VMware vCloud Director con Hitachi Compute Blade 2000 e Hitachi Virtual Storage Platform - Architettura di riferimento
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
VMware® vCloud™ Director con Hitachi
Compute Blade 2000 e Hitachi Virtual
Storage Platform
Architettura di riferimento
Henry Chu
Agosto 2011
Soluzioni storage Hitachi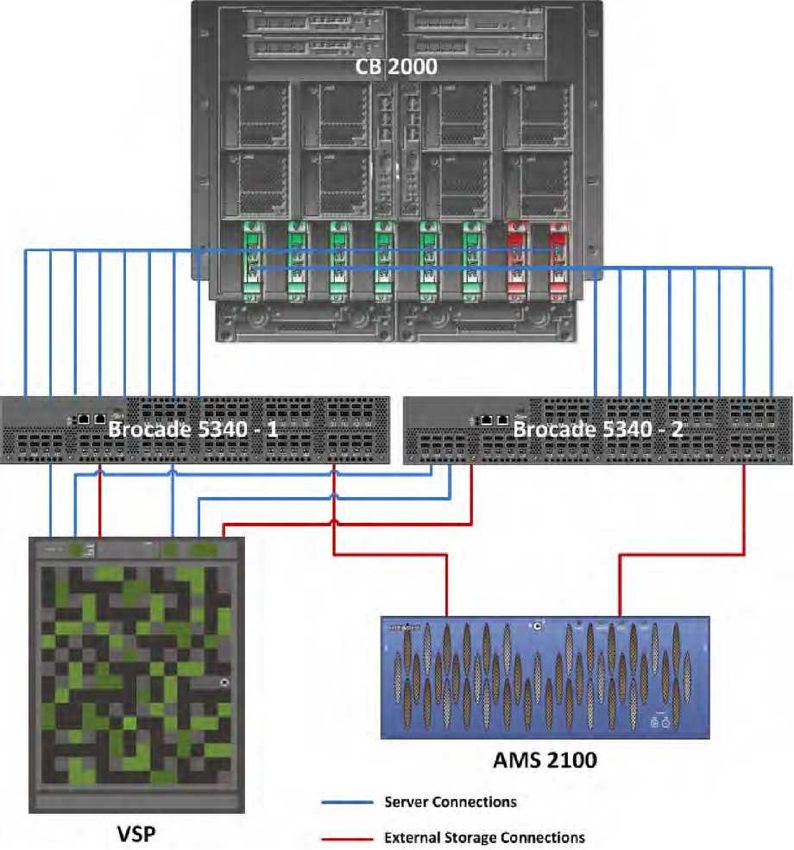
Feedback
Hitachi Data Systems è lieta di ricevere il vostro feedback. Potete comunicarci il vostro parere inviando un'e-mail
a SolutionLab@hds.com. Non dimenticate di menzionare il titolo di questo white paper nel vostro messaggio.
1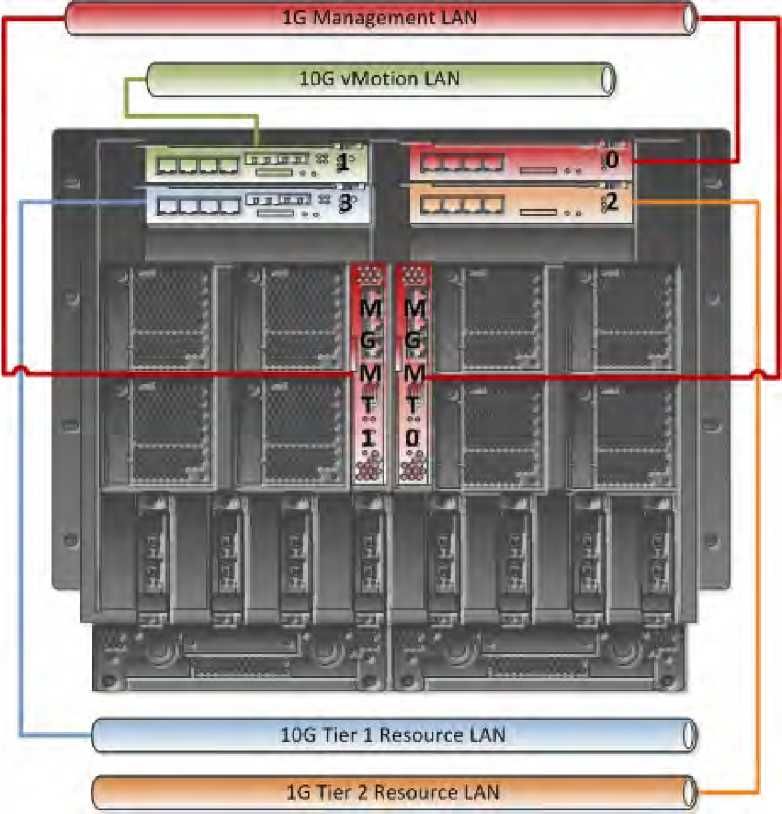
Indice
Panoramica della soluzione ................................................................................................................... 4
Componenti della soluzione .................................................................................................................. 5
Hitachi Compute Blade 2000.................................................................................................................. 5
Hitachi Virtual Storage Platform ............................................................................................................. 5
La famiglia Hitachi Adaptable Modular Storage 2000 ............................................................................ 6
VMware vCloud Director 1.0 .................................................................................................................. 7
VMware vSphere 4.1 .............................................................................................................................. 7
Design della soluzione ........................................................................................................................... 7
Infrastruttura di calcolo .......................................................................................................................... 7
Infrastruttura di rete ............................................................................................................................... 14
Infrastruttura di storage .......................................................................................................................... 18
Prestazioni e scalabilità.......................................................................................................................... 23
Prestazioni di calcolo .. ......................................................................................................................... 26
Prestazioni di storage ............................................................................................................................ 29
Prestazioni applicative .......................................................................................................................... 34
Conclusione ............................................................................................................................................ 37
Appendice—Terminologia...................................................................................................................... 38
2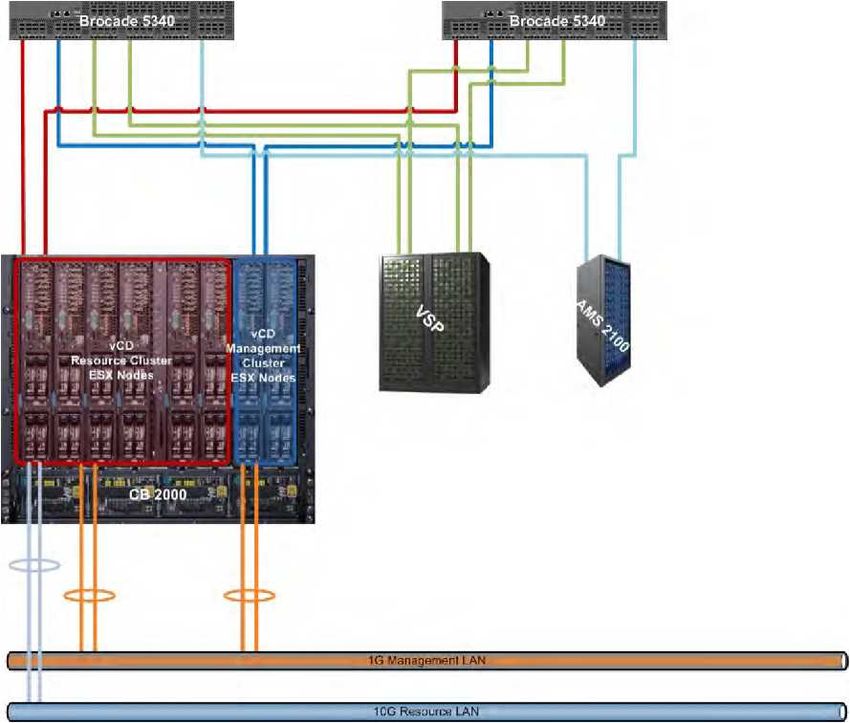
VMware® vCloud™ Director con Hitachi
Compute Blade 2000 e Hitachi Virtual
Storage Platform
Architettura di riferimento
L'utilizzo di un'infrastruttura VMware vSphere può migliorare l'agilità dei data center e la loro efficacia. Tuttavia non
tutti i silos infrastrutturali utilizzano le risorse in modo efficiente: per ogni silo il grado di utilizzazione può variare, da
molto basso fino a un valore prossimo alla piena capacità. La gestione manuale delle risorse per affrontare i
momenti di massima utilizzazione può richiedere del tempo e risultare complessa. Un modello a silos spesso
comporta un utilizzo non efficiente delle risorse, che non soddisfa così le crescenti esigenze gestionali delle
aziende.
Un nuovo approccio privilegia un'infrastruttura con servizi condivisi per aggregare risorse da tutti i silos disponibili
per tutte le organizzazioni. Tuttavia, per questa soluzione sono necessari una multi-tenancy integrata, elevata
disponibilità, un sistema integrato di controllo della qualità di servizio e facilità di provisioning.
VMware vCloud Director consente di affrontare e vincere queste sfide grazie a una piattaforma di cloud computing
IaaS (Infrastructure as a Service, infrastruttura come servizio). La condivisione dell'infrastruttura VMware vSphere
con vCloud Director fornisce pool di risorse dinamici, con capacità on-demand, sulla base di un modello self-
service.
VMware vCloud Director introduce il concetto di provider virtual data center (vDC), che assicura una chiara
separazione delle risorse organizzate in un pool. Ogni organizzazione utilizza i propri pool di risorse tramite portali
self-service individuali. vCloud Director, costruito su vSphere, fornisce il livello di astrazione necessario per
consentire mobilità all'infrastruttura cloud e multi-tenancy.
L'infrastruttura sottostante deve assicurare grande disponibilità ed elasticità. Per consentire una fluida gestione
delle risorse on-demand, anche l'infrastruttura di storage deve possedere le stesse caratteristiche. Hitachi Virtual
Storage Platform è la piattaforma di storage ideale per VMware vCloud Director, poiché offre una capacità di
virtualizzazione tale da consentire una gestione centralizzata di sistemi di storage multipli, inclusi quelli che non
dispongono delle funzionalità di Virtual Storage Platform.
Tutte le dotazioni e le funzioni di Hitachi Virtual Storage Platform possono essere applicate a un ambiente storage
eterogeneo, rendendolo omogeneo. Hitachi Dynamic Provisioning può creare pool di risorse dinamici con
disponibilità on-demand.
Grazie a VMware vStorage APIs for Array Integration le risorse di storage vengono integrate in VMware vSphere,
incrementando così l'efficienza operativa tramite l'accelerazione dell'hardware.
L'architettura di riferimento è concepita per amministratori di sistemi di storage, vCloud, vSphere e applicazioni che
devono gestire ambienti di grandi dimensioni e dinamici, richiede familiarità con i sistemi di storage basati su
storage area network (SAN), VMware vSphere e le generali pratiche operative nell'ambito dello storage.
3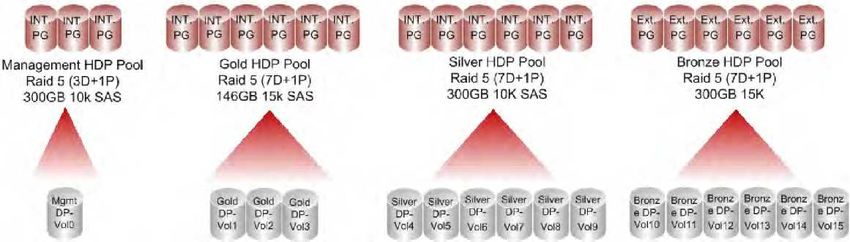
Panoramica della soluzione
L'architettura di riferimento utilizza:
■ Hitachi Compute Blade 2000 (CB 2000)—Una piattaforma su server di classe enterprise
■ Hitachi Virtual Storage Platform (VSP)—Una soluzione di storage ad alte prestazioni ed elevata scalabilità
■ Hitachi Adaptable Modular Storage 2100 (AMS 2100)—Una soluzione di storage low cost, con funzione active-
active completamente operativa, di classe midrange
■ Switch Brocade 5340 Fibre Channel — Garantisce la connettività SAN alla rete dei data center
■ VMware vSphere 4.1 — La tecnologia di virtualizzazione che costituisce la base del cloud computing
■ VMware vCloud Director 1.0—Piattaforma cloud basata su un'infrastruttura VMware vSphere per consentire
l'utilizzo del cloud computing di tipo IaaS (Infrastructure as a Service, infrastruttura come servizio)
In figura 1 si riporta un diagramma dell'architettura di riferimento che mostra la connettività di rete e Fibre
Channel, caratterizzata da ridondanza.
Figura 1
4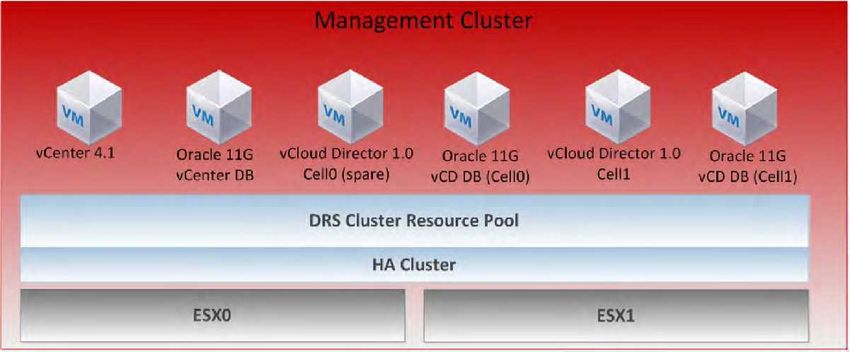
Componenti della soluzione
Di seguito si descrivono i componenti dell'architettura di riferimento.
Hitachi Compute Blade 2000
Hitachi Compute Blade 2000 è una piattaforma su blade server di classe enterprise, che offre le seguenti funzionalità:
■ Un'architettura bilanciata che elimina i colli di bottiglia nelle prestazioni e nella produttività
■ Virtualizzazione con partizione logica integrata
■ Flessibilità di configurazione
■ Risparmio energetico ecosostenibile
■ Sistema di ripristino rapido basato su cold standby N+1, che consente la sostituzione dei server non funzionanti
nel giro di pochi minuti
La virtualizzazione con partizione logica è integrata nel firmware di Hitachi Compute Blade 2000. Questa tecnologia
collaudata, di classe mainframe, unisce l'esperienza acquisita da Hitachi nel partizionamento logico alla tecnologia
Intel VT, con miglioramenti in termini di prestazioni, affidabilità e sicurezza. La virtualizzazione con partizione logica
integrata non compromette le prestazioni delle applicazioni e non richiede l'acquisto e l'installazione di componenti
aggiuntivi.
Hitachi Virtual Storage Platform
Hitachi Virtual Storage Platform è una piattaforma di storage con scalabilità 3D che, grazie alla possibilità di
combinare le funzioni di scale up, scale out e scale deep contemporaneamente in un singolo sistema di storage,
consente di adeguare prestazioni, capacità, connettività e virtualizzazione in modo flessibile.
■ Scale Up— Per aumentare le prestazioni, la capacità e la connettività aggiungendo cache, processori,
connessioni e dischi al sistema di base.
■ Scale Out— Per combinare più chassis in un singolo sistema logico con risorse condivise.
■ Scale Deep — Per estendere le funzioni avanzate della Virtual Storage Platform allo storage esterno multivendor.
Hitachi Virtual Storage Platform dispone di funzionalità complementari a VMware vCloud Director.
Pool di risorse con VMware DRS e Hitachi Dynamic Provisioning
Hitachi Dynamic Provisioning, una funzionalità di Hitachi Virtual Storage Platform, aggrega le risorse di storage in un
pool analogamente a come VMware DRS è in grado di aggregare le risorse computazionali. I provider virtual data
center (vDC) in VMware vCloud Director sono associati direttamente VMware DRS per i pool di risorse
computazionali e a Hitachi Dynamic Provisioning per i pool di risorse di storage. Le capacità di creazione di pool di
VMware DRS e Hitachi Dynamic Provisioning sono in grado di creare una base di calcolo dinamica e attribuire le
risorse ai provider virtual data center.
Con Hitachi Dynamic Provisioning è possibile incrementare o ridurre la capacità di storage e le prestazioni,
aumentando o diminuendo i blocchi di parità nel pool di dynamic provisioning. Hitachi Dynamic Provisioning consente
inoltre l'oversubscription della capacità e fornisce la funzione di striping che consente un'ampia suddivisione su tutti i
dischi del pool.
5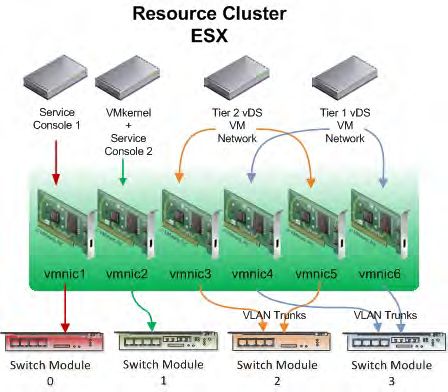
Agilità nell'elaborazione dei dati con Mware Storage vMotion e Hitachi Tiered Storage Manager
Hitachi Tiered Storage Manager è in grado di migrare volumi logici allo storage interno ed esterno su Hitachi Virtual
Storage Platform senza interruzioni della normale operatività. Utilizzate Hitachi Tiered Storage Manager per i volumi
logici a livello del sistema di storage: le migrazioni eseguite con questa funzionalità sono completamente trasparenti
per la macchina virtuale e per gli host ESX.
La migrazione dei volumi logici in modalità non-disruptive garantisce la mobilità dei dati per i provider virtual data
center. Si tratta di una soluzione di migrazione dei dati di storage multilivello per i provider virtual data center, in cui, a
seconda delle esigenze gestionali, è possibile passare in modo dinamico a un livello di servizio superiore o inferiore.
Storage vMotion è un componente di VMware che migra in modo non-disruptive i dischi della macchina virtuale ai
datastore VMFS sugli host ESX. Utilizzate VMware Storage vMotion su una macchina virtuale a livello del datastore
VMFS.
Funzione di accelerazione dell'hardware per le normali operazioni vSphere
Le operazioni chiave sui dati di Hitachi Virtual Storage Platform sono gestite da VMware vStorage APIs for Array
Integration (VAAI) anziché dal layer del server ESX, in modo da ridurre l'utilizzo delle risorse e potenziali colli di
bottiglia su server fisici, garantendo inoltre una performance del server più costante e una densità maggiore della
macchina virtuale.
Hitachi Virtual Storage Platform supporta tutte le primitive VMware vSphere 4.1 VAAI API. Le seguenti primitive API
procurano vantaggi diretti in un ambiente vCloud:
■ Full copy—Consente a Hitachi Virtual Storage Platform di realizzare copie complete dei dati all'interno del
sistema di storage, senza che siano necessarie la lettura e la scrittura da parte dell'host ESX. Le operazioni di
lettura e scrittura vengono quindi scaricate su Hitachi Virtual Storage Platform, con una sostanziale riduzione dei
tempi di provisioning per la clonazione delle macchine virtuali in vCloud Director.
■ Hardware-assisted locking — Consente all'host ESX di eseguire l'offload di operazioni di blocco su Hitachi
Virtual Storage Platform L'offload delle operazioni di blocco consente di disporre di una piattaforma di storage ad
alta scalabilità per vCloud Director, nel caso in cui le risorse di storage comuni siano condivise da un elevato
numero di macchine virtuali. È disponibile anche un metodo di blocco granulare LUN che consente di eseguire il
locking a livello dell'indirizzo LBA (logical block address) senza fare ricorso alle prenotazioni SCSI o senza dover
bloccare l'intero LUN mediante altri host.
Per ulteriori informazioni consultare la pagina Hitachi Virtual Storage Platform sul sito Internet di Hitachi Data
Systems.
Hitachi Adaptable Modular Storage 2000 Family
I sistemi della famiglia Adaptable Modular Storage 2000, di classe midrange, sono dotati di Hitachi Dynamic Load
Balancing Controller, che assicura un bilanciamento integrato, automatico e di tipo hardware del carico I/O front-to-
back-end, eliminando così per i soggetti che gestiscono lo storage l'esecuzione di task complessi e ai quali è
necessario dedicare molto tempo. In questo modo il traffico I/O verso le unità disco back-end è gestito e bilanciato
dinamicamente ed è condiviso in modo equo tra i due controller. L'architettura back-end point-to-point elimina ritardi
nel traffico I/O e i problemi di contesa che si verificano con la topologia Arbitrated Loop di Fibre Channel, fornendo
inoltre una larghezza di banda significativamente più elevata e un I/O perfettamente simultaneo.
Grazie alle porte Fibre Channel con configurazione active-active l'utente non deve preoccuparsi della proprietà del
controller; il traffico I/O viene infatti trasferito al controller mediante una comunicazione cross-path e qualsiasi
percorso può essere utilizzato come percorso normale. I controller di Hitachi Dynamic Load Balancing bilanciano il
carico del microprocessore trasversalmente ai diversi sistemi di storage. Se un microprocessore risulta troppo carico,
il LU management si attiva immediatamente per eseguire il bilanciamento. Per ulteriori informazioni sulla serie
Adaptable Modular Storage 2000 consultare il sito Internet Hitachi Data Systems Adaptable Modular Storage .
6
VMware vCloud Director 1.0
VMware vCloud Director 1.0 raggruppa le risorse dei data center formando un'infrastruttura di cloud computing, sfruttando
l'efficiente pooling consentito da infrastrutture virtuali on-demand e autogestite per mettere a disposizione risorse
utilizzabili come servizi. L'architettura di riferimento è focalizzata sull'utilizzo di VMware vCloud Director come livello IaaS
(Infrastructure as a Service - infrastruttura come servizio).
VMware vCloud Director, in abbinamento a VMware vSphere, estende le capacità della vostra infrastruttura virtuale
nella fornitura dei servizi di cloud computing.
Ulteriori informazioni su VMware vCloud Director sono disponibili sul sito Internet di VMware.
VMware vSphere 4.1
VMware vSphere 4.1 è una piattaforma di virtualizzazione molto efficiente che fornisce un'infrastruttura per data center
robusta, scalabile e affidabile. VMware vSphere dispone di funzionalità come VMware Distributed Resource Scheduler
(DRS). VMware High Availability e VMware Fault Tolerance costituiscono una piattaforma facile da gestire.
VMware vSphere 4.1 supporta vApp, un raggruppamento logico di una o più VM in formato aperto di virtualizzazione, in
cui è possibile incapsulare un'applicazione multilivello con livelli di servizio e policy.
L'utilizzo della policy di multipath round-robin fornita dall'hypervisor VMware ESX 4, con bilanciamento del
carico dinamico grazie al controller simmetrico active-active di VMware DRS, consente di distribuire il carico
su diversi host bus adapter (HBA) e porte di storage.
Ulteriori informazioni sono disponibili alla pagina Internet VMware vSphere.
Design della soluzione
Di seguito sono descritte le infrastrutture di calcolo, di rete e di storage utilizzate per l'architettura di riferimento.
Infrastruttura di calcolo
L'infrastruttura di calcolo nell'architettura di riferimento è la seguente:
■ VMware vCloud Director 1.0
■ VMware vSphere 4.1
■ Hitachi Compute Blade 2000
VMware vCloud Director 1.0
VMware vCloud Director crea risorse astratte dall'infrastruttura VMware vSphere. Ogni risorsa astratta viene quindi messa
a disposizione con il deployment della sua stessa macchina virtuale. Il set completo delle risorse astratte costituisce lo
stack delle risorse.
La figura 2 rappresenta lo stack delle risorse di VMware vCloud Director utilizzato nell'architettura di riferimento.
7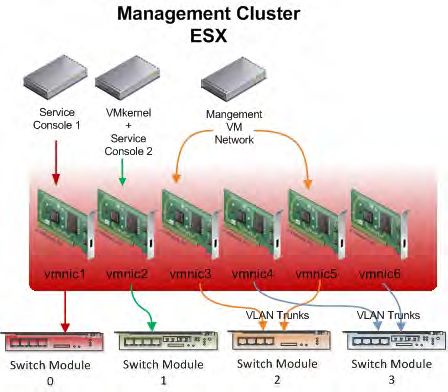
Figura 2
Esistono provider virtual data center e organization virtual data center.
Gli utenti finali accedono al virtual data center dell'organizzazione come portale self-service. L'utente effettua il login
all'interfaccia web di VMware vCloud Director che consente l'accesso alle risorse computazionali, di rete e di storage
allocate.
Un organization virtual data center può allocare risorse computazionali in tre modi:
■ Allocation Pool — Una percentuale delle risorse allocate è assegnata a un organization virtual data center.
L'overcommit è controllato dall'amministratore di sistema.
■ Pay-As-You-Go—Le risorse allocate sono assegnate a un organization virtual data center solo quando si crea
una vApp.
■ Reservation Pool — Tutte le risorse allocate sono assegnate a un organization virtual data center. In qualsiasi
momento gli utenti possono controllare l'overcommit della capacità.
L'architettura di riferimento è stato utilizzato il modello Allocation Pool, che consente di controllare l'allocazione delle
risorse nel miglior modo possibile. Le risorse sono assegnate a un'organizzazione con o senza overcommit. La
tabella 1 mostra la distribuzione delle risorse per il pool di allocazione; in questo caso non è possibile l'overcommit
delle risorse.
8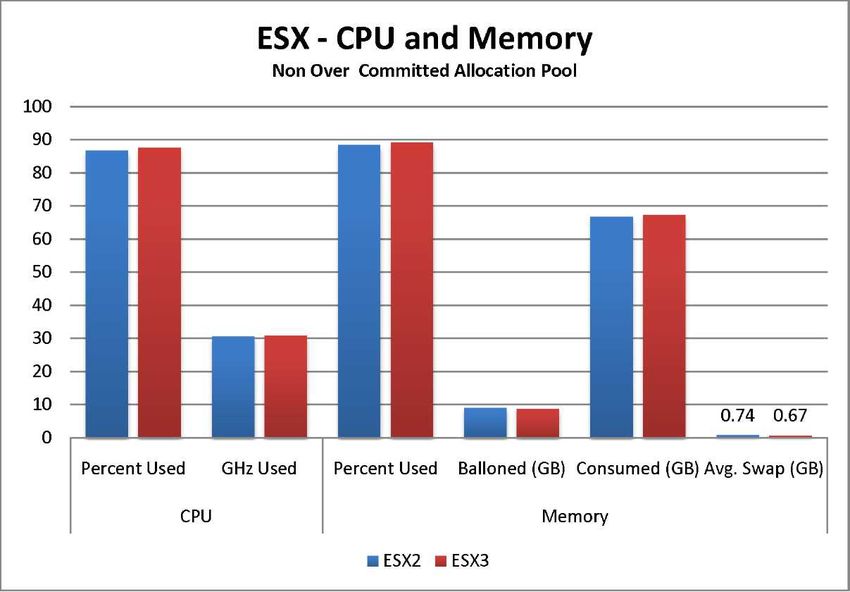
Tabella 1. Allocazione delle risorse a livello di organization virtual data center per pool senza overcommit
Organizzazione di livello oro Organizzazione di livello Organizzazione di livello bronzo
argento
CPU 100% di 81 GHz 100% di 63 GHz 100% di 51 GHz
Memoria 100% di 138GB 100% di 132 GB 100% di 123 GB
Un organization virtual data center può essere autorizzato ad accedere ad un grande pool di risorse di CPU e di
memoria contenuto nel pool di risorse del proprio provider virtual data center. La tabella 2 mostra la distribuzione
delle risorse per i pool di allocazione che consentono l'overcommit delle risorse.
Tabella 2. Allocazione delle risorse a livello di organization virtual data center per pool con overcommit
Organizzazione di livello oro Organizzazione di livello Organizzazione di livello bronzo
argento
CPU 39% di 200 GHz 31% di 200 GHz 25% di 200 GHz
Memoria 34% di 402 GB 33% di 402 GB 31% di 402 GB
La percentuale di risorse prenotata può essere utilizzata per garantire un minimo di risorse sempre disponibile
all'organization virtual data center. Eventuali risorse rimanenti sono disponibili per l'organization virtual data center
solo quando possono essere fornite dal provider data center. Questo modello può essere utilizzato per l'overcommit
di risorse.
Le risorse computazionali possono essere modificate in modo dinamico per ogni organizzazione. Poiché le esigenze
in termini di risorse computazionali delle singole organizzazioni sono in continuo mutamento, le risorse di CPU e di
memoria possono essere incrementate o ridotte in modo individuale per venire incontro alle richieste del provider
data center.
Ogni organization virtual data center è associato a un provider data center, il quale può essere utilizzato per
classificare determinare livelli di service level agreement o persino le tipologie applicative. In figura 2 sono riportati i
tre provider data center utilizzati nell'architettura di riferimento: oro, argento e bronzo. Ciascuno di essi garantisce
livelli diversi per quanto riguarda le risorse di CPU e di memoria.
Ogni provider data center è associato a un pool di risorse all'interno di un cluster VMware vSphere DRS. Questi pool
di risorse non sono creati da VMware vCloud Director, ma vengono creati manualmente con VMware vCenter e sono
utilizzati per raggruppare logicamente diversi provider virtual data center.
Di norma si consiglia di configurare solo un pool di risorse per ogni livello di servizio, in modo da differenziare i vari
livelli. Per esempio, potete configurare un pool di risorse per ogni provider virtual data center di livello oro, argento e
bronzo. Configurate e create tutti i pool di risorse di livello subordinato per mezzo di vCloud Director.
VMware vSphere 4.1
L'infrastruttura VMware vSphere 4.1 rappresenta la base a seconda della quale vCloud Director definisce le risorse.
Per ottenere le migliori prestazioni da vCloud Director è necessaria un'infrastruttura robusta e dall'elevata
disponibilità.
L'infrastruttura VMware vSphere è stata configurata in due parti:
■ Cluster di management—Fornisce le applicazioni e i servizi necessari a VMware vCloud Director.
■ Cluster di risorse—Fornisce le risorse a ogni macchina virtuale installata tramite VMware vCloud Director come
cluster dedicato, con capacità di calcolo raw per il consumo da parte dei tenant.
9Si garantisce così una chiara separazione tra le risorse destinate alle operazioni di management e le risorse cloud.
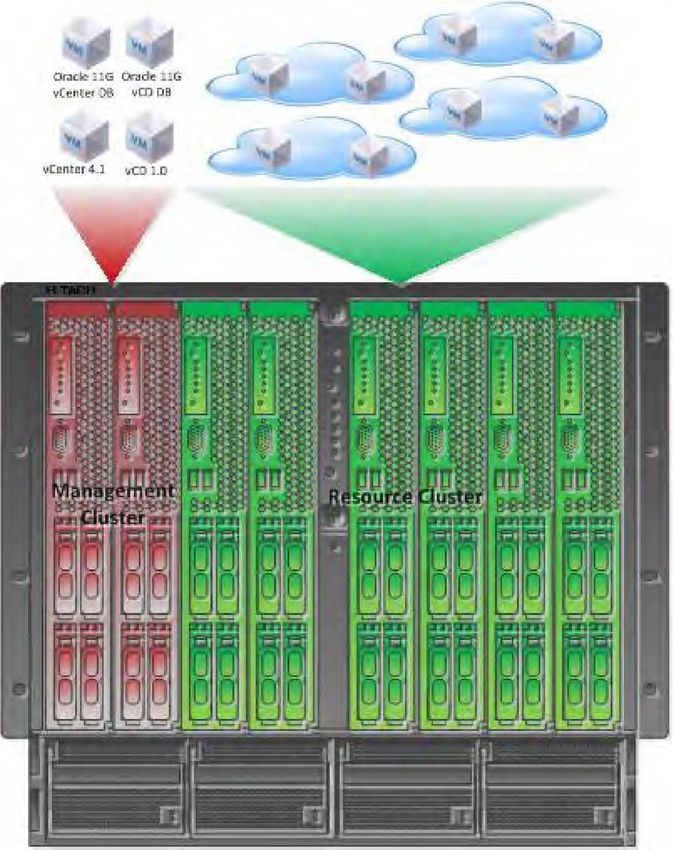
Cluster di management
La figura 3 rappresenta il cluster di management utilizzato per far fronte alle esigenze in termini di infrastruttura
connesse con l'esecuzione di VMware vCenter, Oracle Database e VMware vCloud Director.
Figura 3
Il cluster di management contiene i seguenti componenti e funzionalità:
■ vCenter Server 4.1 — Gestione generale dell'infrastruttura virtualizzata
■ Oracle 11G — Macchine virtuali Red Hat Enterprise Linux 5 con Oracle 11G. Necessario per le istanze del
database di vCenter Server 4.1 e vCloud Director 1.0
■ vCloud Director 1.0 Cell — Una singola istanza VMware vCloud Director che costituisce il componente core di
vCloud Director. Si crea così un nuovo livello di astrazione che facilita la comunicazione tra i server vCenter ed
ESX, con l'accettazione delle richieste dei clienti finali tramite un portale web integrato e le chiamate vCloud
API.
■ vShield Manager—Componente di management di vShield Suite. È responsabile dell'installazione dell'agente
vShield (vShield Edge), della configurazione delle regole del firewall e della gestione.
VMware segnala la seguente raccomandazione in relazione al numero di celle necessarie:
Numero di celle VMware vCloud = Numero di istanze VMware vCenter + 1
La cella aggiuntiva indicata nella formula viene utilizzata nei casi seguenti:
■ Come cella di riserva per failover
■ Quando è necessario disattivare una cella per interventi di manutenzione
Inoltre su una singola cella vCloud dovrebbe essere mappata un'unica istanza vCenter, in modo da assicurare un
consumo delle risorse maggiormente bilanciato tra le celle in termini di carico.
Per altre informazioni sulle best practice relative a vCloud Director consultare VMware vCloud Director 1.0 -
Prestazioni e best practice.
10La tabella 3 descrive la configurazione della macchina virtuale per ogni servizio. VMware vCenter e VMware
vCloud Director si trovano su macchine virtuali separate rispetto alle loro applicazioni database.
Tabella 3. Configurazione della macchina virtuale per ogni servizio del cluster di management
Applicazione SO CPU Memoria Disco Virtuale
VMware vCenter 4.1 Microsoft Windows 2 vCPU 4096 MB 100 GB Eagerzeroedthick (SO)
Server 2008 R2
Enterprise
Oracle Database 11g (vC Microsoft Windows 4 vCPU 8192 MB 40 GB Eagerzeroedthick (SO), 256 GB
DB) 2008 R2 Enterprise Eagerzeroedthick (DB)
VMware vCloud Director Red Hat Enterprise 2 vCPU 4096 MB 40 GB Eagerzeroedthick (SO)
1.0 Linux 5.5
Oracle Database 11g (vCD Microsoft Windows 4 vCPU 8192 MB 40 GB Eagerzeroedthick (SO), 100 GB
DB) 2008 R2 Enterprise Eagerzeroedthick (DB)
Nel cluster di management il carico delle macchine virtuali è distribuito da Dynamic Resource Scheduler (DRS) di
VMware tra due host hypervisor ESX 4.1. Quando gli host ESX sono configurati in un cluster VMware DRS, le risorse
sono aggregate in un pool che consente il loro utilizzo come se fossero un'unica entità.
Una macchina virtuale può utilizzare le risorse di ogni host nel cluster invece di dipendere da un unico host. VMware
DRS gestisce queste risorse come un pool, assegnando automaticamente le macchine virtuali a un host e monitorando
successivamente l'allocazione delle risorse. VMware DRS utilizza VMware vMotion per trasferire le macchine virtuali da
un host all'altro se riscontra un vantaggio in termini di performance o sulla base di criteri di ottimizzazione.
Il cluster ad alta disponibilità di VMware assicura ridondanza a tutte le macchine virtuali: se si verifica un
malfunzionamento o un'interruzione sulla linea di un host ESX, le macchine virtuali assegnate ad esso si riavviano
rapidamente su un altro host disponibile. Grazie all'architettura di riferimento è possibile il guasto di un solo host.
Maggiore ridondanza si ottiene aggiungendo altri host ESX al cluster di management.
Cluster di risorse
La figura 4 mostra la configurazione del cluster di risorse che contiene le macchine virtuali per l'elaborazione del carico di
lavoro dell'utente.
Figura 4
11In un cluster pool VMware DRS sono stati creati tre pool di risorse (oro, argento e bronzo), ognuno dei quali è
mappato su un unico provider virtual data center. Questo tipo di mappatura 1:1 facilita la separazione delle
caratteristiche in termini di prestazioni di ogni singolo provider virtual data center.
Nel cluster di risorse il carico delle macchine virtuali è distribuito da DRS di VMware tra sei host ESX. Dal momento
che tutte le risorse degli host ESX in un cluster VMware DRS sono aggregate in modo dinamico, è possibile
incrementare o ridurre le risorse di CPU e memoria, aggiungendo o rimuovendo gli host ESX al cluster. La risorsa
dinamica si riflette direttamente nel pool di risorse su cui è mappato il provider virtual data center.
La configurazione massima supportata da VMware vCenter è di 32 host ESX in un cluster DRS. Una volta raggiunto
il limite massimo con la funzione di scale-up, grazie alla scalabilità orizzontale è possibile creare un ulteriore cluster
VMware DRS per ospitare altri 32 host ESX. Una singola istanza VMware vCenter può supportare al massimo 1000
host ESX.
VMware High Availability (HA) fornisce ridondanza al cluster di risorse e alle macchine virtuali per l'elaborazione del
carico di lavoro dell'utente: se si verifica un malfunzionamento o un'interruzione sulla linea di un host ESX, le
macchine virtuali assegnate ad esso si riavviano rapidamente su un altro host disponibile.
Hitachi Compute Blade 2000
Per l'infrastruttura VMware vSphere 4.1 è stato utilizzato Hitachi Compute Blade 2000. La tabella 4 mostra la
configurazione hardware, mentre le 8 blade del server sono rappresentate nella figura 5.
Tabella 4. Configurazione Hitachi Compute Blade 2000
Modello CPU RAM
8xX55A2 2 x 6 nuclei Intel Xeon 5670 a 2,93 GHz 72 GB DDR3 Registered
Cache 12 MB DIMM
Bus di sistema 6.40 GT/s
12Figura 5
13La tabella 5 mostra la distribuzione delle risorse di Hitachi Compute Blade 2000. Vi è la possibilità di una crescita
parallela a quella dell'infrastruttura VMware vCloud e VMware vSphere.
Tabella 5. Distribuzione delle risorse Hitachi Compute Blade 2000
Cluster di management Cluster di risorse
Utilizzo VMware vCenter 4.1 Oracle Macchine virtuali per il carico di lavoro dell'utente
Database 11g VMware vCenter ■ Pool risorse oro
DB VMware vCloud Director 1.0 ■ Pool risorse argento
vShield Manager 4.1 ■ Pool risorse bronzo
ESX0, ESX1 ESX2, ESX3, ESX4, ESx5, ESX6, ESX7
Blade del server 2 6
CPU 35,16 GHz 210,96 GHz
Memoria 144 GB 432 GB
Infrastruttura di rete
L'infrastruttura di rete nell'architettura di riferimento è la seguente. La versione di Hitachi Compute Blade 2000
utilizzata in questa soluzione contiene l'hardware di rete descritto alla tabella 6.
Tabella 6. Hardware di rete Hitachi Compute Blade 2000
Schede di rete NIC Modulo switch 0 Modulo switch 1 Modulo switch 2 Modulo switch 3
2 porte onboard Intel Switch LAN 1 Gb Switch LAN 1 Gb/10 Switch LAN 1 Gb Switch LAN 1 Gb/10
82576 Gigabit Ethernet 20 porte interne Gb 20 porte interne Gb
(SERDES) 1000Base-SERDES 20 porte interne 1000Base-SERDES 20 porte interne
1 porta mezzanine 4 porte esterne 1000Base-SERDES 4 porte esterne 1000Base-SERDES
quad (SERDES) 1000Base- 4 porte esterne 1000Base- 4 porte esterne
Intel 82576 Gigabit T/100Base-TX/10- 1000Base-T/100Base- T/100Base-TX/10- 1000Base-T/100Base-
Ethernet Base-T TX/10- Base-T TX/10-
Base-T Base-T
2 porte 10GBase- 2 porte 10GBase-
LR/SR (XFP) LR/SR (XFP)
Ogni blade del server contiene 6 schede di rete NIC Gigabit. Ogni scheda di rete è connessa tramite il midplane dello
chassis alle porte interne del suo modulo switch.
Nota—La prima VMNIC (vmnic0) numerata in ESX è Intel 825672LF-2. Non utilizzarla in ESX per il traffico di rete.
14Cluster di management
Ogni cluster contiene una rete di management, una per VMKernel e una per la macchina virtuale. Ogni rete del
cluster è configurata per uno scopo specifico. La figura 6 mostra la configurazione di rete del cluster di
management.
Figura 6
Il cluster di management utilizza uno switch virtuale standard per la rete della console di servizio, di VMkernel e
della macchina virtuale. Sono state usate due porte per la console di servizio.
VMNIC1, dedicata alla console di servizio 1, fornisce le seguenti funzionalità:
■ Traffico di management verso VMware vCenter
■ La rete heartbeat VMware High Availability per gli altri host ESX sullo stesso cluster ad alta disponibilità
VMware High Availability è un meccanismo di avvio del failover su rete. Per evitare un failover indesiderato di un
servizio ad alta disponibilità o l'isolation response dell'host, utilizzare una rete aggiuntiva heartbeat VMware High
Availability.
VMNIC2, dedicata alla console di servizio 2, è la rete heartbeat ridondante per VMware High Availability.
15Un altro vantaggio derivante dall'utilizzo di Hitachi Compute Blade 2000 per VMware High Availability è che la
connessione tra le VMNIC e i moduli switch avviene mediante le porte SERDES collegate direttamente al
midplane dello chassis, eliminando così l'eventualità che un cavo venga tirato accidentalmente o di un cablaggio
difettoso. Dal momento che le strutture heartbeat ad alta disponibilità per ogni rete VMware High Availability si
trovano su un unico modulo switch e dominio di trasmissione, si riduce l'eventualità che un malfunzionamento
della rete esterna possa interrompere la rete heartbeat per VMware High Availability.
VMNIC2 fornisce anche una rete dedicata VMkernel per il traffico VMware vMotion, per gestire il traffico vMotion
tra i due host ESX nel cluster di management all'interno dello chassis.
VMNIC3 e VMNIC5, dedicate al traffico tra macchine virtuali, agiscono congiuntamente per bilanciare il
traffico in uscita.
Cluster di risorse
Il cluster di risorse fa uso dello stesso hardware del cluster di management, ma dispone di una configurazione
leggermente diversa, concepita in modo specifico per le macchine virtuali VMware vCloud che elaborano il carico
di lavoro dell'utente. La figura 7 mostra la configurazione di rete del cluster di risorse.
Figura 7
La configurazione della scheda VMNIC per la console di servizio e VMkernel è identica a quella del cluster di
management, mentre la rete della macchina virtuale viene configurata in vNetwork Distributed Switch (vDS) di
VMware. Centralizzata in un livello cluster, vDS si estende a molteplici host ESX. Anche il management della rete
degli host ESX è centralizzato, come consigliato per VMware vCloud Director.
16Per il traffico tra macchine virtuali sono configurati due switch VMware vDS dal livello 1 e dal livello 2, con due
uplink per host ESX. Oltre a 6 host nel cluster di risorse, sono disponibili 12 uplink fisici (VMNICS) per ogni
VMware vDS.
I due uplink disponibili per ogni host ESX per VMware vDS agiscono congiuntamente per bilanciare il carico in
uscita sulla base dell'algoritmo calcolato per l'ID della porta. Ogni porta utilizzata dalle VMNIC sul modulo switch 2
e sul modulo switch 3 è inoltre configurata come trunk VLAN 802.1Q, per consentire a molteplici segmenti LAN il
transito di traffico virtuale.
I diversi livelli di VMware vDS sono determinati dalla larghezza di banda dell'uplink per ogni modulo switch su
chassis. La figura 8 mostra gli uplink esterni per ogni modulo switch.
Figura 8
Il modulo switch 0, collegato al modulo di management 0 e al modulo di management 1, è dedicato alla rete di
management degli host ESX, di VMware vCenter, delle blade individuali del server (tramite interfaccia web) e alla
gestione dello chassis di Hitachi Compute Blade 2000. La rete di management utilizza una connessione Ethernet 1
Gbit.
Il modulo switch 1 è dedicato al traffico VMware vMotion. Se il traffico VMware vMotion avviene tra le blade del
server situate sullo stesso chassis, non è necessario un uplink esterno, mentre se è disponibile una rete VMware
vMotion dedicata all'interno di un data center fisico, ai fini della connettività è possibile usare da tale switch l'uplink
10 Gbit.
Il modulo switch 2, dedicato al traffico inter-chassis tra macchine virtuali di livello 2, utilizza connessioni in rame
Ethernet 1 Gbit.
Il modulo switch 3, dedicato al traffico inter-chassis tra macchine virtuali di livello 1, utilizza connessioni in fibra
Ethernet 10 Gbit.
17Infrastruttura di storage
Si descrive qui l'infrastruttura di storage. Hitachi Compute Blade 2000 (CB 2000) consente di utilizzare schede
HBA dual-port mezzanine con moduli switch dual per Fibre Channel oppure schede HBA dual per Fibre Channel
PCIe. L'architettura di riferimento utilizza le schede Fibre Channel dual port 8G bit/sec Five-EX family PCIe di
Hitachi.
La figura 9 mostra l'architettura di rete della storage area
Figura 9
Sono stati utilizzati due switch Brocade 5340. La prima porta su ogni HBA è stata collegata allo switch 1, mentre la
seconda porta su ogni HBA è stata collegata allo switch 2. La policy di multipath sull'ESX è stata impostata su
round-robin
Per la connessione allo switch 1 sono state utilizzate due porte, una da ogni cluster di Hitachi Virtual Storage
Platform, mentre per la connessione allo switch 2 sono state utilizzate altre due porte, una da ogni cluster di
Hitachi Virtual Storage Platform, Tale interconnessione consente di aumentare la ridondanza. Infatti, in caso di
guasto di uno switch, l'host ESX dispone ancora di due percorsi, uno su ogni cluster di Hitachi Virtual Storage
Platform.
Analogamente sono state utilizzate due porte di ogni controller su Hitachi Adaptable Modular Storage 2100 per la
connessione alle porte esterne di Hitachi Virtual Storage Platform.
18La tabella 7 mostra la configurazione delle zone per il cluster di
Tabella 7. Configurazione delle zone del cluster di management per il gruppo di host di storage
Host Numero Nome della zona Porta di
HBA host storage
ESX 0 3B
HBA1_1 esx0_hba1_1_vsp_3B_4B
4B
5B
HBA1_2 esx0_hba1_2_vsp_5B_6B
6B
ESX 1 3B
HBA1_1 esx1_hba1_1_vsp_3B_4B
4B
5B
HBA1_2 esx1_hba1_2_vsp_5B_6B
6B
Per quanto riguarda la configurazione delle zone è stato utilizzato un initiator singolo, per cui ogni porta HBA è
mappata su 2 porte di destinazione, una su ogni cluster di Hitachi Virtual Storage Platform.
Con due porte per initiator e quattro porte di destinazione, sono disponibili in tutto quattro percorsi, che vengono
utilizzati da ogni host ESX in modalità round-robin.
Per semplificare la gestione e garantire la coerenza dei LUN mappati sugli host per il cluster di management, è
stato utilizzato un unico gruppo di host di storage per le quattro porte di destinazione (3B, 4B, 5B, 6B)
La tabella 8 mostra la configurazione delle zone per il cluster di risorse.
19Tabella 8. Configurazione delle zone del cluster di risorse per il gruppo di host di storage
Numero Numero Nome della zona Porta di
HBA Host storage
3B
HBA1_1 esx2_hba1_1_vsp_3B_4B
ESX 2 4B
5B
HBA1_2 esx2_hba 1_2_vs p_5 B_6B
6B
3B
HBA1_1 esx3_hba1_1_vs p_3 B_4B
ESX 3 4B
5B
HBA1_2 esx3_hba 1_2_vs p_5 B_6B
6B
3B
HBA1_1 esx4_hba1_1_vs p_3 B_4B
ESX 4 4B
5B
HBA1_2 esx4_hba 1_2_vs p_5 B_6B
6B
3B
HBA1_1 esx5_hba1_1_vs p_3 B_4B
ESX 5 4B
5B
HBA1_2 esx5_hba 1_2_vs p_5 B_6B
6B
3B
HBA1_1 esx6_hba1_1_vs p_3 B_4B
ESX 6 4B
5B
HBA1_2 esx6_hba 1_2_vs p_5 B_6B
6B
3B
HBA1_1 esx7_hba1_1_vs p_3 B_4B
ESX 7 4B
5B
HBA1_2 esx7 _hba1_2_vsp_5B_6B
6B
Il cluster di risorse è stato configurato nello stesso modo del cluster di management, per cui sono disponibili
quattro percorsi per gli host ESX. È stato però utilizzato un diverso gruppo di host di storage per garantire la
coerenza dei LUN mappati sugli host per il cluster di risorse.
La tabella 9 mostra la configurazione delle zone per lo storage esterno.
Tabella 9. Configurazione delle zone per lo storage esterno
Host Porta esterna Nome della zona Porta di storage
3D vsp_5D_ams2K_0A 0A
VSP
4D vsp_6D_ams2K_1A 1A
20Due porte di Hitachi Virtual Storage Platform sono state configurate come porte esterne. Analogamente alla configurazione
della storage area network, una porta è stata utilizzata da ogni cluster di Hitachi Virtual Storage Platform. Una porta su ogni
cluster è stata assegnata alla porta di un controller, in modo da mappare un cluster di Hitachi Virtual Storage Platform su
un controller di Hitachi Adaptable Modular Storage.
Configurazione del sottosistema di storage
Si descrive qui la configurazione del sottosistema di storage. Questa soluzione si avvale Hitachi Virtual Storage
Platform come storage principale. Lo storage virtualizzato viene trasmesso agli host ESX come se fosse situato su
Hitachi Virtual Storage Platform Sullo storage esterno è così possibile utilizzare le funzionalità avanzate di Hitachi
Virtual Storage Platform, tra cui VMware vStorage APIs for Array Integration, anche nel caso in cui esso non le
supporti.
La figura 10 mostra la configurazione del sottosistema di storage.
Figura 10
L'architettura di riferimento utilizza volumi di dynamic provisioning da 1,8 TB senza oversubscription. Mentre per
l'insieme dei volumi di dynamic provisioning è ammessa l'oversubscription, ESX 4.1 supporta una dimensione
massima dei LUN di 2 TB.
Pool di management di HDP
La figura 10 illustra il pool di management di HDP, con tre blocchi di parità che utilizzano dischi SAS RAID 5
(3D+1P) 300 GB 10K, per un volume di dynamic provisioning (Management DP-Vol) di 2 TB. Questo volume di
dynamic provisioning è presentato come un LUN nei confronti degli host nel cluster di management, in modo da
garantire capacità e prestazioni sufficienti per la maggior parte delle implementazioni.
Grazie alla natura dinamica di Hitachi Dynamic Provisioning è possibile far fronte a maggiori esigenze in termini di
prestazioni e capacità, aggiungendo facilmente blocchi di parità al pool di management di HDP.
21Pool oro di HDP
La figura 10 mostra il pool oro di HDP, con sei blocchi di parità che utilizzano dischi SAS RAID 5 (7D+1P) 146 GB
15K in tre volumi di dynamic provisioning da 1,8 TB (Gold DP-Vol), per un totale di 5,4 TB. Questi volumi di dynamic
provisioning sono presentati come tre LUN nei confronti degli host ESX nel cluster di risorse.
I LUN mappati da Gold DP-Vol1, Gold DP-Vol2 e Gold DP-Vol3 sono destinati allo storage di livello 1 nel provider
virtual data center oro.
Pool argento di HDP
La figura 10 mostra il pool argento di HDP, con sei blocchi di parità che utilizzano dischi SAS RAID 5 (7D+1P) 300
GB 10K in sei volumi di dynamic provisioning da 1,8 TB (Silver DP-Vol), per un totale di 10,8 TB. Questi volumi di
dynamic provisioning sono presentati come sei LUN nei confronti degli host ESX nel cluster di risorse.
Per il pool argento di HDP, anche se simile al pool oro di HDP, è stato usato un tipo di disco differente, con
prestazioni leggermente inferiori a causa di minori regimi di rotazione, ma di maggiore capacità rispetto ai dischi del
pool oro di HDP. Grazie alla maggiore capacità disponibile, il pool argento di HDP dispone di sei volumi di dynamic
provisioning.
I LUN mappati da Silver DP-Vol1, Silver DP-Vol2, Silver DP-Vol3, Silver DP-Vol4, Silver DP-Vol5 e Silver DP-Vol6
sono destinati allo storage di livello 2 nel provider virtual data center argento.
Pool bronzo di HDP
La figura 10 mostra il pool bronzo di HDP, con sei blocchi di parità che utilizzano dischi SAS RAID 5 (7D+1P) 300 GB
15K in sei volumi di dynamic provisioning da 1,8 TB (Bronze DP-Vol), per un totale di 10,8 TB. Questi volumi di
dynamic provisioning sono presentati come sei LUN nei confronti degli host ESX nel cluster di risorse.
I blocchi di parità sono stati creati mediante Hitachi Universal Volume Manager.
L'architettura di riferimento utilizza la funzionalità Hitachi Dynamic Provisioning messa a disposizione non da Hitachi
Adaptable Modular Storage 2100, bensì da Hitachi Virtual Storage Platform.
I LUN mappati da Bronze DP-Vol1, Bronze DP-Vol2, Bronze DP-Vol3, Bronze DP-Vol4, Bronze DP-Vol5 e Bronze
DP-Vol6 sono destinati allo storage di livello 3 nel provider virtual data center bronzo.
Gruppo percorsi esterni
La tabella 10 mostra la configurazione utilizzata per il collegamento di uno storage esterno da Hitachi Adaptable
Modular Storage 2100 a Hitachi Virtual Storage Platform.
22Tabella 10. Configurazione gruppo percorsi esterni
Numero di Controllo del Lunghezza della
Modello di storage Modalità cache
percorsi flusso in entrata coda dei dati
Hitachi Adaptable Modular Storage 2100 2 Disabilitata Disabilitato 32
Nell'architettura di riferimento è stata disabilitata la modalità cache per una maggiore facilità di gestione. Di
seguito si riportano i risultati derivanti dalla disabilitazione o abilitazione della modalità cache:
■ Se la modalità cache è abilitata, viene utilizzata la cache di Hitachi Virtual Storage Platform che segnala
all'host il completamento delle operazioni di I/O ed esegue il trasferimento asincrono sul sistema di storage
esterno.
■ La modalità cache disabilitata comporta l'elaborazione sincrona dei dati delle operazioni di I/O. Hitachi Virtual
Storage Platform segnala all'host il completamento di un'operazione di I/O solo dopo l'esecuzione della
scrittura sincronica dei dati sullo storage esterno da parte di Hitachi Virtual Storage Platform.
L'abilitazione della modalità cache migliora i tempi di risposta. La disabilitazione della modalità cache consente di
gestire più agevolmente i dispositivi logici esterni, ma comporta l'incremento del tempo di latenza.
Per migliorare la latenza si consiglia pertanto di abilitare la cache. Dopo aver abilitato la cache, dedicare una
partizione della cache ai dispositivi logici esterni, in modo date che questi ultimi non condividano le stesse
partizioni della cache dei dispositivi logici interni. Lo storage esterno potrebbe non raggiungere gli stessi livelli di
prestazioni di Hitachi Virtual Storage Platform. Il trasferimento dei dati allo storage esterno potrebbe pertanto
risultare più lento, con un incremento dell'utilizzo della cache e conseguenze per i dispositivi logici interni.
Nell'utilizzo delle partizioni della cache prestare particolare attenzione al dimensionamento e al
ridimensionamento, in funzione della variazione del volume esterno e del carico di lavoro.
Nell'architettura di riferimento è stato disabilitato il controllo del flusso in entrata per una maggiore facilità di
gestione. Il controllo del flusso in entrata determina la modalità di accettazione dei dati di I/O da parte dell'host
ESX quando un volume esterno è bloccato o non è disponibile. Di seguito si riportano i risultati derivanti dalla
disabilitazione o abilitazione del controllo del flusso in entrata:
■ Se si disabilita il controllo del flusso in entrata, è ammessa la scrittura dei dati di I/O sulla cache da parte
dell'host ESX durante un'operazione di retry, anche quando non è possibile un'operazione di scrittura sullo
storage esterno. La scrittura continua finché la cache è disponibile e i dati presenti nella cache vengono
trasmessi al volume esterno non appena quest'ultimo diventa disponibile.
■ L'abilitazione del controllo del flusso in entrata blocca i dati di I/O dall'host ESX alla cache quando il volume
esterno è bloccato o non è disponibile.
Se la cache è disabilitata e quindi non viene utilizzata, è opportuno disabilitare anche il controllo del flusso in
entrata e viceversa.
Dal momento che la cache è disabilitata in questa soluzione, è stato disabilitato anche il controllo del flusso in
entrata. In Hitachi Virtual Storage Platform non viene utilizzata la cache.
Prestazioni e scalabilità
Questa sezione prende in esame le prestazioni e la scalabilità dell'architettura di riferimento VMware vCloud
Director.
Per l'esecuzione dei test è stato utilizzato un carico di lavoro misto, composto da messaggi e-mail, pagine web e
OLTP. Il carico di lavoro è stato raggruppato in un sistema tile-based per misurare le prestazioni e la scalabilità
dell'applicazione. Ogni tile contiene carichi di lavoro misti che impegnano risorse critiche di calcolo e di storage.
Questi carichi di lavoro possono rappresentare un ambiente VMware vSphere con finalità generali.
23Ogni tile comprende le seguenti macchine virtuali elencate nella tabella 11.
Tabella 11. Macchine virtuali per ogni tile.
Mail Server Olio Web Olio DVD Store 2 DVD Store 2 Standby
(Exchange Server Database Database Web Server
2007) Server Server
Quantità 1 1 1 1 3 1
CPU 4 vCPU 4 vCPU 2 vCPU 4 vCPU 2 vCPU 1 vCPU
Memoria 8192 MB 6144 MB 2048 MB 4096 MB 2048 MB 512 MB
Test eseguiti su un totale di 6 tile tra 2 host ESX nel cluster di risorse. Sono state impiegate 48 macchine virtuali,
con 126 CPU virtuali e 159 GB di memoria virtuale configurata. Ogni tile è controllato da un unico client e ciascun
client del tile è controllato da un client primario. I client girano su altri host, esternamente agli host ESX destinati
all'elaborazione del carico di lavoro delle macchine virtuali. La tabella 12 indica la distribuzione dei tile.
Tabella 12. Distribuzione dei tile
Tile 1 Tile 2 Tile 3 Tile 4 Tile 5 Tile 6
Host ESX 2 3 2 3 2 3
Pool di risorse Organization Organization Organization Organization Organization Organization
virtual data virtual data virtual data virtual data virtual data virtual data
center center center center center center
oro oro argento argento bronzo bronzo
Storage Datastore Datastore Datastore Datastore Datastore Datastore
oro (livello 1) oro (livello 1) argento (livello argento (livello bronzo (livello bronzo (livello
2) 2) 3) 3)
Poiché sono stati utilizzati solo due host ESX, il pool di dynamic provisioning per ogni organization virtual data
center è stato ridimensionato in base a tale configurazione.
La tabella 13 riporta la configurazione di storage dei datastore.
Tabella 13. Configurazione di storage dei datastore
Datastore oro Datastore argento Datastore bronzo
(livello 1) (livello 2) (livello 3)
Tipo di disco 146 GB 15K SAS 300 GB 10K SAS 300 GB 15K SAS
Blocchi di parità in HDP 2 RAID 5 (7D+1P) 2 RAID 5 (7D+1P) 2 RAID 5 (7D+1P)
Numero di LUN 1 1 1
Per simulare i carichi di lavoro di ogni organization virtual data center sono stati attribuiti 2 tile a ogni pool di
risorse dell'organization virtual data center stesso, oltre al datastore mappato per ogni virtual data center. In
questo modo si garantisce che le macchine virtuali in ogni tile saranno impegnate dalle risorse allocate per ogni
organization virtual data center. I test hanno misurato prestazioni in termini di calcolo, storage e applicazioni.
I carichi di lavoro sono stati eseguiti in due diverse occasioni e utilizzando due diverse configurazioni del pool di
allocazione delle risorse di VMware vCloud, con e senza overcommit.
24La tabella 14 mostra il pool di allocazione in cui le risorse sono impegnate al 100% per le allocazioni delle risorse
di CPU e memoria. L'uso delle risorse non supera il 100% delle risorse di CPU e di memoria.
Tabella 14. Pool di allocazione senza overcommit
Organizzazione di livello oro Organizzazione di livello Organizzazione di livello
argento bronzo
CPU 100% di 27 GHz 100% di 21 GHz 100% di 17 GHz
Memoria 100% di 46 GB 100% di 44 GB 100% di 41 GB
La tabella 15 mostra la configurazione del pool di allocazione con overcommit.
Tabella 15. Pool di allocazione con overcommit
Organizzazione di livello oro Organizzazione di livello Organizzazione di livello
argento bronzo
CPU 39% di 67,75 GHz 31% di 67,75 GHz 25% di 67,75 GHz
Memoria 34% di 134 GB 33% di 134 GB 31% di 134 GB
Le massime risorse disponibili per ogni organizzazione sono pari a 67,75 GHz per la CPU e 134 GB per la
memoria. Tali valori vengono ottenuti con l'uso di due soli host ESX nel cluster di risorse. La percentuale delle
risorse di CPU e di memoria garantite per ogni organizzazione è risultata equivalente a quella della tabella 15,
tuttavia con la possibilità di superare la propria allocazione, fino a raggiungere il valore massimo di 67,75 GHz per
la CPU e 134 GB per la memoria.
I virtual data center e la memoria delle macchine virtuali sono stati testati nelle due configurazioni del pool di
allocazione eseguendo due tile per ogni organizzazione. La memoria totale configurata per le macchine virtuali per
2 tile è di 54 GB. È disponibile una sovrallocazione di circa 8 GB per l'organizzazione oro, 10 GB per
l'organizzazione argento e 13 GB per l'organizzazione bronzo.
Il pool di allocazione senza overcommit non dispone di sufficienti risorse di memoria per far fronte alla richiesta
totale. Il pool di allocazione con overcommit può ammettere l'allocazione della memoria configurata per le
macchine virtuali nel caso in cui venga superata la percentuale prenotata, tuttavia le risorse oltre la percentuale
prenotata non sono garantite.
25Prestazioni di calcolo
Sono state rilevate le prestazioni delle risorse di calcolo sia per i pool di allocazione con overcommit che senza
overcommit.
La figura 11 mostra l'utilizzo della CPU e della memoria del pool di allocazione senza overcommit per
ogni organization virtual data center.
Figura 11
Nel pool di allocazione senza overcommit, le risorse medie utilizzate dal virtual data center di ciascuna
organizzazione si avvicinano molto all'allocazione riportata nella tabella 14, ma non superano mai l'allocazione
del 100%. Poiché si è verificata una sovrallocazione della memoria delle macchine virtuali, è avvenuto un
recupero della memoria tramite ballooning. Come previsto, tra i tre organization virtual data center il valore più
basso di ballooning della memoria si riscontra per il centro oro.
La figura 12 mostra l'utilizzo della CPU e della memoria del pool di allocazione con overcommit per ogni
organization virtual data center.
26Figura 12
La figura 12 mostra l'utilizzo della CPU e della memoria degli organization virtual data center nel pool di
allocazione con overcommit, come descritto nella tabella 15. In questa configurazione, al virtual data center di
ogni organizzazione è consentito di superare la percentuale di risorse assegnate nel caso in cui siano
disponibili altre risorse non impegnate.
27La figura 13 mostra, per ESX, l'utilizzo della CPU e della memoria del pool di allocazione senza overcommit
per ogni organizzazione.
Figura 13
La figura 13 mostra, per ESX, l'utilizzo medio della CPU e della memoria del pool di allocazione senza
overcommit. Alcune risorse di CPU e di memoria sono ancora disponibili e non utilizzate.
28La figura 14 mostra, per ESX, l'utilizzo della CPU e della memoria del pool con overcommit per ogni
Figura 14
La figura 14 mostra, per ESX, l'utilizzo medio della CPU e della memoria del pool di allocazione con overcommit. .
L'utilizzo di funzioni come swap e ballooning è diminuito sensibilmente grazie alla modifica dinamica dalla
configurazione del pool di allocazione delle risorse, per il quale è ora ammesso l'overcommit. È questo il
vantaggio di una configurazione che consente l'overcommit delle risorse. Gli host ESX sono in grado di garantire
l'effettiva disponibilità delle risorse prenotate. Il pool di allocazione con overcommit consente l'utilizzo di maggiori
risorse hardware.
Questi risultati indicano che l'impiego di un pool di allocazione di risorse di CPU e di memoria di maggiori
dimensioni può incrementare l'utilizzo dell'hardware, pur assegnando solo una determinata percentuale del pool
delle risorse a ogni organization virtual data center.
Prestazioni di storage
Questa sezione prende in esame le prestazioni di storage dell'architettura di riferimento, che sono state analizzate
con l'overcommit del pool di allocazione sia abilitato che disabilitato.
Prestazioni di storage di ESX
Le prestazioni di storage, come riportato da ESX, sono state analizzate per il datastore VMFS di ogni
organizzazione. Il test è stato eseguito per il pool di allocazione sia con overcommit, sia senza questa
funzionalità.
La figura 15 mostra il valore IOPS per ESX del pool di allocazione senza overcommit per organizzazione.
29Figura 15
La figura 15 mostra il valore IOPS per ogni host ESX e ogni datastore utilizzato da ciascun organization virtual
data center in un pool di allocazione senza overcommit. La distribuzione I/O tra gli host è piuttosto equa.
La figura 16 mostra il valore IOPS per ESX del pool di allocazione con overcommit per organizzazione.
Figura 16
La figura 16 mostra il valore IOPS per ogni host ESX e ogni datastore utilizzato da ciascun organization virtual
data center in un pool di allocazione con overcommit. La distribuzione I/O tra tutti gli host è piuttosto equa.
Dal confronto tra il pool di allocazione senza overcommit e quello con overcommit emerge che quest'ultimo
genera più IOPS a causa del maggior numero di risorse di calcolo disponibili per ogni organization virtual data
center.
30Prestazioni di Virtual Storage Platform
L'analisi prende in esame in particolare modo il pool di allocazione con overcommit proprio perché genera più
IOPS e sottopone il sistema a maggiori sollecitazioni.
La figura 17 mostra il valore IOPS per ogni dispositivo logico nel pool di allocazione con overcommit di Hitachi
Virtual Storage Platform.
Figura 17
La figura 17 mostra il valore IOPS prodotto dal dispositivo logico per ogni datastore del pool di allocazione con
overcommit. Il valore IOPS qui riportato è quasi identico a quello combinato dei due host ESX indicati nella figura
16; ne consegue che, in termini di I/O, esiste un overhead molto ridotto tra l'host ESX e Hitachi Virtual Storage
Platform.
31Puoi anche leggere

















































