La verifica dei modelli meteorologici - Elena Oberto Webinar "La verifica dei modelli meteorologici" 26/04/2021 - Arpa Piemonte
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Webinar “La verifica dei modelli meteorologici” - 26/04/2021
La verifica dei modelli
meteorologici
Elena Oberto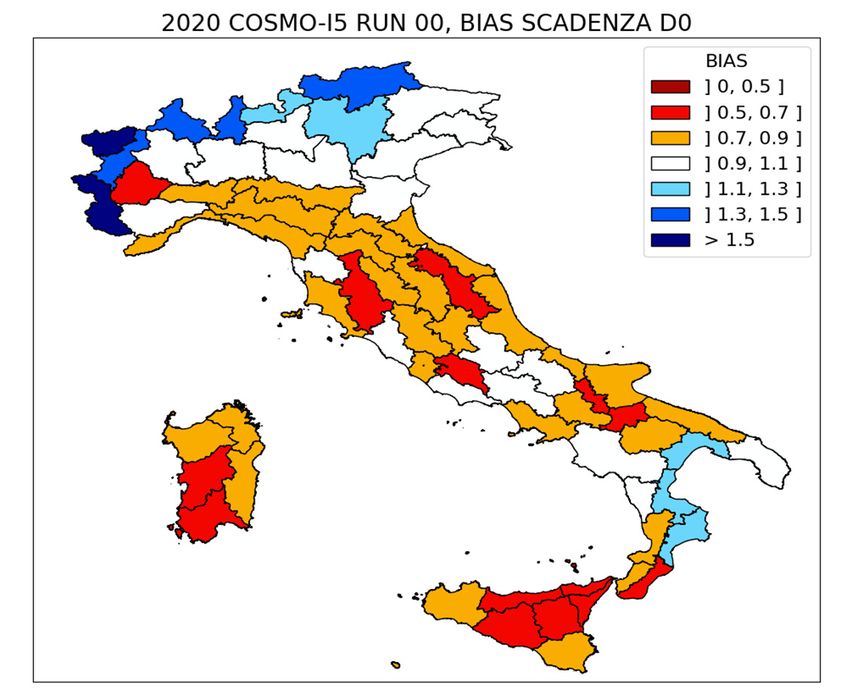
Che cosa è la verifica di una previsione?
https://www.cawcr.gov.au/projects/verification/
• Verifica della previsione = processo che valuta la qualità di una previsione
• La previsione è verificata con la corrispondente osservazione, o miglior stima della
realtà
• Verifica: qualitativa e/o quantitativa (accuratezza di una previsione → grado di
corrispondenza previsto/osservato)
• Monitorare la qualità della previsione: grado di accuratezza? grado di miglioramento nel
tempo?
• Migliorare la qualità della previsione: imparare dagli errori
• Confrontare la qualità dei diversi sistemi di previsione: come valutare le differenti
performance? La previsione meteorologica non può prescindere dai risultati della verifica!!!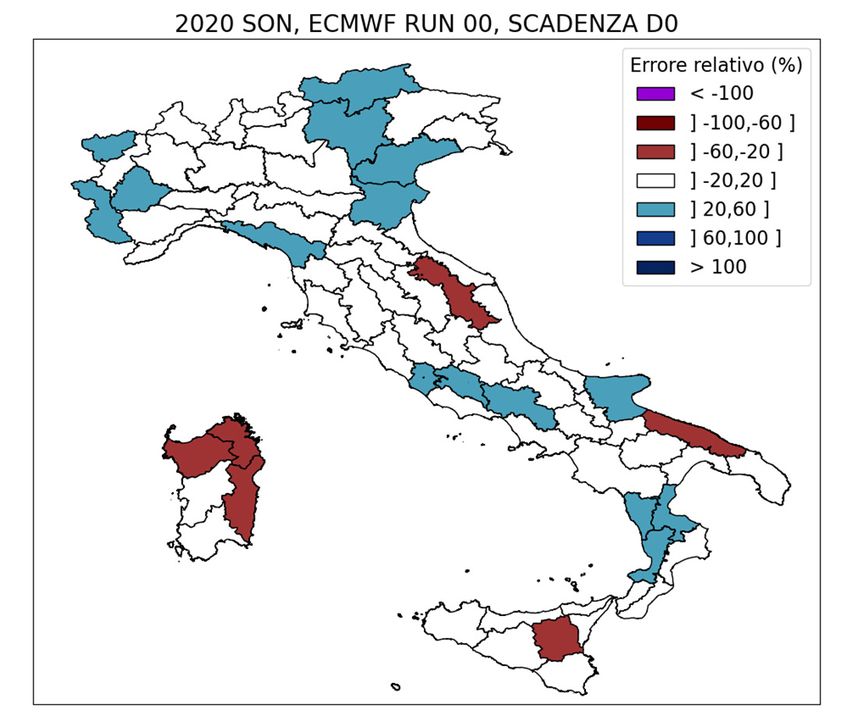
La bontà di una previsione
Bias grado di corrispondenza tra /
Associazione misura della relazione lineare tra prev/oss -> coeff. Corr. Lin.
covarianza
dev. standard (ovvero la varianza, misura disp. attorno x)
Accuratezza grado di accordo tra prev/realtà. La differenza tra prev e oss è l’errore MSE=(-)2
Skill misura accuratezza relativa rispetto previsione di riferimento (persistenza, climatologia…)
Affidabilità accordo tra valori previsti/osservati (~bias, ~bias condizionale)
Raffinatezza capacità di prevedere eventi estremi
Discriminazione alta frequenza di successi nella previsione di eventi (estremi)
Incertezza grado di variabilità delle osservazioni, maggiore è l’incertezza più grande è la difficoltà di prevedere.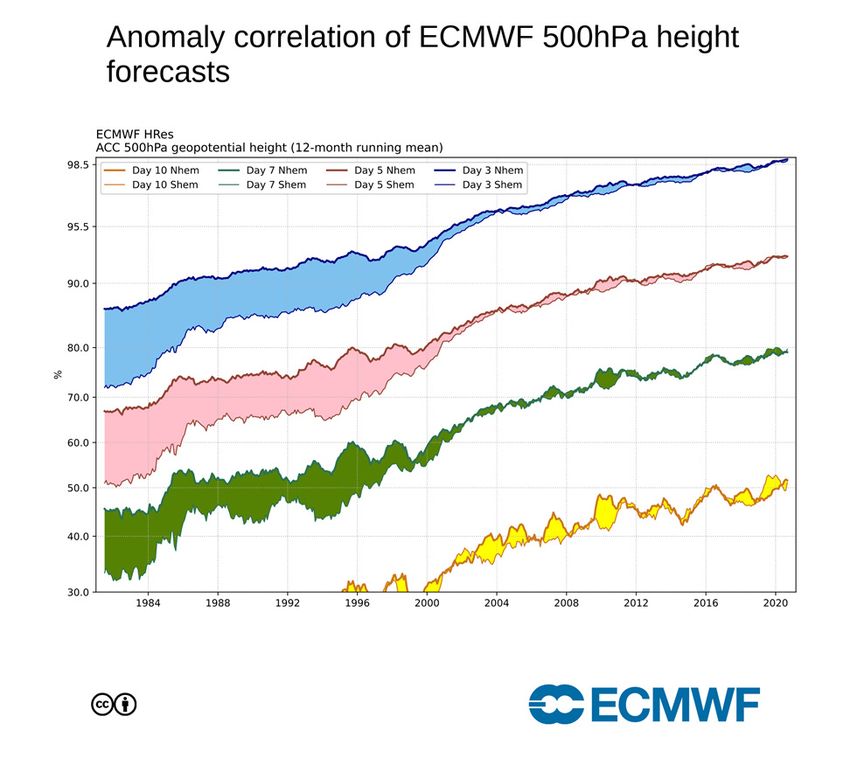
Valore e qualità di una previsione
Qualità -> Una previsione è di alta qualità se predice bene le condizioni osservate secondo alcuni criteri oggettivi o soggettivi. Ha
valore se aiuta l'utente a prendere una decisione migliore.
Valore –> capacità di soddisfare le esigenze dell’utenza
Mancati eventi o falsi allarmi ???? -> dipende dai costi/benefici!
Rappresentatività delle osservazioni
Osservazioni -> rete di osservazioni al suolo, radar, copertura nuvolosa da satellite, analisi di altezza di geopotenziale….
Sorgenti di incertezza -> errori casuali e sistematici, errori di campionamento e rappresentatività, errori di reanalisi e
upscaling/downscaling
Rappresentatività della verifica
I risultati della verifica sono più affidabili quando la quantità e la qualità dei dati sono elevate. È consigliata la banda di errore
specie in caso di eventi rari in cui la dimensione del campione è piccola, quando i dati mostrano molta variabilità e quando si
desidera sapere se un sistema di previsione è significativamente migliore di un altro.
Tecnica Bootstrap: le barre di errore indicano il 2,5 ° e il 97,5 ° percentile di distribuzione ricampionata, applicata al modello "di
riferimento". La differenza di score è statisticamente significativa se si trova al di fuori di un dato intervallo di confidenza (95%)
Metodo per previsioni dicotomiche
Previsione dicotomica -> Hit – eventi previsti correttamente
occorrenza di un evento
(previsione si/no) Miss – eventi mancati
False alarm – eventi previsti non
Distribuzione accaduti
Tabella di contingenza -> congiunta
conta la frequenza si/no Correct negative – eventi non
previsti/osservati previsti e non accaduti
OSSERVATI
P SI NO
R
E SI Hits False
V alarms Indici statistici categorici
I
S NO Misses Correct
T
negatives
Totale = Hits + False Alarms + Misses +
I Correct Negatives
Indici statistici categorici
Range 0/1, fornisce la frazione
Accuracy (fraction correct) di previsioni corrette. Non
utilizzabile per eventi rari.
Range 0/∞, frequenza p/o, indice di
Bias score (frequency bias)
sovrastima/sottostima (bias moltiplicativo= F/O
va da -∞/+∞)
Range 0/1, rappresenta la frazione degli osservati
Probability of detection (hit rate) correttamente previsti. sensibile agli hits ma
ignora i falsi allarmi.
Range 0/1, frazione dei previsti che non si sono osservati.
False alarm ratio Sensibile ai falsi allarmi ma ignora i mancati allarmi
Threat score (critical success index)
Range 0/1, indica corrispondenza “previsti si/osservati si” anche a livello spazio/temporale, sensibile agli hits,
penalizza misses e falsi allarmi. Discrimina poco gli eventi rari, non distingue la sorgente dell’errore
Equitable threat score (Gilbert skill score) Range –1/3/1, Misura la frazione di eventi osservati e/o previsti correttamente previsti, con un hit random (ad esempio, è più facile prevedere correttamente la pioggia in un clima umido che in un clima secco). L'ETS viene utilizzato nella verifica delle precipitazioni nei NWP perché la sua "equità" consente di confrontare i diversi regimi climatici. Penalizza allo stesso modo sia gli errori mancati che i falsi allarmi, non distingue la fonte dell'errore di previsione. Hanssen and Kuipers discriminant Range –1/1, the best è 1. Usa tutti gli elementi della tabella di contingenza, non dipende dalla frequenza climatologica, capacità di discriminare evento/no evento, quanto bene la previsione ha separato gli eventi "sì" dagli eventi "no" Heidke skill score Range -1/1, 0 no skill, the best è 1. Misura la frazione di previsioni corrette dopo aver eliminato quelle che sarebbero corrette in maniera random (ovvero: si usa la climatologia (valore medio a lungo termine) o la persistenza (previsione = osservazione più recente, cioè nessun cambiamento)).
Metodo per previsioni di variabili continue
Quantifica le differenze e le corrispondenze tra valore pre/oss, la
corrispondenza migliore previsto/osservato è attorno alla
Scatter plot bisettrice. Valuta gli “outliers”.
Errore medio
- ∞ /∞ non misura la grandezza né corrispondenza tra pre/oss. Rischio di compensazione errori.
Semplice, intuitivo no esaustivo
Bias moltiplicativo
- ∞ /∞ non misura la grandezza né corrispondenza tra pre/oss. Rischio di compensazione errori. Indice di stima
Errore assoluto medio 0 /∞ esprime l’ampiezza media dell’errore. Non indica la stima
Radice dell’errore quadratico medio
0 /∞ misura l’errore medio. Non indica la stima né la direzione della direzione. Semplice, intuitivo non esaustivo
Errore quadratico medio 0 /∞ misura della differenza quadratica media tra pre/oss
Coefficiente di correlazione
-1 /1 corrispondenza tra i valori pre/oss, buona misura dell’associazione lineare o della fase dell’errore. Misura quanto i
punti nello scatter plot sono vicini alla bisettrice o dispersi. Non tiene conto del bias.
Coefficiente di correlazione anomala
-1 /1, corrispondenza tra le anomalie dei pre/oss rispetto alla climatologia. L'Anomaly Correlation Coefficient (ACC) è una delle
misure più utilizzate nella verifica dei campi spaziali. È la correlazione spaziale tra l'anomalia della previsione e l'anomalia
dell'analisi calcolata rispetto al modello di riferimento basato su ERA-Interim (una rianalisi del passato usando modello IFS)
Skill score
Quantifica il miglioramento relativo a un forecast di riferimento (persistenza/climatologia…)Brevi cenni sulla verifica delle previsioni probabilistiche
Un sistema probabilistico previsionale dà la probabilità che un evento accada. In genere si verifica un set di previsioni
(pi) vs osservazioni di eventi accaduti (oi =1) o non accaduti (oi =0)
probabilistiche
Affidabilità – accordo tra la previsione probabilistica e la frequenza media osservata: statisticamente le probabilità
previste concordano con le frequenze osservate, cioè prendendo tutti i casi in cui è previsto che l’evento accada con una
probabilità del x %, quell’evento dovrebbe accadere esattamente nel x % di quei casi. Un “attribute diagram” mostra se un
sistema previsionale è affidabile (reliable) o produce previsioni probabilistiche over-confident / under-confident.
Diagramma degli attributi: frequenze osservati vs probabilità
previsti divisa in classi. Accordo tra probabilità di un evento e
frequenza osservati. La deviazione dal perfetto accordo è il
bias condizionale che indica sovra/sotto stima.
Più piatta è la curva minore è la risoluzione (frequenza
relativa degli osservati rimane la stessa per le varie classi):
misura quanto le probabilità condizionali date le diverse
previsioni differiscono dalla media climatica; la climatologia
non ha risoluzione, non distingue evento/non evento. La
raffinatezza è indicata dalla frequenza del forecast per
ciascuna classe.Esempio: 30 giorni x 2200 GP = 66000 previsioni
Quanto spesso è stato previsto l’evento (T > 25) con una probabilità X?
FC # FC “perfect FC” “real”
100
Prob. OBS-Freq. OBS-Freq.
• 100% 8000 8000 (100%) 7200 (90%)
•
OBS-Frequency
90% 5000 4500 ( 90%) 4000 (80%)
• 80% 4500 3600 ( 80%) 3000 (66%)
…. …. …. ….
…. …. …. ….
• •
0 …. …. …. ….
0 FC-Probability 100
10% 5500 550 ( 10%) 800 (15%)
over-confident model 0% 7000 0 ( 0%) 700 (10%)Abilità nel discriminare – Per verificare l’abilità del sistema nel discriminare tra evento e non-evento a seconda della soglia di probabilità: se accade l’evento Y, qual’era la previsione X? Basato sul “signal-detection theory” la “Relative Operating Characteristic (ROC)” misura questa qualità: La ROC curve è definita come la curva dell’hit rate (H) sul false alarm rate (F); H e F sono calcolati dalla classica tabella di contingenza. Una previsione che discrimina perfettamente deve avere una curva ROC che parte in basso a sinistra, segue l'asse y (False alarm rate=0) fino al top, poi l'asse x (Hit rate o Pod=1) fino all'angolo in alto a destra. ROC area: va da 0/1, 0.5 no skill
Accuratezza – si misura con il Brier Score, considerando N coppie di previsioni– osservazioni:
1
BS = −
con p: probabilità prevista
o: osservata (1 se l’evento accade; 0 se l’evento non accade)
BS varia da 0 (perfetta previsione) a 1 (perfettamente sbagliata). Il Brier Score è l'analogo del Root Mean Error per la
previsione deterministica.
Per valutare qual è il sistema più accurato conviene usare il brier skill score (BSS), costruito per dare alla previsione
perfetta il valore 1 e a quella di riferimento 0:
score Previsione – score Pr Rif. BS
BSS = =1−
score Pr perfetta – score Pr Rif. BSrif.
In questo modo se il BSS è positivo (negativo) allora il sistema previsionale è meglio (peggio) rispetto al sistema di
riferimento.Modello cost/loss e valore relativo (Richardons)
Matrice costo:
Event occurs Event does not occur
• Forecast basata solo su info climatologiche il
costo medio è il min(C,PclimL),
Action taken C C Pclim=climatological base rate
Action not taken L 0 • Forecast perfetto il costo medio è Pclim*C
• Forecast system il costo medio è 1/N (hits*C +
false_alarms*C + misses*L) tenuto conto della
tabella di contingenza
Ealways < Enever action
Ealways = C Ealways > Enever no action
No forecast info Optimal strategy=mean expense=minimise losses
Enever = PclimL
Eclimate = min(C,PclimL)Modello cost/loss e valore relativo
V of forecast system = (Eclimate-Eforecast)/(Eclimate-Eperfect)
A maximum value is when the system perfectly forecasts the future. If V >0 the decision maker will gain economic benefit by using
forecast info in addition to climatology.
Vrelative = [min(C/L,s)-F(1-s)C/L+Hs(1—C/L)-s]/[min(C/L,s)-sC/L], s=a+c (base rate)
V relative depends on quality of system, observed base rate and user’s C/L
1) Il valore relativo massimo si raggiunge quando C/L ratio coincide con la probabilità climatologica.
2) C/L ratio è differente per i diversi utenti.
3) Il Relative Value (formula di Richardson, Wilks) varia da -∞ a 1 con Perfect score = 1.
Rappresenta lo skill della spesa prevista, con la climatologia come previsione di riferimento. Poiché il rapporto costi/perdite è
diverso per i diversi utenti delle previsioni, il valore viene plottato in funzione del rapporto C/L: l’utente potrà quantificare il
guadagno derivato dall’utilizzo della previsione all’interno del processo decisionale. Se l’utente è la Protezione Civile ed il
processo decisionale è volto all’emissione di un’allerta per superamento di soglia, si guardano valori C/L molto bassi e
prossimi allo zero, in quanto possono entrare in gioco perdite (L) molto elevate.
Alla previsione meteorologica si associa sempre un valore economico che però varia a seconda dell’utente che ne beneficia.EDS (extreme dependency score)
serve per valutare le performance del NWP in caso di eventi rari (Stephenson et al.)
base rate BR = (hits+misses)/n [0,1] Rappresenta la probabilità che un evento accada.
Per definizione viene plottato 1-BR al crescere
della soglia e rappresenta la prob che la quantità di
prec non superi la data soglia.
extreme EDS= [-1,1] best 1 Qual è l’associazione tra eventi rari previsti ed
osservati? EDS è indipendente dal bias, deve
dependency 2[ln((hits+misses)/n)/ essere presentato assieme
score ln(hits/n)]-1
EDS =1 → Attenzione!! il sistema di previsione potrebbe avere un numero elevato di falsi allarmi!!
Se BR è costante, un aumento dell'EDS implica una migliore probabilità di rilevamento (hit rate).
Se solo HR è costante, un aumento dell'EDS è dovuto solo a una maggiore probabilità di eventi.
EDS va confrontato per eventi con stesso BR: EDS migliore significa un miglioramento della qualità del sistema di previsione o è
dovuto alla variabilità degli eventi nel corso degli anni?
L'equazione che definisce l'EDS utilizza il lato sinistro della tabella di contingenza e il numero totale di casi (dimensione del
campione). Quindi c’è una maggiore libertà per i falsi allarmi e per i correct neg, che possono variare liberamente con l'unico
vincolo che la loro somma deve essere costante. Pertanto, è fondamentale utilizzare l'EDS in combinazione con altri indici che
includano il lato destro della tabella di contingenza, come il BIAS. (Ghelli e Primo, 2009)
L'EDS è scritto in funzione di BR:
EDS =[ln(BR) − ln(HR)]/[ln(BR) + ln(HR)]
quando HR = 1, EDS = 1 e quando BR = 1 (evento che si verifica sempre), EDS = −1 (non serve questo indice)Rete ad altissima risoluzione, circa 3000 pluviometri provenienti dalle reti dei CF regionali
% of valid data
February 2020Grid point
Station point N
1
FOR= ∑ ( for )i
N i= 1
Mean value Number of i-th grid point
24h/12h/6h/ grid points precipitation
cumulated inside alert value
precipitation area
FOR MAX =MAX ( for ) forecasted K
i 1
OBS = ∑ ( obs )i
OBS MAX =MAX ( obs )
K i= 1
i
Mean value Number of i-th station
24h/12h/6h/ station points precipitation
cumulated inside alert value
precipitation area
observedLe 70 zone di vigilanza Gli indici statistici vengono calcolati considerando medie e massime su queste aree
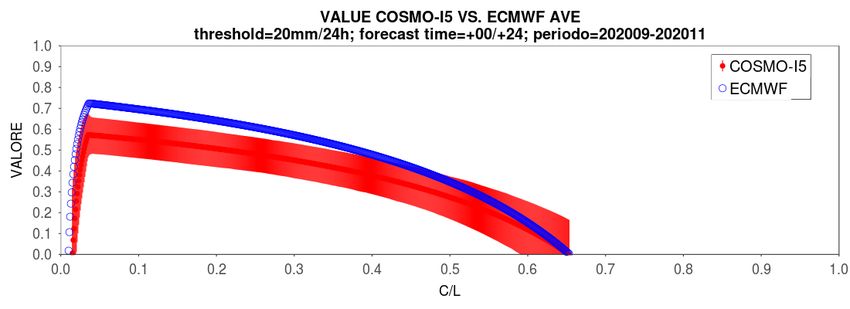
Verifica su lungo periodo L’analisi aggregata per intervalli temporali più o meno lunghi (mesi o stagioni), mette in evidenza le caratteristiche e gli andamenti del modello valutato, mettendo in risalto i miglioramenti e le criticità a seconda del periodo considerato e dei miglioramenti apportati alla catena modellistica stessa. 4 indici (bias, pod, far ed ets) per D0 e D1 al variare della soglia crescente (0.2mm/24h, 2mm/24h, 10mm/24h, 20mm/24h).
Relative Value
SON’20 → valori massimi
su 20mm/24h COSMO-I5
vs. COSMO-2I
SON’20 → valori medi su
20mm/24h COSMO-I5 vs.
ECMWFScatter plot
Mappe dell’errore relativo e degli indici statistici
Performance diagrams ANNO 2020 → valori massimi su 20mm/24h SON 2020 → valori medi su 20mm/24h
EDS
ROC diagram
In conclusione qualche osservazione…
https://www.cawcr.gov.au/projects/verification/
Verso il 1990, la previsione della temperatura dell'aria a 24 ore era
calcolata con una precisione di circa il 70%. Nel 2018, l'accuratezza
delle previsioni a 24 ore è aumentata a circa il 90% e le previsioni a
72 ore sono affidabili come quelle a 24 ore di 30 anni fa.
Sono tre i fattori principali della crescente accuratezza dei modelli
negli ultimi 40 anni:
Condizioni iniziali
Risoluzione orizzontale (e verticale) sempre più elevata
Parametrizzazioni migliori della sub-griglia
Domande?Puoi anche leggere

















































