Analisi dei risultati - Linguistica italiana II Mirko Tavosanis A. a. 2018-2019 - Unipi
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Valutazione dei sistemi automatici di interazione
linguistica in italiano – Modulo B
14. Analisi dei risultati
8 aprile 2019 Linguistica italiana II
Mirko Tavosanis
A. a. 2018-2019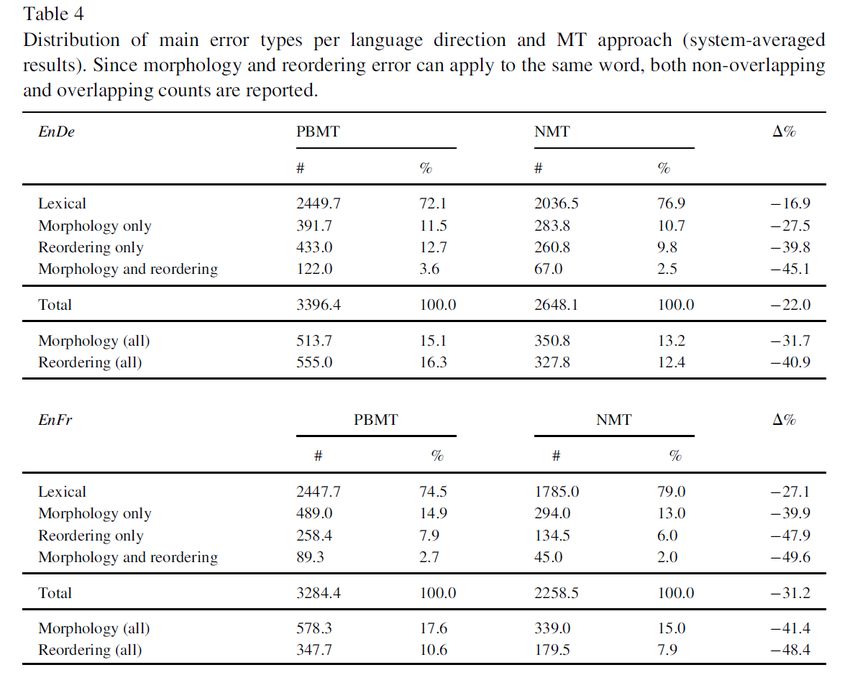
Oggi • Il dettaglio degli errori • Metodi usati nei contributi recenti
Analisi dei testi prodotti dalla NMT • In generale, possono essere analizzati (anche con strumenti come Dylan) e valutati come qualunque altro tipo di testo; per esempio, dal punto di vista di: • Composizione del lessico • Complessità delle strutture sintattiche • Leggibilità • La risposta a queste domande è interessante in rapporto alla diffusione: sono testi che potrebbero essere letti da un numero sempre maggiore di esseri umani e avranno un impatto linguistico • Inoltre, possono essere analizzati anche per vedere qual è la loro qualità… in particolare, per quanto riguarda la presenza di errori
Che cosa sappiamo sugli errori?
Per il prodotto di NMT, si dice di solito:
• Gli errori morfologici sono sorprendentemente ridotti,
rispetto alla traduzione PBST, ma sono comunque
presenti
• Può produrre traduzioni grammaticalmente corrette, ma
prive di rapporto con il testo di partenza
• Questo sembra un problema ridotto, a livello di frase (= frasi
completamente inventate), ma frequente all’interno
• Le frasi lunghe creano più problemi, rispetto alle frasi
breviAbbiamo visto un esempio di analisi nella tesi di Simone Gallo (6 marzo)
Prerequisito per l’interpretazione • Per discutere gli errori di significato occorre conoscere la lingua del testo originale! • Il livello B2 richiesto da Informatica umanistica per l’inglese dovrebbe essere abbondantemente sufficiente (= possono anche sfuggire degli errori, ma pochi) • Lo stesso lavoro può essere fatto su qualunque altra lingua, purché conosciuta a livello sufficiente • In altri termini: inutile provare a confrontare gli errori di traduzione dal cinese, se non conosciamo il cinese – possiamo solo valutare la correttezza grammaticale dell’italiano, e farci venire sospetti sulla coerenza del testo, ma non è possibile toglierci i dubbi
Analisi degli errori Qui vedremo il modo in cui è stato svolto il lavoro in Luisa Bentivogli, Arianna Bisazza, Mauro Cettolo, Marcello Federico, Neural versus phrase-based MT quality: An in-depth analysis on English-German and English-French, «Computer Speech & Language» 49, 2018, pp. 52-70 (su ScienceDirect, accessibile da rete Unipi) Constatazioni di senso comune (Bentivogli e altri 2018, p. 54): • L’analisi manuale è molto costosa e complicata • L’analisi automatica produce molti errori ed è influenzata dalle caratteristiche della traduzione di riferimento (una, o comunque poche) Un compromesso con molte possibilità di sviluppo: analisi degli errori eseguita dopo che un testo è stato revisionato
Categorie di analisi di uso comune A livello di parola: • Morfologia • Ordine delle parole • Parole mancanti • Parole aggiunte • Scelta lessicale (= parole sbagliate)
Categorie di analisi semplificate A livello di parola (Bentivogli e altri 2018): • Morfologia • Ordine delle parole • Scelta lessicale (= parole sbagliate)
Soggetto • Punto di partenza: trascrizioni umane di 12 discorsi tenuti in inglese durante altrettanti TED Talk (circa 2500 token a discorso) • Il fatto che i testi originali siano trascrizioni del parlato (cioè con sintassi semplificata, rispetto allo scritto) fa pensare che la differenza nell’ordine delle parole dall’originale alla traduzione possa essere relativamente ridotta, rispetto a un corpus di testi scritti • Traduzione automatica (con sistemi non commerciali): • dall’inglese in tedesco (4 sistemi NMT, 3 PBMT) • dall’inglese in francese (2 sistemi NMT, 3 PBMT) • La traduzione automatica è stata poi revisionata da traduttori umani
Due tipi di controllo Il controllo della qualità è stato eseguito calcolando il TER- Translation Edit Rate, che viene calcolato confrontando la traduzione automatica e la versione revisionata da un essere umano (ne abbiamo parlato l’11 marzo) In particolare sono stati usati: • Multi-Reference TER (mTER): tra più versioni della stessa frase, prodotte da più revisori umani, viene scelta come riferimento quella più vicina all’output della traduzione automatica • Human-targeted TER (HTER): l’output di partenza viene confrontato con la revisione automatica
Applicabilità per noi? • Potremmo sostituire le versioni revisionate con traduzioni umane degli articoli originali? • Non ho fatto confronti, ma temo di no: i testi hanno probabilmente differenze notevoli (come abbiamo visto in alcuni casi), e questo li rende oggetti diversi • In sostanza, occorre avere dei revisori professionisti: cosa che si può fare con un progetto dedicato, o in alternativa...
Progetto Wikipedia • L’applicabilità va verificata, ma è promettente • Alla base: usare il tracciamento delle versioni di Wikipedia per vedere quanto viene modificato un testo • All’interno di un PRIN recentemente finanziato, conto di usarlo (almeno in via sperimentale) per individuare quali sono i tratti di scrittura degli studenti universitari che vengono modificati dalle revisioni successive • Richiede molti adattamenti e un buon livello di sviluppo (per distinguere gli interventi sulla frase da quelli generati da semplici interventi sui collegamenti interni, e simili)
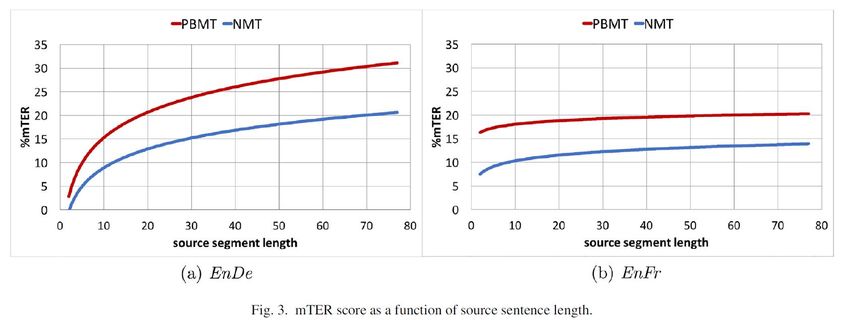
Risultato base Come ormai ci aspettiamo, per NMT è stato necessario un numero di interventi molto minore rispetto a quello di PBMT Per il tedesco, per esempio, le medie NMT rispetto a quelle PBMT sono state: • mTER 13,8 contro 21,7 • HTER 22,6 contro 29,0 Il fatto che i punteggi mTER siano più bassi viene interpretato come indicazione del fatto che mTER «is a viable way to control and overcome post-editors variability, thus ensuring a more reliable and informative evaluation about the real overall performance of MT systems» (p. 57)…. Ma non sono sicuro del perché
Valutazione in base alla lunghezza • La percentuale degli errori aumenta effettivamente in base alla lunghezza della frase • Tuttavia, «differently from what observed in previous investigations, NMT seems not to suffer from performance degradation more than PBMT as the input lengh increases» (p. 58) • Aggiungo che sarei curioso di vedere che cosa succede alla qualità delle traduzioni umane nelle stesse circostanze!
Valutazione degli errori • La valutazione di diversi tipi di errore, inclusi quelli di traduzione, in molti casi è molto difficile • In alcune aree è perfettamente possibile: errori ortografici, errori di accordo… • In altre, perfino dare dei numeri è molto complicato: si può fare, ma c’è un margine molto alto di incertezza • Soprattutto, si incontrano problemi metodologici • In passato ho provato la valutazione di errori: • Ortografici (facili) • Morfosintattici (più difficili) • Concordanza soggetto – verbo (facili) • Semantici (molto difficili)
Analisi degli errori in vari contesti • I testi prodotti da madrelingua in contesti formali sono abbastanza analizzabili e i casi di incertezza sono ridotti • I testi prodotti come lingua straniera o lingua seconda spesso contengono elementi non interpretabili e non descrivibili: questa è una delle manifestazioni dell’interlingua • Vedremo la questione dal punto di vista ortografico e per i testi scritti: in questo caso il margine d’errore è ridotto, ma non assente, anche per le produzioni di non madrelingua umani • Nei sistemi NMT gli errori ortografici sono ormai pochissimi, quindi avrà poco senso analizzarli!
Tipi di errore ortografico • errori linguistici (misspellings): errori commessi per mancata conoscenza della lingua o delle norme ortografiche (squola) • errori di battitura (typos): errori commessi per motivi – psicologici (caporalo) – meccanici (cer5to) • deviazioni volontarie: una categoria del tutto separata (che include leetspeak, sostituzioni espressive)
Errori di battitura: cause ⚫ Psicologiche (caio, come stai?) Studiate dalla filologia tradizionale e (per quel che vale) dalla psicanalisi ⚫ Meccaniche (ciao, come s5tai?) Tipicamente, si pigia qualche tasto in più o al posto di quello che si voleva premere ⚫ Tecniche (perche me lo chiedi?) Tipicamente per problemi di codifica Ci dicono qualcosa sul grado di revisione di un testo, e poco altro
Deviazioni intenzionali: cause ⚫ necessità stilistiche (k, leetspeak) ⚫ desiderio di superare limitazioni di natura tecnica (lettera + apice invece di lettera accentata) ⚫ desiderio di ingannare sistemi automatici (blog di spam, siti che sfruttano gli errori di ortografia...) In ogni caso, evidentemente queste deviazioni richiedono – su uno o più piani – competenze superiori rispetto al livello base
Errori tipici dalla scuola superiore
in su (Zanichelli)
accellerare / accelerare
anedottico / aneddotico
appropiato / appropriato
aeroporto / aeroporto
Caltanisetta / Caltanissetta
collutazione / colluttazione
colluttorio / collutorio
conoscienza / conoscenza
coscenza / coscienza
eccezzionale / eccezionale
efficenza / efficienzaErrori linguistici:
possibili cause
⚫ Conosco la lingua, ma non so scrivere rispettando in
tutto l’ortografia standard (casi comuni in inglese, meno
comuni in italiano)
⚫ Non so come si scrivono parole che hanno un uso quasi
solo scritto (meteorologia)
⚫ Non conosco abbastanza la lingua (tipicamente:
sono straniero)
Errori di questo genere rivelano qualcosa sulle competenze
linguistiche di chi scrive: esseri umani, ma anche sistemi
informaticiOltre l’ortografia • Si può considerare l’errore come un tentativo imperfetto di raggiungere una forma target • Il problema: al di fuori dell’ortografia, molto spesso non si riesce a ricostruire quale sia la forma target e questo problema vale anche per le traduzioni • Per esempio: «In oltre la vasta gamma dei lessici fiorentini aveva dato la presenza dei doppioni nel lessico ed aveva additato come i vocabili da fuggire nello stile illustre» Dove cominciano e finiscono gli errori?
Discussione Andorno e Rastelli • Fonte: Cecilia Andorno e Stefano Rastelli, Un’annotazione orientata alla ricerca acquisizionale, in Corpora di italiano L2, Perugia, Guerra, 2008, pp. 49-70 • Il problema di annotare le forme non standard è strutturale per questo genere di ricerche • Esistono numerosi schemi di annotazione
ICLE
(International Corpus Learner English, 1998)
• Formal
• Grammatical
• LeXico-Grammatical
• Lexical
• Register
• Word redundant / word missing / word order
• Style
Ogni categoria può essere poi articolata in
sottocategorieEsempio ICLE • «Molti personi hanno stato annoiosi» (p. 51) • Per annoiosi l’errore potrebbe essere annotato GVCONJGEND2AUXACR
Problema:
come annotare gli errori?
L’annotazione «tradizionale» va bene in molti contesti (abbiamo visto
che per esempio non pone molti problemi per l’ortografia)
V. anche: M. Tavosanis, A Causal Classification of Orthography Errors
in Web Texts, in Proceedings of the IJCAI-2007 Workshop on
Analytics for Noisy Unstructured Text Data, IAPR - IBM Research,
vol. I, pp. 99-106.
http://research.ihost.com/and2007/cd/Proceedings_files/p99.pdf
Un caso più sofisticato: Fabiana Rosi, «Non ha saputo dove è stato»:
come annotare le forme non-target in un corpus di italiano L2?, in
Corpora di italiano L2Rosi Predicati non-target a livello: • Lessicale • Morfosintattico • Azionale • Aspettuale Alcune indicazioni sono fornite attraverso i valori dell’attributo comm («commento»). Per esempio, valore "was" (wrong actionality selection): … quindi il capo della panatteria è andato un’altra volta a parlare con il poliziotto che il ladro non era Charles…
Problemi con l’aspetto
• I predicati sono contenuti all’interno di un elemento
XML
• L’attributo asp riporta informazioni sull’aspetto
• Due valori possibili per asp sono:
– «dev» («deviante») quando «la scelta della marca aspettuale da
parte dell’apprendente è agrammaticale» (p. 87)
Poi C. C. ha preso il sale/cocaina sul cibo ed è diventato un po’
pazzo. Non ha saputo dove è stato
– «amb» («ambigua») quando «la codifica aspettuale è
grammaticale ma non coincide con la forma più naturale e
frequente nella produzione nativa» (p. 87)
… ma come/siccome non ha
avuto i soldi non potevo/poteva pagareIn pratica
• In Bentivogli e altri 2018 si usa un sistema poco solido
dal punto di vista metodologico (gli «errori» potrebbero
non essere davvero errori) ma molto pratico
• In sostanza, si considerano come errori le parole che
vengono modificate nella revisione
– Tra l’altro, questo richiede che ci sia un testo da normalizzare…
cioè, dà per scontato che la qualità del prodotto di NMT sia
sufficientemente alta da creare un contesto ricostruibile
• I testi di partenza e di origine vengono lemmatizzati e gli
«errori» ripartiti in tre grandi categorie:
– Errori lessicali (somma di inserimenti, cancellazioni e sostituzioni)
– Errori morfologici (lemma corretto, ma forma diversa)
– Errori nell’ordine delle parole (i casi in cui TER, a differenza di
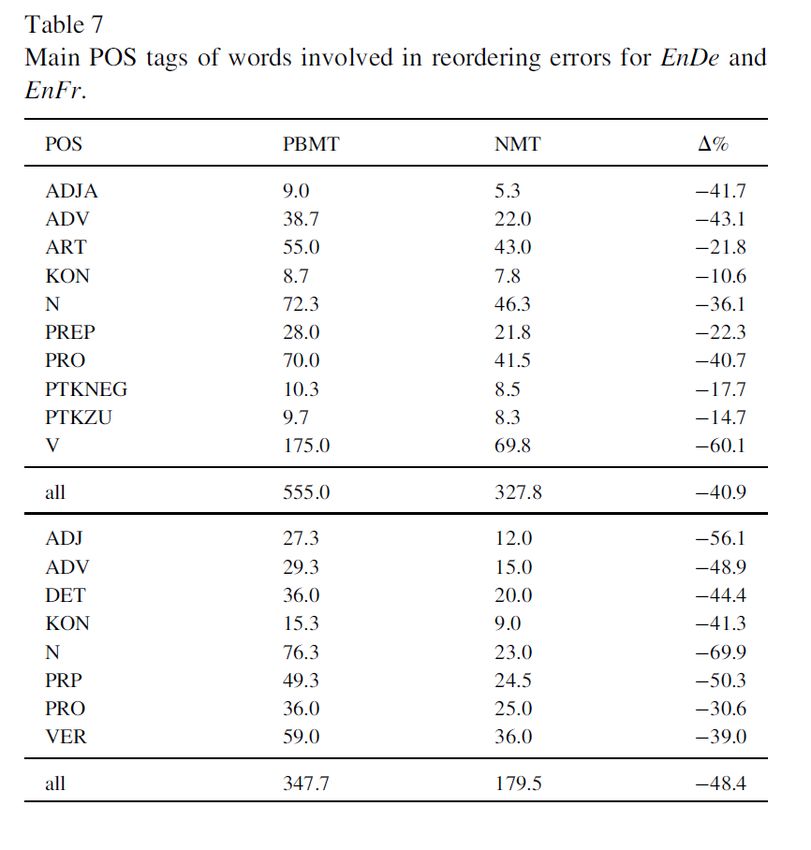
WER, individua un’operazione di spostamento)A fini di confronto • Il calcolo degli errori in Bentivogli e altri 2018 è svolto a fini di confronto tra due sistemi • La conclusione fondamentale (p. 60): NMT fa calare gli errori, ma la percentuale di «lexical errors» sul totale degli errori aumenta • Viceversa, si ha una notevole riduzione negli errori morfologici: – 41,4% in meno per la traduzione in francese – 31,7% in meno per quella in tedesco • Soprattutto, c’è una notevole riduzione per gli errori di ordine delle parole: – 48,4% in meno per la traduzione in francese – 40,9% in meno per quella in tedesco
Nel vostro lavoro • Ci sono varie possibilità; io ne consiglio due interessanti, che richiedono impegno diverso: • valutazione degli errori di concordanza (in particolare soggetto-verbo); l’adozione di NMT ne ha ridotto radicalmente il numero, ma proprio per questo il problema è gestibile • individuazione di errori semantici: la valutazione dell’errore è difficile, ma relativamente facile a livello di frase (cioè, contando 1 ogni frase che contiene un errore di traduzione, indipendentemente dalla sua gravità) – In sostanza, si tratterebbe di identificare le frasi sbagliate
Lessico e grammatica • La differenza tra lessico e grammatica è un po’ meno rigida del modo in cui la vede la grammatica tradizionale – Alcune parole hanno «regole grammaticali» autonome – Alcune regole si applicano solo ad alcune parole • Per gli apprendenti (o per chi deve familiarizzare con un linguaggio settoriale) questi aspetti sono molto difficili da imparare • Esamineremo il problema dal punto di vista della «combinatoria» di una lingua
Categorie a restrizioni crescenti • Lessico (in libera collocazione; ne abbiamo già parlato) • Collocazioni • Polirematiche (e da qui verso i modi di dire, i proverbi, le frasi fatte e i cliché…) I confini tra le categorie non sono molto chiari Per un primo orientamento, consiglio le voci Collocazioni e Polirematiche, parole dell’Enciclopedia dell’Italiano Treccani Anche on line: • http://www.treccani.it/enciclopedia/collocazioni_%28Enciclopedia- dell'Italiano%29/ • http://www.treccani.it/enciclopedia/parole-polirematiche_%28Enciclopedia- dell'Italiano%29/
Ai confini delle regole grammaticali Abbiamo visto i casi in cui l’uso dell’articolo è richiesto o vietato dalla lingua senza che ci siano ragioni chiare Problemi simili si pongono per situazioni simili: • Scelta delle preposizioni (perché si deve dire «è tempo di andare» invece di «è tempo per andare», come «è un buon momento per chiudere»?) • Scelta del verbo supporto (perché «lo rese famoso» invece di «lo fece famoso», come «ti fa bella»?)
Collocazioni
• Intuitivamente: le parole non si distribuiscono a caso in un
testo, il lessico non si combina a caso
• Dal punto di vista statistico, alcune parole compaiono assieme
più di frequente rispetto a quanto non ci si aspetterebbe sulla
base di una distribuzione casuale
• Questa distribuzione si può spiegare sulla base di
– regole grammaticali (piuttosto rigide):
«il + cane» sarà più frequente di «il + aquila»
– vincoli semantici:
«costruire + case» sarà più frequente di «costruire alberi»
– ragioni linguistiche (collocazioni):
«mangiare + bene» sarà più frequente di «mangiare + a un buon livello
qualitativo»
• L’esame di questi fenomeni è stato incoraggiato dalla
disponibilità di strumenti elettronici per il calcolo delle
probabilitàIndici matematici • Per il calcolo delle collocazioni esistono diversi sistemi, che forniscono valutazioni diverse • Il principio di base è comunque lo stesso: vedere se due (o più) parole adiacenti, o separate da un numero di parole deciso dal ricercatore, si presentano con una frequenza nettamente superiore rispetto a ciò che ci si aspetta da una distribuzione casuale del lessico
Il CORIS / CODIS Lo strumento mette a disposizione online quattro sistemi di calcolo delle collocazioni: • Log-Likelihood Ratio • Mutual information, calcolata con la formula MI = 100 * log2 f(node,collocate)*DimCorpus / (f(node)*f(collocate)) particolarmente utile perché permette di isolare le parole piene! • T-score = 100 * (f(node,colloc) - f(node)*f(colloc)/DimCorpus) / sqrt(f(node,colloc)) • Raw Frequency Fonte delle formule: M. Stubbs (1995), “Collocations and semantic profiles”, Functions of Language, 2, 1, pp. 23-5
Combinazioni preferenziali e collocazioni Simone (2006) distingue due livelli: • Combinazioni preferenziali • Collocazioni vere e proprie (che incorporano la propria testa e bloccano la sinonimia) Qui parleremo per entrambi i casi solo di «collocazioni» Il senso linguistico è un po’ diverso da quello puramente matematico: non si tratta di eventi definiti dalla probabilità ma di sequenze di cui è stata definita la natura
Tratti identificativi delle collocazioni
a. non-composizionalità: il significato di una collocazione non risulta dalla somma
dei significati dei costituenti, ma presenta un elemento semantico aggiuntivo
dato proprio dalla loro co-occorrenza (cfr. giornata nera, caffè nero, umore
nero)
b. non-sostituibilità: il costituente di una collocazione non può essere sostituito con
un sinonimo (…) senza rischiare che si crei una combinazione inusuale o
innaturale (cfr. umore nero rispetto a umore scuro); in altri termini, i sinonimi
non possono scambiarsi liberamente;
c. allo stesso tempo, possibilità di sostituire un collocato con un altro
semanticamente analogo senza cambiare il senso della collocazione (cfr. dirimere
una controversia e risolvere una controversia);
d. relativa autonomia dei costituenti: a differenza delle espressioni idiomatiche, i
componenti di una collocazione mantengono le proprie funzioni grammaticali
anche variandone l’ordine (la guerra è scoppiata / è scoppiata la guerra), e tra il
nodo (o base) e il collocato è sempre possibile inserire altre parole (cfr. la guerra
che tanto si temeva è quindi scoppiata);
e. inalterabilità semantica delle parole della collocazione: le parole mantengono il
loro significato letterale.
(Faloppa 2011)Tipi di collocazioni 1. verbo + articolo + nome (oggetto): «scattare una fotografia» 2. (articolo) + nome (soggetto) + verbo: «la situazione precipita» 3. nome + aggettivo: «nodo cruciale» 4. aggettivo + nome: «vasto orizzonte» 5. nome + nome: «parola chiave» 6. nome + preposizione + nome: «tavoletta di cioccolato» 7. avverbio + aggettivo: «diametralmente opposto» 8. verbo + avverbio: «rifiutare categoricamente» (Faloppa 2011)
Polirematiche
• Studiate soprattutto da Tullio De Mauro
• Rispetto alle collocazioni hanno una maggiore rigidità
• Si possono definire «parole polirematiche» perché in effetti svolgono
funzioni assimilabili a quelle di una parola
• Spesso i parlanti non riescono neanche a ricostruire i motivi per cui
una polirematica ha quel significato: «luna di miele» non è una luna e
non ha nulla a che fare con il miele
– Il fenomeno è simile a quello che si ritrova nell’evoluzione del significato delle
parole singole: oggi il parlante non riesce a ricondurre fegato al nome di un piatto
(iecur ficatum)
– In molte lingue questo è un procedimento normale di formazione delle parole: nel
tedesco si arriva spesso all’uniformazione grafica (Weltanschauung invece di
visione del mondo)
• La categoria si sovrappone in buona parte a quella dei modi di dire: in
pratica i modi di dire possono essere considerati polirematiche (e lo
stesso vale per i proverbi)Differenza rispetto alle collocazioni
• Le collocazioni possono essere facilmente modificate con:
– inversioni
– inserimento di altre parole all’interno dell’espressione («sono stati banditi
cinque concorsi»)
• Le polirematiche tollerano molto meno questo tipo di
interventi («una luna indiscutibilmente di miele»?)Rigidità per polirematiche a) non ammettono la sostituzione sinonimica dei costituenti interni (camera a gas → * stanza a gas) o la variazione per via di flessione, sia per quanto riguarda gli elementi che non sono testa del sintagma (fare acqua → *fare acque; gioco di carte → *gioco di carta), sia anche per lo stesso elemento testa (alte sfere → *alta sfera); b) non possono essere interrotte con l’interposizione di altre parole (casa di cura → *casa spaziosa di cura); c) non permettono dislocazioni (permesso di soggiorno → *è di soggiorno quel permesso?) o altri cambiamenti nell’ordine delle parole (alti e bassi → *bassi e alti); d) non consentono di pronominalizzare uno dei costituenti interni (prestare attenzione → *che cosa hai prestato? attenzione; cartone animato → *quelli animati sono i cartoni che mi piacciono di più). Tuttavia queste, più che regole assolute, sono tendenze. (Masini 2011)
Rigidità decrescente Le polirematiche sono ammesse nel ruolo di diverse parti del discorso, ma la loro resistenza alle alterazioni è variabile. In ordine di resistenza decrescente: • Preposizioni («in preda a»), congiunzioni («al fine di») • Avverbi («all’aria aperta») e aggettivi («in erba») • Sostantivi («uscita di sicurezza») • Verbi («prender piede») Tipicamente, nel caso dei verbi il verbo si può coniugare («le abitudini presero piede», mentre nel caso dei sostantivi si può mettere al singolare o al plurale («uscite di sicurezza») (Masini 2011)
Testa
Il componente che determina le caratteristiche di un oggetto
composto
• Testa categoriale: determina la parte del discorso (le
polirematiche possono appartenere a tutte le parti del discorso)
• Testa semantica: determina il significato della parola (un
«permesso di soggiorno» è un tipo di permesso, non un tipo di
soggiorno)
(Masini 2011)Sostantivi polirematici a. Nome + Aggettivo: «carta telefonica», «casa editrice», «anno accademico» b. b. Aggettivo + Nome: «prima serata», «doppio senso», «terzo mondo» c. Nome + Sintagma preposizionale: «punto di vista», «carta di credito», «mulino ad acqua» «A quest’elenco si potrebbero aggiungere, pur con qualche incertezza, le combinazioni Nome + Nome (punto vendita, viaggio lampo, treno merci). Tali strutture hanno però statuto incerto, poiché (proprio come i composti) non hanno elementi relazionali o di accordo, e allo stesso tempo sembrano presentare un grado di separabilità leggermente maggiore rispetto ai composti veri e propri (si veda un esempio come quello merci non è ancora partito, riferito a treno merci, che può essere accettabile). Dunque, probabilmente le combinazioni Nome + Nome costituiscono il punto di incontro tra le parole polirematiche e i composti veri e propri.» (Masini 2011)
Aggettivi e avverbi polirematici Aggettivi polirematici a. Preposizione + Nome o Aggettivo: fuori stagione, in bianco b. b. Preposizione + Determinante + Nome o Aggettivo: alla mano, al verde Avverbi polirematici a. Preposizione + Nome o Aggettivo: a rate, a caldo b. Preposizione + Determinante + Nome o Aggettivo: sulla carta, al verde Aggettivi polirematici formati da binomi irreversibili a. Aggettivo + Congiunzione + Aggettivo: vero e proprio b. Nome + Congiunzione + Nome: acqua e sapone c. Verbo + Congiunzione + Verbo: usa e getta d. Preposizione + Nome + Congiunzione + Nome: senza arte né parte (Masini 2011)
Oltre le polirematiche Oggi si riconoscono diverse categorie di verbi che contribuiscono in modo complesso alla definizione di un significato (molte sono state proposte da Raffaele Simone): • Verbi pronominali («prenderla male») • Verbi sintagmatici, con avverbio o altra prosecuzione («portare avanti») • Verbi supporto, in cui il significato è dato da un sostantivo o da un aggettivo e il verbo ha solo una funzione ausiliare («prendere coraggio»)
Puoi anche leggere

















































