Servizi di ricerca nel Web (Web search) - Generalità
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
SeQ dei servizi su internet
Servizi di ricerca nel Web
(Web search)
Generalità
Introduzione
Il web è il più grande database mondiali di contenuti. É un contenitore di
informazioni che vengono pubblicate, modificate, cancellate, inserite
ogni giorno.
Sarebbe impossibile utilizzare in modo proficuo contenuti senza uno o più
strumenti di ricerca.
In Internet gli strumenti di ricerca su contenuti delle pagine web sono veri
e propri servizi forniti da “providers”.
Le ricerche in Internet sono generalmente gratuite per l’utente del servizio,
i providers principalmente guadagnano su:
• Dati forniti dall’utente durante la sua ricerca (quali sono gli interessi del
momento etc...)
• Presenza di link sponsorizzati (ditte che pagano per potere apparire
all’inizio della lista dei risultati)
© 2009 Università degli Studi di Pavia, C.Parisi 2
© 2009 Università degli Studi di Pavia,
C.Parisi 1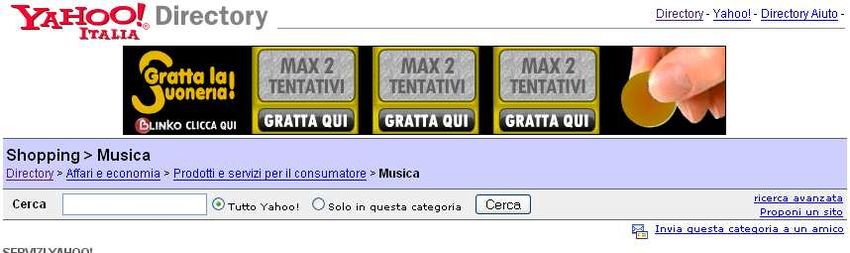
SeQ dei servizi su internet
Tipi di ricerche
Data l’enorme quantità di documenti presenti rete e le differenti lingue con
cui sono scritti quasi qualunque parola anche la più strana può essere
presente in un documento (es “sajkaska”).
In generale le ricerche che vengono effettuate possono distinguersi in :
1) Ricerca esplorativa su un argomento di cui si conosce molto poco o
niente del tutto. Questa potrebbe anche richiedere un tempo non
indifferente.
2) Ricerca specifica su di un argomento piuttosto vasto, un
approfondimento su di un argomento di cui però non si conosce il
grado a cui si vuole arrivare, ma lo si definisce strada facendo.
3) Ricerca puntuale ovvero data una domanda ben definita e che
presuppone una risposta altrettanto definita che in genere non lascia
adito ad ulteriori approfondimenti. (ricerche di date, luoghi, nomi
etc...)
© 2009 Università degli Studi di Pavia, C.Parisi 3
Web Search
Strumenti di ricerca
© 2009 Università degli Studi di Pavia,
C.Parisi 2
SeQ dei servizi su internet
Strumenti web per ricerche
Quali sono i tipi di servizi che il world wide web mette a
disposizione dell’utente per fare ricerche.
Tipi di risorse che abbiamo a disposizione si possono
suddividere in:
• Subject Tree
• Clearinghouse
• General search engine
© 2009 Università degli Studi di Pavia, C.Parisi 5
Subject Tree
É uno strumento di ricerca
strutturato ad albero
come una directory che
contiene le principali
categorie dei documenti
e ciascuna categoria a
sua volta è suddivisa in
sottocategorie via via più
specializzate
( http://dir.yahoo.com/ o
http://it.dir.yahoo.com )
Fonte internet
© 2009 Università degli Studi di Pavia, C.Parisi 6
© 2009 Università degli Studi di Pavia,
C.Parisi 3SeQ dei servizi su internet
Subject Tree
Scegliendo una delle
principali categorie alla
sinistra della pagina (ad
es. Entertainment) si
accede alla directory con
le sotto categorie
relative.
Da notare la presenza di
“sponsored links” nella
parte alta della pagina !
Fonte internet
© 2009 Università degli Studi di Pavia, C.Parisi 7
Subject Tree
Yahoo directory è un esempio di subject tree.
La ricerca all’interno dei subject tree è limitata ai documenti indicizzati dal sito
stesso si dice cioè “site based” in contrapposizione alla ricerca “web based”
(fatta sul web nella sua globalità).
Analogo servizio è offerto da google (http://www.google.it/dirhp) e comunque dai
principali motori di ricerca.
I documenti sono aggiunti dagli stessi utenti che, definita la categoria, lo possono
aggiungere alla directory di Yahoo!
Fonte internet
© 2009 Università degli Studi di Pavia, C.Parisi 8
© 2009 Università degli Studi di Pavia,
C.Parisi 4SeQ dei servizi su internet
Subject Tree
Aggiungere un documento alla directory del subject tree significa solo
aggiungere il link del documento (cioè non viene fatta una copia del
documento originale sul sito per esempio di Yahoo).
L’aggiunta di un documento e/o sito alla directory non garantisce un
controllo nè di qualità sull’analisi del contenuto nè sulla categorizzazione
stessa del documento che rispecchia la classificazione fatta dalla
persona che ne ha richiesto l’aggiunta.
Inoltre stessi documenti potrebbero appartenere a diverse categorie, per
cui mantenere un subject tree strutturato e coerente non è facile.
© 2009 Università degli Studi di Pavia, C.Parisi 9
Subject tree
Siti differenti che offrono servizio di ricerca basate su subject tree hanno
differenti categorizzazioni, non esiste un regola generale ma dipende
dallo schema mentale delle singole persone.
Si utilizza il subject tree quando si effettua una ricerca di tipo esplorativo
su un argomento. La struttura ad albero permette all’utente di avere
una visione di insieme dell’argomento.
Alcuni subject tree :
• www.about.com mantiene una vera e propria recensione dei documenti
non un semplice link alla risorse in rete, maggiore attenzione al
contenuto del documento.
• http://www.dmoz.org/ Open directory Project, simile a Yahoo!
© 2009 Università degli Studi di Pavia, C.Parisi 10
© 2009 Università degli Studi di Pavia,
C.Parisi 5SeQ dei servizi su internet
Clearinghouse
Le clearinghouse sono delle grandi collezioni di documenti e risorse in
Internet specializzate su di uno o più argomenti.
(Ad esempio “Environmental Law Net” è specializzata in leggi, regolamenti
e casi legali relativi alla normativa ambientale)
Alcune sono gratuite ed i contenuti sono curati da ricercatori sovvenzionati
dallo stato o tramite fondi specifici, altre hanno scopi commerciali ed i
loro contenuti sono disponibili a pagamento.
Il materiale è soggetto a revisione e quindi presentano un buon livello
qualitativo.
Quando utilizzarle: negli approfondimenti in merito ad un argomento.
Alcuni link :
http://www.ipl.org Internet Public Library
http://scholar.google.it/ google scholar
© 2009 Università degli Studi di Pavia, C.Parisi 11
General Search Engine
Motori di ricerca generalizzati sono quelli maggiormente utilizzati dai
navigatori in rete e quelli più indicati per ricerche puntuali su
determinati aspetti di un argomento.
I tre principali utilizzati nel web sono:
• http://www.google.com
• http://ask.com
• http://yahoo.com
http://www.lib.berkeley.edu/TeachingLib/Guides/Internet/SearchEngines.h
tml breve scheda comparativa sulle principali differenze tra alcuni
motori di ricerca
© 2009 Università degli Studi di Pavia, C.Parisi 12
© 2009 Università degli Studi di Pavia,
C.Parisi 6SeQ dei servizi su internet
General Search Engine
Per tutti i principali motori d ricerca esiste la possibilità di effettuare la ricerca sui
documenti presenti nel web, ma anche sulle immagini e video. In particolare
google tramite il servizio di googlemaps consente la ricerca e la visualizzazione
di mappe geografiche di buona parte della terra.
Fonte internet
© 2009 Università degli Studi di Pavia, C.Parisi 13
Web search engine
Come utilizzarli
Tecniche per utilizzare al meglio i motori di ricerca:
• Utilizzare per la ricerca solo parole chiave senza articoli, preposizioni
etc.. che in genere vengono filtrati dal motore di ricerca
• Non sempre al primo tentativo si ottengono i documenti richiesti, ma in
base ai risultati ottenuti raffinare ulteriormente la ricerca
• Se nelle prime due pagine (sono già tante) non c’è un documento
rilevante per la nostra ricerca significa che la ricerca non era ben posta,
cambiare.
• Utilizzare più di un motore di ricerca in quanto non tutti hanno visibilità
su tutto.
• Alcuni motori supportano utilizzo di wildcard (*), operatori booleani
(and/or) e/o esclusione di parole specifiche, per conoscere bene come
lavora il motore di ricerca che utilizziamo leggere l’help o i “search tips”.
© 2009 Università degli Studi di Pavia, C.Parisi 14
© 2009 Università degli Studi di Pavia,
C.Parisi 7SeQ dei servizi su internet
Web search engine
Come utilizzarli
Fonte internet
© 2009 Università degli Studi di Pavia, C.Parisi 15
Meta search Engine
Meta search engine sono motori di ricerca che inviano la richiesta
dell’utente ad altri motori di ricerca (per questo vengono detti “meta”) e
presentano i risultati delle diverse interrogazioni in un unica pagina.
Data la vastità dei contenuti web è difficile per un singolo motore di ricerca
riuscire ad effettuare una ricerca esaustiva in rete.
L’utilizzo di diversi motori e l’unione dei risultati dovrebbe portare ad una
maggiore copertura dello spazio di ricerca evitando così l’interrogazione
di diversi motori di ricerca.
Alcuni di questi
• http://www.dogpile.com/
• http://www.webcrawler.com/
© 2009 Università degli Studi di Pavia, C.Parisi 16
© 2009 Università degli Studi di Pavia,
C.Parisi 8SeQ dei servizi su internet
Search Engine
Come funzionano
I motori di ricerca mantengono all’interno dei loro server una lista delle
pagine (database) contenute nel web (ovviamente non esaustiva). Il
contenuti delle pagine sono catalogati ed indicizzati secondo determinati
criteri.
La ricerca di una serie di parole (detta “query”) determina l’estrazione dal
database del motore di ricerca dell’elenco delle pagine (url) che meglio
corrispondono alla parole ricercate.
© 2009 Università degli Studi di Pavia, C.Parisi 17
Search Engine
Come funzionano
I motori di ricerca utilizzano programmi detti Web Spider o Web Crawler
che ricercano i documenti presenti in rete ed aggiornano la lista dei
link (url) delle pagine web.
I web crawler prima di analizzare il contenuto di un sito web devono (o
dovrebbero) analizzare il file ‘robots.txt’. Se presente nel sito il file è
salvato nell’URL http:///robots.txt
I file robots.txt (spesso erroneamente chiamati robot.txt, col singolare)
vengono creati dai webmaster per marcare quei file e quelle directory
di un sito web che non si vuole rendere accessibili agli spider dei
motori di ricerca (o ad altri tipi di robot).
Esiste un formalismo per la compilazione del file robots.txt e siti che
analizzano e validano il formato del file.
© 2009 Università degli Studi di Pavia, C.Parisi 18
© 2009 Università degli Studi di Pavia,
C.Parisi 9SeQ dei servizi su internet
Search Engine
Come funzionano
Le pagine vengono poi analizzate nel seguente modo:
1. Analisi lessicale del contenuto delle pagine con la quale si ricavano i
termini chiave (detti keywords) specifici della pagina. L’analisi del
contenuto riguarda o una sola porzione del testo oppure l’intero testo
del documento. (Selective-text vs. Full-text indexing)
2. Valutazione delle parole chiave selezionate rispetto al documento
stesso in modo da ricavare il “peso” che ciascuna parola ha all’interno
del documento (ovvero quanto la keyword è “rilevante” per quel
documento).
Dall’analisi lessicale del contenuto della pagina si ricava quindi l’elenco
delle parole che meglio la identificano e descrivono.
© 2009 Università degli Studi di Pavia, C.Parisi 19
Search Engine
Come funzionano
Data la “query” si estraggono dal database tutti i documenti per cui quelle
parole sono indicate come “rilevanti” .
L’ordine di presentazione dei risultati della ricerca dipende dal “ranking” del
documento. Il ranking è determinato da diversi fattori tra cui
principalmente il numero di riferimenti che quel documento o sito ha
all’interno del web, cioè a parità di parole chiave rilevanti i documenti
che sono più referenziati da altri nel web sono i primi della lista dei
risultati.
Diverso è il criterio per i cosiddetti “link sponsorizzati”.
Da notare che l’analisi del contenuto SOLO di tipo lessicale ed esula da
qualunque considerazione sulla qualità del documento.
© 2009 Università degli Studi di Pavia, C.Parisi 20
© 2009 Università degli Studi di Pavia,
C.Parisi 10SeQ dei servizi su internet
Invisible Web
I motori di ricerca riescono a indicizzare molti dei documenti e pagine
contenuti nel web ma non tutti quelli presenti in particolare non
riescono ad analizzare:
• Le pagine generate dinamicamente sulla base di una richiesta
dell’utente (per esempio richieste inviate a database in rete)
• Le pagine ad accesso limitato cioè per le quali è necessario avere una
login
Non si conosce esattamente la dimensione del “web invisibile” ma è stato
stimato essere di gran lunga superiore a quello visibile.
© 2009 Università degli Studi di Pavia, C.Parisi 21
Ricerca di immagini
I motori di ricerca sono specializzati nella ricerca delle sole parole
contenute nelle pagine web e non sono in grado di analizzare il
contenuto di un immagine e/o di un video.
La ricerca di immagini si riduce alla ricerca di parole che sono associate
all’immagine stessa. Il linguaggio html insieme al tag che specifica
l’elemento immagine () definisce anche alcuni attributi tra cui:
• src per il reperimento del file immagine
• alt per la definizione di una serie di parole descrittive associate
all’immagine
Ad esempio
© 2009 Università degli Studi di Pavia, C.Parisi 22
© 2009 Università degli Studi di Pavia,
C.Parisi 11SeQ dei servizi su internet
Ricerca di file multimedia
I siti i cui contenuti sono principalmente file di tipo multimediale (ad es.
youTube con video, flickr con foto) utilizzano per la classificazione e
quindi anche una eventuale ricerca il sistema dei “tag clouds”.
Fonte internet
© 2009 Università degli Studi di Pavia, C.Parisi 23
Tag cloud
Un tag cloud è una resa grafica del complesso dei tag generati dall’utente
per descrivere il contenuto di un particolare sito web, video, fotografia.
Il tag cloud è una tecnica utilizzata specialmente all’interno di siti di
condivisione di file multimediali (da YouTube a Flickr etc) ed in genere
di social networking, ciascun utente ha la possibilità di associare uno o
più tag ad un video, foto etc...
L’elenco di tag associati agli elementi del sito viene reso graficamente in
modo che ciascun singolo tag (parola) ha un suo colore e/o dimensione
che rispecchia la popolarità di quel tag all’interno del sito.
© 2009 Università degli Studi di Pavia, C.Parisi 24
© 2009 Università degli Studi di Pavia,
C.Parisi 12SeQ dei servizi su internet
Web Search
Qualità del Servizio
Qualità del Servizio
Parametri oggettivi del servizio di ricerca in web sono principalmente dati
da:
• Tempo impiegato nell’eseguire la ricerca (molto basso in tutti i motori di
ricerca a causa dell’indicizzazione delle pagine)
• Presentazione dei risultati, cioè quanto il risultato è rispondente alle
nostre aspettative. Questo dipende sia dal metodo di “voto” delle
pagine utilizzato dal motore di ricerca che dalla rispondenza delle parole
che inseriamo nella query di ricerca.
Il problema più importante una volta ottenute le informazioni richieste è
quello legato alla “Qualità dell’informazione” ovvero l’attendibilità della
fonte.
© 2009 Università degli Studi di Pavia, C.Parisi 26
© 2009 Università degli Studi di Pavia,
C.Parisi 13SeQ dei servizi su internet
Qualità dell’informazione
L’attendibilità delle fonti non è un problema specifico dei contenuti del
web, ma presente sempre ogniqualvolta si conducono delle ricerche
anche se il materiale trovato è su supporto cartaceo, video o altro.
Il Web è un “content neutral medium” pubblica di tutto senza che vi sia
necessariamente un controllo sulla qualità, veridicità, attendibilità del
contenuto.
Il riferimento ad informazioni errate potrebbe danneggiare la stessa
credibilità di chi le utilizza.
Diventa di fondamentale importanza analizzare due aspetti in particolare:
• Qualità della fonte
• Qualità del contenuto (non il modo in cui viene presentata “look and
feel”)
© 2009 Università degli Studi di Pavia, C.Parisi 27
Qualità dell’informazione
Per attendibilità della fonte si intende la legittimità del sito che ha
pubblicato il documento, dell’istituzione, ente e/o società che lo
gestisce.
In internet i singoli domini vengono rilasciati a istituzioni, aziende, privati
senza alcuna verifica sia sulla loro veridicità e tantomeno sulla qualità
dell’operato e/o onorabilità.
In genere documenti provenienti da domini del tipo .edu, .gov, .mil sono
attendibili in quanto provenienti da istituti di ricerca, autorità
governative o militari che revisionano attentamente i contenuti prima di
renderli pubblici.
© 2009 Università degli Studi di Pavia, C.Parisi 28
© 2009 Università degli Studi di Pavia,
C.Parisi 14SeQ dei servizi su internet
Qualità dell’informazione
Attendibilità e referenze dell’autore.
Documenti “attendibili” indicano sempre il nome dell’autore e le sue
referenze che dovrebbero evidenziare quanto egli sia autorevole nella
campo o nella materia trattata nell’articolo.
L’autore dovrebbe pubblicare almeno l’indirizzo di posta elettronica allo
scopo di fornire informazioni aggiuntive in merito all’argomento trattato.
Nell’articolo si deve evidenziare se il materiale è originale o se si riferisce
ad altro materiale presente in web, in questo caso bisogna citare la
fonte originale e l’autore.
© 2009 Università degli Studi di Pavia, C.Parisi 29
Qualità dell’informazione
Analisi lessicale del contenuto.
Il contenuto deve essere chiaro, preciso, non deve sembrare essere stato
scritto casualmente e di fretta.
Eventuali citazioni devono sempre essere referenziate (possibilmente con
link al documento e alla home page dell’autore se esiste)
Deve essere chiaro - nel caso in cui l’autore facesse parte di un ente
commerciale o fosse in qualche modo affiliato ad esso - dove finisce il
contenuto informativo/tecnico e dove inizia quello prettamente
commerciale.
Nell’ambito della comunità scientifica ed accademica i documenti pubblicati
o che vengono presentati a convegni sono revisionati da studiosi
autorevoli nel settore specifico (si parla di “peer review”). Questo per
garantire affidabilità e qualità del contenuto stesso.
Diffidare di pubblicazioni che si dichiarano scientifiche e che non sono state
soggette a revisioni sulla qualità ed attendibilità del contenuto.
© 2009 Università degli Studi di Pavia, C.Parisi 30
© 2009 Università degli Studi di Pavia,
C.Parisi 15SeQ dei servizi su internet
Web Search
Sicurezza
Sicurezza del servizio
Il servizio di ricerca in rete è dato dalla presentazione all’interno di una o
più pagine web dei risultati della ricerca cioè una serie di link alle
pagine che rispondono maggiormente alla query effettuata.
La visualizzazione dei risultati della ricerca non comporta di per sè
minaccia in termini tecnici e fisici alle risorse del sistema quali presenza
di virus o worm (questo potrebbe eventualmente insorgere nel
momento in cui accedo ad un sito della lista).
Il problema invece riguarda la sicurezza “indiretta” ovvero attribuire
autorevolezza ad una pagina che in realtà non ne ha. Questo perchè è
possibile (anche se non banale) costruire pagine che sono classificate
dai motori di ricerca con un ranking alto ma che non effettivamente
rispondono a criteri qualitativi reali.
© 2009 Università degli Studi di Pavia, C.Parisi 32
© 2009 Università degli Studi di Pavia,
C.Parisi 16SeQ dei servizi su internet
Sicurezza del servizio
Alcune aspetti relativi alla sicurezza “indiretta” sono relativi a:
Pagine fraudolente cioè quelle pagine e/o siti che si dichiarano appartenere
ad un ente/organizzazione e invece sono fasulle ma imitano alla
perfezione il sito di riferimento.
Dal momento che il motore di ricerca non esegue un’analisi di veridicità di
quanto indicizzato sulla legittimazione del sito stessa ma risponde a dei
criteri puramente numerici (numero di collegamenti alla pagina data
etc...) la presenza di pagine fraudolente non viene segnalata e/o
filtrata da parte dei motori di ricerca.
© 2009 Università degli Studi di Pavia, C.Parisi 33
Web search
Wikipedia
© 2009 Università degli Studi di Pavia,
C.Parisi 17SeQ dei servizi su internet
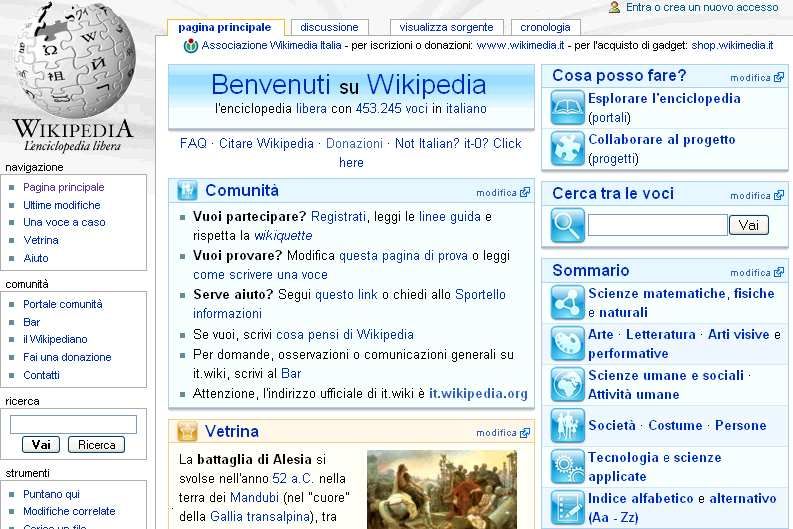
Wikipedia
Wikipedia è enciclopedia
on-line formata da
documenti ipertestuali
i cui contenuti sono
redatti in modo
collaborativo da
volontari. Redatta in
più lingue è sostenuta
da un’organizzazione
senza fini di lucro
“Wikimedia
Foundation”
Fonte internet
© 2009 Università degli Studi di Pavia, C.Parisi 35
Wikipedia
Attualmente la versione italiana è composta di 560.000 voci circa, quella
inglese di quasi 3.000.000 voci. (68 milioni di visitatori in un mese
circa).
La modifica dei testi è aperta e libera a chiunque si registri, per data voce
ogni versione è salvata in modo eventualmente da ripristinare una
precedente versione.
Wiki supporta ricerche di vario tipo, da full text al solo titolo, alla ricerca
per argomento (tipo subject tree).
Gli autori delle voci, che non devono avere necessariamente alcuna
competenza o qualifica sugli argomenti trattati, sanno però che i loro
contributi possono essere cancellati, o a loro volta modificati, nei
termini della licenza e delle linee guida interne.
© 2009 Università degli Studi di Pavia, C.Parisi 36
© 2009 Università degli Studi di Pavia,
C.Parisi 18SeQ dei servizi su internet
Servizi di ricerca su database
Whois
Whois.net
http://whois.net è il sito
che fornisce il servizio
di ricerca dei dati di un
dominio
In particolare fornisce i
dettagli relativi al
registrar e registrant, il
periodo di validità
etc....
© 2009 Università degli Studi di Pavia, C.Parisi 38
© 2009 Università degli Studi di Pavia,
C.Parisi 19SeQ dei servizi su internet
Whois.net
Assegnazione di un dominio
Il registrant (google) chiede VERISIGN
l’assegnazione del dominio al registrar REGISTRY (.com)
(intermediario)
Il registrar (società intermediaria) google.com
richiede all’autorità di competenza del google.com assigned
dominio di I livello la registrazione del
dominio google.com. Markmonitor inc
Nel particolare caso la VERISIGN assegna REGISTRAR
il dominio ed abbina l’indirizzo
del’intermediario al dominio
“google.com” nelle sue tabelle. google.com
google.com assigned
La società Markmonitor inc.
(intermediario) tramite servizio di web REGISTRANT
hosting - pubblica la mappa degli
indirizzi per potere risolvere il dominio Google.com
google.com
© 2009 Università degli Studi di Pavia, C.Parisi 39
Whois.net
Per interrogare il database inserire il nome del dominio, selezionare
il dominio di primo livello dall’elenco e premere il tasto GO.
© 2009 Università degli Studi di Pavia, C.Parisi 40
© 2009 Università degli Studi di Pavia,
C.Parisi 20SeQ dei servizi su internet
Whois.net
© 2009 Università degli Studi di Pavia, C.Parisi 41
Whois
© 2009 Università degli Studi di Pavia, C.Parisi 42
© 2009 Università degli Studi di Pavia,
C.Parisi 21SeQ dei servizi su internet
Whois
© 2009 Università degli Studi di Pavia, C.Parisi 43
© 2009 Università degli Studi di Pavia,
C.Parisi 22Puoi anche leggere

















































