L'Intelligenza Artificiale a supporto dell'Asset Management - SIAT
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

L’Intelligenza Artificiale
a supporto dell’Asset Management
Roberto Malnati Giovanni Trombetta
r.malnati@tensigma.ch info@gandalfproject.com
www.gandalfproject.com
SIAT Professional Member
Partner di Ten Sigma Sagl SIAT Professional Member
Head of Research & Development
Gandalf Project
Anche se la programmazione tradizionale dei computer sembra complicata, in realtà è molto semplice. Dovete solo dare al computer alcune istruzioni estremamente precise su ciò che volete ottenere dai dati che intendete elaborare. L'apprendimento automatico è ancora più semplice rispetto alla programmazione tradizionale perché utilizza un approccio completamente diverso. Dovete dare al computer alcuni dati di input e di output che sono presumibilmente correlati, e chiedere al computer di capire quale relazione è più adatta per ottenere dai dati di input i dati di output più corretti, anche per casi che non si sono mai presentati in precedenza.

Relativamente al settore finanziario, per prevedere l’andamento dei mercati, potete
programmare dei trading system, sperando che i movimenti del passato si ripetano
per un tempo sufficientemente lungo prima di dover intervenire sul codice o sui
parametri.
o in alternativa
Potete usare uno o più strumenti di apprendimento automatico lasciando al sistema
tutte le incombenze del caso.
Sia in oriente sia in occidente, dai tempi più remoti, indovini, sacerdoti, maghi e
astrologi predicono il futuro interpretando eventi atmosferici, comete e moto degli
astri, comportamenti animali, nascite mostruose, tavolette d’argilla, fuoco, sogni, ossa
e viscere. Profeti, sciamani e veggenti, invece, si lasciano possedere dalla divinità e le
danno voce. Anche la Bibbia è piena di profeti e profezie.
Greci e romani impiegano entrambe le forme di predizione: gli àuguri interpretano la
volontà degli dèi osservando il volo degli uccelli. Dispensano ambigui oracoli, anche
grazie a un aiutino psicotropo, le pizie (le sacerdotesse di Apollo, a Delfi) e le sibille (in
Italia, Grecia, Asia Minore, Nordafrica). Ma anche le centurie di Nostradamus, in
quanto ad ambiguità, non scherzano.
Né l’Inquisizione, che perseguita e scomunica gli indovini, né l’età dei lumi, che valorizza la scienza, cancellano il sogno di poter predire il futuro: del resto, “la condizione umana riposa sulla necessità di riuscire a sapere cosa accadrà domani per poter agire sin da ora” (Georges Minois). Tuttavia, al di là dell’occhiata all’oroscopo un sensato, razionale e possibile negoziato con il futuro può passare dalla diversità che c’è tra due parole in apparenza assai simili: “predire” e “prevedere”. “Predire” riguarda l’annunciare eventi futuri e il fare profezie. “Prevedere” riguarda il fare ipotesi e supposizioni, a partire dai dati disponibili, su quanto potrebbe accadere in futuro. Gli studi sul futuro integrano discipline eterogenee: psicologia, sociologia, matematica e statistica hanno cominciato a svilupparsi a metà del secolo scorso. Chi se ne occupa cerca di individuare schemi ricorrenti, se ce ne sono, e ragiona in termini di scenari: possibili, probabili, preferibili o da evitare, con l’obiettivo generale di aiutare società e individui a compiere scelte sagge avendo un po’ più chiare le opzioni disponibili e le loro conseguenze possibili. A saper fare le previsioni migliori non sono tanto i superesperti, quanto le persone dotate di un alto grado di apertura mentale.

In termini psicologici, essere mentalmente aperti significa saper affrontare l’incertezza, essere capaci di esaminare le questioni da molte prospettive, non avere preconcetti, essere pronti a cambiare idea e saper evitare le trappole mentali (bias cognitivi) che possono fuorviare anche le persone più accorte. Proviamo “Prevedere” il miglior futuro possibile, con l’ausilio di una rete neurale, partendo dall’indice Msci World e proseguendo con il reverse engineering dei valori ottenuti.



27
Artificial Intelligence “If a machine is expected to be infallible, it cannot also be intelligent.” Alan Turing
Perchè adesso…?
Oltre la legge di MooreLa previsione di fenomeni complessi…
Algoritmi di Machine Learning
utilizzati in finanza
1. Algoritmi di Regressione
2. Algoritmi di Classificazione (RF Random Forest
SVM Support Vector Machine)
1. Reti Neurali
• Reti Neurali Backpropagation (NNBP BackPropagation Neural
Networks)
• Reti Neurali Profonde (DNN Deep Neural Networks)
• Reti Neurali Convoluzionali (CNN Convolutional Neural
Networks)
• Reti Neurali Ricorrenti (RNN Recurrent Neural Networks
LSTM Long Short Term Memory)
3. Programmazione Genetica (GP Genetic Programming
GA Genetic Algorithms) 31Previsione per errori
Modelli “Black Box” & “White Box”
Dati Dati
Black Modello
Futuro
Box
Reti Programmazione
Neurali Genetica
33Cosa non funziona…
“E’ inutile cercare oro in una cava di marmo”: prima di procedere in un addestramento
mirato va misurata la correlazione tra gli input e gli output di una serie.
Se e solo se tale relazione esiste esistono le basi (ancora solo potenziali) per
addestrare un algoritmo a rete neurale.
34Delay Effect anche con DNN
35Cambiamo il modo di vedere le cose…
Processiamo i nostri input in modo da evidenziare il segnale a discapito del
rumore:
INPUT
• Serie logaritmiche
• Serie delle differenze
• Serie normalizzate per l’estrazione del segnale
MOTORE
• Utilizziamo reti DNN, LSTM e CNN stratificate
• Aggiungiamo moduli per la classificazione dell’output
OUTPUT
• Prevediamo la probabilità che un determinato fenomeno accada
• Classifichiamo il contesto
36Nuovi Modelli a Reti Neurali
D
Movement
N
Forecating
N
R Intermarket
N Analysis
N Equity Control
C
Portfolio
N
Classification
NPrevisione Probabilità di Crescita
Previsione Probabilità di Crescita
LSTM RNN 12-1 su ES 1380 minuti
Percentuali di accuracy inferiori al 50% potrebbero
trarre in inganno: anche un 30% di accuracy può
corrispondere ad un 70% di riconoscimento del segno
del movimento!
40Asset Allocation oltre la Correlazione
Cluster 1: Pepsi, Coca Cola, Kellogg
Cluster 2: Apple, Amazon, Yahoo
Cluster 3: GlaxoSmithKline, Novartis, Sanofi-Aventis
Cluster 4: Comcast, Time Warner, Cablevision
Cluster 5: ConocoPhillips, Chevron, Total, Valero Energy, Exxon
Cluster 6: CVS, Walgreen
Cluster 7: Navistar, Sony, Marriott, Caterpillar, Canon, Toyota, Honda, Mitsubishi, Xerox, Unilever
Cluster 8: Kimberly-Clark, Colgate-Palmolive, Procter Gamble
Cluster 9: American express, Ryder, Goldman Sachs, Wal-Mart, General Electrics, Pfizer, Wells Fargo,
DuPont de Nemours, Bank of America, AIG, Home Depot, Ford, JPMorgan Chase, Mc Donalds
Cluster 10: Microsoft, SAP, 3M, IBM, Texas instruments, HP, Dell, Cisco
Cluster 11: Raytheon, Boeing, Lookheed Martin, General Dynamics, Northrop Grumman
41Gestore Intelligente a rete Neurale
Modelli ad Algoritmo Genetico
Cluster
of
C
Driven Rules R
M
U
O
T
[Breakout Logic Rules] S
A
[Trend Following Logic Rules] S
T
O
[Reversal Logic Rules] I
V
[Bias Logic Rules] O
E
….. N
R
Money & Position
Management RulesTrading System Genetico 1
ES (1 min - 1380 min)
IS-OoS comb period:
[01/01/2000 - 31/12/2011]
Incubation period:
[01/01/2012 - 31/12/2013]
Real Money
From
01/01/2014Trading System Genetico 2
TY (1 min - 1380 min)
IS-OoS comb period:
[01/01/2000 - 31/12/2011]
Incubation period:
[01/01/2012 - 31/12/2013]
Real Money
From
01/01/2014Trading System Genetico 3
CL (460 min)
IS-OoS comb period:
[01/01/2000 - 31/12/2012]
Incubation period:
[01/01/2012 - 31/12/2014]
Real Money
From
01/01/2015Selettore Darwin 2/6
Time: 10 years
Rotational Selector: 2 of 6 TS
Operations Window: 30
Operations Ranking: 90
21.9% Yearly
19.4% Draw Down on Yearly Profit
Yearly Profit – Max DrawDown Ratio > 548
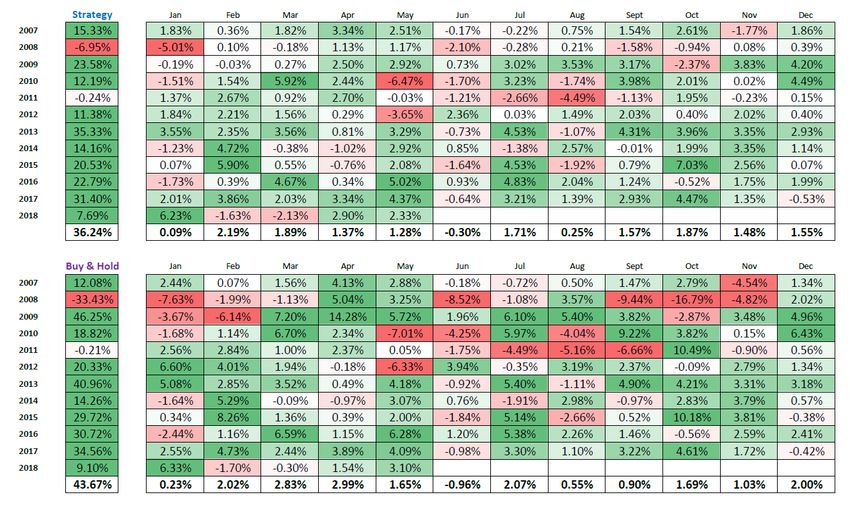
Dalla Teoria alla Pratica “In theory, theory and practice are the same. In practice they are not” Albert Einstein
Strategie ad elevata congruenza
con il modello: bassa varianza
Model: In Sample + Out of Sample
Model
Real
Real MoneyTollerabile variazione dal modello:
media varianza
Model: In Sample + Out of Sample
Model
Real
Real MoneySignificativa variazione dal modello:
elevata varianza
Model: In Sample + Out of Sample
Model
Real
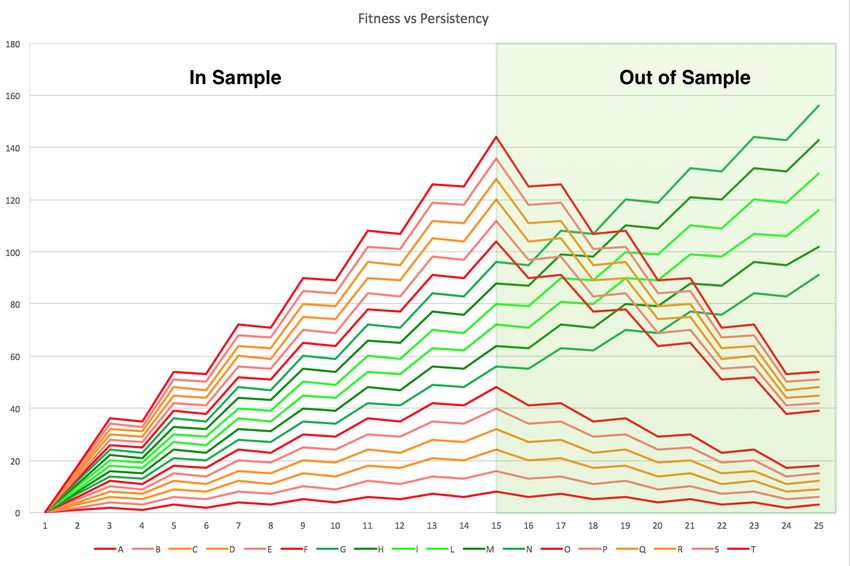
Real MoneyIl concetto di “persistenza”
Fitness
TimeL’importanza del preprocessing dei dati
Open = Open + Noise-Factor
High = High + Noise-Factor
Low = Low + Noise-Factor
Close = Close + Noise-Factor
Noise Noise-Factor = Price +/- Price x Noise-Percentage
Addiction
Module Noise-Percentage = Random[0,ceiling]
Synthetic Data SeriesGrazie!
Roberto Malnati Giovanni Trombetta
r.malnati@tensigma.ch info@gandalfproject.com
www.gandalfproject.com
SIAT Professional Member
Partner di Ten Sigma Sagl SIAT Professional Member
Head of Research & Development
Gandalf ProjectPuoi anche leggere

















































