Analytics Lens Canone di architettura AWS
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Analytics Lens Canone di architettura AWS
Analytics Lens Canone di architettura AWS Analytics Lens: Canone di architettura AWS Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon.
Analytics Lens Canone di architettura AWS
Table of Contents
Riassunto .......................................................................................................................................... 1
Riassunto .................................................................................................................................. 1
Introduzione ....................................................................................................................................... 2
Definizioni .................................................................................................................................. 2
Livello di acquisizione ......................................................................................................... 2
Livello di sicurezza e accesso ai dati ..................................................................................... 3
Livello di ricerca e catalogo .................................................................................................. 3
Livello di storage centrale .................................................................................................... 4
Livello di analisi ed elaborazione .......................................................................................... 5
Livello di interfaccia e accesso degli utenti ............................................................................. 5
Principi generali di progettazione .......................................................................................................... 7
Scenari ............................................................................................................................................. 9
Data Lake ................................................................................................................................. 9
Caratteristiche .................................................................................................................... 9
Architettura di riferimento ................................................................................................... 10
Note di configurazione ....................................................................................................... 12
Elaborazione dei dati in batch ..................................................................................................... 12
Caratteristiche .................................................................................................................. 13
Architettura di riferimento ................................................................................................... 14
Note di configurazione ....................................................................................................... 15
Acquisizione in streaming ed elaborazione dei flussi ....................................................................... 16
Caratteristiche .................................................................................................................. 16
Architettura di riferimento ................................................................................................... 17
Note di configurazione ....................................................................................................... 19
Architettura Lambda .................................................................................................................. 19
Caratteristiche .................................................................................................................. 19
Architettura di riferimento ................................................................................................... 20
Note di configurazione: ...................................................................................................... 21
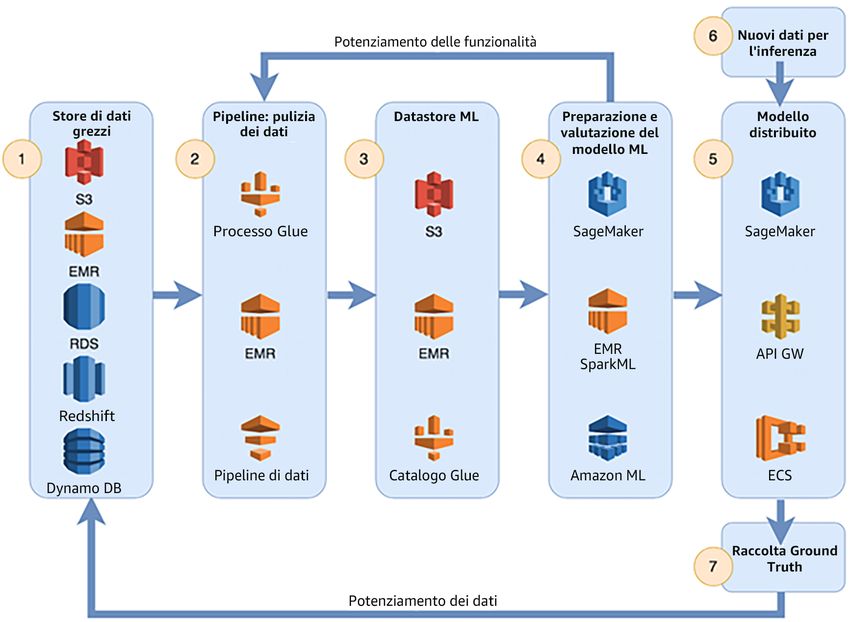
Data Science ........................................................................................................................... 21
Caratteristiche .................................................................................................................. 22
Architettura di riferimento ................................................................................................... 23
Note di configurazione ....................................................................................................... 23
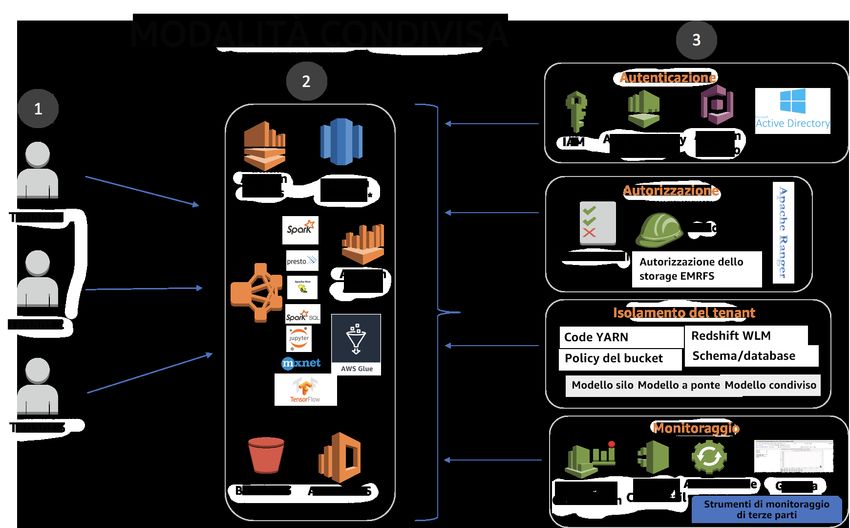
Analisi multi-tenant .................................................................................................................... 24
Caratteristiche: ................................................................................................................. 24
Architettura di riferimento ................................................................................................... 25
Note di configurazione: ...................................................................................................... 26
I principi del canone di architettura ...................................................................................................... 28
Principio dell'eccellenza operativa ................................................................................................ 28
Principi di progettazione ..................................................................................................... 28
Definizione ....................................................................................................................... 28
Best practice .................................................................................................................... 28
Risorse ............................................................................................................................ 32
Principio della sicurezza ............................................................................................................. 32
Definizione ....................................................................................................................... 32
Principi di progettazione: .................................................................................................... 33
Best practice .................................................................................................................... 33
Risorse ............................................................................................................................ 39
Principio dell'affidabilità .............................................................................................................. 40
Definizione ....................................................................................................................... 40
Principi di progettazione ..................................................................................................... 41
Best practice .................................................................................................................... 41
Risorse ............................................................................................................................ 43
Il principio dell'efficienza delle prestazioni ..................................................................................... 43
Definizione ....................................................................................................................... 43
iii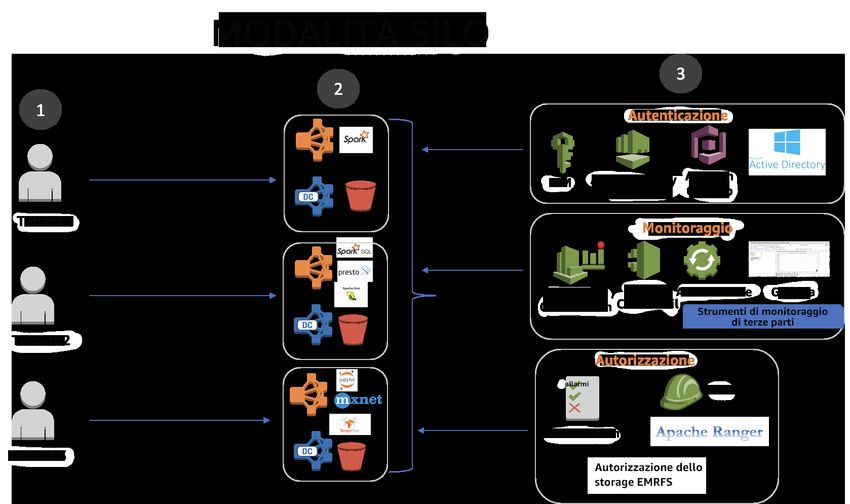
Analytics Lens Canone di architettura AWS
Principi di progettazione ..................................................................................................... 44
Best practice .................................................................................................................... 44
Risorse ............................................................................................................................ 47
Principio dell'ottimizzazione dei costi ............................................................................................ 47
Definizione ....................................................................................................................... 48
Principi di progettazione ..................................................................................................... 48
Best practice .................................................................................................................... 48
Risorse ............................................................................................................................ 54
Conclusione ..................................................................................................................................... 56
Collaboratori ..................................................................................................................................... 57
Approfondimenti ................................................................................................................................ 58
Revisioni del documento .................................................................................................................... 59
Avvisi .............................................................................................................................................. 60
iv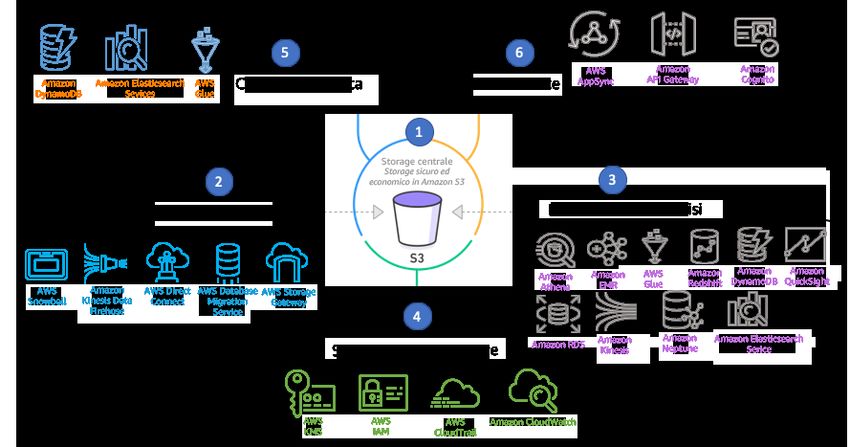
Analytics Lens Canone di architettura AWS
Riassunto
Approfondimento sull'analisi: Canone
di architettura AWS
Data di pubblicazione:: Maggio 2020 (Revisioni del documento (p. 59))
Riassunto
Questo documento illustra l'Analytics Lens per il Canone di architettura AWS. Il documento illustra i normali
scenari delle applicazioni di analisi e identifica gli elementi chiave per garantire che i carichi di lavoro siano
progettati secondo le best practice.
1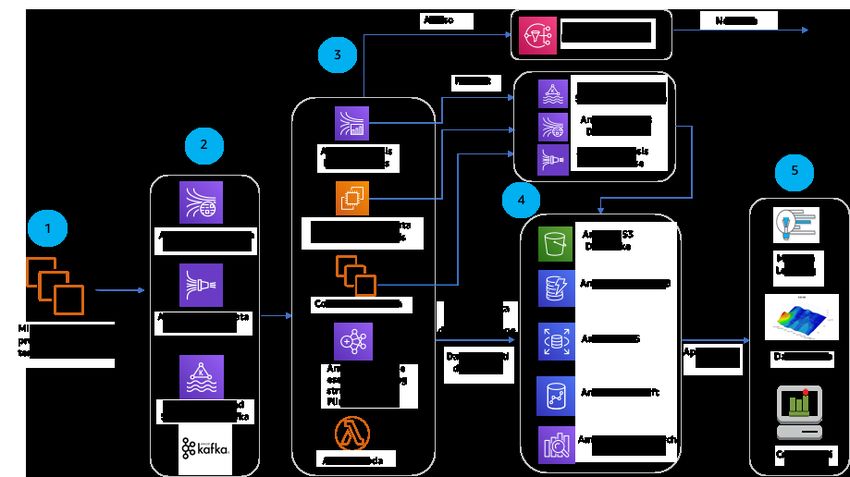
Analytics Lens Canone di architettura AWS
Definizioni
Introduzione
Il Canone di architettura AWS aiuta a comprendere i pro e i contro delle decisioni prese durante la
progettazione di sistemi in AWS.
Utilizzando il framework, scoprirai le best practice architetturali per progettare e gestire sistemi affidabili,
sicuri, efficienti e convenienti nel cloud. Il framework permette di misurare in modo coerente le architetture
rispetto alle best practice e identificare le aree da migliorare. Disporre di sistemi ben architettati aumenta
notevolmente la probabilità di successo aziendale.
In questo approfondimento ci concentriamo su come progettare, distribuire e progettare i carichi di lavoro
delle applicazioni di analisi in AWS Cloud. Per essere efficaci, abbiamo deciso di prendere in esame i
dettagli del Canone di architettura AWS specifici dei carichi di lavoro di analisi. È consigliabile, in ogni caso,
considerare anche le best practice e le domande che non vengono spiegate in questo documento durante
la progettazione di un'architettura. Consigliamo di leggere il whitepaper Canone di architettura AWS.
Questo documento è rivolto a chi svolge ruoli tecnologici, per esempio Chief Technology Officer (CTO),
progettisti, sviluppatori e membri del team operativo. Leggendo questo documento sarà possibile
comprendere le best practice e le strategie di AWS da utilizzare durante la progettazione di architetture per
applicazioni e ambienti di analisi.
Definizioni
Il Canone di architettura AWS si basa su cinque principi: eccellenza operativa, sicurezza, affidabilità,
efficienza delle prestazioni e ottimizzazione dei costi. Per ambienti e carichi di lavoro di analisi, AWS
fornisce diversi componenti principali che consentono di progettare architetture solide per applicazioni
di analisi. In questa sezione, presenteremo una panoramica dei servizi che verranno utilizzati in questo
documento.
Organizzare le architetture di dati in "livelli" concettuali permette i controlli di accesso appropriati, pipeline,
flussi ETL (estrazione, trasformazione e caricamento) e integrazioni specifiche per il caso d'uso. Sono sei le
aree da considerare durante la creazione di un carico di lavoro di analisi.
Argomenti
• Livello di acquisizione (p. 2)
• Livello di sicurezza e accesso ai dati (p. 3)
• Livello di ricerca e catalogo (p. 3)
• Livello di storage centrale (p. 4)
• Livello di analisi ed elaborazione (p. 5)
• Livello di interfaccia e accesso degli utenti (p. 5)
Livello di acquisizione
Il livello di inserimento dei dati è responsabile dell'inserimento dei dati in uno storage centrale per l'analisi,
come ad esempio un data lake. Comprende servizi che permettono il consumo dei set di dati in batch
e streaming in tempo reale da origini esterne, come clickstream di siti Web, flussi di eventi di database,
transazioni finanziarie, feed di social media, registri IT, eventi di tracciamento della posizione, dati di
telemetria IoT, origini dati in locale e datastore nativi per il cloud.
Amazon Kinesis è una famiglia di servizi per l'acquisizione di dati in tempo reale e fornisce funzionalità
per caricare e analizzare in modo sicuro i dati in streaming e inviarli a Amazon Simple Storage Service
2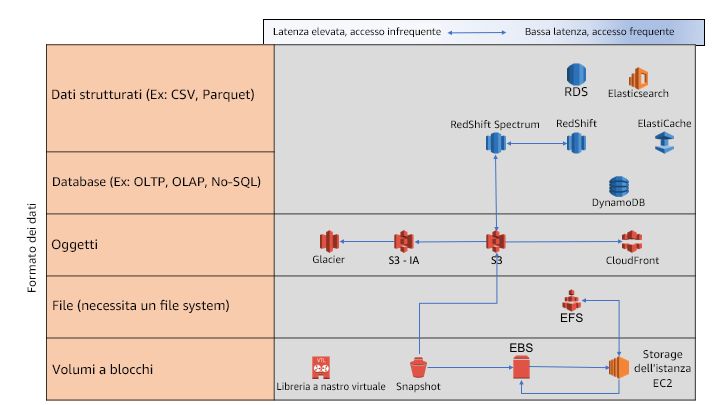
Analytics Lens Canone di architettura AWS
Livello di sicurezza e accesso ai dati
(Amazon S3) per lo storage a lungo termine. Forniamo anche Amazon Managed Streaming for Apache
Kafka (MSK), un servizio completamente gestito che permette di eseguire cluster Apache Kafka sicuri e a
disponibilità elevata per elaborare dati in streaming senza il bisogno di modificare la base di codice.
Grazie a AWS Database Migration Service (DMS) è possibile replicare e acquisire i database esistenti
senza compromettere la completa operatività dei database di origine. Il servizio supporta diverse origini
dati e destinazioni, compresa la scrittura dei dati direttamente su Amazon S3. Per accelerare le migrazioni
DMS, è possibile utilizzare AWS Snowball, che utilizza dispositivi fisici e sicuri per trasferire grandi quantità
di dati da e verso AWS Cloud. Consigliamo di considerare anche AWS Direct Connect, che permette di
creare una connessione di rete privata e coerente tra il data center e AWS.
È anche possibile avere ulteriori punti di inserimento dei dati, come AWS IoT Core, una piattaforma gestita
in grado di elaborare e instradare i messaggi su vasta scala in datastore AWS affidabili e sicuri. AWS
DataSync è un servizio di trasferimento dati che semplifica, automatizza e accelera lo spostamento e la
replica dei dati tra sistemi di storage in locale come NFS e servizi di storage AWS, come Amazon EFS e
Amazon S3 per l'acquisizione da parte del carico di lavoro di analisi.
Livello di sicurezza e accesso ai dati
Il livello di sicurezza e accesso ai dati fornisce un meccanismo per l'accesso agli asset di dati garantendone
al contempo la protezione, assicurando che i dati sono archiviati in modo sicuro e l'accesso è fornito solo a
chi è in possesso dell'autorizzazione. Questo livello permette:
• Accesso sicuro ai dati al repository centrale (ovvero il data lake)
• Accesso sicuro al Data Catalog centrale
• Controllo degli accessi a grana fine per database, tabelle e colonne del Data Catalog
• Crittografia degli asset di dati in transito e inattivi
È necessario utilizzare AWS Identity and Access Management (IAM) per gestire in modo sicuro l'accesso
ai servizi e alle risorse AWS. Grazie a IAM, è possibile creare e gestire utenti e gruppi AWS e utilizzare le
autorizzazioni per consentire o negare l'accesso alle risorse AWS. Con AWS CloudTrail puoi registrare,
monitorare continuamente e conservare l'attività dell'account relativamente alle operazioni di accesso ai
dati di tali utenti e ruoli nell'infrastruttura AWS. Puoi anche utilizzare Amazon CloudWatch per raccogliere
dati operativi e di monitoraggio, sotto forma di registri, parametri ed eventi per il carico di lavoro di analisi.
Per la crittografia dei dati inattivi, usa AWS Key Management Service (KMS), un servizio sicuro e resiliente
che semplifica la creazione e il controllo delle chiavi di crittografia dei tuoi dati. Alcune normative richiedono
di accoppiare KMS con AWS CloudHSM, un modulo di sicurezza hardware basato sul cloud (HSM) che
permette di generare e utilizzare in modo semplice le tue chiavi di crittografia. AWS CloudHSM aiuta a
dimostrare la conformità con sicurezza, privacy e normative anti-manomissione come HIPAA, FedRAMP e
PCI. È possibile configurare KMS per utilizzare il cluster CloudHSM come archivio di chiavi personalizzato
al posto di quello predefinito KMS.
AWS Lake Formation è un servizio di data lake integrato che semplifica acquisizione, pulizia,
catalogazione, trasformazione e messa in sicurezza dei dati rendendoli anche disponibili per machine
learning (ML) e analisi. Lake Formation fornisce il proprio modello di autorizzazioni, che aumenta quello
IAM di AWS per configurare l'accesso ai dati e le policy di sicurezza per i data lake e per verificare
e controllare gli accessi dai servizi di analisi e ML di AWS. Questo modello di autorizzazioni definito
centralmente permette l'accesso granulare ai dati archiviati nei data lake attraverso un semplice
meccanismo di assegnazione/revoca.
Livello di ricerca e catalogo
Il livello di ricerca e catalogo del carico di lavoro di analisi gestisce il rilevamento e la catalogazione
dei metadati che appartengono agli asset di dati. Questo livello fornisce anche le funzionalità di ricerca
3
Analytics Lens Canone di architettura AWS
Livello di storage centrale
necessarie a gestire la crescita degli asset di dati in quantità e dimensioni: è piuttosto comune trovarsi nella
situazione in cui si vuole trovare una tabella in base a criteri definiti ed estrarre sotto-set di dati, quando si
lavora con le applicazioni di analisi.
AWS Glue è un servizio ETL completamente gestito che semplifica ai clienti la preparazione e il
caricamento dei dati per l'analisi. È possibile puntare AWS Glue ai tuoi dati archiviati su AWS per rilevare i
dati e archiviare i relativi metadati (per esempio la definizione e lo schema della tabella) nel AWS Glue Data
Catalog. Una volta catalogati i dati saranno immediatamente disponibili per ricerche, query ed ETL.
Con Amazon OpenSearch Service è possibile distribuire cluster Elasticsearch completamente gestiti in
AWS Cloud per cercare gli asset di dati. Ottieni accesso diretto alle API Elasticsearch: applicazioni e codice
esistenti lavorano senza interruzioni con il servizio che include Kibana gestito, l'integrazione con Logstash e
altri servizi AWS, allarmi integrati e query SQL.
Amazon Relational Database Service (Amazon RDS) consente di impostare, gestire e dimensionare
facilmente un database relazionale nel cloud. Oltre a AWS Glue è possibile utilizzare Amazon RDS per
creare un metastore Hive per EMR. Il metastore contiene una descrizione della tabella e dei dati sottostanti
sui quali è montato, inclusi i nomi della partizione, i tipi di dati e così via.
Amazon DynamoDB è un datastore NoSQL che può essere utilizzato per creare indici esterni economici
a prestazioni elevate che mappano gli attributi sui quali è possibile eseguire query alle chiavi di oggetto
Amazon S3. Amazon DynamoDB si ricalibra automaticamente e mantiene la disponibilità elevata senza il
bisogno di mantenere i server tradizionali.
Livello di storage centrale
Il livello di storage centrale gestisce lo storage di dati durante le acquisizioni da produttori differenti e li
rende disponibili per le applicazioni a valle. Questo livello si trova al centro del data lake e deve supportare
l'alloggiamento di tutti i tipi di dati: non strutturati, semi-strutturati e strutturati. Man mano che i dati crescono
nel tempo, questo livello deve essere in grado di dimensionare in modo elastico, sicuro ed economico.
Nelle pipeline di elaborazione dei dati, essi potrebbero venire archiviati durante fasi intermedie
dell'elaborazione, sia per evitare duplicazioni inutili del lavoro fino a quel punto nella pipeline, sia per
rendere disponibili i dati intermedi a più consumatori a valle. I dati intermedi possono venire aggiornati
spesso, archiviati temporaneamente o a lungo termine, a seconda del caso d'uso.
Amazon S3 fornisce una base ottimale per lo storage centrale grazie alla sua scalabilità praticamente
illimitata, durabilità del 99,9% (11 "noni"), crittografia nativa e funzionalità di controllo degli accessi. Con
la crescita dei requisiti di storage dei dati nel coso del tempo, i dati possono essere spostati a livelli più
economici, come l'accesso infrequente di S3 o Amazon S3 Glacier, attraverso le policy del ciclo di vita
per risparmiare sui costi di storage preservando comunque i dati grezzi originali. Puoi anche utilizzare S3
Intelligent-Tiering, che ottimizza i costi di storage automaticamente al cambiare dei modelli di accesso ai
dati, senza influenzare le prestazioni o generare sovraccarichi operativi.
Amazon S3 semplifica la creazione di un ambiente multi-tenant, nel quale numerosi utenti possono
aggiungere i propri strumenti di analisi dei dati in un set di dati comune. Questo migliora costi e governance
dei dati rispetto alle soluzioni tradizionali che normalmente necessitano più copie distribuite dei dati. Per
consentire l'accesso facile, Amazon S3 fornisce API RESTful semplici e supportate da Apache Hadoop e
dalla maggior parte dei produttori di software indipendenti (ISV) e fornitori di strumenti di analisi di terze
parti.
Con Amazon S3 il data lake può disaccoppiare lo storage da calcolo ed elaborazione dei dati. Nelle
soluzioni data warehouse e Hadoop tradizionali, storage e calcolo sono strettamente accoppiate, rendendo
difficile l'ottimizzazione dei costi e dei flussi di lavoro di elaborazione dei dati. Amazon S3 ti permette di
archiviare tutti i tipi di dati nei loro formati nativi e utilizzare tutti i server virtuali necessari all'elaborazione
dei dati. Puoi anche integrare soluzioni serverless come AWS Lambda, Amazon Athena, Amazon Redshift
Spectrum, Amazon Rekognition e AWS Glue per elaborare i dati senza effettuare il provisioning o gestire i
server.
4Analytics Lens Canone di architettura AWS
Livello di analisi ed elaborazione
Amazon Elastic Block Store (EBS) offre volumi di storage a blocchi permanenti da utilizzare con istanze
Amazon EC2 in AWS Cloud. Ogni volume Amazon EBS è replicato automaticamente all'interno della sua
zona di disponibilità per fornire protezione in caso di errore di un componente, insieme a disponibilità e
durabilità elevate. Per i carichi di lavoro di analisi puoi utilizzare EBS con i motori di analisi di Big Data
(come l'ecosistema Haddop/HDFS o i cluster Amazon EMR), database relazionali e NoSQL (come
Microsoft SQL Server e MySQL o Cassandra e MongoDB), applicazioni di elaborazione di registri e flussi
(come Kafka e Splunk) e applicazioni di data warehousing (come Vertica e Teradata) in esecuzione su
istanze EC2.
Livello di analisi ed elaborazione
Il livello di analisi ed elaborazione è responsabile dell'offerta di strumenti e servizi per le query e
l'elaborazione (ovvero pulizia, convalida, trasformazione, arricchimento e normalizzazione) dei set di dati
per ottenere informazioni aziendali dettagliate sia in batch che in streaming. Esistono numerosi servizi che
possono essere utilizzati per il livello di analisi ed elaborazione.
Amazon EMR è un servizio gestito utile a eseguire, ricalibrare facilmente grandi framework di Big Data
come Apache Spark, Hadoop, HBase, Presto, Hive e altri, tra istanze Amazon EC2 scalabili dinamicamente
e interagire con i dati presenti in altri datastore AWS come Amazon S3 e Amazon DynamoDB.
Amazon Redshift è un data warehouse completamente gestiti che rende più semplice ed economica
l'analisi di tutti i dati con gli strumenti standard SQL e BI (Business Intelligence) esistenti. Redshift
Spectrum è una funzionalità di Amazon Redshift che permette di eseguire query su exabyte di dati non
strutturati in Amazon S3, senza il bisogno di caricamento o ETL. Redshift Spectrum può eseguire query
altamente sofisticate su exabyte di dati e più, in pochi minuti.
Amazon Athena è un servizio di query interattivo che semplifica l'analisi dei dati in Amazon S3 con gli
strumenti SQL standard. Athena è serverless, non prevede infrastruttura da gestire e si pagano solo le
query che vengono eseguite. Athena si integra con AWS Glue Data Catalog, consentendo di creare un
repository unificato di metadati tra più servizi, scansionare le origini dati per rilevare schemi, popolare il
catalogo con tabelle nuove, modificate e le definizioni della partizione, oltre a mantenere il controllo di
versione dello schema.
Con Amazon Neptune è possibile creare un database a grafo veloce, affidabile e completamente gestito
che semplifica la creazione e l'esecuzione di applicazioni che funzionano con set di dati altamente
connessi. Supporta modelli di grafico comuni come Property Graph e RDF di W3C, nonché i rispettivi
linguaggi, Apache TinkerPop Gremlin e SPARQL. Amazon Neptune può alimentare casi d'uso di di
relazione di grafici come i motori di raccomandazione, il rilevamento delle frodi, grafici di conoscenza,
rilevamento di farmaci e sicurezza di rete.
Amazon SageMaker è una piattaforma di machine learning completamente gestita che permette a
sviluppatori e data scientist di costruire, addestrare e distribuire in modo facile e veloce modelli di machine
learning su qualsiasi scala. I data scientist possono utilizzarla per creare, formare e distribuire modelli ML in
modo semplice su elementi del data lake.
Anche i servizi esistenti possono essere utilizzati per elaborazione e analisi, inclusi Amazon Kinesis,
Amazon RDS, Apache Kafka e i processi ETL di AWS Glue.
Livello di interfaccia e accesso degli utenti
Il livello di interfaccia e accesso degli utenti fornisce un mezzo sicuro per l'accesso degli utenti e
un'interfaccia di amministrazione per la loro gestione.
AWS Lambda consente di eseguire applicazioni serverless stateless su una piattaforma gestita che
supporta architetture di microservizi, distribuzione e gestione dell'esecuzione a livello di funzione.
Con Amazon API Gateway è possibile eseguire un'API REST completamente gestita che si integra con
Lambda per eseguire la logica di business e include la gestione del traffico, il controllo delle autorizzazioni e
5Analytics Lens Canone di architettura AWS
Livello di interfaccia e accesso degli utenti
degli accessi, il monitoraggio e la funzione di controllo di versione dell'API. Per esempio, è possibile creare
un'API del data lake utilizzando API Gateway che riceve le richieste via HTTPS. Quando viene effettuata
una richiesta API, Amazon API Gateway sfrutta autorizzazioni ad hoc (una funzione Lambda) per garantire
che tutte le richieste vengano autorizzate prima dell'invio dei dati.
Con Amazon Cognito, è possibile aggiungere facilmente registrazione, accesso degli utenti e
sincronizzazione dei dati alle applicazioni serverless. Amazon Cognito user pools fornisce schermate
di accesso e federazione integrate con Facebook, Google e Amazon, tramite SAML (Security Assertion
Markup Language). Le identità federate di Amazon Cognito consentono di fornire accesso mirato alle
risorse AWS che fanno parte della tua architettura serverless.
6Analytics Lens Canone di architettura AWS
Principi generali di progettazione
Il Canone di architettura identifica una serie di principi generali che consente di facilitare la corretta
progettazione nel cloud per le applicazioni di analisi:
• Automatizza l'acquisizione dei dati: l'acquisizione dei dati deve essere automatizzata mediante trigger,
pianificazioni e rilevamento delle modifiche. L'automazione del processo di acquisizione elimina i
processi manuali soggetti a errori, permette l'elaborazione dei dati all'arrivo e consente di creare
e replicare i sistemi a basso costo. È possibile sfruttare i pianificatori disponibili tra gli strumenti di
orchestrazione per pianificare e attivare l'acquisizione a intervalli periodici o eseguire gli script di
acquisizione continuamente per le applicazioni in streaming.
• Progetta l'inserimento per evitare errori e duplicati: l'inserimento attivato da richieste ed eventi deve
essere idempotente, poiché possono verificarsi errori e un determinato messaggio potrebbe essere
consegnato più di una volta. Includi nuovi tentativi appropriati per le chiamate a valle.
• Conserva i dati origine iniziali: i dati grezzi acquisiti devono essere conservati così come sono,
consentendo di ripetere il processo ETL qualora si verificassero errori. Durante l'esecuzione della
pipeline non deve verificarsi alcuna trasformazione ai file di dati originali.
• Descrivi i dati con i metadati: i set di dati tendono a crescere in varietà e volume, per questo è
fondamentale che tutti i set di dati siano rilevabili e classificati all'interno dell'ambiente del datastore.
Acquisisci i metadati relativi al datastore per assicurarti che tutte le applicazioni a valle siano in grado di
sfruttare i set di dati acquisiti. Assicurati che questa attività sia automatizzata e ben documentata.
• Stabilisci la derivazione dei dati: la derivazione dei dati si riferisce al monitoraggio dell'origine dati e
il relativo flusso tra sistemi di dati differenti. Avere la possibilità di visualizzare, monitorare e gestire il
flusso di dati durante il suo spostamento tra l'origine e la destinazione può semplificare notevolmente il
tracciamento degli errori lungo la pipeline di analisi e permettere di ottenere informazioni approfondite
sull'evoluzione dei dati.
• Usa lo strumento ETL giusto per il processo: quando si tratta di estrarre, trasformare e caricare gli
strumenti (ETL, Extract, Transform, Load), esistono numerose opzioni. Alcune sono compilazioni
personalizzate per risolvere problemi specifici, assemblati da progetti open source e piattaforme ETL con
licenza commerciale. Seleziona lo strumento ETL che si avvicina il più possibile ai requisiti in modo da
snellire il flusso di lavoro tra l'origine e la destinazione. I fattori da esaminare includono il supporto per i
flussi di lavoro complessi, le API e i linguaggi specifici, i connettori a diversi datastore, le prestazioni, il
budget e la dimensione aziendale.
• Orchestra i flussi di lavoro ETL: automatizza i flussi di lavoro ETL. In un ambiente di analisi, l'output di
un processo o un'attività normalmente funziona da input per un altro lavoro. Incatenare i processi ETL
assicura l'esecuzione senza interruzioni del flusso di lavoro ETL permettendo al contempo di tracciare ed
eseguire il debug di eventuali errori.
• Scegli il livello di storage corretto: archivia i dati nel livello ottimale per sfruttare le migliori caratteristiche
dei servizi di storage per le applicazioni di analisi. Per la scelta del servizio di storage appropriato
è necessario tenere in considerazione due parametri di base: il formato e la frequenza di accesso.
Distribuire i set di dati in servizi diversi e passare da un servizio all'altro permette di creare
un'infrastruttura solida di storage back-end per le applicazioni di analisi.
• Proteggi, gestisci e rendi sicura l'intera pipeline di analisi: asset e infrastruttura dei dati per
l'archiviazione, l'elaborazione e l'analisi dei dati devono essere sicuri. La sicurezza degli asset
dei dati inizia con l'implementazione di controlli granulari che permettono agli utenti autorizzati di
visualizzare determinati asset, accedervi, elaborarli e modificarli, garantendo al contempo che gli utenti
non autorizzati non possano eseguire alcuna operazione che potrebbe compromettere sicurezza e
riservatezza dei dati. I ruoli di accesso possono cambiare nei differenti livelli di una pipeline, è necessario
quindi assicurarsi che solo gli utenti autorizzati abbiano accesso a ciascun livello.
• Progetta pipeline di analisi affidabili e scalabili: rendi gli ambienti di calcolo dell'esecuzione di analisi
sicuri e scalabili per fare in modo che il volume o la velocità dei dati non influenzi negativamente le
7Analytics Lens Canone di architettura AWS
pipeline di produzione. Fornire un'elevata affidabilità dei dati e prestazioni di query ottimizzate per
supportare diverse applicazioni di analisi, da ingestioni in batch e in streaming, query veloci ad hoc al
data science sono da considerarsi priorità principali durante la progettazione di flussi di lavoro di analisi.
8Analytics Lens Canone di architettura AWS
Data Lake
Scenari
In questa sezione vengono illustrati i cinque scenari chiave comuni in molte applicazioni di analisi e
come possono influenzare la progettazione e l'architettura dei carichi di lavoro degli ambienti di analisi in
AWS. Illustriamo le linee guida per ciascuno di questi scenari, gli elementi comuni per la progettazione e
un'architettura di riferimento per l'implementazione di ognuno di essi.
Argomenti
• Data Lake (p. 9)
• Elaborazione dei dati in batch (p. 12)
• Acquisizione in streaming ed elaborazione dei flussi (p. 16)
• Architettura Lambda (p. 19)
• Data Science (p. 21)
• Analisi multi-tenant (p. 24)
Data Lake
Un data lake è un repository centralizzato che consente di archiviare tutti i dati strutturati e non strutturati,
indipendentemente dalla loro portata. Dà la possibilità di archiviare i dati così come sono, senza prima
strutturarli ed eseguire diversi tipi di analisi (da pannelli di controllo e visualizzazioni fino all'elaborazione dei
Big Data, all'analisi in tempo reale e al machine learning) per migliorare il processo decisionale.
Le organizzazioni che generano con successo valore aziendale dai propri dati utilizzando un data lake
sono in grado di eseguire nuovi tipi di analisi, come machine learning sui dati provenienti da file di registro,
clickstream, social media e dispositivi connessi a Internet. Questo può aiutare a identificare e cogliere
le opportunità far crescere l'azienda più velocemente attraendo e fidelizzando i clienti, aumentando la
produttività, mantenendo proattivamente i dispositivi e prendendo decisioni informate.
La problematica più grande relativa alle architetture di data lake è legata all'archiviazione senza
supervisione dei contenuti dei dati grezzi. Per rendere i dati utilizzabili è necessario definire i meccanismi
di catalogazione e sicurezza dei dati. Senza tali meccanismi i dati non possono essere trovati o essere
considerati affidabili, generando una "palude di dati". Per rispondere alle esigenze dei diversi stakeholder è
necessario che il data lake sia coerente dal punto di vista semantico e che vi siano controllo degli accessi e
governance.
Argomenti
• Caratteristiche (p. 9)
• Architettura di riferimento (p. 10)
• Note di configurazione (p. 12)
Caratteristiche
• Indipendentemente dal tipo di origine, dalla struttura dei dati o dalla quantità, tutti i dati di origine iniziali
devono trovarsi in un luogo unico, creando quella che viene chiamata "unica fonte di attendibilità".
9Analytics Lens Canone di architettura AWS
Architettura di riferimento
• Un data lake deve sempre disaccoppiare storage e calcolo.
• Un data lake deve supportare acquisizione e consumo veloci, non solo in termini di velocità ma anche
relativamente alla flessibilità nella struttura dei dati. Ai fornitori di dati bisogna solo comunicare dove
inserire i dati, ovvero nel bucket S3. La scelta della struttura dello storage, dello schema, della frequenza
di acquisizione e della qualità dei dati è responsabilità del produttore dei dati.
• Un data lake supporta lo schema in lettura. È possibile utilizzare più schemi quando si acquisiscono dati
da un data lake in un ambiente di calcolo, diversamente dalla struttura fissa dei dati di record archiviati
all'interno di un data warehouse.
• Un data lake deve essere progettato per storage a basso costo. Questo consente di archiviare più a
lungo e a costi inferiori i dati cronologici, il cui valore aziendale diminuisce con il tempo.
• Un data lake supporta regole di sicurezza e protezione che forniscono meccanismi per consentire di
accedere ai dati solo se in possesso di autorizzazione e di tracciare le modalità di utilizzo dei dati mentre
si spostano tra i livelli nel data lake.
Architettura di riferimento
Figura 1: dinamiche organizzative di un data lake
• I produttori di dati sono i generatori di ricavi organizzativi. Queste entità, siano esse logiche (software)
o fisiche (utenti dell'applicazione) non sono obbligati alla conformità con alcun contratto (schema,
frequenza, struttura, ecc.) associato con i dati che producono, a parte per l'ubicazione dei dati prodotti
all'interno del data lake.
• Il team del data lake spesso è composto da un team operativo che definisce i meccanismi di sicurezza
e policy, obbligatori nel data lake, e da un team di sviluppo che supporta lo schema in divenire e la
gestione di ETL.
• I consumatori dei dati recuperano i dati dal data lake utilizzando i meccanismi autorizzata dal team del
data lake ed eseguono un'ulteriore iterazione sui dati per rispondere alle esigenze aziendali.
10Analytics Lens Canone di architettura AWS
Architettura di riferimento
Figura 2: architettura di riferimento tecnico per data lake di alto livello
1. Amazon S3 si trova al centro di un data lake su AWS. Amazon S3 supporta lo storage di oggetti di tutti
i set di dati iterativi e grezzi creati e utilizzati dagli ambienti di analisi ed elaborazione ETL. La struttura
di alto livello che ospita i dati all'interno di Amazon S3 è organizzata in due o tre livelli a seconda dei
requisiti aziendali del data lake
• Storage di livello 1 (dati grezzi): questo livello di storage è composto da uno o più bucket S3 che
ospitano i dati grezzi in arrivo dai servizi di acquisizione. È importante che i dati archiviati in questo
livello vengano mantenuti e preservati nella loro forma originale, senza alcuna trasformazione.
• Storage di livello 2 Ottimizzato per l'analisi: questo livello di storage ospita i set di dati iterativi frutto
della trasformazione dei dati grezzi nel livello 1 nei tradizionali formati a colonne (come Parquet,
ORC o Avro) tramite l'elaborazione dei processi ETL (per esempio, Spark su EMR o AWS Glue).
Organizzare i dati in partizioni e archiviarli nel formato a colonne consente prestazioni migliori e costi
inferiori agli ambienti di calcolo che acquisiscono i dati dal livello 2.
• Data mart per casi d'uso specifici di livello 3 (facoltativo): i dati ospitati in questo livello fanno parte di
un sotto-set di dati proveniente dal livello 2 organizzato per data mart per casi d'uso specifici. I dati del
livello 3 hanno spesso elevati limiti di sicurezza e accesso. A seconda del caso d'uso, i dati vengono
forniti da più ambienti di analisi e calcolo, come Amazon EMR, Amazon Redshift, Amazon Neptune e
Amazon Aurora.
2. Il componente dell'acquisizione dei dati dell'architettura del data lake rappresenta un processo per
rendere persistenti i dati in Amazon S3. I dati che hanno origine in questa sezione del data lake sono
da intendersi come dati grezzi di livello 1. I servizi che producono dati non hanno vincoli, requisiti di
conformità della struttura o contratti sui dati, a eccezione di un bucket S3 predeterminato in cui i dati
vengono archiviati.
3. L'elaborazione e l'analisi consistono in servizi AWS utilizzati per elaborare o eseguire l'ETL sui dati dal
livello 1 e inviarli elaborati al livello 2. I dati nel livello 2 possono quindi essere consumati dall'ambiente di
analisi o machine learning che esegue query interattive o machine learning e compilazione di modelli.
4. Protezione e sicurezza è un'astrazione generale che si integra nei diversi servizi che compongono il data
lake. Questa sezione del data lake serve per comunicare l'importanza di autenticazione, autorizzazione,
audit, conformità e crittografia in transito/sui dati inattivi quando si tratta delle porzioni del data lake
di acquisizione, storage ed elaborazione/analisi. La maggior parte di questi concetti di sicurezza
sono integrati in ogni servizio di elaborazione dei dati sotto forma di set di funzionalità per proteggere
l'accesso e l'integrità dei dati dei servizi gestiti. Per ulteriori informazioni su come i diversi servizi relativi
11Analytics Lens Canone di architettura AWS
Note di configurazione
alla sicurezza, come KMS, IAM e CloudTrail vengono integrati nei servizi di analisi e acquisizione come
Kinesis e Amazon Redshift, consulta la sezione sul principio di sicurezza.
5. Il componente ricerca e catalogo garantisce che i metadati sui set di dati ospitati nella sezione di storage
(Amazon S3) del data lake vengano raccolti, governati, mantenuti, indicizzati e sia possibile eseguire
ricerche su di essi. Questo spesso richiede un'indicazione organizzativa sul set di metadati minimo
(ovvero descrizione, tag, istruzioni di utilizzo) necessario per tutti i set di dati gestiti nel catalogo del data
lake. Questo garantisce anche che tutti gli oggetti individuali che compongono un set di dati di un data
lake vengano mappati nel record generale dei metadati del set di dati. È possibile sfruttare servizi AWS
come DynamoDB, Amazon OpenSearch Service e AWS Glue Data Catalog per tracciare e indicizzare i
metadati dei set di dati ospitati all'interno del tuo data lake. Utilizzando le funzioni AWS Lambda attivate
da Amazon S3 durante gli eventi di oggetti nuovi o aggiornati, è possibile tenere aggiornato il catalogo in
modo semplice.
6. Accesso e interfaccia utente
Su AWS, i servizi inclusi Amazon API Gateway, AWS Lambda e AWS Directory Service permettono di
tracciare ed eseguire in sicurezza:
• Creazione, modifica ed eliminazione dei nuovi set di dati del data lake e i relativi metadati.
• Creazione e gestione dei processi ETL che creano, aggiornano e uniscono set di dati iterativi che
trasformano i dati grezzi di livello 1 in dati di livello 2 performativi, compressi e in formato colonna.
• Creazione, eliminazione o modifica degli ambienti di calcolo di analisi che inseriscono dati di livello 2
per query successive, sviluppo di visualizzazioni e analisi di approfondimenti.
Note di configurazione
• Scegli una posizione per l'acquisizione del data lake (ovvero il bucket S3). Seleziona un meccanismo di
frequenza e isolamento che risponda alle tue necessità aziendali.
• Per i dati di livello 2, partizione i dati con chiavi allineate con i filtri di query comuni. Ciò aumenta le
prestazioni e consente l'eliminazione mediante strumenti di analisi comuni che funzionano su file di dati
non elaborati.
• Scegli le dimensioni ottimali dei file per ridurre i cicli completi di Amazon S3 durante l'acquisizione
nell'ambiente di calcolo:
• Consigliati: 512 MB - 1 GB in formato a colonne (PRC/Parquet) per partizione.
• Esegui compattazioni pianificate frequenti per allineare i file alle dimensioni ottimali di cui sopra.
• Per esempio, se i file orari sono troppo piccoli, compattali in partizioni giornaliere.
• Per i dati con eliminazioni o aggiornamenti frequenti (ovvero i dati modificabili):
• Archivia temporaneamente i dati replicati in database come Amazon Redshift, Apache Hive o Amazon
RDS fino a che i dati non diventano statici; successivamente, scaricali in Amazon S3 o
• Aggiungi i dati ai file delta per partizione e compattali regolarmente utilizzando AWS Glue o Apache
Spark su EMR.
• Con i i dati di livello 2 e 3 archiviati in Amazon S3:
• Esegui la partizione dei dati utilizzando una chiave a cardinalità elevata. Questo è possibile utilizzando
Presto, Apache Hive e Apache Spark e migliora le prestazioni del filtro di query su quella chiave.
• Ordina i dati in ogni partizione con una chiave secondaria allineata con le query di filtro comuni. Questo
permette ai motori di query di salta i file e ottenere i dati richiesti più velocemente.
Elaborazione dei dati in batch
La maggior parte delle applicazioni di analisi richiedono elaborazione in batch frequente, per esempio,
per aggiornare i datastore con risultati aggregati precedentemente per eseguire query di report più
velocemente e in modo più semplice per gli utenti finali. I sistemi in batch devono essere progettati per
12Analytics Lens Canone di architettura AWS
Caratteristiche
adattarsi a tutte le dimensioni di dati e crescere in modo proporzionale alle dimensioni del set di dati in
elaborazione.
L'espansione rapida delle origini e dimensioni dei dati richiede un sistema di elaborazione dei dati flessibile
senza compromessi di sorta. I requisiti aziendali potrebbero imporre alle attività di elaborazione dei dati
in batch la conformità con uno SLA o determinate soglie di budget. Questi requisiti devono determinare le
caratteristiche dell'architettura di elaborazione in batch.
Su AWS, servizi come Amazon EMR, AWS Glue e AWS Batch ti permettono di eseguire framework di
calcolo distribuiti tra istanze EC2 scalabili dinamicamente o ambienti completamente gestiti. Nel contesto
dell'elaborazione in batch, Amazon EMR fornisce la capacità di leggere e scrivere dati su Amazon S3,
NoSQL su DynamoDB, database SQL su Amazon RDS, Amazon Redshift HDFS (Hadoop Distributed
File Systems) e altri. Per distribuire il lavoro su cluster dimensionati dinamicamente è possibile utilizzare
framework più diffusi, come Spark, MapReduce e Flink. AWS Batch può essere utilizzato per eseguire
processi singoli o in gruppo utilizzando i container Docker distribuiti su un'infrastruttura di calcolo in
container dimensionati dinamicamente. Con AWS Glue, è possibile eseguire i processi Spark senza dover
gestire nessuna istanza EC2.
Lettura e scrittura dei dati da origini esterne separate dagli ambienti di calcolo di elaborazione in batch
permette di disaccoppiare lo storage dal calcolo. In questo modo è possibile esaminare le risorse Amazon
EMR, AWS Batch e AWS Glue in esecuzione solamente quando i processi sono pianificati. Il risultato è
un cambio di paradigma dal modello tradizionale per i sistemi di elaborazione in batch. Ora è possibile
eseguire le risorse di calcolo in modo transitorio solo quando stanno realmente elaborando i dati. Amazon
EMR e AWS Batch si integrano perfettamente anche con le istanze Spot EC2, consentendo di eseguire
istanze EC2 e risparmiare sui costi, rispetto ai prezzi delle istanze EC2 on demand.
Argomenti
• Caratteristiche (p. 13)
• Architettura di riferimento (p. 14)
• Note di configurazione (p. 15)
Caratteristiche
• È necessario creare un sistema di elaborazione in batch con una gestione minima dei cluster e delle
risorse di calcolo.
• È necessario ridurre il tempo necessario alla tua azienda o ai tuoi utenti finali per eseguire query di
approfondimento e semplificare la comprensione dei dati.
• È necessario eseguire risorse di calcolo di elaborazione dei dati in batch solo quando serve e
interromperle quando non serve.
13Analytics Lens Canone di architettura AWS
Architettura di riferimento
Architettura di riferimento
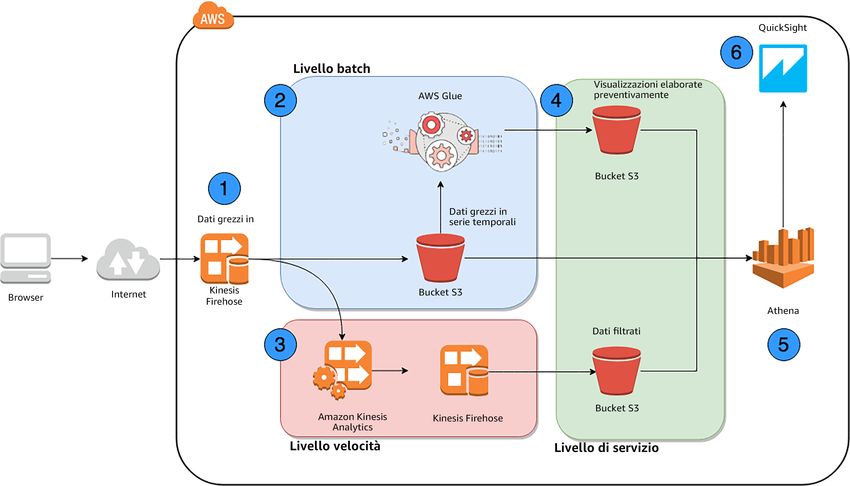
Figura 3: architettura di elaborazione dei dati in batch di alto livello
1. I sistemi di elaborazione dei dati in batch normalmente hanno bisogno di un datastore persistente per i
dati di origine. Questo è un fattore molto importante da considerare quando si tratta dell'affidabilità del
sistema. L'archiviazione dei set di dati di origine in storage duraturo permette di ritentare i processi di
elaborazione in caso di guasti e attivare nuovi flussi di valore in futuro. Su AWS esistono moltissime
opzioni per lo storage dei dati di origine. Amazon S3, Amazon RDS, Amazon DynamoDB, Amazon EFS,
Amazon OpenSearch Service, Amazon Redshift, e Amazon Neptune sono servizi di storage e database
gestiti che è possibile utilizzare come datastore di origine. È anche possibile utilizzare Amazon EC2 ed
EBS per eseguire le proprie soluzioni di storage e database. Consulta gli scenari Data lake e Creare un
livello di storage efficiente per l'analisi per ulteriori informazioni su queste opzioni.
2. I sistemi di elaborazione di dati in batch devono essere automatizzati e pianificati per affidabilità,
efficienza delle prestazioni e ottimizzazione dei costi. È possibile utilizzare Amazon CloudWatch Events
per attivare i processi a valle in base alle pianificazioni (per esempio, una volta al giorno) o eventi (per
esempio, quando vengono caricati nuovi file).
3. È normale che i processi di elaborazione dei dati in batch siano composti da molte fasi, alcune delle
quali possono succedersi o avvenire in parallelo. Per semplificare l'implementazione di flussi di lavoro
automatizzati per processi di elaborazione semplici e complessi, è possibile utilizzare un servizio di
orchestrazione, come AWS Step Functions. AWS Step Functions permette di creare applicazioni
di elaborazione di dati distribuite utilizzando i flussi di lavoro visuali. All'interno di un flusso di lavoro
14Analytics Lens Canone di architettura AWS
Note di configurazione
AWS Step Functions è possibile utilizzare le funzioni Lambda e le integrazioni di servizio native per
attivare i passaggi di Amazon EMR, i processi ETL AWS Glue, AWS Batch, Amazon SageMaker e quelli
personalizzati su Amazon EC2 o in locale.
4. AWS Batch, AWS Glue, e Amazon EMR forniscono servizi e framework gestiti per l'esecuzione di attività
in batch specifici per il proprio caso d'uso. Esistono diverse opzioni per l'esecuzione dei processi. Per
i processi semplici che possono essere eseguiti in container Docker, come l'elaborazione di materiale
video, formazione di machine learning e compressione di file, AWS Batch fornisce un modo economico
per inviare i processi sotto forma di container Docker all'infrastruttura di calcolo in container su Amazon
EC2. Per i processi Apache Spark in PySpark o Scala è possibile utilizzare AWS Glue che esegue
i processi Spark in un ambiente Spark completamente gestito. Per altri processi di elaborazione
prettamente paralleli, Amazon EMR fornisce framework come Spark, MapReduce, Hive, Presto, Flink e
Tez che vengono eseguiti su istanze Amazon EC2 nel VPC.
5. Come i datastore di origine, i processi in batch necessitano di storage affidabile per archiviare risultati
o output. È possibile utilizzare l'SDK AWS per interagire con Amazon S3 e DynamoDB e utilizzare i
normali protocolli di file e le connessioni JDBC per archiviare i risultati in file system o database.
6. I set di dati dei risultati vengono normalmente archiviati in modo persistente e richiamati
successivamente mediante strumenti di visualizzazione come le API Amazon QuickSight e query di
ricerca. In base ai modelli di accesso è possibile scegliere i datastore che più si adattano al proprio caso
d'uso. Consulta gli scenari Data lake e Creare un livello di storage efficiente per l'analisi per ulteriori
informazioni su queste opzioni di storage.
Note di configurazione
1. Utilizza i processi di elaborazione in batch per preparare set di dati massivi e di grandi dimensioni
per l'analisi a valle. Per set di dati complessi di grandi dimensioni potrebbe rendersi necessario poter
fornire tali dati a utenti finali e analisti in modo che possano eseguire query facilmente. Di contro, questi
utenti potrebbero avere delle difficoltà nell'eseguire query sui dati grezzi mentre cercano di trovare
aggregazioni semplici. Per esempio, potrebbe essere necessario elaborare preventivamente una
visualizzazione riepilogativa delle vendite giornaliere dei dati per le vendite del giorno precedente.
Questa operazione fornisce agli utenti una tabella con meno righe e colonne, semplificando e
velocizzando le operazioni di query sui dati.
2. Evita di trasferire l'elaborazione in batch su AWS. Trasferendo i sistemi di elaborazione in batch
tradizionali in AWS, corri il rischio di eseguire risorse con provisioning esagerato su Amazon EC2. Per
esempio, spesso si effettua un provisioning esagerato dei cluster Hadoop tradizionali che poi restano
inattivi in strutture locali. Utilizza servizi gestiti di AWS come AWS Glue, Amazon EMR e AWS Batch
per semplificare l'architettura ed evitare il pesante lavoro generico di gestione degli ambienti distribuiti di
cluster.
Sfruttare realmente questi servizi con architetture di elaborazione in batch moderne che separano
storage e calcolo offre la possibilità di risparmiare sui costi eliminando le risorse di calcolo inattive o lo
spazio di storage su disco inutilizzato. Anche le prestazioni possono essere migliorate utilizzando i tipi
di istanza EC2 ottimizzati per le specifiche attività di elaborazione in batch, invece che utilizzare cluster
persistente per scopi multipli.
3. Automatizza e orchestra ovunque. In un ambiente tradizionale di elaborazione dei dati in batch, è bene
applicare la best practice relativa alla pianificazione dei processi nel sistema. In AWS è importante
sfruttare l'automazione e l'orchestrazione per i processi di elaborazione di dati in batch insieme alle API
di AWS per avviare e terminare anche interi ambienti di calcolo per poter pagare solamente i servizi di
calcolo che utilizzi. Per esempio, quando viene pianificato un processo, un servizio di flusso di lavoro,
come AWS Step Functions, utilizza l'SDK AWS per effettuare il provisioning di un nuovo cluster EMR,
inviare il lavoro e arrestare il cluster quando il processo è terminato.
4. Usa le istanze Spot per risparmiare sui processi di elaborazione in batch flessibili. Sfrutta le istanze
Spot quando gestisci pianificazioni di processi flessibili per ritentare i processi e disaccoppiare i dati
dal calcolo. Usa il parco istanze Spot, il parco istanze EC2 e le funzionalità delle istanze Spot in EMR e
AWS Batch per gestire le istanze Spot.
15Analytics Lens Canone di architettura AWS
Acquisizione in streaming ed elaborazione dei flussi
5. Monitora continuamente e migliora l'elaborazione in batch. I sistemi di elaborazione in batch evolvono
rapidamente all'aumentare dei volumi di origine dati, all'autorizzazione di nuovi processi di elaborazione
in batch e all'avvio di nuovi framework di elaborazione in batch. Implementa i processi con parametri,
timeout e allarmi per ottenere parametri e informazioni dettagliate per prendere decisioni informate sulle
modifiche al sistema di elaborazione dei dati in batch.
Acquisizione in streaming ed elaborazione dei flussi
Acquisire ed elaborare dati in streaming in tempo reale richiede scalabilità, affidabilità e bassa latenza per
supportare diverse applicazioni. Queste applicazioni includono tracciamento delle attività, elaborazione
di ordini delle transazioni, analisi del clickstream, pulizia dei dati, generazione di parametri, filtraggio dei
log, indicizzazione, analisi dei social media, telemetria e misurazione dei dati dei dispositivi IoT. Queste
applicazioni sono spesso complesse ed elaborano migliaia di eventi al secondo.
AWS permette di sfruttare i vantaggi dei servizi di dati in streaming gestiti offerti da Amazon Kinesis o
distribuire e gestire la propria soluzione di dati in streaming sul cloud su Amazon EC2. Consulta la sezione
delle definizioni per i dettagli sui servizi di streaming che possono essere distribuiti su AWS.
Tieni in considerazione le seguenti caratteristiche per la progettazione della pipeline di elaborazione del
flusso per l'acquisizione in tempo reale e l'elaborazione continua.
Argomenti
• Caratteristiche (p. 16)
• Architettura di riferimento (p. 17)
• Note di configurazione (p. 19)
Caratteristiche
• Scalabile: per le le analisi in tempo reale è necessario pianificare un'infrastruttura in grado di adattarsi
alle modifiche alla velocità dei dati che si spostano nel flusso. Il dimensionamento viene normalmente
eseguito da un'applicazione di amministrazione che monitora i parametri di gestione dei dati di partizione
e shard. È necessario che i worker rilevino automaticamente i nuovi shard e partizioni aggiunti e che li
distribuiscano in modo equo tra tutti i worker disponibili per l'elaborazione.
• Duraturo: i sistemi di streaming in tempo reale devono fornire elevata disponibilità e durabilità dei dati.
Per esempio, Amazon Kinesis Data Streams replica i dati in tre zone di disponibilità fornendo l'elevata
durabilità necessaria alle applicazioni di streaming.
• Letture riproducibili: i sistemi di elaborazione in streaming devono fornire l'ordine dei record e la
possibilità di leggere o riprodurre i record nello stesso ordine a più consumatori in lettura dal flusso.
• Tolleranza ai guasti, checkpoint e riproduzione: il checkpoint si riferisce alla registrazione del punto
più lontano nel flusso che i record di dati hanno consumato ed elaborato. Se l'applicazione subisce un
arresto temporaneo, è possibile ripristinare la lettura del flusso a partire da quel punto invece che dover
iniziare dall'inizio.
• Abilitazione di più applicazioni di elaborazione in parallelo: la possibilità per più applicazioni di consumare
lo stesso flusso contemporaneamente è una caratteristica fondamentale per un sistema di elaborazione
di flussi. Per esempio, puoi avere un'applicazione che aggiorna un pannello di controllo in tempo
reale e un'altra che archivia i dati in Amazon Redshift. Sicuramente, vuoi che entrambe le applicazioni
consumino i dati dallo stesso flusso contemporaneamente e indipendentemente.
• Semantica della messaggistica: in un sistema di messaggistica distribuita, è possibile che i componenti
subiscano un guasto o un errore separatamente. Diversi sistemi di messaggistica implementano diverse
garanzie semantiche tra un produttore e un consumatore in caso di un guasto di questo tipo. Le garanzie
di consegna del messaggio più comuni sono:
• Al massimo una volta: i messaggi che non sono stati consegnati o sono andati perso, non vengono
riconsegnati.
16Puoi anche leggere

















































