Interpolazioni e geostatistica - M. Alberti - 2010 www.malg.eu - OSF
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Interpolazioni
e geostatistica
M. Alberti - 2010
www.malg.eu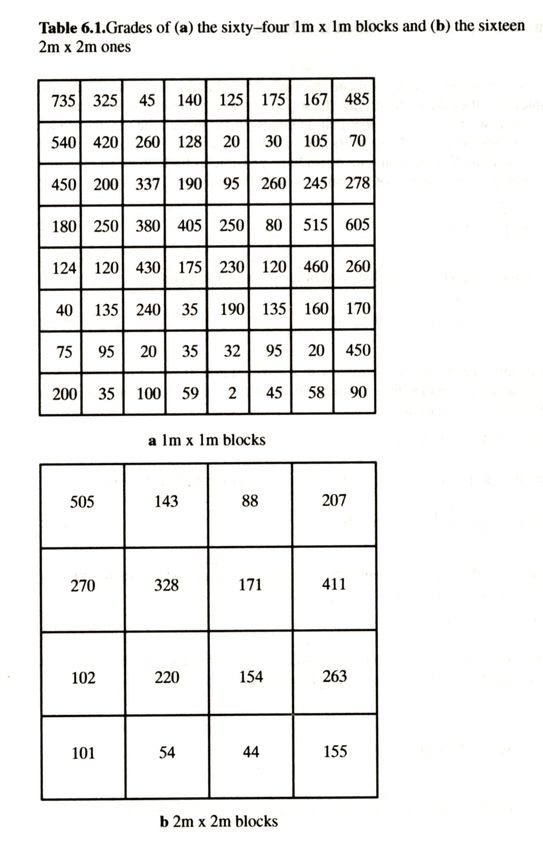
“Campi” di variabili
Fenomeni naturali rappresentabili come campi:
• Topografia
• Batimetria
• Concentrazioni di composti chimici
• Etc.
Come si strutturano i
valori di un campo?
Da Terrengmodellering - Gaute Aarbakke
Solaas, Geodata Punti Isolinee Grid(raster)
Punti Isolinee Grid(raster)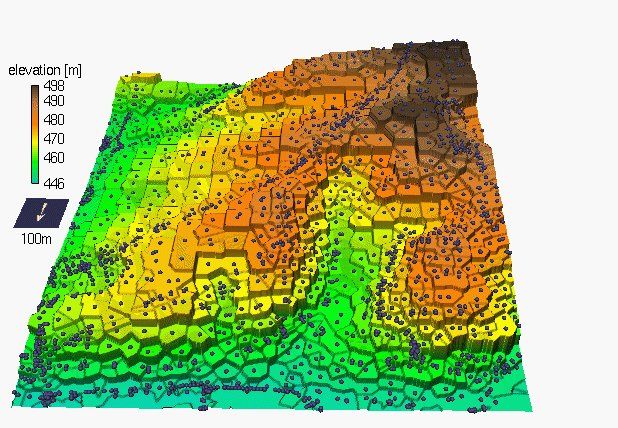
Interpolazione spaziale di campi scalari
Da Mitas & Mitasova, 2005.
Dati gli N valori di un fenomeno scalare studiato z j, j = 1, .., N, misurato in punti discreti r j =
(xj[1], xj [2], …., xj[d]), situati all’interno di una regione specificata di uno spazio d-dimensionale,
occorre determinare una funzione F(rj) che passi attraverso i punti (o li approssimi):
F(rj) = zj , j = 1, …, N
Da Geospatial Analysis and Modeling: Lecture notes. Helena Mitasova, NCSU MEAS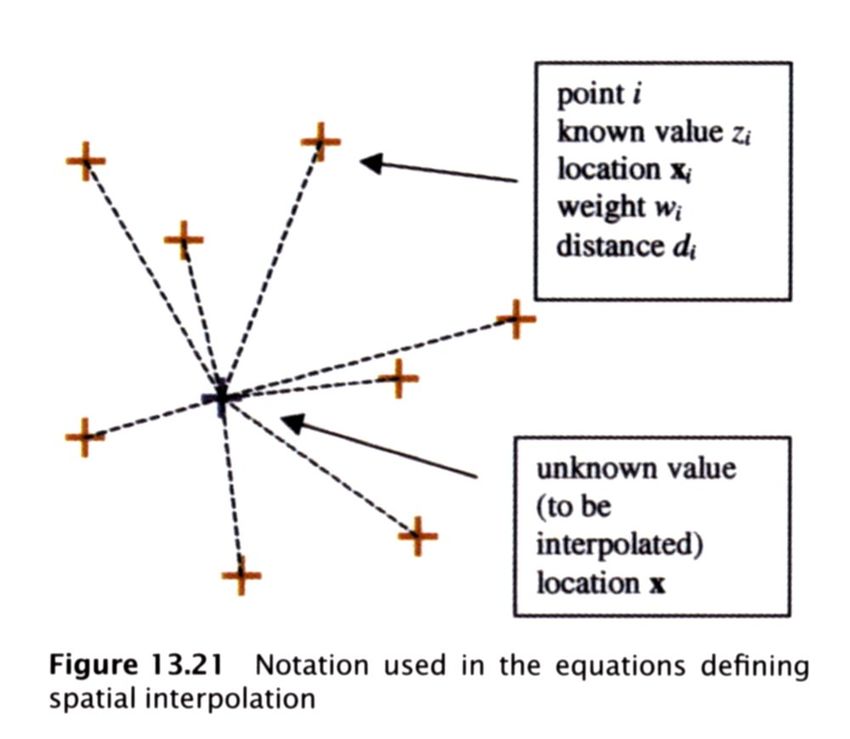
Interpolazione spaziale di campi scalari Esiste un numero infinito di funzioni che soddisfano questa funzione -> sono necessari criteri addizionali devono essere aggiunti per rendere la soluzione unica. -Ogni set di criteri particolari definisce un particolare metodo di interpolazione. - Non esiste a priori nessun metodo più “vero” degli altri. - Per scegliere un particolare metodo fra i numerosi proposti, dobbiamo disporre di informazioni addizionali, cioè hard data – misure oggettive - o soft data – conoscenze o ipotesi soggettive - sul fenomeno studiato. -A seconda del tipo di fenomeno modellato possono essere preferiti metodi di interpolazione differenti.
Tipi di interpolatori
Interpolatori esatti
metodi di interpolazione che per
i punti misurati stimano valori
uguali a quelli effettivamente
osservati.
Interpolatori non-esatti
metodi che non interpolano
precisamente i valori osservati
nei punti di misura.
Da Lecture5Week7SpatialInterpolation.ppt
Tipi di interpolatori
Interpolatori globali Interpolatori locali
Utilizzano tutte le osservazioni disponibili per Utilizzano le sole osservazioni situate
derivare la superficie continua. nella immediata prossimità del punto
dal interpolare.
Interpolazioni globali sono in generale usate
per rimuovere un trend dai valori osservati, ed
analizzare i residuali delle osservazioni.
Da Longley et al., 2001, fig. 13.21.
Su quale supporto si misura?
Supporto: area o volume del
campione fisico sul quale viene
effettuata la misura.
Le misure reali si dovrebbero
basare sempre su una estensione
areale o volumetrica costante in
tutta la zona investigata, perché i
valori misurati e le loro proprietà
statistiche dipendono dalla
estensione effettivamente utilizzata.
L’uso di due differenti supporti di
misura produce valori differenti per le
singole celle
Da Armstrong, 1998, Table 6-1.
Interpolatori globali
Trend surface analysis (global polynomials)
Si utilizzano superfici definite da polinomiali che approssimano i punti
osservati -> interpolatore non-esatto
Piano grigio → trend surface
Da Terrengmodellering - Gaute Aarbakke
Solaas, Geodata
Trend surface analysis
I coefficienti delle
equazioni vengono
determinati
minimizzando la
somma degli errori
quadratici (differenza
tra valore interpolato e
valore osservato) per i
punti misurati.
Da Sullivan & Unwin, 2003, fig. 9.4.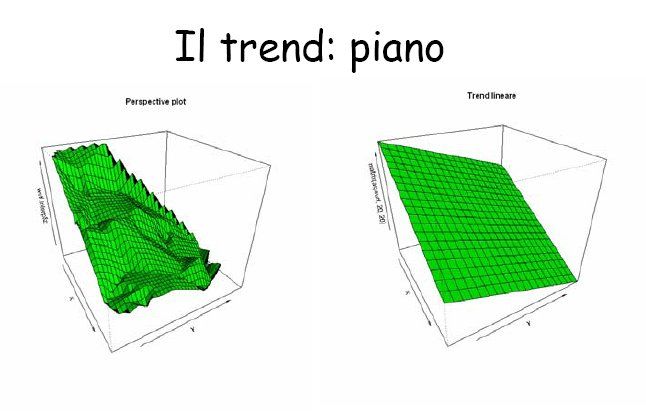
Trend surface analysis Il grado delle equazioni polinomiali generalmente utilizzato può andare da 1 (piano) sino a 4-5-6. Es. z = ax + by +c z = ax2 + bxy + cy2 + dx + ey + f
Trend Surface Analysis
L’entità dei residuali
diminuisce con
l’aumentare del grado
delle equazioni
utilizzate ma non
necessariamente
aumenta l’accuratezza
dei valori interpolati.
Da Davis, 1973, figg. 6.11.Tecniche di stima locale
Esistono numerosi metodi. Fra gli altri:
• Poligoni di Thiessen
• IDW
• Radial basis functions
• Kriging
Da Terrengmodellering - Gaute Aarbakke
Solaas, GeodataScelta osservazioni prossime
Raggio fisso Numero fisso di punti
(fixed-radius) (fixed-neighbours number)
R = 100 R = 100 R = 20 R = 160
Dati noti = 4 Dati noti = 1 Dati noti = 4 Dati noti = 4
http://www.quantdec.com/SYSEN597/GTKAV/section9/chapter_29b.htmBarriere
Le barriere sono brusche variazioni nella superficie da
interpolare, indotte p.e. da faglie e scarpate.
Alcune tecniche di interpolazione
permettono di definire barriere
prima dell’esecuzione
dell’interpolazione, in maniera
tale che nella stima di un
punto che ricade da un lato
della barriera vengono usati i
soli dati misurati dallo stesso
lato.
Fig. da Spatial Analyst Lesson 4.pptPoligoni di influenza Proximity polygons Poligoni di Thiessen o di Voronoï o di Dirichlet. Principio base: la miglior informazione su un sito non misurato è fornita dalla misura nel sito più vicino. Accettabile con variabili categoriali, sconsigliato per variabili continui. Poligoni di influenza: ogni poligono contiene tutti i punti che sono più vicini all’osservazione interna -> gradiente di elevazione nullo + barriera Da Sullivan & Unwin, 2003, fig. 8.6
Poligoni di influenza All’interno di un singolo poligono il valore interpolato rimane costante. La varianza dell’intera distribuzione ottenuta tramite questo metodo è esattamente uguale a quella delle osservazioni di partenza. Osservazioni addensate: poligoni di limitate dimensioni. Osservazioni isolate: p. di notevoli dimensioni. Osservazioni disposte su griglia regolare con spaziatura costante: poligoni di Thiessen quadrati.
Poligoni di influenza
Svantaggi
Le dimensioni e la forma dei poligoni
dipendono dalla configurazione dei punti
campionati.Questo è evidente soprattutto
ai bordi della zona esaminata.
• Al passaggio da un poligono all’altro
possono essere presenti brusche
discontinuità: questo non crea problemi
nel caso di variabili categoriali/nominali,
ma rimane comunque un artefatto senza
alcuna giustificazione fisica sia per dati
categoriali sia per quelli continui.
• Il valore di un punto non campionato è
stimato basandosi su un solo valore,
quello noto più prossimo: questo non
permette di formarsi un’idea sul margine Da Geospatial Analysis and Modeling:
di incertezza nella stima. Lecture notes. Helena Mitasova, NCSU
MEASNatural neighbour Metodo proposto da Sibson (1981). Utilizza i dati più vicini al punto da interpolare Interpolato un nuovo valore in base alla media pesata dei dati noti. • Viene creato un reticolato di Thiessen (poligoni bianchi in figura) usando la localizzazione dei dati noti • In corrispondenza del punto col valore da interpolare (cerchio nero) si crea un nuovo poligono di Thiessen (blu) • Ad ogni dato noto viene attribuito un peso proporzionale al rapporto tra l'area del suo poligono ricoperta da quello del punto da interpolare e l'area di quest'ultimo (peso rappresentato dai cerchi verdi). Markluffel, Wikipedia - CC
Triangolazioni
Le triangolazioni suddividono lo spazio campionato in triangoli con i lati
contigui, ed aventi come vertici i punti campionati.
Esistono varie tecniche per creare i lati tra i triangoli.
La più nota è quella di Delaunay: ha la proprietà che i triangoli derivati sono i
più equilaterali possibili. Questo è utile per la rappresentazione di modelli del
terreno basandosi su punti quotati.
E’ collegata ai POLIGONI DI
INFLUENZA: tre punti formano un
triangolo se essi condividono un
vertice comune del POLIGONO DI
INFLUENZA.
Da Sullivan & Unwin, 2003, fig. 2.5Inverse Distance Weighting (IDW)
Metodo proposto da Shepard (1968).
Interpolatore esatto nella versione originale, in versioni più recenti
è definibile un fattore di smoothing che lo rende inesatto.
Applicazione di una media pesata
in base alla distanza dei punti
rispetto al punto di osservazione.
Generalmente viene usato un
raggio di ricerca per limitare il
numero di punti utilizzati.
Da Longley et al., 2001, fig. 13.21.Inverse Distance Weighting (IDW) Formula ż = ∑ni=1 wi zi / ∑ni=1 wi ż: valore interpolato della variabile n: numero di osservazioni usate per il calcolo del valore interpolato wi : peso attribuito ad ogni singola osservazione
Inverse Distance Weighting (IDW)
Peso wi applicato alle osservazioni
wi = 1 / di n
d: distanza tra osservazione e punto con valore
interpolato
n: esponente definito dall’utilizzatoreInverse Distance Weighting (IDW) In generale il valore utilizzato per l’esponente n è di 2 (valore arbitrario). Tanto maggiore è l'esponente applicato a d, tanto maggiore è l'influenza del valore della distanza sul risultato e viceversa. Se l'esponente è 0, allora tutti i punti entro il “raggio” di ricerca sono “pesati” ugualmente, e ricadremo nel caso della media mobile semplice. Se l’esponente tende ad infinito, il peso viene attribuito per intero all’osservazione più prossima al punto interpolato, e si ricade nel caso del poligoni di influenza.
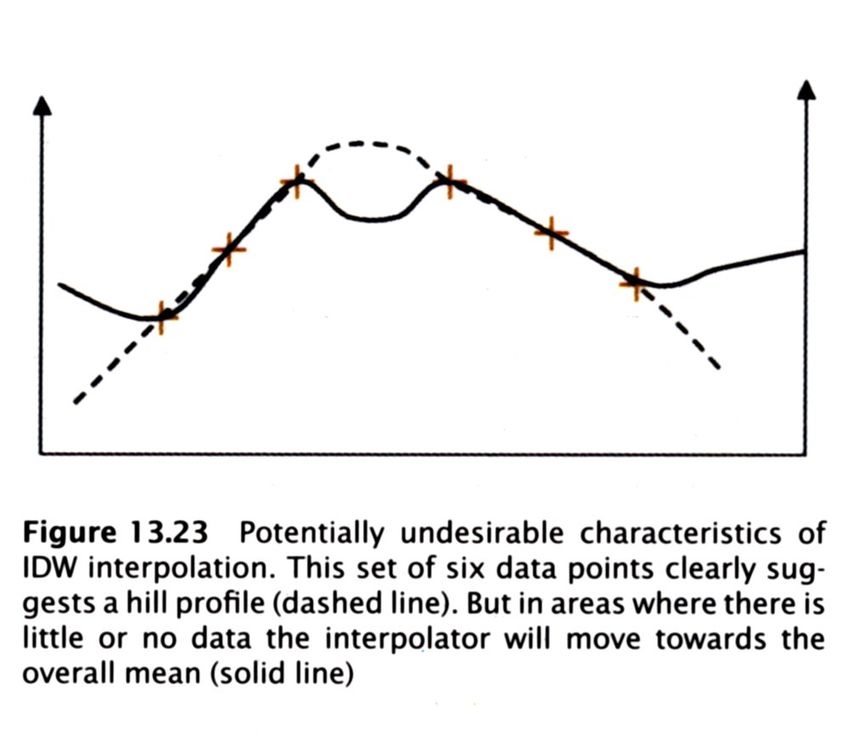
IDW - problematiche
In alcuni casi le
interpolazioni potranno
non essere del tutto
soddisfacenti per la
caratteristica dell’IDW di
essere una media
pesata, quindi con
tendenza dei risultati a
regredire verso la media
locale.
Da Longley etal., 2001, fig. 13-23.
In quanto rappresenta una media con pesi sempre positivi, la varianza
dei valori interpolati sarà minore di quella del data set di partenza.IDW - problematiche Un artefatto tipico dell’IDW è la creazione dei cosiddetti “bull eyes”, strutture circolari attorno alle osservazioni disperse. Difficilmente questi artefatti trovano giustificazioni naturali.
Radial Basis Functions
Interpolatori basati su polinomiali definite localmente che producono
superfici “morbide”.
Sono definite da una famiglia di funzioni che rendono minimi parametri
legati alla curvatura della superficie da interpolare.
Da Terrengmodellering - Gaute Aarbakke
Solaas, GeodataRadial Basis Functions
Possono essere interpolatori sia esatti (l’interpolazione onora
esattamente i dati misurati) sia inesatti (con un parametro di
smoothing da definire).
Vari metodi proposti, con
successivi miglioramenti:
– Spline: thin-plate s., s. with
tension, completely
regularized s., inverse
multiquadric spline
– Multiquadric function
Da Geospatial Analysis and Modeling:
Lecture notes. Helena Mitasova, NCSU
MEASSplines
Regularized: controllo delle derivate terze
Tension: controllo delle derivate seconde
Tension
4000
Elevation
Regularized
3000
2000
Distance
Variando il parametro di controllo delle derivate la superficie
risultante tende a diventare più o meno rigida.Regularized spline with tension and smoothing Una versione avanzata di spline è la “Regularized spline with tension and smoothing” che consente di applicare uno smoothing ai dati, trasformando così il metodo spline da esatto ad inesatto, utile quando i dati originali contengono errori. Implementato in Grass.
Regularized spline with tension and smoothing
Nella implementazione di Grass, due parametri importanti.
Tensione: valori elevati di tensione tendono a ridurre I gradienti della superficie
interpolata, che presenta quindi valori simili a quelli misurati nel loro intorno.
Valori ridotti di tensione invece permettono una maggiore variabilità dei dati
interpolati rispetto a quelli originari. Si possono così ottenere dei valori che sono
fortemente inferiori o superiori a quelli misurati nel loro intorno, così come i valori
estremi interpolati possono uscire dal range inziale dei dati misurati.
Smoothing: stabilisce quanto la superficie interpolata deve essere prossima ai
valori misurati. Un valore nullo indica che la superficie deve passare esattamente
per I valori noti (interpolazione esatta). Valori positivi consentono all'interpolazione
di deviare dai valori misurati in corrispondenza dei punti di osservazione.Metodi e parametri ottimali di interpolazione Come riconoscere il metodo Regularized spline che si adatta meglio al tipo di with tension dati di cui si dispone? E come da GRASS definire parametri come per esempio tensione e smoothing Miglior risultato: per il Regularized Spline with tension=90; Tension and Smoothing? smoothing (w) = 0.1 Un metodo molto usato è la cross- validation che permette di stimare un errore di interpolazione prodotto dai vari metodi e dai loro parametri basandosi sui dati misurati. Viene quindi scelto il metodo o I parametri che producono I minimi errori di interpolazione complessivi.
Cross-validation Esistono due versioni: una si basa sulla definizione di un subset di validazione, che comprende per esempio il 20% dei dati misurati e che viene escluso dal processo di interpolazione. I dati di validazione vengono poi confrontati con I corrispondenti valori interpolati tramite tecniche come il Root Mean Square Error (slide successiva). Un altro metodo è il “leave-one-out” (o “jack-knife”), che invece esclude dall'interpolazione una singola osservazione per volta, effettua il confronto tra valore interpolato e valore noto escluso, e applica via via questo processamento a tutti I dati noti.
Misure di differenza tra dataset
Permettono di quantificare la differenza complessiva tra due dataset numerici.
Possono essere usate per riconoscere fra varie superfici interpolate quella che
meglio approssima i dati noti. Il metodo ed i parametri usati per produrre quella
superficie saranno quindi quelli più adatti per il dataset a disposizione.
n 2
•Si basano sulla somma delle differenze
(residuali) tra i due valori corrispondenti ∑ (Z
i= 1
i
int erpolato
− Z ireale )
nei dataset da confrontare. Queste RMSE =
differenze possono essere considerare n
in valore assoluto - mean absolut error -
o elevate al quadrato – root square error
-.
Nel caso della Root Mean Square Error
(RMSE), la sommatoria delle differenze Z iint erpolato Valore interpolato nel punto Pi
al quadrato viene divisa per il numero di
osservazioni e poi ne viene calcolata la
radice quadrata. Z ireale Valore reale, misurato, nel punto PiBordi della zona da interpolare
Può essere utile usare
osservazioni anche
esterne alla zona da
interpolare, per migliorare
la qualità del risultato
finale.
Dopo l’interpolazione la
zona eccedente può
essere ritagliata.
DeMers, 2000, Fig.10-14.Puoi anche leggere