Università degli Studi di Padova - SIAGAS
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Università degli Studi di Padova
Dipartimento di Matematica "Tullio Levi-Civita"
Corso di Laurea in Informatica
Sviluppo di un’applicazione web a
microservizi con Java SpringBoot
Tesi di laurea triennale
Relatore Laureando
Dott.Armir Bujari Giovanni Righi
Anno Accademico 2017-2018
Giovanni Righi: Sviluppo di un’applicazione web a microservizi con Java SpringBoot, Tesi di laurea triennale, c Dicembre 2018.
“In un universo infinito dove la realtà viene filtrata attraverso le nostre mutevoli
percezioni, dare una qualsiasi definizione su qualsivoglia cosa non è che speculazione
basata su dati empirici”
— Timmy Turner
Ringraziamenti
Innanzitutto,vorrei ringraziare il Dott. Armir Bujari, relatore della mia tesi, per la
disponibilità e l’aiuto fornitomi durante la stesura del lavoro e nel periodo di stage .
Desidero ringraziare con affetto i miei genitori i miei fratelli e mia nonna che mi
hanno sempre supportato in questi anni.
Ringrazio anche i miei amici per tutte le aventure vissute in questi anni delle quali
avrò per sempre dei bellisimi ricordi.
Padova, Dicembre 2018 Giovanni Righi
iiiIndice
1 Introduzione 1
1.1 Il progetto di stage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 L’azienda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2.1 Profilo aziendale . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2.2 Servizi offerti . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Processi e metodologie . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3.1 Strumenti di supporto . . . . . . . . . . . . . . . . . . . . . . . 3
1.3.2 Sistema di versionamento . . . . . . . . . . . . . . . . . . . . . 4
1.3.3 Ambiente di lavoro . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Vantaggi aziendali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.5 Struttura del documento . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Descrizione dello stage 7
2.1 Introduzione al progetto . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Analisi preventiva dei rischi . . . . . . . . . . . . . . . . . . . . 7
2.1.2 Prodotti attesi . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.3 Obbiettivi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Vincoli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Vincoli tecnologici . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.2 Vincoli metodologici . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.3 Vincoli temporali . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3 Tecnologie Utilizzate 11
3.1 Java . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2 IntelliJ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.3 Git . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.4 GitHub . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.5 Framework Spring . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.5.1 Spring Boot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.5.2 Spring Data (Hibernate) . . . . . . . . . . . . . . . . . . . . . . 13
3.5.3 Spring Cloud . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.5.4 Spring Security (OAuth2) . . . . . . . . . . . . . . . . . . . . . 13
3.6 MySQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.7 Postman . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4 Analisi dei requisiti 17
4.1 Casi d’uso . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.1.1 Attori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
vvi INDICE
4.1.2 Elenco casi d’uso . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.2 Requisiti individuati . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.2.1 Requisiti funzionali . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.2.2 Requisiti qualitativi . . . . . . . . . . . . . . . . . . . . . . . . 21
4.2.3 Requisiti di vincolo . . . . . . . . . . . . . . . . . . . . . . . . . 22
5 Progettazione e codifica 23
5.1 Architettura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5.1.1 Architettura monolitica . . . . . . . . . . . . . . . . . . . . . . 23
5.1.2 Service Oriented Architecture SOA . . . . . . . . . . . . . . . . 24
5.1.3 Microservizi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.1.4 Architettura del prodotto . . . . . . . . . . . . . . . . . . . . . 25
5.2 Descrizione dei processi . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5.2.1 Inserimento e modifica . . . . . . . . . . . . . . . . . . . . . . . 28
5.2.2 Lettura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.2.3 Cancellazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.3 Database . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.3.1 Progettazione database . . . . . . . . . . . . . . . . . . . . . . 30
5.4 Cross-origin resource sharing . . . . . . . . . . . . . . . . . . . . . . . 31
6 Verifica e validazione 33
6.1 Analisi statica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
6.2 Analisi dinamica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
7 Conclusioni 35
7.1 Ripartizione oraria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
7.2 Raggiungimento degli obbiettivi . . . . . . . . . . . . . . . . . . . . . . 35
7.3 Sviluppo futuro dell’applicativo . . . . . . . . . . . . . . . . . . . . . . 36
7.4 Considerazioni personali . . . . . . . . . . . . . . . . . . . . . . . . . . 36
Glossario 37
Bibliografia 41Elenco delle figure
1.1 Logo Synclab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2.1 Diagramma di gantt . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.1 Logo di Java . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2 Logo di Git . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.3 Logo di Spring . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.4 Logo di hibernate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.5 Logo di OAuth . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.6 Logo di Postman . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.1 use case principali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.2 use case modifiche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.3 use case non implementati . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.1 Architettura monolitica . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5.2 Architettura a microservizi . . . . . . . . . . . . . . . . . . . . . . . . 25
5.3 Architettura dell’applicazione . . . . . . . . . . . . . . . . . . . . . . . 25
5.4 Funzionamento Oauth2 . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.5 Pannello di controllo Server Eureka . . . . . . . . . . . . . . . . . . . 27
5.6 Operazione di inserimento e modifica . . . . . . . . . . . . . . . . . . . 28
5.7 Operazione di lettura . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.8 Operazione di cancellazione . . . . . . . . . . . . . . . . . . . . . . . . 29
5.9 Schema del database . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.10 Flowchart che mostra come un browser gestisce le chiamate CORS . . 31
viiviii ELENCO DELLE TABELLE
Elenco delle tabelle
2.1 Tabella del tracciamento degli obbiettivi . . . . . . . . . . . . . . . . . 9
4.1 Tabella del tracciamento dei requisti funzionali . . . . . . . . . . . . . 21
4.2 Tabella del tracciamento dei requisti qualitativi . . . . . . . . . . . . . 21
4.3 Tabella del tracciamento dei requisti di vincolo . . . . . . . . . . . . . 22
7.1 Tabella del raggiungimento degli obbiettivi . . . . . . . . . . . . . . . 35Capitolo 1
Introduzione
In questo capitolo viene introdotto il contesto dell’azienda nella quale è stato fatto lo
stage. Inoltre sarà presentata la struttura del documento, compresa la suddivisione dei
capitoli e le norme tipografiche che sono state adottate.
1.1 Il progetto di stage
Negli ultimi anni con l’avvento del cloud computing[g] e delle web application ci si è
trovati a dover gestire il cambiamento rapido della richiesta di prodotti software e al
dover scalare i sistemi rapidamente,questo ha portato la maggior parte delle aziende
ad adottare un approccio allo sviluppo e alla gestione delle applicazioni passando da
un architettura monolitica ad una a microservizi.
Lo scopo del progetto di stage di Sync Lab è quello di far si che lo studente prenda
conoscenza di queste nuove tecnologie realizzando un’applicazione a microservizi che
consenta di gestire gli ordini di una pizzeria.
1.2 L’azienda
1.2.1 Profilo aziendale
Sync Lab S.r.l. è una società di consulenza informatica fondata nel 2002 con sedi a
Napoli, Roma, Milano e Padova.
Fin dai primi anni Sync Lab è rapidamente cresciuta nel mercato ICT, consolidando i
rapporti con clienti e partner ha raggiunto un organico aziendale di oltre 200 risorse,
una solida base finanziaria e una diffusione sul territorio attraverso le sue quattro sedi.
L’organico aziendale è andato crescendo in modo continuo e rapido, in relazione
all’apertura delle varie sedi ed alla progressiva crescita delle stesse.
La grande attenzione alla gestione delle risorse umane ha fatto di Sync Lab un
riferimento in positivo per quanti volessero avviare o far evolvere in chiave professionale
la propria carriera.
Il basso turn-over testimonia la voglia dei collaboratori di condividere il progetto
comune, assumendo all’interno di esso ruoli e responsabilità che solo un processo
evolutivo così intenso può offrire.
12 CAPITOLO 1. INTRODUZIONE
I ricavi hanno avuto un incremento proporzionale alla crescita dell’azienda beneficiando
dell’approccio adattivo e diversificato al mercato.
Figura 1.1: Logo Synclab
1.2.2 Servizi offerti
Sync Lab Srl è un’azienda leader nella consulenza tecnologica, impegnata in un processo
continuo di identificazione e messa in opera di soluzioni per i clienti finalizzate alla
creazione di valore. Supporta le esigenze di innovazione di tutte le organizzazioni ed in
ogni settore di mercato nell’ambito dell’ Information Technology, con servizi in ambito:
∗ Business Consultancy
∗ Project Financing
∗ IT Consultancy
L’azienda ha come punti di forza la qualità dei servizi offerti (certificazioni ISO
9001, ISO 14001, ISO 27001, OHSAS 18001) ed un’accurata gestione delle risorse
umane. L’approfondita conoscenza di processi e tecnologie, maturata in esperienze
altamente significative e qualificanti, fornisce l’expertise e Know How necessari per
gestire progetti di elevata complessità, dominando l’intero ciclo di vita: Studio di
fattibilità, Progettazione, Implementazione, Governance e Post Delivery.
L’offerta di consulenza specialistica trova le punte di eccellenza nella progettazione
di architetture Software avanzate, siano esse per applicativi di dominio, per sistemi
di supporto al business (BSS), per sistemi di integrazione (EAI/SOA), per sistemi di
monitoraggio applicativo/territoriale.
Il nostro laboratorio RD è sempre al passo con i nuovi paradigmi tecnologici e di
comunicazione, ad esempio Big Data, Cloud Computing,Internet of Things, Mobile
e Sicurezza IT, per supportare i propri clienti nella creazione ed integrazione di
applicazioni, processi e dispositivi.
Le attività in ambito Educational ed RD ci hanno permesso di acquisire una profonda
conoscenza degli strumenti di finanza agevolata fruendone direttamente ed interagendo
con enti di supporto ai progetti innovativi dei propri clienti. L’azienda, grazie alla rete
di relazioni a livello nazionale ed internazionale, ha ottenuto importanti finanziamenti
in progetti RD europei (FP7 e H2020) della Comunità Europea.
1.3 Processi e metodologie
Il ciclo di vita adottato da Synclab S.r.l. segue un modello di tipo Agile.
I principi su cui si basa la metodologia agile sono i seguenti:1.3. PROCESSI E METODOLOGIE 3
∗ Le persone e le iterazioni sono più importanti dei processi e degli strumenti;
∗ Avere software funzionante è più importante dell’avere documentazione;
∗ Collaborazione con i cliente;
∗ Essere pronti a rispondere al cambiamento delle esigenze del cliente.
Nello specifico il team di sviluppo cerca di seguire un approccio di tipo Scrum, il
quale è basato sui seguenti concetti:
∗ Sprint: rappresenta un’unità base dello sviluppo Scrum ed ha una durata fissa.
Durante uno sprint non è possibile modificare gli obiettivi precedentemente
pianificati;
∗ Riunioni: il team svolge riunioni nei seguenti casi:
– Prima di uno Sprint, in modo da pianificare gli obiettivi e i tempi stimati
per il successivo Sprint;
– Dopo uno Sprint, per verificare il lavoro svolto e discutere di eventuali
migliorie da apportare al modello di lavoro;
– Quotidianamente(Daily Scrum), durante lo sprint, viene tenuta una riunione
tra i membri del team di progetto;
– Riunioni con i clienti, in modo da comprendere più a fondo i requisiti del
software.
∗ Product Backlog: rappresenta una lista ordinata dei requisiti relativi ad un
prodotto software, ognuno dei quali avente una priorità. Rappresenta ciò che
deve essere fatto, organizzato in base all’ordine relativo in cui dovrà essere
realizzato;
∗ Sprint Backlog: lista del lavoro che il team di sviluppo deve effettuare nel corso
dello sprint successivo, viene generata selezionando una quantità di storie/funzio-
nalità a partire dalla cima del product backlog determinata da quanto il Team di
sviluppo ritiene possa realizzare durante lo sprint;
∗ Incremento: è la somma di tutti gli elementi del Product Backlog completati
durante gli sprint precedenti;
1.3.1 Strumenti di supporto
Come strumenti di supporto per la gestione di progetto l’azienda utilizza i seguenti
strumenti:
∗ Slack: una piattaforma di messaggistica per team che integra insieme diversi canali
di comunicazione in un unico servizio con l’obiettivo di migliorare l’esperienza
lavorativa aumentando l’interazione tra differenti servizi, per esempio integra
Google Drive, GitHub e altre applicazioni, in questo modo si ha un unico
contenitore/archivio di informazioni accessibili da un team tramite la possibilità
di organizzare la comunicazione attraverso canali specifici.
I canali potranno essere accessibili a tutto il team o solo ad alcuni membri ed è
possibile comunicare anche attraverso chat individuali private o chat con due o
più membri;4 CAPITOLO 1. INTRODUZIONE
∗ Asana: un’applicazione web progettata per migliorare la collaborazione e la
gestione del lavoro di squadra. Si possono creare progetti ed assegnare attività
ai compagni di squadra attraverso task, eventualmente gerarchizzati. Ogni task
può avere una data di scadenza ed è possibile assegnare uno o più follower,
cioè persone che seguono l’andamento del task con la possibilità di intervenire
commentando il flusso della gestione. Include anche strumenti di reporting, file
allegati, calendari e altro.
1.3.2 Sistema di versionamento
Come sistema di versionamento Synclab S.r.l. utilizza git. Git è un software per il
versionamento che serve a tener traccia dei cambiamenti che vengono effettuati su uno
o più file nel tempo, in questo modo è possibile in caso di bisogno risalire a versioni
precedenti in un qualsiasi momento e permette di coordinare il lavoro di più persone
che lavorano sugli stessi file.
1.3.3 Ambiente di lavoro
IDE
L’ambiente di sviluppo varia a seconda delle tecnologie impiegate nel progetto in
questione. Vengono utilizzati i seguenti IDE[g] :
∗ Eclipse: per lo sviluppo di applicativi in Java;
∗ Sts(Spring Tool Suite): per lo sviluppo di applicazioni utilizzando il framework[g]
Spring;
∗ DBeaver: per lo sviluppo di database Oracle.
Sistemi operativi
Per quanto riguarda i sistemi operativi da utilizzare i dipendenti utilizzano sistemi
Windows e/o Linux a seconda delle proprie preferenze e delle esigenze del progetto.
1.4 Vantaggi aziendali
Per le strategie di Sync Lab i percorsi di tirocinio in accompagnamento alla tesi/tesina
sono fondamentali in quanto permettono all’azienda di venire in contatto con i ragazzi
e lavorarci assieme.
Questo consente da un lato al laureando di capire se è l’azienda in cui vorrebbe costruire
una futura carriera lavorativa ed dall’altro lato ovviamente permettere all’azienda di
valutare le potenzialità dei ragazzi per procedere poi eventualmente con l’assunzione.
Gli argomenti delle tesine poi vengono scelti assieme ai ragazzi in base alle inclinazioni
di ognuno. Si fa attenzione inoltre ad indirizzare i percorsi in modo da renderli utili
per la rivedibilità sul mercato, cioè i ragazzi poi potranno essere subito pronti per le
attività lavorative che il mondo enterprise dell’informatica richiede. I ragazzi che invece
dimostrano l’interesse per continuare con la specialistica l’azienda cerca di indirizzare
invece i percorsi su tematiche più teoriche, quindi tematiche magari non richieste dal
mercato però molto interessanti per la formazione del tesista.
In Sync Lab inoltre viene messa a disposizione un’aula per mettere assieme i ragazzi
e favorire il più possibile l’interazione tra loro, coadiuvata dal tutor aziendale. Il1.5. STRUTTURA DEL DOCUMENTO 5
team-working in azienda è visto come elemento fondamentale per favorire lo scambio
di esperienze e punti di vista, per arrivare alla risoluzione dei problemi in modo coope-
rativo.
1.5 Struttura del documento
Riguardo la stesura del testo, relativamente al documento sono state adottate le
seguenti convenzioni tipografiche:
• le abbreviazioni e i termini ambigui o di uso non comune menzionati vengono
definiti nel glossario, situato alla fine del presente documento;
• le parole in blu seguite da il simbolo [g] sono definite nel glossario, viene evidenziata
soltanto la prima occorrenza di ogni parola;
• i termini in lingua straniera o facenti parti del gergo tecnico sono evidenziati con
il carattere corsivo.
Il documento è suddiviso nei seguenti capitoli
Capitolo 2: Descrive il progetto svolto durante lo stage;
Capitolo 3: Descrive le tecnologie utilizzate nel progetto;
Capitolo 4: Approfondisce i requisiti del progetto;
Capitolo 5: Approfondisce le parti di progettazione e codifica, in particolare
l’architettura dell’applicazione e del database;
Capitolo 6: Approfondisce le parti di verifica e validazione del progetto;
Capitolo 7: Contiene le considerazioni dello studente relative allo stage.Capitolo 2
Descrizione dello stage
Questo capitolo descrive il progetto, i requisiti e gli obbiettivi che sono stati fissati,e la
pianificazione.
2.1 Introduzione al progetto
Lo scopo di questo progetto di stage consiste nell’acquisizione delle competenze relative
al framework Spring e dei vari tool disponibili come Spring Cloud,Spring Data e
Spring Security, ed in particolare nel realizzare un applicazione con architettura a
microservizi. Nello specifico il progetto prevede la realizzazione della parte di Back-
end[g] di un’applicazione web per la gestione degli ordini di una pizzeria .
Le caratteristiche principali della soluzione proposta sono:
• Gestione del login all’applicazione;
• gestione dei prodotti in vendita (pizze,bibite,fritti etc..) e suddivisione in categorie
di questi;
• gestione dei clienti dei quali si vuole sapere almeno il nome o il cognome e nel
caso di clienti che richiedono la consegna a domicilio si vuole conoscere anche
l’indirizzo e il numero di telefono;
• gestione degli ordini ;
• stampa delle comande e degli scontrini fiscali;
• gestione dei resoconti giornalieri degli ordini effettuati.
2.1.1 Analisi preventiva dei rischi
Durante la fase di analisi sono stati individuati alcuni rischi che si potevano incontrare
durante il progetto.Sono state quindi individuate delle possibili soluzioni a tali rischi.
1. Inesperienza sulle tecnologie da utilizzare
Descrizione: Le tecnologie da utilizzare nel progetto sono poco note allo stagista.
Soluzione: Lo stagista si documenterà autonomamente sulle tecnologie e nel
caso sorgano dei dubbi richiederà informazioni ai colleghi.
78 CAPITOLO 2. DESCRIZIONE DELLO STAGE
2. Sottostima dei tempi di realizzazione
Descrizione: Data l’inesperienza da parte dello stagista per quanto riguarda
la pianificazione di un progetto potrebbe verificarsi una sottostima dei tempi di
realizzazione dello stesso.
Soluzione: Lo stagista aggiornerà giornalmente con il proprio tutor aziendale e
settimanalmente con il tutor interno per prevenire eventuali ritardi e effettuando
ove necessario le opportune correzioni di pianificazione.
3. Inesperienza degli strumenti da utilizzare
Descrizione: L’approccio al metodo di lavoro risulta nuovo. Sono richieste
capacità di pianificazione e di analisi che lo stagista non possiede a causa dell’i-
nesperienza. Alcune conoscenze richieste richiedono tempo per essere apprese.
Soluzione: Lo stagista si documenterà in maniera autonoma sugli strumenti da
utilizzare e richiederà informazioni ai colleghi nel caso siano sorti dei dubbi.
4. Problemi personali
Descrizione: Lo stagista potrebbe avere degli impegni personali o dei problemi
di salute che non gli permetterebbero di essere presente in azienda e continuare
il progetto.
Soluzione: Nel caso in cui lo stagista non sia disponibile per un periodo di tempo
dovrà comunicarlo tempestivamente al tutor aziendale,il quale riorganizzerà il
lavoro da svolgere.
5. Problemi aziendali
Descrizione: E’ possibile che per motivi aziendali gli uffici dell’azienda non
siano aperti per qualche giorno.
Soluzione: L’azienda metterà a disposizione degli strumenti per far si che lo
stagista possa lavorare al progetto anche da casa.
2.1.2 Prodotti attesi
L’attività di stage prevedeva la produzione di un insieme di oggetti, frutto di tale
attività. Di seguito, ne è riportato l’elenco:
• Documentazione dell’applicazione
• Codice sorgente dell’applicazione
• Allegato tecnico
2.1.3 Obbiettivi
All’inizio dell’attività di stage sono stati concordati con il tutor interno dell’azienda gli
obbiettivi del progetto. Si farà riferimento agli obbiettivi secondo la seguente notazione
X.Y dove X è una lettera tra:
O per i requisiti obbligatori;
D per i requisiti desiderabili;
F per i requisiti facoltativi.2.2. VINCOLI 9
e Y è il numero identificativo del requisito.
ID Descrizione
Obbligatori
O.01 Acquisire le competenze sui framework
O.02 Definizione e documentazione interfacce (tra microservizi)
O.03 Implementazione di un back-end basato su microservizi usando
il framework Spring
O.04 Test e verifica dell’implementazione
O.05 Realizzazione dell’analisi tecnica
Desiderabili
D.01 Studio e utilizzo del framework Spring Security
D.02 Studio e utilizzo del framework Spring Cloud
Facoltativi
F.01 Integrazione con Google Maps[g]
F.02 Stampa comande e scontri fiscali
Tabella 2.1: Tabella del tracciamento degli obbiettivi
2.2 Vincoli
2.2.1 Vincoli tecnologici
Per lo sviluppo del prodotto l’azienda ha richiesto l’utilizzo del linguaggio Java in
particolare del framework Spring e MySql come DBMS[g] .
Per quanto riguarda gli strumenti di sviluppo come l’IDE o il sistema di versionamento
non sono stati imposti vincoli.
2.2.2 Vincoli metodologici
Per lo svolgimento dello stage è stato concordato con l’azienda che dovesse essere
effettuato presso la sede dell’azienda.
Essendo che il progetto prevedeva che lo studente realizzasse il lato back-end di un
applicativo mentre un altro studente realizzava la parte front-end per poter decidere la
configurazione dell’applicazione e successivamente per testarla i due studenti dovevano
essere entrambi presenti in azienda.
Inoltre vista la presenza in azienda di altri stagisti che lavoravano a progetti diversi
ma che utilizzavano le stesse tecnologie è stato possibile collaborare scambiandosi
informazioni per arrivare ad una soluzione ai problemi comuni.
Il fatto che lo studente fosse in azienda durante lo stage ha favorito il dialogo tra studente
e tutor aziendale e anche con gli altri dipendenti dell’azienda.Lo studente ha potuto co-
sì confrontarsi con programmatori più esperti e chiedere informazioni in caso di bisogno.
2.2.3 Vincoli temporali
Le stage prevede lo svolgimento di 300 ore di lavoro complessive. Queste ore sono
state suddivise nell’arco di 8 settimane lavorative di cui 7 da 40 ore e una da 20 ore.
L’orario di lavoro è stato dal Lunedì al Venerdì dalle 9:00 alle 18:00 con un ora di10 CAPITOLO 2. DESCRIZIONE DELLO STAGE
pausa pranzo. Prima dell’inizio dello stage è stato redatto il piano di lavoro il quale
includeva la seguente pianificazione settimanale:
• Prima Settimana - (40 ore):
Studio Architettura a Microservizi e REST[g] ful;
• Seconda Settimana - (40 ore):
Studio Framework Spring e SpringRest;
• Terza Settimana - (40 ore):
Studio Hibernate/Spring Data;
• Quarta Settimana - (40 ore):
Studio di integrazione dei temi studiati nelle settimane precedenti;
• Quinta Settimana - (40 ore):
Studio e Implementazione Base Dati del progetto;
• Sesta Settimana - (40 ore):
Studio e Implementazione dei singoli microservizi del progetto;
• Settima Settimana - (40 ore):
Studio e Implementazione dei singoli microservizi del progetto ’Pizza’;
• Ottava Settimana - (20 ore):
Test e Collaudo Finale .
Figura 2.1: Diagramma di ganttCapitolo 3
Tecnologie Utilizzate
In questo capitolo verranno descritte le tecnologie utilizzate nel progetto.
3.1 Java
Java è un linguaggio di programmazione ad alto livello orientato agli oggetti. L’intento
è quello che gli sviluppatori "Scrivano una volta, eseguano ovunque" ossia che il codice
Java compilato sia eseguibili in tutte le piattaforme che supportano Java senza essere
ricompilato. Di seguito sono elencati i cinque obbiettivi che i creatori di Java si sono
posti:
• Deve essere semplice,orientato agli oggetti e familiare;
• Deve essere robusto e sicuro;
• Deve essere portabile e non deve dipendere dall’architettura;
• Deve avere alte performance di esecuzione;
• Deve essere interpretato,dinamico.
Figura 3.1: Logo di Java
3.2 IntelliJ
IntelliJ IDEA è un ambiente di sviluppo integrato per il linguaggio di programmazione
Java. IntelliJ supporta numerose tecnologie e framework tra i quali Spring.
1112 CAPITOLO 3. TECNOLOGIE UTILIZZATE
3.3 Git
Figura 3.2: Logo di Git
Git è un software di controllo versione distribuito utilizzabile da interfaccia a riga di
comando, creato da Linus Torvalds nel 2005.
Permette di gestire il codice di un progetto informatico in maniera efficace.
3.4 GitHub
Servizio di hosting per progetti software che implementa il software di controllo di
versione distribuito Git.
Gli sviluppatori possono caricare il loro codice sorgente sulla piattaforma cosicché’
gli altri utenti possono interagirvi tramite un sistema di issue tracking, pull request
e commenti che permette di migliorare il codice del repository risolvendo bug o
aggiungendo funzionalità.
3.5 Framework Spring
3.5.1 Spring Boot
Figura 3.3: Logo di Spring
Spring è un framework open source[g] per lo sviluppo di applicazioni su piattaforma
Java. Spring Boot in particolare è una soluzione per creare applicazioni stand-alone
all’interno delle quali possono essere inserite le librerie di Spring e di terze parti
permettendo cosi ai programmatori di concentrarsi meno sulla parte di configurazione
e di più nella parte di sviluppo. Le sue principali caratteristiche sono:
• Creazione di applicazioni stand-alone
• Incorpora direttamente i server Tomcat, Jetty o Undertow.
• Creazione automatica dei file di configurazione di Maven[g] o Gradle[g] ,
• Configurazione automatica delle librerie di Spring e di terze parti.3.5. FRAMEWORK SPRING 13
Figura 3.4: Logo di hibernate
3.5.2 Spring Data (Hibernate)
In Java le Java Persistence API[g] (JPA) sono un framework che si occupa della persi-
stenza nei dati all’interno di un database.
Per fare ciò Spring Data incorpora uno dei più famosi JPA, Hibernate, una piattaforma
middelware open source.
Hibernate fornisce un servizio di Object-relational mapping(ORM) che consente
di mappare le classi Java in tabelle di un database relazionale; sulla base di questo
mapping Hibernate gestisce il salvataggio e il reperimento,producendo ed eseguendo
automaticamente le query SQL, di tali classi sul database. L’obbiettivo principale
di Hibernate è di far si che il programmatore non si prenda in carico la persistenza
dei dati,riducendo cosi il carico di lavoro è rendendo il codice più leggibile. L’unica
richiesta per la persistenza di una classe è la presenza del costruttore senza parametri.
3.5.3 Spring Cloud
Spring Cloud: Fornisce dei tool per implementare rapidamente i pattern utilizzati nei
sistemi distribuiti. I tool utilizzati nel progetto sono:
• Netflix Eureka: Tool che permette la Service Discovery, ovvero un registro dei
servizi disponibili in modo che i moduli possano registrarvisi e trovarsi a vicenda;
• ZUUL API Gateway: È l’entrypoint del sistema, fa in modo che non venga
percepita l’atomicità dei sistemi sottostanti, che possono essere liberamente
sostituiti o replicati;
• Config Server: È il sistema di Configuration Management che permette di
centralizzare e ridistribuire le configurazioni dei vari moduli del sistema.
3.5.4 Spring Security (OAuth2)
Spring Security è un framework per l’autenticazione e la gestione dell’accesso per le
applicazioni basate su Spring,permettendo di ottenere le informazioni tramite LDAP,
database e altri servizi per la gestione del login.
In particolare Spring Security Oauth fornisce il supporto per utilizzare Spring Security
e OAuth2 utilizzando i modelli e le configurazioni standard di Spring.
Oauth è un protocollo open che permette l’autorizzazione di API di sicurezza con
un metodo standard e semplice. Il protocollo è compatibile con qualsiasi tipologia di
applicazione: desktop, web e mobile.
L’idea di base è quella di autorizzare terze parti a gestire documenti privati senza
condividere la password. La condivisione della password infatti presenta molti limiti a
livello di sicurezza, come per esempio non garantisce supporto per singoli privilegi su
determinati file o operazioni, e soprattutto rende accessibile l’intero account e il pan-
nello di amministrazione. In particolare questo accesso incondizionato è indesiderato.14 CAPITOLO 3. TECNOLOGIE UTILIZZATE
Figura 3.5: Logo di OAuth
Inoltre l’unico modo per revocare l’accesso è cambiare la password dell’intero account.
OAuth è nato quindi con il presupposto di garantire l’accesso delegato ad un client
specifico per determinate risorse sul server per un tempo limitato, con possibilità di
revoca.
OAuth2 è un evoluzione di OAuth, presenta una chiara divisone dei ruoli, implementan-
do un mediatore tra client e server.Un altro vantaggio rispetto alla precedente versione
è dato dalla possibilità di prolungare il tempo di utilizzo del token di accesso qualora
desiderato. OAuth 2.0 prevede i seguenti ruoli:
• Resource Owner è il proprietario della risorsa da proteggere.
• Resource Server è il server che espone la risorsa protetta. Riceve le richieste da
un client che si identifica tramite un access-token e fornisce la risposta richiesta.
• Client è l’applicazione fruitrice della risorsa che richiede il token di accesso.
• Authorization Server: è il server che, a fronte di un grant da parte del Resource
Owner,fornisce al client i token di accesso alla risorsa.
3.6 MySQL
MySQL è un Relational database management system (RDBMS[g] ) open source . E’
una delle soluzioni più adottate nell’ambito delle applicazioni web ed è una delle
componenti principali della piattaforma software di sviluppo WAMP,acronimo che
indica le componenti software con cui è realizzata:"Windows,Apache,MySQL,PHP". I
vantaggi offerti dall’utlizzo di MySQL sono i seguenti:
• È veloce. L’obbiettivo principale degli sviluppatori di MySQL è stata la velocità;
• È facile da utilizzare. È possibile creare e interagire con un database MySQL
utilizzando alcune affermazioni semplici nel linguaggio SQL, che è lo standard
linguaggio per la comunicazione con RDBMS;
• È sicuro.Il sistema flessibile di MySQL consente ad alcuni o tutti privilegi di
database a specifici utenti o gruppi di utenti. Le password sono criptate attraverso
moderni algoritmi.3.7. POSTMAN 15
3.7 Postman
Figura 3.6: Logo di Postman
Postman è un’applicazione del browser[g] Google Chrome che consente di costruire,
testare e documentare API più velocemente. Tramite Postman è possibile effettuare
delle chiamate API senza dover mettere mano al codice dell’applicazione, consentendo
di effettuare le chiamate tramite questo plugin che fornisce un’utile interfaccia grafica.
Le richieste possono essere effettuate sia verso un server locale che verso un server
online impostando tutti i dati di una tipica chiamata API, dagli headers al body.
Alcune delle caratteristiche di Postman sono:
• Cronologia della chiamate effettuate;
• Consente di creare velocemente le API;
• Personalizzazione con gli script;
• Robustezza dei framework dei test;
• Creare delle collezioni di API.Capitolo 4
Analisi dei requisiti
Questo capitolo descrive l’attività di analisi dei requisiti svolta durante il progetto.
Vengono descritti, di seguito, i casi d’uso principali e i requisiti individuati.
4.1 Casi d’uso
Lo scopo di questa fase è stato stilare la lista dei casi d’uso che una volta implementati
avrebbero soddisfatto i requisti del prodotto da realizzare. Per stilare i casi d’uso è
stato effettuato un brainstorming con il tutor aziendale e lo stagista che si è occupato
del front-end per individuare i requisiti del prodotto discutendo i possibili scenari di
utilizzo ed individuare le funzionalità da implementare.
4.1.1 Attori
Sono stati individuati due attori, L’utente non autenticato e l’utente autenticato.
Per utente si intende la persona che tramite il front-end manda delle richieste al
back-end che rappresenta il sistema che reagisce alle richieste.
L’utente non autenticato rappresenta l’utente che non ha ancora effettuato l’autentica-
zione e che quindi non può accedere alle funzionalità dell’applicativo.
L’utente autenticato è l’utente che ha effettuato l’autenticazione e può accedere alle
funzionalità dell’applicativo.
4.1.2 Elenco casi d’uso
Per facilitarne la consultazione e la gestione i casi d’uso verranno numerati con un
codice del tipo: UC[numero caso d’uso].
I casi d’uso principali individuati sono i seguenti:
• UC1: Autenticazione effettuata tramite passaggio di username e password;
• UC2: Possibilità di richiedere la lista delle categorie di items.
• UC3: Possibilità di richiedere gli items di una categoria
• UC4: Possibilità di cercare uno o più ordini effettuati.
– UC4.1: Ricerca ordine per data;
– UC4.2: Ricerca ordine per cliente.
1718 CAPITOLO 4. ANALISI DEI REQUISITI
• UC5: Possibilità di cercare un cliente;
– UC5.1: Ricerca cliente per nome;
– UC5.2: Ricerca cliente per cognome;
– UC5.3: Ricerca cliente per indirizzo.
Figura 4.1: use case principali
I casi d’uso per la gestione dei dati sono i seguenti:
• UC6: Possibilità di gestire le categorie di items presenti;
– UC6.1: Inserimento di una nuova categoria;
– UC6.2: Modifica di una categoria esistente;
– UC6.3: Cancellazione di una categoria esistente.
• UC7: Possibilità di gestire gli items presenti;
– UC7.1: Inserimento di un nuovo item;
– UC7.2: Modifica di un item esistente;
– UC7.3: Cancellazione di un item esistente.4.1. CASI D’USO 19
• UC8: Possibilità di gestire gli ordini presenti;
– UC8.1: Inserimento di una nuovo ordine;
– UC8.2: Modifica di un ordine esistente;
– UC8.3: Cancellazione di un ordine esistente.
• UC9: Possibilità di gestire i clienti presenti;
– UC9.1: Inserimento di una nuovo cliente;
– UC9.2: Modifica di un cliente esistente;
– UC9.3: Cancellazione di un cliente esistente esistente.
Figura 4.2: use case modifiche
I casi d’uso che non sono stati implementati sono i seguenti:20 CAPITOLO 4. ANALISI DEI REQUISITI
• UC10: Possibilità di stampare la comanda di un ordine ;
• UC11: Possibilità di stampare lo scontrino fiscale di un ordine;
• UC12: Possibilità di richiedere il resoconto giornaliero;
• UC13: Possibilità di identificare il percorso migliore di consegna tramite Google
Maps;
Figura 4.3: use case non implementati
4.2 Requisiti individuati
Attraverso l’analisi dei requisiti e tramite gli use case individuati è stata stilata la
tabella che traccia i requisiti in rapporto agli use case.
Sono stati individuati diversi tipi di requisiti e si è quindi fatto utilizzo di un codice
identificativo per distinguerli.
Il codice dei requisiti è così strutturato R(F/Q/V)(N/D/O) dove:
R = requisito;
F = funzionale;
Q = qualitativo;
V = di vincolo;
O = obbligatorio;
D = desiderabile;
F = facoltativo.
Nelle seguenti tabelle sono riassunti i requisti4.2. REQUISITI INDIVIDUATI 21
4.2.1 Requisiti funzionali
ID Descrizione Fonti
Obbligatori
RFO1 L’utente puòrichiedere la lista delle categorie di Items UC2
RFO2 L’utente puòrichiedere gli items di una specifica categoria UC3
RFO3 L’utente puòricercare un ordine UC4
RFO4.1 L’utente puòricercare un ordine in base alla data in cui è stato effettuato UC4.1
RFO4.2 L’utente puòricercare un ordine in base al cliente che l’ha effettuato UC4.2
RFO5 L’utente puòricercare un cliente UC5
RFO5.1 L’utente puòricercare un cliente in base al nome UC5.1
RFO5.2 L’utente puòricercare un cliente in base al cognome UC5.2
RFO5.3 L’utente puòricercare un cliente in base all’indirizzo UC5.3
RFO6 L’utente puògestire le categorie di items UC6
RFO6.1 L’utente puòinserire una nuova categoria UC 6.1
RFO6.2 L’utente puòmodificare una categoria esistente UC6.2
RFO6.3 L’utente puòcancellare una categoria esistente UC6.3
RFO7 L’utente puògestire gli items UC7
RFO7.1 L’utente puòinserire una nuovo item UC 7.1
RFO7.2 L’utente puòmodificare un item esistente UC7.2
RFO7.3 L’utente puòcancellare un item esistente UC7.3
RFO8 L’utente puògestire gli ordini UC8
RFO8.1 L’utente puòinserire un nuovo ordine UC 8.1
RFO8.2 L’utente puòmodificare un ordine esistente UC8.2
RFO8.3 L’utente puòcancellare un ordine esistente UC8.3
RFO9 L’utente puògestire i clienti UC9
RFO9.1 L’utente puòinserire un nuova cliente UC 9.1
RFO9.2 L’utente puòmodificare un cliente esistente UC9.2
RFO9.3 L’utente puòcancellare un cliente esistente UC9.3
Desiderabili
RFD1 L’utente per accedere all’applicazione deve effettuare il login UC1
Facoltativi
RFF1 L’utente può richiedere la stampa della comanda dell’ordine UC 10
RFF2 L’utente può richiedere la stampa dello scontrino fiscale dell’ordine UC 11
RFF3 L’utente può richiedere il resoconto giornaliero degli ordini UC 12
RFF4 Il sistema consiglia il percorso migliore di consegna all’utente UC 13
Tabella 4.1: Tabella del tracciamento dei requisti funzionali
4.2.2 Requisiti qualitativi
ID Descrizione Fonti
RQO1 Viene fornito l’allegato tecnico dell’applicativo Capitolato
RQO1 Vengono effettuati test dell’applicativo Capitolato
Tabella 4.2: Tabella del tracciamento dei requisti qualitativi22 CAPITOLO 4. ANALISI DEI REQUISITI
4.2.3 Requisiti di vincolo
ID Descrizione Fonti
Obbligatori
RVO1 L’applicativo deve essere sviluppato in Java Capitolato
RVO2 L’applicativo deve utilizzare un architettura a microservizi Capitolato
RVO3 L’applicativo deve utilizzare il framework Spring Capitolato
Desiderabili
RVD1 L’applicativo deve utilizzare il framework Spring Cloud Capitolato
RVD2 L’applicativo deve utilizzare il framework Spring Security Capitolato
Facoltativi
RVF1 L’applicativo deve utilizzare integrare Google Maps Capitolato
Tabella 4.3: Tabella del tracciamento dei requisti di vincoloCapitolo 5
Progettazione e codifica
Questo capitolo descrive l’attività di progettazione svolta durante il periodo di stage.
Viene illustrata l’architettura dell’applicazione, la struttura del database, l’implemen-
tazione di essa attraverso la descrizione dei microservizi implementati.
5.1 Architettura
L’evoluzione dell’informatica ha cambiato la prospettiva di business mondiale. Inizial-
mente l’informatica era pensata per svolgere funzioni di supporto alle organizzazioni
riducendo il lavoro manuale di alcune funzioni.
Al giorno d’oggi però l’informatica non è più utilizzata come funzione di supporto ma
è diventata il fulcro del business mondiale.
Per gestire il cambiamento rapido della richiesta di prodotti software e per scalare
i sistemi rapidamente,lo sviluppo ha bisogno di spostarsi da un sistema statico ad
uno dinamico. Essere in grado di sviluppare,evolvere e scalare grandi applicazione è
processo un critico per le organizzazioni.
Per questo i microservizi sono diventati il pattern dominante per sviluppare le moderne
applicazioni Cloud suddividendo i singoli componenti in servizi indipendenti incentrati
in specifiche funzionalità. Ma prima dei microservizi come venivano sviluppate le
applicazioni?
5.1.1 Architettura monolitica
Figura 5.1: Architettura monolitica
L’architettura monolitica è stato il principale approccio per lo sviluppo di applica-
zioni distribuite come singole unità.
Questo tipo di architettura è adatta allo sviluppo di applicazioni piccole e poco soggette
ai cambiamenti ma non appena ci si trova a sviluppare applicazioni complesse e che
evolvono rapidamente i limiti dell’architettura vengono fuori.
2324 CAPITOLO 5. PROGETTAZIONE E CODIFICA
Il problema principale di questa architettura è che qualsiasi modifica apportata a un
qualunque modulo può portare ad avere effetti collaterali in altri moduli e quindi
richiede che l’intera applicazione venga testata in modo da verificare l’assenza di errori.
Inoltre unico modo per poter scalare questo tipo di applicazione è quello di replicarla
interamente con conseguente aumento delle risorse necessarie e di conseguenza dei
costi.
5.1.2 Service Oriented Architecture SOA
La Service Oriented Architecture è l’architettura software nata per fronteggiare le
problematiche dell’architettura monolitica. Essa prevede la scomposizione dell’applica-
zione in servizi indipendenti, quindi con basso accoppiamento, ognuno dei quali ha una
piccola e specifica funzionalità. In questo modo le applicazioni possono usare un certo
numero di servizi e connetterli in base alle loro esigenze.
E’ quindi possibile modificare,in maniera relativamente semplice, la modalità di ite-
razione tra i servizi,oppure la combinazione con la quale i servizi vengono utilizzati.
Inoltre risulta più semplice aggiungere o modificare i servizi per rispondere alle esigenze
dell’applicazione.
Nonostante questo modello abbia fornito un notevole miglioramento nella costruzione
di architetture più efficaci, nella pratica è stata generalmente inefficace a causa di
inutili astrazioni e protocolli legacy complessi.
Gli sviluppatori si sono trovati ad utilizzare SOA per collegare una vasta gamma di ap-
plicazioni che parlavano una lingua diversa, e che hanno richiesto l’implementazione di
un ulteriore livello, usato per la comunicazione che è l’ Enterprise Service Bus. Questo
porta a configurazioni costose che non possono tenere il passo come la tecnologia e il
business di oggi.
5.1.3 Microservizi
Il modello a microservizi è una variante del SOA che ne migliora le funzionalità
ereditandone l’idea di base per questo motivo viene definito come SOA a "grana fine".
Invece che suddividere le funzionalità dell’applicazione tramite l’utilizzo di servizi,
quindi avere un servizio per funzionalità , il modello a microservizi mira a creare
una singola applicazione composta da servizi indipendenti ognuno dei quali segue il
principio di singola responsabilità.
Di fatti la filosofia dei microservizi è la stessa di UNIX che dice "Se fai una cosa, falla
bene" ed è definita dalle seguenti proprietà:
• I servizi sono piccoli, "a grana fine" per eseguire singole funzioni.
• Consente l’automazione dei test e della distribuzione. In questo permette a
diversi team di sviluppo di lavorare in modo indipendente.
• Consente di comprendere fallimenti e difetti.
• Ogni servizio è elastico,resiliente,componibile,minimale e completo.
Nell’architettura a micorservizi la comunicazione tra i servizi è basata su HTTP[g]
tramite le API Restful, passando i dati in formato JSON[g] , spesso attraverso una coda
di messaggi, quando è necessario garantire l’affidabilità.
I singoli microservizi sono generalmente trattati in modo asincrono, innescati da un
evento come una chiamata ad una API o un inserimento di un dato in coda. Questo5.1. ARCHITETTURA 25
tipo di comunicazione basata su un protocollo “leggero” quale è l’HTTP è un ulteriore
differenza tra microservizi e SOA.
Figura 5.2: Architettura a microservizi
5.1.4 Architettura del prodotto
Il seguente diagramma mostra la struttura architetturale dell’applicativo realizzato:
Figura 5.3: Architettura dell’applicazione
Sono stati identificati i seguenti microservizi:26 CAPITOLO 5. PROGETTAZIONE E CODIFICA
Microservizi gestione dati
Questi servizi gestiscono i dati dell’intero applicativo, implementano Hibernate per
mappare gli oggetti con le entità nel database. Ricevono le chiamate HTTP dal
gateway e interrogano il loro database per effettuare operazioni sui dati(reperimento,
inserimento, modifica, cancellazione).
I Microservizi per la gestione dei dai sono i seguenti:
Order-Service: Gestione dei dati relativi agli ordini.
Product-Service: Gestione dei dati relativi agli items e alle categorie.
Customer-Service: Gestione dei dati relativi ai clienti.
Login-Service
Microservizio per la gestione del login all’applicativo è di fatto l’authorization server
del protocollo OAuth2.
Esso riceve dal client, nel nostro caso lo Spring Gateway Server, le credenziali, ne
controlla la validità interrogando il database e se sono valide crea un token di accesso
e lo restituisce al client.
Ogni volta che il client vuole accedere ad una risorsa protetta deve fornire il token che
viene controllato, se il token è valido può accedere alle risorse nel caso il token non sia
presente o sia scaduto bisognerà effettuare di nuovo l’autenticazione per ricevere un
altro token.
Figura 5.4: Funzionamento Oauth2
Spring Config Server
Microservizio per la gestione della configurazione centralizzata.
Contiene la configurazione dei vari moduli del sistema nel caso del progetto contiene
informazioni relative alla porta sulla quale il modulo dovrà lavorare e quelle relative al
database.
Ogni qualvolta un modulo viene eseguito richiede al Config Server la sua configurazione
questo permette di avere diverse configurazioni per i diversi ambienti in cui i microservizi
possono essere eseguiti.5.1. ARCHITETTURA 27
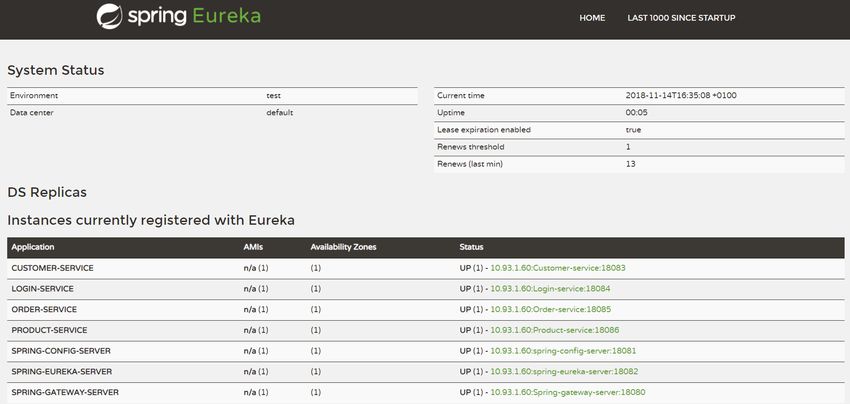
Spring Eureka Server
Microservizio che implementa il tool Netflix Eureka per la Service Discovery, esso
contiene un registro dei servizi disponibili.
In questo modo quando un servizio viene lanciato deve conoscere solo l’indirizzo
e la porta del Server Eureka per poter risalire al Config Server e ottenere la sua
configurazione, una volta ottenuta la comunica al Server Eureka che la salva nel suo
registro.
Quando un servizio vuole comunicare con un altro basta che ne conosca l’id per poter,
tramite il Server Eureka, risalire al suo indirizzo e alla porta, in questo modo i servizi
non devono conoscere le configurazioni degli altri servizi per poterci comunicare ma
basta che ne conoscano l’id.
Figura 5.5: Pannello di controllo Server Eureka
Spring Gateway Server
Microservizio che funge da entrypoint del sistema implementando il tool Zuul API
Gateway.
Immaginiamo di avere un applicazione con più microservizi e di dover implementare
una UI che effettua chiamate ai microservizi per cercare e mostrare le informazioni.
Poiché ogni microservizio espone una REST API per la comunicazione il client dovrà
conoscere i dettagli di ogni REST API e gli URL e le porte per chiamarle.
Inoltre se si pensa ad altri aspetti come la sicurezza, l’autenticazione e la Cross Origin
Resurce Sharing ogni microservizio dovrà implementare ognuno di questi aspetti al suo
interno ciò porterebbe ad avere lo stesso codice replicato più volte.
Zuul nasce per risolvere queste problematiche fungendo da API Gateway,esso riceve
tutte le richieste dalla UI e le delega ai microservizi interni appropriati.
Il vantaggio di questo design è che i vari aspetti come la sicurezza, l’autenticazione e
la CORS vengono implementati in un unico servizio centralizzato in questo tutti gli
aspetti comuni vengono applicati a tutte le richieste senza aver codice replicato, inoltre
nel caso ci sia bisogno di effettuare modifiche bisogna solo aggiornare il microservizio
che implementa Zuul.
Inoltre si possono implementare regole di routing o filtri per determinate richieste.28 CAPITOLO 5. PROGETTAZIONE E CODIFICA
Questo microservizio ha un altra funzione ossia l’aggregazione di richieste, è possibile
quindi aggregare più richieste del client destinate a più microservizi interni in una
singola richiesta. Questo schema è particolarmente utile quando il client necessita di
informazioni da svariati microservizi.
Con questo approccio,il client invia una singola richiesta al gateway API che invia
diverse richieste ai microservizi interni, per poi aggregare i risultati e inviare nuovamente
tutti i dati al client.
Il vantaggio e l’obiettivo principali di questo schema progettuale consistono nel ridurre
le comunicazioni frammentate tra il client e i microservizi e anche le comunicazioni tra
microservizi. Per fare un esempio nel applicativo realizzato si ha un associazione tra
clienti ed ordini che però non è gestita tramite database in quanto i dati si trovano in
database diversi. Quindi se il client avesse bisogno dei dati di un cliente e i relativi
ordini nel caso non ci fosse il gateway dovrebbe fare due chiamate ai singoli servizi
una per i dati del cliente e una per gli ordini, la stessa cosa averebbe nel caso in cui
il gateway non facesse da aggregatore ma in questo caso le due chiamate verrebbero
gestite dal gateway. Nel nostro caso poiché il gateway funge anche da aggregatore il
client fa un unica chiamata specifica al gateway che chiama a due microservizi aggrega
i dati ricevuti e li restituisce al client.
5.2 Descrizione dei processi
5.2.1 Inserimento e modifica
Figura 5.6: Operazione di inserimento e modifica
Poiché i processi di inserimento e modifica e dei dati dal database sono simili
verranno descritti tramite un unico esempio. In questi processi il client, tramite una
chiamata REST, invia i dati da inserire/modificare in formato JSON all’API Gateway
il quale interroga il server Eureka per ottenere gli Endpoint[g] del microservizio che
gestisce la specifica chiamata REST e gli invia i dati. Nel microservizio tramite un
controller che mappa le chiamate REST viene richiamata la funzione richiesta per la
manipolazione dei dati nel database.5.2. DESCRIZIONE DEI PROCESSI 29
5.2.2 Lettura
Nel processo di lettura di dati dal database, il client invia una richiesta di dati, tramite
una chiamata REST, all’API Gateway il quale interroga il server Eureka per ottenere
gli endpoint del microservizio che gestisce la specifica chiamata REST e gli invia la
richiesta. Nel microservizio tramite un controller che mappa le chiamate REST viene
richiamata la funzione di lettura dei dati nel database. Una volta ottenuti i dati dal
database il microservizio li passa all’API gateway che a sua volta li invia al client.
Figura 5.7: Operazione di lettura
5.2.3 Cancellazione
In questo processo il client invia una richiesta di cancellazione, tramite una chiamata
REST, all’API Gateway il quale interroga il server Eureka per ottenere gli endpoint
del micro servizio che gestisce la specifica chiamata REST e gli invia la richiesta. Nel
micro servizio tramite un controller che mappa le chiamate REST viene richiamata la
funzione che gestisce la cancellazione dei dati nel database.
Figura 5.8: Operazione di cancellazione30 CAPITOLO 5. PROGETTAZIONE E CODIFICA
5.3 Database
Per la persistenza dei dati si è deciso di utilizzare un database MySQL.
A differenza dell’architettura monolitica, dove i dati dell’applicativo vengono salvati in
un unico grande database, l’architettura a microservizi prevede che per la persistenza
dei dati ogni microservizio abbia un proprio database.
In questo modo si posso utilizzare tecnologie diverse a seconda delle esigenze del
microservizio e le modifiche effettuate ai database per implementare nuove funzionalità
necessarie ad un servizio non vanno ad interrompere gli altri microservizi.
Inoltre nel caso di un elevato numero di richieste al database, se si è nel caso nel quale
si ha un unico database per tutti i microservizi, quest’ultimi si troveranno tutti con le
richieste verso il database congestionate andando così a rallentare il funzionamento
dell’intera applicazione.
Questo va contro la filosofia che c’è dietro l’architettura a microservizi permette nel
caso in cui un servizio sia congestionato innanzitutto di non avere congestione negli
altri microservizi e inoltre di poter replicare il microservizio e il suo database in modo
da poter riuscire a bilanciare il traffico di dati.
5.3.1 Progettazione database
Per quanto riguarda la progettazione del database dell’applicativo poiché non vi era
esperienza di progettazione di database per microservizi inizialmente si è definito uno
schema del database con architettura monolitica definendo i dati da memorizzare e le
relazioni tra i diversi elementi presenti.
Dopodiché si è scomposto il database monolitico nei vari database dei singoli microser-
vizi, si sono implementati i microservizi e sono stati testati singolarmente dopodiché si
è implementato lo Spring Gateway Server che funge da aggregatore come spiegato in
precedenza e si sono testate le chiamate aggregate.
Il seguente schema mostra la struttura monolitica del database e la suddivisione nei
vari database dei microservizi.
Figura 5.9: Schema del database5.4. CROSS-ORIGIN RESOURCE SHARING 31
5.4 Cross-origin resource sharing
Questo paragrafo spiega il funzionamento del Cross-origin resource sharing (CORS)
meccanismo del quale non si era a conoscenza in fase di analisi e che ha portato via
diverso tempo in fase di realizzazione del prodotto per essere configurato in modo
adeguato.
Il CORS è un meccanismo che consente ai domini esterni di accedere alle risorse protette
di un domino. Per ragioni di sicurezza, i browser limitano le cross-origin HTTP requests
che vengono generate all’interno degli scripts. Ciò significa che un’applicazione web può
solamente richiedere risorse HTTP dalla stessa origine di caricamento dell’applicazione,
a meno che la risposta dall’altra origine includa i corretti header CORS.
Lo standard Cross-Origin Resource Sharing funziona aggiungendo nuovi header HTTP
che consentono ai server di descrivere l’insieme di origini che sono autorizzate a leggere
quelle informazioni tramite un web browser. In aggiunta, per i metodi di richiesta
HTTP che possono causare effetti collaterali sui dati del server la specifica prevede che
il browser "anticipi" la richiesta (questa operazione è detta "preflight"), richiedendo al
server i metodi supportati tramite una richiesta HTTP OPTIONS, e poi, dopo una
"approvazione" del server, invii la richiesta effettiva con il metodo HTTP effettivo. I
server possono anche informare i client se delle "credenziali" (inclusi Cookies e dati di
autenticazione HTTP) debbano essere inviate insieme alle richieste.
Figura 5.10: Flowchart che mostra come un browser gestisce le chiamate CORSPuoi anche leggere

















































