Universit'a degli Studi di Cagliari - Corsi
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Università degli Studi di Cagliari
Facoltà di Ingegneria e Architettura
Corso di Laurea in Ingegneria Elettrica ed Elettronica
Direzioni future della codifica video.
Considerazioni e relative prospettive hardware
Relatore: Tesi di:
Dott. Ing. Francesca Palumbo Nicola Motzo
Corelatore:
Dott. Ing. Carlo Sau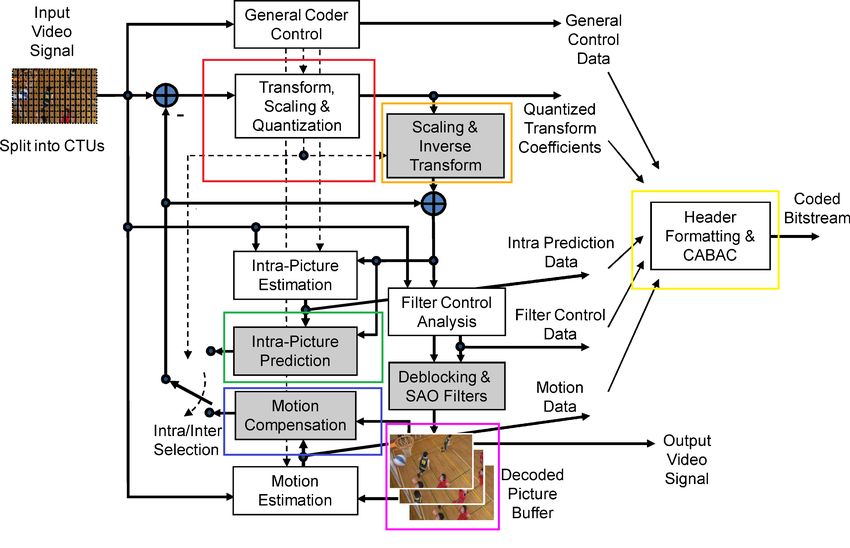
Indice
1 Introduzione 2
2 Metodi generali della compressione video 4
2.1 Generalità sulla rappresentazione digitale delle sequenze video . . . . . . . . . 4
2.2 Le ridondanze nelle sequenze video . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3 Riepilogo delle metodologie di rimozione delle ridondanze . . . . . . . . . . . 12
3 Gli standard della codifica/decodifica video 13
3.1 Cenni su Motion JPEG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2 Cenni su H.264 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.3 Confronti fra Motion JPEG e H.264 . . . . . . . . . . . . . . . . . . . . . . . . 16
4 Standard High Efficiency Video Coding (HEVC o H.265) 17
4.1 Generalità HEVC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.2 Struttura e novità del livello di codifica . . . . . . . . . . . . . . . . . . . . . . 20
4.3 Alcuni aspetti dell’implementazione hardware . . . . . . . . . . . . . . . . . . 23
4.4 Considerazioni finali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5 Il futuro degli standard di codifica video 33
5.1 Generalità ed Analisi dei brainstorming . . . . . . . . . . . . . . . . . . . . . . 33
5.2 Analisi dei test JEM 7 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.3 Risultati dei test esplorativi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
6 Conclusioni 45
1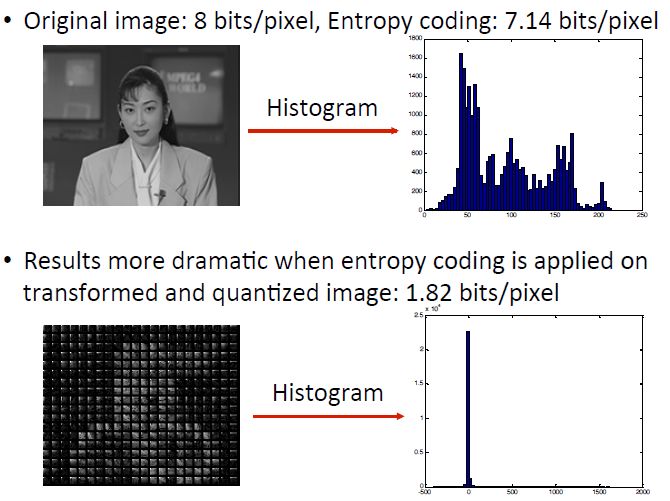
Capitolo 1
Introduzione
I contenuti video hanno assunto un’importanza sempre maggiore nelle nostre vite, a causa del
crescente traffico dei dati, dovuto ai moderni video ad alta definizione, alla diversità di servizi
che occupano e all’influenza che hanno attraverso la rete internet, basti pensare al frequentis-
simo utilizzo che se ne fa in ambito privato (video streaming a carattere ricreativo vedi Netflix,
YouTube ecc.) e in ambito lavorativo (Skype call, Hangouts ecc.). Fra tutti gli aspetti legati ai
servizi video, quello che ci interessa maggiormente è la qualità delle immagini che si visua-
lizzano, cioè la nostra necessità è diventata quella di avere immagini che rispecchino il più
fedelmente possibile la realtà. Sono state sviluppate, infatti, delle tecnologie che, nell’ultimo
decennio, hanno avuto un impatto sempre maggiore sul mercato e sulla vita di tutti i giorni. Si
parla delle TV Full HD (e negli ultimi anni dell’Ultra HD), per non parlare delle modernissime
tecnologie delle immagini in tre dimensioni. L’obbiettivo di questa tesi è un’analisi dello stan-
dard corrente e la definizione delle prospettive future della codifica video, in base alle richieste
di mercato, ormai sempre più esigenti. Nel resto di questa tesi analizzeremo quelle che sono le
tecniche di compressione video più comuni, in altre parole, quelle tecniche che si basano sulla
rimozione della ridondanza d’informazioni da una sequenza video (Capitolo 2). Analizzeremo
poi l’evoluzione degli standard di codifica video, con una visione generale di due dei più comu-
ni standard di codifica del passato, Motion JPEG e di H.264 /AVC, osservando quali tecniche
di compressione utilizzano e facendo un confronto finale fra quelli che sono i vantaggi e gli
svantaggi dei due standard (Capitolo 3). Studieremo in maniera più accurata l’attuale standard
HEVC, analizzando le novità introdotte e alcuni aspetti dell’implementazione hardware sia dal
2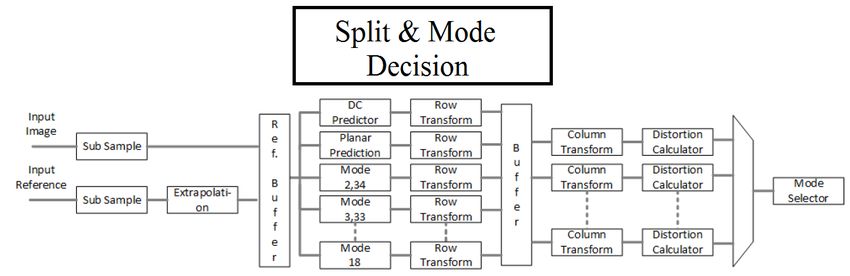
punto di vista del codificatore (encoder), sia da quello del decodificatore (decoder) (Capitolo 4).
Il capitolo finale (Capitolo 5), si concentrerà sul punto cruciale della tesi, ovvero capire qua-
li direzioni si stanno prendendo per il futuro degli standard di codifica video, in particolare,
analizzando i risultati emersi dal brainstorming riguardo alle necessità delle aziende che ne
hanno preso parte (Huawei e Netflix per citarne alcune), confrontandoli infine, con i risultati
ottenuti dall’ultimo test esplorativo che è stato svolto.
3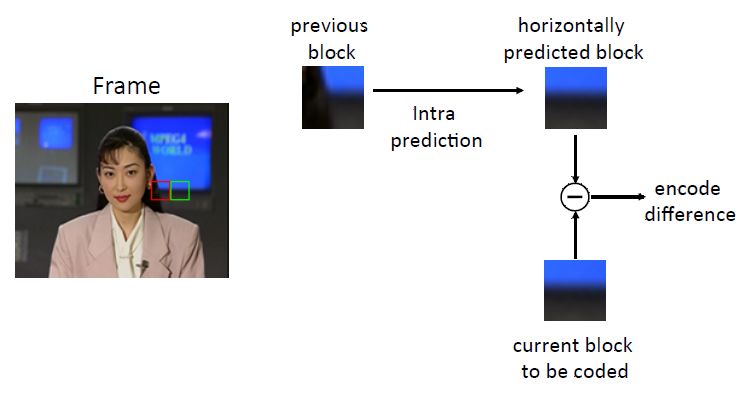
Capitolo 2
Metodi generali della compressione
video
Per analizzare e capire i concetti espressi e i termini usati in questa tesi, è necessario avere
chiara la terminologia utilizzata. Nei paragrafi successivi verranno spiegate a grandi linee,
quelle che sono le terminologie nel campo della compressione e memorizzazione dei dati, con
particolari riferimenti alla compressione di dati video.
2.1 Generalità sulla rappresentazione digitale delle sequen-
ze video
Per iniziare, è necessario chiarire che “dato” e “informazione” non sono sinonimi. I dati sono
gli strumenti tramite i quali è rappresentata l’informazione e con diverse quantità di dati si
può rappresentare la stessa informazione. La compressione, si basa sulla rimozione della ri-
dondanza dei dati e questo è un concetto matematicamente quantificabile. Dati due insiemi
differenti di dati b1 e b2 , utilizzati per rappresentare la stessa informazione, possono essere de-
finiti il Rapporto di compressione C e la Ridondanza relativa R, rispettivamente come mostrato
nelle formule 2.1 e 2.2 [19].
b1
C= (2.1)
b2
4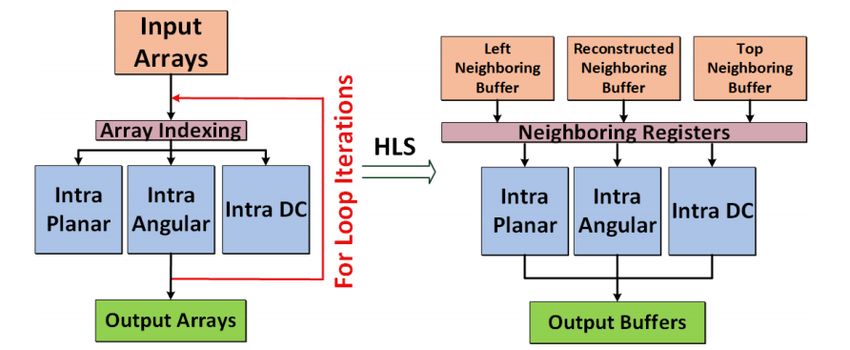
1
R=1− (2.2)
C
Un video è una rapida successione di immagini (frame) , che a seconda del numero e della
velocità in cui si susseguono, vengono interpretate come un movimento fluido da parte del
sistema visivo umano. Il frame rate è la velocità di successione dei frame e si misura in fps,
ovvero frame per second. Il movimento sarà tanto più fluido quanto più grande sarà il frame
rate. I frame sono immagini digitalizzate, ovvero composte da una matrice di punti (o pixel)
che assumono dei valori numerici a dipendenti dal numero di bit da cui sono codificati[5]. I
pixel possono rappresentare i colori tramite codifica. Esistono diversi spazi di colore ed il più
utilizzato specie per la codifica video è YUV () (o YCC), il più noto invece e l’RGB (Red-Green-
Blue) [7]. Questi colori possono avere una profondità diversa, ovvero possono rappresentare
una gamma di colore tanto più ampia, quanto più è alto il numero di bit con cui vengono rap-
presentati. Per esempio, con 8 bit si può rappresentare un valore che va da 0 a 255 per ogni
colore, cosi che ognuno di essi possa avere diverse tonalità. La qualità di una immagine è de-
finita dalla risoluzione, ovvero dal numero di pixel che compongono l’immagine; maggiore è
la quantità di pixels che formano l’immagine, maggiore sarà la risoluzione[28].
La crescita dell’informazione, che negli ultimi anni ha avuto un incremento considerevole, può
rapidamente diventare un problema, sia in termini di tempi di trasmissione (oggi tutto viaggia
in rete) che di memorizzazione (che viene parzialmente risolto dalla trasmissione, visti i nume-
rosi servizi cloud per esempio). Si è reso perciò indispensabile lo sviluppo di opportune stra-
tegie che consentano l’abbattimento della quantità di memoria che tali informazioni richieste
dai video occupano, attraverso l’utilizzo di codec, ovvero algoritmi che rimuovono le infor-
mazioni ridondanti presenti nelle sequenze video. Il concetto di ridondanza è proprio quello
che sta alla base delle tecniche di compressione dell’informazione, in quanto la compressione
viene ottenuta rimuovendo quanta più ridondanza possibile dall’informazione utile.
2.2 Le ridondanze nelle sequenze video
Nel seguito verranno analizzate le diverse tipologie di ridondanza presenti nell’informazio-
ne delle sequenze video e verranno mostrate le principali tecniche utilizzate per rimuovere
5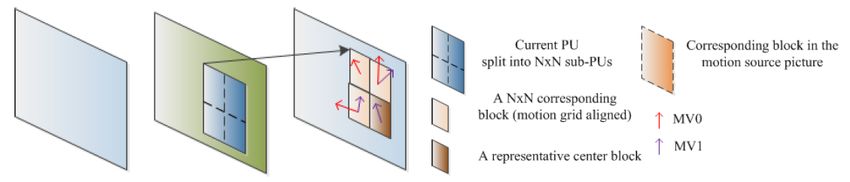
ciascuna di esse.
Ridondanza percettiva
Dal punto di vista percettivo, le immagini sono composte da regioni che contengono mag-
giori informazioni utili rispetto ad altre. Infatti ci saranno delle aree dove si avrà più o meno
uniformità nel colore e delle aree dove invece ci saranno consistenti differenze cromatiche, do-
vute, per esempio, ai particolari presenti in una determinata zona dell’immagine [30]. Un’idea
esplicativa di questo concetto la possiamo notare nella Figura 2.1 .
Figura 2.1: Particolari di un immagine dove viene evidenziata la uniformità del livello cromati-
co (bassa frequenza-quadrato rosso) e un insieme di livelli cromatici differenti (alta frequenza-
quadrato blu)
L’immagine rappresenta un primo piano di una ragazza, in cui viene evidenziato un blocco
rosso sulla sinistra, corrispondente alla guancia della ragazza, dove i pixel hanno tutti un colo-
re molto simile tra loro e un blocco blu sulla destra, che racchiude una porzione dell’immagine
che contiene i capelli della ragazza, dove invece il colore dei pixel differisce in maniera sostan-
ziale. La rimozione di ridondanza percettiva si basa sull’efficienza del sistema visivo umano,
infatti esso risulta essere più sensibile alle basse frequenze spaziali piuttosto che a quelle alte.
Sempre dall’immagine in Figura 2.1, infatti, il dettaglio contenuto nel blocco blu è difficilmente
distinguibile nell’immagine intera. Dal momento che il nostro sistema visivo non è in grado di
6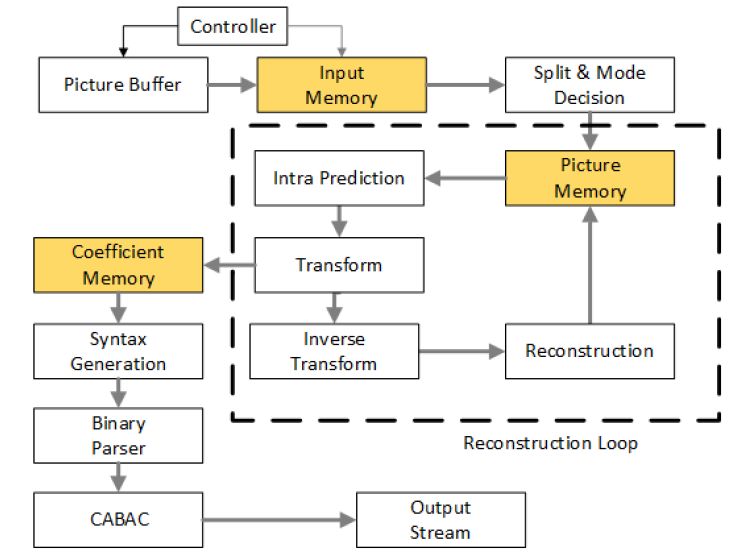
rilevare variazioni significative nel dominio delle frequenze spaziali, le alte frequenze spaziali
(che altro non sono che variazioni brusche di luminosità e contrasto), vengono quindi comune-
mente attenuate, o addirittura azzerate, attraverso due operazioni in cascata: la trasformazione
e la quantizzazione [19]. Per passare dal dominio dello spazio a quello della frequenza spazia-
le, viene applicata una particolare trasformata chiamata DCT(Discrete Cosine Transform)[11],
[21]. Dopo la trasformazione, i coefficienti sono piccoli per frequenze basse e grandi per fre-
quenze alte e vengono salvati in una matrice. Viene allora applicata la quantizzazione, che
taglia le alte frequenze. I coefficienti per le alte frequenze attenuati, diventano quantità de-
cimali e vengono successivamente arrotondate all’intero più vicino [20], [9]. Nel caso della
compressione d’immagini, salvo alcuni casi specifici, l’esigenza di non perdere informazione
durante la codifica è eccessiva nella maggior parte dei casi. Sulla base di questo concetto, la
quantizzazione è il metodo principale che rispetta questo principio. Essa consiste nel determi-
nare la conversione tra un intervallo di valori elevato a uno molto più limitato. Risulta evidente
che un sistema di quantizzazione opera una compressione di un’immagine, in quanto riducen-
do l’intervallo di valori possibili (Full Scale Range, FSR), permette di rappresentarli con parole
di codice di lunghezza minore. Un esempio può essere i 256 livelli di grigio rappresentabili con
parole di 8 bit, che dopo la quantizzazione, vengono ridotti a 16 livelli rendendo cosi possibile
la loro rappresentazione con parole di 4 bit[10].
Nella Figura 2.2(b) possiamo notare sulla destra la matrice che contiene i valori dei pixel
nel dominio dello spazio (matrice in alto) e la stessa matrice dopo che si è passati nel dominio
della frequenza spaziale. I coefficienti non rappresentano più il valore del livello di colore ma,
quanto velocemente cambia il valore dei pixel nello spazio. Il numero in alto a sinistra è la
componente DC (la continua, f=0) e, visto il suo valore, è anche la frequenza dominante nel
blocco (la maggior parte delle variazioni tra pixel vicini sono piccolissime o nulle).
Ridondanza statistica
La ridondanza statistica si concentra sulle probabilità di occorrenza del valore dei pixel di
un’immagine (o dell’immagine trasformata). In generale essi non occorrono con la stessa pro-
babilità in un’immagine. Nella rimozione della ridondanza statistica si usa la codifica entropica,
7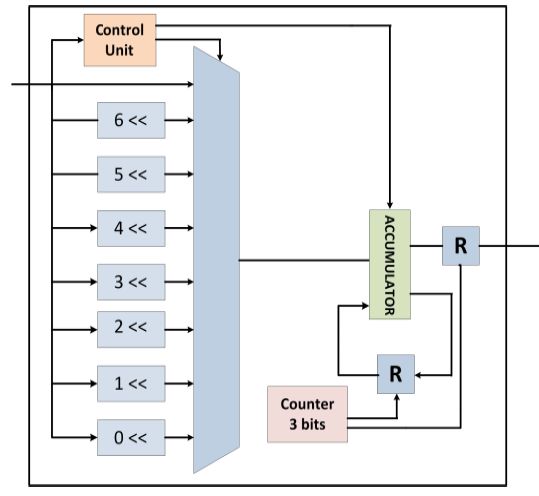
(a) (b)
Figura 2.2: matrice dei coefficienti nel dominio spaziale (Figura 2.2(b) in alto) e nel dominio
della frequenza spaziale (Figura 2.2(b) in basso), riferita all’immagine Figura 2.2(a)
ovvero una tecnica di codifica basata sull’assegnare a ciascun valore di pixel, un unico codice
prefissato (codeword) a lunghezza variabile. Per comprimere l’immagine, si avranno:
• codewords corte usate per rappresentare i valori più frequenti
• codewords più lunghe per rappresentare i valori meno frequenti [19].
Nell’esempio seguente mostrato in Figura 2.3. Si nota che la codifica entropica (che sfrutta la
Figura 2.3: Esempio della qualità della codifica entropica
ridondanza statistica) applicata all’immagine nel dominio del colore, non ha una capacità di
compressione molto buona (7.14 bits/pixel), mentre se la si applica all’immagine portata nel
dominio della frequenza e quantizzata, la capacità di compressione sarà molto elevata a causa
della alta presenza di zeri nell’immagine trasformata e quantizzata (1,82 bits/pixel).
8Un esempio di codifica entropica è la codifica di Huffman, molto utilizzato per la codifica
video [10], [22].
Ridondanza spaziale
La ridondanza spaziale si basa sul concetto che in ogni immagine possano esserci delle carat-
teristiche visive simili in diversi punti. Se consideriamo la Figura 2.4 possiamo notare come,
anche se in posizioni diverse, ci siano delle porzioni di spazio molto simili fra loro. Per elimina-
Figura 2.4: Ridondanza spaziale
re la ridondanza, tipicamente si attua la intra-frame prediction (orizzontale ,verticale, obliqua).
Questa tecnica sfrutta le somiglianze fra i blocchi all’interno dello stesso frame. In particolare,
per un dato blocco da codificare, viene identificato un opportuno blocco di riferimento. Solo
la locazione del blocco di riferimento verrà codificata, invece che l’intero blocco da codificare.
Tipicamente viene calcolata la differenza fra il blocco di riferimento selezionato e il blocco da
codificare. Spesso, per consentire una ricostruzione del frame più fedele, anche tale differenza
viene codificata, ma quest’ultima, data la somiglianza tra i blocchi in questione, sarà una ma-
trice di valori quasi interamente nulla. Si ha un esempio visivo del metodo nella Figura 2.5.
Tipicamente la codifica della differenza tra blocco di riferimento e blocco da codificare, date le
sue caratteristiche, avviene utilizzando tecniche di compressione che sfruttano la ridondanza
statistica [30], [10], [27].
9Figura 2.5: intra-prediction encoding
Ridondanza temporale
La ridondanza temporale è legata al fatto che una sequenza video è composta da frame che si
susseguono tipicamente con frequenze (fps) molto alte. Ciò significa che l’intervallo temporale
che separa due frame successivi è molto breve, per cui la scena immortalata da frame succes-
sivi, difficilmente differisce in maniera sostanziale. Ad esempio nella Figura 2.6, il frame al
tempo t (frame 4) e il frame al tempo t-1 (frame 3) sono confrontati e su essi ne viene calcolata
la differenza (frame 4 - frame 3).
Figura 2.6: ridondanza temporale
La ridondanza temporale in una sequenza video è presente in quantità molto elevate e la sua
rimozione consente di ottenere efficienze di compressione molto performanti. La tecnica che
attua tale rimozione viene chiamata inter-frame prediction. Analogamente alla intra-frame
10prediction, un blocco da codificare viene associato ad un blocco di riferimento stavolta non
più appartenente allo stesso frame ma collocato in un frame differente, anch’esso chiamato di
riferimento. Non verrà codificato l’intero blocco da codificare ma solamente l’informazione
relativa al frame di riferimento (essa può essere condivisa con altri blocchi dello stesso frame)
e ad una eventuale dislocazione spaziale (orizzontale, verticale o obliqua) del blocco di riferi-
mento nel frame di riferimento rispetto alla proiezione del blocco da codificare nel frame di
riferimento stesso. Anche nel caso della inter-prediction, per consentire una ricostruzione del
frame più fedele, spesso viene codificata anche la differenza tra il blocco da codificare e quello
di riferimento, che sarà ancora una volta una matrice di valori prevalentemente nulli. Anche
in tal caso si usano tecniche per lo sfruttamento della ridondanza percettiva e statistica sulla
differenza tra i blocchi per raggiungere una più alta efficienza di compressione.
In generale dunque, una sequenza video codificata è composta da “3 tipi” di frame differenti,
ovvero:
• I-frame (Intra coded frame): codificato senza alcuna conoscenza degli altri frame che
compongono il video
• P-frame (Predictively-coded frame): codificato tenendo conto che si ha una conoscen-
za dei frames precedenti e dunque si può sfruttare, oltre alla ridondanza percettiva,
statistica e spaziale, la ridondanza temporale
• B(b)-frame (bidirectional predictively-coded frame): codificato tenendo conto che si ha
una conoscenza sia dei frames precedenti che di quelli successivie. Dunque è possibi-
le sfruttare somiglianze temporali, oltre che con frame passati, anche con frame futuri
rispetto al frame in questione.
La Figura 2.7 ci aiuta a capire meglio questi concetti:
Figura 2.7: Picture coding type
112.3 Riepilogo delle metodologie di rimozione delle ridon-
danze
Nelle sezioni precedenti, si è analizzato in che modo sia possibile codificare in maniera efficien-
te le sequenze video, sfruttando la rimozione di dati superflui. In particolare si sono analizzate
le tecniche che consentono la rimozione delle ridondanze presenti in un video. Nella Tabella
2.1 riportata di seguito, si riassumono tutte le 4 principali ridondanze presenti in una sequenza
video, quali tecniche si adoperano per la loro rimozione e quali vantaggi comportano.
Tabella 2.1: Riepilogo delle varie tecniche di rimozione di ridondanza nelle immagini
Ridondanza Tecnica di rimozione meccanismo Vantaggi
Percettiva Trasformazione Dopo la quantizzazione, i dati Risparmio di me-
e quantiz- in eccesso vengono tagliati moria
zazione
Statistica Codifica Si sfruttano proprietà sta- Migliore capacità
entropica tistiche che si basano sul- di compressione
l’occorrenza dei pixel in un
immagine
Spaziale Intra- Viene codificato solo il bloc- Minonore
prediction co di riferimento e la sua complessità
locazione nell’immagine da computazionale
codificare
Temporale Inter- Viene cercato il blocco nel Elevata efficienza
Prediction/motion frame precedente che corri- di compressione
estimator sponde al blocco nel frame
attuale
12Capitolo 3
Gli standard della codifica/decodifica
video
In questo capitolo si andranno ad analizzare quelli che sono alcuni degli standard di encodin-
g/decoding video più utilizzati degli ultimi anni. Analizzeremo in breve gli standard Motion
JPEG e H.264, in quanto hanno avuto un ruolo importante per la nascita e lo sviluppo dell’
ultimo e attualmente più utilizzato standard HEVC, anche noto come H.265. Per iniziare, trat-
teremo quanto visto nel Capitolo 1 in relazione ai due standard in esame, in particolare quali
metodi utilizzano entrambi per le rispettive codifiche.
3.1 Cenni su Motion JPEG
Lo standard Motion JPEG è uno standard che utilizza le tecniche di compressione JPEG [2],
uno dei codec più utilizzati per quanto riguarda la codifica delle immagini. Come descritto
nella parte introduttiva del Capitolo 1, un video è una serie di immagini (o frame) che si sus-
seguono ad una velocità tale per cui il sistema visivo umano non riesce a rendersi conto del
passaggio fra un frame e l’altro, percependo tutto come un movimento fluido. Il Motion JPEG
(M-JPEG), codifica ognuno dei frame come una serie di immagini JPEG. I vantaggi sono che
ogni frame è codificato come se fosse una singola immagine JPEG, con una buona flessibilità
sia in termini di qualità, sia in termini di rapporto di compressione (he migliora leggermente),
a discapito però di una maggiore complessità computazionale. Lo svantaggio principale del
13M-JPEG è che, dal momento che converte ogni frame singolarmente, non sfrutta la ridondan-
za temporale presente nel video e legata alle somiglianze fra frame adiacenti, ma solo quella
legata alle somiglianze tra le varie parti del frame. Questo ha delle ripercussioni sul rapporto
di compressione, in particolare questo risulta essere minore rispetto a quello che si avrebbe
con le altre tecniche di compressione video.
Analizziamo ora quali tecniche vengono usate per la compressione M- JPEG. La principale mo-
dalità di compressione che utilizza il M-JPEG si basa sulla rimozione della ridondanza percet-
tiva e statistica. Si opera, anche in questo caso, un partizionamento dell’immagine in blocchi.
Si esegue un cambio di dominio attraverso la DCT. La trasformata viene applicata su blocchi di
pixel 8x8, riducendo al minimo la probabilità di perdita di informazione. In un immagine di 8x8
elementi, i termini minimi del coseno non sono legati ai valori dei pixel, quindi essi possono
essere calcolati una volta per tutte creando una matrice di 8x8 elementi, che saranno utilizza-
ti per la successiva decodifica. Per ciascun blocco si elimina un certo numero di coefficienti
scelti in base a delle tabelle chiamate matrici di quantizzazione. Dopo questa operazione molti
coefficienti sono diventati degli 0. I nuovi coefficienti vengono riordinati e codificati tramite
la codifica di Huffman.
3.2 Cenni su H.264
H.264 è il risultato di un progetto congiunto fra Video Coding Expert Group ITUT e ISO/IEC
Moving Pictures Expert Group (MPEG) [1], [3]. Un nuovo campo applicativo di questo stan-
dard è la codifica video IP- based nelle telecamere di rete. Un punto di forza di questo standard è
sicuramente il fatto che, se comparato con uno standard MJPEG, è in grado di ridurre le dimen-
sioni dei file digitali di oltre l’80%, senza compromessi in termini di qualità delle immagini[8].
Questo standard è anche conosciuto con il nome di H.264/AVC (Advanced Video Coding). A
caratterizzare l’H.264/AVC troviamo degli strumenti e delle estensioni rispetto ad altri stan-
dard, in particolare, l’utilizzo di blocchi a dimensione variabile , che utilizzerà per la rimozione
di ridondanza percettiva, o che utilizzerà nella inter e intra prediction (predizione temporale
e spaziale) . Le dimensioni di tali blocchi possono essere 16x16, 8x8, 16x8 o 4x4 (Figura 3.1) e
viene utilizzato il vettore di movimento codificato, in base a una gerarchia di predizione che
14parte dal macro blocco 16x16[25]. Un altro degli aspetti rilevanti di questo standard è che la
Figura 3.1: Flexible Block dimension
intra-picture viene eseguita predeterminando l’intero blocco da campioni di blocchi adiacenti.
È possibile prevedere blocchi 4x4, 8x8 e 16x16 dove, per i casi 16x16 e 8x8 è consentita solo
intra-prediction planare (orizzontale e verticale). Nel caso di blocchi 4x4 sono supportati 9 tipi
di previsione (DC e 9 modalità di previsione spaziale angolare). Per quanto riguarda codifica
entropica, lo standard ne specifica diversi tipi, alternativi alla codifica di Huffman:
• VLC (Variable Lenght Coding): basata su tabelle di assegnazione statiche
• CAVLC (Context-Adaptive VLC): utilizza diverse tabelle VLC specificatamente ottimiz-
zate. A seguito della predizione, trasformazione e quantizzazione i valori relativi ai coef-
ficienti sono molto spesso nulli o molto piccoli: la codifica a lunghezza variabile sfrutta
le sequenze di zero, l’elevata frequenza di valori +1 e -1, e la correlazione fra il numero
di coefficienti non nulli di un blocco e quello nei blocchi adiacenti
• CABAC (Context-adaptive Binary Arithmetic Coding): sfrutta in modo ancora più effi-
ciente la correlazione fra simboli perché utilizza la statistica dei simboli precedentemente
15codificati per stimare la probabilità condizionata, usata per selezionare uno fra i diversi
modelli possibili [28].
Sono tutti metodi universalmente applicabili. Il CABAC in particolare è un metodo di codifica
per segnali binari, quindi prima di essere usato, bisogna applicare una “binarizzazione” dei
coefficienti di trasformazione o dei vettori di movimento [25].
3.3 Confronti fra Motion JPEG e H.264
Avendo analizzato a grandi linee gli aspetti principali fra due dei più diffusi metodi di codifica
video, confrontiamo ora le caratteristiche di entrambi i metodi. Come prima cosa possiamo no-
tare un particolare abbastanza ovvio, ovvero che sicuramente l’ H.264/AVC è migliore rispetto
al M-JPEG, in quanto è uno standard che utilizza dei metodi finalizzati alla codifica di sequen-
ze video, mentre come detto nella Sezione 2.1., M-JPEG basa il suo metodo di compressione
sulla codifica di immagini, applicata ad ogni frame. L’H.264/AVC sfrutta quindi le tecniche di
rimozione di ridondanza spaziale e temporale che MJPEG non utilizza. Entrambi gli standard
sono utilizzati nei medesimi campi di applicazione, come per esempio la video sorveglianza o
in sistemi di trasmissione remota che utilizzano lo scambio dei dati video attraverso la rete.
16Capitolo 4
Standard High Efficiency Video Coding
(HEVC o H.265)
In questo capitolo si andranno ad analizzare quelle che sono state le esigenze che hanno portato
allo sviluppo dell’attuale standard High Efficiency Video Coding (HEVC o H.265) e quali nuove
caratteristiche sono state introdotte. L’HEVC si è imposto rispetto ai precedenti standard per
rispondere alle esigenze che i sistemi video di ultima generazione hanno imposto. Verranno in-
fine analizzati alcuni articoli scientifici che riportano alcune architetture hardware, implemen-
tate principalmente su FPGA (Field Programmable Gate Array), per i blocchi che si occupano
della rimozione della ridondanza spaziale (intra-prediction) e temporale (inter-prediction), e
quelli che eseguono le trasformate.
4.1 Generalità HEVC
Con il meeting preliminare, svoltosi a Dresden, in Germania, organizzato dal Motion Pictu-
res Expert Group (MPEG [3]), riguardo le esigenze del mercato e dei consumatori imposte
dalla veloce crescita tecnologica nel campo dei video digitali, si è giunti alla conclusione che
lo standard H.264/AVC fosse diventato ormai poco performante riguardo alla qualità sempre
maggiore che i contenuti video avevano raggiunto. HEVC era stato progettato per ridurre di
un fattore pari a due il bit rate, a confronto con l’H.264/AVC. I risultati che si sono raggiun-
ti furono maggiori di quelli prospettati. Dopo l’applicazione di test esplorativi, si era notato
17infatti che non solo si era raggiunto l’obiettivo prefissato, ma si era ridotto del 70% il bitrate
rispetto al H.264/AVC[15]. Nonostante la crescita della complessità degli “intra e inter pre-
diction modes”, il tempo impiegato per la compressione, è stato una altro aspetto positivo per
quanto riguarda la codifica real-time dei grandi formati video (per esempio per i video HD
che hanno introdotto una maggiore risoluzione p.e. 1280 x 720p e 1920 x 1080p). Esso infat-
ti, era cresciuto rispettivamente, per codifica e decodifica, solo del 10% e del 60% rispetto ai
tempi del’H.264/AVC [14]. Molti strumenti di codifica dell’ HEVC sono ripresi dal H.264/AVC
e migliorati. Fra le migliorie introdotte dal HEVC troviamo l’incremento della risoluzione vi-
deo, il miglioramento dell’efficienza di codifica, della resilienza alla perdita dei dati, nonché
l’implementabilità utilizzando architetture di elaborazione parallela [15]. Fra le novità asso-
lute dell’HEVC, che verranno riprese in seguito, troviamo inoltre l’introduzione di un nuovo
schema di partizionamento in blocchi dell’immagine, con blocchi di dimensione 64x64[26]. I
metodi di codifica dell’HEVC sono ibridi (come per gli standard precedenti fin già dal H.261),
ovvero utilizzano congiuntamente la codifica basata su inter-/intra prediction e la 2D block
transform. Vediamo ora come opera un tipico algoritmo di codifica/decodifica.
Algoritmo di codifica dell’HEVC
Nella Tabella 4.1, sono raccolti i principali blocchi della Figura 4.1 con le loro funzionalità. In
Figura 4.1 è mostrato lo schema a blocchi che utilizza il codec HEVC per codifica e decodifi-
ca. Ogni immagine è divisa in regioni con blocchi di forma diversa e l’esatto partizionamento
dei blocchi viene inviato al decoder. La prima immagine di una sequenza video, o la prima
che viene trovata dopo un accesso casuale in un punto del video, è codificata solo con la ri-
mozione della ridondanza spaziale utilizzando la intra-prediction. Per i restanti frame della
sequenza, vengono usati dei metodi di codifica tramite la predizione temporale. L’immagine
da processare, già divisa in CTU, viene mandata in input a quattro blocchi: il General Coder
Control, che manda i segnali di controllo per ogni blocco, il Filter Control Analysis, che esegue
operazioni di filtraggio opportune, l’Intra-Picture Estimation, il Motion Estimation e a un nodo
sommatore (Figura: 4.1). In ingresso al blocco Transform,Scaling and quantization (riquadro
rosso nella Figura: 4.1), troviamo la differenza fra la predizione effettuata dai blocchi della
intra-prediction (4.1 riquadro verde), o dalla inter-prediction (4.1 riquadro blu), con il segnale
18Figura 4.1: Schema a blocchi della codifica/decodifica HEVC
di input. Il metodo di predizione è deciso attraverso un selettore che commuta fra il blocco del-
la intra-prediction e della inter-prediction. Il segnale uscente dal blocco Transform,Scaling and
Quantization andrà in ingresso a un blocco che genera un segnale successivamente usato per
la intra-predizione e a un blocco facente parte del decoder, lo Scaling and Inverse Transform,
che esegue le operazioni di scaling (arrotondamento a numeri interi) e la trasformata inversa
(4.1 riquadro arancio). L’immagine in output, prima che venga inviata al buffer di decodifica
(4.1 riquadro viola), passa attraverso un opportuno blocco del decoder chiamato Deblocking
and SAO Filters, che consente di migliorare i frame della sequenza video, in modo tale che gli
errori dovuti al partizionamento in blocchi dell’immagine, vengano adeguatamente filtrati. In-
fine, un blocco che eseguirà la CABAC per codificare il bitstream in uscita (4.1 riquadro giallo),
riceverà i segnali dal blocco di trasformazione, dal General Coder Control,dai blocchi della intra
e inter-prediction e dal Deblocking and SAO Filters.
19Tabella 4.1: Sintesi dei blocchi che costituiscono la parte algoritmica dell’HEVC
Blocco Encoder Decoder Funzionalità
General Coder Control Si No Genera segnali di
controllo
Transform,Quantization and Scaling Si Si Esegue un cambio
di dominio (colore-
frequenza),arrotonda
a numeri interi, taglia
alte frequenze
Intra-prediction Si Si Elimina ridon-
danza spaziale,
ricostruzione frame
Inter-prediction Si Si Elimina ridon-
danza temporale,
ricostruzione frame
Deblocking and Filters Si Si Elimina i difetti ge-
nerati dal partiziona-
mento in CTU
Header Formating and CABAC Si No Esegue codifica CA-
BAC e prepara il flus-
so di dati per la tra-
smissione
4.2 Struttura e novità del livello di codifica
In questa sezione andremo ad analizzare alcune delle principali migliorie introdotte dall’HEVC
rispetto al suo predecessore, l’H.264/AVC
20Figura 4.2: Divisione in macroblocchi 32x32 utilizzata nei precedenti standards (a) e divisione
in CTU 64x64 in HEVC
Struttura ad albero per il partizionamento in blocchi
Il cuore del livello di codifica dei precedenti standard era la suddivisione del frame in macro
blocchi di dimensione massima 16x16 e i macro blocchi erano le unità base che dovevano es-
sere processate. Era compito dell’encoder scegliere quale metodo di compressione dovesse
essere utilizzato per ogni macro blocco. HEVC è stato pensato come standard per i video ad
alta qualità, HD e UHD che hanno risoluzioni rispettivamente 1280x720 o 1920x1080 e 3840 x
2160 pixels. La struttura analoga introdotta nell’HEVC è una struttura ad albero, che ha come
unità base le Coding Tree Units (CTU), dove le grandezze di queste vengono scelte dall’encoder
e possono essere maggiori rispetto ai macro blocchi utilizzati dai precedenti standard, ovvero
64x64 pixel.
Nella Figura 4.2 [31] viene mostrato il cambiamento introdotto dalle CTU nell’HEVC rispetto
21ai macroblocchi dei precedenti standards. Le CTU hanno le stesse funzioni dei macro blocchi
dei precedenti standard, ma sono state introdotte per rendere l’HEVC più flessibile. Come si
vede dalla Figura 4.3, i CTU sono divisi in blocchi ancora più piccoli chiamati Coding Unit (CU),
che a loro volta possono essere divisi e codificati secondo la predizione spaziale o temporale
(intra e inter prediction) in Prediction Units (PU) [15]. Infine, le PU possono essere divise in
Transform Unit (TU), con dimensioni che vanno da blocchi quadrati 4 x 4 a 32 x 32, che saranno
utilizzate per la trasformazione. Le CU di dimensione NxN, codificate con l’intra-prediction
(spaziale), possono essere divise solo in blocchi quadrati di dimensione N/2xN/2. Le CU codi-
ficate con l’inter-prediction (temporale) invece, possono essere divise in PU quadrate e non,
La divisione può essere anche asimmetrica, fino a che un lato della forma non quadrata risulti
lungo almeno quattro pixel.
Figura 4.3: Struttura ad albero per la divisione dell’immagine in CTU, CU e PU
La intra-prediction ha avuto dei notevoli cambiamenti. Si è passati da 10 a 35 modi di pre-
dizione spaziale (Figura 4.4), rispetto all’H.264/AVC. Si hanno infatti 33 direzioni angolari di
predizione, la predizione planare (che può essere verticale e orizzontale) e il modo di predi-
zione DC. Per quanto riguarda la inter-prediction, questa è stata migliorata rispetto a quello
che era per i precedenti standards. In particolare la predizione temporale usa L’Advanced Mo-
tion Vector Prediction (AMVP)[26]. In aggiunta a ciò, il blocco Integer-pel Motion Estimation
(IME) esegue la stima del movimento ed è composta da un algoritmo di ricerca e una procedura
di ottimizzazione chiamata Rate/Distortion (R/D), che riduce in modo ottimale la ridondanza
temporale trovata nella sequenza video. Questo blocco è è uno dei più critici nella codifica
22Figura 4.4: I 35 modi di predizione dell’intra prediction dell’HEVC
video, perché risulta il più complesso dell’encoder richiede più del 90% del tempo di codifica
[6].
4.3 Alcuni aspetti dell’implementazione hardware
Gli encoder/decoder hardware possono essere implementati su specifici circuiti integrati (ASIC)
o su schede programmabili chiamate FPGA. Le soluzioni ASIC hanno prestazioni più elevate
ma maggior costo economico, in più sono progettate solo per un determinato funzionamento.
Le implementazioni su FPGA invece, utilizzano piattaforme hardware riconfigurabili e sono
più convenienti in termini economici. In questa sezione si andranno ad analizzare alcune im-
plementazioni hardware specifiche, utilizzate dall’encoder e dal decoder, per l’algoritmo di
intra e inter prediction e per il blocco delle trasformate visti ed analizzati nella Figura 4.1 del-
la Sezione 4.1. In particolare, verranno spiegati nel dettaglio gli articoli [29], [17] e [4], e in
aggiunta verranno brevemente illustrate altre implementazioni alternative.
Architettura Hardware intra-prediction
Nell’articolo [29], viene proposta una architettura hardware per il blocco della intra-prediction,
implementata su FPGA. L’architettura è studiata per video HD real-time con risoluzione 1920
x 1080p e framerate uguale a 30 fps. Ogni modulo implementato, può operare a 200 MHz e l’en-
coder può ottenere una codifica in tempo reale con una frequenza di funzionamento minima di
23140 MHz. Questa architettura. L’architettura suggerita in questo articolo, è stata implementata
su Xlinx Zynq ZC706, ed è studiata per incrementare il parallelismo delle operazioni e ridurre
il consumo di risorse e si focalizza inoltre su questi aspetti:
• struttura e modalità di partizionamento iniziale dei blocchi dell’immagine evitano il
processo di ottimizzazione
• viene usata un’architettura pipelined di codifica delle Transform Unit (TU) con blocchi
4x4 per ciclo
• l’architettura di Intra-prediction è ottimizzata per blocchi 4x4 per prevedere 19 modalità
di previsione in parallelo.
Uno schema dell’architettura è rappresentato nella Figura 4.5 e favorisce il pipelining. Un mo-
Figura 4.5: Architettura dell’encoder
dulo di controllo per il buffer dell’immagine in input e una memoria interna, insieme al modulo
di partizionamento veloce costituiscono la prima parte dell’architettura. Il modulo “Split and
Mode Decision” seleziona la struttura ad albero quadrato e la direzione di predizione adatta
per ogni CU. Questi dati, insieme ai pixel grezzi, vengono passati alla memoria dell’immagine.
La seconda tappa include il ciclo di ricostruzione, dove vengono creati, con i pixel di riferimen-
to tramite il modulo “intra-prediction”, i blocchi di riferimento. Questa fase è ottimizzata per
24ridurre la latenza del ciclo e i tempi di codifica. Dopo la trasformazione dei blocchi effettua-
ta dal modulo che esegue la trasformata, si passa all’ultima parte dell’architettura, dove una
memoria immagazzina i coefficienti appena calcolati. Dopo la binarizzazione dei coefficienti
viene effettuata la codifica CABAC e viene generato l’output. La intra-prediction è strettamen-
te legata al modulo di Split e Mode Decision. Nella Figura 4.6 ne viene mostrato lo schema. il
Figura 4.6: Architettura del modulo Split e Mode Decision
modulo ha dei sotto moduli che si occupano delle predizioni angolari, la predizione DC e quel-
la planare. L’output di ogni modulo è di 4 pixel per ogni ciclo di clock. Tramite operazione di
shift e di moltiplicazione, eseguita dai moduli di previsione angolare, si possono ricavare tutti
i modi di predizione angolare, con un conseguente risparmio e riutilizzo di risorse. Con una
serie di shift e di somme viene eseguita la modalità planare. Per la modalità DC, un albero di
sommatori è implementato per calcolare il valore DC. L’output generato, passa in un modulo
che lo trasforma tramite la Trasformata di Handmard (modulo “Row Transform” Fig.4.6) e i
coefficienti generati vengono mandati in ingresso a un buffer. Un Multiplexer, infine, sceglie
il modo di previsione adatto. Questo schema è studiato per massimizzare il troughput dei dati,
l’implementazione parallela dei sotto moduli e per ridurre la latenza dei moduli della intra-
predizione.
Nell’articolo [29], l’architettura appena analizzata, è confrontata con alcuni articoli, fra questi
l’articolo [16]. Nell’articolo [16] l’architettura proposta è presentata nella Figura 4.7: La parti-
colarità di quest’architettura è che sono presenti due cicli di ricostruzione, uno che si occupa
dei blocchi 8x8, 16x16 e 32x32, e uno che si occupa solo dei blocchi 4x4. In questo modo, ven-
25Figura 4.7: Schema architettura proposto nell’articolo [16].
gono migliorati i tempi di codifica. Il ritardo introdotto dal nuovo ciclo di ricostruzione per i
blocchi 4 x 4, è limitato con la rimozione di alcune funzionalità. Ogni ciclo, fornisce i dati tra-
mite due diversi percorsi, passando in entrambi i casi attraverso i moduli di stima RATE e DIST.
Per il ciclo dei blocchi 4x4, vi è un modulo chiamato MODE DECISION, per quello dei restanti
blocchi, un modulo chiamato MODE DECISION and VOTING (Figura 4.7). Il segnale generato
dal modulo MODE DECISION, viene inviato al modulo MODE DECISION and VOTING, dove
viene scelto il metodo di decisione opportuno. Il segnale generato da quest’ultimo passerà at-
traverso un modulo che esegue la binarizzazione dei coefficienti, che a sua volta genererà un
segnale che sarà inviato al modulo che eseguirà la codifica CABAC per il flusso di dati generato
come output. Questa architettura è stata implementata su Arria II GX. Un altra implementa-
zione hardware la troviamo nell’articolo [12], dove l’architettura proposta (Figura 4.8) è stata
implementata su una FPGA Xilinx XC6VLX130T FF1156. In questa implementazione, i modi
di predizione angolare, planare e DC sono supportati per tutte le dimensioni delle PU (4x4,
8x8, 16x16 e 32 x32). Le moltiplicazioni che si utilizzano nel modo di predizione DC, sono
eseguite tramite moduli di shift e moduli di somma. Per il modo planare, sono utilizzati invece
moduli moltiplicatori. 16 vettori sono usati per immagazzinare i pixel dei blocchi adiacenti,
dopodiché vengono caricati in 64 cicli di clock e 3 diverse funzioni sono usate per calcolare i
26Figura 4.8: Desing dell’architettura dell’articolo [12].
modi di predizione, per tutte le dimensioni delle PU. La funzione per le predizioni angolari può
processare 32 pixel in un ciclo di clock, quella per le predizioni planari 4 pixel/ciclo e infine,
quella per la predizione DC 1 pixel/ciclo.
Architettura Hardware inter-prediction
Il blocco Integer-pel Motion Estimation (IME), che si occuppa della rimozione di ridondanza
temporale, è il blocco che ha il carico di lavoro più oneroso. Nell’articolo [13] analizzato in
questa sezione, verrà proposta una nuova implementazione hardware che può eseguire velo-
cemente i calcoli dell’IME e ridurre la complessità computazionale dell’encoder. L’architet-
tura è stata implementata su FPGA Xilinx, Virtex-7 XC7VX550T-3FFG1158. Le proposte per
raggiungere questi obbiettivi sono:
• un nuovo disegno di progetto per il modulo sommatore SAD con una struttura ad albero
• nuovo ordine di scansione della memoria.
L’implementazione hardware proposta per l’HEVC, fornisce i SAD minimi e i relativi vetto-
ri di movimento associati, per tutte le partizioni possibili di un blocco 64x64. Sfrutta inoltre
il parallelismo in modo efficiente. La nuova struttura ad albero del modulo SAD, consente
di migliorare le operazioni di somma nel primo livello dell’albero, partendo dalla dimensione
massima delle CTU, dimezzando il numero di operazioni nei successivi livelli dell’albero. Si è
riusciti ad ottenere la minima latenza possibile nelle operazioni, grazie alle risorse fornite dal-
la FPGA. Per quanto riguarda il nuovo ordine di scansione della memoria, sono stati utilizzati
27una serie di moduli di shift riconfigurabili e moduli Processing Element (PE), che si occupano
della memorizzazione dei pixel necessari sia per i blocchi predetti, sia per i blocchi di riferi-
mento, mantenendo tali pixel sempre disponibili per il modulo SAD e per il calcolo del vettore
di movimento. Nella Figura 4.9, è mostrata la struttura proposta. Il sistema è composto da due
Figura 4.9: Architettura del blocco di inter-prediction
memorie, una per i CU di riferimento e una per l’area di ricerca , 64 moduli Processing Unit (PU)
(in rosso), il nuovo modulo (in verde) SAD Adder Tree Block (SATB) e un blocco di confronto
che salva i valori minimi forniti dal SATB e i relativi vettori di movimento corrispondenti per
tutte le partizioni CU. Come mostrato in Figura 4.10, un modulo PU, è costituito da 64 moduli
PE ed ognuno calcola la differenza fra il pixel corrente e quello di riferimento (Figura 4.11).
In un solo ciclo di clock, ad ognuno dei moduli PU vengono consegnate le colonne di pixel
Figura 4.10: Modulo PU
28correnti e quelle di riferimento, e ognuno di essi calcola i valori di distorsione dei pixel di un
blocco 64 x 64. Il modulo successivo SATB, calcola il SAD per tutte le possibili unità di pre-
visione (più di 600). Ogni PE calcola la differenza fra il pixel corrente e quello di riferimento
(Figura 4.11). Infine il blocco di confronto (Figura 4.9 blocco blu) è incaricato di memorizzare
Figura 4.11: Modulo PE
il minimo SAD con i rispettivi MV per ogni CU.
Un altro desing hardware è proposto nell’articolo [23]. In quest’articolo vengono introdotti
due moduli: L’Horizontal Reference SRAM e il Vertical Reference SRAM. Questi sfruttano il co-
siddetto “2-D reuse”. L’architettura di riferimento proposta è mostrata nella Figura 4.12. In
Figura 4.12: Architettura articolo [23]
un’architettura che utilizza una sola SRAM, i pixel del frame di riferimento vengono “bufferiz-
zati”. Ai pixel allocati nella prima riga, si può accedere attraverso l’indirizzo 0, a quelli nella
seconda con l’indirizzo 1 e cosi via. Per la ricerca di un frame, sono necessari 64 cicli di clock,
per caricare un blocco 64x64 conservato nella SRAM, nel modulo di divisione in PU. Tuttavia,
per i successivi blocchi di riferimento, è necessario solamente un ciclo di clock, poiché i pixel
mancanti sono allocati negli stessi indirizzi del blocco di riferimento. Questo è un esempio
di cosa sia il “1-D reuse”. Il “2-D reuse”, è quindi sfruttato tramite l’inserimento dei moduli
Horizontal Reference SRAM (riquadro rosso in Figura 4.12) e Vertical Reference SRAM (riquadro
29verde in Figura 4.12). L’utilizzo di due SRAM al posto di una, consente di abbattere il costo
in termini di cicli di clock, riducendo i tempi di previsione e la complessità computazionale.
Negli alberi SAD generali, i costi di tutti i livelli delle PU (8x8, 16x16, 32x32), adatti per la
ricerca completa, sono sempre calcolati. Nel modulo che compie queste operazioni (riquadro
blu, Figura 4.12), alcune PU potrebbero essere bypassate per risparmiare inutili consumi ener-
getici. Oltre a questo, anche facendo uso di “2-D reuse”, sono necessari alcuni cicli di clock
aggiornare il Reference Register Array e il Current Register Array, se i frame sono lontani l’u-
no dall’altro. Durante questo processo, l’intero albero SAD può anche essere bypassato per
risparmiare energia.
Architettura Hardware del blocco delle trasformate
L’architettura hardware per il blocco di trasformazione proposta nell’articolo [4], sfrutta la de-
composizione della matrice di coefficienti interi della DCT unidimensionale, in blocchi chiama-
ti B2 e C2 (matrici 4x4). L’architettura proposta ha TU di dimensione 4x4, 8x8, 16x16 e 32x32,
che operano in parallelo per calcolare la trasformazione DCT 2-D , utilizzando una matrice
di coefficienti DCT 1-D e una memoria di trasposizione. La trasformata 1D viene precedente-
mente calcolata e la trasformazione corrispondente è immagazzinata in una memoria. I dati
memorizzati vengono utilizzati, in un secondo momento, per ottenere la trasformazione DCT
2-D, utilizzando lo stesso blocco usato per il calcolo della DCT 1-D. Inoltre, questa architettura
è basata su shift e su somme, invece che moltiplicazioni, per il calcolo della trasformazione.
L’architettura è implementata su una FPGA Xilinx Artix-7 (Zynq- 7000). Le operazioni di mol-
tiplicazione sono sostituite da un acceleratore hardware chiamato Processing Element (PE), che
serve a rimpiazzare i moltiplicatori, tramite la conoscenza di tutti i possibili coefficienti della
DCT 1-D (Figura 4.13). Si utilizza questo modulo per il risparmio di risorse. Nella Figura 4.14
Figura 4.13: Coefficienti della DCT 1-D corrispondenti alle dimensioni del blocco TU
30è mostrato lo schema dell’architettura del modulo PE.
Il Top-Module del PE è composto da moduli di shift, un accumulatore, un contatore a tre bit,
un multiplexer, due registri e da un modulo di controllo che azzera la memoria, il contatore e
comanda il MUX. Il PE opera nel seguente modo:
Figura 4.14: Architettura proposta per il blocco di trasformazione
dopo che i coefficienti sono stati precedentemente calcolati, sulla base della decomposizione
della DCT 1-D, l’operazione inizia con uno shift che serve per identificare il coefficiente che
viene ricevuto in ingresso (un ciclo di clock per ogni shift). L’accumulatore viene utilizzato per
salvare il valore dato dall’operazione precedente. Il contatore è limitato a 3 bit perché i cicli
necessari affinché il modulo PE svolga la sua funzione, sono 6. Il modulo appena esaminato è
utilizzato in due distinte architetture per il calcolo delle due matrici, una la B2 (Figura 4.15(a)
) e la C2 (Figura 4.15(b) ). Come detto all’inizio della sezione, il calcolo della DCT bidimensio-
(a) (b)
Figura 4.15: Architettura proposta per il blocco di trasformazione
nale viene svolto tramite la decomposizione della matrice di coefficienti interi della DCT 1-D
in blocchi, e in Figura 4.16, è riportato lo schema finale dell’architettura.
31Figura 4.16: Architettura per il calcolo della DCT-2D
4.4 Considerazioni finali
L’HEVC è uno standard nato dalle necessità che sono sorte con la costante crescita, negli an-
ni passati, dei servizi video, che hanno occupato una grossa fetta del traffico internet (circa
l’86% nel 2016). Anche la nascita delle nuove tecnologie video, come ad esempio le TV Ultra
HD, che hanno risoluzioni importanti (4096 x 2160p) hanno influito sulla necessità di avere un
nuovo standard specifico per queste applicazioni. In questo capitolo, sono state presentate le
novità introdotte nell’HEVC rispetto al precedente standard H.264/AVC, con particolare focus
sugli algoritmi delle tecniche di intra e inter previsione e di trasformazione. L’implementazio-
ne hardware di tali tecniche è risultata più performante rispetto a quella software, per questo
motivo sono state analizzate delle architetture hardware specifiche per i blocchi di predizione
spaziale e temporale e per i blocchi di trasformazione. In particolare, si sono analizzate delle
architetture proposte negli articoli [29], [?], [4], che si occupano rispettivamente del blocco
di intra-previsione, del blocco di inter-previsione e del blocco di trasformazione. Tutte le ar-
chitetture presentate sono state implementate su FPGA. Proprio l’implementazione su FPGA
potrebbe essere la chiave per il futuro standard, dal momento che la FPGA è uno strumento
potente, economicamente vantaggioso e che permette il riuso di risorse.
32Capitolo 5
Il futuro degli standard di codifica video
Nel seguente capitolo, verrà svolta un’analisi riguardo tutti gli aspetti che sono stati solleva-
ti nella conferenza di Strasburgo, la riunione del gruppo MPEG con le principali compagnie
mondiali che si occupano di video coding, svoltasi in Ottobre 2014. Verranno analizzati i cam-
biamenti implementati nell’ultimo test esplorativo (JEM7) e quali miglioramenti si sono otte-
nuti nel JEM rispetto a quelli che erano stati gli aspetti emersi dai brainstorming del meeting
di Strasburgo.
5.1 Generalità ed Analisi dei brainstorming
ITU-T VCEG [1] e ISO/IEC MPEG [3] si sono uniti per formare un gruppo di lavoro che nasce
dalla necessità, che si è avuta negli ultimi anni, di creare un nuovo standard per quelli che
sono i principali bisogni del futuro della codifica video. Il gruppo di ricerca, conosciuto come
Joint Video Exploration Team (JVET), sta eseguendo un’attività di esplorazione congiunta,
per valutare i potenziali cambiamenti in chiave tecnologica. Il 21 ottobre 2014 si è svolto a
Strasburgo, in Francia, un incontro ospitato dal Moving Picture Experts Group (MPEG) con
ospiti i membri della comunità dell’industria video. Lo scopo della conferenza era quello di
capire, tramite un gruppo di discussione e un brainstorming mirato, quale direzione dovesse
essere percorsa per il futuro degli standard per i video codec. I punti chiave definiti per la
conferenza possono essere raccolti nelle 6 domande proposte ai partecipanti:
331. How much additional compression (compared to HEVC) do you foresee to be needed for
your market(s)? What are the desirable frame rates and resolutions?
2. What should be “the bar” to surpass to make a new standard? (In terms of tradeoff of
compression benefit versus complexity, compatibility with existing designs, etc.)
3. How would it affect your business (and in what time frame) if a new video codec would
deliver 25% reduction in data rate for the same video quality compared to HEVC?
4. Do you see market segments where HEVC may not be successful due to lack of functio-
nality?
5. What will be the applications with highest amount of video data delivery 5-10 years
from now?
6. What would change if the industry uses the new codec as (partly or totally) royalty-free?
In questa sezione verranno raccolti i principali risultati emersi da questo incontro, andando ad
analizzare alcune delle presentazioni di diverse aziende ospiti, fra cui Netflix, Ericson, Google,
Huawei, Orange, Qualcomm e Samsung [3]. In questo lavoro di tesi, delle sei domande propo-
ste nella conferenza, verranno analizzate solo le prime cinque, in quanto hanno una valenza
prettamente tecnologica. La domanda numero sei non verrà dunque presa in considerazione.
Google evidenzia la necessità di un nuovo codec, dovuta alla crescita della qualità e dell’utilizzo
dei video, tenendo conto del fatto che le tecnologie sono ormai superiori rispetto i tradizionali
video 2D. Quello che si auspica venga raggiunto con il nuovo codec, è sicuramente un miglio-
ramento in termini di riduzione delle dimensioni dei video. Analizzando la presentazione di
Netflix si evince, anche in questo caso che c’è la necessità di migliorare qualcosa in termini di
risparmio di memoria. Nel loro intervento, viene presentata una “codec wish list” che riporta
i seguenti punti:
• Bisogno di un elevato frame rate
• Maggiore gamma di colori rappresentabile
• Un maggiore “Dinamic Range”(l’intervallo tra le aree visibili più chiare e quelle più
scure)
34• Maggiore qualità video e non solo fedeltà del segnale
• La necessità di risparmiare memoria
In risposta alla domanda numero 3 , Netflix afferma che la riduzione della velocità di trasmis-
sione del 25% non sia sufficiente. Orange (Telecom francese) mostra come i servizi video siano
la tipologia di contenuti che utilizza la maggior quantità di dati nella sua rete. Sottolinea la
necessità di migliorare la gamma di colori e la fluidità dell’immagine, aumentando il framerate.
Dai futuri standard, vorrebbe la riduzione della complessità di implementazione e dei consumi
di energia. In particolare, vorrebbe la riduzione del 50% del bitrate e un framerate di 100 Hz
per le applicazioni televisive. Ritiene che la riduzione della velocità di trasmissione del 25% in-
fluenzerebbe marginalmente gli affari. L’ultima presentazione che viene analizzata è quella di
Huawei. Il colosso cinese sottolinea il fatto che le reti stanno diventando lente in confronto alle
moderne tecnologie dei dispositivi. Mostra infatti come, nel campo mobile, il 50% della banda è
occupata da servizi video, con una conseguente formazione di colli di bottiglia. Anche Huawei
dichiara che la riduzione della velocità di trasmissione del solo 25% non sia sufficiente, e pone
enfasi alla necessità di sviluppare un codec video che sia pensato anche per le applicazioni in
servizi mobile. Un aspetto secondo loro da tenere in considerazione, deve essere sicuramente
il miglioramento della tecnologia hardware utilizzata [24]. I risultati emersi dalla conferenza
possono essere riassunti nella Tabella 5.1. Nella colonna di sinistra è riportata una sintesi delle
domande, in quella di destra le necessità fatte presenti dalle aziende. Come segnalato all’inizio
della Sezione 4.1 la domanda numero sei non verrà presa in considerazione perché non rientra
negli obbiettivi di questa tesi.
35Tabella 5.1: Riepilogo delle necessità emerse dopo la conferenza di Strasburgo.
Domande della conferenza Risposte degli intervistati
Google Netflix Orange Huawei
D1: Quanta compressione aggiuntiva si Risoluzioni Framerate 1080p per Risoluzioni
prevede di aver bisogno (in relazione al- mirate an- elevato, mobile, 4K maggiori
l’HEVC)? Si vuole un framerate e una che alle risolzioni per TV di 720p
risoluzione specifica? tecnologie maggiori per ap-
3D dell’HD plicazioni
mobile
D2: Quali sono i limiti da superare nella Riduzione Risparmio Riduzione Minor
realizzazione di un nuovo standard? dimen- memoria, del bitrate bitrate,
sioni maggiore del 50%, miglior
video gamma minor computa-
di colori consumo zione con
e qualità di energia consumi
video energetici
accettabili
D3: Come cambierebbero i vostri affari se – Non basta Impatto –
la velocità di trasmissione nel nuovo codec un incre- marginale
venisse incrementata del 25%? mento del
25%
D4: Pensi che in qualche area del mercato – No No No
HEVC possa non avere successo a causa di
mancanza di funzionalità?
D5: Quale sarà il campo di applicazione Video 3D Cloud Servizi Videosharing
dove il traffico di dati video si distribuirà televisivi, e appli-
maggiormente nei prossimi anni? appli- cazioni
cazioni mobile
social
36Puoi anche leggere

















































