamento delle prestazioni dei computer non è stata crescente ma è stata costituita da alti e bassi. Tuttavia i motivi di questa discontinuità non sono chiari e alcuni ritengono che i 1 Articolo “Computing machinery and intelligence” apparso sulla rivista Mind 2 Ad oggi ancora si discute su chi possa essere considerato un interrogatore medio, anche se molti test vengono fatti da esperti del settore e questo sfavorisce la riuscita del test da parte della macchina 4

motivi possano essere dovuti ad un aumento delle aspettative degli esaminatori, che quindi diventano sempre più esigenti nelle loro valutazioni. Nel 1956 Herb Simon e Allen Newell riuscirono a costruire la prima macchina pensante in grado di risolvere autonomamente alcuni problemi matematici basilari. Quest’anno fu molto importante anche perché John McMarty coniò per la prima volta il termine “Artificial Intelligence” in una conferenza a Dartmouth per descrivere macchine in grado di ragionare e compiere operazioni che necessitano di intelligenza umana. Decise quest’espressione anche per distinguere il suo lavoro da quello dei colleghi che stavano lavorando nel campo della cibernetica. L’obbiettivo della conferenza era quello di espandere l’utilizzo dei computer oltre la mera elaborazione di dati. Da qui si iniziò a diffondere il termine “Intelligenza Artificiale”. Il 1956 fu quindi un anno importante, ma già da tempo gli essere umani pensavano a sistemi in grado di emulare il comportamento umano, infatti nel 1700 il Barone Von Kempelen realizzò il giocatore di scacchi per impressionare l’imperatrice Maria Teresa. Questo giocatore era posizionato di fronte ad una scacchiera e venne presentato come una vera macchina intelligente in grado di giocare in modo autonomo, ma quello che gli spettatori non sapevano era che all’interno della macchina si nascondeva uno scacchista che svolgeva tutto il lavoro, e che quindi era tutto un inganno. In questi anni ci fu un ottimismo crescente e iniziarono i primi dibattiti sulla possibilità dell’Intelligenza Artificiale di eguagliare l’intelligenza umana. Molti ritenevano che l’Intelligenza Artificiale potesse imitare e ricreare perfettamente il funzionamento del cervello umano e questo portò notevoli fondi ed interesse da parte del grande pubblico. Alcuni informatici come Stephen Cook e Richard Karp identificarono classi computazionali che avrebbero dovuto funzionare in linea torica, ma intuirono che avrebbero avuto bisogno di enormi quantità di tempo di elaborazione e di memoria per portarli a compimento. Nel 1966 Joseph Weisenbaum programmò ELIZA che è considerato il primo esemplare di chatbot 3. ELIZA era in grado di fornire risposte prestabilite a seconda di ciò che le veniva chiesto. Anche se agiva in modo limitato, riuscì comunque a farsi credere uno psicologo da diverse persone. Purtroppo negli anni 70’ non si arrivò ai risultati desiderati e questo portò a una brusca interruzione della ricerca dovuta a un interesse sempre minore e alla conseguente diminuzione dei fondi per lo sviluppo della stessa. La difficoltà maggiori furono determinate dai limiti della potenza di calcolo e dalle limitate capacità dei computer, nonché dai pochi dati disponibili in quel periodo. Ci si rese conto che l’ottimismo era stato eccessivo e che per un computer l’elaborazione di una semplice immagine richiedeva molte informazioni. L’interesse dei filosofi portò a una riconsiderazione sul fatto che una macchina potesse davvero pensare. John Searle espose il problema della stanza cinese4 a dimostrazione del fatto che non si può considerare una macchina come pensante perché essa non comprende i simboli che comunica. Searle arrivò alla conclusione che se il test fosse fatto da una persona che non comprende il cinese ma che possiede delle istruzioni come quelle del computer si arriverebbe allo stesso output ma non si potrebbe dire che la persona ha compreso ciò 3 I chatbot sono software che simulano una conversazione tra essere umani 4 La stanza cinese è un test che consiste nel far acquisire ad un computer caratteri cinesi come input in modo da produrre come output altri caratteri cinesi date alcuni istruzioni di un programma 5

che ha scritto e per questo neanche il computer può comprenderlo. La conclusione a cui giunge Searle è che l’esecuzione di un programma per computer non genera comprensione e quindi non può essere considerato intelligente. I computer non hanno comportamenti intelligenti ma simulano solamente dei comportamenti intelligenti. In questi anni vengono comunque studiate diverse tipologie di rappresentazioni di problemi e di soluzioni che permettono di ottenere programmi migliori al fine di raggiungere le prestazioni degli essere umani. Negli anni 80’ si assistette ad una rinascita dell’interesse per l’Intelligenza Artificiale e questo fu dovuto a uno sviluppo più pratico che teorico, in modo tale da affrontare i problemi tramite sistemi esperti in determinati settori. Le discussioni filosofiche continuarono ma in maniera indipendente rispetto ai progressi pratici. Infine ci fu uno sviluppo della robotica che influenzò l’Intelligenza Artificiale in modo tale da creare un’intelligenza reale in grado di percepire il mondo circostante, tramite il processo dell’emboiment 5. Il crescente entusiasmo ritrovato portò a numerosi applicazioni in diverse aree industriali che contribuirono al miglioramento della stessa. In diversi ambiti l’Intelligenza Artificiale riuscì a superare l’uomo. Grazie alle ricerche di Geoffrey Hinton e Yann LeCun è stato ripreso e intensificato lo studio delle reti neurali. L’11 maggio 1997 Deep Blue, progettata da IMB, riuscì a battere Garry Kasparov in una competizione di scacchi. Questi tipi di intelligenza non furono basati tecnologie recenti ma furono dovute alla potenza computazionale disponibile, infatti, Deep Blue era 10 milioni di volte più veloce del computer di Ferranti progettato nel 1951. Il progresso tecnologico è descritto dalla legge di Moore, ideata da Gordon Moore, secondo la quale la velocità e la capacità di memoria dei computer raddoppiano ogni 18 mesi. Quando Moore propose la sua teoria si basò su pochi dati, ma le sue previsioni furono piuttosto adeguate. Si basò sull’aumento del numero dei transistor6 introducibili in un circuito. Ad oggi assistiamo ancora a questo fenomeno che permette un incremento esponenziale delle capacità di calcolo dei computer. La collaborazione dei gruppi ha permesso un notevole sviluppo perché scoperta la soluzione ad un problema, questa va a beneficio anche degli altri gruppi. La legge di Moore può essere anche considerata come una profezia che si autorealizza perché se smettessimo di cercare di migliorare i circuiti attuali il miglioramento non ci sarebbe, quindi è necessaria la volontà di migliorare le tecnologie esistenti e non pensare di aver raggiunto il limite. Lo svantaggio di questa legge deriva da un limite fisco perché non si potranno ridurre i transistor all’infinito. Alpha Go, progettata da Google7, nel 2016 riuscì a sfidare e a battere il campione cinese di Go 8, Lee Sedol. Questa tecnologia riuscì ad apprendere il gioco giocando contro sé stessa e migliorando partita dopo partita. Negli ultimi anni è emerso il metodo degli agenti intelligenti, che consiste nell’imitazione di un cervello tramite l’unione di diversi agenti intelligenti specializzati per singoli problemi. Questo approccio ha portato a notevoli sviluppi come il data mining e il riconoscimento vocale. L’avvento del wireless è stato fondamentale per l’evoluzione di computer perché senza questa tecnologia i computer vengono considerati come singoli, 5 L’embodiment è un processo mediante il quale si dota una rete neurale artificiale di un corpo fisico per permettergli di interagire con gli oggetti circostanti 6 I transistor potevano essere utilizzati come componete economica e affidabile per i calcoli dei computer 7 Progettata in seguito all’acquisizione della startup DeepMind per migliorare i servizi di ricerca delle immagini 8 Il Go è un gioco, originario della Cina per due giocatori, bianco e nero, caratterizzato da regole molto semplici che danno origine ad una strategia sorprendentemente complessa 6

mentre con una rete globale che li collega possono essere considerati come uno solo grande cervello con amplia distribuzione e con un’ampia connettività. Questo è un enorme vantaggio per l’Intelligenza Artificiale rispetto all’intelligenza umana, perché permette un’integrazione della conoscenza. L’andamento storico della ricerca nell’ambito dell’Intelligenza Artificiale ha avuto un andamento ondulatorio con periodi di grande ottimismo e ingenti finanziamenti, e periodi meno floridi nei quali non si riuscirono ad essere all’altezza dei risultati attesi facendo perdere parte dell’interesse per l’argomento e molti dei finanziamenti con la conseguenza di una crescita più lenta e difficile. 1.2 Intelligenza: cos’è, è possibile definirla? Per comprendere l’Intelligenza Artificiale bisogna partire dalla comprensione di che cosa sia l’intelligenza. Nel considerare una qualsiasi definizione di intelligenza bisogna considerare la natura soggettiva della definizione stessa. Ognuno ha una concezione personale di intelligenza dovuta a fattori come le credenze, le esperienze e i valori, che sono mutevoli nel tempo, e sono influenzati dalla cultura. Alla fine del 18° secolo Franz Joseph Gall elaborò la disciplina della frenologia, secondo la quale le differenze volumetriche dei crani determinerebbero le funzioni psichiche degli essere umani. Questi studi furono smentiti successivamente constatando che le dimensioni e la forma del cranio non forniscono informazioni riguardo all’intelligenza di un individuo. Nel 1904 Alfred Binet elaborò un test d’intelligenza per determinare il quoziente intellettivo (QI) degli essere umani. Nell’elaborazione del test prese in considerazione elementi come la memoria, la comprensione, l’attenzione. Per quanto diffusi questi test, sono molto criticati perché si focalizzano solo su determinate capacità e quindi non sull’intelligenza in sé. Secondo Howard Gardner ogni persona è dotata di diversi tipi di intelligenza e quindi non sarebbe corretto dare un’unica definizione di intelligenza. Un’altra questione che riguarda l’intelligenza è la sua origine. Gli studiosi si chiedono se l’intelligenza sia innata o se sia qualcosa che tutti possono apprendere dall’esperienza e dall’educazione. Non c’è una risposta univoca, ed entrambi i fattori devono essere presi in considerazione. Per cercare di rispondere a questa domanda gli studiosi si sono concentrati sui gemelli omozigoti, data la loro particolare struttura genetica. Nel 1966 Cyril Burt studiò 53 coppie di gemelli omozigoti separati alla nascita e constatò che l’educazione aveva un peso molto maggiore nella determinazione dell’intelligenza, tuttavia fu criticato per la validità dei gemelli presi in esame. Nel 1976 John Loehlin prese in esame 850 gemelli e constatò che l’intelligenza è prevalentemente determinata dal patrimonio ereditario, anche se considerò coppie di gemelli cresciuti in contesti simili. Quando si cerca di definire l’intelligenza e come si sviluppa è necessario tenere in considerazione una moltitudine di fattori interni ed esterni ed è estremamente difficile considerarli tutti. È quindi molto importante considerare che ogni individuo considera un atto intelligente in base ai processi del suo pensiero e alle competenze alle quali lui attribuisce un valore. Quindi il concetto di intelligenza non ha significato se è estratto dal contesto sociale di riferimento. 7

Tendendone presenti i limiti, possiamo considerare la definizione di intelligenza della Treccani 9, che la definisce: “Complesso di facoltà psichiche e mentali che consentono all’uomo di pensare, comprendere o spiegare i fatti o le azioni, elaborare modelli astratti della realtà, intendere e farsi intendere dagli altri, giudicare, e lo rendono insieme capace di adattarsi a situazioni nuove e di modificare la situazione stessa quando questa presenta ostacoli all’adattamento; propria dell’uomo, in cui si sviluppa gradualmente a partire dall’infanzia e in cui è accompagnata dalla consapevolezza e dall’autoconsapevolezza, è riconosciuta anche, entro certi limiti agli animali, specialmente mammiferi” Questa definizione è incentrata sull’uomo ma riconosce anche agli animali un certo grado di intelligenza. Per quanto riguarda l’intelligenza degli animali può essere molto difficile considerare intelligenti determinate capacità perché per noi sono prive di significato. Considerando il contesto generale nel quale agiscono gli essere umani e gli animali si potrebbe definire intelligente la capacità di raggiungere determinati obiettivi. Gli obiettivi primari potrebbero essere legati alla sopravvivenza della specie, ma andrebbero comunque considerati obiettivi più immediati legati al piacere. Quando consideriamo l’intelligenza delle macchine dobbiamo domandarci se per definirle intelligenti dobbiamo considerare il raggiungimento degli stessi obiettivi posti per gli esseri viventi. Per le macchine un obiettivo che noi consideriamo primario potrebbe non essere un obiettivo primario. Date le difficoltà nella comprensione di cosa sia l’intelligenza negli esseri viventi, definire l’Intelligenza Artificiale risulta molto difficile e controverso. Rapportando l’Intelligenza Artificiale all’intelligenza umana ci si deve chiedere se sia importante il risultato o la comprensione del procedimento per arrivare a quel risultato. Se si considerasse solamente il risultato finale non si porrebbe importanza al modo con il quale si arriva allo stesso. Considerando un testo si potrebbe giungere alla formulazione di un discorso di senso compiuto prendendo casualmente dei tasti e ciò è completamente differente dall’elaborazione dello stesso seguendo un ragionamento logico e comprendendolo. Nella valutazione dell’operato degli essere umani diamo per scontato che dietro ad un risultato ci siano determinate abilità logiche e di comprensione, ma il modo in cui si raggiunge un risultato diventa rilevante se lo scopo è testare l’intelligenza di una macchina perché non possiamo presupporre che utilizzino le nostre stesse abilità. Utilizzare le capacità umane come confronto è molto limitante, anche perché numerosi compiti svolti dalla macchine sono impossibili da replicare per gli esseri umani. Bisogna quindi partire dal presupposto che ad oggi il cervello umano e i computer non possono funzionare allo stesso modo perché abbiamo una comprensione troppo limitata del funzionamento del cervello per replicarlo. La misurazione dell’Intelligenza Artificiale, quindi, non deve essere vincolata all’intelligenza umana soprattutto se si tratta di affrontare problemi ripetitivi in maniera veloce. Bensì si potrebbe considerare 9 https://treccani.it/vocabolario/intelligenza/ 8

una macchina come intelligente se fosse capace di acquisire determinate abilità a svolgere dei compiti senza però ricevere delle istruzioni precise. Considerando il problema dal punto di vista degli errori possiamo notare come l’essere umano sbagli frequentemente ma possieda anche l’abilità di imparare dai suoi errori. Questo può essere considerato la base del comportamento intelligente. Se invece è il computer a fare un errore e quest’errore è dovuto ad un errore di programmazione, il computer non riuscirà ad imparare dall’errore e non riuscirà a superare il problema, pertanto, non potrà essere considerato intelligente. Molti campi, che ritenevamo eseguibili solamente dall’intelligenza umana, stanno iniziando ad essere svolti con successo anche dall’Intelligenza Artificiale. Essendo campi molto specifici si tende a non considerare queste applicazioni come intelligenti perché svolgono solo quell’attività. A fronte di questo, però, la tecnologia ha la tendenza all’unificazione di tecnologie diverse. Ma perché dovremmo considerare le macchine come intelligenti se intese come insieme mentre se prese singolarmente no? È importante riconoscere specifici aspetti dell’Intelligenza Artificiale anche presi singolarmente perché sarebbe sbagliato considerare un Intelligenza Artificiale programmata per uno scopo preciso non intelligente solamente perché non è in grado di svolgere compiti tipici dell’intelligenza umana. Ci sono una moltitudine di input intorno a noi che non riusciamo a cogliere, come i raggi infrarossi o gli ultrasuoni, solamente perché i nostri sensi sono limitati e se venissimo valutati solo sulla base di non poterli rilevare, allora non dovremmo essere considerati esseri intelligenti. L’Intelligenza Artificiale, come l’intelligenza umana, non ha una definizione univoca e il modo in cui la valutiamo è soggetto a diverse limitazioni dovute all’ambiente nella quale la si valuta e al confronto che facciamo con determinate caratteristiche. 1.3 Le basi dell’Intelligenza Artificiale: Nonostante tutte le limitazioni di una definizione, può essere utile dare una definizione di Intelligenza Artificiale per comprendere meglio l’ambito di applicazione della stessa e i componenti necessari per il suo sviluppo. La Treccani10 definisce l’Intelligenza Artificiale come: “La disciplina che studia se e in che modo si possano riprodurre i processi mentali più complessi mediante l'uso di un computer. Tale ricerca si sviluppa secondo due percorsi complementari: da un lato l'Intelligenza Artificiale cerca di avvicinare il funzionamento dei computer alle capacità dell'intelligenza umana, dall'altro usa le simulazioni informatiche per fare ipotesi sui meccanismi utilizzati dalla mente umana.” In questa definizione si evince quanto siano fondamentali i computer come mezzo per l’applicazione dell’Intelligenza Artificiale. I computer sono macchine elettroniche e digitali perché hanno una tecnologia che sfrutta il movimento degli elettroni, di materiali come il silicio, cioè di materiali conduttori di elettricità, e utilizzano i bit per rappresentare l’informazione. La tendenza dei computer a diventare sempre più potenti in termini di memoria e di velocità di elaborazione sono dovuti alla creazione di tecnologie sempre più miniaturizzate che permettono di inserire maggiori componenti dentro lo stesso. Il computer è composto anche 10 https://www.treccani.it/enciclopedia/intelligenza-artificiale 9

da un hardware che al suo interno contiene dei componenti che si attivano miliardi di volte in un secondo a seconda dell’algoritmo inserito nel programma scritto in un linguaggio informatico, ad esempio C e C++, e poi convertito in bit. Gli elementi all’interno del computer sono organizzati secondo l’architettura elaborata dal John Von Neumann che permette di avere un sistema coerente ed efficace. Le funzioni dell’architettura sono le unità di controllo (CPU), la memoria interna (RAM), e i dispositivi di ingresso e di uscita (IO). La disciplina dell’Intelligenza Artificiale richiede una vasta gamma di competenze e può essere vista come una materia multidisciplinare perché è stata, e continua ad essere influenzata da molte discipline diverse, che la rendono affascinante complessa tramite l’apporto di nuove idee e tecniche. La filosofia ha posto molte questioni interessanti che sono ancora attuali nelle discussioni riguardanti l’Intelligenza Artificiale. Già nel IV secolo a.C. Aristotele tentò di formulare un insieme preciso di leggi rappresentative della mente razionale umana, e non fu l’unico. Molti secoli dopo, Hobbes ipotizzò che il ragionamento avesse delle affinità con il calcolo numerico. Ci furono anche persone come Leonardo da Vinci, che nel 1500 progettò un calcolatore meccanico11, e Leibnitz che costruì un calcolatore per eseguire operazioni su concetti, anche se era un prototipo molto limitato. Si instaurò, quindi, il presupposto che alla base della parte formale e razionale della mente ci fosse un insieme di regole che possano descriverlo. Nel periodi successivi si instaurarono idee come il dualismo della mente e, in contrapposizione a questo, il materialismo. Con l’empirismo si cercò la fonte della conoscenza. Carnap elaborò la teoria del positivismo logico, secondo la quale tutta la conoscenza può essere espressa dalle percezioni sensoriali, e quindi da enunciati osservabili. Lo stesso Carnap, con l’aiuto di Hempel elaborò la teoria della conferma per spiegare come si acquisisce conoscenza dall’esperienza. La filosofia infine pone la questione del collegamento tra la conoscenza e l’azione che è fondamentale nell’applicazione dell’Intelligenza Artificiale. La filosofia è alla base dei concetti riguardanti l’Intelligenza Artificiale, ma la matematica ha dato una formalizzazione in termini di logica, computazione e probabilità. Boole, nel 19° secolo, ha elaborato i principi della logica booleana e in seguito Frege la integrò agli oggetti, andando a creare la logica di primo ordine che oggi permette di rappresentare la conoscenza. Quando si considera il primo algoritmo non banale si fa rifermento a quello di Euclide per calcolare il massimo comun denominatore. Nel 1900 Hilbert stilò una lista di 23 problemi, ancora attuali, tra cui il problema della concreta possibilità di scrivere un algoritmo per decretare il grado di verità di qualsiasi proporzione logica dei numeri naturali, cioè l’Entscheidungsproblem. Nel 1930 Gödel elaborò l’esistenza di una procedura per dimostrare ogni proporzione vera nella logica di primo ordine, ma che questa non poteva esprimere il principio di induzione matematica necessario per definire i numeri naturali. Quindi propose il teorema di incompletezza nel quale stabilisce che in ogni linguaggio in grado di descrivere le proprietà dei numeri naturali esistono delle proposizioni vere indecidibili, e quindi esistono numeri incomputabili. Turing partì da questo presupposto per definire quali sono le funzioni computabili. Si ha l’intrattabilità di un problema quando il tempo di risoluzione cresce esponenzialmente con le dimensioni dell’istanza. Nel 1971 Cook e Karp proposero la teoria della NP-completezza per riconoscere quando un problema è intrattabile. Sono riusciti a dimostrare che le classi di problemi che rientrano nella 11 Leonardo da Vinci non riuscì a costruire il suo progetto, ma recentemente è stato costruito e si è dimostrato corretto 10
categoria dei problemi NP-completi sono probabilmente intrattabili anche aumentando le capacità computazionali. Infine, nella matematica, il contributo della probabilità è stato fondamentale. Il primo a formulare i termini di possibili risultati fu Cardano. Bayes propose una regola per aggiornare i valori di probabilità in base ai dati raccolti di volta in volta in modo da porre le basi per il ragionamento in condizioni di incertezza. L’economia, iniziata ad essere considerata una vera scienza grazie al contributo di Adam Smith, pose le sue basi su sistemi economici considerati come agenti tesi a massimizzare il proprio benessere economico. Quindi l’economia dovrebbe portare le persone a prendere decisioni razionali in modo da massimizzare la propria utilità portando a risultati graditi. Fu elaborata la teoria delle decisioni, fondendo i concetti di probabilità e computazione, in modo da aiutare nelle decisioni incerte. Importante fu la teoria dei giochi, nella quale le azioni di un giocatore possono influenzare l’utilità degli altri giocatori, e quindi si devono considerare scelte esterne per massimizzare la propria utilità. Nel 1957 Bellman formulò una classe di problemi basati sulle decisioni, detti processi decisionali di Markov. L’economia è stata molto utile nella definizione dell’agente intelligente e nella complessità dell’attività di prendere decisioni razionali quando si hanno termini di incertezza. Simon vinse il premio Nobel per l’economia per i modelli economici basati sulla soddisfazione che non prevedevano una decisione sempre ottimale, ma che erano più rappresentativi della realtà. Le neuroscienze sono una disciplina fondamentale per l’Intelligenza Artificiale dato che quest’ultima si è iniziata a sviluppare cercando di replicare il funzionamento del cervello umano. Il cervello fu inteso come sede della coscienza solo nel 18° secolo. Nel 1861 Boca, con gli studi sulle afasie, dimostrò l’esistenza di aree specifiche del cervello responsabili di precise funzioni cognitive. Orami l’idea che il cervello fosse formato da neuroni era stata accettata e nel 1873 Gori sviluppò una tecnica per permettere di visualizzare i singoli neuroni. Ad oggi ancora non siamo riusciti a comprendere il meccanismo che permette a determinate aree di prendere il controllo di determinate funzioni in caso di danni alle aree che solitamente svolgono quel compito. In questo campo sono fondamentali tecnologie innovative come l’elettroencefalografo (EEG) e la risonanza magnetica funzionale (fMRI) che permettono di avere immagini dell’attività celebrare in un determinato momento. Non siamo comunque vicini a comprendere come si sviluppi un processo cognitivo. Ad oggi ci sono chip di computer che riescono ad essere molto più rapidi dei neuroni ma non riescono, a differenza dei neuroni, ad essere attivati simultaneamente. Le origini della psicologia risalgono a quando Hermann von Helmholtz applicò il metodo scientifico alla visione umana. Nel 1879 Wundt fece i primi esperimenti controllati nei quali si dovevano seguire determinati attività percettive mentre le persone ispezionate si concentravano sui processi mentali. Watson, con il movimento behaviorista, rifiutò queste teorie sostenendo che i dati introspettivi non erano affidabili. James diede un importante contributo sviluppando la visione del cervello tramite la psicologia cognitiva. Secondo Craik i requisiti fondamentali per un agente che si basa sulla coscienza sono che lo stimolo deve avere una rappresentazione interna, la quale deve essere manipolata da determinati processi cognitivi in modo da ottenere rappresentazioni interne, che, infine, devono essere trasformate in azioni. I modelli computazionali si sono basati sulla scienza cognitiva. Secondo Anderson una teoria cognitiva può essere considerata al pari di un 11
programma per computer visto che entrambe devono descrivere in modo dettagliato un meccanismo di elaborazione dell’informazione. L’ingegneria informatica è fondamentale nel fornire gli artefatti, cioè i computer, che permettono lo sviluppo dell’Intelligenza Artificiale. Il modello di computer elettronico digitale si diffuse durante la Seconda guerra mondiale in maniera indipendente grazie a Turing, Zuse e Atanasoff. Da allora la potenza computazionale è cresciuta enormemente. I software sono stati anch’essi fondamentali per lo sviluppo dell’Intelligenza Artificiale. Lo sviluppo della stessa ha però portato a notevoli sviluppi anche in altre aree dell’informatica generale tra cui la gestione automatica della memoria. La cibernetica ha esempi molto lontani nel tempo, perché già nel 250 a.C. Ctesibio di Alessandria inventò un orologio ad acqua con un regolatore che manteneva il flusso d’acqua costante in maniera autonoma. Nel 18° secolo Warr elaborò i primi sistemi di regolazione dei motori a vapore. Winer elaborò la teoria del controllo in contrapposizione alla teoria behaviorista. La moderna teoria del controllo ha lo scopo della massimizzazione della funzione obiettivo. L’Intelligenza Artificiale è nata cercando di superare i limiti matematici tipici della teoria del controllo. La linguistica è nata negli stessi anni dell’Intelligenza Artificiale ed entrambe si sono influenzate. Chomsky dimostrò che la teoria behaviorista non considerava la creatività del linguaggio e riuscì a creare una teoria abbastanza solida da poter essere programmata. La complessità della linguistica inizialmente era sottovalutata data la difficoltà della comprensione stessa del linguaggio. Questa disciplina ha permesso la nascita e lo sviluppo della linguistica computazionale. Compresi gli elementi e le discipline che stanno alla base dell’Intelligenza Artificiale si possono fare delle distinzione riguardanti la stessa e il modo nel viene concepita. Si può dividere l’Intelligenza Artificiale in due grandi categorie. Si parla di Intelligenza Artificiale debole quando si hanno macchine che cercano di emulare azioni tipicamente intelligenti e ripetitive con una base logica abbastanza semplice. È il tipico approccio utilizzato per il problem solving tramite l’elaborazione di diverse soluzioni, a partire da una base di dati, e si definisce la soluzione più razionale in base alle regole impartite dal programma. Questo tipo di macchine non possono apprendere autonomamente e quindi non riescono ad auto-migliorarsi ed è necessario il costante monitoraggio umano. Viene anche definita l’intelligenza del “come se” perché agisce come se pensasse ma senza capacità di capire ciò che fa, con lo scopo di semplificare e velocizzare processi che se fossero svolti dagli essere umani sarebbe difficile realizzare con la stessa efficienza dato che l’Intelligenza Artificiale debole consente di verificare le ipotesi in maniera estremamente precisa. In contrapposizione all’Intelligenza Artificiale debole si ha l’Intelligenza Artificiale forte. Questo tipo di Intelligenza Artificiale non si limita alla mera emulazione delle azioni umani ma ha l’obiettivo di compiere azioni in modo tale da apprendere da sola nuove informazioni e migliorarsi. L’intervento dell’uomo è iniziale e fornisce alcune regole e procedure alla macchina che poi continua l’applicazione in maniera autonoma. Questo tipo di intelligenza riesce quindi a comprendere le azioni che svolge e quindi non è uno mero strumento da utilizzare. Ha l’obiettivo di riprodurre e apprendere le competenze degli esperti di determinati settori in 12
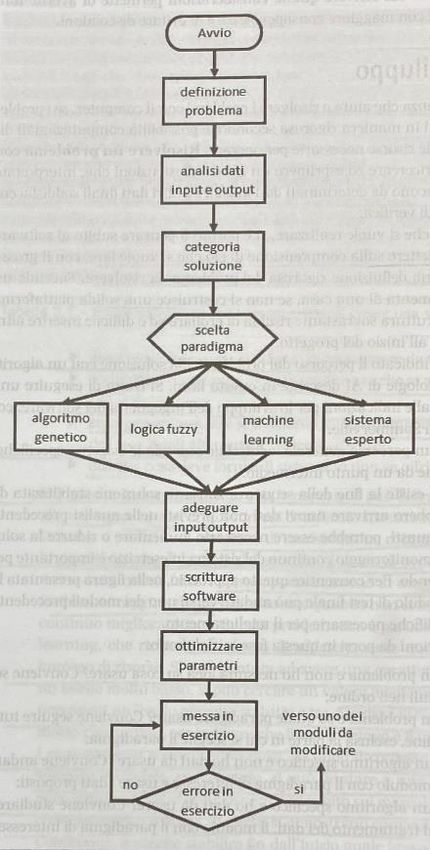
modo tale da fornire risposte immediate a determinati problemi. Ad oggi però l’Intelligenza Artificiale forte è difficilmente applicabile12. 1.4 Paradigmi dell’Intelligenza Artificiale: Al fine del funzionamento dell’Intelligenza Artificiale è determinate la scelta dell’algoritmo che sta alla base della stessa. È sempre necessario un algoritmo per far funzionare i dati che vengono inseriti nel programma. Un algoritmo richiede sempre una serie di passaggi per risolvere un problema che viene scomposto in calcoli elementari. Bisogna porsi delle domande prima di iniziare. Si deve comprendere cosa si vuole creare, le motivazioni alla base, il come si deve fare, l’arco temporale e quali sono i costi stimati. Si può quindi optare per una soluzione con un livello di utilità non massimo se questo permette una maggiore fattibilità del progetto. Stabilire preliminarmente linee guida per la risoluzione di problemi si può rilevare molto utile in modo da sapere a priori dove ci si sta dirigendo. L’informatica permette di risolvere problemi con il computer date regole e risorse necessarie ad operare. Risolvere un problema significa, dati degli input, arrivare ad un output soddisfacendo un criterio di verifica. È molto opportuno comprendere ciò che si vuole realizzare e questo lo si può fare solo definendo nel dettaglio il problema da risolvere. Durante lo svolgimento del processo è comunque necessaria una supervisione attiva perché il sopraggiungimento di dati non previsti potrebbe interferire con il raggiungimento dell’output. La figura 1 mostra, in forma schematica, i passaggi necessari per la risoluzione del problema. Questo schema non deve essere applicato in maniera rigorosa ma deve essere adattato al caso specifico. Figura 1 - Sequenza di operazioni per realizzare un algoritmo basato sull’Intelligenza Artificiale. Fonte: libro Algoritmi per l'Intelligenza Artificiale di Roberto Marmo 12 https://www.intelligenzaartificiale.it/intelligenza-artificiale-forte-e-debole/ 13
La definizione del problema è quindi il primo passo fondamentale da fare e deve essere svolto dall’uomo che avrà poi il supporto dell’Intelligenza Artificiale. Questa fase prevede l’individuazione dei dati in ingresso, la scelta degli obiettivi da raggiungere e la relazione esistente tra i dati e i risultati. Bisogna sempre verificare se il problema è ben definito perché un’errata definizione comprometterebbe i risultati successivi. Se i passaggi preliminari sono corretti si può passare alla scelta dei dati da inserire. I dati sono fondamentali ma è opportuno inserire solo quelli necessari in modo tale da non sovraccaricare la macchina, e si devono considerare anche i tempi e i costi che una raccolta di dati può richiedere. Successivamente si va a scegliere la tipologia di agente che si intende utilizzare. Si può avere un approccio orientato alla ricerca, ottimale nel caso di applicazioni matematiche, orientato all’apprendimento, ottimale nel caso dell’utilizzo di esperienze passate, orientato alla pianificazione, ottimale con una sequenzialità delle operazioni, e orientato al ragionamento automatico. In base all’approccio adottato si deve definire il paradigma, che deve essere dipendete dalla scelta precedente perché ogni paradigma ha vantaggi e svantaggi che è consigliabile sfruttare a seconda del caso concreto. Il primo paradigma tra cui scegliere è l’evolutionary algorithm che si basa su metodi euristici di ricerca e sul principio di selezione naturale. Esiste poi, l’expert system che cerca di riprodurre le preazioni degli esperti in un determinato campo di attività. Un altro paradigma utilizzabile è il fuzzy logic che è una funzione logica che permette l’attribuzione di un grado di verità, espresso in percentuale, a ogni proposizione. Infine, un altro paradigma che si può utilizzare è il macchine learning che permette di acquisire in maniera automatica nuove conoscenze. Definito il paradigma più adatto al caso concreto si devono adattare gli input e gli output allo stesso. Si può poi iniziare la programmazione tramite il linguaggio di programmazione cercando di ottimizzare i parametri che regolano il funzionamento del programma al fine di ottenere il risultato migliore. Si procede poi con l’applicazione concreta del programma per verificare la sua validità e nel caso si riscontrassero degli errori si cerca di risolversi fino a quando l’esercizio non avrà successo. Man mano che si raccoglieranno altri dati si continuerà a verificarli in modo da permettere all’Intelligenza Artificiale di apprendere e si ha quindi un apprendimento continuo. Come abbiamo visto in precedenza la definizione dell’agente è un passo fondamentale per la definizione di un sistema, per questo motivo è importante comprendere i vari tipi e le caratteristiche. L’agente definisce l’Intelligenza Artificiale che è inserita in un determinato ambiente, che viene percepito tramite sensori, ed è dotata dell’autonomia necessaria per affrontarlo in maniera autonoma tramite attuatori. L’agente deve essere considerato razionale, cioè deve riuscire a raggiungere gli scopi prefissati sulla base dei dati disponibili e deve svolgere attività considerate complesse. Deve inoltre massimizzare il valore atteso. La razionalità perfetta è difficilmente raggiungibile dati i limiti computazionali. Il compito dell’Intelligenza Artificiale è quello di andare a creare il programma agente in modo tale da metterlo in relazione con le percezioni e le azioni. Nel tempo sono stati sviluppati tipi di agenti diversi con caratteristiche e capacità via via più sviluppate e complesse. Inizialmente venivano utilizzati agenti con riflessi semplici che era in grado di rispondere solamente agli stimoli ricevuti senza però avere memoria degli stessi. Si è passati poi ad agenti con riflessi che si basa, oltre alla percezione attuale, anche sulla precedente sequenza percettiva in modo tale da aggiornarsi nel tempo permettendo all’agente di modificare il modello. Successivamente l’agente basato su obiettivi ha 14
dato la possibilità di conseguire la pianificazione da svolgere in base alla combinazione dello stato interno e dell’obiettivo prefissato ma considerando anche gli effetti di tale azioni in modo da garantire una certa flessibilità. L’agente basato sull’utilità esprime il grado di soddisfazione per un determinato risultato andando a selezionare il migliore e privilegiarlo. Infine si è arrivati all’agente che apprende in modo tale da migliorarsi in maniera automatica. Quest’ultimo approccio è il più utilizzato data la difficoltà nella programmazione manuale degli agenti. Nell’Intelligenza Artificiale oltre agli agenti si posso avere i sistemi esperti, che a differenza degli agenti non sono associati ad un ambiente, e cercano di emulare il comportamento di esperti umani, in determinati campi, sulla base di un determinato numero di dati e regole in modo tale da formulare un’ipotesi e fornire una soluzione razionale. I sistemi esperti cercano di emulare il comportamento del cervello umano in determinate situazioni tramite l’applicazione di determinate regole, dettate dagli stessi esperti del settore in questione, quando si introducono nuove informazioni. Uno dei primi sistemi esperti era chiamato MYCIN e consisteva in un sistema medico di infezioni del sangue che conteneva oltre 450 regole dettate da medici esperti in base alle valutazioni pratiche che utilizzano nella valutazione delle infezioni del sangue. Le regole seguono l’espressione IF (condizione) THEN (conclusione), che premette di trarre una conclusione data una condizione iniziale. Le condizioni possono coesistere tra loro e devono essere attivate tutte per arrivare ad una determinata conclusione. Nel caso si verificassero dei conflitti tra le regole si deve stabilire, a priori, una risoluzione dei conflitti e quindi devono essere stabilite delle priorità. Si possono applicare criteri differenti che possono essere la regola della priorità più elevata, le condizioni a priorità più elevata, la prossimità temporale, la maggiore specificità e la limitazione in base al contesto. Molti sistemi esperti prevedono la presenza di regole che dipendono l’una dall’altra e quindi soddisfatta una condizione si riesce ad accedere alla regola successiva. Questo comporta maggiore precisione ma anche maggiore complessità. I sistemi esperti possono lavorare con una concatenazione in avanti, cioè, generate un determinato numero di regole, verranno innescati ulteriori eventi che attiveranno determinate regole per raggiungere una conclusione definitiva. Con questo metodo si cerca di scoprire il più possibile partendo da una determinata base di dati. Il metodo opposto a questo è la concatenazione all’indietro, che consiste nel ricercare determinate regole per scoprire quali dati si sono verificati per arrivare a quella determinata conclusione. Questo tipo è utile alla verifica del sistema conoscendo a priori la conclusione alla quale giungere. I vantaggi dei sistemi esperti sono la facilità di programmazione e le regole sono aggiornabili a seconda dei nuovi dati disponibili. Poi uno stesso sistema esperto potrebbe essere usato in differenti campi a seconda dei dati disponibili. I sistemi esperti possono hanno un’elevata velocità di risposta. Una volta che un sistema raggiunge determinate conclusioni si possono ricompensare le regole aumentando le probabilità di essere selezionate successivamente. Esistono poi una serie di svantaggi. Può essere abbastanza difficile raccogliere le regole necessarie perché è difficile per gli esperti descrivere in modo semplificato i procedimenti che svolgono e ogni esperto potrebbe agire in modo diverso per arrivare alla medesima conclusione, e non sempre è possibile fare una media dei risultati. Un ulteriore problema potrebbe essere l’esplosione combinatoria che implicherebbe un sistema troppo grande che perderebbe la velocità di esecuzione, dato che in linea teorica deve considerare tutte le regole che si potrebbero verificare. Anche il 15
debug può risultare complicato perché le regole rischiano di invalidarsi a vicenda e senza raggiungere una conclusione. I sistemi esperti sono solo un tipo di Intelligenza Artificiale. I sistemi fuzzy non danno per scontato, come i sistemi esperti, che una determinata condizione esista oppure no, e contemplano la possibilità che una conclusione sia solo parzialmente vera in una determinata percentuale (%). Il primo passo da svolgere è la fuzzificazione, che consiste nel pendere una dato e sfumarlo per poi inserirlo nel sistema. Si deve quindi avere presente il rapporto esistente tra il valore reale e il valore fuzzy. Si procede poi all’applicazione delle regole sul valore fino ad ottenere un valore fuzzy. Come per i sistemi esperti, possono coesistere più condizioni e più regole contemporaneamente. Possono essere previsti diversi operatori booleani (AND, OR e NOT). Spesso si ha il caso in cui si attivano più regole contemporaneamente ed ognuna determina un valore differente e questi dovranno essere uniti per formare un’unica conclusione coerente con il mondo esterno. I metodi più utilizzati sono la media, la media ponderata e il center of gravity13 (COG). La defuzzificazione consiste nel considerare di meno una regola che non si è attivata recentemente. Per ottenere un sistema fuzzy ottimale è necessario procedere per tentativi ed errori, imparando da essi. Questo sistema permette di seguire tutte le regole per coprire tutte le eventualità previste dal sistema. Il problem solving è un paradigma dell’Intelligenza Artificiale utilizzato per risolvere determinati problemi umani in cui sappiamo dove vogliamo arrivare e il punto da cui partiamo e vogliamo capire il procedimento da seguire. È utile perché può essere molto più veloce di un essere umano. Si possono avere diversi modi per giungere alla soluzione migliore. Un primo approccio è la ricerca breadth-first nel quale si analizzano tutte le soluzioni possibili, operando un confronto tra le stesse, in modo tale da scegliere la soluzione migliore adatta al caso specifico. Il problema di quest’approccio è che quando le soluzioni sono tante si rischia di sovraccaricare la macchina in termini di memoria e avere costi troppo elevati. Un altro approccio è la ricerca depth-first nel quale si verifica un percorso completo dall’inizio alla fine e si compie un confronto immediato con il percorso precedente in modo da scegliere subito il migliore dei due e in un successivo confronto andare a confrontare il percorso migliore trovato con il nuovo percorso. Questo andrà a ottimizzare la memoria perché una volta scartato un percorso questo sarà eliminato. Il problema di quest’approccio è che una scelta iniziale non ottimale potrebbe compromettere il risultato finale e potrebbe passare molto tempo prima di avere una soluzione. Poi si può utilizzare il metodo depth-limited nel quale si determina un limite di profondità in modo da limitare la ricerca depth-first. In questo metodo si deve applicare del buon senso e una certa conoscenza del problema. Infine si può utilizzare la ricerca bidirezionale che prevede di dividere la ricerca in due parti. La prima parte è una ricerca normale dal punto di partenza fino alla fine, mentre la seconda parte prevede di partire dalla fine e andare a ritroso. Questo metodo permette di risparmiare tempo nel trovare una soluzione ma richiede una quantità significativa di memoria. È utile una conoscenza del problema a priori. Un problema di questo tipo di ricerche è lo spreco di tempo dovuto alla revisione continua dei percorsi già toccati e la conseguente capacità di memoria che produce costi maggiori. Confrontare i dati precedenti è necessario in 13 Nel COG ogni valore percentuale si moltiplica per un coefficiente ad esso associato e le risposte sono addizionate e divise per il valore di tutti i valori ponderati e sommati. 16
Puoi anche leggere