UNIVERSITÀ DEGLI STUDI DI NAPOLI "FEDERICO II"
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
UNIVERSITÀ DEGLI STUDI DI NAPOLI
“FEDERICO II”
Scuola Politecnica e delle Scienze di Base
Area Didattica di Scienze Matematiche Fisiche e Naturali
Dipartimento di Fisica “Ettore Pancini”
Laurea Magistrale in Fisica
E-GAN for DBT data augmentation
Relatore: Candidato:
Giovanni Mettivier Lorenzo D’Errico
Correlatore: Matr. N94000545
Mariacarla Staffa
Anno Accademico 2019/2020
Indice
Elenco delle figure iii
1 Deep learning e imaging medico: analisi del problema 1
1.1 Carcinoma mammario: cos’è, quanto è diffuso e la prevenzione . . 1
1.1.1 Gli esami diagnostici: la mammografia e la DBT . . . . . 4
1.2 Intelligenza artificiale in medicina . . . . . . . . . . . . . . . . . 8
1.3 Obiettivi del lavoro . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Tecniche e strumenti utilizzati: lo stato dell’arte 11
2.1 Il data augmentation: un overview . . . . . . . . . . . . . . . . . 11
2.2 Tecniche di data augmentation per le immagini . . . . . . . . . . 13
2.2.1 Data augmentation basato sulla manipolazione di immagini 13
2.2.2 Data augmentation basato sul deep learning . . . . . . . . 19
2.2.3 Confronto . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.3 GAN: il framework . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.3.1 Il generatore . . . . . . . . . . . . . . . . . . . . . . . . 25
2.3.2 Il processo di training . . . . . . . . . . . . . . . . . . . . 25
2.4 GAN: le funzioni di costo . . . . . . . . . . . . . . . . . . . . . . 25
2.4.1 La funzione di costo del discriminatore . . . . . . . . . . 25
2.4.2 La funzione di costo del generatore . . . . . . . . . . . . 27
2.5 GAN: un esempio di architettura . . . . . . . . . . . . . . . . . . 29
2.6 Data augmentation basato sulle GAN . . . . . . . . . . . . . . . . 30
3 L’esperimento: l’architettura EGAN e i risultati ottenuti 33
3.1 EvolutionaryGAN per il data augmentation: cosa c’è di nuovo? . . 33
3.1.1 L’algoritmo evoluzionistico . . . . . . . . . . . . . . . . 34
3.1.2 Le mutazioni . . . . . . . . . . . . . . . . . . . . . . . . 35
3.1.3 Valutazione . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.1.4 L’algoritmo . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.1.5 Gli esperimenti . . . . . . . . . . . . . . . . . . . . . . . 38
3.2 EGAN per il data augmentation di immagini DBT . . . . . . . . . 42
3.2.1 Descrizione del dataset e del network utilizzati . . . . . . 42
3.2.2 Apparato strumentale e ottimizzazione del dataset . . . . . 44
i
3.3 Risultati e discussione . . . . . . . . . . . . . . . . . . . . . . . . 44
3.3.1 Prove con l’intero dataset . . . . . . . . . . . . . . . . . . 44
3.3.2 Ulteriori test . . . . . . . . . . . . . . . . . . . . . . . . 46
3.4 Analisi dei dati . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4 Conclusione 54
Bibliografia 55
ii
Elenco delle figure
1.1 Anatomia della mammella . . . . . . . . . . . . . . . . . . . . . 1
1.2 Tumore duttale in situ . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Incidenza tumori in Europa . . . . . . . . . . . . . . . . . . . . . 2
1.4 Mortalità del tumore alla mammella nel tempo . . . . . . . . . . . 3
1.5 Attenuazione dei raggi X nei tessuti . . . . . . . . . . . . . . . . 4
1.6 Schema dell’apparato per mammografie . . . . . . . . . . . . . . 4
1.7 Viste mammografia. . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.8 Schema di acquisizione di una DBT . . . . . . . . . . . . . . . . 6
1.9 Mammografia Vs DBT . . . . . . . . . . . . . . . . . . . . . . . 6
1.10 Confronto tecniche di imaging . . . . . . . . . . . . . . . . . . . 7
1.11 Architettura di una CNN. . . . . . . . . . . . . . . . . . . . . . . 8
2.1 Flipping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2 Rotation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Noise injection . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4 Color space transformation . . . . . . . . . . . . . . . . . . . . . 15
2.5 Geometrical Vs Photometric transformation . . . . . . . . . . . . 16
2.6 Esperimenti mixing . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.7 Esempio di applicazione della tecninca di mixing [50] . . . . . . . 18
2.8 Random erasing . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.9 Cutout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.10 Autoencoder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.11 GAN publications . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.12 Neural style transfer . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.13 Confronto accoppiamenti tecniche . . . . . . . . . . . . . . . . . 23
2.14 GAN framework . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.15 Discriminatore . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.16 Varianti di gioco GAN . . . . . . . . . . . . . . . . . . . . . . . 28
2.17 DCGAN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.18 DCGAN bedrooms . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.19 CycleGAN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.20 Risultati dei test visivi di Turing su immagini generate da DCGAN
e WGAN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
iii
3.1 EGAN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.2 Mutazioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.3 Algoritmo EGAN . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.4 Dataset sintetici . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.5 Inception Score . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.6 LSUN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.7 CelebA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.8 CelebA interpolate . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.9 Slice DBT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.10 Risultato prima epoca . . . . . . . . . . . . . . . . . . . . . . . . 45
3.11 Risultato cinquantesima epoca . . . . . . . . . . . . . . . . . . . 45
3.12 Risultato novantesima epoca . . . . . . . . . . . . . . . . . . . . 46
3.13 Risultato immagini iniziali . . . . . . . . . . . . . . . . . . . . . 47
3.14 Risultato immagini centrali . . . . . . . . . . . . . . . . . . . . . 48
3.15 Risultato immagini finali . . . . . . . . . . . . . . . . . . . . . . 48
3.16 Tabella dati raccolti . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.17 Heatmap DBT . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.18 Pair Plot dati DBT . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.19 Heatmap cifar-10 . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3.20 Pair Plot dati CIFAR-10 . . . . . . . . . . . . . . . . . . . . . . . 52
iv
Sommario Le tecniche di deep learning, ed in particolare le reti neurali convoluzionali (Con- volutional Neural Network, CNN), hanno portato ad un ampio miglioramento in diversi campi della computer vision, principalmente utilizzando dataset "etichetta- ti" su larga scala. Ottenere un tale tipo di dataset nel settore dell’imaging medico per la diagnostica risulta tutt’ora una sfida aperta. Il motivo principale è che i da- ti sensibili di questo genere sono sottoposti a stringenti limitazioni in materia di privacy, inoltre le annotazioni specialistiche come la segmentazione di organi o lesioni su multi-slices 2D o volumi 3D eseguite da osservatori esperti sono opera- zioni complesse e tempisticamente esose. La dimensione limitata dei dataset per l’addestramento delle reti neurali può inficiare le performance degli algoritmi di apprendimento supervisionato che necessitano di grandi quantità di dati per evitare il problema del sovra-campionamento (overfitting). Da qui, la maggior parte degli sforzi in tale ambito è orientata all’estrazione del maggior numero di informazioni possibili dai dati disponibili. Le reti generative avversarie (Generative Adversarial Network, GAN) rappresentano una possibile soluzione innovativa per l’estrazione di informazioni aggiuntive da un dataset poiché sono in grado di generare campio- ni sintetici indistinguibili dai dati reali. Il presente lavoro di tesi esplora l’utilizzo delle GAN nel campo della Digital Breast Tomosythesis (DBT) ed in particolare l’utilizzo di un approccio di ottimizzazione del processo di apprendimento delle reti GAN basato su tecniche evoluzionistiche che, simulando i meccanismi di mutazio- ne ed evoluzione di una popolazione di generatori, sono in grado di selezionare generatori di campioni sintetici sempre più accurati. In particolare, una misura di performance (funzione obiettivo/fitness function) viene utilizzata al termine di ogni ciclo di apprendimento per misurare la qualità e la diversità dei campioni generati in modo tale che solo i generatori performanti vengano preservati ed utilizzati per il successivo ciclo di allenamento della rete.

Capitolo 1
Deep learning e imaging medico:
analisi del problema
1.1 Carcinoma mammario: cos’è, quanto è diffuso e la
prevenzione
Il tumore del seno (carcinoma mammario o tumore alla mammella) è una forma-
zione di tessuto costituito da cellule che crescono in modo incontrollato e anomalo
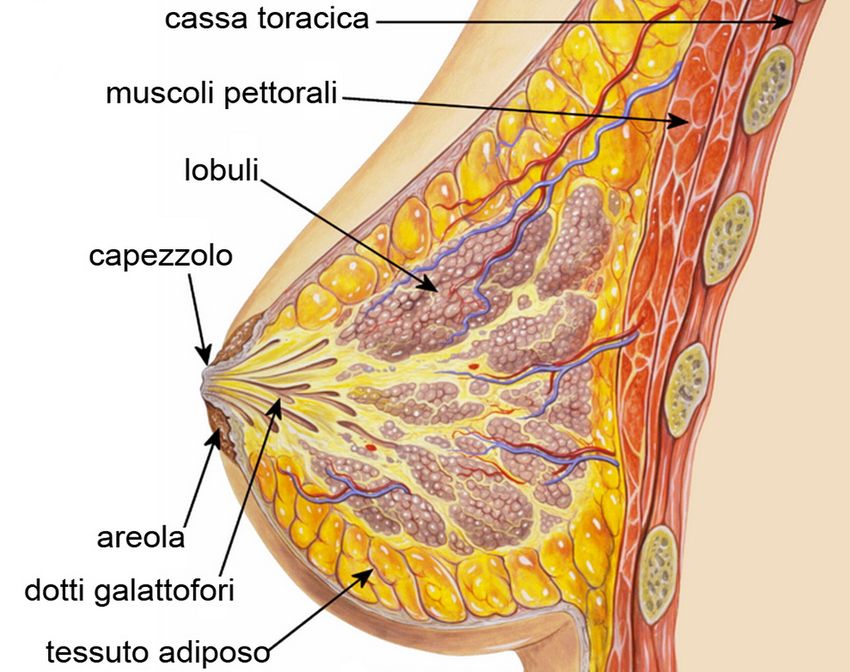
all’interno della ghiandola mammaria. Il seno è costituito da grasso, tessuto con-
nettivo e una serie di strutture ghiandolari (lobuli) organizzata nei cosiddetti lo-
bi, responsabili della produzione di latte che viene escreto attraverso sottili canali
definiti dotti mammari.
Figura 1.1: Anatomia della mammella [1].
Ci sono diversi tipi di tumore al seno, che possono svilupparsi in differenti parti
della mammella. Una prima importante distinzione può essere fatta tra forme non
invasive e forme invasive. Le forme non invasive, dette anche carcinoma in situ, si
sviluppano nei dotti e non si espandono al di fuori del seno: difficilmente questa
1
forma dà luogo a noduli palpabili al tatto, più spesso viene identificata attraverso la
mammografia. La più comune forma di carcinoma in situ è il carcinoma duttale in
situ (Fig.1.2). Il cancro al seno invasivo ha la capacità di espandersi al di fuori del
seno, la forma più comune è il carcinoma duttale infiltrante che rappresenta circa i
3/4 di tutti i casi di cancro della mammella.
Figura 1.2: Tumore duttale in situ [2].
Il cancro al seno è il tumore più frequente nel sesso femminile. I numeri del cancro
in Europa nel 2020 confermano che il carcinoma mammario è la neoplasia più dia-
gnosticata nelle donne, in cui circa un tumore maligno ogni tre (30%) è un tumore
mammario. In Italia è il tumore più frequentemente diagnosticato con poco meno
di 55mila nuovi casi nel 2020, pari al 14,6% di tutte le nuove diagnosi (ref.[3]).
Figura 1.3: Incidenza dei tumori in Europa nel 2020 [4].
2
Dalla fine degli anni Novanta si osserva una continua tendenza alla diminuzione
della mortalità per carcinoma mammario (-0,8%/anno), attribuibile alla maggiore
diffusione dei programmi di diagnosi precoce e quindi all’anticipazione diagnosti-
ca e anche ai progressi terapeutici.
Figura 1.4: Mortalità del tumore alla mammella nel tempo [5].
Risulta dunque evidente il ruolo fondamentale dello screening per il trattamento del
carcinoma mammario e l’esigenza di tecniche sempre più efficaci per la diagnosi
precoce.
31.1.1 Gli esami diagnostici: la mammografia e la DBT
La mammografia rappresenta la procedura radiografica standard per la rilevazione
di patologie della mammella. L’impiego della tecnologia a raggi X è giustificata in
quanto è una procedura a basso costo e a bassa incidenza di dose. Le piccole diffe-
renze di attenuazione dei raggi X tra il tessuto sano e quello canceroso richiedono
l’utilizzo di una tecnica ottimizzata per la mammella. Le differenze di attenuazio-
ne tra questi tessuti (Fig.1.5) sono più evidenti a basse energia (dai 10 ai 15 KeV)
mentre si attenuano notevolmente per energie superiori (maggiori ai 35 KeV).
(a) Attenuazione dei raggi X per i vari tessuti in (b) Contrasto percentuale nei tessuti in funzione
funzione dell’energia. dell’energia
Figura 1.5
Per minimizzare la dose e ottimizzare la qualità dell’immagine è stato necessario
l’impiego di un apparato specifico che prevede tubi a raggi X specializzati, dispo-
sitivi di compressione, griglie antiscatter, fotimetri e sistemi di rilevazione. Lo
schema dell’apparato è rappresentato nella Fig.1.6.
Figura 1.6: Schema dell’apparato per mammografie.
4Durante l’esame la mammella viene compressa per ridurne lo spessore. Questa
procedura è effettuata per:
• ridurre il fenomeno di scattering;
• ridurre il blurring geometrico delle strutture anatomiche:
• ridurre la dose ai tessuti della mammella.
L’esame di routine prevede l’acquisizione di due immagini, la cranio-caudale (CC)
e la medio-laterale obliqua (MLO) (Fig.1.7).
Figura 1.7: Le viste di una mammografia [6].
La tomosintesi digitale della mammella (dall’inglese, Digital Breast Tomosynthe-
sis, DBT), anche nota come mammografia 3D, è una forma avanzata di imaging
per la mammella che impiega un sistema di raggi X a bassa dose e la ricostruzione
computerizzata per creare immagini tridimensionali della mammella. A differen-
za della mammografia che produce un esame, il mammogramma, bidimensionale,
nella DBT sono acquisite diverse immagini da angolazioni differenti (Fig.1.8).
5Figura 1.8: Schema di acquisizione di una DBT.
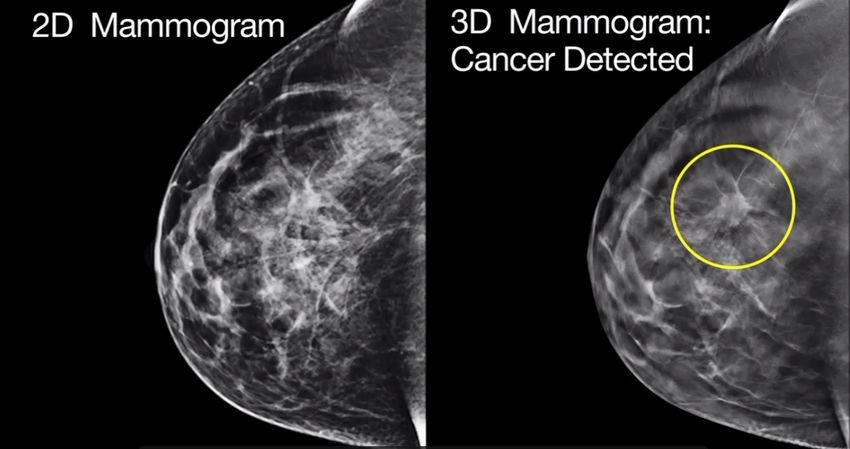
Queste immagini sono ricostruite o "sintetizzate" in un set di immagini 3D da un
computer. Tali immagini aiutano a minimizzare la sovrapposizione dei tessuti che
può rendere difficile da distinguere eventuali anomalie o addirittura nasconderle
(Fig.1.9).
Figura 1.9: Confronto tra un mammogramma 2D ed uno 3D. Nella DBT il tumore è rilevato,
a differenza della mammografia in cui il sovrapporsi dei tessuti ostacola la visuale del medico
specialista.
6Studi effettuati sulla specificità1 di tali test diagnostici (ref.[7]) evidenziano la
superiorità della DBT nella rilevazione di anomalie all’interno della mammella
(Fig.1.10).
Figura 1.10: Confronto della specificità dei test diagnostici per la mammella [7].
Sebbene superiori, in termini statistici, questo esame produce più immagini rispetto
alla mammografia che necessitano uno sforzo maggiore da parte dello specialista
che le osserva, il senologo. Ciò comporta tempi di lettura e dunque di diagnosi più
lunghi oltre che aumentare la possibilità di commettere un errore. Per sostenere il
lavoro del senologo sono stati introdotti i sistemi CAD (Computer Aided Diagno-
sis)2 basati su reti neurali come i classificatori di immagini. Ottenere un sistema
CAD affidabile nell’ambito delle DBT rappresenta un problema tutt’oggi ancora
aperto e questo lavoro di tesi si inserisce in tale contesto.
1
In termini statistici, la specificità di un test è la probabilità di un risultato negativo in soggetti
sicuramente sani e si esprime come il rapporto fra i veri negativi e il totale dei sani. La specificità di
un test sarà inversamente proporzionale alla quota di falsi positivi, cioè dei soggetti sani identificati
però dal test come malati. Un test molto specifico, in definitiva, diminuisce la probabilità che un
soggetto sano risulti positivo al test
2
Sono piattaforme informatiche che aiutano il medico radiologo nella formulazione della diagno-
si, ad esempio evidenziando le più probabili sedi di malattia e/o suggerendo la natura, benigna o
maligna, di un reperto. In generale si riferisce a un sistema computerizzato che rileva (in maniera
automatica o assistita da un operatore) una serie di sospetti sulle immagini segnalandole al radiologo,
al quale spetta di determinare quali delle segnalazioni sono lesioni e quali falsi positivi del sistema.
Tutti i sistemi si pongano come aiuto al medico (e non come sostituto dello stesso), ponendosi come
strumento atto a ridurre l’enorme mole di lavoro al quale il medico radiologo è sottoposto nella fase
di analisi delle immagini biomedicali.
71.2 Intelligenza artificiale in medicina
L’avvento dell’intelligenza artificiale, ed in particolare le tecniche di deep learning
(DL), in ambito medico hanno raggiunto traguardi incredibili negli ultimi anni [8],
basti pensare all’applicazione in task di analisi di immagini mediche per classifica-
zione di lesioni epatiche, analisi di scansioni al cervello, etc. Questo è stato possibi-
le dallo sviluppo di architetture "profonde" (deep architecture) sempre più avanzate
e complesse, dal potenziamento delle prestazioni di calcolo e l’accesso ai big data.
Le reti neurali profonde sono state applicate con successo a task di computer vi-
sion come la classificazione di immagini, rilevamento di oggetti e la segmentazione
grazie allo sviluppo delle CNN (Convolutionary Neural Network, [9]). Queste reti
neurali (Fig.1.11) utilizzano dei filtri (kernel) parametrizzati debolmente connessi
tra loro che preservano le caratteristiche spaziali dell’immagine.
Figura 1.11: Architettura di una CNN [10].
I layer convoluzionali, ossia gli strati più interni che compongono la rete, sotto
campionano in maniera sequenziale la risoluzione dell’immagine mentre estendo-
no la profondità delle loro feature map3 . Questa serie di trasformazioni può creare
una rappresentazione delle immagini a dimensioni molto inferiori e più utili di
quanto possa essere gestito manualmente. Molte branche di studio cercano di mi-
gliorare le attuali performance applicando reti neurali profonde a task di computer
vision: la capacità di generalizzare di un modello di rete si riferisce alla differen-
za, in termini di accuratezza, delle performance valutate sul training set (il dataset
contenente i dati di allenamento) rispetto al test set (il dataset contenente dati sco-
nosciuti alla rete su cui viene appunto testato il modello ottimizzato). Modelli poco
generalizzabili incorrono nella problematica del overfitting (sovra campionamen-
to), il fenomeno per cui un modello statistico molto complesso (nel caso in esame,
una rete neurale) si adatta ai dati osservati (il campione) perché ha un numero ec-
cessivo di parametri rispetto al numero di osservazioni. L’ipotesi largamente diffu-
sa è che dataset più ampi conducano a risultati e modelli di DL migliori [11], [12].
3
Rappresenta l’output di un filtro applicato da un layer precedente, in tal senso è anche conosciuta
come mappa di attivazione.
8Purtroppo però costruire dataset così grandi può essere eccessivamente complicato
a causa degli sforzi necessari per collezionare ed etichettare i dati. In particolar
modo questo è un problema di primaria importanza nell’ambito delle immagini
mediche. Fornito il dataset adeguato, infatti, il successo dei modelli di DL in tale
ambito è notevole (si veda ad esempio il lavoro di Esteva et al [13]). La maggior
parte delle immagini studiate provengono dalla tomografia computerizzata (CT) e
imaging di risonanza magnetica (MRI), tecniche costose e che necessitano di un
lavoro intensivo per essere collezionate e annotate. Inoltre, costruire un dataset di
immagini mediche risulta un lavoro complesso anche a causa dei problemi legati
alla privacy dei pazienti, alla necessità di medici esperti che refertino le immagini
e ai costi e agli sforzi manuali necessari a processarle. Un’ulteriore problematica
è legata al non bilanciamento dei dataset: ciò si verifica quando una determinata
classe abbonda rispetto all’altra o alle altre [14], questo accade nel caso della fra-
zione di immagini etichettabili come "sane" rispetto a quelle "non sane". Questi
ostacoli hanno spostato molti studi dalla risoluzione di task di classificazione al da-
ta augmentation, in particolare impiegando l’oversampling effettuato con i modelli
GAN. Negli esempi classici di classificazione come "cane vs gatto" l’algoritmo
deve essere in grado di fronteggiare problematiche come punti di vista, illumi-
nazione, occlusione, sfondo, scala e simili. L’obiettivo del data augmentation è
inserire queste variazioni nel dataset così che il modello risultante sia comunque
performante. In un modello correttamente allenato l’errore sul validation set4 deve
continuare a decrescere assieme all’errore del training set. Il data augmentation è
una tecnica molto efficace in tale senso. Il dataset ampliato contiene, infatti, un
insieme maggiore e più dettagliato di possibili punti che minimizza così la distan-
za tra training e validation set (e dunque, dal test set). Questa però non è la sola
tecnica utilizzata per gestire l’overfitting: soluzioni funzionali come dropout, batch
normalization, transfer learning e pretraining sono state sviluppate per estendere le
tecniche di DL anche ai dataset più piccoli [15]. A differenza di tali tecniche, però,
il data augmentation affronta il problema alla radice, e cioè sul training set. L’idea
è che si possano ottenere molte più informazioni dal dataset originale ampliandolo
mediante tecniche di alterazione o sovra-campionamento dei dati:
• l’alterazione dei dati (data warping) prevede la trasformazione di immagi-
ni esistenti conservando però la loro "etichetta" (label). Questo compren-
de tecniche come trasformazioni geometriche e di colore, random erasing,
adversarial training etc;
• il sovra-campionamento (oversampling), invece, crea delle istanze sinteti-
che e le aggiunge al training set. Questo include il mixing delle immagini,
l’ampliamento dello spazio delle caratteristiche (feature space e i modelli
generativi avversari (GANs).
4
Un’ulteriore suddivisone del dataset di allenamento utilizzata per la corretta impostazione degli
iperparametri del modello.
91.3 Obiettivi del lavoro
La necessità di dataset voluminosi per l’applicazione delle tecniche di DL va in
contrasto con la disponibilità di immagini mediche per i motivi sopra citati e a
maggior ragione nel caso dell’analisi di immagini di DBT: essendo stata introdotta
solo recentemente e non essendo utilizzata in fase di screening ma solo come esame
di secondo livello (questa viene infatti richiesta nel caso di un esame mammografi-
co dubbio), la quantità di immagini disponibile è ulteriormente ridotta. L’impiego
di tecniche di data augmentation, ed in particolare di modelli generativi, rappre-
senta una possibile soluzione al problema. Questo lavoro di tesi approfondisce tale
tematica, in particolare viene esplorata una soluzione innovativa nel campo dei mo-
delli generativi proposta per la prima volta da Wang et Al. in [16] in cui la fase di
apprendimento è affrontata da un punto di vista evoluzionistico (si parla, infatti, di
Evolutionary-GAN, E-GAN). Nell’approccio E-GAN proposto, un discriminatore
agisce da ambiente (nel senso che fornisce una funzione di costo adattiva) mentre
una popolazione di generatori muta per produrre una prole che si adatti all’am-
biente. Inoltre, fissato il miglior discriminatore attuale, sono valutate la qualità e la
diversità dei campioni generati e, seguendo il principio di "sopravvivenza del più
adatto", la prole meno performante è rimossa lasciando solo quella migliore per fu-
turi step di allenamento. Nelle successive sezioni verrà descritto lo stato dell’arte
circa le tecniche di data augmentation ed i modelli generativi, in particolare il mo-
dello GAN, inoltre sarà analizzato l’algoritmo evoluzionistico presente in [16], che
successivamente verrà applicato, dopo opportuni adattamenti, ad un dataset di im-
magini di DBT. I risultati saranno quindi analizzati e discussi nell’ultimo capitolo.
Il lavoro si colloca nella fase iniziale di un progetto ben più ampio e complesso in
ambito Artificial Intelligence in Medicine (AIM) a cui partecipa il gruppo di Fisica
Medica della Federico II: lo scopo è quello di realizzare un’architettura di DL per la
sintetizzazione di TAC della mammella per il cui funzionamento ottimale si rende
necessario un ampliamento dei campioni di slices nel dataset. Da qui, lo sviluppo
della E-GAN per la generazione di modelli bidimensionali partendo da oggetti 3D
o da oggetti 2D (come le slices che compongono una DBT). Nel presente lavoro
sono state prodotte singole slice di DBT.
10Capitolo 2
Tecniche e strumenti utilizzati: lo
stato dell’arte
2.1 Il data augmentation: un overview
Nella forma di data warping l’ampliamento di dataset di immagini è possibile tro-
varlo in LeNet-5 [17]. Questa fu una delle prime applicazioni di una CNN per la
classificazioni di cifre scritte a mano. Circa la tecnica del oversampling le prime
applicazioni invece riguardano il problema del non bilanciamento dei dataset in
cui il classificatore applicato presenta un bias verso le classi di istanza presenti in
maggioranza:
• random oversampling (ROS), è un approccio in cui, semplicemente, le im-
magini provenienti dalla classe in minoranza vengono duplicate fino al rag-
giungimento di una soglia prestabilita;
• Synthetic Minority Over-sampling Technique (SMOTE), sviluppata da Cha-
wla et al. [18], crea nuove istanze interpolando nuovipunti da istanze esi-
stenti tramite k-Nearest Neighbors 1 .
L’architettura CNN AlexNet sviluppata da Krizhevinsky et al [9] ha rivoluzionato
la classificazione di immagini applicando una rete convoluzionale al dataset Ima-
geNet2 . Il data augmentation è utilizzato nei loro esperimenti per incrementare
1
È un algoritmo utilizzato nel riconoscimento di pattern per la classificazione di oggetti basandosi
sulle caratteristiche degli oggetti vicini a quello considerato. In entrambi i casi, l’input è costituito
dai k esempi di addestramento più vicini nello spazio delle funzionalità. Nella classificazione k-NN,
l’output è un’appartenenza a una classe. Un oggetto è classificato da un voto di pluralità dei suoi
vicini, con l’oggetto assegnato alla classe più comune tra i suoi k vicini più vicini.
2
Molti studi utilizzano dataset accademici di immagini pubbliche per testare i risultati. Questi
includono il MNIST, CIFAR-10/100, ImageNet, MIT places, Standford Cars etc. I più popolari e
utilizzati sono il CIFAR-10/100 e ImageNet. Spesso considerati come big data vengono utilizzati
sotto-campioni di tali dataset per simulare situazioni reali.
11le dimensioni del dataset di un fattore 2048: questo è ottenuto ritagliando casual-
mente patches 224x224 dalle immagini originali, capovolgendole orizzontalmente
e cambiando l’intensità dei canali RGB. Questo tipo di lavoro ha aiutato a ridurre
l’overfitting in fase di allenamento della rete. Gli autori, infatti, rivendicano una
riduzione dell’errore sul modello del 1%. Da allora, le GAN sono state introdot-
te nel 2014 [19], il Neural Style Transfer nel 2015 [20] e la Neural Architecture
Search (NAS) nel 2017 [21]. Diversi lavori su estensioni delle GAN ([22], [23],
[24], [25] per citarne alcuni) sono stati pubblicati successivamente, tra il 2015 e
il 2017. Miglioramenti dell’algoritmo di Neural Style Transfer ci sono stati nel
2016 [26]. Applicazioni di data augmentation sempre più popolari che sfruttano i
NAS ci sono stati a partire dai lavori [27], [28] e [29] sviluppati tra 2017 e 2018.
L’impiego delle GAN nel imaging medico è ben documentato nella review di Yi et
al [30]. La review ripercorre l’utilizzo delle GAN nella ricostruzione come il CT
denoising [31], l’imaging accelerato di risonanza magnetica [32], PET denoising
[33] e applicazioni di segmentazione della vascolarizzazione retinica in super ri-
soluzione [34]. Vi sono inoltre riferimento all’impiego delle GAN nella sintesi di
immagini mediche come le MRI al cervello [35], immagini di malattie della pelle
in super risoluzione [36] e classificazione di anormalità in radiografie al petto [37].
Un esempio di data augmentation ottenuto mediante GAN lo si può trovare nel la-
voro di Frid-Adar et al [38] pubblicato nel 2018 per la classificazione di malattie
del fegato. Nel lavoro si ottengono miglioramenti delle performance di classifica-
zione dal 78.6% di sensibilità e 88.4% di specificità utilizzando tecniche classiche
di data augmentation al 85.7% di sensibilità e 92.4% di specificità utilizzando il
data augmentation basato sulle GAN. La maggior parte dei lavori elencati impiega
il data augmentation per il miglioramento delle prestazioni di modelli designati al
riconoscimento di immagini supervisionato (e.g. data un’immagine in input, il mo-
dello predice un output come "cane" o "gatto"). Comunque è possibile estendere i
risultati ottenuti nel riconoscimento di immagini ad altri task della computer vision
come il rilevamento di oggetti ottenuto mediante gli algoritmi YOLO [39], la seg-
mentazione semantica [40], la predizione dei frame dei video ([41], [42]), l’editing
([43], [44]), e diversi altri task ([45], [46]).
122.2 Tecniche di data augmentation per le immagini
Le prime implementazioni di tecniche di data augmentation riguardano trasforma-
zioni semplici come il capovolgimento verticale/orizzontale, l’ampliamento dello
spazio dei colori, il cropping casuale etc. Queste trasformazioni codificano diverse
delle invarianze discusse precedentemente. Verranno brevemente discusse, e quin-
di elencati i pro e i contro, tecniche di trasformazioni geometriche, dello spazio
dei colori, applicazione di filtri, fusione di immagini, cancellazione casuale, am-
pliamento dello spazio delle caratteristiche, allenamento avversario, trasferimento
neurale e schemi di meta apprendimento.
2.2.1 Data augmentation basato sulla manipolazione di immagini
Le trasformazioni appartenenti a questa categoria possono essere caratterizzate dal-
la loro semplicità di implementazione. Saranno descritte anche dal punto di vista
della sicurezza di applicazione che si riferisce alla proprietà di preservare l’etichetta
(il label) dell’immagine post-elaborazione. Ad esempio, le rotazioni e i capovolgi-
menti sono generalmente sicuri per le immagini di ImageNet come ad esempio in
"cane vs gatto", ma non lo sono altrettanto nel riconoscimento dei caratteri come
ad esempio "6 vs 9". Una trasformazione che non preservi la classe può poten-
zialmente fortificare l’abilità del classificatore a patto che venga eseguito un nuovo
etichettamento post-trasformazione che rappresenta comunque un task particolar-
mente costoso. La sicurezza di una tecnica di data augmentation diventa dunque
un problema di dominio e quindi dimostra la necessità di progettare un modello di
data augmentation appropriato.
Trasformazioni geometriche
Di seguito sono riportate le principali tecniche di trasformazioni geometriche:
• flipping: è una delle tecniche più semplici da implementare ed è stata uti-
lizzata in task di classificazione per dataset come il CIFAR-10 e ImageNet.
Applicata a task di riconoscimento di caratteri come il MNIST o il SVHN,
invece, non preserva l’etichetta;
Figura 2.1: Esempio di flipping orizzontale e verticale.
13• cropping: letteralmente, è un ritaglio effettuato sull’immagine. Può essere
utilizzato sia nei casi in cui l’input abbia differente altezza e larghezza, sia
in maniera casuale per generare effetti simili alla traslazione: a differenza di
quest’ultima, però, non preserva le dimensioni dell’immagine e dunque può
rappresentare una trasformazione "non sicura";
• rotation: si tratta di rotazioni fatte rispetto ad un asse dell’immagine. La
sicurezza dell’operazione risiede nel range angolare di rotazione effettuato.
Trasformazioni comprese tra -20 e +20 preservano la classe dei caratteri del
MNIST, oltre questo range, invece, viene persa;
Figura 2.2: Esempio di rotation da 0 a 45°.
• translation: rappresenta una traslazione rigida dell’immagine in una del-
le quattro direzioni principali e risulta essere una tecnica molto efficace in
quanto evita bias posizionali nei dati. Ad esempio, se tutte le immagini nel
dataset sono centrate (come nel riconoscimento dei volti) questo compor-
ta che il classificatore debba essere testato solo su immagini perfettamente
centrate. Per preservare le dimensioni spaziali originali lo spazio rimanente
dopo la traslazione viene riempito o con un valore costante (come 0 o 255)
o con del rumore gaussiano o casuale;
• noise injection: consiste nell’inserimento di matrici di valori causali pescati
da una distribuzione gaussiana. Testato in [47], è stato dimostrato aiuti le
CNN ad apprendere caratteristiche in modo più robusto.
Figura 2.3: Esempio di noise injection.
14Le trasformazioni geometriche benché semplici da implementare richiedono me-
moria addizionale, costi computazionali per la trasformazione e tempo di addestra-
mento aggiuntivo. Per alcune di esse, come detto, è necessario seguire la procedura
per evitare la perdita dell’etichetta di classificazione. Restano dunque situazionali
e dunque relativamente limitati.
Trasformazioni nello spazio dei colori
Le immagini a colori sono codificate come tre matrici impilate, ciascuna di di-
mensione altezza x larghezza. Queste matrici rappresentano i valori dei pixel per
ciascun canale RGB. I bias relativi alla luminosità sono tra le sfide che si pre-
sentano più spesso nei problemi di riconoscimento. Dunque è comprensibile il
significato delle trasformazioni in tale contesto. Un metodo veloce per modifica-
re la luminosità consiste nell’aggiungere o sottrarre un valore costante ai singoli
pixel, oppure isolare i tre canali. Un’ulteriore possibilità è quella di manipolare
l’istogramma dei colori per applicare filtri che modificano le caratteristiche dello
spazio dei colori. Gli svantaggi relativi a queste tecniche riguardano l’incremento
di memoria richiesto, i costi di trasformazione e il tempo di allenamento. Possono
inoltre comportare la perdita di informazioni riguardo i colori stessi e rappresentare
dunque una trasformazione non sicura. Ad esempio, modificare i valori dei pixel di
un’immagine per simulare un ambiente più scuro potrebbe comportare la difficoltà
nel riconoscimento di alcuni oggetti. Si prenda ad esempio [48]: in questa appli-
cazione le CNN cercano di predire il valore emotivo di un’immagine come: molto
negativa, negativa, neutrale, positiva, molto positiva. Un elemento che può deter-
minare la distinzione tra negativo e molto negativo è la presenza del sangue; infatti
il colore rosso scuro del sangue è la componente chiave per distinguere il sangue
dall’acqua o la pittura. Risulta dunque evidente che trasformazioni nello spazio
dei colori potrebbero comportare l’incapacità del classificatore nel distinguere il
sangue e dunque non preservare l’etichetta di classe.
Figura 2.4: Esempi di trasformazioni nello spazio dei colori.
15Trasformazioni geometriche Vs fotometriche
Taylor e Nitschke [49] hanno fornito uno studio comparativo sull’efficacia delle
trasformazioni geometriche e fotometriche testate sul dataset Caltech101 con una
4-fold cross-validation3 . Di seguito la tabella dei risultati ottenuti.
Figura 2.5: Risultati degli esperimenti di Taylor e Nitschke [49].
Filtri kernel
Rappresentano una tecnica diffusa per ottenere immagini affinate o sfocate. Lavo-
rano facendo scorrere una matrice n x n sull’immagine con dei filtri di tipo gaus-
siano che la sfocano o di tipo edge ad elevato contrasto orizzontale o verticale che
la evidenziano lungo i bordi. Aumentare la sfocatura serve ad aumentare la re-
sistenza al problema del motion blur mentre immagini più definite consentono di
acquisire più dettagli circa gli oggetti di interesse. Tale tecnica però risulta simile
al meccanismo interno delle CNN che utilizzano dei kernel parametrici per appren-
dere il modo ottimale di rappresentare le immagini layer-per-layer e sono, per que-
sto motivo, implementati all’interno della rete piuttosto che come trasformazione
esterna.
3
La convalida incrociata cosiddetta k-fold consiste nella suddivisione dell’insieme di dati totale
in k parti di uguale numerosità e, a ogni passo, la k-esima parte del insieme di dati viene a essere
quella di convalida, mentre la restante parte costituisce sempre l’insieme di addestramento. Così si
allena il modello per ognuna delle k parti, evitando quindi problemi di sovradattamento, ma anche
di campionamento asimmetrico (e quindi affetto da distorsione) del campione osservato, tipico della
suddivisione dei dati in due sole parti (ossia addestramento/convalida). In altre parole, si suddivide
il campione osservato in gruppi di egual numerosità, si esclude iterativamente un gruppo alla volta
e si cerca di predirlo coi gruppi non esclusi, al fine di verificare la bontà del modello di predizione
utilizzato.
16Mixing
Mescolare immagini mediando il valore dei loro pixel ((Fig.2.7a e Fig.2.7b) è un
approccio controintuitivo rispetto al classico data augmentation: le immagini pro-
dotte non sembreranno utili da un punto di vista prettamente umano. Nonostante
ciò, Ionue [50] ha dimostrato come questo approccio possa realmente essere svi-
luppato in un’effettiva strategia di data augmentation. In questo esperimento due
immagini vengono ridimensionate (cropping) da 256x256 a 224x224 e casualmen-
te capovolte orizzontalmente, queste sono state poi mescolate mediando i valori dei
pixel per ciascun canale. L’etichetta di classe assegnata alla nuova immagine è la
stessa della prima selezionata. Sul CIFAR-10 Ionue ha riportato una riduzione del
error rate da 8.22 a 6.93% utilizzando tale tecnica. Si riportano di seguito i risultati
(Fig.2.6).
Figura 2.6: Risultati degli esperimenti di Ionue sul CIFAR-10 [50].
Altri studi hanno approfondito tale tematica utilizzando ad esempio metodi non-
lineari per combinare le immagini [51] oppure ritagliando casualmente immagini
e concatenandole successivamente in un’unica immagine [52]. Uno svantaggio di
questa tecnica risiede nella complessità di comprensione circa il suo funzionamen-
to. Una spiegazione potrebbe essere che aumentando la numerosità del dataset
i risultati siano più robusti nell’apprendimento di caratteristiche di basso livello
come linee e bordi.
17(a) (b)
Figura 2.7: Esempio di applicazione della tecninca di mixing [50]
Random erasing
È una tecnica analoga a quella del dropout regularization4 implementata però sui
dati di input piuttosto che all’interno della rete stessa. Ideata per superare il pro-
blema dell’occlusione (ossia quando parte di un oggetto non è chiara o è coperta
parzialmente da qualche altro oggetto) nel riconoscimento di oggetti: la tecnica
forza la rete ad apprendere più informazioni prevenendo l’overfitting rispetto ad
una precisa area dell’immagine.
Figura 2.8: Esempio di random erasing [53].
4
Il termine si riferisce al dropping out ossia all’omissione di alcune unità durante il processo di
allenamento della rete e che rappresenta dunque una tecnica di regolarizzazione in quanto evita il
co-adattamento al training set.
18I risultati ottenuti in [54] utilizzando una tecnica simile, nota come Cutout, sono
tra i più alti ottenuti sul CIFAR-10.
Figura 2.9: Risultati ottenuti da DeVries e Taylor utilizzando il Cutout [54].
Gli svantaggi legati a questa tecnica risiedono nel fatto che non sempre preserva
l’etichetta di classificazione. Ad esempio nella classificazione delle autovetture
sul dataset Standford Cars la cancellazione di tutto o parte del logo può rendere
il marchio irriconoscibile e dunque può essere necessario un successivo intervento
manuale.
Tecniche combinate
Ciascuna delle tecniche appena discusse può essere combinata con le altre produ-
cendo così dataset decisamente grandi che possono però condurre ad overfitting,
soprattutto se il dataset di partenza è piccolo. È perciò consigliabile ricercare un
algoritmo per la selezione del miglior sottoinsieme di tecniche da implementare
così come dei dati da utilizzare per l’allenamento delle reti.
2.2.2 Data augmentation basato sul deep learning
Feature space augmentation
Tutti i metodi descritti precedentemente sono applicati alle immagini in input. È
possibile sfruttare le capacità di mappatura delle reti neurali per trasformare input
multidimensionali in rappresentazioni di dimensioni inferiori come a classi binarie
o in vettori n x 1 in layer appiattiti. Il processo sequenziale di una rete può essere
manipolato in modo tale che le rappresentazioni intermedie possano essere sepa-
rate per intero dalla rete. Le rappresentazioni a dimensioni inferiori che si trovano
negli strati più interni di una CNN (o comunque di una rete) sono noti come feature
space, ossia spazio delle caratteristiche. De Vries e Taylor [55] hanno presentato
un lavoro in cui viene discusso l’ampliamento proprio in questo spazio: aggiunta
di rumore, interpolazione, ed estrapolazione sono alcune delle forme più comuni
di "feature space augmentation". Una possibilità è quella di troncare una CNN ed
estrapolare i vettori in output per allenare qualsiasi altro modello di ML. Lo svan-
taggio di questa tecnica risiede nella difficoltà di interpretazione dei vettori ottenuti
in output: sarebbe possibile ricostruire le immagini, partendo dai vettori, utilizzan-
19do una rete autoencoder5 (Fig.2.10) che risulterebbe, però, in reti eccessivamente
complicate da allenare e dispendiose temporalmente.
Figura 2.10: Esempio di funzionamento di un autoencoder.
Adversarial training
L’allenamento avversario consiste in un ambiente in cui due o più reti sono uti-
lizzate con obiettivi contrastanti, opposti, codificati mediante le loro funzioni di
costo. Si parla in tal caso di adversarial attacking: una rete apprende la tecnica
di augmentation basandosi sugli errori di classificazione della rete classificatrice
avversaria. Questo dimostra che la rappresentazione delle immagini è molto meno
robusta di ciò che ci si aspetta. Moosavi e Dezefooli [56] lo hanno dimostrato uti-
lizzando la rete DeepFool che cerca il rumore minimo da inserire nell’immagine
per produrre una classificazione errata con elevata confidenza. Allo stesso modo
Su et al [57] hanno dimostrato che le immagini possono essere classificate errata-
mente solo cambiando un pixel. Limitando l’insieme di ampliamenti e distorsioni
disponibili ad una rete avversaria, questa può apprendere come produrre dati che
risultino in una classificazione errata e rappresentare quindi un algoritmo di ricer-
ca. Questi dati possono dunque essere utilizzati per irrobustire punti deboli del
modello di classificazione. Tuttavia, l’efficacia di un allenamento avversario è un
concetto relativamente nuovo ed inesplorato, e i risultati a cui può condurre sono
ancora poco chiari.
5
Un autoencoder è un tipo di rete neurale artificiale utilizzata per apprendere codifiche di dati
in modo non supervisionato. Lo scopo di un autoencoder è apprendere una rappresentazione (codi-
fica) per un insieme di dati ignorando il "rumore" del segnale. Insieme al lato di riduzione, viene
appreso un lato di ricostruzione, dove l’autoencoder cerca di generare dalla codifica ridotta una
rappresentazione il più vicino possibile al suo input originale, da cui il nome.
20Data augmentation basato sulle GAN
Una strategia alternativa è quella dell’impiego di modelli generativi. Per "modelli
generativi" si fa riferimento alla pratica di creare istanze artificiali da un dataset in
modo tale che queste presentino caratteristiche simili a quelle originali. Le GAN,
approfondite in dettaglio successivamente, rappresentano una strada per "sblocca-
re" informazioni aggiuntive da un dataset [58]. Sebbene non siano l’unico modello
generativo ne rappresentano decisamente l’avanguardia (Fig.2.11). Inoltre, questa
architettura può essere utilizzata come tecnica di sovra-campionamento per risol-
vere problemi di squilibrio di classi. Nel lavoro di Lim et al [59] viene mostrato
come, producendo campioni di occorrenze che si verificano con piccole probabili-
tà, le GAN siano capaci di ridurre la frequenza dei falsi positivi nel rilevamento di
anomalie. Il problema relativo all’impiego di tale architettura risiedere nella diffi-
coltà di produrre output in alta risoluzione poiché aumentarne le dimensioni in fase
di generazione creerebbe instabilità durante l’allenamento e problemi di non con-
vergenza. Inoltre, i risultati prodotti sono strettamente legati alla quantità di dati
forniti in input, perciò, a seconda di quanto sia limitato il dataset iniziale l’utilizzo
delle GAN potrebbe non essere una soluzione pratica.
Figura 2.11: Impiego delle GAN nel corso degli anni [30].
Neural style transfer
L’idea generale [20] è quella di manipolare la rappresentazione delle immagini
create nelle CNN. Lo scopo è quello di "trasferire" lo stile di un’immagine ad
un’altra lasciando inalterato il suo contenuto originale. Infatti, per questo moti-
vo, questa tecnica è spesso utilizzata in ambito artistico (Fig.2.12). Relativamente
agli scopi del data augmentation questa tecnica è simile alle trasformazioni sul-
la luminosità nell’ambito dello spazio dei colori. Modificando luci e stili artistici
è possibile ottenere nuove immagini. Lo "stile" rispetto al quale produrre nuove
istanze è peculiare del task. Si prenda ad esempio il problema delle self-driving
cars.
21Figura 2.12: Esempio di ricostruzione nel neural style transfer [60].
In tale situazione è consigliabile trasferire ai campioni lo stile notturno partendo da
quello diurno, o quello invernale partendo da quello estivo, o quello piovoso par-
tendo da quello soleggiato. In altri contesti però la scelta potrebbe non essere così
semplice. Ciò che generalmente si fa è importare k stili differenti ed applicarli a
tutto il dataset. Questa tecnica è stata anche utilizzata per le transizioni da ambien-
ti simulati a reali utili nel reinforcement learning6 per evitare danni all’hardware
testato nel mondo reale [61]. Lo svantaggio legato a questa tecnica è relativo al-
la scelta del set di stili da utilizzare: se troppo piccolo potrebbe inserire dei bias
nel dataset, se troppo grande potrebbe rallentare eccessivamente l’allenamento e
richiedere una quantità di memoria ingente.
Meta learning data augmentation
Il concetto di meta learning nel DL si riferisce generalmente al processo di otti-
mizzazione di reti neurali mediante altre reti neurali. Questo approccio è diventato
molto popolare dopo la pubblicazione del NAS [21] di Zoph et al. Il NAS utilizza
una rete ricorsiva allenata tramite RL per progettare architetture che risultino nella
miglior accuratezza possibile. Applicazioni di differenti approcci al meta learning
per il data augmentation possono essere trovate in [27], [28] e [29]. Uno svantaggio
6
L’apprendimento per rinforzo (o reinforcement learning) è una tecnica di apprendimento auto-
matico che punta a realizzare agenti autonomi in grado di scegliere azioni da compiere per il con-
seguimento di determinati obiettivi tramite interazione con l’ambiente in cui sono immersi. Rap-
presenta uno dei tre paradigmi principali dell’apprendimento automatico, insieme all’apprendimento
supervisionato e a quello non supervisionato. A differenza degli altri due, questo paradigma si oc-
cupa di problemi di decisioni sequenziali, in cui l’azione da compiere dipende dallo stato attuale
del sistema e ne determina quello futuro. La qualità di un’azione è data da un valore numerico di
"ricompensa", ispirata al concetto di rinforzo, che ha lo scopo di incoraggiare comportamenti corretti
dell’agente.
22di tale approccio è che è relativamente nuovo e i risultati sono difficili da confronta-
re. Inoltre gli schemi utilizzati possono essere molto complessi e impiegare tempi
piuttosto lunghi.
2.2.3 Confronto
Esistono pochi studi comparativi circa le tecniche citate in precedenza. Uno di
questi è stato erffettuato in [62] da Shijie et al. in cui sono stati comparati GAN,
WGAN, flipping, cropping, shifting, PCA jittering, color jittering, noise injection,
rotation e alcune loro combinazioni. Inoltre lo studio comparativo è stato effettuato
su dataset di diversa grandezza: uno piccolo contenente 2k campioni, uno medio
con 10k campioni ed uno grande contenente 50k campioni. Ciascuno di questi
è stato testato su tre livelli: con augmentation, senza augmentation e con valori
intermedi. Ciò che ne è risultato è che generalmente cropping, flipping, WGAN
e rotation performano meglio delle altre tecniche. In assoluto, la combinazione
di flipping e cropping, e flipping e WGAN rappresentano le migliori combinazio-
ni fornendo incrementi di 3% e 3.5% relativamente al task di classificazione sul
dataset CIFAR-10.
Figura 2.13: Risultati ottenuti da Shijie et al su task di classificazione sul CIFAR-10 [62].
232.3 GAN: il framework
L’idea di base delle GAN è quella di impostare un gioco tra due giocatori. Uno
di questi è chiamato generatore. Il generatore crea dei campioni intesi come pro-
venienti dalla stessa distribuzione dei dati di allenamento. L’altro giocatore è il
discriminatore. Il discriminatore esamina i campioni per determinare se questi
siano veri o falsi. Il discriminatore apprende utilizzando tecniche tradizionali di
apprendimento supervisionato, dividendo gli input in due classi (reali e falsi). Il
generatore, invece, è allenato per ingannare il discriminatore. Si può pensare al
generatore come un contraffattore che cerca di produrre denaro falso, e il discri-
minatore come la polizia che cerca legittimare le banconote e individuare quelle
contraffatte. Per vincere il gioco il contraffattore deve apprendere come produrre
denaro che sia indistinguibile da quello vero. Il processo è illustrato nella figura
sottostante.
Figura 2.14: GAN framework.
Formalmente, le GAN sono un modello probabilistico strutturato (si veda il capito-
lo 16 di [63] per un’introduzione ai modelli probabilistici strutturati) che contiene
una variabile latente z e una variabile osservata x. I due giocatori all’interno del
gioco sono rappresentati attraverso due funzioni, ciascuna delle quali differenzia-
bile rispetto ai proprio input e i propri parametri. Il discriminatore è una funzione
D che prende x come input e utilizza Θ(D) come parametri, mentre il generatore
è rappresentato dalla funzione G che prende z come input e Θ(G) come parametri.
Ciascun giocatore ha funzioni di costa definite in termini di entrambi i giocatori. Il
discriminatore tenta di minimizzare J (D) (Θ(D) , Θ(G) ) e deve farlo mentre control-
la esclusivamente Θ(D) . Dal suo canto, il generatore invece, tenta di minimizzare
J G) (Θ(D) , Θ(G) ) e lo fa mentre controlla esclusivamente Θ(G) . Dato che la fun-
zione di costo di ciascun giocatore dipende dai parametri dell’altro giocatore, ma
nessuno dei due giocatori può controllare i parametri dell’altro, questo scenario è
più facilmente rappresentabile come un gioco che non come problema di ottimiz-
zazione. La soluzione ad un problema di ottimizzazione è un minimo (locale), un
24punto nello spazio dei parametri dove tutti i punti vicini hanno un costo eguale o
superiore. La soluzione ad un gioco è un equilibrio di Nash7 . In tale contesto,
un equilibrio di Nash è rappresentato da una tupla (Θ(D) , Θ(G) che è un minimo
locale di J (D) rispetto a Θ(D) e un minimo locale di J (G) rispetto a Θ(G) .
2.3.1 Il generatore
Il generatore è una funzione differenziabile G. Quando z viene campionato da
qualche distribuzione definita a priori, G(z) fornisce un campione di x provenien-
te/pescato da pmodel . Tipicamente G è rappresentata da una rete neurale profonda
(e.g. una CNN). In generale ci sono quindi poche restrizioni sulla rete: z deve
avere almeno le stesse dimensioni di x e G deve essere differenziabile.
2.3.2 Il processo di training
Il processo di allenamento consiste di step di SGD (Stochastic Gradient Descend)
simultanei. Ad ogni step sono campionati due minibatch: uno di valori di x pro-
venienti dal dataset e uno di valori di z provenienti dal modello a priori scelto per
la variabile latente. A tal punto sono effettuati due step di SGD: uno che aggiorna
Θ(D) per ridurre J (D) e uno che aggiorna Θ(G) per ridurre J (G) . In entrambi i ca-
si è possibile utilizzare algoritmi di ottimizzazione del gradiente di propria scelta.
Generalmente, l’algoritmo Adam [64] è una buona scelta.
2.4 GAN: le funzioni di costo
2.4.1 La funzione di costo del discriminatore
Tutti i modelli di gioco presenti per le GAN utilizzano la stessa funzione di costo
per il discriminatore, J (D) . Differiscono solo nei termini del costo utilizzato per il
generatore, J (G) . La funzione di costo utilizzata è la seguente:
1 1
J(D)(Θ(D) , Θ(G) ) = − Ex∼pdata log(D(x)) − Ez log(1 − D(G(z))). (2.1)
2 2
7
L’equilibrio di Nash è una combinazione di strategie in cui ciascun giocatore effettua la migliore
scelta possibile sulla base delle aspettative di scelta dell’altro giocatore. L’equilibrio di Nash è la
combinazione di mosse (mossa1, mossa2) in cui la mossa di ciascun giocatore è la migliore risposta
alla mossa effettuata dall’altro giocatore. Ogni giocatore formula delle aspettative sulla scelta del-
l’altro e, in base a queste, decide la propria strategia. Un equilibrio di Nash è un equilibrio stabile,
poiché nessun giocatore ha interesse a modificare la propria decisione. Ogni giocatore trae l’utili-
tà massima possibile dalle proprie scelte, tenendo conto della migliore scelta dell’altro giocatore.
Qualsiasi variazione strategica potrebbe soltanto peggiorare la sua posizione.
25Questa rappresenta la classica funzione di costo nota come cross entropy8 impie-
gata nella classificazione a due livelli con un output di forma sigmoidale. L’unica
differenza è che il classificatore è allenato su due minibatch di dati: uno prove-
niente dal dataset in cui l’etichetta di classe è 1 per tutti gli esempi, e una prove-
niente dal generatore, dove invece l’etichetta di classe è 0. In tutti le versioni del
gioco il discriminatore è incoraggiato a ridurre questa funzione. In ogni caso il
discriminatore presenta la medesima strategia ottimale:
pdata (x)
D(x) = (2.2)
pdata (x) + pmodel (x)
Ciò che è possibile notare è che mediante l’allenamento del discriminatore si ottie-
ne una stima del rapporto pdata (x)/pmodel (x) per ogni punto x (Fig.2.15). Questa
è l’approssimazione tecnica chiave che differenzia le GAN da altri modelli genera-
tivi come i VAE o le BM. Gli altri modelli generativi sviluppano approssimazioni
basandosi su legami meno stringenti o sulle catene di Markov; le GAN ottengono
queste stime mediante tecniche di apprendimento supervisionato. Per tale motivo,
infatti, soffrono delle stesse problematiche legate a questo tipo di apprendimen-
to: overfitting e underfitting. Con una buona ottimizzazione dell’algoritmo e un
dataset sufficientemente grande questi problemi, però, possono essere superati.
Figura 2.15: Il discriminatore (linea blu a puntini) stima il rapporto tra la densità dei dati (punti
neri) e la somma dei dati e del modello di densità. Il generatore può imparare a produrre un mo-
dello di densità migliore seguendo la risalita del discriminatore: ogni G(z) dovrebbe muoversi nella
direzione che aumenta il valore di D(G(z))
Dato che il framework GAN può essere analizzato con gli strumenti della teoria
del gioco, vengono chiamate "avversarie". Si può pensare alle due reti anche co-
8
L’entropia incrociata (o cross-entropia) fra due distribuzioni di probabilità p e q, relative allo
stesso insieme di eventi, misura il numero medio di bit necessari per identificare un evento estratto
dall’insieme nel caso sia utilizzato uno schema ottimizzato per una distribuzione di probabilità q
piuttosto che per la distribuzione vera p.
26Puoi anche leggere