Data Mining: Introduzione alle nozioni di base - 18 Aprile 2019 - PADOVA - BNova
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Data Mining: Introduzione alle nozioni di base 18 Aprile 2019 - PADOVA
RELATORI Laura Margara Data scientist, BI analyst @bnova

AGENDA: • Data mining: nozioni di base • Casi d’uso: Market Basket Analysis • R&D: Analisi predittiva nel Progetto Manifold • R&D: Analisi multimodale nel Progetto MUSE • Q&A
Terminologia: cos’è il Data Mining?
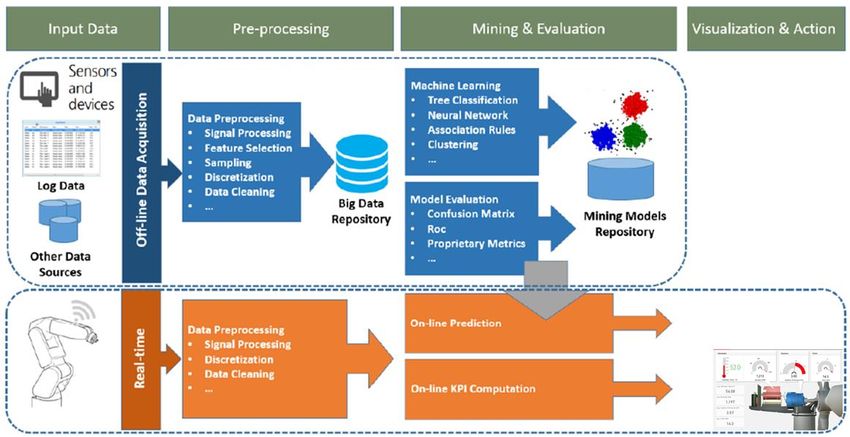
Il data mining è l'insieme delle tecniche e delle metodologie che hanno per oggetto
l'estrazione di informazioni utili da grandi quantità di dati attraverso metodi automatici
o semi-automatici.
Oggi il data mining ha una duplice valenza:
• estrazione, con tecniche analitiche all'avanguardia, di informazione implicita,
nascosta, da dati già strutturati, per renderla disponibile e direttamente utilizzabile;
• esplorazione ed analisi, eseguita in modo automatico o semiautomatico, su grandi
quantità di dati al fine di scoprire pattern significativi.
VALORE AGGIUNTO Sistemi di
Supporto alle Decisioni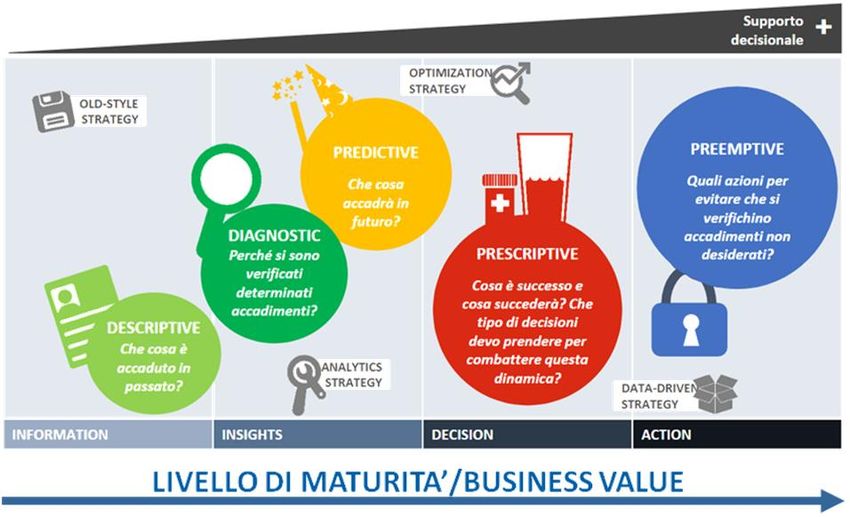
BI: Fasi del processo KDD
http://yourfreetemplates.com
Data Mining – Modello CRISP
Prodotto neutrale definito da un consorzio di
numerose società per la standardizzazione del
processo di Knowledge Discovery.
6 fasi:
1. Comprensione del business
2. Comprensione dei dati
3. Preparazione dei dati
4. Modellizzazione
5. Valutazione
6. Implementazione
Shearer C.,The CRISP-DM model: the new blueprint for data mining, J Data Warehousing (2000); 5:13—22.
8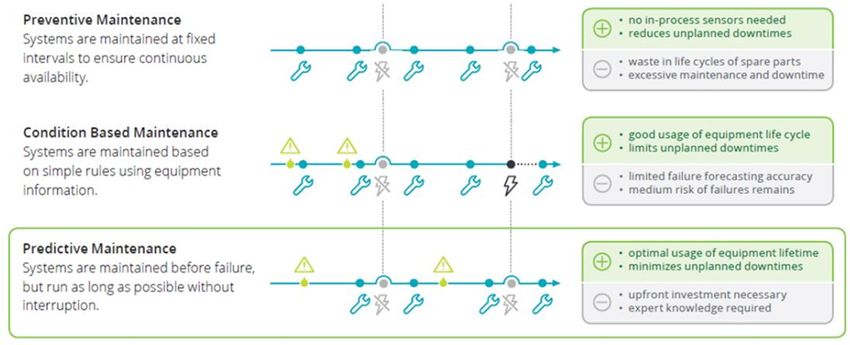
Data Mining – Business & Data understanding
Business understanding:
Perché è importante?
Comprensione del contesto aziendale:
• Selezione delle fonti • La conoscenza del contesto e dei
• Affiancamento con esperti del business dati è fondamentale per capire le
necessità aziendali e la fattibilità
Data understanding: delle richieste per impostare
Comprensione dei dati: tutte e sole le analisi utili
• Semantica dei dati
su tutti e soli i dati necessari.
• Individuazione caratteristiche (es. dipendenze) e
«anomalie» (es. outliers, missing value)
9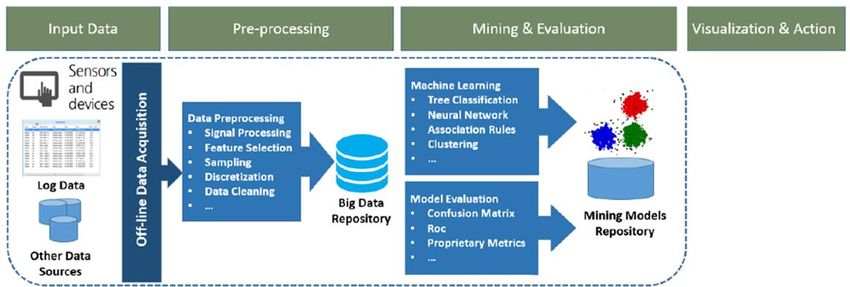
Data Mining – Data preparation (1)
Preparare i dati significa trasformarli in modo che
Perché è importante?
assumano la forma più adatta alle analisi
successive. • La definizione di una
struttura corretta ( → più adatta)
• Data reduction porta a
• Sampling risultati migliori ( → più utili)
• Data cleaning delle analisi successive
10
Data Mining – Data preparation (2)
• Data reduction:
Si tratta della riduzione della dimensione dei dati. L’idea è di ridurre l’amout dei dati in modo da
ottenere alla fine dell’operazione un set di dati limitato, ma più significativo.
Si applica ad esempio tramite funzioni di aggregazione, filtro su parametri predisposti, …
- Verticale
- Orizzontale
11
Data Mining – Data preparation (3)
• Sampling:
Si tratta di tecniche per il campionamento statistico: l’idea è individuare delle logiche a partire
dalle quali suddividere il dataset intero in sotto-dataset diversi e tra loro complemetari.
Tecnica utile per individuare il training set e il test set necessari per applicare tecniche di mining
per la definizione (calcolo) e la valutazione di un modello
- Random sampling
- Stratified sampling
12Data Mining – Data preparation (4)
• Data cleaning:
Processo capace di garantire, con una certa soglia di affidabilità, la correttezza di una grande
quantità di dati (DB, DWH, dataset, ...).
Unificazione delle sorgenti dati
Correzioni degli errori:
- missing value
- outliers
- informazioni irrilevanti o non valide
13Data Mining – Modeling: Tipologie di analisi (1)
Data Mining – Modeling: Tipologie di analisi (2) Data Mining
Data Mining – classificazione degli algoritmi
Data Mining
Semi-supervisionati
Alg. Supervisionati Alg. Non Supervisionati
Reinforcement learning
Classificazione
Clustering
RegressioneData Mining – supervised vs unsupervised
Data Mining – classificazione degli algoritmi
Data Mining – Algoritmi supervisionati
• Base Classifiers
• Decision Tree based Methods
• Regression
• Rule-based Methods
• Nearest-neighbor
• Naïve Bayes and Bayesian Belief Networks
• Support Vector Machines
• Ensemble Classifiers
• Boosting, Bagging, Random ForestsData Mining – Algoritmi supervisionati: Decision tree
Training Data
Home Marital Annual Defaulted Splitting Attributes
Owner Status Income Borrower
Home
1 Yes Single 125K No
Owner
2 No Married 100K No
Yes No
3 No Single 70K No
4 Yes Married 120K No
NO MarSt
5 No Divorced 95K Yes
Married
6 No Married 60K No Single, Divorced
7 Yes Divorced 220K No
Income NO
8 No Single 85K Yes
9 No Married 75K No
< 80K > 80K
10 No Single 90K Yes
10
NO YES
https://www-users.cs.umn.edu/~kumar001/dmbook/index.php#item4
20Data Mining – Esempio di classificazione
Indice gradimento nelle elezioni USA
Goal
• Measure the sentiment in terms of positive and
negative words
• Analysis along geographic and time dimensions
Data
• Twitter and social data
Techniques
• Cleansing and preparation, from unifying records
to removing stop words
• Sentiment Analysis and text mining
https://web.stanford.edu/~jesszhao/files/twitterSentiment.pdfData Mining – Algoritmi non supervisionati: Clustering
Tecniche di analisi multivariata dei
dati volte alla selezione e
raggruppamento di elementi omogenei
in un insieme di dati.
DISTANZA intesa come somiglianza
https://www-users.cs.umn.edu/~kumar001/dmbook/index.php#item4Data Mining – Clustering: Algoritmo K-means
Data Mining – Esempio di clustering
Driver profiling
Data
• Space-time distribution measures (average distance,
time spent)
• Context-aware measures (Distance travelled on
highways or inside urbar areas)
• Behavioural measures (e.g. acceleration, speed limit)
Goal
• Create a driving profile of a customer
Methodology
• Hierarchical clustering
https://dl.acm.org/citation.cfm?id=2912148Data Mining – Association Rules
TID Items
Association Rule: 1 Bread, Milk
Algoritmi per la ricerca di relazioni tra I dati 2 Bread, Diaper, Beer, Eggs
3 Milk, Diaper, Beer, Coke
- Quale sarà il prossimo acquisto di un 4 Bread, Milk, Diaper, Beer
cliente che ha appena comprato il 5 Bread, Milk, Diaper, Coke
prodotto A?
{Milk , Diaper} {Beer}
(Milk , Diaper, Beer)
2
s= = = 0.4
|T| 5
{A} => {B} (Milk, Diaper, Beer) 2
c= = = 0.67
(Milk , Diaper) 3
https://www-users.cs.umn.edu/~kumar001/dmbook/index.php#item4Data Mining – Association Rules (2)
Metriche di valutazione
Few items
Support (s): percentuale di record che contengono sia with high
gli elementi a sinistra sia quelli a destra della regola support
Valori considerati buoni in letteratura: 2-10% Many items
with low
Confidence (c): è una probabilità condizionata: rispetto support
ai record che contengono gli elementi di sinistra, si
tratta della percentuale di quelli che contengono
ANCHE quelli a destra
Valori considerati buoni in letteratura : 80-100%
https://www-users.cs.umn.edu/~kumar001/dmbook/index.php#item4Data Mining – Come si valuta un modello
Confusion Matrix Confronto sulla base di metriche e KPI:
• Metrics: accuracy, precision, recall, …
• Speed
• Robustness
• Scalability
• Interpretability
• …
Cost Matrix
LiftAGENDA: • Data mining: nozioni di base • Casi d’uso: Market Basket Analysis • R&D: Analisi predittiva nel Progetto Manifold • R&D: Analisi multimodale nel Progetto MUSE • Q&A
Market Basket Analysis Scopo: - Analizzare i comportamenti di acquisto con lo scopo di individuare dei pattern frequenti Obiettivi aziendali: - Fare previsioni di acquisto - Dare suggerimenti di acquisto al cliente - Creare campagne marketing personalizzate - …
Market Basket Analysis: l’applicativo (1)
Analisi predittiva del comportamento dei clienti
Obiettivo: ricerca delle correlazioni tra i prodotti
Supporto alle decisioni per Marketing e Business
• Caratteristiche del processo: • Approccio ibrido:
- Iterativo - Analisi quantitative
- Interattivo - Analisi data mining
- TrasparenteMarket Basket Analysis: l’applicativo (3) Caratteristiche generali: • Cambio del punto di vista • Prospettiva cliente • Prospettiva transazione • Sempre aggiornato perché basato su DWH aziendale con analisi in tempo reale • Profilazione degli accessi • Alto livello di personalizzabilità
Market Basket Analysis: l’applicativo (4) - Con che frequenza giacche e accessori moda vengono acquistai insieme? Quali modelli in particolare? Ci sono colori o materiali più correlati? - Che caratteristiche hanno i clienti che acquistano pellicce e orologi? Sono riconducibili ad un pattern comune? - Il pattern individuato per i clienti europei vale anche per i clienti americani? Quali sono le abitudini di acquisto che hanno in comune e in cosa invece differiscono?
Analisi predittiva e multimodale 18 Aprile 2019 - PADOVA
AGENDA: • Data mining: nozioni di base • Casi d’uso: Market Basket Analysis • R&D: Analisi predittiva nel Progetto Manifold • R&D: Analisi multimodale nel Progetto MUSE • Q&A
• Contesto Definizione di un sistema industriale per la realizzazione di forme per calzature tramite stampa 3D • Processo di innovazione • Tempi di produzione ridotti al 50% • Peso delle forme ridotto fino al 40% • Minimizzazione degli sfridi di lavorazione • Controllo delle condizioni ottimali di produzione • Manutenzione predittiva
MANIFOLD –Timeline e Obiettivi
OO1: Progettazione della piattaforma robotica
OO2: Progettazione del robot antropomorfo e del sistema di manutenzione predittiva
OO3: Realizzazione del robot antropomorfo e
del sistema di manutenzione predittiva
OO4: Fase di test
Robot
Antropomorfo
Piattaforma
Sensori- Servizio di
Data Platform
Manutenzione
Predittiva
Stampante 3DMANIFOLD – Metodologie per la Predictive Maintenance
Clustering
Classification
Time-series
Neural Network
Anomaly Detection
Rule-based models
Unsupervised
Supervised
VS
+ Precisione e accuratezza + Non necessario un attributo di classificazione
- Disponibilità di dati storici - Complessità della metodologia
- Sbilanciamento tra classi - Valutazione delle performance del modello
- Alta dimensionalità dei datiMANIFOLD – Maintenance Strategies SOURCE: Analytics Institute (2016). Predictive Maintenance - taking pro-active measures based on advanced data analytics to predict and avoid machine failure.
MANIFOLD – Keplero: Architettura della piattaforma IoT
MANIFOLD – Predictive Maintenance Architecture
AGENDA: • Data mining: nozioni di base • Casi d’uso: Market Basket Analysis • R&D: Analisi predittiva nel Progetto Manifold • R&D: Analisi multimodale nel Progetto MUSE • Q&A
MUSE: Analisi combinata Immagini e Testo MUSE, MUltimodal Semantic Extraction: Analisi Multimodale di testi e immagini Obiettivo: Creare modello per sfruttare le sinergie tra NLP (Natural Language Processing) e CV (Computer Vision) Natural Language Processing Computer vision • Tokenizzazione • Image recognition • Sentence Splitting • Object detection • PoS-Tagging • Facial analysis • Lemmatizzazione • OCR
MUSE: Attori e ruoli
Recupero dati:
immagini e
testi
CoLingLab
Classificazione Laboratorio Linguistica
Analisi delle Computazionale
immagini
Estrazione
embeddings di
tag e labels
Combinazione
risutati analisi
multimodaleMUSE: selezione campo di applicazione
MUSE: Recovery, soluzioni e problematiche (1)
Recupero dati:
Pentaho PDI:
immagini e testi
Classificazione
Analisi delle
immagini
Estrazione
embeddings di
tag e labels
Combinazione
risutati analisi
multimodale
11/12/18 → cambio policyMUSE: Recovery, soluzioni e problematiche (2)
Recupero dati:
Pentaho PDI:
immagini e testi
Classificazione
Analisi delle
immagini
Estrazione
embeddings di
tag e labels
Combinazione
risutati analisi
multimodaleMUSE: Recovery, soluzioni e problematiche (3)
Recupero dati:
Problematiche emerse:
immagini e testi
Classificazione
• Solo il 10% dei post contengono un’immagine
Analisi delle • Scartare i post senza immagine
immagini • Analizzare solo i testi → NLP vs Multimodal
• …
Estrazione
embeddings di • Tipologie diverse di immagini
tag e labels
• Foto
• Articoli giornale
Combinazione
risutati analisi • Screenshot
multimodale • Pubblicità/locandine
• …MUSE: Classificazione delle immagini, soluzioni e problematiche (1)
Fase in sviluppo:
• creazione dataset delle immagini su cui addestrare la rete neurale
Recupero dati:
immagini e testi
Classificazione
Analisi delle
immagini
Estrazione
embeddings di
tag e labels
Combinazione Object Detection
risutati analisi
multimodale
Facial analysis
OCR
Semantic analysis
OCR +
Object detectionMUSE: Classificazione delle immagini, soluzioni e problematiche (2)
Fase in sviluppo:
• creazione dataset delle immagini su cui addestrare la rete neurale
Recupero dati:
immagini e testi
Classificatore a 3 classi:
Classificazione
Analisi delle
immagini Foto Miste Testo
Estrazione
embeddings di
tag e labels
Combinazione
risutati analisi
multimodaleMUSE: Classificazione delle immagini, soluzioni e problematiche (3)
Fase in sviluppo:
• creazione dataset delle immagini su cui addestrare la rete neurale
Recupero dati:
immagini e testi
Classificatore a 2 classi:
Classificazione
Analisi delle
immagini Foto Testo
Estrazione
embeddings di
tag e labels
Combinazione
risutati analisi
multimodaleMUSE: architettura logica
MODULO APPLICAZIONE
MODELLI NLP STANFORD
MOTORE RECOVERY MODULO
INTEGRAZIONE
RISULTATI
MODULO APPLICAZIONE Analisi per tema
MODELLI VGG-Net OXFORD
PRECLASSIFICATORE
Disambiguazione
Motori di ricercaAGENDA: • Data mining: nozioni di base • Casi d’uso: Market Basket Analysis • R&D: Analisi predittiva nel Progetto Manifold • R&D: Analisi multimodale nel Progetto MUSE • Q&A
GRAZIE Contatto: laura.margara@bnova.it
Puoi anche leggere

















































