Teorema Limite Centrale - Monica Musio
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Teorema Limite Centrale
Monica Musio
1 / 26
Esempio - Normale
L’Italia è il paese in Europa con la maggiore percentuale di anziani.
Supponiamo di modellizzare l’età delle donne italiane con una
variabile aleatoria normale di media 49 e deviazione standard 25.
Secondo tale modello:
1. Qual è la percentuale di italiane con più di 60 anni ?
2. Qual è la percentuale di italiane con età compresa tra i 20 e i
40 anni ?
3. Qual è l’ età al di sopra della quale si trovano il 5% delle
italiane?
2 / 26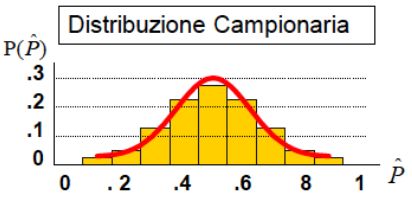
Esempio - Normale
1.
X − 49 60 − 49
P(X > 60) = P( > ) = P(Z > 0, 44) = 0, 33
25 25
Il 33% delle donne italiane ha più di 60 anni
2.
P(20 ≤ X ≤ 40) = P(−1, 16 ≤ Z ≤ −0, 36) =
= P(0, 36 ≤ Z ≤ 1, 16) = F (1, 16) − F (0, 36) = 0, 27
La percentuale cercata è il 27%
3.
x − 49 x − 49
P(X > x) = 0, 05 → P(Z > ) = 0, 05 → P(Z ≤ ) = 0, 95
25 25
x−49
Pertanto 25 = 1, 645 → x = 1, 645 · 25 + 49 = 90, 125
il 5% di italiane secondo questo modello ha un’età superiore a 90
anni
3 / 26Esercizi - Normale
I Si sa che il voto di maturità degli studenti segue una legge
normale di media 75 e varianza 104.
1. Qual è la percentuale di voti più alti di 81?
2. Se i candidati con voto inferiore a 60 vengono bocciati, qual è
la percentuale di bocciati?
I Supponiamo di modellizzare la lunghezza delle trote di lago
secondo una v.a. X con distribuzione Normale di media
µ = 28 cm e varianza σ 2 = 4 cm2 .
1. Quante trote misurano più di 30 cm ?
2. Quante hanno una lunghezza compresa tra 28 e 32 cm ?
3. Per condurre un esperimento si selezionano il 15% delle trote
più lunghe. Quale sarà la lunghezza minima rispetto alla quale
i pesci sono selezionati?
4 / 26Esercizio - Normale
La distribuzione del peso corporeo è normale. Un allevatore vuole
selezionare gli animali più pesanti per la riproduzione in una
popolazione in cui il peso medio è di 10Kg e la varianza è di 5Kg 2 .
Questo è comunemente fatto dalla selezione del troncamento: tutti
gli animali al di sopra di una soglia T di peso vengono allevati,
mentre quelli al di sotto di T non sono autorizzati a riprodursi.
L’allevatore, tuttavia, deve riprodurre una certa frazione della
popolazione per mantenere il numero di animali. Questa frazione
dipende dalla fecondità (se un animale ha un sacco di discendenti,
allora pochi genitori sono sufficienti per produrre la prossima
generazione, altrimenti saranno necessari più genitori per produrre
altrettanti prole quanti più animali l’allevatore aveva nella
popolazione iniziale). Calcola T se l’allevatore deve selezionare per
la riproduzione
1. 5% degli animali
2. 60% degli animali
5 / 26Esercizio - Normale
Il numero di casi di malaria in un anno riscontrati tra i turisti
nell’Africa sub-sahariana segue una legge normale di media 1350 e
varianza 1600.
1. Qual è la probabilità che in un anno il numero di casi sia
inferiore a 1480 ?
2. Qual è il numero di casi ammissibile affinchè la proporzione
totale dei casi non superi il 0,20 ?
3. Sapendo che in un dato anno il numero dei casi è superiore a
1300, qual è la probabilità che tale numero sia compreso tra
1360 e 1460 ?
6 / 26Approssimazione Binomiale − Normale
I La forma della distribuzione binomiale è approssimativamente
Normale se n è grande
I La normale è una buona approssimazione della binomiale se
risulta
np > 5 np(1 − p) > 5
I In questo caso allora posto
X −µ X − np
Z= =p
σ np(1 − p)
possiamo assumere che Z abbia approssimativamente
distribuzione normale standard
!
a − np b − np
P(a < X < b) ≈ P pApprossimazione Binomiale − Normale: esercizio
Supponiamo che un seme di abete piantato in una certa area abbia
una probabilità dello 0.7 di sopravvivere oltre il primo anno.
Calcolare la probabilità che su 200 semi piantati:
a) più di 150 siano sopravvissuti;
b) siano sopravvissuti tra i 150 e i 155 semi.
La distribuzione di probabilità è di tipo binomiale in quanto
l’evento di interesse è binario, sopravvivenza o meno, e si hanno un
numero di 200 prove indipendenti tra loro. Sia indicato il successo
con la sopravvivenza, allora la variabile casuale X che misura il
numero di semi sopravvissuti ha distribuzione:
X ∼ Binom(200, 0.7)
8 / 26Approssimazione Binomiale − Normale: esercizio
X ∼ Binom(200, 0.7)
applicare la formula della binomiale sarebbe lungo, ma osserviamo
che
np = .200 · 0.7 = 140 >> 5 np(1 − p) = 200 · 0.7 · 0.3 = 42 >> 5
possiamo quindi applicare l’approssimazione con la distribuzione
Normale. Calcoliamo le probabilità che:
a) più di 150 semi siano sopravvissuti;
!
X − 200 · 0.7 150 − 200 · 0.7
P(X > 150) = P p > p =
200 · 0.7(1 − 0.7) 200 · 0.7(1 − 0.7)
150 − 140
P Z> = P (Z > 1.54) = 1 − P (Z < 1.54) = 1 − 0.9382 ≈ 0.0618
6.48
9 / 26Approssimazione Binomiale − Normale: esercizio
X ∼ Binom(200, 0.7)
b) siano sopravvissuti tra i 150 e i 155 semi
!
150 − 200 · 0.7 155 − 200 · 0.7
P(150 < X < 155) = P pEsercizio
Un docente ha riscontrato che la probabilità che uno studente di
biologia superi l’esame di matematica con un voto superiore a 26 è
pari a 0,5.
1. Qual è la probabilità che su 10 studenti presenti a un appello
il numero di studenti che supera l’esame con un voto superiore
al di 26 sia compreso tra 5 e 7 (estremi inclusi)?
2. Calcola la stessa probabilità se il numero di studenti ora è pari
a 30.
3. Nell’ultimo caso usi un calcolo esatto o approssimato ?
11 / 26Statistica Descrittiva vs Inferenza Statistica
I Statistica descrittiva: analisi esplorativa dei dati
I Statistica inferenziale: vogliamo utilizzare le informazioni del
campione per fare delle affermazioni sulle caratteristiche di
tutta la popolazione
I Tra Statistica Descrittiva ed Inferenza Statistica esiste una
ovvia fratellanza e, nelle applicazioni, i problemi di inferenza
vengono normalmente affrontati in accordo allo schema:
descrizione caratteristiche campione =⇒ affermazioni
caratteristiche della popolazione
12 / 26Inferenza Statistica e Probabilità
I Il trucco alla base dell’inferenza statistica consiste nel
descrivere la relazione tra popolazione e campione utilizzando
il Calcolo delle Probabilità
I Interpreteremo i risultati sperimentali (i dati) come uno dei
tanti risultati che un meccanismo probabilistico (esperimento
casuale) poteva fornirci
I Si può considerare un modello matematico per il processo
generatore dei dati: i dati sono visti come risultato di un
esperimento casuale
13 / 26Inferenza Statistica e Probabilità
I Calcolo delle Probabilità: nota la distribuzione di probabilità
che regola un fenomeno prevedere il risultato di un
esperimento; Il calcolo delle probabilità è una disciplina
matematica
I Statistica inferenziale: partendo da un campione osservato,
supposto generato da una certa distribuzione di probabilità
non totalmente nota, trarre informazioni su tale distribuzione
I Inferenza Statistica, il punto di vista è rovesciato: si dispone
dei dati, e da questi, assunta la loro generazione da una
distribuzione di probabilità, si cerca di risalire alla legge di
probabilità (in parte ignota) corrispondente
Inferenza statistica = Probabilità−1
14 / 26Esempio
Consideriamo un bosco di pioppi coltivato su un terreno che abbia
inquinamento da cadmio. Siamo interessati a misurare la quantità
di cadmio assorbita dai pioppi (che sono bio-accumulatori di
cadmio)
Preleviamo ora le corteccie di 15 pioppi lontani tra di loro che
possono quindi essere considerati indipendenti) i dati (in gr/cm3
sono i seguenti)
9.1, 8.3, 7.5, 7.4, 6.7, 7.3, 8.1, 9.2, 7.4, 6.5, 7.2, 8.7, 9.3, 7.6, 6.8
a partire da questi dati si vuole stabilire quanto i pioppi sono stati
inquinati
15 / 26Esempio
I I dati x1 , x2 , · · · , x15 possono essere visti come realizzazioni di
un campione casuale X1 , X2 , · · · , X15 dalla popolazione
(virtuale) delle infinite misurazioni ottenibili con lo stesso
procedimento
I Possiamo pensare di modellizzare la variabile quantità di
cadmio assorbita con una v.a. continua con distribuzione
normale X ∼ N (µ, σ 2 ) con µ e σ 2 entrambi incogniti sono i
parametri del modello
16 / 26Parametri e Statistiche
I Nell’inferenza statistica siamo interessati a ottenere
informazioni sui parametri del modello sulla base dei dati
I Si utilizzano statistiche calcolate sui dati del campione, per
fare inferenza sui parametri del modello, e quindi sulla
popolazione di riferimento
I In generale una statistica è una funzione della variabili di
campione X1 , · · · , Xn , se la usiamo per stimare un parametro
lo chiamiamo stimatore del parametro. Il valore che lo
stimatore assume in corrispondenza di una realizzazione
campionaria si chiama stima del parametro
I La statistica è una v.a. e quindi ha una sua distribuzione di
probabilità. Usiamo questa distribuzione per determinare
quanto è probabile che una statistica cada vicino al parametro
della popolazione
P
xi
Nell esempio
P precedente µ e σ 2 sono
P i parametriP
mentre x̄ = n e
(xi −x̄)2 Xi (Xi −X̄)2
s2 = n−1 sono le stime, X̄ = n e S2 = n−1 i
corrispondenti stimatori 17 / 26La media campionaria
Sia (X1 , X2 , . . . , Xn ) un campione casuale estratto da una
popolazione. Allora la media campionaria è definita come:
n
X Xi
X̄ =
i=1
n
La media campionaria X̄ è una variabile casuale in quanto il suo
valore può cambiare per ogni campione selezionato, campioni
diversi della stessa dimensione estratti dalla stessa popolazione
produrranno in genere medie campionarie diverse.
Possiamo calcolare la variabilità di questa variabile casuale come:
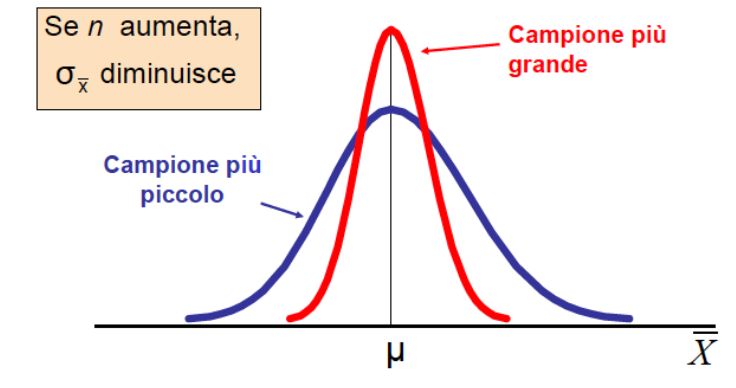
σ
σX̄ = √
n
La deviazione standard della media campionaria diminuisce quando
il campione cresce.
18 / 26Media campionaria: popolazione normale
Se la popolazione è normale con media µ e deviazione standard σ,
ossia se
X ∼ N (µ, σ 2 )
allora anche la distribuzione campionaria di X̄ è normale con
σ
µX̄ = µ σX̄ = √
n
ossia
σ2
X̄ ∼ N (µ, )
n
e quindi per la standardizzazione si ha:
X̄ − µX̄ X̄ − µ
Z= = σ ∼ N (0, 1)
σX̄ √
n
19 / 26Media campionaria: popolazione normale
20 / 26Media campionaria: popolazione NON normale
Se la popolazione non è normale si può applicare il seguente
risultato.
TEOREMA DEL LIMITE CENTRALE (TLC)
Per un campione casuale di dimensione n estratto da una
popolazione con media µ e deviazione standard σ, al crescere della
dimensione campionaria n, la distribuzione campionaria della
media campionaria X̄ si avvicina sempre di più a una distribuzione
approssimativamente normale coi seguenti parametri:
σ
µX̄ = µ σX̄ = √ .
n
Si considera n sufficientemente grande a partire da n ≥ 30.
21 / 26Teorema del limite centrale
I Qualunque sia la distribuzione delle variabili Xi , si può quindi
affermare che la distribuzione di X̄ è approssimativamente
normale con media µ e varianza σ 2 /n, per n sufficientemente
grande
22 / 26La proporzione campionaria
Molto spesso si è interessati a studiare la proporzione di oggetti con delle
specifiche caratteristiche in una popolazione:
I la proporzione di semi che sopravvivono un anno dopo essere stati
piantati;
I la proporzione di una specie animale in un’area protetta;
I la proporzione di alberi infettati da un parassita in un’area.
La proporzione è associata ad una variabile casuale discreta binaria di
tipo successo o insuccesso, in quanto la caratteristica studiata può
presentarsi o meno.
Stiamo quindi descrivendo una variabile casuale binomiale e la
popolazione segue una distribuzione binomiale con probabilità
determinata dalla proporzione di successi osservati in n prove.
23 / 26La proporzione campionaria
p = proporzione della popolazione che possiede
una certa caratteristica
Se selezioniamo un campione di n osservazioni da una popolazione
binomiale con parametro p,e indichiamo con xi = 1 il successo e
con xi = 0 l’insuccesso, allora la media campionaria sarà la
proporzione di successi:
n
X xi numero di successi
x̄ = p̂ = =
i=1
n n
la proporzione campionaria fornisce una stima della proporzione
reale.
I 0 ≤ p̂ ≤ 1
24 / 26La proporzione campionaria
Indichiamo con
n
Y numero di successi X
P̂ = = , Y= Xi
n n i=1
la variabile casuale che considera le proporzioni di successo in n prove
Si ha che
Y 2 Y p(1 − p)
E(P̂) = E =p σP̂ = var =
n n n
Se n è sufficientemente grande (n ≥ 30), allora per il TLC la distribuzione
della proporzione campionaria è approssimativamente normale
25 / 26Proporzione campionaria: esercizio
La proporzione, p, di carciofi infettati da un certo parassita in una
piantagione è 0.04. Qual è la probabilità che, in un campione di 45
carciofi, la proporzione di carciofi infettati sia maggiore di 0.07?
n ≥ 30 e di conseguenza possiamo usare l’approssimazione normale con
r r
p(1 − p) 0.04(0.96)
E(P̂) = p = 0.04 σP̂ = = ≈ 0.02921
n 45
Costruiamo la variabile Z standardizzata sottraendo il valor medio e
dividendo per la deviazione standard:
0.07 − 0.04
P(P̂ > 0.07) = P Z > ≈ P(Z > 1.03) ≈ 1−P(Z < 1.03) ≈ 1−0.8485 ≈ 0.1515
0.02921
26 / 26Puoi anche leggere

















































