Corso di Economia delle Istituzioni - prof. Vincenzo Visco Comandini Università di Roma "Tor Vergata"
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Corso di Economia delle Istituzioni
prof. Vincenzo Visco Comandini
Slides no. 7 Il modello di business dei motori di ricerca e dei
social network
Università di Roma “Tor Vergata”
anno accademico 2020-2021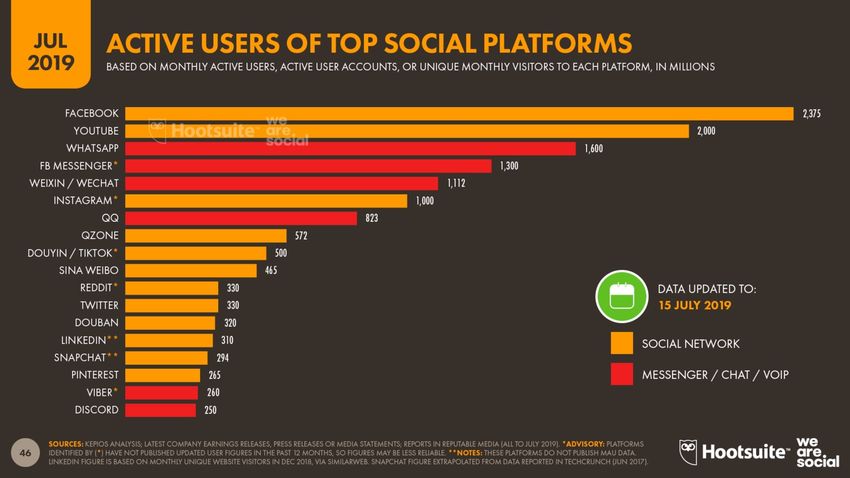
1. L’economia dei motori di
ricerca
[da Hal R. Varian]
Sept 31, 2007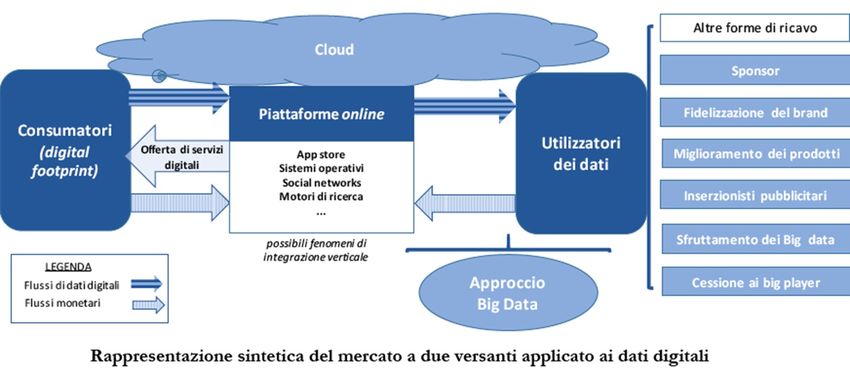
Oggi una grandissima parte dei testi scritti, audio, foto, video è prodotta direttamente in formato digitale La tecnologia digitale presenta questi tre fondamentali caratteri economici: 1) Il costo di produzione della prima copia è fisso, in genere molto elevato, irrecuperabile, normalmente sostenuto prima di passare alla fase produttiva e distributiva 2) Il costo di produzione della seconda copia e di quelle successive è molto basso (costo marginale ≈ a zero). I vincoli alla capacità produttiva sono quasi nulli 3) I beni informativi prodotti, anche quelli tradizionali non digitali, non sono quasi mai perfettamente omogenei fra loro, ma tendono a differenziarsi agli occhi dei consumatori (es. concorrenza limitata fra film, più intensa fra generi simili; limitata concorrenza fra Giornale e Repubblica, più intensa fra quest’ultima il Corriere della Sera)
Utilizzo dei motori di ricerca
• I motori di ricerca sono molto popolari
– 84% dei navigatori su Internet li utilizza
– 56% dei navigatori ogni giorno
• Sono molto profittevoli
– Ricavi vengono dalla vendita di pubblicità
collegata alle ricerche
– I costi marginali sono molto bassi
Pubblicità (Ads) sui motori di
ricerca
• Ads molto efficaci grazie alla loro rilevanza
– Che però richiedono volumi elevati capaci di
realizzare economie di scala
• 2% delle ads viene cliccata
• 2% dei clicks si trasforma in acquisto
• quindi solo 4 utenti su mille che le vedono procede
all’acquisto
• I prezzi per pagina visitata (CPI) o per click (CPC) sono
contenuti (motori usano CPC)
• Migliori performances rispetto alle ads tradizionali su TV
o giornali
• La tecnologia dei motori di ricerca mostra
rendimenti crescenti di scala
– Alti costi fissi per l’infrastruttura, bassi costi
marginali per offrire il servizio
Economics fondamentali
dell’industria dell’ad on-line
• Elevati costi di entrata (per raggiungere la profittabilità) dovuti ad
elevati costi fissi
• Dal lato della domanda, switching costs degli utenti piuttosto bassi
• Negli USA il 56% dei navigatori utilizza contemporaneamente più
motori di ricerca
• Gli inserzionisti cercano spazi laddove cadono gli occhi dei
navigatori (follow the eyeballs)
– piazzano le ads dove c’è un n. sufficiente di utilizzatori, senza
esclusività per un sito (multihoming)
• Pertanto, il mercato tende ad essere così configurato:
– Pochi grandi motori di ricerca per ciascuna lingua/paese
– Molto contendibile per gli utilizzatori
– Le esternalità di rete dal lato della domanda non arrivano a
generare la condizione di monopolio naturale: coesistono più
(grandi) imprese
– E’ un mercato a più versanti (multisided market)
Quali servizi offrono i motori di
ricerca?
• Google mette in collegamento soggetti diversi, é
matchmaker come fa il sensale che combina matrimoni
(yenta in yiddish) o il sacerdote pontifex in latino
– Dal lato della domanda: fa incontrare le info di chi le
cerca con chi ne dispone
– Dal lato della pubblicità: fa incontrare acquirenti e
venditori
L’advertising nei motori di ricerca è un tipico multisided
market, dove una piattaforma (Google) soddisfa gli editori
di siti che vogliono vendere attenzione (impressions), e gli
inserzionisti che vogliono acquistare clicks
STRUTTURA DEL MERCATO DEI MOTORI DI RICERCA
Breve storia dell’information
retrieval (IR)
• Inizia negli anni ‘70, con l’incrocio dei termini
della ricerca (query) con quelli nei documenti
• Negli anni ’90 diventa scienza matura
• DARPA (Advanced Defense Research Project
Agency) inizia la Text Retrieval Conference
– offre pacchetti di training per query-documenti
rilevanti accoppiate
– offre procedure interessanti per gruppi di documenti e
query
– partecipano allla Conferenza circa 30 team di ricerca
Esempio di algoritmo di IR
• Prob (documento rilevante) = funzione delle
caratteristiche del documento e della query
– Ad esempio, regressione logistica pi = Xi b
• Variabili esplicative
– Termini in comune
– Lunghezza della query
– Dimensione del documento
– Frequenza dell’occorrenza del termine nel documento
– Frequenza dell’occorrenza del termine nell’insieme
dei documenti
– Rarità del termine nell’insieme dei documentiL’avvento del web
• Negli anni ’90 gli algoritmi sono ormai maturi
• Ma arriva il web…..
– I ricercatori di IR lenti a reagire alle sollecitazioni
– invece i ricercatori di Computer Science rapidi a
reagire
• La struttura dei Link sul Web diventa una nuova
variabile esplicativa
– PageRank = misura quanti siti importanti sono
collegati con un determinato sito
– I risultati del search migliorano in modo sensibileStoria di Google • Brin e Page tentano di vendere il loro algoritmo a Yahoo per 1milione di $ (non lo compra!) • Fondano Google senza un’idea precisa su come fare soldi • Fanno grandi sforzi per migliorare l’algoritmo: i valori di PageRank sono pesati con quelli di IR • L’idea di base è che quando un sito è puntato da altri siti importanti ha una più alta probabilità di contenere l’informazione rilevante che il consumatore cerca
Perchè il business online è
diverso
• I business Online (Amazon, eBay, Google…)
fanno e sono costretti a fare esperimenti continui
– Parola giapponese kaizen = “miglioramento continuo”
– Molto difficile da realizzare per le imprese offline
come il manifatturiero o i servizi
– Molto facile da realizzare online
• Conduce a rapidi e a volte sottili miglioramenti
• Adotta come norma il Learning-by-doing che fornisce un
vantaggio competitivo significativo
• In pratica utilizza i dati di miliardi di transazioni passate per
effettuare simulazioni di piccoli cambiamenti (nella grafica,
prezzi, procedure) di cuisi può subito valutare l’effetto sui
ricaviTecnicamente i motori di ricerca svolgono tre diverse funzioni:
1) Navigazione in Internet con programmi chiamati spiders o
crawlers che analizzano il web e catalogano le info in una
serie di indici e grafi:
• quali siti web esistono
• quali siti li linkano
• contenuti dei siti
oggi spiders sono molto migliorati, analizzano l’intero web
(tutte le pagine di ogni sito, video, PDF, oggetti Microsoft
Office, audio, metadata)
2) Indicizzazione di ciò che si è trovato, rispetto alla rilevanza,
quella su cui Google eccelle
3) Creazione programmi di fornitura dei risultati dagli indici in
risposta alla ricerca
Il santo Graal dei motori di ricerca è la fornitura dei risultati perfettamente
rilevanti con la ricerca dell’utente, anche quando questi non ha piena certezza
di ciò che sta cercando (Balto, 2011)I motori di ricerca debbono continuamente “ripulire” i risultati dei loro algoritmi (i cosiddetti risultati organici) dagli spammer (coloro che desiderano mostrarsi ai primi posti di una ricerca senza avere un buon contenuto, ma solo al fine di essere cliccati) e dagli imbrogli deliberati (creare numerosi siti finti che puntano il sito di cui si vuole artificialmente migliorare la posizione) Nel febbraio 2011 Google ha scoperto che un importante sito di e- commerce J.C. Penney risultava sempre ai primi posti dei risultati per praticamente tutti i suoi prodotti, e che questo sito aveva deliberatamente e artificiosamente creato un link di puntamento da un elevatissimo numero di siti di scarsa o scarsissima rilevanza al solo fine di accrescere il proprio page rank
Business model
• Aste Ad
– Il primo modello brevettato con risultati del search messi
all’asta era GoTo
– Go To non funzionava perché la willingness to pay per
accedere ad una posizione più elevata era irrilevante per
l’utente che effettua la ricerca [non c’era ancora la teoria dei
multisided market]
– cambiò nome in Overture, in cui le ads erano messe all’asta
– Kamangar e Veach che lavoravano a Google proposero
all’azienda di acquistare Overture: a Google piacque l’idea di
usare il modello per le aste delle inserzioni migliorandolo
• Modello originale Overture
– Le ads erano ordinate attraverso un’asta
– Le ads assegnate agli slot [le posizioni sulla pagina dei
risultati della ricerca] sulla base delle offerte dell’asta
• Le offerte più alte prendono gli slot migliori [più in alto
sulla pagina]
• I migliori offerenti pagavano il prezzo offerto (asta al primo
prezzo)Inserzioni pubblicitarie sui motori di ricerca
• Ads sono
mostrate in base
alla ricerca+ asta
sulle parole
chiave
• L’ordinamento
delle ads è
basato sui ricavi
slot 1 slot 2 slot 3 attesi
• Lo slot 1 riceve
più click dello slot
2, che a sua volta
riceve più click
dello slot 3Le ads dei motori di ricerca • Google scopre che un’asta con offerta unica al primo prezzo non è attraente per gli inserzionisti, perché questi tendono a pagare il minimo prezzo necessario a mantenere la posizione scelta sulla pagina • Per calcolare il prezzo minimo, è necessario fare calcoli complessi che occupano molto i server, così viene preferita l’asta con prezzo pagato dalla seconda offerta L’ordinamento delle ads rimane basato sui ricavi attesi
Le aste di Google search
Utilizza il metodo del secondo prezzo
generalizzato, Generalized Second Price (GSP)
• L’ordine delle ads dipende dall’offerta x il tasso
di click (click through rate, CTR) atteso
– Prezzo per click x clicks per impr = prezzo per
impression
– perché ha senso: ricavo = prezzo x quantità
• Ciascun offerente paga il prezzo determinato
dall’offerta che lo segue (es. le aste Ebay)
– Prezzo = prezzo minimo necessario a mantenere la
posizione desiderata
– Meccanismo determinato da un algoritmo
ingegneristico, non dall’offertaCome funziona l’asta GSP di
Google
• È abbastanza semplice calcolare l’equilibrio di
Nash di un’asta Google GSP
• Inserzionisti scelgono fra diversi slot, di cui alcuni hanno
un tasso atteso di click maggiore
– Principio di base: in equilibrio ciascun partecipante
all’asta preferisce la posizione scelta a tutte le altre
– Per descrivere l’equilibrio si possono analizzare
alcune diseguaglianze
– Le ineguaglianze possono essere invertite per
ottenere valori in funzione dell’astaCome funziona l’asta GSP di
Google
• Ipotizziamo vi sia un inserzionista che vuole
partecipare ad un’asta per una certa parola
chiave
• L’inserzionista ha di fronte una certa curva di
offerta: più alta l’offerta, maggiore il n. dei
partecipanti all’asta spiazzati, più alta la
posizione dove sono maggiori i click attesi
• L’inserzionista valuta il costo incrementale per
click (ICC)Come funziona l’asta GSP di Google • ricorda: il valore è la disponibilità a pagare di ciascun partecipante all’asta • se ICC < valore per click → aumenta l’offerta • se ICC > valore per click → riduci l’offerta • In equilibrio: ICC > valore per click ma il risparmio incrementale di scendere di una posizone < valore per click
Implicazioni dell’analisi • Risultato di base: il costo incrementale per click deve essere crescente all’aumentare del tasso atteso di click • È approccio simile al pricing nel classico mercato competitivo: se il prezzo = costo marginale, questo deve essere crescente • In pratica, l’ICC osservato è una buona stima del valore del click, perchè dipende non da costi tecnologico - produttivi, ma dal costo incrementale rispetto a cui deve decidere l’inserzionista
Esempio v = valore costante
ps= prezzo pagato per lo slot s
Ipotizziamo che: xs = clicks recevuti da s
r = prezzo di riserva
• supponiamo che tutti gli inserzionisti abbiano lo
stesso valore per click v
• caso 1: asta non interamente assegnata,
ovvero ci sono più slot che partecipanti all’asta
• caso 2: asta assegnata con un n. degli slot
disponibili inferiore a quello dei partecipanti
• Prezzo di riserva
– caso 1: prezzo minimo per click è pm (~ 5 cent).
– caso 2: l’ultimo inserzionista che ottiene lo slot paga il
prezzo dichiarato dal primo esclusov = valore costante
Caso 1 asta non ps= prezzo pagato per lo slot s
interamente
xs = clicks recevuti da s
assegnata
r = prezzo di riserva
• inserzionista deve essere indifferente fra pagare ps
e prendere xs, oppure pagare r e prendere xm (clicks
ricevuti dall’ultimo slot m)
( v - p s ) x s = ( v - r ) xm
ovvero ps xs = v( xs - xm ) + rxm
• il pagamento per lo slot s = valore incrementale del
click + pagamento dell’ultima posizionev = valore costante
Caso 1 asta non
interamente ps= prezzo pagato per lo slot s
assegnata xs = clicks recevuti da s
r = prezzo di riserva
• esempio con due slot e due partecipanti:
x1 = 100 clicks
x2 = 80 clicks
ps xs = v( xs - xm ) + rxm
v = 50 cent
r = 5 cent
• Risolvi equazione:
p1 x 100 = .50 x 20 + .05 x 80
p1 = 14 cent, p2= 5 cent
Ricavo = .14 x 100 + .05 x 80 = $18Caso 2 asta assegnata • Ciascun inserzionista deve essere indifferente fra ottenere il suo slot e non ottenerlo (profitto =0): • così (v - p s ) x s = 0 ps = v • Con l’esempio precedente di 2 slot, con 3 inserzionisti ps = 50 cent, il ricavo = .50 x 180 = $90 • Ricavo cresce molto non a causa del numero degli inserzionisti, ma per il fatto che questi debbono competere per ottenere uno slot!
Tipologie di asta utilizzate on-line
Ø nelle search ads si usa il modello GSP (ma Google ha dichiarato
che dal 2020, per rendere più trasparente il meccanismo,
tornerà all’asta al primo prezzo)
Ø nelle display ads il modello Vickrey tradizionale (asta a busta
chiusa al secondo miglior prezzo)
Ø nelle ads contextual display (YouTube dal 2012 o Facebook) si
usa invece il modello Vickrey-Clarke-Groves (VCG) che è una
generalizzazione di quello di Vickrey
Ø VCG ordina le ads:
– facendo pagare a ciascun inserzionista un prezzo pari al
costo che la sua partecipazione impone agli altri partecipanti
all’asta
– fa in modo che l’offerta ottimale sia il valore vero,
indipendentemente da quanto offrono gli altri partecipanti
all’astaRilevanza e qualità dell’ad
• Inserzionisti acquistano la parola chiave e scelgono
fra:
Ø Corrispondenza esatta → ad è mostrata solo se la
ricerca include la parola esatta
Ø Corrispondenza larga → ad è mostrata se la ricerca
include diverse definizioni, sinonimi e espansioni di
significato
• Qualità dell’ad
– Il tasso stimato di click deriva da due diversi effetti:
Ø posizione dell’ad nella pagina web
Ø Effetto specifico dell’ad ea misurato da esperimenti
quali una regressione con la storia pregressa dei
click ricevuti + altre variabiliRilevanza e qualità dell’ad
• L’ordine delle ad è quindi basato sulle offerte
moltiplicate per l’effetto specifico:
b a • ea
$ per click n. clicks per ad per pagina
– E’ importante determinare quale ad mostrare
nella pagina e quale ad non mostrare nella pagina
– Infatti mostrare un’ad sbagliata non rilevante ha
un impatto negativo sulla futura propensione dei
navigatori a cliccare: il classico trade-off fra ricavi
attuali e futuriElementi di economia dei
social network
I Social Network (Facebook, Twitter, LinkedIn) sono
anch’essi finanziati da inserzioni pubblicitarie
Nel Social Network sono fondamentali le
dimensioni della rete, fattore scatenante le
esternalità, e anche la dominanza di mercato
Tecnologia search : motore di ricerca
Tecnologia social network: social graphDifferenze delle caratteristiche economiche dei motori di ricerca (MR) e dei
grandi social network (SN)
profilo Search (Google) Social Network (Facebook)
lato mercato Finalità cercare contenuti attraversocondividere con amici
utenti parole chiave contenuti ed esperienze
Efficacia semantica del motore di dimensione della piattaforma
ricerca (n. amici effettivi o
potenziali connessi)
Coinvolgimento razionale e individuale emozionale, collettivo e
virale
Privacy bassa disponibilità a alta disponibilità a concedere
concedere dati personali dati personali
Piattaforma uso selettivo condividere informazioni
personali
lato mercato Finalità target determinati da motore target definiti
inserzionisti di ricerca e asta per le discrezionalmente
pubblicitari inserzioni
Efficacia utenti interessati ad utenti interessati ad
effettuare acquisti via effettuare acquisti via social
rilevanza ricerca commerce
Forma tipica di pay-per-click pay-per-impression→ pay-
pagamento per-clickLa user experience dell’utente è molto diversa sotto il profilo psicologico fra le due piattaforme MR e SN: • razionale e individuale nel caso del motore di ricerca (MR) • emotiva, collettiva e virale in quello dei Social Network (SN) Utente usa: Øil proprio lato razionale quando cerca contenuti sul web in modo individuale ØI propri lati emotivi quando inserisce i suoi contenuti sul SN o cerca informazioni su individui iscritti
Con MR predisposizione a concedere dati personali è bassa, perché utente vede differenza fra sua utilità e manipolazione dei propri dati: vede con fastidio le inserzioni personalizzate se non perfettamente coerenti con la sua ricerca Con SN predisposizione a concedere dati personali è alta perché utente non vede differenza fra immissione volontaria di info sul proprio profilo e rilascio degli stessi a fini di privacy
La centralità dell’esperienza emozionale dei SN è testimoniata dalle critiche di tipo morale, quali l’idea che le motivazioni personali ad utilizzarli sono composte da un mix di: Ø esibizionismo (“tutti possono vedermi nelle azioni che io decido di rendere pubbliche”) Ø voyerismo (“osservo di nascosto cosa fanno i miei amici e con chi sono a loro volta connessi”) Sentimenti rafforzati dalle opzioni gerarchiche offerte dal SN di mostrare alcuni contenuti a tutti, altri ad una cerchia più ristretta, altri ancora solo a singoli individui eletti
STRUMENTI ANALITICI DEI SOCIAL NETWORK
IL SOCIAL GRAPH
Il social graph è un algoritmo matematico applicato al web
che descrive le relazioni fra individui online attraverso le
connessioni esistenti fra essi
esempio di disegno di graph, in cui ogni individuo è rappresentato da un
cerchio numerato (nodo) e la relazione di amicizia da una linea (legame)
Il social graph è di proprietà esclusiva della piattaforma, e
costituisce un forte vantaggio competitivo nei confronti dei
concorrenti, perché genera effetti di lock-inNumero degli utilizzatori attivi di social network e messaging nel luglio 2019
Istagram ha meno della metà degli utenti Facebook, ma ha un power index 15 volte superiore
Modelli di business sui SN Social shopping (SS) = attivato dalla funzione “mi piace” q aggiunge emozioni, condivisioni giudizi su prodotti, fiducia q aumenta del 25% la shopping chart, e ben del 50% il valore medio dell’ordine q Grazie a SS, Facebook è riuscita ad aumentare fino al 60% (anno 2009, fonte InsideFacebook.com) la propria quota di ricavi generati da tariffazione pay-per-click, possibile dai post collocati dagli inserzionisti, in cui si è invogliati a commentare un certo prodotto o servizio e ad esprimere le proprie preferenze q Molti consumatori rinunciano ad acquistare un prodotto perché non sanno bene cosa, come e con quali modalità potranno utilizzarlo: SS interviene proprio su questo punto critico, con il cosiddetto Zero Moment of Truth o Zmot (che si pronuncia zee-mot), ovvero l’esperienza presa in prestito da altri di cui ci si fida e che diventa verità
Sui social network, in particolare Facebook, il criterio della scelta delle ads da mostrare, basato sulla massimizzazione dei ricavi, può avere conseguenze negative sull’equità. L’8 marzo 2019 il Department of Housing and Urban Development (HUD) ha aperto una procedura contro Facebook per aver adottato un algoritmo che impedisce che le ads vengano mostrate ad alcune categorie di utenti (coppie con bambini, non americani, non cristiani, ispanici, disabili), evidentemente poco profittevoli per la piattaforma. Sarebbe cioè stato violato il Fair Housing Act che impedisce ogni forma di discriminazione nei confronti di categorie protette. Se Facebook, nel caso ora citato, ha modificato il proprio algoritmo per adempiere alle indicazioni del HUD, rimane però un problema centrale dell’industria delle ads su Internet, verosimilmente destinato ad allargarsi.
Pubblicità on line negli USA per tipologia e anno Tipologia 2011 2012 2016 motori di ricerca 48,0% 49,4% 46,9% banners 24,1% 23,4% 20,5% video 6,3% 7,9% 15,0% annunci ed elenchi 7,8% 6,4% 5,2% sponsorizzazioni 3,4% 3,5% 4,2% email 0,4% 0,4% 0,3% altro 10,0% 9,0% 7,9% totale mercato on line (mln $) 32.0 39.5 62.0
Quote di mercato dei primi 4 motori di ricerca per ricavi
pubblicitari nel mondo
anno 2017
I ricavi di Google derivavano nel gennaio 2018:
•70,9% dal portale
•16,0% da altri siti del network Google
•13,0% da siti terzi anno 2017Quote di mercato dei primi 5 operatori
nella pubblicità on-line display* negli USA per anno
2011 2012 2013 2014
Facebook 14,0% 16,8% 17,7% 17,1%
Google 13,8% 16,5% 19,8% 21,7%
Yahoo! 12,0% 9,1% 8,1% 7,5%
Microsoft 4,5% 4,4% 4,3% 4,4%
AOL 4,3% 4,0% 3,8% 3,7%
Totale primi 5 operatori 47,4% 50,7% 53,8% 54,4%
totale mercato display (mln $) 12.40 15.39 18.57 21.91
* include banner, rich-media, sponsorizzazioni e mobileModello di asta VCG 1 • I beni in asta sono assegnati massimizzando la somma delle utilità dei partecipanti; ogni partecipante paga il costo opportunità che la sua presenza impone agli altri giocatori. Questo costo opportunità è definito come il totale delle offerte degli altri giocatori che avrebbero vinto se il primo giocatore avesse rinunciato a partecipare, meno il totale delle offerte degli attuali vincitori • Si supponga, ad esempio, un’asta per 2 slot con tre inserzionisti: • L’inserzionista A vuole 1 slot e offre $5 • L’inserzionista B vuole 1 slot e offre $2 • L’inserzionista C vuole entrambi gli slot e offre $6 (non è interessato a comperarne solo uno)
Modello di asta VCG 2 Il risultato dell’asta è determinato dalla massimizzazione del ricavo ottenuto: gli slot sono assegnati ad A e B (5+2$ > 6$) I prezzi si ottengono attraverso la seguente formula: •Prezzo pagato da A: B e C hanno un’utilità totale di $2 (insieme pagano $2 + $0) – se A fosse escluso, la loro utilità totale sarebbe di $6 ($0 + $6). Quindi A paga $4 ($6 − $2). •Prezzo pagato da B: A e C hanno un’utilità totale di $5 (insieme $5 + $0) – se B fosse escluso, la loro utilità totale sarebbe di $6 (0 + 6). Quindi B paga $1 ($6 − $5). •Prezzo pagato da C: A e B hanno un’utilità totale di $7 (5+2), escludendo C, C paga $0 (5 + 2) − (5 + 2) = $0
Modello di asta VCG 3 La procedura viene applicata agli slot pubblicitari e ai click ricevuti di Youtube e Facebook Algoritmo che calcola il pagamento netto dell’inserzionista A nello slot 1 (ipotesi 4 slot mostrati): (i) ogni volta che c’è un click nello slot 1, metti nel conto di A il prezzo dello slot 2 (ii) ogni volta che c’è un click nello slot s>1, togli dal conto di A la differenza fra prezzo dello slot 1 e quello dello slot 2.
Modello di asta VCG 4 Alla fine della giornata ci saranno: •x1 click ricevuti dallo slot 1 che implicano un pagamento da parte di A pari al prezzo dello slot 2 per x1 •x2 click ricevuti dallo slot 2 che implicano un pagamento ad A (prezzo slot 2 – prezzo slot 3) per x2 •x3 click ottenuti nello slot 3 che implicano un pagamento ad A (prezzo slot 3 - prezzo slot 4) per x3. Il pagamento netto totale di A è dunque pari a: prezzo slot 2 per x1 – [[(prezzo slot 2 – prezzo slot 3) per x2 + (prezzo slot 3 – prezzo slot 4) per x3]].
Numero di slot mostrati
Mostra più inserzioni (pro)
– spinge in alto i ricavi, specie se si passa da asta non
interamente assegnata ad asta assegnata
Mostra più inserzioni (contro)
– La rilevanza diminuisce
– I navigatori cliccheranno meno in futuro
Scelta ottimale dipende dal bilanciamento fra
profitto di breve periodo e obiettivi di lungo
periodoNelle aste search GSP il problema è poco rilevante perchè i partecipanti sono in genere molti, lo diventa invece nelle aste contextual display Le aste contextual display prevedono 4 slot, assegnati col criterio della rilevanza rispetto al contenuto mostrato (qui non è lo stesso algoritmo a generare risultati organici e ad rilevanti) In tutte le aste gli inserzionisti acquistando la parola chiave scelgono fra: Øcorrispondenza esatta → ad è mostrata solo se la ricerca include la parola esatta (es. cibo per cani) Øcorrispondenza estesa → ad è mostrata se la ricerca include diverse definizioni, sinonimi e espansioni di significato (es. mostrare cibo per cani in un video sui cani)
Nelle aste contextual display con corrispondenza estesa capita spesso che la prima ad offerta sia molto rilevante ma le altre due o tre molto meno: Google in questa fattispecie adotta il cosiddetto Dynamic resizing, ovvero ingrandisce l’ad rilevante e scarta le altre due, riuscendo in questo modo ad aumentare il n. totale dei click ricevuti (ovvero massimizza i ricavi) Con l’asta VCG questa procedura è facile da applicare, mentre è molto difficile con l’asta GSP (ecco perchè Google è passata a VCG nel contextual display)
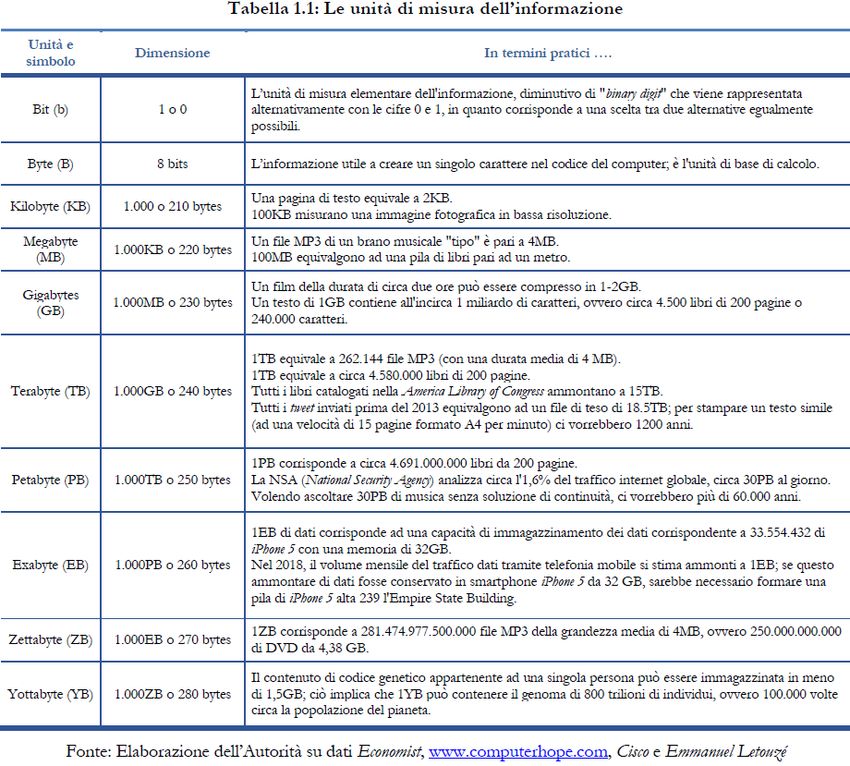
I Big Data Su Internet si trasformano in dati, le cui fonti sono qualsiasi device, sensore, sistema operativo, motore di ricerca, social network e in particolare le parole, la posizione geografica, le interazioni social, gli oggetti, se connessi in rete (IoT) Lo scambio dei dati è illustrabile nel seguente schema di mercato multiversante
I Big Data
Le tre dimensioni dei big data: volume, velocità, varietà
i processi interni dell’ecosistema dei big data sono complessi e comprendono, tra
gli altri:
• i momenti e le modalità di acquisizione del dato (data gathering & storage),
• il funzionamento degli algoritmi (algorithm accountability),
• i modi di conservazione e analisi (data analytics), le informazioni derivate, e gli
usi (primari e secondari) che ne derivano.I Big Data
Il volume
Molti dati raccolti sono ridondanti, ma la ridondanza nei Big Data
serve. L’insieme delle informazioni che ciascun utente genera nel
momento in cui svolge le proprie attività su internet diventano dati.
Per tale ammasso di dati grezzi è stato coniato il termine di data
exhaust: si tratta di informazioni (cookies, file temporanei, logfiles,
parole digitate, ecc.) che presentano al contempo un enorme
volume, devono essere acquisite a grandi velocità, e sono
composte dai formati più vari.
Dall’analisi congiunta, spesso in tempo reale, di questi dati è
possibile estrarre un enorme valore, dal momento che vengono
inferite abitudini e caratteristiche degli utenti.
Il valore effettivo dei dati, quindi, è nettamente superiore a quello
derivante dal loro primo utilizzo.La varietà
Small data si utilizzano dati strutturati, tipicamente
fogli di calcolo per riga e colonna
Big data Utilizza dati non strutturati che richiedono
tecniche sofisticate per tramutare il dato in
informazione (immagini, foto, testi, email,
RSS feed, video, sensori, Social media,
ecc.
Un’email include dati
sia strutturati (ora,
mittente/destinatario)
che non (il testo e gli
allegati)I Big Data
La velocità
La velocità è connessa alle tempistiche con cui le banche dati vengono
alimentate, in particolare alla alta frequenza con cui i dati circolano da
un punto di origine a uno di raccolta.
Solo con enorme velocità è possibile, come ormai accade
frequentemente, che il gestore di Big Data utilizzi meccanismi
decisionali in tempo reale.
Non più dead data (dati passati), ma real time data
«Most decisions should probably be made with somewhere around
70% of the information you wish you had. If you wait for 90%, in most
cases, you’re probably being slow»
Jeff BezosI Big Data
IL PERCORSO CIRCOLARE DEI BIG DATA
L’utente attraverso
le “cose” che gli
appartengono, L’utente riceve attraverso algoritmi di
genera il dato (di raccomandazione servizi personalizzati
qualsiasi tipo) e inserzioni pubblicitarie
Il dato è acquisito e Ciascun utente viene classificato in un
raccolto dalle “tipo” (in termini socioeconomici e/o
piattaforme digitali politici)
Il dato è aggregato L’insieme dei dati è processato con
ad altre basi dati tecniche di big data analytics che
(semistrutturate) individuano gli idealtipi (segmentazione
degli utenti)I CAMPI DEL SAPERE A CUI SI APPLICANO I BIG DATA • automazione (attività in precedenza gestite dall’uomo vengono svolte automaticamente da macchine) • intelligenza artificiale (attività per rendere intelligenti le macchine) • machine learning (incluso il deep learning), capacità di un computer di imparare modificare i propri processi sulla base dei nuovi dati ricevuti) • robotica (sistemi artificiali progettati per eseguire compiti o servizi per le persone, ad es. i cd Bot) • natural language processing, sviluppi in ambito linguistico che hanno creato assistenti virtuali che dialogano in modo naturale con gli umani (Alexa, Siri, Verdana, Google Home) • feedback processing usano i dati dei giudizi e commenti espressi dagli utenti per orientare le decisioni di consumo (online e offline). Sono la base della sharing economy (Uber, Tinder, Blablacar, ecc.) e diventano esse stesse un servizio per gli utenti
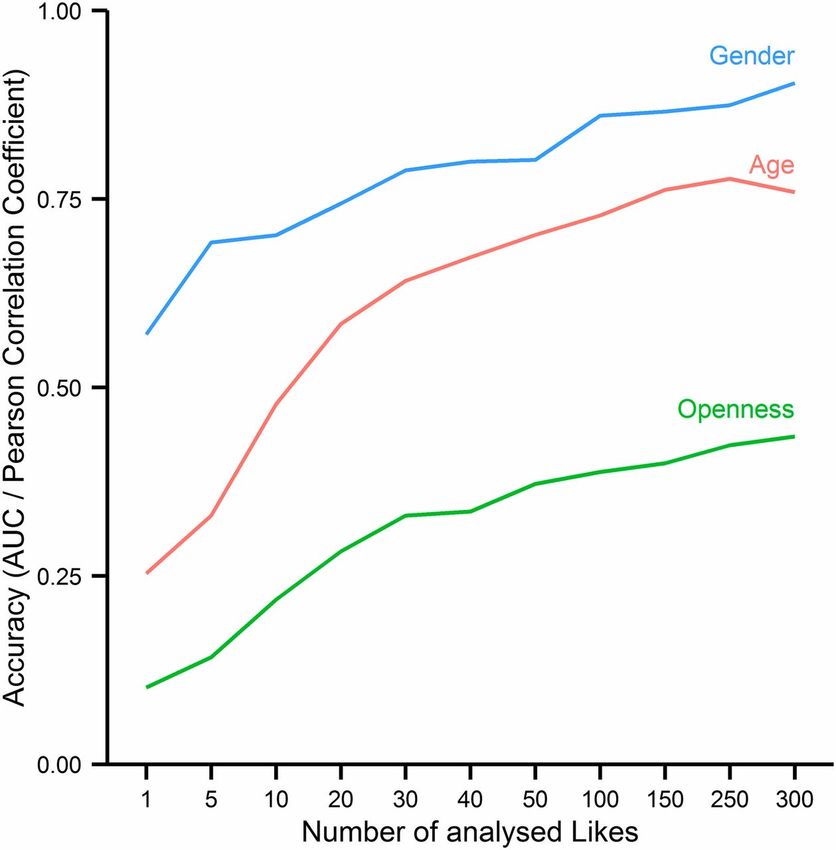
grazie agli studi compiuti da Mccrae & Costa e John, oggi con i big data sono sufficienti cinque variabili qualitative essenziali descrittive della personalità, note come “big five”. Ciascuna di esse è associata al suo simmetrico speculare: all’estroversione corrisponde l’introversione, alla gradevolezza la sgradevolezza, alla coscienziosità la negligenza, alla nevrosi la stabilità emotiva, all’apertura mentale la chiusura mentale.
Precisione di alcune predizioni in funzione del numero dei Like disponibili
Fonte: Michal Kosinski et al. PNAS 2013;110:15:5802-5805Il mercato dei dati nelle relazioni contrattuali fra
cittadini-utenti e soggetti che ne acquisiscono i dati
È basato su due fasi:
1) cessione dei dati dai consumatori ad una pluralità di soggetti
(inclusi i broker) che li acquisiscono;
2) cessione dei dati dai broker ai soggetti che li utilizzano per
finalità commerciali.
Ma che cos’è un dato dal punto di vista economico?Informazione e big data
assenza di rivalità nel consumo
L’informazione è un bene pubblico
non escludibilità nel consumo
Il diritto d’autore protegge l’autore dell’informazione sotto forma di un pieno diritto
temporaneo di proprietà (x anni), ma non tutte le informazioni presentano il medesimo
carattere, ad es. le impronte digitali non hanno nulla di creativo, ossia sono direttamente
beni pubblici, di dominio pubblico a cui possiamo accedere perché sono già stati rivelati
lasciando l’impronta.
I Big Data, tuttavia, non sono stati rilasciati in ambiente pubblico e, nel caso di consenso
al loro rilascio, diventano proprietà privata de facto di chi se ne appropria in via esclusiva
per finalità commerciali di profilazione pubblicitaria.
Emerge un paradosso: se una proprietà privata sui dati viene di fatto attribuita ex-post,
perché non deve essere riconosciuta inizialmente a chi quei dati ha generato?
Dunque la concessione al rilascio dei dati è uno scambio implicito non misurato da prezzi
dedicati e trasparenti: il mercato fallisce!Il fallimento di mercato dipende dal fatto che i diritti di proprietà non sono ben definiti, in cui il valore aggiunto si sposta dal contenuto al dato, dall’editore al nuovo intermediario capace di sfruttarlo economicamente. I dati hanno valore economico perché forniscono il materiale necessario a tipizzare i consumatori/target in modo da effettuare predizioni su come questi si comporteranno nei consumi o in politica. Tutti gli agenti economici scontano, nei propri comportamenti, l’assenza di un meccanismo istituzionale che regoli il commercio di dati. I consumatori sono disposti a concedere i propri dati solo a fronte di minori prezzi delle applicazioni mobili; Gli operatori web offrono le loro APP a prezzi minori, al limite nulli, solo a fronte dell’acquisizione di informazioni di dettaglio sugli utenti dei servizi. In assenza di regole, l’ecosistema digitale si è auto-regolato scontando l’incompletezza delle transazioni all’interno del prezzo dei servizi attraverso cui i dati vengono acquisiti dagli operatori e ceduti dagli utenti.
Pro e contro gli interventi antitrust nei confronti degli operatori di Big Data
Perché si
La fonte della dominanza della piattaforma dipende da un insieme di
fattori:
1. La natura dei dati raccolti
2. L’efficacia degli algoritmi (che dipende anche da 1.)
3. Le economie di rete (aumentano il costo-opportunità di uscita verso
piattaforme alternative)
4. Le economie di scala
5. Le economie di varietà
6. I costi di coordinamento all’uscita (come 3.)
7. Assenza di interoperabilità
8. Assenza di portabilità dei dati
Esserci sulla piattaforma è un must per un’impresa digitale (Spotify
costretta a pagare una royalty del 30% ad Apple per essere presente su
Apple Music, nonostante disponga di un proprio portale, caso aperto
presso la CE nel marzo 2019)Perché si Il multihoming degli utenti di per sé non risolve, perché per un’effettiva parità occorrono costi di transazione per utenti e consumatori molto bassi, che non sono tali per tutte le cause sopraricordate. Si rilevano conflitti di interesse fra i lati delle piattaforme: ad es. nei motori di ricerca l’ordinamento dei risultati organici e/o sponsorizzati Nel giugno 2017 la Commissione Europea ha sanzionato Google per 2,4 mld€ per aver favorito nei risultati di ricerca Google Shopping retrocedendo quelli dei concorrenti: il controllo di due dei lati (inserzionisti ed utenti) alimenterebbe un effetto clessidra in cui le economie di rete di ciascun lato si cumulano e rafforzano reciprocamente. Nel marzo 2019 la Commissione Europea ha sanzionato per 1,49mld€ Google per il suo servizio Adsense i cui contratti erano pieni di clausole di esclusiva. Anche le economie di varietà contano: offrire servizi diversi (come Gmail, Maps, YouTube, Google Drive, Play Store, Google News) consente alla piattaforma di gestirli tutti utilizzando un’unica base dati dei clienti.
Perché si I gestori delle piattaforme dispongono di un’elevatissima liquidità generata dai profitti che consente loro livelli di investimento impossibili per le piattaforme concorrenti (deep pocket). Nel 2006 Eisenmann e colleghi stimavano il break- even di una piattaforma search pari a 1,2 mld$ in ricavi pubblicitari on-line, AGCOM ritiene che oggi tale valore sia di circa 10mld$, ipotizzando che i costi variabili siano circa il 15-17% del fatturato pubblicitario. Istagram, lanciato sul mercato nel 2010, nel 2012 è stato acquisito da Facebook per circa 1mld$ e in breve tempo è diventato il secondo social network. L’accusa alle piattaforme globali è che esse, anziché essere il solo risultato di dinamiche concorrenziali replicabili, siano divenute ormai nuovi contesti istituzionali che si sostituiscono al mercato e lo governano.
Perché no • Le piattaforme favoriscono l’innovazione attraverso una differenziazione del prodotto. Secondo la teoria di Schumpeter, la concorrenza spinge verso il monopolio e il monopolio stimola la concorrenza, se ci sono basse barriere all’entrata. In tale visione le grandi piattaforme rischierebbero continuamente di avere vita effimera perché se fallissero nell’innovare qualcuno le spodesterebbe. «Competition is a click away» disse Larry Page davanti alla Commissione Giustizia del Senato americano, parafrasando quanto sostenuto da Varian. In sostanza non ci sarebbero posizioni di vantaggio permanente come nei monopoli perché i costi di uscita sarebbero bassi. L’esempio classico è quello di Yahoo! spodestato da Google, ma anche Nokia annientato da Samsung e Apple nei cellulari. • Se la disponibilità di Big Data consente la profilazione quasi perfetta dei consumatori, esiste una soglia critica di profilazione per ciascun individuo, oltre cui i rendimenti diventano decrescenti. Per una buona profilazione sono sufficienti pochi dati, e ciò è realizzabile anche dai nuovi entranti. I dati, sostengono, non sono un’infrastruttura essenziale come le reti nei servizi fisici perché sono replicabili. Limitare la libertà d’impresa è quindi socialmente inefficiente, perché deprime gli investimenti. • Multihoming, portabilità dei dati (come impone il GDPR in Europa e interoperabilità (favorita da Google e avversata da Apple) impedirebbero il monopolio.
Puoi anche leggere

















































