SISTEMI INFORMATICI MOBILI
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
SISTEMI INFORMATICI MOBILI
VinX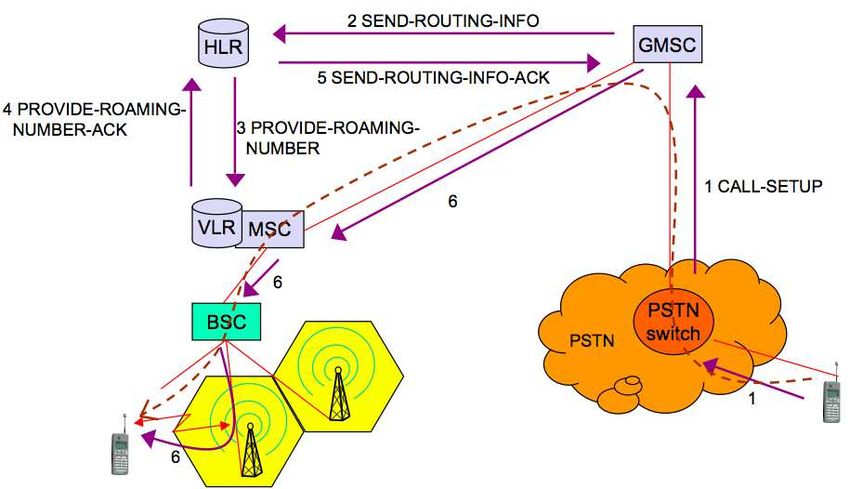
Indice
1 Introduzione 1
1.1 Da dove veniamo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Dove andiamo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2.1 Struttura base di un sistema nomadico . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2.2 Modello a clessidra . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2.3 Mattoni e clessidra . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Applicazione ed Interfacce 4
2.1 Adattabilità e trasparenza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Adattamento dei dati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.2 Interazione e/o distribuzione componenti: Estensione modello client/server . . . . 5
2.1.3 Mobilità del codice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Cambiamento: altri modelli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Architettura tuple space . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.2 Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2.3 Peer-To-Peer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.4 Middleware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.5 Livello orizzontale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2.6 Livello verticale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Piattaforme orizzontali: WWW . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3.1 Nuove tecnologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3.2 Rimedi a livello architetturale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4 Piattaforme Orizzontali: WAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4.1 WAP2.0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.5 Piattaforme Orizzontali: I-Mode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.6 Piattaforme Orizzontali: J2ME . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.7 Impatto sul sistema operativo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3 Comunicazione Wireless 22
3.1 Caratteristiche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2 Modalità di utilizzo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.2.1 Tecniche di condivisione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.2.2 Regole d’uso delle tecniche (protocolli) . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.3 Wireless LAN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.1 Protocollo IEEE802.11 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.3.2 802.11: livello logico MAC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.4 HiperLAN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.5 Wireless WAN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.5.1 GSM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.5.2 GPRS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.5.3 Wireless 3G . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.5.4 UMTS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4 Gestione della mobilità 40
4.1 Algoritmi di Tracking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.1.1 Tracking Esplicito . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.1.2 Tracking Implicito . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.1.3 Tracking Ibrido . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.2 Reti con infrastruttura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.2.1 Routing per nodo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
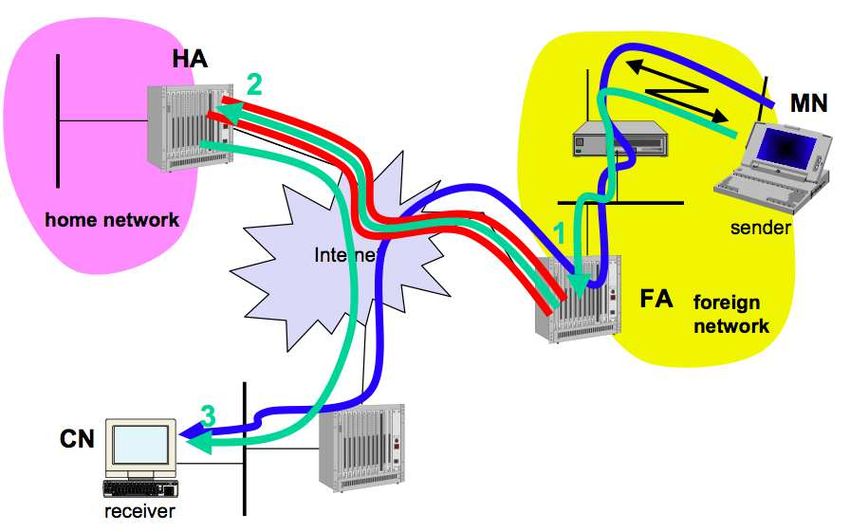
4.2.2 Cambiare indirizzo IP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.2.3 MobileIP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.2.4 Cellular IP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.2.5 HAWAII . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
I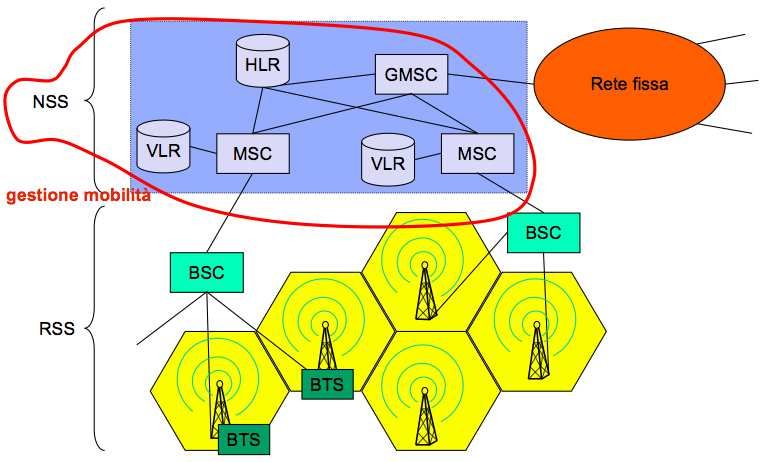
4.3 HMIPv6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.4 Reti senza infrastruttura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.4.1 DSDV . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.4.2 OLSR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.4.3 DSR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.4.4 Routing gerarchico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.4.5 Metriche di routing: LRI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.5 Reti cellulari . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
4.5.1 Architettura del GSM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
4.5.2 Architettura del GPRS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
4.5.3 Operazioni: GSM/GPRS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
4.5.4 GPRS Architettura del protocollo di comunicazione . . . . . . . . . . . . . . . . . 69
4.6 TCP in reti mobili . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
4.6.1 Problemi TCP in ambiente mobile . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.6.2 Indirect TCP (I-TCP) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
4.6.3 Snooping TCP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
4.6.4 MobileTCP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
4.6.5 Fast Retrasmit/Fast Recovery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.6.6 Selective Retransmission (SACK) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.6.7 Transaction Oriented TCP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.6.8 Confronto tra i diversi approcci . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.6.9 Miglioramenti a TCP per reti cellulari . . . . . . . . . . . . . . . . . . . . . . . . . 78
II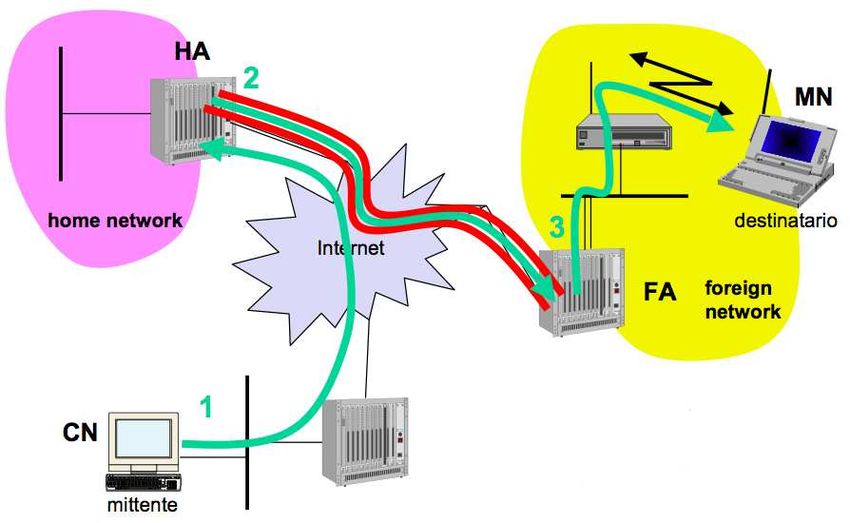
1 Introduzione
I sistemi informatici mobili possono essere visti come sistemi distribuiti aventi le seguenti proprietà:
• ubiquità: disponibilità di interconnessione in rete su scala globale;
• nomadicità: disponibilità di servizi anche lontano dall’ambiente di riferimento;
• pervasività: presenza diffusa di servizi anche in ambienti non specifici.
In altre parole sono sistemi distribuiti dove la posizione delle entità cambia durante il loro ciclo di vita.
Qui di seguito sono elencati alcuni esempi che descrivono questo tipo di sistemi:
• Commesso viaggiatore: gli archivi sono centralizzati e consistenti, mentre l’utente si può connettere
da qualsiasi postazione.
• Rimpiazzamento di reti fisse: vengono sostituite reti con sensori remoti, lan in edifici storici, ecc...
• Divertimento, istruzione, ecc...: accesso ad Internet in ambienti esterni, guida di viaggio intelli-
gente con informazioni aggiornate adattate alla posizione attuale oppure reti ad-hoc per giochi
multiplayer.
• Servizi “location aware”: sono servizi come stampante, telefono, fax, ecc... che si trovano nella rete
locale.
• Servizi “follow on”: trasmissione dell’ambiente di lavoro verso la posizione attuale, come ad esempio
l’inoltro automatico delle chiamate.
• Servizi di informazione: vengono suddivisi in servizi “push” (ad esempio offerte speciali che sono
fatte in un supermercato in un determinato istante) e servizi “pull” (ad esempio conoscere dove si
trova la pasticceria più vicina).
• Servizi di supporto: permettono il caching, informazioni di stato e seguono il dispositivo mobile
attraverso la rete fissa.
1.1 Da dove veniamo
I nodi in un sistema distribuito tradizionale sono inamovibili. Ogni nodo ha un’elevata potenza di calcolo,
un’elevata memoria ram, numerosi dispositivi di i/o ed energia illimitata. La comunicazione tra nodi
invece viene attuata da supporti fisici basati su cavi di varia natura. Questi possiedono una banda elevata
ed un tasso di errore (ber) molto piccolo.
osi Livello Protocollo
2 Datalink mac
3 Network ip Instradamento nodo-nodo
Algoritmi di routing: distance vector, link state
4 Trasporto udp/tcp/rpc Comunicazione tra processi end-to-end con diverse proprietà:
udp asincrono demultiplexing service
tcp reliable byte stream service
rpc request reply service
5 Session Application Basi di dati, filesystem, sistemi ipertestuali.
Ogni applicazione è basata su punti di vista
6 Presentation ovvero la tipologia di applicazioni abilitate
7 Application ad entrare in contatto con quel tipo di dato.
Il middleware è un livello intermedio tra il sistema operativo e le applicazioni, ciò alza il livello di
astrazione della macchina. Un esempio di middleware può essere rappresentato dalle api per applicazioni
distribuite object-oriented.
Dobbiamo notare che per ogni applicazione viene utilizzata una specifica tipologia di dati. Le basi di
dati, ad esempio, forniscono un accesso ad un insieme di strutture dati sulle quali compiono operazioni
1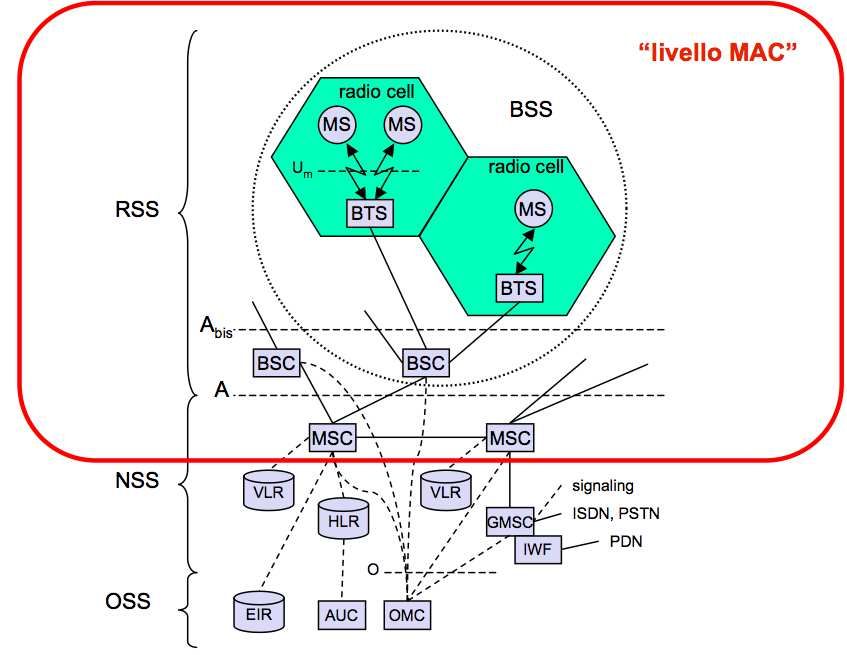
relazionali. Mentre un filesystem è composto da un insieme di oggetti con nome, struttura gerarchica ed
operazioni.
I dati possono contenere informazioni isocrone, ovvero oggetti che devono essere ricevuti e decodificati in
sincronia sia in ricezione che in trasmissione. Invece i dati push permettono la diffusione dell’informazione
da una sorgente ad una molteplicità di utenti dichiarati (sottoscrittori) o potenziali.
1.2 Dove andiamo
Ciò che abbiamo detto nel paragrafo precedente sarà esteso in modo da poter definire cos’è un sistema
nomadico, in particolare questo genera nuovi problemi rispetto ai sistemi statici. Infatti nei sistemi
statici quello che cambia è l’esecuzione, mentre nei nomadici la regola. I cambiamenti possono riferirsi
alla posizione dei nodi ed oggetti, al controllo della visibilità di ogni posizione e dell’interoperabilità tra
nodi. Quindi vogliamo che in un sistema nomadico siano presenti questi comportamenti.
Notiamo che i nodi facenti parte dei sistemi nomadici possiedono una potenza di calcolo e memoria molto
variabile tra loro quindi bisogna far coesistere questi nodi nel sistema. Inoltre il canale di comunicazione
si basa su radio frequenze e la banda è anch’essa soggetta ad un’alta varianza.
Un sistema nomadico possiede gli stessi parametri di interesse rispetto ai sistemi statici, ma siccome i
nodi si spostano, sono piccoli e leggeri, allora i risultati di interesse cambiano drammaticamente durante
il movimento di ogni singolo nodo. Quindi il primo problema consiste nel garantire la comunicazione tra
i nodi quando sono in movimento.
1.2.1 Struttura base di un sistema nomadico
La soluzione generale per alcuni problemi consiste nello stabilire delle “ricette” condivise da tutti o
comunque dalla maggioranza. Tale approccio risulta vantaggioso per l’utente perché può confrontare
più prodotti dai vari fornitori. Quindi bisogna definire un adattamento, ovvero la capacità di reagire e
comportarsi bene in un ambiente che può cambiare rapidamente.
1.2.2 Modello a clessidra
Per i sistemi distribuiti classici si utilizza il modello a strati, ovvero uno stack di protocolli. Tale approccio
non è adeguato per i sistemi che stiamo trattando, infatti si presuppone che il sistema sia omogeneo e
di conseguenza si dà troppa importanza alla comunicazione. Anche l’utilizzo di un comune middleware
risulta non sufficiente a risolvere questo problema.
Il modello a clessidra consiste nell’utilizzare uno speciale middleware che deve essere in grado di
gestire risorse distribuite su scala globale. Tuttavia molto spesso la trasparenza delle risorse non è
garantita da questo tipo di middleware. Ciò nonostante, l’interfaccia fornita da questi middleware non
è esente da problemi causati dalla lontananza delle risorse. Quindi il middleware può essere visto come
una generalizzazione del sistema operativo a livello globale. Tuttavia il collo di bottiglia è presente a
livello di rete. Di conseguenza bisogna utilizzare una grande varietà di tecnologie che sfruttano i vari
livelli dello stack di protocolli.
2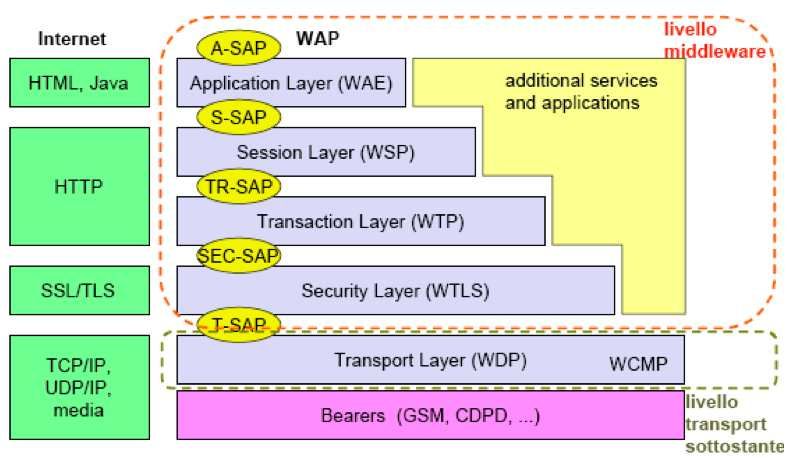
Non è possibile costruire un sistema automatico proprio per la grande varietà di contesti ed elementi
da gestire, sopratutto quando i protocolli di basso livello sono stati standardizzati mentre quelli di alto
livello sono ancora in corso di definizione.
Purtroppo l’utilizzo del protocollo ip è estremamente vincolante dato che i sistemi nomadici sono
molto eterogenei. L’ip backbone fornisce un supporto all’interazione tra sistemi eterogenei aventi reti
fisse e mobili, dove gli handover verticali consistono nel passare da una tipologia di rete ad una diversa
(si espande in ampiezza), mentre gli handover orizzontali consistono nel passare da una rete all’altra
dello stesso tipo.
1.2.3 Mattoni e clessidra
Per quanto riguarda il livello applicativo dobbiamo trattare aspetti come l’architettura software, il midd-
leware ed il sistema operativo. In un sistema nomadico la comunicazione non si esaurisce durante la
comunicazione mobile, pertanto sorgono i seguenti problemi:
• disomogeneità hardware, ovvero bisogna supportare le diverse capacità di elaborazione dei nodi;
• movimento fisico, tipicamente molto rapido;
• movimento logico, ovvero l’attraversamento di domini amministrativi.
L’adattamento in un sistema nomadico a livello di rete genera il problema sulla gestione degli handover/
prefetching, mentre a livello applicativo bisogna adottare una codifica multi-livello ed una riallocazione
dinamica. Per garantire la mobilità del sistema bisogna quindi adottare una speciale tecnologia che
permetta di spostare sia i nodi (con l’handover per la mobilità su piccola scala e localizzazione su grande
scala) che le reti (con l’uso del routing e reti di ad-hoc). Bisogna inoltre specificare quali canali wireless
utilizzare per far dialogare diversi sistemi tra loro, senza contare che è necessario definire una politica
per la gestione dell’energia.
3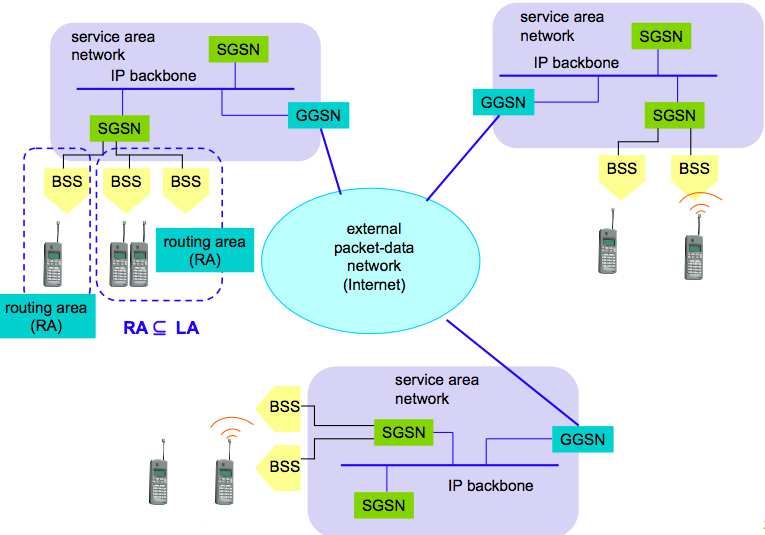
2 Applicazione ed Interfacce
Un sistema nomadico non è rappresentato da un solo sistema di comunicazione mobile. Nel precedente
capitolo abbiamo visto che sono presenti un gran numero di problematiche legate al sistema che spaziano
dalla disomogeneità dell’hardware ai vincoli sulle prestazioni, dal movimento fisico a quello logico. Tali
problematiche impattano a livello architetturale sia di quello del middleware che su quello del sistema
operativo.
Il problema relativo alle applicazioni ed interfacce verrà trattato sotto tre aspetti:
1. architettura software: dove parleremo di adattamento e/o cambiamento.
2. middleware.
3. sistema operativo.
L’architettura software è la strutturazione di un’applicazione in:
• componenti: avendo a che fare con un ambiente di nodi mobili aventi risorse limitate, si suggerisce
di collocare la maggior parte delle funzionalità sui nodi della rete fisica, tuttavia l’inaffidabilità
della rete wireless ci suggerisce di collocare tali funzionalità sui nodi mobili.
• modalità di interazione: è necessario capire se l’approccio classico di richiesta/risposta sia adatto
in un sistema nomadico.
2.1 Adattabilità e trasparenza
Per poter rispettare i vincoli definiti per questo tipo di sistemi siamo costretti ad adottare soluzioni
differenti per ognuno di questi, ciò implica che per ottenere una soluzione che accomuna le singole
decisioni prese per ogni vincolo bisogna costruire una “versione” dell’architettura che si adatta al variare
delle condizioni ambientali. Per fare ciò bisogna innanzitutto identificare quale modello sia adattabile e
quale livello di trasparenza devono avere le applicazioni.
L’adattabilità può quindi essere realizzata in due modi, variando:
1. la qualità dei dati disponibili ai nodi mobili, ovvero cambiare il grado di fedeltà rispetto all’originale.
2. la modalità di interazione: partizionamento variabile dei compiti tra nodi mobili e nodi di rete
fissa. Data una una certa strutturazione cambio le varie parti, ad esempio la mobilità del codice.
Occorre poi trattare problemi su quale elemento sarà il responsabile della realizzazione dell’adattamento.
Quindi bisogna definire il grado di trasparenza nei seguenti casi:
1. application transparent: al di sotto dell’applicazione ci sarà un qualcosa che cerca di appiattire
l’eterogeneità in modo da permettere di lavorare a livello applicativo come se non esistessero. Ma
dato che non si ha il controllo completo dell’adattabilità la soluzione potrebbe essere non ottimale.
2. laissez-faire: nel livello inferiore all’applicazione vengono passate solo informazioni e parametri.
Ciò non richiede il supporto del sistema ma ha potenziali problemi dovuti all’assenza di arbitraggio
e richiede un grande sforzo di sviluppo.
3. application aware: consiste in una collaborazione tra chi sta sotto e chi sta al livello superiore. Ad
esempio un’applicazione che sfrutta le informazioni provenienti dal livello inferiore per realizzare
qualche forma di adattamento, nel caso in cui non riesca può chiedere aiuto al livello sottostante.
2.1.1 Adattamento dei dati
Il problema in questo caso consiste in una sorgente che spedisce ad un destinatario attraversando
collegamenti con capacità diverse.
4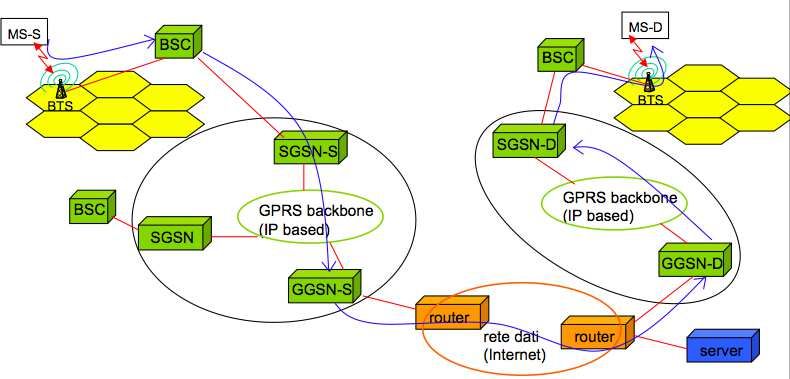
Per risolvere tale problema si usa l’adaptation agency, ovvero si associa un’entità ad ogni (non necessa-
riamente) nodo.
La struttura aa è composta dal modello rappresentato nella seguente figura dove i componenti interni
sono:
• event manager (em): vengono considerati gli eventi rilevanti per pilotare la qualità, ovvero per
pilotare l’adattamento. Tale componente ha il compito di informarsi sugli eventi o caratterizzare
uno stato. Ad esempio la sicurezza oppure le informazioni appartenenti ad altri nodi.
• resource manager (rm): gestisce le risorse necessarie all’adattamento.
• application specific adapter (asa): è il modulo che implementa le modifiche.
Il comportamento di questo modello è costituito dai seguenti passi:
1. arrivano i dati,
2. asa comunica le risorse modificate al rm,
3. rm riceve da em le informazioni sullo stato delle informazioni e le elabora,
4. em riceve le informazioni dal rm e comunica le modifiche all’asa.
2.1.2 Interazione e/o distribuzione componenti: Estensione modello client/server
Si prende in considerazione come modello di base quello client/server. Tale modello possiede la caratteri-
stica di accoppiamento stretto, ovvero abbiamo una comunicazione sincrona (accoppiamento temporale)
ed il mittente/destinatario devono conoscersi (accoppiamento spaziale). Sfruttando questo modello siamo
in grado di realizzare i protocolli rpc. Purtroppo questo modello difficilmente si adatta ad un contesto
in cui i nodi si muovono proprio perché richiede un accoppiamento sia spaziale che temporale. Quindi
nasce la necessità estendere questo modello con l’adattamento oppure utilizzare modelli alternativi.
Le estensioni del modello client/server possono essere:
1. Modello base con accodamento: stiramento al modello progettuale dove si abbandona o si rende
meno stringente l’esigenza di comunicazioni sincrone.
5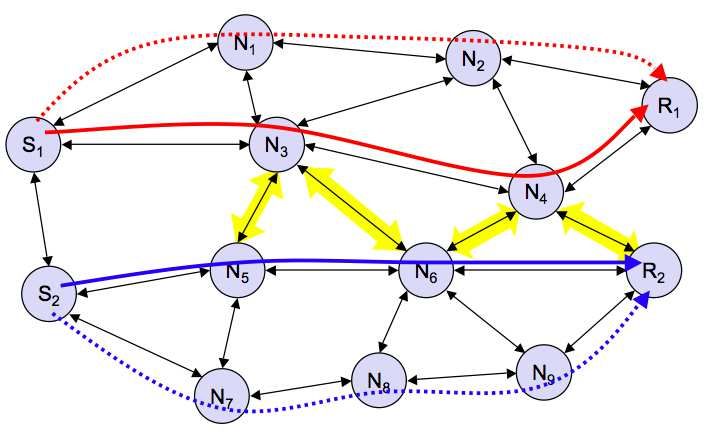
In questo caso si realizzano meccanismi di accodamento per rendere più asincrona la comunicazione,
ovvero vengono inoltrate richieste solo se il canale risulta disponibile, altrimenti vengono mantenute
e poi spedite in base a determinate politiche di scheduling.
2. Modello client/agent/server: in questo caso viene utilizzato il componente aggiuntivo chiamato
agent. L’agent ha il compito di agire nella rete fissa come sostituto del nodo mobile nella rete fissa,
in quanto il nodo mobile potrebbe non essere sempre connesso. Ciò rende il client sempre visibile
nella rete anche se esso non è realmente connesso.
Tipicamente questo approccio serve a gestire il risparmio energetico, ad esempio il client sa che
una particolare richiesta richiede un tempo non trascurabile. La inoltra e si spegne. In tal caso
l’agente è in grado di raccogliere la risposta fornita dal server.
Questa tecnica è migliore rispetto al caso di client leggeri, che si poggiano cioè solo su nodi mobili.
A tal proposito distinguiamo l’agente intermediario in due tipi:
(a) agente generalista: intermediario per varietà di client (vicino al server), ovvero legato ad uno
specifico tipo di server.
(b) agente dedicato: dedicato ad uno specifico tipo di client (vicino al client).
3. Modello client/intercept/server: per risolvere i problemi lato client, ad esempio la perdita di una ri-
chiesta, viene inserito un componente aggiuntivo sul nodo mobile, ovvero sul client. Questo modello
rappresenta l’estensione del modello con accodamento sfruttando il modello client/agent/server.
Infatti i due agenti cooperano per ridurre le trasmissioni sul collegamento wireless, per migliorare
la disponibilità dei dati e supportare le computazioni interrotte del nodo mobile. Inoltre si può
realizzare un’ottimizzazione della trasmissione, per specifiche applicazioni e di gestire nei due sensi
le disconnessioni.
Tale modello è adatto per client pesanti, ad esempio quelli che usando il prefetching, oppure quando
i nodi comunicano molto spesso tra loro.
2.1.3 Mobilità del codice
Anche in questo caso abbiamo diverse possibilità su come fornire la mobilità del codice:
1. Sistema location unaware: lo schema di interazione tra i componenti è sempre lo stesso a prescindere
dalla loro collocazione fisica.
6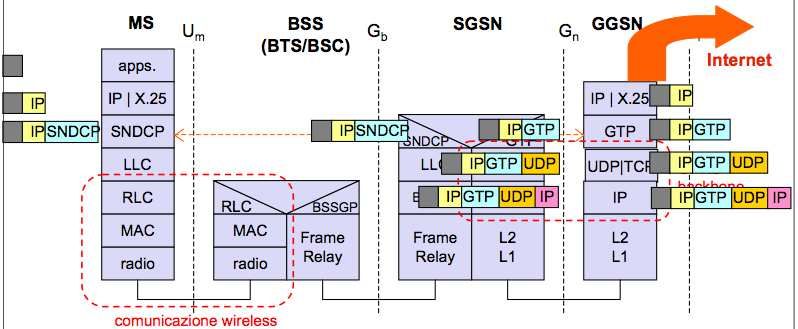
L’ambizione è quella di avere un livello trasparente. Tuttavia si presenta il problema di localizza-
zione, ovvero se l’entità che si trova nel livello inferiore è eterogenea e dinamica (come i nodi mobili
che stiamo considerando), bisogna scoprire se le entità che si trovano nel livello superiore siano
vicini o meno. Per risolvere questo problema bisogna separare i vari componenti in compartimenti
stagni in modo da avere un sistema location aware.
2. Sistema location aware: in questo caso i componenti sono partizionati e possono cambiare la loro
posizione in momenti separati. In questo modo abbiamo un miglioramento delle prestazioni del
sistema ed è supportata la mobilità dei componenti software.
Anche questo caso possiede però un ulteriore problema, ovvero bisogna decidere se e quando spo-
stare un componente. Tocca sottolineare il fatto che la mobilità del codice non consiste nella
migrazione di processi e di conseguenza non è un aspetto gestibile dal progettista software. Dato
che non esiste una soluzione univoca a tale problema bisogna decidere caso per caso.
Un componente è composto da:
1. codice: parte statica che rappresenta la logica dell’applicazione.
2. stato: parte dinamica composta dal valore delle variabili locali, dallo stack di esecuzione e dal
program counter.
3. risorse: descrittori di file.
Per poter spostare un componente possiamo usare le seguenti tecniche:
71. si sposta solo il codice:
(a) remote execution: un nodo spedisce il codice ad un’altra locazione, delegando gli altri nodi
alla sua esecuzione.
Ad esempio, il nodo A vuole eseguire del codice su un nodo esterno. Supponiamo che il nodo
B possieda le risorse di interesse per l’esecuzione del codice di A. A questo punto il nodo A
spedice il codice al nodo B, esegue il codice su B ed attende i risultati dell’esecuzione.
(b) code on demand : A trova del codice in un’altra locazione che estende le sue funzionalità e lo
richiede.
2. viene spostato sia il codice che lo stato:
(a) strong mobile agent: A si muove su un’altra locazione con tutto il suo stato (program counter,
stack e dati). A può riprendere la sua esecuzione in una nuova locazione dal punto esatto in
cui si è bloccato.
(b) weak mobile agent: A si muove verso un’altra locazione solo con i suoi dati privati. A ha
bisogno di metodi per determinare il punto in cui aveva interrotto la sua esecuzione.
(c) close-to: B è associato ad A e deve rimanere connesso. Se A si muove ad una nuova locazione
B lo deve eseguire.
8Questa tecnica comporta un adattamento dei server a particolari esigenze ed una riduzione del
traffico sulla rete. Inoltre sono supportate le operazioni di disconnessione o quelle debolmente
connesse. Questa tecnica permette l’accompagnamento nella rete fissa di nodi mobili.
Gli agenti mobili non sono necessariamente intelligenti. Se sono dotati di capacità decisionali bisogna
utilizzare due tipi di linguaggi, uno per programmare le operazioni ed uno per rappresentare la conoscenza
in modo da esprimere obiettivi, compiti, preferenze, ecc...
Tuttavia abbiamo un problema di sicurezza. Infatti l’architettura basata su codice mobile non è
ortogonale a quella client/server (o le sue estensioni). Ad esempio nel modello client/agent/server,
l’agente può essere visto come un caso particolare di agente statico.
Il modello ad agenti mobili è un caso particolare di rilassamento architetturale organizzato secondo
l’idea che il codice eseguibile di una applicazione può cambiare locazione mentre l’applicazione è in
esecuzione. Tuttavia se un client è un nodo mobile, l’interazione con N server diventa molto dispendiosa.
Una possibile soluzione a questo problema consiste nello spedire la parte che implementa la logica del-
l’applicazione verso il server con il quale si interagisce ogni volta. Dopo che il componente intelligente
ha elaborato la risposta, questa viene rispedita al client e di conseguenza anche il relativo componente.
Un’altra soluzione è quella in cui si sposta il componente tra vari server. Questo componente può
contenere:
• solo il codice eseguibile;
• sia codice eseguibile che stato (tipico degli agenti mobili).
Una volta elaborata la risposta viene rispedito sia il componente che la risposta al client. Ciò permette
un notevole risparmio di risorse rispetto alla precedente soluzione. Tuttavia quest’ultimo approccio si
può applicare solo se è garantita l’esistenza di un ambiente sicuro su ogni nodo di esecuzione. In generale
la macchina che ospita tali applicazioni è la jvm.
Tale modello può essere visto come un’estensione del modello client/server perché per far interagire le
entità, queste devono interagire tra loro. Ovvero si deve creare un bind tra le interfacce (accoppiamento).
2.2 Cambiamento: altri modelli
In questo paragrafo riportiamo alcuni modelli alternativi al modello client/server che si adattano alle
esigenze delle applicazioni nomadiche e non richiedono particolari adattamenti. Rispetto alla modalità
di interazione possiamo considerare due modelli di comunicazione alternativi a quello client/server: tuple
space e broadcast.
2.2.1 Architettura tuple space
Questa modalità permette una comunicazione generativa dove abbiamo interazione e coordinazione tra
i componenti asincrona e connectionless.
Per implementare un tuple space viene usato un apposito linguaggio di coordinazione: linda. Le Operazioni
operazioni messe a disposizione da questo linguaggio sono le seguenti:
• out(T): aggiunge una nuova tupla allo spazio;
• in(T): estrae la tupla T e la elimina dallo spazio;
• rd(T): estrae la tupla T e la mantiene;
9• eval(T): aggiungo una tupla attiva, almeno un processo.
dove una tupla rappresenta una sequenza di dati, record, struttura e campi contigui.
Bisogna notare che le operazioni in() ed rd() si basano sul concetto di pattern matching, ovvero se Pattern
Matching
abbiamo una tupla T si trova nel tuple space e la confrontiamo con un’altra tupla Ts allora si ha un
pattern matching solo se:
• i numeri dei componenti sono identici;
• e se, rispetto all’i-esimo elemento:
– se T e Ts sono costanti con lo stesso valore;
– se T e Ts variabili e sono dello stesso tipo;
– se T costante e Ts variabile allora T deve avere lo stesso tipo di Ts .
Il protocollo linda definisce inoltre le seguenti regole: Regole
1. non si può stabilire un percorso diretto tra mittente e destinatario;
2. il mittente e destinatario non devono necessariamente conoscersi (disaccoppiamento spaziale);
3. l’iterazione è tipicamente asincrona (disaccoppiamento temporale).
In generale le tuple presenti nel tuple space non contengono le informazioni relative all’autore della tupla.
Quindi tramite il tuple space vengono ignorate sia le informazioni relative agli utilizzatori di una tupla
che quelle che identificano chi l’ha prodotta.
In realtà esiste un meta-livello che garantisce una relazione tra il produttore ed il consumatore, infatti
senza questo accordo la comunicazione fallisce. Per il matching delle richieste (risposte) tra produttori
(consumatori) vengono definite:
1. sintassi: desidero una strutturazione;
2. semantica: desidero che abbia un significato comprensibile.
Le ontologie rappresentano un modo in cui si può manifestare un accordo. È facile vedere come sono
costruite le strutture dati in un tuple space. Consideriamo un caso semplice ma importante: possiamo Esempio
salvare un vettore di n elementi come n tuple aventi la seguente forma:
(‘‘V’’, 1, primo-elemento)
(‘‘V’’, 2, secondo-elemento)
...
(‘‘V’’, n, ennesimo-elemento)
Per leggere il j-esimo elemento del vettore ed associare il valore x si esegue il seguente comando:
rd(‘‘V’’, j, ? x)
Per cambiare l’i-esimo elemento in un ambiente locale eseguiamo i seguenti comandi:
in(‘‘V’’, i, ? vecchio-valore)
out(‘‘V’’, i, nuovo-valore)
invece se l’ambiente è esterno e condiviso a tutti eseguiamo:
in(‘‘V’’, i, ? vecchio-valore)
out(‘‘V’’, i, computer-remoto())
Questo tipo di comunicazione si colloca bene nei sistemi nomadici, infatti abbiamo: Proprietà dei
nodi mobili
1. disaccoppiamento spaziale e temporale.
102. non è necessario il re-binding: un tuple space non è associato a nessun mittente o destinatario
particolare.
3. fornisce di per sè un servizio di accodamento, la tupla infatti è persistente.
4. il tuple space può essere utilizzato per rendere disponibile a chiunque sia interessato variazioni degli
indici di qos di qualsiasi tipo.
Il modello simile è il publish/subscribe dove:
• un’entità produce informazioni e le pubblica;
• le entità interessate ad una specifica informazione effettuano una sottoscrizione al relativo servizio;
• un servizio invia le informazioni a tutte le entità che sono sottoscritte ad esso.
Tuttavia tra publish/subscribe e tuple space ci sono le seguenti differenze:
• Nel publish/subscribe non esiste il concetto di contenitore, ovvero le informazioni sono volatili.
Di conseguenza tali informazioni appena vengono prodotte sono subito consegnate al destinatario,
quindi se vengono prodotte prima che qualcuno abbia mostrato il proprio interesse queste vengono
perse.
• Nel il tuple space abbiamo un disaccoppiamento spaziale e temporale dal punto di vista del pro-
duttore. Ciò può essere esteso con una versione non bloccante delle letture, garantendo cosı̀ anche
un disaccoppiamento dei consumatori.
2.2.2 Broadcast
Rispetto all’approccio del tuple space, l’operazione di broadcasting risulta limitata, infatti l’informazione
viene definita in un insieme di elementi aventi un contenuto ed una chiave univoca dove lo scambio dei
dati avviene in modalità request/response (on demand). Questo paradigma viene usato nei database.
Ogni utente invia una richiesta inviando una chiave, la risposta è singolare, ovvero il numero di richieste
è pari al numero di risposte.
Tuttavia se gli utenti sono mobili sorgono dei problemi. Infatti il problema principale è il consumo
energetico in quanto il client rimane acceso finché non riceve una risposta (tempi di risposta esponenziali).
Una soluzione è che il database piuttosto che funzionare in maniera reattiva, manda le informazioni
quando vengono richieste, le raggruppa e le spedisce in un unico blocco (burst). Se un client è interessato
all’elemento j-esimo non deve effettuare richieste, ma accendersi ed aspettare che arrivi.
I vantaggi di una simile modalità sono:
1. Qualunque sia il numero di utenti che accedono, il tempo di attesa è medio. Quindi il sistema è
esente da congestioni e gli utenti non si manifestano.
2. Non c’è consumo di energia, infatti il consumo energetico risulta maggiore per le richieste rispetto
alle risposte.
Gli indici di prestazione di questo approccio sono:
latenza (access time) il tempo medio che passa quando il nodo mobile n manifesta interesse ad una
informazione, a quando compare. In altre parole è il tempo trascorso tra la richiesta di un elemento
e la sua occorrenza nel broadcast.
11consumo di energia (tuning time) il tempo di ascolto tra la richiesta di un elemento e la sua occor-
renza nel broadcast. Indica per quanto tempo l’interfaccia mobile deve rimanere in attesa.
Solitamente la latenza è maggiore o uguale al consumo di energia.
Per ottimizzare gli indici di prestazione:
• lato server vengono usati:
broadcast schedule posso modificare lo schema classico (cerchio di informazioni) rispetto alle
richieste. In questo modo viene aumentata la frequenza di trasmissione dell’elemento più
popolare.
Ciò permette una riduzione sia dell’access time che del tuning time medio, ma genera il
problema che non si conosce la popolarità dal momento che gli utenti non si manifestano. Per
risolvere tale problema si può schedulare un messaggio contenente le statistiche relative alle
richieste.
broadcast index i dati che devono essere comunicati sono indicizzati.
Ad esempio, il client si accende, scarica l’indice relativo alla risorsa a cui è interessato, si
spegne e si riconnette quando passa la risorsa.
Ciò porta ad una riduzione dell’access time medio ma ad un aumento del tuning time medio
(ovvero trasmetto dati ed indice).
• lato client normalmente si usa il broadcast index in modo tale da ridurre il consumo energetico.
Inoltre si possono usare tecniche come il caching/prefetching1 , in questo modo si riduce sia l’access
time che il consumo energetico.
Purtroppo la riduzione del consumo energetico non è garantita poiché anche se è vero che esiste
una probabilità non nulla che una determinata risorsa verrà utilizzata, è anche vero che esiste una
probabilità complementare che questa risorsa non sarà utilizzata. Quindi tutto dipende dalla bontà
delle previsioni che una data risorsa sarà utilizzata.
2.2.3 Peer-To-Peer
In questo modello non c’è nessuna distinzione tra client e server, infatti ogni nodo della rete possiede
entrambe i comportamenti. Permette l’implementazione di un’architettura decentralizzata e quindi le
responsabilità sono condivise tra i vari nodi del sistema. Ogni nodo può entrare ed uscire dalla rete con
relativa libertà. Inoltre il p2p è adeguato a situazioni in cui non è possibile adottare un’architettura
client/server.
2.2.4 Middleware
È uno strato software che si appoggia sul sistema operativo di rete2 . I protocolli di rete usati da questo
sistema operativo rendono accessibili le risorse locali da parte di nodi remoti e forniscono delle interfacce
per accedervi.
Purtroppo non si può standardizzare un middleware generando problemi come la riconfigurazione dei
dispositivi fisici, riconfigurazione delle applicazioni, monitoraggio del contesto e gestione delle informa-
zioni.
1 Per prefetching si intende il prelievo anticipato delle informazioni che sono probabilmente le più richieste.
2 Rappresenta il sistema operativo vero e proprio con i protocolli di rete.
12Lo strato middleware può essere scritto in linguaggi forniti per sistemi distribuiti. Questi linguaggi
possono essere classificati in:
• linguaggi orizzontali : offrono servizi generici che vanno bene per qualunque applicazione;
• linguaggi verticali : offrono uno specifico supporto ad una classe particolare di applicazioni.
Nei seguenti paragrafi analizzeremo in primo luogo gli aspetti di un middleware a livello orizzontale, cioè
non vincolati dalle applicazioni, nello specifico tratteremo le modalità di interazione/coordinazione. A
seguire tratteremo gli aspetti verticali.
2.2.5 Livello orizzontale
Il livello orizzontale viene anche detto modello request/response. Questo modello è fortemente legato
al modello client/server sull’organizzazione dell’architettura software dove è presente un meccanismo
di elezione per le applicazioni distribuite. La comunicazione è tipicamente connection-oriented, ovve-
ro è sincrona (accoppiamento temporale stretto) dove il mittente ed il destinatario devono conoscersi
(accoppiamento spaziale stretto), ciò viene realizzato dai protocolli rpc.
Dobbiamo considerare l’impatto sulla mobilità che consiste nell’attraversamento dei confini fisici (possi-
bile disconnessione dei nodi) o dei confini logici (cambio dei diritti di accesso, ingresso in diversi domini
amministrativi). A tal proposito esiste una variante del modello request/response, chiamata rpc-like,
che lo rende adattivo. L’adattamento può essere di tre tipi:
1. most platform: monitoraggio della qos del canale di comunicazione tramite stima del round trip
time (rtt). L’informazione sul qos stimata viene passata al livello applicativo, ciò è realizzato
usando il protocollo udp.
2. mobiledce: introduce il concetto di dominio, ovvero un insieme di macchine con risorse condivise
gestite da un manager di dominio (dm). Ogni client mobile possiede un manager locale. Quando
un nodo mobile entra in un nuovo dominio, dialoga con i dm per decidere se:
• mantenere il bind con un servizio remoto;
• fare re-bind ad un nuovo servizio nel nuovo dominio;
• emulare localmente, in caso di disconessione, il servizio e poi reinviare i messaggi quando la
connessione ritorna.
3. rover toolkit: fornisce il supporto per rendere asincrone le procedure di chiamate remote (accoda-
mento). Quindi supporta la migrazione del codice da un nodo fisso ad un nodo mobile. Ciò si
presenta come un insieme di librerie che forniscono delle funzionalità. Tale tecnica si basa su due
concetti:
(a) rdo: oggetti rilocabili dinamicamente;
(b) qrpc (rpc accodate): qrpc è un protocollo che gestisce l’accodamento delle chiamate. Lo
scheduler decide come e quando svuotare la coda.
La comunicazione tra rdo usando qrpc consiste nel seguente procedimento: ogni qrpc emessa
da un rdo nel client viene accodata in un registro locale (log) ed il controllo ritorna ad rdo. Uno
scheduler di rete invia al server le qrpc accodate in background quando la connessione è attiva,
eventualmente compattando e riordinando le richieste.
La proprietà dell’approccio rpc-like consiste nell’avere caratteristiche comuni ai tre ambienti:
1. rilassamento della sincronia (meccanismi di ritardo ed accodamento di rpc in caso di cattiva qos
o disconnessione).
2. approccio connection-oriented (bind e re-bind in caso di sconnessione con meccanismi di emulazione
local).
Tuttavia rimane il problema che abbiamo un’interfaccia non uniforme per informazioni sulla qos non
riguardanti la comunicazione (ad esempio il consumo di energia).
132.2.6 Livello verticale
Abbiamo precedentemente detto che un middleware può avere due tipi di livelli, uno orizzontale ed uno
verticale, specifico per le varie applicazioni. Vediamo alcuni servizi di quello verticale:
Filesystem ha come obiettivo quello di fornire un accesso trasparente ed efficiente a file condivisi
cercando di garantire la consistenza dei dati.
I problemi generici che possono sorgere sono le risorse limitate dei dispositivi mobili, poca banda
e variabile, le frequenti disconnessioni, l’eterogeneità sia dell’hardware che del software, le reti
wireless poco affidabili e filesystem standard quasi inutilizzabili. Per risolvere tali problemi di
solito si adotta una replicazione dei dati ed una raccolta anticipata dei dati.
Possiamo avere anche problemi di consistenza, ovvero consistenza debole e rilevamento di conflitti.
Se vogliamo accedere ad un filesystem con connettività limitata abbiamo dei problemi di:
1. simmetria: relazione client/server o peer-to-peer, supporto nella rete fissa, singolo filesystem
o filesystem multiplo, un namespace per i file o più namespace.
2. trasparenza: nascondere il supporto alla mobilità alle applicazioni sui nodi mobili, gli utenti
non dovrebbero accorgersi di meccanismi addizionali.
3. modello di consistenza: ottimo (tutti la stessa visione del file) o pessimistico.
4. caching e prefetching: singoli file o directory che vengono cachati permanentemente o tempo-
raneamente.
5. gestione dei dati: gestione dei dati nel buffer e copie, sono necessari richieste di aggiornamento
e rilevamento delle modifiche sui dati.
6. risoluzione conflitti: può essere specifica per l’applicazione o generale, errori.
Il fileststem coda è un’estensione del modello client/server che è trasparente alle applicazioni. La
consistenza è gestita con approccio ottimistico, a grana grossa cioè per file di grandi dimensioni.
Database le caratteristiche di un database sono:
1. elaborazione delle richieste: risparmio energia, dipendenza dalla posizione, efficienza.
2. gestione delle repliche (simile al filesystem).
3. gestione della posizione: mantiene traccia della posizione degli utenti mobili per fornire dati
replicati o dipendenti dalla posizione al momento e nel luogo esatti (hlr nel gsm).
4. elaborazione delle transazioni: abbiamo transazioni mobili (non si basano necessariamente
sullo stesso modello delle transazioni su rete fissa acid (atomicità, consistency, isolation,
durability), modelli a transazioni deboli.
142.3 Piattaforme orizzontali: WWW
www è caratterizzato dal protocollo http e dal linguaggio html. http1.0 è stateless, usa un modello
di tipo request/response. Il protocollo è connection-oriented, ovvero viene usato tcp. http è stato
progettato per essere utilizzato su banda larga con un basso delay, inoltre sono presenti header di grandi
dimensioni ed i file sono trasferiti senza compressione. Oltre al protocollo tcp, viene usato il lookup del
dns e ciò causa del traffico addizionale.
Anche html non è adatto per dispositivi mobili poiché è stato progettato per pc ad alte prestazioni. Il
problema consiste nel fatto che i dispositivi mobili possiedono schermi piccoli a bassa risoluzione, quindi
le pagine Web si adattano poco all’eterogeneità dei sistemi finali.
Il Web non è paragonabile ad un filesystem, infatti le pagine non sono semplicemente da scaricare. Queste
possono avere un contenuto sia statico che dinamico e richiede comunque l’interazione con il server per
poter fornire le corrette informazioni. Il caching viene spesso disabilitato dagli isp proprio perché sono
presenti contenuti dinamici. Gli hyperlink vengono caricati, ricaricati automaticamente o reindirizzati.
Per quello che è stato appena detto, si evince che i due componenti di www non sono stati progettati
per ambienti mobili e ciò crea non pochi problemi. Lo stack di protocolli che supporta il Web non è
particolarmente indicato alle esigenze che il sistema offre. Infatti i dispositivi mobili stanno “stretti” in
questa pila di protocolli. Il caching ad esempio non può essere utilizzato da parte dei nodi mobili per
problemi di sicurezza. A tal proposito sono state proposte due soluzioni: nuove tecnologie e rimedi a
livello architetturale.
2.3.1 Nuove tecnologie
È possibile utilizzare:
1. una tecnologia push, dove non è richiesto un pull da parte del client.
2. il protocollo http1.1 che usa connessioni persistenti, richieste multiple, aumento del numero di
header per il controllo della cache e supporto ai meccanismi di codifica/compressione.
3. i cookies che permettono l’uso di sessioni statefull.
2.3.2 Rimedi a livello architetturale
Possiamo usare:
1. browser potenziati : si usa il meccanismo di caching lato client. Il problema che può nascere è
proprio che il server che fornisce le pagine blocca tale operazione.
2. componenti addizionali : caching (se offline) e prefetching di pagine.
153. proxy: è un agente che si interpone in maniera trasparente.
Il client proxy permette l’uso offline dei contenuti, caching e prefetching. Migliora la qualità, il
tempo di risposta ed il controllo di energia.
Il network proxy si adatta al contenuto (rende general-purpose l’applicazione), supporta il cachin-
g/prefetching (miglioramento delle prestazioni del sistema), ma i componenti non sono fruibili
offline.
Possiamo combinare sia il client proxy che il network proxy, in questo modo si combinano le
caratteristiche dei due approcci semplificando i protocolli. Infatti viene utilizzato un protocollo
specializzato.
2.4 Piattaforme Orizzontali: WAP
wap sta per wireless application protocol. È una piattaforma pensata per adattare il modello ad una
situazione in cui i nodi hanno una capacità ridotta sia di hardware che di comunicazione.
Bisogna ricreare lo stesso modello architetturale concettuale alla base del Web cioè il modello clien-
t/server riprendendo, specificando e modificando i concetti fondamentali (standard uri, tipo di mime,
codifica delle informazioni html, standard di trasferimento http).
L’architettura del wap si presenta ad alto livello con i seguenti componenti:
161. Interprete: Nella precedente figura è presente un gateway. In questo caso il modello di programma-
zione wap mantiene alcune caratteristiche quali: browser (microbrowser); linguaggio; formato dei
contenuti. Inoltre aggiunge alcuni protocolli utili in modo tale che possano appoggiarsi a quelli co-
munemente usati nel Web (ad esempio wta-wtai è usato per sfruttare gli standard delle compagnie
telefoniche). Sempre nella precedente figura, il gateway effettua una codifica al nuovo protocollo,
ovvero traduce i dati provenienti dal Web in oggetti usabili nel wap.
2. wml: è un linguaggio di markup simile all’html indicato per reti povere.
3. Stack di protocolli : è componibile, ovvero non è detto che l’applicazione debba usare tutti i
protocolli.
Descriviamo la precedente figura:
WAE comunica direttamente con il browser. Viene usato su sistemi con risorse limitate, dove utilizza i
seguenti elementi:
1. linguaggi di markup:
• wml a differenza dell’html prevede un formato specifico.
Sfrutta la metafora deck & card, ovvero immaginiamo una serie di carte successive disposte
in una sequenza, ognuna delle quali definisce una logica del documento. Ogni carta
contiene uno o più elementi e definisce istruzioni o il contenuto. Ciò rappresenta lo stato
dell’oggetto.
Quindi wml descrive in modo astratto solo la logica dell’interazione. Mentre lo strato di
presentazione è dipendente dalle caratteristiche del dispositivo. Solitamente questo strato
fornisce un supporto a documenti testuali, interazione utente, navigazione e gestione del
contesto (persistente).
• wml script: è un linguaggio dichiarativo, procedurale, con loop e condizioni. Inoltre tutte
le variabili sono globali ed è estendibile tramite librerie. Ciò ci permette la creazione di
programmi aventi una logica più complessa. Tale linguaggio di scripting è necessario per
incorporare costrutti di programmazione logica e funzionale.
2. microbrowser : rappresenta l’interprete dei linguaggi di markup, ovvero effettua le richieste e
fa parsing delle risposte. Questo opera in un ambiente limitato, quindi mantiene variabili in
modo persistente.
3. meccanismi di integrazione telefonica wta: sono usati dei server ad-hoc. Tali meccanismi
risultano indipendenti dal dispositivo di rete e sono asincroni, ovvero pilotati ad eventi. Ad
esempio una segreteria telefonica.
Il modello logico di wae permette due tipi di interazione:
1. richiesta/risposta;
172. push/pull:
• service indication: il server dice solo dove è disponibile il servizio (breve comunicazione
del servizio tramite push ovvero identificazione tramite uri).
• caricamento del servizio: il servizio viene fornito automaticamente (breve comunicazione
push al client tramite uri, ovvero l’user agent decide sull’utilizzo tramite pull e quindi
trasparente per un utente).
WSP si occupa del mantenimento di connessioni persistenti. L’obiettivo è quello di garantire ed imple-
mentare il concetto di sessione tra client e server. Quindi wsp fonisce servizi a livello applicazione
sia di tipo push che pull, a seconda del protocollo che si sta utilizzando, di tipo:
• connection oriented (wtp): gestione di sessione, invocazione dei metodi, comunicazione in
caso di errori, push senza conferma, push con conferma, interruzione/ripresa sessione.
• connectionless (wdp): invocazione di metodi, push, generalmente affidabile.
Sia wtp che wdp possono usare wtls per creare connessioni sicure. Attualmente supporta
applicazioni di tipo browsing come wsp/b statefull mentre http1.1 è stateless.
WTP sta per wireless transaction protocol ed ha il compito di gestire lo scambio delle richieste/risposte.
È un servizio molto leggero basato su transazioni datagram. Le transazioni di richiesta/risposta
sono implementate in modo affidabile, ovvero ogni applicazione può selezionare l’affidabilità e
l’efficienza opportuna.
Questo protocollo fornisce una comunicazione unidirezionale che può essere affidabile, ad esempio
il server vuole sapere quello che riceve, o non affidabile, ad esempio il server non è interessato alla
ricezione.
È efficiente poiché usa tecniche come segmentazione/riassemblaggio, ritrasmissione selettiva, com-
pressione degli header e setup della connessione ottimizzato.
WTLS è il protocollo che serve a garantire la sicurezza.
WDP sta per wireless datagram protocol. È simile ad udp, la cui comunicazione è trasparente usando
tecnologie di trasporto differenti. Non è affidabile per comunicazioni di tipo end-to-end.
L’obiettivo è quello di creare un sistema di trasporto su scala mondiale interoperabile. Se una
piattaforma wap si poggia su Internet non c’è bisogno della sua implementazione.
WCMP simile a icmp
Qui di seguito vediamo degli esempi di architetture che possono essere fatte tramite wap:
1. applicazione ipertestuale con ambiente di sviluppo wap
2. applicazione client/server
183. solo mapping tra funzioni wap ed udp
4. architettura wap push con proxy-gateway
2.4.1 WAP2.0
wap2.0 è nato dalla standardizzazione di html (o meglio xhtml che fornisce una sintassi rigorosa)
e delle specializzazioni dei protocolli tcp/http pensate per ambienti wireless. Questa nuova versione
permette di avere una grafica a colori, animazioni e caricamento di grandi quantità di dati.
L’obiettivo consiste nell’integrare diverse tecnologie come www, Internet, wap ed I-mode. Data l’ambi-
ziosità del progetto non è stata ancora realizzata completamente.
Qui di seguito sono presenti varie tipologie di architetture:
• Dispositivo wap/Gateway/Web Server: il gateway fa la conversione tra gli stack di protocolli. Nel
dispositivo wap bisogna avere tutto lo stack di protocolli. Abbiamo però un problema quando si
fa la conversione tra wtls e tls, infatti tale conversione mette in chiaro le informazioni.
• Dispositivo wap/wap-proxy/Web Server: in questo caso sono usati i protocolli tcp’ ed http’ che
sono stati adattati all’ambiente mobile.
• Dispositivo wap/wap-proxy/Web Server/tls tunneling: viene usato per la risoluzione delle debo-
lezze relative alla sicurezza.
19• Dispositivo wap/ip router/Web Server: si usa semplicemente quello che c’è sullo strato di rete.
2.5 Piattaforme Orizzontali: I-Mode
È stato proposto da NTT DoCoMo Japan ed ha avuto un grande successo in questa nazione. Il motivo di
un cosı̀ grande successo è dovuto dal modello di business che ne ha promosso l’uso (guadagnava molto chi
forniva il contenuto) e dalle attività sociali come ad esempio parlare in treno o giocare con un cellulare.
La caratteristica principale è quella dell’adattabilità. Infatti sono stati usati protocolli Internet riadattati
al mondo wireless.
Può anche basarsi su wap, come è avvenuto in europa, in particolar modo in germania.
2.6 Piattaforme Orizzontali: J2ME
Solitamente le applicazioni sono fortemente dipendenti dal sistema operativo sottostante. Tramite j2me
si evitano questo genere di problemi. Infatti questa piattaforma è composta dal seguente stack di
componenti:
20Applicazioni
Profilo (mdp) Configurazione specializzata in un profilo
dei dispositivi.
Configurazione (cdc, cldc) Insieme ridotto di librerie Java.
java virtual machine (jvm)
Sistema Operativo
Hardware
Con questa tecnologia abbiamo solo due possibili architetture. La prima è relativa a dispositivi con poca
memoria e poca capacità di calcolo, mentre la seconda è adatta a dispositivi con capacità maggiori in
entrambe i sensi.
Queste architetture sfruttano wap o I-mode. Inoltre dato che sono basate su una jvm minimale allora
viene garantita l’indipendenza dall’hardware sottostante.
2.7 Impatto sul sistema operativo
Per i dispositivi mobili non è possibile usare un sistema operativo general-purpose. Infatti è necessario che
il sistema operativo consumi poca memoria ovvero abbiamo bisogno di un sistema operativo specializzato
che sfrutti la memoria flash del dispositivo.
La memoria flash è più affidabile poiché non possiede testine e consuma poca energia data l’assenza delle Memoria Flash
componenti meccaniche. Inoltre i tempi di lettura sono molto buoni, quasi come la dram ma a differenza
della dram e degli hard disk abbiamo un consumo di energia minore. Il problema sta sulle scritture che
richiedono tempi lunghi, oltre alla presenza dell’usura per questo tipo di memorie (numero limitato di
scritture).
Per questo tipo di memoria il filesystem viene modificato secondo le seguenti regole:
1. Organizzazione fisica:
• nessuna necessità di copiare file nello spazio di indirizzamento della dram poiché i tempi
di accesso sono paragonabili a quelli della dram. Di conseguenza abbiamo un risparmio di
energia e di tempo.
• viene usato un buffer nella dram per file riscritti più volte in modo da ridurre le scritture
sulla memoria flash in modo tale che si possa prevenire l’usura.
2. Per quanto riguarda l’organizzazione logica non c’è bisogno nè di raggruppare i file correlati nè di
avere la presenza di livelli multipli di redirezione.
Ad esempio l’impatto sul sistema operativo di una memoria flash necessita delle seguenti modifiche sulla
memoria virtuale:
• si deve garantire la protezione tra processi senza aumentare la dimensione dello spazio di indiriz-
zamento.
• il codice può essere allocato ed acceduto direttamente sulla memoria flash mentre i dati e lo stack
rimangono sulla dram. Quindi la parte dinamica sta in ram, mentre quella statica sulla flash
memory.
213 Comunicazione Wireless
Finora abbiamo trattato le problematiche relative allo sviluppo/supporto di applicazioni in ambiente
mobile, in particolar modo considerando i modelli concettuali, la strutturazione e le proposte tecnologice.
In questo paragrafo scenderemo di livello focalizzando l’attenzione sul wireless link mettendolo in
relazione agli standard e sistemi conosciuti. Tratteremo le problematiche relative alle tecnologie ed ai
protocolli wireless per realizzare l’interazione tra i vari nodi del sistema di tipo wireless. Dopo una
panoramica sulle modalità di utilizzo (tecniche di condivisione e protocolli generali che utilizzano tali
tecniche) passeremo all’analisi della wireless lan.
3.1 Caratteristiche
Le caratteristiche generiche delle reti wireless sono le seguenti:
1. ber maggiore;
2. tasso di trasmissione basso;
3. forti variazioni di qualità;
4. generalmente la comunicazione è di tipo broadcast;
5. è realizzato con due tecnologie: infrarossi e radiofrequenze.
Le radio frequenze possiedono una banda più alta ma necessitano di permessi da parte di organi
governativi. Mentre gli infrarossi sono facilmente bloccabili da parte di ostacoli.
La rete wireless può essere classificata in due modi: reti con infrastruttura e reti senza infrastruttura.
Nelle reti con infrastruttura esistono nodi specializzati, gli access point (ap), che gestiscono il traffico
di una certa zona. Quindi la comunicazione tra due nodi della rete non è mai diretta, infatti per
comunicare con un nodo bisogna spedire un messaggio prima sull’ap, successivamente il messaggio verrà
instradato su altri ap fino ad arrivare al nodo destinazione. In questo tipo di reti abbiamo le seguenti
proprietà:
• progettazione semplificata dei client;
• non abbiamo il problema del terminale nascosto (vedi il punto 2 dei protocolli basati su contesa);
• la gestione della rete è semplice;
• è poco flessibile.
Nelle reti senza infrastruttura, tutti i nodi possiedono le stesse responsabilità. Dove ogni nodo è in grado
di comunicare con qualsiasi altro nodo che si trova nelle sue vicinanze. Se due nodi fanno parte di due
reti diverse non possono comunicare. L’unico modo per farlo consiste nel mettere un ap di confine,
ovvero costruire una rete ad-hoc.
Tale approccio richiede maggior carico sulle responsabilità dei singoli nodi, di conseguenza aumenta il
consumo energetico e il carico computazionale. Tuttavia questa rete è molto veloce, flessibile e meno
invasiva. Questa classificazione vale per reti wireless non necessariamente mobili.
La portata di reti wireless è la seguente:
Ampia wireless wide area network (wwan)
Media wireless local area network (wlan)
Piccola wpan/wdan
Dobbiamo quindi introdurre un compromesso, infatti più aumenta il raggio di copertura, più diminuisce
la capacità di trasmissione. In altre parole all’aumentare della capacità di banda c’è una diminuzione
dello spostamento possibile.
Come si vede nella seguente figura studieremo la tassonomia delle reti wireless, in particolare guarderemo
il livello link e quello networking.
22Puoi anche leggere

















































