Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite - Red Hat Cluster Suite per Red Hat Enterprise Linux 5 Edizione 3 Landmann
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite Red Hat Cluster Suite per Red Hat Enterprise Linux 5 Edizione 3 Landmann
Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite Red Hat Cluster Suite per Red Hat Enterprise Linux 5 Edizione 3 Landmann rlandmann@redhat.co m
Nota Legale Copyright © 2009 Red Hat, Inc. T his document is licensed by Red Hat under the Creative Commons Attribution-ShareAlike 3.0 Unported License. If you distribute this document, or a modified version of it, you must provide attribution to Red Hat, Inc. and provide a link to the original. If the document is modified, all Red Hat trademarks must be removed. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, MetaMatrix, Fedora, the Infinity Logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus T orvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat Software Collections is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. T he OpenStack ® Word Mark and OpenStack Logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation's permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community. All other trademarks are the property of their respective owners. Sommario La Panoramica su Red Hat Cluster Suite fornisce una panoramica del Red Hat Cluster Suite per Red Hat Enterprise Linux 5.
Indice
Indice
.Introduzione
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4. . . . . . . . . .
1. Convenzioni del documento 4
1.1. Convenzioni tipografiche 5
1.2. Convenzioni del documento 6
1.3. Note ed avvertimenti 7
2. Commenti 8
.Capitolo
. . . . . . . . .1.
. . Panoramica
. . . . . . . . . . . . .su
. . .Red
. . . . Hat
. . . . .Cluster
. . . . . . . .Suite
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .9. . . . . . . . . .
1.1. Concetti di base del cluster 9
1.2. Red Hat Cluster Suite Introduction 10
1.3. Cluster Infrastructure 11
1.3.1. Cluster Management 11
1.3.2. Lock Management 12
1.3.3. Fencing 13
1.3.4. Il Cluster Configuration System 16
1.4. Gestione dei servizi High-availability 17
1.5. Red Hat GFS 20
1.5.1. Prestazione e scalabilità superiori 21
1.5.2. Prestazione, scalabilità e prezzo moderato 22
1.5.3. Risparmio e prestazione 22
1.6. Cluster Logical Volume Manager 23
1.7. Global Network Block Device 25
1.8. Linux Virtual Server 26
1.8.1. T wo-T ier LVS T opology 28
1.8.2. T hree-T ier LVS T opology 30
1.8.3. Metodi di instradamento 31
1.8.3.1. NAT Routing 31
1.8.3.2. Instradamento diretto 32
1.8.4. Persistenza e Firewall Mark 34
1.8.4.1. Persistence 34
1.8.4.2. Firewall Mark 34
1.9. T ool di amministrazione del cluster 34
1.9.1. Conga 35
1.9.2. GUI di amministrazione del cluster 37
1.9.2.1. Cluster Configuration T ool 37
1.9.2.2. Cluster Status T ool 39
1.9.3. T ool di amministrazione della linea di comando 40
1.10. GUI di amministrazione del server virtuale di Linux 41
1.10.1. CONT ROL/MONIT ORING 42
1.10.2. GLOBAL SET T INGS 43
1.10.3. REDUNDANCY 44
1.10.4. VIRT UAL SERVERS 45
1.10.4.1. Sottosezione SERVER VIRT UALE 46
1.10.4.2. Sottosezione REAL SERVER 48
1.10.4.3. EDIT MONIT ORING SCRIPT S Subsection 50
.Capitolo
. . . . . . . . .2.
. . Sommario
. . . . . . . . . . .dei
. . . .componenti
. . . . . . . . . . . . di
. . .Red
. . . . Hat
. . . . Cluster
. . . . . . . . Suite
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
............
2.1. Componenti del cluster 52
2.2. Pagine man 57
2.3. Hardware compatibile 59
. . . . . . . . . . . . della
Cronologia . . . . . .revisione
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
............
1
Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite
.Indice
. . . . . . analitico
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
............
C 60
F 60
I 60
L 61
M 61
N 61
O 61
P 61
R 62
T 62
2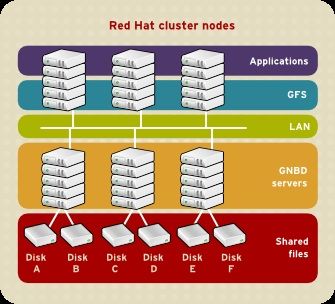
Indice
3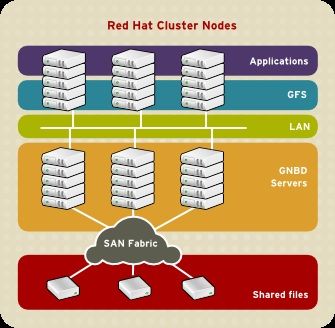
Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite
Introduzione
Questo documento fornisce una buona panoramica sul Red Hat Cluster Suite per Red Hat Enterprise
Linux 5, ed è organizzato nel modo seguente:
Capitolo 1, Panoramica su Red Hat Cluster Suite
Capitolo 2, Sommario dei componenti di Red Hat Cluster Suite
Anche se le informazioni presenti in questo documento sono generali, l'utente dovrebbe essere in
possesso di una conoscenza pratica avanzata con Red Hat Enterprise Linux, e capire i concetti di
computazione del server, in modo da comprendere correttamente le informazioni presenti.
Per maggiori informazioni su come utilizzare Red Hat Enterprise Linux, consultate le seguenti risorse:
Red Hat Enterprise Linux Installation Guide — Fornisce tutte le informazioni necessarie per
l'installazione di Red Hat Enterprise Linux 5.
Red Hat Enterprise Linux Deployment Guide — Fornisce tutte le informazioni necessarie per
l'impiego, la configurazione e l'amministrazione di Red Hat Enterprise Linux 5.
Per maggiori informazioni su Red Hat Cluster Suite per Red Hat Enterprise Linux 5, consultate le
seguenti risorse:
Configurazione e gestione di un Red Hat Cluster — Contiene informazioni sull'installazione,
configurazione e gestione dei componenti del Red Hat Cluster.
LVM Administrator's Guide: Configuration and Administration — Provides a description of the Logical
Volume Manager (LVM), including information on running LVM in a clustered environment.
Global File System: Configurazione e Amministrazione — Contiene informazioni su come installare,
configurare e gestire il Red Hat GFS (Red Hat Global File System).
Global File System 2: Configurazione e Amministrazione — Contiene informazioni su come installare,
configurare e gestire il Red Hat GFS (Red Hat Global File System 2).
Utilizzo del Device-Mapper Multipath — Fornisce tutte le informazioni necessarie per l'impiego del
Device-Mapper Multipath di Red Hat Enterprise Linux 5.
Utilizzo di GNBD con il Global File System — Fornisce una panoramica su come usare il Global
Network Block Device (GNBD) con Red Hat GFS.
Amministrazione del server virtuale di Linux — Fornisce le informazioni su come configurare i servizi
ed i sistemi ad alte prestazioni con il Linux Virtual Server (LVS).
Note di rilascio di Red Hat Cluster Suite — Fornisce informazioni sulla release corrente del Red Hat
Cluster Suite.
La documentazione di Red Hat Cluster Suite ed altri documenti di Red Hat sono disponibili nelle versioni
HT ML, PDF, e RPM sul CD di documentazione di Red Hat Enterprise Linux, e online su
http://www.redhat.com/docs/.
1. Convenzioni del documento
Questo manuale utilizza numerose convenzioni per evidenziare parole e frasi, ponendo attenzione su
informazioni specifiche.
Nelle edizioni PDF e cartacea questo manuale utilizza caratteri presenti nel set Font Liberation. Il set
Font Liberation viene anche utilizzato nelle edizioni HT ML se il set stesso è stato installato sul vostro
sistema. In caso contrario, verranno mostrati caratteri alternativi ma equivalenti. Da notare: Red Hat
Enterprise Linux 5 e versioni più recenti, includono per default il set Font Liberation.
4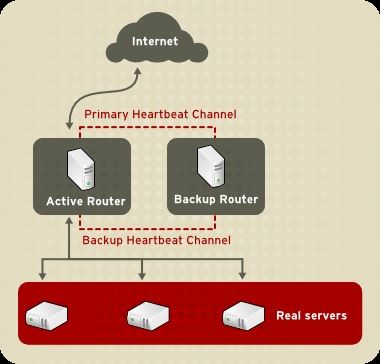
Introduzione
1.1. Convenzioni tipografiche
Vengono utilizzate quattro convenzioni tipografiche per richiamare l'attenzione su parole e frasi
specifiche. Queste convenzioni, e le circostanze alle quali vengono applicate, sono le seguenti.
Neretto m onospazio
Usato per evidenziare l'input del sistema, incluso i comandi della shell, i nomi dei file ed i percorsi.
Utilizzato anche per evidenziare tasti e combinazione di tasti. Per esempio:
Per visualizzare i contenuti del file m y_next_bestselling_novel nella vostra directory
di lavoro corrente, inserire il comando cat m y_next_bestselling_novel al prompt
della shell e premere Invio per eseguire il comando.
Quanto sopra riportato include il nome del file, un comando della shell ed un tasto, il tutto riportato in
neretto monospazio e distinguibile grazie al contesto.
Le combinazioni si distinguono dai tasti singoli tramite l'uso del segno più, il quale viene usato per
creare una combinazione di tasti. Per esempio:
Premere Invio per eseguire il comando.
Premere Ctrl+Alt+F2 per usare un terminale virtuale.
Il primo esempio evidenzia il tasto specifico singolo da premere. Il secondo riporta una combinazione di
tasti: un insieme di tre tasti premuti contemporaneamente.
Se si discute del codice sorgente, i nomi della classe, i metodi, le funzioni i nomi della variabile ed i valori
ritornati indicati all'interno di un paragrafo, essi verranno indicati come sopra, e cioè in neretto
m onospazio. Per esempio:
Le classi relative ad un file includono filesystem per file system, file per file, e dir per
directory. Ogni classe possiede il proprio set associato di permessi.
Proportional Bold
Ciò denota le parole e le frasi incontrate su di un sistema, incluso i nomi delle applicazioni; il testo delle
caselle di dialogo; i pulsanti etichettati; le caselle e le etichette per pulsanti di selezione, titoli del menu e
dei sottomenu. Per esempio:
Selezionare Sistema → Preferenze → Mouse dalla barra del menu principale per
lanciare Preferenze del Mouse. Nella scheda Pulsanti, fate clic sulla casella di dialogo
m ouse per m ancini, e successivamente fate clic su Chiudi per cambiare il pulsante
primario del mouse da sinistra a destra (rendendo così il mouse idoneo per un utilizzo con
la mano sinistra).
Per inserire un carattere speciale in un file gedit selezionare Applicazioni → Accessori
→ Mappa del carattere dalla barra del menu principale. Selezionare successivamente
Cerca → T rova… dal menu Mappa del carattere, digitare il nome desiderato nel campo
Cerca e selezionare Successivo. Il carattere desiderato sarà evidenziato nella T abella
dei caratteri. Eseguire un doppio clic sul carattere per poterlo posizionare nel campo
T esto da copiare e successivamente fare clic sul pulsante Copia. Ritornare sul
documento e selezionare Modifica → Incolla dalla barra del menu di gedit.
Il testo sopra riportato include i nomi delle applicazioni; nomi ed oggetti del menu per l'intero sistema;
nomi del menu specifici alle applicazioni; e pulsanti e testo trovati all'interno di una interfaccia GUI, tutti
presentati in neretto proporzionale e distinguibili dal contesto.
5
Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite
Corsivo neretto monospazio o Corsivo neretto proporzionale
Sia se si tratta di neretto monospazio o neretto proporzionale, l'aggiunta del carattere corsivo indica un
testo variabile o sostituibile . Il carattere corsivo denota un testo che non viene inserito letteralmente, o
visualizzato che varia a seconda delle circostanze. Per esempio:
Per collegarsi ad una macchina remota utilizzando ssh, digitare ssh
username@ domain.name al prompt della shell. Se la macchina remota è exam ple.com ed
il nome utente sulla macchina interessata è john, digitare ssh john@ exam ple.com .
Il comando m ount -o rem ount file-system rimonta il file system indicato. Per esempio,
per rimontare il file system /hom e, il comando è m ount -o rem ount /hom e.
Per visualizzare la versione di un pacchetto attualmente installato, utilizzare il comando
rpm -q package. Esso ritornerà il seguente risultato: package-version-release.
Da notare le parole in corsivo grassetto - username, domain.name, file-system, package, version e
release. Ogni parola funge da segnaposto, sia esso un testo inserito per emettere un comando o
mostrato dal sistema.
Oltre all'utilizzo normale per la presentazione di un titolo, il carattere Corsivo denota il primo utilizzo di
un termine nuovo ed importante. Per esempio:
Publican è un sistema di pubblicazione per DocBook.
1.2. Convenzioni del documento
Gli elenchi originati dal codice sorgente e l'output del terminale vengono evidenziati rispetto al testo
circostante.
L'output inviato ad un terminale è impostato su tondo m onospazio e così presentato:
books Desktop documentation drafts mss photos stuff svn
books_tests Desktop1 downloads images notes scripts svgs
Gli elenchi del codice sorgente sono impostati in tondo m onospazio ma vengono presentati ed
evidenziati nel modo seguente:
6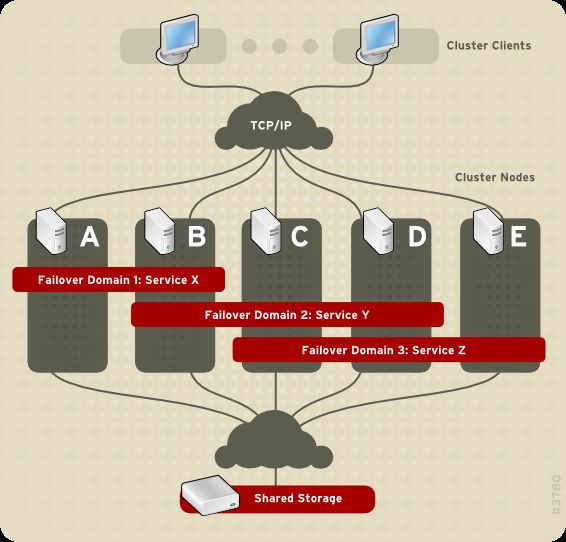
Introduzione
static int kvm_vm_ioctl_deassign_device(struct kvm *kvm,
struct kvm_assigned_pci_dev *assigned_dev)
{
int r = 0;
struct kvm_assigned_dev_kernel *match;
mutex_lock(&kvm->lock);
match = kvm_find_assigned_dev(&kvm->arch.assigned_dev_head,
assigned_dev->assigned_dev_id);
if (!match) {
printk(KERN_INFO "%s: device hasn't been assigned before, "
"so cannot be deassigned\n", __func__);
r = -EINVAL;
goto out;
}
kvm_deassign_device(kvm, match);
kvm_free_assigned_device(kvm, match);
out:
mutex_unlock(&kvm->lock);
return r;
}
1.3. Note ed avvertimenti
E per finire, tre stili vengono usati per richiamare l'attenzione su informazioni che in caso contrario
potrebbero essere ignorate.
Nota
Una nota è un suggerimento o un approccio alternativo per il compito da svolgere. Non dovrebbe
verificarsi alcuna conseguenza negativa se la nota viene ignorata, ma al tempo stesso potreste
non usufruire di qualche trucco in grado di facilitarvi il compito.
Importante
Le caselle 'importante' riportano informazioni che potrebbero passare facilmente inosservate:
modifiche alla configurazione applicabili solo alla sessione corrente, o servizi i quali necessitano
di un riavvio prima di applicare un aggiornamento. Ignorare queste caselle non causa alcuna
perdita di dati ma potrebbe causare irritazione e frustrazione da parte dell'utente.
Avvertimento
Un Avvertimento non dovrebbe essere ignorato. Se ignorato, potrebbe verificarsi una perdita di
dati.
7Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite
2. Commenti
Se individuate degli errori, o pensate di poter contribuire al miglioramento di questa guida, contattateci
subito! Vi preghiamo di inviare un report in Bugzilla (http://bugzilla.redhat.com/bugzilla/) contro il
componente Documentazione-cluster.
Be sure to mention the document's identifier:
Cluster_Suite_Overview(EN)-5 (2008-12-11T15:49)
By mentioning this document's identifier, we know exactly which version of the guide you have.
Se avete dei suggerimenti per migliorare la documentazione, cercate di essere il più specifici possibile.
Se avete trovato un errore, vi preghiamo di includere il numero della sezione, e alcune righe di testo, in
modo da agevolare le ricerca dell'errore stesso.
8Capitolo 1. Panoramica su Red Hat Cluster Suite
Capitolo 1. Panoramica su Red Hat Cluster Suite
I sistemi clusterizzati forniscono affidabilità, scalabilità e disponibilità ai i servizi critici di produzione.
Utilizzando Red Hat Cluster Suite, è possibile creare un cluster in grado di far fronte alle vostre
esigenze di prestazione, high availability, di bilanciamento del carico, scalabilità, file sharing e di
risparmio. Questo capitolo fornisce una panoramica sui componenti di Red Hat Cluster Suite e le sue
funzioni, e consiste nelle seguenti sezioni:
Sezione 1.1, «Concetti di base del cluster»
Sezione 1.2, «Red Hat Cluster Suite Introduction»
Sezione 1.3, «Cluster Infrastructure»
Sezione 1.4, «Gestione dei servizi High-availability»
Sezione 1.5, «Red Hat GFS»
Sezione 1.6, «Cluster Logical Volume Manager»
Sezione 1.7, «Global Network Block Device»
Sezione 1.8, «Linux Virtual Server»
Sezione 1.9, «T ool di amministrazione del cluster»
Sezione 1.10, «GUI di amministrazione del server virtuale di Linux»
1.1. Concetti di base del cluster
Un cluster è costituito da due i più computer (chiamati nodi o membri), che operano insieme per
eseguire un compito. Sono presenti quattro tipi principali di cluster:
Storage
High availability
Bilanciamento del carico
Elevate prestazioni
I cluster storage forniscono una immagine coerente del file system sui server presenti in un cluster,
permettendo ai server stessi di leggere e scrivere simultaneamente su di un file system condiviso
singolo. Un cluster storage semplifica l'amministrazione dello storage, limitando l'installazione ed il
patching di applicazioni su di un file system. Altresì, con un file system cluster-wide, un cluster storage
elimina la necessità di copie ridondanti di dati dell'applicazione, semplificando il processo di backup e di
disaster recovery. Red Hat Cluster Suite fornisce uno storage clustering attraverso Red Hat GFS.
I cluster High-availability forniscono una disponibilità continua dei servizi tramite l'eliminazione dei così
detti single points of failure, e tramite l'esecuzione del failover dei servizi da un nodo del cluster ad un
altro nel caso in cui il nodo diventi non operativo. Generalmente i servizi presenti in un cluster high-
availability leggono e scrivono i dati (tramite un file system montato in modalità di lettura-scrittura). Per
questo motivo un cluster high-availability deve essere in grado di garantire l'integrità dei dati, poichè un
nodo del cluster può assumere il controllo di un servizio da un altro nodo. La presenza di errori in un
cluster high-availability non risulta essere visibile da parte di client esterni al cluster. (I cluster high-
availability sono talvolta indicati come cluster di failover.) Red Hat Cluster Suite fornisce un clustering
high-availability attraverso il proprio componente High-availability Service Management.
I cluster a bilanciamento del carico 'cluster load-balancing' inviano le richieste del servizio di rete a nodi
multipli del cluster, in modo da bilanciare il carico richiesto tra i nodi del cluster. Il bilanciamento del carico
fornisce una scalabilità molto economica, poichè è possibile corrispondere il numero di nodi in base ai
requisiti del carico. Se un nodo all'interno del cluster risulta essere non operativo, il software per il
bilanciamento del carico rileva l'errore e ridireziona le richieste ad altri nodi del cluster. Il fallimento di un
nodo nel cluster load-balancing non risulta essere visibile da parte dei client esterni al cluster. Red Hat
9Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite
Cluster Suite fornisce un bilanciamento del carico attraverso LVS (Linux Virtual Server).
I cluster High-performance utilizzano i nodi del cluster per eseguire processi di calcolo simultanei. Un
cluster high-performance permette alle applicazioni di lavorare in parallelo aumentando così la
prestazione delle applicazioni. (I cluster High performance vengono anche identificati come cluster
computational o grid computing.)
Nota Bene
I cluster sopra citati rappresentano le configurazioni di base; in base alle vostre esigenze
potreste aver bisogno di una combinazione dei tipi di cluster appena descritti.
1.2. Red Hat Cluster Suite Introduction
Il Red Hat Cluster Suite (RHCS) è un set integrato di componenti software il quale può essere impiegato
in una varietà di configurazioni idonee per far fronte alle vostre esigenze di prestazione, high-availability,
di bilanciamento del carico, scalabilità, file sharing e di risparmio.
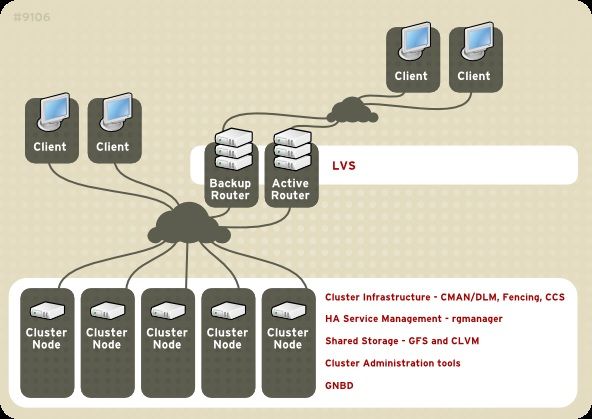
RHCS consists of the following major components (refer to Figura 1.1, «Red Hat Cluster Suite
Introduction»):
Infrastruttura del cluster — Fornisce le funzioni fondamentali per i nodi in modo che gli stessi
possano operare insieme come un cluster: gestione della configurazione-file, gestione
appartenenza, lock management, e fencing.
High-availability Service Management — Fornisce il failover dei servizi da un nodo del cluster ad un
altro, in caso in cui il nodo non è più operativo.
T ool di amministrazione del cluster — T ool di gestione e configurazione per l'impostazione, la
configurazione e la gestione di un cluster di Red Hat. È possibile utilizzare i suddetti tool con i
componenti dell'infrastruttura del cluster, e con componenti per la Gestione del servizio, High
availability e storage.
Linux Virtual Server (LVS) — Software di instradamento che fornisce l'IP-Load-balancing. LVM viene
eseguito su di una coppia di server ridondanti, che distribuisce le richieste del client in modo
omogeneo ai real server dietro i server LVS.
È possibile integrare con Red Hat Cluster Suite i seguenti componenti facenti parte di un pacchetto
opzionale (e non parte di Red Hat Cluster Suite):
Red Hat GFS (Global File System) — Fornisce il file system del cluster per un utilizzo con Red Hat
Cluster Suite. GFS permette ai nodi multipli di condividere lo storage ad un livello del blocco, come se
lo storage fosse collegato localmente ad ogni nodo del cluster.
Cluster Logical Volume Manager (CLVM) — Fornisce la gestione del volume del cluster storage.
Nota
When you create or modify a CLVM volume for a clustered environment, you must ensure that
you are running the clvm d daemon. For further information, refer to Sezione 1.6, «Cluster
Logical Volume Manager».
Global Network Block Device (GNBD) — Un componente ausiliario di GFS in grado di esportare uno
storage del livello del blocco su Ethernet. Esso rappresenta un modo molto economico per rendere
disponibile il suddetto storage a Red Hat GFS.
10Capitolo 1. Panoramica su Red Hat Cluster Suite
For a lower level summary of Red Hat Cluster Suite components and optional software, refer to
Capitolo 2, Sommario dei componenti di Red Hat Cluster Suite.
Figura 1.1. Red Hat Cluster Suite Introduction
Nota Bene
Figura 1.1, «Red Hat Cluster Suite Introduction» includes GFS, CLVM, and GNBD, which are
components that are part of an optional package and not part of Red Hat Cluster Suite.
1.3. Cluster Infrastructure
L'infrastruttura del cluster di Red Hat Cluster Suite fornisce le funzioni di base per un gruppo di
computer (chiamati nodi o membri), in modo da poter operare insieme come un cluster. Una volta
formato il cluster utilizzando l'infrastruttura del cluster stesso, è possibile utilizzare altri componenti del
Red Hat Cluster Suite, in modo da far fronte alle esigenze del proprio cluster (per esempio per
l'impostazione di un cluster per la condivisione dei file su di un file system GFS, oppure per
l'impostazione del servizio di failover). L'infrastruttura del cluster esegue le seguenti funzioni:
Cluster management
Lock management
Fencing
Gestione configurazione del cluster
1.3.1. Cluster Management
Cluster management manages cluster quorum and cluster membership. CMAN (an abbreviation for
cluster manager) performs cluster management in Red Hat Cluster Suite for Red Hat Enterprise Linux 5.
CMAN is a distributed cluster manager and runs in each cluster node; cluster management is distributed
across all nodes in the cluster (refer to Figura 1.2, «CMAN/DLM Overview»).
CMAN keeps track of cluster quorum by monitoring the count of cluster nodes. If more than half the
11Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite
nodes are active, the cluster has quorum. If half the nodes (or fewer) are active, the cluster does not
have quorum, and all cluster activity is stopped. Cluster quorum prevents the occurrence of a "split-
brain" condition — a condition where two instances of the same cluster are running. A split-brain
condition would allow each cluster instance to access cluster resources without knowledge of the other
cluster instance, resulting in corrupted cluster integrity.
Il quorum viene determinato tramite la presenza di messaggi inviati tra i nodi del cluster via Ethernet.
Facoltativamente il quorum può essere anche determinato da una combinazione di messaggi via
Ethernet e attraverso un quorum disk. Per il quorum via Ethernet, esso consiste nel 50 per cento dei voti
del nodo più 1. Invece per un quorum tramite il quorum disk, esso consiste nelle condizioni specificate
dall'utente.
Nota Bene
Per default ogni nodo possiede un voto. Facoltativamente è possibile configurare ogni nodo in
modo da avere più di un voto.
CMAN controlla l'appartenenza tramite il monitoraggio dei messaggi provenienti da altri nodi del cluster.
Quando l'appartenenza del cluster cambia, il cluster manager invia una notifica agli altri componenti
dell'infrastruttura, i quali a loro volta intraprendono l'azione appropriata. Per esempio, se il nodo A si
unisce al cluster e monta un file system GFS già montato sui nodi B e C, allora sarà necessario per il
nodo A un journal ed un lock management aggiuntivi per poter utilizzare il file system GFS in questione.
Se il nodo non trasmette alcun messaggio entro un ammontare di tempo prestabilito il cluster manager
rimuove il nodo dal cluster, e comunica agli altri componenti dell'infrastruttura del cluster che il nodo in
questione non risulta più essere un membro. Ancora, altri componenti dell'infrastruttura del cluster
determinano le azioni da intraprendere, previa notifica, poichè il nodo non è più un membro del cluster.
Per esempio, il fencing potrebbe isolare il nodo non più membro.
Figura 1.2. CMAN/DLM Overview
1.3.2. Lock Management
Lock management is a common cluster-infrastructure service that provides a mechanism for other
cluster infrastructure components to synchronize their access to shared resources. In a Red Hat cluster,
DLM (Distributed Lock Manager) is the lock manager. As implied in its name, DLM is a distributed lock
manager and runs in each cluster node; lock management is distributed across all nodes in the cluster
(refer to Figura 1.2, «CMAN/DLM Overview»). GFS and CLVM use locks from the lock manager. GFS
uses locks from the lock manager to synchronize access to file system metadata (on shared storage).
12Capitolo 1. Panoramica su Red Hat Cluster Suite
CLVM uses locks from the lock manager to synchronize updates to LVM volumes and volume groups
(also on shared storage).
1.3.3. Fencing
Fencing is the disconnection of a node from the cluster's shared storage. Fencing cuts off I/O from
shared storage, thus ensuring data integrity. T he cluster infrastructure performs fencing through the
fence daemon, fenced.
Quando CMAN determina la presenza di un nodo fallito, esso lo comunica agli altri componenti
dell'infrastruttura del cluster. fenced, una volta notificata la presenza di un errore, isola il nodo in
questione. Successivamente gli altri componenti dell'infrastruttura del cluster determinano le azioni da
intraprendere — essi eseguiranno qualsiasi processo necessario per il ripristino. Per esempio, subito
dopo la notificata di un errore a DLM e GFS, essi sospendono l'attività fino a quando non accerteranno il
completamento del processo di fencing da parte di fenced. Previa conferma del completamento di tale
operazione, DLM e GFS eseguono l'azione di ripristino. A questo punto DLM rilascia i blocchi del nodo
fallito e GFS ripristina il jounal del suddetto nodo.
Fencing determina dal file di configurazione del cluster il metodo da utilizzare. Per la definizione del
suddetto metodo è necessario prendere in considerazione due elementi principali: il dispositivo fencing
ed il fencing agent. Questo programma esegue una chiamata nei confronti di un fencing agent
specificato nel file di configurazione del cluster. Il fencing agent a sua volta, isola il nodo tramite un
dispositivo di fencing. Una volta completato, il programma esegue la notifica al cluster manager.
Red Hat Cluster Suite fornisce una varietà di metodi usati per il fencing:
Power fencing — Esso è il metodo utilizzato da un controllore di alimentazione per disalimentare il
nodo non utilizzabile.
Fibre Channel switch fencing — Rappresenta il metodo attraverso il quale viene disabilitata la porta
del Fibre Channel la quale collega lo storage ad un nodo non utilizzabile.
GNBD fencing — A fencing method that disables an inoperable node's access to a GNBD server.
Altri tipi di fencing — Diversi metodi per il fencing che disabilitano l'I/O o l'alimentazione di un nodo
non utilizzabile, incluso gli IBM Bladecenters, PAP, DRAC/MC, HP ILO, IPMI, IBM RSA II, ed altro
ancora.
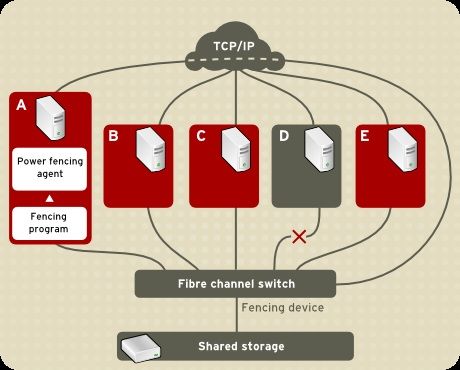
Figura 1.3, «Power Fencing Example» shows an example of power fencing. In the example, the fencing
program in node A causes the power controller to power off node D. Figura 1.4, «Fibre Channel Switch
Fencing Example» shows an example of Fibre Channel switch fencing. In the example, the fencing
program in node A causes the Fibre Channel switch to disable the port for node D, disconnecting node D
from storage.
13Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite Figura 1.3. Power Fencing Example Figura 1.4 . Fibre Channel Switch Fencing Example Specificare un metodo significa modificare il file di configurazione del cluster in modo da assegnare un nome per il metodo di fencing desiderato, il fencing agent, ed il dispositivo di fencing per ogni nodo nel cluster. T he way in which a fencing method is specified depends on if a node has either dual power supplies or multiple paths to storage. If a node has dual power supplies, then the fencing method for the node must specify at least two fencing devices — one fencing device for each power supply (refer to Figura 1.5, 14
Capitolo 1. Panoramica su Red Hat Cluster Suite
«Fencing a Node with Dual Power Supplies»). Similarly, if a node has multiple paths to Fibre Channel
storage, then the fencing method for the node must specify one fencing device for each path to Fibre
Channel storage. For example, if a node has two paths to Fibre Channel storage, the fencing method
should specify two fencing devices — one for each path to Fibre Channel storage (refer to Figura 1.6,
«Fencing a Node with Dual Fibre Channel Connections»).
Figura 1.5. Fencing a Node with Dual Power Supplies
Figura 1.6. Fencing a Node with Dual Fibre Channel Connections
15Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite È possibile configurare un nodo con uno o più metodi di fencing. Quando configurate un nodo per un determinato metodo di fencing, tale metodo risulterà l'unico perseguibile per eseguire il fencing del nodo in questione. Se configurate invece un nodo con metodi di fencing multipli, i suddetti metodi seguiranno una determinata sequenza, da un metodo ad un altro seguendo l'ordine riportato nel file di configurazione del cluster. Se un nodo fallisce, esso viene isolato utilizzando il primo metodo specificato nel file di configurazione del cluster. Se il primo metodo fallisce, verrà utilizzato il metodo successivo per quel nodo. Se nessun metodo è riuscito ad isolare il nodo, allora il processo di fencing inizierà nuovamente seguendo l'ordine appena descritto e specificato nel file di configurazione del cluster, fino a quando il nodo non verrà isolato con successo. 1.3.4. Il Cluster Configuration System T he Cluster Configuration System (CCS) manages the cluster configuration and provides configuration information to other cluster components in a Red Hat cluster. CCS runs in each cluster node and makes sure that the cluster configuration file in each cluster node is up to date. For example, if a cluster system administrator updates the configuration file in Node A, CCS propagates the update from Node A to the other nodes in the cluster (refer to Figura 1.7, «CCS Overview»). Figura 1.7. CCS Overview Other cluster components (for example, CMAN) access configuration information from the configuration file through CCS (refer to Figura 1.7, «CCS Overview»). 16
Capitolo 1. Panoramica su Red Hat Cluster Suite
Figura 1.8. Accessing Configuration Information
Il file di configurazione del cluster (/etc/cluster/cluster.conf) è un file XML che descrive le
seguenti caratteristiche:
Nome del cluster — Mostra il nome del cluster, il livello della revisione del file di configurazione, e le
proprietà di base sul tempo necessario per l'esecuzione del fencing, usate quando un nodo si
unisce al cluster o viene isolato.
Cluster — Mostra ogni nodo del cluster, specificandone il nome, l'ID ed il numero di voti del quorum
del cluster insieme al metodo per il fencing corrispondente.
Fence Device — Mostra i dispositivi per il fencing nel cluster. I parametri variano a seconda del tipo di
dispositivo. Per esempio, per un controllore dell'alimentazione usato come un dispositivo per il
fencing, la configurazione del cluster definisce il nome del controllore dell'alimentazione, l'indirizzo IP
relativo, il login e la password.
Risorse gestite — Mostrano le risorse necessarie per creare i servizi del cluster. Le risorse gestite
includono la definizione dei domini di failover, delle risorse (per esempio un indirizzo IP), e dei servizi.
Insieme, le risorse gestite definiscono i servizi del cluster ed il comportamento del failover dei servizi
del cluster.
1.4. Gestione dei servizi High-availability
La gestione del servizio High-availability fornisce la possibilità di creare e gestire servizi cluster high-
availability in un cluster Red Hat. Il componente principale per la gestione di un servizio high-availability
in un cluster Red Hat, rgm anager, implementa un cold failover per applicazioni commerciali. In un
cluster di Red Hat un'applicazione viene configurata con altre risorse del cluster in modo da formare un
servizio high-availability. È possibile eseguire un failover nei confronti di tale servizio da un nodo del
cluster ad un altro, senza interruzione apparente per i client. Il failover del servizio può verificarsi se un
nodo fallisce o se un amministratore di sistema del cluster muove il servizio da un nodo ad un altro (per
esempio, per una interruzione pianificata di un nodo).
Per creare un servizio high-availability, è necessario prima configurarlo all'interno del file di
configurazione del cluster. Un servizio è composto da svariate risorse. Le suddette risorse sono
costituite da blocchi di costruzione da voi creati e gestiti nel file di configurazione del cluster — per
17Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite
esempio, un indirizzo IP, uno script di inizializzazione dell'applicazione, o una partizione condivisa di
Red Hat GFS.
You can associate a cluster service with a failover domain. A failover domain is a subset of cluster
nodes that are eligible to run a particular cluster service (refer to Figura 1.9, «Domini di failover»).
Nota Bene
I domini di failover non sono necessari per questa operazione.
Il servizio può essere eseguito su di un nodo per volta in modo da garantire l'integrità dei dati. È
possibile specificare la priorità di failover in un dominio di failover. T ale priorità consiste in una
assegnazione di un livello di priorità ad ogni nodo in un dominio di failover. Il suddetto livello determina
l'ordine di failover — determinando così il nodo sul quale un servizio del cluster deve essere eseguito in
presenza di un failover. Se non specificate alcuna priorità, allora sarà possibile eseguire il failover del
servizio su qualsiasi nodo presente nel proprio dominio di failover. Altresì, è possibile specificare se un
servizio sia limitato durante la sua esecuzione, e quindi eseguibile solo su nodi presenti nel dominio di
failover associato. (Quando associato con un dominio di failover non limitato, il servizio del cluster può
essere eseguito su qualsiasi nodo, nel caso in cui nessun membro del dominio di failover risulti
disponibile.)
In Figura 1.9, «Domini di failover», Failover Domain 1 is configured to restrict failover within that domain;
therefore, Cluster Service X can only fail over between Node A and Node B. Failover Domain 2 is also
configured to restrict failover with its domain; additionally, it is configured for failover priority. Failover
Domain 2 priority is configured with Node C as priority 1, Node B as priority 2, and Node D as priority 3. If
Node C fails, Cluster Service Y fails over to Node B next. If it cannot fail over to Node B, it tries failing
over to Node D. Failover Domain 3 is configured with no priority and no restrictions. If the node that
Cluster Service Z is running on fails, Cluster Service Z tries failing over to one of the nodes in Failover
Domain 3. However, if none of those nodes is available, Cluster Service Z can fail over to any node in
the cluster.
18Capitolo 1. Panoramica su Red Hat Cluster Suite
Figura 1.9. Domini di failover
Figura 1.10, «Web Server Cluster Service Example» shows an example of a high-availability cluster
service that is a web server named "content-webserver". It is running in cluster node B and is in a
failover domain that consists of nodes A, B, and D. In addition, the failover domain is configured with a
failover priority to fail over to node D before node A and to restrict failover to nodes only in that failover
domain. T he cluster service comprises these cluster resources:
Risorsa indirizzo IP — Indirizzo IP 10.10.10.201.
An application resource named "httpd-content" — a web server application init script
/etc/init.d/httpd (specifying httpd).
A file system resource — Red Hat GFS named "gfs-content-webserver".
19Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite
Figura 1.10. Web Server Cluster Service Example
I client sono in grado di accedere al servizio del cluster tramite l'indirizzo IP 10.10.10.201, permettendo
una interazione con l'applicazione del web server, httpd-content. L'applicazione httpd-content utilizza il
file system gfs-content-webserver. Se il nodo B fallisce, il servizio del cluster content-webserver
eseguirà il failover sul nodo D. Se il nodo D non risulta disponibile o se fallito, è possibile eseguire il
failover sul nodo A. Il processo di failover si verificherà con nesuna interruzione apparente al client del
cluster. Il servizio del cluster sarà accessibile da un altro nodo tramite lo stesso indirizzo IP prima del
verificarsi del processo di failover.
1.5. Red Hat GFS
Red Hat GFS è un file system del cluster che permette ad un cluster di nodi di accedere
simultaneamente ad un dispositivo a blocchi condiviso tra i nodi. GFS è un file system nativo che
interfaccia con il livello VFS dell'interfaccia del file system del kernel di Linux. GFS impiega i metadata
distribuiti e journal multipli, per operare in maniera ottimale all'interno di un cluster. Per mantenere
l'integrità del file system, GFS utilizza un lock manager per coordinare l'I/O. Quando un nodo modifica i
dati su di un file system GFS, tale modifica sarà visibile immediatamente da parte di altri nodi del cluster
che utilizzano quel file system.
Utilizzando Red Hat GFS, è possibile ottenere l'uptime massimo dell'applicazione attraverso i seguenti
benefici:
Semplificazione della vostra infrastruttura dei dati
Installazione e aggiornamenti eseguiti una sola volta per l'intero cluster.
Elimina la necessità di copie ridondanti dei dati (duplicazione).
Abilita un accesso lettura /scrittura simultaneo dei dati da parte di numerosi client.
Semplifica il backup ed il disaster recovery (backup o ripristino di un solo file system)
20Capitolo 1. Panoramica su Red Hat Cluster Suite
Massimizza l'utilizzo delle risorse dello storage, e minimizza i costi di amministrazione.
Gestisce lo storage nella sua totalità invece di gestirlo tramite ogni singola partizione.
Diminuisce le necessità di spazio, eliminando la necessita di replicare i dati.
Varia la dimensione del cluster aggiungendo server o storage, durante il suo normale funzionamento.
Non è più necessario il partizionamento dello storage con tecniche complicate.
Aggiunge il server al cluster semplicemente montandoli al file system comune
I nodi che eseguono il Red Hat GFS sono configurati e gestiti tramite i tool di configurazione e gestione
del Red Hat Cluster Suite. Il Volume management viene gestito attraverso il CLVM (Cluster Logical
Volume Manager). Red Hat GFS permette una condivisione dei dati tra i nodi del GFS all'interno di un
cluster di Red Hat. GFS fornisce una panoramica singola ed uniforme sullo spazio del nome del file
system, attraverso i nodi del GFS in un cluster di Red Hat. GFS permette l'installazione e l'esecuzione
delle applicazioni senza avere una conoscenza dettagliata dell'infrastruttura dello storage. Altresì, GFS
fornisce alcune caratteristiche spesso necessarie in ambienti enterprise, come ad esempio i quota,
journal multipli ed il supporto multipath.
GFS fornisce un metodo versatile per lo storage networking basato sulle prestazioni, sulla scalabilità e
sulle esigenze economiche del vostro ambiente storage. Questo capitolo fornisce alcune informazioni di
base abbreviate come background, per aiutarvi a comprendere il GFS.
You can deploy GFS in a variety of configurations to suit your needs for performance, scalability, and
economy. For superior performance and scalability, you can deploy GFS in a cluster that is connected
directly to a SAN. For more economical needs, you can deploy GFS in a cluster that is connected to a
LAN with servers that use GNBD (Global Network Block Device) or to iSCSI (Internet Small Computer
System Interface) devices. (For more information about GNBD, refer to Sezione 1.7, «Global Network
Block Device».)
Le seguenti sezioni forniscono alcuni esempi su come implementare GFS in modo da soddisfare le
vostre esigenze di prestazione, scalabilità e di risparmio:
Sezione 1.5.1, «Prestazione e scalabilità superiori»
Sezione 1.5.2, «Prestazione, scalabilità e prezzo moderato»
Sezione 1.5.3, «Risparmio e prestazione»
Nota Bene
Gli esempi relativi all'implementazione del GFS riflettono le configurazioni di base; nel vostro caso
potreste richiedere una combinazione di configurazioni riportate con i seguenti esempi.
1.5.1. Prestazione e scalabilità superiori
You can obtain the highest shared-file performance when applications access storage directly. T he GFS
SAN configuration in Figura 1.11, «GFS with a SAN» provides superior file performance for shared files
and file systems. Linux applications run directly on cluster nodes using GFS. Without file protocols or
storage servers to slow data access, performance is similar to individual Linux servers with directly
connected storage; yet, each GFS application node has equal access to all data files. GFS supports over
300 GFS nodes.
21Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite Figura 1.11. GFS with a SAN 1.5.2. Prestazione, scalabilità e prezzo moderato Multiple Linux client applications on a LAN can share the same SAN-based data as shown in Figura 1.12, «GFS and GNBD with a SAN». SAN block storage is presented to network clients as block storage devices by GNBD servers. From the perspective of a client application, storage is accessed as if it were directly attached to the server in which the application is running. Stored data is actually on the SAN. Storage devices and data can be equally shared by network client applications. File locking and sharing functions are handled by GFS for each network client. Figura 1.12. GFS and GNBD with a SAN 1.5.3. Risparmio e prestazione Figura 1.13, «GFS e GNBD con uno storage collegato direttamente» shows how Linux client applications can take advantage of an existing Ethernet topology to gain shared access to all block storage devices. Client data files and file systems can be shared with GFS on each client. Application failover can be fully 22
Capitolo 1. Panoramica su Red Hat Cluster Suite
automated with Red Hat Cluster Suite.
Figura 1.13. GFS e GNBD con uno storage collegato direttamente
1.6. Cluster Logical Volume Manager
Il Cluster Logical Volume Manager (CLVM) fornisce una versione cluster-wide di LVM2. CLVM fornisce le
stesse caratteristiche di LVM2 su di un nodo singolo, rendendo i volumi disponibili su tutti i nodi in un
cluster di Red Hat. I volumi logici creati con CLVM, rende gli stessi disponibili a tutti i nodi presenti in un
cluster.
T he key component in CLVM is clvm d. clvm d is a daemon that provides clustering extensions to the
standard LVM2 tool set and allows LVM2 commands to manage shared storage. clvm d runs in each
cluster node and distributes LVM metadata updates in a cluster, thereby presenting each cluster node
with the same view of the logical volumes (refer to Figura 1.14, «CLVM Overview»). Logical volumes
created with CLVM on shared storage are visible to all nodes that have access to the shared storage.
CLVM allows a user to configure logical volumes on shared storage by locking access to physical
storage while a logical volume is being configured. CLVM uses the lock-management service provided by
the cluster infrastructure (refer to Sezione 1.3, «Cluster Infrastructure»).
Nota Bene
Lo storage condiviso con Red Hat Cluster Suite necessita di una esecuzione del cluster logical
volume manager daemon (clvm d) o degli High Availability Logical Volume Management agent
(HA-LVM). Se non siete in grado di utilizzare il demone clvm d o HA-LVM per ragioni operative, o
perchè non siete in possesso degli entitlement corretti, è consigliato non usare il single-instance
LVM sul disco condiviso, poichè tale utilizzo potrebbe risultare in una corruzione dei dati. Per
qualsiasi problema si prega di consultare un rappresentante per la gestione dei servizi di Red
Hat.
23Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite
Nota Bene
L'utilizzo di CLVM richiede piccole modifiche di /etc/lvm /lvm .conf per il cluster-wide locking.
Figura 1.14 . CLVM Overview
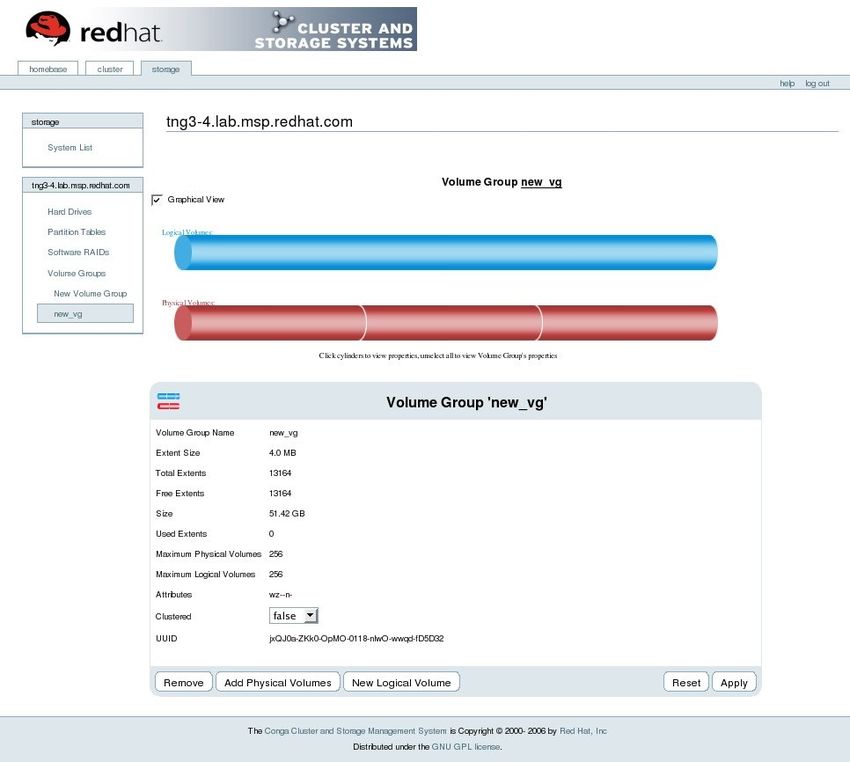
You can configure CLVM using the same commands as LVM2, using the LVM graphical user interface
(refer to Figura 1.15, «LVM Graphical User Interface»), or using the storage configuration function of the
Conga cluster configuration graphical user interface (refer to Figura 1.16, «Conga LVM Graphical User
Interface») . Figura 1.17, «Creating Logical Volumes» shows the basic concept of creating logical
volumes from Linux partitions and shows the commands used to create logical volumes.
Figura 1.15. LVM Graphical User Interface
24Capitolo 1. Panoramica su Red Hat Cluster Suite
Figura 1.16. Conga LVM Graphical User Interface
Figura 1.17. Creating Logical Volumes
1.7. Global Network Block Device
25Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite
Il Global Network Block Device (GNBD) fornisce un accesso ai dispositivi a blocchi per Red Hat GFS
attraverso T CP/IP. GNBD è simile nel concetto a NBD; tuttavia GNBD è specifico al GFS, e viene regolato
solo per un suo utilizzo con il GFS. GNBD è utile se è necessario utilizzare tecnologie più robuste, il
Fibre Channel o lo SCSI single-initiator non sono necessari o presentano costi proibitivi.
GNBD consists of two major components: a GNBD client and a GNBD server. A GNBD client runs in a
node with GFS and imports a block device exported by a GNBD server. A GNBD server runs in another
node and exports block-level storage from its local storage (either directly attached storage or SAN
storage). Refer to Figura 1.18, «Panoramica di GNBD». Multiple GNBD clients can access a device
exported by a GNBD server, thus making a GNBD suitable for use by a group of nodes running GFS.
Figura 1.18. Panoramica di GNBD
1.8. Linux Virtual Server
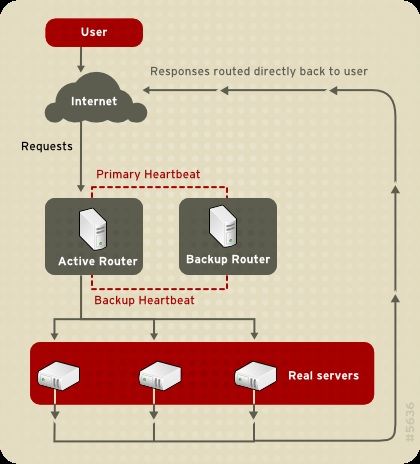
Il Linux Virtual Server (LVS) è un insieme di componenti software integrati per il bilanciamento del carico
IP attraverso un set di real server. LVS viene eseguito su di una coppia di computer configurati in modo
simile: un router LVS attivo ed un router LVS di backup. Il router LVS attivo viene utilizzato per:
Bilanciare il carico attraverso i real server.
Controllare l'integrità dei servizi su ogni real server.
Il router LVS di backup monitorizza il router LVS attivo, sostituendolo nel caso in cui il router LVS attivo
fallisce.
Figura 1.19, «Components of a Running LVS Cluster» provides an overview of the LVS components and
their interrelationship.
26Capitolo 1. Panoramica su Red Hat Cluster Suite
Figura 1.19. Components of a Running LVS Cluster
Il demone pulse viene eseguito sia sul router LVS attivo che su quello passivo. Sul router LVS di
backup, pulse invia un heartbeat all'interfaccia pubblica del router attivo, in modo da assicurarsi che il
router LVS attivo funzioni correttamente. Sul router LVS attivo, pulse avvia il demone lvs, e risponde
alle interrogazioni heartbeat provenienti dal router LVS di backup.
Una volta avviato, il demone lvs chiama l'utilità ipvsadm per configurare e gestire la tabella
d'instradamento IPVS (IP Virtual Server) nel kernel, e successivamente avvia un processo nanny per
ogni server virtuale configurato su ogni real server. Ogni processo nanny controlla lo stato di un
servizio configurato su di un real server, ed indica al demone lvs se è presente un malfunzionamento
del servizio su quel real server. Se tale malfunzionamento viene rilevato, il demone lvs indica a
ipvsadm di rimuovere il real server in questione dalla tabella d'instradamento di IPVS.
Se il router LVS di backup non riceve alcuna risposta dal router LVS attivo, esso inizia un processo di
failover attraverso la chiamata send_arp, riassegnando tutti gli indirizzi IP virtuali agli indirizzi hardware
NIC (indirizzo MAC) del router LVS di backup, ed inviando un comando al router LVS attivo tramite
l'interfaccia di rete privata e quella pubblica in modo da interrompere il demone lvs sul router LVS attivo.
A questo punto verrà avviato il demone lvs sul router LVS di backup ed accettate tutte le richieste per i
server virtuali configurati.
Per un utente esterno che accede ad un servizio hosted (come ad esempio le applicazioni databese o
website), LVS può apparire come un unico server. T uttavia l'utente accede ai real server situati oltre i
router LVS.
Poichè non è presente alcun componente interno a LVS per condividere i dati tra i server reali, sono
disponibili due opzioni di base:
La sincronizzazione dei dati attraverso i real server.
L'aggiunta di un terzo livello alla topologia per l'accesso dei dati condivisi.
Verrà utilizzata la prima opzione per i server che non permettono un numero di utenti molto grande per
27Red Hat Enterprise Linux 5 Panoramica sul Cluster Suite caricare o modificare i dati sui real server. Se i real server permettono un numero esteso di utenti per la modifica dei dati, come ad esempio un sito web e-commerce, allora sarà preferita l'aggiunta di un terzo livello. Sono disponibili diverse modalità per la sincronizzazione dei dati tra i real server. Per esempio è possibile utilizzare gli script della shell per postare simultaneamente le pagine web aggiornate sui real server. Altresì è possibile utilizzare programmi come rsync, per replicare i dati modificati attraverso tutti i nodi in un intervallo di tempo determinato. T uttavia in ambienti dove gli utenti caricano spesso file o emettono transazioni del database, l'utilizzo di script o del comando rsync per la sincronizzazione dei dati, non funzionerà in maniera ottimale. Per questo motivo per real server con un numero di upload molto elevato, e per transazioni del database o di traffico simile, una topologia three-tiered risulta essere più appropriata se desiderate sincronizzare i dati. 1.8.1. Two-Tier LVS Topology Figura 1.20, «T wo-T ier LVS T opology» shows a simple LVS configuration consisting of two tiers: LVS routers and real servers. T he LVS-router tier consists of one active LVS router and one backup LVS router. T he real-server tier consists of real servers connected to the private network. Each LVS router has two network interfaces: one connected to a public network (Internet) and one connected to a private network. A network interface connected to each network allows the LVS routers to regulate traffic between clients on the public network and the real servers on the private network. In Figura 1.20, «T wo- T ier LVS T opology», the active LVS router uses Network Address Translation (NAT) to direct traffic from the public network to real servers on the private network, which in turn provide services as requested. T he real servers pass all public traffic through the active LVS router. From the perspective of clients on the public network, the LVS router appears as one entity. Figura 1.20. T wo-T ier LVS T opology Le richieste del servizio che arrivano ad un router LVS vengono indirizzate ad un indirizzo IP virtuale o VIP. Esso rappresenta un indirizzo instradabile pubblicamente che l'amministratore del sito associa con un fully-qualified domain name, come ad esempio www.example.com, e assegnato ad uno o più server virtuali [1] . Nota bene che un indirizzo IP migra da un router LVS ad un altro durante un failover, 28
Capitolo 1. Panoramica su Red Hat Cluster Suite
mantenendo così una presenza in quel indirizzo IP, conosciuto anche come Indirizzi IP floating.
È possibile eseguire l'alias degli indirizzi VIP, sullo stesso dispositivo che esegue il collegamento del
router LVS con la rete pubblica. Per esempio, se eth0 è collegato ad internet, allora sarà possibile
eseguire l'alias dei server virtuali multipli su eth0:1. Alternativamente ogni server virtuale può essere
associato con un dispositivo separato per servizio. Per esempio, il traffico HT T P può essere gestito su
eth0:1, ed il traffico FT P gestito su eth0:2.
Solo un router LVS alla volta può essere attivo. Il ruolo del router LVS attivo è quello di ridirezionare le
richieste di servizio dagli indirizzi IP virtuali ai real server. Questo processo si basa su uno degli otto
algoritmi per il bilanciamento del carico:
Round-Robin Scheduling — Distribuisce ogni richiesta in successione all'interno di un gruppo di real
server. Utilizzando questo algoritmo, tutti i real server vengono trattati allo stesso modo, senza
considerare la loro capacità o il loro carico.
Weighted Round-Robin Scheduling — Distribuisce ogni richiesta in successione all'interno di un
gruppo di real server, dando un carico di lavoro maggiore ai server con maggiore capacità. La
capacità viene indicata da un fattore di peso assegnato dall'utente, e viene modificata in base alle
informazioni sul carico dinamico. Essa rappresenta la scelta preferita se sono presenti differenze
sostanziali di capacità dei real server all'interno di un gruppo di server. T uttavia se la richiesta di
carico varia sensibilmente, un server con un carico di lavoro molto elevato potrebbe operare oltre ai
propri limiti.
Least-Connection — Distribuisce un numero maggiore di richieste ai real server con un numero
minore di collegamenti attivi. Questo è un tipo di algoritmo di programmazione dinamico, il quale
rappresenta la scelta migliore se siete in presenza di una elevata variazione nelle richieste di carico.
Offre il meglio di se per un gruppo di real server dove ogni nodo del server presenta una capacità
simile. Se i real server in questione hanno una gamma varia di capacità, allora il weighted least-
connection scheduling rappresenta la scelta migliore.
Weighted Least-Connections (default) — Distribuisce un numero maggiore di richieste ai server con
un numero minore di collegamenti attivi, in base alle proprie capacità. La capacità viene indicata da un
peso assegnato dall'utente, e viene modificata in base alle informazioni relative al carico dinamico.
L'aggiunta di peso rende questo algoritmo ideale quando il gruppo del real server contiene un
hardware di varia capacità.
Locality-Based Least-Connection Scheduling — Distribuisce un numero maggiore di richieste ai
server con un numero minore di collegamenti attivi, in base ai propri IP di destinazione. Questo
algoritmo viene utilizzato in un cluster di server proxy-cache. Esso indirizza i pacchetti per un
indirizzo IP al server per quel indirizzo, a meno che il server in questione non abbia superato la sua
capacità e sia presente al tempo stesso un server che utilizzi metà della propria capacità. In questo
caso l'indirizzo IP verrà assegnato al real server con un carico minore.
Locality-Based Least-Connection Scheduling con Replication Scheduling — Distribuisce un numero
maggiore di richieste ai server con un numero minore di collegamenti attivi, in base ai propri IP di
destinazione. Questo algoritmo viene usato anche in un cluster di server proxy-cache. Esso
differisce da Locality-Based Least-Connection Scheduling a causa della mappatura dell'indirizzo IP
target su di un sottoinsieme di nodi del real server. Le richieste vengono indirizzate ad un server
presente in questo sottoinsieme con il numero più basso di collegamenti. Se tutti i nodi per l'IP di
destinazione sono al di sopra della propria capacità, esso sarà in grado di replicare un nuovo server
per quel indirizzo IP di destinazione, aggiungendo il real server con un numero minore di
collegamenti del gruppo di real server, al sottoinsieme di real server per quel IP di destinazione. Il
nodo maggiormente carico verrà rilasciato dal sottoinsieme di real server in modo da evitare un
processo di riproduzione non corretto.
Source Hash Scheduling — Distribuisce le richieste al gruppo di real server, cercando l'IP sorgente
in una tabella hash statica. Questo algoritmo viene usato per i router LVS con firewall multipli.
29Puoi anche leggere