SQL Server 2017 su Linux High Availability - Danilo Dominici #SQLSAT777 - SQLSaturday
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Danilo Dominici
#SQLSAT777
SQL Server 2017 su Linux
High Availability
Chi sono • Consulente freelance, Trainer, Speaker, Autore • Mentor @ SolidQ • Dev/DBA @ Università Politecnica delle Marche • Microsoft Certified Trainer dal 2000 • Microsoft Data Platform MVP dal 2014 • Co-leader del PASS Global Italian Virtual Chapter #SQLSAT777
Organizers
GetLatestVersion.it
#SQLSAT777
Sponsors
ApexSQL
#SQLSAT777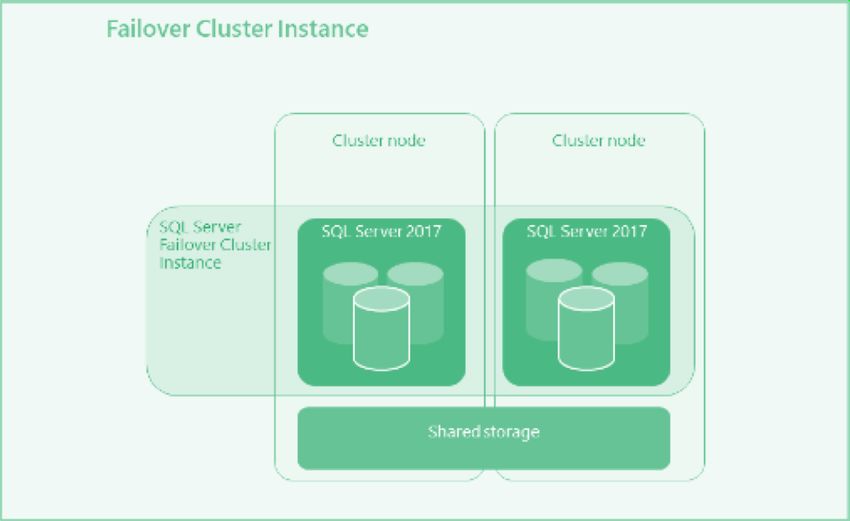
Agenda Riassunto delle puntate precedenti Perchè High Availability e Disaster recovery Panoramica sulle soluzioni disponibili in SQL 2017 Linux Log shipping AlwaysOn Failover Cluster e Availability Groups Azure Kubernetes Services (AKS) #SQLSAT777

Riassunto
delle puntate
precedenti…
#SQLSAT777
Installare SQL Server su Linux Ubuntu 16.04LTS / RHEL 7.3+ / SLES 12 SP2 Trick per installare su Ubuntu 18.04LTS: https://bit.ly/2TpaKJ9 Processore x64 almeno 2 GHz e 2 core +2GB RAM File system XFS o EXT4 6GB spazio disco #SQLSAT777

Installare SQL Server su Linux Installare le chiavi GPG del repository pubblico wget -qO- https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add – Registrare il repository pubblico sudo add-apt-repository "$(wget -qO- https://packages.microsoft.com/config/ubuntu/16.04/mssql-server-2017.list)" Installare e configurare SQL Server (engine) sudo apt-get update sudo apt-get install -y mssql-server sudo /opt/mssql/bin/mssql-conf setup #SQLSAT777

Alta affidabilità
e Disaster recovery
#SQLSAT777
Approccio agli scenari di HA/DR Ogni installazione di SQL Server necessita di una forma di HA/DR Non esiste una soluzione che vada bene per tutti Quando si parla di HA/DR occorre iniziare a discuterne partendo dai requisiti, NON dalle tecnologie #SQLSAT777
Quali sono i requisiti ? SLA fissati dall’azienda Recovery Point Objective – quanti dati posso perdere? Recovery Time Objective – quanto tempo ho per il ripristino dell’operatività? Costo della soluzione Complessità della soluzione Vincoli imposti dall’architettura esistente/dal management #SQLSAT777
HA/DR in SQL Server
Backup/Restore Failover cluster Availability Groups
• Protezione contro la • Protezione a livello di • Protezione a livello di
corruzione o la istanza database
cancellazione accidentale • Failover automatico • RTO in pochi secondi
dei dati
• Disaster Recovery • RTO variabile da alcuni • Nessuna perdita di dati
secondi a diversi minuti (sincrono)
• RTO variabile da alcuni
minuti a diverse ore • Sopporta guasti sia a • Nessun downtime per
livello del S.O. che di manutenzione del
SQL Server server
Log Shipping
• I secondari possono
• Disaster recovery essere usati per ripartire
• Automatizza il ciclo di Basic Availability Groups
• AG tra due repliche il carico o per i backup
backup/restore tra due
server • Sostituisce il database • Failover geografico su
• La replica può essere in secondari remoti
mirroring
standby o in sola letturaBackup & Restore
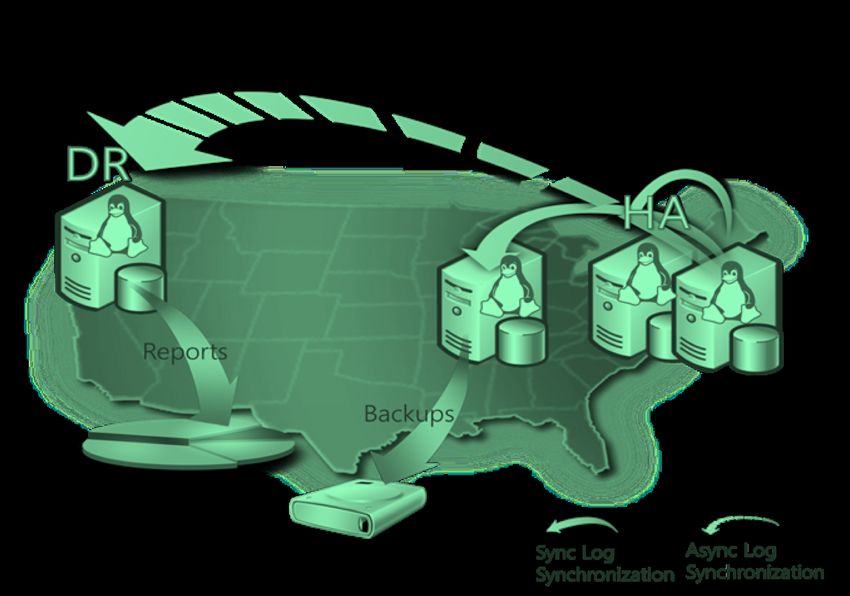
#SQLSAT777Backup/Restore Protezione a livello di database Soluzione di disaster recovery Dettata dal modello di recovery: Simple, Full, Bulk-Logged Tre tipi principali di backup: Full, Differenziale, Log Compressione, checksum, mirrored backups Cross-platform Windows-Linux #SQLSAT777
Backup/Restore E se ripristinassimo il database in un server secondario ? Una licenza passiva ogni licenza attiva di SQL Server Serve per prima cosa a verificare che il ripristino di un backup funzioni !!! Si può utilizzare per effettuare il DBCC CHECKDB su una copia del database di produzione (però mi serve una seconda licenza) #SQLSAT777
Log Shipping
#SQLSAT777Log shipping Protezione a livello di database Soluzione di disaster recovery Automazione del processo di backup/restore dei transaction logs su un server secondario Richiede SAMBA/CIFS I database devono essere in FULL recovery model Failover manuale #SQLSAT777
Log shipping Permette di avere più copie in location diverse Potenzialmente potrei perdere il contenuto della coda del transaction log del primario, non ancora estratta, in caso di crash del server Cross-platform Windows-Linux #SQLSAT777
Demo #SQLSAT777
AlwaysOn
#SQLSAT777AlwaysOn
Failover cluster instance Availability Groups
Protezione a livello di istanza Protezione a livello di database
Dischi condivisi (SAN/SMB) Dischi locali (DAS)
Il failover può impiegare diversi Il failover impiega pochi secondi
minuti – dipende dal carico Fino a 8 nodi secondari
Fino a 8 nodi secondari I nodi secondari possono essere
I nodi secondari sono passivi attivi in sola lettura
#SQLSAT777Failover cluster Protezione a livello di istanza Soluzione di High Availability Riaccende il servizio SQL Server in caso di guasto del nodo principale Disponibile su RHEL e SLES tramite Pacemaker #SQLSAT777
Come cambia il cluster da Windows a Linux
Windows Failover Cluster svc Pacemaker
Integrazione forte con SQL Integrazione debole con SQL
Server Server
SQL gestito come risorsa SQL trattato come istanza
cluster singola
SQL Server non sa di essere in
Accesso alle informazioni del
cluster
cluster e gestione del failover
No gestione del failover
da SQL Server
No info sul cluster
#SQLSAT777Configurare un Failover cluster su Linux Setup del sistema operativo Installazione di SQL Server su ogni nodo Configurazione dei dischi condivisi e spostamento dei database di sistema Installazione e configurazione di Pacemaker su ogni nodo Creazione del cluster #SQLSAT777
Scenari di utilizzo Mission-critical HADR utilizzando Always On Availability Groups Disaster recovery geografico #SQLSAT777
Scenari di utilizzo Mission-critical HADR utilizzando Always On Availability Groups Bilanciamento del carico di lavoro per maggiori performance e scalabilità #SQLSAT777
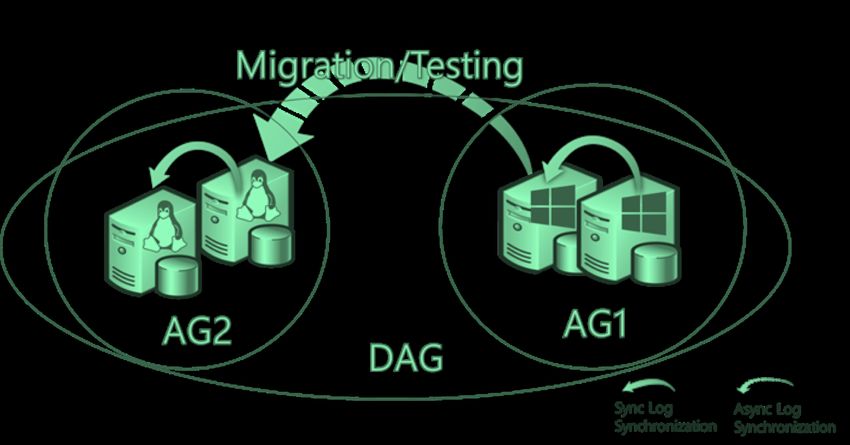
Scenari di utilizzo Migrazione/test utilizzando AlwaysOn Availability Groups Sincronizzazione cross-platform #SQLSAT777
Azure
Kubernetes Service
(AKS)
#SQLSAT777Che cos’è Kubernetes E’ un sistema di orchestrazione di containers sviluppato da Google (nome in codice “Borg”) e scritto in Go Installato come cluster con un nodo master e container multipli I containers vengono creati all’interno di “pods” in esecuzione sui nodi Sicurezza gestita a livello di pods Distribuzione/gestione attraverso il client kubectl #SQLSAT777
Azure Kubernetes Service Servizio specifico per semplificare la creazione e gestione di cluster Kubernetes in Azure I cluster possono essere creati con una riga di codice (letteralmente) Le applicazioni possono essere distribuite tramite un singolo file in formato YAML Gestito attraverso Azure-CLI/powershell e kubectl #SQLSAT777
Creare un istanza SQL Server in Kubernetes
Creazione di un nuovo Resource Group
az group create --name myAKSClusterRG --location
westeurope
{
"id": "/subscriptions/xxxxxxxxxxxxx/resourceGroups/myAKSClusterRG”,
"location": "westeurope",
"managedBy": null,
"name": "myAKSClusterRG",
"properties": { "provisioningState": "Succeeded" },
"tags": null
}
#SQLSAT777Creare un istanza SQL Server in Kubernetes Creazione di un nuovo cluster AKS az aks create -g MyAKSClusterRG -n MyAKSCluster --node- count 3 --enable-addons monitoring --generate-ssh-keys Installazione del client kubectl per la gestione di Kubernetes az aks install-cli #SQLSAT777
Creare un istanza SQL Server in Kubernetes Download credenziali accesso al cluster Kubernetes e configurazione kubectl az aks get-credentials --resource-group myAKSClusterRG -- name MyAKSCluster #SQLSAT777
Creare un istanza SQL Server in Kubernetes Verifica connessione al cluster AKS kubectl get nodes NAME STATUS ROLES AGE VERSION aks-nodepool1-40277451-0 Ready agent 29m v1.9.9 aks-nodepool1-40277451-1 Ready agent 29m v1.9.9 aks-nodepool1-40277451-2 Ready agent 29m v1.9.9 #SQLSAT777
Creare un istanza SQL Server in Kubernetes Creazione della password per l'utente 'sa' e memorizzazione in modo sicuro kubectl create secret generic mssql --from- literal=SA_PASSWORD="P@ssw0rd!" #SQLSAT777
Creare un istanza SQL Server in Kubernetes Creazione del volume persistente dove saranno memorizzati i databases kubectl apply -f persistentstorage.yml #SQLSAT777
Creare un istanza SQL Server in Kubernetes
Controllo che il volume sia stato creato correttamente
kubectl describe pvc mssql-data
Name: mssql-data
Namespace: default
StorageClass: azure-disk
Status: Bound
Volume: pvc-cbcaf263-ef20-11e8-95dc-56fbe1d41779
Labels:
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"PersistentVolumeClaim","metadata":{"annotations":{"volume.beta.kubernetes.io/storage-class":"azure-disk"},"name...
pv.kubernetes.io/bind-completed: yes
pv.kubernetes.io/bound-by-controller: yes
volume.beta.kubernetes.io/storage-class: azure-disk
volume.beta.kubernetes.io/storage-provisioner: kubernetes.io/azure-disk
Finalizers: []
Capacity: 8Gi
Access Modes: RWO
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ProvisioningSucceeded 22s persistentvolume-controller Successfully provisioned volume pvc-cbcaf263-ef20-11e8-95dc-56fbe1d41779 using
kubernetes.io/azure-disk
Mounted By:
#SQLSAT777Creare un istanza SQL Server in Kubernetes Creazione del’istanza SQL Server kubectl create -f sqlserver.yml Controllo che l’istanza sia stata creata correttamente kubectl get services #SQLSAT777
SQL Server 2017+AKS à HA/DR senza cluster
Node Node Node
Pod Pod
Load Balancer
SQL Server Service SQL Server
Kubernetes
User
Pod
SQL Server
Persistent Volume Storage
#SQLSAT777Demo #SQLSAT777
Novità in SQL Server 2019
AlwaysOn Pod Pod
Operator Load balancer
Pod Pod Pod
SQL Server SQL Server SQL Server
AG
primary
secondary primary
secondary secondary
AG agent AG agent AG agent
Pod
Load balancer
#SQLSAT777Novità in SQL Server 2019 Big Data clusters #SQLSAT777
Riepilogando SQL Server 2017 su Linux… è SQL Server Stessa affidabilità, stessa scalabilità, stesse prestazioni Le tecnologie per l’HA/DR sono principalmente le stesse della versione per Windows e cross-platform Su Azure possiamo utilizzare Kubernetes per creare cluster SQL Server senza l’onere del servizio cluster #SQLSAT777
Thanks!
Ricordatevi i feedback !!!
#SQLSAT777Puoi anche leggere