Progetto e Sviluppo di Tecniche di Intelligenza Artificiale su Big Data per l'Analisi Previsionale dei Dati Provenienti da Modena Automotive Smart ...
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Università degli studi di Modena e Reggio Emilia
Dipartimento di Scienze Fisiche Informatiche e Matematiche
Corso di Laurea in Scienze dell’Informazione
Progetto e Sviluppo di Tecniche di Intelligenza Artificiale su
Big Data per l’Analisi Previsionale dei Dati Provenienti da
Modena Automotive Smart Area
Relatori Candidato
Riccardo Martoglia
Gabriele Savoia
Roberto Cavicchioli
Anno accademico 2019/2020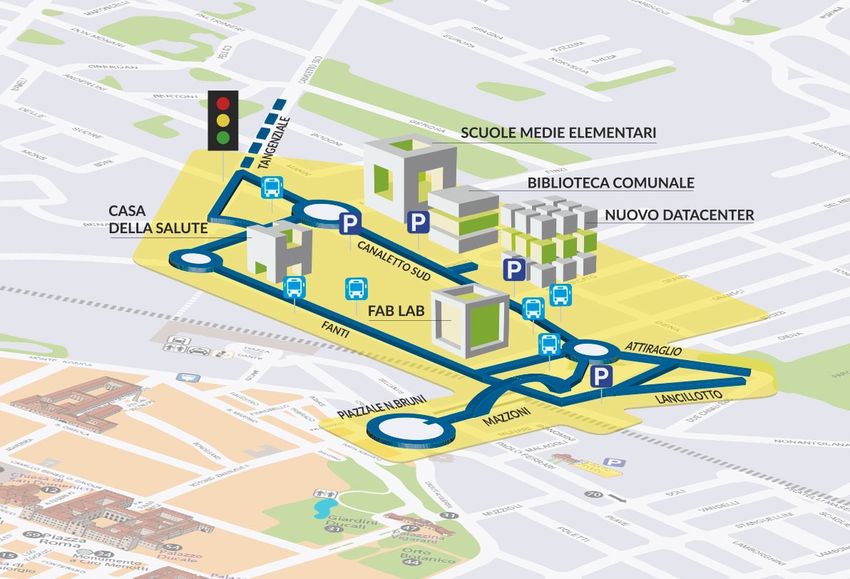
AMBITI DELLA TESI
Big Data Analisi Previsionale
• Grande fonte di informazioni • Serie temporali
• Dimensione totale nell’ordine di miliardi di GB • Previsione valori futuri
• Necessità di nuove tecnologie per la loro gestione • Metodologie statistiche e di machine learning
CONTESTO DI APPLICAZIONE
Modena Automotive Smart Area (MASA) :
• Progetto nato a Modena e attivo dal 2017
• Primo laboratorio nazionale “a cielo aperto” per la sperimentazione e la certificazione
delle tecnologie di guida autonoma
• Obiettivi : applicazione delle nuove tecnologie in ambito urbano (smart city),
autonomous driving, risparmio energetico e miglioramento delle condizioni
sociali dei cittadini
Smart Model Area
• Area urbana all’interno della città di
Modena
• Costituita da diverse infrastrutture tra
cui semafori interconnessi, segnaletica
digitale, telecamere per riconoscimento
ostacoli …
OBIETTIVI TESI
Studio delle metodologie più opportune per eseguire analisi
1 previsionali della densità del traffico nei diversi punti dalla
Smart Model Area
Implementazione delle metodologie studiate in un framework
2 scalabile in grado di gestire la grande quantità di dati
proveniente dalle infrastrutture del MASA
3 Valutazione dell’accuratezza dei metodi studiati in funzione
delle diverse aggregazioni temporali dei dati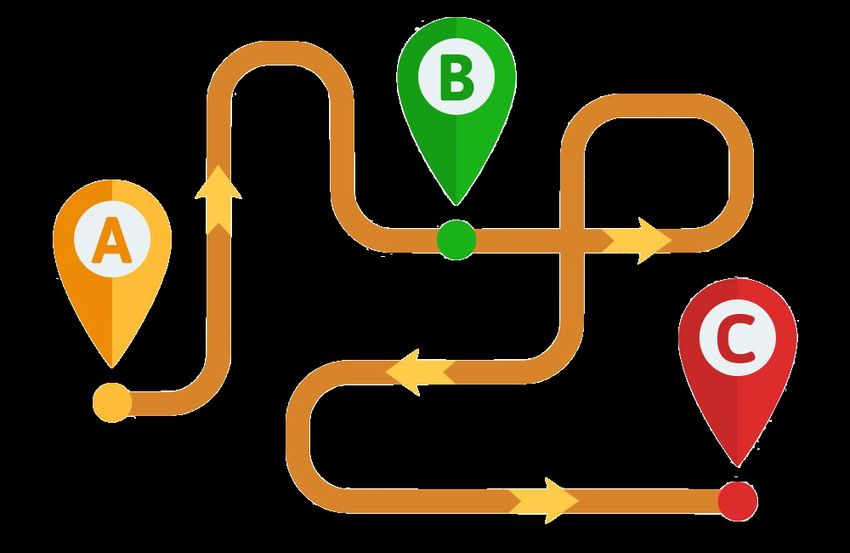
01 Strumenti e librerie 02 Punto di partenza 03 Progettazione 04 Analisi dei risultati 05 Sviluppi futuri

STRUMENTI E LIBRERIE
• Framework per il • Libreria Python per la • Libreria Python per • statsmodels
calcolo distribuito di manipolazione e eseguire previsioni implementa modelli e
dati su larga scala l’analisi di dati efficienti su serie definisce numerose
temporali operazioni statistiche
• MLlib per
l’esecuzione di • pmdarima
algoritmi di machine permette una versione
learning automatizzata del
modello Arima
01 Strumenti e librerie 02 Punto di partenza 03 Progettazione 04 Analisi dei risultati 05 Sviluppi futuri
PUNTO DI PARTENZA
Tesi
Structured Aggregazione dati
Sorgente Dati Streaming Spark (1 min, 15 min, 1 h)
“Progetto e sviluppo di
un’applicazione Big Data
per la gestione e l’analisi
dei dati provenienti da Reverse
Modena Automotive Smart Smart Model Area Visualizzatore
Geocoder
Area”
Autore
(33.93 , 40.78)
Francesco Barbanti
(Via Canaletto Sud, tratto 3)
Anno Accademico
2019/202001 Strumenti e librerie 02 Punto di partenza 03 Progettazione 04 Analisi dei risultati 05 Sviluppi futuri
MODELLI UTILIZZATI
Arima
Prophet
Decision Tree
MLlib
DecisionTreeRegressor
Gradient Boosted Tree … MLlib
GBTRegressorPROGETTAZIONE
SCOPO PROGETTAZIONE
A partire dal flusso di lavoro esistente :
• Integrazione dei modelli Arima, Prophet, DT e GBT in Spark tramite
2 approcci
• Implementazione delle funzionalità di preprocessing per entrambi gli Preprocessing
MLlib
approcci MLlib
Structured 2 Approcci
Aggregazione dati
Sorgente Dati Streaming Spark (1 min, 15 min, 1 h)
Pandas
Preprocessing Function
Reverse Pandas API in
Visualizzatore Spark
Geocoder
Flusso di lavoro esistente Approcci al problemaAPPROCCI AL PROBLEMA
MLlib Pandas Function API Spark
Modello
TimeSerie1
.
Pandas
Previsione N TimeSerie . Previsione
1 TimeSerie MLlib Function
1 TimeSerie . N TimeSerie
API
Modello
TimeSerie N
• Decision Tree
• Gradient Boosted Tree
• Arima
• Prophet
Esecuzione scalabile di 1 modello Esecuzione parallela di N modelli
(DT o GBT) per la previsione di (Arima o Prophet) per la previsione
1 serie temporale simultanea di N serie temporaliPREPROCESSING
MLlib Pandas Function API Spark
1 1
Ricampionamento Ricampionamento
3 2 3 2
Gestione valori Gestione valori
Orario osservazioni Orario osservazioni
nulli nulli
4 5 4
Valori di lag VectorAssembler Logaritmo
Pipeline MLlib Pandas
Utilizzata per i modelli DT , GBT Utilizzata per i modelli Arima , Prophet01 Strumenti e librerie 02 Punto di partenza 03 Progettazione 04 Analisi dei risultati 05 Sviluppi futuri
SERIE TEMPORALI ANALIZZATE
C
A
BPREVISIONI 1-STEP
Arima Prophet Decision Tree Gradient Boosted Tree
Serie temporale A Serie temporale B Serie temporale C
15% 40% 60%
12% 28% 42%
MAPE
MAPE
MAPE
8% 17% 23%
5% 5%
5%
1h 15 min 1 min 1h 15 min 1 min 1h 15 min 1 min
Granularità Granularità
Granularità
• Prophet peggiora l’accuratezza per previsioni di 15 min e 1 min
• Arima performa meglio rispetto agli altri modelli Risulta più facile prevedere la densità
• Prevedere la densità al minuto successivo in alcuni casi (B) genera un del traffico nell’ora, nei 15 minuti o nel
errore più piccolo, mentre in altri (C) genera un errore più elevato minuto successivo?PREVISIONI 1-STEP
Reale Previsto
Previsioni con dati aggregati 1 ora Previsioni con dati aggregati 1 minuto
Serie A
Serie B
Serie CPREVISIONI DENSITÁ 1 ORA e 12 ORE
Arima Prophet
Serie temporale A Serie temporale B Serie temporale C
Come varia l’errore di previsione della
14% 28% 8% densità nell’ora successiva se si
utilizzano granularità di dati diverse?
MAPE 20,5%
9,5% 4%
Previsione
densità 5% 13% 0%
Modelli : Arima e Prophet
1 Ora 1h 15 min 1 min 1h 15 min 1 min 1h 15 min 1 min
Granularità Granularità Granularità
50% 17% 6%
MAPE
• Per le serie A e C granularità fini (1
25% 9,5% 3% minuto) portano ad una aumento
Previsione dell’errore
densità
12 Ore
0%
1h 15 min 1 min
2%
1h 15 min 1 min
0%
1h 15 min 1 min
• Per la serie B, l’utilizzo di granularità
fini (al minuto) porta ad un
Granularità Granularità Granularità
miglioramento delle performanceANALISI EFFICIENZA
Pandas Function API MLlib
Spark su Singola macchina
5 serie temporali 1 serie temporale
CPU : Intel Core 3,3 GHz i7 quad-core
RAM : 16 GB
Arima Prophet DT GBT
17,8 2,89
1 ora 1 ora
19,9 2,92
Maggiore efficienza
con Spark rispetto a
Granularità
Granularità
33,2 Pandas 3,66
15 min 15 min
27,8 3,97
294,9 4,32
1 min 1 min
45,5 4,67
10 100 2 3,4 4,8
Tempo esecuzione (secondi) Tempo esecuzione (secondi)01 Strumenti e librerie 02 Punto di partenza 03 Progettazione 04 Analisi dei risultati 05 Sviluppi futuri
SVILUPPI FUTURI • Utilizzo di metodologie apposite per il tuning dei parametri riferiti ai modelli • Considerazione di features aggiuntive come la condizione atmosferica, i lavori stradali in corso ecc. • Integrazione del lavoro svolto nei sistemi di ottimizzazione dei tragitti stradali (es. navigatori) • Supporto alla segnaletica digitale
Grazie per l’attenzione
Puoi anche leggere

















































