Progetto Forensics per Mac
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Università degli Studi dell’Insubria
Facoltà di Scienze Matematiche, Fisiche e Naturali
Corso di Laurea Specialistica in Informatica
Progetto Forensics per Mac
Corso di Informatica Giuridica
Autori:
Lucia Noce (matr. nr. 614804)
Fabio Rusconi (matr. nr. 705448)
Alessandro Zamberletti (matr. nr. 704178)
Anno Accademico 2010-2011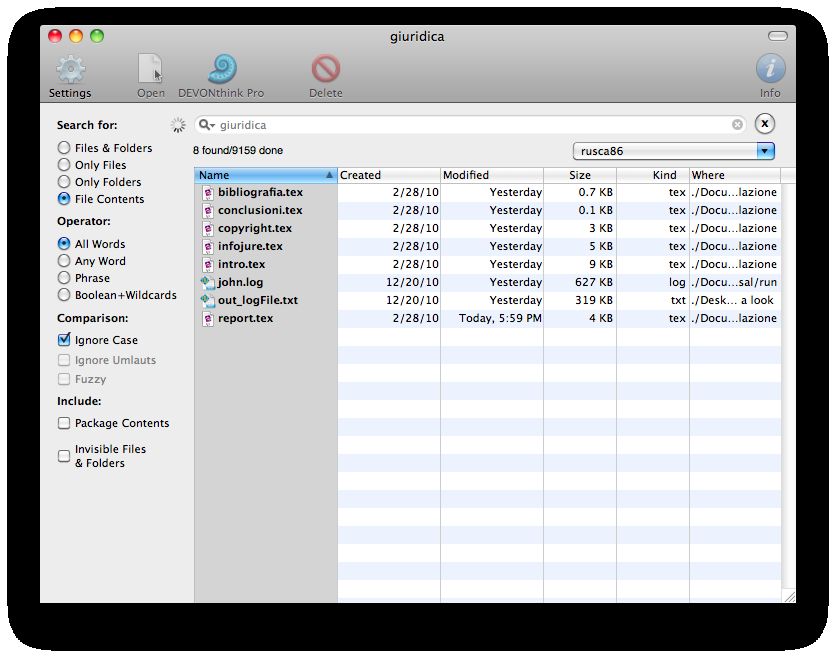
Indice
1 Introduzione 2
1.1 Informatica forense . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Funzione di Hash . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2.1 Algoritmi di hash . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2.2 Hash come metodo di validazione di prove . . . . . . . . . . . . . . 3
1.2.3 Hashbot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Copia bit stream . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Progetto Forensics per Mac 6
2.1 Acquire a device bitstream image . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Acquire and validate a device bitstream image . . . . . . . . . . . . . . . 8
2.3 Perform hash calculation of data . . . . . . . . . . . . . . . . . . . . . . . 10
2.4 Analyze an image or partition (Autopsy) . . . . . . . . . . . . . . . . . . . 11
2.5 Recover lost data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.6 Perform hexadecimal analysis of a file . . . . . . . . . . . . . . . . . . . . 15
2.7 Perform a deep search of files . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.8 Analyze system logs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.9 Recover user password . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.10 Analyze Safari bookmarks . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.11 Sniff network’s packets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
1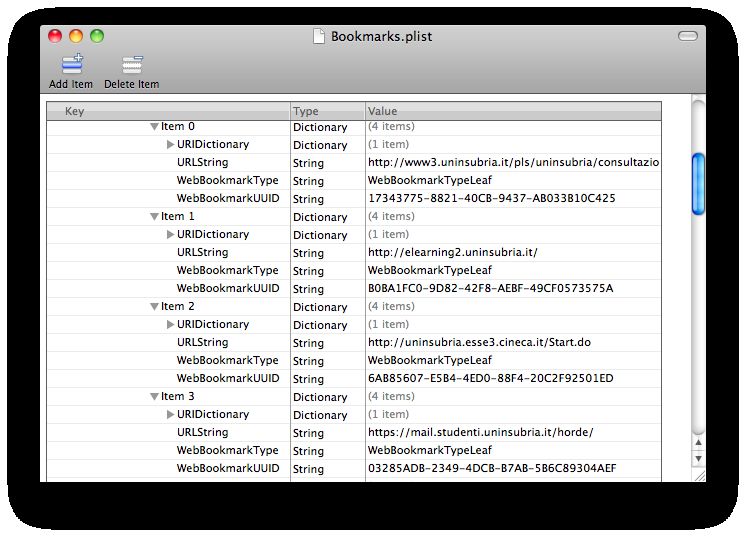
1 Introduzione
1.1 Informatica forense
L’informatica forense o computer forensics è la disciplina che si occupa di studiare l’in-
sieme delle attività rivolte all’analisi e alla soluzione di casi legati alla criminalità infor-
matica; tra questi, i crimini realizzati con l’uso di un computer, diretti a un computer o
in cui il computer rappresenta una fonte di prova.
I principali scopi dell’informatica forense sono la conservazione, l’identificazione, l’acqui-
sizione, la documentazione e l’interpretazione di dati presenti su un computer. A livello
generale si tratta di individuare le modalità migliori per:
• acquisire ed analizzare le prove senza alterare il sistema informatico su cui si
trovano;
• garantire che le prove acquisite su altro supporto siano identiche a quelle originarie.
L’informatica forense comprende le attività di verifica dei supporti di memorizzazione
dei dati (hard disk, ssd, . . . ) e delle componenti informatiche, delle immagini, audio e
video generate da computer, dei contenuti di archivi e basi dati e delle azioni svolte nelle
reti telematiche.
1.2 Funzione di Hash
Nel linguaggio matematico e informatico, la funzione hash è una funzione non inietti-
va che mappa un file di lunghezza arbitraria in una stringa alfanumerica di lunghezza
predefinita, detta digest.
1.2.1 Algoritmi di hash
La funzione di hash è realizzata da algoritmi soddisfanti i seguenti requisiti:
• l’output dell’algoritmo è una stringa di numeri e lettere ottenuta a partire da un
flusso di bit di lunghezza arbitraria;
• per ogni documento, la stringa in output è univoca1 e ne è un identificatore
(utilizzabile come firma digitale);
1
In realtà, nessun algoritmo di hash è in grado di garantire l’univocità della stringa prodotta in
output; un algoritmo di hash che genera digest a B bit è in grado, infatti, di generare al più 2B possibili
stringhe di hash. Tali collisioni possono essere tuttavia ridotte (ma mai annullate) mediante l’utilizzo
abbinato di più algoritmi di hash.
2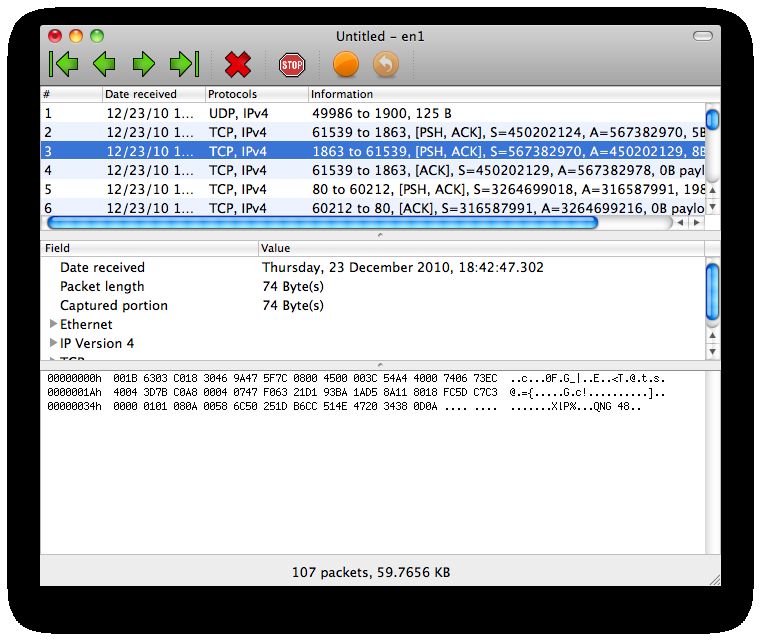
• l’algoritmo è non invertibile; non è dunque possibile ricostruire il documento
originale a partire dalla stringa che viene restituita in output.
Alcuni algoritmi di hash molto utilizzati sono:
• SHA1 (Secure Hash Algorithm): la specifica originale dell’algoritmo fu pubblicata
nel 1993 come Secure Hash Standard; genera un digest da 160 bit.
• SHA2 : con questo termine si indicano 4 funzioni di hash facenti parte della famiglia
SHA, ognuna con un digest più lungo di quello originale (224 bit, 256 bit, 384 bit
e 512 bit)
• CRC (Cyclic Redundancy Check ): algoritmo semplice da realizzare, ma poco affi-
dabile per verificare la completa correttezza dei dati contro tentativi intenzionali
di manomissione.
• MD2 (Message Digest 2 ): sviluppato da Ronald Rivest nel 1989, l’algoritmo è
ottimizzato per computer ad 8 bit. Attualmente risulta poco diffuso.
• MD4 : molto simile al MD2 ma studiato per migliorare le performance.
• MD5 : realizzato nel 1991 da Ronald Rivest, produce un digest da 128 bit. A oggi,
la disponibilità di algoritmi efficienti capaci di generare stringhe che collidono in
un tempo ragionevole ha reso MD5 sfavorito rispetto ad altri algoritmi di hashing,
sebbene la sua diffusione sia a tutt’oggi molto estesa.
• MDC2 (Modification Detection Code): è una funzione di hash con un output pari
a 128 bit. Per ragioni di brevetti, il supporto per MDC2 è disabilitato in OpenSSL
e in molte distribuzioni Linux.
• RIPEMD160 (RACE Integrity Primitives Evaluation Message Digest): è un algo-
ritmo crittografico di hashing ideato da Hans Dobbertin, Antoon Bosselaers e Bart
Preneel che genera in output un hash di 160 bit.
• WHIRLPOOL: si tratta di una funzione di hash relativamente nuova, ideata da
V. Rijmen e P.S.L.M. Barreto. Opera su messaggi che abbiano una dimensione
inferiore a 2256 bit producendo digest di 512 bit.
1.2.2 Hash come metodo di validazione di prove
Dalle proprietà precedentemente descritte della funzione di hash è facile intuire come que-
st’ultima possa essere utilizzata nell’ambito giuridico. L’analisi forense richiede infatti
3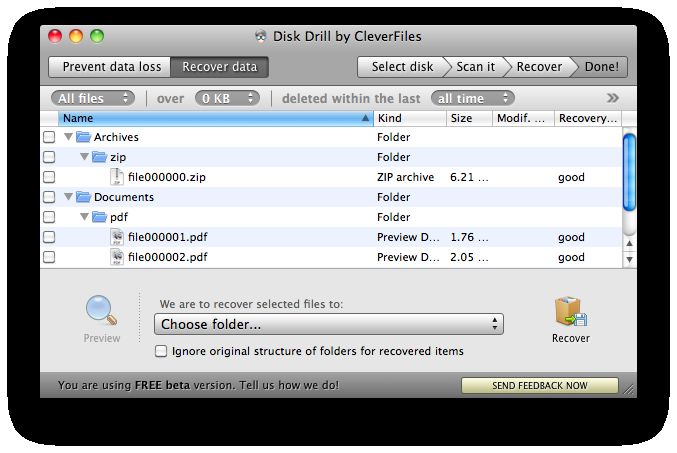
una validazione delle copie per poter garantire che esse non abbiano subito alterazioni
in fase di acquisizione o nei momenti ad essa successivi. La caratterizzazione delle copie
avviene includendo in esse informazioni ausiliarie (come la data ed ora in cui avviene la
copia). Tali elementi vengono sottoposti ad un processo di hashing assieme ai dati utili
ed i valori calcolati rimangono definitivamente storicizzati in supporti ausiliari a quelli
di destinazione della copia. A questo proposito, nell’ambito della computer forensics, si
impiegano delle funzioni di hash standard come MD5, SHA1 o combinazioni delle pre-
cedenti come esposto in precedenza. I valori di hash calcolati durante la copia sono utili
per garantire due fatti essenziali:
• Data la possibilità di calcolare l’hash sia sui dati di partenza che su quelli copiati
e fermo restando le proprietà di univocità degli algoritmi che implementano la
funzione di hash, è possibile verificare l’aderenza “assoluta” della copia ai dati
di partenza durante il processo di clonazione, impiegando tale metodo come un
rigoroso sistema di controllo errore.
• Successivamente alla copia, la disponibilità del valore di hash, consente di stabilire
se la copia è ancora valida e se sono intervenute delle alterazioni (volontarie e/o
involontarie).
La validazione della prova risulta tuttavia essere notevolmente difficoltosa qualora si
debba acquisire una risorsa telematica (sito web, . . . ) in quanto quest’ultime evolvono
continuamente; in particolare è necessario catturare lo stato della risorsa in un determi-
nato istante temporale. Uno dei più noti e meglio progettati strumenti per tale scopo è
Hashbot.
1.2.3 Hashbot
Il contenuto di una singola pagina web può cambiare velocemente. Per questo è nato
hashbot.com, web application sviluppata da Davide Baglieri e Gianni Amato, che consen-
te di validare scientificamente qualsiasi documento web. Basta indicare all’applicazione
l’URL del documento che si vuole congelare. Hashbot scarica il documento, calcola gli
hash MD5 e SHA1, assegna un codice univoco al singolo processo di acquisizione e salva
tali informazioni nel suo database. Alla fine l’utente non deve fare altro che scaricare
l’archivio contenente il documento validato e le informazioni di certificazione scientifica.
Da questo momento in poi è possibile interrogare il database per chiedere verifica della
validazione. Inserendo nell’apposita form il codice di validazione e l’hash (a scelta MD5
4
o SHA1), l’applicazione restituisce tutte le informazioni salvate in sede di acquisizione
del documento.
È possibile utilizzare hashbot come strumento per provare un dato di fatto in giudizio,
ma dipenderà dal giudice se accettarlo o meno come prova.
1.3 Copia bit stream
La copia dei dati di un dispositivo può avvenire in modi differenti:
• copia di livello fisico (o copia bit stream), in cui il contenuto dell’unità fisica
viene letto sequenzialmente (la sequenza è stabilita dall’indirizzamento fisico, in
genere gestito dal controller dell’unità di memoria) caricando la minima quantità
di memoria di volta in volta indirizzabile (negli hard disk il settore fisico, nelle
ROM il byte, . . . ) per poi registrarla nella stessa sequenza su di un comune file
binario (immagine fisica dell’unità);
• copia di basso livello del file system (o copia cluster), in cui il contenuto di una
partizione logica (strutturatasi a seguito di una formattazione correlata ad un
preciso file system) viene letto sequenzialmente caricando la minima quantità di
memoria che il file system consente di indirizzare di volta in volta (il cluster in
FAT o NTFS) per poi registrarla nella stessa sequenza su di un comune file binario
(immagine di basso livello del file system);
• copia del file system, in cui parte o tutto il contenuto di alto livello di una partizione
logica (strutturatasi a seguito di una formattazione correlata ad un preciso file
system), ivi intendendo i contenuti di file e directory evidenti (non cancellati),
viene sottoposto a backup su di un file di particolare formato (dipendente dal tool
impiegato).
Questi livelli di copia non sono affatto equivalenti se lo scopo è individuare elementi
probatori di tipo forense. In particolare la copia fisica mantiene tutte le informazioni
possibili anche sul partizionamento, quella a basso livello di file system contiene sia i
file cancellati che quelli evidenti ma non i dati sulle partizioni includendo una sola di
esse, mentre quella di alto livello mantiene solo il contenuto di file e directory evidenti.
Ovviamente a tali fattori si contrappongono la velocità di svolgimento della copia. La
scelta del tipo di copia da svolgere dipende quindi molto dal tipo di prova digitale che
si intende ottenere e dal tempo che si ha a disposizione.
5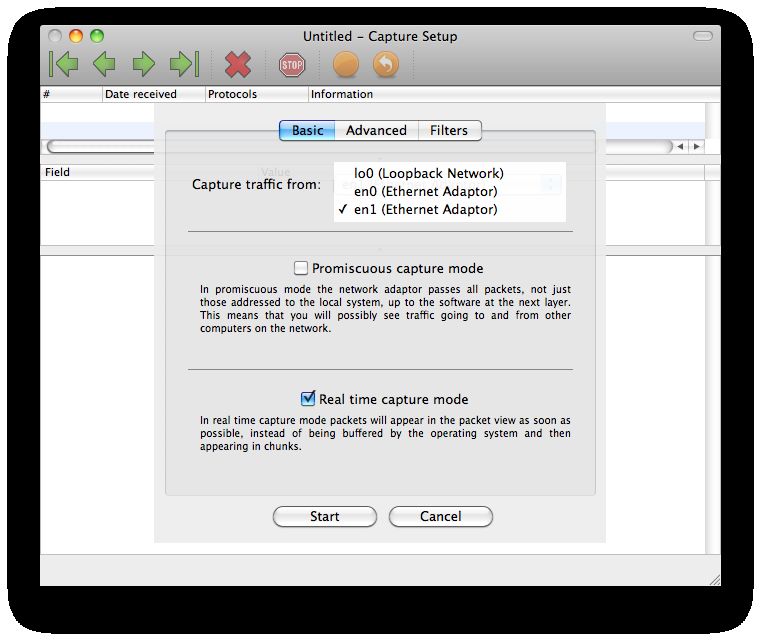
2 Progetto Forensics per Mac
Il Progetto Forensics per Mac consiste nello sviluppo di un’applicativo eseguibile in
ambiente Mac OSX utile nell’effettuare analisi forensi. Qualsiasi operazione effettuata
all’interno dell’applicazione viene opportunamente registrata all’interno di un file di log.
Figura 1: Schermata principale.
Di seguito verranno presentate le funzionalità che il programma mette a disposizione.
6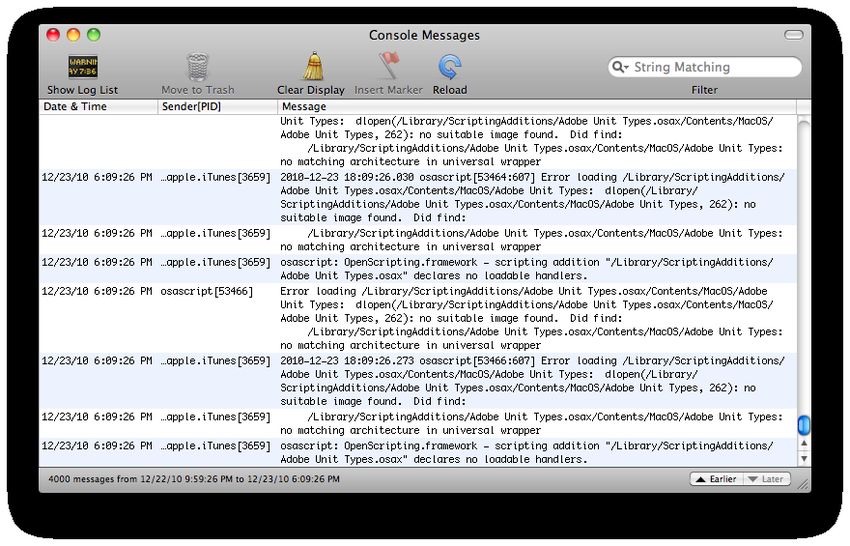
2.1 Acquire a device bitstream image
Questa funzionalità permette di effettuare l’acquisizione bitstream di un dispositivo
collegato al proprio Mac; il suo funzionamento dipende dall’utility di sistema dd 2 .
Nella figura 2 è possibile visualizzare le fasi di acquisizione del device:
1. selezione del dispositivo di cui effettuare l’acquisizione
2. acquisizione in corso
3. acquisizione terminata con successo
Figura 2: Acquire a device bitstream image
2
Comando dei sistemi operativi Unix e Unix-like, e più in generale dei sistemi POSIX, che copia dei
dati in blocchi, opzionalmente effettuando conversioni. Licenza: GNU General Public License.
7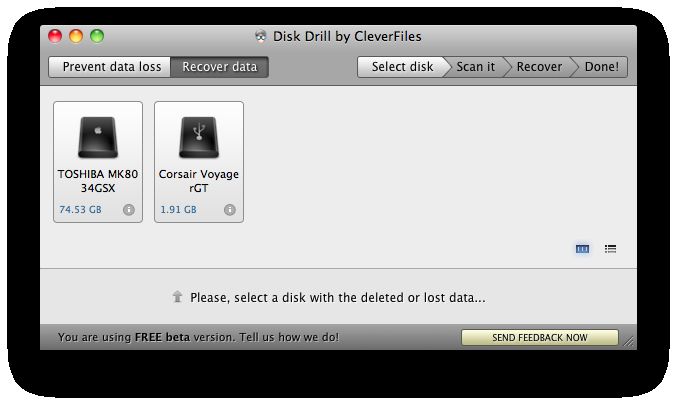
2.2 Acquire and validate a device bitstream image
Questa funzionalità riprende le capacità dell’acquisizione bitstream di un dispositivo
(vedi 2.1), rendendola più avanzata. Oltre alla copia del device si occupa, infatti, anche
di verificare che questa sia avvenuta senza alterazioni, sfruttando di algoritmi di hash.
Di contro, c’è la richiesta di maggior tempo di elaborazione.
Gli algoritmi di hash messi a disposizione sono:
• SHA1, SHA224, SHA256, SHA384, SHA512
• MD4, MD5
• MDC2
• RIPEMD160
• WHIRLPOOL
Per maggiori dettagli sui singoli algoritmi, si veda il paragrafo 1.2.
Ancora una volta, la procedura può essere distinta in fasi, mostrate in figura 3:
1. selezione del dispositivo di cui effettuare l’acquisizione
2. selezione dell’algoritmo di hash
3. calcolo dell’hash del dispositivo originale
4. acquisizione
5. calcolo dell’hash della copia del dispositivo
6. verifica della coincidenza degli hash
8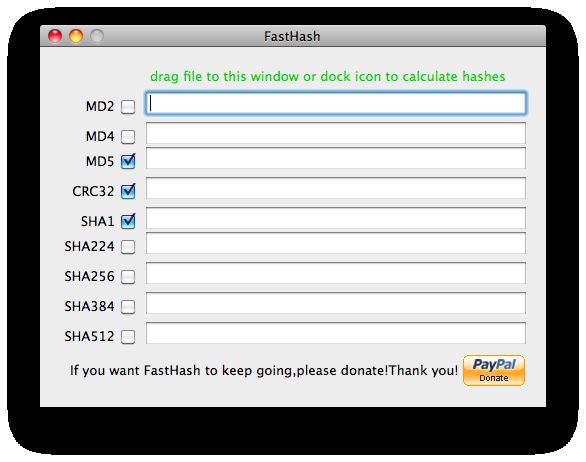
Figura 3: Acquire and validate a device bitstream image
92.3 Perform hash calculation of data
L’applicazione permette di effettuare il calcolo dell’hash di un qualsiasi file utilizzando
FastHash.
FastHash è un programma agile e leggero, non ha particolari richieste operative ed è
gratuitamente scaricabile dal sito ufficiale3 del suo creatore: Henrik Zheng.
FastHash supporta i seguenti algoritmi:
• SHA1, SHA224, SHA256, SHA384, SHA512
• MD2, MD4, MD5
• CRC32
Per calcolare l’hash di un file è sufficiente trascinare quest’ultimo sulla finestra di Fa-
stHash.
Figura 4: FastHash
3
http://web.me.com/henrikzheng/FastHash/Welcome.html
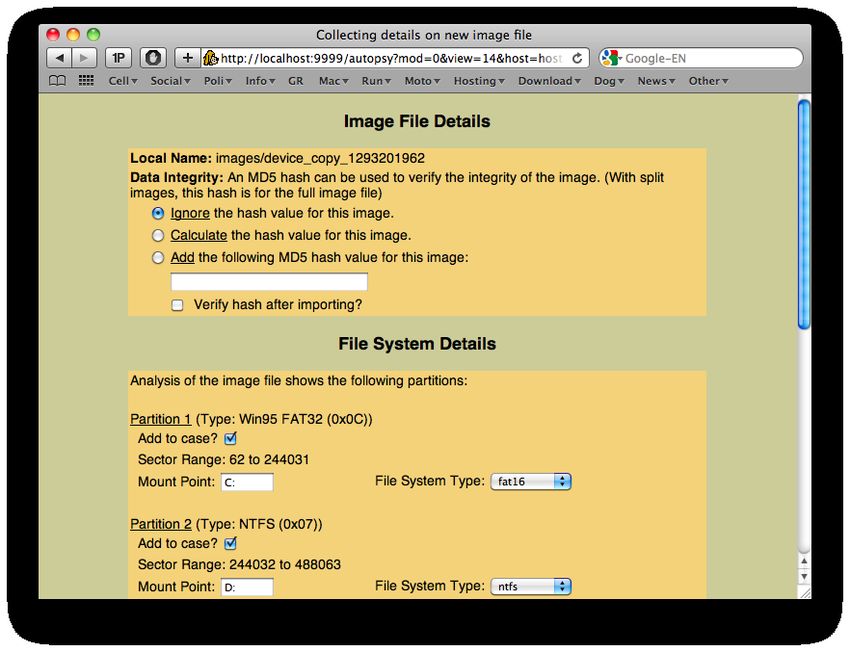
102.4 Analyze an image or partition (Autopsy)
The Sleuth Kit (TSK) in combinazione con Autopsy fornisce un valido framework Open
Source per l’analisi forense di immagini e partizioni con il supporto per vari filesystem, tra
i quali FAT, NTFS e HFS/HFS+. Diversamente dalla maggior parte delle piattaforme di
computer forensics, la struttura di Sleuthkit & Autopsy è completamente modulare: The
Sleuth Kit non è un programma, bensı̀ un insieme di tools a linea di comando sviluppati
in C e Perl, ognuno dei quali esegue operazioni specifiche in ambito specifico. Autopsy
Forensic Browser fornisce invece l’interfaccia grafica e l’ambiente di collegamento dei vari
programmi, permettendo di ottenere risultati omogenei ed una gestione strutturata del
caso.
Il primo impatto ad una struttura simile è spesso “frastornante”, in particolare per chi è
abituato al lavoro attraverso un’interfaccia lineare; le iniziali difficoltà di apprendimento
e le perplessità relative all’utilizzo di un’interfaccia web per la gestione dell’indagine
sono però presto sostituite dal compiacimento per un ambiente potente e facilmente
integrabile con gli altri tool open source disponibili.
Lo sviluppo dei tool presenti in TSK ha inizio nel 1999, quando Dan Farmer e Wietse
Venema presentano una serie di programmi per l’analisi post-mortem di sistemi Unix,
battezzata col nome evocativo di “The Coroner’s Toolkit” (TCT). Al lavoro dei due
ricercatori si aggiunge presto il contributo di Brian Carrier attraverso le TCUTILS,
una serie di utility complementari che contribuiscono ad integrare, tra le altre cose, un
supporto di base per ulteriori filesystem quali FAT e NTFS.
Benchè l’utilità degli strumenti fosse già evidente, il difetto principale era costituito
dall’usabilità, visto che i programmi erano esclusivamente a linea di comando, difficili e
scomodi da utilizzare in indagini estese. Nasce cosı̀ Autopsy, un’interfaccia web composta
da svariati script in Perl e C, capace di elaborare gli output dei vari comandi e presentarli
attraverso un’interfaccia più funzionale e sfruttabile.
Nel frattempo il gruppo di ricerca di @stake (recentemente acquisito da Symantec) ac-
coglie il progetto e ne diventa il principale sviluppatore, sfornando gli aggiornamenti
sotto il nome di TASK (The @stake Sleuth Kit). Attualmente i programmi sono raccolti
sotto il nome di “The Sleuth Kit” (TSK) ed il progetto è portato avanti da Brian Car-
rier, ricercatore della Purdue University e del CERIAS, nonchè collaboratore scientifico
della @stake Academy. Le piattaforme supportate per l’installazione della suite sono
Linux, OpenBSD, FreeBSD, Solaris, e Mac OS X. È possibile il porting in ambiente
Win32 attraverso la mediazione dell’ambiente Cygwin. I filesystem supportati sono i
più comuni: NTFS, FAT, FFS, EXT2FS, EXT3FS, HFS/HFS+ e le funzionalità inte-
11grate permettono la maggior parte delle operazioni necessarie nell’indagine forense, in
particolare:
• rilevazione caratteristiche del file system
• recupero file eliminati
• rilevazione tipologia dei file attraverso gli header
• creazione di timeline activity
• raccolta spazio non allocato
• ricerca testo
• calcolo hash
• integrazione di db hash (known good, bad)
• lista per tipologia
• visualizzazione di metadata e Active Data Stream (NTFS)
È bene chiarire come TSK non sia un tool “tuttofare”, non ha funzionalità di copia
e duplicazione disco, non permette la maggior parte delle analisi funzionali a livello
applicativo ( es. Analisi Registry Windows, analisi mail, .dat files) e non è adatto alla
network forensics. Ciò nonostante svolge al meglio le funzioni per le quali è progettato, in
particolare l’analisi a livello file system, senza considerare che le caratteristiche mancanti
sono facilmente integrabili con i vari strumenti open source preposti alle altre specifiche
operazioni (dd, Pasco, Rifiuti, Galleta, ecc.).
12Figura 5: Autopsy
132.5 Recover lost data
Disk Drill è un’applicativo in fase beta che richiede Mac OSX 10.5 o superiore ed un
Mac con processore Intel. La beta e tutti gli aggiornamenti saranno gratuiti fino all’u-
scita della versione finale, a pagamento. Vista l’assenza di date di scadenza, essa potrà
continuare ad essere utilizzata anche in futuro.
Con questo software è possibile recuperare file cancellati dal sistema; sono supportati i
filesystem HFS/HFS+, FAT e NTFS. Il funzionamento è semplice: l’applicazione esegue
una scansione (a scelta tra veloce ma poco approfondita e approfondita ma lenta) del-
l’intero disco mostrando gli elementi che è possibile ripristinare, lasciando poi all’utente
la possibilità di selezionarli tutti o solo alcuni di essi. Disk Drill è in grado di recuperare
foto, musica, video, documenti e file in molti altri formati. Il software può essere uti-
lizzato su dischi rigidi, memorie di massa USB, macchine fotografiche digitali, qualsiasi
tipo di lettore multimediale e sui computer Mac. Inoltre è possibile eseguire il ripristino
di intere partizioni eliminate.
(a) Disk Drill all’avvio (b) Selezione del dispositivo da cui tentare il
recupero di file
(c) Scansione del dispositivo (d) File di cui possibile tentare il recupero
Figura 6: Disk Drill
142.6 Perform hexadecimal analysis of a file
Lo studio di file in esadecimale è di notevole importanza nell’ambito dell’informatica
forense. Il nostro software permette di sfruttare le potenzialità di HexEdit, applicazione
open source capace di mostrare in formato esadecimale di qualunque file. È anche
possibile effettuare modifiche sui singoli byte direttamente in formato esadecimale e di
eseguire ricerche all’interno del file partendo sia da normali stringhe di testo che da una
serie di caratteri esadecimali. Consente anche di copiare un blocco di byte in un nuovo
file, permettendo di scomporre dei file di grosse dimensioni in una serie di file piú piccoli.
Figura 7: HexEdit
152.7 Perform a deep search of files
EasyFind è una potente applicazione freeware per la ricerca di file e cartelle, sviluppata
da DEVONtechnologies4 . È possibile effettuare una ricerca utilizzando operatori boo-
leani. Permette inoltre di trovare file all’interno di pacchetti (resi “invisibili” dal sistema
operativo), e di visualizzare un’anteprima dei file trovati.
Figura 8: EasyFind
4
http://www.devon-technologies.com/
162.8 Analyze system logs
Console è un software sviluppato da Apple e fornito assieme al sistema operativo che
consente di visualizzare i messaggi scambiati tra le varie componenti di Mac OSX (ap-
plicazioni o il sistema operativo stesso). Tale programma fornisce dunque un log di tutto
ciò che avviene all’interno del proprio Mac.
Figura 9: Console
172.9 Recover user password
Questa funzionalità consente il recupero della password dell’account di un utente confi-
gurato in Mac OSX, utilizzando John the Ripper.
John the Ripper è un software, sviluppato originariamente per ambienti UNIX e rila-
sciato con licenza GNU GPL, per il cracking delle password. È in grado di eseguire
la decriptazione di password criptate da diversi algoritmi, mettendo a disposizione più
modalità di utilizzo: modalità dizionario, brute force, incrementale, ecc.
La tipologia di attacco sfruttata dal nostro software è quella a forza bruta, adattata
per essere più efficiente mediante l’utilizzo del dizionario “English Open Word List”
(EOWL), sviluppato da Ken Loge5 .
EOWL deriva quasi completamente dallo “UK Advanced Cryptics Dictionary” (UKACD),
sviluppato da J. Ross Bereford. Poichè UKACD è un prodotto freeware, la stessa licenza
viene ereditata dalla EOWL.
La EOWL contiene 129009 parole, tutte di lunghezza inferiore a 10 caratteri, cosı̀
distribuite:
• numero parole inizianti per A: 7296
• numero parole inizianti per B: 7272
• numero parole inizianti per C: 11382
• numero parole inizianti per D: 7217
• numero parole inizianti per E: 5151
• numero parole inizianti per F: 5389
• numero parole inizianti per G: 4747
• numero parole inizianti per H: 4500
• numero parole inizianti per I: 3685
• numero parole inizianti per J: 1287
• numero parole inizianti per K: 1577
• numero parole inizianti per L: 4126
• numero parole inizianti per M: 6891
5
http://dreamsteep.com/contact
18• numero parole inizianti per N: 2522
• numero parole inizianti per O: 3681
• numero parole inizianti per P: 10278
• numero parole inizianti per Q: 720
• numero parole inizianti per R: 6794
• numero parole inizianti per S: 15917
• numero parole inizianti per T: 7289
• numero parole inizianti per U: 4425
• numero parole inizianti per V: 2364
• numero parole inizianti per W: 3147
• numero parole inizianti per X: 122
• numero parole inizianti per Y: 606
• numero parole inizianti per Z: 624
John the Ripper inizierà a verificare se la password è tra quelle presenti nel dizionario.
In caso di insuccesso, tenterà l’attacco brute force.
19Figura 10: Recover user password
202.10 Analyze Safari bookmarks
Safari risulta essere il browser più utilizzato dagli utenti Mac in quanto quest’ultimo
viene fornito da Apple come browserr predefinito per i proprio sistemi operativi Mac
OS. I preferiti di Safari risultano dunque essere molto interessanti dal punto di vista
dell’analisi forense.
L’analisi dei preferiti di Safari avviene utilizzando Property List Editor ; vista la pos-
sibilità dell’esistenza di più utenti con un proprio account all’interno di Mac OSX, è
necessario che l’analista forense selezioni l’utente del quale desidera effettuare l’ana-
lisi dei preferiti (fig. 11(a)), fatto ciò sarà possibile visualizzare approfonditamente le
informazioni relative a quest’ultimi (fig. 11(b)).
2.11 Sniff network’s packets
Packet Peeper è un software open source che permette di effettuare l’intercettazione
passiva dei dati che transitano in una rete telematica; nel campo informatico, i software
che permettono di effettuare tale operazione prendono il nome di packet sniffer (più
comunemente “sniffer”).
Affinchè sia possibile effettuare lo sniffing dei pacchetti in transito su una rete è necessario
che l’utente scelga l’interfaccia (cioè la scheda di rete) sulla quale si desidera “mettersi
in ascolto”; fatto ciò è possibile sfruttare tutte le funzionalità offerte da Packet Peeper
utilizzando la sua semplice ed intuitiva interfaccia grafica. Se la rete sulla quale ci si
è posti in ascolto è protetta da password, il contenuto dei pacchetti in transito risulta
ovviamente essere illegibile.
21(a)
(b)
Figura 11: Analyze Safari bookmarks
22(a)
23
(b)
Figura 12: Packet PeeperPuoi anche leggere

















































