WAC: Wikipedia Articles Classi cation - Universit a degli Studi di Salerno
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Università degli Studi di Salerno
Dipartimento di Informatica
Progetto di
Sistemi operativi II
WAC: Wikipedia Articles
Classification
Docente Studenti
Prof. Giuseppe Cattaneo Daniele Casola
Ivan Ferrante
Francesco Foresta
Anno Accademico 2013-2014
Indice
1 Introduzione 1
1.1 Scopo del documento . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2.1 Paradigma Map-Reduce . . . . . . . . . . . . . . . . . 2
1.3 HBase . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Ontologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.5 WordNet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.6 Struttura del documento . . . . . . . . . . . . . . . . . . . . . 8
2 Analisi del sistema: Scelte progettuali 9
2.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 Road map . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Criticità riscontrate . . . . . . . . . . . . . . . . . . . 10
2.3 Soluzione I: Semantic measures library . . . . . . . . . . . . . 11
2.3.1 Problematiche . . . . . . . . . . . . . . . . . . . . . . 11
2.4 Soluzione II: DBPedia spotlight . . . . . . . . . . . . . . . . . 12
2.4.1 Problematiche . . . . . . . . . . . . . . . . . . . . . . 12
2.5 Soluzione finale: WordNet&HBase . . . . . . . . . . . . . . . 12
2.6 Assestamento road map . . . . . . . . . . . . . . . . . . . . . 14
3 Sviluppo del progetto 15
3.1 Architettura del sistema . . . . . . . . . . . . . . . . . . . . . 15
3.1.1 Wikipedia Parser . . . . . . . . . . . . . . . . . . . . . 17
3.1.2 Wikipedia KeyPhrases Extraction . . . . . . . . . . . 17
3.1.3 Wikipedia Ontology Mapping . . . . . . . . . . . . . . 23
3.1.4 Semantic classification . . . . . . . . . . . . . . . . . . 23
3.2 Formato dell’input . . . . . . . . . . . . . . . . . . . . . . . . 25
3.3 Implementazione algoritmi . . . . . . . . . . . . . . . . . . . . 26
3.3.1 Distribuito . . . . . . . . . . . . . . . . . . . . . . . . 26
i
INDICE ii
3.3.2 Sequenziale . . . . . . . . . . . . . . . . . . . . . . . . 29
4 Test e valutazioni 31
4.1 Configurazioni . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.1.1 Configurazioni del cluster . . . . . . . . . . . . . . . . 32
4.1.2 Configurazioni dell’algoritmo . . . . . . . . . . . . . . 37
4.2 Test di scalabilità . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.2.1 Test algoritmo sequenziale . . . . . . . . . . . . . . . . 38
4.2.2 Test algoritmo distribuito . . . . . . . . . . . . . . . . 42
4.2.3 Valutazioni test . . . . . . . . . . . . . . . . . . . . . . 55
5 Conclusioni 61
Bibliografia 62
Capitolo 1
Introduzione
1.1 Scopo del documento
In questo documento sarà esposta la tecnica d’implementazione utilizzata
per classificare le pagine di Wikipedia, mediante il paradigma Map-Reduce
fornito da Hadoop e attraverso l’utilizzo del database distribuito HBase.
In particolare, per quanto riguarda la classificazione, vedremo una tecnica
innovativa capace di mettere insieme due potenti strumenti come WordNet
ed ontologie.
1.2 Hadoop
Hadoop rappresenta un framework che può essere installato su un cluster di
macchine linux per permettere la computazione e l’analisi di dati distributi.
Esso mette a disposizione un robusto file system, l’HDFS, e fornisce delle
Java-based API che consentono l’elaborazione parallela di tutti i nodi del
cluster utilizzando il paradigma Map-Reduce. Le principali caratteristiche
di questo framework possono essere cosi riassunte:
Fault-tolerant - Hadoop è in grado di rilevare i task failure e riavviare
quest’ultimi su nodi del cluster funzionanti. I task failure sono gestiti
in maniera del tutto automatica;
1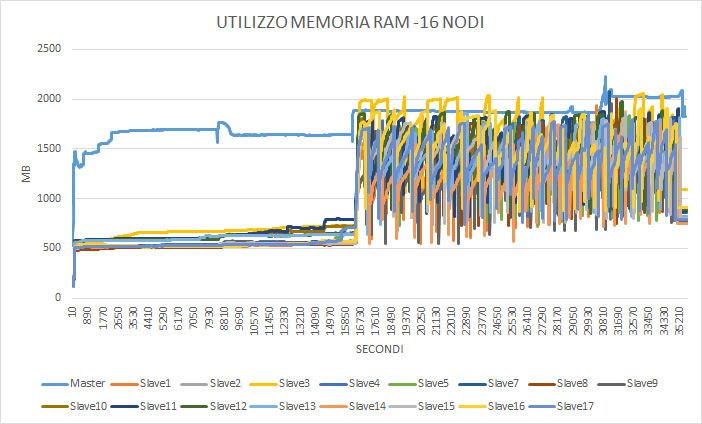
CAPITOLO 1. INTRODUZIONE 2
Affidabilità - i dati vengono replicati su più nodi evitando di applicare
tecniche di RAID;
Supporto agli sviluppatori - fornisce una infrastruttura che si pre-
dispone all’utilizzo del paradigma Map-Reduce semplificando lo svi-
luppo di applicazioni di larga scala e fault-tolerant su un gruppo di
macchine (possibilmente eterogenee);
Paradigma MapReduce - si avvale di un motore di escuzione Ma-
p/Reduce per implementare il suo sistema di calcolo distribuito per i
dati memorizzati nel file system distribuito.
1.2.1 Paradigma Map-Reduce
Esisitono due fasi fondamentali nel paradigma Map-Reduce: la fase di Map
e la fase di Reduce. Ogni step viene eseguito in parallelo ed ognuno opera
su un insieme di coppie chiave-valore. L’esecuzione di un applicazione che
si avvale di questo paradigma risulta, cosi, divisa in due fasi e quest’ultime
suddivise dal trasferimento dei dati tra i nodi nel cluster.
Figura 1.1: Hadoop Map-Reduce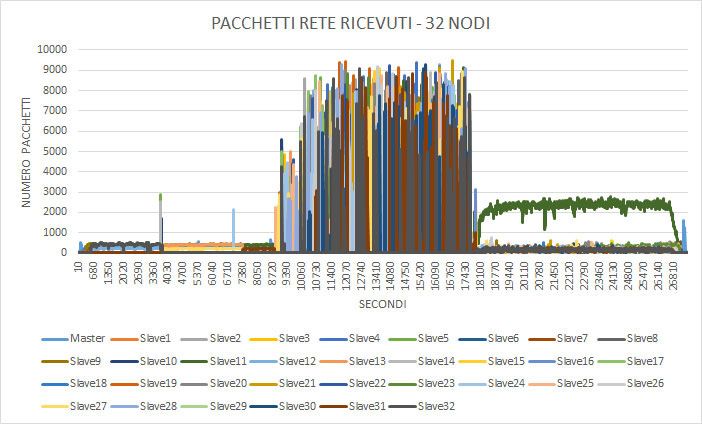
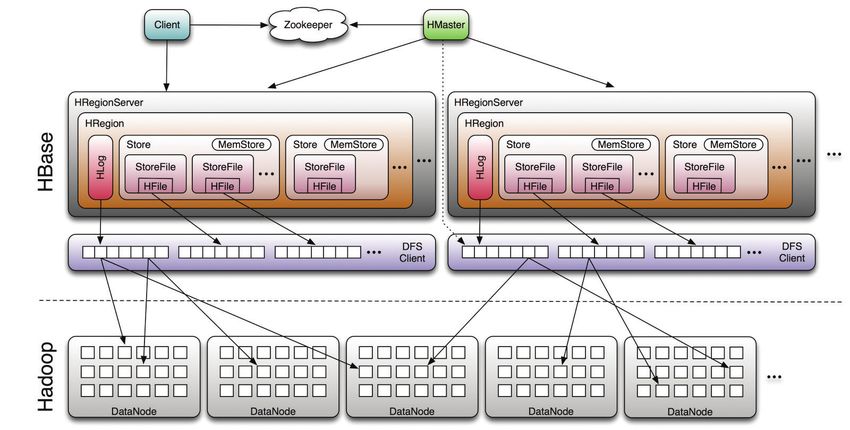
CAPITOLO 1. INTRODUZIONE 3 Nella prima fase, i nodi eseguono una funzione Map() su una parte dell’in- put. Il risultato della funzione map sarà un insieme di coppie chiave-valore memorizzate sul nodo che l’ha eseguita. Tutte le coppie chiave-valore sa- ranno sparse sui vari nodi del cluster e quest’ultime verrano date in input al Reduce. In questa seconda fase le coppie saranno aggregate utilizzando il valore della chiave ed il Reduce processerà tutti i dati forniti dalle funzioni di Map(). Infine, l’output del Reduce risulterà essere un ulteriore insieme di coppie chiave-valore. 1.3 HBase HBase, un progetto Apache open-source, è un database distribuito fault- tolerant ed altamente scalabile. Esso risulta essere orientanto alle colonne, non utilizza SQL ed è costruito sull’HDFS. HBase è utilizzato per appli- cazioni che richiedono l’uso di opreazioni di lettura/scrittura real time su database molto ampi. Da un punto di vista logico, come già detto, HBase fornisce un organizzazio- ne dei dati in tabelle ed in particolare ogni tabella risulta essere memorizzata come una mappa multidimensionale sparsa. Ogni tabella possiede le righe ordinate per chiave ed un numero arbitrario di colonne. Le celle sono ‘versio- ned’, ovvero è assegnato di default un numero di versione che risulta essere il timestamp di quando quest’ultima è stata inserita. Ogni cella è taggata da una famiglia di colonne e dal nome della colonna. Una cella risulta essere una array di byte univocamente identificato dalla seguente tupla (Tabella, Chiave primaria, Colonna). Tutte le tabelle a cui viene fatto l’accesso at- traverso la chiave primaria sono il risultato di un job Map/Reduce.
CAPITOLO 1. INTRODUZIONE 4
Figura 1.2: Esempio di tabella HBase
Le tabelle in HBase sono costituite da molti file e blocchi sull’HDFS, dove
ognuno di esso può essere replicato da Hadoop. Le tabelle sono automa-
ticamnete divise in regioni ed ogni regione comprende un sottoinsieme di
righe. Ogni regione è definita dalla prima riga, dall’ultima e da un identifi-
cativo casuale.
HBase fornisce dei cataloghi speciali per le tabelle memorizzate chiamati
‘ROOT’ e ‘.META’ con la quale mantiene la lista, lo stato, l’history e la
locazione di tutte le regioni. La tabella ROOT possiede una lista di tabelle
.META, e a sua volta ogni tabella .META mantiene la lista di dove sono
situate le regioni di una tabella.
In modo del tutto simile all’HDFS e Map/Reduce, anche HBase adotta un
architettura master/slave. Un HMaster (master) è responsabile dell’asse-
gnazione delle regioni agli HRegionServer (slave) e per il recovery in caso di
malunzionamento da parte di un HRegionServer.
HRegionServer è responsabile della gestioni delle richieste (lettura/scrittu-
ra) da parte dei client.
HBase utilizza un servizio chiamato ZooKeeper per la gestione dei clu-
ster, infatti, esso rappresenta un servizio centralizzato in grado di forni-
re sincronizzazione distribuita mantenendo informazioni di configurazione e
CAPITOLO 1. INTRODUZIONE 5
denominazione.
Figura 1.3: Architettura HBase
1.4 Ontologie
Negli ultimi anni il termine ontologia’ si è fatto spazio nel campo dell’in-
formatica poiché normalmente questo termine viene utilizzato nella branca
della filosofia che si occupa dello studio ‘dell’essere’. L’ontologia, in infor-
matica, rappresenta sostanzialmente un modo in cui diversi schemi sono
combinati in una struttura dati contenente tutte le entità rilevanti e le loro
relazioni in un dominio. Le ontologie attualmente sono utilizzate per diversi
scopi tra cui quello della classificazione di documenti. La definizione di on-
tologia più largamente accettata è quella di Tom Gruber: una specificazione
di una concettualizzazione
Un ontologia risulta essere costituita da:
Classi (concetti generali del dominio di interesse )
Relazioni tra queste classi
Proprietà (attributi, slot, ruoli) assegnate a ciascun concetto, che ne
descrivono vari tipi di attributi o proprietà
CAPITOLO 1. INTRODUZIONE 6
Restrizioni sulle proprietà (facet, role restrictions). Impongono il tipo
di dato sul valore che la proprietà può assumere.
L’ontologia utilizzata per la risoluzione del nostro problema è di tipo N-
Triples, in particolare abbiamo utilizzato una serializzazione del formato
RDF. Ogni linea che compone quest’ontologia ha la forma di un commento
o un istanza di una tripla. Un’istanza è cositutita da tre parti, separate da
un whitespace:
Soggetto;
Predicato;
Oggetto.
Il soggetto può essere rappresentato da una URI o da un nodo vuoto; il
predicato può essere una URI, un nodo vuoto o un letterale. Le URI sono
delimitate da parentesi angolari ed i nodi vuoti sono rappresentati da una
stringa alfanumerica il cui prefisso è un ‘ :’. Di seguito è riportato un
esempio dei come sia strutturata l’ontologia utilizzata.
.
.
.
.
CAPITOLO 1. INTRODUZIONE 7
.
.
1.5 WordNet
WordNet è un ampio database lessicale della lingua inglese. Sostantivi, ver-
bi, aggettivi e avverbi sono raggruppati in insiemi di sinonimi, ognuno dei
quali esprime un concetto distinto. Questi insiemi sono collegati per mezzo
di relazioni concettuali-semantiche e lessicali. Grazie a questi dati sono a
disposizione strumenti accessori per il calcolo di indici di relazione tra ter-
mini.
L’insieme risultante di parole e concetti legate semanticamente è reso pub-
blico e disponibile per il download. La struttura di WordNet è ideale per la
linguistica computazionale e l’elaborazione di testi in linguaggio naturale.
Esso, come già detto, raggruppa la parole sulla base del loro significato ed
etichetta le relazioni semantiche tra esse.
La principale relazione tra le parole di WordNet è la ‘sinonimia’ (Es. auto
ed automobile) poiché sinonimi che denotano lo stesso concetto sono inter-
cambiabili in molti contesti. Ogni insieme di parole presente in WordNet
è collegato ad altri sottoinsiemi attraverso un piccolo numero di relazioni
concettuali. Le parole che che possono assumere molti significati distinti
sono rappresentate in molti insiemi distinti di modo che la coppia forma-
significato diventi unica.
WordNet divide il significato di parola in due concetti: la ‘Word Form’, la
forma scritta, e la ‘Word Meaning’ ovvero il concetto espresso da tale parola.
Quindi il punto d’inizio della classificazione delle parole secondo WordNetCAPITOLO 1. INTRODUZIONE 8 sono le relazioni che intercorrono fra lemma e significato. La base della teoria sta nella Matrice Lessicale, nelle righe vengono elencati i significati delle parole e nelle colonne i lemmi. Ad esempio per la colonna relativa alla Word Form function i possibili Word Meaning, ovvero le righe della Matrice Lessicale, potrebbero essere: mathematical relation, subroutine, religious ce- rimony, quando function appartiene alla categoria lessicale dei nomi, oppure operate e officiate, nel caso sia utilizzata come verbo. 1.6 Struttura del documento Dopo l’introduzione delle tecnologie che sono state utilizzate nei seguenti capitoli verranno descritte le possibili soluzioni vagliate per poter classificare le pagine di Wikipedia, verrà descritta la soluzione ibrida (WordNet&HBase) adottata e le motivazioni che ci hanno spinto ad una tale scelta. Negli ultimi capitoli sarà possibile prendere visione dei test effettuati sul cluster e quali conclusioni sono state tratte dai test.
Capitolo 2
Analisi del sistema: Scelte
progettuali
2.1 Introduzione
L’analisi delle possibili soluzioni implementative è stata una delle fasi più
critiche di tutto lo sviluppo del progetto. Diverse sono state le soluzioni
analizzate e, in alcuni casi, testate per verificarne l’effettiva applicabilità
nel nostro dominio. Tuttavia, dopo aver analizzato due possibili soluzioni,
che descriveremo nei primi paragrafi del capitolo, abbiamo adottato una
soluzione radicalmente diversa dalle scelte inizialmente fatte.
In questo capitolo descriveremo le soluzioni vagliate, seguendo una sorta di
timeline, che ci ha portato alla decisione finale.
2.2 Road map
Lo sviluppo del progetto è stato suddiviso in varie fasi, che possono essere
cosı̀ riassunte:
WIKIDUMP: la prima fase riguarda l’analisi e l’elaborazione del dataset
a disposizione, il dump di wikipedia; in questo step andremo ad elabo-
9CAPITOLO 2. ANALISI DEL SISTEMA: SCELTE PROGETTUALI 10
rare i vari articoli forniti in xml in modo da estrarre il testo dell’articolo
stesso oltre ad altre informazioni rilevanti;
Keyphrases extraction: una volta ottenuto il testo dell’articolo, lo sco-
po è quello di estrarre le frasi più rilevanti, tali frasi o parole chiave
saranno poi l’oggetto del processo di classificazione;
Named entity recognition: l’output della fase precedente viene poi pas-
sata ad un modulo che avrà lo scopo di mappare le keyphrases in entità
ontologiche;
Semantic classification: una volta ottenute le varie entità l’obiettivo è
trovare la categoria di appartenenza dell’articolo attraverso l’estrazio-
ne di misure di similarità tra le risorse che identificano le categorie e
quelle dell’articolo;
Come si può notare, il processo di classificazione di ogni articolo risulta
molto complesso e ogni fase deve essere ottimizzata in modo da ottenere il
miglior risultato possibile.
2.2.1 Criticità riscontrate
I problemi più importanti riscontrati durante l’analisi del progetto sono rela-
tivi al mapping delle frasi chiave trovate all’interno del testo con le rispettive
entità ontologiche e successivamente, il calcolo di similarità tra queste.
Le iniziali difficoltà risiedevano infatti nelle enormi dimensioni dell’ontologia
fornita da dbpedia che nella maggior parte degli algoritmi della letteratura,
funzionanti su piccole istanze spesso riguardanti un dominio specifico, dove-
va risiedere in memoria, in secondo luogo l’assenza di termini sinonimi (ad
esempio è presente football ma non soccer) e la conseguente impossibilità
nel gestire facilmente il grafo generato dalle triple rdf.
Per questo motivo, le soluzioni che illustreremo, saranno incentrate in par-
ticolar modo sulle ultime due fasi del processo di classificazione. Per quan-
to riguarda la prima parte del progetto, tutto il processo di elaborazioneCAPITOLO 2. ANALISI DEL SISTEMA: SCELTE PROGETTUALI 11
e sintesi delle informazioni verrà descritto nel capitolo successivo, quando
parleremo della struttura della soluzione utilizzata
2.3 Soluzione I: Semantic measures library
La prima soluzione che abbiamo analizzato è stata quella di utilizzare una
libreria open source per l’analisi della similarità tra due concetti ontologici.
La libreria in questione (SML: Semantic measures library) permette infatti
il confronto tra due entità in maniera molto semplice: viene costruito un
grafo di tutte le triple RDF e, attraverso vari algoritmi che vengono messi
a disposizione dal toolkit, permette di generare un indice di similarità, che,
per la quasi totalità degli algoritmi presenti nella libreria, era calcolato su
base della distanza delle due risorse confrontate.
2.3.1 Problematiche
La prima soluzione risultava essere molto semplice ed efficiente se:
fosse stata utilizzata con ontologie di piccole dimensioni;
l’ontologia avesse un dominio specifico dove la presenza di sinonimi
non è cruciale;
avessimo utilizzato macchine dotate di una quantità di memoria RAM
adeguata ( 8GB).
Purtroppo nessun requisito è soddisfatto nel nostro caso.
Infatti, semplici test effettuati confrontando solo due entità con l’intera on-
tologia di Wikipedia ed utilizzando computer con 4GB di RAM, hanno mo-
strato che la soluzione risultava inapplicabile nel nostro dominio, il continuo
swap che veniva effettuato sul disco rallentava l’esecuzione dell’algoritmo
non riuscendo il più delle volte a calcolare alcun indice di similarità.
Il problema era dovuto sia dal fatto che l’ontologia generava un grafo molto
grande che doveva risiedere in memoria principale,improponibile nel caso diCAPITOLO 2. ANALISI DEL SISTEMA: SCELTE PROGETTUALI 12 ontologie di grandi dimensioni, sia dal fatto che parole molto comuni non sono presenti nell’ontologia in esame. 2.4 Soluzione II: DBPedia spotlight La seconda soluzione analizzata era basata sull’utilizzo di un framework che potesse in maniera efficiente estrarre le risorse ontologiche all’interno del testo. In particolare la scelta è ricaduta su dbpedia spotlight, un framework java-based, sviluppato proprio sul dump di Wikipedia, che offre la possibilità di estrarre le entità ontologiche all’interno di un testo. DBPedia spotlight può essere utilizzato si attraverso api java, si come web service. 2.4.1 Problematiche Anche in questo caso non sono mancati i problemi, ancora una volta relativi alle risorse di memoria RAM richieste dal framework. Tuttavia DBpedia spotlight non è l’unico framework che permette il riconoscimento di entità ontologiche all’interno del testo; molte sono le soluzioni in questo campo come Fox oppure Nerd. Tuttavia, tutte queste soluzioni presupponevano la disponibilità di memoria RAM sui nodi su cui venivano utilizzate molto superiore ai 4GB, il che le rendeva inutilizzabili. 2.5 Soluzione finale: WordNet&HBase Le soluzioni inizialmente vagliate soffrivano tutte di problemi di memoria: costruire un intero grafo in memoria riduce drasticamente le prestazioni de- gli algoritmi al crescere della dimensione del grafo stesso. Per questo motivo, l’utilizzo di un database per memorizzare l’intero dataset dell’ontologia ri- sultava l’unica soluzione efficiente per la risoluzione del problema. Anche in questo caso non sono mancate le scelte da dover effettuare, ini- zialmente infatti avevamo pensato di utilizzare un database graph-based in modo da poter utilizzare le stesse euristiche e gli stessi algoritmi per il cal- colo della similarità tra concetti già analizzate nelle soluzioni precedenti. In
CAPITOLO 2. ANALISI DEL SISTEMA: SCELTE PROGETTUALI 13 particolare due sono stati i graph-based db analizzati: Neo4J e AllegroGra- ph. Tuttavia, anche se le prestazioni erano migliori, in alcuni casi le risorse necessarie erano troppo elevate, tali da non permetterne un utilizzo su i nodi del cluster. Quindi, siamo passati ad analizzare soluzioni distribuite, in particolare Hy- perTable e HBase. Hypertable, la prima soluzione analizzata, garantiva maggiori prestazioni rispetto HBase. Le problematiche riscontrate in questo caso erano relative all’incongruenza tra documentazione e versione del prodotto. Infatti, poichè le librerie aggiornate erano state rilasciate recentemente, la documentazione di supporto per l’istallazione e l’utilizzo del sistema non erano ancora ag- giornate e pertanto sono stati riscontrati non pochi intoppi nel tentativo di configurazione ed integrazione. HBase, invece, ci garantiva una miglior semplicità di utilizzo e configurazio- ne, oltre ad offrire ottime prestazioni. Inoltre HBase risultava la soluzione ad-hoc per il nostro progetto. Infatti HBase, come già descritto in prece- denza, è sostanzialmente una HashMap distribuita, pertanto una collezione di elementi chiave-valore; nel nostro caso la chiave avrebbe rappresento la nostra entità ontologica mentre il valore quelle in relazione. Un altro problema riscontrato, tuttavia, era fortemente legato al mapping tra le frasi chiave e le entità ontologiche (come già detto, l’assenza di sinonimi e termini generici). Per rilevare l’entità all’interno del testo abbiamo deciso di utilizzare anche WordNet nella fase di entity mapping ma le euristiche presenti in letteratura per il mapping tra parole chiave e entità ontologiche, utilizzando esclusivamente ontologie, richiedono una gran numero di risorse di memoria (i test effettuati su tali algoritmi erano eseguiti su PC con 64GB di ram), rendendola di fatto per noi impraticabile e facendoci dirigere quindi verso una soluzione ibrida, descritta seguentemente. Lo stesso WordNet ha a disposizione una propria collezione di insiemi di termini in lingua inglese, relazioni tra essi e alcuni strumenti per il calcolo di indici di similarità. Si è quindi pensato di affrontare il problema utiliz- zando questo meccanismo in primo luogo e successivamente, affiancare un
CAPITOLO 2. ANALISI DEL SISTEMA: SCELTE PROGETTUALI 14
altro tipo di ontologia da caricare sul database offerto da HBase, comunque
basata su Wikipedia, che non contiene le relazioni fra le varie risorse, ma solo
l’appartenenza di queste a una o più categorie. Come vederemo successiva-
mente in dettaglio, HBase viene utilizzato nella fase di entity discovering per
rilevare tutte quelle entità non presenti in WordNet (es. ‘Ferrari’ in quanto
nome proprio), il che giustifica anche l’uso di uno strumento come HBase
che non è adatto per pochi dati, come quelli tutti quelli fino ad ora in nostro
possesso (pochi GB delle ontologie), ma che diventa una soluzione valida se
viene usato solo in determinate situazioni. L’utilizzo di WordNet e di HBa-
se è risultata quindi la scelta decisiva per affrontare lo sviluppo del progetto.
2.6 Assestamento road map
Lo sviluppo del progetto è stato quindi ridefinito nelle seguenti fasi:
WIKIDUMP: come pianificato;
Keyphrases extraction: come pianificato;
Named entity recognition: (opzionale) durante la fase di estrazione,
alcune parole chiave possono non essere riconosciute nel calcolo della
similarità a causa di termini specifici, queste parole vengono quindi
passate ad un modulo che avrà lo scopo di trasformare solo quelle
particolari keyphrases in entità più generiche (si passa ad esempio da
‘Aristotle’ a ‘Philosopher, Person’;
Semantic classification: (con l’utilizzo di WordNet) una volta otte-
nute le varie parole chiave l’obiettivo è trovare la categoria di appar-
tenenza dell’articolo attraverso l’estrazione di misure di similarità tra
le risorse che identificano le categorie e le risorse dell’articolo;Capitolo 3
Sviluppo del progetto
I problemi riscontrati nella gestione delle risorse dell’ontologia ci ha portato
ad utilizzare una soluzione che potesse sfruttare un sistema di gestione dei
dati distribuito, utilizzando query per recuperare le informazioni necessarie
nel processo di classificazione. Andiamo ora ad analizzare step-by-step i
dettagli del sistema sviluppato, soffermandoci sugli algoritmi utilizzati.
3.1 Architettura del sistema
L’architettura del sistema è molto semplice. Come si può notare anche dalla
3.1, è suddivisa in quattro moduli, ognuno con funzionalità specifiche che
rispecchiano il processo di classificazione.
Il processo di classificazione infatti attraversa varie fasi che possono essere
cosı̀ riassunte:
Le pagine wikipedia vengono prelevate ed analizzate. Il dump di wi-
kipedia è costituito da un file in formato XML, che rappresenta i vari
articoli, e in cui sono memorizzate le informazioni aggiuntive, come
titolo, testo ed autore, oltre ad alcune meta-informazioni come la data
dell’ultima modifica; Il modulo WP (Wikipedia Parser) ha il com-
pito di elaborare i file XML ed estrarre solo le informazioni utili per
15CAPITOLO 3. SVILUPPO DEL PROGETTO 16
Figura 3.1: Processo di classificazione di un documento
la classificazione dell’articolo, in particolare il titolo e il testo vero e
proprio;
Il secondo step rigurda l’estrazione delle frasi chiave dal documento. Il
modulo WKE (Wikipedia Keyphrases Extraction) effettua varie
operazioni sul testo, estraendo come ultima fase k-keyphrase che sa-
ranno scelte come quelle più rappresentative. Nel paragrafo successivo
analizzaremo in dettaglio il processo di estrazione;
Il modulo WOM (Wikipedia Ontology Mapping) analizza le pa-
role chiave che sono termini specifici come i nomi propri, queste parole
vengono quindi passate ad un modulo che avrà lo scopo di trasformare
solo quelle particolari keyphrases in entità più generiche (si passa ad
esempio da ‘Aristotle’ a ‘Philosopher, Person’;
Infine sarà compito del modulo Classifier che, una volta ottenute
le varie parole chiave cercherà la categoria di appartenenza dell’arti-CAPITOLO 3. SVILUPPO DEL PROGETTO 17
colo attraverso l’estrazione di misure di similarità tra le risorse che
identificano le categorie e le risorse dell’articolo;
Nei prossimi paragrafi analizziamo in dettaglio la struttura di ognuno dei
moduli e successivamente descriveremo come i moduli sono stati utilizzati
nella versione sequenziale e distribuita dell’algoritmo.
3.1.1 Wikipedia Parser
Il primo modulo del sistema si occupa di leggere il dataset di input, in for-
mato xml, ed estrarre tutte le info necessarie per la classificazione. In par-
ticolare viene estratto titolo e testo di ogni articolo. Ogni articolo, poichè
contiene informazioni ridondanti e/o non utili per il calcolo della similarità,
viene analizzato e ‘ripulito’ da tutti i token non necessari.
Il formato di ogni articolo è quello definito da MediaWiki. Inoltre, vengono
filtrati e scartati tutti quegli articoli che rappresentano pagine di redirect
oppure di disambiguazione.
Infine tutti gli articoli che hanno un numeri di caratteri al di sotto di una so-
glia stabilita, vengono scartati in quanto non forniscono sufficiente contenuto
informativo utile per il calcolo della similarità.
3.1.2 Wikipedia KeyPhrases Extraction
Il modulo WKE ha il compito di prelevare il testo dell’articolo ed estrarre
le frasi chiave che saranno poi utilizzate per la fase di entity discovering. Il
processo di estrazione delle chiavi viene suddiviso in vari step; tali step rap-
presentano una sorta di raffinazione delle informazioni presenti nell’articolo,
in modo da estrarre le notizie più rilevanti. I vari step possono essere cosı̀
riassunti:
Step 1: Estrazione delle frasi chiave dal documento;
Step 2: Calcolo di un vettore di feature per ognuna delle frasi estratte;CAPITOLO 3. SVILUPPO DEL PROGETTO 18
Step 3: Calcolo di uno score per ognuna delle keyphrase in base ai
valori del vettore di feature e generare una classifica delle frasi in base
ai valori dello score calcolato.
Step 1: Candidate Phrase Extraction
Il processo di selezione delle frasi candidate per essere scelte come chiave
attraversa vari passaggi, utili a ridurre l’insieme delle possibili scelte.
Suddivisione del testo in frasi. La prima fase richiede la suddivisione
del testo in frasi attraverso l’utilizzo di un delimitatore. La suddivi-
sione, tuttavia, utilizza alcune euristiche per ottimizzare la selezione.
In particolare:
simboli speciali come ’,’, ’.’, ’@’, ’&’, ’ ’, ’/’ sono sostituite con
il simbolo di delimitazione se non sono incapsulate all’interno di
parole, come ad esempio la parola ‘ad-hoc’;
gli apostrofi vengono rimossi e l’intera parola è convertita inte-
ramente in minuscolo, a meno che non vengano utilizzate come
genitivo sassone (es. Anna’s book).
A questo punto si ottiene una lista di frasi, ognuna costituita da vari
token.
Part-of-speech tagging. Le frasi ottenute nella prima fase vengono poi
‘taggate’ in modo da individuare il tipo di ognuna delle parole, se si
tratta cioè di nomi (es. ‘Ferrari/NN’), di verbi (es. ‘meet/VB’), di
aggettivi (es. ‘beauty/JJ’) o di altre particolari forme linguistiche.
Questa fase risulta estremamente importante, poichè alcune delle ca-
ratteristiche verranno scelte proprio basandosi sul numero, ad esempio,
di parole con tag NN all’interno di una frase.
Durante questa fase viene utilizzato lo Stanford POS tagger [?].
Di seguito una porzione del codice utilizzato dal modulo:
0 //INITIALIZE TAGGERCAPITOLO 3. SVILUPPO DEL PROGETTO 19
1 tagger = new MaxentTagger("models/english-caseless-"
2 + "left3words-distsim.tagger");
3 //GET TAG SENTENCE
4 documentPreprocessor.setTokenizerFactory(ptbTokenizerFactory);
5 for (List sentence : documentPreprocessor) {
6 sentence = stemmer.stemNGram(sentence);
7 List taggedSent = tagger.tagSentence(sentence);
8 int tagsize = taggedSent.size();
9
10 //REMOVE SOME UNNECESSARY TAGS
11 List tagToRemove = new ArrayList();
12 for(int i = 0; iCAPITOLO 3. SVILUPPO DEL PROGETTO 20
combinazioni di nomi e aggettivi.
Rimozione delle stopwords. Vengono eliminate dalle grammatiche tutte
le frasi che iniziano o terminano con una stopword. Inoltre, attraver-
so un processo di stemming, vengono uniformate le forme plurali e
singolari dei nomi, in quanto rappresentano sostanzialmente lo stesso
concetto. In questa fase viene utilizzato l’algoritmo di Porter stemmer.
Dopo queste fasi, le grammatiche vengono suddivise in tre liste diverse,
una per le uni-gram, una per le bi-gram e infine una per le tri-gram. La
separazione risulta importante al fine di calcolare correttamente i valori delle
caratteristiche.
Step 2: Calcolo vettore di caratteristiche
Dal primo step abbiamo ottenuto una lista di frasi che sono tutte candidate
ad essere scelte per il processo di classificazione. Tuttavia dobbiamo estrarne
solo un sottoinsieme; per scegliere quali delle frasi selezionare, per ognuna
delle frasi calcoliamo un vettore di caratteristiche che verra utilizzato nel
processo di ranking. Per calcolare il vettore, andiamo a sfruttare proprietà
sia statistiche che linguistiche delle frasi. In particolare ci affidiamo a 5
diversi valori che vengono calcolati attraverso 5 diverse procedure. Andiamo
ad analizzarne una per una.
Frequenza delle frasi. Questa caratteristiche è la classica tf (term fre-
quency) utilizzata in molti processi di estrazione delle frasi chiave. In
questo caso viene calcolata la frequenza di una frase come il rapporto
tra il numero di volte che quest’ultima compare all’interno della lista
in cui è inserita e il numero totale di frasi all’interno della lista.
Analisi dei pos tag. Viene calcolato il numero di volte che una parola
‘taggata’ come NOUN è presente all’interno della frase, normalizzato
per il numero totale di parole all’interno della frase. Ad esempio per
una frase nella lista tri-gram che contiene tre NOUN, il valore sarà pariCAPITOLO 3. SVILUPPO DEL PROGETTO 21
ad 1, mentre se ne contiene solo una il valore della caratteristica sarà
0.33. Nel caso in cui una frase non ha nessun tag NOUN, di default il
valore della caratteristica sarà 0.25.
Profondità. Questa caratteristica viene calcolata in basa alla posizione
della parola all’interno del testo. Se una frase compare all’inizio del
testo probabilmente sarà più significativa rispetto ad una che compare
alla fine. Quindi una frase che compare inizio avrà un valore prossimo
ad uno, mentre una frase che compare verso la fine avrà un valore per
questa caratteristica che tende a 0.
Ultima occorrenza. Si calcola questa caratteristica in questo caso ancora
una volta sfruttando la posizione della frase, ma in questo caso vie-
ne utilizzata la posizione dell’ultima occorrenza normalizzata per il
numero totale di parole nel documento.
Differenza tra le occorrenze. Infine, come ultimo valore del vettore, si
calcola la differenza tra l’ultima occorrenza di una frase e la sua prima
posizione all’interno del documento, ancora una volta normalizzata per
il numero totale di parole all’interno del documento. Questo significa
che, se una frase compare all’inizio del documento e viene ripetuta
più volte fino alla fine, avrà un alto valore per questa caratteristica,
prossimo ad uno. Frasi che, invece, compaiono una sola volta avranno
valore pari a 0.
Di seguito, parte del codice utilizzato per il calcolo delle caratteristiche:
0 \\GET FEATURE VECTOR
1 private void getFeatureVector(ArrayList gram,
2 HashMap map, int k){
3 float size = gram.size()+0.0f;
4 for(StringList str: gram){
5 float[] f = new float[]{0.0f,0.0f,0.0f,0.0f,0.0f};
6 if(!map.containsKey(str)){
7 CandidateKey key = new CandidateKey(str);CAPITOLO 3. SVILUPPO DEL PROGETTO 22
8 key.setFirstIndexOccurance(firstIndex(str, k));
9 key.setLastIndexOccurance(lastIndex(str, k));
10 f[0] = model.getCount(str)/size;
11 f[1] = getPosValue(str);
12 f[2] = 1.0f - ((float)key.getFirstIndexOccurance()
13 /(float)documentSize);
14 f[3] = ((float)key.getLastIndexOccurance()/
15 (float)documentSize);
16 f[4] = (float)(key.getLastIndexOccurance() -
17 key.getFirstIndexOccurance())/
18 ((float)documentSize);
19 key.setFeatureVector(f);
20 map.put(str, key);
21 }
22 }
23 }
Step 3: Classificazione delle frasi
Una volta ottenuto un vettore di caratteristiche per ognuna delle frasi è
necessario calcolare uno score per ognuna delle frasi. Lo score viene calcolato
come combinazione lineare delle cinque caratteristiche:
∑5
i=1 wi ∗ fi
∑ 5
i=1 wi
dove i wi rappresentano i diversi pesi che vengono attribuiti ad ognuna delle
caratteristiche.
Non tutte le caratteristiche, infatti, hanno lo stesso peso. Alcune vengono
considerate più rilevanti rispetto ad altre. Tali valori sono stati trovati per
via sperimentale, attraverso vari test. In particolare possono essere cosı̀
sintetizzate:
Frequenza: 0.10;
Pos tag: 0.30;CAPITOLO 3. SVILUPPO DEL PROGETTO 23 Profondità: 0.32; Ultima occorrenza: 0.16; Differenza tra le occorrenze: 0.12. A questo punto, per ognuna delle frasi, abbiamo calcolato uno score come descritto in precedenza. Selezioniamo quindi k frasi per ognuna delle liste, in base al proprio valore di score. Il valore k può essere differente per ognuna delle lista; in particolare si preferisce solitamente selezionare più frasi delle prime due liste, ovvero quelle delle uni-gram e bi-gram, mentre meno frasi per le tri-gram. Il motivo sta nel fatto che le frasi formate da tre parole sono spesso meno rilevanti rispetto alle altre due liste. 3.1.3 Wikipedia Ontology Mapping Il processo di mapping delle frasi chiave in entità ontologiche viene suddivisa in due fasi. Nella prima parte, viene utilizzato WordNet per una prima ricer- ca delle parole chiave estratte; nel caso in cui questa fase fallisce, e quindi le parole chiave non vengono trovate in WordNet, viene interrogato HBase per la ricerca all’interno dell’ontologia di chiavi che fanno match con la parola chiave estratta. Per ogni risultato trovato nell’ontologia, vengono estratte le categorie. Per garantire una più elevata affidabilità del processo di classificazione, dal- l’ontologia vengono estratte più chiavi che iniziano per la parola chiave. Una volta verificata la presenza delle entità all’interno di WordNet o, in caso negativo, nell’ontologia, si passa al processo di classificazione vero e proprio. Si calcola cioè la similarità tra ognuna delle entità trovate e un insieme di categorie prescelte. 3.1.4 Semantic classification Per il calcolo della similarità, dopo aver testato varie metriche, abbiamo scel- to di utilizzare come misure di similarità quella di Leacock-Chodorow [?].
CAPITOLO 3. SVILUPPO DEL PROGETTO 24
Questa tecnica conta il numero di archi tra concetti che sono collegati da
archi del tipo ‘is-a’ nella gerarchia di WordNet. Il valore è poi scalato in base
al valore di massima profondità della gerarchia ‘is-a’. Un valore di similarità
è ottenuta prendendo il logaritmo negativo di questo valore scalato.
Successivamente viene effettuata una media dei risultati e si estrae la cate-
goria con valore di media più elevato. Per il calcolo delle metriche è stata
utilizzata la libreria ‘WordNet Similarity for Java (ws4j)’.
Di seguito parte del codice utilizzato per il calcolo dei valori di similarità:
0 Double[][] partialScan = new Double[categoryList.length][1];
1
2 for (int i=0; iCAPITOLO 3. SVILUPPO DEL PROGETTO 25
27 }
28 }
29 }
30 }
3.2 Formato dell’input
Gli input del nostro algoritmo sono sostanzialmente due:
Wikipedia: L’input principale del nostro algoritmo è costituito dal-
l’intero dataset di Wikipedia; gli articoli sono forniti in formato xml
seguendo lo schema previsto da MediaWiki;
AccessibleComputing
0
10
381202555
381200179
2010-08-26T22:38:36Z
OlEnglish
7181920
[[Help:Reverting|Reverted]] edits by
[[Special:Contributions/76.28.186.133|76.28.186.133]]
([[User talk:76.28.186.133|talk]])
to last version by Gurch
#REDIRECT
[[Computer accessibility]] {{R from CamelCase}}
lo15ponaybcg2sf49sstw9gdjmdetnkCAPITOLO 3. SVILUPPO DEL PROGETTO 26
wikitext
text/x-wiki
Ontologia: Il secondo input è invece costituito da un ontologia, estratta
proprio da Wikipedia, e fornita da DBPedia. Il formato utilizzato è
NTriples (nt). L’ontologia, come già descritto in precedenza, verrà
utilizzata nella fase di calcolo della similarità.
3.3 Implementazione algoritmi
Gli algoritmi implementati, sequenziale e distribuito, sono stati strutturati
in modo tale da poter utilizzare tutte le funzionalità inserite nei vari moduli
seguendo lo stesso processo di elaborazione. Le maggiori differenze rispetto
tra la versione sequenziale e quella distribuita risiedono nell’acquisizione dei
dati dal dataset di Wikipedia e nella gestione dell’ontologia.
3.3.1 Distribuito
La versione distribuita dell’algoritmo implementa il paradigma di MapRe-
duce attarverso l’utilizzo di Hadoop.
Cominciamo col mostrare come sono state gestite le differenze tra le due
versioni dell’algoritmo, passeremo poi ad analizzare la classe Mapper. Il pa-
radigma Map/Reduce è stato implementato utilizzando le risorse del toolkit
open source fornito da Cloud9 [?]. Il toolkit Cloud9 è una collezione di tool
ideata per Hadoop e per l’elaborazione di grandi quantità di dati. Gli stru-
menti messi a disposizione dal toolkit sono pensati per lavorare in algoritmi
che seguono il paradigma MapReduce. Tuttavia abbiamo utilizzato le stesse
funzionalità anche per l’algoritmo sequenziale, in quanto alcune classi per-CAPITOLO 3. SVILUPPO DEL PROGETTO 27
mettevano semplicemente l’elaborazione dei vari campi del file XML, utile
sia per la versione distribuita dell’algoritmo che per quella sequenziale.
Nella fase ‘Wikipedia Parser’ l’uso di un parser che necessita dell’inte-
ro input è ovviamente inutile in questa tipologia di approccio poiché è
distribuito sui nodi elaboratori, abbiamo quindi in questo caso sfrut-
tato una delle caratteristiche di Hadoop che permette di suddividerlo
sui vari nodi e di processarlo, specificando come recuperare tali dati,
grazie alle librerie Cloud9 ed implementando uno splitter che esamina
i tag della struttura xml del dataset.
Nella fase ‘Wikipedia KeyPhrases Extraction’ l’implementazione segue
quella descritta nell’architettura del sistema.
Nella fase opzionale Wikipedia Ontology Mapping abbiamo utilizzato
HBase per la memorizzazione delle risorse ontologiche e delle relative
categorie di appartenenza in modo distribuito. La ricerca delle parole
viene effettuata interrogando il database distribuito e recuperando le
chiavi che iniziano con la stringa in esame.
La parte relativa al caricamento dei dati nel database è stata effettua-
ta separatamente e prima dell’avvio del processo descritto da queste
quattro fasi.
Nella fase ‘Semantic classification’ l’implementazione segue quella de-
scritta nell’architettura del sistema.
Per quanto riguarda la classe Mapper:
private static class WikiMapper
extends Mapper {
private static final SimCalculator simCalculator;
private static final ExtractionManager extractionManager;
private String articleContent;
private String articleName;CAPITOLO 3. SVILUPPO DEL PROGETTO 28
public WikiMapper () {
simCalculator = new SimCalculator();
extractionManager = new ExtractionManager();
}
@Override
public void map(LongWritable key, WikipediaPage p, Context context)
throws IOException, InterruptedException {
if (p==null || !p.isArticle() || articleContent.length()4000){
articleContent = articleContent.substring(0,4000);
}
articleName = p.getTitle().replaceAll("[\\r\\n]+", " ");
articleContent = p.getContent().replaceAll("[\\r\\n]+", " ");
articleContent = articleContent.replace("(", " ");
articleContent = articleContent.replace(")", " ");
extractionManager.calculateKPhrases(articleContent);
ArrayList bestKey = extractionManager.getKPhrases(5, 1);
ArrayList words = new ArrayList();
for(StringList list: bestKey){
Iterator it = list.iterator();
while (it.hasNext()) {
words.add(it.next().split("/")[0]);
}
}
String category = simCalculator.getNearestCategory(words);
context.write(new Text(category), new Text(articleName));
}
}CAPITOLO 3. SVILUPPO DEL PROGETTO 29
In particolare per il parsing degli articoli Wikipedia abbiamo utilizzato la
classe WikipediaPage e EnglishWikipediaPage che permettono di estrarre il
testo e il titolo di un articolo, oltre ad alcune meta-informazioni.
Ogni Map task prende in input una coppia ¡LongWriteable,WikipediaPage¿,
la prima inutilizzata, la seconda necessaria per l’estrapolazione dei dati. Il
risultato non è sottoposta alla fase di reduce poichè non necessaria in quanto
il nostro output prevede la scrittura di ogni titolo di un articolo del dataset
preceduto dalla categoria a cui è stato assegnato.
3.3.2 Sequenziale
Prima della realizzazione abbiamo vagliato due scelte per quanto riguarda
il tipo di esecuzione: utilizzo di Hadoop su un singolo nodo e in modalità
uber mode o modalità stand-alone senza nessuna relazione col frameword
Hadoop. La prima soluzione ci avrebbe dato la possibilità di riutilizzare il
modulo per il mapping con l’ontologia che sfrutta HBase per la memoriz-
zazione e estrazione dei dati, ma avrebbe avuto la necessita di un maggior
consumo di risorse per gestire le componenti, seppur in stato minimale, di
Hadoop. La seconda opzione invece consiste, grazie al quantitativo maggiore
di memoria libera rispetto alla versione distribuita, nel tenere in memoria
l’ontologia, guadagnandone in efficienza in termini di tempo di accesso ai
dati. La scelta è ricaduta sulla seconda possibilità principalmente per il fat-
to che il confronto tra le due versioni deve essere fatto prendendo in esame
le migliori implementazioni possibili per entrambe.
Quali sono quindi le fasi che distinguono questa tipologia di approccio da
quella esaminata precedentemente?
Nella fase ‘Wikipedia Parser’, avendo a disposizione l’intero dataset di
Wikipedia sull’elaboratore sul quale verranno eseguiti i test, abbiamo
utilizzato un semplice parser xml per ottenere le singole pagine, che
in seguito vengono processate per eliminare tag di stile o impagina-
zione tipici delle risorse di Wikipedia. Questo processo viene eseguito
dalle librerie open source disponibili sul web [?] descritte precedente-CAPITOLO 3. SVILUPPO DEL PROGETTO 30
mente, l’output di tale fase è l’entità WikiPage dalla quale è possibile
estrarre la tipologia di pagina e eventualmente il titolo e il contenuto
dell’articolo in analisi.
Nella fase ‘Wikipedia KeyPhrases Extraction’ l’implementazione segue
quella descritta nell’architettura del sistema.
Nella fase opzionale ‘Wikipedia Ontology Mapping’ abbiamo utilizza-
to una SortedHashMap in cui inseriamo tutte le entità (chiave) con
i collegamenti verso i propri diretti genitori (un valore con multiple
informazioni). La ricerca delle parole viene effettuata completamente
in memoria centrale recuperando le chiavi che iniziano con la stringa
in esame.
Nella fase ‘Semantic classification’ l’implementazione segue quella de-
scritta nell’architettura del sistema.Capitolo 4
Test e valutazioni
In questa sezione andremo a valutare la soluzione da noi progettata basan-
doci su vari test che sono stati effettutati sul cluster. Espermienti iniziali
hanno mostrato come i risultati dei test variano di molto, non solo al variare
della configurazione del cluster, ma anche al variare dei parametri di input
che vengono forniti al programma, sia nella versione distribuita sia nella
versione sequenziale. Per questo motivo, nelle prime sezioni descriveremo
le varie configurazioni utilizzate per i test. Successivamente analizzeremo le
prestazioni dell’algoritmo in termini di consumo delle risorse e scalabilità.
4.1 Configurazioni
I parametri di configurazione, come già precedentemente accennato, si sud-
dividono in due classi:
Configurazioni del cluster;
Configurazioni dell’algoritmo.
Andiamo ad analizzare in dettaglio entrambe le configurazioni.
31CAPITOLO 4. TEST E VALUTAZIONI 32 4.1.1 Configurazioni del cluster La configurazione del cluster riguarda tutte quelle caratteristiche intrinseche di Hadoop, come numero di repliche, block size, numero di nodi slave, oltre ai parametri specifici di HBase (regionsize, zookeeper). I test, sia sequenziale che sul cluster, sono stati effettuati utilizzando mac- chine x86 presso il laboratorio RETI del Dipartmento di Informatica. Le macchine possiedono le seguenti caratteristiche: processore Intel(R) Celeron(R) CPU G530 @ 2.40GHz (dual-core); Memoria fisica totale 4,00 GB; S.O. Microsoft Windows 7 Professional 64 bit; Scheda di rete Realtek PCIe GBE Family Controller1; Hard Disk di 250GB. Hadoop è stato installato sulle medesime macchine ma su un sistema ope- rativo Ubuntu virtualizzato utilizzando VMware Player; le caratteristiche delle macchine virtuali sono le seguenti: processore Intel(R) Celeron(R) CPU G530 @ 2.40GHz (dual-core); Memoria fisica totale 3,1 GB; S.O. Ubuntu 12.04 LTS; Scheda di rete Realtek PCIe GBE Family Controller; Hard Disk di 120GB. La versione di Hadoop utilizzata è la 2.2 rilasciata il 15 ottobre 2013. Per raccogliere i dati relativi alla computazione effettuata da ogni nodo (memo- ria, CPU, rete, ecc..) abbiamo utilizzato il software Dstat installato su tutti i nodi del cluster. Il tool è stato avviato su ogni nodo ed è rimasto attivo in tutte le fasi del test: caricamento dell’ontologia su HBase, caricamento dell’input sull’HDFS e fase di map.
CAPITOLO 4. TEST E VALUTAZIONI 33
File di configurazione HBase
I test eseguiti sulla griglia sono stati effettuati utilizzando le seguenti confi-
gurazioni di HBase, in particolare sono stati modificati due file hbase-site.xml
e regionserver
Listing 4.1: hbase-site.xml
1
2
3
4
5
6
7 hbase . z o o k e e p e r . quorum
8 s l a v e 1 , s l a v e 3 , s l a v e 5
9 Comma s e p a r a t e d l i s t o f s e r v e r s i n
t h e ZooKeeper Quorum .
10 For example , h o s t 1 . mydomain . com , h o s t 2 . mydomain .
com , h o s t 3 . mydomain . com
11 By d e f a u l t t h i s i s s e t t o l o c a l h o s t f o r l o c a l
and pseudo−d i s t r i b u t e d modes
12 o f o p e r a t i o n . For a f u l l y −d i s t r i b u t e d setup ,
t h i s s h o u l d be s e t t o a f u l l
13 l i s t o f ZooKeeper quorum s e r v e r s . I f
HBASE MANAGES ZK i s s e t i n hbase−env . sh
14 t h i s i s t h e l i s t o f s e r v e r s which we w i l l
s t a r t / s t o p ZooKeeper on .
15
16
17
18
19 hbase . r o o t d i r
20 h d f s : // m a s t e r : 9 0 0 0 / hbase
21 The d i r e c t o r y s h a r e d by R e g i o n S e r v e r s .
22
23
24
25 hbase . c l u s t e r . d i s t r i b u t e dCAPITOLO 4. TEST E VALUTAZIONI 34
26 t r u e
27
28
29
Il file hbase-site.xml è stato modificato in modo da indicare i nodi sulla
quale lanciare il servizio di ZooKeeper facendo attenzione ai nodi effetti-
vamente utilizzati nei vari test da 32, 16 ed 8 nodi. Il file regionserver è
stato modificato listando al suo interno i nodi designati per l’avvio del servi-
zio HRegionServer, nel nostro caso i regionserver coincidevano con gli slave
elencati nel file slaves di hadoop. Tutte le volte che si apportano modifi-
che ai file di configurazione bisogna aggiornare questi file nella directory di
HBase/conf di tutti i nodi del cluster.
File di configurazione Hadoop
Per quanto riguarda Hadoop sono state apportate modifiche ai file yarn-
site.xml, mapred-site.xml e hdfs-site.xml.
Di seguito è riportato un frammento di testo del file yarn-site.xml dove sono
state cambiati i valori relativi alla memoria che un nodo può utilizzare.
Listing 4.2: yarn-site.xml
1
2 yarn . nodemanager . r e s o u r c e . memory−mb
3 3072
4 Amount o f p h y s i c a l memory , i n MB, t h a t can
be a l l o c a t e d f o r c o n t a i n e r s .
5
Nel file mapred-site.xml la principale modifica è stata fatta alla dimensione
dell’heap utilizzabile da ogni nodo nella fase di map.
Listing 4.3: mapred-site.xml
1
2
3
4CAPITOLO 4. TEST E VALUTAZIONI 35
5 mapreduce . framework . name
6 yarn
7
8
9 mapreduce . map . memory . mb
10 3072
11 L a r g e r r e s o u r c e l i m i t f o r maps .
12 mapreduce . map . memory . mb = yarn . s c h e d u l e r . maximum−
a l l o c a t i o n −mb − mapreduce . map . c h i l d . j a v a . o p t s
13
14
15 mapreduce . map . j a v a . o p t s
16 −Xmx2048M
17 L a r g e r heap−s i z e f o r c h i l d jvms o f maps .
18
19
20 mapreduce . r e d u c e . memory . mb
21 3072
22 L a r g e r r e s o u r c e l i m i t f o r r e d u c e s .
23
24
25 mapreduce . r e d u c e . j a v a . o p t s
26 −Xmx2560M
27 L a r g e r heap−s i z e f o r c h i l d jvms o f r e d u c e s
.
28
29
Nel file hdfs-site.xml è stato modificato il numero di repliche dei blocchetti
sull’hdfs e la taglia di quest’ultimi (nel nostro caso di 128MB).
Listing 4.4: hdfs-site.xml
1
2
3
4CAPITOLO 4. TEST E VALUTAZIONI 36
5
6 d f s . r e p l i c a t i o n
7 3
8 D e f a u l t b l o c k r e p l i c a t i o n .
9 The a c t u a l number o f r e p l i c a t i o n s can be s p e c i f i e d when
the f i l e i s created .
10 The d e f a u l t i s used i f r e p l i c a t i o n i s not s p e c i f i e d i n
c r e a t e time .
11
12
13
14 d f s . b l o c k s i z e
15 134217728
16 The d e f a u l t b l o c k s i z e f o r new f i l e s , i n
bytes .
17 You can u s e t h e f o l l o w i n g s u f f i x ( c a s e i n s e n s i t i v e ) : k (
k i l o ) , m( mega ) , g ( g i g a ) , t ( t e r a ) , p ( p e t a ) , e ( exa )
18 t o s p e c i f y t h e s i z e ( such a s 128 k , 512m, 1g , e t c . ) ,
19 Or p r o v i d e c o m p l e t e s i z e i n b y t e s ( such a s 134217728
f o r 128 MB) .
20
21
22
23 d f s . namenode . name . d i r
24 f i l e : /home/ h d u s e r /mydata/ h d f s /namenode
25
26
27 d f s . datanode . data . d i r
28 f i l e : /home/ h d u s e r /mydata/ h d f s / datanode
29
30
In tutti i test effettuati le configurazioni di Hadoop sono rimaste tali tranne
per il file slaves di cui è stato necessario modificarlo ad ogni test per cambiare
il numero di slave da utilizzare.CAPITOLO 4. TEST E VALUTAZIONI 37
4.1.2 Configurazioni dell’algoritmo
I parametri di configurazione dell’algoritmo, invece, sono fortemente legate
alla qualità dell’algoritmo stesso; qualità non relativa all’efficienza ma piut-
tosto relativa alla bontà dei risultati ottenuti in output dall’algoritmo. In
particolare sono tre i parametri fondamentali nell’eseguizione del software:
# keyphrase da estrarre: Il primo parametro riguarda il numero di
frasi chiave da estrarre; è opportuno notare che aumentando il numero
di frasi chiave da estrarre non sempre il risultato della classificazione
sarà migliore. Questo perchè se estraiamo più frasi, aumenta la proba-
bilità di estrarre concetti più generici che non sono utili per disinguere
tra diverse categorie e che quindi potrebbero portare a risultati errati;
# entity da scegliere: Per ogni keyphrase non trovata in WordNet,
bisogna interrogare l’ontologia per verificare l’eventuale presenza di
queste keyphrase. Poichè l’ontologia può contenere più risorse che
‘matchano’ la keyphrase cercata, bisogna selezionare un sottoinsieme
di quest’ultime;
Dimensione delle grammatiche: Abbiamo visto nel capitolo pre-
cedente che le grammatiche vengono scelte di dimensione 1, 2 o tre
(unigram, bigram e trigram). Tuttavia per ridurre la complessità del
sistema abbiamo scelto di rendere configurabile tale valore.
Numero di caratteri da considerare: Gli articoli possono esse-
re anche molto grandi; per questo motivo abbiamo scelto di poter
restringere il numero di caratteri su cui effettaure l’analisi semantica.
Una nota importante circa i parametri di input riguarda la complessità e i
tempi di esecuzione dell’algoritmo. I primi test, sulla versione sequenziale
dell’algoritmo, hanno mostrato come aumentando i parametri elencati pre-
cedentemente migliora la bontà dei risultati, ma allo stesso tempo cresce la
complessità dell’elaborazione e soprattutto aumentano i tempi di esecuzione.
Per il primo test effettuato, infatti, avevamo stimato un tempo di esecuzioneCAPITOLO 4. TEST E VALUTAZIONI 38 totale dell’algoritmo sequenziale pari a circa 1000 ore (un mese e mezzo). Ovviamente, se pur potesse risultare interessante verificare poi l’ottimalità del processo di classificazione, test cosı̀ lunghi richiedevano troppo tempo per essere valutati. Nel nostro caso, i test sono stati effettuati tutti con la medesima configura- zione, con i valori cosı̀ settati: # keyphrase da estrarre: 5; # entity da scegliere: 3; Dimensione delle grammatiche: 1; # caratteri da considerare: 4000. 4.2 Test di scalabilità Abbiamo valutato la scalabilità dell’algoritmo effettuando vari test su una diversa configurazione del numero di nodi slave utilizzati per la computa- zione. Inizieremo con l’analisi dell’algoritmo sequenziale, che può essere considerato come l’esecuzione dell’algoritmo su un singolo nodo. Valutere- mo poi la scalabilità del software eseguendo la versione distribuita prima su 8 nodi, poi passeremo a 16 ed infine ad una configurazione con 32 nodi. 4.2.1 Test algoritmo sequenziale Il primo test è stato effettuato per valutare il tempo di esecuzione dell’al- goritmo sequenziale, oltre ad una valutazione sul consumo ed utilizzo delle risorse hardware. Il test è stato effettuato senza hadoop, utilizzando uno dei pc utilizzati anche durante il test sul cluster. Il tempo totale di esecuzione per la computazione completa è stato stimato in circa 76 ore, con una fase di setup di circa 10minuti. La fase di setup è relativa all’inizializzazione della hash map per la gestione dell’ontologia. Nella versione distribuita questa fase riguarderà sia il caricamento di HBase che la copia sull’hdfs.
CAPITOLO 4. TEST E VALUTAZIONI 39
CPU User% Sys% Wait% Idle% CPU%
Avg 44,9 5,6 0,1 49,4 50,5
Max 97,0 37,5 49,1 85,4 100,0
Tabella 4.1: Valori riassuntivi della CPU
Figura 4.1: Utilizzo della CPU
I valori riportati nella seguente tabella mostrano i risultati complessivi sul-
l’utilizzo della CPU nel test sequenziale, che si possono verificare anche dalla
figura 4.1.
Come si può notare l’utilizzo medio della CPU è pari a circa il 50%; il motivo
è dovuto al fatto che l’algoritmo, cosı̀ come è stato implementato, non sfrutta
il multithreading (Figura 4.2. I picchi che si possono notare all’interno del
grafico sono relativi a fasi di swap necessari per rilasciare risorse di memoria
utilizzate dall’algoritmo.
La figura 4.2 chiarisce ancor meglio l’inutilizzo di entrambe le CPU da parte
dell’algoritmo.
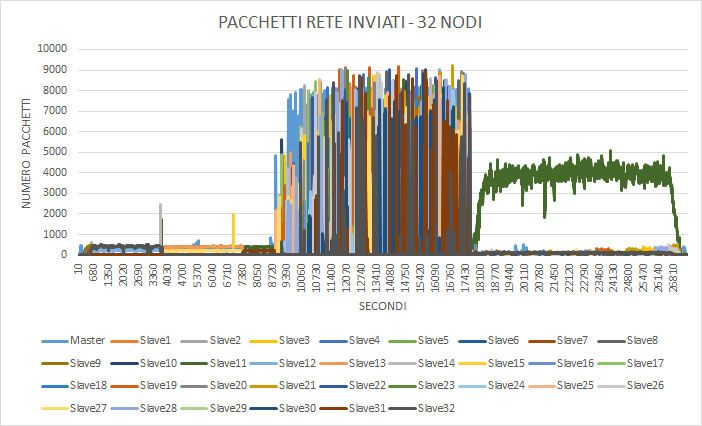
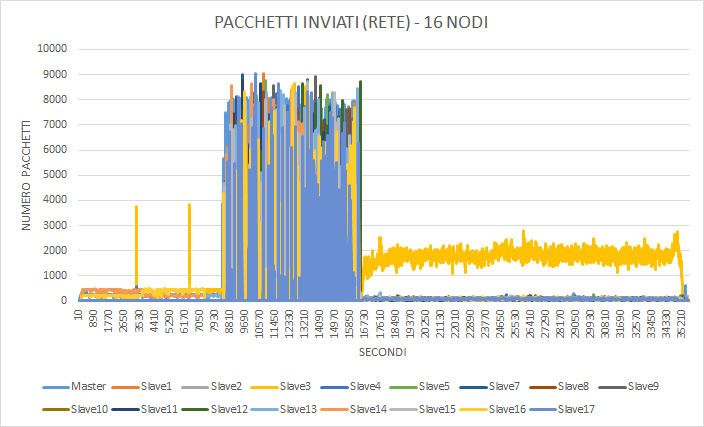
I grafici seguenti invece mostrano l’utilizzo di memoria e I/O durante l’e-
secuzione. Come si può notare l’algoritmo consuma molta memoria RAM,
arrivando a quasi saturare l’intera memoria a disposizione della VM. I picchiCAPITOLO 4. TEST E VALUTAZIONI 40
Figura 4.2: Bilanciamento carico tra cpu
Disk write sda sda1 sda5 sda2 sdb sdb1
Avg 5,7 5,7 0 0 0 0
WAvg. 2956,7 2956,0 17,2 0 0 0
Max. 5824,6 5825,3 0 0 0 0
Tabella 4.2: Valori riassuntivi dei dischi
che si possono notare in entrambi i grafici sono relativi a fasi di swap che
avvengono durante l’esecizione dell’algoritmo.
Un incremento della memoria ram disponibile, come si nota dal grafico 4.3,
corrisponde ad un picco nella fase di scrittura sul disco riscontrabile nel
grafico 4.4 e nel grafico 4.5.
Nel test sequenziale l’utilizzo di memoria RAM è stato uno degli elementi
più critici, dovuto essenzialmente alla quantità elevata di risorse che l’al-
goritmo deve mantere in memoria principale. In effetti questo è stato uno
dei limiti che ci ha bloccato anche nello sviluppo della versione multithread
dell’algoritmo sequenziale in quanto anche se sfruttavamo più CPU la me-
moria veniva ben presto saturata e quindi il guadagno che ottenevamo in
termini di cicli di CPU venivano persi in una quantità maggiore di swap chePuoi anche leggere

















































