Strumenti per rilevare anomalie e relazioni informative in dati del commercio internazionale
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Strumenti per rilevare anomalie e relazioni informative
in dati del commercio internazionale
24 Novembre 2021
Università di Parma
Dipartimento di Scienze Economiche e Aziendali
Domenico Perrotta
Commissione Europea
Centro Comune di Ricerca
domenico.perrotta@ec.europa.eu
Gli esempi contenuti in questa presentazione sono a puro scopo illustrativo
e non si riferiscono necessariamente a investigazioni passate o in corso
SOMMARIO DEGLI ELEMENTI TRATTATI
• Politiche. Le Istituzioni Europee analizzano i dati del commercio internazionale
operato dalle aziende Europee per migliorare le politiche economico-commerciali e
salvaguardare l’UE da frodi ad alto impatto economico.
• Dati. I dati sul commercio internazionale sono pubblici: potete usarli per approfondire
i meccanismi del mercato o studiare le proprietà dei vostri metodi e modelli su dati
reali di grande qualità e rilevanza.
• Identificazione di anomalie e schemi ricorrenti («pattern») nei dati. La regressione
robusta.
• Inaspettate associazioni tra categorie associate ai dati. L’analisi delle corrispondenze.
• Relazioni tra le variabili dei dati. Correlazione e riduzione alle componenti principali.
• Software. Uso del «Flexible Statistical Data Analysis» (FSDA) toolbox per MATLAB.
POLITICHE: DISCENDONO DAL TRATTATO FONDATIVO DELLA UE
ROMA, 25 MARZO 1957
POLITICHE: COMPETENZE ESCLUSIVE E COMPETENZE CONDIVISE

POLITICHE: L’ UNIONE DOGANALE E’ COMPETENZA ESCLUSIVA

POLITICHE: L’ ANTI-FRODE E’ COMPETENZA CONDIVISA

POLITICHE: RISULTATI CONCRETI
OTTENUTI CON L’AUSILIO DEGLI STRUMENTI STATISTICI
IN QUESTA PRESENTAZIONE
DATI: COMEXT
Aggregati mensili
di quantita’ e valori scambiati dagli Stati Membri dell’UE
per ogni prodotto, origine e destinazione
Interfaccia guidata: http://epp.eurostat.ec.europa.eu/newxtweb/
CSV: https://ec.europa.eu/eurostat/estat-navtree-portlet-prod/BulkDownloadListing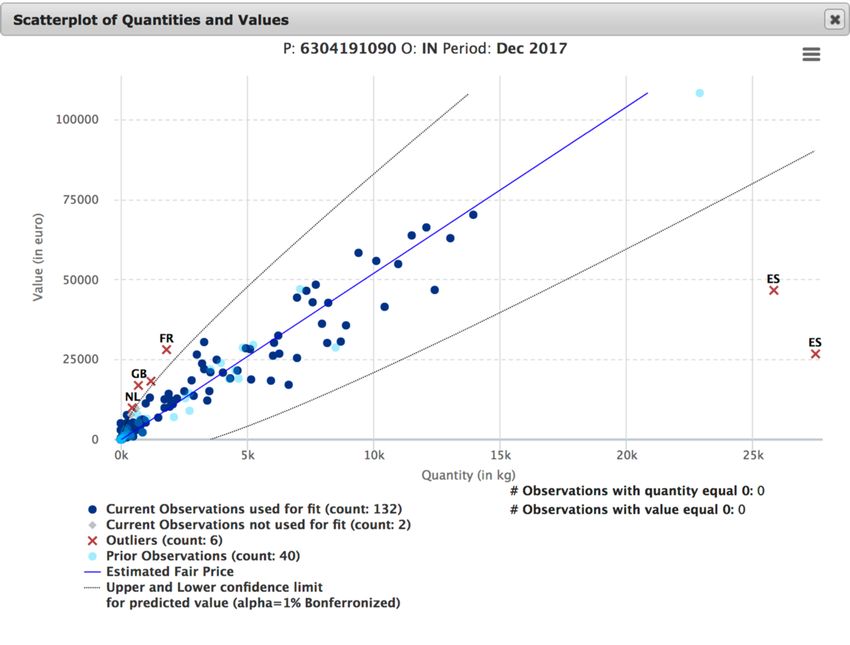
Esempio di
potenziale frode
(sottofatturazione)
episodica
Importazione di lenzuola di cotone
dall’India
Prezzo stimato: 5.16 €/Kg
Prezzo dichiarato: 0.97 & 1.81 €/Kg
Esempio di frode
(sottofatturazione)
sistematica
Importazione di scarpe
dalla Cina
I dati rivelano che la frode
si sta muovendo da un
paese all’altroSOFTWARE USATO PER LA PRESENTAZIONE http://rosa.unipr.it/fsda.html ------ http://fsda.jrc.ec.europa.eu
SOFTWARE USATO PER LA PRESENTAZIONE
GitHub: https://github.com/UniprJRC/FSDA
File Exchange: https://it.mathworks.com/matlabcentral/fileexchange/72999-fsdaOUTLIER NELL’ANALISI CON REGRESSIONE LINEARE
Dataset “Forbes”
148
17 osservazioni del punto di ebollizione
100 x log(pressure) -- in inches of Mercury
146
dell’acqua a pressioni differenti.
144
L’obiettivo è stimare il valore della pressione a
partire da un qualunque punto di ebollizione.
142
140
138
load('forbes.txt'); 136
y=forbes(:,2);
X=forbes(:,1); 134
X = (X - 32) * 5/9; % Convert to Celsius
132
plot(X,y,'o');
xlabel('Boiling point','Fontsize',16);
130
ylabel('100 x log(pressure)','Fontsize',16); 90 92 94 96 98 100 102
f1 = gcf ; figure(f1); Boiling point -- in degrees COUTLIER NELL’ANALISI CON REGRESSIONE LINEARE
148
Contaminazione:
100 x log(pressure) -- in inches of Mercury
146
Aggiungiamo un outlier “pesante” 144
(ossia influente o di alto leverage)
142
140
138
136
yc = y; yc(end) = yc(end)-3;
134
Xc = X; Xc(end) = Xc(end)+6;
hold on
132
plot(Xc(end),yc(end),'o');
figure(f1); 130
90 92 94 96 98 100 102 104 106 108
Boiling point -- in degrees COUTLIER NELL’ANALISI CON REGRESSIONE LINEARE
Fitting dei dati con un modello di regressione lineare
Usiamo i minimi quadrati ordinari (Ordinary Least Squares, OLS)
% calcoliamo i parametri degli OLS Obiettivo degli OLS: minimizzare la somma dei quadrati delle
% usando in quattro modi equivalenti
differenze tra i valori y osservati (log[pressione]) e quelli predetti
int = ones(size(Xc,1),1); % intercetta da una funzione lineare (retta) dei valori delle x (le temperature).
Xic = [int Xc];
Ogni termine della somma non è altro che il quadrato della
beta0 = (Xic'*Xic)\(Xic'*yc);
distanza verticale tra ogni punto noto (dato) e il punto
oppure
beta1 = Xic\yc; corrispondente intercettato sulla retta di regressione allo stesso
oppure valore dell’ascissa.
beta2 = regress(yc,Xic);
oppure
Più piccole sono queste differenze, migliore è la qualità della
beta3 = fitlm(Xc,yc,'y ~ 1 + x1');
rappresentazione fornita dal modello.OUTLIER NELL’ANALISI CON REGRESSIONE LINEARE
155
Tracciamo la linea stimata con gli OLS
100 x log(pressure) -- in inches of Mercury
La presenza dell’outlier causa un’evidente 150
deviazione della retta di regressione,
pregiudicando la bontà del modello.
145
140
b = beta1;
fit = @(z) b(1) + b(2)*z;
hold all 135
plot(Xc, fit(Xc), 'r', 'LineWidth', 1);
figure(f1);
130
90 92 94 96 98 100 102 104 106 108
Boiling point -- in degrees COUTLIER NELL’ANALISI CON REGRESSIONE LINEARE
Ora proviamo un fitting robusto: regressione 160
tramite i Least Trimmed Squares (LTS)
100 x log(pressure) -- in inches of Mercury
Idea: minimizzare la somma dei quadrati dei
155
residui solo su un sottoinsieme ℎ degli " punti:
tipicamente ℎ = "/2. I rimanenti " − ℎ punti
150
che non sono usati non influenzano il fit.
145
140
[outLTS]=LXS(yc,Xc);
b = outLTS.beta;
plot(Xc,b(1)+b(2)*Xc,'b','LineWidth',1);
135
figure(f1);
% La Linea degli LTS in blu 130
90 92 94 96 98 100 102 104 106 108
% si adatta molto bene ai dati! Boiling point -- in degrees COUTLIER NELL’ANALISI CON REGRESSIONE LINEARE
Ora proviamo un altro fit robusto: la Forward Search
Idea: minimizzare la somma dei quadrati dei residui 14
dell’insieme di ! punti (n ≤ !) senza outlier. Envelope based on 17 obs.
L’obiettivo è massimizzare !, in modo che i rimanenti 12
$ – ! punti siano proprio gli outlier cercati.
Minimum deletion residual
10
[out]=FSReda(yc,Xc,outLTS.bs); 8
% Plot minimum deletion residual (MDR) 6
close all;
mdrplot(out,'xlimx’,[6,17],'ylimy’,[0,14],'Fon
tSize',16); 99%
4
set(gca,'FontSize',14);
50%
2
% Il plot degli MDR mostra un “salto” quando
% il sottoinsieme degli m punti contiene tutti 1%
0
% i punti buoni, e gli outlier (non facendo 6 8 10 12 14 16
% parte del sottoinsieme) mostrano residui Subset size m
% molto grandi rispetto a quelli dei
% punti del sottoinsieme “buono”.OUTLIER NELL’ANALISI CON REGRESSIONE LINEARE
Brushing interattivo iniziando dal grafico del monitoring dei residui
2
databrush=struct;
% Rectangular selection
1
databrush.selectionmode='Rect';
% Enable repeated mouse selections
0
databrush.persist='on';
% Write labels of trajectories while selecting
databrush.Label='on'; -1
Scaled residuals
% Do not remove labels after selection
databrush.RemoveLabels='off'; -2
%remove yellow
17
databrush.RemoveTool='on'; -3
cascade; -4
resfwdplot(out,'databrush',databrush);
-5
% Values of the residuals of all units 17
% while the m-subset increases. -6
2 4 6 8 10 12 14 16 18
Subset size mOUTLIER NELL’ANALISI CON REGRESSIONE LINEARE
Brushing interattivo iniziando dal grafico del monitoring dei residui
2
All’ultima iterazione solo il residuo del punto 1
contaminante 17 si distingue bene dagli altri. 12
Invece, la traiettoria del residuo del punto 12 0
(in rosso) all’ultima iterazione entra nel
-1
“ventaglio” degli altri residui.
Scaled residuals
Ciò significa che il punto 12 non può essere -2
identificato come outlier sulla base dei residui 17
-3
stimati nell’ultima iterazione.
E’ solo esaminando la storia nelle iterazioni -4
precedenti che si riesce a capire che il punto
-5
12 è effettivamente un outlier, come il 17. 17
-6
2 4 6 8 10 12 14 16 18
Subset size mOUTLIER NELL’ANALISI CON REGRESSIONE LINEARE
Una volta selezionato con il mouse un 14
insieme di traiettorie nel grafico di 12
Envelope based on 17 obs.
monitoring dei residui, i punti
Minimum deletion residual
10
corrispondenti sono automaticamente 8
evidenziati anche negli altri grafici.
6
2
4 99%
1 2 50%
12 1%
0 0
6 8 10 12 14 16
Subset size m
-1
Scaled residuals
148
-2
146
17
-3 144
142
-4
140
y
-5 138
17 17
136
-6 Unbrushed units
2 4 6 8 10 12 14 16 18 Brushed units 1
134
Subset size m Brushed units 2
132
90 92 94 96 98 100 102 104 106
X1OUTLIERS (PREZZI) NEL COMMERCIO INTERNAZIONALE
Prodotti ittici: 677 transazioni di un prodotto Lobsters data for years 2003 and 2004
6000
ittico (aragoste) in Europa tra il 2003 e il
2004. Per ogni transazione si riportano il
valore in migliaia di euro e la quantità in 5000
Values (Thousands of Euros)
tonnellate.
4000
lobsters = readtable(’lobsterIDyears.xlsx’,
'ReadRowNames',true); 3000
selected = find(or((lobsters.anno0 == 4) ,
(lobsters.anno0 == 3)));
lobstersS = lobsters(selected,:);
2000
y = lobstersS.VALUE_1000EURO;
X = lobstersS.QUANTITY_TON;
close all;
figure;plot(X,y,'*'); 1000
xlabel('Quantity (Tons)','Fontsize',16);
ylabel('Values (Thousands of Euros)','Fontsize',16);
title('Lobsters data for years 2003 and 0
2004','FontSize',16); 0 50 100 150 200 250 300 350 400
f1 = gcf; figure(f1); Quantity (Tons)OUTLIERS (PREZZI) NEL COMMERCIO INTERNAZIONALE
Regressione tramite Forward Search applicata ai prodotti ittici
n = size(y,1);
[out]=FSRr(y,X,'plots',1,'bonflev',1-0.01/n);
pout = out.outliers;
8
5000 Good units
Outliers
4500
7
4000
3500
6
3000
2500
y
5
2000
1500
4
1000
500
3
0
0 50 100 150 200 250 300 350
180 200 220 240 260 280 300 320 X1OUTLIERS (PREZZI) NEL COMMERCIO INTERNAZIONALE
Quali stati membri UE sono associati agli outlier nei prezzi?
lobstersS.DECLARANT_LAB(pout)
ans = 26×1 cell array
{'France' } {'Greece' } {'Spain' }
{'Spain' } {'Spain' } {'Spain' }
{'Spain' } {'Spain' } {'Spain' }
{'Spain' } {'Spain' } {'Spain' }
{'Spain' } {'Spain' } {'Spain' }
{'Spain' } {'Spain' } {'Spain' }
{'Spain' } {'Spain' } {'Spain' }
{'Spain' } {'Spain' } {'Belgium'}
{'Belgium'} {'Belgium'}
Pare abbastanza evidente chi sta sottofatturando in questo caso …
Ma più in generale?APPLICAZIONE DELL’ ANALISI DELLE CORRISPONDENZE
AL COMMERCIO INTERNAZIONALE
Dataset con più di 90.000 flussi d’importazione di tessili: ogni «flusso» è una combinazione di
Prodotto, Origine e Destinazione (POD) caratterizzata da un unico prezzo d’importazione
stimato in modo robusto con le tecniche e i dati visti in precedenza.
Ogni POD è stato poi classificato automaticamente in uno di k gruppi caratterizzanti la fascia
di prezzo dei tessili considerati: 1 = fascia di prezzo più bassa; 5 = fascia più alta;
load('POD_G_Price_W.mat’);
X = POD_G_Price_W;
textiles = cell2table(X, 'VariableNames’,…
{'Product','Origin’, 'Destination', …
'Cluster','EstPrice','Qvar'});APPLICAZIONE DELL’ ANALISI DELLE CORRISPONDENZE
AL COMMERCIO INTERNAZIONALE
Focalizziamoci sui flussi di origine Cinese:
booci = strcmp('CN',X(:,2));
Xcn = X(booci,:);
E costruiamo una tabella di contingenza, le cui righe si
riferiscono ai 28 Stati Membri (MS) di destinazione, mentre le
colonne riportano il numero di volte in cui ogni MS è associato
ad un certo segmento di prezzo x1, x2, …, x5.
[tbl,chi2,p,labels] =
crosstab(cell2mat(Xcn(:,3)),cell2mat(Xcn(:,4)));
[I,J]=size(tbl);
TBL = array2table(tbl,
'RowNames',labels(1:I,1),
'VariableNames’,genvarname(labels(1:J,2)));
disp(TBL)ANALISI DELLE CORRISPONDENZE
Obiettivo: analizzare la relazione tra due variabili
qualitative
• Segmenti di prezzo (5)
• Righe Nazioni (28)
Obiettivo: quale nazione è associata a quale segmento di
prezzo?
• Quali sono le nazioni associate (prevalentemente) al
segmento x1?
• Quali sono le nazioni associate (prevalentemente) al
segmento x2?
• ….APPLICAZIONE DELL’ ANALISI DELLE CORRISPONDENZE
AL COMMERCIO INTERNAZIONALE
Se c'è dipendenza tra righe e colonne, per capire
quali righe sono principalmente associate a quali
colonne, applichiamo l’analisi delle
corrispondenze (CA).
out = CorAna(TBL(:,1:numgruppi));
CA decompone la statistica Chi2 associata alla
tabella di contingenza delle frequenze in fattori
ortogonali. I due fattori principali sono
rappresentati in figura, e spiegano circa il 95%
della variabilità complessiva.
L’asse orizzontale, che spiega oltre 85% di tale
variabilità, sembra catturare il livello complessivo
di prezzo all’importazione (si veda l’ordine dei
gruppi da sinistra a destra). Dettaglio a seguire …APPLICAZIONE DELL’ ANALISI DELLE CORRISPONDENZE
AL COMMERCIO INTERNAZIONALE
Se c'è dipendenza tra righe e colonne, per capire
quali righe sono principalmente associate a quali
colonne, applichiamo l’analisi delle 0.5
corrispondenze (CA). 0.4
0.3
out = CorAna(TBL(:,1:numgruppi)); 0.2 SK
LU
AT
SI x5
Dimension 2 ( 10.7%)
IE
x1
CA decompone la statistica Chi2 associata alla 0.1 MT
GB NL ES
GR EE HR
DE CZ
x4 BE
tabella di contingenza delle frequenze in fattori 0 FR
HU PL FI
LT
DK
ortogonali. I due fattori principali sono -0.1 IT
x3 SE
PT
rappresentati in figura, e spiegano circa il 95% -0.2 RO x2
della variabilità complessiva. -0.3
LV
BG
CY
L’asse orizzontale, che spiega oltre 85% di tale -0.4
variabilità, sembra catturare il livello complessivo -0.5
di prezzo all’importazione (si veda l’ordine dei
gruppi da sinistra a destra). Dettaglio a seguire … -0.8 -0.6 -0.4 -0.2
Dimension 1 ( 83.3%)
0 0.2 0.4ANALISI DELLE CORRISPONDENZE
Termini di riferimento
0.5
0.4
0.3
LU
AT
0.2 SK
SI x5
Dimension 2 ( 10.7%)
IE
0.1 x1 MT
GB NL ES
GR EE HR
DE CZ
x4 BE
0 FR
HU PL FI
DK LT
-0.1 IT
x3 SE
PT
-0.2 RO x2
BG
LV
CY
-0.3
-0.4
-0.5
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4
Dimension 1 ( 83.3%)ANALISI DELLE CORRISPONDENZE
Input-output
y1 y2 Output (matrice 28 x 2)
2 nuove variabili che
riassumono i punti riga
Input (matrice 28 x 5)
y1 y2
x1 Output (matrice 5x2) 2
x2 nuove variabili che
x3
x4 riassumono i punti
x5 colonnaANALISI DELLE CORRISPONDENZE
Interpretazione asse x (prima dimensione latente)
0.5
0.4
• Andando da sinistra vs destra il livello di 0.3
prezzo passa da x1 (low price) a x5 (high 0.2 SK
LU
AT
SI x5
price).
Dimension 2 ( 10.7%)
IE
0.1 x1 MT
GB NL ES
GR EE HR
DE CZ
x4 BE
0 FR
PL FI
• Quest’asse può essere interpretato come
HU
DK LT
-0.1 IT
x3 SE
livello di prezzo -0.2 RO x2
PT
BG
LV
CY
-0.3
• Es. Le nazioni con valori della prima
-0.4
dimensione inferiore a 0 lavorano -0.5
generalmente con livelli di prezzo x1 e x2
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4
Dimension 1 ( 83.3%)
Livelli bassi Livelli alti di
di prezzo prezzoANALISI DELLE CORRISPONDENZE
Interpretazione asse y (seconda dimensione latente)
Prezzi
0.5 estremi
0.4
0.3
• Andando dal basso verso l’alto 0.2 SK
LU
AT
SI x5
passiamo da prezzi intermedi (x2, x3)
Dimension 2 ( 10.7%)
IE
0.1 x1 MT
GB NL ES
GR EE HR
DE CZ
a prezzi estremi (x4, x1 e x5) 0 FR
HU
x4 BE
PL FI
DK LT
-0.1 IT
x3 SE
• Quest’asse può essere interpretato -0.2 RO x2
PT
come «non normalità nel livello di
BG
LV
CY
-0.3
prezzo». -0.4
Prezzi
-0.5 normali
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4
Dimension 1 ( 83.3%)ANALISI DELLE CORRISPONDENZE
Interpretazione dei punti del II quadrante (quadrante in alto sinistra)
Prezzi
• Le nazioni che si trovano
0.5
0.4
estremi
nel II quadrante sono
0.3
caratterizzate da livelli di 0.2
LU
AT
SK
prezzo bassi ed estremi SI x5
Dimension 2 ( 10.7%)
IE
0.1 x1 MT
GB NL ES
EE HR
(SK, GR, MT, GB)
GR
Livelli bassi FR
DE CZ
x4 BE Livelli alti di
0
di prezzo HU PL FI
DK LT prezzo
-0.1 IT
x3 SE
PT
-0.2 RO x2
BG
LV
CY
-0.3
-0.4
-0.5
Prezzi
normali
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4
Dimension 1 ( 83.3%)ANALISI DELLE CORRISPONDENZE
Interpretazione punti vicini e lontani dall’origine
0.5
0.4
• I punti vicini all’origine degli assi sono i 0.3
punti vicini al centroide (profilo medio) 0.2 SK
LU
AT
SI x5
Dimension 2 ( 10.7%)
IE
0.1 x1 MT
GB NL ES
GR EE HR
• I punti lontani dall’origine 0 FR
DE CZ
x4 BE
PL FI
HU
LT
rappresentano punti distanti dal profilo
DK
-0.1 IT
x3 SE
PT
medio (Es. SK e x1) -0.2 RO
BG
x2
LV
CY
-0.3
-0.4
-0.5
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4
Dimension 1 ( 83.3%)ANALISI DELLE CORRISPONDENZE Interpretazione lunghezza delle frecce che si dipartono dall’origine e arrivano ai punti • La lunghezza della freccia è proporzionale alla quota di varianza (comunalità) spiegata dalle prime due dimensioni latente. • x1 = livello di prezzo spiegato meglio
ANALISI DELLE CORRISPONDENZE Interpretazione angoli vicini a 0 tra due frecce • Angoli vicini a zero indicano che le due modalità sono vicine • Es. Angolo basso tra x3 e x4 indica che questi due livelli di prezzo sono simili
ANALISI DELLE CORRISPONDENZE
Interpretazione angoli vicini a 90 gradi
• Angoli vicini a 90 gradi indicano che le
due modalità non sono legate tra di
loro
• Es. Angolo vicino a 90 gradi tra x1 e x2
segnala che questi due livelli di prezzo
non sono correlati tra loroANALISI DELLE CORRISPONDENZE Interpretazione angoli vicini a 180 gradi • Angoli vicini a 180 gradi indicano che le due modalità sono legate tra di loro in maniera forte e inversa • Es. Angolo vicino a 180 gradi tra x1 e x4 e x5 segnala che il livello di prezzo x1 è correlato negativamente con i livelli di prezzo x4 e x5
ANALISI DELLE CORRISPONDENZE Interpretazione angoli tra una freccia ed un asse • Angoli vicini a 180 gradi tra la direzione di una freccia ed un asse indicano che una modalità e’ collegata in maniera inversa all’asse • Es. Angolo vicino a 180 gradi tra x1 e la prima componente latente segnala che il livello di prezzo x1 è correlato negativamente con la prima dimensione latente
ANALISI DELLE CORRISPONDENZE Interpretazione nazioni che si trovano nella direzione di una freccia • Punti che si trovano nella direzione di una freccia segnalano valori elevati per la modalità associata alla freccia • Es. Nella direzione di x1 si trovano le nazioni SK, MT, GR e GB. Queste quattro nazioni sono caratterizzati prevalentemente da livelli di prezzo x1.
ANALISI DELLE CORRISPONDENZE: FSDA CorAna.m riporta in automatico: • Il contributo dei diversi punti alla spiegazione della varianza delle dimensioni latenti • Il contributo di ogni dimensione alla spiegazione della variabilità (distanza) del punto dal profilo medio • La quota di varianza spiegata dalle diverse dimensioni latenti • Infine è possibile sovrapporre intervalli di confidenza ad ogni punto riga (colonna) per verificare in maniera inferenziale quanto un punto riga è vicino ad un punto colonna
ANALISI DELLE CORRISPONDENZE ROBUSTA • Obiettivo: identificare un sottoinsieme di h profili riga per cui la matrice di varianze- covarianze ha il determinante piu piccolo, tramite lo stimatore MCD (Rousseeuw, 1999). • Lo stimatore MCD per il parametro di posizione e di scala minimizza la somma troncata:
APPLICAZIONE DELL’ ANALISI DELLE CORRISPONDENZE ROBUSTA
AL COMMERCIO INTERNAZIONALE: mcdCorAna
0.5
0.4
0.3
LU
AT
0.2 SK
SI x5
Dimension 2 ( 10.7%)
IE
0.1 x1 MT
GB NL ES
GR EE HR
DE CZ
x4 BE
0 FR
HU PL FI
DK LT
-0.1 IT
x3 SE
PT
-0.2 RO x2
BG
LV
CY
-0.3
-0.4
-0.5
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4
Dimension 1 ( 83.3%)APPLICAZIONE DELL’ ANALISI DELLE CORRISPONDENZE ROBUSTA
AL COMMERCIO INTERNAZIONALE: mcdCorAna
[RAW,REW, varargout] = mcdCorAna(N,varargin);
%RAW and REW contain info on outliers
out = CorAna(good_data,'Sup',outliers);
Type for more info: help mcdCorAna
help CorAnaORA TOCCA A VOI!
Puoi anche leggere

















































