L'Agricoltura (e l'Animal Science) nell'era della (iper) informazione - Giuseppe Pulina, Alberto S. Atzori & Corrado Dimauro
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

In God We Trust.
All others bring
data.
Edwar Deming.
L’Agricoltura (e l’Animal Science)
nell’era della (iper) informazione
Giuseppe Pulina, Alberto S. Atzori & Corrado Dimauro
Copyright Giuseppe Pulina, Università di Sassari
La catena del valore dell’informazione
(Abbasi et al., 2016)
Dati
Azioni Informazione
Decisioni Conoscenza
Copyright Giuseppe Pulina, Università di Sassari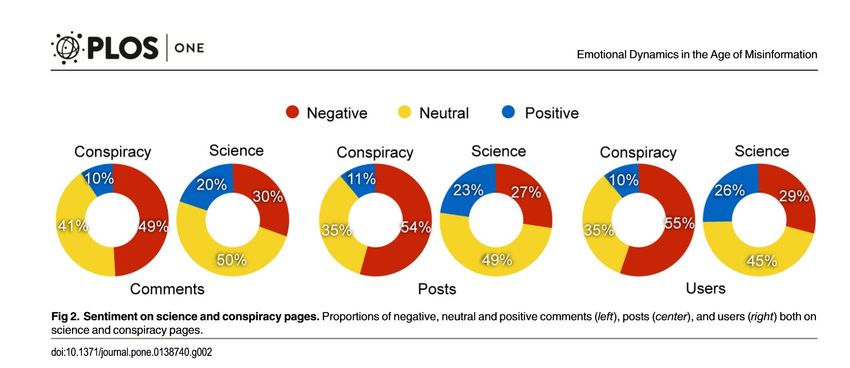
L’Era dell’iper-informazione
• Oggi ogni due giorni l’umanità crea una
quantità di dati equivalente a quella prodotta
dall’origine della civiltà al 2003 (E. Schidt, CEO
di Google)
• Ogni giorno l’umanità genera 500 milioni di
tweet, 70 milioni di foto, 4 miliardi di video su
Facebook (Grossman, Time Magazine, 2015)
• Ogni giorno creiamo 2,5 quintilioni di dati: il
90% dei dati odierni sono stati generati negli
ultimi 2 anni (Calude e Longo, 2016)
Copyright Giuseppe Pulina, Università di Sassari
Siamo entrati nell’era dei
(cosidetti) Big-data.....
Copyright Giuseppe Pulina, Università di Sassari
..e della distruzione della
conoscenza attraverso i social media
Copyright Giuseppe Pulina, Università di Sassari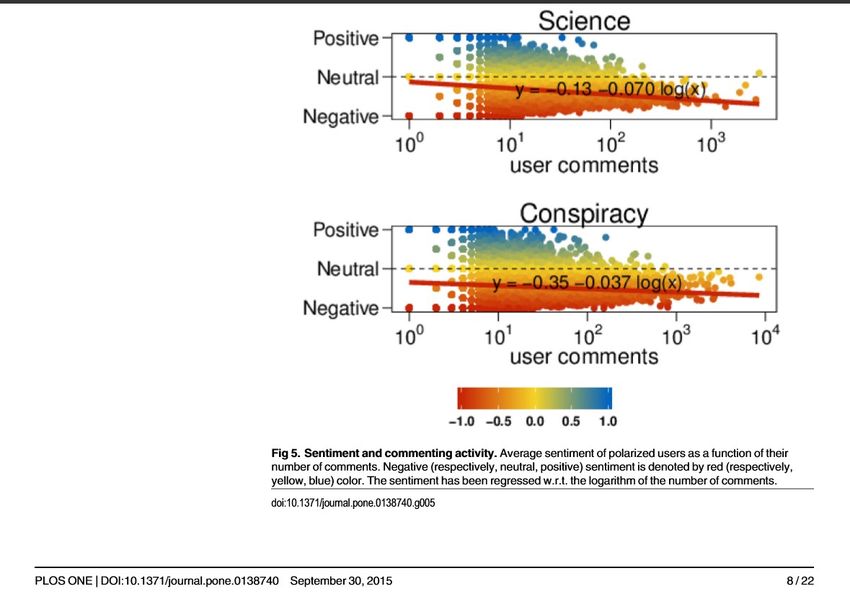
Cosa dimostreremo in questo intervento?
• La disintermediazione dei social media alimenta
teorie errate a scapito di informazioni corrette
• La pervasività dei social media può provocare
dannose distorsioni nell’opinione pubblica (e di
riflesso sugli scienziati)
• I big data e i social NON possono essere distrutivi
della catena del valore dell’informazione e del
metodo scientifico
Copyright Giuseppe Pulina, Università di Sassari
Inoltre....
• I big data pondono problemi etici all’agricoltura
• La precision farm genera big data; come
utilizzarli?
• Il mondo scientifico deve risolvere le distorsioni
legate ai big data e al “publish or perish”
Copyright Giuseppe Pulina, Università di Sassari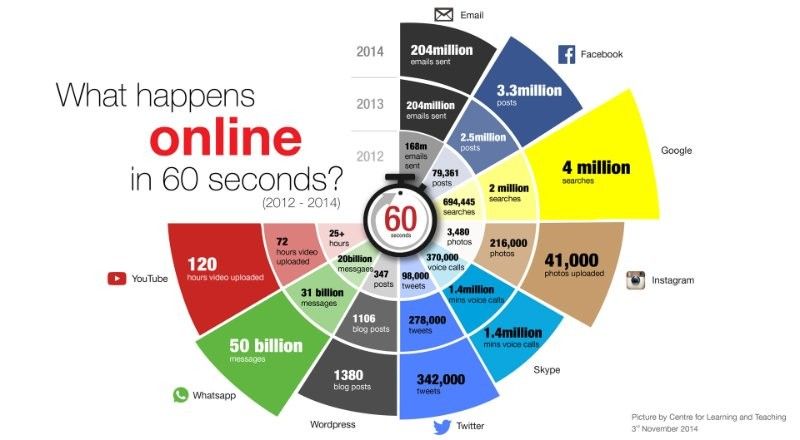
Informare correttamente. Come?
Copyright Giuseppe Pulina, Università di Sassari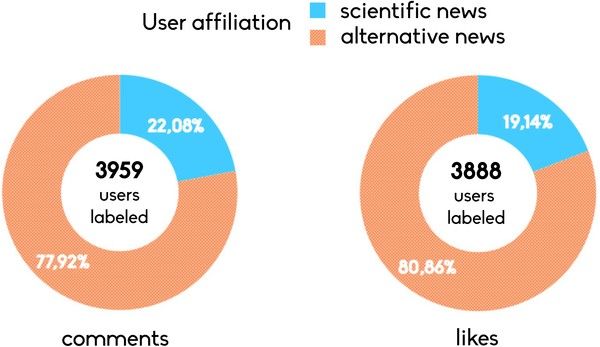
Cosa succede all’informazione?
• L’informazione sta cambiando rapidamente
connotati.
• L’avvento dei social net comporta che la
produzione e il consumo dei contenuti sono
fortemente disintermediati
• Chiunque pubblica ciò che crede senza una
verifica sulla fondatezza o sostenibilità di quanto
pubblicato
• Stiamo entrando nell’era della disinformazione?
(Quattrociochi, Le Scienze, febbraio 2016)
Copyright Giuseppe Pulina, Università di Sassari
Il World Economic Forum (2013) ritiene che “The global
risk of massive digital misinformation sits at the centre
of a constellation of technological and geopolitical risks
ranging from terrorism to cyber attacks and the failure
of global governance”.
Source: World Economic ForumI giovani sono i più attivi sui social.
Il fenomeno ha imponenti effetti
trasformativi.
Copyright Giuseppe Pulina, Università di SassariStudi quantitativi dimostrano che l’essere umano non è
razionale e in un contesto informativo non filtrato prende
tutto ciò che più gli aggrada (confirmation bias).
Il web ha facilitato l’interconnessione e l’accesso ai contenuti:
ha spinto la formazione di Echo chambers, comunità che
condividono interessi e selezionano informazioni secondo
una narrazione del mondo condivisa.
Copyright Giuseppe Pulina, Università di SassariIndagine quantitativa sui social in Italia di 4 anni. 2 cluster di utenti: esposti a news scientifiche o alternative (prive di fonte). I commenti negativi prevalgono di gran lunga sui positivi.
I gruppi di utenti si polarizzano
Fig 6. Polarized users on false information. Bessi A, Coletto M, Davidescu GA, Scala A, Caldarelli G, et al. (2015) Science vs Conspiracy: Collective Narratives in the Age of Misinformation. PLoS ONE 10(2): e0118093. doi:10.1371/journal.pone.0118093 http://journals.plos.org/plosone/article?id=info:doi/10.1371/journal.pone.0118093
I commenti negativi
si concentrano nella comunità polarizzata
alternativa (conspiracy) verso la polarizzata
scientificaL’aumento dei contatti provoca il peggioramento del sentiment
554–559 | PNAS | January 19, 2016 | vol. 113 | no. 3 La cascata di interesse si difonde più lentamente per la comunità cospiracy, ma si allarga maggiormente .
Ed è uguale per le quattro narrative principali esplorate: a) Geopolitica b) Dieta c) Ambiente d) Salute
Fig 3. Attention patterns. Bessi A, Zollo F, Del Vicario M, Scala A, Caldarelli G, et al. (2015) Trend of Narratives in the Age of Misinformation. PLoS ONE 10(8): e0134641. doi:10.1371/journal.pone.0134641 http://journals.plos.org/plosone/article?id=info:doi/10.1371/journal.pone.0134641
Fig 2. Communities of conspiracy terms. Bessi A, Zollo F, Del Vicario M, Scala A, Caldarelli G, et al. (2015) Trend of Narratives in the Age of Misinformation. PLoS ONE 10(8): e0134641. doi:10.1371/journal.pone.0134641 http://journals.plos.org/plosone/article?id=info:doi/10.1371/journal.pone.0134641
I social sono distruttivi della catena
del valore dell’informazione
• 1. Perchè favoriscono false teorie rispetto a
fatti certificati (teorie complottiste vs
paradigmi scientifici)
• 2. Perchè rinforzano segnali umorali irrazionali
rispetto ad analisi razionali
• 3. Perchè indeboliscono la fiducia pubblica nei
confronti della scienza
Copyright Giuseppe Pulina, Università di SassariIn definitiva, il pericolo è il deragliamento della
informazione di origine controllata (media.DOC) su
quella non controllata di blog e social (media.SPAM),
con la conseguenza di orientare l’opinione pubblica su
teorie antiscientifiche capaci di influenzare i cittadini e
di screditare la comunità scientifica
Copyright Giuseppe Pulina, Università di SassariI big data
L’avvento dei big data preoccupa le
associazioni scientificheCaratteristiche di big data (Abbasi et al., 2015; St. Pierre, 2016)
1. Volume
• Equivalenze (1 byte = 1 granello di sabbia):
1 megabyte = 1 cucchiaino di sabbia
1 terabyte = 1 scatola di sabbia (2 feet x 1 inch)
1 petabyte = 1 spiaggia lunga 1 miglio
1 exabyte = 1 spiaggia dal Maine al N. Carolina
• Molte companies USA hanno oggi più di 100
terabyte di dati stoccati
• I dati sanitari stoccati al 2011 erano pari a 150
exabyte
Copyright Giuseppe Pulina, Università di Sassari2. Velocità
• New York Stock Exchange, cattura 1 terabyte
di informaizoni al giorno
• Wal Mart raccoglie 2,5 petabytes di
transazioni dei clienti ogni ora
• Ogni giorno si registrano 5 miliardi di
domande sui motori di ricerca
Copyright Giuseppe Pulina, Università di Sassari3. Varietà delle fonti
4. Veridicità Web spam account for over 20% of all WWW content (Abbasi & Adjeroh, 2014)
I big data sono distruttivi della catena
del valore dell’informazione?
(Abbasi et al., 2016)
• 1. Nuovi players e nuovi processi
• 2. Amalgama di tecnologie in “piattaforme” e
di processi entro “pipelilnes” nella fase di
derivazione della conoscenza
• 3. Maggiore ricorso a data scientist o analyst
per supportare decisioni di tipo self-service o
real-time a scapito della derivazione della
conoscenza da dato [si salta la fase
della’analisi di significato ritenuta inutile]
Copyright Giuseppe Pulina, Università di SassariI big data sono distruttivi del metodo
scientifico
(Callude & Longo, 2016)
• “With enough data, the number speak for
themselves” Per cui i big data rendono il metodo
scientifico obsoleto (C. Anderson, Wired Magazine,
2008)
• Tutti i modelli sono sbagliati (ma alcuni sono utili,
massima di Box), e si può avere sempre più
successo senza loro
• Correlazioni trovate in immensi data-base possono
sostituire l’analisi di significato tipica della scienza
Copyright Giuseppe Pulina, Università di SassariIl potere e i limiti delle correlazioni
Il potere delle correlazioni
• 1. Una correlazione è essenzialmente una
coincidenza, rappresenta cose che avvengono
insieme
• 2. Le correlazioni sono utili per il loro potere
predittivo
• 3. Molte conoscenze scientifiche derivano dall’
osservazione di correlazioni controintuitive
Copyright Giuseppe Pulina, Università di SassariI limiti delle correlazioni
• 1. Le correlazioni non spiegano perchè due variabili
sono legate
• 2. Non c’è via per evidenziare una correlazione spuria
se non attaverso una teoria
• 3. La teoria Egodica e il teorema di Ramsey
dimostrano che in grandi data-set si realizzano
correlazioni spurie proporzionali alla dimensione
dell’insieme numerico
• 4. Troppe informazioni tendono a comportarsi come
poche informazioni: vi è difficoltà a trarne un senso
Copyright Giuseppe Pulina, Università di SassariI big data NON sono in grado di
distruggere il metodo scientifico
• 1. In assenza di teorie i dati mancano di
ordine, senso e significato
• 2. Le teorie senza dati (quali quelle che
circolano nei social) sono vuote, i dati senza
teoria sono ciechi (Harington, 2005)
• 3. I big data possono rappresentare un aiuto
agli scienziati per riconsiderare la natura delle
teorie scientifiche in un mondo di abbondanza
di informazioni
Copyright Giuseppe Pulina, Università di SassariI big data e l’etica dell’Agricoltura
Big data e agribusisness • 1. Le agrobusisness companies sono interessate ai big data per la costruzione di modelli di gestione riguardanti ogni aspetto delle imprese agricole • 2. Monsanto ha acquistato la Climate corp per 930 MUSD, azienda che produce modelli su big data per trattamenti e previsioni produttive • 3. I big data hanno immenso valore per le speculazioni (futures di mais, soia e grano) • 4. John Deere e General Motor hanno messo il copyright sui software dei macchinari da loro prodotti Copyright Giuseppe Pulina, Università di Sassari
Big data e autonomia degli agricoltori • 1. Le grandi companies si comportano da data brokers: acquisiscono dati da sensori o direttamente dagli agricoltori senza obblighi nei loro confronti • 2. Occorre una riorganizzazione sociale dell’agricoltura che limiti la proprietà del controllo delle produzioni da parte delle companies detentrici dei big data • 3. Finanziare open source analytics per rendere utilizzabili i dati a chi lo produce (ISO-blue, Pordue University) Copyright Giuseppe Pulina, Università di Sassari
Precision Agriculture: big data, big
farms?
Una delle prime 10 rivoluzioni in campo agricolo (Crookston,
2006).
Inizia nel 1990, si sviluppa dopo il 2003 (Daberkow and Mc
Bride, 2003)
The precision agriculture o l’agricoltura di precisione è la
fonte principale di big data in agricoltura
Precision livestock farming è la zootecnia di precisione
Copyright Giuseppe Pulina, Università di SassariPrecision Farming
Deriva dall’applicazione delle tecnologie della
informazione e comunicazione (ICT) in agricoltura e
zootecnia:
• Uso di strumenti per la raccolta di informazioni
(podometri, sensori vari)
• Uso di software gestionali come sistemi di supporto
alle decisioni (DSS) (Cox, 2002)
Copyright Giuseppe Pulina, Università di SassariLe fasi della precision farming
• Acquisizione di informazioni su ogni singolo animale
allevato
• Aumento della efficienza media aziendale attraverso
il miglioramento delle performance di ogni animale
• Miglioramento del processo decisionale (scelte su
singoli capi per calori, fecondazioni, trattamenti,
riforma, etc) e risparmio di tempo per altre attività,
principalmente gestione delle informazioni aziendali
e gestione strategica degli obiettivi (Lawson et al.,
2011).
Copyright Giuseppe Pulina, Università di SassariSupporti decisionali (DSS) e big data Decision Support System (DSS) e Information and Communication Technologies (ICT) sono diventati i più importanti cooperatori aziendali che aiutano l’allevatore nelle scelte aziendali (Eastwood et al., 2012). Come funzionano? Raccolgono, archiviano ed elaborano i dati animali e aziendali: •Anagrafica •Produzione •Riproduzione •Fisiologia della ruminazione •Sanità •Conto economico •Tracciabilità Ricercatori, tecnici e allevatori sono impegnati nella comprensione e ottimizzazione dell’uso della tecnologia (Bewley, 2012)
Generatori di big data
Identificazione dei calori
Gestione della mungitura
Copyright Giuseppe Pulina, Università di SassariGestione della riproduzione e dell’allevamento
Copyright Giuseppe Pulina, Università di SassariUso dei dei supporti decisionali informatici
e profitto aziendale (in €/mese per vacca)
Ricavo mensile per vacca presente €/capo)
400 in 150 stalle della provincia di Oristano
(ordinate per dal ricavo più alto al ricavo più basso)
350
RIcavo per vacca presente, €/mese
300
250
200
Stalle senza supporti informatici
150 Stalle con supporti informatici
100
Copyright Giuseppe Pulina, Università di Sassari (Atzori et al., 2014)Letteratura recente sulla precision farming
(Halachmi et al., 2015)Effetto teorico virtuoso della precision farming
sulle performance aziendali
La sottoutilizzazione e la errata interpretazione delle informazioni provenienti
da ICT e DSS porta elevate perdite economiche (Bewley, 2012)
(Atzori et al., 2014)
Collo di bottiglia: molta adozione, spesso poca utilizzazione
(la tecnologia oggi si vende, ma non si spiega bene agli allevatori)
Per elaborare bene le informazioni disponibili ocorrono
“modelli interpretativi” robuste
Copyrightteorie scientifiche!
Giuseppe Pulina, Università di SassariScienza e iper-informazione
[come aggiornarsi nell’era del
publish or perish]Cosa è la Scienza?
E’ un sistema per testare la corrispondenza delle
nostre idee con la realtà attraverso il metodo
ipotetico-deduttivo
Tesi
realtà teoria
Ipotesi
Copyright Giuseppe Pulina, Università di SassariIl metodo ipotetico-deduttivo
Teoria Ipotesi
[o paradigma] speriementale
Si
Conferma Disegno sperimentale
Conferma
Ipotesi?
la Teoria?
[Funziona?] No
Spiegazione Esperimento
Controllo Dati
Pevisione
Realtà
Copyright Giuseppe Pulina, Università di SassariScienza e iper-informazione [1]
Papers repertoriati da PubMed per anno
1400000
1200000
1000000
800000
600000
400000
200000
0
1985 1990 1995 2000 2005 2010 2015 2020
Copyright Giuseppe Pulina, Università di SassariScienza e iper-informazione [2]
Cumulativo dei paper repertoriati da PubMed
20000000
18000000
16000000
14000000
12000000
10000000
8000000
6000000
4000000
2000000
0
1985 1990 1995 2000 2005 2010 2015 2020
Copyright Giuseppe Pulina, Università di SassariScienza e iper-informazione [3]
Vet Science repertoriati da PubMed
35000
30000
25000
20000
15000
10000
5000
0
1985 1990 1995 2000 2005 2010 2015 2020
Copyright Giuseppe Pulina, Università di SassariScienza e iper-informazione [4]
dairy & animal science (ISI Thompson)
7000
6500
6000
5500
5000
4500
4000
3500
3000
2004 2006 2008 2010 2012 2014 2016
Copyright Giuseppe Pulina, Università di SassariScienza e iper-informazione [5]
vet science (ISI Thompson)
15000
14500
14000
13500
13000
12500
12000
11500
11000
10500
10000
2004 2006 2008 2010 2012 2014 2016
Copyright Giuseppe Pulina, Università di SassariChe fare?
• 1. Studiare le review
• 2. Utilizzare le meta-analisi
Copyright Giuseppe Pulina, Università di SassariHowever, “Huston, we have SOME problems...”
1. La commercializzazione della
scienzaLa buona scienza è solo quella utile?
• 1. L’utilitarismo in campo scientifico sta portando
ad un forte aumento dei conflitti di interesse (COI)
• 2. La ricerca finanziata dalle companies NON è
pubblicata se NON ottiene risultati in linea con la
politica commerciale delle stesse
• 3. I grandi Journals perseguono la politica di non
pubblicare i lavori che dimostrano l’ipotesi zero o
a non pubblicare lavori che ripetono esperimenti
già pubblicati [alla faccia della ripetibilità degli
esperimenti]
Copyright Giuseppe Pulina, Università di SassariConseguenze: l’oggettività
scientifica è a rischio!
• 1. La pressione publish or perish sta portando
singoli ricercatori e intere comunità scientifiche
nella sfera del COI
• 2. La mancata pubblicazione di lavori con
risultati “non significativi” distorce la potenza
delle review e, soprattutto, delle meta-analisi
• 3. Politiche pubbliche e private di fund rising
scoraggiano i ricercatori dalla funzione critica
(referee, public letters, ecc....)
Copyright Giuseppe Pulina, Università di SassariRimedi
• 1. Finanziamenti pubblici diretti prevalentemente
verso la ricerca curiosity driven
• 2. Favorire la diversità di opinioni e il dibattito nelle
comunità scientifiche
• 3. Incentivare l’open access per garantire
trasparenza al processo di oggettività scientifica,
anche nelle ricerche finanziate dalla companies
• 4. Rimuovere il bias della maggiore probabilità che i
risultati positivi siano pubblicati rispetto a quelli
negativi
Copyright Giuseppe Pulina, Università di SassariTuttavia, qualcosa si muove.....
Copyright Giuseppe Pulina, Università di Sassari2. Il P-value • Il valore di P indica la probabilità di dire il falso se si afferma che una differenza osservata fra trattementi sperimentali è vera. La soglia convenzionale è P
Il cattivo uso di P
I principi dell’ASA per un corretto
uso del P-valueI big data e il P-value deflazionato • L’immensa massa di dati rende il P inefficace perchè quasi tutto è significativamente differente
Allora?
Con grandi data set il problema non è “se le
differenze sono significative, ma se sono
significativamente interessanti”Conclusioni: a che punto siamo?
False
REALTA’
Social
teorie
Public Metodo Comunità
trust scientifico scientifica
Big Knowledge Big
Data bias Companies
Copyright Giuseppe Pulina, Università di SassariConclusioni: che fare?
False
REALTA’
Social
teorie
Media
Public Metodo Comunità
trust scientifico scientifica
Big Knowledge Big
Data bias Companies
Copyright Giuseppe Pulina, Università di SassariGrazie, thank you, gracias, dank, obrigado,谢谢, ευχαριστίες…..
Puoi anche leggere

















































