Sviluppo di un bot Telegram per la visualizzazione di dati aziendali
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Università degli Studi di Padova
Dipartimento di Matematica "Tullio Levi-Civita"
Corso di Laurea in Informatica
Sviluppo di un bot Telegram per la
visualizzazione di dati aziendali
Tesi di laurea triennale
Laureando : Relatore :
Marco Giorgio Prof. Gilberto Filè
Anno Accademico 2016/2017
Sommario Questo documento descrive l'esperienza di stage curricolare svolta dal 3 Luglio 2017 al 10 Settembre 2017, presso l'azienda Miriade, con sede a Thiene (VI). Il documento ha lo scopo di: • illustrare il contesto aziendale nel quale il laureando è stato inserito; • descrivere il progetto di stage; • riportare le attività svolte durante lo stage;

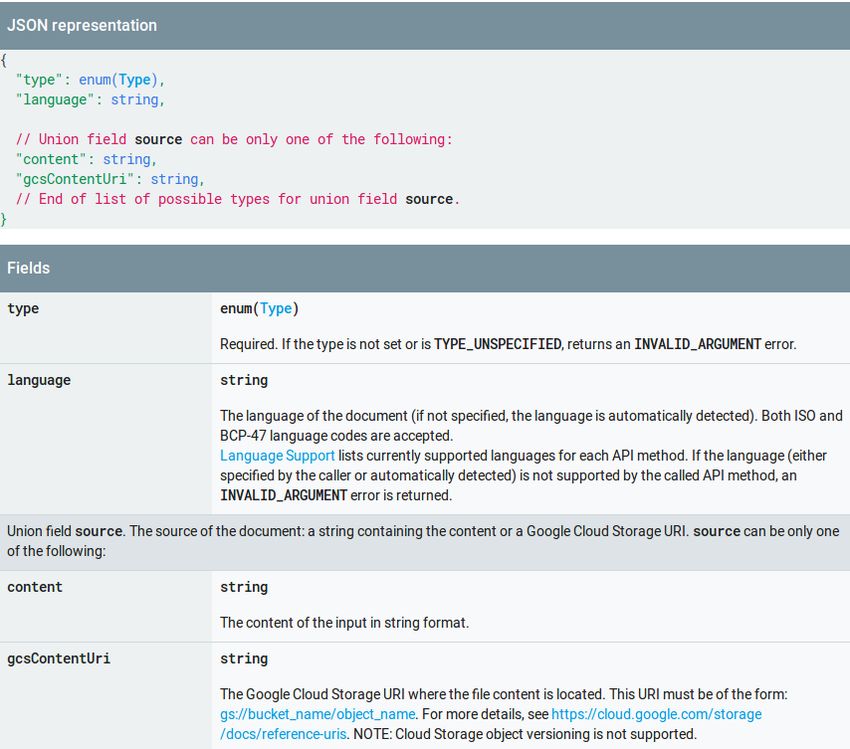
Ringraziamenti
Desidero ringraziare con aetto la mia famiglia, che mi ha supportato e sopportato nei
momenti di di
coltà
Sono grato a tutti i colleghi di Miriade, per avermi aiutato a portare a termine questo
progetto. Un pensiero speciale va al mio amico Riccardo, il cui aiuto è stato determinante
per raggiungere questo traguardo.
Marco Giorgio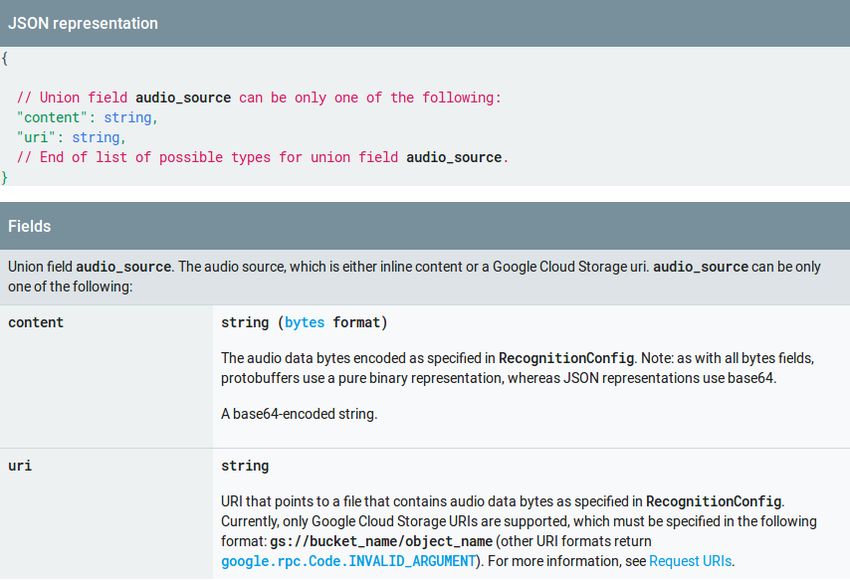
Indice
1 Analisi del contesto aziendale 1
1.1 Miriade e il suo ambito di attività . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Organizzazione aziendale . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2.1 Struttura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2.2 Comunicazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Sviluppo software . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3.1 Metodo di lavoro . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Presentazione dello stage 3
2.1 Descrizione del progetto di stage . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Prodotti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.2 Tecnologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3 Svolgimento dello stage 11
3.1 Metodo di lavoro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2 Attività preliminari . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2.1 Preparazione dell'ambiente di lavoro . . . . . . . . . . . . . . . . . 11
3.2.2 Studio individuale . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.3 Sviluppo del bot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3.1 Analisi dei requisiti . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3.2 Progettazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.3.3 Implementazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.4 Analisi dei principali problemi . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.4.1 Utilizzo di Spring . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.4.2 Utilizzo di pgAdminIII . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.4.3 Metodo agile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4 Conclusioni 43
4.1 Obiettivi raggiunti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.1.1 Funzionalità del bot . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.1.2 Formazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.2 Considerazioni sull'esperienza di stage . . . . . . . . . . . . . . . . . . . . 44
4.2.1 Motivazioni per cui ho intrapreso lo stage . . . . . . . . . . . . . . 44
I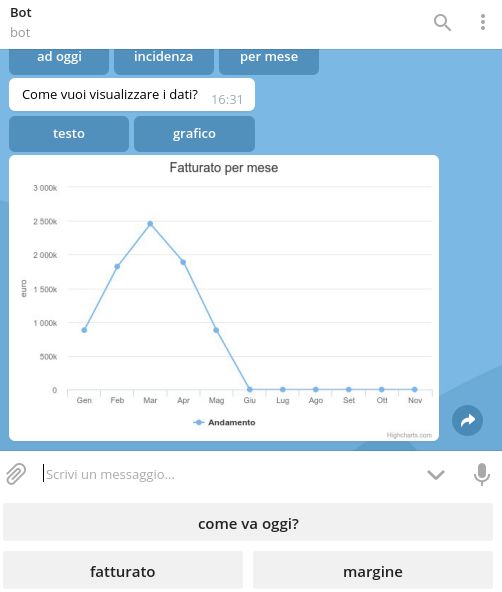
4.2.2 Aspettative . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.2.3 Obiettivi dello stage . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.2.4 Aspettative soddisfatte . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.2.5 Valore dello stage . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.3 Considerazioni sul corso di laurea . . . . . . . . . . . . . . . . . . . . . . . 46
Glossario 47
Sitogra
a 50
II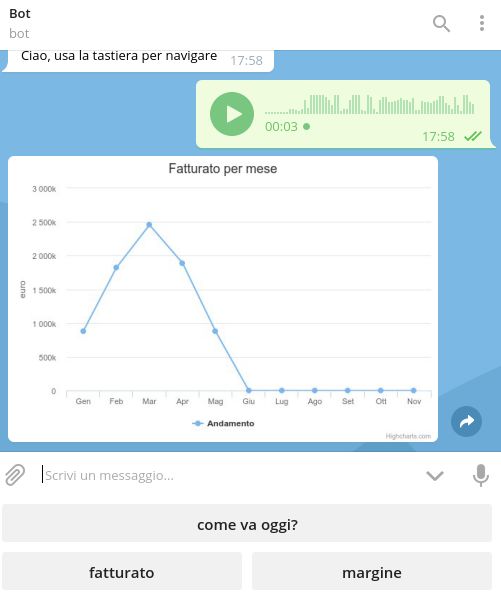
Elenco delle
gure
1.1 Logo di Miriade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
2.1 Esempio di tastiera . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Esempio di tastiera inline . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3 Esempio indicatore/
ltri . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.4 Esempio visualizzazione con gra
co . . . . . . . . . . . . . . . . . . . . . . 7
2.5 Logo Telegram . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.6 Logo Google Cloud Speech . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.7 Logo Google Cloud Natural Language . . . . . . . . . . . . . . . . . . . . 9
2.8 Logo Spring . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.9 Architettura Spring . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.1 Logo Linux Mint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2 Logo IntelliJ IDEA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.3 Logo Git . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.4 Logo PostgreSQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.5 Logo Highcharts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.6 Esempio gra
co di output . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.7 Conversazione relativa al fatturato. . . . . . . . . . . . . . . . . . . . . . . 21
3.8 Conversazione relativa al margine. . . . . . . . . . . . . . . . . . . . . . . 21
3.9 JSON di input servizio Speech-to-text . . . . . . . . . . . . . . . . . . . . 23
3.10 Dettaglio "con
g" JSON di con
gurazione . . . . . . . . . . . . . . . . . . 24
3.11 Dettaglio "audio" JSON di con
gurazione . . . . . . . . . . . . . . . . . . 25
3.12 JSON di risposta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.13 JSON di input Natural Language API . . . . . . . . . . . . . . . . . . . . 27
3.14 JSON di risposta Natural Language API . . . . . . . . . . . . . . . . . . . 28
3.15 Esempio di dependency tree . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.16 Database Access Object Pattern . . . . . . . . . . . . . . . . . . . . . . . 30
3.17 Tabella contenente le conversazioni . . . . . . . . . . . . . . . . . . . . . . 30
3.18 Schermata iniziale con generazione dinamica tastiera . . . . . . . . . . . . 36
3.19 Output stato iniziale Fatturato . . . . . . . . . . . . . . . . . . . . . . . . 37
3.20 Output testuale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.21 Output gra
co . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.22 Elaborazione messaggio vocale . . . . . . . . . . . . . . . . . . . . . . . . . 40
III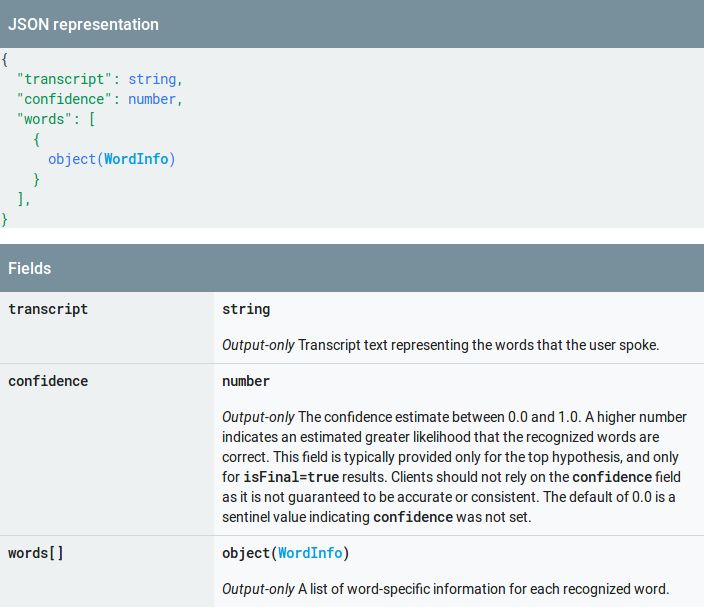
3.23 Funzionalità "Come va oggi?" . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.24 Crash pgAdminIII . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
IVCapitolo 1
Analisi del contesto aziendale
1.1 Miriade e il suo ambito di attività
Miriade è una piccola azienda con sede a Thiene e Padova. Essa ore servizi di consu-
lenza informatica di vario tipo (sistemistico, di sviluppo, amministrazione di database e
business intelligence).
Figura 1.1: Logo di Miriade1
1.2 Organizzazione aziendale
1.2.1 Struttura
L'azienda è suddivisa in tre macro unità:
• Area amministrativa: Gestione degli aspetti economici e
nanziari.
• Area commerciale: Si occupa di piani
care le strategie di mercato, di vendere il
prodotto e di assistere i clienti.
1
Fonte immagine http://www.miriade.it
1• Area ricerca e sviluppo: Si occupa di creare e migliorare il prodotto.
A sua volta l'Area ricerca e sviluppo si articola in:
• Area sistemi: Si occupa di ideare soluzioni riguardanti l'ambito sistemistico
(gestione server, migrazioni, con
gurazione di software aziendali.
• Area sviluppo: Si occupa della progettazione e dello sviluppo dei prodotti soft-
ware.
• Area database: Si occupa della creazione e gestione dei database.
• Area business intelligence: Si occupa di progettare soluzioni per organizzare e
rielaborare le informazioni di un'azienda.
1.2.2 Comunicazione
La comunicazione tra colleghi avviene prevalentemente a voce, in modo diretto. Tutta-
via capita spesso che alcune
gure professionali, soprattutto per quanto riguarda l'area
sistemi, siano in trasferta. Per ovviare a questo problema si utilizzano spesso Hangouts
e Gmail, poiché ogni dipendente ha un account aziendale su piattaforma Google.
1.3 Sviluppo software
1.3.1 Metodo di lavoro
Il modello di sviluppo software adottato dall'azienda segue la metodologia agile. Il re-
sponsabile d'area assegna dei task agli sviluppatori, che devono essere portati a termine
entro la
ne dello sprint. Settimanalmente viene eettuato uno scrum tra tutti i membri
del team di sviluppo.
2Capitolo 2
Presentazione dello stage
2.1 Descrizione del progetto di stage
2.1.1 Prodotti
AsOneBot
Ad un'azienda sono associati una serie di indicatori economici, che ne descrivono il be-
nessere. Normalmente si accede a questi dati mediante strumenti di business intelligence
che permettono ad un manager di monitorare la situazione aziendale e piani
care le azio-
ni successive. Miriade utilizza a questo scopo un'applicazione web, il cui limite risulta
essere la non portabilità, poiché la sua interfaccia non è ottimizzata per la fruizione su
smartphone e tablet. L'obiettivo dello stage era quello di realizzare uno strumento che
permettesse la consultazione degli stessi dati ottenuti dal servizio di business intelligence,
che potesse essere consultato in mobilità.
La prima soluzione considerata era quella di interfacciarsi direttamente allo strumento
di business intelligence, ma questa strada è stata scartata poiché le API oerte non lo
consentivano, oltre al fatto che la documentazione messa a disposizione era molto sca-
dente. Si è pensato quindi di memorizzare i dati di interesse in un database realizzato
appositamente, in modo che qualsiasi applicazione potesse reperire le informazioni con
facilità.
Avendo un database dedicato, sono state individuate almeno tre soluzioni per risolvere il
problema:
• Sviluppo di un'applicazione nativa per smartphone.
• Sviluppo di un sito mobile-friendly.
• Sviluppo di un bot Telegram.
Se si fosse realizzata un'app per smartphone, sarebbe stato necessario sviluppare due
distinte applicazioni, una per sistema operativo Android e una per iOS. Lo sviluppo
di un sito web avrebbe permesso di evitare questo problema, tuttavia ci sarebbe stata
comunque la necessità di sviluppare sia il front-end che il back-end. La creazione di un
3bot Telegram, invece, avrebbe consentito di realizzare solamente il back-end. Un bot
è infatti un'applicazione eseguita all'interno del client di messaggistica di Telegram, a
cui l'utente può inviare comandi mediante l'interfaccia di chat messa a disposizione dal
client. I comandi vengono inviati al bot sia scrivendo dei messaggi, come se fosse una
conversazione con un'altra persona, sia mediante apposite tastiere:
• Tastiera normale
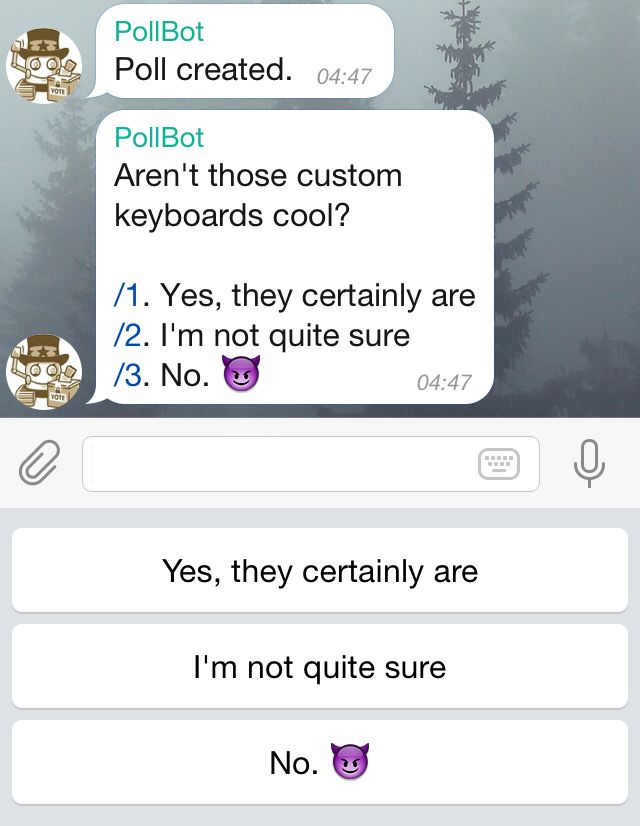
• Tastiera inline
La tastiera normale si presenta come una serie di pulsanti cliccabili che compaiono
nella metà inferiore della
nestra di chat. Quando si preme un bottone, viene inviato al
bot il messaggio presente sopra di esso.
Figura 2.1: Esempio di tastiera
La tastiera inline invece, permette di allegare dei pulsanti direttamente ad un mes-
saggio, e la pressione di uno di essi causa una callbackQuery, un input personalizzabile
dallo sviluppatore.
4Figura 2.2: Esempio di tastiera inline
L'interazione dell'utente con il bot usando i meccanismi descritti è veloce ed intuitiva,
ciò permette di ottenere informazioni in modo rapido ed in mobilità, il tutto senza la
necessità di sviluppare un'interfaccia di front-end. Per questi motivi l'implementazione
di un bot Telegram è risultata essere la soluzione migliore tra quelle elencate.
Nell'ambito di interesse, un comando accettato dal bot può rappresentare due cose
distinte:
• L'indicatore economico di cui si vogliono conoscere i dettagli.
• I
ltri da usare per aggregare i dati dell'indicatore economico scelto (periodo
temporale, output testuale o gra
co...).
Si è pensato quindi di utilizzare la tastiera normale per elencare gli indicatori e la tastiera
inline per speci
care i
ltri. Prendiamo ad esempio l'indicatore economico del fatturato.
A questo possono essere applicati diversi
ltri, come il fatturato aggiornato alla data
corrente, oppure quello per mese o la sua incidenza. La
gura che segue rappresenta il
risultato voluto considerando l'esempio del fatturato.
5Figura 2.3: Esempio indicatore/
ltri
Per poter sostituire lo strumento di business intelligence, era importante che il bot
potesse mostrare i dati anche mediante l'uso di gra
ci per alcuni
ltri. Ad esempio,
considerando sempre l'indicatore del fatturato, si voleva dare la possibilità all'utente di
visualizzare i dati per mese mediante gra
co, per rendersi conto a colpo d'occhio del suo
andamento.
6Figura 2.4: Esempio visualizzazione con gra
co
In
ne, si voleva rendere il bot capace di ricevere ed interpretare messaggi vocali,
contenenti dei comandi espressi in linguaggio naturale. L'utente avrebbe potuto mandare
ad esempio la seguente richiesta: "Qual è il fatturato ad oggi?", e il bot avrebbe presentato
direttamente i dati richiesti senza interagire mediante la tastiera.
2.1.2 Tecnologie
Telegram
Figura 2.5: Logo Telegram
Telegram è un servizio di messaggistica no-pro
t cross-platform basato su cloud. Sono
stati sviluppati client per tutte le piattaforme maggiormente utilizzate: Android, iOS,
Windows Phone, Windows NT, macOS e Linux. Come esperienza utente si presenta
7molto simile a Whatsapp, di cui è il principale competitor. Le funzionalità distintive di
Telegram sono:
• Multiaccesso: Telegram permette di accedere da smartphone o tablet sprovvisti
di scheda SIM.
• Client desktop: Telegram è dotato di un client desktop separato rispetto ai
client mobile. Questo consente ad esempio di accedere al servizio anche avendo
lo smartphone spento.
• Cloud: Telegram memorizza tutte le informazioni, compresi audio, foto e allegati,
in cloud. Ciò consente di avere la stessa esperienza d'uso su dispositivi diversi
contemporaneamente.
Telegram Bot Java API
Le API che Telegram ore per creare i bot sono HTTP, ne esistono quindi diverse imple-
mentazioni in vari linguaggi di programmazione che ne sempli
cano l'utilizzo. Nel mio
progetto ho utilizzato l'implementazione Java reperibile a questo link: Telegram Bot API
Java.
Google Cloud Speech API
Figura 2.6: Logo Google Cloud Speech
Google Cloud Speech è un servizio di speech-to-text facente parte della suite di API
cloud messe a disposizione da Google. Supporta oltre 110 lingue e restituisce i risultati
in tempo reale grazie ad una potente rete neurale. Ci si può interfacciare al servizio
mediante chiamate REST, inviando un JSON di input contenente la codi
ca in base
64 di un
le audio. In risposta si ottiene un JSON contenente il testo riconosciuto
analizzando il
le audio.
8Google Cloud Natural Language API
Figura 2.7: Logo Google Cloud Natural Language
Google Cloud Natural Language API è un servizio che permette di eettuare l'analisi
sintattica di una frase, estraendo da quest'ultima i token e le entità, ottenendo informa-
zioni su come i componenti della frase siano in relazione tra loro. Anche questo servizio
fa parte della suite di Google Cloud e si utilizza in modo similare al precedente. Si invia
un JSON di input contenente la frase da analizzare e si ottiene in risposta un altro JSON,
che rappresenta la frase decomposta ed analizzata.
Spring
Figura 2.8: Logo Spring
Spring è un framework open source per lo sviluppo di applicazioni su piattaforma Java.
La sua architettura è modulare, per questo è possibile utilizzare solo i componenti di cui
si ha bisogno. Le parti in cui il framework è suddiviso sono quattro:
• Core: Costituisce il nucleo del framework, sopra di esso sono sviluppati gli altri
moduli. All'interno del core, sono implementate le funzionalità di Dependency
injection e Inversion of control.
• Data Access: È il modulo che fornisce funzionalità di astrazione per l'accesso ai
dati. Ciò si traduce nella gestione di connessioni, transazioni ed eccezioni molto
sempli
cata.
• AOP: Implementa le funzionalità per la programmazione Aspect oriented.
9• Web: Permette lo sviluppo di un'applicazione Web. Particolarmente utile è l'im-
plementazione del pattern MVC.
Figura 2.9: Architettura Spring
Durante lo stage ho fatto largo uso delle funzionalità di Dependency injection e di
accesso ai dati oerti da questo framework.
10Capitolo 3
Svolgimento dello stage
3.1 Metodo di lavoro
Per l'intera durata dello stage ho seguito i principi del modello agile, comunemente usato
in azienda per lo sviluppo di prodotti. Ciò ha permesso di realizzare le prime funzionalità
del bot molto presto e mi ha invogliato sempre di più a proseguire nello sviluppo. Inoltre,
adottando questa metodologia di lavoro, ho potuto mostrare
n da subito l'interazione
utente-bot al mio tutor, che ha potuto darmi un suo feedback molto velocemente.
3.2 Attività preliminari
3.2.1 Preparazione dell'ambiente di lavoro
Sistema operativo
Figura 3.1: Logo Linux Mint
Il primo giorno di stage è stato dedicato all'installazione e alla con
gurazione del sistema
operativo e dei programmi necessari per lo sviluppo del bot. Come sistema operativo ho
scelto di utilizzare Linux Mint 18.2, apprezzato per la sua stabilità. Esso è basato su
Ubuntu 16.04, una versione LTS.
11IDE
Figura 3.2: Logo IntelliJ IDEA
Come IDE ho deciso di utilizzare IntelliJ IDEA, ormai il nuovo punto di riferimento
per quanto riguarda Java. Ore funzionalità molto utili come il refactor del codice, la
ricerca di linee duplicate, un autocompletamento e
cace e ha a disposizione un debugger
intuitivo e semplice da usare. È disponibile in due versioni, una a pagamento e una open
source e gratuita. Durante il mio stage ho usato la versione open source.
Git
Figura 3.3: Logo Git
Per eettuare il versionamento del codice ho deciso di usare Git, sfruttando l'hosting
oerto dalla piattaforma GitHub. Inoltre ho installato GitKraken, un client che ore
un'interfaccia visuale per eettuare le operazioni tipiche del sistema Git.
12PostgreSQL
Figura 3.4: Logo PostgreSQL
In azienda è già presente un server di test con database PostgreSQL, ho deciso quindi di
sfruttare questo server per il mio bot. Come client ho usato pgAdmin III, in seguito me
ne sono pentito perché è fatto male e garantisce un'esperienza utente pessima.
Highcharts Server
Figura 3.5: Logo Highcharts
Per implementare la possibilità per il bot di generare gra
ci ho utilizzato il servizio Hi-
ghcharts. Esso consente di creare moltissime tipologie di gra
ci, riceve in input un JSON
contenente i dati ed il tipo di gra
co e restituisce l'immagine corrispondente.
La con
gurazione di un server Highcharts non è stata di
coltosa, l'unico requisito ri-
chiesto è la presenza di node.js sul pc, che è possibile installare con un solo comando
da terminale. In seguito ho seguito le istruzioni presenti a questo link per installare
Highcharts: Installazione Highcharts.
133.2.2 Studio individuale
API Telegram
Ho dedicato la prima settimana di stage allo studio delle API di Telegram e alla creazione
di un bot associato ad un numero di telefono fornito dall'azienda. La documentazione di
queste API è molto ben fatta, metodi e tipi messi a disposizione sono ben de
niti e facili
da capire.
Ho invece incontrato qualche problema nello studiare la libreria Java che implementa le
API, in quanto non segue precisamente la documentazione u
ciale. Ad esempio il metodo
sendMessage() non è presente ed è invece sostituito da execute(), poiché assolve anche
ad altri compiti. Inoltre la proprietà chatId che nella documentazione ha tipo Integer,
è stata implementata come Long. Sono insomma presenti alcune piccole incongruenze
che hanno rallentato lo studio.
La creazione di un bot invece è molto semplice ed avviene tramite l'interazione con un
altro bot, chiamato BotFather. Si manda a BotFather l'username del bot che si vuole
creare e viene restituito un token da inserire all'interno dell'applicazione.
Google Cloud API
Le API di Google Cloud sono ben documentate e sono semplici da usare poiché non sono
altro che chiamate HTTP di tipo POST. È possibile testarne il funzionamento diretta-
mente online, poiché Google mette a disposizione un front-end che simula la chiamata
che si fa all'interno delle applicazioni. Per avere un'idea ancora migliore sul tipo di input
accettato e l'output restituito, ho usato un'estensione di Chrome chiamata Postman, che
permette di eettuare diversi tipi di chiamate HTTP.
Spring
Per realizzare il bot, avrei potuto fare a meno di usare Spring, tuttavia le ore necessarie
per l'apprendimento di questo framework sono state ben spese. Esso consente infatti di
realizzare la Dependency injection e la connessione a diversi tipi di database in modo
estremamente semplice.
Il framework mette a disposizione l'IoC container, un contesto con
gurabile per la crea-
zione e risoluzione delle dipendenze di componenti che vengono chiamati bean. L'IoC
container può essere visto come un contenitore dove vengono inseriti oggetti che pos-
sono essere utilizzati ovunque nell'applicazione, poiché vengono iniettati dove servono
direttamente dal framework. Il container è realizzato per attraverso due interfacce:
• BeanFactory: De
nisce le funzionalità di base di gestione dei bean.
• ApplicationContext: Estende le funzionalità oerte da BeanFactory aggiungen-
do la gestione degli eventi, l'internazionalizzazione e l'integrazione con AOP.
In particolare, l'interfaccia BeanFactory si occupa di:
• creare i bean necessari all'applicazione.
14• inizializzare le loro dipendenze attraverso l'utilizzo dell'injection.
• gestirne l'intero ciclo di vita.
Per svolgere tali mansioni, il container necessita di con
gurazioni impostate dallo
sviluppatore che speci
cano i bean che dovranno essere gestiti e le loro dipendenze. In
passato, per descrivere una con
gurazione, si usavano
le XML. Tale pratica è stata ab-
bandonata in favore dell'uso di annotation. Immaginiamo ad esempio di avere due classi
Driver e License, con Driver che necessita di un oggetto License per assolvere al suo
compito.
Per realizzare l'injection, è su
ciente decorare la classe License con l'annotation @Com-
ponent, che indica a Spring che tale classe deve essere un bean disponibile nel contai-
ner. Inoltre nella classe Driver, si crea un attributo ti tipo License, decorato con
l'annotation @Autowired. Ciò indica al framework che deve inizializzare l'oggetto con
l'istanza contenuta nel container.
@Component
public class License {
private String number="123456ABC";
@Override
public String toString() {
return "License [number=" + number + "]";
}
// getter e setter
}
Listing 3.1: Uso di @Component
@Component("driver")
public class Driver {
@Autowired
private License license ;
// getter e setter
@Override
public String toString() {
return "Driver [ license =" + license + "]";
}
}
Listing 3.2: Uso di @Autowired
All'interno del mio progetto, interrogo il database PostgreSQL piuttosto spesso,
Spring JDBC ha consentito di sempli
care queste operazioni.
15Di norma in Java si usa JDBC per eseguire operazioni su database, tuttavia questo
necessita di occuparsi di alcuni problemi:
• Bisogna scrivere del codice prima e dopo una query, ad esempio per creare una
connessione, chiudere un resultSet, chiudere la connessione.
• Bisogna gestire le eccezioni.
• Bisogna gestire le transazioni.
Spring JDBC ore delle classi che permettono l'esecuzione diretta di query e si
occupano di risolvere i problemi descritti in modo automatico:
• JdbcTemplate
• NamedParameterJdbcTemplate
• SimpleJdbcTemplate
• SimpleJdbcInsert
• SimpleJdbcCall
Durante il progetto ho fatto largo uso di JdbcTemplate e NamedParameterJdbcTem-
plate.
3.3 Sviluppo del bot
3.3.1 Analisi dei requisiti
Come descritto nel capitolo relativo alla presentazione generale dello stage, lo scopo del
bot è quello di permettere l'accesso immediato ad alcuni indicatori economici aziendali e
per ciascuno di essi, visualizzare i dati utilizzando speci
ci
ltri. Un indicatore e la lista
dei suoi
ltri possono essere visti come una conversazione. Ad esempio la conversazio-
ne relativa al fatturato è composta dall'indicatore economico "fatturato" e dai
ltri "ad
oggi", "per mese", "incidenza"...
È lecito pensare che ciascuna azienda voglia de
nire le proprie conversazioni personaliz-
zate, per questo motivo la logica del bot non deve dipendere da un set di conversazioni
prede
nite, ma funzionare con tutte quelle possibili. Per realizzare ciò, le conversazioni
devono risiedere su un database, e non devono essere integrate direttamente nel codice
del bot.
Un bot Telegram è di default pubblico, tutti possono accedervi conoscendo l'username.
Per la natura del bot oggetto dello stage, è necessario implementare un meccanismo di
permessi, memorizzati su database, che consenta di accedere al bot ai soli utenti auto-
rizzati.
Per evitare di inserire manualmente nel database conversazioni e permessi, un obiettivo
16facoltativo prevede l'implementazione di un modo per importare questi dati da spread-
sheet presenti su Google Drive nel database in modo automatico.
Un altro obiettivo facoltativo consiste nel memorizzare i dati relativi ai vari indicatori
economici non su database locale, ma in cloud, in particolare usando i database distribuiti
messi a disposizione da Google, che è possibile interrogare mediante il servizio BigQuery.
Di seguito si speci
ca l'elenco dei requisiti:
• Obbligatori
Implementazione di un bot Telegram che permette l'accesso agli indicato-
ri economici fatturato e margine, mediante l'uso delle tastiere messe a
disposizione da Telegram.
Implementazione di un modo per separare la logica del bot dalle conversazioni,
rendendolo utilizzabile per tutte le aziende.
Implementazione di un sistema di permessi che consenta di accedere al bot
solo agli utenti autorizzati.
• Opzionali
Permettere al bot di inviare i dati sotto forma di gra
co, dove necessario.
Permettere al bot di ricevere in input un messaggio vocale contenente la ri-
chiesta dell'utente, e restituire in output i dati desiderati dopo aver elaborato
l'audio del messaggio.
Implementazione di un modo per importare le conversazioni e i permessi da
spreadsheet memorizzati su Google Drive, al database locale.
Memorizzare i dati di interesse degli indicatori economici non su database
locale, ma in cloud, usando il servizio Google BigQuery.
3.3.2 Progettazione
Struttura delle conversazioni
Ad alto livello, si voleva che il bot desse informazioni in merito a due indicatori economici
aziendali:
• Fatturato
• Margine
In particolare si volevano ottenere i seguenti dati:
• Fatturato
Fatturato ad oggi.
Fatturato per mese.
Incidenza del fatturato sul budget ad oggi.
17 Incidenza del fatturato sul budget per mese.
Incidenza del fatturato rispetto all'anno precedente.
• Margine
Margine ad oggi.
Margine per mese.
Incidenza del margine consuntivo sul budget ad oggi.
Incidenza del margine consuntivo sul budget per mese.
Incidenza del margine rispetto all'anno precedente.
Per entrambe queste conversazioni, si voleva che il bot restituisse i dati in forma di gra-
co, qualora le informazioni richieste fossero state di cadenza mensile.
Per quanto riguarda l'output testuale, il bot doveva restituire stringhe di testo contenenti
i dati richiesti, ad esempio: "Il fatturato al 06/11/2017 è di 7922145.32 euro" rispon-
de alla richiesta di mostrare il fatturato aggiornato alla data corrente (nell'esempio il
06/11/2017).
L'output gra
co, invece, doveva essere simile a quello ottenuto usando lo strumento di
business intelligence. Segue l'esempio di gra
co che si voleva ottenere per visualizzare il
fatturato per mese.
Figura 3.6: Esempio gra
co di output
18Gestione dei permessi
Poiché i bot Telegram sono pubblici, si voleva realizzare un sistema di controllo dei per-
messi che consentisse di accedere al bot ai soli utenti autorizzati. In particolare, il bot
doveva restituire in output il messaggio: "Mi dispiace, ma non hai i permessi per accedere
a questo bot", ad ogni messaggio inviato da un utente non autorizzato.
Oltre a ciò, vi era la necessità di implementare un sistema di permessi anche per le
conversazioni. Ad esempio si voleva che la conversazione relativa al fatturato fosse acces-
sibile solo da alcuni utenti, mentre il margine fosse disponibile per tutti. Il bot si sarebbe
dovuto occupare di gestire anche queste tipologie di autorizzazioni.
Interpretazione di un messaggio vocale
Oltre all'interazione con il bot mediante tastiera, si voleva permettere all'utente di man-
dare richieste in linguaggio naturale mediante l'invio di un messaggio vocale. Ad esempio
alla richiesta: "Qual è il fatturato ad oggi?", il bot avrebbe dovuto rispondere con il
messaggio: "Il fatturato al 06/11/2017 è di 7922145.32 euro". Nello speci
co:
• I messaggi non dovevano essere prede
niti, ad esempio: "Qual è il fatturato ad og-
gi?" e "Ad oggi, qual è il fatturato?" dovevano essere accettati entrambi e restituire
lo stesso output.
• La richiesta dell'utente doveva essere interpretata quanto più possibile. Ad esempio
se l'utente avesse mandato il messaggio generico: "Qual è il fatturato?", il bot non
avrebbe dovuto rispondere che non poteva accettare la richiesta, ma avrebbe dovuto
chiedere all'utente se desiderava i dati del fatturato ad oggi o per mese.
Anche nell'interpretazione di un messaggio vocale, il bot avrebbe dovuto tenere in conto
dei permessi dell'utente di accedere solo ad alcune conversazioni.
Database cloud
Si voleva permettere ai dati di risiedere sia su database cloud che locale contemporanea-
mente, in maniera del tutto trasparente per l'utente. Ciò signi
ca ad esempio fare in
modo che i dati della conversazione relativa al fatturato siano su database locale, e quelli
del margine in cloud. I problemi da arontare erano i seguenti:
• Discriminare il caso in cui i dati risiedessero in locale dal cloud.
• Restituire all'utente lo stesso output nei due casi, anche se i dati venivano reperiti
in due modi dierenti.
193.3.3 Implementazione
Struttura di una conversazione
All'inizio della mia esperienza di stage, mi sono stati forniti i dati che il bot avrebbe
dovuto visualizzare, essi corrispondono alle possibili richieste elencate nel capitolo 3.3.2.
Era importante quindi strutturare le richieste, in modo che potessero essere facilmente
elaborate. Inoltre vi era la necessità che il modo di rappresentare queste richieste fosse
generale, per consentire al bot di funzionare ugualmente indipendentemente dai dati da
visualizzare.
Innanzitutto ho deciso di raggruppare le richieste per conversazione, separando le richie-
ste relative al fatturato da quelle relative al margine. Successivamente ho pensato che
ogni conversazione potesse essere composta da più passi, ciascuno dei quali avrebbe per-
messo di capire meglio la richiesta
nale dell'utente
ltrando progressivamente i dati da
visualizzare. Ad esempio, prendendo in considerazione la seguente richiesta: "Incidenza
del fatturato sul budget ad oggi". La conversazione di riferimento è quella del fatturato,
e i passi da cui è composta sono:
• Incidenza
• sul budget
• ad oggi
In questo senso, una conversazione può essere pensata come un automa a stati
niti.
Lo stato iniziale indica appunto l'inizio della conversazione (fatturato o margine), e le
transizioni verso un altro stato corrispondono ai diversi passi in cui si articola la conver-
sazione, che equivalgono agli input accettati dal bot per capire la richiesta dell'utente.
Uno stato è
nale quando si è capito cosa l'utente vuole sapere e si può procedere quindi
alla restituzione dei dati, in formato gra
co o testuale.
Segue una rappresentazione gra
ca delle conversazioni e dei passi da cui sono composte.
20Figura 3.7: Conversazione relativa al fatturato.
Figura 3.8: Conversazione relativa al margine.
21A livello di implementazione su database, ho realizzato due tabelle, una per rap-
presentare le conversazioni, e una per rappresentare gli stati, in relazione uno a molti.
Ciascuno stato è composto da un output, una serie di input accettati, e gli stati successivi
da raggiungere a seguito della ricezione dei diversi input. Utilizzando questa logica si
possono de
nire conversazioni personalizzate, ognuna articolata in diversi passi, anch'essi
de
niti a piacimento, che il bot sarà in grado di gestire poiché la struttura di base rimane
identica.
Gestione dei permessi
Quando il bot riceve un messaggio, insieme ad esso viene trasmesso l'id univoco dell'u-
tente Telegram che lo ha mandato. È stato naturale quindi sfruttare questa informazione
per implementare la gestione dei permessi per accedere al bot. Ho creato una tabella nel
database per memorizzare gli utenti, e una tabella per i permessi (ad esempio admin,
utente base) in relazione molti-a-molti. Inoltre ho messo in relazione molti-a-molti la
tabella delle conversazioni con quella dei permessi.
In questo modo una volta che l'utente manda un messaggio al bot vengono prelevati i suoi
permessi e confrontati con quelli necessari per accedere alla conversazione desiderata. Se
il grado di autorizzazione non è su
ciente viene mandato all'utente un messaggio che gli
comunica che non può accedere alla conversazione.
Generazione di gra
ci mediante Highcharts
Lo strumento di business intelligence usato dall'azienda sfrutta Highcharts per generare
gra
ci. È stato quindi naturale usare lo stesso servizio per replicare la medesima espe-
rienza utente.
Per poter generare un gra
co, Highcharts necessita dei parametri del gra
co stesso, che
ne descrivono tipologia, colori e i dati da visualizzare. Per rendere il codice Java più
generale possibile, è bastato inserire come proprietà all'interno dello stato
nale di una
conversazione che richiede un output gra
co, un campo dati di tipo JSON, che rappre-
senta il template del gra
co in cui iniettare i dati reperiti da query che mi sono state
fornite dall'azienda. Usando questo espediente, se il bot rileva che si è entrati in uno stato
che necessita di interrogare il servizio Highcharts, tutto quello che deve fare è reperire
il template del gra
co dal database, eseguire la query associata per ottenere i dati da
visualizzare, inserirli nel template e mandare la richiesta al server di Highcharts.
Interpretazione di un messaggio vocale
L'interpretazione di un messaggio vocale dell'utente passa attraverso due step consecutivi:
• Estrapolazione del testo dal messaggio vocale mediante il servizio Google Speech-
to-text
• Interpretazione del testo mediante il servizio Google Natural language
22Ho optato per i servizi oerti da Google per la loro semplicità di utilizzo e poiché
l'azienda aveva già a disposizione degli account abilitati all'uso di queste API.
La chiamata HTTP al servizio di speech-to-text richiede un input JSON che sia della
forma seguente:
Figura 3.9: JSON di input servizio Speech-to-text
L'elemento "con
g" contiene la con
gurazione necessaria per elaborare correttamen-
te la richiesta. È necessario ad esempio speci
care la lingua, la codi
ca audio e la sua
frequenza. Segue un immagine che descrive i parametri richiesti.
23Figura 3.10: Dettaglio "con
g" JSON di con
gurazione
L'elemento "audio" invece contiene l'audio vero e proprio. La caratteristica interes-
sante del servizio consiste nel fatto che è possibile usare come valore per questo campo
24una stringa, che costituisce la rappresentazione del
le audio in codi
ca base 64. Il fra-
mework Spring ore un metodo che permette di convertire un oggetto Java di classe
File in un array di byte. Una volta ottenuto l'array, è su
ciente utilizzare un metodo
statico contenuto nel package java.util.Base64 per ottenere la stringa desiderata. Una
volta eettuate queste operazioni è su
ciente inserire la stringa come valore del campo
"content" e si ottiene il JSON di input da inviare a Google.
Figura 3.11: Dettaglio "audio" JSON di con
gurazione
Se tutto è andato a buon
ne, il servizio risponde con un altro JSON della seguente
forma:
25Figura 3.12: JSON di risposta
Il campo "transcript" contiene la stringa di testo che corrisponde a ciò che l'utente
ha detto nel messaggio vocale.
Dopo aver convertito l'audio inviato dall'utente in una stringa testuale, si è reso necessario
utilizzare un servizio che aiutasse a capire la richiesta dell'utente. Google ore delle
API REST che svolgono proprio questa funzione. Come per lo speech-to-text, le API
accettano come input un JSON e ne restituiscono un altro che contiene l'analisi sintattica
della frase inviata.
26Figura 3.13: JSON di input Natural Language API
Come si vede in
gura, è necessario speci
care il tipo di input inviato, che nel caso
di una stringa è PLAIN_TEXT, la lingua e la frase da analizzare. Ho quindi estrapolato
il risultato ottenuto dal servizio di speech-to-text e l'ho inserito come valore del campo
"content". Ciò che si ottiene in risposta è un JSON di questo tipo:
27Figura 3.14: JSON di risposta Natural Language API
L'oggetto di interesse è l'array di token restituito. Ciascun token rappresenta un
elemento sintattico della frase e, per ognuno di essi, si ottengono le seguenti informazioni:
• text: è il token oggetto di analisi
• partOfSpeech: è la parte del discorso (nome, articolo, pronome...) di cui il token
fa parte.
• dependencyEdge: rappresenta la relazione che intercorre tra il token e suo padre,
un altro token a cui è collegato.
Nel complesso ciò che si ottiene è l'analisi di ciascun elemento della frase, insieme
al tipo di relazione che intercorre tra elementi diversi. Nella documentazione questo
concetto è chiamato dependency tree ed è rappresentato mediante questo esempio:
Figura 3.15: Esempio di dependency tree
28Questo strumento si è rilevato cruciale per capire la richiesta dell'utente nel caso in
cui un input fosse composto da parole multiple. Nello speci
co, il modo con cui il bot
interpreta una frase intera è il seguente:
• Come prima cosa bisogna capire in quale conversazione vuole entrare l'utente,
quindi si scorrono i token in cerca delle parole chiave "fatturato" o "margine".
• Una volta entrato in conversazione, l'utente si trova nel suo primo stato, a cui sono
associati una serie di input che permettono la transizione ad uno stato successivo.
Solitamente gli input sono composti da una parola, quindi si scorre la lista di token
in cerca di un match con uno degli input accettati dallo stato corrente. Se il match
ha successo, si passa ad un altro stato e si ripete il processo
no ad arrivare ad uno
stato
nale. Può capitare però che l'input accettato sia composto da più parole.
In questo caso si rivela fondamentale sfruttare l'albero di dipendenza fornito dalle
API. Per ogni token è possibile infatti risalire l'albero, componendo un passo alla
volta il token
glio con il padre, tentando il match con uno degli input,
no ad
arrivare alla radice.
In questo modo si evita di comporre token che non hanno relazione logica tra loro
per tentare il match con input formati da più parole.
Usando questo approccio vengono soddisfatte entrambe le condizioni descritte al capitolo
3.3.2.
Google BigQuery
Una volta arrivati a uno stato
nale di una conversazione, è necessario reperire i dati.
Ciò signi
ca eseguire una query a un database. Si è reso necessario quindi, discriminare il
caso in cui la query andasse eseguita su un database locale dall'interrogazione al database
in cloud mediante BigQuery. Per separare i due casi ho inserito in ciascuno stato
nale,
un campo booleano che speci
casse dove la query andasse eseguita. I risultati della query
vengono restituiti da Google in formato JSON, ho quindi implementato un servizio che
convertisse il JSON nello stesso oggetto Java usato per rappresentare i dati restituiti
dall'esecuzione della query in locale. In questo modo l'esperienza utente è stata resa
uniforme in entrambi i casi.
Struttura del bot
Ho strutturato il bot in due livelli distinti:
• Repository
• Service
Il livello Repository è il layer di persistenza dei dati, dove sono de
nite le entità
Java che corrispondono alle tabelle del database e le relative operazioni CRUD. Il pattern
usato per strutturare questo livello è il Data Access Object. Ciò consente di separare
la logica di business da quella di accesso ai dati.
29Figura 3.16: Database Access Object Pattern
Il funzionamento del pattern è descritto attraverso il seguente esempio.
Supponiamo che nel database sia presente la tabella conversations, che contiene tutte
le possibili conversazioni. Sarebbe comodo avere un modo semplice per operare sulla
tabella lato Java. La soluzione si compone di tre passi:
• Si implementa una classe Java che corrisponde alla tabella nel database. Questo
signi
ca che gli attributi della classe devono corrispondere ai campi della tabella.
• Si implementa l'interfacciaRowMapper, che contiene la logica per convertire i tipi
di dato dei campi della tabella, negli attributi della classe Java.
• Si implementa una classe che incapsula le operazioni da eettuare sulla tabella, che
fa uso della rispettiva classe Java.
Poniamo di aver bisogno di reperire tutte le conversazioni dal database. Seguen-
do il primo passo del ragionamento, serve una classe Java corrispondente alla tabella
contenente le conversazioni, de
nita in questo modo:
Figura 3.17: Tabella contenente le conversazioni
30Scriviamo quindi la seguente classe Java, i cui attributi corrispondono a quelli della
tabella. Ciò signi
ca tradurre il tipo di dato SQL in un tipo di dato Java compatibile.
Nel nostro esempio:
• bigserial e bigint diventano long.
• string (varchar) diventa String
• int rimane int.
Alla
ne otteniamo la seguente classe:
public class Conversation {
private long conversationId;
private String name;
private long customerId;
private int menuIndex;
// costruttori
// getter e setter
}
Listing 3.3: Conversation
Il secondo passo prevede di implementare RowMapper, un'interfaccia fornita da Spring,
che si occupa di reperire i valori dei campi della tabella conversations ed inizializzare
un oggetto Java Conversation, matchando campi con attributi. Più precisamente, i
valori saranno ottenuti dall'esecuzione di una query, e di norma sono incapsulati in un
oggetto di classe ResultSet. Ciò che bisogna fare è estrapolare i valori da questo oggetto
e usarli per inizializzare gli attributi di Conversation, mediante l'uso dei metodi setter.
public class ConversationRowMapper implements RowMapper {
@Override
public Conversation mapRow(ResultSet resultSet, int i) throws SQLException {
Conversation conversation = new Conversation();
conversation.setConversationId(resultSet .getLong("conversation_id"));
conversation.setName(resultSet.getString("name"));
conversation.setCustomerId((resultSet.getLong("customer_id")));
conversation.setMenuIndex((resultSet.getInt("menu_index")));
return conversation;
}
}
Listing 3.4: RowMapper per l'entità Conversation
Avendo a disposizione un modo per convertire i record di una tabella in oggetti Java,
ciò che ci si era pre
ssato di ottenere all'inizio (la lista delle possibili conversazioni)
si traduce di fatto nel reperire una List. Si implementa quindi una
31classe che, tra le altre operazioni, permette di assolvere a questo compito mediante il
metodo getConversations().
@Repository
public class ConversationDaoImpl implements ConversationDao {
@Autowired
private JdbcTemplate jdbcTemplate;
@Override
public List getConversations() {
return jdbcTemplate.query("SELECT ∗ FROM conversations", new
ConversationRowMapper());
}
}
Listing 3.5: Reperimento delle entità da query
Questo metodo fa uso di query(String sql, RowMapper rowMapper). Esso si oc-
cupa di eseguire la query e matchare i valori restituiti, contenuti nell'oggetto di classe
ResultSet, con gli attributi della classe Java Conversation, sfruttando le regole de
-
nite in precedenza da ConversationRowMapper.
Seguendo questa logica ho de
nito le seguenti classi Java che matchano la rispettiva
tabella presente nel database:
• Conversation: Modella una conversazione.
• State: Modella lo stato di una conversazione.
• User: Modella un utente.
• Role: Modella un permesso.
Inoltre ho progettato e implementato le seguenti interfacce, che contengono le opera-
zioni necessarie da eseguire sulle tabelle:
• ConversationDao: Incapsula le operazioni che si possono eettuare sull'entità
Conversation.
• ConversationRolesDao: Incapsula le operazioni che si possono eettuare sulla
tabella che mette in relazione le conversazioni con i permessi.
• RoleDao: Incapsula le operazioni che si possono eettuare sull'entità Role.
• StateDao: Incapsula le operazioni che si possono eettuare sull'entità State.
• UserDao: Incapsula le operazioni che si possono eettuare sull'entità User.
• UserRoles: Incapsula le operazioni che si possono eettuare sulla tabella che
mette in relazione gli utenti e i permessi.
32Il livello Service contiene la logica del bot e fa uso del livello Repository. I servizi
implementati sono i seguenti:
• ConversationService: Incapsula la logica delle conversazioni. In particolare:
Permette di ottenere la lista delle coversazioni presenti nel database.
Permette di ottenere la lista delle conversazioni a cui un determinato utente
è abilitato ad accedere.
• GoogleCloudService: Incapsula le chiamate REST alle API di Google usate per
lo speech-to-text e per l'analisi sintattica. In particolare:
Dato un input accettato per lo speech-to-text, permette di ottenere il JSON
contenente il risultato della conversione audio/testo.
Dato un input accettato dal servizio di analisi sintattica, permette di ottenere
il JSON contenente l'analisi dell'input.
• HighchartsService: Incapsula il servizio Highcharts per la generazione dei gra
ci.
In particolare:
Dato un JSON contenente i parametri del gra
co che deve essere generato,
permette di ottenere un oggetto di classe File che contiene il gra
co richiesto.
• HTTPService: Permette di eettuare una chiamata HTTP di tipo POST ad un
certo url, inviando un JSON come parametro di input.
Dato un
le JSON di input e un oggetto di classe URL, contenente l'indirizzo
a cui eettuare la richiesta, permette di ottenere una stringa contenente il
risultato della chiamata HTTP.
• JsonService: Permette la creazione e manipolazione di oggetti JSON. In partico-
lare:
Dato un oggetto di classe File, contenente un audio, restituisce un JSON
che rappresenta l'audio in formato base64, nella forma accettata dal servizio
Google per lo speech-to-text.
Data una stringa di testo contenente il risultato del servizio di speech-to-text,
permette di ottenere un JSON nella forma accettata dal servizio di analisi
sintattica.
Data una stringa di testo contenente una query da eseguire tramite il servizio
BigQuery, permette di ottenere un JSON accettato dal servizio, che incapsula
la query.
• LevenshteinService: Permette di confrontare stringhe di testo tra loro per veri-
carne l'uguaglianza considerando un certo margine di errore. In particolare:
33 Data una stringa da matchare, un array di stringhe, e una soglia di errore,
permette di ottenere l'indice dell'elemento nell'array che costituisce il miglior
match, ammettendo una certa soglia di errore. Ad esempio, la stringa "fattu-
rat" e l'elemento dell'array "fatturato", costituiscono un match con soglia di
errore 1.
• MessageService: È il servizio che si occupa di comporre i messaggi da inviare
all'utente. In particolare:
Permette di comporre un messaggio con una inline keyboard associata.
Permette di comporre il messaggio testuale da restituire all'utente contenente
i dati estratti dal database.
• NavigationButtonService: È il servizio che permette di comporre la tastiera
generale mostrata all'utente. In particolare:
Dato un utente, restituisce la tastiera generale contenente solamente le con-
versazioni a cui l'utente è abilitato ad accedere (ha i permessi su
cienti).
• PicService: È il servizio che si occupa di comporre la foto di un gra
co generato
mediante Highcharts.
• SpeechConversationService: È il servizio che permette di interpretare la stringa
ottenuta dal servizio di speech-to-text. Ovvero cerca di matchare l'input di un certo
stato con un insieme di parole, relazionate tra loro dalle API Natural Language.
• StateService: È il servizio che implementa la logica di movimento tra gli stati
della conversazione.
• UpdateService: È il servizio di alto livello che si occupa di gestire la ricezione di
un messaggio vocale o testuale.
• UserService: È il servizio che si occupa di gestire l'utente, in particolare gestisce
il suo stato di conversazione.
• BigQueryService: È il servizio che incapsula le chiamate REST alle API Big-
Query di Google. In particolare:
Dato un input accettato dal servizio BigQuery, permette di ottenere un JSON
contenente il risultato della query.
• DriveSpreadsheetService: È il servizio che permette di leggere i dati di con
gu-
razione (utenti, permessi, conversazioni e stati) del bot da fogli Drive e li importa
nel database locale.
• GCredentialService: È il servizio che incapsula il meccanismo di autenticazione
OAUTH2 di Google.
34• ScheduledJobService: È il servizio che si occupa periodicamente di veri
care
se i permessi di un utente sono stati modi
cati, inviando la tastiera aggiornata di
conseguenza.
Funzionamento del bot
Per poter ricevere i messaggi mandati dagli utenti, è necessario creare una classe che
estenda TelegramLongPollingBot, de
nita nelle API, ed eettuare l'override del metodo
onUpdateReceived(Update). Un oggetto Update rappresenta un messaggio mandato al
bot, può essere di tipo testuale, un audio, un'immagine, una posizione ottenuta dal GPS o
un generico
le inviato in allegato. La prima cosa da controllare è che l'update sia di tipo
testuale o audio, poiché questi sono gli unici input accettati dal bot. Subito dopo bisogna
assicurarsi che l'utente sia abilitato ad accedere al bot, ciò è prerogativa del servizio
UserService, che accede al database delegando la richiesta al livello Repository. Una volta
autenticato l'utente, si procede ad inviare la tastiera attraverso cui può inviare comandi al
bot. Questo compito è svolto da NavigationButtonService che compone in modo dinamico
la tastiera a seconda dei permessi speci
ci dell'utente per ogni conversazione.
35Figura 3.18: Schermata iniziale con generazione dinamica tastiera
Successivamente viene delegata la gestione di un messaggio testuale o vocale a due
metodi diversi del servizio UpdateService, che si occupano di elaborare la richiesta a
seconda del caso speci
co.
• Messaggio testuale: Quando viene ricevuto un messaggio, l'utente può trovarsi
già all'interno di una conversazione (quindi è in uno stato), oppure no. Nel caso
in cui non si trovi in una conversazione viene controllato se l'utente ha i permessi
per accedere alla conversazione selezionata, e in caso positivo, viene registrato nel
database che l'utente è nel primo stato di una certa conversazione, dopodiché si
esegue l'output dello stato iniziale. Questo signi
ca che il bot invia un messaggio
per capire cosa l'utente desideri sapere, insieme a dei bottoni che corrispondono
agli input accettati per lo stato.
36Figura 3.19: Output stato iniziale Fatturato
Può succedere anche che l'utente non si trovi in nessuna conversazione, ma nella
cronologia dei messaggi sia presente un messaggio con dei bottoni associati, che
puntano ad un certo stato di una conversazione passata. Se l'utente preme su uno
di questi bottoni il bot è in grado di capire lo stato e la conversazione associati al
bottone, quindi, dopo aver controllato i permessi, inserisce l'utente direttamente
nello stato e nella conversazione desiderata.
Se l'utente si trova già all'interno di una conversazione, il bot è in attesa che l'utente
prema su uno dei bottoni associati al messaggio, che costituiscono una transizione
verso un altro stato. Quando questo si veri
ca, lo stato corrente dell'utente viene
aggiornato e si esegue l'output del prossimo stato. Si prosegue in questo modo
no
al raggiungimento di uno stato
nale, dove si possono veri
care due scenari:
I dati da restituire all'utente devono essere in formato testuale.
I dati da restituire all'utente devono essere sotto forma di gra
co generato da
Highcharts.
37Se il formato in cui restituire i dati è testuale, nel database è presente una stringa
di testo che costituisce il template di risposta in cui vengono inseriti i dati ottenuti
mediante l'esecuzione della query associata allo stato. I dati vengono iniettati in
questo template mediante la sostituzione di un carattere speciale inserito a questo
scopo.
Figura 3.20: Output testuale
Ad esempio, in riferimento alla
gura precedente, sono stati iniettati i dati corri-
spondenti alla data corrente e il valore del fatturato nella stringa "Il fatturato YTD
al # è di # euro".
Se bisogna restituire un immagine, il principio di funzionamento è lo stesso, ma i
dati vengono iniettati in un JSON di template dal servizio PicService.
38Figura 3.21: Output gra
co
Una volta restituiti i dati nella forma richiesta, l'utente viene fatto uscire dalla
conversazione corrente poiché è stato raggiunto uno stato
nale.
• Messaggio vocale: Anche nel caso in cui il bot riceva un messaggio vocale lo sce-
nario di partenza non cambia, l'utente può trovarsi già all'interno di una conversa-
zione oppure no. Se l'utente non si trova all'interno di una conversazione, bisogna
cercare all'interno dei token restituiti dal servizio di analisi sintattica, quello che
corrisponde al nome di una delle conversazioni a cui l'utente è abilitato ad accedere.
Una volta trovato, si inserisce l'utente all'interno della conversazione giusta, e ci
si riconduce al caso in cui l'utente si trovi già all'interno di uno stato. Si procede
quindi ad elaborare il messaggio cercando un input accettato per lo stato corrente,
e in seguito per gli stati successivi attraverso il metodo descritto al capitolo 3.3.3.
Nella
gura che segue, è rappresentato l'invio del messaggio vocale: "Qual è il
fatturato per mese con gra
co?".
39Figura 3.22: Elaborazione messaggio vocale
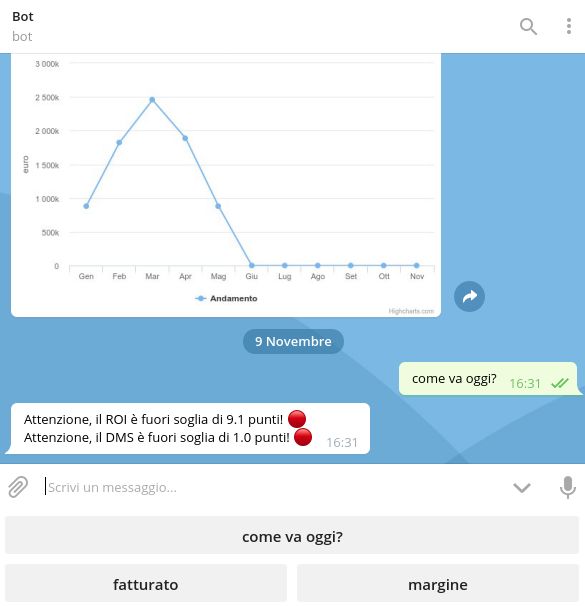
Il bot consente inoltre di reperire informazioni su parametri critici con un solo click.
L'azienda mi ha infatti chiesto di aggiungere alla tastiera di navigazione il pulsante "Come
va oggi?", che indica all'utilizzatore del bot se ci sono dei valori fuori soglia, in modo da
poter intervenire tempestivamente. Per implementare questa funzionalità, ho aggiunto
una tabella nel database dove tengo traccia delle soglie di tolleranza accettate per ciascun
indicatore.
Alla pressione del pulsante, vengono reperiti i valori correnti di tutti gli indicatori e, per
ciascuno di essi, viene controllato se rientrano nelle soglie speci
cate. Tutti i valori fuori
soglia vengono noti
cati all'utente.
40Puoi anche leggere