I "Big Data" e La Crisi Della Riproducibilita' - Luca Munaron & Federico Alessandro Ruffinatti - Accademia delle Scienze
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Laboratorio di Angiogenesi
Cellulare e Molecolare
I "Big Data"
e
La Crisi Della Riproducibilita’
Luca Munaron & Federico Alessandro Ruffinatti
11 marzo 2019
BIOLOGIA E RICADUTE APPLICATIVE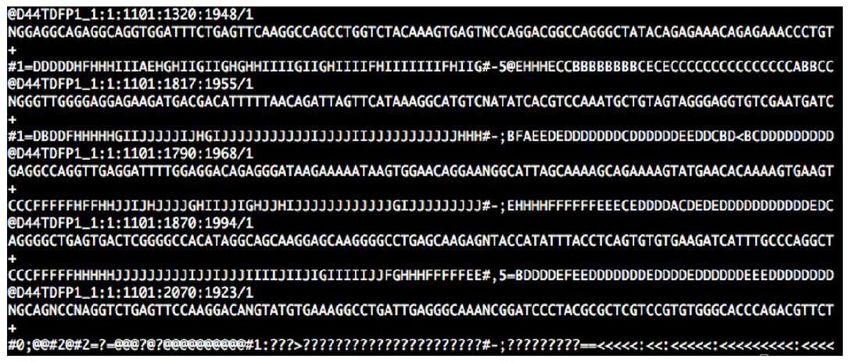
Il punto di partenza: siamo in presenza di una ‘crisi’?
§ 2009: Replicati 2/18 studi di espressione genica basati su microarrays (Ioannidis et al.)
§ 2012: Replicati 6/53 studi preclinici su sviluppo di farmaci (Begley & Elllis)
§ 2015: Replicati da 1/3 a 1/5 di studi di psicologia pubblicati in riviste ad elevato
impatto (Progetto Open Science Collaboration)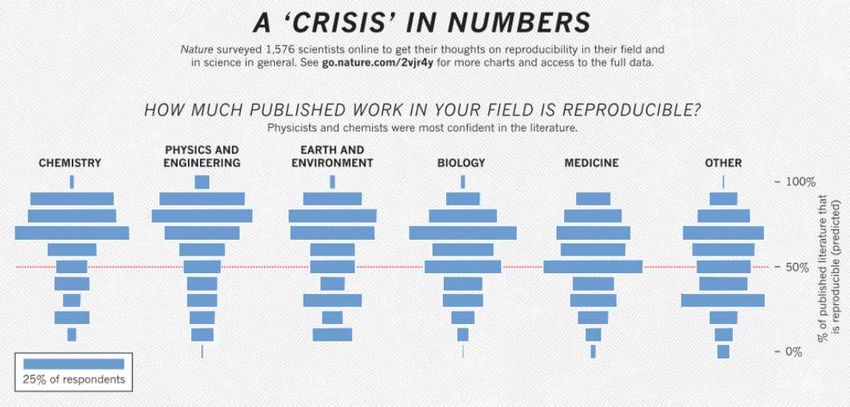
§ 2015: Irriproducibilità di 75-90% di studi preclinici e 85% di studi di
ricerca in ambito biomedico (Begley e Ioannidis)
§ 2016: 70% di ricercatori non ha riprodotto dati altrui
50% non ha riprodotto i propri (Monya Baker, Nature)
§ Altre riviste e giornali generalisti hanno trattato la questione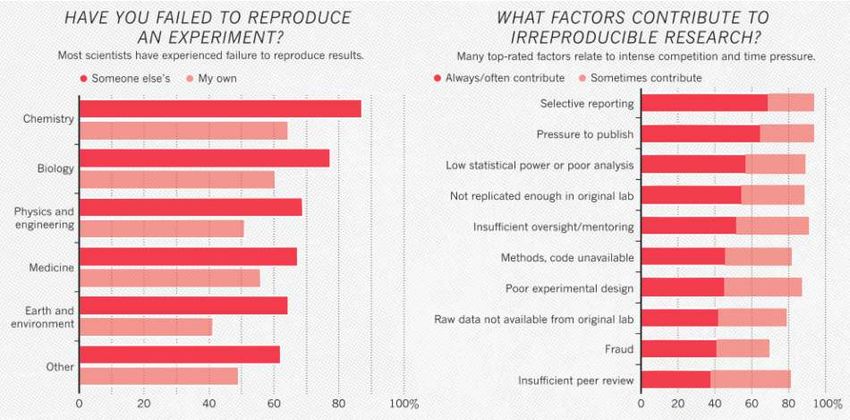
from Monya Baker, Nature 2016
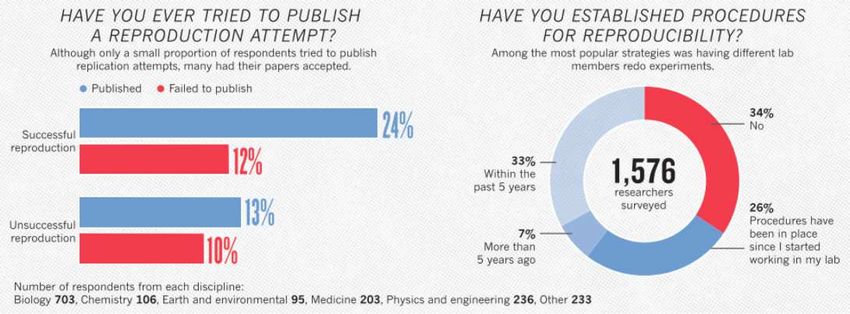
from Monya Baker, Nature 2016
from Monya Baker, Nature 2016

from Monya Baker, Nature 2016
from Monya Baker, Nature 2016

from Monya Baker, Nature 2016

O la crisi è solo una ‘narrazione’?
From Fanelli, PNAS 2018Cause che influenzano la riproducibilità:
• Protocollo sperimentale (la esatta e dettagliata procedura utilizzata)
• Condizioni sperimentali (pipette, soluzioni, kit, variabili ambientali di laboratorio)
• Modello sperimentale (tipo cellulare, organismo, ceppo...)
• Analisi statistica dei dati sperimentali (potenza statistica, selezione del campione,
tipo di test utilizzato, standardizzazione, automatizzazione)
• Variabilità biologica intrinsecaNon esiste una definizione formale di ricerca riproducibile
(RR): Replicabilità, riproducibilità, ripetibilità
Analisi dettagliata: attenta valutazione e riproduzione dei risultati di un
lavoro originale
Validazione indipendente: ripetizione di uno studio indipendente dal
ricercatore originaleInferenza: quanto è generalizzabile la mia ricerca?
A quale popolazione di applica?
tr o llate m on
do r
c on eale
diz ioni ui
c on i in divid tale)
ed en
elezion sperim
(s lo
odel
om
From Schiele, Doppio Egon
Quali strumenti statistici utilizzare?Qualche osservazione generale
§ La ricerca scientifica è sempre più quantitativa
§ Si accumula una grande quantità di data sets che richiedono
o strumenti di analisi sempre più raffinati
o competenze sempre più complesseLe scienze statistiche consentono di estrarre informazione dai dati George Box: ‘tutti i modelli statistici sono sbagliati…tuttavia, quando adeguatamente implementati alcuni di essi possono rivelarsi utili’. Grandi datasets non risolvono i limiti di protocollo sperimentale, inferenza e predizione (parabola di Google Flu, Lazer 2014): più dati non significano necessariamente maggiore informazione
protocolli sperimentali
‘omici’
Big data sets (dati grezzi)
oggetto di studio biologico
(cellula, organismo…)
strumenti statistici
informazione biologica (risultato sperimentale)Una questione di Metodo Galileo (1564-1642) sensate esperienze: esperimento dimostrazioni necessarie: matematica ‘Nissuna umana investigazione si può dimandare vera scienza, s'essa non passa per le matematiche dimostrazioni.’ Leonardo (1452-1512) Trattato sulla pittura
Nel 1865, con la pubblicazione
dell'Introduction à l'étude de la médecine
Léon-Augustin Lhermitte, Claude Bernard con i suoi allievi, 1889,
Académie nationale de médecine.
expérimentale, Claude Bernard tenta di
adottare un metodo, detto sperimentale, nel
settore della medicina.Metodo induttivo Sir Francis Bacon
1561-1626
Secondo questa metodologia, la scienza si baserebbe
sulla raccolta di osservazioni riguardo ad un certo
fenomeno X, da cui trarre una legge generale che
permetta di prevedere una futura manifestazione di X.
singoli casi particolari legge universale
From WikipediaIl filosofo e logico inglese Bertrand Russell (1872-1970) sollevò un importante problema riguardo al metodo dell'induzione. Russell e l’obiezione del tacchino induttivista: ‘Anche il tacchino americano, che il contadino nutre con regolarità tutti i giorni, può arrivare a prevedere che anche domani sarà nutrito... ma "domani" è il giorno del Ringraziamento e l'unico che mangerà sarà l'allevatore (a spese del tacchino)! ‘
Gli animali domestici si aspettano di ricevere il cibo quando vedono la persona che di solito gliene porge. Sappiamo che questa fiducia piuttosto sprovveduta nell’uniformità può indurre in errore. L’uomo da cui il pollo ha ricevuto il cibo per ogni giorno della sua vita gli tirerà alla fine il collo, dimostrando che un’idea meno primitiva dell’ uniformità della natura sarebbe stata utile all’animale
Hume, Compte, Mill, Russell, Bayes elaborano critiche al metodo induttivo
È vero che il compito della scienza è di scoprire leggi di uniformità,
come le leggi del moto e la legge di gravità, alle quali, secondo la
nostra esperienza, non ci sono eccezioni,
ma tutto quello che possiamo sperare di ottenere è la probabilitàKarl Popper (1902-1994): definizione di metodo scientifico
deduttivo basata sul criterio di falsificabilità, anziché su
quello induttivo di verificabilità.
§ Gli esperimenti empirici non possono mai ‘verificare’ una teoria, possono al massimo
smentirla.
§ Il fatto che una previsione formulata da un'ipotesi si sia realmente verificata, non
vuol dire che essa si verificherà sempre.
§ Perché l'induzione sia valida occorrerebbero cioè infiniti casi empirici che la
confermino; poiché questo è oggettivamente impossibile, ogni teoria scientifica non
può che restare nello status di congettura.Se tuttavia una tale ipotesi resiste ai tentativi di confutarla per via deduttiva tramite esperimenti, noi possiamo (pur provvisoriamente) ritenerla più valida di un'altra che viceversa non abbia retto alla prova dei fatti. La sperimentazione, dunque, svolge una funzione importante ma unicamente negativa; non potrà mai dare certezze positive, cioè non potrà rivelare se una tesi è vera, può dire solo se è falsa.
Il criterio di falsificabilità fu suggerito a Popper della teoria
della relatività di Albert Einstein
Einstein (1879-1955) formulò la relatività generale NON partendo da esperimenti o
da osservazioni empiriche, ma basandosi su ragionamenti matematici e analisi
razionali compiuti a tavolino (‘un puro gioco inventivo’).‘Max Planck non capiva nulla di fisica perché durante l'eclissi del 1919 è rimasto in piedi tutta la notte per vedere se fosse stata confermata la curvatura della luce dovuta al campo gravitazionale. Se avesse capito davvero la teoria avrebbe fatto come me e sarebbe andato a letto.’ (Archivio Einstein 14-459)
metodo induttivo metodo ipotetico-deduttivo
From Wikipedia
From WikipediaHypothesis driven research
by Duncan Hull
Sean Carroll e David Goodstain: Defining the scientific method (Nature Methods)Hypothesis driven research Data driven research:
produzione di big data sets e estrazione di
informazione (semantica?) con deep learning
e metodi statistici avanzati
by Duncan Hull
Sean Carroll e David Goodstain: Defining the scientific method (Nature Methods)Approccio data-driven L’analisi integrata di dati di genomica, proteomica, metabolomica funzionale accoppiata col modeling computazionale possono direzionare esperimenti di laboratorio e originare nuove scoperte.
Systems biology: biologia dei sistemi complessi
from RDconnect
from Biocompare
from ETHzurichdata driven,
Systems biology
Descrizione olistica di funzioni cellulari bioinformatica,
omics, statistica
analisi funzionale
Induzione
reti metaboliche
connessione reti regolatorie
Bottom-up di ‘moduli’ Top-down
reti di segnali
aggregazione modulare
di componenti Deduzione
analisi dei singoli componenti
hypothesis driven
Informazione biologica/conoscenza
esperimenti mirati,
Modified from Asenjo J, Universitad de Chile
equazioni differenzialiI big data producono ipotesi
e non conoscenza biologica
verificata sperimentalmente
Big data
Ipotesi da validare
sperimentalmente
LetteraturaEBI (European Bioinformatics Institute) contiene 20 petabytes (1015 bytes) di dati su
geni (2 pb), proteine e piccole molecole. Il CERN contiene circa 3 volte tanto.
Nel 2012 EBI ha ricevuto 9 milioni di richieste online ogni giorno (il 60% più del 2011)
from Marx ,Nature 2013maneggiare
re
r o c essa
p muovere
int
eg
r ar
eg
r an
di
da
ta
se
ts
from Marx ,Nature 2013maneggiare
re
r o c essa
p muovere
int
eg
r ar
eg
r an
di
da
ta
se
ts
comprendere,
from Marx ,Nature 2013
estrarre informazioneBig data: 3 V. Volume, varietà, velocità
I 2 lavori più citati in MoBC sono tra i primi di big data
(Spellman 98 e Gasch 2000)
I big data possono compensare il ‘rumore’ dei singoli
data set: segnali che si ripetono in multipli data set sono
più robusti.
From Progetto Forward
Serve longevità e stabilità dei softwarePassato: generazione di dati come unica fonte di informazione
Presente: informazione anche dall’analisi dei dati
Anneghiamo nei dati ma siamo in carenza di conoscenzaServono tecniche statistiche per isolare
il segnale dal rumore.
From Intelligenza ArtificialeQuesto approccio è meno biased verso la conoscenza pregressa e consente predizioni anche in ambiti con scarse informazioni pregresse.
Questo approccio è meno biased verso la Il prezzo da pagare è il conoscenza pregressa e consente predizioni maggiore potenziale di anche in ambiti con scarse informazioni errore dovuto al rumore. pregresse.
Cos’è il Data Mining? • Estrazione di informazione interessante (non banale, implicita, sconosciuta e potenzialmente utile) da dati in grandi databases
Perchè il data mining? Punto di vista commerciale
• Molti dati collezionati e depositati
Web data, e-commerce
Transazioni bancarie
• I computers sono sempre più economici e potenti
• La pressione competitiva è forte
Fornire servizi migliori e customizzatiPunto di vista scientifico
• Dati collezionati a enorme velocità (Gb/ora)
sensori remoti sui satelliti
telescopi
microarrays di espressione genica
simulazioni scientifiche (Tb)
• Tecniche tradizionali inutilizzabili
• Data mining può aiutare gli scienziati a
clusterizzare e classificare i dati
produrre ipotesiEsempi: cosa è (e non è) il data mining
Cosa non è data mining Cosa è data mining
o Cercare un numero di telefono o Alcuni nomi sono più prevalenti in certe località
in una guida telefonica (O’Brien, O’Rurke, O’Reilly…a Boston)
o Chiedere a un motore di ricerca o Raggruppare documenti simili restituiti da
cos’è Amazon motori di ricerca in funzione del loro contest
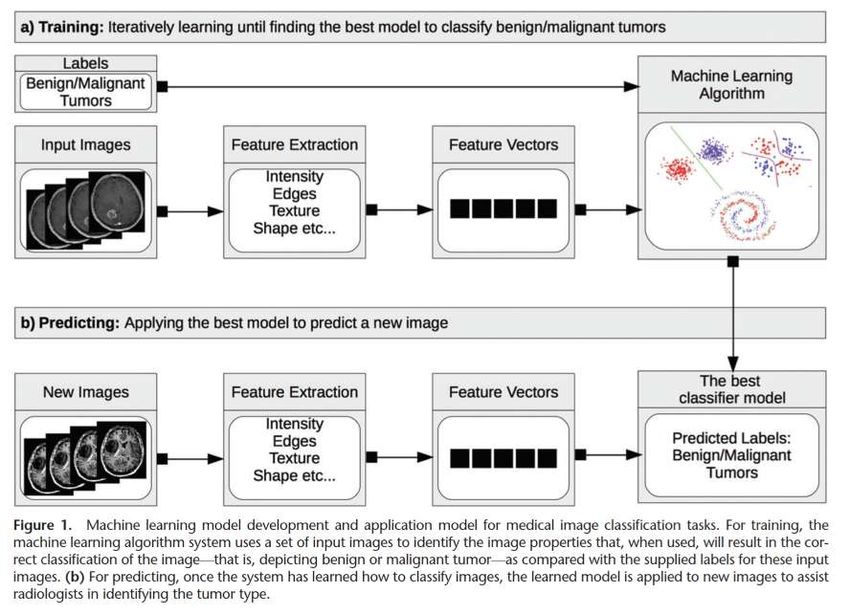
(foresta amazzonica, amazon.com)RadioGraphics 2017; 37:505–515
RadioGraphics 2017; 37:505–515
Cause che influenzano la riproducibilità:
• Protocollo sperimentale (la esatta e dettagliata procedura utilizzata)
• Condizioni sperimentali (pipette, soluzioni, kit, variabili ambientali di laboratorio)
• Modello sperimentale (tipo cellulare, organismo, ceppo...)
• Analisi statistica dei dati sperimentali (potenza statistica, selezione del campione,
tipo di test utilizzato, standardizzazione, automatizzazione)
• Variabilità biologica intrinsecaI dati biologici sono più eterogenei di quelli fisici:
vasta gamma di esperimenti con tanti tipi di informazione (sequenze geniche,
interazioni proteiche, registrazioni mediche, imaging).
Attese irrealistiche sulla riproducibilita’ aumentano la percezione della crisi
Condizioni strettamente controllate e
modelli animali invarianti limitano la
possibilità di generalizzare i risultati From Learn Genetics,
Genetic Science learning CenterFrom National Geographic Italia
dati ‘veri’ ma non robusti perché non tengono
conto della variabilità intrinseca nel modo
biologico reale.
From Evolvati ca…
is varianza della distribuzione del
s tat carattere
o ta
an Fattori da considerare nella
un scelta della dimensione del
campione
ampiezza dell’intervallo di
confidenza desideratoti ca…
is varianza della distribuzione del
s tat carattere
o ta
an Fattori da considerare nella
un scelta della dimensione del
campione
ampiezza dell’intervallo di
confidenza desiderato
In una popolazione teorica composta da n individui tutti identici fra loro, lo
studio di 1 solo individuo è sufficiente per ottenere una indicazione precisa
riguardo alla intera popolazione.
From Alamy.comti ca…
is varianza della distribuzione del
s tat carattere
o ta
an Fattori da considerare nella
un scelta della dimensione del
campione
ampiezza dell’intervallo di
confidenza desiderato
In una popolazione teorica composta da n individui tutti identici fra loro, lo
studio di 1 solo individuo è sufficiente per ottenere una indicazione precisa
riguardo alla intera popolazione.
From Alamy.com
varianza elevata campione grande
From Study.comCi attendiamo più variabilità tra pazienti in uno studio clinico che tra topi
geneticamente omogenei e mantenuti in un ambiente simile.
From Centro Medici Mythril From Scienze FanpageStudi in vitro, su animali e trials clinici tendono ad presentare
§ diverse dimensioni campionarie
§ diversa variabilità
della specifica popolazione in studio.
From Scienze Fanpage
From Science Photo Library / Alamy Stock Photo www.fivehundredwords.itReproducibility in Bioinformatics
Two real-world examples
Luca Munaron & Federico Alessandro RuffinattiReproducibility in Bioinformatics
What?
Starting from the same input raw data and algorithms,
it is not obvious to reproduce the output results:
1 – yourself (at a later time)
2 – among peers (in different labs)Reproducibility in Bioinformatics
How?
Rule 1: For Every Result, Keep Track of How It Was Produced (record the workflow)
Rule 2: Avoid Manual Data Manipulation Steps (use scripts)
Rule 3: Archive the Exact Versions of All External Programs Used (virtualize)
Rule 4: Version Control All Custom Scripts (track code evolution)
Rule 5: Record All Intermediate Results, When Possible in Standardized Formats (semantic debug)
Rule 6: For Analyses That Include Randomness, Note Underlying Random Seeds
Rule 7: Always Store Raw Data behind Plots (e.g. when binning)
Rule 8: Generate Hierarchical Analysis Output, Allowing Layers of Increasing Detail to Be Inspected
Rule 9: Connect Textual Statements to Underlying Results
Rule 10: Provide Public Access to Scripts, Runs, and ResultsReproducibility in Bioinformatics
Why?
• Moral responsibility with respect to the scientific field
• Apply on new data previously developed methodology
• Reuse of code and results for new projects
• Time saving in the longer run
• Personal gain (faster publishing, more citations)
Sandve et al. PLOS Comp Biol. 2013Reproducibility in Bioinformatics
1 Two real-world examples
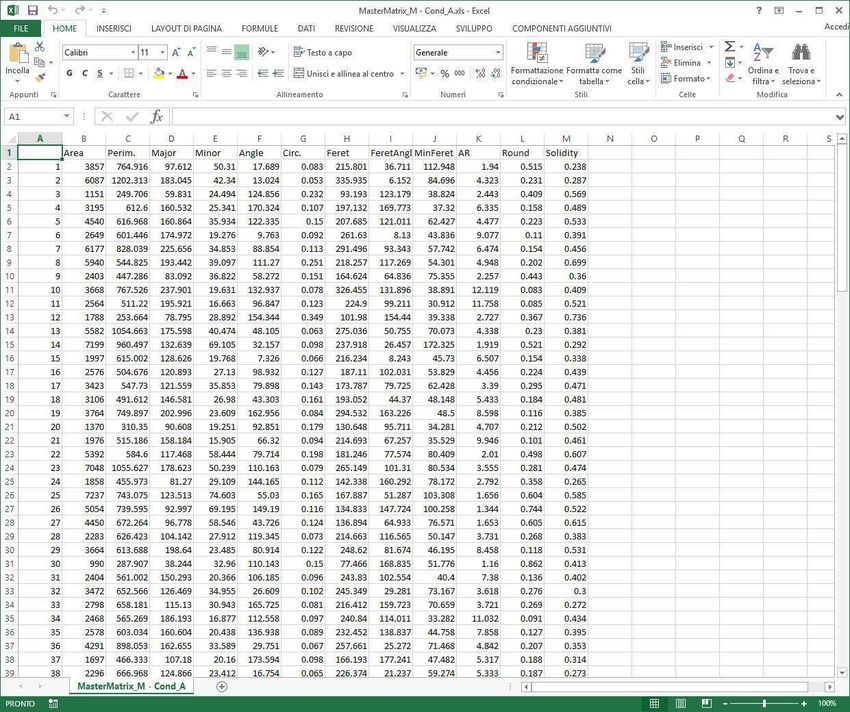
Morphometry
proliferation
differentiation
Cell Biological migration
motility
Morphology Processes growth dynamics
adhesion to particular substrates
physiology-pathology transition
[...]
Shape-Function Paradigm
(…working at every evolutionary scale)Shape Descriptors
Modified from:
Lobo et al. An insight into morphometric descriptors of
cell shape that pertain to regenerative medicine. J
Tissue Eng Regen Med (2015)Fluorescence Images
Segmentation
Cell Selection
Final Output
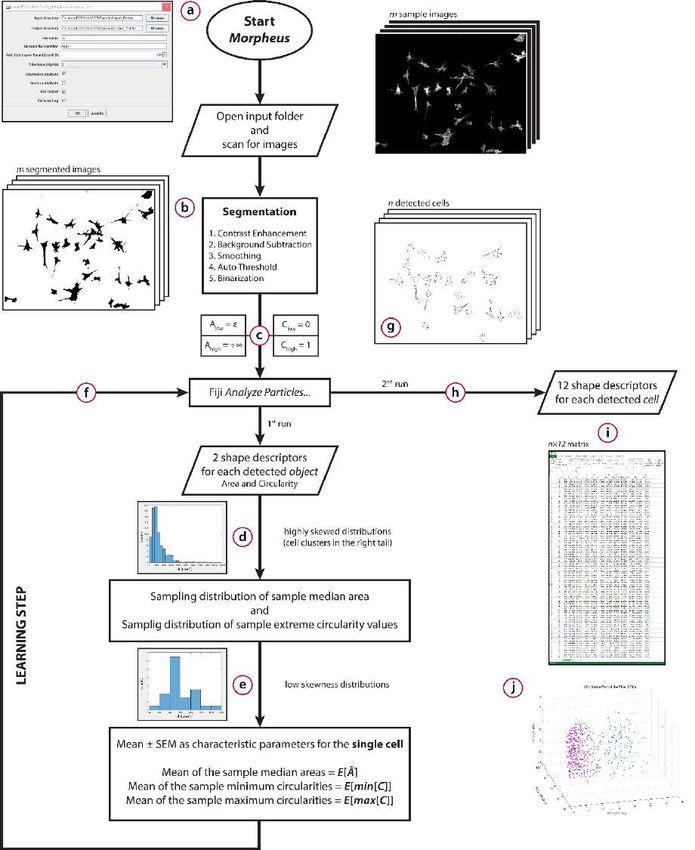
Morpheus Sub-versions control (Rule 4)
All intermediate results are stored (Rule 5)
Fixed workflow (Rule 1 compliant)
General and adaptative algorithm for No randomness (Rule 6 compliant)
all the experiments (no user
intervention or bias):
• Always the same segmentation (b) Store raw data behind plots (Rule 7)
• No threshold to choose (c)
• Automated cell detection (d,e,f,g)
• No descriptor chosen a priori (h)
Log file to record the exact versions of
every SW layers (Rule 3)
Script avoids manual data
manipulation (Rule 2)
System architecture
OS
Automation over the entire pipeline
JRE-JVM
and dataset until the final result (i,j)
ImageJ
(no error from repetitive and time
Morpheus plugin
consuming tasks)
Both rule 1 and 2 address the
problem of tracking the commands,
a core feature of reproducibility Morpheus is Open Source (Rule 10)Reproducibility in Bioinformatics
2 Two real-world examples
Transcriptomics
Even if the related High-Level analysis is almost the same
for every high-throughput technology and all the Omics:
Microarray
qRT-PCR
RNA-Seq
Proteomics
Metabolomics
fMRI…FASTQ file format (Bioinformatics starts here…)
(Fragmentation)
Kukurba KR et al. RNA Sequencing and Analysis.
Cold Spring Harb Protoc.
doi:10.1101/pdb.top084970RNA-Seq workflow
[…from FASTQ file]
Preprocessing Condition_A Condition_A Condition_B Condition_B […]
(Quality control) Sample_1 Sample_2 Sample_1 Sample_2
Gene_1 Value_11 Value_12 Value_13 Value_14 […] Low-count filtering
Gene_2 Value_21 Value_22 Value_23 Value_24 […]
Read Alignment
Gene_3 Value_31 Value_32 Value_33 Value_34 […] Between-sample
Gene_4 Value_41 Value_42 Value_43 Value_44 […]
Normalization
Quantification
Gene_5 Value_51 Value_52 Value_53 Value_54 […]
Gene_6 Value_61 Value_62 Value_63 Value_64 […] Differential expression
Within-sample
[…] […] […] […] […] […]
Normalization
Gene_N Value_N1 Value_N2 Value_N3 Value_N4 […] Functional Profiling
CountsCondition_A Condition_A Condition_B Condition_B […] ROWS:
Sample_1 Sample_2 Sample_1 Sample_2
# human genes
Gene_1 Value_11 Value_12 Value_13 Value_14 […]
Gene_2 Value_21 Value_22 Value_23 Value_24 […] • Protein-coding = 20k
• Isoforms (alternative splicing) = 100k
Gene_3 Value_31 Value_32 Value_33 Value_34 […]
• + long noncoding RNA = +60k (maybe +270k)
Gene_4 Value_41 Value_42 Value_43 Value_44 […]
Gene_5 Value_51 Value_52 Value_53 Value_54 […]
Gene_6 Value_61 Value_62 Value_63 Value_64 […]
COLUMNS:
[…] […] […] […] […] […]
# samples (for having a good statistical power)
Gene_N Value_N1 Value_N2 Value_N3 Value_N4 […]
• Cell lines: > 3 replicates
• (Inbreed) animals: > 6 replicates
• Humans: > 10 replicates for pilot experiment
Finding differentially expressed (DE) genes
between two (or more) groups/conditions
Statistical testA 3-layer standard analysis environment (from counts on):
R + Bioconductor + Packages
genefilter
BiocInstaller
annotate
Packages Biobase
limma
DESeq2
RankProd […]A 3-layer standard analysis environment (from counts on):
R + Bioconductor + Packages R/Bioconductor environment is
constitutively compliant with most
genefilter of the aforementioned rules for
BiocInstaller
annotate reproducibility in bioinformatics:
Packages Biobase
limma
DESeq2 • Scripts allow for storable
RankProd […] workflows, avoiding manual data
manipulation
• Both Bioconductor and R allow
retrieving even the oldest versions
of all their components
• Everything is open source and
open access (community of users)However actual layers are more than 3…
Some function of R/Bioconductor may
genefilter more deeply depend from system
BiocInstaller libraries… so functional reproducibility
annotate
Packages Biobase cannot be guaranteed.
limma
DESeq2
RankProd […]
Things worsen when including the
alignment step in your pipeline, since
this task is typically accomplished out
of R/Bioconductor environment
Virtualization could be the only way to
strictly observe Rule 3:
“Archive the Exact Versions of All
System Libraries
External Programs Used”
Operating System KernelBest Practice
Small functional units can be containerized in order to
keep the algorithms of interest frozen forever
not be limited to a single environment
keep separated
i/o data
software (apps + libs)
logic of analysisRecap…
FASTQ file format (Bioinformatics starts here…)
(Fragmentation)
Kukurba KR et al. RNA Sequencing and Analysis.
Cold Spring Harb Protoc.
doi:10.1101/pdb.top084970Puoi anche leggere

















































