Università degli Studi di Padova - SIAGAS
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Università degli Studi di Padova
Dipartimento di Matematica ‘Tullio Levi-Civita’
Corso di Laurea in Informatica
Anno accademico 2017/2018
Standard Prototype InfoCert: un framework per
la produzione di software di qualità
Studente Todescato Matteo, matricola 1121857
Relatore Dott. Vardanega Tullio
Azienda ospitante InfoCert S.P.A.
Tutor aziendale Menegon Federico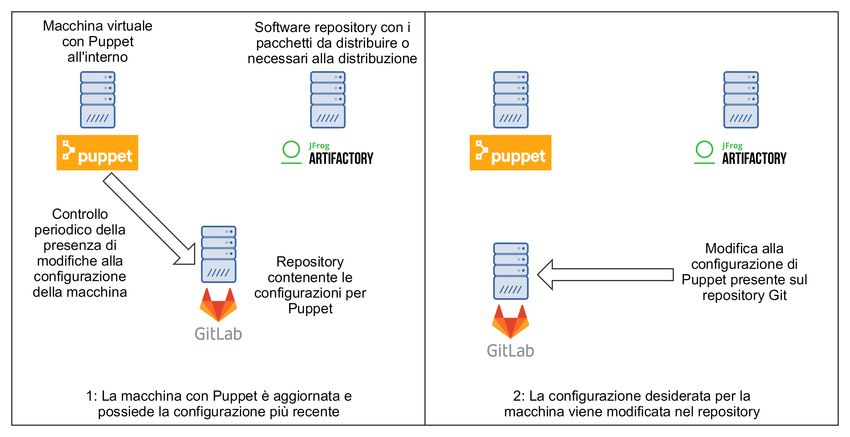
Matteo Todescato, 18 settembre 2018
Dedicato alla mia famiglia
Sommario
Il presente documento descrive il lavoro svolto durante il periodo di stage, della
durata di trecentoventi ore, dal laureando Matteo Todescato presso l’azienda
InfoCert S.P.A. Gli obiettivi da raggiungere erano molteplici.
In primo luogo il progetto ha previsto lo sviluppo di una web application che
utilizzasse i nuovi framework aziendali per sviluppo. In secondo luogo il progetto
ha previsto un rilascio di questa applicazione, con la creazione di un ambiente di
sviluppo. Tutto questo corredato da documentazione, necessaria per distribuire
l’applicazione internamente all’azienda come esempio del nuovo standard.
v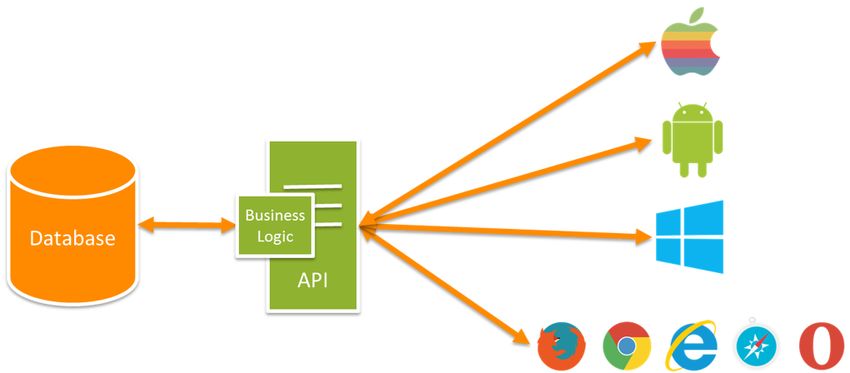
INDICE
Indice
1 L’Azienda 1
1.1 Profilo aziendale . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Modello di sviluppo . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Organizzazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4 Tecnologie utilizzate e processi aziendali . . . . . . . . . . . . . . 5
1.5 InfoCert e l’innovazione . . . . . . . . . . . . . . . . . . . . . . . 7
2 Perché questo stage? 9
2.1 Il problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 La strategia di InfoCert . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 Motivazioni della scelta dello stage . . . . . . . . . . . . . . . . . 10
2.4 Obiettivi e vincoli dello stage . . . . . . . . . . . . . . . . . . . . 10
2.5 Pianificazione dello sviluppo . . . . . . . . . . . . . . . . . . . . . 11
2.5.1 Milestone . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.6 Vincoli tecnologici e metodologici . . . . . . . . . . . . . . . . . . 13
2.6.1 Metodo di sviluppo . . . . . . . . . . . . . . . . . . . . . . 13
2.6.2 Gherkin e Cucumber . . . . . . . . . . . . . . . . . . . . . 14
2.6.3 BECON . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.6.4 FECON . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.6.4.1 Redux . . . . . . . . . . . . . . . . . . . . . . . . 17
2.6.5 Creazione degli ambienti per lo sviluppo . . . . . . . . . . 19
2.6.6 Confluence . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3 Lo Sviluppo di SPICe 23
3.1 Metodo di lavoro e tecnologie aggiuntive . . . . . . . . . . . . . . 23
3.1.1 Test-driven development . . . . . . . . . . . . . . . . . . . 23
3.1.2 Versionamento e gestione delle configurazioni . . . . . . . 24
3.1.2.1 GitFlow . . . . . . . . . . . . . . . . . . . . . . . 24
3.1.3 Stile di codifica . . . . . . . . . . . . . . . . . . . . . . . . 27
3.1.4 Diagrammi UML . . . . . . . . . . . . . . . . . . . . . . . 28
3.2 Sviluppo di SPICe . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.2.1 Analisi dei requisiti . . . . . . . . . . . . . . . . . . . . . . 29
3.2.2 Progettazione . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2.3 Codifica . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.2.4 Verifica . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.2.5 Deployment . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.2.6 Validazione . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.3 Risultati raggiunti . . . . . . . . . . . . . . . . . . . . . . . . . . 39
viiINDICE
4 Valutazione retrospettiva 41
4.1 Raggiungimento degli obiettivi di stage . . . . . . . . . . . . . . . 41
4.1.1 Raggiungimento obiettivi formativi . . . . . . . . . . . . . 42
4.2 Competenze richieste per lo svolgimento del progetto . . . . . . . 42
4.3 Conoscenze acquisite . . . . . . . . . . . . . . . . . . . . . . . . . 43
Glossario 45
Acronimi 49
viiiELENCO DELLE FIGURE
Elenco delle figure
1.1 Modello di sviluppo Scrum, fonte: DTU apppm wiki, [Voc16] . . 2
1.2 Confronto tra lo sviluppo agile con un metodo tradizionale a ca-
scata nella struttura dei rilasci, fonte: Wikipedia Commons, [Lit09] 4
1.3 Fasi dello sviluppo DevOps, fonte: Wikipedia Commons, [Kha16] 4
1.4 Schema di una applicazione API REST-based, fonte: Microsoft
Developer Network, [Kea15] . . . . . . . . . . . . . . . . . . . . . 6
1.5 Immagine rappresentante la toolchain DevOps utilizzata in InfoCert 7
2.1 Diagramma di Gantt rappresentate la pianificazione della tabel-
la 2.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2 Diagramma delle classi di un servizio Representational State Trans-
fer (REST) sviluppato con BECON . . . . . . . . . . . . . . . . 16
2.3 interfaccia grafica di esempio . . . . . . . . . . . . . . . . . . . . 17
2.4 Esempio del flusso di passaggio dei dati nelle architetture tradi-
zionali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.5 Esempio del flusso di passaggio dei dati con Redux . . . . . . . . 19
2.6 Architettura del sistema di integrazione . . . . . . . . . . . . . . 21
3.1 Diagramma del ciclo di sviluppo test-driven, fonte: Hanselt.com, [Bog16] 23
3.2 Esempio di repository strutturata con l’utilizzo di GitFlow, fonte:
nvie.com, [Dri10] . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.3 Esempio di ciclo di vita di un branch per l’aggiunta di una nuova
funzionalità, fonte: nvie.com, [Dri10] . . . . . . . . . . . . . . . . 26
3.4 Diagramma delle classi del servizio REST di Standard Prototype
InfoCErt (SPICe) . . . . . . . . . . . . . . . . . . . . . . . . . . 31
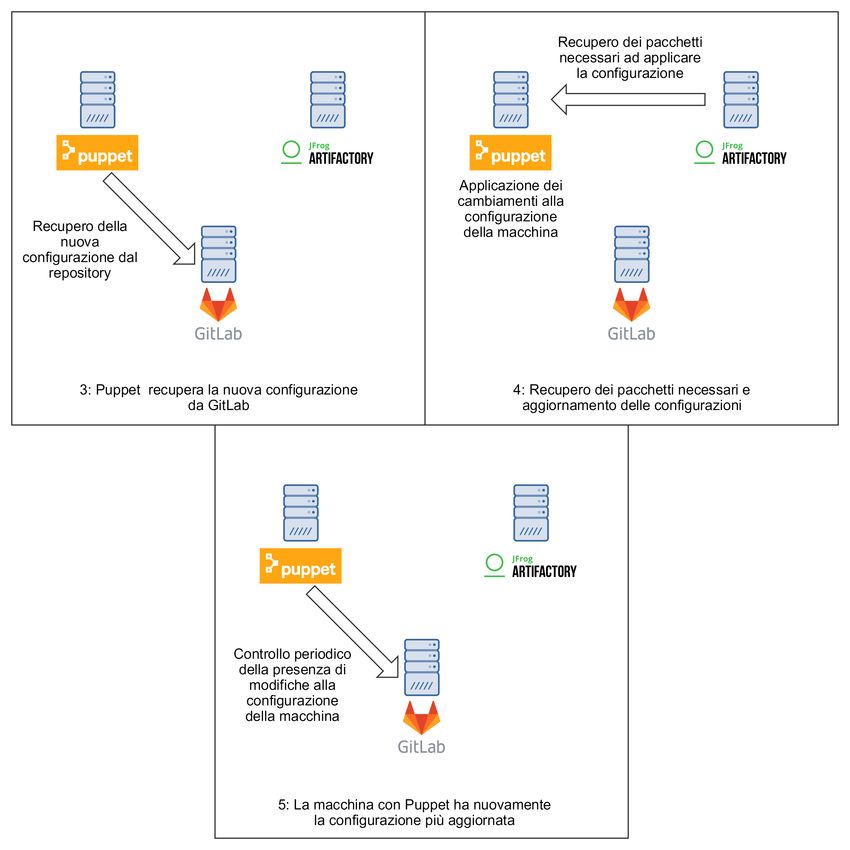
3.5 Aggiornamento della configurazione di Puppet su GitLab . . . . . 37
3.6 Aggiornamento della configurazione della macchina tramite Puppet 38
ixELENCO DELLE TABELLE
Elenco delle tabelle
2.1 Pianificazione della quantità di ore . . . . . . . . . . . . . . . . . 12
3.1 Riepilogo requisiti . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2 Riepilogo del codice prodotto . . . . . . . . . . . . . . . . . . . . 35
3.3 Riepilogo test di unità . . . . . . . . . . . . . . . . . . . . . . . . 36
3.4 Riepilogo test di validazione . . . . . . . . . . . . . . . . . . . . . 39
4.1 Tabella degli obiettivi di stage soddisfatti . . . . . . . . . . . . . 41
xiLISTINGS
Listings
2.1 Esempio di un requisito scritto in Gherkin . . . . . . . . . . . . . 14
2.2 Esempio di implementazione di un test di validazione . . . . . . . 15
3.1 Esempio di codice JavaScript scritto seguendo delle style guide . 28
3.2 Esempio di codifica dei requisti in modo scorretto . . . . . . . . . 29
3.3 Esempio di codifica di un requisito in modo corretto . . . . . . . 30
3.4 Esempio di classe processata da Immutables.org per la creazione
di oggetti immutabili . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.5 Funzione presente nei test di esempio . . . . . . . . . . . . . . . . 35
xiiiCAPITOLO 1. L’AZIENDA
1. L’Azienda
1.1 Profilo aziendale
InfoCert è leader del mercato italiano nei servizi di digitalizzazione e demateria-
lizzazione nonché una delle principali Certification Authority a livello europeo
per i servizi
• Posta Elettronica Certificata. Tipologia particolare di posta elettronica,
con in più alcune caratteristiche di sicurezza e di certificazione della tra-
smissione. Consente infatti di inviare e ricevere messaggi di testo e allegati
con lo stesso valore legale di una raccomandata con avviso di ricevimento.
• Firma Digitale. È l’equivalente informatico di una firma posta su carta.
La sua funzione è quella di attestare la validità, la veridicità e la paternità
di un file di dati.
• Conservazione digitale. È un Processo che permette, nei casi previsti dalla
legge, di distruggere l’originale cartaceo o di non procedere con la sua
stampa. Serve a garantire autenticità, integrità, affidabilità, leggibilità e
reperibilità dei documenti.
Da dicembre 2015 InfoCert è anche gestore accreditato AgID dell’identità di-
gitale di cittadini e imprese, in conformità ai requisiti regolamentari e tecnici
dello SPID (Sistema Pubblico per la gestione dell’Identità Digitale).
InfoCert e di proprietà del gruppo Tecnoinvestimenti SPA che è tra gli operatori
leader in Italia nelle tre aree di business:
• Digital Trust
• Credit Information & Management
• Sales & Marketing Solutions
La Business Unit Digital Trust eroga, attraverso le società InfoCert, Sixtema
e Visura, prodotti e servizi per la digitalizzazione documentale, la fatturazione
elettronica, la posta elettronica certificata (PEC) e la firma digitale.
La società progetta e sviluppa soluzioni informatiche ad alto valore tecnologico
di dematerializzazione dei processi documentali. I clienti, siano essi imprese
o professionisti, vengono accompagnati nella scelta di servizi e soluzioni pie-
namente rispondenti alle esigenze organizzative, così come ai vincoli normativi
generali e specifici di settore.
InfoCert rivolge la propria offerta di prodotti sia ad Ordini Professionali e Profes-
sionisti sia ad piccole e grandi imprese, pubbliche e private operanti in numerosi
settori, InfoCert ha clienti anche di rilevanza internazionale nei settori:
1CAPITOLO 1. L’AZIENDA
• Bancario
• Assicurativo
• Farmaceutico
• Manifatturiero
• Energy
• Utilities
• Distribuzione Commerciale
• Ambiente
• Qualità
• Sicurezza
• Sanità
• Pubblica Amministrazione
Le certificazioni di qualità ISO 9001, 27001 e 20000 testimoniano l’impegno
di InfoCert ai massimi livelli nell’erogazione dei servizi e nella gestione del-
la sicurezza con attenzione ai temi di sostenibilità ambientale (certificazione
ISO14001). Inoltre il Sistema di Gestione della Sicurezza delle Informazioni
InfoCert è certificato ISO/IEC 27001:2013 per le attività EA:33–35.
1.2 Modello di sviluppo
InfoCert negli ultimi anni ha scelto di abbandonare un classico modello di svi-
luppo a cascata e di adottare lo Scrum.
Lo Scrum è un framework di sviluppo agile G per la gestione del ciclo di sviluppo
del software, iterativo ed incrementale, concepito per gestire progetti e prodotti
software o applicazioni di sviluppo. La figura 1.1 illustra la struttura di questo
modello di sviluppo.
Figura 1.1: Modello di sviluppo Scrum, fonte: DTU apppm wiki, [Voc16]
2CAPITOLO 1. L’AZIENDA
In InfoCert i team di sviluppo hanno una dimensione che va dai 5 ai 9
componenti, questi team sono composti dagli sviluppatori, uno ScrumMaster G
che si occupa di facilitare al team il raggiungimento degli obiettivi, ed un Product
Owner G che rappresenta il cliente ed è responsabile nell’assicurare che il team
fornisca valore al business.
Gli sprint hanno una durata di quindici giorni e sono preceduti dallo sprint
planning durante il quale il team affronta le seguenti tematiche:
• definizione degli obiettivi dello sprint e l’insieme di funzionalità su cui
impegnarsi
• stima del tempo e pianificazione per lo sprint
Gli stand-up G , brevi riunioni che il team svolge giornalmente, scandiscono il
corso dello sprint e tengono informato il team degli avanzamenti ed eventuali
criticità.
Al termine dell due settimane il team svolge uno sprint review, riunione che
conclude ogni sprint, all’interno del quale il team tratta dei seguenti argomenti:
• il Product Owner identifica ciò che è stato “Fatto” e ciò che non è stato
“Fatto”
• il team di sviluppo discute su cosa è andato bene durante lo sprint, i
problemi riscontrati e come sono stati risolti o si pensa di risolverli
• il team illustra il lavoro svolto e risponde a domande sull’incremento
Gli sprint retrospective vengono svolti dal team tra la sprint review e lo sprint
planning, e sono riunioni dedicate al controllo sulla qualità degli sprint. Così il
team può valutare lo svolgimento dello sprint dal punto di vista delle persone,
relazioni, processi e strumenti, così da poter identificare un piano per il loro
miglioramento.
InfoCert ha recentemente ristrutturato l’organizzazione interna dei team e delle
divisioni di sviluppo ed operation G per la gestione del ciclo di vita del software,
adottando il modello DevOps, la cui caratteristica principale è l’estesa automa-
zione e monitoraggio per tutte le fasi del ciclo di vita del software, che vanno
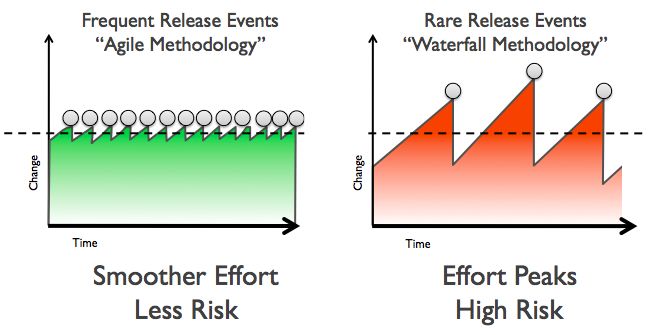
dallo sviluppo fino al rilascio e alla gestione dell’infrastruttura. Il DevOps pun-
ta ad ottenere cicli di sviluppo corti, con rilasci frequenti, più affidabili e meno
onerosi, come illustrato nella seguente figura.
3CAPITOLO 1. L’AZIENDA
Figura 1.2: Confronto tra lo sviluppo agile con un metodo tradizionale a cascata
nella struttura dei rilasci, fonte: Wikipedia Commons, [Lit09]
A differenza della struttura classica che faceva si di separare in modo netto
i team che si occupano dello sviluppo e quelli di operation, in questo modello i
team si occupano sia dello sviluppo che del lato operation durante tutto il ciclo
di vita del software, creando un ciclo continuo, come quello rappresentato nella
figura 1.3.
Figura 1.3: Fasi dello sviluppo DevOps, fonte: Wikipedia Commons, [Kha16]
Questo modello permette ai team di sviluppo di rilasciare il software più
frequentemente e di essere più rapidi nell’affrontare problemi nel software di-
stribuito, questo avviene perché chi scrive il codice si occupa anche del moni-
4CAPITOLO 1. L’AZIENDA
toraggio del software rilasciato e riceve i feedback dai clienti e dagli utenti in
modo diretto.
1.3 Organizzazione
InfoCert ha sedi a Roma, Milano e Padova, presenta un modello organizzativo
organizzativo strutturato su più livelli. Nella sede di Padova dove ho svolto lo
stage ci si occupa principalmente dello sviluppo software, è però anche presente
un’area dedita al supporto clienti ed una che si occupa della gestione delle reti
e dei sistemi aziendali.
Non descriverò l’intera organizzazione, ma mi limiterò alla struttura dell’area
che si dedicata allo sviluppo e alla struttura dei team, visto che non ho interagito
in modo esteso con le altre aree dell’azienda.
L’area dedita allo sviluppo e organizzata in software lab, questi sono formati da
uno o più team DevOps che si occupano in modo diretto dello sviluppo. I team,
come scritto nella sezione precedente, sono formati da gruppi con un numero di
componenti compreso tra 5 e 9, all’interno dei quali ci sono gli sviluppatori, uno
ScrumMaster, e un Product Owner. Vista la presenza di più sedi spesso alcuni
componenti del team lavorano in remoto da casa o da altre sedi, raramente tutti
i componenti di un team DevOps lavorano presso la stessa sede dell’azienda.
1.4 Tecnologie utilizzate e processi aziendali
All’interno dell’ufficio di Padova quasi tutti i team si dedicano nello sviluppo
legato alla creazione, manutenzione ed estensione di prodotti software. Tutti i
team a parte uno sono impiegati nello sviluppo di applicazioni web principal-
mente basate sulle tecnologie:
• Java EE G
• AngularJS G
• Oracle SQL
Principalmente infatti l’azienda sviluppa applicativi web con un’architettura
API REST-based, rappresentata nella seguente immagine:
5CAPITOLO 1. L’AZIENDA
Figura 1.4: Schema di una applicazione API REST-based, fonte: Microsoft
Developer Network, [Kea15]
Lo sviluppo di applicazioni con questo tipo di architettura richiede la crea-
zione di due moduli separati:
• Server. Espone delle Application Programming Interface (API) REST
con le quali i client possono interagire. In InfoCert per la creazione dei
server e delle API REST si utilizza Java Enterprise Edition.
• Client. Possono essere presenti uno o più client, per quanto riguarda le
applicazioni aziendali solitamente è una web application, sviluppata in An-
gularJS, che fornisce un’interfaccia user friendly per usufruire dei servizi
offerti da un server che espone delle API REST .
Questa architettura permette di sviluppare in modo semplice su più piattaforme,
ogni applicazione utilizza la stessa API per ottenere, aggiornare e manipolare
i dati. Tutte le applicazioni hanno le stesse feature e nel caso fossero necessari
dei cambiamenti è sufficiente modificare una sola componente, in linea con il
principio di programmazione Don’t Repeat Yourself (DRY). Le applicazioni non
sono altro che un’interfaccia grafica relativamente leggera, che permettono l’in-
terazione in modo semplice ai servizi REST . Alcuni team hanno recentemente
sviluppato anche delle applicazioni per smartphone e permettere ai clienti di
InfoCert di accedere ai propri servizi anche tramite dispositivi mobili.
Esiste un team che si occupa dello sviluppo dell’applicativo desktop per la firma
digitale, questo e sviluppato con l’utilizzo dei linguaggi C, C++ e un interfaccia
creata tramite le librerie Qt G . Come ho scritto nella sezione 1.2 l’azienda uti-
lizza il modello DevOps, di conseguenza ha adottato un gran numero tecnologie
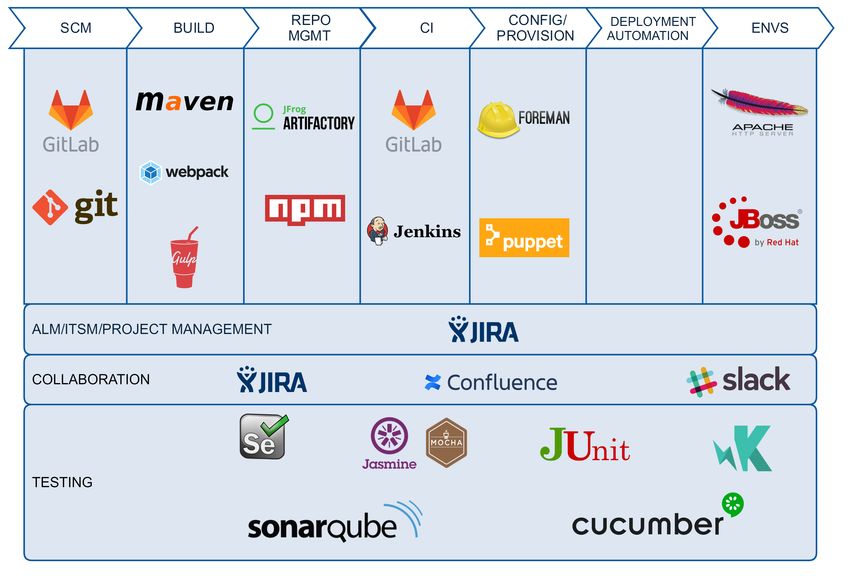
costruendo una toolchain a supporto di questo modello. Nell’Immagine seguen-
te sono rappresentate le tecnologie utilizzate corredate dal loro compito della
toolchain.
6CAPITOLO 1. L’AZIENDA
Figura 1.5: Immagine rappresentante la toolchain DevOps utilizzata in InfoCert
1.5 InfoCert e l’innovazione
InfoCert pone una certa attenzione nello restare al passo con la conoscenza di
nuove tecnologie e con l’innovazione, per quanto riguarda l’ultima, l’azienda col-
labora con alcuni tra i maggiori poli universitari e centri di ricerca del nostro
paese.
Tuttavia InfoCert non è particolarmente veloce nell’adottare nuove tecnologie,
questo in parte è dovuto all’ambiente in cui si trova ad operare, per il quale
l’utilizzo delle tecnologie più moderne sul mercato non è considerato un obiet-
tivo da perseguire a discapito dell’affidabilità degli applicativi. Una seconda
motivazione è dovuta alla dimensione dell’azienda che scoraggia cambi continui
di tecnologie, in quanto sarebbe oneroso formare il personale.
L’azienda è invece particolarmente attenta all’innovazione e alla ricerca del mi-
glioramento per quanto riguarda i suoi processi interni. È stato riformato da
InfoCert il modello di sviluppo utilizzato all’interno dell’azienda e applicato lo
Scrum, negli ultimi anni è stato inoltre riformato la struttura interna dell’azien-
da passando da uno lo stile tradizionale dove ci sono gli sviluppatori e gli ops,
che si occupavano della fase di operation delle applicazioni rilasciate, ad una più
moderna organizzazione in stile DevOps.
7CAPITOLO 2. PERCHÉ QUESTO STAGE?
2. Perché questo stage?
2.1 Il problema
I team di sviluppo non riescono a seguire lo sviluppo di tutto il software di cui
InfoCert ha bisogno, di conseguenza, l’azienda non di rado si avvale dell’utilizzo
di fornitori esterni a cui appalta lo sviluppo.
L’utilizzo di fornitori esterni per sviluppare dei prodotti può essere utile nel caso
non si disponga del personale necessario o che non ha le competenze necessarie
per provvedere allo sviluppo.
Purtroppo appaltare lo sviluppo non è una cosa semplice da fare, in quanto la
scelta e la gestione dei rapporti con i fornitori non è sempre semplice. Le azien-
de che concorrono, hanno competenze abilità ed esperienza differenti, risulta
perciò non sempre facile scegliere la proposta migliore e risulta spesso difficile
gestire la qualità del software prodotto e garantire che il codice sia ben scritto,
manutenibile e con una documentazione esaustiva.
Per InfoCert possedere codice con questo tipo di difetti è un grande problema,
visto che l’azienda poi manterrà quel codice per anni, comportando dei costi
notevoli nell’eseguire normali operazioni di manutenzione ed estensione.
2.2 La strategia di InfoCert
Per far fronte al problema posto nella sezione 2.1, InfoCert negli ultimi due
anni ha condotto un percorso volto a trovare un metodo per ridurre i problemi
derivanti dall’appalto all’esterno della produzione del software al fine di ridurne
i costi e semplificare le attività di gestione.
Questo percorso ha portato alla creazione di due template per lo sviluppo del-
le web application aziendali, Back-End CONtainer (BECON) per il back-end e
Front-End CONtainer (FECON) per il front-end, pensati per dare ai fornitori
dei progetti di base all’interno dei quali sviluppare, ciò che gli è stato commis-
sionato, spingendoli a produrre del codice di buona qualità e con una struttura
nota.
InfoCert ha inoltre adottato numerosi strumenti e tecnologie che hanno l’obiet-
tivo di standardizzare i processi e gli strumenti per fare in modo che il software
prodotto dai fornitori sia il più possibile simile al quello sviluppato dai team
interni all’azienda, agevolando così la manutenzione e l’estensione del software
nel corso degli anni.
È sorto perciò il bisogno che qualcuno che qualcuno provasse ad integrare tutte
queste tecnologie, tramite al creazione di un progetto che ne facesse uso. L’o-
biettivo principale che ho avuto durante lo svolgimento dello stage è stato di
9CAPITOLO 2. PERCHÉ QUESTO STAGE?
creare un’applicazione che utilizzasse tutte le tecnologie e gli strumenti, per fare
in modo di evidenziare eventuali problemi tramite la creazione di una web ap-
plication. Il secondo obiettivo è stato sviluppare l’applicazione in modo tale che
potesse essere utilizzata come un progetto di esempio, da distribuire all’interno
dell’azienda e ed ai fornitori.
Questo perché l’azienda vuole far si che la conoscenza delle tecnologie, che for-
mano il nuovo standard per lo sviluppo dei prodotti software, venga appreso
in modo rapido all’interno dell’azienda e dai fornitori, così da poter iniziare ad
utilizzarlo il prima possibile.
2.3 Motivazioni della scelta dello stage
Le motivazioni che mi hanno portato a scegliere questa proposta di stage sono
state molteplici le principali sono state:
• un progetto di stage definito e chiaro
• la presenza di una strategia aziendale costruita attorno al progetto
• l’utilizzo di tecnologie ritenute più utili per il futuro
Gli altri stage per il quale ero stato contattato invece mancavano di questo, al-
cuni non erano chiari su cosa si dovesse produrre durante lo stage e con l’utilizzo
di quali tecnologie, mentre altri non avevano una strategia e un vero e proprio
obiettivo da raggiungere con lo stage.
Questo era principale dovuto al fatto che erano progetti di ricerca e sviluppo per
i quali l’azienda ospitante non aveva grandi competenze e quindi non sapevano
cosa aspettarsi e se aspettarsi risultati utilizzabili dallo stage.
Un altro fattore determinate nella mia scelta dello stage sono state le tecnologie
che avrei dovuto apprendere ed utilizzare. Ho ritenuto che le tecnologie che avrei
appreso durante questo stage mi sarebbero state più utili a livello professionale,
mentre negli altri stage avrei utilizzato tecnologie più di nicchia.
Da menzionare anche se meno rilevante, è il fatto che alcuni degli stage proposti
era i luoghi irraggiungibili per una persona sprovvista di un veicolo di proprietà
o che non vivesse nelle immediate vicinanze del posto di lavoro.
2.4 Obiettivi e vincoli dello stage
Come scritto nella sezione precedente lo stage consiste nello sviluppo di una web
application che faccia utilizzo di tutte le tecnologie che l’azienda ha deciso di
adottare. I requisiti sono classificati utilizzano le notazioni di seguito riportate:
• min per i requisiti minimi, vincolanti in quanto obiettivo primario richiesto
dal committente;
• max per i requisiti massimi (comprendenti quelli desiderabili e opziona-
li), non vincolanti o strettamente necessari, ma dal riconoscibile valore
aggiunto;
• for per gli obiettivi formativi, rappresentanti valore aggiunto non stretta-
mente competitivo.
10CAPITOLO 2. PERCHÉ QUESTO STAGE?
Le sigle precedentemente indicate sono seguite da una coppia sequenziale di
numeri, creando un codice che identifichi in modo univoco il requisito.
Si prevede lo svolgimento dei seguenti obiettivi:
• Minimi
– min01: Realizzazione Web Application basata sul template aziendale
BECON ;
– min02: Realizzazione ambiente di sviluppo tramite Puppet e Fore-
man G ;
– min03: Suite test automatici di accettazione per componente di back-
end con Cucumber G + RestAssured G ;
– min04: Documentazione di Progettazione e Sviluppo dei componenti
menzionati nei punti precedenti;
• Massimi
– max01: Realizzazione componente di front-end basata sul template
aziendale FECON ;
– max02: Suite test automatici di navigazione per componente di front-
end con Cucumber + Selenium G ;
• Formativi
– for01: Utilizzo della metodologia agile in ambito aziendale;
– for02: Collegato a min02. Studio degli strumenti per la continuous
integration G e continuous delivery G ;
– for03: Collegato a min03. Studio del linguaggio Gherkin G per la
definizione dei test automatici;
2.5 Pianificazione dello sviluppo
La pianificazione, in termini di quantità di ore di lavoro, e stata la seguente:
Settimane Descrizione dell’attività
18 Giugno-29 Giugno 1◦ sprint
16 ore • Introduzione alle tecnologie aziendali per lo
sviluppo e test di applicazioni web, crea-
zione repository su GitLab G , predisposizione
ambiente di sviluppo
20 ore • Progettazione web application (stesura do-
cumentazione: progettazione risorse, lista
requisiti sotto forma di scenari (SP, SI, IM))
4 ore • Revisione progettazione
24 ore • Realizzazione ambiente di sviluppo trami-
te Puppet/Foreman, definizione DataBase
(DB), integrazione con servizio di auten-
ticazione Infocert Secure Access Controller
(ISAC)/Infocert Profile and Access Manager
(IPAM)
11CAPITOLO 2. PERCHÉ QUESTO STAGE?
16 ore • Studio di BECON , scaffolding progetto
di Back End (BE) e aggiunta supporto
Continuous Integration (CI)
2 Luglio-13 Luglio 2◦ sprint
32 ore • completamento BE
16 ore • review BE + integrazione documentazione
24 ore • realizzazione test interfacce REST (scaffol-
ding progetto di test) e aggiunta supporto
CI
8 ore • studio di FECON , scaffolding progetto di
Front End (FE) e aggiunta supporto CI
16 Luglio-27 Luglio 3◦ sprint
16 ore • proseguimento studio di FECON , scaffolding
progetto di FE e aggiunta supporto CI
24 ore • completamento sviluppi FE
16 ore • review FE + integrazione documentazione
24 ore • realizzazione test interfaccia web
30 Luglio-24 Agosto 4◦ sprint
24 ore • realizzazione ambiente di test, produzione e
collaudo
24 ore • sviluppo nuove funzionalità e completamento
lavori
16 ore • review complessiva di tutto il lavoro svolto
16 ore • presentazione del lavoro fatto all’area DevOps
Tabella 2.1: Pianificazione della quantità di ore
Nella figura 2.1 è riportata in modo grafico la pianificazione dei giorni di
lavoro per lo sviluppo descritta nella tabella 2.1.
12CAPITOLO 2. PERCHÉ QUESTO STAGE?
Figura 2.1: Diagramma di Gantt rappresentate la pianificazione della tabella 2.1
2.5.1 Milestone
Di seguito è riportato l’elenco delle milestone G previste nell’arco temporale dello
stage. Ad ogni milestone vengono associate delle baseline G di prodotto che
dovranno essere raggiunte entro ogni corrispondente scadenza. Le milestone
fissate sono le seguenti:
1. M1: Fine 1◦ sprint, scaffolding applicazione di BE , predisposizione am-
biente di sviluppo, documentazione.
2. M2: Fine 2◦ sprint, scaffolding applicazione di FE , test automatici BE .
3. M3: Fine 3◦ sprint, applicazione di FE e relativi test.
4. M4: Fine 4◦ sprint, presentazione, documentazione e applicazioni com-
plete.
2.6 Vincoli tecnologici e metodologici
2.6.1 Metodo di sviluppo
Come modello per lo sviluppo del progetto ho applicato lo Scrum, in quanto
tutti i team all’interno dell’azienda utilizzano questo modello di sviluppo.
Per lo svolgimento dello stage io e il tutor abbiamo adattato il modello classico,
essendo il team formato due componenti, io mi occupavo dello sviluppo e il tutor
aziendale faceva le veci del Product Owner.
Ogni giorno il team svolgeva uno stand-up G nel quale io riportavo e illustravano
i risultati raggiunti nella giornata precedente, esponevo i problemi riscontrati
durante lo sviluppo e assieme al tutor svolgevo la pianificazione per le giornate
13CAPITOLO 2. PERCHÉ QUESTO STAGE?
di lavoro successive. Di conseguenza io ed il tutor abbiamo adattato il modello
con la rimozione degli sprint planning e sprint review, ritenuti non necessari
visto che la pianificazione che sarebbe avvenuta all’inizio di ogni sprint, e la
revisione degli avanzamenti trattati durante la sprint review, sarebbero già stati
trattati durante gli stand-up giornalieri.
2.6.2 Gherkin e Cucumber
Con Gherkin e Cucumber si esegue l’individuazione, la codifica e la validazione
del soddisfacimento dei requisti dell’applicazione.
Cucumber come linguaggio per la definizione e la codifica dei requisti utilizza
Gherkin.
È progettato con lo scopo di essere non tecnico e facilmente comprensibile, il
suo obiettivo è quello di promuovere il Behavior Driven Development all’interno
di tutto il team di sviluppo compresi manager e commerciali.
La semplicità nella comprensione di questo linguaggio è data dalla sua struttura
che fondamentalmente utilizza cinque keyword :
• Feature: descrive in modo generico che tipo di funzionalità quel requisito
richiede ed è formato da uno o più scenari
• Scenario: descrivono il comportamento dell’applicazione date delle pre-
condizioni e un azione da parte dell’utente, ed è formata da un blocco:
Given, When, Then
• Given: indica le precondizioni dello scenario
• When: specifica l’azione che scatena l’esecuzione di un azione da parte
dell’applicazione
• Then: il risultato che ci si aspetta in risposta
Come si può notare dal codice riportato a seguito la scrittura dei requisti risulta
molto naturale e molto comprensibile a chi legge.
1 F e a t u r e : FUN_100 : User can manage h i s t o d o s
2 Logged u s e r can s e e h i s todo l i s t
3 Logged u s e r can add , d e l e t e and e d i t t o d o s from h i s todo l i s t
4
5 S c e n a r i o : FUN_100_1 : User i s shown an empty todo page
6 I f t h e u s e r i s a u t h e n t i c a t e d and has no todo , system w i l l show an
empty todo l i s t
7
8 Given User has an empty todo l i s t
9 When User r e q u e s t t o s e e h i s t o d o s
10 Then System w i l l show an empty page with a message
Listing 2.1: Esempio di un requisito scritto in Gherkin
Cucumber poi utilizza i requisiti scritti con Gherkin per generare la struttura
nella quale poi codificare i test di accettazione automatici necessari per la va-
lidazione del soddisfacimento dei requisiti definiti durane la fase di analisi. Un
14CAPITOLO 2. PERCHÉ QUESTO STAGE?
esempio di come il requisito sopra riportato può essere testato è il seguente:
1 p u b l i c c l a s s ManageTodoStepDef {
2
3 @Given ( "^User has an empty todo l i s t $ " )
4 p u b l i c v o i d userHasAnEmptyTodoList ( ) throws E x c e p t i o n {
5 // mi a s s i c u r o che l ’ u t e n t e non p o s s e g g a n e s s u n todo a l l ’ i n t e n r o
del sistema
6 DBManager . d e l e t e A l l U s e r T o d o s ( " Example " ) ;
7 }
8
9 @When( "^User r e q u e s t t o s e e h i s t o d o s $ " )
10 p u b l i c v o i d u s e r R e q u e s t T o S e e H i s T o d o s ( ) throws E x c e p t i o n {
11 // e s e g u o una chiamata v e r s o i l s e r v i z i o REST p e r v i s u a l i z z a r e
l a l i s t a d i todo d e l l ’ u t e n t e c o r r e n t e
12 Rest . c a l l R e s t S e r v i c e ( g e t ( " / t o d o s " ) ) ;
13 }
14
15 @Then ( "^System w i l l show an empty page with a message$ " )
16 p u b l i c v o i d systemWillShowAnEmptyPageWithAMessage ( ) throws
Exception {
17 // r i c e v o l a r i s p o s t a d a l s e r v i z i o REST e l a immagazzino i n una
variabile
18 S t r i n g t o d o s = Rest . g e t R e s p o n s e ( ) ;
19 // c o n t r o l l o che l a r i s p o s t a s i a vuota i n quanto l ’ u t e n t e non
p o s s i e d e todo
20 Matcher . c h e c k T r u e C o n d i t i o n ( t o d o s . e q u a l s ( " [ ] " ) , " " , " " ) ;
21 }
Listing 2.2: Esempio di implementazione di un test di validazione
2.6.3 BECON
Lo sviluppo della componente di back-end dell’applicazione è svolto con l’utilizzo
dell template aziendale BECON costruito sulle seguenti tecnologie:
• Java SE 1.8
• Java EE 6
• Enterprise JavaBean (EJB) 3.1
• Contexts and Dependency injection (CDI) 1.0
• Maven G 3.3.9
• OpenAPI 2.0
• JBoss G EAP 6.4
• ISAC
• IPAM
BECON fornisce una base sul quale costruire il back-end dell’applicazione, e
impone regole di struttura per quanto riguarda l’architettura ed la scrittura del
codice, con l’obiettivo di ottenere dei servizi REST ben costruiti e facilmente
manutenibili nel tempo.
Lo stile architetturale imposto da BECON permette di ridurre il lavoro per
15CAPITOLO 2. PERCHÉ QUESTO STAGE?
quanto riguarda la progettazione, questo è dovuto al fatto che con la struttura
imposta dal container porta alla creazione di API con un diagramma delle classi
simile al seguente
Figura 2.2: Diagramma delle classi di un servizio REST sviluppato con BECON
strutturate su tre livelli che svolgono funzioni specifiche:
• L’interfaccia contenente la definizione dei servizi e la loro implementazione
si occupano di esporre all’esterno le funzionalità
• Le classi contenenti la business logic G si occupano delle elaborazioni
• La persistance logic assieme alle entity G gestisce tutto quello che riguarda
la lettura e la modifica del database.
Questo porta ad un’architettura che permette di essere estesa e manutenuta nel
tempo, anche a fonte di cambiamenti tecnologici.
Un ulteriore feature di BECON è quella di integrare in modo nativo il supporto
a ISAC ed IPAM , questo permette di integrare nella applicazione in modo
rapido funzioni di login e controllo dei permessi degli utenti che interagiscono
con l’applicazione.
2.6.4 FECON
Lo sviluppo del componete front-end è svolto utilizzando il template aziendale
FECON basato sulle seguenti tecnologie:
• AngularJS
• EcmaScript 6
• Babel
• Redux G
16CAPITOLO 2. PERCHÉ QUESTO STAGE?
• HTML 5
• Bootstrap (angular-ui-bootsrap)
• Sass
• ui-router
FECON fornisce una struttura all’interno della quale costruire la componen-
te front-end di web application, che spinga il programmatore ad organizzare
le componenti e a codificarle rispettando delle linee guida e buone pratiche di
programmazione, che nel tempo hanno dimostrato di dare buoni risultati nel-
l’ottenere applicazioni facili da manutenere e gestire nel tempo. Una di queste
pratiche è la gestione dello stato in modo centralizzato, per fare questo FECON
utilizza Redux, i cui principi verrano trattati nella successiva sottosezione.
2.6.4.1 Redux
In una applicazione creata con un framework JavaScript come AngularJS G lo
stato interno delle componenti è contenuto all’interno delle componenti stesse
sotto forma di variabili. Questo approccio può creare numerosi problemi a livello
di gestione dello stato, e non è raro trovarsi in situazioni che possono presentare
problematiche di questo tipo, un esempio di questo è quando due componenti
utilizzano gli stessi dati, magari in modo differente, questa situazione avviene
quando si ha una lista di oggetti divisa in due sezioni: una contenete delle
informazioni riassunte e l’altra contente tutti i dettagli ad esempio di un todo
per calare l’esempio in SPICe. Poniamo il caso di avere un interfaccia come
quella delle figura 2.3
Figura 2.3: interfaccia grafica di esempio
Dove è presente una lista sulla sinistra ed una visualizzazione specifica sulla
destra, queste due componeti necessitano degli stessi dati, è da escludere la
17CAPITOLO 2. PERCHÉ QUESTO STAGE?
duplicazione dei dati in quanto chi sarebbero due source-of-truth situazione da
evitare, la soluzione usata inizialmente era quella di posizionare i dati in una
componente che racchiude le due componeti interessate nella condivisione dei
dati, come illustrato nella figura 2.4.
Figura 2.4: Esempio del flusso di passaggio dei dati nelle architetture tradizionali
I questo esempio la componete che contiene i dati li passa come argomenti
alle due componenti che necessitano dei dati, questo comporta un flusso dei dati
‘sporco’ che risulta difficile da controllare, nella figura i dati vengono passati dal
componente padre al figlio ma in alcuni casi ci possono essere più passaggi,
questo può portare alla creazione di side-effects G e in caso di errori diventa
complesso risalire a dove siano avvenuti. Per far fronte a questo problema
FECON utilizza Redux come container G , dove conservare e gestire l’interno
stato dell’applicazione. L’utilizzo di questa pratica permette di avere un flusso
dei dati come quello rappresentato nella figura 2.3
18CAPITOLO 2. PERCHÉ QUESTO STAGE?
Figura 2.5: Esempio del flusso di passaggio dei dati con Redux
Come si può notare adesso la gestione dello stato avviene esternamente
alle componenti così da evitare il passaggio dei dati attraverso più strati di
componenti. L’utilizzo di Redux prevede che:
• Lo stato dell’applicazione è rappresentato tramite oggetti e array
• I cambiamenti del sistema sono descritti tramite oggetti
• La logica per gestire i cambiamenti è implementata tramite funzioni pu-
re G , senza side-effects sui dati
Queste regole permettono di ottenere un’architettura per la gestione del flusso
dei dati all’interno dell’applicazione con le seguenti caratteristiche:
• con una singola source-of-truth
• un comportamento consistente, predicibile e idealmente privo di side-
effects
• semplicità nella creazione ed esecuzione di test
Queste proprietà hanno portato InfoCert ad utilizzare in FECON questa prati-
ca, che negli ultimi anni è diventato uno standard de facto nello sviluppo web,
per applicazioni di dimensioni non banali e pensate per durare nel tempo.
2.6.5 Creazione degli ambienti per lo sviluppo
In InfoCert ogni applicazione nel corso del suo ciclo di vita esegue su quattro
ambienti:
• sviluppo
• test
• collaudo
• produzione
19CAPITOLO 2. PERCHÉ QUESTO STAGE?
La creazione di questi avviene tramite l’utilizzo di tre strumenti:
• Artifactory
• Foreman
• Puppet
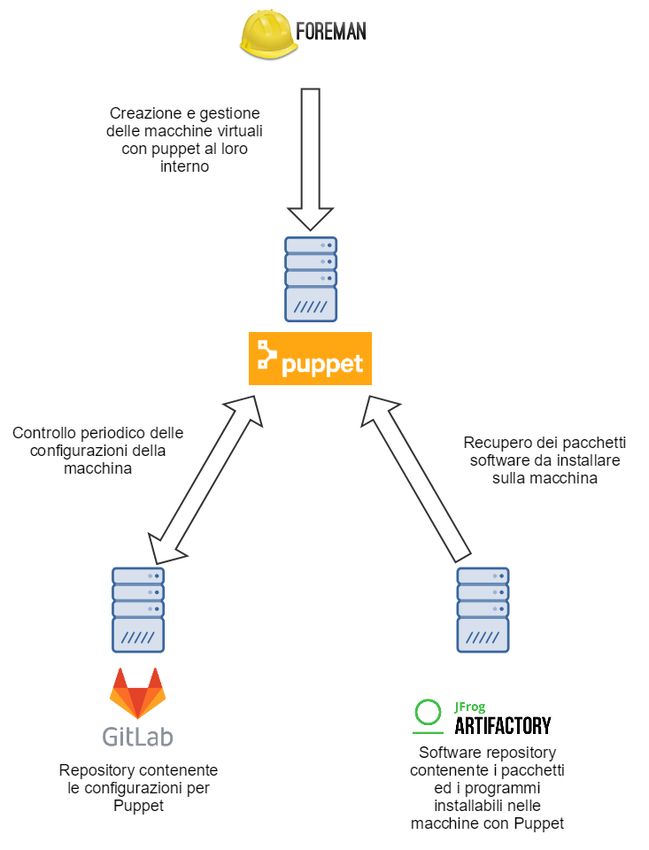
che si appoggiano poi sui repository aziendali per reperire le configurazioni.
L’immagine seguente illustra la struttura organizzativa che permette la creazione
e la gestione degli ambienti per lo sviluppo.
20CAPITOLO 2. PERCHÉ QUESTO STAGE?
Figura 2.6: Architettura del sistema di integrazione
Foreman fornisce le funzionalità per la creazione e gestione delle macchine
virtuali all’interno delle quali poi eseguire le applicazioni. Artifactory è il soft-
ware repository G aziendale all’interno del quale vengono pubblicate le release
dei progetti vengono immagazzinate in forma binaria per poter essere installate
sulle macchine su cui effettuare la distribuzione.
Questo permette di avere un unico luogo che contiene tutte le versioni delle
applicazioni attualmente in servizio sia per i clienti che per il testing interno e
fornisce un integrazione rapida con i più comuni metodi di messa in produzione
21CAPITOLO 2. PERCHÉ QUESTO STAGE?
come Docker, Kubernetes e Puppet.
Puppet è un tool di infrastructure as a code, per la gestione delle configurazioni,
permette all’utente di descrivere le caratteristiche del sistema di cui ha bisogno
indicando dipendenze software e le configurazioni necessarie tramite l’utilizzo
di un linguaggio comprensibile da un calcolatore così da permettere a Puppet di
applicare alla macchina creata con Foreman la configurazione e l’installazione
dei pacchetti necessari all’esecuzione dell’applicazione presente su Artifactory e
di conseguenza ottenere una ambiente nel quale sviluppare, testare o rilasciare
il prodotto in produzione.
2.6.6 Confluence
Per la gestione della documentazione e per reperire la documentazione neces-
saria per l’utilizzo di alcune tecnologie ho utilizzato Confluence, software per
la collaborazione, all’interno del quale è contenuta tutta la documentazione per
progetti e le guide all’utilizzo dei software presenti all’interno dell’azienda.
22CAPITOLO 3. LO SVILUPPO DI SPICE
3. Lo Sviluppo di SPICe
3.1 Metodo di lavoro e tecnologie aggiuntive
Durante lo sviluppo del progetto ho scelto di adottare delle tecnologie e dei
metodi di lavoro aggiuntivi, in alcuni casi per far fronte a problemi di specifiche
componenti e in altri a supporto dell’interno progetto per facilitare lo sviluppo.
3.1.1 Test-driven development
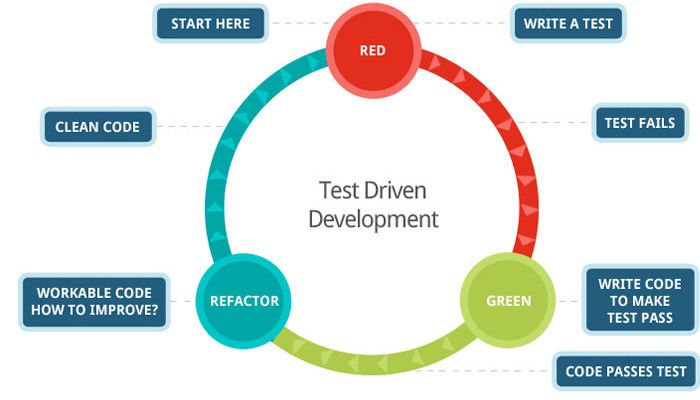
Per lo sviluppo di alcune parti dell’applicazione, io ed il tutor abbiamo deciso di
utilizzare un modello di sviluppo test-driven. Il test-driven development prevede
la ripetizione di un breve ciclo composto da tre fasi.
Figura 3.1: Diagramma del ciclo di sviluppo test-driven, fonte: Han-
selt.com, [Bog16]
Nella ‘fase rossa’, il programmatore scrive i test automatici le nuove funzio-
nalità o funzioni da sviluppare, in questa fase i test falliscono in quando manca il
codice che implementa la funzionalità, da questo è dovuto il nome di fase rossa.
Nella ‘fase verde’, lo sviluppatore scrive il codice necessario a far passare i test.
23CAPITOLO 3. LO SVILUPPO DI SPICE
Nella terza e ultima fase detta ‘fase grigia’ o di refactoring, lo lo sviluppatore si
concentra sul refactoring del codice, così da adeguarlo agli standard richiesti.
3.1.2 Versionamento e gestione delle configurazioni
Per la gestione delle versioni del progetto ho utilizzato Git G con l’utilizzo di
GitFlow, come modello di branching, questo è utilizzato in InfoCert in modo da
favorire lo sviluppo in parallelo da parte di più persone e o team.
3.1.2.1 GitFlow
GitFlow fa questo imponendo regole e categorizzando i branch all’interno del
repository. Questo modello di branching suddivide i branch in due categorie
principali:
• master
• supporto internamente suddivisi in:
– feature
– release
– hotfix
Ognuna di queste categorie di branch svolge un compito specifiche all’interno
del modello, la figura seguente illustra un esempio di come GitFlow spinga ad
organizzare ed utilizzare il repository.
24CAPITOLO 3. LO SVILUPPO DI SPICE
Figura 3.2: Esempio di repository strutturata con l’utilizzo di GitFlow, fonte:
nvie.com, [Dri10]
I branch master e develop sono i considerati principali, in quanto hanno una
vita considerata infinita, il gestore del repository li crea all’inizio del progetto e
non vengono mai eliminati.
I branch principali hanno molta rilevanza nello sviluppo, in quanto lo stato
della HEAD, riferimento simbolico all’ultima commit di un branch, di master e
develop rappresentano rispettivamente il codice che è pronto alla produzione o
25CAPITOLO 3. LO SVILUPPO DI SPICE
è già stato rilasciato e le più nuove funzionalità considerate pronte per essere
inserite nel prodotto finale, develop è un considerato un branch di integrazione
e periodicamente i cambiamenti presenti in questo branch vengono riversati dal
team di sviluppo nel master.
Per riversare i cambiamenti dal branch di sviluppo al master il team utilizza
i release branch. La caratteristica principale dei release branch è che vengono
creati direttamente dal develop e non vengono introdotte nuove feature, il team
di sviluppo in questo branch si focalizza sulla rimozione di bug per poi rilasciare
le modifiche nel master. Per la creazione di nuove feature si utilizzano dei
branch appositamente creati, per ogni nuova funzionalità, il loro ciclo di vita è
rappresentano nella seguente figura.
Figura 3.3: Esempio di ciclo di vita di un branch per l’aggiunta di una nuova
funzionalità, fonte: nvie.com, [Dri10]
Come si può vedere dall’immagine un branch di feature ha una vita molto più
corta rispetto a quella dei branch principali, in quanto le modifiche apportate
dal team di sviluppo all’interno di questo branch sono finalizzati alla creazione
di nuove funzionalità da aggiungere al develop e poi al prodotto finale.
L’ultimo branch previsto dalla struttura di GitFlow è hotfix, unico branch esclu-
so il develop che viene creato a partire dal master. Lo scopo di questo branch
è quello di eseguire dei fix su gravi bug scoperti nel branch master e di conse-
guenza nel prodotto finale, senza dubbio è il branch che deve avere la vita più
breve, il branch di hotfix si caratterizza ulteriormente per il fatto che è l’unico
le cui modifiche vengono apportate a tutti i branch attualmente attivi.
Ho applicato poi le regole aziendali sulla struttura dei messaggi ed il contenuto,
in breve:
• separare l’argomento dal corpo della commit con una linea bianca
• limitare la lunghezza del argomento della commit a 50 caratteri
• la prima lettera dell’argomento deve essere maiuscola
26CAPITOLO 3. LO SVILUPPO DI SPICE
• non terminare l’argomento della commit con il punto
• scrivere l’argomento della commit in modo imperativo
• la lunghezza massima delle righe all’interno del corpo della commit è di
72 caratteri
• spiegare nel corpo della commit perché la si sta facendo e come risolve il
problema
Con l’utilizzo di Git ho inoltre gestito il versionamento delle configurazioni
necessarie a Puppet, che verrà trattato nella sottosezione 2.6.5, per eseguire
i deployment e mantenere il progetto all’interno dell’ambiente di sviluppo.
3.1.3 Stile di codifica
Per garantire uno stile uniforme e che rispettasse lo standard aziendale in via di
applicazione per quanto riguarda lo stile della codifica, ho deciso di utilizzare a
supporto dello sviluppo dei verificatori automatici.
Durante lo sviluppo del back-end ho utilizzato Checkstyle, plugin G Maven adi-
bito al controllo dell’aderenza del codice ad una style guide, per la codifica del
codice Java ho applicato la Google Java Style Guide G .
Per quanto riguarda il front-end ho utilizzato ESLint G come analizzatore sta-
tico, con il quale ho assicurato l’aderenza di tutto il codice JavaScript presente
nel progetto alla Google JavaScript Style Guide G . Uniformare lo stile del co-
dice ha lo scopo di facilitare la code review G durante lo sviluppo, migliorare la
manutenibilità e comprensibilità del codice, in quanto comprendere il funziona-
mento di codice scritto utilizzando molti stili differenti è complesso e richiede
tempo. Effettuare un processo come quello della code review su codice che segue
delle regole per uniformane lo stile permette di velocizzare il lavoro, in quanto
il codice che si dovrà analizzare sarà più simile a quello che la persona che sta
eseguendo il controllo scriverebbe.
L’utilizzo di questo tipo di strumenti avviene anche per linguaggi come Java,
come avviene in BECON , questo bisogno si fa però sentire in maniera più forte
con un linguaggio come JavaScript G che permette una grande varietà di stili
come si può vedere dal codice riportato a seguire.
27CAPITOLO 3. LO SVILUPPO DI SPICE
1 /* No Style Guide */
2
3 var S tr i ng E xa m pl e = " t e s t s t r i n g " ;
4
5 function f o o ( ) {
6 // ...
7 }
8
9 c o n s t f o o = function ( ) {
10 // ...
11 };
12
13
14
15 /* Google JavaCript Style Guide */
16
17 l e t S t r i n g G o o g l e = ’ test String ’ ;
18
19 /* * @return { number } */
20 function h e l p e r F u n c t i o n ( ) {
21 return 4 2 ;
22 }
23
24
25
26 /* AirBnB JavaScript Style Guide */
27
28 l e t s t r i n g A i r B n B = ’ test string ’ ;
29
30 c o n s t s h o r t = function d e s c r i p t i v e F u n c t i o n N a m e ( ) {
31 // ...
32 };
Listing 3.1: Esempio di codice JavaScript scritto seguendo delle style guide
Come si può notare nel eseguire due compiti semplici come dichiarate una va-
riabile contente una stringa e una funzione JavaScript G fornisce numerose pos-
sibilità, cosa che non avviene in linguaggi come Java o C++, dove le possibili
opzioni non cambiano radicalmente lo stile, impattando sulla leggibilità del co-
dice se non si è consueti a quello stile di codifica.
3.1.4 Diagrammi UML
Durante lo sviluppo dell’applicazione ho utilizzato i diagrammi UMLG per inte-
grare la documentazione dell’applicazione in quanto ho ritenuto utile l’aggiunta
di diagrammi per aiutare la comprensione di come ci si aspetta una applicazio-
ne con BECON e FECON venga sviluppata, e facilitare la comprensione delle
interazioni tra le componenti.
Durante il progetto ho utilizzato:
• Diagrammi dei package. Un package raggruppa un numero arbitrario
di elementi UML. I package contengono al loro interno classi, entità che
descrivono gli oggetti che fanno parte di un sistema, oppure altri package,
seguendo così una struttura gerarchica.
I diagrammi dei package permettono di descrivere le dipendenze tra gli
stessi, fornendo un visione ad alto livello dell’architettura dell’applicazio-
ne.
28CAPITOLO 3. LO SVILUPPO DI SPICE
• Diagrammi delle classi. Descrivono le entità che compongono il siste-
ma. Il diagramma delle classi descrive le caratteristiche degli oggetti e le
loro relazioni. Permette di avere una visione architetturale di dettaglio
dell’applicativo.
• Diagrammi di sequenza. Visualizzano lo scambio di messaggi tra le
entità del sistema nel tempo, descrivendo la loro collaborazione nell’im-
plementazione di un comportamento.
3.2 Sviluppo di SPICe
3.2.1 Analisi dei requisiti
L’attività di analisi dei requisiti ha avuto come obiettivo quello di identificare
un insieme di funzionalità sufficienti per dimostrare il funzionamento e l’inte-
grazione tra le tecnologie in uso nello stage.
Vista la natura interna del progetto e il fatto che le funzionalità offerte dal-
l’applicazione non erano importanti per l’azienda, ho potuto sceglierle in modo
libero e le ho poi discusse con il tutor aziendale.
Una volta concordate le funzionalità a grandi linee sono passato all’identifica-
zione e alla codifica dei requisiti con l’utilizzo del linguaggio Gherkin. La chiara
comprensione di come avrei dovuto codificare i requisiti ha richiesto del tempo e
degli studi sul linguaggio, nonostante questo sia semplice da apprendere e com-
prendere, non è banale scrivere degli scenari che sfruttino a pieno le funzionalità
di Gherkin, ma soprattutto di Cucumber, infatti scrivere in modo scorretto e
non utilizzando le feature del linguaggio tende a non penalizzare il risultato per
quello che riguarda l’analisi dei requisiti, porta invece a test difficili da codifica-
re, complessi, male strutturati e ripetitivi.
Il seguente blocco di codice riporta un esempio di non corretto utilizzo degli
strumenti che il linguaggio mette a disposizione.
1 F e a t u r e : FUN_100 : User can l o g i n t h e system
2
3 S c e n a r i o : FUN_100_1 : User l o g i n s u c c e s s
4 The u s e r i s not a u t h e n t i c a t e d
5
6 Given User a c c o u n t c r e d e n t i a l s a r e v a l i d
7 When System r e c i v e s l o g i n r e q u e s t
8 Then System w i l l show l o g i n s u c c e s s page
9
10 S c e n a r i o : FUN_100_2 : User l o g i n f a i l
11 The u s e r i s not a u t h e n t i c a t e d
12
13 Given User a c c o u n t c r e d e n t i a l s a r e i n v a l i d
14 When System r e c i v e s l o g i n r e q u e s t
15 Then System w i l l show l o g i n f a i l page
Listing 3.2: Esempio di codifica dei requisti in modo scorretto
Come si può notare i due scenari sono quasi identici, da questi Cucumber creerà
due test di accettazione separati.
Dopo lo studio approfondito del linguaggio e alcuni tentativi nella creazione
dei test, ho compreso il punto di vista dal quale è più conveniente esprimere i
requisiti.
29CAPITOLO 3. LO SVILUPPO DI SPICE
A mio parere è più efficace scrivere i requisti descrivendoli dal punto di vista del
sistema software, invece che dell’utente come ho trovato in molti esempi durate
lo studio del linguaggio, questo perché permette di scrivere requisiti meno con-
torti a livello logico e permette l’utilizzo in modo più agevole di alcune feature di
linguaggio come gli Scenario Outline. Questi sono come i template di un classi-
co linguaggio di programmazione e permettono di evitare la scrittura di feature
ripetitive, che poi si trasformano in test di accettazione ripetitivi, portando del
carico di lavoro aggiuntivo. Il seguente codice contenente una soluzione alter-
nativa che descrive gli stessi requisti presenti nella feature precedente.
1 F e a t u r e : FUN_100 : User can l o g i n t h e system
2
3 S c e n a r i o O u t l i n e : FUN_100_1 : System l o g i n
4 The u s e r i s not a u t h e n t i c a t e d
5 Given User a c c o u n t c r e d e n t i a l s a r e
6 When System r e c i v e s l o g i n r e q u e s t
7 Then System w i l l show l o g i n page
8
9 Examples :
10 | V a l i d i t y | Response |
11 | valid | success |
12 | invalid | fail |
Listing 3.3: Esempio di codifica di un requisito in modo corretto
In questo caso però l’utilizzo dello Scenario Outline permette di scrivere un solo
scenario che Cucumber trasformerà in un unico test di accettazione con due
parametri. La seguente tabella illustra il numero di requisiti identificati in fase
di analisi.
Tipo Obbligatorio Desiderabile Facoltativo
Funzionale 15 11 0
Di prodotto 0 0 0
Organizzativo 0 0 0
Tabella 3.1: Riepilogo requisiti
3.2.2 Progettazione
Ho svolto la progettazione in modo agile, non andando a progettare le compo-
nenti nello specifico e puntando ad ottenere velocemente software funzionante.
La forte struttura imposta dai template aziendali BECON e FECON ha reso
possibile questo, in quanto la struttura che impongono porta lo sviluppatore
in modo abbastanza naturale alle creazioni di componenti che seguono lo stile
architetturale desiderato. È inoltre rafforzato questo da numerosi esempi e dalla
documentazione che spiega in modo preciso come le componenti vadano orga-
nizzate, codificate e come queste debbano interagire, inoltre il modo in cui sono
costruiti i due container fanno si che ogni qual volta si voglia inserire delle nuove
funzionalità, basta aggiungere un nuovo modulo, questo avrà una struttura in
tutto e per tutto identica a quella degli altri moduli dell’applicazione, quindi
sarebbe poco utile produrre un diagramma delle classi per il nuovo modulo,
in quanto sarebbe come un’istanza generata da un template. L’immagine è un
30CAPITOLO 3. LO SVILUPPO DI SPICE
esempio di questo ed illustra il diagramma delle classi ottenuto con lo sviluppo
in BECON di SPICe.
Figura 3.4: Diagramma delle classi del servizio REST di SPICe
31CAPITOLO 3. LO SVILUPPO DI SPICE
La struttura è aderente a quella precedentemente a quella presente nella
figura 2.2 dove:
• TodosResource: espone i servizi tramite API REST verso l’esterno
• TodoStorage: si occupa della business logic G
• TodoRepository: gestisce la lettura e scrittura verso il database
Il diagramma contiene anche delle interfacce e classi astratte non implementate
che non presenti nel modello della figura 2.2. Le classi astratte ed interfacce
• Todo
• Comment
• JsonTodo
• JsonComment
non appartengono al diagramma di base in quanto non sono obbligatorie da uti-
lizzare e non hanno lo scopo di fornire delle funzionalità ma si il loro obiettivo
è quello di creare oggetti immutabili utilizzati per il trasferimento dei dati al-
l’interno dell’applicazione e vengono generate in modo automatizzato, tratterò
in modo più approfondito nella sottosezione successiva riguardante la codifica.
Ho eseguito la progettazione in modo più approfondito per quanto riguarda
l’interfaccia REST e della sua implementazione TodosResource. Lo svolgimento
della progettazione del interfaccia REST non ha richiesto l’utilizzo di metodi o
strumenti particolari. Questo in quanto mi sono limitato a delineare le risorse
da creare all’interno dell’API in modo riuscire a soddisfare i requisti identificati
nella fase di analisi. Successivamente ho proceduto nell’organizzare la struttura
delle API identificando:
• la struttura interna del servizio, definendo gli Uniform Resource Locator
(URL) per ogni risorsa disponibile all’interno dell API , in modo da poter
identificare e utilizzare le risorse create
• il tipo di richiesta HyperText Transfer Protocol (HTTP) necessario per
interagire con i servizi offerti
• i servizi che non necessitano di autenticazione, ad esempio la risorsa /wel-
come utilizzata generalmente per verificarne lo stato del sevizio, e sevizi
che invece necessitano di un autenticazione e o di permessi di accesso alle
risorse
Per la progettazione dello stato interno dell’applicazione del front-end gestito da
Redux, ho definito in modo accurato la forma che si voleva ottenere dallo stato.
Questo perché la sua forma impatta in modo determinate sulla manutenibilità
e comprensibilità delle operazioni sullo stato.
Ho inizialmente definito le azioni che i reducer poi dovranno gestire, questi sono
paragonabili alla funzione di transizione di un automa a stati, dato in input
uno stato e un azione, in questo caso, producono in uscita il nuovo stato. Ho
utilizzato l’interfaccia REST del servizio di back-end come guida per definire le
azioni, così da fare in modo di utilizzare tutte le funzionalità offerte, in seguito
ho previsto tre varianti:
32Puoi anche leggere

















































