Riconoscimento e tracciamento di elementi su video ad alta risoluzione - SIAGAS
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Università degli studi di Padova
Dipartimento di matematica ”Tullio Levi-Civita”
Corso di laurea in Informatica
Riconoscimento e tracciamento di
elementi su video ad alta risoluzione
Laureando: Relatore:
Davide Liu Prof. Lamberto Ballan
Matricola: Tutor aziendale:
1140717 Leonardo Dal Zovo
Anno Accademico 2018/2019
Indice
1 Introduzione 6
1.1 Scopo del progetto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2 Note esplicative . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3 Struttura del documento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.4 Struttura del lavoro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Ambiente Aziendale 8
3 Analisi dei problemi 9
3.1 Tecniche di computer vision . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.2 Computer vision applicata su immagini ad alta risoluzione . . . . . . . . . . 11
3.3 Frammentazione dell’immagine . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.4 Tecniche di object tracking . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.5 Object tracking con continue object detections . . . . . . . . . . . . . . . . . 15
4 Progettazione 17
4.1 Progettazione algoritmo per riconoscimento di elementi in un’immagine fram-
mentata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.1.1 Scomposizione del frame originale in regioni . . . . . . . . . . . . . . 17
4.1.2 Rimozione degli elementi individuati più volte all’interno delle aree di
sovrapposizione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.1.3 Creazione di raggruppamenti di labels correlate . . . . . . . . . . . . 18
4.1.4 Miglioramento: raggruppamenti di labels utilizzati come region proposal 21
4.2 Progettazione algoritmo per tracciamento di elementi . . . . . . . . . . . . . 23
4.2.1 Filtro di Kalman . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.2.2 Assegnazione detection-tracker . . . . . . . . . . . . . . . . . . . . . . 24
4.2.3 Gestione delle detections e dei trackers non assegnati . . . . . . . . . 26
4.2.4 Utilizzo di metriche di supporto per l’assegnazione detection-tracker . 27
5 Tecnologie 28
5.1 Python . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5.2 Pycharm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5.3 Tensorflow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.4 OpenCV . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.5 Numpy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.6 Matplotlib . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
Tesi di laurea triennale - Davide Liu Pagina 1 di 67
5.7 Pytest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.8 Excel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
6 Sviluppo 31
6.1 Sviluppo algoritmo per ricomposizione delle labels in un’immagine frammentata 31
6.1.1 Implementazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
6.1.2 Test di integrazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
6.1.3 Pipeline completa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
6.2 Sviluppo sistema di tracking . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
7 Risultati ottenuti 39
7.1 Metriche utilizzate per detection su singole immagini . . . . . . . . . . . . . 39
7.1.1 Precision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
7.1.2 Recall . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
7.1.3 F1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
7.1.4 Intersection over union . . . . . . . . . . . . . . . . . . . . . . . . . . 40
7.1.5 Average Precision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
7.1.6 Mean Average Precision . . . . . . . . . . . . . . . . . . . . . . . . . 41
7.2 Dataset utilizzato per detection su singole immagini . . . . . . . . . . . . . . 41
7.2.1 Impostazione parametri detection . . . . . . . . . . . . . . . . . . . . 42
7.3 Risultati ottenuti nella detection su singole immagini . . . . . . . . . . . . . 43
7.3.1 Risultati per categoria . . . . . . . . . . . . . . . . . . . . . . . . . . 43
7.3.2 Risultati per parametri . . . . . . . . . . . . . . . . . . . . . . . . . . 48
7.4 Metriche utilizzate per tracking su video . . . . . . . . . . . . . . . . . . . . 49
7.4.1 Mostly Tracked Trajectories . . . . . . . . . . . . . . . . . . . . . . . 50
7.4.2 Mostly Lost Trajectories . . . . . . . . . . . . . . . . . . . . . . . . . 50
7.4.3 ID switches . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
7.4.4 Fragments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
7.4.5 MOTP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
7.4.6 MOTA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
7.4.7 IDF1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
7.5 Dataset utilizzato per tracking su video . . . . . . . . . . . . . . . . . . . . . 51
7.5.1 Impostazione parametri tracking . . . . . . . . . . . . . . . . . . . . . 52
7.6 Risultati ottenuti nel tracking su video . . . . . . . . . . . . . . . . . . . . . 53
7.6.1 Risultati per categoria . . . . . . . . . . . . . . . . . . . . . . . . . . 53
7.6.2 Risultati per parametri . . . . . . . . . . . . . . . . . . . . . . . . . . 55
7.6.3 Risultati per parametri con detection . . . . . . . . . . . . . . . . . . 57
Tesi di laurea triennale - Davide Liu Pagina 2 di 67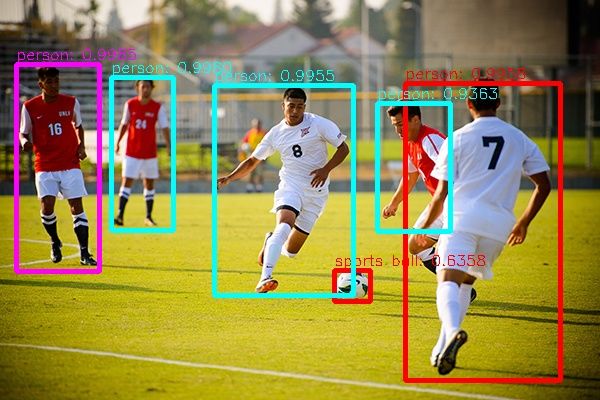
8 Conclusioni 59 8.1 Esperienze acquisite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59 8.2 Difficoltà incontrate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59 9 Glossario 61 10 Bibliografia 64 11 Appendice 66 Tesi di laurea triennale - Davide Liu Pagina 3 di 67
Elenco delle tabelle 1 Risultati detection per categoria, D ne indica la dimensione, R indica la rarità 46 2 Risultati detection con diversi parametri . . . . . . . . . . . . . . . . . . . . 48 3 Risultati tracking per categoria . . . . . . . . . . . . . . . . . . . . . . . . . 53 4 Risultati tracking con diversi parametri . . . . . . . . . . . . . . . . . . . . . 55 5 Risultati tracking con diversi parametri e detection . . . . . . . . . . . . . . 57 Tesi di laurea triennale - Davide Liu Pagina 4 di 67

Elenco delle figure
1 Logo di Studiomapp . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2 Esempio di un’immagine con box, categoria e probabilità per ogni elemento
riconosciuto in essa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3 Esempio di object detection in un frame di un video in 4K . . . . . . . . . . 12
4 Esempio di un’immagine in alta risoluzione suddivisa in regioni senza sovrap-
posizioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
5 Frames di un video nei quali viene tracciata un’ auto (ordinati da sinistra a
destra e dall’alto al basso) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
6 Esempi di labels erroneamente individuate a causa della frammentazione e
relativa corretta ricostruzione . . . . . . . . . . . . . . . . . . . . . . . . . . 19
7 Esempi di labels erroneamente individuate a causa della frammentazione e
relativa errata ricostruzione . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
8 Esempio di assegnazione detection-tracker . . . . . . . . . . . . . . . . . . . 25
9 Logo di Python . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
10 Logo di Tensorflow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
11 Diagramma delle classi del sistema di tracking . . . . . . . . . . . . . . . . . 36
12 Esempio di intersezione e di unione . . . . . . . . . . . . . . . . . . . . . . . 40
13 Immagine satellitare appartenente al dataset utilizzato . . . . . . . . . . . . 42
14 Esempi di oggetti molto difficili da individuare e classificare . . . . . . . . . 47
15 Elaborazione Studiomapp su xView Dataset . . . . . . . . . . . . . . . . . . 67
Tesi di laurea triennale - Davide Liu Pagina 5 di 67
1 Introduzione
Negli ultimi anni la computer vision è diventata un ambito di ricerca molto importante sia
nel mondo accademico, sia per le sue applicazioni nel mondo reale. I due sotto-problemi
principali nei quali essa si suddivide sono la detection ed il tracking.
Il primo problema ha come compito quello di insegnare ad una macchina ad interpretare una
singola immagine mentre il secondo problema estende lo stesso compito ma nell’ambito dei
video, ovvero una sequenza di immagini, correlate tra loro, dette frames. La detection è già
ampiamente utilizzata in ambito commerciale e la si può per esempio trovare nei sistemi di
riconoscimento facciale o di riconoscimento e lettura di testi scritti a mano. Altre sue appli-
cazioni riguardano diagnosi mediche, controllo di prodotti industriali, analisi del territorio,
etc.
Il tracking è invece un argomento di ricerca più recente rispetto alla detection e trova appli-
cazione nei sistemi di video-sorveglianza, veicoli a guida autonoma, riconoscimento di azioni,
etc. Tuttavia alcuni di questi sistemi come per esempio i veicoli a guida autonoma non sono
ancora maturi e sono tuttora oggetto di sperimentazioni.
1.1 Scopo del progetto
Lo scopo del progetto di stage è quello di progettare e realizzare un sistema di riconoscimento
e tracciamento di specifici elementi all’ interno di un video ad alta risoluzione.
Questo progetto comporta sfide e complessità aggiuntive rispetto all’ analisi degli elementi
presenti in una singola immagine, sia per il fatto che un video è composto da una sequenza
di frames anziché da una singola immagine, sia per il fatto che i frames trattati sono in
alta definizione e quindi elaborare l’intero frame con una sola detection comporterebbe una
perdita di qualità significativa.
Riassumendo, i due problemi principali che sono stati affrontati, in ordine sequenziale, sono
i seguenti:
• Riconoscimento di specifici elementi in immagini con frammentazione;
• Tracciamento di specifici elementi in un video;
Ognuno dei sotto-problemi viene prima analizzato a fondo, in seguito ne viene discussa una
sua possibile soluzione ed infine viene mostrato come essa è stata realizzata ai fini di ottenere
un prodotto il più performante possibile. Alla fine, il prodotto finale viene realizzato come
combinazione dei due sotto-prodotti.
Tesi di laurea triennale - Davide Liu Pagina 6 di 67
1.2 Note esplicative Allo scopo di evitare ambiguità a lettori esterni, si specifica che all’interno del documen- to verranno inseriti dei termini con un carattere ’G’ come pedice, questo significa che il significato inteso in quella situazione è stato inserito nel Glossario 1.3 Struttura del documento Il documento è organizzato nel seguente modo. Nel capitolo 2 viene fornita una panoramica riguardante l’azienda presso la quale è stata svolta l’attività di stage. Il capitolo 3 analizza i problemi da affrontare e le varie tecniche utilizzate nello stato dell’arte per provare a risolverli. Il capitolo 4 esamina approfonditamente gli algoritmi sviluppati per far fronte ai problemi proposti mentre il capitolo 5 spiega quali tecnologie e strumenti sono stati impiegati per la loro realizzazione. Il capitolo 6 riguarda l’implementazione degli algoritmi ed il 7 ne riporta i risultati ottenuti. Il capitolo 8 riguarda le conclusioni ed una valutazione retrospettiva dell’esperienza di stage. Infine sono presenti il Glossario e la Bibliografia. 1.4 Struttura del lavoro Lo stage ha avuto una durata di circa 320 ore produttive, di queste, almeno 40 ore sono state utilizzate per lo studio delle tecnologie utilizzate, le quali, includono il linguaggio di programmazione Python e alcune delle sue librerie, tra cui Numpy, OpenCV e Tensorflow. Circa 60 ore sono state impiegate per lo studio delle basi di machine learning e computer vision e per lo studio delle soluzioni più comuni ai problemi da affrontare. Altre 40 ore sono state impiegate per ideare e progettare delle soluzioni efficaci per i risolvere i problemi descritti sulla base di soluzioni già esistenti. Lo sviluppo dei prodotti realizzati ha richiesto circa 140 ore di lavoro, compresi i relativi test. Le restanti 40 ore sono state dedicate alla raccolta ed analisi dei risultati ed alla stesura della documentazione. L’elaborazione dei risultati ha richiesto in totale circa una settimana di tempo ed è stata eseguita su una macchina appositamente dedicata e sempre funzionante in modo da poter svolgere altre attività in parallelo. Tesi di laurea triennale - Davide Liu Pagina 7 di 67

2 Ambiente Aziendale
Figura 1: Logo di Studiomapp
STUDIOMAPP[1], fondata a fine 2015, è una startup innovativa con sedi a Ravenna e Ro-
ma, in Italia. Sviluppa algoritmi di intelligenza artificiale specifici per geo-calcolo e dati
geo-spaziali in modo da fornire soluzioni innovative per smart cities, mobilità, trasporti e
logistica, turismo e beni culturali, immobiliare e real estate, agricoltura, territorio e gestione
delle risorse naturali, adattamento ai cambiamenti climatici.
E’ la prima startup dell’Emilia Romagna selezionata dall’ESA BIC Lazio, l’incubatore
dell’Agenzia Spaziale Europea (ESA) ed è supportata da importanti istituzioni, acceleratori
e grandi attori. Membro fondatore dal 2016 della rete Copernicus Academy, si impegna a
diffondere i benefici dell’utilizzo dei dati di Osservazione della Terra per la qualità della vita
dei cittadini e la competitività delle PMI.
Ha acquisito una solida esperienza nella promozione di Copernicus, il programma europeo
di osservazione della Terra, nell’ecosistema Startup condividendo conoscenza e formazione.
Ad oggi la società ha organizzato più di 40 eventi che hanno raggiunto più di 1000 persone che
vanno dal pubblico generale, agli studenti, alle startup, ai funzionari pubblici, alle autorità
locali, alle PMI.
Tesi di laurea triennale - Davide Liu Pagina 8 di 67
3 Analisi dei problemi
If we want machines to think,
we need to teach them to see.
Li Fei Fei
3.1 Tecniche di computer vision
La computer vision è un ambito dell’intelligenza artificiale il cui scopo è quello di insegnare
alle macchine non solo a vedere un’ immagine, ma anche a riconoscere gli elementi che la
compongono in modo da poter interpretare il suo contenuto come farebbe il cervello di un
qualsiasi essere umano. Nonostante le attuali tecniche di deep learning rendano possibile
questo compito, è comunque necessaria una grande quantità di immagini e di tempo per
poter allenare una rete neurale a sufficienza in modo da riuscire a riconoscere correttamente
degli oggetti in un’ immagine non incontrata durante il processo di allenamento.
L’obiettivo è quindi quello di riconoscere e classificare alcuni specifici elementi presenti in
un’immagine localizzandone anche la posizione esatta all’interno dell’immagine stessa. Una
volta trovata la sua locazione, l’oggetto viene messo in evidenza disegnando un rettangolo
attorno ad esso, detto anche bounding boxG , in modo che lo racchiuda con la maggiore
precisione possibile. La classificazione ha invece come scopo quello individuare la categoria
di appartenenza di un oggetto e la probabilità che essa sia realmente quella corretta.
Per classificare un singolo elemento in un’immagine viene tipicamente utilizzata una Con-
volutional Neural Network (CNN)[2] allenata con grandi quantità di immagini che possono
essere tranquillamente reperite in rete già raggruppate in datasets come ad esempio Image-
Net o Coco.
La vera sfida salta fuori non appena ci troviamo a dover riconoscere e classificare nella stessa
immagine diversi oggetti appartenenti a categorie diverse, di differenti dimensioni e posizioni
e talvolta anche sovrapposti. Questa è una situazione molto comune quando si ha a che fare
con qualsiasi foto rappresentante il mondo reale. Il risultato ottimale sarebbe quindi di avere
una bounding box di dimensioni corrette per ogni oggetto riconosciuto mostrando anche la
categoriaG di appartenenza dell’elemento insieme alla probabilità che la categoria predet-
ta sia veramente quella corretta (detta anche scoreG ). Per semplicità, la rappresentazione
del bounding box di un elemento insieme alla sua categoria ed al suo score verrà chiamata
labelG
Tesi di laurea triennale - Davide Liu Pagina 9 di 67Figura 2: Esempio di un’immagine con box, categoria e probabilità per ogni elemento
riconosciuto in essa
Per localizzare gli elementi, la tecnica più semplice consiste nel far scorrere una sliding
window di varie dimensioni attraverso tutta l’area dell’immagine effettuando una classifi-
cazione per ogni locazione raggiunta. In caso di esito positivo la sliding window corrente
corrisponderà al bounding box dell’oggetto classificato. Al termine del processo è possibile
usare un algoritmo di Non-Max Suppression (NMS) per rimuovere eventuali sovrapposizioni.
Lo svantaggio di questo metodo è che bisognerebbe effettuare una detection per ogni sliding
window comportando quindi un elevato costo computazionale. In particolare, nel caso di
immagini in alta definizione si potrebbe addirittura arrivare ad avere migliaia di sliding win-
dows comportando allo stesso tempo migliaia di detections per una sola immagine. Oltre al
costo computazionale, questo metodo ha lo svantaggio di non sfruttare appieno la potenza
di una rete neurale.
Per effettuare una detection, il metodo più utilizzato allo stato dell’arte è quello di utiliz-
zare una R-CNN (Regional Convolutional Neural Network)[3] la quale sostituisce la tecnica
della sliding window tramite un algoritmo greedy chiamato Selective Search che estrae dal-
l’immagine delle regioni di interesse nelle quali è probabile che vi sia presente un oggetto.
Queste regioni vengono poi date singolarmente in input ad una normale CNN la quale ha
il compito di estrarne le caratteristiche principali per permettere ad una Support Vector
Machine (SVM) presente nell’ultimo strato della CNN di rilevare la presenza di un oggetto
ed eventualmente classificarlo.
Tesi di laurea triennale - Davide Liu Pagina 10 di 67Alternativamente, si possono prima utilizzare dei layers convoluzionali per estrarre una map-
pa delle caratteristiche più significative dall’immagine completa ed in seguito applicarci sopra
un algoritmo di ricerca come Selective Search per trovare le regioni di interesse sulle quali ef-
fettuare la classificazione. Quest’ultimo metodo è conosciuto come Fast R-CNN[4] in quanto
si ha un’ efficienza maggiore rispetto a R-CNN per il fatto che l’operazione di convoluzione
viene svolta solamente una volta per immagine invece che una volta per ogni regione di in-
teresse.
Tuttavia, questi tipi di soluzioni presentano il difetto di richiedere molto tempo per eseguire
l’operazione di ricerca delle regioni di interesse.
La versione più avanzata della Fast R-CNN ed attualmente in uso nei sistemi di computer
vision attuali è chiamata Faster R-CNN[5] e risolve il bottleneck della sua antecedente sosti-
tuendo la Selective Research con una Region Proposal Network (RPN). Essa prende come
input un’immagine di qualsiasi dimensione e restituisce come output un insieme di rettangoli
associati ad una probabilità che essi contengano un oggetto o meno. Come per Fast-CNN,
viene prima effettuata una convoluzione per costruire la mappa delle caratteristiche più signi-
ficative dell’immagine, in seguito viene utilizzata una sliding window per scorrere la mappa
delle caratteristiche e darle in input a due fully-connected layers, dei quali, uno serve per
individuare le coordinate del box dell’oggetto1 mentre l’altro serve per ritornare la probabi-
lità che nel box vi sia effettivamente un oggetto2 . Infine queste regioni vengono passate ad
un’altra rete che avrà come al solito il compito di riconoscere e classificare l’oggetto.
3.2 Computer vision applicata su immagini ad alta risoluzione
Sebbene sul web sia abbastanza facile reperire grandi quantità di immagini con cui allenare
i propri modelli, tuttavia la maggior parte di questi datasets contiene solamente immagini
a bassa risoluzione ed è difficile trovare in rete grandi datasets di immagini o video in alta
risoluzione. Inoltre, la maggior parte dei modelli sono stati progettati per lavorare su im-
magini a bassa risoluzione (tra i 200 e i 600 pixels) sia per il fatto che una bassa risoluzione
è comunque sufficiente per riconoscere e classificare un elemento, sia perchè è più efficiente
lavorare su immagini di bassa qualità che su immagini con una risoluzione molto alta[6].
In aggiunta, la maggior parte dei modelli esistenti tendono a ridurre automaticamente le
dimensioni delle immagini troppo grandi per adattarle alla dimensione massima del proprio
input.
Lo svantaggio che questo comporta è che nelle immagini in bassa risoluzione si perdono molti
dei dettagli che invece potrebbero essere catturati da un immagine o da un video ad alta
1
Box-regression layer
2
Box-classification layer
Tesi di laurea triennale - Davide Liu Pagina 11 di 67risoluzione. In aggiunta, i video in 4K o addirittura 8K sono al giorno d’oggi sempre più
diffusi, perciò anche gli attuali modelli dovranno prima o poi adattarsi per trattare efficace-
mente immagini di tali risoluzioni. Nella figura sottostante si può vedere un esempio di un
frame in alta risoluzione nel quale, diminuendone le dimensioni e perdendo quindi qualità,
non sarebbe stato possibile riconoscere alcune delle persone individuate nel frame.
Figura 3: Esempio di object detection in un frame di un video in 4K
3.3 Frammentazione dell’immagine
Per esempio, un’immagine in 4K ha una risoluzione di 3840 x 2160 pixels per un totale di
8294400 di pixels. Una rete neurale effettuerebbe un ridimensionamento dell’immagine per
adattarla al meglio al suo input con conseguente perdita di risoluzione.
L’idea per aggirare il problema è quella di frammentare l’immagine in diverse sotto-immagini
di dimensioni minori e quindi gestibili efficacemente da una singola rete neurale. Questa par-
ticolare strategia è chiamata frammentazioneG dell’immagine e risulta essere molto utile in
quanto permette di analizzare un’immagine ad alta risoluzione scomponendola in frammenti
di dimensioni minori anziché gestirla nella sua interezza.
Tesi di laurea triennale - Davide Liu Pagina 12 di 67Figura 4: Esempio di un’immagine in alta risoluzione suddivisa in regioni senza
sovrapposizioni
Tuttavia questo procedimento non è esente da difficoltà. Nel caso in cui un oggetto do-
vesse trovarsi su più regioni diverse, esso potrebbe venire identificato più volte o addirittura
essere riconosciuto ogni volta come se fosse un oggetto appartenente ad una categoria diver-
sa.
Un primo approccio per risolvere questo problema è quello di porre maggiore attenzione alle
labels degli oggetti posizionati in prossimità dei confini delle regioni in quanto con molta
probabilità è possibile che l’oggetto continui ad essere presente nella regione adiacente piut-
tosto che essere interamente contenuto nella regione esaminata. Se è quindi presente una
label anche in una regione adiacente si passa allora alla verifica che le due labels possano
effettivamente appartenere allo stesso elemento. Per fare ciò bisogna assicurarsi che le due
labels siano compatibili sia in termini di categoria che di posizione entro una certa soglia ed
in caso affermativo fonderle in una sola label contenente l’oggetto intero.
Un’ altra soluzione esaminata è quella di suddividere l’immagine intera in regioni con so-
vrapposizione il cui scopo è quello di generare intersezioni tra labels in prossimità dei confini
migliorando la qualità delle detections nelle singole regioni. In questo modo un elemento
contenuto all’interno di un’area di sovrapposizione tra più regioni genererebbe due o più
labels parzialmente sovrapposte.
Nel caso più semplice, ovvero quello in cui l’area di sovrapposizione tra due bounding boxes
dovesse essere molto ampia, il problema può essere facilmente gestito con un algoritmo di
non-max suppression, il quale, per ogni insieme di labels parzialmente sovrapposte e con
stessa categoria, tende ad eliminare le labels con probabilità minore tenendo valida solo
quella con probabilità massima.
Tesi di laurea triennale - Davide Liu Pagina 13 di 67Tuttavia, il caso più insidioso ed allo stesso tempo più frequente lo si ha quanto due labels
sono solo leggermente sovrapposte: la prima difficoltà la si ha nel decidere se procedere ad
unificarle in una sola label o meno, la seconda riguarda quale criterio utilizzare per effettuare
la loro unione. E’ proprio per far fronte a questi problemi che è stato ideato ed implementato
un algoritmo il quale verrà descritto nella sezione 4.1.
3.4 Tecniche di object tracking
Il tracciamento di oggetti in un video è uno di quei problemi presenti nell’ambito dell’infor-
matica che non sono ancora stati risolti ottenendo risultati soddisfacenti. Il tracciamento
consiste non solo nel localizzare e tracciare degli oggetti di interesse attraverso una sequenza
di frames ma anche nel riconoscere che l’oggetto tracciato è sempre lo stesso.
Il problema non è per niente banale se pensiamo che in un video uno stesso oggetto può
spostarsi, nascondersi dietro qualche altro elemento, deformarsi, risultare sfocato, cambiare
le sue dimensioni, la sua illuminazione, la sua velocità ed il tipo di background. Nel caso
ancora peggiore un oggetto tracciato potrebbe addirittura scomparire in un frame per poi
ripresentarsi solamente dopo che sono trascorsi un numero casuale di frames.
Un algoritmo di tracking ottimale dovrebbe essere in grado di far fronte a tutti questi pro-
blemi riconoscendo quindi gli oggetti da esso tracciati tramite per esempio l’assegnazione di
un ID univoco.
Una possibile soluzione per affrontare questo problema consiste nell’eseguire inizialmente una
normale detection sul primo frame del video in modo tale da individuarne tutti gli elementi
presenti e le rispettive labels. In seguito, ognuno di questi elementi viene assegnato ad un
trackerG che avrà il compito di tracciare l’elemento nei frames successivi.
Tracciare un elemento è un’ operazione meno onerosa rispetto alla sua individuazione in
quanto il tracker conosce già alcune informazioni relative all’oggetto tracciato, acquisite nei
frames precedenti, potendo cosı̀ tenere in memoria uno storico del suo stato, come per esem-
pio, le sue ultime locazioni. Per aumentare la sua precisione, un tracker non tiene conto
solamente della locazione dell’elemento osservato ma può anche tenere memoria di altre utili
informazioni aggiuntive come la sua direzione, la sua velocità, le sue dimensioni, una pre-
visione delle locazioni future analizzandone la sua traiettoria oppure può memorizzare un
hash3 dei pixels presenti all’interno del bounding box dell’oggetto per poi confrontarlo con
l’hash dello stesso oggetto calcolato nel frame successivo[7].
I trackers più performanti come CSK, MOSSE[8] e GOTURN[9] utilizzano alcune delle infor-
mazioni sopra descritte per costruire un filtro di correlazione in modo da localizzare l’oggetto
3
Al contrario degli hash usati in crittografia, un hash applicato alle immagini è progettato in modo tale
che piccole variazioni dei pixels dell’immagine non risultino in un hash molto diverso da quello originale
Tesi di laurea triennale - Davide Liu Pagina 14 di 67nel frame successivo e migliorare la precisione del filtro con le successive individuazioni. Lo scopo del filtro è quindi quello di minimizzare la differenza tra l’output predetto e quello originale. Nonostante tutti questi accorgimenti è però inevitabile che col trascorrere dei frames i trac- kers cominceranno ad essere sempre più imprecisi nell’individuare il loro oggetto tracciato. In particolare, questa situazione può accadere molto velocemente in quei video dove avven- gono molti spostamenti e sovrapposizioni tra elementi. Inoltre, ad un certo frame del video è possibile che si presentino nuovi elementi o che ne scompaiano alcuni. E’ quindi buona norma aggiornare i trackers con le locazioni corrette dei loro elementi tracciati, creare nuovi trackers per ogni nuovo elemento e cancellare i trackers per gli oggetti spariti effettuando una nuova detection ogni fissato numero di frames. E’ qui che si presenta il problema di maggiore rilevanza: una nuova detection effettuata su un nuovo frame non tiene conto delle informazioni acquisite in precedenza in quanto queste con molta probabilità risulterebbero errate o imprecise. Il problema è quindi quello di rias- segnare a ciascun oggetto individuato lo stesso ID che possedeva in precedenza ed assegnare un nuovo ID ad ogni oggetto comparso nel video per la prima volta. Figura 5: Frames di un video nei quali viene tracciata un’ auto (ordinati da sinistra a destra e dall’alto al basso) 3.5 Object tracking con continue object detections Considerata la scarsa affidabilità degli attuali algoritmi di tracciamento, nella soluzione individuata gli oggetti vengono identificati effettuando una nuova detection per ogni frame del video in modo da assicurarsi di avere sempre una buona accuratezza ed allo stesso tempo migliorare l’efficacia dei trackers migliorando gradualmente la precisione dei loro filtri di Tesi di laurea triennale - Davide Liu Pagina 15 di 67
predizione. Questo metodo sacrifica l’efficienza del processo per migliorarne l’efficacia. A meno che non venga utilizzato un algoritmo di detection molto veloce come SSD (Single Shot Detector)[10] non è possibile applicare il tracking sui video in tempo reale in quanto il frame rate che ne risulterebbe sarebbe troppo basso. A seguito di una nuova detection, per effettuare una corretta riassegnazione degli ID viene fatto un confronto tra le labels presenti nel frame precedente con quelle presenti nel frame corrente con lo scopo di trovare una corrispondenza biunivoca tra due labels e capire quando entrambe si riferiscono allo stesso elemento in modo da garantire un corretto trasferimento dell’ID. Per rendere tutto ciò possibile viene utilizzato un filtro in grado di predire le locazioni future di un oggetto tenendo traccia dei suoi bounding boxes e poi correggersi tramite misurazioni successive. Anche per realizzare questa soluzione è stato ideato ed implementato un algoritmo descritto nella sezione 4.2. Tesi di laurea triennale - Davide Liu Pagina 16 di 67
4 Progettazione
Little by little, we’re giving
sight to the machines. First, we
teach them to see. Then, they
help us to see better.
Li Fei Fei
4.1 Progettazione algoritmo per riconoscimento di elementi in
un’immagine frammentata
Per quanto riguarda il problema della frammentazione dei frames in 4K è stato individuato un
apposito algoritmo in grado di effettuare il riconoscimento degli oggetti nei frames presenti
in un video senza doverli ridimensionare ma utilizzando la tecnica della frammentazione
dell’immagine.
4.1.1 Scomposizione del frame originale in regioni
Un frame in 4K viene quindi scomposto in una matrice di R x C sotto-immagini chiamate
regioniG in modo tale che ogni regione sia efficacemente analizzabile da un modello come
Faster R-CNN senza perdita di risoluzione. Per facilitare l’operazione di riconoscimento
degli elementi da parte della rete, ogni regione può essere leggermente sovrapposta con le
sue regioni adiacenti. Per definire la quantità di pixels da coinvolgere nella sovrapposizione
viene definito uno strideG che indica quanti pixels della regione tralasciare, sia in verticale che
in orizzontale, prima che cominci quella successiva, ovviamente lo stride deve essere minore
della larghezza di una regione. Una Faster R-CNN dopo aver elaborato singolarmente ogni
regione come se fosse una singola immagine darà in output una lista di labels con le seguenti
caratteristiche:
• (max-x, max-y): coordinate del vertice in alto a sinistra del rettangolo rappresen-
tante il bounding box dell’oggetto riconosciuto;
• (min-x, min-y): coordinate del vertice in basso a destra del rettangolo rappresentante
il bounding box dell’oggetto riconosciuto;
• Categoria: è un numero naturale che indica la categoria di appartenenza dell’elemento
individuato;
Tesi di laurea triennale - Davide Liu Pagina 17 di 67• Score: rappresenta la misura di probabilità che la classificazione ottenuta sia effetti-
vamente quella corretta.
Successivamente viene aggiustata la posizione delle labels individuate in modo da traslarle
nella loro posizione corretta all’interno dell’immagine originale non frammentata. Questo
viene fatto aggiungendo un adeguato offset alle coordinate dei vertici dei bounding boxes
delle labels sulla base della loro regione di appartenenza.
4.1.2 Rimozione degli elementi individuati più volte all’interno delle aree di
sovrapposizione
A causa della presenza delle aree di sovrapposizione dovute alla struttura delle regioni,
gli elementi giacenti in queste particolari zone del frame verranno individuati tante volte
quante sono le regioni che si sovrappongono in quella determinata area. Per eliminare le
copie duplicate e tenerne solo una viene utilizzato un algoritmo chiamato Average Non-Max
Suppression (ANMS) che è una variante del Non-Max Suppression tipicamente utilizzato dai
modelli di visione artificiale. Per ogni gruppo di labels sovrapposte, invece che tenere la label
con lo score maggiore ed eliminare tutte le altre, il nuovo bounding box viene calcolato come
la media dei bounding boxes box di tutte labels e lo score viene calcolato come la media tra
tutti gli scores. Questo metodo è fondato sul ragionamento che non bisognerebbe buttare
via delle informazioni già possedute ma piuttosto riutilizzarle per scoprire qualcosa di nuovo.
Per esempio ad uno stesso elemento visualizzato dentro due sezioni differenti di un’ immagine
potrebbero venirgli assegnati due score diversi. Mentre NMS conserverebbe solo il valore più
alto tra i due, ANMS li utilizzerebbe entrambi per ottenere un valore ancora più affidabile
aumentando quindi la veridicità della classificazione. Per tutto il resto del documento la
sigla NMS intenderà la sua versione ANMS.
4.1.3 Creazione di raggruppamenti di labels correlate
A questo punto tutti gli elementi sono stati individuati e classificati ma rimane comunque
il problema che, a causa della precedente scomposizione, gli oggetti situati all’interno o in
prossimità delle aree di sovrapposizione risulterebbero individuati due o più volte. Come si
può vedere in figura 6, questo numero varia in base al numero di regioni sulle quali giace
l’oggetto. Il secondo problema è che due elementi vicini 4 , anche se classificati nella stessa
categoria, non è detto che necessariamente debbano rappresentare lo stesso elemento. Un
esempio di questo caso lo si può sempre notare in figura 6. Un caso ancora peggiore lo si ha
4
Due labels sono considerate vicine se sono intersecate tra di loro ed intersecano lo stesso confine di
regione
Tesi di laurea triennale - Davide Liu Pagina 18 di 67Figura 6: Esempi di labels erroneamente individuate a causa della frammentazione e relativa
corretta ricostruzione
quando non solo l’elemento è situato su più regioni differenti ma sussiste anche il problema che
ogni parte dell’elemento verrebbe classificata in modo diverso a causa della loro ambiguità.
Infine, è anche possibile che un oggetto si distribuisca su più regioni adiacenti ed ogni sua label
presenti dimensioni o categorie diverse per ogni regione. La soluzione individuata consiste
nel raggruppare labels correlate tra loro in insiemi di labels dette raggruppamentiG per poi
racchiuderli in una label che identifica l’elemento rappresentato dal raggruppamento. Due
labels sono in correlazione tra di loro se soddisfano una condizione di correlazione sotto
riportata.
Condizione di correlazione: Per effettuare un corretto raggruppamento delle labels viene
anche tenuta in considerazione la categoria a loro associata tramite la classificazione insieme
allo score assegnato. Per definire il risultato della condizione è inoltre necessario stabilire
una soglia di affidabilitàG che indica lo score minimo che una label deve possedere per
poter considerare la sua classificazione come affidabile o meno. Di seguito vengono riportati
i vari casi per decidere se la condizione è vera o falsa.
• True: Le due labels hanno la stessa categoria ed entrambe con score uguale o maggiore
della soglia;
• True: Le due labels hanno la stessa categoria ma almeno una delle due ha score minore
della soglia;
• True: Le due labels hanno categoria diversa ma almeno una delle due ha score minore
della soglia;
Tesi di laurea triennale - Davide Liu Pagina 19 di 67• False: Le due labels hanno categoria diversa ed entrambe con score uguale o maggiore
della soglia;
Prima di cominciare con il raggruppamento, vengono inizialmente individuate tutte le labels
che intersecano i confini di regioni causati dalle aree di sovrapposizione o che non distino più
di un fissato numero di pixels, detto overlapG , da esse. L’overlap viene definito in quanto
anche se nell’immagine reale un oggetto interseca un confine di regione è possibile che a causa
di errori di imprecisione del modello, il box della label risulti leggermente distaccato dalla
linea che rappresenta il confine. E’ quindi possibile ovviare a questo problema aumentando
lo spessore del confine di tanti pixels quanti indicati dall’overlap. Per lo stesso motivo prece-
dente, ai fini di controllare se una label interseca un’ altra entità o meno viene anche tenuta
in considerazione una tolleranzaG che indica di quanto il bounding box di una label può
essere distante da un’entità affinché questa venga comunque considerata come intersecata.
Per creare i raggruppamenti di labels è stato ideato il seguente algoritmo:
1. Vengono tenute solo le labels che intersecano almeno un confine di regione e vengono
inizializzate come non controllate e non raggruppate;
2. Viene selezionata una label qualsiasi non controllata e la si imposta come controllata;
3. Per ogni label controllata ma non ancora raggruppata controlla se ci sono altre labels
non controllate che rispettino ognuna delle seguenti condizioni:
• Devono essere vicine o distanti entro la tolleranza fissata;
• Devono rispettare la condizione di correlazione;
• La loro box non deve intersecare una regione al di fuori delle aree di sovrapposi-
zione che sia già intersecata da una qualsiasi altra label controllata 5 ;
• Deve essere rispettata una soglia di matchingG : La posizione delle loro boun-
ding boxes deve essere compatibile entro una certa soglia, ovvero che, i lati lungo
il quale le due labels vengono unite siano tali che la differenza tra quello maggiore
e quello minore sia inferiore ad una certa soglia che può essere sia definita come
una proporzione rispetto ad uno dei due lati oppure come un valore in pixels.
4. Le labels cosı̀ trovate diventano a loro volta controllate;
5. Si ripetono i punti 3 e 4 fino a che non sia più possibile trovare ulteriori labels;
5
Questo perché se due labels sono state individuate come elementi distinti all’interno di una regione allora
è probabile che lo siano anche nell’immagine intera in quanto viene supposto che un modello non commetta
errori di riconoscimento
Tesi di laurea triennale - Davide Liu Pagina 20 di 676. Tutte le label controllate vengono ora classificate come raggruppate e viene assegnato
un numero progressivo ad ogni label raggruppata in modo da identificarne il gruppo di
appartenenza;
7. Si ripetono i punti da 2 a 6 fino a che tutte le labels non vengano raggruppate. L’algo-
ritmo in questo modo termina sempre ed è possibile che un raggruppamento comprenda
una sola label.
E’ da notare che labels intersecanti ma interamente comprese in una sola regione non so-
no motivo di interesse in quanto l’algoritmo di NMS utilizzato dalla rete in fase di post-
processing ci assicura che labels intersecanti nella stessa regione individuino elementi diversi.
In seguito bisogna trasformare ogni raggruppamento in una nuova label che racchiuda tutte
le labels che lo compongono. Per fare questo vengono esaminate le coordinate di ogni vertice
di tutte le bounding boxes di un raggruppamento in modo tale da trovare quattro nuovi
vertici di un rettangolo che soddisfi i requisiti sopra discussi. La nuova label cosı̀ creata
andrà a sostituire le labels del rispettivo raggruppamento e per deciderne la categoria e lo
score viene applicata una regola di classificazione: categoria e score assegnati saranno
pari alla categoria e allo score posseduti dalla label con score maggiore appartenente al rag-
gruppamento.
A questo punto l’algoritmo può dirsi concluso ed è in grado di riconoscere gli elementi in
un’immagine anche in 4K con un’accuratezza accettabile e buona velocità. Tuttavia in casi
particolari come quello mostrato in figura 7 l’algoritmo commetterebbe un errore di clas-
sificazione in quanto individuerebbe due elementi distinti con una sola label comune. In
questi casi non c’è modo di sapere se le due labels effettivamente appartengono a due oggetti
distinti o se rappresentano lo stesso oggetto. In realtà impostando correttamente la soglia
di matching si potrebbe ricostruire correttamente queste labels ma tale soglia, impostata
ad un valore molto alto, potrebbe far fallire la ricostruzione di molte più labels portando
quindi ad un peggioramento generale delle metriche di valutazione.
4.1.4 Miglioramento: raggruppamenti di labels utilizzati come region proposal
Un ulteriore miglioramento dell’algoritmo potrebbe essere ottenuto utilizzando le labels ot-
tenute dal procedimento descritto in precedenza come nuove regioni sulle quali applicare
nuovamente una detection per identificare gli elementi contenuti nella regione ma con mag-
giore precisione in quanto questa volta l’area non verrà affetta da problemi di frammentazione
dando quindi la possibilità alla rete di esaminare l’area per intero. La regione viene prima
inizializzata rimuovendo la sua label e poi ripopolata con le nuove labels identificate dalla
rete.
Il primo problema che salta fuori è che durante questo procedimento la rete identificherà
Tesi di laurea triennale - Davide Liu Pagina 21 di 67Figura 7: Esempi di labels erroneamente individuate a causa della frammentazione e relativa errata ricostruzione nuovamente anche quegli elementi che casualmente si trovavano dentro la regione coinvolta ma che erano già stati trovati anche in precedenza. Tuttavia questo problema viene tran- quillamente risolto applicando un algoritmo di average non-max suppression, utilizzato già in precedenza, per eliminare gli oggetti quasi completamente sovrapposti. Il secondo problema riguarda ancora gli oggetti che stanno a cavallo tra la regione interessata e l’immagine originale, questa volta però, avendoli già individuati nella loro interezza duran- te la prima fase è quindi solamente necessario unire la nuova label con quella già trovata in precedenza in modo da ottenerne una nuova con precisione maggiore. Un caso particolare lo si ha quando la la regione in esame risulti essere cosı̀ estesa da va- nificare i vantaggi ottenuti dalla frammentazione. Per far fronte a questo problema basta ridimensionare l’area coinvolta fino a portarla ad avere dimensioni gestibili da una rete. In questo caso la perdita di risoluzione e quindi di dettagli non comporterebbe un grave problema in quanto gli elementi visibili solo grazie all’alta definizione sarebbero già stati individuati nella fase precedente. Nel caso in cui questi oggetti dovessero venire nuovamente identificati verrebbero gestiti dall’ANMS per ottenerne una migliore approssimazione. Que- sta funzionalità permette di migliorare l’accuratezza quando si vogliono identificare oggetti che si estendono su due o più regioni o per migliorare il riconoscimento di gruppi di elementi sovrapposti e molto vicini tra loro in prossimità di un confine dove il precedente algoritmo potrebbe commettere un errore nel loro riconoscimento come mostrato in figura 7. Tesi di laurea triennale - Davide Liu Pagina 22 di 67
4.2 Progettazione algoritmo per tracciamento di elementi
Per affrontare il problema del tracciamento degli elementi, viene utilizzato un algoritmo di
tracking supportato da una detection applicata ad ogni frame del video al fine di garantirne
una migliore accuratezza[11]. L’algoritmo è indipendente dalle dimensioni dei frames del
video ma se necessario è comunque possibile effettuare la detection utilizzando l’algoritmo
descritto in sezione 4.1 in modo da non ridurre la qualità dei frames.
4.2.1 Filtro di Kalman
Lo scopo di un tracker è quello di predire la posizione di un oggetto in un frame a partire dallo
storico delle sue locazioni passate per mezzo di un filtro. I trackers implementati utilizzano
un filtro di Kalman[12] in quanto esso si rivela molto efficace nell’effettuare predizioni anche
in sistemi soggetti a continui cambiamenti come lo è per esempio un video. Il secondo
vantaggio è quello di garantire una buona resistenza contro i rumori causati da detections
imprecise, le quali possono per esempio avere luogo in presenza di oggetti parzialmente
occultati o deformati a causa di qualche spostamento. Infine, questa tipologia di filtri sono
anche computazionalmente veloci in quanto, una volta implementati, la loro esecuzione si
traduce in semplici moltiplicazioni tra matrici.
L’applicazione del filtro di Kalman consiste in due fasi distinte: predizione ed aggiornamento.
La prima fase ha come scopo quello di usare la locazione precedente per predire quella attuale
effettuando anche una piccola correzione per far fronte alle variazioni introdotte da possibili
fonti esterne (rumore). In seguito sono riportate le formule relative alla fase di predizione:
xk = Fk xk−1 + Bk uk
Pk = Fk Pk−1 FkT + Qk
Dove xk è la predizione della posizione dell’oggetto x nel frame k, Fk è il modello di transizione
di stato applicato alla posizione xk-1 , Bk è una matrice di controllo alla quale viene applicato il
vettore di controllo uk e rappresentano le variazioni subite da xk causate da una fonte esterna,
in questo caso rappresentano movimenti irregolari dell’oggetto rispetto alla sua traiettoria.
Pk è la predizione della covarianza di xk mentre Qk è la covarianza del processo che genera
rumore.
Nella seconda fase, quella di aggiornamento, viene usata la misurazione corrente, che in
questo caso sarà il bounding box dell’oggetto tracciato individuato dalla nuova detection,
per rifinire ulteriormente la sua locazione esatta. In seguito sono riportate le formule relative
alla fase di aggiornamento:
0
xk = xk + K(zk − Hk xk )
Tesi di laurea triennale - Davide Liu Pagina 23 di 670
Pk = Pk − KHk Pk
K = Pk HkT (Hk Pk HkT + Rk )−1
Dove xk ’ è la nuova stima della posizione ottenuta dopo aver effettuato l’aggiornamento, K
è una matrice detta anche guadagno di Kalman, zk è il valore misurato, in questo caso corri-
sponderà alla label individuata con la detection effettuata sul frame k. Hk è una matrice che
serve per scalare zk in modo tale da renderlo compatibile con lo stato dell’oggetto tracciato
ed infine Rk è la covarianza di zk .
Riassumendo, lo scopo del filtro di Kalman è quello di individuare la posizione reale di un
oggetto mettendo insieme due informazioni distinte: una è la predizione della sua locazio-
ne rispetto alla sua posizione precedente e l’altra è la sua posizione individuata con una
detection tenendo però conto che essa può essere soggetta ad imprecisioni.
4.2.2 Assegnazione detection-tracker
Il passo successivo è quello di abbinare ognuno dei bounding box stimati dai filtri dei trackers
con le bounding boxes individuate da una detection.
Questo risultato viene ottenuto tramite un algoritmo di ottimizzazione conosciuto anche
come algoritmo di Munkres[13]. La metrica utilizzata dall’algoritmo è l’IoU tra i bounding
boxes stimati dai trackers durante la fase di predizione dei loro filtri e quelli individuati dalla
detection, tale metrica viene spiegata in dettaglio nella sezione 7.1.3.
L’obiettivo dell’algoritmo è quello di assegnare le detections ai trackers massimizzando la
somma dell’IoU delle bounding boxes associate. Questa soluzione si basa sul ragionamento
che più due bounding boxes sono sovrapposte, più è probabile che esse rappresentino lo stesso
oggetto. Inoltre, perchè due bounding boxes possano essere associate, il loro IoU deve anche
essere maggiore o uguale di una certa soglia, detta soglia di assegnazioneG in quanto tra
due boxes poco sovrapposte è probabile che non vi sia alcuna correlazione.
Il primo passo dell’algoritmo consiste nel creare una matrice di dimensioni n x m dove n è
il numero di oggetti individuati dalla detection ed m è il numero di trackers. Se le colonne
dovessero essere minori delle righe allora bisogna ruotare la matrice in modo tale che le
colonne siano tante almeno quante sono le righe e tenere in considerazione questa eventuale
rotazione per ottenere il risultato finale.
In ogni cella della matrice viene calcolato il valore dell’IoU tra la box predetta dal tracker
i ed il box j individuato dalla detection, con 12. Per ogni colonna, sottrarre il valore minimo della colonna a tutti gli elementi della
stessa colonna. In questo modo, in ogni colonna sarà presente almeno una cella con
valore pari a 0.
3. Tracciare delle linee attraverso tutte le righe e le colonne che contengano almeno un
elemento pari a 0 in modo tale da tracciare il minor numero di linee possibile.
4. Se sono state tracciate esattamente k =min(n,m) allora l’algoritmo termina qui, altri-
menti si procederà con il passo 5.
5. Trova la cella minore che non sia tracciata da alcuna linea e poi sottrarre quel valore a
tutte le righe non tracciate, sommare poi quel valore ad ogni colonna tracciata. Infine
tornare al passo 3.
Al termine dell’algoritmo si selezionano k =min(n,m) zeri dalle celle della matrice tali che
ogni zero appartenga ad una sola riga e ad una sola colonna. Le coordinate di queste
celle corrisponderanno agli assegnamenti tracker-detection ottimali da attuare nella matrice
originale.
Figura 8: Esempio di assegnazione detection-tracker
Come si può vedere in figura 8 i rettangoli rossi raffigurano le bounding boxes dei trackers
mentre quelle verdi rappresentano le bounding boxes individuate dalla detection. I trackers
Tesi di laurea triennale - Davide Liu Pagina 25 di 671 e 2 vengono assegnati regolarmente mentre l’elemento tracciato dal tracker 3 è sparito dal frame ed è comparso un nuovo elemento che verrà tracciato da un nuovo tracker. 4.2.3 Gestione delle detections e dei trackers non assegnati Nel caso in cui nella matrice precedente si abbia avuto che n è diverso da m, significa che sono presenti dei trackers o delle detections che non sono state assegnate. Inoltre, le coppie tracker-detection associate con successo dall’algoritmo il quale IoU sia però inferiore alla soglia stabilita verranno scartate ed aggiunte nelle rispettive liste di trackers e detections non assegnate. La mancata assegnazione di un tracker al suo elemento potrebbe avere due cause scatenanti: la prima è che l’oggetto tracciato sia momentaneamente sparito dal video a causa di una detection non andata a buon fine. Questo evento può essere per esempio dovuto ad una momentanea perdita di qualità di un frame, da un occultamento o da una sfocatura causata da un movimento. La seconda causa è che l’oggetto sia effettivamente assente in un frame del video a causa di un suo movimento verso l’esterno del frame oppure a causa di un cambio di inquadratu- ra. In questo caso è poco probabile che l’oggetto scomparso ritorni a presentarsi nel frame successivo ma è più ragionevole pensare che esso non si ripresenterà più, almeno nel breve periodo. In quanto un tracker non ha modo di sapere quale delle due cause sia quella che abbia realmente portato alla sua mancata assegnazione, allora in presenza di questo evento viene solamente incrementato un contatore interno al tracker che tiene conto dei frames consecutivi trascorsi senza che il tracker venga associato al suo oggetto tracciato. Non appena questo contatore supera una certa soglia, detta soglia di cancellazioneG , il relativo tracker viene cancellato e l’elemento da esso tracciato viene considerato come perduto. Se un elemento perduto dovesse successivamente ricomparire in un frame esso verrà considerato come un nuovo oggetto venendo quindi tracciato da un nuovo tracker. Un discorso analogo vale anche per quelle labels che sono individuate da una detection ma che non vengono assegnate a nessuno dei trackers già esistenti. Con molta probabilità si tratta di una nuovo oggetto ed è quindi opportuno creare un nuovo tracker per iniziare a tracciarlo. Tuttavia, prima che il legame tracker-detection diventi effettivo non basta che l’assegnazione avvenga una sola volta. Potrebbe infatti accadere che a causa di una detection sbagliata, un oggetto di una determinata categoria compaia erroneamente in un solo frame per poi non ripresentarsi più. In questo caso sfortunato si verrebbe a creare un tracker la cui utilità sarebbe poco significativa consumando un ID per essere associato ad un oggetto individuato per errore. Per risolvere questo problema ogni tracker implementa un altro contatore per tenere traccia Tesi di laurea triennale - Davide Liu Pagina 26 di 67
dei frames consecutivi nei quali al tracker stesso viene assegnato un oggetto, questo conta- tore rappresenta quindi la durata in frames del tracciamento. Solamente dopo che questo contatore abbia superato una certa soglia, detta soglia di validazioneG , verrà assegnato un ID al tracker e la sua corrispondente bounding box verrà mostrata nel video. Una volta terminata questa fase, vengono utilizzate le nuove detections per aggiornare i filtri dei trackers e rifinire la stima della locazione degli oggetti tracciati (fase di aggiornamento). 4.2.4 Utilizzo di metriche di supporto per l’assegnazione detection-tracker Durante il processo di assegnazione tracker-detection viene utilizzata solamente l’IoU per calcolare la metrica per decidere come abbinare le varie bounding boxes presenti in un frame. Questa metrica verrà anche chiamata come valore di matchingG tra due bounding boxes e più questo valore è alto, maggiore è la possibilità che due bounding boxes, una predetta dal filtro di un tracker e l’altra individuata da una detection, vengano associate. Tuttavia, in presenza di sovrapposizioni, il valore di matching, facendo affidamento solo sull’IoU, potrebbe non risultare abbastanza affidabile. Pensiamo per esempio al caso in cui due persone A e B che, camminando in direzioni opposte, incrocino brevemente la loro traiettoria. In un determinato frame è possibile che, essendo le bounding boxes delle due persone molto sovrapposte, venga commesso un errore nell’assegnazione tracker-detection causando quindi uno scambio di ID tra le due persone. Da quel frame in poi la persona A verrà quindi tracciata con l’ID B e viceversa. Per ridurre la probabilità che questo sfortunato evento accada, la metrica utilizzata per determinare il valore di matching tra le bounding boxes di una detection e un tracker non sarà soltanto l’IoU tra le loro aree ma possono venire aggiunte anche altre metriche di supporto come il rapporto tra la dimensione delle loro aree ed il rapporto tra le dimensioni dei loro lati[14]. Questo ragionamento si basa sul fatto che tra due frames consecutivi, queste metriche normalmente non possono subire una grande variazione rispetto allo stesso oggetto e quindi possono essere utili nell’effettuare un’eventuale associazione qualora affidarsi all sola IoU non risulterebbe molto efficace. Ovviamente, possono anche essere definiti dei pesi per rendere ciascuna metrica più importante o meno. Tesi di laurea triennale - Davide Liu Pagina 27 di 67
5 Tecnologie
5.1 Python
Il linguaggio di programmazione utilizzato per perseguire gli obiettivi del progetto è stato
Pythonv3.7, si tratta di un linguaggio di programmazione di alto livello il cui obiettivo è
quello di facilitare la leggibilità del codice ed adattarsi a diversi paradigmi di programmazione
come quello procedurale, ad oggetti e funzionale. La motivazione per la scelta dell’utilizzo
di questo linguaggio, oltre alla sua semplicità, è per il suo supporto di numeri frameworks
e moduli relativi al deep learning e alla computer vision tra i quali Tensorflow e OpenCV.
Qualsiasi modulo aggiuntivo può essere semplicemente installato eseguendo il comando:
pip install nome_modulo
Per lanciare un programma viene utilizzato il comando:
python nome_file.py
Altri moduli che sono stati utilizzati comprendono Numpy, Matplotlib e Pytest.
Figura 9: Logo di Python
5.2 Pycharm
Pycharm è un IDE per programmare in Python sviluppato da JetBrains. Le sue caratteri-
stiche più importanti includono:
• Un sistema intelligente di completamento automatico del codice;
• Analisi statica del codice eseguita a tempo di esecuzione;
• Individuazione e risoluzione veloce degli errori tramite proposte di correzione;
• Possibilità di lavorare in un ambiente di sviluppo virtuale dove per ogni progetto
vengono installate solamente le proprie dipendenze ed i propri moduli.
Tesi di laurea triennale - Davide Liu Pagina 28 di 675.3 Tensorflow
Tensorflow[15] è un framework gratuito e open-source per lo sviluppo e l’allenamento di mo-
delli di machine learning come le reti neurali. Ha la particolarità che i dati vengono gestiti
attraverso dei grafi computazionali dove i nodi rappresentano delle operazioni matematiche
da eseguire e gli archi rappresentano degli array multidimensionali contenenti i dati sui quali
svolgere le operazioni (tensori). La sua architettura permette di svolgere le operazioni sia
usando le CPUs che le GPUs in modo da eseguire operazioni con alto livello di paralleli-
smo. Il modello di rete neurale utilizzato per effettuare la detection sulle immagini è stato
implementato con Tensorflow.
Figura 10: Logo di Tensorflow
5.4 OpenCV
OpenCV[16] è una libreria open-source orientata allo sviluppo di applicazioni di computer
vision in tempo reale. E’ stata scritta originariamente in C++ ma offre anche il supporto
ad altri linguaggi di programmazione come Python. OpenCV è un’ ottima libreria quando
si ha bisogno di manipolare immagini e video permettendo di compiere operazioni sia di alto
livello che di basso livello operando sui singoli pixels. Sono inoltre presenti diversi algoritmi
di object detection ed object tracking già implementati permettendo quindi di sperimentarli
tutti senza apportare troppe modifiche al proprio programma. La libreria è stata anche
utilizzata per scomporre un video nei sui singoli frames oltre che per disegnare su di essi.
5.5 Numpy
Numpy[17] è un modulo di Python che fornisce il supporto per la gestione di matrici e array
multidimensionali di grandi dimensioni. Dispone anche di una vasta collezione funzioni
Tesi di laurea triennale - Davide Liu Pagina 29 di 67Puoi anche leggere

















































