I BIG DATA NEL MONDO DEL PHARMA - DIPARTIMENTO DI INFORMATICA UNA SCINTILLA CHE PUÒ SCATENARE L'INFERNO - Marco Serra
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
!1
D I PA RT I M E N TO D I I N F O R M AT I C A
Corso di Laurea in Informatica (Crema)
I B I G D ATA
NEL MONDO DEL PHARMA
UNA SCINTILLA CHE PUÒ
SCATENARE L’INFERNO
R E L ATORE TESI DI LAUREA D I
Prof. Paolo Ceravolo Marco Serra
Matr. 830977
Anno Accademico 2015/2016
I BIG DATA
!2 I BIG DATA
!3
Ringraziamenti
Un ringraziamento a tutti coloro che mi hanno dato il loro supporto,
fisico e morale, aiutandomi nella stesura con suggerimenti,
critiche ed osservazioni: a loro va la mia gratitudine.
Ringrazio anzitutto il Professor Paolo Ceravolo
per la cortesia e la disponibilità, per il supporto teorico e tecnico.
Grazie anche a Jonatan Maggesi e a Guido Lena Cota
per la loro paziente assistenza.
A Luca Tatto, prezioso e insostituibile.
Un grazie di cuore ai miei amici, che anche non comprendendo l’elaborato
nel suo dettaglio, comprendono i miei sogni e permettono che si realizzino.
Un grazie speciale a Veronica, sempre al mio fianco in quest’avventura.
È anche grazie a lei che questa tesi ha visto la luce.
Un grazie, anche se non basterebbe, a mio padre e a mia madre.
I BIG DATA
!4 I BIG DATA
!5 ABSTRACT i Big Data. Tanto grandi ma tanto piccoli I dati sono sempre stati d'interesse fondamentale nell'ambito della definizione delle strategie. Strategie commerciali, politiche, sociali ed economiche. Il settore Pharma non è da meno. A partire dalla digitalizzazione delle cartelle cliniche, che consente di aggregare anni di dati di ricerca e sviluppo in banche dati elettroniche. Anche la trasparenza, intesa come pubblica utilità fornita dalle istituzioni verso i cittadini, ha contribuito a fornire decenni di dati memorizzati utilizzabili, ricercabili e fruibili dal settore sanitario nel suo complesso. Se il cittadino rimarrà al centro1, i Big Data contribuiranno a fornirgli un mondo migliore2. Tutte queste informazioni sono una forma di "big data". Il nome Big Data rende bene il concetto di volume (l'ordine di grandezza è inimmaginabile per un essere umano, ben al di sopra dei terabyte con cui siamo abituati a operare, tanto che il 90% dei dati nel mondo – lo studio3 è del 2011 – è stato creato negli ultimi due anni), ma nasconde al suo interno anche i concetti di complessità (intesa come articolazione del dato), di disomogeneità (i dati rappresentano concetti spesso slegati tra di loro per unità di misura e per contesto) e tempestività richiesta dalla loro analisi. 1 IBM, “Big Data Analytics for Healthcare”. https://www.siam.org/meetings/sdm13/sun.pdf 2 Center for US Health System Reform Business Technology Office, “The ‘big data’ revolution in healthcare » Accelerating value and innovation” Jan-2013. http://www.pharmatalents.es/assets/files/Big_Data_Revolution.pdf 3IBM Study, “StorageNewsletter » Every Day We Create 2.5 Quintillion Bytes of Data,” 21- Oct-2011. http://www.storagenewsletter.com/rubriques/market-reportsresearch/ibm-cmo-study/ I BIG DATA

!6 ALCUNE APPLICAZIONI PRATICHE Con l’aiuto dei Big Data, alcune società di carte di credito hanno individuato delle associazioni inusuali per valutare il rischio finanziario di una persona. Secondo alcune ricerche di data mining, infatti, le persone che comprano i feltrini per i mobili rappresentano i clienti migliori per gli istituti di credito, perché più attenti e propensi a colmare i propri debiti nei tempi giusti, chi acquista più alcolici della media o ha una macchina di piccolo taglio può essere giudicato al contrario meno affidabile, e gli verrà quindi imposto un tasso di interesse più alto4. Nel mondo del Pharma, alcune applicazioni di questi dati consentono ai ricercatori di estrarre i dati per vedere quali sono i trattamenti più efficaci per alcune patologie o identificare i modelli relativi agli effetti collaterali dei farmaci. Alcune aziende innovative nel settore stanno costruendo applicazioni e strumenti analitici per aiutare medici e pazienti a trovare nuovi metodi e opportunità terapeutiche, nonché un uso migliore delle informazioni sanitarie disponibili5. Un aspetto interessante e per nulla secondario nasce nel momento in cui, come tutti i dati, anche i Big Data subiscono l'effetto delle normative sulla privacy, nonché si scontrano con le complessità di un mondo in cui le informazioni non sono solo personali, ma anche sensibili. Lo stato di salute, in Italia, è definito esplicitamente6 come "dato sensibile" e, al pari delle altre informazioni personali classificate in questo paragrafo, dev'essere trattato secondo l'Art. 20 e 22 del D.Lgs 196/2003 in cui, al paragrafo 1. recita: Il trattamento dei dati sensibili da parte di soggetti pubblici è consentito solo se autorizzato da espressa disposizione di legge nella quale sono specificati i tipi di dati che possono essere trattati e di operazioni eseguibili e le finalità di rilevante interesse pubblico perseguite. 4 https://www.pressreader.com/italy/la-lettura/20160417/281556584996731 5 Center for US Health System Reform Business Technology Office, “The ‘big data’ revolution in healthcare » Accelerating value and innovation” Jan-2013. http://www.pharmatalents.es/assets/files/Big_Data_Revolution.pdf 6Art. 4, comma d) del D.Lgs 196/2003. http://garanteprivacy.it/web/guest/home/docweb/-/docweb-display/docweb/1311248 I BIG DATA
!7 In ottemperanza a tale regolamento, ai pazienti, ai medici e a qualsiasi operatore della salute viene assicurato che dati raccolti in un contesto non siano successivamente adoperati per finalità diverse, distorcendo lo scopo per cui erano nati e minando conseguentemente la privacy. RESISTENZE AL CAMBIAMENTO Nonostante l’utilizzo dei Big Data potrebbe, se applicato nelle sue massime potenzialità come in altri settori7 8 9, rivoluzionare in modo significativo le strategie e l’approccio del Pharma al mercato10, si riscontrano ancora reticenze non indifferenti11. Questo perché il dato in sé non ha ancora, nella visione dei vertici aziendali, la valenza di un punto chiave da utilizzare a priori nella definizione delle strategie. Spesso, ci si affida ancora a intuizioni e, grazie ai dati, si verifica l’effettiva realizzazione delle stesse, senza confrontarsi con un più ampio panorama di mercato. In questo contesto, i Big Data consentono di mettere a disposizione un’ampia varietà di considerazioni ex-ante, permettendo la conseguente definizione di strategie ponderate e misurabili. Le tecniche di machine learning consentono poi di perfezionare i risultati delle previsioni, riadattandoli a quelli di mercato, in un circolo virtuoso che si pone come obiettivo quello della perfezione assoluta. 7 MIUR, “BIG DATA @MIUR.” Jul-2016. http://www.istruzione.it/allegati/2016/bigdata.pdf 8Ericsson White paper, “Big data analytics.” Oct-2015. https://www.ericsson.com/res/docs/whitepapers/wp-big-data.pdf 9DHL, "BIG DATA IN LOGISTICS” Dec-2013. http://www.dhl.com/content/dam/downloads/ g0/about_us/innovation/CSI_Studie_BIG_DATA.pdf 10SDA Bocconi, “Big Data: nuove fonti di conoscenza aziendale e nuovi modelli di management” Dec-2012. http://www.sdabocconi.it/sites/default/files/upload/pdf/Report-BigData_final.pdf 11Center for US Health System Reform Business Technology Office, “The ‘big data’ revolution in healthcare » Accelerating value and innovation” Jan-2013. http://www.pharmatalents.es/assets/files/Big_Data_Revolution.pdf I BIG DATA
!8 OBIETTIVI Obiettivo di questo elaborato è quello di realizzare un’insolita relazione tra quello che le persone fanno e quello che sono, al fine di valutare le particolarità di questo andamento. Nello specifico, analizzeremo i dettagli delle vendite nei vari settori del Pharma, considerando il loro andamento stagionale e, in generale, temporale. Di questi dati retail, estrapoleremo un identificativo degli acquirenti, per ciascuno dei quali cercheremo di ricostruire una storia ottenuta sia da attività on-line e offline, delineando un quadro del consumatore. Chi è, cosa fa, cosa compra, cosa gli interessa. Scopriremo cose molto interessanti, che chiameremo relazioni nascoste, ovvero nessi inimmaginabili, spiegabili solo a posteriori, che rappresentano la differenza tra quello che siamo davvero e quello che mostriamo agli altri. I dati raccontano storie12. 12 http://www.sobigdata.it/sites/default/files/BigData%26SocialMining_Giannotti.pdf I BIG DATA
!9
1. I BIG DATA 11
1.1. Data 12
1.2. Infrastruttura di calcolo 13
1.3. Infrastruttura di archiviazione 15
1.4. Analisi 20
1.5. Visualizzazione 23
1.6. Sicurezza e Privacy 24
2. BIG DATA MODEL 25
2.1. Toreador CMap 25
2.2. Declarative model 26
2.3. Gestione dei conflitti 30
3. SOFTWARE 32
3.1. Ambari 33
3.2. Hadoop 35
3.3. Hadoop Common 37
3.4. HDFS 38
3.5. HBASE 41
3.6. HCatalog 42
3.7. Map-Reduce 44
3.8. YARN 45
3.9. Hive 46
3.10. Sqoop 47
3.11. Zookepeer 48
3.12. PIG 49
4. ANALISI 50
I BIG DATA!10
4.1. Servizi 50
4.2. Generazione della popolazione 53
4.3. Dati retail 56
4.4. Dati online (acquisto) 60
4.5. Dati online (navigazione) 64
4.6. Analisi incrociata 67
5. CONCLUSIONI 71
BIBLIOGRAFIA 73
I BIG DATA!11
Capitolo 1
1. I BI G D ATA
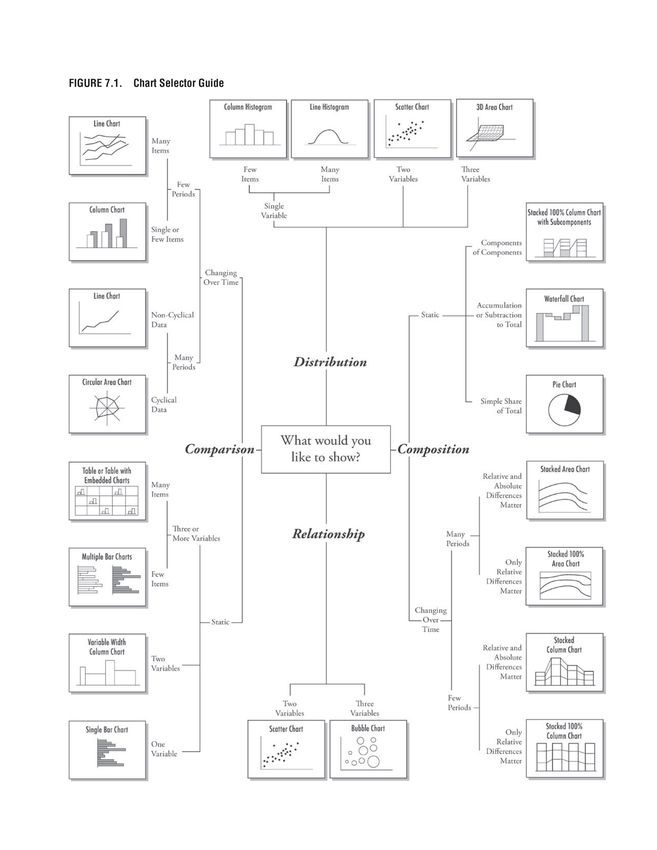
ciò che è vasto, per essere compreso, deve essere rappresentato
Parlare di Big Data vuol dire, per prima cosa, definirne la tassonomia, ovvero
classificare quali sono le dimensioni che li compongono, le procedure e le norme
che li regolano.
fig. 1 - Composizione dei Big Data
Sono sei le dimensioni che derivano dagli aspetti chiave necessari per realizzare
un’infrastruttura con i Big Data (fig. 113 ).
13BIG DATA WORKING GROUP, “Big Data Taxonomy” Sept-2014. https://
downloads.cloudsecurityalliance.org/initiatives/bdwg/Big_Data_Taxonomy.pdf
I BIG DATA!12 1.1. DATA piccoli da soli, grandi insieme I dati non sono tutti uguali. Per prima cosa differiscono del dominio di appartenenza, ovvero del tipo di dato. Il concetto di tipo, o tipizzazione, ha valenza sia logica sia fisica. Dal punto di vista logico permette di restringere il valore che un dato può avere, dandone un significato logico, confrontabile e rappresentabile. Dal punto di vista fisico, consente la creazione di strutture che possano accogliere il tipo di dato ottimizzando al meglio lo spazio impiegato per la sua memorizzazione. I dati differiscono tra loro per altre proprietà: 1.1.1. LATENZA La latenza caratterizza l’arco di tempo nel quale il dato, prodotto, dev’essere analizzato. Questa proprietà è importante all’interno del mondo dei Big Data perché si congiunge con un altro concetto, quello di obsolescenza: con il passare del tempo i dati diventano obsoleti e si storicizzano. Diversi livelli di latenza incidono anche sulla concezione di obsolescenza dello specifico set di dati. Parliamo di dati real-time quando l’elaborazione richiesta dalle applicazioni che ne fanno uso è nell’ordine dei 20-50 millisecondi. Applicazioni che richiedono questo genere di dati sono, ad esempio: annunci online in tempo reale, piattaforme di trading on-line, monitoraggio degli eventi di sicurezza, monitoraggio delle transazioni finanziarie e delle frodi, analisi del traffico online, sistemi predittivi, ottimizzazione di dispositivi, impianti industriali o sistemi logistici in base al comportamento e all’uso che ne viene fatto, sistemi di controllo, analisi del sentiment online. Sono invece ad alta latenza le applicazioni che hanno un tempo di risposta dell'ordine di pochi secondi fino ad alcuni minuti o alcune ore. Nelle piattaforme di analisi solitamente la latenza è nell’ordine di diversi minuti, talvolta anche ore o giorni. Questo consente di salvare i dati in un database e lasciare che l'applicazione lo interroghi per calcolare i risultati desiderati. I BIG DATA
!13 La discriminante non riguarda la frequenza di acquisizione dei dati, quanto la frequenza di analisi: se questa viene effettuata sporadicamente e manualmente nell’ottica di avere dati a disposizione per cambiare una strategia di business, la bassa latenza non è parte dei requisiti. Lo diventa invece se un sistema di controllo deve monitorare diversi indicatori ed agire prontamente in seguito ad una qualunque variazione degli stessi. 1.1.2. STRUTTURA A seconda della loro struttura, i dati possono essere classificati in tre macro gruppi: DATI STRUTTURATI I dati strutturati hanno una struttura analoga a quella di una base di dati relazionale, caratterizzata da vari campi tipizzati. DATI NON STRUTTURATI I dati non strutturati (o informazioni non strutturate) sono informazioni che o non hanno un modello di dati strutturato o non sono organizzate in modo strutturato. Possono essere composti da testi complessi e articolati, che contengono oltre ai caratteri alfanumerici, date o contenuti di tipo multimediale. DATI SEMI-STRUTTURATI I dati semi-strutturati sono a metà tra i dati strutturati e i dati non strutturati. Si tratta di un tipo di dati strutturati a cui manca una struttura rigida imposta da un modello di dati sottostante. Con i dati semi-strutturati vengono utilizzati tag o altri tipi di marcatori allo scopo di identificare particolari elementi all'interno dei dati. Linguaggi XML e altri markup sono spesso utilizzati per gestire i dati semi- strutturati. 1.2. INFRASTRUTTURA DI CALCOLO elaborare vuol dire dare un senso a ciò che, da solo, un senso non ha Sulle analisi raccolte dai tipi di dati a disposizione mostrati nel capitolo precedente e sulle finalità dell’analisi stessa è possibile scegliere diversi strumenti utili per la costruzione di un’infrastruttura di calcolo adeguata al progetto che si intende realizzare. I BIG DATA
!14 Hadoop è la soluzione per la computazione parallela, in batch, che fa uso del modello MapReduce. Il suo funzionamento avviene tramite due funzioni, scritte dall’utente, che hanno come obiettivo quello di mappare coppie chiave/valore per generare un set di coppie chiave/valore intermedie. Il mapping avverrà indipendentemente sui singoli nodi, che si scambieranno successivamente i risultati di questo calcolo sulla base della disponibilità delle risorse di calcolo. Infine, una funzione reduce unirà i risultati così ottenuti sulla base delle chiavi usate nella fase di mapping. Nel caso in cui sia richiesta una computazione a partire da un flusso streaming di dati l'approccio generale è quello di avere a disposizione una porzione di codice ad elaborare ciascuno degli eventi separatamente. Per accelerare il processo, il flusso può essere suddiviso e il calcolo distribuito su cluster. L’attenzione dei framework riguarda in primo luogo la parallelizzazione del carico computazionale; uno strato di archiviazione aggiuntivo è necessaria per memorizzare i risultati ed essere in grado di recuperarli successivamente. Un elenco esaustivo dei software utilizzati per questo progetto è approfondito nel Cap. 3. I BIG DATA
!15
1.3. INFRASTRUTTURA DI ARCHIVIAZIONE
riordinare un cassetto è utile solo se chi lo apre ne capisce il criterio
In base al volume dei dati dati da archiviare e al loro formato, esistono diverse
tipologie di database (fig 1.314).
fig. 1.3 - Infrastruttura di archiviazione
Per garantire la disponibilità dei dati con un’affidabilità e una velocità ottimali, può
essere necessario dover scalare orizzontalmente una base di dati, realizzando così
un'architettura distribuita dei server che ospitano i dati. Questa configurazione
porta ad una sfida unica condivisa da tutti i sistemi informatici distribuiti: il
14BIG DATA WORKING GROUP, “Big Data Taxonomy” Sept-2014. https://
downloads.cloudsecurityalliance.org/initiatives/bdwg/Big_Data_Taxonomy.pdf
I BIG DATA!16 teorema PAC15. Secondo il teorema PAC, un sistema di storage distribuito deve scegliere di sacrificare o la consistenza (tutti i nodi vedano gli stessi dati nello stesso momento) o la disponibilità (la garanzia che ogni richiesta riceva una risposta su ciò che è riuscito o fallito), garantendo sempre la tolleranza di partizione (il sistema continua a funzionare nonostante arbitrarie perdite di messaggi). Una metrica standard con cui i database vengono classificati sono le loro proprietà ACID: • Atomicità: richiede che ogni transazione vada a buon fine oppure venga abortita, non sono ammesse esecuzioni parziali. Se una parte della transazione fallisce, l'intera transazione deve fallire e lo stato del database rimane invariato. • Coerenza: assicura che ogni transazione porterà il database da uno stato valido ad un altro valido. Non devono esserci violazioni a vincoli di integrità. • Isolamento: ogni transazione deve essere eseguita in modo isolato e indipendente dalle altre transazioni, l'eventuale fallimento di una transazione non deve interferire con le altre transazioni in esecuzione. • Durabilità (detta anche persistenza): significa che una volta una transazione ha chiesto il commit, il database garantisce che il risultato della transizione non verrà perso, anche in caso di problemi sul sistema anche non direttamente dipendenti dal database. Al fine di gestire basi di dati per lo più NoSQL, Eric Brewer coniò il termine BASE: Basically Available, Soft state, Eventual consistency16 : • Basically Available indica che il sistema garantisce la disponibilità, nei termini del teorema PAC. • Soft state: indica che lo stato del sistema può cambiare nel tempo, anche in assenza di input. Questo per via dell'Eventual consistency. 15 https://it.wikipedia.org/wiki/Teorema_CAP 16 http://dl.acm.org/ft_gateway.cfm?id=1394128&ftid=827951&dwn=1 I BIG DATA
!17
• Eventual consistency: indica che il sistema diventa consistente nel tempo, in
assenza di input
Illustriamo i modelli di database più comuni, i loro punti di forza e il loro rapporto
tra coerenza e disponibilità17:
1.3.1. DATABASE RELAZIONALI
Oracle, SQLite, PostgreSQL, MySQL. Memorizzano i dati in righe e colonne. I
record padre/figlio possono essere uniti in remoto sul server. Prediligono la
velocità alla scalabilità. Hanno parziale capacità di scalabilità verticale e scarsa
capacità di scalabilità orizzontale. Sono il punto di riferimento per architetture
semplici. È preferibile utilizzare questa tipologia di database quando si dispone di
dati altamente strutturati, con un impiego di risorse noto e con query prevedibili.
HORIZONTAL SCALING
In un architettura che gestisce un database relazionale, la scalabilità orizzontale
è possibile attraverso la replica o la condivisione dei dati tra i nodi ridondati per
garantire la coerenza. Sebbene possibile con una complessità richiesta, questo
tipo di sistema non è indicato per lo scopo.
CAP BALANCE
Privilegia la consistenza alla disponibilità.
1.3.2. DATABASE ORIENTATI AI DOCUMENTI (DOCUMENT-
ORIENTED)
MongoDB, CouchDB, BigCouch, Cloudant. Memorizzano i dati in documenti. I
record padre-figlio possono essere memorizzati nello stesso documento e restituiti
in una sola operazione di recupero senza join. Il server è a conoscenza dei campi
memorizzati all'interno di un documento, può eseguire query e ritornare le loro
proprietà in modo selettivo. Sono ideali quando il singolo record ha una crescita
relativamente limitata ed è in grado di memorizzare tutte le sue proprietà connesse
in un unico documento.
17“Breaking Down ‘Big Data’ – Database Models – SoftLayer Blog.”
http://blog.softlayer.com/2012/breaking-down-big-data-database-models/
I BIG DATA!18
HORIZONTAL SCALING
La scalabilità orizzontale viene fornita tramite replica, o replica in aggiunta al
partizionamento. I database orientati ai documenti di solito non consentono
buone prestazione per l'esecuzione di query ad-hoc in un sistema distribuito.
CAP BALANCE
Privilegia la consistenza alla disponibilità.
1.3.3. DATABASE CHIAVE-VALORE
Couchbase, Redis, PostgreSQL hstore, LevelDB. Memorizzano un valore arbitrario
in una chiave. La maggior parte è adatto per eseguire operazioni semplici su un
singolo valore. Ogni proprietà ha bisogno di più passaggi per essere recuperata (ad
eccezione di Redis). Molto semplice e molto veloce, adatto per schemi molto
semplici o scenari di velocità sostenute (come i contatori in tempo reale).
HORIZONTAL SCALING
La scalabilità orizzontale viene fornita tramite partizionamento.
CAP BALANCE
Privilegia la consistenza alla disponibilità.
1.3.4. DATABASE ISPIRATI A BIG-TABLE
HBase, Cassandra. I dati sono inseriti in un database column-oriented ispirato al
paper BigTable di Google18.
HORIZONTAL SCALING
Buona velocità e capacità di scalabilità orizzontali molto ampi.
CAP BALANCE
Può essere impostato per preferire sia la consistenza sia la disponibilità.
18 http://static.googleusercontent.com/media/research.google.com/it//archive/bigtable-osdi06.pdf
I BIG DATA!19
1.3.5. DATABASE ISPIRATI A DYNAMO
Cassandra, Riak, BigCouch. Database chiave/valore distribuiti ispirati al paper
Dynamo di Amazon19. Dynamo partiziona e replica i dati tramite hashing,
mantenendo la consistenza tramite versioning. Si avvale inoltre di un protocollo di
rilevamento di guasti distribuito, essendo un sistema completamente
decentralizzato con la minima necessità di gestione manuale. Adatto quando il
sistema deve essere sempre disponibile per operazioni di scrittura, in modo
performante e senza perdita di dati.
HORIZONTAL SCALING
Scalabilità e durabilità ottima.
CAP BALANCE
Privilegia la disponibilità alla consistenza.
19 http://www.read.seas.harvard.edu/~kohler/class/cs239-w08/decandia07dynamo.pdf
I BIG DATA!20
1.4. ANALISI
A supporto dell’analisi manuale, intesa come interpretazione dei dati da parte di
un’analista, sono a disposizione diverse forme di algoritmi che prendono il nome di
Machine Learning. Questi algoritmi consento al sistema di apprendere
automaticamente pattern sulla base di elementi comuni e di utilizzare il calcolo
inferenziale per suggerire possibili relazioni. Vedremo in questo elaborato
solamente gli algoritmi che si prestano all’elaborazione di dati strutturati o semi
strutturati (fig. 1.420). Esiste un’ampia varietà di algoritmi che consentono l’analisi
di dati non strutturati.
fig. 1.4 - Algoritmi di Machine Learning
20BIG DATA WORKING GROUP, “Big Data Taxonomy” Sept-2014.
https://downloads.cloudsecurityalliance.org/initiatives/bdwg/Big_Data_Taxonomy.pdf
I BIG DATA!21
1.4.1. MACHINE LEARNING DI DATI STRUTTURATI O SEMI-
STRUTTURATI
Gli esseri umani sono soliti rimanere ancorati a decisioni già prese. Un computer
non ha sentimenti (non ancora, nell’anno in cui è scritta questa tesi) e non è
soggetto a questa caratteristica umana. Riesaminando i dati è in grado di
apprendere nuovi elementi sulla base dell’esperienza maturata, rimettendo anche in
discussione le scelte già fatte.
Per semplicità indicheremo con il termine classificazione una qualunque delle
operazioni di classification, regression, clustering o dimensionality reduction in
quanto dipendono unicamente dallo scopo dell’analisi e non dalla metodologia del
processo di classificazione.
SUPERVISED LEARNING
Di questa categoria fanno parte tutti quegli algoritmi di machine learning in
grado di mappare i dati di input ad una specifica classe di riferimento (label) o
ad un valore prefissato stabiliti a priori. È richiesto un intervento manuale
iniziale per istruire l’algoritmo sulle condizioni del mapping, che deve avvenire
su un campione rappresentativo di dati. Questa condizione lo rende difficilmente
applicabile su basi di dati numerose per via della grandezza della campionatura
manuale.
UNSUPERVISED LEARNING
Di questa categoria fanno parte tutti quegli algoritmi di machine learning in
grado di acquisire autonomamente la struttura nascosta dei dati di input senza
aver bisogno di una classificazione preesistente.
REINFORCEMENT LEARNING
Di questa categoria fanno parte tutti quegli algoritmi di machine learning in
grado di apprendere l’associazione tra dati di input e azione da intraprendere in
funzione della “migliore ricompensa” di cui potrà beneficiare il sistema in un
periodo di tempo definito. È necessario quindi un preciso parametro di
riferimento e una corrispettiva valutazione dell’efficacia.
I BIG DATA!22 SEMI-SUPERVISED CLASSIFICATION Di questa categoria fanno parte tutti quegli algoritmi di machine learning in grado di partire da una ristretta classificazione dei dati di input per coniugarla con una più ampia classificazione non definita a priori come nel caso degli algoritmi unsupervised learning. 1.4.2. METRICHE DI CONFRONTO Definita una categoria, per scegliere quale algoritmo utilizzare faremo riferimento a questi parametri: ACCURATEZZA La capacità di classificare correttamente dati di input non ancora etichettati. VELOCITÀ Il costo computazionale di ciascuna classificazione. ROBUSTEZZA La capacità di classificare correttamente i dati di input data la loro parziale incompletezza o inconsistenza. SCALABILITÀ L’accuratezza dell’algoritmo data la dimensione variabile del dataset. INTERPRETABILITÀ La soggettiva comprensibilità delle classificazioni elaborate. I BIG DATA
!23
1.5. VISUALIZZAZIONE
rappresentazione di un’idea
In quanti modi si può rappresentare un’idea? A seconda dell’obiettivo gli assi
cartesiani, la forma e la dimensione dei punti o delle linee possono essere un valido
aiuto (fig 1.421).
fig. 1.5 - Rappresentazione dei Big Data
21 Andrew Abela, Ph. D., “Advanced Presentation by Design”.
I BIG DATA!24 Il nostro obiettivo, in questo elaborato, è rappresentare la relazione tra coppie di variabili, per studiarne il comportamento. 1.6. SICUREZZA E PRIVACY da dove vengono i dati? L’analisi dei dati non deve in alcun modo pregiudicare la sicurezza e la privacy dei titolari delle informazioni contenute all’interno dei dati stessi. Dev’essere tutelata sia l’acquisizione delle stesse presso soggetti non titolati al trattamento, sia l’inferenza di relazioni che evidenziano dati sensibili, deducibile da analisi su campioni di popolazione non adeguatamente proporzionati. 1.6.1. WEB Oltre all’utilizzo di protocolli di comunicazione crittografici, applicazioni web possono garantire la riservatezza dei dati tramite l’utilizzo di tecniche forensi. Il NIST ha pubblicato una guida per le best practice22. 1.6.2. RETAIL AND FINANCIAL DATA Data l’estrema riservatezza e sensibilità di queste informazioni, le best practice per il trattamento di questi dati comprendono il mantenimento dei dati criptati in tutte le fasi di archiviazione e trasferimento. Standard come PCI DSS definiscono più precisamente i termini di trattamento per questa tipologia di dati, inclusi gli aspetti legali. 22K. Kent and et. al., “Guide to Computer Security Log Management. SP 800-92.” http://dl.acm.org/citation.cfm?id=2206303 I BIG DATA
!25 Capitolo 2 2. BI G D ATA MO D E L un valido aiuto alla rappresentazione del processo Big Data Il primo passo è quello di rappresentare la struttura del processo Big Data. Questo processo ci permette rispondere ai requisiti che il framework dovrà rispettare, fotografando la mappa concettuale che rappresenta il cammino del dato, dall’acquisizione fino all’analisi. 2.1. TOREADOR CMAP TOREADOR CMap è uno strumento che consente, tramite l’applicazione di mappe concettuali a granularità variabile, di definire per ogni Market Domain i processi Big Data i modo chiaro e non ambiguo, aiutando così la definizione degli obiettivi. In questo elaborato, useremo il modello dichiarativo per definire l’area di pertinenza dei Big Data. La scelta del modello risente di alcune necessità e contraddizioni, descritte successivamente. I BIG DATA
!26
2.2. DECLARATIVE MODEL
In questa tipologia di modellazione, rappresentiamo il processo Big Data
definendone l’insieme delle caratteristiche23 24 25 26 27 che appartengono al processo
stesso, suddividendole in base a criteri di funzionalità e specificità.
2.2.1. DATA REPRESENTATION
DATA STRUCTURE
I dati di riferimento sono dati strutturati (structured), come fogli excel (dati
provenienti da retail e fonti istituzionali) e semi-strutturati (semi-structured),
come estratti di pagine web, a cui manca una struttura rigida imposta da un
modello di dati sottostanti. All’interno dei dati semi-strutturati sono presenti tag
o altri tipi di marcatori che vengono utilizzati per identificare alcuni elementi
all'interno dei dati, tramite successive elaborazioni.
DATA MODEL
Da preferire la consistenza (consistency) alla disponibilità (availability). I dati
devono potere essere scalati facilmente, perché la loro dimensione prevista è
considerevole. La complessità, che pure esiste, non è particolarmente
significativa. Il data model che più si adatta è il column-based (BigTable-
inspired)
23DeustoTech, University of Deusto, “Linked Open Data Visualization Revisited: A Survey”
2014. http://www.semantic-web-journal.net/system/files/swj937.pdf
24BIG DATA WORKING GROUP, “Big Data Taxonomy” Sept-2014.
https://downloads.cloudsecurityalliance.org/initiatives/bdwg/Big_Data_Taxonomy.pdf
25Jinbao Zhu, Principal Software Engineer, and Allen Wang, Manager, Software Engineering,
CA Technologies, “Data Modeling for Big Data”. http://www.ca.com/br/~/media/Files/Articles/
ca-technology-exchange/data-modeling-for-big-data-zhu-wang.pdf
26 Katy Borner, “Atlas of Knowledge » Anyone Can Map”.
27IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS,
“Information Visualization and Visual Data Mining” Jan-March 2002.
I BIG DATA!27 CONSISTENCY Forte consistenza (strong consistency) dei dati. Questa proprietà garantisce che le analisi, quando richieste, siano sempre corrette. QUERY-ABILITY Non è richiesta disponibilità (availability o query-ability) all’interrogazione dei dati, essendo l’analisi in batch e orientata ad attuare scelte strategiche di lungo periodo. PARTITIONING La frammentazione (clustering) dei dati sui nodi è richiesta. STORAGE LAYOUT Il data model che più si adatta è il column-based (columnar). TEMPORAL DEPENDENCY No (sequenced-data) 2.2.2. DATA PREPARATION DATA TRANSFORMATION AND SELECTION Regole (rule): riorganizzare i dati semi-struttati facendo loro assumere una forma strutturata. Inquadramento dei dati strutturati selezionando le informazioni utili per le successive analisi ORDERING Chiave (key) per l’ordinamento sono le mention su un dato argomento, che costituiscono la massa critica (in statistica: la popolazione) di riferimento per la validità dei dati. ANONYMIZATION MODEL PPDM (Privacy Preserving Data Mining). In questo modello, i dati archiviati così come risultano dalle fasi precedenti. Le tecniche di anonimizzazione avvengono in fase successiva, nel momento in cui devono essere visualizzati. Questo consente l’incrocio di dati provenienti da più fonti diverse, che sarebbe I BIG DATA
!28 altrimenti impossibile, causando la perdita di informazioni preziose. Questa scelta va di pari passo con una più stringente politica di accesso ai dati e di gestione della sicurezza informatica sugli stessi. ANONYMIZATION TECHNIQUES Differential privacy. L’obiettivo è quello di massimizzare l'accuratezza delle query, riducendo al minimo le possibilità di identificare i suoi record. La soluzione impiegata è exponential mechanism. DATA CLEANING AND INTEGRATION Al termine dell’estrazione, i dati vengono normalizzati (normalization) affinché le basi dati siano coerenti e le informazioni mancanti da una delle due vengono completate (missing values). 2.2.3. DATA ANALYTICS MODELS Diagnostic. Il nostro obiettivo è scoprire cosa è accaduto e perché, mettendo in relazione diverse sorgenti di dati. LEARNING APPROACH Semi-supervised. Nei dati semi-strutturati risiedono dati non etichettabili (labelled and unlabelled), che possono facilmente essere mappati dalle funzioni di questo tipo di machine learning. Partendo da una ristretta classificazione dei dati di input è possibile coniugarla con una più ampia classificazione non definita a priori. STATE Stateless. L’analisi non è strettamente dipendente dal periodo in cui la si effettua. TASK Classification and Regression. Il tipo di analisi dipende strettamente dal approccio deciso (semi-supervised learning approach). I BIG DATA
!29 2.2.4. DATA PROCESSING LATENCY High. L’analisi è in batch, non essendo richiesto un tempo di analisi immediato, funzionale nel caso in cui sia propedeutico a decisioni da prendere in un lasso di tempo ristretto. PROCESSING TYPE Batch. L’analisi in batch consente una gestione ottimizzata delle risorse per gli scopi prefissi da questo data processing. ROUNDS Single. LOCALITY Distributed. La computazione è distribuita sui nodi per ottimizzare le performance. 2.2.5. DATA DISPLAY AND REPORTING PROCESSING TYPE Relationship. L’obiettivo è quello di mettere in relazione valori alla base di comportamenti che altrimenti non sarebbero paragonabili. DIMENSIONALITY 2D. Questi grafici permettono il confronto tra due o tre variabili in comparazione, senza tener presente l’evoluzione temporale. INTERACTION L’analisi visiva dei dati passa solitamente da tre fasi: una prima fase di overview, in cui si può percepire la totalità dei dati, sulla quale effettuare la seconda fase di zoom and filter, che permette di selezionare sottoinsiemi di dati e, a seconda del livello di zoom, di fornire più o meno dettagli (granularità). Infine, nella fase details-on-demand, l’utente è in grado di trovare esattamente i dettagli di suo interesse. In questa fase, con la tecnica dell’interactive distortion, è possibile analizzare una porzione di dati, mantenendo l’attenzione sull’overview. I BIG DATA
!30 DATA DENSITY High. DATA TYPE Interval. I dati hanno valenza matematica e possono essere paragonati, ordinati e sommati. USER Domain experts. Non serve un tecnico per comprendere il dettaglio dei dati, tuttavia la conoscenza del settore è indispensabile per coglierne appieno il senso. 2.2.6. DATA INGESTION SOURCE Social Feeds (Kafka). RDBMS (Sqoop). DATA DOMAIN Social Networking (Web). Sorgente dati per l’acquisizione dei tracciati di navigazione. Retail. Sorgente dati per l’acquisizione dei dati di vendita. DATA TYPE Graph Data. Provenienti da domini Web. Sequence Data. Provenienti da domini retail. 2.3. GESTIONE DEI CONFLITTI Di seguito è rappresentata la mappa dei conflitti tra le caratteristiche e delle dirette dipendenza del processo. Questa mappa ha come scopo quello di verificare che il modello non contenga contraddizioni e sia, per tanto, compatibile formalmente con la rappresentazione del processo. I BIG DATA
!31
• Data model: column-oriented stores (Big Table-Inspired) implica strong
Consistency e low Availability. Inoltre implica Storage layout columnar
• Availability: low implica Processing type Batch
• Temporal dependency: No implica un Stateless State
• Learning approach: Semi-supervised implica Classification and Regression
Task
• Processing type: Batch implica Latency High
• Data structure: Semistructured and structured implica Anonymyzation
Model diverso da PPDM
• Anonymization model: PPPM implica Anonymization Tecnique diverso da
K-anonymity
• Processing Type: Relationship implica Dimensionality diverso da 1D e tree
I BIG DATA!32
Capitolo 3
3. S O F T WA R E
In questo capitolo descriveremo l’architettura utilizzata per l’analisi dei Big Data
(Cap. 4) trattando ciascun componente separatamente. Partiremo dall’ambiente
generale in cui i componenti sono installati (Hadoop) e dal software che ne
consente la gestione tramite GUI (Ambari). Analizzeremo poi ciascun componente
nel dettaglio e nelle relazioni che intercorrono tra gli stessi.
L’architettura di Hadoop è simile a quella di un tetris, meglio rappresentato
dall’immagine (fig 328) in cui ogni componente appartiene ad un layer che ha
fondamento con il layer sottostante e offre soluzioni a quello sovrastante.
Componenti che si posizionano tra più layer mettono in relazione tra loro i
componenti dei layer su cui poggiano, mettendo a disposizione funzionalità di
coordinamento e gestione dei dati e delle risorse.
fig. 3 - Hadoop, architettura
28 Gaetano Esposito, “Guida Hadoop”. http://www.html.it
I BIG DATA!33
3.1. AMBARI
un software per la gestione e il monitoraggio dei cluster di Hadoop
Apache Ambari è uno strumento per la gestione e il monitoraggio di cluster
Hadoop. Ambari fornisce un’interfaccia Web attraverso la quale è possibile
svolgere i compiti amministrativi. Le componenti Hadoop supportate, con le
relative versioni, sono riportate in tabella (tab. 3.1).
Per ognuno di questi componenti, Ambari permette di:
• utilizzare un wizard per la procedura d’installazione
• fornire gli strumenti per far partire e fermare i servizi su ciascun nodo
• effettuare il monitoraggio sia attraverso una dashboard che espone diverse
metriche, sia attraverso un sistema di alert che invia segnalazioni tramite
messaggi di posta elettronica in presenza di situazioni critiche.
I servizi presenti installati su 3 diversi nodi (c6501, c0602, c6503) sono i seguenti.
Nella colonna “Requisiti” vengono evidenziati i requisiti descritti nel Capitolo 2
che i Servizi soddisfano.
S E RV I Z I O V E R S I O N E DESCRIZIONE REQUISITI
DATA REPRESENTATION
HDFS 2.7.1.2.4 Apache Hadoop Distributed File > PARTITIONING
System. Il layer consente di avere una DATA PROCESSING >
gestione del File System distribuita LOCALITY
DATA ANALYTICS > TASK
YARN + 2.7.1.2.4 Apache Hadoop NextGen MapReduce
MapReduce2 (YARN). Garantisce una corretta
esecuzione dei Task di Classification e
Regression
DATA ANALYTICS >
Tez 0.7.0.2.4 Tez è il framework per l’elaborazione di LEARNING APPROACH
Query Hadoop. Garantisce
l’elaborazione secondo l’approccio
semi-supervised
I BIG DATA!34
S E RV I Z I O V E R S I O N E DESCRIZIONE REQUISITI
DATA PROCESSING >
Hive 1.2.1.2.4 Sistema di Data warehouse per query LATENCY
ad-hoc e analisi di grandi dataset. DATA PROCESSING>
Gestisce il tipo di processamento dei PROCESSING TYPE
DATA DISPLAY AND
dati e la sua corretta visualizzazione REPORTING > [ALL]
DATA REPRESENTATION
HBase 1.1.2.2.4 Database distribuito non relazionale. > DATA MODEL
Rappresenta i dati secondo un modello DATA REPRESENTATION
column-oriented > STORAGE LAYOUT
DATA PREPARATION >
Pig 0.15.0.2.4 Piattaforma di scripting per l’analisi di DATA CLEANING AND
grandi dataset. Esegue computazioni sui INTEGRATION
dati
DATA REPRESENTATION
Sqoop 1.4.6.2.4 Tool per il trasferimento massivo di dati > DATA STRUCTURE
tra Hadoop e database strutturati, come i DATA INGESTION > [ALL]
database relazionali. Utile per la
preparazione dei dati e per la loro
corretta rappresentazione
DATA REPRESENTATION
ZooKeeper 3.4.6.2.4 Servizio centralizzato che garantisce un > PARTITIONING
affidabile coordinamento distribuito.
Garantisce la corretta partizione dei dati
su HDFS
DATA ANALYTICS >
Falcon 0.6.1.2.4 Piattaforma per la gestione e il [ALL]
processamento dei dati. Utile per
l’analisi dei dati
DATA REPRESENTATION
Flume 1.5.2.2.4 Servizio distribuito per la raccolta, > PARTITIONING
l’aggregazione e lo spostamento di
grandi quantità di dati all’interno di
HDFS
DATA REPRESENTATION
Kafka 0.9.0.2.4 Sistema distribuito per l’invio di > DATA STRUCTURE
messaggi ad alta frequenza. Utile per la DATA INGESTION > [ALL]
preparazione dei dati e per la loro
corretta rappresentazione
tab. 3.1 Ambari Components
I BIG DATA!35 3.2. HADOOP il framework software per gestire i Big Data 3.2.1. COS’È HADOOP Hadoop è un framework software concepito per scrivere facilmente applicazioni che elaborano grandi quantità di dati in parallelo, su cluster di grandi dimensioni (costituiti da migliaia di nodi) assicurando un’elevata affidabilità e disponibilità (fault-tolerance). 3.2.2. LA NASCITA DI HADOOP Uno dei principi chiave per operare con i Big Data è lo stoccaggio di tutti i dati originali, indipendentemente da quando questi saranno utilizzati. Hadoop nacque per sopperire ad un grave problema di scalabilità di Nutch, un crawler Open Source basato sulla piattaforma Lucene di Apache. I programmatori Doug Cutting e Michael J. Cafarella hanno lavorato ad una versione iniziale di Hadoop a partire dal 2004; proprio in quell’anno furono pubblicati documenti tecnici riguardanti il Google File System e Google MapReduce, documenti da cui Doug e Michael attinsero le competenze fondamentali per lo sviluppo di HDFS e di un nuovo e innovativo pattern per l’elaborazione distribuita di elevate moli di dati: MapReduce. Oggi MapReduce è uno dei componenti fondamentali di Hadoop. 3.2.3. COME FUNZIONA Per garantire queste caratteristiche, Hadoop utilizza numerosi macro-sistemi tra cui HDFS, un file system distribuito, progettato appositamente per immagazzinare grandi quantità di dati, in modo da ottimizzare le operazioni di archiviazione e accesso a un ristretto numero di file di grandi dimensioni. Hadoop offre librerie che permettono la suddivisione dei dati da elaborare direttamente sui nodi di calcolo, permettendo di ridurre al minimo i tempi di accesso. Il framework garantisce inoltre un’elevata affidabilità: le anomalie e tutti gli eventuali problemi del sistema sono gestiti a livello applicativo. Un’altra I BIG DATA
!36
caratteristica di Hadoop è la scalabilità che è realizzabile semplicemente
aggiungendo nodi al cluster in esercizio.
3.2.4. HADOOP VS RDBMS
RDBMS HADOOP
Schema on Write: lo schema Schema on Read: i dati sono semplicemente
dei dati deve essere creato copiati nel file system, nessuna
prima che i dati stessi trasformazione è richiesta
vengano caricati
Ogni dato da caricare deve I dati delle colonne sono estratte durante la
essere trasformato nella fase di lettura
struttura interna del
database
Nuove colonne devono essere I nuovi dati possono essere aggiunti ed
aggiunte esplicitamente prima estratti in qualsiasi momento
che i nuovi dati per tali
colonne siano caricate nel
database
3.2.5. I LIMITI DI HADOOP
Hadoop è generalmente considerato inadatto per flussi di dati che non sono di
terminazione. Questo perché per ogni suo ciclo di lavoro, Hadoop presuppone che
tutti i dati siano disponibili in file su vari nodi. Per le applicazioni di streaming, in
cui vi è un flusso costante di dati, questo modello non è ottimale in termini di
prestazioni.
Hadoop non è adatto anche per gli algoritmi iterativi che dipendono da risultati
valutati all’interno dell’algoritmo stesso.
I BIG DATA!37 3.3. HADOOP COMMON strato software comune che fornisce funzioni di supporto agli altri moduli Hadoop Common fa riferimento alla raccolta di utility e librerie comuni che supportano altri moduli Hadoop. Si tratta di una modulo essenziale del Framework di Apache Hadoop, insieme ad HDFS, YARN e MapReduce. Hadoop Common è anche noto come Hadoop Core in quanto fornisce servizi essenziali e processi di base, come l'astrazione del sistema operativo sottostante e il suo file system. Hadoop Common contiene i file e gli script necessari Java Archive (JAR) necessari per avviare Hadoop. I BIG DATA
!38 3.4. HDFS file system distribuito che fornisce un’efficace modalità di accesso ai dati 3.4.1. COS’È HDFS HDFS è un file system distribuito ideato in grado di gestire file di dimensioni nell’ordine dei terabyte e di numero di milioni, attraverso la realizzazione di cluster che possono contenere migliaia di nodi. 3.4.2. COME FUNZIONA HDFS presenta i file organizzati in una struttura gerarchica di cartelle. Sia la dimensione dei blocchi, sia il numero di repliche possono essere configurate per ogni file. Le repliche sono utilizzate sia per garantire l’accesso a tutti i dati (anche in presenza di problemi a uno o più nodi) sia per rendere più efficiente il recupero dei dati. Le richieste di lettura dati avvengono scegliendo i nodi più vicini al client che effettua la lettura. La creazione di un file non avviene direttamente attraverso il NameNode: il client HDFS crea un file temporaneo in locale e solo quando tale file supera la dimensione di un blocco, viene preso in carico dal NameNode, che crea il file all’interno della gerarchia del file system, identifica un DataNode e i blocchi su cui posizionare i dati. Successivamente DataNode e blocchi sono comunicati al client HDFS che provvede a copiare i dati dalla cache locale alla sua destinazione finale. Dal punto di vista dell’architettura, un cluster è costituito dai seguenti tipi di nodi: NAMENODE Il Namenode è l’applicazione che gira sul server principale. Gestisce il file system ed in particolare il namespace, cioè l’elenco dei nomi dei file e dei blocchi (i file infatti vengono divisi in blocchi da 64/128MB) e controlla l’accesso ai file, eseguendo le operazioni di apertura, chiusura e modifica dei nomi di file. Inoltre, determina come i blocchi dati siano distribuiti sui nodi del cluster e la strategia di replica che garantisce l’affidabilità del sistema. I BIG DATA
!39 Il NameNode monitora anche che i singoli nodi siano in esecuzione senza problemi e in caso contrario decide come riallocare i blocchi. Il NameNode distribuisce le informazioni contenute nel namespace su due file: il primo è fsimage, che costituisce l’ultima immagine del namespace; il secondo è un log dei cambiamenti avvenuti al namespace a partire dall’ultima volta in cui il file fsimage è stato aggiornato. Quando il NameNode parte effettua un merge di fsimage con il log dei cambiamenti così da produrre uno snapshot dell’ultima situazione. DATANODE I Datanode sono applicazioni che girano su altri nodi del cluster, generalmente una per nodo, e gestiscono fisicamente lo storage di ciascun nodo. Queste applicazioni eseguono, logicamente, le operazioni di lettura e scrittura richieste dai client e gestiscono fisicamente la creazione, la cancellazione o la replica dei blocchi dati. SECONDARYNAMENODE Il SecondaryNameNode, noto anche come CheckPointNode, si tratta di un servizio che aiuta il NameNode ad essere più efficiente. Infatti si occupa di scaricare periodicamente il file fsimage e i log dei cambiamenti dal NameNode, di unirli in un unico snapshot che è poi restituito al NameNode. BACKUPNODE Il Backupnode è il nodo di failover e consente di avere un nodo simile al SecondaryNameNode sempre sincronizzato con il NameNode. I BIG DATA
!40
3.4.3. COMANDI
COMANDO DESCRIZIONE ESEMPIO
dfs esegue un comando nativo
sul file system di Hadoop
cat Copia i file specificati hdfs dfs -cat /user/hadoop/file
sullo standard output
get Copia un file da HDFS al hdfs dfs -get /user/hadoop/file
file system locale file-locale
put Copia un file dal file hdfs dfs -put file-locale /
system locale ad HDFS user/hadoop/file
ls Restituisce informazioni hdfs dfs -ls /
su file e directory
mkdir Crea una cartella nel hdfs dfs -mkdir /data/test-
percorso indicato folder
rm Elimina cartelle e file hdfs dfs -rm /data/test-folder
specificati
rmr rm in versione ricorsiva hdfs dfs -rmr file-locale /
data/test
count Restituisce il conteggio hdfs dfs -count PATH /data/test
di directory e file
contenuti nel percorso
indicato.
I BIG DATA!41
3.5. HBASE
il database di Hadoop. Distribuito. Scalabile
3.5.1. COS’È HBASE
HBASE consente accesso in realtime in lettura e scrittura ai dati, anche non
sequenziali, di HDFS. Le caratteristiche di scalabilità e distribuzione di HBASE
consentono di lavorare con tabelle con milioni di colonne e miliardi di righe.
HBASE si basa sul modello non relazionale, inspirato alle BigTable di Google29.
Alcune delle caratteristiche di HBASE:
• Lineare e scalabilità modulare;
• Operazioni di lettura e scrittura rigorosamente coerenti;
• Sharding automatico e configurabile;
• Supporto dei guasti automatico tra RegionServers.
3.5.2. REGIONSERVER
Il compito del Region Server è essenzialmente quello di bufferizzare le
comunicazioni I/O e gestire la scrittura dei dati su HDFS.
29 https://research.google.com/archive/bigtable.html
I BIG DATA!42
3.6. HCATALOG
vista tabellare sui dati
3.6.1. COS’È HCATALOG
HCatalog presenta agli utenti una vista tabellare dei dati presenti in HDFS,
indipendentemente dal formato di origine, rendendo più semplice la creazione e la
modifica dei metadati
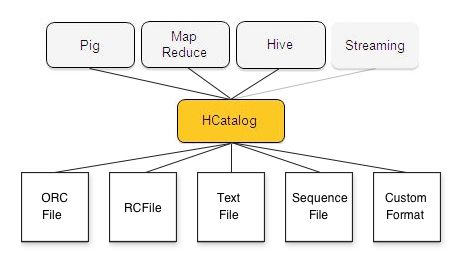
3.6.2. ARCHITETTURA
HCatalog (fig. 3.6.230) incorpora DDL di Hive. Fornisce interfacce di lettura e
scrittura per Pig e MapReduce e utilizza l'interfaccia a riga di comando di Hive per
le altre richieste.
fig. 3.6.2 HCATALOG, architettura
INTERFACCE
L'interfaccia HCatalog per Pig è costituito da HCatLoader e HCatStorer, che
implementano rispettivamente le interfacce di caricamento e memorizzazione di
Pig.
L'interfaccia HCatalog per MapReduce, HCatInputFormat e HCatOutputFormat, è
un'implementazione di Hadoop InputFormat e OutputFormat.
I dati sono definiti utilizzando l'interfaccia a riga di comando di HCatalog (CLI).
HCatalog CLI supporta tutte le DDL di HIVE, consentendo agli utenti di creare,
modificare, cancellare tabelle. La CLI supporta anche l’esplorazione dei dati della
30 https://cwiki.apache.org/confluence/display/Hive/HCatalog+UsingHCat
I BIG DATA!43 riga di comando Hive, come ad esempio la possibilità di mostrare e descrivere le tabelle. DATA MODEL HCatalog presenta una visione relazionale dei dati, memorizzati in tabelle. Le tabelle possono anche essere hash partizionate su una o più chiavi; cioè, per un dato valore di una chiave (o un insieme di chiavi) ci sarà una partizione che contiene tutte le righe con tale valore (o un insieme di valori). Ad esempio, se una tabella è partizionata alla data e ci sono tre giorni di dati nella tabella, vi saranno tre partizioni della tabella. Le partizioni sono multi-dimensionali e non gerarchiche e i record sono divisi in colonne tipizzate. I BIG DATA
!44 3.7. MAP-REDUCE pattern che permette di realizzare sistemi di computazione parallela 3.7.1. COS’È MAP-REDUCE MapReduce è il cuore del sistema di calcolo distribuito di Hadoop. Si basandosi sul concetto di functional programming. MapReduce lavora secondo il principio del divide et impera, suddividendo l’operazione di calcolo in diverse parti processate in modo autonomo. Una volta che ciascuna parte del problema è stata calcolata, i vari risultati parziali sono “ridotti” (cioè ricomposti) a un unico risultato finale. È MapReduce stesso che si occupa dell’esecuzione dei vari task di calcolo, del loro monitoraggio e della ripetizione dell’esecuzione in caso si verifichino problemi. Il framework lavora attraverso i compute node cioè dei nodi di calcolo che si trovano assieme ai DataNode di HDFS. 3.7.2. A COSA SERVE MapReduce si presta bene all’esecuzione di numerose operazioni sui dati. Data la varietà di operazioni che MapReduce può effettuare in modo efficiente, i potenziali utilizzi del framework sono moltissimi: • creazione di liste di parole da documenti di testo, indicizzazione e ricerca. • analisi di strutture dati complesse, come grafi • data mining e machine learning; • esecuzione di task distribuiti • correlazioni, operazioni di unione, intersezione, aggregazione e join Grazie alla Big Data analytics, non ci si limita più ad una business intelligence orientata all’analisi dati strutturati per trarre conclusioni a posteriori. Grazie alla varietà dei dati che è possibile analizzare, all’enorme quantità che è possibile immagazzinare con le moderne tecnologie e allo stesso tempo alla velocità che non è più un limite nell’analisi di enormi moli di informazioni, si possono elaborare modelli di analisi che possono fornire predizioni e non limitarsi ad analisi descrittive. I BIG DATA
!45
3.8. YARN
framework per la creazione di applicazioni per il calcolo distribuito
3.8.1. COS’È YARN
Acronimo di Yet-Another-Resource-Negotiator, YARN è un framework che
consente di creare applicazioni o infrastrutture di calcolo distribuito di qualsiasi
tipo. YARN si prende carico della gestione delle risorse quali la memoria e la CPU,
e monitora l’esecuzione delle applicazioni.
3.8.2. A COSA SERVE
L'idea fondamentale di YARN è di dividere le funzionalità di gestione delle risorse
in un ResourceManager globale (RM) e il processo di pianificazione e di controllo
in un ApplicationMaster (AM). Il ResourceManager e NodeManager costituiscono
il Framework dei dati di calcolo. Il ResourceManager mantiene il controllo delle
risorse condivise tra tutte le applicazioni presenti nel sistema. Il NodeManager è
responsabile di monitorare l’utilizzo delle risorse (CPU, memoria, disco, rete) e
riportare lo stesso al ResourceManager. L’ApplicationMaster ha il compito di
negoziare le risorse dal ResourceManager e lavorare con il NodeManager per
eseguire e monitorare le attività (fig 3.8.231).
fig. 3.8.2 YARN, architettura
31 https://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/YARN.html
I BIG DATA!46 3.9. HIVE datawarehouse che consente l'esecuzione di query ad hoc 3.9.1. COS’È HIVE Apache Hive è un'infrastruttura data warehouse costruita su Hadoop per fornire riepilogo dei dati, nonché la loro interrogazione e analisi. Hive consente di accedere via SQL (vedi cap. successivo “HiveQL”) ai dati presenti nei database e mette a disposizione processi ETL (Extract, Transform, Load). I dati sono salvati su HBase o direttamente sul file system HDFS. Hive supporta tre differenti motori di estrazione: Tez, Spark o MapReduce. Trova la sua migliore applicazione come data warehouse e non è progettato per funzionare come OLTP (OnLine Transaction Processing). I dati in input sono caricati a partire da file fisici o stream di dati, programmabili tramite script. Durante la creazione, vengono assegnate una o più partizioni alle tabelle in relazione ai campi utilizzati come chiave. Questa scelta inficerà sulla velocità di esecuzione delle query in dipendenza del campo scelto come chiave della partizione. I dati di output generati tramite query HiveQL sono organizzati in tabelle ed esportabili in grafici costruiti a partire dai campi che si desidera mappare sugli assi (x, y), in righe (row) o colonne (column), per dimensione (size) o colore (colour). 3.9.2. HIVEQL HiveQL è un linguaggio basato su SQL, tramite il quale è possibile effettuare le quei di Hive su Hadoop. Non segue strettamente lo standard SQL-92 ma la gran parte delle funzionalità di SQL sono supportate. 3.9.3. BEELINE Beeline è la CLI (Command Line Interface) di HIVE dalla quale è possibile eseguire i comandi I BIG DATA
Puoi anche leggere

















































