REALIZZAZIONE E ANALISI COMPARATIVA DI ALGORITMI PER IL FACE-RECOGNITION
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Università Politecnica delle Marche
Facoltà di Ingegneria
Corso di laurea triennale in Ingegneria
Informatica e dell'Automazione
REALIZZAZIONE E ANALISI
COMPARATIVA DI ALGORITMI PER IL
FACE-RECOGNITION
Relatore: Candidato:
Prof. Aldo Franco Dragoni Matteo Marinelli
Correlatore:
Ing. Gianluca Dolcini
Anno Accademico 2011/2012
Indice generale
Indice generale...................................................................................................I
Indice figure.......................................................................................................II
1 - Introduzione.................................................................................................1
1.1 - Scenario................................................................................................................... 1
1.2 - Obiettivo.................................................................................................................. 2
1.3 - Risultati................................................................................................................... 2
1.4 - Descrizione lavoro.................................................................................................. 3
2 - Stato dell'arte..............................................................................................4
2.1 - Eigenfaces (PCA).................................................................................................... 4
2.2 - Scale Invariant Feature Transform (SIFT)............................................................7
2.3 - Support Vector Machine (SVM)..........................................................................11
3 - Descrizione Algoritmi..............................................................................15
3.1 - 2DPCA................................................................................................................... 15
3.2 - Fisherfaces (FLD - LDA)....................................................................................... 17
3.3 - Speeded Up Robust Feature (SURF)...................................................................20
3.4 - Multi Layer Perceptron (MLP).............................................................................26
4 - Sviluppo e test...........................................................................................33
4.1 - Sviluppo................................................................................................................. 33
4.2 - Test......................................................................................................................... 35
5 - Conclusioni e sviluppi futuri...................................................................51
5.1 - Conclusioni............................................................................................................ 51
5.2 - Sviluppi futuri....................................................................................................... 54
6 - Bibliografia.................................................................................................56
I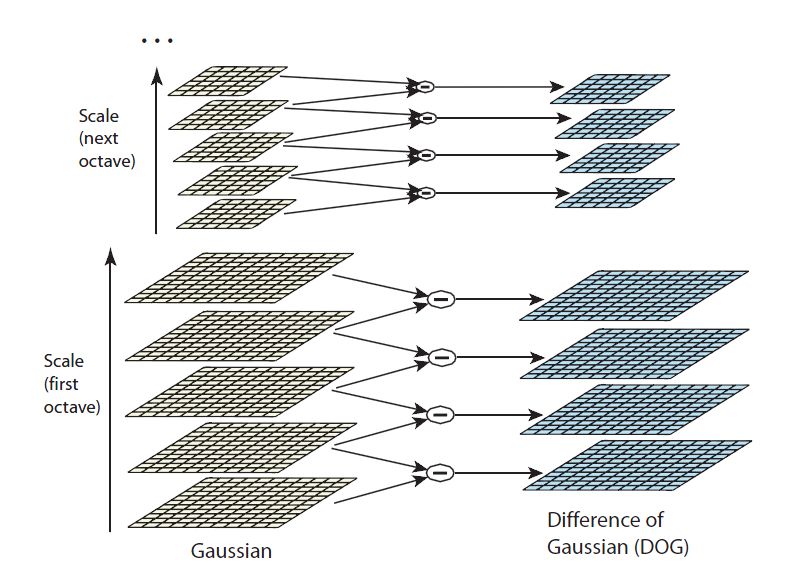
Indice delle illustrazioni
Fig. 2.1.1 - Esempio di database di volti (a) e delle relative eigenfaces (b)..............5
Fig. 2.2.1 - Rappresentazione del calcolo della Difference-of-Gaussian...................8
Fig. 2.2.2 - Rappresentazione dei punti considerati nel processo di estrazione dei
keypoints.............................................................................................................................. 9
Fig. 2.2.3 - Esempio di immagine (a) dalla quale vengono mostrati tutti i possibili
keypoints estraibili (b) e quelli mantenuti perchè considerati più stabili (c).........10
Fig. 2.3.1 - Esempi di iperpiani di decisione per dati linearmente separabili con
differenti valori del margine di separazione...............................................................12
Fig. 2.3.2 - Esempio di dati non linearmente separabili.............................................13
Fig. 2.3.3 - Esempio di dati non linearmente separabili e che richiedono l'utilizzo
di una funzione di mapping.............................................................................................14
Fig. 3.2.1 - Confronto di principal component analysis (PCA) and fisher's linear
discriminant (FLD) per un problema a due classi........................................................19
Fig. 3.3.1 - Rappresentazione del concetto di integral images.................................21
Fig. 3.3.2 - Rappresentazione dell'approssimazione apportata dal filtro box 9 x 9:
le regioni in grigio sono uguali a zero...........................................................................22
Fig. 3.3.3 - Rappresentazione della piramide di scalatura (sinistra) con riduzione
dell'immagine e con up-scaling del filtro di convoluzione (destra).........................23
Fig. 3.3.4 - Rappresentazione dei pixel coinvolti durante la localizzazione dei
punti d'interesse............................................................................................................... 23
Fig. 3.3.5 - Rappresentazione del calcolo dell'orientamento dei keypoitns SURF 24
Fig. 3.3.6 - Risposta delle haar wavelet per una regione omogenea (sinistra), una
regione con frequenze lungo x (centro) e una regione la cui intensità decresce
gradualmente (destra)..................................................................................................... 25
Fig. 3.3.7 - Confronto fra SIFT keypoints (sinistra) e SURF keypoints (destra).......25
Fig. 3.4.1 - Schema di un neurone biologico.................................................................26
Fig. 3.4.2 - Schema di rete neurale 128x40x40 utilizzabile con descrittori SIFT e 40
diversi soggetti nel training set..................................................................................... 28
Fig. 3.4.3 - Rappresentazione grafica della funzione sigmoid simmetrica.............30
Fig. 3.4.4 - Rappresentazione dell'istogramma generato nella fase di
II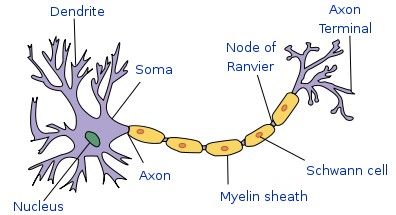
identificazione................................................................................................................... 31
Fig. 4.2.1 - Tempo di estrazione e descrizione dei keypoints per il database ORL.
............................................................................................................................................. 36
Fig. 4.2.2 - Tempi di apprendimento SVM e MLP su database ORL.........................37
Fig. 4.2.3 - Tempi di predizione SVM e MLP nel database ORL.................................39
Fig. 4.2.4 - Percentuali di riconoscimento SIFT e SURF con classificatore MLP –
ORL...................................................................................................................................... 39
Fig. 4.2.5 - Percentuali di riconoscimento SIFT e SURF con classificatore SVM –
ORL...................................................................................................................................... 40
Fig. 4.2.6 - Percentuali di riconoscimento complessive di SIFT e SURF con SVM e
MLP sul database ORL..................................................................................................... 40
Fig. 4.2.7 - Tempo di creazione del modello per algoritmi PCA, 2DPCA, LDA –
ORL...................................................................................................................................... 42
Fig. 4.2.8 - Tempo di predizione degli algoritmi PCA, 2DPCA, LDA – ORL..............42
Fig. 4.2.9 - Percentuali di riconoscimento di PCA, 2DPCA, LDA sul database ORL.
............................................................................................................................................. 43
Fig. 4.2.10 - Percentuali di riconoscimento di tutti le tecniche sul database ORL.
............................................................................................................................................. 43
Fig. 4.2.11 - Numero medio di keypoints estratti con SIFT e SURF su database
Faces.................................................................................................................................... 44
Fig. 4.2.12 - Tempi di estrazione e descrizione di keypoints SIFT e SURF – Faces. 45
Fig. 4.2.13 - Tempi di apprendimento SVM e MLP su database Faces.....................46
Fig. 4.2.14 - Tempi di predizione per classificatori SVM e MLP su database Faces.
............................................................................................................................................. 47
Fig. 4.2.15 - Precisione di predizione del classificatore SVM su database Faces.. .48
Fig. 4.2.16 - Tempo di creazione del modello per PCA, 2DPCA e LDA - Faces........49
Fig. 4.2.17 - Tempo di predizione per PCA, 2DPCA e LDA su database Faces........49
Fig. 4.2.18 - Tempi di predizioni generali sul database Faces...................................50
IIIIntroduzione
1 - Introduzione
1.1 - Scenario
Questo lavoro si colloca nell'ambito della computer vision (anche detta visione
artificiale) la quale si compone di processi che mirano alla creazione di un
modello approssimato del mondo reale 3D a partire da immagini 2D ottenute
tramite strumenti ottici quali fotocamere o videocamere.
L'obiettivo principale della computer vision è quello di riprodurre la vista umana
e la capacità di interpretare i contenuti osservati.
Nel caso queste tecniche vengano applicate su frame raffiguranti volti umani la
visione artificiale può essere suddivisa in due aspetti fondamentali:
• Face-detection: verifica della presenza ed estrazione di volti da immagini.
• Face-recognition: confronto ed identificazione di un volto presente in
un'immagine con altri volti contenuti in un database e utilizzati come set
di apprendimento.
In questo lavoro è stato preso in considerazione esclusivamente l'aspetto di
face-recognition.
I contesti in cui è possibile applicare queste tecniche sono vari:
• Sicurezza: in generale in ambiti di video sorveglianza, in particolare nel
monitoraggio di accessi e nella concessione di accessi previa
identificazione.
• Media: catalogazione di contenuti multimediali verificando e catalogando
la presenza di specifici individui.
• Sistemi intelligenti: realizzare sistemi in grado di adattare il proprio
comportamento basandosi sulla presenza di soggetti in un determinato
spazio.
1Introduzione
1.2 - Obiettivo
L'obiettivo prefissato per questo lavoro era quello di analizzare varie tecniche
per il riconoscimento e l'identificazione di volti partendo dal presupposto che i
frame analizzati contenessero sicuramente uno e un solo volto.
Il motivo di questa analisi è quello di capire quale sia la tecnica ottimale da
utilizzare a seconda del contesto in cui questa andrà applicata.
I parametri fondamentali da considerare sono:
• Percentuale di corretta identificazione
• Percentuale di errata identificazione
• Tempo di predizione: indica il tempo impiegato da un algoritmo per
determinare la classe di appartenenza del volto analizzato nell'immagine.
• Tempo di apprendimento: indica il tempo impiegato dalla tecnica di
riconoscimento analizzata per apprendere il set di frame utilizzato come
database o per creare il modello matematico corrispondente.
Quelli sopra elencati sono i parametri comuni che caratterizzano ogni algoritmo
o tecnica di face-recognition, in aggiunta a questi sarà interessante verificare
anche altri parametri valutabili solo per alcuni algoritmi e che in seguito saranno
introdotti.
1.3 - Risultati
I parametri analizzati per ogni algoritmo sono stati ottenuti utilizzando due
diversi database di soggetti:
• ORL Database: database con un limitato numero di soggetti e un limitato
numero di frame per ogni soggetto i quali però sono abbastanza differenti
tra loro, questo rende i risultati qui ottenuti molto validi per valutare le
percentuali di corretta ed errata identificazione.
• Faces94 Database: questo database ha un elevato numero di soggetti e di
frame per soggetto i quali però sono abbastanza simili tra loro, questo
2Introduzione
rende superflua la verifica delle percentuali di identificazione ma
permette di avere un'analisi molto valida sui tempi di predizione e di
apprendimento al crescere delle dimensione del database di soggetti.
Questi test hanno mostrato che le tecniche di riconoscimento che si appoggiano
ad algoritmi di machine learning non sono adatte ad ambiti real-time, ma
possono garantire tassi di riconoscimento molto elevati.
1.4 - Descrizione lavoro
Dopo questa breve introduzione alle tematiche trattate, la tesi prosegue nel
seguente modo:
• Stato dell'arte: verranno presentate le due “famiglie” di tecniche
analizzate e le loro differenze per poi passare alla descrizione
dell'algoritmo principale di ognuna delle due famiglie.
• Descrizione algoritmi: verranno presentati e descritti tutti gli algoritmi
implementati ed analizzati spiegandone il funzionamento.
• Sviluppo e test: verranno descritti la tecnologia, l'ambiente, l'architettura
e i database con i quali tutti i test sono stati realizzati, in seguito verranno
presentati in modo dettagliato i risultati ottenuti ed il loro confronto.
• Conclusioni e sviluppi futuri: dopo aver fatto il punto sui risultati,
verranno indicati alcuni possibili sviluppi futuri ed approfondimenti
interessanti che sono emersi duranti la realizzazione di questo progetto.
3Stato dell'arte
2 - Stato dell'arte
Le tecniche di riconoscimento implementate possono essere suddivise in due
gruppi a seconda di come elaborano le immagini:
• Globali: rientrano in questa categoria gli algoritmi PCA (Principal
Component Analysis, noto principalmente come Eigenfaces), 2DPCA (2
Dimensional Principal Component Analysis) e LDA (Linear Discriminant
Analysis, noto principalmente come Fisherfaces) i quali sfruttano i frame
interamente per le loro elaborazioni, inoltre questi algoritmi non
sfruttano algoritmi di machine learning ma si creano un loro modello
matematico per rappresentare l'intero set di apprendimento.
• Locali: gli algoritmi che rientrano in questa categoria sono SIFT (Scale
Invariante Feature Transform) e SURF (Speeded Up Robust Feature) i quali
poi vanno ad utilizzare come algoritmi di apprendimento e classificazione
il SVM (Support Vector Machine) ed il MLP (Multi Layer Perceptron), in
queste tecniche dai frame vengono estratti dei keypoint ai quali verrà
associato un descrittore che sarà poi utilizzato come input per gli
algoritmi di classificazione e apprendimento.
2.1 - Eigenfaces (PCA)
Il metodo che verrà ora introdotto è stato presentato nel 1991, le sue
caratteristiche principali sono: velocità, semplicità ed accuratezza.
Questo metodo si basa sull'analisi delle componenti principali, presentata nel
1901 da Karl Pearson, la quale consiste in una procedura matematica che
attraverso una trasformazione ortogonale converte un insieme di variabili
correlate in un insieme ridotto di variabili non correlate, dette componenti
principali.
L'applicazione diretta del PCA in ambito di face recognition prende il nome di
4Stato dell'arte
Eigenfaces [1][2].
L'obiettivo di questa metodologia è quello di trovare un set di immagini, le
eigenfaces, in grado di rappresentare tutto il database di volti, ed è qui che
l'analisi PCA viene utilizzata, infatti viene essa viene sfruttata con l'obiettivo di
trovare gli autovettori dominanti, cioè quelli relativi ad autovalori maggiori e che
garantiscono la massima robustezza di rappresentazione dell'intero set di volti.
Queste eigenfaces saranno poi utilizzati per rappresentare in maniera
approssimata, tramite combinazione lineare, tutti i volti del database, ai quali
sarà associato un vettore dei pesi, corrispondente ai pesi della combinazione
lineare.
Quando ci sarà la necessità di verificare un nuovo volto, questo verrà proiettato
nello spazio dei volti ottenuto come span delle eigenfaces, ricavandone il
corrispondente vettore dei pesi che sarà poi utilizzato per identificare il
soggetto.
L'identificazione può essere effettuata attraverso il calcolo della distanza
geometrica.
Fig. 2.1.1 - Esempio di database di volti (a) e delle relative eigenfaces (b)
5Stato dell'arte
Ricapitolando:
• Individuazione delle eigenfaces rappresentanti l'intero database.
• Proiezione del nuovo volto nello spazio dei volti per ricavare il vettore dei
pesi.
• Verifica tramite il vettore dei pesi dell'appartenenza del soggetto al
database e della sua identità.
Considerando ora un'immagine di N*M pixels vediamo come avviene il calcolo
delle eigenfaces.
Come prima cosa è necessario calcolare il volto medio fra quelli del training set
Γ1, . . . , Γm e le relative distanze dal volto medio Φ1, . . . , Φm
m
1
Ψ= ∑ Γ i Φ i=Ψ−Γ i
m i=1
A questo punto, definendo A = [ Φ1 … Φm ] sarà possibile calcolare la matrice
di covarianza C:
m
1 T T
C= ∑ Φi Φi = AA
m i=1
Dalla matrice di covarianza è possibile calcolare gli autovettori uj (eigenvectors)
utilizzando il metodo Jacobiano[8]
m
1 T
λ j= ∑ u j Φi
m i=1
A questo punto selezionando un sottoinsieme di autovettori, k < m, si avrà una
riduzione della complessità del problema a spese di una approssimazione dello
stesso.
Ora che le eigenfaces sono state calcolate è possibile sfruttarle per classificare
un nuovo volto, come già detto occorre proiettarlo nello spazio dei volti in modo
da ricavare il vettore dei pesi.
Definendo il vettore dei pesi Ω = [ ω1 . . . ωk ] si avrà per il singolo peso:
6Stato dell'arte
ω j=u j (Γ−Ψ) j=1,... , k
Ottenuto il vettore dei pesi del nuovo volto lo si confronterà con i vettori dei pesi
relativi a tutti i volti del training set calcolandone la distanza euclidea.
La distanza minore corrisponde alla classe di appartenenza del nuovo volto.
2 2
ϵ j=∥Ω−Ω j∥ j=1,... , k
2.2 - Scale Invariant Feature Transform (SIFT)
Proposto da D. Lowe [14] questo algoritmo si prefigge l'obiettivo di estrarre da
un'immagine delle features che sono invarianti rispetto la rotazione, la scalatura
e parzialmente invarianti rispetto al cambio di illuminazione.
Per ricavare queste features occorre per prima cosa estrarre dei keypoints
dall'immagine, successivamente ad ogni punto estratto verrà associato un
descrittore: l'insieme di questi descrittori rappresenterà il volto da cui sono stati
calcolati, cioè la classe di appartenenza.
Successivamente si dovrà utilizzare un metodo di classificazione per poter
distinguere i soggetti tra di loro, per questo scopo può essere utilizzata la
distanza geometrica o metodi più complessi come l'AdaBoost [12], il support
vector machine [13] o il multi layer perceptron [11].
L'estrazione delle features può essere decomposta in 4 fasi principali:
• Keypoint localization in scale-space
• Elimination of weak keypoints
• Assigning rotation
• Construction of descriptor
La prima fase ha come obiettivo quello di identificare tutti i punti dell'immagine
che risultano invarianti al cambiamento di scala, questo lo si può ottenere
determinando lo scale-space:
7Stato dell'arte
−( x 2+ y2 )
1 2 σ2
L( x , y , σ)=G ( x , y ,σ)∗I ( x , y ) con G ( x , y , σ)= 2
e
2πσ
dove I(x,y) rappresenta l'immagine e * l'operatore di convoluzione.
Per la selezione dei punti nello scale-space si utilizza la funzione
Diffrence-of-Gaussian (DoG), ottenuta come differenza tra due scale vicine
separate da un fattore moltiplicativo k:
DoG ( x , y , σ)=L( x , y , k σ)−L ( x , y ,σ)
Una volta ottenuta la prima ottava, la DoG viene applicate alle immagini
gaussiane (L(x,y,σ)) scalate di un fattore 2.
Nella Fig. 2.2.1 viene data una rappresentazione grafica di questa operazione.
A questo punto per localizzare i keypoints effettivi ogni punto di una DoG viene
confrontato con gli 8 punti a lui vicini nella stessa scala e con i 9 punti a lui vicini
nella scala precedente e successiva.
Fig. 2.2.1 - Rappresentazione del calcolo della Difference-of-Gaussian
8Stato dell'arte
I punti che sono maggiori o minori di tutti i suoi vicini sono candidati a diventare
keypoints, di questi vanno scartati quelli posizionati sui bordi e quelli con uno
scarso contrasto, in modo da ottenere un insieme di punti che sono il più
possibile stabili.
Nella Fig. 2.2.2 vengono mostrati i punti considerati nel'estazione dei keypoints,
mentre nella Fig. 2.2.3 vengono mostrati i keypoints estratti da un'immagine.
Fig. 2.2.2 - Rappresentazione dei punti considerati
nel processo di estrazione dei keypoints
La fase successiva serve ad assegnare ad ogni punto estratto un valore di
modulo ed uno di orientamento, a questo scopo viene creato un istogramma
formato dall'orientamento dei gradienti della regione attorno al keypoint.
L'istogramma è formato da 36 valori, così da coprire tutti i 360° attorno al punto:
il picco massimo sull'istogramma degli orientamenti corrisponde alla direzione
dominante e viene utilizzato come orientamento del keypoint.
Per ogni altra orientazione con valore maggiore dell'80% del picco massimo,
viene creato un nuovo keypoint.
Infine il punto viene ruotato nella direzione di orientamento e normalizzato:
9Stato dell'arte
m( x , y )=√ ( L ( x+1, y)−L ( x−1, y))2 +( L( x , y +1)−L ( x , y−1))2
−1 L ( x+1, y)−L ( x−1, y)
Θ( x , y)=tan
L ( x , y+1)−L( x , y−1)
Fig. 2.2.3 - Esempio di immagine (a) dalla quale vengono mostrati tutti i possibili
keypoints estraibili (b) e quelli mantenuti perchè considerati più stabili (c).
L'ultimo passo dell'algoritmo SIFT consiste nella creazione del descrittore: l'area
attorno al keypoint viene suddivisa in 4 * 4 sottoregioni, per ognuna delle quali
viene creato un istogramma di orientamento formato da 8 valori.
Concatenando gli istogrammi si avrà quindi per ogni keypoint un vettore di 128
elementi (4 * 4 * 8) che sarà opportunamente ruotato secondo il valore di
orientamento del keypoint, determinato nella fase precedente, al fine di rendere
i descrittori comparabili tra loro.
10Stato dell'arte
2.3 - Support Vector Machine (SVM)
Come anticipato, per poter utilizzare i descrittori calcolati con l'algoritmo SIFT o
SURF si ha la necessità di utilizzare degli algoritmi d classificazione.
Il termina classificare indica lo scopo di determinare la classe di appartenenza di
un determinato oggetto, farlo tramite algoritmo aggiunge che questo
procedimento deve essere realizzato in modo automatico.
Per poter distinguere diversi oggetti tra loro, questi algoritmi necessitano di una
fase di apprendimento nella quale vengono forniti dei campioni di oggetti
appartenenti ad ogni classe: questo approccio viene detto supervisionato.
L'algoritmo Support Vector, alla base delle SVM [3][4], fa parte della statistical
learning theory, o teoria di Vapnik – Chervonenkis, la teoria VC caratterizza le
proprietà degli algoritmi di apprendimento che permettono loro di “estendere la
conoscenza” a dati nuovi, in base ad elementi appresi in precedenza.
Una SVM è un classificatore binario che apprende il confine fra esempi
appartenenti a classi diverse, per fare questo proietta gli elementi del training
set in uno spazio multidimensionale e poi trova un iperpiano di separazione
(detto anche di decisione) in questo spazio.
Fra i vari iperpiani di decisione va scelto quello ottimo (si faccia riferimento alla
Fig. 2.3.1 per una rappresentazione grafica), ovvero occorre selezionare quello
che massimizza la sua distanza (margine) dagli esempi di training più vicini:
questo è importante perché massimizzando il margine si riduce la possibilità di
overfitting, cioè in altri termini si aumenta la capacità di generalizzazione.
Inoltre nell'apprendimento della SVM la regione più importante nello spazio dei
dati di training è quella attorno all'iperpiano di decisione perché è proprio in
quella zona che è più più frequente riscontrare degli errori.
11Stato dell'arte
Fig. 2.3.1 - Esempi di iperpiani di decisione per dati linearmente separabili con
differenti valori del margine di separazione.
Occorre ora specificare che i dati del training set possono essere di due tipi:
• Linearmente separabili.
• Non linearmente separabili.
Il caso di dati linearmente separabili è ovviamente il più semplice, trovare
l'iperpiano non crea problemi e l'unico obiettivo è quello di ottimizzare la scelta.
Nel secondo caso invece siamo in presenza di punti in posizione anomala rispetto
agli altri della stessa classe: questo provoca l'aggiunta di una costante di scarto
(si veda la Fig. 2.3.2) proporzionale alla anomalia e introduce una certa
tolleranza agli errori che permette l'utilizzo dello stesso classificatore lineare del
caso precedente:
f ( x)=sign( ∑ y i λi ( x∗xi )+bi )
i ∈S
I punti xi corrispondenti a moltiplicatori λi strettamente maggiori di zero
vengono detti support vector e rappresentano i punti critici del training set
essendo quelli più vicini all'iperpiano di separazione.
Resta da considerare il caso in cui non esiste la possibilità di separare i dati con
un classificatore lineare ed occorre introdurre una funzione di mapping Ф per
passare da una condizione di non separabilità ad una condizione di separabilità
12Stato dell'arte
lineare attraverso la mappatura dei dati originari in un altro spazio.
Le funzioni di mapping però possono far insorgere problemi di calcolo in quanto
la separazione dei dati porta ad un aumento della dimensione dello spazio.
Per limitare questo inconveniente si introducono delle funzioni di kernel:
K ( x i , x j )=Φ(x i )∗Φ( x j )
le quali possono avere diverse formulazioni e a seconda del problema da
affrontare sarà necessario scegliere la più opportuna, in generale le funzioni di
kernel utilizzabili sono tutte quelle che soddisfano il teorema di Mercer [9].
In questo caso si è utilizzata una funzione Radial Basis:
−γ∥xi −x j∥2
K ( x i , x j )=e
Con l'aggiunta della funzione di kernel, il classificatore diventa:
f ( x)= sign( ∑ y i λi Φ( xi )∗Φ( x j )+bi )=sign (∑ yi λ i K ( xi , x j )+bi )
i ∈S i∈S
Fig. 2.3.2 - Esempio di dati non linearmente separabili.
13Stato dell'arte
Fig. 2.3.3 - Esempio di dati non linearmente separabili e che richiedono l'utilizzo di una
funzione di mapping.
14Descrizione Algoritmi
3 - Descrizione Algoritmi
Nel precedente capitolo sono stati introdotti alcuni degli algoritmi utilizzati, in
questo capitolo verranno invece descritte le restanti metodologie di
riconoscimento adottate.
Nell'insieme gli algoritmi implementati per effettuare i test sono stati i seguenti:
• Eigenfaces (PCA)
• 2DPCA Elaborazione dell'immagine globale
• Fisherfaces (LDA)
• SIFT con SVM
• SIFT con MLP
• SURF con SVM Elaborazione dell'immagine locale
• SURF con MLP
3.1 - 2DPCA
Dopo aver visto la tecnica PCA [1][2], passiamo ad analizzare una sua variante: la
Two-Dimensional Principal Component Analysis.
L'idea su cui si basa la 2DPCA [5] è le stessa che abbiamo visto in precedenza per
la PCA ma con l'introduzione di una variazione fondamentale: le elaborazioni
sono effettuate su matrici 2D anziché su vettori 1D.
Quanto detto mette subito in evidenza alcuni miglioramenti:
• l'immagine sotto forma di matrice non necessita di essere trasformata in
un vettore;
• la matrice di covarianza può essere direttamente determinata usando le
immagini di partenza e la sua dimensione è molto ridotta, rendendo
inoltre la sua valutazione molto più semplice;
• il tempo necessario al calcolo degli autovettori è molto inferiore.
15Descrizione Algoritmi
L'idea è dunque quella di proiettare una immagine A, rappresentata come
matrice m x n, su un vettore x di dimensioni n x 1, utilizzando la seguente
trasformazione lineare:
Y = AX
così da ottenere un vettore y di dimensioni m x 1, detto vettore di proiezione
delle feature.
Vediamo come procedere: come primo passo è necessario calcolare il volto
medio, quindi considerando M frame nel training set, si avrà:
M
̃ = 1 ∑ Aj
A
M j =1
A questo punto è possibile calcolare la matrice di covarianza (o matrice di
diffusione), la quale avrà dimensioni n x n:
M
1 ̃ )T ( A j − A
Gt = ∑ ( A j − A ̃)
M j =1
Per misurare il potere discriminante del vettore di proiezione (x) possiamo
verificare la dispersione totale del vettore proiettato (y).
Così introducendo il criterio generalizzato di dispersione totale
t
J ( x)= X G t X
possiamo trovare il vettore che massimizza la dispersione.
Questo ci consente di determinare l'asse ottimo di proiezione, che corrisponde
all'autovettore relativo al più grande autovalore della matrice di covarianza.
In generale un solo asse di proiezione non è sufficiente, quindi selezioneremo d
assi di proiezione che soddisfano la condizione:
{ X 1 ,... , X d }=arg max J ( X )
T
X i X j =0 , i≠ j , i , j=1,... , d
Gli assi ottimi di proiezione risultano essere gli autovettori ortonormali relativi
agli d autovalori maggiori.
16Descrizione Algoritmi
I vettori di proiezione appena determinati sono utilizzati per il calcolo dei vettori
delle feature, detti componenti principali dell'immagine, i quali ci permettono di
determinare la matrice B, di dimensioni m x d, delle features:
Y i =AX i , i=1,... , d B=[Y 1 ⋯Y d ]
Confrontando la matrice delle features appena ricavata con quelle dei volti
presenti nel training set possiamo classificare il soggetto presente nel frame, per
questo scopo si utilizza un classificatore nearest neighbor e la classe di
appartenenza del soggetto sarà determinata dalla distanza minima calcolata.
d
( j)
d ( B , B J )= ∑ ∥Y k −Y K ∥2 j=1,... , M
k=1
3.2 - Fisherfaces (FLD - LDA)
Abbiamo visto con la tecnica PCA un metodo che ha come obiettivo la ricerca di
quei vettori che offrono la migliore rappresentazione dei dati di input.
La tecnica che verrà ora descritta, Linear Discriminant Analysis [6], ha invece come
obiettivo la ricerca di quei vettori che discriminano al meglio fra le differenti
classi; in altre parole, dato un certo numero di caratteristiche indipendenti
rispetto alle quali i dati vengono descritti, la LDA crea una combinazione lineare
di queste caratteristiche che produce le maggiori differenze medie tra le classi
analizzate.
Nella Fig. 3.2.1 viene mostrata la differenza fra PCA e LDA, in particolare FLD.
Ogni componente facciale (feature) offre un diverso potere discriminante al fine
di identificare una persona, il suo sesso, la sua etnia o la sua età.
La LDA ha avuto diversi sviluppi, in questo caso prenderemo in considerazione la
Fisher's Linear Discriminant, sviluppata da Robert Fisher nel 1936 [5].
L'implementazione di questa analisi viene effettuata tramite l'utilizzo delle
matrici di diffusione, in particolare si calcolano la matrice di diffusione di una
17Descrizione Algoritmi
classe SW e la matrice di diffusione fra le diverse classi SB, quindi considerando N
immagini {x1, . . . , x N} con valori in uno spazio n-dimensionale e c classi di
appartenenza {X1, . . . , Xc}, si possono ricavare le matrici tramite:
c
T
S B =∑ N i (ui−u)(ui−u)
i=1
c
T
S W =∑ ∑ (x k −ui )( xk −ui )
i =1 x k ∈X i
dove ui rappresenta l'immagine media della classe X i mentre Ni è il numero di
immagini nel training set per la classe Xi.
L'estrazione delle features tramite trasformazione lineare che ci porta da uno
spazio n-dimensionale ad uno spazio m-dimensionale, con m < n è del tipo:
T
yk =W x k , k =1,…, N
dove W è una matrice n x m di colonne ortonormali.
Se la matrice Sw non è singolare, la proiezione ottima Wopt può essere scelta nel
seguente modo:
T
∥W S B W ∥
W opt =arg max T
=[w 1 ⋯w m ]
W ∥W S W W∥
dove {wi | i=1,...,m} è l'insieme di autovettori di S B e SW corrispondenti agli m
maggiori autovalori {λi | i=1,...,m}:
S B w i=λ i S W w i , i=1,… , m
Nei problemi di face-recognition però si ha l'inconveniente che la matrice S W è
sempre singolare, per ovviare a questo problema si proietta il set di immagini in
uno spazio a dimensione ridotta così da avere la matrice non singolare.
Come intuibile questo può essere fatto applicando prima la tecnica delle PCA,
così da ridurre la dimensione dello spazio delle feature, così che poi si potrà
applicare la FLD senza problemi.
Dopo queste considerazioni avremo per Wopt:
18Descrizione Algoritmi
T T T
W opt =W fld W pca
T
W pca =arg max∣W S T W∣
W
T T
∣W W pca S B W pca W∣
W fld =arg max T T
W ∣W W pca S W W pca W ∣
Per la classificazione si utilizza come nel metodo PCA la distanza euclidea
minima.
Fig. 3.2.1 - Confronto di principal component analysis (PCA) and fisher's linear
discriminant (FLD) per un problema a due classi.
19Descrizione Algoritmi
3.3 - Speeded Up Robust Feature (SURF)
L'algoritmo SURF è stato presentato nel 2006 da Herbert Bay, Tinne Tuytelaars,
e Luc Van Gool [9][10], il loro obiettivo era quello di fornire un meccanismo per la
ricerca e la descrizione di punti d'interesse in un'immagine.
Questa metodologia nell'ambito del face recognition rientra nelle tecniche che
utilizzano l'immagine in modo locale al fine di permettere la classificazione di un
volto presente nell'immagine.
In altre parole viene analizzata l'immagine alla ricerca di features locali, dette
keypoints, alle quali verrà associato un descrittore.
Questi descrittori, e quindi i punti localizzati, devono essere il più possibile
robusti, cioè non devono soffrire quando l'immagine subisce alcune variazioni, in
particolare la descrizione dei punti fornita dall'algoritmo SURF deve garantire:
• invarianza rispetto alla rotazione dell'immagine;
• invarianza rispetto al cambiamento di scala nell'immagine;
• invarianza rispetto a variazioni dell'illuminazione;
• invarianza rispetto a piccole variazioni nel punto di vista dell'immagine.
Queste caratteristiche sono garantite anche dall'algoritmo SIFT, che pur essendo
molto valido ha la caratteristica di essere lento, quindi con questo nuovo
algoritmo si vuole sopperire a questa carenza.
Le fasi principali di cui si compone l'algoritmo SURF sono:
• rilevamento feature;
• assegnamento orientazione;
• creazione descrittore;
Iniziamo col descrivere la fase di rilevamento feature.
Il SURF detector si basa sull'utilizzo della Matrice Hessiana [15][16], la quale viene
approssimata mediante l'utilizzo delle immagini integrali [17], le quali
permettono un'implementazione veloce del filtro box di convoluzione.
Il detector così modificato prende il nome di Fast-Hessian.
Nella Fig. 3.3.1 viene rappresentato il concetto di integral images.
20Descrizione Algoritmi
Fig. 3.3.1 - Rappresentazione del concetto di integral images.
i ≤x j ≤ y
I Σ ( x , y)=∑ ∑ I (i , j)
i=0 j=0
Il miglioramento apportato alla velocità sta nel fatto che avendo determinato I Σ,
il calcolo dell'intensità di un'area rettangolare S, richiede quattro somme:
S =A+ B+C + D
Data un'immagine I, la matrice Hessiana alla scala σ, viene definita come:
H ( x , y , σ)=
[ L xx ( x , y , σ) L xx ( x , y , σ)
L xx ( x , y , σ) L xx ( x , y , σ)
2
]
L xx ( x , y , σ)= ∂ 2 G ( x , y , σ)∗I ( x , y ,σ )
∂x
Dove le funzioni Lxy, Lyx, Lyy, sono definite in maniera analoga a L xx ed è proprio nel
calcolo di queste funzioni che l'approssimazione con il filtro box della derivata
21Descrizione Algoritmi
del secondo ordine tramite integral images viene sfruttata (la Fig. 3.3.2 mostra il
risultato dell'approssimazione).
Fig. 3.3.2 - Rappresentazione dell'approssimazione apportata dal filtro
box 9 x 9: le regioni in grigio sono uguali a zero.
L'analisi dello spazio di scalatura invece che attraverso consecutive riduzioni della
dimensione dell'immagine viene realizzata tramite un up-scaling del filtro box: 9
x 9, 15 x 15, 21 x 21, 25 x 25, inoltre per ogni ottava l'incremento del filtro viene
raddoppiato: 6, 12, 24. Nella Fig. 3.3.3 viene mostrata questa differenza.
22Descrizione Algoritmi
Fig. 3.3.3 - Rappresentazione della piramide di scalatura (sinistra) con riduzione
dell'immagine e con up-scaling del filtro di convoluzione (destra).
Come mostrato nella Fig. 3.3.4, per localizzare i punti d'interesse dell'immagine
attraverso le varie scale si utilizza la non-maximum suppression considerando una
vicinanza 3 x 3 x 3: in questo modo scansionando lungo la direzione del gradiente
dell'immagine vengono messi a zero i pixel che non corrispondono a massimi
locali.
Fig. 3.3.4 - Rappresentazione dei pixel coinvolti
durante la localizzazione dei punti d'interesse.
Ora che i punti d'interesse sono stati rilevati si può procedere con la fase di
23Descrizione Algoritmi
descrizione dei keypoints.
Per determinare l'orientazione delle feature rilevate, si calcolano la risposte
delle haar wavelet [18][19] di dimensione 4σ nella direzione x ed y per l'insieme
di punti compresi in una circonferenza di raggio 6σ, attorno al punto in analisi.
Con σ si fa riferimento alla scala in cui il keypoint è stato rilevato.
6σ
4σ
Fig. 3.3.5 - Rappresentazione del calcolo dell'orientamento dei keypoitns
SURF
Il risultato così ottenuto viene rappresentato tramite vettore, la risposta
orizzontale ci da l'ascissa mentre la risposta verticale ci da l'ordinata, sommando
questi due contributi otteniamo un vettore locale di orientamento.
L'orientazione dominante viene stimata calcolando il vettore locale attraverso
una finestra scorrevole di apertura π/3: il vettore più lungo determina
l'orientamento del punto, si veda la Fig. 3.3.5.
Per la creazione del descrittore viene presa in considerazione una regione
quadrata di dimensione 20σ centrata sul keypoint, la regione viene a sua volta
divisa in 4 x 4 sotto-regioni, per ogni sotto-regione viene calcolata la haar
wavelets di dimensione 2σ per 5 x 5 punti.
Con questa suddivisione ogni sotto-regione contribuisce con quattro valori:
v= [ ∑ d x , ∑ d y , ∑ ∣d x∣, ∑ ∣d y∣]
24Descrizione Algoritmi
Concatenando i valori ottenuti da tutte le sotto-regioni si ottiene come
descrittore un vettore 4 x 4 x 4 (64 valori contro i 128 del SIFT): il descrittore così
ottenuto è invariante rispetto alla rotazione e alla luminosità, normalizzandolo si
ottiene l'invarianza anche rispetto al fattore di scala.
Nella Fig. 3.3.6 viene mostrato il comportamento delle haar wavelet per alcune
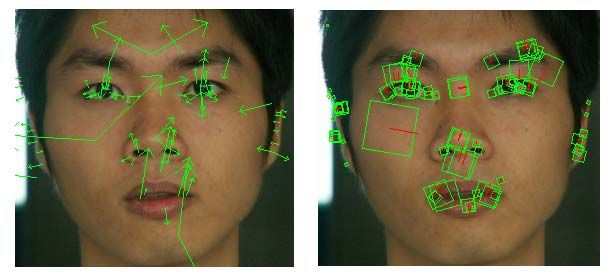
immagini di esempio; nella Fig. 3.3.7 vengono invece mostrati i punti estratti
tramite SIFT e SURF per un volto di esempio.
Fig. 3.3.6 - Risposta delle haar wavelet per una regione omogenea (sinistra), una
regione con frequenze lungo x (centro) e una regione la cui intensità decresce
gradualmente (destra).
Fig. 3.3.7 - Confronto fra SIFT keypoints (sinistra) e SURF keypoints (destra).
25Descrizione Algoritmi
3.4 - Multi Layer Perceptron (MLP)
Gli algoritmi di estrazione delle features, come è stato già ribadito più volte,
richiedono delle tecniche di classificazione per poterne identificare la classe di
appartenenza, finora sono stati trattati già due metodi per ottenere questa
classificazione:
• il calcolo della distanza minima (detto anche classificatore nearest
neighbor);
• le support vector machine.
In questo lavoro è stata presa in considerazione un'ulteriore tecnica di machine
learning: la rete neurale Multi Layer Perceptron.
L'intento di una rete neurale è quello di emulare il funzionamento della mente
umana, la quale è composta da un'inseme di neuroni tra loro collegati.
I neuroni sono le cellule che costituiscono la nostra mente e che trasmettono i
segnali nervosi (sia tra loro che verso altre parti del corpo), questi neuroni sono
variamente collegati tra loro attraverso una struttura che prende il nome di
sinapsi.
Ogni neurone possiede un lungo prolungamento chiamato assono e diverse
ramificazioni più piccole che prendono il nome di dendriti (Fig. 3.4.1).
Attraverso i dendriti, che sono collegati agli assoni di altri neuroni, la cellula
riceve i segnali che gli vengono inviati, mentre attraverso l'assone viene mandato
un nuovo segnale.
Fig. 3.4.1 - Schema di un neurone biologico.
26Descrizione Algoritmi
In generale, quando un neurone riceve un segnale, se esso supero una certa
soglia (detta soglia di attivazione), il neurone lo propaga attraverso il suo assone
agli altri neuroni, altrimenti resta inattivo.
Un neurone artificiale tenta di emulare il comportamento di quello biologico,
anche se in maniera molto semplificata, vediamo come.
Ogni neurone ha una serie di collegamenti pesati in ingresso e fornisce un
output in base agli input ricevuti dai collegamenti.
Per collegamento pesato si intende un collegamento al quale è anche associato
un peso, che rappresenta la forza del collegamento e quindi come esso dovrà
influenzare l'output del neurone.
L'informazione trasportata dal collegamento viene moltiplicata per il peso, che
solitamente ha un valore compreso fra [0,1] o [-1,+1].
Sarà proprio il valore dei pesi a determinare l'esattezza dei risultati prodotti, ed
è appunto variando i pesi tramite opportuni algoritmi che si tenta di raggiungere
una configurazione ottimale della rete.
Il neurone, dopo aver ricevuto gli input pesati da tutti i collegamenti (dendriti) li
somma, la sommatoria ottenuta viene poi passata ad una funzione di chiamata
funzione di attivazione che fa propagare il segnale.
Una rete neurale è formata da un certo numero di neuroni, i quali sono
organizzati in diversi livelli, ognuno dei quali ha un preciso compito.
Il primo strato è quello di input: contiene i neuroni che ricevono l'input e non
hanno collegamenti pesati, infatti i dati che ricevono non sono provenienti da
altri neuroni e il loro compito è semplicemente quello di immagazzinare l'input e
trasmetterlo al livello successivo.
Lo strato di input può essere collegato direttamente a quello output oppure tra
di essi si può trovare un certo numero di livelli nascosti (hidden layers).
Nella Fig. 3.4.2 viene rappresenta una rete neurale con un solo livello nascosto.
Dobbiamo ora mostrare come la rete possa apprendere, esistono due tipi di
apprendimento:
• supervisionato;
27Descrizione Algoritmi
• non supervisionato.
Fig. 3.4.2 - Schema di rete neurale 128x40x40 utilizzabile con descrittori
SIFT e 40 diversi soggetti nel training set.
Con l'apprendimento supervisionato la rete necessita di una prima fase di
addestramento durante la quale le vengono forniti alcuni esempi comprendenti
sia l'input che l'output desiderato, nel caso del face recognition vanno forniti i
descrittori dei keypoint estratti e la relativa classe di appartenenza.
La rete viene eseguita con questi input di cui si conosce già in precedenza il
risultato e tramite alcuni algoritmi vengono modificati i pesi della rete per
fornire risultati sempre più accurati.
Quando la fase di addestramento è completata, cioè si è raggiunta una soglia
minima di errore prestabilita, la rete è in grado di fornire un risultato esatto sia
nel caso gli vengano forniti come input i dati del training set che nel caso
vengano forniti dati di input che la rete non ha mai visto.
Più è vasto il training set maggiore sarà la capacità di generalizzazione della rete,
cioè di fornire risultati corretti con dati di input non appartenenti al training set.
Dalla descrizione fatta fino a questo momento è evidente che la parte più
importante per l'apprendimento della rete neurale è la fase di modifica dei pesi
fra le connessioni dei neuroni: l'algoritmo più famoso è quello di retro
propagazione dell'errore (error backpropagation).
28Descrizione Algoritmi
L'idea di base dell'algoritmo di apprendimento backpropagation è quella di
modificare i pesi delle connessioni in modo tale che si minimizzi una certa
funzione di errore:
N
1 h h 2
E= ∑ ∑ ( s k − yk )
2 h=1 k
dove N indica il numero di elementi nel training set e l'indice k il valore relativo al
k-esimo neurone di output di ciò che la rete restituisce s e ciò che dovrebbe
restituire y.
La funzione di errore in generale dipenderà dai pesi E(w), per minimizzarla
possiamo applicare il metodo della discesa del gradiente, il quale, se preso col
segno negativo ci da la direzione di massimo decremento:
∂ E ∂ E ∂ si ∂ net i
=
∂ w ij ∂ si ∂ net i ∂ w ij
dove wij è il peso dal neurone j al neurone i e net i è la somma degli input del
neurone i.
Applicando il metodo della discesa del gradiente avremo:
∂E
w ij (t +1)=w ij (t)−ϵ (t)
w ij
La scelta del fattore di scala per il gradiente (ε) ha una notevole importanza in
quanto influenza Il tempo impiegato dalla rete per raggiungere la convergenza.
Se questo valore fosse troppo piccolo sarebbero necessari troppi passi par
giungere alla soluzione, mentre se fosse troppo grande potrebbe generare
un'oscillazione che impedirebbe all'errore di scendere sotto il valore di soglia
stabilito, impedendo il raggiungimento della convergenza.
Questo problema è in parte risolvibile con l'introduzione del termine di
momento, il quale fornisce una certa inerzia alle fluttuazioni sopra citate,
smorzando l'influenza del passo precedente su quello corrente:
29Descrizione Algoritmi
∂E
Δ w ij (t+1)=−ϵ (t)+μ Δ w ij (t −1)
w ij
Tuttavia anche il fattore di scala del momento è affetto dallo stesso problema
del fattore di scala del gradiente, quindi il miglioramento che introduce è
limitato.
In precedenza abbiamo accennato alla funzione di attivazione del neurone, per la
rete MLP con backpropagation la funzione solitamente utilizzata è la sigmoid
simmetrica (la Fig. 3.4.3 ne fornisce una rappresentazione grafica):
−α x
1−e
f ( x)=β −α x
1+e
Fig. 3.4.3 - Rappresentazione grafica della funzione sigmoid simmetrica.
Ricapitolando l'algoritmo di backpropagation può essere diviso in due passi:
• forward step: l'input della rete viene propagato a tutti i livelli,
permettendo il calcolo di E(w);
• backward step: l'errore fatto dalla rete viene propagato all'indietro e i pesi
sono opportunamente aggiornati.
30Descrizione Algoritmi
A questo punto ricavare la classe di appartenenza dell'input testato è banale:
• la classe di appartenenza del keypoint testato dovrebbe avere il
corrispondente valore del neurone di output prossimo a +1;
• tutti i neuroni di output non corrispondenti alla classe di appartenenza
della feature testata dovrebbero avere un valore prossimo a -1.
Per il processo di identificazione di un volto, avendo estratto n keypoints dalla
relativa immagine, non resta altro che testare sulla rete già addestrata le n
features e raccogliere in un istogramma la classe di appartenenza assegnata
dalla rete ad ogni keypoint.
Come mostrato nella Fig. 3.4.4 nell'istogramma ci sarà una classe con un valore
maggiore rispetto alle altre, ed è questo che determina la classe del soggetto.
Fig. 3.4.4 - Rappresentazione dell'istogramma generato nella fase di
identificazione.
Citiamo infine un ulteriore miglioramento applicabile che in questo lavoro non è
stato preso in considerazione: nel machine learning vi è la possibilità applicare
una tecnica detta di bootstrapping [8], la quale iterativamente allena e valuta il
31Descrizione Algoritmi
classificatore al fine migliorarne la performance.
Questa idea può essere applicata per selezionare in modo più intelligente il
training patterns da utilizzare [11] per la fase di allenamento, infatti una classe di
volti può necessitare di meno immagini di apprendimento rispetto ad altre.
32Sviluppo e test
4 - Sviluppo e test
4.1 - Sviluppo
L'obiettivo di questo lavoro era quello di confrontare diverse metodologie di face
recognition al fine di capire in base al contesto l'algoritmo migliore da utilizzare.
Il primo passo è stato quindi quello dell'implementazione degli algoritmi: si è
scelto di utilizzare il linguaggio c++ in quanto offre ottime capacità
computazionali rispetto ad altri linguaggi come ad esempio il Java.
Inoltre utilizzando il linguaggio c++ è stato possibile usufruire delle librerie
OpenCV [20], le quali mettono a disposizione molte funzioni per l'elaborazione
delle immagini, diversi algoritmi per il machine learning e molte altre funzioni
matematiche di supporto, come ad esempio il calcolo di trasposte.
Lo sviluppo del software, e anche i successivi test, sono stati effettuati in
ambiente linux, utilizzando la distribuzione Ubuntu 12.04 LTS 64-bit [21]; in
questo ambiente ci sono diverse alternative per la scelta dell'editor, ma vista la
sua completezza, come IDE è stato utilizzato QT Creator, il quale si integra
perfettamente anche con le librerie OpenCV.
I software implementati sono due, in base al loro scopo:
• training: questo programma permette di effettuare gli apprendimenti per
le metodologie che richiedono un algoritmo di machine learning, quindi
dopo aver estratto e descritto tutte le features, associando per ognuna la
classe di appartenenza, il programma procede nel realizzare gli
apprendimenti; le metodologie interessate da questo programma sono:
◦ SIFT con SVM;
◦ SIFT con MLP;
◦ SURF con SVM;
◦ SURF con MLP;
• testing: questo software effettua tutti i test dei vari algoritmi, nel caso di
33Sviluppo e test
test sugli algoritmi che richiedono una fase di training, il relativo file di
apprendimento, precedentemente realizzato, sarà caricato, nel caso
invece degli altri algoritmi prima della fase di test verrà anche creato il
modello del training set; in entrambi i casi sarà comunque necessaria una
fase in cui siano estratte le features dai volti da testare.
Per effettuare i test e gli apprendimenti è stato necessario l'utilizzo di una
workstation portatile Dell Precision, con un processore i7-vPro, 16 GB di ram e
un hard-disk con caching SSD da 32 GB, in quanto con un “normale” PC il tempo
necessario per la realizzazione degli apprendimenti sarebbe stato estremamente
elevato. Inoltre va aggiunto che non è stato possibile installare il sistema
operativo direttamente su hard disk ed è stato necessario ricorrere all'utilizzo di
una macchina virtuale, per la quale sono stati impiegati 12 GB di ram anziché 16.
Le prestazioni su macchina virtuale sono state ridotte solo in parte perché il
processore i7-vPro sfrutta una tecnologia che punta proprio a migliore le sue
performance in contesti di virtualizzazione.
Inoltre volendo stimare le performance degli algoritmi, è stato scelto di non
realizzare un'interfaccia grafica per i software implementati, che sono utilizzabili
da riga di comando, così da avere la potenza della CPU tutta a disposizione degli
algoritmi da testare.
I parametri da valutare sono già stati anticipati nell'introduzione, fra questi ci
sono diversi tempi, per la loro misura sono state sfruttate due funzioni delle
librerie OpenCV:
• una che restituisce il numero di tick a partire da un certo evento
(accensione macchina);
• una che restituisce la frequenza dei tick, ovvero quanti tick al secondo
sono eseguiti;
In questo modo calcolando la differenza di tick fra due momenti e dividendola
per la frequenza (il cui valore restituito dalla funzione è 1 GHz) è possibile
ottenere un tempo in secondi.
34Sviluppo e test
4.2 - Test
Ora che è stato introdotto l'hardware e il sistema utilizzato per eseguire i test
possiamo passare all'analisi dei risultati e al loro confronto, come già detto in
precedenza sono stati sfruttati due diversi database di immagini, uno più adatto
per verificare le percentuali di identificazione e l'altro più utile per la stima dei
tempi di predizione ed apprendimento con molti soggetti nel training set.
Partiamo con il primo, il database ORL, il quale è formato da 40 soggetti, per
ognuno dei quali ci sono 10 diverse immagini.
I test sono stati effettuati utilizzando da 1 a 5 immagini di apprendimento per
ogni soggetto (nei grafici questo sarà indicato con FPS), individuando 5 gruppi,
per ogni gruppo sono state selezionate 10 diverse sequenze di immagini da
introdurre nel training set; in questo modo si sono ottenuti per ogni parametro,
10 valori utilizzando una sola immagine di apprendimento, 10 utilizzando 2
immagini di apprendimento e così via, il valore preso come stima del parametro
in ogni gruppo, sarà dato dalla media dei valori ottenuti con le singole sequenze.
Questo scelta porta a due benefici:
• la minimizzazione dell'influenza dello stato momentaneo del calcolatore
sul valore del singolo risultato temporale;
• la possibilità di selezionare in modo casuale tutte le possibili immagini di
ogni soggetto.
Valutiamo per primi gli algoritmi di estrazione features SIFT e SURF, in
precedenza è stato spiegato per entrambi come vengano estratti i keypoint e
come vengano ricavati i relativi descrittori.
L'obiettivo del SURF rispetto al SIFT era proprio quello di ridurre il tempo di
estrazione e descrizione dei keypoint, questo viene evidenziato dalla Fig. 4.2.1,
nella quale viene riportato il tempo di estrazione sommato a quello di
descrizione totale per ogni gruppo.
Una delle principali differenze evidenziate dalla descrizione dei due algoritmi di
estrazione features è relativa alla dimensione stessa del descrittore ricavato.
I descrittori vengono rappresentati come dei vettori di:
35Sviluppo e test
• 128 elementi per l'algoritmo SIFT;
• 64 elementi per l'algoritmo SURF.
Come algoritmi di classificazione sono stati scelti SVM e MLP, gli elementi che
vengono passati come input a questi classificatori sono i descrittori dei keypoints
estratti e le relative classi di appartenenza.
Per entrambi gli algoritmi è stato scelto come criterio di arresto che l'errore
commesso sia inferiore a 1e-05 (cioè 0.00001), inoltre per la rete MLP sono stati
scelti come valori per il fattore di scala del gradiente e per il termine di momento
rispettivamente: 0.001 e 0.005.
La rete neurale utilizzata ha la seguente struttura:
• SIFT: 128 – 80 – 40;
• SURF: 64 – 80 – 40;
dove ovviamente il livello di input corrisponde alla dimensione del descrittore e il
livello di output corrisponde al numero di soggetti presenti nel training set, la
dimensione del livello nascosto è invece dovuta ad alcune prove pratiche.
Tempo di estrazione e descrizione keypoints - ORL
4,500
4,000
3,500
3,000
2,500 SIFT
SEC
2,000 SURF
1,500
1,000
0,500
0,000
1 2 3 4 5
FPS
Fig. 4.2.1 - Tempo di estrazione e descrizione dei keypoints per il database ORL.
36Puoi anche leggere

















































