Università degli Studi di Padova - SIAGAS
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Università degli Studi di Padova
Dipartimento di Matematica "Tullio Levi-Civita"
Corso di Laurea in Informatica
Implementazione di un’applicazione web
orientata ai microservizi basata su Java
Spring
Tesi di laurea triennale
Relatore
Prof.Francesco Ranzato
Laureando
Riccardo Dario
Anno Accademico 2019-2020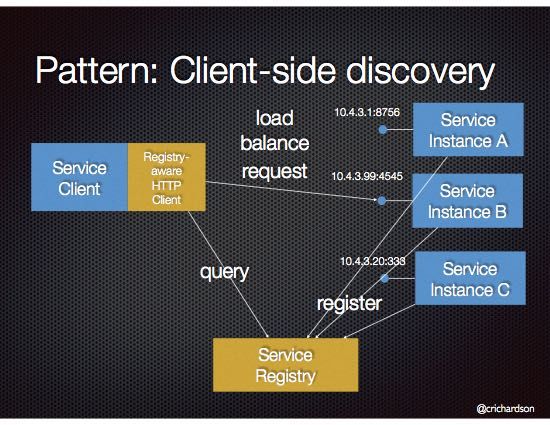
Riccardo Dario: Implementazione di un’applicazione web orientata ai microservizi basata su Java Spring, Tesi di laurea triennale, c Dicembre 2019.
“Nessuno sa cosa ci riserva il futuro. Ecco perchè il suo potenziale è infinito.”
— Rintaro Okabe
Dedico questo lavoro ai miei genitori, che mi hanno supportato in questi anni,
rendendo possibile questo grande traguardo.
Una dedica speciale va a te James, che mi hai dato la forza per superare gli ultimi
ostacoli.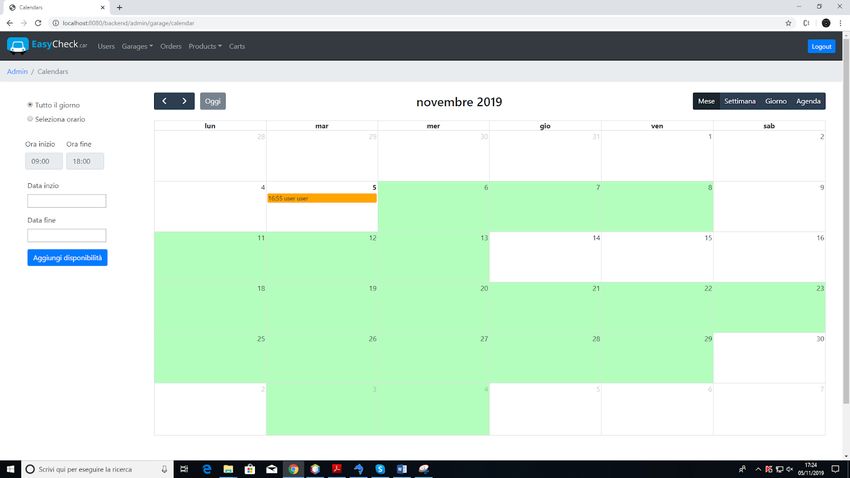
Sommario
Questo documento presenta il progetto sviluppato durante il periodo di stage formativo
di trecento ore, dal laureando Riccardo Dario presso l’azienda EXO Automotive Spa.
Il progetto, denominato "EasyCheck", si proponeva di creare una nuova applicazione
web a partire da zero.
Per fare ciò era richiesto di utilizzare il framework Java Spring ed utilizzare un’archi-
tettura orientata ai microservizi.
v“Sometimes, the questions are complicated and the answers are simple.”
— L Lawliet
Ringraziamenti
Innanzitutto, desidero ringraziare con affetto i miei genitori per il sostegno, il grande
aiuto e per essermi stati vicini.
Inoltre vorrei esprimere la mia gratitudine al Prof. Francesco Ranzato, relatore della
mia tesi, per l’aiuto e il sostegno fornitomi durante la stesura del lavoro e il tutor
interno Carlo Gambirasio, per aver reso l’esperienza di stage fantastica.
Ringrazio anche tutti i miei amici per avermi sopportato come una seconda famiglia.
Padova, Dicembre 2019 Riccardo Dario
viiIndice
1 Introduzione 1
1.1 L’azienda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 L’idea - EasyCheck . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.3 Organizzazione del testo . . . . . . . . . . . . . . . . . . . . . . . . . . 1
2 Java Spring Framework 3
2.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Spring Boot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.3 Spring Cloud . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.4 Spring Cloud Data Flow . . . . . . . . . . . . . . . . . . . . . . . . . . 4
3 Descrizione dello stage 7
3.1 Introduzione al progetto . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.2 Requisiti e obiettivi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.3 Pianificazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3.4 Piano di lavoro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
4 Progettazione e codifica 9
4.1 Tecnologie e strumenti . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
4.2 Progettazione architetturale . . . . . . . . . . . . . . . . . . . . . . . . 10
4.3 Design Pattern utilizzati . . . . . . . . . . . . . . . . . . . . . . . . . . 11
4.3.1 Database per Service . . . . . . . . . . . . . . . . . . . . . . . . 12
4.3.2 Aggregator o API compostion Pattern . . . . . . . . . . . . . . 13
4.3.3 Gateway Routing Pattern . . . . . . . . . . . . . . . . . . . . . 14
4.3.4 Service Discovery Pattern . . . . . . . . . . . . . . . . . . . . . 15
4.3.5 Circuit Breaker Pattern . . . . . . . . . . . . . . . . . . . . . . 16
5 Microservizi 17
5.1 Service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
5.1.1 config . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
5.1.2 discovery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.1.3 gateway . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.2 Core . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.2.1 Caratteristiche comuni . . . . . . . . . . . . . . . . . . . . . . . 19
5.2.2 car-service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.2.3 cart-service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5.2.4 garage-service . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.2.5 good-service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.2.6 order-service . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
ixx INDICE
5.2.7 user-service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5.3 Aggregator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.3.1 Frontend . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.3.2 Backend . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
6 Conclusioni 35
6.1 Raggiungimento degli obiettivi . . . . . . . . . . . . . . . . . . . . . . 35
6.2 Sviluppo futuro dell’applicativo . . . . . . . . . . . . . . . . . . . . . . 35
6.3 Conoscenze acquisite . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
6.4 Lavoro in team . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
6.5 Valutazione personale . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
Glossary 37
Acronyms 43
Bibliografia 45Elenco delle figure
4.1 Design Patterns for Microservices. url: https : / / medium . com /
@madhukaudantha/microservice-architecture-and-design-patterns-
for-microservices-e0e5013f . . . . . . . . . . . . . . . . . . . . . . 11
4.2 Database per service . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.3 Aggregator Pattern . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.4 Gateway Routing Pattern . . . . . . . . . . . . . . . . . . . . . . . . . 14
4.5 Service Discovery Pattern . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.6 Circuit Breaker Pattern . . . . . . . . . . . . . . . . . . . . . . . . . . 16
5.1 Repository Bitbucket EasyCheck-config . . . . . . . . . . . . . . . . . 18
5.2 Frammento di dashboard Eureka . . . . . . . . . . . . . . . . . . . . . 19
5.3 Database car-service . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.4 Database cart-service . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5.5 Database garage-service . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5.6 Calendario utente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.7 Calendario admin . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.8 Calendario officina . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.9 Database good-service . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5.10 Database order-service . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5.11 Database user-service . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
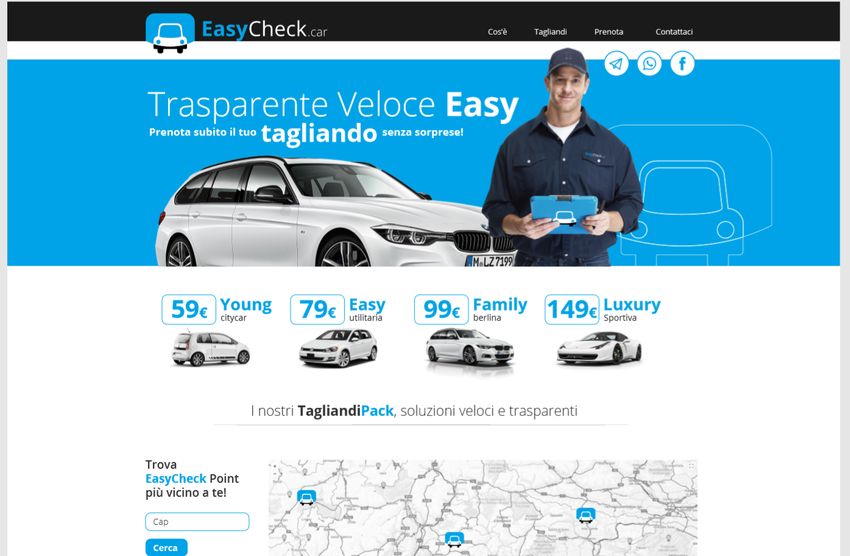
5.12 Home page . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.13 Controllers Backend . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5.14 Services Backend . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
5.15 Diagramma delle classi Backend . . . . . . . . . . . . . . . . . . . . . . 34
xiCapitolo 1
Introduzione
1.1 L’azienda
EXO Automotive opera da oltre 20 anni in Italia e all’estero posizionandosi tra le
aziende di riferimento nell’aftermarket dei ricambi per auto.
Inizia come distributore esclusivo per l’Italia del marchio europeo Remsa, leader nella
fabbricazione di componenti freno, e cresce introducendo Open Parts, un proprio
marchio di ricambi per auto con un pacchetto prodotti completo e dall’ottima qualità.
1.2 L’idea - EasyCheck
L’ obiettivo dello stage è la creazione di un portale online per la prenotazione e vendita
di servizi dedicati alla manutenzione dell’auto; i servizi vengono prenotati online e
forniti tramite una rete di autofficine dislocate nel territorio italiano.
Il progetto è basato sul framework Spring e utilizza tecnologie Microservices e RESTful
webservices.
1.3 Organizzazione del testo
Il secondo capitolo descrive il Framework Java Spring
Il terzo capitolo descrive lo stage
Il quarto capitolo approfondisce le fasi dello stage
Il quinto capitolo approfondisce i vari microservizi implementati
Nel sesto capitolo vengono infine fatte delle valutazioni
Riguardo la stesura del testo, relativamente al documento sono state adottate le
seguenti convenzioni tipografiche:
∗ gli acronimi, le abbreviazioni e i termini ambigui o di uso non comune menzionati
vengono definiti nel glossario, situato alla fine del presente documento;
∗ per la prima occorrenza dei termini riportati nel glossario viene utilizzato il
seguente simbolo: [g] ;
1Capitolo 2
Java Spring Framework
In questo capitolo presenterò Java Spring Framework, sul quale era basato l’intero progetto
2.1 Introduzione
Spring Framework è un framework open source per applicazioni e un IOC[g] container
per la piattaforma Java.
Questo framework si suddivide in tre moduli principali i quali sono:
∗ Spring Boot;
∗ Spring Cloud;
∗ Spring Cloud Data Flow.
Spring è basato su alcuni principi della programmazione tra i quali l’Inversion of
Control che permette di creare un cointainer autogestito integrabile poi con diversi
sistemi. Per far questo il programmatore deve definire degli oggetti (detti anche bean)
che poi possono essere ottenuti utilizzando una Dependency Injection[g] .
Il fatto che ognuno di questi container sia indipendente dagli altri ne aumenta la
mantenibilità e la testabilità.
Spring framework è basato inoltre sull’aspect oriented programming, un paradigma di
programmazione utilizzato per aumentare la modularità permettendo la separarazione
dei problemi trasversali.
Spring ha inoltre il proprio MVC[g] framework, il quale è stato creato per sopperire alle
mancanze del già esistente Jakarta Struts Web framework.
Questo MVC framework è request-based e fornisce delle strategy interfaces per gestire
tutte le richieste che devono essere gestite da un framework del suddetto tipo.
Fonte: Spring Framework. url: https : / / en . wikipedia . org / wiki / Spring _
Framework.
34 CAPITOLO 2. JAVA SPRING FRAMEWORK
2.2 Spring Boot
Per la creazione di questo progetto è stato utilizzato Spring Boot, modulo che per-
mette al programmatore di non dover configurare niente che non si distacchi da una
normale implementazione, utilizzando il paradigma di programmazione Convention
over configuration[g] .
Tra le features di questo modulo possiamo trovare:
∗ creazione di applicazioni stand-alone;
∗ collegamento a Tomcat o Jetty diretto;
∗ messa a disposizione di POM configurabili;
∗ configurazione automatica di Spring quando possibile;
∗ funzionalità utili per la produzione;
∗ nessun requisito per la configurazione XML.
2.3 Spring Cloud
Spring Cloud è il modulo che permette di implementare alcuni dei più comuni pattern
dei sistemi distribuiti (gestione della configurazione, individuazione dei servizi, circuit
breakers, ecc). Usando Spring Cloud gli sviluppatori possono mettere in piedi facil-
mente dei servizi che utilizzano questi pattern e che lavorano bene sia sul computer
dello sviluppatore, sia all’interno di applicazioni enterprise. Tra le features di questo
modulo possiamo trovare:
∗ configurazione distribuita e versionata;
∗ individuazione e registrazione dei servizi;
∗ indirizzamento;
∗ chiamate tra servizi;
∗ distribuzione del carico;
∗ circuit breakers;
∗ messaggi distribuiti.
2.4 Spring Cloud Data Flow
Spring Cloud Data Flow rende facile costruite e gestire pipeline di dati cloud native
per casi d’uso come digestione di dati, analisi real-time e import/export di dati. Spring
Cloud Data Flow rende facile la connessione di sistemi, rendendo disponibili connettori
pronti all’uso per i più comuni scenari di integrazione. Tra le features di questo modulo
possiamo trovare:2.4. SPRING CLOUD DATA FLOW 5
∗ elaborazione dei dati in stream in tempo reale;
∗ digestione, trasformazione, analisi e immagazzinamento dati;
∗ connettori per vari Database Management System[g] ;
∗ dashboard operazionale: metriche, controllo stato e gestione da remoto;
∗ piattaforme supportate: Cloud Foundry, Kubernetes, Apache Yarn, Apache
Mesos;Capitolo 3
Descrizione dello stage
In questo capitolo andrò a descrivere più in dettaglio le attività svolte durante lo stage.
3.1 Introduzione al progetto
Il progetto EasyCheck, come descritto nel primo capitolo all’interno della sezione 2, si
proponeva come obiettivo la creazione di un’applicazione web la quale permettesse ad
un cliente di prenotare il tagliando dell’auto online ad un prezzo competitivo.
Il progetto è partito da un’idea del direttore dell’azienda che, in concomitanza con il
consulente informatico, nonchè il mio tutor interno, hanno definito delle linee guida
per la creazione del suddetto portale.
Le tecnologie da utilizzare sono state scelte dal tutor interno poichè ritenute da lui
(anche in base alla sua esperienza) le più adatte allo scopo.
3.2 Requisiti e obiettivi
Il macro-requisito fondamentale del progetto era la creazione di una struttura articolata
in microservizi per il sito.
A questo seguivano vari requisiti opzionali i quali sono stati preventivamente decisi dal
tutor aziendale e inseriti all’interno di un file di testo.
Giorno per giorno completavamo l’implementazione di uno o più requisiti e, in seguito
ad una consultazione con il tutor aziendale, ne venivano aggiunti di nuovi.
Abbiamo inoltre fatto un paio di riunioni con la direzione dell’azienda, durante le
quali è stato verificato lo stato di avanzamento del progetto e sono state fatte alcune
modifiche ai requisiti, aggiungendone diversi.
Praticamente tutti i requisiti sono stati definiti nello specifico durante il corso del
tirocinio, a progetto già avviato.
78 CAPITOLO 3. DESCRIZIONE DELLO STAGE
3.3 Pianificazione
Per la prima settimana io e l’altra stagista abbiamo implementato diverse applicazioni di
prova per imparare ad utilizzare i vari moduli del framework Spring, l’ IDE[g] Netbeans
e il database in MySql.
Durante questa fase sono stati creati tre microservizi "di servizio" che abbiamo poi
utilizzato anche nel progetto vero e proprio (descritti nella sezione 5.1) e abbiamo fatto
delle prove anche con Hystrix e i log, seguendo questo esempio
https://howtodoinjava.com/spring-cloud/microservices-monitoring/.
Per lo sviluppo abbiamo utilizzato una metodologia simile a quella agile sia all’interno
del team di sviluppo, sia a livello progettuale. Questo grazie al fatto che avevamo la
possibilità di confrontarci quasi quotidianamente con il tutor aziendale per mostrare
i progressi e decidere come procedere, e, un po’ meno di frequente, ci siamo potuti
confrontare anche con il direttivo dell’azienda.
Come prima attività del progetto vero e proprio, abbiamo deciso, durante una riunione,
come frammentare il database pensando a come suddividere in diversi microservizi la
struttura del sito.
Dopo questa prima fase collettiva la creazione dei microservizi è stata divisa in due
parti uguali tra me e l’altra stagista.
Durante questa fase abbiamo creato e testato i diversi microservizi, creando così la
struttura sulla quale si basa il sito.
Infine ci siamo suddivisi la parte di Frontend dedicata all’utente finale e la parte di
Backend dedicata invece alla parte amministrativa.
Come strumento di versionamento abbiamo utilizzato Bitbucket e come supporto per
la comunicazione con il tutor (che non sempre era presente) abbiamo utilizzato Skype.
3.4 Piano di lavoro
Il piano di lavoro redatto dal tutor aziendale Carlo Gambirasio era così composto:
∗ Prima settimana: studio microservices e web services RESTful;
∗ Seconda settimana: studio Framework Spring e Spring Cloud;
∗ Terza settimana: Hibernate/Spring Data, implementazione Basi Dati del proget-
to;
∗ Quarta settimana: Realizzazione Frontend del portale;
∗ Quinta settimana: Analisi e implementazione dei microservizi del progetto;
∗ Sesta settimana: Analisi e implementazione dei microservizi del progetto;
∗ Settima settimana: Analisi e implementazione dei microservizi del progetto;
∗ Ottava settimana: Test e collaudo finale.
Inizialmente era strutturato così, ma poi ci siamo resi conto che tre settimane di studio
erano troppe, e abbiamo deciso di fare piuttosto un training on the job, in modo da
poter portare il più avanti possibile il progetto.Capitolo 4
Progettazione e codifica
In questo capitolo verranno descritte più in dettaglio la fase di progettazione e codifica del
sito web.
4.1 Tecnologie e strumenti
Di seguito viene data una panoramica delle tecnologie e strumenti utilizzati.
Netbeans
NetBeans (https://netbeans.org/) è un progetto open source di successo con un’am-
pia base di utenti, una comunità in crescita, e oltre 100 partners in tutto il mondo.
Sun Microsystems ha fondato il NetBeans open source project nel Giugno del 2000 e
continua ad essere lo sponsor principale del progetto. A tutt’oggi esistono due prodotti:
NetBeans IDE e NetBeans Platform.
NetBeans IDE è un ambiente di sviluppo destinato ai programmatori per scrivere,
compilare ed eseguire il debug ed il deploy di programmi. E’ scritto in Java ma può
supportare qualsiasi linguaggio di programmazione. Esiste anche un gran numero
di moduli utili per estendere le funzionalità di NetBeans IDE. NetBeans IDE è un
prodotto gratuito senza alcuna restrizione riguardante il suo uso.
Entrambi i prodotti sono open source e gratuiti, per uso commerciale e non. Il codice
sorgente è disponibile sotto la Common Development and Distribution License[g] .
Fonte:Netbeans. url: https://netbeans.org/index_it.html
SQLYog
SQLYog (https://www.webyog.com/product/sqlyog) è un software semplice da usa-
re ed estremamente compatto che offre un’interfaccia grafica per la gestione di qualsiasi
server MySQL. E’ possibile configurare il server e i database da remoto.
Offre la possibilità di importare dati molto velocemente, dispone di uno strumento per
la sincronizzazione dei dati e molto altro ancora.
910 CAPITOLO 4. PROGETTAZIONE E CODIFICA
Bitbucket
Bitbucket (https://bitbucket.org/) è più che uno strumento di gestione del codice
Git: Bitbucket mette a disposizione dei team uno spazio in cui pianificare i progetti,
collaborare su codici, effettuare test e distribuirne i risultati.
Tra le sue features possiamo trovare:
∗ Repository privati illimitati gratuiti;
∗ Integrazione con Jira[g] e Trello[g] ;
∗ Continuos delivery integrata.
4.2 Progettazione architetturale
Come architettura è stato scelta quella a microservizi.
I microservizi sono una tecnica di sviluppo software, una variante dello stile strutturale
dell’architettura orientata ai servizi, che organizza un’applicazione come una raccolta
di servizi liberamente associati. In un’architettura di microservizi, i servizi sono precisi
e i protocolli sono leggeri.
Ogni servizio è:
∗ Facilmente manutenibile e testabile;
∗ Ha una bassa dipendenza dagli altri servizi;
∗ Rilasciabile indipendentemente;
∗ Sviluppabile da un piccolo team;
I servizi interagiscono tra loro attraverso il protocollo HTTP[g] /REST[g] . Ogni servizio
ha il proprio database, proprio per massimizzare l’indipendenza tra servizi.4.3. DESIGN PATTERN UTILIZZATI 11
4.3 Design Pattern utilizzati
Figura 4.1: Design Patterns for Microservices. url: https : / / medium . com /
@madhukaudantha/microservice-architecture-and-design-patterns-for-
microservices-e0e5013f
Come possiamo notare nella figura soprastante i microservizi hanno dei propri
design patterns.
Di seguito verranno riportarti i pattern utilizzati nel dettaglio.12 CAPITOLO 4. PROGETTAZIONE E CODIFICA
4.3.1 Database per Service
Figura 4.2: Database per service
Come possiamo notare nelle precedente immagine ogni servizio ha il proprio database,
accessibile solo attraverso l’utilizzo dell’API[g] del servizio stesso.
Questo favorisce l’indipendenza tra servizi ma allo stesso tempo forza l’utilizzo di più
servizi per alcune transizioni.
Fonte: Database per Service Pattern. url: https://microservices.io/patterns/
data/database-per-service.html4.3. DESIGN PATTERN UTILIZZATI 13
4.3.2 Aggregator o API compostion Pattern
Figura 4.3: Aggregator Pattern
Per ovviare al "problema" delle informazioni distribuite nei diversi microservizi,
l’aggregator si occupa di mettere insieme le varie informazioni richiamare i diversi
microservizi.
Nella figura 5.15 possiamo notare diverse classi denominate "nomeClasseDetails", le
quali sono il risultato di questo pattern.
Queste classi sono implementate nei due servizi classificati appunto come "Aggregator",
cioè backend e frontend.
Fonte: API Composition Pattern. url: https://microservices.io/patterns/
data/api-composition.html14 CAPITOLO 4. PROGETTAZIONE E CODIFICA
4.3.3 Gateway Routing Pattern
Figura 4.4: Gateway Routing Pattern
Indirizza tutte le richieste per i microservizi ad un singolo gateway (sezione 5.1.3) ,
il quale si occupa poi di inoltrale ai giusti microservizi.
Questo permette di esporre un unico indirizzo (quello del gateway) per poter effettuare
le richieste ai microservizi.
Fonte: Gateway Routing Pattern. url: https://docs.microsoft.com/bs- cyrl-
ba/azure/architecture/patterns/gateway-routing4.3. DESIGN PATTERN UTILIZZATI 15
4.3.4 Service Discovery Pattern
Figura 4.5: Service Discovery Pattern
Questo pattern è implementato attraverso il servizio "discovery" (sezione 5.1.3) il
quale permette di tenere traccia di tutti i servizi attivi e utilizzabili tenendo traccia
dei loro URL[g] .
Fonte: Service Discovery Pattern. url: https://microservices.io/patterns/
client-side-discovery.html16 CAPITOLO 4. PROGETTAZIONE E CODIFICA
4.3.5 Circuit Breaker Pattern
Figura 4.6: Circuit Breaker Pattern
Serve per gestire gli errori che possono avvenire nei microservizi, moderandone il
carico quando vanno in sovraccarico (half-open) oppure fornendo una via alternativa
quando non sono disponibili (closed).
Fonte: Circuit Breaker Pattern. url: https://docs.microsoft.com/bs- cyrl-
ba/azure/architecture/patterns/circuit-breakerCapitolo 5
Microservizi
In questo capitolo verranno approfonditi meglio i vari microservizi implementati e le loro
implementazioni
5.1 Service
In questa sezione verranno spiegati i tre servizi "di servizio" cioè non specifici del-
l’applicazione stessa, ma utili trasversalmente a qualsiasi applicazione implementata
attraverso l’utilizzo di Spring Cloud.
5.1.1 config
Questo servizio rappresenta il server di configurazione per tutti i servizi. Questo server
espone una API REST attraverso la quale i vari servizi possono consumare le proprietà
di configurazione. I file di configurazione dei vari servizi sono memorizzati in una
repository su Bitbucket creata appositamente per il config server.
Nella figura sottostante possiamo vedere i vari file di configurazione (uno per servizio)
denominati come nomeservizio.properties.
Possiamo infine notare le varie porte assegnate ai servizi.
1718 CAPITOLO 5. MICROSERVIZI
Figura 5.1: Repository Bitbucket EasyCheck-config5.2. CORE 19
5.1.2 discovery
Questo servizio utilizza Eureka Server per mappare tutti i servizi attivi. Eureka Server
è un modulo di Spring Cloud Netflix che permette di registrare i microservizi sulle
loro porte e mostrarli su una dashboard una volta attivi. Qui sotto possiamo vedere
un frammento di dashboard estratto dal libro: Craig Walls. Spring in Action, Fifth
Edition. MANNING, 2019.
Figura 5.2: Frammento di dashboard Eureka
5.1.3 gateway
Questo servizio prende in carico qualsiasi richiesta avvenga da un altro microservizio,
dalla richiesta di configurazione alla chiamata ad un microservizio, indirizzandola al
servizio giusto. Il suo indirizzo infatti è l’unico esposto.
5.2 Core
In questa sezione verranno invece descritti i servizi caratteristici dell’applicazione stessa
5.2.1 Caratteristiche comuni
Ogni microservizio è funzionante indipendentemente dagli altri microservizi. Un singolo
microservizio è composto da:
∗ model: classe contenitore che corrisponde all’entità all’interno del database;
∗ repository: interfaccia utilizzata per le interazioni con il database;
∗ service: servizio che elabora le risposte. Viene richiamato dal controller e utilizza
repository;
∗ controller: interfaccia principale dalla quale vengono gestite le richieste al
microservizio;
∗ application: classe base per avviare il microservizio;
∗ bootstrap-properties: file che “guida” il recupero della configurazione da cloud
(Bitbucket).
Ogni microservizio ha il proprio database sul quale memorizza o dal quale recupera i
dati necessari.
Le chiamate ai microservizi vengono processate dal gateway e arrivano ai singoli
microservizi, dove, attraverso il mapping fatto nei controller, viene richiamato il
service necessario e viene restituita una response entity con un codice HTTP e un
JSon[g] contenente i dati.20 CAPITOLO 5. MICROSERVIZI
5.2.2 car-service
Servizio che si occupa di memorizzare le caratteristiche di una macchina. Il campo
ktype è ottenuto richiamando un web-service esterno il quale inserendo la targa fornisce,
attraverso una chiamata REST, tutte le info relative alla macchina. Metodi mappati:
∗ findAllCar() : ritorna una lista con tutte le macchine;
∗ getCarById(Long id) : ritorna la macchina identificata dall’id inserito nel path;
∗ deleteCarById(Long id) : cancella la macchina identificata dall’id inserito nel
path;
∗ updateCarById(Long id, Car car) : aggiorna la macchina identificata dall’id
inserito nel path utilizzando la macchina all’interno del request body;
∗ saveCar(Car car) : aggiunge una nuova macchina o ne aggiorna una già esistente;
∗ getCarByKtype(Long kType) : restituisce la macchina identificata dal ktype
inserito nel path.
Figura 5.3: Database car-service5.2. CORE 21
5.2.3 cart-service
Servizio che si occupa della gestione dei carrelli salvati per l’utente, memorizzando
anche i dati della sua auto. È prevista inoltre una tabella di log per memorizzare anche
i carrelli non salvati oppure fatti da utenti non loggati. Metodi mappati:
∗ findAllCart() : ritorna una lista con tutti i carrelli;
∗ getCartById(Long id) : ritorna il carrello identificato dall’id inserito nel path;
∗ deleteCartById(Long id) : cancella il carrello identificato dall’id inserito nel path;
∗ updateCartById(Long id, Cart cart) : aggiorna il carrello identificato dall’id
inserito nel path utilizzando il carrello all’interno del request body;
∗ saveCar(Cart cart) : aggiunge un nuovo carrello o ne aggiorna uno già esistente;
∗ getCarByUserId(Long userId) : restituisce il carrello identificato dall’userId
inserito nel path.
∗ saveProds(Long[] prods,Long cartId): aggiunge al carrello identificato dall’id
inserito nel path i prodotti con gli id corrispondenti ai valori presenti in prods;
∗ saveUtils(Long[] utils,Long cartId): aggiunge al carrello identificato dall’id inserito
nel path i servizi con gli id corrispondenti ai valori presenti in utils.
Figura 5.4: Database cart-service22 CAPITOLO 5. MICROSERVIZI
5.2.4 garage-service
Servizio che si occupa della gestione delle officine e dei network di officine. Per la
gestione delle aperture di ogni officina è stato pensato di creare una stringa formattata
in un certo modo per poi poterla parsare.
All’interno di garage vengono memorizzate anche longitudine e latitudine per poter
poi creare una mappa delle officine con Google Maps.
La tabella delle disponibilità è volta a memorizzare gli orari che l’autofficina mette
a disposizione del servizio, invece quella delle prenotazioni serve a memorizzare le
prenotazioni di ogni officina.
Il controller di garage, a differenza degli altri dei servizi core, i quali sono tutti REST
controller, è un controller ibrido.
Metodi mappati:
∗ findAllGarage() : ritorna una lista con tutti i garage;
∗ getGarageById(Long id) : ritorna il garage identificato dall’id inserito nel path;
∗ deleteGarageById(Long id) : cancella il garage identificato dall’id inserito nel
path;
∗ updateGarageById(Long id, Garage garage) : aggiorna il garage identificato
dall’id inserito nel path utilizzando il garage all’interno del request body;
∗ saveGarage(Garage garage) : aggiunge un nuovo garage o ne aggiorna uno già
esistente;
∗ findAllNetwork() : ritorna una lista con tutti i network;
∗ getNetworkById(Long id) : ritorna il garage identificato dall’id inserito nel path;
∗ deleteNetworkById(Long id) : cancella il network identificato dall’id inserito nel
path;
∗ saveNetwork(Network network) : aggiunge un nuovo network o ne aggiorna uno
già esistente;
∗ getCalendar(Long garageId,Long packId) : restituisce una pagina calendario per
il garage specificato nel path. La pagina sarà diversa in base all’utente che la
richiede (vedi sotto). Il packId è un parametro richiesto solo se la richiesta viene
fatta da un normale utente;
∗ addEvent(Long garageId, MultiValueMap event) : aggiunge
l’evento creato nella pagina calendario al garage corrente;
∗ deleteEvent(Long garageId, MultiValueMap event) : rimuove
l’evento selezionato nella pagina calendario del garage corrente.5.2. CORE 23
Figura 5.5: Database garage-service
micro-frontend
All’interno di questo microservizio è presente un micro-frontend1 il quale permette di
restituire delle pagine web da inserire all’interno di una pagina ospite come frammento.
In questo caso si tratta di un calendario, implementato utilizzando fullcalendar.io
(https://fullcalendar.io/) il quale, in base a chi effettua la chiamata, esporrà delle
funzionalità diverse.
calendario utente
Il calendario sottostante è quello visto dall’utente, il quale, cliccando sulle aree verdi,
può decidere quando fissare l’appuntamento con l’officina richiesta.
1 Microfrontends in our application. url: https : / / lucamezzalira . com / category / micro -
frontends/.24 CAPITOLO 5. MICROSERVIZI
Figura 5.6: Calendario utente
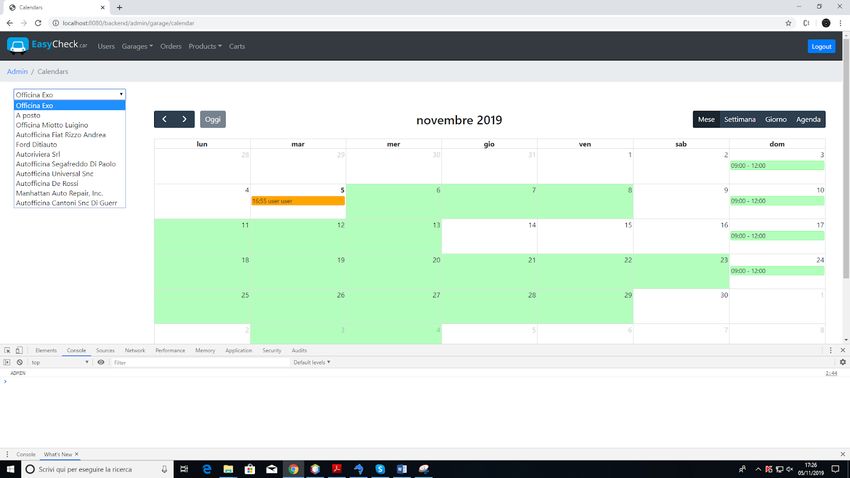
calendario admin
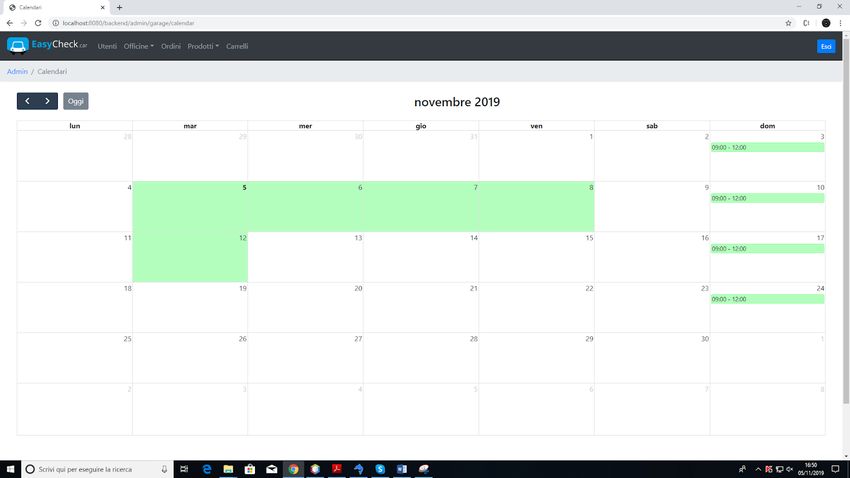
Questo calendario invece è quello visto dall’admin, il quale può scegliere tutte le officine
col menù a sinistra e vedere tutte le disponibilità o gli appuntamenti dell’officina
selezionata.
Figura 5.7: Calendario admin5.2. CORE 25
calendario officina
Infine il calendario dell’officina, la quale può aggiungere le disponibilità per la propria
officina e vedere le prenotazioni attive con i dettagli.
Figura 5.8: Calendario officina26 CAPITOLO 5. MICROSERVIZI
5.2.5 good-service
Servizio che si occupa della gestione dei prodotti del portale.
Per l’internazionalizzazione sono presenti i nome sia in inglese che in italiano. Metodi
mappati:
∗ findAllPack() : ritorna una lista con tutti i pacchetti;
∗ getPackById(Long id) : ritorna il pacchetto identificato dall’id inserito nel path;
∗ deletePackById(Long id) : cancella il pacchetto identificato dall’id inserito nel
path;
∗ savePack(Pack pack) : aggiunge un nuovo pacchetto o ne aggiorna uno già
esistente;
∗ findAllProduct() : ritorna una lista con tutti i prodotti;
∗ getProductById(Long id) : ritorna il prodotto identificato dall’id inserito nel
path;
∗ deleteProductById(Long id) : cancella il prodotto identificato dall’id inserito nel
path;
∗ saveProduct(Product product) : aggiunge un nuovo prodotto o ne aggiorna uno
già esistente;
∗ findAllService() : ritorna una lista con tutti i servizi;
∗ getServiceById(Long id) : ritorna il servizio identificato dall’id inserito nel path;
∗ deleteServiceById(Long id) : cancella il servizio identificato dall’id inserito nel
path;
∗ saveService(Service service) : aggiunge un nuovo servizio o ne aggiorna uno già
esistente;5.2. CORE 27
Figura 5.9: Database good-service
5.2.6 order-service
Servizio che si occupa della gestione degli ordini.
In order-status viene tenuto traccia dello storico degli stati di ogni ordine. Metodi
mappati:
∗ findAllOrder() : ritorna una lista con tutti gli ordini;
∗ getOrderById(Long id) : ritorna l’ordine identificato dall’id inserito nel path;
∗ deleteOrderById(Long id) : cancella l’ordine identificato dall’id inserito nel path;
∗ saveOrder(Order order) : aggiunge un nuovo ordine o ne aggiorna uno già
esistente;
∗ findAllStatus() : ritorna una lista con tutti i prodotti;
∗ getStatusById(Long id) : ritorna il prodotto identificato dall’id inserito nel path;
∗ findOrderStatusByOrderId(Long id) : ritorna lo stato dell’ordine identificato
dall’id inserito nel path;
∗ findOrderByGarageId(Long id) : ritorna una lista degli ordini del garage identifi-
cato dall’id nel path.28 CAPITOLO 5. MICROSERVIZI
Figura 5.10: Database order-service
5.2.7 user-service
Servizio che si occupa della gestione degli utenti.
Ogni utente può avere più indirizzi, più macchine e più ruoli.
La tabella token serve invece all’attivazione degli utenti.
Metodi mappati:
∗ findAllUser() : ritorna una lista con tutti gli utenti;
∗ getUserById(Long id) : ritorna l’utente identificato dall’id inserito nel path;
∗ deleteUserById(Long id) : cancella l’utente identificato dall’id inserito nel path;
∗ saveUser(User user) : aggiunge un nuovo utente o ne aggiorna uno già esistente;
∗ getUserByUsername(String username) : ritorna l’utente identificato dall’userna-
me inserito nel path;
∗ saveNewToken(Token token) : aggiunge un nuovo token ricavandolo dal body
della richiesta;
∗ getUserByEmail(String email) : ritorna l’utente identificato dall’email inserita
nel path;
∗ getAllUserAddressByUserId(Long userId) : ritorna una lista con tutti gli indirizzi
dell’utente identificato dall’userid inserito nel path;5.2. CORE 29
∗ getUserAddressById(Long id) : ritorna l’indirizzo utente identificato dall’id
inserito nel path;
∗ deleteUserAddressById(Long id) : cancella l’indirizzo utente identificato dall’id
inserito nel path;
∗ saveUserAddress(UserAddress userAddress) : aggiunge un nuovo indirizzo utente
o ne aggiorna uno già esistente;
∗ getUserCarById(Long id) : ritorna la macchina utente identificato dall’id inserito
nel path;
∗ findUserCarByUserId(Long userId) : ritorna la macchina utente identificata
dall’id inserito nel path;
∗ deleteUserCarById(Long id) : cancella la macchina utente identificata dall’id
inserito nel path;30 CAPITOLO 5. MICROSERVIZI
Figura 5.11: Database user-service
5.3 Aggregator
I due servizi che espongono le funzionalità all’utente attraverso le pagine web, elabo-
rando i dati attraverso chiamate REST ai microservizi.
5.3.1 Frontend
Questo servizio si occupa di gestire tutte le pagine destinate all’utente finale, come ad
esempio l’home page. Non parlerò di questo servizio, dato che la sua implementazione
non è stata fatta da me.5.3. AGGREGATOR 31
Figura 5.12: Home page
5.3.2 Backend
Questo servizio si occupa della gestione delle pagine amministrative, ossia per utenti
admin o garage (officine).
Come gli altri servizi anche il modulo di backend ha i propri controller e servizi, i quali
si occupano rispettivamente di gestire le chiamate in entrata e di effettuare le chiamate
agli altri microservizi.
Controllers32 CAPITOLO 5. MICROSERVIZI
Figura 5.13: Controllers Backend
Services5.3. AGGREGATOR 33
Figura 5.14: Services Backend
Diagramma delle classi
Di seguito troviamo la lista di tutte le classi che sono state create come contenitori di
dati per il modulo di Backend.34 CAPITOLO 5. MICROSERVIZI
Figura 5.15: Diagramma delle classi BackendCapitolo 6
Conclusioni
6.1 Raggiungimento degli obiettivi
Alla fine del tirocinio abbiamo fatto una riunione con il tutor interno, il quale si è
ritenuto veramente soddisfatto del lavoro svolto.
Abbiamo creato una struttura solida per il portale e abbiamo portato a termine diversi
requisiti facoltativi.
Se avessimo avuto più tempo avremmo potuto creare più test (ad esempio quelli di
integrazione) e magari deployare il sito con l’utilizzo di Docker[g] .
6.2 Sviluppo futuro dell’applicativo
L’applicazione web ha un grande impatto innovativo come idea e di sicuro può essere
una buona risorsa su cui investire.
Il portale non è ancora pronto per essere utilizzato ma comunque grazie alla solida
base che abbiamo creato, necessiterà di poco lavoro per poter diventare fruibile.
Da questo punto di vista abbiamo cercato di inserire tutti i commenti necessari per
la comprensione del codice da noi scritto, oltre ad un manuale sviluppatore sia per i
microservizi implentati, sia per la parte di frontend che per la parte di backend.
L’azienda ha già espresso il suo interesse nel portare a termine il progetto, per poterlo
poi utilizzare.
6.3 Conoscenze acquisite
Grazie a questo tirocinio sono riuscito ad apprendere diverse nozioni che durante il
corso di studi non avevo mai visto, oppure erano state viste in maniera sbrigativa.
Tra le nuove conoscenze acquisite ci sono:
∗ framework Java Spring;
∗ architettura a microservizi;
∗ microservizi RESTful;
∗ jQuery;
3536 CAPITOLO 6. CONCLUSIONI
∗ Hibernate.
Tra le conoscenze approfondite ci sono:
∗ Java;
∗ html;
∗ css;
∗ MySql;
∗ javascript;
∗ git.
6.4 Lavoro in team
Grazie a questa esperienza ho migliorato le mie abilità nel lavoro di squadra, soprattutto
a livello di comunicazione diretta, poichè lavoravamo a contatto diretto.
Grazie poi alla collaborazione con l’altra stagista siamo riusciti ad accelerare i tempi
cercando di aiutarci ove possibile, anche scambiandoci parti di codice quando necessa-
rio.
Inoltre, grazie alle riunioni a cadenza giornaliera con il tutor interno e alle riunioni con
il dirigente, ho capito come prendere decisioni sul progetto in base ai tempi stimati.
6.5 Valutazione personale
Mi ritengo pienamente soddisfatto dell’esperienza in Exo, dove ho acquisito delle
conoscenze professionali utili e ho imparato cosa significa lavorare all’interno di un
ufficio non solo informatico.
Inizialmente ero un po’ titubante per il semplice fatto che sarei andato a lavorare in
un’azienda non prettamente informatica, ma, dopo aver conosciuto Carlo Gambirasio,
persona, a mio parere, di grande spessore professionale, mi sono convinto che l’espe-
rienza sarebbe stata positiva.
Alla fine ho capito che non mi sbagliavo, infatti questa esperienza lavorativa mi ha
sicuramente aiutato a crescere non solo dal punto di vista professionale, ma anche da
quello umano, dato che l’ambiente era giovane e stimolante.
Ho imparato inoltre a gestire il rapporto innanzitutto tra colleghi, oltre che con il
responsabile e, seppur marginalmente, con la dirigenza.Glossario
API In informatica, entro un programma, con Application Programming Interface
(API) si indica un insieme di procedure (in genere raggruppate per strumenti
specifici) atte all’espletamento di un dato compito; spesso tale termine designa le
librerie software di un linguaggio di programmazione.
Esistono vari design model per le API. Le interfacce intese per la massima velocità
di esecuzione spesso consistono in una serie di funzioni, procedure, variabili e
strutture dati. Esistono anche altri modelli come gli interpreti usati per valutare
le espressioni come con ECMAScript/JavaScript. Una buona API fornisce una
"scatola nera", cioè un livello di astrazione che evita al programmatore di sapere
come funzionano le API ad un livello più basso. Questo permette di riprogettare
o migliorare le funzioni all’interno dell’API senza cambiare il codice che si affida
ad essa. 12, 37
CDDL Common Development and Distribution License (CDDL) è una licenza open
source sviluppata da Sun Microsystems. La licenza è basata sulla Mozilla Public
License, versione 1.1. La CDDL è stata sottoposta per l’approvazione alla Open
Source Initiative il 1o dicembre 2004, e riconosciuta come licenza open source nel
gennaio del 2005. Come la MPL, si tratta di una licenza debolmente copyleft:
richiede infatti che solo il codice originale modificato sia distribuito con lo stesso
tipo di licenza, non l’intera opera che usa quel codice. È incompatibile con
la GNU GPL e con la GNU LGPL, come avviene normalmente per le licenze
copyleft che non siano pensate esplicitamente per esserlo. Dopo aver acquisito
SUN, Oracle ha rilasciato una nuova versione (1.1) della licenza, aggiungendo
una clausola riguardante i brevetti. 9, 43
Convention over configuration in informatica con il termine Convention over con-
figuration (ing. interfaccia di programmazione di un’applicazione) si indica ogni
insieme di procedure disponibili al programmatore, di solito raggruppate a for-
mare un set di strumenti specifici per l’espletamento di un determinato compito
all’interno di un certo programma. La finalità è ottenere un’astrazione, di solito
tra l’hardware e il programmatore o tra software a basso e quello ad alto livello
semplificando così il lavoro di programmazione. 4, 37
DBMS In informatica, un Database Management System, abbreviato in DBMS o
Sistema di gestione di basi di dati, è un sistema software progettato per consentire
la creazione, la manipolazione e l’interrogazione efficiente di database, per questo
detto anche "gestore o motore del database", è ospitato su architettura hardware
dedicata oppure su semplice computer. La teoria dei database e dei DBMS
rappresenta da sempre uno dei filoni più solidi e importanti dell’informatica.
3738 Glossary
Se in passato i DBMS erano diffusi principalmente presso le grandi aziende e
istituzioni che potevano permettersi l’impegno economico derivante dall’acquisto
delle grandi infrastrutture hardware necessarie per realizzare un sistema di
database efficiente, oggi il loro utilizzo è diffuso praticamente in ogni contesto.
L’espressione applicazione enterprise, che nel gergo informatico si riferisce ad
applicazioni legate al business delle aziende che le utilizzano, implica quasi "per
definizione" la presenza di una o più basi di dati amministrate da uno o più
DBMS. Un DBMS è differente dal concetto generale di applicazione sulle banche
dati in quanto è progettato per sistemi multi-utente: i DBMS si appoggiano a
kernel che supportano nativamente il multitasking e il collegamento in rete, infatti
una tipica applicazione per la gestione dei database non includerebbe queste
funzionalità, ma si appoggerebbe al sistema operativo per consentire all’utente
di usufruirne. 5, 43
DI Dependency injection (DI) è un design pattern della Programmazione orientata agli
oggetti il cui scopo è quello di semplificare lo sviluppo e migliorare la testabilità
di software di grandi dimensioni.
Per utilizzare tale design pattern è sufficiente dichiarare le dipendenze di cui un
componente necessita (dette anche interface contracts). Quando il componente
verrà istanziato, un iniettore si prenderà carico di risolvere le dipendenze (attuan-
do dunque l’inversione del controllo). Se è la prima volta che si tenta di risolvere
una dipendenza l’injector istanzierà il componente dipendente, lo salverà in un
contenitore di istanze e lo restituirà. Se non è la prima volta, allora restituirà la
copia salvata nel contenitore. Una volta risolte tutte le dipendenze, il controllo
può tornare al componente applicativo. 3, 43
Docker Docker è un progetto open-source che automatizza il deployment (consegna o
rilascio al cliente, con relativa installazione e messa in funzione o esercizio, di
una applicazione o di un sistema software tipicamente all’interno di un sistema
informatico aziendale) di applicazioni all’interno di contenitori software, fornendo
un’astrazione aggiuntiva grazie alla virtualizzazione a livello di sistema operativo
di Linux. Docker utilizza le funzionalità di isolamento delle risorse del kernel
Linux come ad esempio cgroups e namespaces per consentire a "container"
indipendenti di coesistere sulla stessa istanza di Linux, evitando l’installazione e
la manutenzione di una macchina virtuale. I namespace del kernel Linux per lo più
isolano ciò che l’applicazione può vedere dell’ambiente operativo, incluso l’albero
dei processi, la rete, gli ID utente ed i file system montati, mentre i cgroups
forniscono l’isolamento delle risorse, inclusa la CPU, la memoria, i dispositivi di
I/O a blocchi e la rete. A partire dalla versione 0.9, Docker include la libreria
libcontainer per poter utilizzare direttamente le funzionalità di virtualizzazione
del kernel Linux, in aggiunta alle interfacce di virtualizzazione astratte come
libvirt, LXC e systemd-nspawn. Docker implementa API di alto livello per
gestire container che eseguono processi in ambienti isolati. Poiché utilizza delle
funzionalità del kernel Linux (principalmente cgroups e namespaces), un container
di Docker, a differenza di una macchina virtuale, non include un sistema operativo
separato. Al contrario, utilizza le funzionalità del kernel e sfrutta l’isolamento
delle risorse (CPU, memoria, I/O a blocchi, rete) ed i namespace separati per
isolare ciò che l’applicazione può vedere del sistema operativo. Docker accede
alle funzionalità di virtualizzazione del kernel Linux o direttamente utilizzando la
libreria libcontainer, che è disponibile da Docker 0.9, o indirettamente attraverso
libvirt, LXC o systemd-nspawn. Utilizzando i container, le risorse possono essereGlossary 39
isolate, i servizi limitati ed i processi avviati in modo da avere una prospettiva
completamente privata del sistema operativo, col loro proprio identificativo, file
system ed interfaccia di rete. Più container condividono lo stesso kernel, ma
ciascuno di essi può essere costretto ad utilizzare una certa quantità di risorse,
come la CPU, la memoria e l’I/O. L’utilizzo di Docker per creare e gestire
i container può semplificare la creazione di sistemi distribuiti, permettendo a
diverse applicazioni o processi di lavorare in modo autonomo sulla stessa macchina
fisica o su diverse macchine virtuali. Ciò consente di effettuare il deployment di
nuovi nodi solo quando necessario, permettendo uno stile di sviluppo del tipo
platform as a service (PaaS) per sistemi come Apache Cassandra, MongoDB o
Riak. Docker inoltre semplifica la creazione e la gestione di code di lavori in
sistemi distribuiti. 35, 38
HTTP In telecomunicazioni e informatica l’HyperText Transfer Protocol (HTTP)
(protocollo di trasferimento di un ipertesto) è un protocollo a livello applicativo
usato come principale sistema per la trasmissione d’informazioni sul web ovvero
in un’architettura tipica client-server. Le specifiche del protocollo sono gestite
dal World Wide Web Consortium (W3C). Un server HTTP generalmente resta
in ascolto delle richieste dei client sulla porta 80 usando il protocollo TCP a
livello di trasporto. L’HTTP è un protocollo che lavora con un’architettura di
tipo client/server: il client esegue una richiesta e il server restituisce la risposta
mandata da un altro host. Nell’uso comune il client corrisponde al browser ed il
server la macchina su cui risiede il sito web. Vi sono quindi due tipi di messaggi
HTTP: messaggi richiesta e messaggi risposta. HTTP differisce da altri protocolli
di livello 7 come FTP, per il fatto che le connessioni vengono generalmente
chiuse una volta che una particolare richiesta (o una serie di richieste correlate)
è stata soddisfatta. Questo comportamento rende il protocollo HTTP ideale per
il World Wide Web, in cui le pagine molto spesso contengono dei collegamenti
(link) a pagine ospitate da altri server diminuendo così il numero di connessioni
attive limitandole a quelle effettivamente necessarie con aumento quindi di
efficienza (minor carico e occupazione) sia sul client che sul server. Talvolta
però pone problemi agli sviluppatori di contenuti web, perché la natura senza
stato (stateless) della sessione di navigazione costringe ad utilizzare dei metodi
alternativi - tipicamente basati sui cookie - per conservare lo stato dell’utente.
10, 43
IDE Un ambiente di sviluppo integrato (in lingua inglese integrated development
environment ovvero IDE, anche integrated design environment o integrated de-
bugging environment, rispettivamente ambiente integrato di progettazione e
ambiente integrato di debugging), in informatica, è un software che, in fase di
programmazione, supporta i programmatori nello sviluppo del codice sorgente di
un programma.
Spesso l’IDE aiuta lo sviluppatore segnalando errori di sintassi del codice diretta-
mente in fase di scrittura, oltre a tutta una serie di strumenti e funzionalità di
supporto alla fase di sviluppo e debugging. 8, 43
IOC In programmazione, soprattutto quella ad oggetti, l’inversione del controllo (in
inglese inversion of control, abbreviato in IoC) è un pattern per cui un componente
di livello applicativo riceve il controllo da un componente appartenente a un
libreria riusabile. Questo schema ribalta quello tradizionale della programmazione40 Glossary
procedurale, dove il codice applicativo svolge i propri compiti richiamando (e
quindi passando il controllo a) procedure di libreria. 3, 43
Json In informatica, nell’ambito della programmazione web, JSON, acronimo di
JavaScript Object Notation, è un formato adatto all’interscambio di dati fra
applicazioni client/server. È basato sul linguaggio JavaScript Standard ECMA-
262 3a edizione (dicembre 1999), ma ne è indipendente. Viene usato in AJAX
come alternativa a XML/XSLT. La semplicità di JSON ne ha decretato un
rapido utilizzo specialmente nella programmazione in AJAX. Il suo uso tramite
JavaScript è particolarmente semplice, infatti l’interprete è in grado di eseguirne
il parsing tramite la funzione JSON.parse(). Questo lo ha reso velocemente molto
popolare a causa della diffusione della programmazione in JavaScript nel mondo
del Web. I tipi di dati supportati da questo formato sono:
∗ booleani;
∗ interi;
∗ stringhe;
∗ array;
∗ array associativi;
∗ null.
. 19, 43
Jira Jira è una suite di software proprietari per il tracciamento delle segnalazioni
sviluppato da Atlassian, che consente il bug tracking e la gestione dei progetti agile.
Il nome del prodotto è un troncamento di Gojira, traslitterazione giapponese di
Godzilla.
Secondo Atlassian, Jira viene utilizzata per il monitoraggio dei problemi e la
gestione dei progetti da oltre 75.000 clienti in 122 paesi.
Jira si divide in quattro pacchetti:
∗ Jira Core è concepito come project management generico;
∗ Jira Software include il software di base, comprese le funzionalità di gestione
dei progetti agile (precedentemente un prodotto separato: Jira Agile);
∗ Jira Service Desk è destinato all’uso da parte dei desk IT o di servizi
aziendali;
∗ Jira Align è un aggregatore di dati a livello di team per la condivisione del
lavoro in tempo reale.
. 10, 40
MVC in informatica, è un pattern architetturale molto diffuso nello sviluppo di sistemi
software, in particolare nell’ambito della programmazione orientata agli oggetti,
in grado di separare la logica di presentazione dei dati dalla logica di business. 3,
43
REST Representational State Transfer (REST) è uno stile architetturale (di archi-
tettura software) per i sistemi distribuiti. L’espressione "representational state
transfer" e il suo acronimo "REST" furono introdotti nel 2000 nella tesi diGlossary 41
dottorato di Roy Fielding, uno dei principali autori delle specifiche dell’Hypertext
Transfer Protocol (HTTP), e vennero rapidamente adottati dalla comunità di
sviluppatori su Internet. Il termine REST rappresenta un sistema di trasmissione
di dati su HTTP senza ulteriori livelli (quali ad esempio SOAP). I sistemi REST
non prevedono il concetto di sessione (sono stateless). L’architettura REST si
basa su HTTP; il funzionamento prevede una struttura degli URL ben definita
(atta a identificare univocamente una risorsa o un insieme di risorse) e l’utilizzo
dei verbi HTTP specifici per il recupero di informazioni (GET), per la modifica
(POST, PUT, PATCH, DELETE) e per altri scopi (OPTIONS, ecc.). 10, 43
Trello Trello è un software gestionale in stile Kanban basato sul web. Originariamente
prodotto da Fog Creek Software nel 2011, è stato trasferito ad una società separata
nel 2014, per essere successivamente venduto ad Atlassian nel gennaio 2017. La
società ha sede a New York. Gli utenti possono creare le loro schede attività
con più colonne e scambiare le attività tra di loro. In genere le colonne sono
organizzate in stati dell’attività: Da fare, In corso, Fatto. Il software è utilizzabile
per uso personale e aziendale. Ha una varietà di possibilità di impiego, come
la gestione immobiliare, la gestione di progetti software, i bollettini scolastici,
la pianificazione delle lezioni, la contabilità, il web design, i giochi e la gestione
di casi legali. Una ricca API e la funzionalità di posta elettronica consentono
l’integrazione con i sistemi aziendali o con servizi di integrazione basati su cloud
come IFTTT e Zapier. 10, 41
URL La locuzione Uniform Resource Locator (in acronimo URL), nella terminologia
delle telecomunicazioni e dell’informatica, è una sequenza di caratteri che identifica
univocamente l’indirizzo di una risorsa su una rete di computer, come ad esempio
un documento, un’immagine, un video, tipicamente presente su un host server e
resa accessibile a un client.
È perlopiù utilizzato dai programmatori per indicare risorse web (http), risorse
recuperabili tramite protocolli di trasferimento file (ftp), condivisioni remote
(smb) o accessi a sistemi esterni (ssh). La risoluzione dell’URL in indirizzo IP,
necessario per l’instradamento con il protocollo IP avviene tramite DNS. 15, 41Acronimi
CDDL Common Development and Distribution License. 37
DBMS Database Management System. 37
DI Dependendency Injection. 38
HTTP HyperText Transfer Protocol. 39
IDE Integrated Development Environment. 39
IOC Inversion of Control. 39
Json JavaScript Object Notation. 40
MVC Model View Controller. 40
REST Representational State Transfer. 40
43Bibliografia
Riferimenti bibliografici
Walls, Craig. Spring in Action, Fifth Edition. MANNING, 2019 (cit. a p. 19).
Siti web consultati
API Composition Pattern. url: https://microservices.io/patterns/data/api-
composition.html (cit. a p. 13).
Circuit Breaker Pattern. url: https://docs.microsoft.com/bs-cyrl-ba/azure/
architecture/patterns/circuit-breaker (cit. a p. 16).
Database per Service Pattern. url: https://microservices.io/patterns/data/
database-per-service.html (cit. a p. 12).
Design Patterns for Microservices. url: https://medium.com/@madhukaudantha/
microservice - architecture - and - design - patterns - for - microservices -
e0e5013f (cit. a p. 11).
Gateway Routing Pattern. url: https://docs.microsoft.com/bs-cyrl-ba/azure/
architecture/patterns/gateway-routing (cit. a p. 14).
Microfrontends in our application. url: https://lucamezzalira.com/category/
micro-frontends/ (cit. a p. 23).
Netbeans. url: https://netbeans.org/index_it.html (cit. a p. 9).
Service Discovery Pattern. url: https://microservices.io/patterns/client-
side-discovery.html (cit. a p. 15).
Spring Framework. url: https : / / en . wikipedia . org / wiki / Spring _ Framework
(cit. a p. 3).
45Puoi anche leggere

















































