La tecnologia e l' esperienza al servizio delle piccole e medie imprese
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
1 La tecnologia e l’ esperienza al servizio delle piccole e medie imprese
Alnus Business Intelligence 2
Alnus Business Intelligence
Informazioni generali.
Il modulo di Business Intelligence di Alnus è strutturato su due livelli.
1. Il primo è relativo alla costruzione di un Data Warehouse nativo nel sistema nel quale vengono convogliati tutti i dati del
sistema gestionale che possono avere una qualche rilevanza rispetto alle analisi statistiche o alla rilevazione di KPI e
misure di perfomance.
2. L’altra parte del sistema è la parte di presentazione dei dati tramite cruscotti (Dashboard) che è realizzata con Hyperion
Interactive Reporting Studio.
Data Warehouse
Il Data Warehouse presente in Alnus è realizzato secondo le logiche del modello dimensionale così come è stato teorizzato da
Ralph Kimball (Ralph Kimball, The Data Warehouse Toolkit, John Wiley & Sons, 1996; Ralph Kimball, Laura Reeves, Margy
Ross, Warren Thornthwaite, The Data Warehouse Lifecycle Toolkit, John Wiley & Sons, 1998).
Un Data Warehouse è un contenitore di dati provenienti da diverse fonti che li rende pronti per essere analizzati in modo da
estrarre informazioni che siano di supporto ai processi decisionali.
L’uso dei Data Warehouse è giustificato dalla necessità di considerare l’azienda nel suo complesso, da un unico punto di vista,
invece di considerarla come un insieme di dipartimenti divisi e delimitati. Per questo i Data Warehouse vengono progettati per
contenere dati prelevati da sistemi operazionali (più conosciuti come database) che appartengono alle diverse unità funzionali o
divisionali dell’azienda, permettendo così di svolgere analisi interfunzionali e di avere una visione integrata della stessa.
Un Data Warehouse, quindi, proprio per quelli che sono i suoi usi e finalità, presenta delle caratteristiche nettamente differenti alle
basi di dati tradizionali.
Queste ultime svolgono la funzione di memorizzare i dati operazionali, cioè generati da operazioni svolte durante l’esecuzione dei
processi gestionali. Questa operazione tende sì a velocizzare e nel contempo a ridurre i costi del processo di gestione delle
informazioni attraverso una sua automazione, ma è comunque una operazione a valore aggiunto nullo, in quanto non crea nulla ma
semplicemente memorizza dati.
Il Data Warehouse, invece, assieme agli altri strumenti della Business Intelligence, è qualcosa che produce ricchezza, poiché
consente di riorganizzare ed elaborare queste grosse quantità di dati al fine di estrarre informazioni utili al management aziendale.
Da quanto esposto finora, risulterà chiaro che la basi di dati hanno un carico di lavoro predefinito, eseguono principalmente
operazioni di inserimento, cancellazione e modifica, trattano quindi singoli dati raggruppati in record in un numero limitato alla
volta, e sono soggetti a continui aggiornamenti.
Un Data Warehouse, invece, ha un carico di lavoro variabile a seconda delle esigenze dell’utente, deve elaborare migliaia di
record alla volta, calcolando spesso valori di sintesi prevalentemente numerici, e viene aggiornato (cioè riempito con i dati
provenienti dai database) periodicamente con dati sia correnti che storici, per effettuare delle analisi su diversi periodi temporali.
Proprio per le diverse caratteristiche e funzioni che un database e un data Warehouse sono chiamati ad assolvere, diverso dovrà
essere anche il modo in cui i dati sono organizzati al loro interno.
In un database relazionale è necessario non avere alcuna ridondanza nei dati memorizzati, per cercare di velocizzare e ottimizzare
le procedure transazionali, in modo che una operazione di modifica comporti un intervento in un solo punto del database e non in
più punti, come succederebbe se il dato fosse replicato più volte. Il prezzo da pagare è una maggiore lentezza nell’esecuzione di
join fra tabelle, ma è compensato dal fatto che è una operazione che si esegue più raramente rispetto alle altre. Il modello così
risultante va sotto il nome di modello normalizzato.
In un data Warehouse, invece, le operazioni che riguardano query complesse contenenti più tabelle contemporaneamente sono
molto più frequenti, e quindi è necessario adottare un modello che tenda a minimizzare il numero di join da effettuare tra tabelle
per diminuire i tempi di risposta del sistema. Il concetto generale del modello dimensionale (che sorprende per la sua semplicità) è
che un corretto uso della ridondanza è utile appunto per diminuire le operazioni di join, che sono molto onerose da eseguire, ma
diminuire il tempo di esecuzione delle query.
Alnus Business Intelligence 3 Nel modello dimensionale le tabelle si dividono in tabelle dei fatti e tabelle delle dimensioni. Le tabelle dei fatti sono quelle in cui si memorizzano le misurazioni della performance di una particolare attività del nostro business. Per “fatto” si intende proprio ogni singolo evento che accade durante un processo aziendale (l’emissione di una fattura, di una bolla di acquisto, la ricezione di un materiale, la terminazione di una lavorazione, ecc…). Poiché ogni riga in una tabella dei fatti corrisponde ad una misurazione di un singolo evento del processo aziendale, queste tabelle raggiungono rapidamente dimensioni considerevoli, arrivando a contenere anche milioni di righe. Per questo bisogna cercare di risparmiare spazio usando solo gli attributi necessari per rappresentare i fatti, evitando delle forme di replicazione dei dati al suo interno. Ne risulta che le tabelle dei fatti tendono ad essere profonde nel numero di righe e strette in termini del numero di colonne. Inoltre, poiché si tratta di misurazioni, gli attributi devono essere per la maggior parte numerici ed additivi, in modo da poter effettuare delle analisi aggregate calcolando dei dati di sintesi per ottenere delle informazioni a un livello di dettaglio più alto. Tutte le tabelle dei fatti hanno una o più chiavi esterne che le collegano alle tabelle delle dimensioni, producendo quello che viene chiamato star join schema o schema a stella. Esempio di star join schema: Le dimensioni sono le prospettive dalle quali interessa analizzare i fatti. Se come fatto consideriamo l’emissione di uno scontrino da parte di una grande catena di negozi, alcune possibili dimensioni di interesse possono essere la data, il prodotto, il cliente e il negozio in cui è avvenuta la vendita. Avremo quindi una tabella dei fatti a cui sono collegate quattro tabelle delle dimensioni. Le tabelle delle dimensioni sono in genere molto più larghe delle tabelle dei fatti, poiché contengono molte più colonne, la maggior parte delle quali hanno un contenuto testuale, per dare una descrizione completa della dimensione in analisi. Questa maggiore occupazione di spazio in larghezza è compensata dalla relativa poca profondità di queste tabelle, che in genere possono arrivare a contenere solo qualche migliaia di righe. Le tabelle delle dimensioni sono in genere altamente denormalizzate, nel senso che contengono molti dati ripetuti al loro interno. Si pensi ad esempio alla tabella riferita ai prodotti; per ognuno di essi si memorizza la descrizione della marca, la categoria merceologica a cui appartiene, diversi altri livelli di raggruppamento a seconda delle caratteristiche del prodotto, ecc… Questi dati, essendo ripetuti più volte nella tabella, producono una notevole ridondanza, che comunque, come detto in precedenza, può essere utile per diminuire il tempo di interrogazione della tabella. Una alternativa a questa soluzione può essere quella di esplodere la tabella delle dimensioni in più tabelle collegate tra di loro attraverso una serie di chiavi esterne, cercando di diminuire la ridondanza e producendo lo schema chiamato snowflake o fiocco di neve. In questo modo si diminuisce lo spazio occupato nel disco, ma in caso di interrogazioni che riguardano dati presenti in diverse tabelle, i tempi di risposta saranno più lunghi a causa delle operazioni di join da effettuare tra le diverse tabelle.
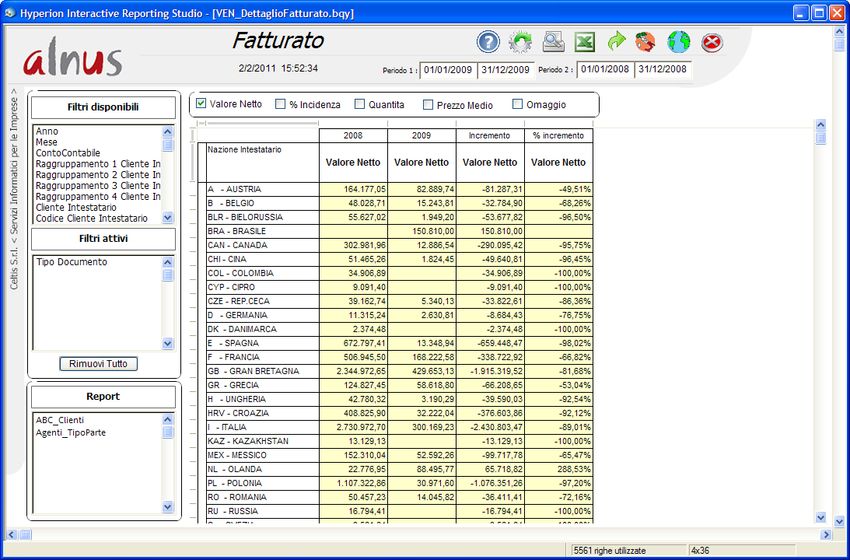
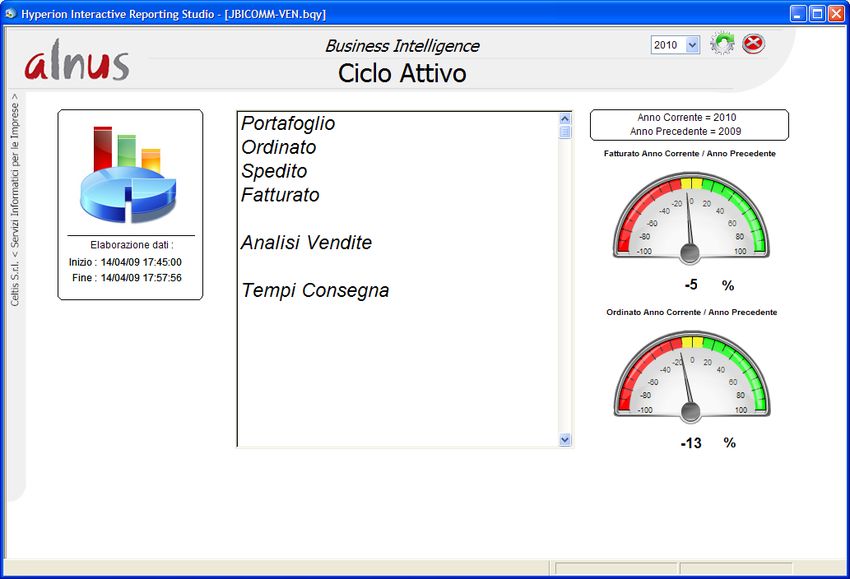
Alnus Business Intelligence 4 Dashboard. Utilizzando Hyperion Interactive Reporting Studio, sono state create template che permettono all’utilizzatore di realizzare in modo estremamente rapido ed efficace qualunque analisi sui dati contenuti nel Data Wharehouse. Questa prima immagine mostra come si presenta il menu standard del “Ciclo Attivo” Come esempio di dashboard standard vediamone uno dell’area vendite e in particolare il “Fatturato”: In apertura, vengono visualizzate queste informazioni: Dettaglio mensile diviso per anno e visualizzazione del fatturato netto con relativo incremento a valore e in percentuale.
Alnus Business Intelligence 5 E' possibile selezionare anche i seguenti valori: La % di incidenza indica la percentuale del valore netto in base alla dimensione della colonna a sinistra sul valore totale (in questo caso il mese, ma si possono utilizzare numerosi campi “dimensionali”). Le quantità possono essere in unità di misura interna oppure convertite secondo l'unita di misura statistica. Infine sono presenti il prezzo medio ed eventualmente l'omaggio.
Alnus Business Intelligence 6
Sotto il titolo, è visualizzata la data dell'ultimo aggiornamento
Nella parte in alto a destra sono previste alcune funzioni :
Le descriviamo in sequenza da sinistra verso destra:
Per visualizzare eventuali note inserite come promemoria.
Aggiornamento manuale dei dati dal server
Anteprima di stampa
Esportazione in excel
Passaggio a modalità avanzata Pivot a tutto schermo
Analisi Geo Market Italia
Analisi Geo Market Mondo
Uscita
Sotto, le date di estrazione con la possibilità di inserire le coppie “da – a” per un solo periodo od entrambi.
L'aggiornamento automatico viene effettuato in maniera notturna, con la possibilità di impostare le date in maniera dinamica
(solitamente : Periodo 1 = dal 1/1 al 31/12 dell'anno in corso; Periodo 2 = dal 1/1 al 31/12 dell'anno precedente)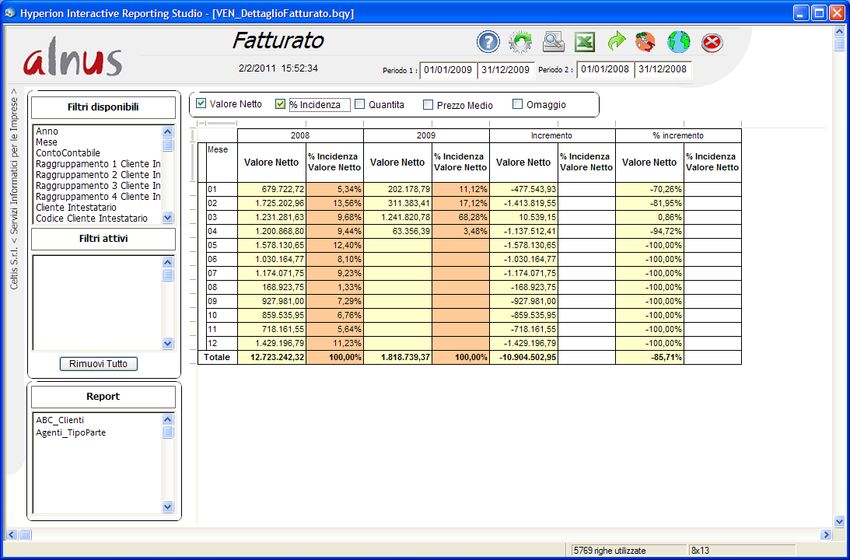
Alnus Business Intelligence 7
Questa sezione permette di fare molteplici selezioni.
E' possibile scegliere uno o più campi statistici di anagrafica clienti e articoli, ed altre
informazioni collegate al documento.
Quando viene impostato il filtro, l'indicazione passa nella sezione sottostante .
Esempio:
Selezionando il tipo documento (la stessa cosa vale per le altre analisi in particolare per selezionare ordini, offerte e campionature)
si apre una finestra contenente i valori disponibili. Cliccando su uno o più di questi, la Pivot verrà visualizzata con i dati
aggiornati.
Passando alla Pivot, è possibile visualizzare dati diversi a seconda delle necessità: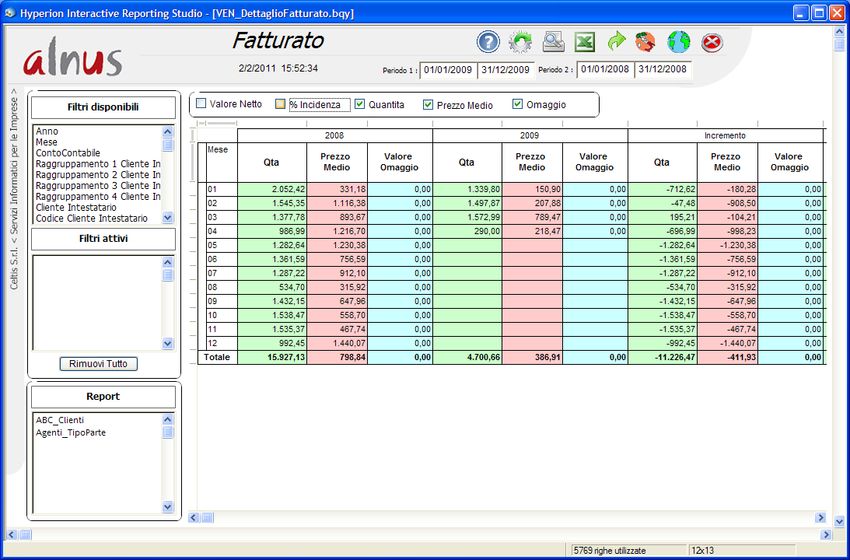
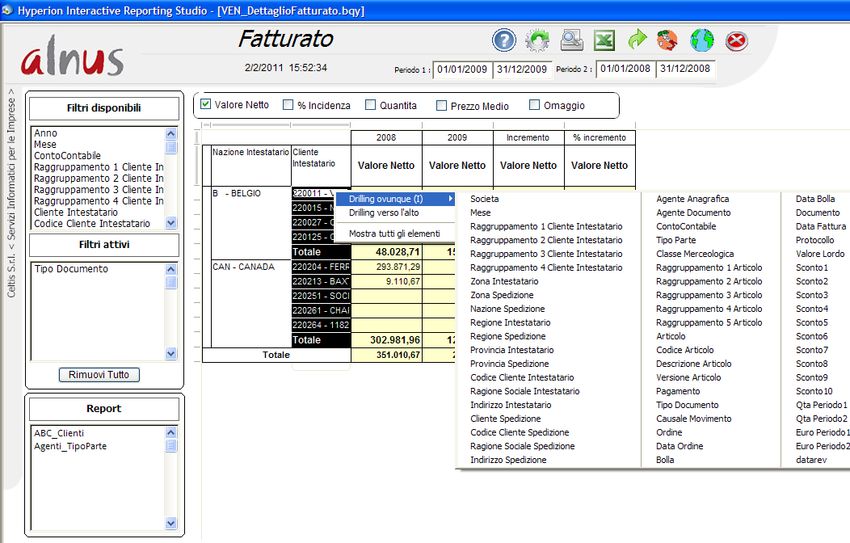
Alnus Business Intelligence 8 In questo caso abbiamo visualizzato il fatturato diviso per nazione, e successivamente possiamo farlo ulteriormente per cliente (N.B.: ho selezionato solo due nazioni). Qui sotto vediamo anche i campi disponibili.
Alnus Business Intelligence 9
In questa sezione invece è possibile inserire dei report predefiniti, che solitamente sono
utilizzati regolarmente in maniera ripetitiva.
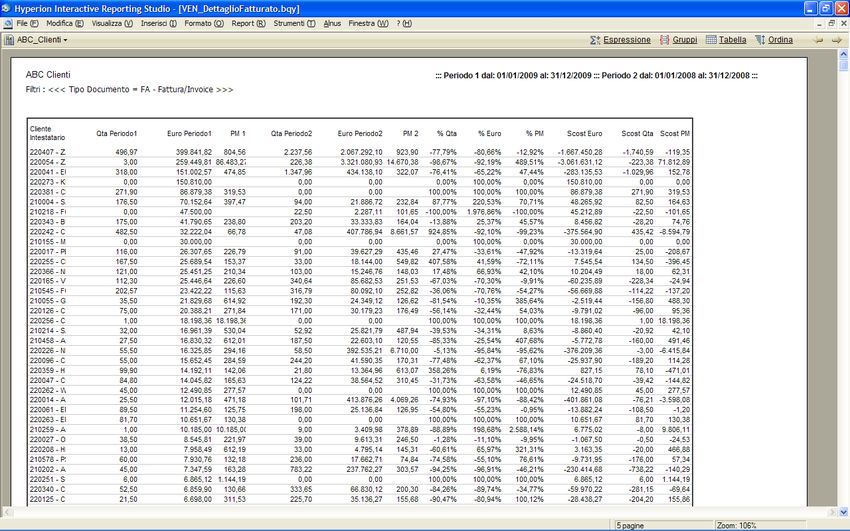
Ad esempio vediamo il report ABC_Clienti (esportabile in pdf, excel o html statico) che evidenzia i clienti col valore del fatturato
decrescente ed una serie di dati correlati.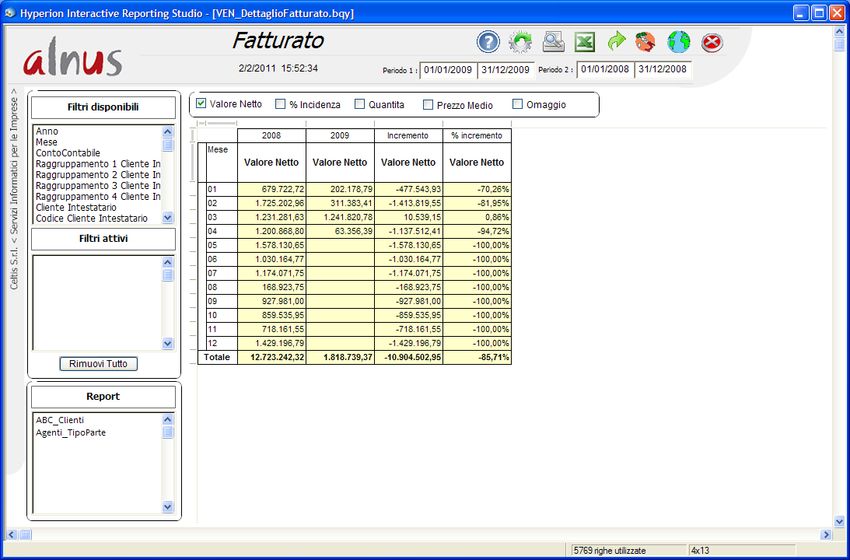
Alnus Business Intelligence 10 Nella parte in basso (sotto la Pivot) è presente un grafico che in questo caso rappresenta l'andamento del valore del fatturato dei due periodi (Nota: il Periodo 1 è incompleto, perché i dati sono solo fino ad Aprile)
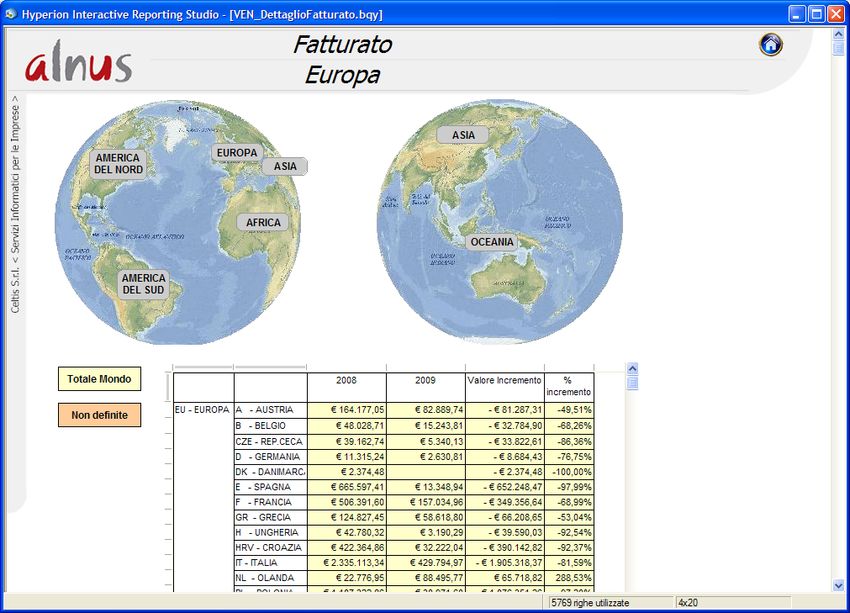
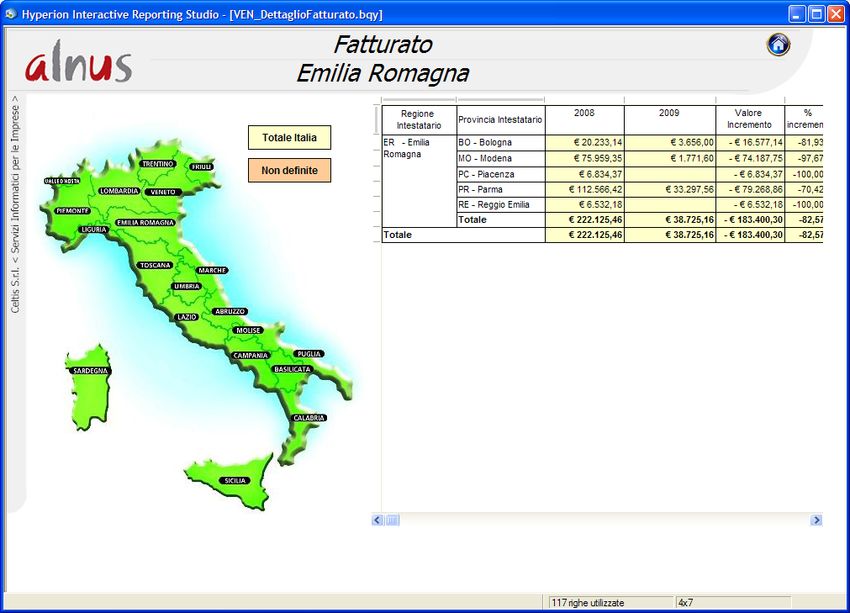
Alnus Business Intelligence 11 Codificando in maniera opportuna regioni e zone/nazioni possiamo visualizzare i dati in questo modo. Per l'Italia oppure per il Mondo :
Puoi anche leggere

















































