Identificazione di antiidrogeno tramite DNN - Gusso Gabriele
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Machine Learning ©ESO 2021
17 luglio 2021
Identificazione di antiidrogeno tramite DNN
Gusso Gabriele, Iannarilli Gabriele
Dipartimento di Fisica, Sapienza Università di Roma, Piazzale Aldo Moro, 5, 00185, Roma, Italia
e-mail: gusso.1869299@studenti.uniroma1.it
e-mail: iannarilli.1871300@studenti.uniroma1.it
SOMMARIO
Obiettivi. Migliorare la rivelazione delle annichilazioni di antiidrogeno, registrate da rivelatori installati attorno ad una trappola di
antimateria, tramite algoritmi di DNN. Si analizzano i risultati degli esperimenti volti a testare la simmetria CPT fondamentale.
Metodi. Analisi tramite DNN dei dati simulati con il metodo di Monte Carlo, in modo tale che riflettano le condizioni realistiche del-
l’esperimento ASACUSA. Elaborazione dei dati lungo percorsi separati poi fusi per convoluzione negli hidden layers. Ogni percorso
consiste in un’alternanza di strati di convoluzione 1D e max-pooling, tenendo conto delle invarianze traslazionali del rivelatore.
Risultati. Dalle curve ROC si osserva come le CNN a canale doppio riescano ad ottenere prestazioni migliori, confrontandole con
quelle a canale singolo per il dataset in analisi. Inoltre si ottengono risultati maggiormente significativi rispetto all’algoritmo VF.
Parole Chiave. ASACUSA – CERN – antiidrogeno – Machine Learning – DNN
section 1 - Introduzione di transizione negli atomi di antiidrogeno, da confrontare con le
loro controparti della materia.
In questo documento si propone un approccio alternativo di Le misurazioni della frequenza di transizione iperfine del-
analisi dati relativamente all’esperimento ASACUSA, miglio- l’antiidrogeno, sono eseguite misurando il tasso di produzione
rando la classificazione dei singoli eventi di annichilazione del- di atomi di antiidrogeno in una trappola Penning-Malmberg. Si
l’antiidrogeno che avvengono nello stesso. In particolare, si pro- controllano le condizioni di iniezione dell’antiprotone, il tempo
pone un’alternativa al classico metodo di tracciamento e rico- di sovrapposizione durante la miscelazione dei plasmi di antima-
struzione del vertice adottato nella fisica delle alte energie per teria e altri parametri chiave che consentono di legare il processo
distinguere la traccia lasciata dall’antiidrogeno, che emette di- di ricombinazione a tre corpi (p + 2e+ → H + e+ ), all’evoluzio-
versi pioni carichi nel vertice di annichilazione, dal segnale di ne temporale del livello di popolazione degli antiatomi formati
fondo. Con l’apprendimento tramite deep learning e reti neurali (Radics B. et al. 2014). Pertanto, la sensibilità dell’esperimento
si può ovviare al problema principale che presentano gli espe- dipende direttamente dal rivelamento efficace di annichilazioni
rimenti con trappole per antimateria, ovvero la scarsa predispo- di antiidrogeno.
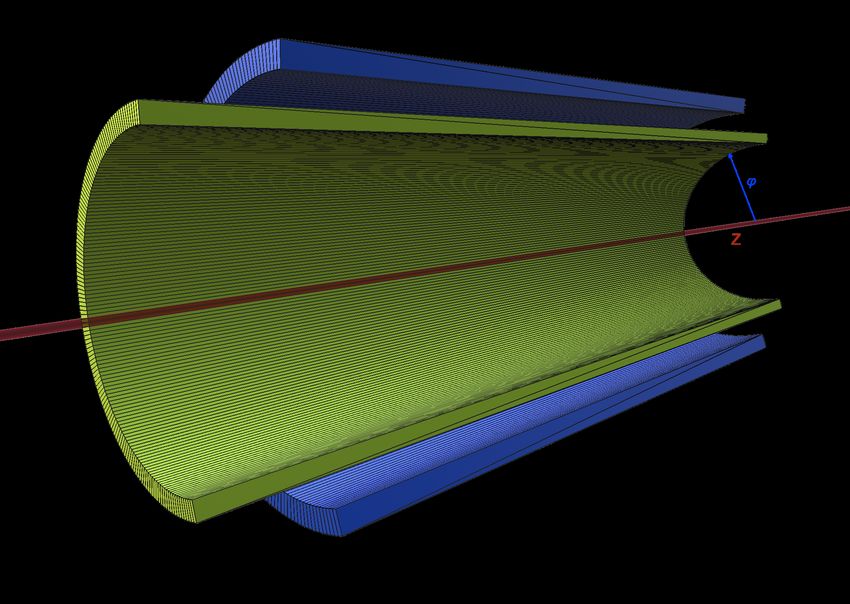
sizione per l’alta risoluzione e per l’efficienza di tracciamento Il rivelatore è l’Asacusa Micromegas Tracker (AMT), il qua-
causate dalla struttura stessa delle trappole, la quale necessita di le rivela i pioni emessi sia dalle annichilazioni degli antiidroge-
strati di camere a vuoto, elettrodi multi-anello e isolamento ter- ni, fenomeno di interesse, che da quelle degli antiprotoni, con-
mico che ne inficiano le prestazioni. Inoltre, il metodo del ver- siderate come rumore di fondo. Lo strumento è composto da
tice di annichilazione permette una classificazione del solo 25% due strati di scintillatori, approssimabili come due strati cilindri-
degli eventi; con il metodo del DNN (Deep Neural Network) si ci concentrici e individuabili con gli appellativi di inner e outer
incrementa tale percentuale sino all’80%, difatti il restante 20% (figura 1). Gli eventi sono identificati dalle coordinate assiali Z
degli eventi non produce alcuna hit nel rivelatore. e azimutali φ, come riportato nello schema.
section 2 - Esperimento e datasets
2.1 Esperimento ASACUSA
La collaborazione "Atomic Spectroscopy And Collisions
Using Slow Antiprotons" (ASACUSA) studia le simmetrie fon-
damentali tra materia e antimateria, mediante la spettroscopia di
precisione di atomi contenenti un antiprotone. Questo documen-
to si concentra sullo studio degli antiatomi puri (antiidrogeni),
che ha lo scopo di confrontare direttamente la frequenza di tran-
sizione iperfine dello stato fondamentale dell’idrogeno con quel-
la dell’antiidrogeno presso l’Antiproton Decelerator del CERN:
un test del principio di invarianza CPT. La simmetria fondamen-
tale della CPT prevede che materia e antimateria abbiano pro-
prietà uguali o di segno opposto. Tuttavia, sono possibili misura-
zioni precise delle proprietà dell’antimateria, come le frequenze Figura 1. Schema del rivelatore AMT.
pagina 1 di 4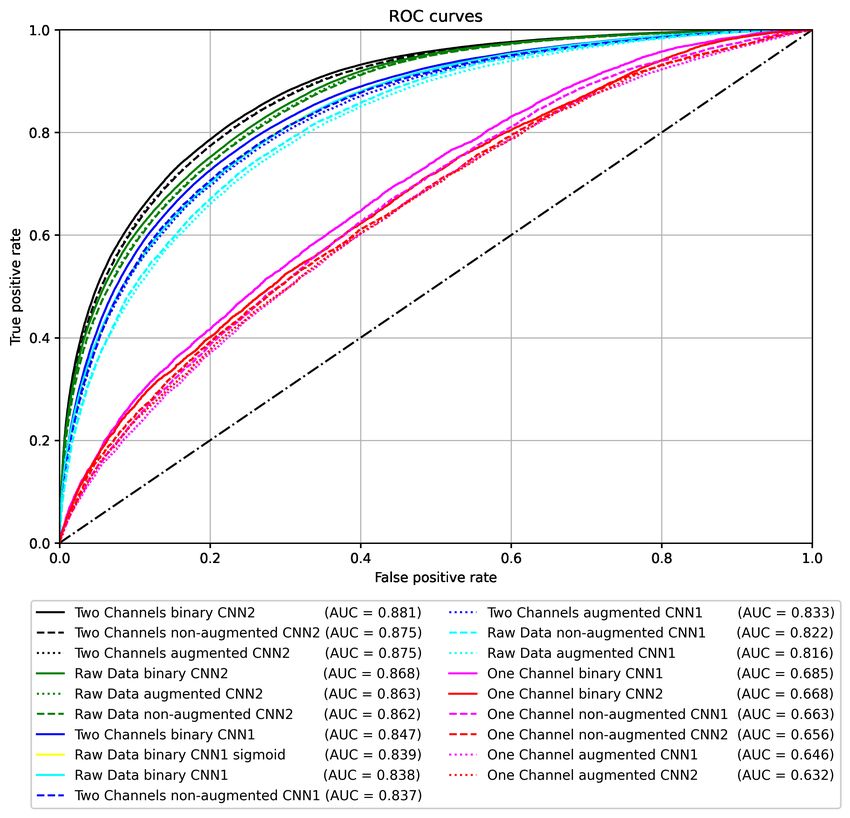
2.2 Dataset da simulazione Monte Carlo to omogenea a causa dell’effetto ghost, ovvero siccome a ogni n
hits effettive ne corrispondono altrettante n fantasma spurie.
Le trappole elettromagnetiche per materia e antimateria nel-
l’esperimento ASACUSA catturano particelle cariche sull’asse 2.4 Separazione nei subdatasets
centrale Z del rivelatore, mentre gli atomi neutri finiscono sulla
Si separano i datasets di train, valid e test in tre subsets:
parete interna e, annichilendo, emettono pioni carichi che posso-
no essere rivelati. Durante il processo la continua annichilazione – Raw Data: composto da tutti gli eventi indiscriminati del
degli antiprotoni intrappolati sugli atomi di gas residuo, produce dataset originale, ovvero dagli eventi in cui qualsiasi canale
eventi di annichilazione di fondo che emettono gli stessi pioni. di rivelazione (inner, outer o entrambi) risulti essere colpito,
Questi ultimi tendono a trovarsi sull’asse centrale, anziché sulla senza possibilità di ricostruire i vertici di annichilazione.
parete interna, dunque è possibile distinguerli da quelli dovuti – One Channel: costituito dagli eventi in cui entrambi i canali
all’annichilazione degli antiidrogeni nel caso in cui la posizione di rivelazione (interno ed esterno) registrano hits.
– Two Channels: formato dagli eventi in cui un solo canale di
sia deducibile dai dati di rivelazione da parte dell’AMT. rivelazione viene colpito.
Per testare la capacità di discriminazione tra segnale e fondo
degli algoritmi di DNN implementati, sono stati utilizzati dati di Dei dati generati tramite metodo di Monte Carlo, sono stati
eventi simulati attraverso metodo Monte Carlo, i quali rifletto- utilizzati solo quelli per cui il rivelatore risulti riportare alme-
no le reali condizioni di rivelazione dell’AMT nell’esperimento no una hit, ovvero l’80% del totale. Rispetto al totale (100%),
ASASCUSA. Il dataset è diviso in tre files, contenenti i dati re- tale sottoinsieme è costituito da un 7% proveniente dal subset
gistrati dal rivelatore sotto tale simulazione, suddivisi in train del One Channel, un 48% da quella parte del Two Channels per
(∼ 60%), test (∼ 20%) e valid (∼ 20%), per un totale di 1595894 cui non sia stato possibile ricostruire un vertice di annichilazio-
eventi. Essi sono composti da una colonna di target binari (1 se ne tramite l’algoritmo VF (Vertex Finding) e un 25% dall’altra
l’evento corrisponde a un antiidrogeno e 0 in caso contrario), 447 parte del Two Channels per cui tale algoritmo risulti essere uti-
colonne di features relative alla coordinata assiale Z dello strato lizzabile; il Raw Data è la loro somma, ovvero l’80%. Dunque,
interno del rivelatore, 246 colonne di features relative alla coor- si opera esclusivamente su quell’80% di casi per cui il rivelatore
dinata azimutale φ dello strato interno, 447 colonne di features riporti almeno una hit per evento.
relative alla coordinata assiale Z dello strato esterno e 290 co- Prendendo tale 80% come totalità dei dati, si osserva come
lonne di features relative alla coordinata azimutale φ dello strato i subdatasets del One Channel e Two Channels siano rispettiva-
esterno (Sadowski P. 2017). mente composti dall’8.4% e dal 91.6% di questo nuovo insie-
me (riferendosi esclusivamente al train dataset). Volendo visua-
2.3 Studio del dataset lizzare gli eventi di questi due subdatasets, si sviluppano due
istogrammi per ciascuno di essi, in modo tale da poter separare
Operando tramite pandas si importano i datasets di cui so- gli eventi relativi a Z (inner e outer) e φ (inner e outer), con Z
pra, difatti l’utilizzo di pandas (pd.read_csv) in tale fase velo- normalizzato e φ riportato in gradi (figura 3).
cizza significativamente la lettura dei files e, inoltre, risulta più
veloce una conversione da un dataframe a un array numpy (Da-
taFrame.to_numpy) rispetto all’importare i datasets direttamente
tramite numpy (np.loadtxt).
Siccome il rivelatore non è in grado di discernere eventi con
un singolo punto nello spazio Z vs φ, poiché a ogni rivelazio-
ne in Z corrispondono tutte le φ rivelate e viceversa, allora si
è deciso di graficare delle strisce di hit nel formato 2D (figura
2). Siccome il campione del train dataset è di notevole dimen-
sione (957400 eventi di 1430 features), si è ottimizzato il pro-
cesso di creazione dell’istogramma bidimensionale utilizzando
l’histogram2d di fast_histogram ed è stato suddiviso il dataset di
train in 598 subsets, composti da 1601 eventi ciascuno, riuscen-
do dunque a campionare 957398 eventi su un totale di 957400.
Tali accortezze sono risultate necessarie per limitazioni di RAM.
Figura 3. Istogrammi relativi al numero rivelazioni in funzione di Z e
di φ, nel caso in cui solo uno tra stati inner o outer risulti essere colpito
(in alto) e in quello in cui entrambi risultino essere colpiti (in basso).
Si nota come nel One Channel subdataset vi sia un’eleva-
ta disparità nel numero di rivelazioni tra gli stati inner e outer;
in particolare l’inner risulta essere colpito un numero maggio-
re di volte rispetto all’outer. Inoltre, si osservano anche delle
Figura 2. Istogramma bidimensionale della distribuzione di Z e φ per notevoli irregolarità sotto forma di cuspidi. Per il Two Chan-
lo strato inner (sinistra) e outer (destra), con L = 1/447 cm. nels subdataset, invece, i due strati risultano avere quasi il me-
desimo numero di hits. Tali istogrammi monodimensionali per-
Si notano due addensamenti di eventi in prossimità di Z ≈ mettono una maggiore comprensione della struttura del dataset,
140 cm e Z ≈ 10 cm. Inoltre, la loro distribuzione risulta alquan- scomponendo difatti gli istogrammi bidimensionali in figura 2.
pagina 2 di 4Gusso Gabriele, Iannarilli Gabriele: Identificazione di antiidrogeno tramite DNN
Da ognuno di questi subdatasets (Raw Data, One Channel e uno per φ (inner e outer) con shape (246,2). Viene impostato
Two Channels) se ne ricavano altri tre di eguale dimensione: un singolo output con attivazione di tipo sigmoid (equazione
1) e vengono utilizzate MAE (Mean Absolute Error) e Bina-
– binary: corrisponde al dataset originale, è dunque ryCrossentropy rispettivamente come metrics e loss, insieme
composizione di soli 1 e 0. all’optimizer Adam. Si è scelta la funzione sigmoidea poi-
– non-augmented: si traduce il dataset originale da valori ché consente una buona predizione di un risultato binario,
booleani in quantità fisiche; si fa corrispondere a ogni Z il restituendo un valore ∈ (0, 1) e pesando maggiormente gli
suo valore in cm (da 1 a 447 cm) e a ogni φ uno proporzio- estremi rispetto ai valori intermedi.
nale a quello in gradi, ovvero lo si moltiplica per un numero – CNN a canale singolo (softmax) (CNN 1): vengono forni-
progressivo da 1 a 246 in funzione delle colonne (in modo ti al modello della rete neurale due inputs di canale singolo:
tale da poter sempre operare tramite interi a 16 bit massimo). uno per Z (inner e outer) con shape (894,1) e uno per φ (inner
– augmented: si svolge la medesima conversione utilizza- e outer) con shape (536,1). Viene impostato un doppio out-
ta per il caso non-augmented e, inoltre, si traslano di t ∼ put con attivazione softmax (formula 2) e vengono utilizzate
U(99, 347), estremi compresi, tutti i valori di Z appartenenti accuracy e sparse_categorical_crossentropy rispettivamente
a un evento, e lo si fa per l’intero dataset. Tale traslazione è come metrics e loss, insieme all’optimizer Adam.
necessaria, siccome non vi è alcun modello fisico sinora noto – CNN a canale singolo (sigmoide) (CNN 1): gli inputs so-
che permetta una predizione della corretta coordinata assiale no nel medesimo formato già trattato nel caso della CNN a
Z per gli atomi di antiidrogeno nelle condizioni dell’AMT. canale singolo (softmax). Viene però impostato un singolo
output con attivazione di tipo sigmoid e vengono utilizzate
L’accortezza di operare sempre con interi di al più 16 bits, è MAE (Mean Absolute Error) e BinaryCrossentropy rispet-
necessaria a causa di limitazioni di RAM. Ciò comporta una leg- tivamente come metrics e loss, insieme all’optimizer Adam.
gera perdita di informazione nel caso in cui si operi il downsam- Quest’ultimo algoritmo è stato applicato al solo subdataset di
pling dell’outer φ per i subdatasets non-augmented e augmented, tipo Raw Data binary, per confrontarlo con i risultati ottenuti
ma risulterà in una maggiore perdita nel binary subdataset. tramite l’algoritmo CNN a canale singolo (sigmoide) relativo
al medesimo subdataset. L’attivazione sigmoid, con MAE e
section 3 - Algoritmi CNN BinaryCrossentropy, risulta migliore rispetto all’attivazione
3.1 CNN a canale singolo (softmax) softmax, con accuracy e sparse_categorical_crossentropy,
relativamente al tempo di compilazione, nonostante le AUC
L’approccio deep learning utilizzato permette di classifica- (Area Under the Curve) siano pressoché immutate.
re le annichilazioni direttamente a partire dei dati grezzi (Raw
Data) del rivelatore e, in particolare, anche nei casi in cui sia 3.2 Curve ROC
possibile ricostruire una sola traccia (One Channel) o entram- Per analizzare l’accuratezza del modello, si confronta il va-
be le tracce (Two Channels). La rete neurale è stata addestrata lore predetto dal modello stesso con il valore atteso (target). Il
con una varietà di combinazioni di iperparametri, al fine di ot- confronto delle prestazioni è stato effettuato tracciando le curve
timizzare le prestazioni di generalizzazione sul set di validazio- Caratteristiche Operative del Ricevitore (curve ROC) e valutan-
ne. L’architettura della rete neurale realizzata consiste in cinque do la bontà di discriminazione da parte degli algoritmi, ovvero
strati convoluzionali 1D con dimensioni dei nuclei (kernels) ri- calcolando l’area sottesa dalle stesse (AUC). Le curve, mostrate
spettivamente di 7, 3, 3, 3 e 3 per ogni strato; le dimensioni dei in figura 4, riportano il TPR (True Positive Rate) in funzione del
canali (channels) vengono scelte di 8, 16, 32, 64 e 128 per gli FPR (False Positive Rate), definiti dalle equazioni 3 e 4.
strati di cui sopra. Si utilizza la funzione di attivazione ReLU
(Rectified Linear Unit). Ciascuno strato convoluzionale è inol- section 4 - Risultati e conclusioni
tre seguito da uno strato di max-pooling con dimensione 2 della
pool e lunghezza del passo (stride length) di 2. Costruiti due L’algoritmo DNN utilizzato sui datasets generati mediante
rami separati di tal tipo per φ e Z, sono stati concatenati e si è simulazione Monte Carlo riesce a identificare, con un’ottima co-
proseguito con l’aggiunta di due strati completamente connessi pertura, gli eventi di annichilazione dell’antiidrogeno, ottenendo
(fully-connected) con ReLU di 50 e 25, preceduti entrambi da risultati nettamente migliori rispetto all’algoritmo VF (Sadow-
uno strato di eliminazione (dropuot) del 50% per ridurre l’over- ski P. et al. 2017). Con l’approccio del deep learning, il modello
fitting. Si è concluso con un output booleano. I pesi del modello di rete neurale end-to-end riesce ad estrarre maggiori informa-
sono stati inizializzati da una distribuzione normale scalata, in zioni statistiche dai dati grezzi, arrivando ad ottenere per il Raw
seguito è stato utilizzato l’optimizer Adam (β1 = 0.9, β2 = 0.999, Data binary un’AUC di 0.868, utilizzando la rete convoluziona-
= 1e − 8) con aggiornamenti delle mini-bash di dimensione le a canale doppio (CNN 2). Tale algoritmo ha una copertura
128 (CNN a canale singolo) o 100 (CNN a canale doppio), per decisamente migliore per quanto riguarda gli eventi in cui so-
l’ottimizzazione del modello. Inoltre, è stato utilizzato un tas- no stati colpiti esclusivamente entrambi gli strati del rivelatore,
so di apprendimento (learning rate) inizializzato a 0.0001, con ottenendo un’AUC di 0.881 sul Two Channels binary subdataset.
decadimento dell’1% alla fine di ogni epoca. L’addestramento La CNN 2 riesce ad ottenere un incremento di prestazioni
viene arrestato automaticamente nel momento in cui l’obietti- pari a circa il 4% (in termini di AUC) rispetto a quella a cana-
vo di validazione (validation loss) non risulti migliorare per tre le singolo (CNN 1) per il Two Channels binary subdataset e, in
epoche consecutive. I modelli sono stati implementati in keras e generale, risulta migliore rispetto a quest’ultima, come apprez-
addestrati mediante processori Tesla T4. zabile dalla legenda delle curve di ROC riportata in figura 4.
A partire da tale architettura neurale di base sono state testate Anche i risultati relativi al One Channel subdataset si rivelano
tre diverse CNN, presentanti le seguenti caratteristiche: interessanti, pur ottenendo delle AUC peggiori rispetto alle al-
tre casistiche analizzate, siccome si opera su un numero ristretto
– CNN a canale doppio (CNN 2): vengono forniti al modello di eventi (∼ 8.4% di quelli analizzati) e in precedenza tali da-
della rete neurale due inputs, ciascuno formato da due canali, ti non erano analizzabili tramite algoritmo VF; inoltre, per tale
così suddivisi: uno per Z (inner e outer) con shape (447,2) e subdataset la CNN 1 ottiene AUC migliori rispetto alla CNN 2.
pagina 3 di 4appendice A- Formule
1 TP
f (x)sigmoid = (1) T PR = = 1 − FNR (3)
1 + e−x T P + FN
ex j
f (x) jsoftmax = PK (2) T NR =
TN
= 1 − FPR (4)
k=1 e xk T N + FP
appendice B- Grafico
Figura 4. Curve di ROC e relativi valori dell’AUC, riportati in legenda, per le casistiche analizzate.
Riferimenti bibliografici
[1] Radics B., Murtagh D. J.,Yamazaki Y. and Robicheaux F., 2014, Phys. Rev. [A. 90 032704]
[2] Sadowski P. et al., 2017, J. Phys. Commun. [1 025001]
[3] Sadowski P., 2017 [datasets]
pagina 4 di 4Puoi anche leggere