Segmentazione Foreground - Background attraverso un "codebook model"
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Università degli Studi di Milano
Dipartimento di Informatica e Comunicazione
Corso di Laurea Magistrale in Informatica
Segmentazione Foreground – Background
attraverso un “codebook model”
Alessandro Ferrari
alessandro.ferrari3@studenti.unimi.it
www.imageprocessing.altervista.org
Introduzione
• Articolo di riferimento: “Realtime foreground-background segmentation
using codebook model” - K.Kim, T.H.Chalidabhongse, D.Harwood, L.Davis.
• E’ un algoritmo per segmentare le immagini di un flusso video nelle
componenti (quasi) statiche di background e dinamiche di foreground
(situazione tipica: videocamera di sorveglianza in un parcheggio).
• Discriminare il background dal foreground e ricavare informazione
sfruttando la coerenza spaziale dei blob in movimento. Non è visual
tracking!
Panoramica sull’algoritmo
• E’ suddiviso in due macro-fasi ben distinte:
– Learning (background model building)
– Foreground detection (ricerca del movimento)
• Nel learning viene creato il modello che rappresenta l’informazione
statica della scena in esame. All’inizio della sequenza video deve
essere prevista una fase statica dove è presente solo il background
(o quasi).
• Nella fase di detection si verifica la presenza di moto e si aggiorna il
modello di descrizione della scena.
Caratteristiche algoritmo • Background Model compatto, multi layer e variabile nel tempo • Sensibile sia piccoli movimenti che a cambiamenti a lungo termine (funzione di adattamento alle variazioni di illuminazione) • Fase di training robusta a rumore e movimento indesiderato • Utilizza un approccio totalmente pixel based, basato su misure di luminanza, crominanza e di distanza temporale. Nessuna inferenza statistica.
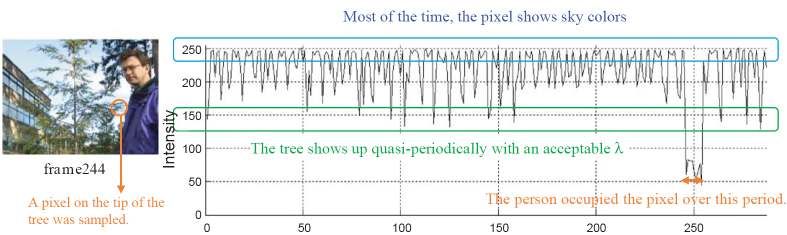
Fase di Learning • Nella fase di learning viene creato il modello che rappresenta l’informazione statica della scena in esame • Durante il periodo di training ogni frame viene campionato e analizzato secondo metriche euclidee nello spazio colore RGB e considerazioni di carattere temporale. • I campioni usati vengono “clusterizzati” in “codeword”(cw) ; Il numero di cw associato a ciascun pixel è variabile

Definizione del modello • Ad ogni pixel di posizione (x,y) vengono associati uno o più codeword che rappresentano l'informazione cromatica, di luminanza e di carattere temporale. • L'insieme dei codeword associati ad un pixel di posizione (x,y) è detto codebook. • Attraverso i codebook si costituiscono i modelli di background e cache. • I due modelli, seppur uguali a livello di “codifica”, rappresentano informazione decisamente diversa.
Definizione del modello Luminanza minima e massima dei pixel assegnati a questo cw Frequenza di occorrenza del cw Durata massima dell’intervallo di “non-scelta” del cw durante la fase di training Primo e ultimo accesso al cw

Analisi del modello • La costruzione del modello proposta è per immagini a colori ma è facilmente estendibile a immagini in scale di grigio • Ogni pixel ha un numero diverso di cw e quindi un codebook di dimensione diversa (richiede quindi allocazione dinamica in fase di elaborazione)
Costruzione del modello di bg
• Fissiamo l’attenzione su un solo pixel e vediamo il loop di
costruzione del relativo codebook per il background (pixel fissato,
itera nel tempo)
1. Recupero terna e calcolo luminanza per il pixel in esame al
tempo t
2. Iterando sui cw cerco il primo che rispetta le condizioni su color_dist e
brightness (è la metrica di similarità, approfondiremo il modello dello
spazio colore usato)
– Se non trovo nessun cw che rispetta le condizioni elencate al punto 2 creo
un nuovo cw secondo la definizione del modello precedentemente data.
– Se invece trovo un cw simile, procedo alla sua modifica secondo una logica
di aggiornamento “temporale”Costruzione del modello di bg
Maximum negative run-length
• Il codebook creato fino allo step 2 è detto fat_codebook poichè vengono
tenuti in memoria tutti i cw trovati; non è pensabile gestirne l’allocazione e
l’analisi in tempo reale!
• Il parametro MNRL è fondamentale per discriminare i cw non scelti da
più tempo e quindi presumibilmente relativi a rumore impulsivo o piccoli
oggetti non conformi al background.
• Sperimentalmente si fissa pari alla metà del numero di frame di learningSpazio colore utilizzato Attraverso epsilon e le luminanze estese si definisce il cilindro di accettazione della proiezione p del pixel di input.
Foreground detection • Ogni pixel viene confrontato con le cw corrispondenti secondo le condizioni previste (ii.a e ii.b). • Se non è riconducibile per colore e luminanza ad una delle cw presenti nel modello di bg viene etichettato come movimento.
Foreground detection
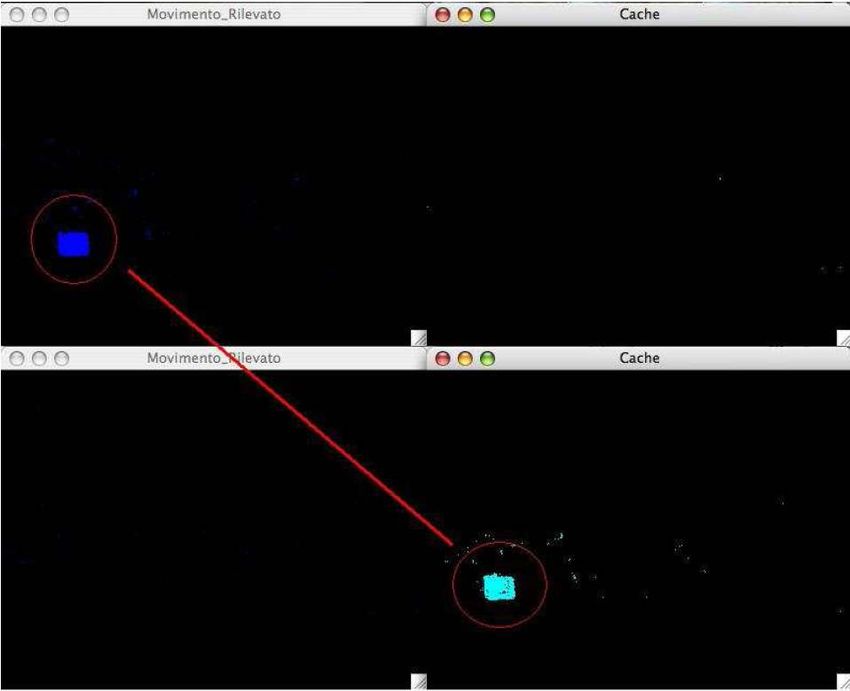
Cache Improvement • Fino a questo punto abbiamo analizzato la versione base che discrimina solo il foreground dal background • Vengono proposte alcune estensioni dell’algoritmo per ampliarne l’efficacia in condizioni di background mutevole nel tempo. • Esempio: un’auto che si ferma in un parcheggio per un certo tempo è ragionevole pensare diventi background; l’algoritmo presentato fino qui continua a trovare pixel di foreground nonostante non ci sia effettivo movimento!
Modello di cache • Introduciamo tre nuovi parametri per l’analisi temporale dei dati: • Il modello di cache è strettamente collegato con le fasi di filtraggio.
Parametri di filtraggio
• : soglia di filtraggio per il modello di background fat; dopo la fase di learning
vengono eliminati quei codeword che non rappresentano realmente
informazione statica ma sono elementi di disturbo della fase di apprendimento.
• : soglia di eliminazione di cw che hanno un periodo di non-presenza relativa
superiore alla soglia. Tenere una soglia relativamente bassa in modo da pulire la
cache dai cw inutili frequentemente
• : soglia che determina quali codeword vengono promossi a background
model. Tali cw vengono etichettati con la label di short term background.
• : soglia che determina quali cw short term vengono eliminati dal
background model. Vengono presi in esame solo i cw non etichettati come
permanent (cioè quelli aggiunti secondo la condizione relativa a Tadd).Tipologia di codewords • Permanent background • Short-term background • Foreground found in cache • New foreground.
Esempio di oggetto “promosso” Tempo t Tempo t+1
Un esempio più complesso
Dove siamo arrivati?
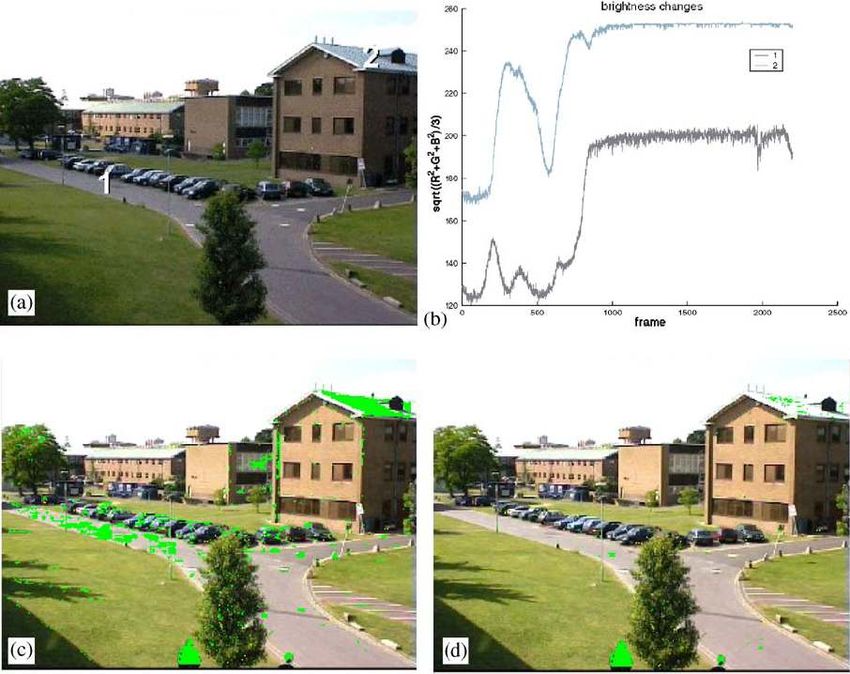
Filtraggio cwCodebook updating – illumination changes • Fino a questo punto abbiamo un algoritmo che discrimina background e movimento, analizza oggetti entranti nella scena che diventano statici e li tratta come background temporaneo. • Ma se le condizioni di luminosità globale cambiano riusciamo a discriminare il movimento dalle naturali variazioni di luminosità?
Codebook updating – illumination changes • Cambiamenti di illuminazione globale dovuti ad esempio al movimento delle nuvole rendono difficile la motion detection in scenari “outdoor”. • Tale problema si traduce in over-detection, false detection, o bassa sensibilità alle vere detection. • E’ una istanza di un problema più generale e complesso di aggiornamento e apprendimento secondo una funzione di adattamento.
Codebook updating – illumination changes
Move in – Move out Improvement • Fino a questo punto abbiamo un algoritmo che discrimina background da movimento, analizza oggetti entranti nella scena che diventano statici e li tratta come background temporaneo e si adatta ai cambiamenti globali di luminosità. • Ma siamo in grado di capire se un oggetto è entrato davvero in scena oppure è un oggetto che uscendo lascia “un vuoto” interpretato come movimento?
Move in – Move out • Non è una feature prevista dall’articolo ma nella versione del LAIV, implementata in Matlab, è presente. • L’idea è quella di studiare le componenti connesse di un oggetto in movimento in relazione alle componenti cromatiche che troviamo campionando il bordo con un numero arbitrario di normali ad esso.
Move in – Move out • Se si trovano colori decisamente diversi dentro e fuori dalla regione connessa inferisco MOVE IN. Se si trovano colori simili dentro e fuori dalla regione connessa inferisco MOVE OUT • Se l’oggetto individuato risulta frammentato si rischia di classificarlo come MOVE OUT (coerenza dei colori dentro e fuori la regione) • E’ necessario gestire il fatto che un oggetto “si ferma” in un intervallo di tempo che interessa più frame. Il problema è quindi decisamente complesso.
Motion layering • La caratteristica più interessante dell’algoritmo riguarda l’etichettatura “temporale” degli oggetti che stazionano nella scena in esame per un tempo rilevante. • Attraverso la soglia Tadd spostiamo i cw degli oggetti divenuti statici dal modello di cache al modello di background classificandoli come short term codeword. • In un'ottica di successive analisi della scena, vogliamo raggruppare tutti i punti appartenenti ad un oggetto senza post-processing (estrazione bordi, analisi distribuzione punti, compattezza oggetti, ecc…). • La soluzione deve essere semplice, efficiente e utilizzare l'informazione implicitamente contenuta nei cw trasferiti.
Motion layering • Apponendo una opportuna label ai cw spostati al frame t stiamo intrinsecamente assegnando dell'informazione sulla correlazione temporale e spaziale di un oggetto; • Tuttavia la nostra visuale è ristretta al singolo pixel, è quindi necessario introdurre un meccanismo che permetta di etichettare in modo consistente i cw che spostiamo durante la fase di filtraggio evitando fenomeni di sovra-segmentazione o segmentazione errata.
Motion layering – soglia statica • Analizzando il numero di cw spostati da cache a background model si nota che esiste una correlazione diretta tra presenza di oggetti in movimento che diventano statici e numero di cw trasferiti. • Una possibile implementazione consiste nell'utilizzo di una soglia fissa che permetta di discriminare cw appartenenti a layer diversi. • Abbiamo anche provato una sogliatura dinamica che calcolava una percentuale massimo del picco trovato ma con scarsi risultati.
Motion layering – soglia statica
Effettuando il cambio di layer in prossimità di
valori vicini allo zero è ragionevole che i tre
oggetti apparterranno a tre layer differentiMotion layering – esempio 1
Motion layering – soglia statica
Ma in situazioni più complesse diventa un
problema di non facile soluzione.
Sovra-segmentazione dei layer.
? ?Motion layering – esempio 2
Criticità della scelta della soglia
• La scelta della soglia è un problema critico che offre soluzioni soddisfacenti solo
in caso di facili detection dove gli oggetti entrano in tempi ben distinti e con
velocità apprezzabili (né troppo lentamente, né troppo velocemente)
• la scelta della soglia ottimale può essere effettuata solo con una fase di analisi
del grafico dei cw spostati. In un ottica di analisi on line,non è pensabile
effettuare analisi accurate “a posteriori” e quindi è necessario fare delle
assunzioni a priori sulla soglia.
• Ad esempio soglia statica molto piccola per video non rumorosi e con moto
ordinato. La soglia si alza per video rumorosi o caotici.
• Va ricordato che si sta lavorando ad un livello basso rispetto alla semantica
dell'immagine; in un progetto più ampio, si può pensare di introdurre tecniche di
miglioramento dell'immagine o tenere conto anche di aspetti legati alla
correlazione spazio-temporale del movimento (stima moto, compattezza ecc…).Aspetti implementativi
• L’algoritmo, seppur nato per essere eseguito in tempo reale, è comunque
computazionalmente pesante e necessità di molta cura durante lo sviluppo specie in
relazione alle scelte implementative delle strutture dati.
• In linea di principio allocare staticamente la memoria per i codeword offre migliori
prestazioni a regime ma scarsissima flessibilità in termini di complessità dei dati raccolti.
• Si è optato per una strategia dinamica pagando un piccolo prezzo in termini di prestazione
ma che ha permesso di semplificare decisamente lo sviluppo e la gestione della memoria.Fase di sviluppo del progetto
• Di questo algoritmo esistono due implementazioni disponibili, una in MATLAB (40 secondi
per frame) e una in C++ che lavora in tempo reale.
• Le funzioni base per la elaborazione delle immagini sono facilmente utilizzabili attraverso
le libreria Intel OpenCv (http://www.intel.com/technology/computing/opencv/) e Intel IPP
(opzionale per ottimizzazione - http://www.intel.com/cd/software/products/asmo-
na/eng/302910.htm)
• Sul sito è disponibile anche la relazione di accompagnamento al progetto che può essere
utile come traccia per lo sviluppo di altri progetti per il corso di “elaborazione delle
immagini II“.Università degli Studi di Milano
Dipartimento di Informatica e Comunicazione
Corso di Laurea Magistrale in Informatica
Per domande, approfondimenti:
alessandro.ferrari3@studenti.unimi.it
www.imageprocessing.altervista.orgPuoi anche leggere

















































