Piattaforme per il Processamento e l'Immagazzinamento di Big Data - Fabrizio Montecchiani Dipartimento di Ingegneria, Università degli Studi di ...
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Piattaforme per il Processamento e l'Immagazzinamento di Big Data Fabrizio Montecchiani Dipartimento di Ingegneria, Università degli Studi di Perugia Punto Impresa Digitale, Perugia, 23.05.2019
OUTLINE Cosa sono i Big Data? A cosa servono i Big Data? Come si usano i Big Data? Piattaforme distribuite: idee chiave e tecnologie

COSA SONO I BIG DATA?
QUALCHE DEFINIZIONE Risorse informative ad alto volume, ad alta velocità e/o ad alta varietà che richiedono nuove forme di elaborazione per consentire un processo decisionale avanzato, nuove intuizioni e l'ottimizzazione dei processi. (Gartner, 2012)

QUALCHE DEFINIZIONE Risorse informative caratterizzate da un volume, una velocità e una varietà così elevati da richiedere tecnologie e metodi analitici specifici per la sua trasformazione in valore. (De Mauro et al., 2016)
LE V DEI BIG DATA Volume Velocità Varietà Variabilità Veracità Visualizzazione Valore
VOLUME
Data set molto grandi difficili da gestire e mantenere.
Quanti dati ci sono nel mondo?
160 Exabytes nel 2006 (1EB = 1018B)
4.5 Zettabytes nel 2013 (1ZB = 1021B)
1 ZB = una pila di hard disk da 1TB alta 25,400 km
Quanti dati produciamo al giorno?
2.5 EB = 2.5 106 TB
8 TB, Twitter
50 TB, Facebook
90% dei dati sono stati generati negli ultimi 2 anni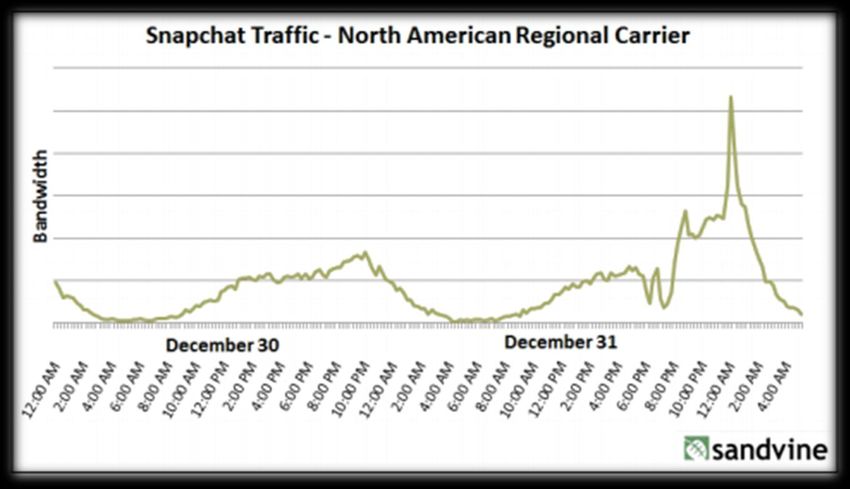
VOLUME
VARIETÀ I dati possono essere di varia natura e presentarsi sotto tante forme. Testi, video, audio e altri dati non strutturati o semi-strutturati richiedono architetture diverse e tecnologie nuove per essere gestiti.

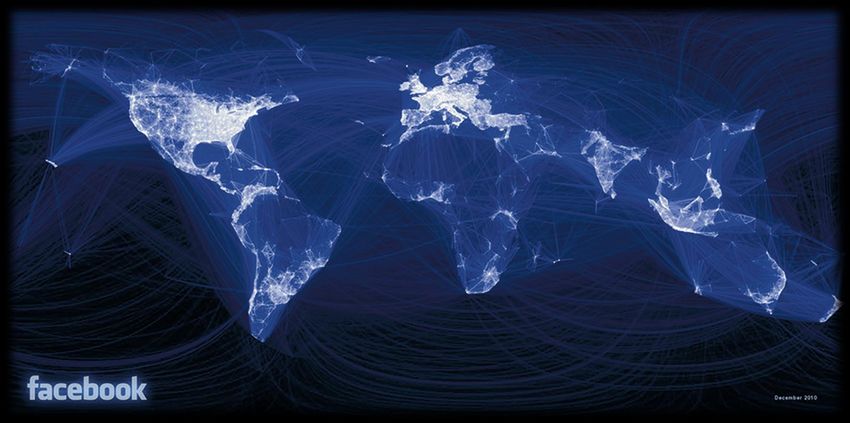
VELOCITÀ I dati sono generati e vanno processati ad alta velocità. Organizzazioni come Facebook e Twitter ricevono e processano grandi moli di piccoli messaggi ogni secondo.
VARIABILITÀ Oltre ad essere veloce, il flusso di dati può essere molto variabile nel tempo, con picchi giornalieri, stagionali o scatenati da un evento difficilmente prevedibile.
source: floq.to/AKs9E
VERACITÀ I dati provengono da tante fonti eterogenee, la loro qualità può variare molto e influenzare negativamente il processamento e l’analisi dei dati stessi.
VALORE I dati possono generare grandi vantaggi economici (ad esempio, predizioni più accurate).
VISUALIZZAZIONE La complessità dei dati richiede nuove forme grafiche di rappresentazione per consentire una analisi più efficiente e favorire nuove intuizioni.
NETWORK OF NEWS
A COSA SERVONO I BIG DATA?
DATA MINING Il valore non sta tanto nei dati o nella loro numerosità, quanto nella capacità di utilizzarli per estrarre informazioni e conoscenza.
PRINCIPALI UTILIZZI DEI BIG DATA Micro-segmentazione: offrire prodotti e servizi più personalizzati ai clienti (ad esempio, cure mediche mirate). Velocità di sintesi: fornire informazioni in tempo reale da masse di dati per accelerare processi decisionali o proporre offerte e servizi (ad esempio, decisioni in base ai dati di geo-localizzazione in tempo reale). Combinazioni di dati: mettere insieme più set di dati per fornire nuove informazioni (ad esempio modelli meteorologici a lungo termine e vendite di abbigliamento).
RETAIL: SISTEMI DI RACCOMANDAZIONE Generano automaticamente proposte di acquisto sulla base degli interessi di un cliente rispetto a quelli di milioni di altri clienti simili (collaborative filtering). Richiedono l’elaborazione di tutti i dati provenienti ad esempio dalla navigazione di un utente, dai suoi precedenti acquisti, dai prodotti valutati o ricercati.
RETAIL: CUSTOMER INSIGHTS L’acquisizione ed elaborazione dei dati relativi all’interazione dei clienti con i vari canali (mobile, social, negozi fisici, e-commerce…) consentono il miglioramento dei tassi di conversione dei clienti, la personalizzazione delle campagne per aumentare i ricavi, l'abbassamento dei costi di acquisizione dei clienti e altro ancora.
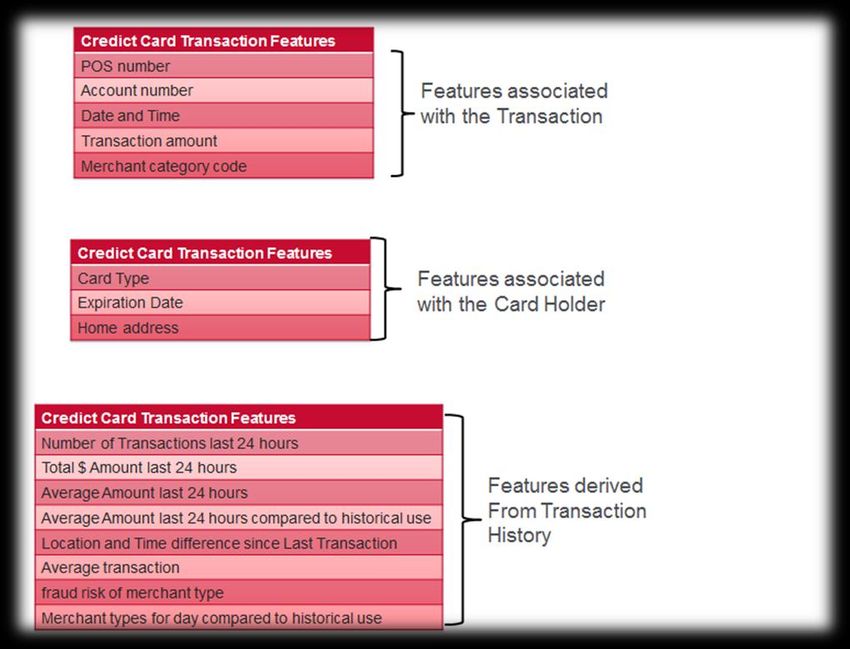
FINANCE: SCOPERTA DI FRODI Le società che gestiscono carte di credito possono individuare delle operazioni sospette confrontandole rispetto a milioni di altre operazioni.
INDUSTRY: MANUTENZIONE PREDITTIVA Analizzare il flusso di dati che proviene da tutta una serie di dispositivi e sistemi integrati di rilevazione (IoT) consente di valutare i rischi potenziali che possono crearsi per l’associazione di particolari condizioni. In questo modo è possibile calcolare il tempo che intercorre prima del guasto di un componente e limitare gli interventi di manutenzione preventiva o ordinaria.
INDUSTRY: MANUTENZIONE PREDITTIVA
R&D: PROFILAZIONE RISORSE
PIÙ DATI = PIÙ INTELLIGENZA? Sì: Gli algoritmi funzionano meglio. Maggiore tolleranza agli errori. Ma: Servono le domande giuste!
PIÙ DATI = PIÙ INTELLIGENZA?
Google Translate è un servizio web di traduzione
automatica.
Basato su un modello di apprendimento
supervisionato addestrato con coppie
continuamente arricchito.
Il Web è pieno di frammenti di testo tradotti.
Più ne usiamo per addestrare il modello e più
sarà accurato.
Questo approccio ha soppiantato l’utilizzo di
complessi insiemi di regole/eccezioni uniti a
dizionari.COME SI USANO I BIG DATA?
IL PROCESSO DEI BIG DATA
Acquisition
Decision Extraction
Interpretation Integration
AnalysisIL PROCESSO DEI BIG DATA
Acquisition
Decision Extraction
Interpretation Integration
AnalysisACQUISIZIONE Operazioni su dati grezzi (non processati): Selezione Filtraggio Generazione di metadati …
IL PROCESSO DEI BIG DATA
Acquisition
Decision Extraction
Interpretation Integration
AnalysisESTRAZIONE Operazioni su dati parzialmente processati: Trasformazione Normalizzazione Pulizia Aggregazione …
IL PROCESSO DEI BIG DATA
Acquisition
Decision Extraction
Interpretation Integration
AnalysisINTEGRAZIONE Operazioni su dati processati: Standardizzazione Gestione conflitti Riconciliazione …
IL PROCESSO DEI BIG DATA
Acquisition
Decision Extraction
Interpretation Integration
AnalysisANALISI
Operazioni su dati integrati:
Esplorazione (ad esempio tramite visualizzazione)
Estrazione di nuovi dati (ad esempio tramite machine
learning)
…IL PROCESSO DEI BIG DATA
Acquisition
Decision Extraction
Interpretation Integration
AnalysisINTERPRETAZIONE Richiede: Conoscenza del dominio applicativo Identificazione di pattern ricorrenti (visualizzazione, metodi statistici, machine learning, pattern matching) …
IL PROCESSO DEI BIG DATA
Acquisition
Decision Extraction
Interpretation Integration
AnalysisDECISIONE Richiede: Competenze manageriali e/o scientifiche …
DATA GOVERNANCE Comprendere a fondo i benefici che i dati possono apportare all’interno della propria organizzazione. Considerare i dati come asset aziendali strategici. Definire processi e responsabilità per la gestione e il trattamento dei dati. Investire in figure professionali esperte (data scientists). Investire in tecnologie.
PA: ANALISI RISCHIO FISCALE
CRESCITA DELL’INFORMAZIONE Dimensione indice motori di ricerca (numero di documenti indicizzati): 1994: ~105 1997: ~108 2000: ~1010 2018: ~1020 Ricerche al giorno: 1994: ~103 1997: ~107 2018: ~1010
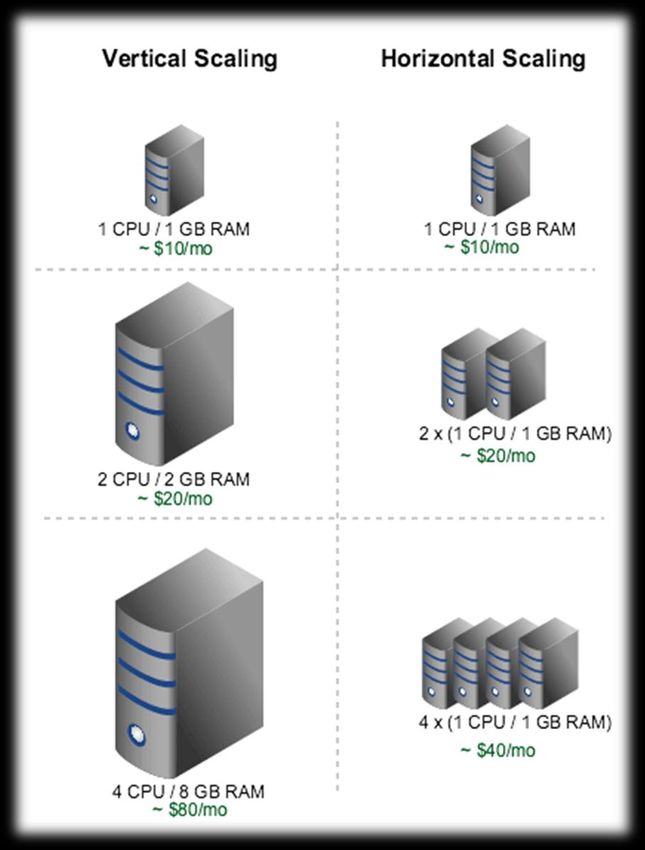
SCALABILITÀ VERTICALE
L’approccio tradizionale prevede l’utilizzo di costosi e
potenti computer (Symmetric MultiProcessing) per
processare grandi moli di dati.
Molti processori connessi ad una singola memoria
condivisa, controllata da un unico OS.SCALABILITÀ VERTICALE SMP: Tecnologia matura. Tecnologia costosa (costo non scala linearmente con le risorse). Consumo di energia anche in stato di riposo. A volte semplicemente non basta!
SCALABILITÀ ORIZZONTALE Utilizzo di tanti computer a basso costo interconnessi in rete e che collaborano per processare grandi moli di dati. Il mercato «low-end» offre prezzi bassi, componenti intercambiabili, economia di scala.
RISORSE ELASTICHE La scalabilità orizzontale consente di aggiungere o rimuovere risorse in base all’effettivo bisogno. Minori sprechi di energia. Scalabilità (quasi) lineare dei costi rispetto alle risorse.
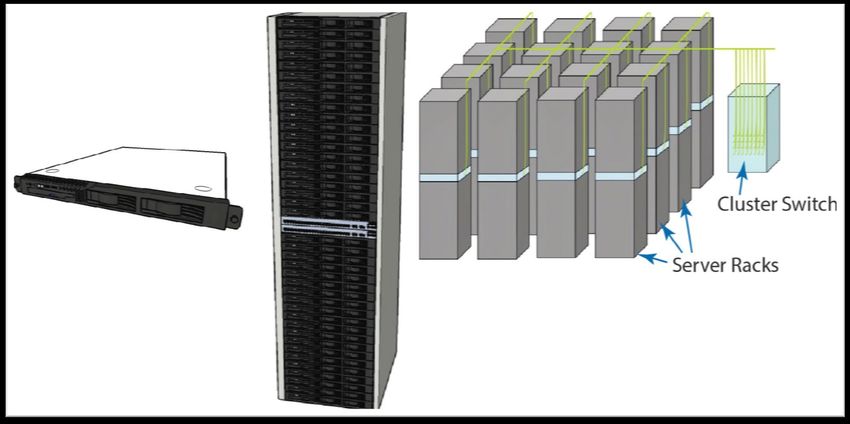
CLUSTER
Anatomia di un cluster:
Insieme di computer «low-end» montati su dei rack
interconnessi tramite switch Ethernet.
Switch a livello di rack (Gbps) che interconnettono i vari
rack.
Switch di secondo livello che interconnettono più cluster
insieme (fino a migliaia di computer).ANATOMIA DI UN CLUSTER
CLUSTER @ GOOGLE https://www.google.com/about/datacenters
IL MODELLO GOOGLE
Cluster multipli dislocati su scala mondiale.
Load balancing basato su vicinanza geografica
(tramite DNS).
Disaster recovery.
Ogni cluster contiene alcune migliaia di computer.
Ogni rack contiene 40-80 computer.
Costo pari a circa $280,000.
Ogni cluster contiene 30 rack (o più).IL MODELLO GOOGLE Affidabilità spostata da hardware a software. Applicazioni altamente parallelizzabili. Servizi replicati su più macchine per aumentare la capacità di servizio e la tolleranza a guasti. Acquisto di hardware che ottimizza il rapporto prezzo/performance.
PIATTAFORME DISTRIBUITE: IDEE E CHIAVE E TECNOLOGIE
IDEE CHIAVE
L’obiettivo di tutti i paradigmi per la gestione dei Big Data è
parallelizzare input e output attraverso la distribuzione.
Distribuzione dei dati: i dati sono distribuiti tra i nodi del
cluster.
Distribuzione delle applicazioni: le applicazioni vengono
anch’esse distribuite per lavorare in parallelo.DISTRIBUZIONE DEI DATI
I dati vengono distribuiti tra i nodi del cluster.
Ogni blocco di dati è replicato su più di un nodo per
migliorare la robustezza a guasti.
Molti nodi partecipano poi al processamento dei dati
per migliorare le performance.DISTRIBUZIONE DELLE APPLICAZIONI Ogni nodo del cluster possiede una copia dell’applicazione. Per un cluster con centinaia di nodi, questo può rappresentare un grosso problema di gestione e manutenibilità. Occorrono software che gestiscano trasparentemente l’infrastruttura. L’affidabilità viene spostata dall’hardware al software.
DIVIDE ET IMPERA
Divide Work
Combine ResultsDIVIDE ET IMPERA Il lavoro da svolgere viene diviso in una serie di compiti più semplici, che possono essere eseguiti in parallelo. Questo procedimento può ripetersi fintanto che il lavoro non è ulteriormente scomponibile o si raggiunge una complessità accettabile. I risultati parziali vengono poi riaggregati per costruire una soluzione completa.
PROCESSAMENTO DISTRIBUITO: SFIDE
Gestione risorse: i singoli compiti (task) vanno assegnati ai
vari nodi del cluster in maniera efficiente ed efficace.
Le risorse del cluster vanno suddivise in «pacchetti» tali
che ogni compito può essere eseguito attraverso un
pacchetto di risorse.
Le risorse del cluster vanno assegnate a più applicazioni
concorrenti secondo logiche di priorità.PROCESSAMENTO DISTRIBUITO: SFIDE
Gestione fallimenti: vanno gestiti i casi di fallimento dei
nodi.
Le risorse vanno riassegnate e i compiti falliti vanno
schedulati sulle nuove risorse.
Avere pacchetti di risorse liberi può servire a eseguire più
copie dello stesso compito.PROCESSAMENTO DISTRIBUITO: SFIDE
Comunicazione: va gestito lo scambio di dati tra nodi.
Vanno evitati picchi di traffico sulla rete.
Va ottimizzata la località dei dati rispetto alle
applicazioni.
Sincronizzazione: il lavoro dei vari nodi va sincronizzato.
I nodi lavorano principalmente in parallelo, ma in alcuni
momenti devono scambiarsi dati e sincronizzarsi.HADOOP Hadoop è una implementazione open-source del framework MapReduce introdotto da Google nel 2004. Sviluppo iniziato nel 2005. Nel 2006 adottato da Yahoo! Ospitato dalla Apache Software Foundation. http://hadoop.apache.org/ Oggi è il framework MapReduce più noto e diffuso nel mercato.
HADOOP: ARCHITETTURA DI ALTO LIVELLO API MapReduce Pig HBase PROCESSING ENGINE MapReduce v2 RESOURCE MANAGEMENT YARN DISTRIBUTED STORAGE HDFS
MAPREDUCE
MEMORIZZAZIONE E INTERROGAZIONE:
SFIDE
Affidabilità e disponibilità: l’affidabilità diminuisce
all’aumentare del volume dei dati.
Occorre replicare i dati per aumentarne la disponibilità e
robustezza.
La replicazione richiede però una gestione della
consistenza del dato.
Gestire la consistenza dei dati è complicato se non a
scapito della disponibilità/latenza del servizio.DATABASE RELAZIONALI E SCALABILITÀ
I database relazionali classici si appoggiano su architetture
centralizzate per garantire affidabilità, prestazioni e
consistenza (proprietà ACID).
Non sono progettati per funzionare su cluster di
macchine inaffidabili.
Garantire le proprietà ACID in un ambiente distribuito
richiede protocolli complessi ad alta latenza.
Costi di licenza elevati per installazioni multi-server.NUOVI PARADIGMI Negli anni 2000, grandi aziende (Amazon e Google in prima fila) hanno iniziato a sviluppare in casa i propri database, introducendo nuovi paradigmi più adatti alla scalabilità orizzontale. Google BigTable (2006) e Amazon Dynamo (2007) sono due dei database NOSql più popolari.
NOSQL DATA MODELS I principali modelli NoSQL: Key-value pairs Documents Column-families Graphs (Nota: il termine NOSQL indica un movimento piuttosto che una specifica tecnologia.)
DATABASE NOSQL Non usano il modello relazionale (sebbene possono consentire delle relazioni tra dati). Progettati per essere eseguiti su cluster. Tipicamente open-source (sebbene esistono molte soluzioni commerciali). Schema flessibile.
DATABASE NOSQL La popolarità di questi database è cresciuta velocemente a causa di: Problemi di scalabilità. Nuovi paradigmi di integrazione tra applicazioni. Infrastrutture distribuite più economiche e semplici da usare (XaaS). Tipi di dati non uniformi/variabili gestiti più facilmente con schemi flessibili.
POLYGLOT PERSISTENCE
SERVIZI CLOUD
GRAZIE PER L’ATTENZIONE
Puoi anche leggere

















































