Clustering dei profili di consumo di energia elettrica - C10097 Nicol Allegra - in SUPSI ...
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Clustering dei profili di consumo di
energia elettrica
Studente/i Relatore
Nicol Allegra Andrea Emilio Rizzoli
Correlatore
Marco Derboni
Committente
Andrea Emilio Rizzoli
Corso di laurea Modulo
C10097 Progetto di diploma
Anno
2018/2019
Data
9 settembre 2019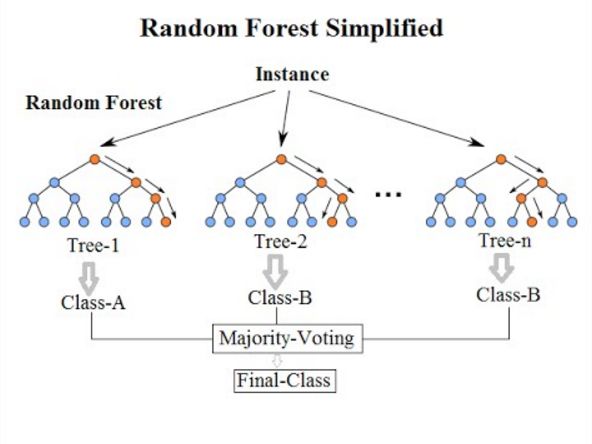

i
Indice
1 Introduzione 5
2 Richiami Teorici 7
2.1 Apprendimento supervisionato . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Regressione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.1.1 Regressione lineare . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.2 Classificazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.2.1 Support Vector Machine . . . . . . . . . . . . . . . . . . . . 10
2.1.2.2 Random forest . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2 Apprendimento non supervisionato . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2.1 Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2.1.1 Tecniche di clustering . . . . . . . . . . . . . . . . . . . . . . 17
2.2.1.2 Kmeans . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3 Tecnologie utilizzate 21
3.1 Linguaggi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2 Piattaforme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.3 Librerie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4 Strutturazione dei dati 27
4.1 Database . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.1.1 Classi utilizzate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.2 Pretrattamento dei dati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2.1 One-hot encoding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.3 Creazione dataframes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5 Analisi 37
5.1 Regressione lineare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.2 K-means . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5.2.1 Creazione classi di consumo . . . . . . . . . . . . . . . . . . . . . . . 40
5.3 SVM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
Clustering dei profili di consumo di energia elettrica
ii INDICE
5.4 Random Forest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
6 Risultati 43
6.1 Features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
6.2 Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
6.3 Classificatori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
6.3.1 Confronto tra algoritmi . . . . . . . . . . . . . . . . . . . . . . . . . . 50
6.3.1.1 Classi suddivise equamente . . . . . . . . . . . . . . . . . . 51
6.3.1.2 Classi suddivise per range di consumo . . . . . . . . . . . . 56
6.3.1.3 Classi suddivise utilizzando K-Means . . . . . . . . . . . . . 61
7 Conclusioni 67
7.1 Problemi riscontrati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
7.2 Sviluppi futuri . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
7.3 Considerazioni personali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
Allegati 69
Clustering dei profili di consumo di energia elettrica
iii
Elenco delle figure
2.1 Esempio grafico di regressione lineare [1] . . . . . . . . . . . . . . . . . . . . 8
2.2 Esempio di possibili iperpiani, preso da [2] . . . . . . . . . . . . . . . . . . . . 10
2.3 Esempio di iperpiano ottimale, preso da [2] . . . . . . . . . . . . . . . . . . . 11
2.4 Esempio di albero di decisione, preso da [3] . . . . . . . . . . . . . . . . . . . 13
2.5 Esempio di random forest, preso da [4] . . . . . . . . . . . . . . . . . . . . . 14
4.1 Comandi per creare database . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.2 Diagramma classi utilizzate . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.3 Query finale per interrogare i database . . . . . . . . . . . . . . . . . . . . . 32
4.4 One-hot encoding con heating source type . . . . . . . . . . . . . . . . . . . 33
4.5 One-hot encoding con la nazionalità . . . . . . . . . . . . . . . . . . . . . . . 33
4.6 One-hot encoding con building type . . . . . . . . . . . . . . . . . . . . . . . 34
4.7 One-hot encoding sulle mensilità . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.8 Aggregate method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.9 One-hot encoding con quattro stagioni . . . . . . . . . . . . . . . . . . . . . . 35
4.10 One-hot encoding con tre stagioni . . . . . . . . . . . . . . . . . . . . . . . . 35
6.1 Risultati regressione dataframe mensile . . . . . . . . . . . . . . . . . . . . . 44
6.2 Risultati regressione dataframe stagionale . . . . . . . . . . . . . . . . . . . . 44
6.3 Features importanti dataframe mensile con classi eque . . . . . . . . . . . . . 45
6.4 Features importanti dataframe mensile con classi per range . . . . . . . . . . 46
6.5 Features importanti dataframe mensile con classi con K-Means . . . . . . . . 46
6.6 Cluster sulla nazionalità . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
6.7 Cluster sull’heat pump . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
6.8 Cluster sul riscaldamento a elettricità . . . . . . . . . . . . . . . . . . . . . . 49
6.9 Cluster sul tipo di edifici . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
6.10 Informazioni classificatore con dataframe mensile . . . . . . . . . . . . . . . . 51
6.11 Probabilità con dataframe mensile . . . . . . . . . . . . . . . . . . . . . . . . 51
6.12 Forchetta di consumo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
6.13 Informazioni classificatore con dataframe mensile . . . . . . . . . . . . . . . . 52
6.14 Probabilità con dataframe mensile . . . . . . . . . . . . . . . . . . . . . . . . 53
Clustering dei profili di consumo di energia elettricaiv ELENCO DELLE FIGURE
6.15 Forchetta di consumo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
6.16 Informazioni classificatore con dataframe mensile . . . . . . . . . . . . . . . . 54
6.17 Probabilità con dataframe mensile . . . . . . . . . . . . . . . . . . . . . . . . 54
6.18 Forchetta di consumo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
6.19 Informazioni classificatore con dataframe stagionale . . . . . . . . . . . . . . 56
6.20 Probabilità con dataframe stagionale . . . . . . . . . . . . . . . . . . . . . . . 56
6.21 Forchetta di consumo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
6.22 Informazioni classificatore con dataframe stagionale . . . . . . . . . . . . . . 57
6.23 Probabilità con dataframe stagionale . . . . . . . . . . . . . . . . . . . . . . . 58
6.24 Forchetta di consumo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6.25 Informazioni classificatore con dataframe stagionale . . . . . . . . . . . . . . 59
6.26 Probabilità con dataframe stagionale . . . . . . . . . . . . . . . . . . . . . . . 59
6.27 Forchetta di consumo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
6.28 Informazioni classificatore con dataframe mensile . . . . . . . . . . . . . . . . 61
6.29 Probabilità con dataframe mensile . . . . . . . . . . . . . . . . . . . . . . . . 61
6.30 Forchetta di consumo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
6.31 Informazioni classificatore con dataframe mensile . . . . . . . . . . . . . . . . 62
6.32 Probabilità con dataframe mensile . . . . . . . . . . . . . . . . . . . . . . . . 63
6.33 Forchetta di consumo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
6.34 Informazioni classificatore con dataframe mensile . . . . . . . . . . . . . . . . 64
6.35 Probabilità con dataframe mensile . . . . . . . . . . . . . . . . . . . . . . . . 64
6.36 Forchetta di consumo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
Clustering dei profili di consumo di energia elettricav
Elenco delle tabelle
3.1 Linguaggi utilizzati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2 Piattaforme utilizzate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3 Librerie utilizzate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.1 Mensilità per quattro stagioni . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.2 Mensilità per tre stagioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.3 Dataframe creati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.1 Alcuni esempi dei coefficienti . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.2 Funzioni di regressione lineare con relativi coefficienti . . . . . . . . . . . . . 39
Clustering dei profili di consumo di energia elettricavi ELENCO DELLE TABELLE Clustering dei profili di consumo di energia elettrica
1
Abstract
Italiano
La SUPSI è impegnata in un progetto di ricerca chiamato enCOMPASS. Tale progetto mira
a intraprendere un cambiamento comportamentale per quanto concerne il risparmio ener-
getico rendendo noti ai propri utenti i loro consumi. Questi dati sul consumo vengono rilevati
attraverso dei contatori intelligenti e sono campionati ogni 15 minuti per un totale di circa
400 utenti.
Lo scopo di questo progetto è quello di analizzare e studiare queste moli di dati per capire
l’affidabilità e la veridicità di quest’ultimi. Analiticamente si vogliono scoprire quali sono, se
ci sono, le principali fonti di consumo. Inoltre, si vuole anche realizzare una classificazione
per analizzare e identificare l’intervallo di consumo, partendo unicamente dal profilo di un
nuovo utente e dai suoi dati riguardanti la domotica.
Per soddisfare tutti i compiti e gli obiettivi si è deciso di utilizzare il linguaggio di programma-
zione Python in quanto esistono già diverse librerie che implementano algoritmi di machine
learning mirati al compimento del progetto. Il presente documento andrà a spiegare detta-
gliatamente il lavoro svolto sui dati e gli algoritmi adottati, quali K-means, Support Vector
Machine, Random Forest e la regressione lineare.
Eseguendo un’analisi preliminare dei dati forniti e una loro scrematura, eliminando alcuni
valori errati e/o inconsistenti, si raggiungono in modo ottimale gli obiettivi prefissati:
• Conseguiamo le features che aggravano maggiormente sul consumo dell’energia elet-
trica, anche se i risultati non sono esattamente quelli che ci si aspettava a livello
teorico e alcuni non sono molto soddisfacenti.
• I classificatori, dandogli in input dei dataframe significativi, lavorano egregiamente
riuscendo a identificare la classe di appartenenza di un nuovo utente.
Clustering dei profili di consumo di energia elettrica2 ELENCO DELLE TABELLE
English
SUPSI is involved in a research project called enCOMPASS. This project aims to undertake
a behavioral change with regard to energy saving by making its consumption known to its
users. This consumption data is collected through smart meters and is sampled every 15
minutes for a total of about 400 users.
The purpose of this project is to analyze and study these amounts of data to understand
their reliability and their veracity. Analytically we want to find out what are, if any, the main
sources of energy consumption. Furthermore, we also want to create a classification to
analyze and identify the consumption interval, starting from the profile of a new user and the
respective data relating to home automation.
To meet all the tasks and objectives I decided to utilize Python programming language as
there are many libraries that implement valid machine learning algorithms to complete the
project. This document will explain in detail the work carried out on the data and the adopted
algorithms, such as K-means, Support Vector Machine, Random Forest and Linear Regres-
sion.
Performing a preliminary analysis of the data provided and skimming them, eliminating so-
me incorrect and/or inconsistent values, the pre-established objectives are reached in an
optimal way:
• We achieve the features that affect on electricity consumption the most, even if the
results are not exactly what was expected at the theoretical level and some are not
very satisfactory.
• The classifiers, by giving them significant data frames, work very well, managing to
identify the class to which a new user belongs.
Clustering dei profili di consumo di energia elettrica3
Progetto assegnato
Descrizione
Nel contesto del cambiamento energetico (energiewende) e del continuo aggiornamento
delle reti di distribuzione dell’energia elettrica, i contatori intelligenti svolgono un ruolo fon-
damentale permettendo la raccolta di dati di consumo a risoluzione molto più elevata di
quanto fosse possibile in passato.
La SUPSI partecipa ad un progetto di ricerca nel quale ha accesso a dati di consumo di
energia misurati ogni 15 minuti per un insieme di circa 400 utenti in tre località diverse.
Oltre ai dati di consumo, sono presenti dati rilevati da sensori di temperatura e umidità, oltre
che dei dati sulla luminanza e sulla presenza e assenza degli utenti nell’abitazione. L’obiet-
tivo di questo lavoro è quello di utilizzare alcuni algoritmi di feature selection e di clustering,
correntemente disponibili, al fine di individuare i principali fattori che influenzano il consumo
di energia, e di organizzare i profili degli utenti secondo dei cluster scoperti durante l’analisi
dei dati.
Compiti
• Organizzare e strutturare i dati per l’analisi.
• Utilizzare diversi algoritmi di feature selection per identificare quali sono, nell’insieme
di dati disponibili, i principali fattori che influenzano il consumo.
• Utilizzare diversi algoritmi di clustering per organizzare i gruppi di utenti in funzione
delle feature identificate al passo precedente.
Clustering dei profili di consumo di energia elettrica4 ELENCO DELLE TABELLE
Obiettivi
• Identificare i principali fattori di consumo dell’energia elettrica a partire dai dati dispo-
nibili.
• Essere in grado di assegnare un nuovo utente ad un determinato cluster, in base
al suo profilo e quindi, implicitamente, determinare quale potrebbe essere una sua
"forchetta" di consumo (consumo minimo e massimo stimato).
Clustering dei profili di consumo di energia elettrica5
Capitolo 1
Introduzione
La continua evoluzione del mercato dell’energia elettrica in Svizzera, come in molti altri stati,
unitamente ai costi crescenti e alla maggiore attenzione dell’opinione pubblica, dei governi
nazionali e internazionali sul tema del risparmio energetico, hanno indotto gli utenti finali
ad attivare processi tesi alla riduzione dei consumi e, conseguentemente, della spesa com-
plessiva.
La SUPSI, assieme ad altri istituti Europei, partecipa ad un progetto di ricerca chiamato
enCOMPASS.
Tale progetto ha lo scopo di implementare un approccio socio-tecnico integrato al cambia-
mento comportamentale per quanto concerne il risparmio energetico, sviluppando strumen-
ti digitali innovativi e di facile utilizzo per rendere il consumo di dati energetici disponibili e
comprensibili per i diversi utenti, consentendo loro di collaborare per riuscire a risparmiare
e gestire il proprio fabbisogno energetico in modo efficiente ed economico.
EnCOMPASS sfrutta la rete dei contatori intelligenti (smart meter) già installati da alcune
aziende elettriche e si appoggia anche a una serie di sensori, installati appositamente negli
edifici che partecipano al progetto, che rilevano la presenza delle persone nei locali e leg-
gono automaticamente temperatura e umidità.
I dati rilevati sono analizzati in tempo (quasi) reale, in modo da fornire agli utenti informazioni
semplici e comprensibili sulle proprie abitudini di consumo e suggerimenti su come ridurli.
Questi dati di consumo di energia sono misurati ogni 15 minuti per un insieme di circa 400
utenti per tre località differenti.
Clustering dei profili di consumo di energia elettrica6 Introduzione Uno degli obiettivi scientifici di questo progetto di ricerca è proprio quello di diffondere questi dati e i relativi risultati per realizzare dei lavori transdisciplinari nei diversi campi di interesse. Ed è da questa ideazione che prende vita l’attuale progetto sui clustering, in quanto avendo a disposizione queste informazioni e dati, si vuole comprendere se ci sono dei fattori molto determinanti che aggravano sul consumo di energia elettrica e inoltre, si vuole riuscire a individuare, nel momento in cui giunge un nuovo utente non legato al progetto enCOMPASS, la forchetta di consumo (consumo minimo e massimo) avendo a disposizione solo il profilo di quest’ultimo, cioè le informazioni sugli elettrodomestici in possesso, sul numero persone che risiedono nell’abitazione e ulteriori dati. Clustering dei profili di consumo di energia elettrica
7
Capitolo 2
Richiami Teorici
Questo capitolo vuole introdurre il lettore al mondo del machine learning in modo da svi-
luppare delle conoscenze di base prima di gettarsi nella parte pratica del progetto dove si
andranno a utilizzare degli algoritmi di machine learning.
Il tutto non vuole essere una ricerca o documentazione specifica per ogni singolo algoritmo,
anche perché si potrebbero scrivere innumerevoli informazioni e così deviare dallo scopo
ultimo del progetto, ma una visione d’insieme delle principali differenze.
Inoltre, informazioni più dettagliate ci saranno solo per gli algoritmi di clustering, regressione
e classificazione utilizzati per adempiere ai compiti e agli obiettivi prefissati.
2.1 Apprendimento supervisionato
L’apprendimento supervisionato è una tecnica di apprendimento automatico che mira a
istruire un sistema informatico, consentendogli così di elaborare automaticamente previ-
sioni sui valori di uscita di un sistema basato su un input generato da una serie di esempi
ideali, costituiti da coppie di input e di output, che gli vengono inizialmente forniti.
Con l’apprendimento supervisionato si cerca dunque di costruire un modello partendo da
dei dati di addestramento etichettati, con i quali si cerca di fare previsioni su dati non dispo-
nibili o futuri. Si suppone quindi che nel nostro insieme dei campioni (o dataset), i segnali di
output desiderati sono già noti poiché precedentemente etichettati.
Principali tecniche:
• Regressione
• Classificazione
Clustering dei profili di consumo di energia elettrica8 Richiami Teorici
2.1.1 Regressione
L’analisi della regressione è una tecnica usata per analizzare una serie di dati che consisto-
no in una variabile dipendente e una o più variabili indipendenti.
Lo scopo è stimare un’eventuale relazione funzionale esistente tra la variabile dipendente e
le variabili indipendenti.
2.1.1.1 Regressione lineare
La regressione rappresenta un metodo statistico che mira ad identificare la presenza di una
relazione tra una variabile dipendente e una o più variabili indipendenti. Nella regressione
lineare la relazione è espressa dal seguente polinomio di primo grado:
f (x) = xw + b
Graficamente questa relazione lineare può essere rappresentata come una retta che passa
il più vicino possibile a tutti i punti costituiti da input X e output Y.
Figura 2.1: Esempio grafico di regressione lineare [1]
La regressione lineare si usa quando si vuole prevedere un valore continuo. Se la variabile
di input è solo una allora la regressione lineare si dice semplice, altrimenti in caso contrario
la regressione lineare si dice multipla.
Clustering dei profili di consumo di energia elettrica9
2.1.2 Classificazione
La classificazione è una tecnica utilizzata nell’apprendimento con supervisione dove l’obiet-
tivo, in base alle analisi di dati precedentemente etichettati, è quello di riuscire a prevedere
l’etichettatura delle classi di dati future.
Questo insieme di dati può essere semplicemente di due classi (come identificare se la
persona è maschio o femmina o che la posta è spam o non spam) o può anche essere di
più classi.
Il processo di classificazione può essere suddiviso in tre fasi:
1. Addestramento: si produce un modello da un insieme di addestramento.
2. Stima dell’accuratezza: si stima l’accuratezza del modello usando un insieme di test.
3. Utilizzo del modello: si classificano istanze di classe ignota.
Ci sono diversi algoritmi che permettono di svolgere l’attività di classificazione, di seguito
alcuni esempi:
• Naïve Bayes
• Reti neurali
• Macchine a vettori di supporto (SVM)
• Regressione Logistica
• Random Forest
• Alberi di decisione
• ...
Clustering dei profili di consumo di energia elettrica10 Richiami Teorici
2.1.2.1 Support Vector Machine
Support Vector Machine, abbreviato come SVM, è un algoritmo preferito da molti esperti di
machine learning in quanto produce una precisione significativa con meno potenza di cal-
colo rispetto ad altri algoritmi di classificazione.
SVM può essere utilizzato sia per attività di regressione che di classificazione ma è ampia-
mente usato negli obiettivi di classificazione e questo progetto ne è l’esempio.
L’obiettivo del support vector machine è quello di trovare un iperpiano in uno spazio N-
dimensionale, dove N è il numero di features, che classifica distintamente i data points.
Figura 2.2: Esempio di possibili iperpiani, preso da [2]
Clustering dei profili di consumo di energia elettrica11
Per separare le due classi, ci sono molti possibili iperpiani che potrebbero essere scelti.
L’obiettivo è quello di trovare un piano che ha il margine massimo, cioè la distanza massima
tra i punti di entrambe le classi.
La massimizzazione della distanza del margine fornisce un’importante informazione in mo-
do che i futuri punti possano essere classificati con maggiore sicurezza.
Figura 2.3: Esempio di iperpiano ottimale, preso da [2]
Gli iperpiani sono limiti decisionali che aiutano a classificare i data points.
I punti che cadono su entrambi i lati dell’iperpiano possono essere attribuiti a diverse classi.
Inoltre, la dimensione dell’iperpiano dipende dal numero di features: se il numero di caratte-
ristiche di input è 2, allora l’iperpiano è una retta, se il numero di elementi di input è 3, allora
l’iperpiano diventa un piano bidimensionale, ovviamente diventa difficile immaginare cosa
avviene con un numero di features maggiore di 3.
I vettori di supporto sono i punti più vicini all’iperpiano e quindi ne influenzano la posizione e
l’orientamento, il loro utilizzo massimizza il margine del classificatore. Tali punti dipendono
dal set di dati che si sta analizzando e se vengono rimossi o modificati alterano la posizione
dell’iperpiano divisorio. Per questo motivo, possono essere considerati gli elementi critici di
un set di dati.
Clustering dei profili di consumo di energia elettrica12 Richiami Teorici
Per riuscire a identificare l’iperpiano che meglio divide i vettori di supporto in classi, l’algo-
ritmo esegue questi step:
1. Cerca un iperpiano linearmente separabile o un limite di decisione che separa i valori
di una classe dall’altro. Se ne esiste più di uno, cerca quello che ha margine più alto
con i vettori di supporto, per migliorare l’accuratezza del modello.
2. Se tale iperpiano non esiste, SVM utilizza una mappatura non lineare per trasformare
i dati di allenamento in una dimensione superiore (a due dimensioni, valuterà i dati in
3 dimensioni). In questo modo, i dati di due classi possono sempre essere separati
da un iperpiano, che sarà scelto per la suddivisione dei dati.
Clustering dei profili di consumo di energia elettrica13
2.1.2.2 Random forest
Il Random forest è un classificatore d’insieme composto da alberi decisionali, ovvero da
modelli predittivi, i cui nodi interni rappresentano le variabili, un arco verso un nodo figlio
rappresenta un possibile valore per quella proprietà e una foglia il valore predetto per la
variabile obiettivo a partire dai valori delle altre proprietà.
Con "path" dell’albero si intende il cammino che parte dal nodo root, passa sui nodi che
rappresentano le altre proprietà, e arriva al nodo foglia, che di conseguenza è influenzato
dalle ’risposte’ alle ’domande’ precedenti.
Figura 2.4: Esempio di albero di decisione, preso da [3]
Normalmente un albero di decisione viene costruito utilizzando tecniche di apprendimento
a partire dall’insieme dei dati iniziali, il quale può essere diviso in due sottoinsiemi: il training
set sulla base del quale si crea la struttura dell’albero e il test set che viene utilizzato per
testare l’accuratezza del modello predittivo così creato.
Clustering dei profili di consumo di energia elettrica14 Richiami Teorici
Nel data mining un albero di decisione viene utilizzato per classificare le istanze di grandi
quantità di dati (per questo viene anche chiamato albero di classificazione).
In questo ambito un albero di decisione descrive una struttura ad albero dove i nodi foglia
rappresentano le classificazioni e le ramificazioni l’insieme delle proprietà che portano a
quelle classificazioni.
Di conseguenza ogni nodo interno risulta essere una macro-classe costituita dall’unione
delle classi associate ai suoi nodi figli.
L’idea fondamentale dietro il random forest è quella di combinare molti alberi decisionali in
un unico modello.
Individualmente, le previsioni fatte dagli alberi decisionali possono non essere accurate, ma
combinate insieme, le previsioni saranno in media più vicine al target cercato. Un random
forest è migliore di un singolo albero decisionale in quanto ogni albero porta la propria
’esperienza’, Inoltre, ogni albero decisionale nella foresta considera un sottoinsieme casuale
di caratteristiche quando si formano le domande e ha accesso solo ad un insieme casuale
di punti di dati di formazione.
Questo aumenta la diversità nella foresta, portando a previsioni generali più solide; quando
arriva il momento di fare una previsione, il bosco casuale prende una media di tutte le
singole stime degli alberi decisionali se si tratta di un problema di regressione, se si vuole
classificare invece ogni albero darà un ’voto’ alla classe prevista e la foresta sceglierà la
label più votata.
Figura 2.5: Esempio di random forest, preso da [4]
Clustering dei profili di consumo di energia elettrica15
L’algoritmo di random forest è tra i più apprezzati, ecco alcune sue caratteristiche:
• Funziona in modo efficiente su grandi basi di dati.
• Può gestire migliaia di variabili di input.
• Fornisce stime di quali variabili sono importanti nella classificazione.
• Dispone di un metodo efficace per stimare i dati mancanti e mantiene l’accuratezza
quando ne mancano in gran parte.
• Dispone di metodi per bilanciare gli errori nelle classi di dati non equilibrati della
popolazione.
• Le foreste generate possono essere salvate per un uso futuro su altri dati.
• Vengono calcolati prototipi che forniscono informazioni sulla relazione tra le variabili e
la classificazione.
Clustering dei profili di consumo di energia elettrica16 Richiami Teorici
2.2 Apprendimento non supervisionato
L’apprendimento non supervisionato è una tecnica di apprendimento automatico che con-
siste nel fornire al sistema informatico una serie di input (esperienza del sistema) che egli
riclassificherà ed organizzerà sulla base di caratteristiche comuni per cercare di effettua-
re ragionamenti e previsioni sugli input successivi. La validità di questi algoritmi è legata
all’utilità delle informazioni che riescono ad estrarre dalla base di dati.
Le tecniche di apprendimento non supervisionato lavorano confrontando i dati e ricercando
similarità o differenze. Sono molto efficienti con elementi di tipo numerico, dato che possono
utilizzare tutte le tecniche derivate dalla statistica, ma risultano essere meno efficienti con
dati non numerici.
Principali algoritmi:
• Clustering
• Regole di associazione
2.2.1 Clustering
Il clustering è una tecnica di Machine Learning che prevede il raggruppamento di punti dati
in classi omogenee. Dato un insieme di punti, si può usare un algoritmo di clustering per
classificare ogni punto in un gruppo specifico.
Questi gruppi vengono, per l’appunto, chiamati cluster e sono un insieme di oggetti che pre-
sentano tra loro delle similarità, ma che, per contro, presentano dissimilarità con oggetti in
altri cluster.
L’input di un algoritmo di clustering è costituito da un campione di elementi, mentre l’output
è dato da un certo numero di cluster in cui gli elementi del campione sono suddivisi in base
a una misura di similarità.
Gli algoritmi di clustering forniscono come output anche la descrizione delle caratteristiche
di ciascun cluster, il che è fondamentale per poi prendere decisioni strategiche sulle azioni
da compiere verso tali gruppi.
Clustering dei profili di consumo di energia elettrica17
Il clustering è un metodo di apprendimento non supervisionato ed è una tecnica comune
per l’analisi statistica dei dati utilizzata in molti campi:
• Ricerche di mercato
• Riconoscimento di pattern
• Segmentazione del mercato
• Posizionamento dei prodotti
• Analisi dei social network
• Identificazione degli outliers
2.2.1.1 Tecniche di clustering
Le tecniche di clustering si possono basare principalmente su due "filosofie":
• Dal basso verso l’alto (metodi aggregativi o bottom-up):
Questa filosofia prevede che inizialmente tutti gli elementi siano considerati cluster a
sé, e poi l’algoritmo provvede ad unire i cluster più vicini. L’algoritmo continua ad unire
elementi al cluster fino ad ottenere un numero prefissato di cluster, oppure fino a che
la distanza minima tra i cluster non supera un certo valore, o ancora in relazione ad
un determinato criterio statistico prefissato.
• Dall’alto verso il basso (metodi divisivi o top-down):
All’inizio tutti gli elementi sono un unico cluster, e poi l’algoritmo inizia a dividere il
cluster in tanti cluster di dimensioni inferiori. Il criterio che guida la divisione è natural-
mente quello di ottenere gruppi sempre più omogenei. L’algoritmo procede fino a che
non viene soddisfatta una regola di arresto generalmente legata al raggiungimento di
un numero prefissato di cluster.
Clustering dei profili di consumo di energia elettrica18 Richiami Teorici
Queste tecniche si possono nuovamente suddividere a dipendenza della possibilità che un
elemento possa o meno essere assegnato a più cluster o tenendo conto del tipo di algoritmo
utilizzato per dividere lo spazio:
• Clustering esclusivo: ogni elemento può essere assegnato ad uno e ad un solo
gruppo. Quindi i cluster risultanti non possono avere elementi in comune. Questo
approccio è detto anche hard clustering.
• Clustering non-esclusivo, in cui un elemento può appartenere a più cluster con gradi
di appartenenza diversi. Questo approccio è noto anche con il nome di soft clustering
o fuzzy clustering, dal termine usato per indicare la logica fuzzy.
• Clustering partizionale (detto anche non gerarchico, o k-clustering), in cui per definire
l’appartenenza ad un gruppo viene utilizzata una distanza da un punto rappresenta-
tivo del cluster (centroide, medioide ecc.), avendo prefissato il numero di gruppi della
partizione risultato.
Gli algoritmi di clustering partizionali sono più adatti a data set molto grandi, per i
quali la costruzione di una struttura gerarchica dei cluster porterebbe a uno sforzo
computazionale molto elevato.
• Clustering gerarchico, in cui viene costruita una gerarchia di partizioni caratterizzate
da un numero (de)crescente di gruppi, visualizzabile mediante una rappresentazione
ad albero (dendrogramma), in cui sono rappresentati i passi di accorpamento/divisio-
ne dei gruppi.
Clustering dei profili di consumo di energia elettrica19
2.2.1.2 Kmeans
Il clustering K-means è uno degli algoritmi di apprendimento automatico non supervisionato
e partizionale tra i più semplici e popolari; esso trova un numero fisso di cluster in un insie-
me di dati.
L’obiettivo che l’algoritmo si prepone è di minimizzare la varianza totale intra-cluster.
Ogni cluster viene identificato mediante un centroide o punto medio.
L’algoritmo segue una procedura iterativa; inizialmente crea K partizioni e assegna ad ogni
partizione i punti d’ingresso casualmente o usando alcune informazioni euristiche; quindi
calcola il centroide di ogni gruppo.
Costruisce, di conseguenza, una nuova partizione associando ogni punto d’ingresso al clu-
ster il cui centroide è più vicino ad esso, infine vengono ricalcolati i centroidi per i nuovi
cluster e così via, finché l’algoritmo non converge.
Vediamo più nel dettaglio come funziona l’algoritmo passo per passo:
1. Inizializzazione k-means
• Lo si fa scegliendo l’ampiezza del set di dati e k centroidi iniziali disposti casual-
mente. Scegliendo il numero di centroidi, si scelgono i cluster cui il data set sarà
composto e quindi i raggruppamenti che si vogliono effettuare e visualizzare.
2. Assegnazione del cluster
• l’algoritmo analizza ciascuno dei data points e li assegna al centroide più vicino.
Quindi viene calcolata la distanza euclidea1 tra ogni data points e ogni centroide.
Ogni data points sarà poi assegnato al centroide la cui distanza risulti minima.
Questo è il riassunto di ciò che avviene in termini matematici:
arg min dist (ci , x)2
ci ∈ C
dove ci è un centroide nell’insieme C (che include tutti i centroidi), x sono i
datapoints e dist () è la distanza euclidea
p
d(P1 , P2 ) = (x2 − x1 )2 + (y2 − y1 )2
1
Esistono diversi metodi per calcolare le distanze ma questa è tra le più utilizzate
Clustering dei profili di consumo di energia elettrica20 Richiami Teorici
3. Aggiornamento della posizione del centroide
• Dopo il passaggio 2 è probabile che si siano formati nuovi cluster, in quanto a
quelli precedenti si saranno assegnati (o tolti a seconda che essi siano passati
ad un altro cluster) nuovi data points. Di conseguenza, si ricalcola la posizione
media dei centroidi. Il nuovo valore di un centroide sarà la media di tutti i data
points che sono stati assegnati al nuovo cluster, matematicamente parlando ci
troviamo in questa situazione:
1 X
ci = xi
|Si |
xi ∈ Si
Dove Si rappresenta la somma dei data points assegnati al cluster i-esimo. Si
ottiene la nuova posizione del centroide dalla media di tutti i data points assegnati
al cluster nello step precedente.
Dopodiché i passaggi 2 e 3 verranno ripetuti finché i centroidi non verranno più modificati,
ossia si raggiunge un punto di convergenza tale per cui non si hanno più modifiche dei
cluster.
I questi casi vuol dire che si è raggiunta la condizione di stop, questo avviene quando si
verificano una delle seguenti opzioni:
• nessun data points cambia cluster;
• la somma delle distanze è ridotta al minimo;
• viene raggiunto un numero massimo di iterazioni.
Clustering dei profili di consumo di energia elettrica21
Capitolo 3
Tecnologie utilizzate
Un altro aspetto da considerare prima di concentrarci sullo sviluppo vero e proprio è quello
delle tecnologie utilizzate.
Ovviamente navigando per il web si trovano un’immensa varietà di linguaggi e IDE che si
potrebbero utilizzare per progetti di data science e machine learning, questo capitolo elenca
quelli che sono stati scelti.
Le scelte sono state influenzate sia da un background già acquisito durante il percorso sco-
lastico, sia dalle esperienze dei data scientist.
Anche alcune librerie, solo le più importanti, verranno brevemente descritte per comprende-
re il loro utilizzo.
Inoltre, non meno importanti, vengono elencate anche le tecnologie utilizzate per la gestione
dei database e le interrogazioni con quest’ultimi.
Clustering dei profili di consumo di energia elettrica22 Tecnologie utilizzate
3.1 Linguaggi
Tecnologia Nome Descrizione
Python è un linguaggio di programmazione ad alto livello,
orientato agli oggetti, adatto, tra gli altri usi, a sviluppare
applicazioni distribuite, scripting, computazione numerica e
system testing.
Per il progetto è stato scelto perché, per quanto riguarda il
Python
machine learning e il data science, le sue librerie per analisi
dei dati e calcolo numerico, quali Numpy, Pandas, Scikit-learn
ecc., lo rendono il linguaggio ideale.
Inoltre, se si hanno già delle conoscenze di base di
programmazione, è molto semplice da imparare e utilizzare.
In informatica, SQL (Structured Query Language) è un
linguaggio standardizzato per database basati sul modello
relazionale (RDBMS).
Come verrà descritto più avanti, i dati disponibili provenivano
SQL
da tre diversi database, di conseguenza si è utilizzato SQL
per le interrogazioni.
Indispensabile per tutta la durata del progetto per l’analisi dei
dati e soprattutto per verificare la veridicità dei risultati.
Tabella 3.1: Linguaggi utilizzati
Clustering dei profili di consumo di energia elettrica23
3.2 Piattaforme
Tecnologia Nome Descrizione
MySQL o Oracle MySQL è un Relational database mana-
gement system (RDBMS) composto da un client a riga di
comando e un server.
È il database open source più diffuso al mondo e inoltre, ha
MySQL
ottime performance e un elevato fattore di sicurezza.
Nel corso del progetto è stato utilizzato per far eseguire gli
script sql e di conseguenza creare localmente i database.
DataGrip è un ambiente di gestione di database per svilup-
patori. È progettato per l’interrogazione, la creazione e la
gestione di database.
Per utilizzare questo IDE si è creata una connessione con
DataGrip MySQL, in questo modo si poteva lavorare sui database
preventivamente creati.
Necessario per tutta la durata del progetto in quanto le query
e quindi le interrogazioni al database sono state eseguite in
questo ambiente di sviluppo.
Anaconda è una distribuzione gratuita e open-source dei
linguaggi di programmazione Python e R per l’informatica
scientifica.
Anaconda
Le versioni dei pacchetti sono gestite dal sistema di gestione
dei pacchetti conda.
Clustering dei profili di consumo di energia elettrica24 Tecnologie utilizzate
Tecnologia Nome Descrizione
Project Jupyter è un’organizzazione no-profit creata per
sviluppare software open-source, standard aperti e servizi per
il calcolo interattivo in decine di linguaggi di programmazione.
Per il progetto è stato utilizzato Jupyter Notebook che è un’ap-
Jupyter
plicazione client-server che consente di modificare ed esegui-
re documenti notebook (documenti prodotti dalla Jupyter No-
tebook, che contengono sia codici informatici che elementi di
testo) tramite un browser web.
PyCharm è un ambiente di sviluppo integrato utilizzato nella
programmazione informatica, in particolare per il linguaggio
Python.
Fornisce analisi del codice, un debugger grafico, un tester
PyCharm
integrato di unità, integrazione con sistemi di controllo delle
versioni.
Il progetto finale è stato tutto implementato in PyCharm per la
praticità di tale IDE.
Tabella 3.2: Piattaforme utilizzate
Clustering dei profili di consumo di energia elettrica25
3.3 Librerie
Tecnologia Nome Descrizione
Pandas è una libreria software scritta per il linguaggio di
programmazione Python per la manipolazione e l’analisi
dei dati. In particolare, offre strutture dati e operazioni per
manipolare tabelle numeriche e serie temporali.
Pandas È un software libero rilasciato sotto la licenza BSD.
Indispensabile fin dal principio dello sviluppo del progetto per
riuscire a creare un dataframe iniziale partendo dalla query sui
database, più altre funzionalità che si incontreranno oltre.
NumPy è una libreria open source per il linguaggio di pro-
grammazione Python, che aggiunge supporto a grandi matrici
e array multidimensionali insieme a una vasta collezione di
funzioni matematiche di alto livello per poter operare efficien-
temente su queste strutture dati.
NumPy
Per il progetto è stata ampiamente utilizzata, appunto, per la
facile gestione di array semplici e multidimensionali e soprat-
tutto per le funzioni matematiche messe a disposizione per
calcolare velocemente medie, deviazioni standard ecc.
Scikit-learn è una libreria open source di apprendimento
automatico per il linguaggio di programmazione Python.
Contiene algoritmi di classificazione, regressione, clustering e
macchine a vettori di supporto, regressione logistica, classifi-
Scikit-learn
catore bayesiano, k-mean e DBSCAN.
Questa libreria è il cuore di tutto il progetto in quanto contiene
tutti gli algoritmi sopracitati di cui l’implementazione e gli import
specifici verranno dettagliati nei capitoli successivi.
Clustering dei profili di consumo di energia elettrica26 Tecnologie utilizzate
Tecnologia Nome Descrizione
Plotly è una società di informatica tecnica che sviluppa
strumenti di analisi dei dati online e di visualizzazione.
Plotly fornisce strumenti grafici, analitici e statistici online per
Plotly gli individui oltre a librerie di grafici scientifici per Python, R,
MATLAB e altri linguaggi.
La libreria grafica Python di Plotly rende interattivi i grafici.
Matplotlib è una libreria per la creazione di grafici per il
linguaggio di programmazione Python e la libreria matematica
NumPy.
Con poche righe di codice è possibile generare grafici, isto-
Matplotlib
grammi, spettri di potenza, diagrammi a barre, diagrammi di
errore, diagrammi a dispersione, ecc.
Per l’utente finale, si ha il pieno controllo degli stili tramite
un’interfaccia orientata agli oggetti.
Tabella 3.3: Librerie utilizzate
Clustering dei profili di consumo di energia elettrica27
Capitolo 4
Strutturazione dei dati
Appresi i fondamenti teorici degli argomenti riguardanti il progetto, si può passare alla parte
pratica dove si spiegherà dettagliatamente in quale modo si è giunti alla realizzazione dei
compiti e degli obiettivi prefissati.
Il primo compito, fondamentale per la buona riuscita del progetto, è quello di organizzare e
preparare i dati per eseguire l’analisi in modo efficiente.
In questo capitolo ci si vuole soffermare sui passi eseguiti e le scelte intraprese durante
questa fase.
Clustering dei profili di consumo di energia elettrica28 Strutturazione dei dati
4.1 Database
Come già accennato precedentemente, il progetto enCOMPASS a cui sta lavorando SUPSI,
raccoglie informazioni sul consumo di energia elettrica; queste vengono campionate ogni 15
minuti per un insieme di circa 400 utenti.
Queste informazioni sono raccolte in tre database differenti in base al luogo di campio-
namento, difatti gli utenti interessati a questo progetto provengono da tre diverse nazioni:
Svizzera, Germania e Grecia.
Per riuscire ad accedere alle informazioni, partendo da tre diversi script sql forniti, sono stati
ricreati localmente i database utilizzando MySQL, questi sono i comandi usati per creare i
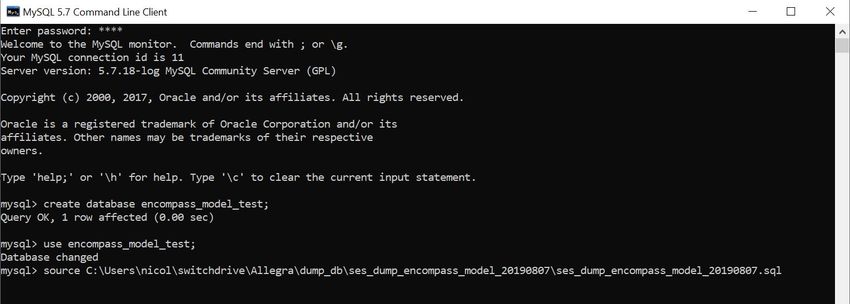
database e far eseguire gli script:
Figura 4.1: Comandi per creare database
Anche se i database contengono informazioni diverse, la loro struttura è identica:
• 61 tabelle per ogni database,
• gli attributi, per ogni tabella, sono equivalenti,
• le relazioni tra le tabelle sono le stesse.
L’allegato [1]: Diagramma delle classi, mostra, come suggerito dal nome, il diagramma delle
classi di questi database fornendo informazioni sulle tabelle, i loro attributi e le relazioni.
Concentrandoci sul numero di utenti presenti per ogni database, in quello svizzero ce ne
sono 95, in quello tedesco 157 mentre in quello greco 196, per un totale di 448 utenti. Le
date di inizio e fine campionamento sono diverse per i tre database ma all’incirca si hanno
dati da inizio anno 2018 fino a fine luglio 2019.
Clustering dei profili di consumo di energia elettrica29
4.1.1 Classi utilizzate
Dalle informazioni fornite precedentemente si evince che le dimensioni dei database sono
abbastanza voluminose, per questo si è deciso di limitare l’analisi del consumo unicamen-
te sul profilo dell’utente tralasciando dunque i valori forniti dai sensori interni che fornivano
informazioni sull’umidità, la temperatura, la luminanza e la presenza di attività all’interno di
una stanza. Anche le condizioni esterne, come per esempio il meteo, non sono state valu-
tate. Inoltre, la maggior parte delle tabelle sono superflue allo scopo del progetto.
Eseguendo questo accorgimento il numero di tabelle si è ridotto a un totale di 10, come si
può vedere dal diagramma delle classi in figura 4.2.
Figura 4.2: Diagramma classi utilizzate
Clustering dei profili di consumo di energia elettrica30 Strutturazione dei dati
Di seguito un’analisi delle tabelle per capire più dettagliatamente il loro contenuto:
• User: contiene le informazioni sull’utente inerenti alla registrazione sull’app creata nel
progetto enCOMPASS come per esempio l’username, l’e-mail, il giorno di nascita ecc.
• User_profile: contiene tutte le informazioni dell’utente che interesseranno in seguito
l’analisi. Sono prensenti informazioni sugli elettrodomestici, sul numero di componenti
del nucleo famigliare ecc.
• Heating_source_type: indica il tipo di fonte di riscaldamento, in questo caso può
essere a olio, a elettricità, a gas oppure a legna.
• Heating_type: anche questa tabella è sul riscaldamento, qui le informazioni possono
essere elementi radiatori, serpentina a pavimento oppure convezione d’aria
• Main_lighting_type: indica il tipo di illuminazione principale dove le lampadine posso-
no essere alogene, led, a basso consumo o a incandescenza; c’è anche la possibilità
che l’utente non sia a conoscenza di questa informazione.
• Dwelling: contiene le informazioni sull’abitazione a livello di nucleo familiare, indispen-
sabile per la connessione tra l’utente e lo smart meter.
• Building: contiene le informazioni sul palazzo fisico.
• Building_type: procura le informazioni sul tipo di palazzo che potrebbe essere una
casa indipendente, un appartamento, una casa bifamiliare, una villetta a schiera, un
edificio pubblico, una scuola oppure degli edifici residenziali.
• Smart_meter: contiene le informazioni sul contatore intelligente installato nelle abita-
zioni
• Meter_consumption: contiene i valori di consumo campionati dallo smart meter e
l’istante di tempo a cui fa riferimento.
Clustering dei profili di consumo di energia elettrica31
4.2 Pretrattamento dei dati
Ora che è stato ridotto il numero di tabelle e si è a conoscenza di dove si trovano le infor-
mazioni necessarie, ci si può concentrare sulla loro analisi più approfondita.
Come già accennato in precedenza, le date di inizio e fine campionamento non sono uguali
per i tre database, dunque si è scelto un arco di tempo della durata di un anno partendo
dal’01/06/2018 fino al’31/05/2019.
Sempre sulla questione date, un ulteriore taglio è stato eseguito sulle festività: con un pic-
colo script sono state calcolate tutte le domeniche presenti nelle dodici mensilità e per ogni
nazione sono stati inseriti i giorni festivi di maggior importanza.
La lista di queste date viene esclusa dalla query finale e di conseguenza le informazioni
del consumo di quelle giornate non saranno presenti nell’analisi, questa scelta è avvenuta
in quanto durante le domeniche e i giorni festivi è molto più probabile consumare maggior-
mente poiché è possibile che tutto il nucleo familiare si trovi nell’abitazione o viceversa.
Inoltre, le festività variano a seconda della nazione e per tali giorni le informazioni, non es-
sendo eque, avrebbero ’sporcato’ i risultati finali.
Il progetto si vuole concentrare sullo studio del profilo dei semplici utenti considerando un
insieme di features e di valori equi, per questa motivazione si sono eliminati gli edifici che
non erano abitazioni private come per esempio le scuole e i municipi.
All’interno dei database sono presenti degli utenti di test che devono essere rimossi. Dopo
le rimozioni eseguite sulle date e sugli edifici, per alcuni utenti persistevano alcune infor-
mazioni contrastanti. In accordo con il relatore si è deciso di non considerare gli utenti del
database greco poiché nel corso del progetto enCOMPASS non ci sono stati più contatti con
il rispettivo istituto di ricerca che gestisce il database e dunque le informazioni presenti non
erano molto affidabili. Per quanto concerne il database tedesco, ci sono alcuni utenti che
hanno abbandonato il progetto e altri i quali dati riportano dei buchi temporali significativi,
anche questi utenti sono stati rimossi.
Clustering dei profili di consumo di energia elettrica32 Strutturazione dei dati
La query finale utilizzata per interrogare il database e creare i primi dataframe con le
restrizioni sopraelencate è la seguente:
Figura 4.3: Query finale per interrogare i database
Dove con ’building’ si fa riferimento al tipo di edificio accettato, nel nostro caso quelli resi-
denziali, ’final_string’ contiene tutta la lista delle date da non considerare e i numeri fanno
riferimento agli id degli utenti che devono essere rimossi per un totale di 27 utenti.
Otteniamo due dataframe, uno utilizzando il database svizzero e l’altro usando quello tede-
sco. Per delle analisi che vogliamo svolgere in seguito, a entrambi aggiungiamo due colonne
nominate ’Switzerland’ e ’Germany’ che potranno assumere il valore 0 o 1 a seconda se il
dato da analizzare proviene da uno piuttosto che dall’altro dataframe; in questo modo man-
teniamo l’informazione sulla nazionalità. Questa modalità è denominata one-hot encoding
e verrà spiegata successivamente.
Per ottenere un unico dataframe eseguiamo una semplice concatenazione dei due, purtrop-
po questo dataframe contiene dei valori NaN (tramandati dai due dataframe iniziali) che non
permettono l’avanzamento delle operazioni necessarie a realizzare i cluster e la classifica-
zione.
Per sostituire questi valori è stata dapprima effettuata un’interpolazione lineare ma analiz-
zando più approfonditamente i dati in possesso non è risultata la scelta più adatta in quanto
potevano esserci molti NaN consecutivi o capitava che i valori scelti per interpolare non
fossero adatti. Tenendo conto che i dati di campionamento non sono pochi, analizzando
il problema con il relatore, si è deciso semplicemente di rimuoverli utilizzando la funzione
dropna().
Un altro piccolo problema notato durante questa fase è che per alcuni utenti ci sono mol-
ti valori NaN consecutivi e poi l’ultimo giorno del mese ha un valore del consumo elevato
essendo la somma dei giorni mancanti, la soluzione a questo ostacolo verrà illustrata nel
sottocapitolo successivo che tratta della modalità di creazione dei dataframe.
Clustering dei profili di consumo di energia elettrica33
Ricapitolando, eliminando dall’analisi tutti gli utenti greci più quelli problematici, il numero di
utenti è più che dimezzato passando da 448 a 179. Facendo un breve calcolo si può capire
con quante informazioni si andrà a lavorare durante l’analisi. I campionamenti avvengono
ogni 15 minuti, quindi nell’arco della giornata sono 96 in totale. L’analisi è stata delimitata
a un anno di rilevamenti, quindi 365 giorni. Per ogni utente si hanno dunque 35’040 dati
sul consumo, in totale moltiplicando questo numero per il numero di utenti analizzabili si
arriva teoricamente a 6’272’160, andando però a controllare la dimensione del dataframe
completo a cui sono stati rimossi i valori NaN otteniamo 5’058’941 che nonostante tutte le
restrizioni è un ottimo numero per permettere la buona riuscita dell’analisi.
4.2.1 One-hot encoding
One-hot encoding è un processo mediante il quale le variabili categoriche1 vengono conver-
tite in una forma che permette agli algoritmi di machine learning di fare un lavoro migliore
durante la previsione.
Si tratta semplicemente di creare delle nuove colonne corrispondenti ai valori che può as-
sumere la variabile categorica, dopodiché verrà inserito il valore 1 se la condizione è soddi-
sfatta oppure 0 in caso contrario.
Questo approccio, come anticipato prima, è stato utilizzato per inserire le informazioni sulla
nazionalità ma anche per i tipi di riscaldamento, i tipi di luce e i tipi di edifici. Di seguito sono
riportate alcune immagini esempio catturate dal dataframe.
Figura 4.4: One-hot encoding con Figura 4.5: One-hot encoding con la
heating source type nazionalità
1
variabili che contengono label anziché valori numerici
Clustering dei profili di consumo di energia elettrica34 Strutturazione dei dati
Figura 4.6: One-hot encoding con building type
4.3 Creazione dataframes
Applicato il processo di one-hot encoding, un’ultima miglioria da applicare al dataframe è
quella di eliminare le colonne non rilevanti al fine ultimo del progetto poiché per tutti gli utenti
è presente lo stesso valore e di conseguenza la feature risulta inutile. Si pensi al frigo o alla
televisione che possiedono tutti.
Si ottiene, finalmente, il dataframe unico e completo, con un totale di 44 colonne equivalenti
alle features di interesse. Le informazioni sul consumo sono però abbastanza insignificanti
in quanto sono presenti i campionamenti ogni quarto d’ora, di conseguenza si creano dei
nuovi dataframes aggregando i dati del consumo, ottenendo in questa maniera i consumi
medi per ogni utente.
Il primo dataframe creato contiene la media giornaliera mensile, per ottenere questa aggre-
gazione si sono dapprima sommati i valori del consumo di un singolo giorno ottenendo così
il consumo giornaliero, dopodiché dei valori trovati si è eseguita la media per ogni mese.
Il problema principale nella creazione di questo dataframe nasce dai valori in cui l’ultimo
giorno contiene la somma dei consumi di tutto il mese, per ovviare a questo il consumo
indicato viene diviso per il numero di giorni di quello specifico mese in modo da ottenere
approssimativamente il consumo medio giornaliero per quel mese.
Inoltre, per questo dataframe non si voleva perdere l’indicazione sulla mensilità a cui il va-
lore medio trovato fa riferimento, per questo le informazioni sono state aggiunte in modalità
one-hot encoding. (Figura 4.7)
Figura 4.7: One-hot encoding sulle mensilità
Clustering dei profili di consumo di energia elettrica35
La figura 4.8 mostra il codice d’esempio su un’aggregazione mensile dove si va a calcolare
la media dei valori.
Figura 4.8: Aggregate method
Per utilizzare i metodi di aggregazione, l’indice del dataframe dev’essere di tipo DateTime,
le prime due righe di codice servono per l’appunto a impostare come indice la colonna ’da-
tetime’ che contiene le informazioni sull’istante di tempo in cui è stato campionato il valore
del consumo.
Il groupby() è indispensabile per avere i dati raggruppati per ogni utente (si vuole la media di
quel determinato mese per quel determinato utente e non la media di quel mese di tutti gli
utenti), infine il resample con chiave ’M’ che identifica la mensilità non fa altro che aggregare
i dati su base mensile eseguendo la media dei valori.
Tutte le funzioni di aggregazione sono impostate con la stessa metodologia.
Il secondo dataframe contiene la media mensile per ogni utente, è stato creato ottenendo
dapprima il consumo totale per ogni mese, quindi facendo un’aggregazione su base mensile
e sommando i valori, e infine si è calcolata la media dei valori trovati.
Il terzo dataframe è molto semplice: contiene il consumo di tutto l’anno per ogni utente.
Nel quarto dataframe invece troviamo unicamente i consumi giornalieri.
Il quinto e il sesto contengono le media mensile stagionale, per crearli si sono dapprima
calcolati i consumi per ogni mese e poi si è fatta la media dei mesi che compongono una
determinata stagione. La differenza tra i due si consegue nella suddivisione delle stagiona-
lità, il primo è basto su quattro stagione mentre il secondo su tre unendo assieme primavera
e autunno.
Per entrambi i dataframe sono state aggiunte, in modalità one-hot encoding, le informazioni
per tenere traccia della stagione a cui si fa riferimento.
Figura 4.9: One-hot encoding con Figura 4.10: One-hot encoding con
quattro stagioni tre stagioni
Clustering dei profili di consumo di energia elettricaPuoi anche leggere

















































