Elaborazione del linguaggio naturale ed estrazione di informazioni da Twitter Natural Language Processing and Information Extraction from Twitter
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica Elaborato finale in INTELLIGENZA ARTIFICIALE Elaborazione del linguaggio naturale ed estrazione di informazioni da Twitter Natural Language Processing and Information Extraction from Twitter Anno Accademico 2019/2020 Candidato: Vincenzo Coppola matr. N46 003356
Dopo tre intensi anni è finalmente arrivato il tanto atteso giorno. È stato un periodo di grande apprendimento, non solo per l’istruzione ricevuta, ma anche a livello personale. Vorrei pertanto ringraziare tutte le persone che mi hanno aiutato e sostenuto in questo percorso. Prima di tutto, vorrei ringraziare i miei relatori, la professoressa Amato Flora e il professore Cozzolino Giovanni, che, oltre ad avermi guidato nella stesura di questo lavoro, sono stati sempre disponibili e mi hanno fornito preziosi consigli per intraprendere la strada giusta e portare a compimento la mia tesi. Un ringraziamento va anche a tutti i professori per le conoscenze, la passione e l’entusiasmo che mi hanno trasmesso. Vorrei ringraziare i miei genitori per essere sempre presenti, per i loro consigli e per la loro capacità di ascoltarmi e supportarmi anche nelle situazioni peggiori. Ringrazio mia sorella, i miei nonni e tutta la mia famiglia che mi è sempre stata vicina. Un ringraziamento va anche a tutti i miei colleghi, in particolare ad Alberto, Antonio, Dario e Salvatore, con i quali ho condiviso a pieno questi tre anni. Per ultimi, ma non per importanza, vorrei ringraziare Cristiana, Ferdinando, Giuseppe, Raffaele e tutti i miei amici, che ogni giorno hanno condiviso con me gioie, sacrifici e successi senza mai voltarmi le spalle. L’affetto e il sostegno che mi avete dimostrato rendono questo traguardo ancora più prezioso... siete la mia seconda famiglia. Un sentito grazie a tutti! Vincenzo Coppola
INDICE
Indice III
Introduzione 4
Capitolo 1: Natural Language Processing 5
1.1 Cos'è il Natural Language Processing 5
1.2 Storia del NLP 6
1.3 NLP e Deep Learning 6
1.4 NLP per il dialogo 7
1.5 Social Network e Big Data alla base dei progressi del NLP 8
Capitolo 2: Analisi testuale 10
2.1 Analisi del contenuto 10
2.2 Specifiche di progetto e strumenti utilizzati 12
2.2.1 Twitter 12
2.2.2 spaCy 12
2.2.3 Python 13
2.3 Descrizione analisi 14
2.4 Esempio di Output 17
Capitolo 3: Information Extraction 19
3.1 Gli strumenti per l'IE 20
3.2 IE from Twitter: Tweepy 21
3.2.1 StreamAPI 22
3.2.2 RestAPI 24
3.3 Analisi dei tweet 26
3.3.1 Sentiment Analysis 27
Conclusioni 31
Bibliografia 33
III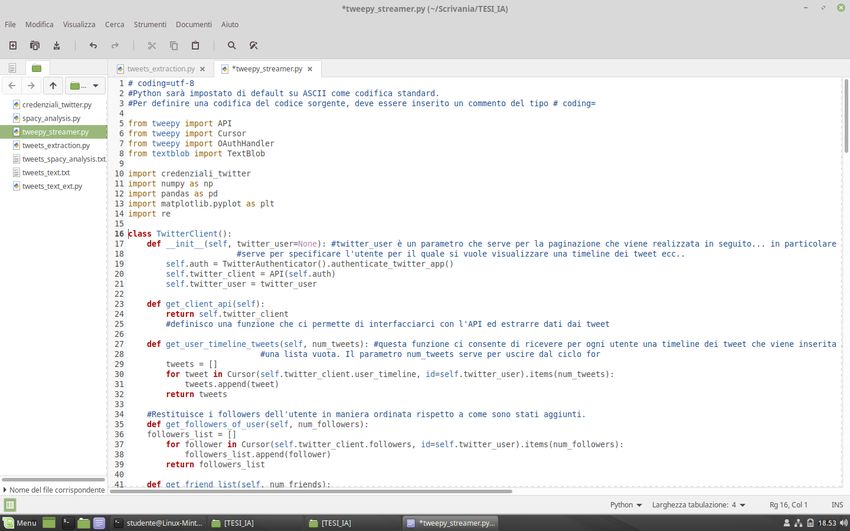
Introduzione
Alla base di questo studio vi è l’analisi del linguaggio naturale al fine di poter estrarre delle
informazioni di interesse.
In particolare, si pone l’attenzione sul Natural Language Processing che offre numerosi
spunti di analisi.
La motivazione principale che mi ha spinto ad approfondire tale tema è la curiosità nel
capire come sia possibile che, sistemi come Alexa di Amazon o Siri di Apple, siano in grado
non solo di imitare il dialogo umano ma anche di rispondere a domande su argomenti di
diversa natura ed eseguire operazioni molto complesse.
L’obiettivo di questa tesi di laurea è quello di fornire delle informazioni riguardanti le
tecniche di Natural Language Processing ed Information Extraction e mettere in evidenza i
risultati ottenuti da quest’analisi.
In particolare, è stata effettuata un’analisi di tweet, estratti da Twitter, con l’obiettivo di
poter estrarre alcune informazioni di interesse.
La tesi è articolata in tre capitoli: nel primo viene fornita un’introduzione del fenomeno del
Natural Language Processing e come esso si approccia con altri campi di studio; nel secondo
capitolo si fa riferimento all’analisi testuale, facendo particolare leva sull’analisi del
contenuto, e viene proposto un semplice progetto in cui si va ad analizzare il contenuto di
un tweet utilizzando la libreria spaCy; il terzo e ultimo capitolo si concentra invece
sull’Information Extraction e su come questa possa essere realizzata utilizzando le funzioni
messe a disposizione dalla libreria Tweepy.
A tal proposito, è stato realizzato un progetto dimostrativo di cui sono riportati anche i
risultati.
Infine, nelle conclusioni di questa tesi, sono state riportate le principali sfide di ricerca
ancora aperte e quali possono essere le possibili soluzioni.
4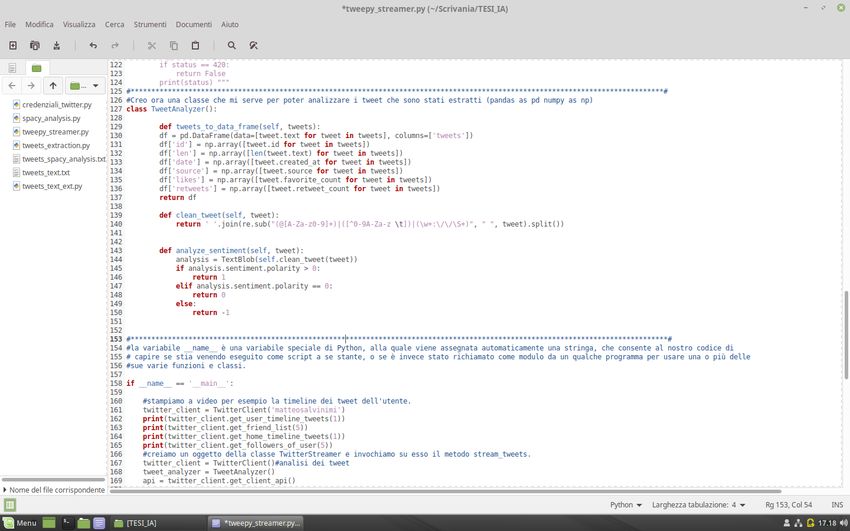
Capitolo 1: Natural Language Processing
1.1 Cos’è il Natural Language Processing
Il Natural Language Processing è un campo di ricerca interdisciplinare che coinvolge
informatica, intelligenza artificiale e linguistica, il cui scopo è quello di sviluppare
algoritmi che siano in grado di analizzare, rappresentare e comprendere il linguaggio
naturale.
Per linguaggio naturale si intende la lingua che utilizziamo tutti i giorni ed è sinonimo di
linguaggio umano, principalmente per poterlo distinguere dal linguaggio formale a cui
appartiene il linguaggio dei computer.
Così com’è, il linguaggio naturale è la forma di comunicazione umana più comune non solo
nella sua versione parlata, ma anche in quella scritta che sta crescendo esponenzialmente
negli ultimi anni attraverso i social media. Rispetto al linguaggio formale, il linguaggio
naturale è molto più complesso, contiene spesso ambiguità che lo rendono molto difficile
da elaborare e comprendere.
Determinante per la comprensione del linguaggio naturale è la suddivisione di esso in vari
livelli di dettaglio: dalle parole, in relazione al loro significato ed alla loro appropriatezza
d’uso all’interno di un contesto, fino alla grammatica ed alle regole di strutturazione sia
delle frasi, sia dei paragrafi e sia delle pagine.
In primo luogo, l’NLP fornisce soluzioni per analizzare la struttura sintattica del testo,
associando alle singole parole le rispettive categorie morfologiche (ad esempio nome,
verbo, aggettivo), così da poter identificare entità, classificarle in varie categorie ed estrarre
dipendenze sintattiche e relazioni semantiche.
In secondo luogo, l’NLP consente di comprendere la semantica del testo, identificando il
significato delle parole all’interno del contesto in cui vengono utilizzate, e le modalità di
utilizzo (per esempio ironia, sarcasmo, sentimento).
5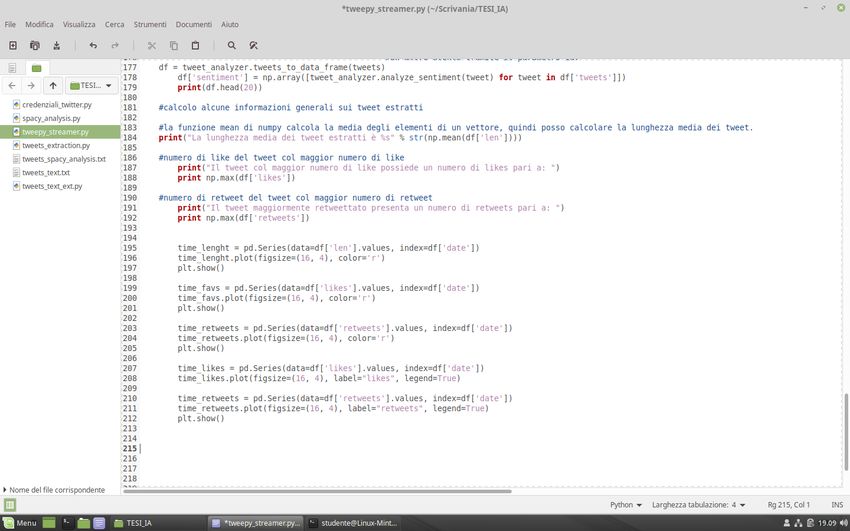
1.2 Storia del NLP
La storia di questo campo di ricerca ha inizio negli anni ’50, quando Alan Turing pubblicò
il suo articolo “Machine and Intelligence”, in cui propose un test per valutare l’abilità di
un computer nel mostrare comportamenti intelligenti, indistinguibili da quelli di un essere
umano, conversando in linguaggio naturale.
Fino agli anni ’80, la maggior parte degli approcci NLP ha provato a formalizzare nei
computer i vocabolari e le regole del linguaggio naturale con risultati però poco
soddisfacenti a causa della rigidità e non scalabilità delle regole scritte a mano.
Negli anni ’90 i risultati iniziarono ad essere più soddisfacenti vista la comparsa dei primi
approcci di NLP basato su corpora, ossia grandi collezioni di testi scritti o orali prodotti in
contesti comunicativi reali.
I corpora permettono quindi di osservare l’uso effettivo di una lingua e di verificare
tendenze generali su base statistica.
Non è quindi più necessaria una codifica manuale preliminare e risulta pertanto risolto il
problema degli approcci a regole, consentendo ad una macchina di apprendere
autonomamente le preferenze lessicali e strutturali.
1.3 NLP e Deep Learning
Data l’estrema varietà e quantità di contenuti espressi in linguaggio naturale, l’intelligenza
artificiale assume un ruolo fondamentale, favorendo la realizzazione di soluzioni innovative
non solo per l’elaborazione e la comprensione del linguaggio ma anche per la produzione
automatica di dati testuali.
In particolare, negli ultimi anni, si è assistito alla nascita di nuovi approcci che vanno ad
integrare l’elaborazione del linguaggio naturale con gli algoritmi di apprendimento
profondo, i cosiddetti algoritmi di Deep Learning; grazie a questi ultimi oggi è possibile
tradurre sia testi che parlato in lingue differenti in maniera del tutto automatica e con
prestazioni molto elevate, dialogare con le macchine in linguaggio naturale (Siri, Alexa) o
6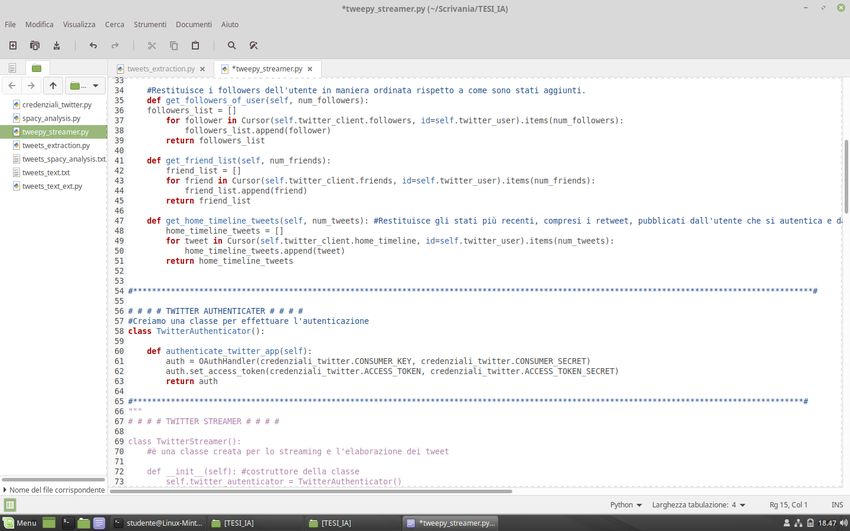
ancora generare contenuto in linguaggio naturale per sintetizzare le informazioni chiave di
un documento.
Il Deep Learning si basa sul concetto di rete neurale artificiale, ossia un modello
matematico ispirato dal punto di vista funzionale ai sistemi neurali del cervello umano.
Una prima caratteristica fondamentale di tali reti è che sono in grado di apprendere, in
maniera autonoma, sia una rappresentazione di tipo gerarchico delle caratteristiche
descrittive dei dati in ingresso, sia le modalità con le quali combinare al meglio queste
informazioni per risolvere un compito specifico.
Una seconda caratteristica, anch’essa molto importante, è che tali reti apprendono dalle loro
esperienze: sono quindi in grado di migliorare le loro prestazioni nella risoluzione di un
problema complesso in funzione della quantità di esempi con cui sono addestrate.
C’è però un problema: queste reti neurali sono in grado di elaborare solamente dati numerici
e non stringhe testuali ed è proprio per questo motivo che, a partire dal 2013, sono state
proposte tecniche differenti per la rappresentazione del linguaggio in maniera numerica
come un vettore continuo di numeri reali (word embeddings).
Tra le reti neurali maggiormente utilizzate per problemi di NLP vi sono:
• le reti convolutive, che sono in grado di estrarre caratteristiche complesse operando
localmente su piccole porzioni di testo;
• le reti ricorrenti, che sono in grado di trattare dati sequenziali e quindi apprendono
dipendenze più lunghe all’interno di un testo.
Il Deep Learning, attraverso la combinazione di word embeddings e reti convolutive e
ricorrenti, rappresenta quindi l’approccio maggiormente utilizzato per affrontare
problematiche relative all’elaborazione e alla comprensione del linguaggio naturale.
1.4 NLP per il dialogo
Al giorno d’oggi, le tecniche di NLP basate su deep learning trovano sempre più
applicazione nello sviluppo di sistemi conversazionali intelligenti, ossia sistemi in grado di
emulare il dialogo umano, di rispondere a domande su diversi argomenti ed eseguire compiti
anche molto complessi.
7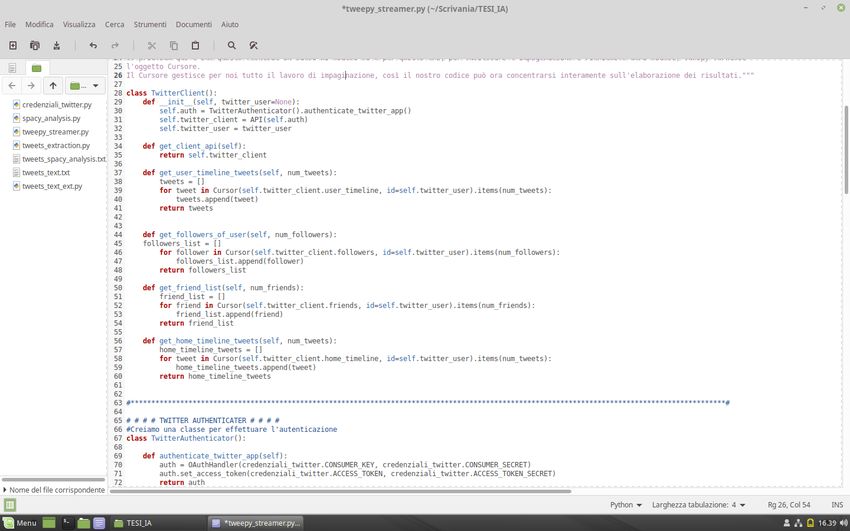
Tra i sistemi conversazionali più noti troviamo Siri di Apple, Alexa di Amazon, Cortana di
Microsoft e Assistant di Google.
Questi sistemi sono capaci di:
• fornire risposte dirette e coincise a domande poste dall’utente in linguaggio naturale su
uno specifico dominio; affinché ciò sia possibile vengono adoperati approcci di deep
learning in grado di analizzare e classificare domande ed estrarre risposte in linguaggio
naturale interrogando basi di conoscenza di grandi dimensioni e/o collezioni di
documenti testuali, come il Web, risolvendo ambiguità e favorendo relazioni di tipo
semantico;
• “conversare” in maniera del tutto naturale con gli esseri umani sfruttando a piena
potenza gli algoritmi di deep learning che consentono di apprendere differenti tipologie
di risposte, su vari domini di interesse, a partire da esempi di dialogo reali;
• supportare l’utente nell’esecuzione di compiti più o meno complessi, come l’acquisto di
un biglietto o la prenotazione di un viaggio; per fare ciò si sfruttano algoritmi addestrati
per comprendere le intenzioni dell’utente, aggiornare lo stato della conversazione in
funzione di tali intenzioni, selezionare la prossima azione da eseguire e convertire
quest’ultima in una risposta anch’essa espressa in linguaggio naturale.
Queste sono solamente alcune delle innumerevoli funzionalità dei sistemi conversazionali
che vengono realizzate attraverso tecniche di NLP e che sono destinate col tempo a
diventare sempre più importanti nel “rapporto” uomo-macchina.
1.5 Social Network e Big Data alla base dei progressi del NLP
A partire dalla nascita di Internet e fino alla comparsa dei primi social networks, la mole di
dati disponibile sul Web era molto scarsa; possiamo quantificarla come una decina di
exabyte.
Per comprendere quanto i social networks siano importanti per l’analisi è sufficiente sapere
che, oggigiorno, questa mole di dati viene prodotta settimanalmente.
8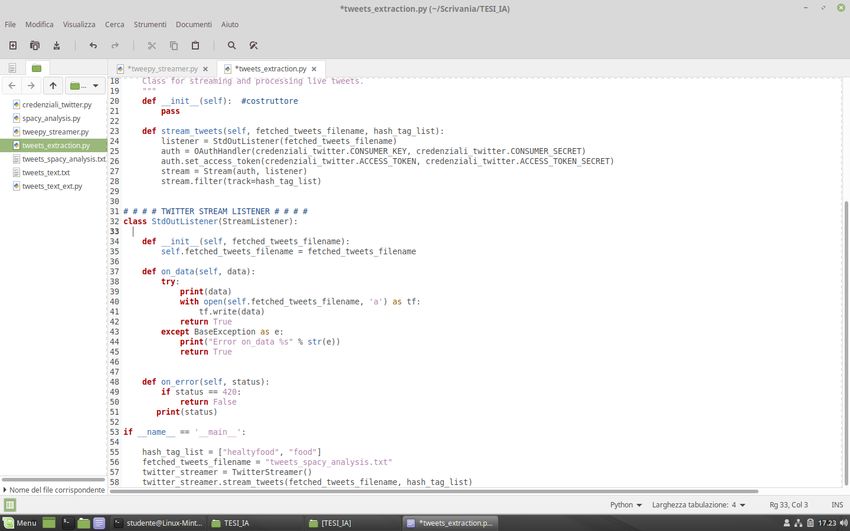
Questo fenomeno di generazione e diffusione di dati può essere ricondotto a diversi fattori:
I. l’avvento del Social Web e la disponibilità di dispositivi tecnologici sempre più alla
portata di tutti, che hanno fatto sì che l’utente, da fruitore passivo, sia passato ad essere
un protagonista attivo, producendo così dei contenuti che danno vita ad una enorme
mole di dati di natura eterogenea;
II. l’informatizzazione dei processi aziendali e la digitalizzazione della maggior parte dei
documenti.
9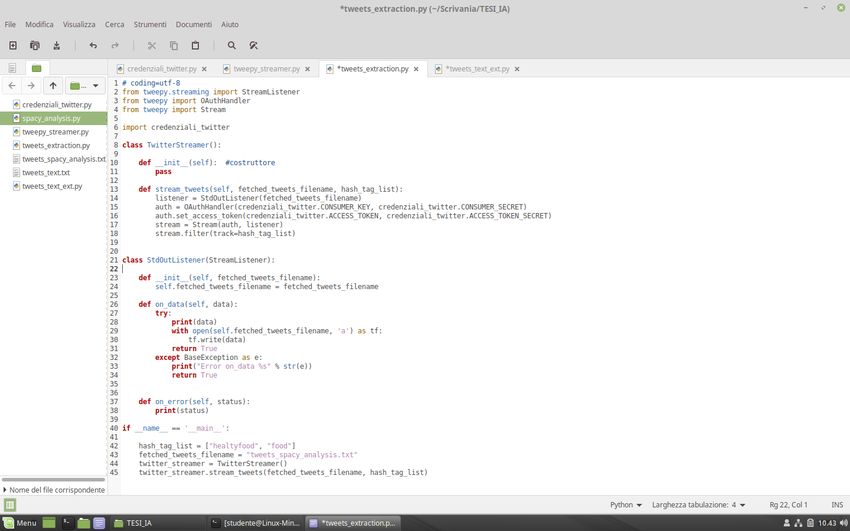
Capitolo 2: Analisi Testuale
“Le diverse tecniche di analisi testuale, attraverso il supporto di specifici software,
rispondono all’esigenza di accostarsi a campi d’indagine complessi e consentono
l’esplorazione, la descrizione, e l’analisi di corpora testuali anche molto estesi e poco
strutturati.”
(Francesca della Ratta Rinaldi, 2007).
Dalla citazione si deduce che, attraverso l’analisi testuale, è possibile esplorare rapidamente
e in modo semi-automatico la struttura di testi, anche molto ampi, con il vantaggio di poter
tornare in qualsiasi momento ai testi originali.
È importante però sottolineare che le procedure di analisi testuale non si limitano
semplicemente al conteggio delle singole parole ma consentono anche di approfondire i
contenuti presenti nel documento attraverso delle operazioni di ricerca, selezione e
classificazione dei testi.
2.1 Analisi del contenuto
L’analisi del contenuto è un insieme di tecniche, manuali o assistite da computer, che ha
come obiettivo interpretare documenti, provenienti da processi di comunicazione, ed
assegnare un significato al loro contenuto con lo scopo di produrre inferenze valide e
attendibili.
Una volta definito l’insieme dei testi da analizzare è necessario eseguire una serie di
operazioni preliminari al fine di curare l’organizzazione interna e la trascrizione dei
documenti.
A tal proposito bisogna verificare in primo luogo la comparabilità dei testi, in secondo
luogo la disponibilità di una o più caratteristiche da associare a ciascun frammento e, infine,
10che i testi siano sufficientemente lunghi al fine di rendere vantaggioso il ricorso a tecniche
automatiche di analisi.
Il punto di partenza è l’analisi delle parole che compongono il corpus così da poter
individuare le cosiddette “parole tema” che consentono di cogliere, in maniera immediata,
gli argomenti principali del testo.
Successivamente è necessario seguire diversi passaggi che consentono di descrivere in
modo semi-automatico il contenuto del testo:
• analisi dei segmenti ripetuti: si tratta di quelle forme composte, costituite da parole che
compaiono nel corpus con la stessa sequenza, che aiutano a fornire una rappresentazione
sintetica dei contenuti del corpus e ad individuare rapidamente oggetti e azioni su cui è
strutturato il testo;
• analisi delle co-occorrenze: consente di studiare le associazioni tra parole, individuando
quelle che compaiono più spesso vicine tra loro;
• analisi delle parole caratteristiche: consente di differenziare le parti di un testo,
evidenziando quelle parole che sono sovra-rappresentate nel linguaggio di una certa
categoria di autori, così da poter caratterizzare il linguaggio;
• analisi del linguaggio peculiare: a ciascuna parola è associata una frequenza che serve
ad indicare l’uso atteso di ogni parola nella comunità linguistica a cui il lessico è riferito;
• analisi delle parole con caratteristiche grammaticali omogenee: utile affinchè l’insieme
dei verbi ricondotti al lemma fornisca una graduatoria delle azioni menzionate nel testo,
l’insieme degli aggettivi fornisca elementi per valutare il tono del testo ed infine i
pronomi diano conto del tipo di interazione presente tra soggetti;
• analisi delle concordanze: tecnica che consente di analizzare il contesto d’uso di una
parola di interesse attraverso l’analisi di n parole precedenti e n parole successive ad
essa; quest’analisi viene eseguita ogni qualvolta la parola di interesse compare nel
corpus, al fine di risolvere le ambiguità semantiche e definire una mappa concettuale tra
parole e temi affrontati;
• analisi delle corrispondenze lessicali: consente di sintetizzare l’informazione contenuta
in una grossa matrice di dati testuali, visualizzando le associazioni tra le parole in analisi
11e cercando la miglior rappresentazione simultanea degli elementi così da poter studiare
le dipendenze tra caratteri.
2.2 Specifiche di progetto e strumenti utilizzati
L’obiettivo di questo primo progetto è quello di realizzare l’analisi testuale utilizzando la
libreria spaCy.
In particolare, si vogliono analizzare documenti prelevati dall’applicazione Twitter, al fine
di effettuare le operazioni di analisi che sono state elencate in precedenza.
2.2.1 Twitter
Twitter è un servizio di notizie e microblogging fornito dalla società Twitter,Inc. su cui gli
utenti “postano” i propri pensieri ed interagiscono con messaggi chiamati tweet.
Ogni utente possiede una propria pagina personale, aggiornabile tramite messaggi di testo
con una lunghezza massima di 280 caratteri.
Il sito web è stato creato nel marzo 2006 ed è stato lanciato nel luglio dello stesso anno.
Grazie alla sua semplicità e all’immediatezza d’uso, oggigiorno, è uno dei social network
più popolari; a partire dal 2016 conta oltre 319 milioni di utenti attivi mensilmente.
Inoltre, è utilizzato dagli utenti anche per diffondere notizie, come strumento di giornalismo
e soprattutto viene utilizzato dalla maggior parte dei politici e dagli organi di stato, motivo
per il quale la sua popolarità è in aumento costante.
Data la vasta mole di utenti, l’insieme dei tweet pubblicati su Twitter costituisce un’enorme
quantità di materiale che può essere utilizzato per effettuare delle analisi.
2.2.2 spaCy
“Se si lavora con un testo di grandi dimensioni, alla fine potrebbe essere utile saperne di
più su di esso. Per esempio, di cosa si tratta? Cosa significano le parole nel contesto? Chi
sta facendo cosa a chi? Quali aziende e prodotti sono menzionati? Quali testi sono simili
tra loro?
12spaCy è progettato specificamente per l'uso produttivo e aiuta a costruire applicazioni che
elaborano e "comprendono" grandi volumi di testo. Può essere utilizzato per costruire
sistemi di estrazione delle informazioni o di comprensione del linguaggio naturale, o per
pre-processare il testo per un apprendimento profondo.”
spaCy è una libreria software open-source1 per l’elaborazione avanzata del linguaggio
naturale; è scritta utilizzando il linguaggio di programmazione Python e mette a
disposizione un gran numero di funzionalità.
Tra queste quelle più importanti sono:
• tokenizzazione;
• named entity recognition;
• grammatical tagging;
• text classification;
• deep learning integration.
Per l’installazione di spaCy è necessario installare prima il comando pip e successivamente
eseguire il comando pip install -U spaCy.
2.2.3 Python
Python è un linguaggio di programmazione ad alto livello, orientato agli oggetti e adatto a
sviluppare applicazioni distribuite e scripting.
È un linguaggio multi-paradigma che ha tra i principali obiettivi dinamicità, semplicità e
flessibilità; supporta inoltre anche il paradigma object oriented, la programmazione
strutturata e molte caratteristiche di programmazione funzionale.
Le principali caratteristiche del linguaggio Python sono le variabili non tipizzate e l’uso
dell’indentazione per la definizione delle specifiche.
1 open-source: software non protetto da copyright e liberamente modificabile dagli utenti.
13Altre caratteristiche, anch’esse molto importanti, sono l’overloading degli operatori, la
presenza di una grande quantità di tipi e funzioni di base e l’opportunità di poter usufruire
di una vasta gamma di librerie.
Il controllo dei tipi è forte (strong typing) e viene eseguito a runtime (dynamic typing); una
variabile è un contenitore a cui viene associata “un’etichetta” che rappresenta il nome della
variabile e che, durante il suo ciclo di vita, può essere associata a diversi contenitori non
necessariamente dello stesso tipo.
La memoria è gestita dai garbage collectors che sono direttamente integrati nell’ambiente
di esecuzione.
Python, infatti, non rilascia necessariamente la memoria al sistema operativo ma possiede
un allocatore dedicato per oggetti di dimensioni inferiori a 512 byte, che mantiene alcuni
pezzi di memoria già allocata per un ulteriore uso futuro.
La quantità di memoria che Python utilizza dipende dal contesto e, in alcuni casi, tutta la
memoria allocata potrebbe essere rilasciata solo quando il processo termina.
Se un processo Python di lunga durata richiede più memoria nel tempo, non significa
necessariamente che si hanno perdite di memoria.
I GC sono quindi, in sintesi, responsabili di liberare automaticamente la memoria
cancellando tutte quelle risorse che sono inutilizzate.
2.3 Descrizione analisi
N.B: Il codice è stato eseguito sul sistema operativo Linux Mint con la versione 2.7 di Python.
Una volta installata la libreria spaCy (par. 2.2.2) bisogna scaricare ed installare un modello
che deve essere successivamente caricato tramite l’istruzione spacy.load().
Questo restituirà un oggetto Language contenente tutti i componenti e i dati necessari per
elaborare il testo.
Nel caso in esame è stato utilizzato il modello per la lingua inglese.
python -m spaCy download en_core_web_sm
Consideriamo ora un documento contenente una serie di tweet da analizzare.
14Lo script realizzato ha come obiettivo soddisfare tutti i punti che costituiscono la pipeline
NLP:
• Pretrattamento del corpus: è stata realizzata una correzione manuale dei caratteri
utilizzati nei tweet al fine di poterli rendere riconoscibili secondo il codice ASCII;
• Annotazione morfo-semantica: è stata assegnata ad ogni termine la categoria di
appartenenza e, successivamente, è stato individuato il lemma;
• Analisi lessico-metrica: Noun Chanks e Navigating the Pars Tree individuano per ogni
termine tutte le parole che sono ad esso associate e le inseriscono all’interno di una lista;
• Estrazione dei termini peculiari: la Named Entity Recognition identifica i nomi e i
concetti con maggiore importanza;
• Identificazione delle relazioni: è stato utilizzato un approccio endogeno in quanto le
informazioni sono state estratte dai corpus stessi.
Possiamo adesso analizzare lo script realizzato in linguaggio Python.
import spacy
nlp = spacy.load('en_core_web_sm')
tweets = open("tweets.txt", "r")
indice = 0
for contenuti in tweets.readlines():
indice += 1
doc = nlp(unicode(contenuti, "utf-8"))
analizzato = open('anallizato.txt', 'a')
analizzato.write("********************...ANALYZING TWEET NUMBER " +str(indice) + "...******************")
analizzato.write("LEMMATIZZATION\n")
analizzato.write("TEXT LEMMA POS TAG DEP\n")
for token in doc:
analizzato.write(token.text + ' ' + token.lemma_ + ' ' + token.pos_ + ' ' + token.tag_ + ' ' + token.dep_
+ '\n')
analizzato.write("\n\nNOUN CHUNKS\n")
analizzato.write("TEXT ROOT_TEXT ROOT_DEP ROOT_HEAD_TEXT\n")
for chunk in doc.noun_chunks:
analizzato.write(chunk.text + ' ' + chunk.root.text + ' ' + chunk.root.dep_ + ' ' + chunk.root.head.text +
'\n')
analizzato.write("\n\nNAVIGATING THE PARSE TREE\n")
analizzato.write("TEXT DEP HEAD_TEXT HEAD_POS CHILDREN\n")
for token in doc:
analizzato.write(token.text + ' ' + token.dep_ + ' ' + token.head.text + ' ' + token.head.pos_ + ' ' +
str([child for child in token.children]) + '\n')
analizzato.write("\n\nITERATING AROUND THE LOCAL TREE\n")
analizzato.write("TEXT DEP N_LEFTS N_RIGTHS ANCESTORS\n")
root = [token for token in doc if token.head == token][0]
subject = list(root.lefts)[0]
for descendant in subject.subtree:
assert subject is descendant or subject.is_ancestor(descendant)
analizzato.write(descendant.text + ' ' + descendant.dep_ + ' ' + str(descendant.n_lefts) + ' ' +
str(descendant.n_rights) + ' ' + str([ancestor.text for ancestor in descendant.ancestors]) + '\n')
analizzato.write("\n\nNAMED ENTITY RECOGNITION\n")
analizzato.write("TEXT START END LABEL DESCRIPTION\n")
for ent in doc.ents:
analizzato.write(ent.text + ' ' + str(ent.start_char) + ' ' + str(ent.end_char) + ' ' + ent.label_)
analizzato.write("\n\nSENTENCE RECOGNITION\n")
for sent in doc.sents:
analizzato.write(sent.text + '\n')
analizzato.close()
print('DOCUMENTO ANALLIZZATO')
15Per prima cosa è stata importata la libreria scaricata in precedenza attraverso l’istruzione
import spacy; successivamente è stato caricato il modello della lingua inglese utilizzando la
funzione spacy.load() ed è stato aperto in lettura il documento di testo contenente i tweet.
Dal momento che ogni tweet occupa una sola riga del documento, sfruttando una variabile
indice è stato possibile tener conto di quale fosse il tweet analizzato.
L’istruzione successiva è la lemmatizzazione che si occupa di riconoscere
automaticamente le diverse flessioni di sostantivi, aggettivi, verbi, e di riportarli alla loro
radice comune.
La lemmatizzazione comporta che le forme dei sostantivi e degli aggettivi vengano
ricondotte al maschile singolare, quelle dei verbi all’infinito presente, quelle delle
preposizioni articolate alla loro forma senza articolo e così via.
Questa porzione di codice individua il lemma, cioè la forma base, il pos, cioè la categoria
di appartenenza del termine, il tag ovvero l’etichetta dettagliata della categoria del termine
e infine il dep, cioè la relazione sintattica tra i vari token che si ottiene attraverso tecniche
di I.E.(information extraction).
Successivamente sono stati analizzati i Noun Chunks, ossia “frasi di base” che hanno un
nome come testa.
In questa fase si determinano: il root text, cioè il testo originale della parola che collega il
noun chunk al resto della frase, il root dep, cioè la relazione di dipendenza che collega la
radice alla sua testa, e infine il root head text, ossia il testo della testa del token della radice.
Navigating the Parse Tree ha come obiettivo quello di analizzare l’albero delle
dipendenze, connettendo i termini che dipendono tra loro con un arco.
In questa fase di analisi possiamo quindi individuare il dep, ossia la relazione sintattica che
collega il “figlio” alla testa, l’head text, cioè il testo originale della testa del token, l’head
pos, ossia la categoria di appartenenza della testa, ed infine il children che altro non è che il
figlio, inteso come relazione di dipendenza, della testa.
L’iterazione rispetto all’albero delle dipendenze locali ha come obiettivo identificare,
per ogni termine, i termini da cui esso dipende.
16Gli attributi Token.lefts e Token.rights forniscono sequenze di “figli” sintattici che si
verificano prima e dopo il token e che servono per individuare le relazioni di gerarchia.
La Named Entity Recognition permette invece di riconoscere i “nomi” all’interno del
documento: in particolare, restituisce il testo originale, a che categoria appartiene e la
posizione in cui si trova all’interno della frase.
Infine è stata realizzata la Sentence Recognition il cui obiettivo è il riconoscimento delle
frasi che compongono il testo.
2.4 Esempio di Output
A scopo illustrativo considereremo un solo tweet, pubblicato da Donald Trump, nonostante
il codice realizzato sia in grado di effettuare l’analisi anche di più tweet, attraverso un ciclo
for che esegue il codice per ogni riga del documento.
“Sorry losers and haters, but my I.Q. is one of the highest -and you all know it! Please don't
feel so stupid or insecure, it's not your fault.”
Eseguendo lo script che è stato commentato in precedenza si ottiene il seguente risultato:
***********ANALYZING TWEET NUMBER 1*************
LEMMATIZZTION
TEXT LEMMA POS TAG DEP
Sorry sorry ADJ JJ amod
losers loser NOUN NNS nsubj
and and CCONJ CC cc
haters hater NOUN NNS conj
, , PUNCT , punct
but but CCONJ CC cc
my -PRON- DET PRP$ poss
I.Q. I.Q. PROPN NNP conj
is be VERB VBZ ROOT
one one NUM CD attr
of of ADP IN prep
the the DET DT det
highest high ADJ JJS pobj
-and -and PUNCT : ROOT
you -PRON- PRON PRP nsubj
all all DET DT appos
know know VERB VBP ROOT
it -PRON- PRON PRP dobj
! ! PUNCT . punct
Please please INTJ UH intj
do do VERB VB aux
n't not ADV RB neg
feel feel VERB VB ROOT
so so ADV RB advmod
stupid stupid ADJ JJ acomp
or or CCONJ CC cc
insecure insecure ADJ JJ conj
, , PUNCT , punct
it -PRON- PRON PRP nsubj
's be VERB VBZ conj
not not ADV RB neg
your -PRON- DET PRP$ poss
17fault fault NOUN NN attr
. . PUNCT . punct
NOUN CHUNKS
TEXT ROOT_TEXT ROOT_DEP ROOT_HEAD_TEXT
Sorry losers losers nsubj is
haters haters conj losers
my I.Q. I.Q. conj losers
you you nsubj know
it it dobj know
it it nsubj 's
your fault fault attr 's
NAVIGATING THE PARSE TREE
TEXT DEP HEAD_TEXT HEAD_POS CHILDREN
Sorry amod losers NOUN []
losers nsubj is VERB [Sorry, and, haters, ,, but, I.Q.]
and cc losers NOUN []
haters conj losers NOUN []
, punct losers NOUN []
but cc losers NOUN []
my poss I.Q. PROPN []
I.Q. conj losers NOUN [my]
is ROOT is VERB [losers, one]
one attr is VERB [of]
of prep one NUM [highest]
the det highest ADJ []
highest pobj of ADP [the]
-and ROOT -and PUNCT []
you nsubj know VERB [all]
all appos you PRON []
know ROOT know VERB [you, it, !]
it dobj know VERB []
! punct know VERB []
Please intj feel VERB []
do aux feel VERB []
n't neg feel VERB []
feel ROOT feel VERB [Please, do, n't, stupid, 's]
so advmod stupid ADJ []
stupid acomp feel VERB [so, or, insecure]
or cc stupid ADJ []
insecure conj stupid ADJ []
, punct 's VERB []
it nsubj 's VERB []
's conj feel VERB [,, it, not, fault, .]
not neg 's VERB []
your poss fault NOUN []
fault attr 's VERB [your]
. punct 's VERB []
. PUNCT []
ITERATING AROUND THE LOCAL TREE
TEXT DEP N_LEFTS N_RIGTHS ANCESTORS
Sorry amod 0 0 [u'losers', u'is']
losers nsubj 1 5 [u'is']
and cc 0 0 [u'losers', u'is']
haters conj 0 0 [u'losers', u'is']
, punct 0 0 [u'losers', u'is']
but cc 0 0 [u'losers', u'is']
my poss 0 0 [u'I.Q.', u'losers', u'is']
I.Q. conj 1 0 [u'losers', u'is']
NAMED ENTITY RECOGNITION
TEXT START END LABEL DESCRIPTION
I.Q. 32 36 GPE
SENTENCE RECOGNITION
Sorry losers and haters, but my I.Q. is one of the highest
-and
you all know it!
Please don't feel so stupid or insecure,it's not your fault.
18Capitolo 3: Information Extraction
L’estrazione di informazioni da una “sorgente” scritta in linguaggio naturale comporta lo
sviluppo di una capacità di interpretazione semantica che è legata alla lingua utilizzata e al
dominio.
La comprensione del linguaggio naturale viene considerata come un problema di IA-
completo perché si ritiene che il riconoscimento del linguaggio richieda una conoscenza
estesa del mondo e una grande capacità di comprensione.
Tuttavia, come abbiamo già detto in precedenza, questo processo è reso molto complicato
a causa delle ambiguità del linguaggio umano ed è quindi necessario suddividerlo in diverse
fasi:
• analisi lessicale: si scompone l’espressione in token;
• analisi grammaticale: si associano le parti del discorso2 a ciascuna parola nel testo;
• analisi sintattica: si definiscono le relazioni tra i token;
• analisi semantica: si assegna un significato alla struttura sintattica e quindi
all’espressione linguistica.
L’IE ha come obiettivo l’estrazione automatica di informazioni strutturate da documenti
non strutturati o semi-strutturati.
Nella maggior parte dei casi quest’attività riguarda l’elaborazione di testi in lingua umana
mediante le tecniche di NLP; tuttavia, grazie alle recenti attività come l’annotazione
automatica e l’estrazione automatica di contenuti da immagini, video e audio, l’information
extraction può essere utilizzata anche per l’estrazione automatica di contenuti da documenti
multimediali.
L'Information Extraction è la parte di un puzzle più ampio che si occupa del problema
dell'ideazione di metodi automatici per la gestione del testo, oltre che alla sua trasmissione,
memorizzazione e visualizzazione.
2 parti del discorso: il discorso è costituito da 9 parti, 5 variabili (articolo, nome, aggettivo, pronome e verbo) e 4
invariabili (avverbio, preposizione, congiunzione e interiezione).
19La disciplina dell’Information Retrieval (IR) ha sviluppato metodi automatici, tipicamente
basati su approcci statistici, per l'indicizzazione di grandi collezioni di documenti e la
classificazione degli stessi.
L’IE si occupa quindi di compiti che sono tra l’IR e il NLP e presuppone l'esistenza di un
insieme di documenti in cui ognuno di essi segue un modello, cioè descrive una o più entità
o eventi in un modo simile a quelli di altri documenti ma diverso nei dettagli.
In un processo di IE è possibile intervenire su tre livelli:
• named entity recognition: riconoscimento di nomi propri di entità, di espressioni
temporali, di luoghi;
• coreference resolution: rilevamento di legami di coreferenza, cioè frasi che si
riferiscono allo stesso referente, e di anafora, cioè riferimenti tra porzioni di testo tra
loro più o meno distanti;
• relationship extraction: riconoscimento di legami associativi tra entità.
3.1 Gli strumenti per l’IE
Esistono numerosi strumenti e piattaforme “open source” di supporto alla progettazione e
realizzazione di applicazioni di IE basate su NLP; ognuna di esse si differenzia per vari
aspetti tra cui il tipo di licenza, i linguaggi di sviluppo e gli ambienti supportati.
Tra gli strumenti più utilizzati troviamo GATE.
GATE è una piattaforma open source gratuita per lo sviluppo di sistemi di IE che comprende
un ambiente integrato per lo sviluppo di componenti di Language Processing chiamato
GATE Developer.
La piattaforma si presta ottimamente per realizzazioni sia “rule based” che “machine
learning”.
In una fase preliminare, l’utente sceglie quante e quali processing resources (PR) utilizzare,
definendo per ognuna di esse le language resources coinvolte.
Il formato per la rappresentazione dei dati in GATE è denominato annotation.
20Un’interessante applicazione basata su GATE è ANNIE, A Nearly-New Information
Extraction system, che utilizza una serie di risorse per riconoscere istanze di entità
all’interno di un testo.
ANNIE si basa su algoritmi a stati finiti e sul linguaggio JAPE (Java Annotation Pattern
Engine) e contiene un set di PR, ognuna delle quali crea nuove annotazioni o modifica quelle
esistenti.
Tra queste quelle più utilizzate sono:
• Document Reset: rimuove le annotazioni create in precedenza per evitare duplicazioni;
• Tokenizer: suddivide il contenuto del testo in Token che andranno poi a formare i
Gazzetteers, ossia file testuali contenenti liste di nomi;
• Sentence Splitter: divide il contenuto del documento in segmenti corrispondenti alle
diverse frasi del testo;
• Pos Tagging (part-of-speech tagging): associa ad ogni parola di una frase una classe
morfologica basandosi su un corpus pre-taggato.
3.2 IE from Twitter: Tweepy
Come abbiamo già detto in precedenza, la vasta mole di utenti iscritti a Twitter da vita ad
un enorme contenitore di informazioni che possono essere estratte e successivamente
analizzate.
Per poter estrarre tali informazioni, lo stesso Twitter mette a disposizione un wrapper, ossia
un oggetto che renda disponibili all'applicazione che si sta scrivendo le funzioni contenute
in una libreria esterna; questa libreria è nota come Tweepy.
Tweepy è una libreria per Python che mette a disposizione un wrapper per l’API3 di Twitter
al fine di rendere il processo di comunicazione con questa semplice e rapido.
Per poter accedere all’API è necessario in primis installare Tweepy, utilizzando il comando
pip install tweepy, e successivamente creare una specifica TwitterApp attraverso la quale
realizzare le ricerche.
3 API: Application Programming Interface.
21Una volta creata l’App avremo a disposizione delle credenziali che ci consentiranno di
accedere direttamente a Twitter utilizzando uno script python.
La prima cosa da fare è quindi creare un semplice script contenente le credenziali, che dovrà
essere essere importato in tutti gli script per l’estrazione di informazioni.
N.B: per motivi di privacy in questo screenshot non vengono mostrate le credenziali di accesso.
A questo punto possiamo procedere con l’estrazione dei tweet.
A tal proposito, Tweepy consente di accedere a due API molto importanti di Twitter:
RestAPI e StreamAPI.
3.2.1 StreamAPI
StreamAPI fornisce l'accesso ai tweet in tempo reale; gli stream possono essere filtrati in
base a parole chiave, lingua, posizione e altre caratteristiche.
Per poter avviare lo stream bisogna importare dalla libreria Tweepy due importanti classi:
• StreamListener: è la classe che consente di realizzare lo stream di tweet in base alla
parola chiave;
• OAuthHandler: è la classe che serve per effettuare l’autenticazione utilizzando le
variabili che sono state memorizzate nel file delle credenziali (par. 3.2).
Importiamo poi anche lo script contenente le credenziali e creiamo due classi:
1. la classe TwitterStreamer, all’interno della quale troviamo il costruttore della classe,
che ha il compito di inizializzare le variabili di istanza, e una funzione stream_tweets
che, sfruttando le credenziali di accesso e le funzioni contenute nella classe
StreamListener, realizza l’estrazione dei tweet;
222. la classe StdOutListener il cui scopo è quello di inserire i tweet estratti all’interno di
un file di testo, con estensione .txt, se il processo di estrazione va a buon fine, altrimenti
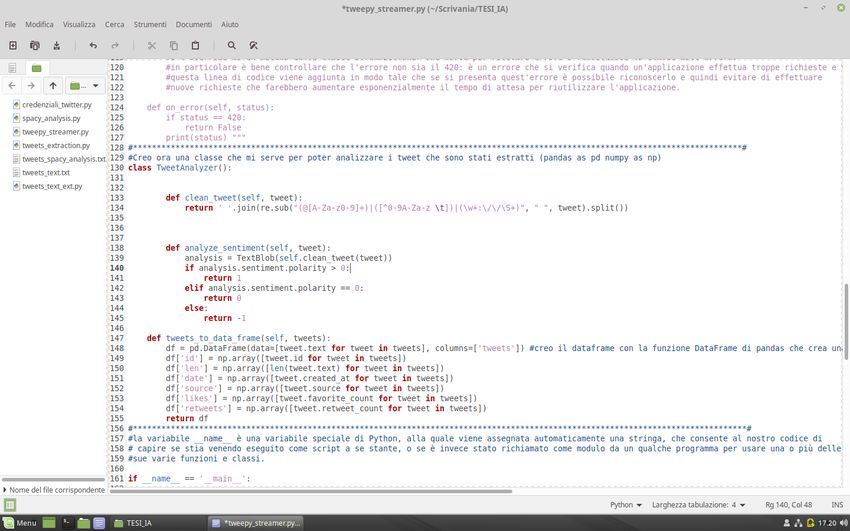
restituire lo status dell’errore che si è verificato; uno degli errori più comuni è l’errore
420 che si verifica quando l’applicazione effettua troppe richieste di stream. Pertanto,
la verifica che l’errore sia il 420 è fondamentale per evitare di effettuare nuove richieste
che farebbero aumentare esponenzialmente il tempo di attesa.
Una volta create le due classi lo stream può essere avviato invocando nel main le funzioni
che sono state realizzate.
23Ogni tweet estratto avrà una forma standard e conterrà una grande quantità di informazioni:
l’id dell’utente che lo ha pubblicato, il testo, il dispositivo dal quale è stato pubblicato, il
nome dell’utente, i followers, la data di creazione del tweet e tante altre informazioni che
possono essere sfruttate per l’analisi.
Per esempio, se volessimo estrarre solamente il testo del tweet per poterlo analizzare,
potremmo usare un semplice script che “splitta” le informazioni estratte e inserisce il solo
testo all’interno di un documento.
3.2.2 RestAPI
REST (Representational State Transfer) è un API che consente agli sviluppatori di accedere
direttamente alle informazioni e alle risorse utilizzando un’invocazione http.
È quindi possibile risalire direttamente ad informazioni come l’utente che ha pubblicato il
tweet, il numero di likes, la lista degli ultimi tweet che egli ha pubblicato, senza doverli
estrarre manualmente come nel caso dello Stream.
Per poter estrarre queste informazioni bisogna importare in primis il file contenente le
credenziali di accesso e successivamente una serie di librerie:
• API: è una libreria che contiene tutti i metodi che permettono di agire direttamente sulle
risorse dei tweet;
• Cursor: nello sviluppo delle API di Twitter viene frequentemente utilizzata la
paginazione, ossia l'iterazione attraverso linee temporali, liste utenti, messaggi diretti;
Tweepy fornisce l'oggetto Cursore che gestisce per noi tutto il lavoro di impaginazione;
• OAuthHandler (par. 3.2.1);
• TextBlob: è una libreria per l’elaborazione dei dati testuali che fornisce una semplice
API per effettuare NLP (nel nostro caso è stata utilizzata per la Sentiment Analysis);
24• numpy: è una libreria per il calcolo in Python; fornisce oggetti multidimensionali ad alte
prestazioni e strumenti per lavorare con gli array;
• pandas: è una libreria che rende molto più facile l’importazione e l’analisi dei dati
rendendo la loro manipolazione molto più leggera;
• matplotlib: è una libreria che mette a disposizione un’interfaccia, chiamata pyplot, che
consente di generare automaticamente grafici;
• re (regular expression): questa libreria contiene dei metodi che vengono utilizzati per
“pulire” il tweet estratto da caratteri trascurabili nella fase di analisi.
Una volta importate le librerie necessarie possiamo creare la classe per effettuare
l’autenticazione attraverso i parametri importati in precedenza.
La classe successiva, denominata TwitterClient, contiene un insieme di funzioni che sono
state realizzate per poter estrarre, dato un utente, alcune informazioni relative al suo account.
La prima funzione è il costruttore della classe che effettua l’autenticazione e definisce il
nome dell’utente preso in considerazione.
La funzione get_client_api serve invece per realizzare l’interfacciamento con l’API al fine
di poter estrarre i tweet.
25get_user_timeline_tweets restituisce una timeline dei tweet pubblicati dall’utente,
inserendoli all’interno di una lista vuota; il numero di tweet da estrarre è fornito come
parametro della funzione.
Allo stesso modo sono state realizzate altre due funzioni, get_followers_of_user e
get_friend_list, che restituiscono rispettivamente gli ultimi n followers dell’utente e una
lista degli amici dell’utente.
Infine, la funzione get_home_timeline_tweets restituisce gli ultimi n stati, compresi i
retweet, pubblicati o dall’utente che si è autenticato o dai suoi amici.
3.3 Analisi dei tweet
Oltre che all’estrazione di informazioni possiamo anche analizzare i tweet che vengono
estratti.
In una prima fase di analisi possiamo ad esempio ricavare il testo del tweet, la lunghezza,
la data di pubblicazione, la sorgente dalla quale è stato pubblicato, il numero di like e anche
il numero di retweet.
Affinché ciò sia possibile bisogna utilizzare le librerie pandas e numpy che abbiamo in
precedenza importato.
26Utilizzando la classe DataFrame di Pandas è possibile realizzare una struttura dati
bidimensionale che contiene i Panda Series Object, ossia degli array unidimensionali (righe
o colonne) etichettati che possono contenere oggetti di qualsiasi tipo.
Nel nostro caso creiamo una tabella che presenta, nella prima colonna, il testo dei tweet che
sono stati estratti.
Successivamente, sfruttando la classe array di Numpy, andiamo a riempire la tabella con
altre colonne che contengono le informazioni che abbiamo elencato in precedenza.
3.3.1 Sentiment Analysis
Una seconda fase di analisi è la Sentiment Analysis.
La Sentiment Analysis, anche nota come opinion mining, è un campo dell’elaborazione del
linguaggio naturale che si occupa di costruire sistemi per l’identificazione e l’estrazione di
opinioni dal testo; consente quindi di raccogliere in tempo reale le reazioni degli utenti ad
un qualsiasi evento.
Essa rappresenta uno strumento accurato per individuare ed “ascoltare” conversazioni
online fornendo alle aziende un’interpretazione del mercato molto realistica.
Sono molteplici i settori in cui la sentiment analysis può essere utilizzata: dalla politica al
marketing, dalla comunicazione ai mercati azionari, dall’ambito sportivo a quello della
medicina e soprattutto per misurare le preferenze del consumatore in relazione ad un
prodotto.
Esistono 4 categorie principali di approcci alla sentiment analysis:
• “spotting” di parole chiave;
27• affinità lessicale;
• metodi statistici;
• tecniche di livello concettuale.
La prima classifica il testo utilizzando parole influenti come contento, triste, annoiato.
L’affinità lessicale assegna alle parole una probabile affinità a emozioni particolari.
I metodi statistici fanno invece leva su elementi tratti dal machine learning come analisi
semantica latente4, collezioni di parole e orientazione semantica.
Gli approcci a livello concettuale fanno invece leva sugli elementi della rappresentazione
della conoscenza, come le ontologie5, e sono quindi capaci di rilevare semantiche che sono
espresse in maniera sottile.
Per realizzare la sentiment analysis sfruttando tweepy sono necessarie le librerie re e
TextBlob.
Per prima cosa realizziamo una funzione che, invocando il metodo sub della libreria Regular
Expression, rimuove dal testo dei tweet tutti quei caratteri che non sono utili per l’analisi.
Successivamente è stata creata la funzione analyze_sentiment che sfrutta il metodo
sentiment della libreria TextBlob; questo metodo restituisce una tupla nella forma (polarity,
subjectivity) dove polarity è una variabile di tipo float che oscilla nel range [-1 ; +1] e
subjectivity è una variabile di tipo float che oscilla nel range [0 ; 1] e che indica quanto
l’analisi è oggettiva/soggettiva.
4 analisi semantica latente: tecnica di elaborazione del linguaggio naturale basata su matrici matematiche che analizza le
relazioni fra insiemi di documenti e produce un insieme di concetti ad essi correlati.
5 ontologia: rappresentazione formale, condivisa ed esplicita di un dominio di interesse.
28A questo punto non ci resta che invocare nel main tutte le funzioni che abbiamo in
precedenza elencato ed eseguire lo script.
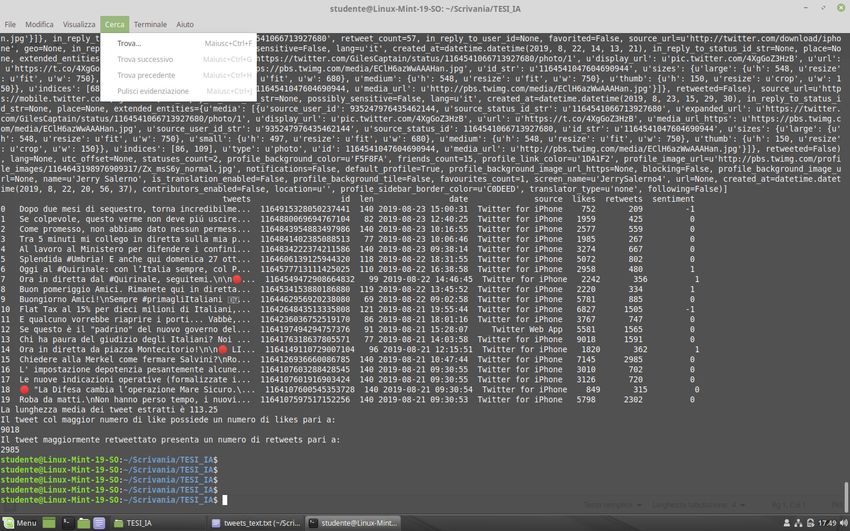
Il risultato dell’esecuzione dello script potrebbe essere di questo tipo:
In questo caso sono stati estratti gli ultimi 20 tweet pubblicati dal Ministro dell’Interno e Vicepresidente del consiglio Matteo
Salvini.
Possiamo notare, per esempio, che nel tweet col maggior numero di likes (9018) il ministro, capo della Lega, afferma di non
aver paura del giudizio degli italiani alle future elezioni in seguito alla crisi di governo.
Da qui possiamo quindi dedurre che il numero di seguaci del partito leghista resta comunque molto elevato nonostante la
situazione a sfavore che si è venuta a creare.
29C’è però una libreria che ancora non è stata utilizzata: matplotlib.pyplot.
Utilizzando questa libreria possiamo ottenere automaticamente dei grafici contenenti le
informazioni desiderate.
Affinché ciò sia possibile è necessario creare dei Panda Series Object, definendo l’ascissa
e l’ordinata del grafico, e successivamente invocare su di essi la funzione plot, che crea il
grafico, e la funzione show che mostra il grafico precedentemente creato.
Eseguendo anche questa porzione di script otteniamo i grafici desiderati.
Esempio:
30Conclusioni
Il Natural Language Processing e l’Information Extraction trovano quindi applicazione in
diversi campi, ognuno dei quali ha obiettivi differenti.
Tuttavia, nonostante gli enormi progressi e i tantissimi risultati ottenuti recentemente nel
campo del NLP grazie all’utilizzo degli algoritmi di deep learning, restano ancora numerose
sfide di ricerca aperte.
Tra queste sicuramente vi è l’elaborazione automatica del linguaggio naturale per quelle
lingue per le quali i dati disponibili non sono in numero elevato.
Gli algoritmi di deep learning, infatti, utilizzano una modalità di apprendimento di tipo
supervisionato, ossia necessitano di dataset di addestramento etichettati con le classi o
fenomeni che si vogliono determinare.
Annotare dataset è però un processo che richiede tempo e risorse umane, soprattutto quando
si tratta di lingue non comuni per le quali vi è carenza di dati utilizzabili.
L’obiettivo che si vuole raggiungere è quello di definire un “modello universale” del
linguaggio, a partire da aspetti comuni identificati tra le diverse lingue, che consenta di
adottare strategie di addestramento per gli algoritmi di deep learning che utilizzino piccoli
insiemi di dati.
Un’altra sfida riguarda la reale comprensione del linguaggio naturale in maniera
automatica, ossia la capacità di leggere e capire un testo proprio come un essere umano.
La comprensione del linguaggio naturale nell’essere umano è strettamente correlata alla
percezione del mondo esterno per cui diventa necessario, al fine di riprodurre nelle
macchine la capacità di comprensione del linguaggio umano, fornire anche rappresentazioni
concettuali di oggetti dell’ambiente circostante.
A tal proposito, esistono sempre più approcci che, integrando conoscenze riguardanti le
neuroscienze e le scienze cognitive, cercano di realizzare sistemi conversazionali che siano
in grado di simulare funzioni cognitive di alto livello, apprendendole attraverso
l’interazione con l’ambiente esterno.
31Tra le sfide più importanti vi è anche la capacità di effettuare ragionamenti di senso comune
al fine di risolvere ambiguità dovute a conoscenza implicita o non specificata.
Per ragionamenti di senso comune si intendono quei ragionamenti immediati che
permettono di capire, per esempio, a chi si riferisce un pronome all’interno di una frase.
Sebbene siano stati fatti importanti progressi, ad oggi non vi è ancora una tecnica ben
definita che permetta ad una macchina di effettuare ragionamenti di senso comune; ciò
rappresenta una delle più grandi barriere che limitano le capacità sia di comprensione dei
fenomeni che accadono nel mondo circostante sia di comunicazione naturale con gli esseri
umani, non consentendo alle macchine di comportarsi in maniera ragionevole in situazioni
sconosciute e di apprendere da nuove esperienze che non sono state considerate in fase di
apprendimento.
In conclusione, sono due le strade che devono convergere per affrontare queste sfide: da un
lato, lo sviluppo di soluzioni avanzate che prendano ispirazione da diverse discipline, a
partire dall’informatica fino alla linguistica e alle neuroscienze, e che consentano di
rappresentare, comprendere e generare testo o parlato in linguaggio naturale proprio come
un essere umano; dall’altro, la necessità di grandi quantità di dati, anche organizzati in base
alla lingua, che permettano di addestrare tali soluzioni e validarne le prestazioni.
32BIBLIOGRAFIA
Albanese, E. (2017, Maggio 24). Introduzione al Natural Language Processing (NLP). Tratto da
alimenaonline: http://www.alimenaonline.eu/enzoalbanese/2017/05/24/introduzione-al-
natural-language-processing-nlp/
API Reference. (2019). Tratto da Tweepy: http://docs.tweepy.org/en/latest/api.html
Aureli Cutillo, E. (2004). Applicazioni di analisi statistica dei dati testuali. (S. Bolasco, A cura di)
Roma: Casa Editrice Università degli studi di Roma, La Sapienza.
Authentication Tutorial. (2019). Tratto da Tweepy:
http://docs.tweepy.org/en/latest/auth_tutorial.html
Bird, S., Klein, E., & Loper, E. (2009). Natural Language Processing with Python. O'Reilly Media.
Carey, B. (2009, Giugno 09). Using the Twitter Rest API. Tratto da IBM:
https://www.ibm.com/developerworks/library/x-twitterREST/index.html
Ceron, A., Curini, L., & Iacus, S. (2013). Social Media e Sentiment Analysis: L'evoluzione dei
fenomeni sociali attraverso la Rete. Springer Verlag.
Cursor Tutorial. (2019). Tratto da Tweepy: http://docs.tweepy.org/en/latest/cursor_tutorial.html
della Ratta Rinaldi, F. (2002). L’analisi testuale, uno strumento per la ricerca qualitativa. In F. della
Ratta Rinaldi, La ricerca qualitativa in educazione. Milano: FrancoAngeli.
Esposito, M. (2019, Febbraio 06). Linguaggio naturale e intelligenza artificiale: a che punto siamo.
Tratto da Agenda Digitale: https://www.agendadigitale.eu/cultura-digitale/linguaggio-
naturale-e-intelligenza-artificiale-a-che-punto-siamo/
Golubin, A. (2019, Agosto 10). Garbage collection in Python: things you need to know. Tratto da
Rushter: https://rushter.com/blog/python-garbage-collector/
Gupta, S. (2018, Gennaio 7). Sentiment Analysis: Concept, Analysis and Application. Tratto da
towardsdatascience: https://towardsdatascience.com/sentiment-analysis-concept-analysis-
and-applications-6c94d6f58c17
Information Extraction (IE). (2019, Luglio). Tratto da Wikipedia:
https://en.wikipedia.org/wiki/Information_extraction
ing. Gallerani, R. (2015, Dicembre 17). Natural Language Processing (NLP) e Information
Extraction (IE). Tratto da www.gallerani.it: https://www.gallerani.it/sito/natural-language-
processing-nlp-e-information-extraction-ie/
Introduction to Tweepy. (2019). Tratto da Tweepy:
http://docs.tweepy.org/en/latest/getting_started.html
Magnani, F. (2014, Maggio 13). Sentiment Analysis: Definizione e campi di applicazione. Tratto da
Beantech: https://www.beantech.it/blog/articoli/sentiment-analysis-definizione-e-campi-di-
applicazione/
matplotlib.pyplot. (2019, Luglio). Tratto da matplotlib:
https://matplotlib.org/3.1.1/api/_as_gen/matplotlib.pyplot.html
Navlani, A. (2019, Aprile 16). Text Classification in Python using spaCy. Tratto da Dataquest:
https://www.dataquest.io/blog/tutorial-text-classification-in-python-using-spacy/
Panda Series. (2019, Luglio). Tratto da GeeksforGeeks: https://www.geeksforgeeks.org/python-
pandas-series/
Piccini, M. P. (2010). L’analisi testuale e l’analisi delle corrispondenze lessicali. Tratto da
uniroma3: http://europa.uniroma3.it/cipriani/files/4e3330e5-f2bc-4961-9185-
9ff91187d9d5.pdf
Python Numpy Array . (2019, Marzo 19). Tratto da Datacamp:
https://www.datacamp.com/community/tutorials/python-numpy-
tutorial?utm_source=adwords_ppc&utm_campaignid=898687156&utm_adgroupid=489472
56715&utm_device=c&utm_keyword=&utm_matchtype=b&utm_network=g&utm_adposti
on=1t1&utm_creative=332602034343&utm_targetid=a
33Puoi anche leggere

















































