Identificazione di elettroni a basso impulso tra-sverso prodotti in decadimenti del mesone B con l'esperimento CMS al Large Hadron Collider ...
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Identificazione di elettroni a basso impulso tra- sverso prodotti in decadimenti del mesone B con l’esperimento CMS al Large Hadron Collider Facoltà di Scienze Matematiche, Fisiche e Naturali Corso di Laurea in Particle and Astroparticle Physics Candidato Alberto Belvedere Matricola 1757444 Relatore Correlatore Dott.sa Chiara Rovelli Dott.sa Francesca Cavallari Anno Accademico 2020-2021
Identificazione di elettroni a basso impulso trasverso prodotti in decadimenti del mesone B con l’esperimento CMS al Large Hadron Collider Tesi di Laurea. Sapienza – Università di Roma © 2021 Alberto Belvedere. Tutti i diritti riservati Questa tesi è stata composta con LATEX e la classe Sapthesis. Email dell’autore: belvedere.1757444@studenti.uniroma1.it
ii
Indice
Introduzione 1
1 Universalità leptonica nelle interazioni deboli 3
1.1 Costante di accoppiamento nelle interazioni deboli . . . . . . . . . . 5
1.2 Universalità leptonica nei decadimenti del mesone B . . . . . . . . . 7
2 LHC e l’esperimento CMS 10
2.1 Il Large Hadron Collider (LHC) . . . . . . . . . . . . . . . . . . . . . 10
2.2 Il rivelatore Compact Muon Solenoid (CMS) . . . . . . . . . . . . . 13
2.2.1 Il dataset B-parking in CMS . . . . . . . . . . . . . . . . . . 18
3 Ricostruzione e selezione degli elettroni in CMS 21
3.1 Algoritmi di ricostruzione degli elettroni in CMS . . . . . . . . . . . 21
3.2 Ricostruzione di elettroni con l’algoritmo Particle Flow . . . . . . . . 22
3.3 Ricostruzione di elettroni con l’algoritmo low-pt . . . . . . . . . . . . 23
3.4 Identificazione di elettroni . . . . . . . . . . . . . . . . . . . . . . . . 24
4 Algoritmo di identificazione con tecniche di Machine Learning 26
4.1 Trattazione matematica dell’algoritmo XGBoost . . . . . . . . . . . 26
4.2 Simulazione di eventi con decadimenti B ± → J/ψ(e+ e− )K ± . . . . . 30
4.3 Scelta delle variabili discriminanti . . . . . . . . . . . . . . . . . . . . 30
4.3.1 Ripesamento della cinematica in segnale e fondo . . . . . . . 33
4.3.2 Selezione delle variabili di input o feature . . . . . . . . . . . 35
4.4 Ottimizzazione dei parametri dell’algoritmo . . . . . . . . . . . . . . 44
4.5 Studio delle prestazioni . . . . . . . . . . . . . . . . . . . . . . . . . 46
5 Studio del decadimento B ± → J/ψ(e+ e− )K ± 51
5.1 Selezione degli eventi . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.1.1 Impatto della selezione degli eventi sulle distribuzioni . . . . 59
Indice iii
5.2 Confronto tra dati e simulazione . . . . . . . . . . . . . . . . . . . . 61
5.2.1 Studio del confronto dati Monte Carlo con la tecnica degli SPlot 64
5.2.2 Confronto dati Monte Carlo sul fondo . . . . . . . . . . . . . 69
Conclusioni 74
Bibliografia 75
1
Introduzione
Nuovi processi fisici che siano oltre il Modello Standard possono essere cercati di-
rettamente, attraverso la ricerca di nuove particelle, o indirettamente, attraverso
lo studio della produzione e del decadimento di particelle del Modello Standard.
In particolare processi vietati al tree level nel Modello Standard, che però possono
avvenire attraverso diagrammi a box o a pinguino, sono particolarmente sensibili ad
eventuali particelle o interazioni non predette dalla teoria. Negli ultimi anni ci sono
stati diversi risultati sperimentali in tensione con le predizioni del Modello Standard
riguardo l’universalità leptonica nei decadimenti del mesone B, sia nelle transizioni
b → sll che b → clν. In particolare, vari esperimenti tra cui LHCb, hanno studiato il
decadimento B ± → J/ψ(l+ l− )K ± con il fine di misurare con la maggior precisione
possibile il valore di RK :
Γ(B ± → K ± µ+ µ− )
RK ≡
Γ(B ± → K ± e+ e− )
Questo valore è previsto essere pari ad uno dal Modello Standard ma nelle ultime
misure dell’esperimento LHCb è stata evidenziata una discrepanza di 3.1 deviazioni
standard che, se confermata raccogliendo un maggior numero di dati, sarebbe una
prova dell’esistenza di fisica oltre il Modello Standard.
Per confermare questo risultato è importante studiare il processo in esperimenti che
sfruttano tecniche diverse, per questo motivo l’esperimento CMS ha intensificato
lo studio della fisica del B. L’esperimento CMS è uno dei quattro esperimenti al
Large Hadron Collider del CERN e uno dei suoi obiettivi principali è la ricerca di
fisica oltre il Modello Standard. Questo esperimento è stato progettato per studiare
processi che avvengono ad alte energie per cui per poter selezionare un maggior nu-
mero di eventi contenenti decadimenti del mesone B è stata introdotta una tecnica
innovativa, chiamata B-parking, che sfrutta la diminuzione di luminosità istantanea
durante i fill di LHC per utilizzare trigger con soglie in impulso trasverso via via
sempre più basse.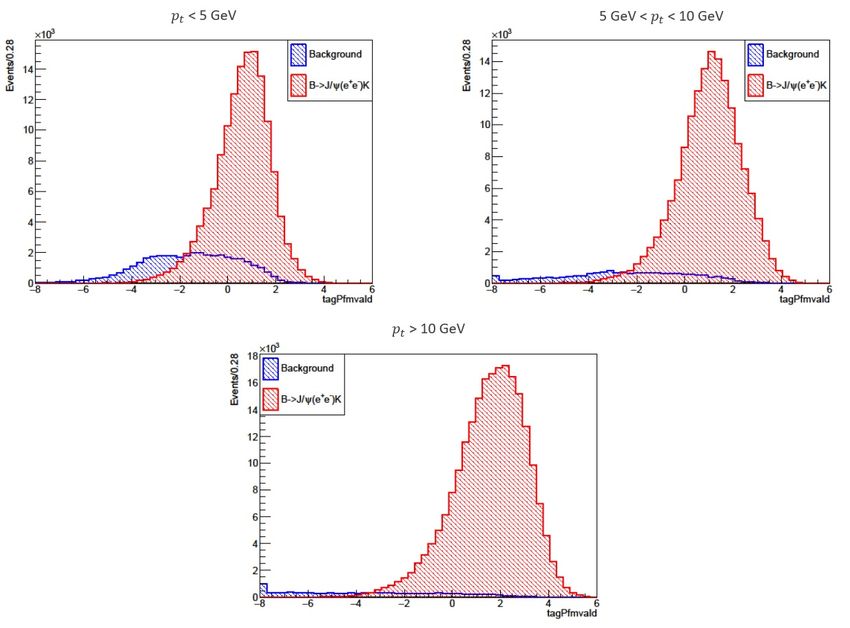
Indice 2 I prodotti di decadimento del mesone B hanno impulso trasverso di pochi GeV, quindi inferiore rispetto alle particelle che vengono solitamente ricostruite dall’e- sperimento CMS. Il problema è particolarmente evidente nel caso degli elettroni, in questo caso l’algoritmo standard di CMS ha efficienza molto bassa nell’intervallo di pt rilevante per questo tipo di fisica, per cui è stato sviluppato un algoritmo apposito per la ricostruzione di elettroni a basso impulso trasverso. Tuttavia avere una buo- na efficienza di ricostruzione comporta anche un elevato rateo di misidentificazione (mistag rate) per questo motivo durante questa tesi è stato sviluppato un algoritmo di identificazione che permette di ridurre il mistag rate senza ridurre eccessivamente l’efficienza. Per riuscire in questo scopo è stato utilizzato un algoritmo basato sul Machine Learning, ossia un algoritmo in grado di apprendere da un insieme di dati per poi riuscire a fare predizioni su di essi. Per l’addestramento di questo algoritmo è stato utilizzato un campione Monte Carlo del processo B ± → J/Ψ(e+ e− )K ± , sono state selezionate le variabili con maggior poter discriminante tra elettroni e fondo ed è stata studiata la correlazione tra le variabili. Inoltre sono anche stati ottimizzati i parametri che definiscono la struttura dell’algoritmo in modo da otte- nere un modello che fosse il più discriminante possibile. Le prestazioni dell’algoritmo sono state valutate sui dati studiando il processo B ± → J/Ψ(e+ e− )K ± sul dataset del B-Parking dopo aver studiato un set di tagli per selezionare eventi con questo tipo di decadimento. In particolare è stato verifi- cato il potere discriminante della variabile che rappresenta l’output dell’algoritmo di identificazione ed è stato effettuato il confronto tra dati e Monte Carlo sulla stessa variabile. La tesi è così strutturata: il primo capitolo è incentrato sull’universalità leptonica nelle interazioni deboli ed in particolare nei decadimenti del mesone B, nel secondo capitolo è descritto l’acceleratore LHC e l’esperimento CMS, nel terzo sono intro- dotti gli algoritmi di ricostruzione per gli elettroni utilizzati all’esperimento CMS, nel quarto è descritto l’algoritmo di Machine Learning utilizzato e le operazioni svolte per il suo addestramento, nel quinto capitolo sono valutate le prestazioni dell’algoritmo sui dati.

3
Capitolo 1
Universalità leptonica nelle
interazioni deboli
N N
Il Modello Standard è una teoria di gauge basata sul gruppo SU (3)C SU (2)L U (1)Y
che descrive l’interazione debole, forte ed elettromagnetica[1][2][3].
Figura 1.1. Particelle elementari del Modello Standard.
4
Le particelle predette del Modello Standard si dividono in bosoni e fermioni (Figura
1.1). I primi hanno spin intero e sono i mediatori delle interazioni fondamentali:
• Gluoni: 8 particelle non massive mediatrici dell’interazione forte.
• Fotone: particella non massiva mediatrice dell’interazione elettromagnetica.
• Bosoni W ± e Z: particelle massive mediatrici dell’interazione debole.
1
I fermioni hanno spin pari ad un multiplo dispari di 2 e si dividono in tre generazio-
ni di quark e leptoni, ciascuna costituita da due quark con carica frazionaria e due
leptoni, uno con carica unitaria e l’altro con carica nulla (neutrino). Le tre genera-
zioni risultano avere esattamente le stesse proprietà, le uniche due differenze sono
la massa e il numero quantico di sapore. La rottura della simmetria elettrodebole
è dovuta ad un meccanismo chiamato Rottura Spontanea di Simmetria per cui il
N
gruppo di simmetria diventa SU (3)C U (1)QED , questo meccanismo è il motivo
delle masse dei bosoni vettori che mediano l’interazione elettrodebole e dei fermioni
carichi ed e’ possibile grazie all’azione del campo di Higgs.
Il Modello Standard descrive con precisione le caratteristiche delle particelle e le
loro interazioni fornendo predizioni che sono state confermate sperimentalmente nel
corso degli anni. Tuttavia non può essere considerato un modello completo poiché
non in grado di spiegare molti aspetti della fisica tra cui: l’asimmetria materia-
antimateria, le osservazioni cosmologiche che hanno portato all’ipotesi dell’esistenza
della materia oscura, la gerarchia delle famiglie del Modello Standard e l’impossi-
bilità di includere la descrizione della forza di gravità. Per tutti questi motivi si
è alla ricerca di nuova fisica che vada oltre il Modello Standard nonostante fino-
ra non vi sia mai stata alcuna prova sperimentale. La ricerca di fisica viene fatta
principalmente in due modi:
• Ricerca diretta: produzione di nuove particelle generalmente di massa igno-
ta, solitamente questo tipo di ricerca è effettuata in collisori adronici.
• Ricerca indiretta: analisi di processi vietati o fortemente soppressi nel Mo-
dello Standard. Una deviazione delle misure sperimentali dai risultati attesi
potrebbe indicare fisica oltre il Modello Standard.
Tra le varie simmetrie previste dal Modello Standard vi è l’universalità leptonica,
che prevede che i leptoni abbiano le stesse costanti di accoppiamento per le varie
interazioni a prescindere dal loro sapore. Il sapore dei fermioni è la principale
sorgente di parametri liberi nel Modello Standard, 9 masse fermioniche, 3 angoli di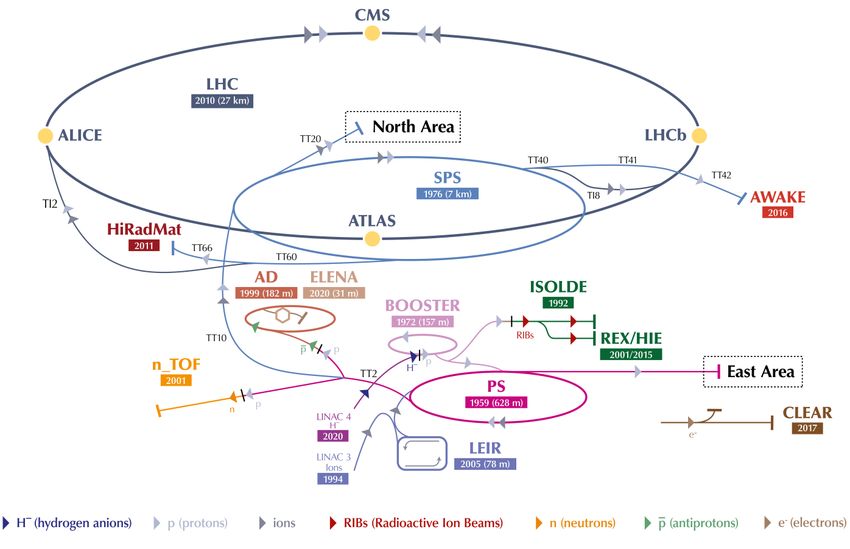
1.1 Costante di accoppiamento nelle interazioni deboli 5
mixing e una fase complessa (assumendo massa nulla per i neutrini), per questo è
soggetto a numerosi studi.
1.1 Costante di accoppiamento nelle interazioni deboli
Nel Modello Standard esistono due tipi di correnti deboli: la corrente carica e la
corrente neutra.
La Lagrangiana della corrente carica è mostrata nella formula (1.1):
g + X X
LCC = √ Wµ ui γ µ (1 − γ5 )Vij dj + ν l γ µ (1 − γ5 )l + h.c. (1.1)
2 2 ij l
dove g è la costante di accoppiamento, γµ e γ5 sono matrici di Dirac, Wµ+ descrive
il campo del bosone W ± , mentre u, d, ν l e l rappresentano rispettivamente i campi
dei quark up e down delle varie famiglie, dei neutrini e dei leptoni carichi. Nel caso
dei quark è possibile il mixing tra le varie famiglie che viene parametrizzato dalla
matrice di Cabibbo–Kobayashi–Maskawa (CKM), per questo motivo nella formula
(1.1) la sommatoria sul sapore dei quark ha due indici ed è presente il termine Vij
a rappresentare l’elemento della matrice CKM.
Il più semplice processo leptonico in cui avviene una variazione di sapore è il deca-
dimento del muone µ− → e− νe νµ (Figura 1.2).
Figura 1.2. Diagramma di Feynman del decadimento del muone.
In questo decadimento avviene lo scambio di un bosone W − , tuttavia, poiché il
momento trasferito è molto piccolo in confronto alla massa del bosone W − (q 2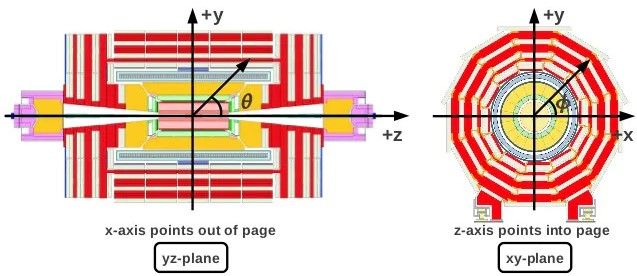
1.1 Costante di accoppiamento nelle interazioni deboli 6
GF g2
√ = 2 (1.3)
2 8MW
Il decadimento del leptone τ segue lo stesso meccanismo del decadimento del muone
tuttavia, poiché più pesante del muone, sono possibili diversi stati finali (Figura 1.3).
Figura 1.3. Diagramma di Feynman del decadimento del leptone τ .
Lo studio dei decadimenti del muone e del leptone τ permette di testare l’universalità
leptonica considerando tre accoppiamenti diversi tra il bosone W ± e i tre leptoni
carichi (ge , gµ e gτ ). È possibile misurare il rapporto tra i tre accoppiamenti tramite
grandezze ottenute dallo studio dei decadimenti del muone e del leptone τ [5]:
gµ Bµ
• ge = Be = 1.0005 ± 0.0030
gτ B e τµ
• gµ = ττ = 1.0001 ± 0.0029
dove Bµ e Be sono rispettivamente i branching ratio dei decadimenti del leptone τ
in muone ed elettrone, mentre τµ e ττ rappresentano i tempi di vita media di muone
e leptone τ .
I leptoni hanno lo stesso accoppiamento anche al bosone Z, in quanto l’accoppia-
mento in questo caso è proporzionale alla carica:
g X
LN C = Zµ lγ µ (gvl − gal γ5 )l (1.4)
2cosθW l
dove g è la costante di accoppiamento, θW è l’angolo di Weinberg, γµ e γ5 sono
matrici di Dirac, Zµ descrive il campo del bosone Z, mentre l e l rappresentano
il campo dei leptoni carichi, gvl e gal identificano rispettivamente gli accoppiamenti
vettoriali ed assiali:
gvl = I3l (1 − 4|Ql |sin2 θW ) gal = I3l (1.5)
con I3l isospin del leptone e Ql carica del leptone.
Un’altra conferma dell’universalità leptonica è stata ottenuta dall’esperimento LEP1.2 Universalità leptonica nei decadimenti del mesone B 7
proprio studiando il bosone Z. Infatti il rapporto tra i branching ratio del bosone Z
nei decadimenti in coppie di leptoni carichi risulta essere sempre pari ad uno entro
l’errore sperimentale[6].
1.2 Universalità leptonica nei decadimenti del mesone
B
Tra i vari tipi di ricerca indiretta vi è lo studio dei decadimenti dei mesoni tramite
l’analisi di processi del tipo Hb → Hs l+ l− dove Hb ed Hs identificano particelle con-
tenenti i quark b e s. Vengono studiati questi decadimenti poiché essendo processi
rari sono previsti pochi eventi e quindi è più facile osservare deviazioni dal Modello
Standard.
In questa tesi è stato analizzato il processo B ± → J/ψ(l+ l− )K ± che ha lo stesso
stato finale del processo B ± → K ± l+ l− (Figura 1.4) in cui avviene una transizione
b → s mediata da particelle virtuali che possono avere massa maggiore della diffe-
renza in massa tra stato iniziale e finale (bosoni W ± , Z e top quark).
Figura 1.4. Diagramma di Feynman del decadimento del mesone B ± in un kaone e due
leptoni.
Come previsto dal Modello Standard questo tipo di processi è fortemente soppres-
so, infatti il branching ratio è dell’ordine di 10−6 [7]. Tuttavia potrebbero esserci
contributi provenienti da fisica oltre il Modello Standard (Figura 1.5) in cui la par-
ticella mediatrice potrebbe avere accoppiamenti diversi con elettrone e muone con
la conseguente osservazione sperimentale della violazione dell’universalità leptonica.
Calcolare il branching ratio del processo B ± → K ± l+ l− è molto complicato a causa
della presenza di adroni e dei conseguenti effetti legati alla cromodinamica quanti-
stica (QCD). Per ovviare a questo problema è possibile misurare il rapporto tra i
branching ratio dei processi B ± → K ± e+ e− e B ± → K ± µ+ µ− poiché l’interazione
forte non si accoppia direttamente ai leptoni e quindi il suo effetto viene cancellato1.2 Universalità leptonica nei decadimenti del mesone B 8
Figura 1.5. Esempio di processo in cui la transizione b → s è mediata da una particella
oltre il Modello Standard, in questo caso un leptoquark.
nel rapporto in questione che si può misurare con elevata precisione[8]:
2
R qmax dB(B ± →K ± µ+ µ− )
2
qmin dq 2
dq 2
RK ≡ 2
R qmax dB(B ± →K ± e+ e− )
(1.6)
2
qmin dq 2
dq 2
Questo rapporto è studiato in diversi intervalli della massa invariante dei due leptoni
(q 2 ) per avere la possibilità di separare le varie regioni per analizzare gli effetti dovuti
ai diversi tipi di fisica.
Nel caso delle misure sperimentali, per evitare di dover calcolare precisamente le
diverse efficienze di ricostruzione per elettroni e muoni il valore di RK è ottenuto
dalla formula (1.7):
B(B ± →K ± µ+ µ− )
B(B ± →J/ψ(µ+ µ− )K ± )
RK = B(B ± →K ± e+ e− )
(1.7)
B(B ± →J/ψ(e+ e− )K ± )
dove ogni branching ratio può essere sostituito con il corrispondente numero di even-
ti dato che i vari denominatori si semplificano a vicenda.
Utilizzando questa tecnica è stato misurato il valore di RK in vari esperimenti
(BaBar[9], Belle[10] e LHCb[11]) ed il valore ottenuto è stato confrontato con le
previsioni del Modello Standard (Figura 1.6).
In particolare il valore misurato dall’esperimento LHCb[11] nell’intervallo 1.1 GeV 2 <
q 2 < 6.0 GeV 2 su 9f b−1 di dati risulta essere:
RK = 0.846+0.044
−0.041 (1.8)
La significanza della discrepanza è di 3.1 deviazioni standard e quindi questa misura
rappresenta un’evidenza di violazione dell’universalità leptonica.
Per validare questo risultato è importante testare il processo in esperimenti che1.2 Universalità leptonica nei decadimenti del mesone B 9 Figura 1.6. Confronto tra le misure di RK ottenute agli esperimenti BaBar, Belle e LHCb. usano tecniche diverse. L’esperimento CMS è stato disegnato per ricerche ad alta energia, tuttavia può essere interessante capire come possa contribuire a questa ricerca.
10 Capitolo 2 LHC e l’esperimento CMS Il CERN (Conseil Européen Pour La Recherche Nucléaire) è il più grande laboratorio di fisica delle particelle al mondo, fondato nel 1954, è situato al confine tra Francia e Svizzera, alla periferia di Ginevra. Lo scopo dei 12 paesi fondatori e dei 23 che ne fanno attualmente parte, è quello di favorire la cooperazione tra scienziati di diversi paesi e di fornire loro i più avanzati strumenti tecnologici attualmente disponibili per migliorare la conoscenza dei costituenti fondamentali della materia. A questo fine è stato costruito, nei primi anni del nuovo millennio, il più grande acceleratore di particelle mai realizzato: LHC. 2.1 Il Large Hadron Collider (LHC) Il Large Hadron Collider (LHC) è un collisore protone-protone con una circonferenza di 27 km situato a 100 metri di profondità in parte in territorio svizzero ed in parte in quello francese. I 27 km dell’anello che costituisce LHC sono quasi interamente coperti da magneti superconduttori che operano alla temperatura di 1.9 K e hanno il compito di mantenere i fasci di particelle sulla corretta orbita tramite un campo magnetico di 8.2 T. Per accelerare le particelle sono presenti numerose cavità a radiofrequenza lungo l’anello e soprattutto una serie di altri acceleratori costruiti nel corso della seconda metà del XX secolo (Figura 2.1) dove i protoni vengono accelerati prima di essere immessi in LHC. I protoni vengono estratti da una bombola di idrogeno e accelerati in pacchetti nell’acceleratore lineare Linac2 finché non raggiungono 50 MeV. Successivamente vengono immessi nel Proton Synchrotron Booster (PSB) dove raggiungono un’e- nergia di 1.4 GeV, a questo punto vengono ulteriormente accelerati all’interno del Proton Synchrotron (PS) finché non raggiungono un’energia pari a 25 GeV, in que-
2.1 Il Large Hadron Collider (LHC) 11
Figura 2.1. Complesso di acceleratori del CERN.
sta macchina i pacchetti vengono distanziati temporalmente di 25 ns uno dall’altro.
L’ultima macchina acceleratrice prima di LHC è il Super Proton Synchrotron (SPS)
dove i protoni vengono accelerati fino a 450 GeV ed infine vengono immessi in LHC
in due direzioni opposte all’interno di due diversi anelli in condizioni di ultra alto
vuoto. Una volta raggiunta l’energia voluta, i due fasci di protoni vengono fat-
ti collidere in quattro diversi punti di interazione dove sono posizionati i quattro
principali esperimenti di LHC:
• ALICE è utilizzato per analizzare le interazioni tra nuclei pesanti (in partico-
lare Pb-Pb) e studiare il quark gluon plasma (QGP), uno stato della materia
in cui quark e gluoni non sono più confinati in adroni a causa della densità e
delle temperature che si raggiungono.
• ATLAS e CMS sono esperimenti a carattere generale progettati per studiare
un vasto numero di processi fisici. Tra gli obiettivi principali ci sono la sco-
perta e la caratterizzazione del bosone di Higgs, la ricerca di fenomeni che
vadano oltre il Modello Standard e misure di precisione di processi previsti
dal Modello Standard. Questi due esperimenti sono stati costruiti in modo da
poter essere complementari, ad esempio ATLAS è molto preciso nelle misure2.1 Il Large Hadron Collider (LHC) 12
che coinvolgono le camere a muoni mentre CMS eccelle per quanto riguarda
le misure del calorimetro elettromagnetico.
• LHCb è stato progettato per studiare approfonditamente le proprietà del
quark b e la violazione di CP.
Un programma dettagliato delle attività di LHC è mostrato in Figura 2.2. LHC è
completamente operativo dal 2010 e dovrebbe continuare ad essere in funzione fino
al 2040. Durante questo periodo di tempo si alternano periodi in cui la macchina
è in funzione e gli esperimenti acquisiscono dati a periodi di manutenzione (Long
Shutdown (LS)) sia della macchina che degli esperimenti.
Figura 2.2. Schema del programma delle attività di LHC.
Al momento LHC è al suo secondo Long Shutdown e nel 2022 inizierà il Run3
che durerà fino al 2025. Seguirà poi un altro Long Shutdown, che vedrà modifiche
sostanziali alla macchina e agli esperimenti e che permetterà di entrare nella fase
HL-LHC (High Luminosity LHC) in cui la luminosità istantanea aumenterà fino a
7.5 volte rispetto alla luminosità nominale (L = 1034 cm−2 s−1 ).
La luminosità istantanea di picco è calcolata come:
nb N 2 frev
L=γ R (2.1)
4πn β ∗
dove γ è il fattore relativistico, nb è il numero di pacchetti che collidono nel punto
di interazione, N è il numero di protoni in ogni pacchetto, frev è la frequenza di
rivoluzione dei pacchetti nell’anello, β ∗ indica la lunghezza focale del fascio mentre
n è l’emittanza trasversa del fascio normalizzata e R un fattore che riduce la lumi-
nosità tenendo conto delle correzioni geometriche.
Per calcolare il numero di interazioni quando due pacchetti collidono è necessario2.2 Il rivelatore Compact Muon Solenoid (CMS) 13
R
misurare il valore della luminosità integrata ( L(t)dt) poiché la luminosità istan-
tanea varia nel tempo a causa della degradazione che il fascio subisce a causa delle
interazioni. In definitiva il numero di collisioni N è dato da:
Z
N = σpp L(t)dt (2.2)
dove σpp è la sezione d’urto nel caso di interazione protone-protone. Di conseguenza
il numero di eventi per un particolare processo sarà:
Z
Ni = σi L(t)dt (2.3)
con σpp = ΣN
i σi dove N è il numero di processi possibili.
Dalla Figura 2.2 si nota che l’energia del centro di massa e la luminosità istantanea
sono aumentate nel tempo grazie agli aggiornamenti che avvengono durante i Long
√
Shutdown, in particolare all’inizio del RunIII si raggiungerà il valore massimo di s
pari a 14 TeV mentre il massimo della luminosità si otterrà solamente con HL-LHC
(L = 7 · 1034 cm−2 s−1 ). Attualmente il valore della luminosità integrata da quando
LHC è entrato in attività è pari a 190f b−1 e ci si aspetta che questo valore arriverà
tra 3000f b−1 e 4000f b−1 prima della fine delle attività della macchina previsto nel
2040.
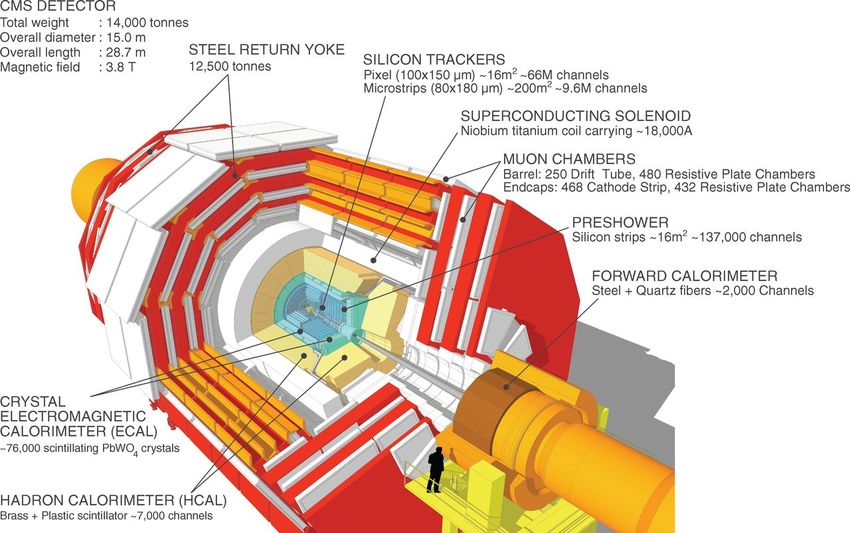
2.2 Il rivelatore Compact Muon Solenoid (CMS)
Il Compact Muon Solenoid[12] è un esperimento a carattere generale progettato
principalmente per la ricerca del bosone di Higgs e di processi fisici non previsti
dal Modello Standard. Il rivelatore ha forma cilindrica, un diametro di 15 metri,
una lunghezza pari a 29 metri e un peso di ∼ 14000 tonnellate. CMS è costituito
da diversi sottorivelatori progettati per identificare particelle diverse prodotte nelle
collisioni e misurarne le proprietà principali come impulso, carica ed energia (Figura
2.3). Per raggiungere questo scopo al meglio è suddiviso in tre parti, una zona
centrale, detta barrel, e due parti laterali, dette endcap.
Poiché LHC è una macchina ad alta luminosità, CMS deve essere in grado di tol-
lerare un alto livello di radiazioni per svariati anni, inoltre deve avere una buona
risoluzione spaziale per gestire il fenomeno del pile-up: un elevato numero di colli-
sioni protone-protone simultanee che può comportare la sovrapposizione nello stesso
elemento del rivelatore di particelle prodotte in interazioni diverse. Un altro im-
portante requisito è l’ermeticità, ossia deve essere in grado di rivelare le particelle a2.2 Il rivelatore Compact Muon Solenoid (CMS) 14
Figura 2.3. Schema della struttura di CMS.
prescindere dall’angolo con cui vengono prodotte, proprio per questo motivo è diviso
in barrel ed endcap in modo da rispettare la simmetria cilindrica attorno all’asse
del fascio.
Il sistema di coordinate usato in CMS è un sistema cartesiano (Figura 2.4) centrato
nel punto di interazione. L’asse z corrisponde alla direzione del fascio e rappresenta
la coordinata longitudinale, l’asse y è perpendicolare al piano di LHC e rappresenta
la coordinata verticale, l’asse x punta verso il centro dell’anello e rappresenta la
coordinata orizzontale. Il piano x-y identifica il piano trasverso alla direzione del
fascio mentre il piano y-z corrisponde a quello longitudinale.
Figura 2.4. Sistema di coordinate usato in CMS.2.2 Il rivelatore Compact Muon Solenoid (CMS) 15
Nel caso in cui si consideri un sistema di coordinate cilindriche si utilizza la distanza
radiale R, l’angolo azimutale φ e l’angolo polare θ. Spesso invece dell’angolo θ viene
usata la pseudorapidità, che è definita come:
θ
η = −ln tan (2.4)
2
viene fatta questa scelta perché nel limite in cui si può trascurare la massa, ipotesi
verificata nella gran parte dei casi possibili ad LHC, la pseudorapidità tende alla
rapidità:
1 E − pz
y = ln (2.5)
2 E + pz
dove c è posto uguale ad 1. La rapidità tende a 0 quando la componente lon-
gitudinale dell’impulso è nulla mentre tende a −∞ quando l’impulso è solamente
longitudinale. Inoltre differenze di rapidità, e quindi, nel limite in cui si può tra-
scurare la massa, anche differenze di pseudorapidità, sono invarianti sotto un boost
di Lorentz nella direzione del fascio.
Figura 2.5. Sezione radiale dell’esperimento CMS con attività dei detector per i vari tipi
di particelle.
Partendo dal punto di interazione si susseguono i seguenti sottorivelatori (Figura
2.5):
• Tracciatore al silicio: è il rivelatore più interno dell’esperimento e per que-
sto motivo riceve il più alto flusso di particelle, la sua funzione è quella di
ricostruire i vertici di interazione e le tracce delle particelle cariche che lo2.2 Il rivelatore Compact Muon Solenoid (CMS) 16
attraversano senza modificarne sensibilmente la cinematica. Sfruttando la
curvatura che le particelle subiscono a causa del campo magnetico è anche
possibile misurarne l’impulso. Il tracciatore ha un raggio di 1.2 metri, una
lunghezza di 5.8 metri e copre la regione con η < |2.5| utilizzando due tec-
nologie entrambe al silicio: pixel e strips. Nel barrel vi sono 3 strati di pixel
e dieci di strips, mentre negli endcap due strati di pixel e dodici di strips. Il
rivelatore a pixel è più interno e quindi è fondamentale per la ricostruzione del
vertice primario e di eventuali vertici secondari. Ha un’accuratezza di 10 µm
nella direzione radiale e di 20 µm in quella trasversa. Il tracciatore a strip,
invece, ha una risoluzione compresa tra 35-52 µm nella direzione radiale e di
530 µm in quella trasversa.
• Calorimetro elettromagnetico (ECAL): è un calorimetro omogeneo co-
stituito da cristalli scintillanti di tungstato di piombo (PbWO4 ), ha un raggio
compreso tra 1.2 e 1.8 metri ed è usato per identificare elettroni e fotoni e
misurarne l’energia. Il calorimetro è diviso in due parti, la regione centrale
(barrel) composta da 61200 cristalli e due sezioni laterali (endcap) composte
da 7324 cristalli ognuna. E’ stato scelto il tungstato di piombo poiché ha una
piccola lunghezza di radiazione (X0 = 0.89 cm) e un piccolo raggio di Molière
(RM = 1.96 cm) per cui contiene in poco spazio lo sciame elettromagnetico,
inoltre ha una risposta molto rapida ('80% della luce e’ raccolto in 25ns) e
un’alta resistenza alla radiazione.
La risoluzione in energia di un calorimetro omogeneo è data dalla Formula
2.6:
2 2 2
σE a b
= √ + + c2 (2.6)
E E E
dove il primo termine rappresenta il contributo stocastico dovuto alle flut-
tuazioni del numero di fotoelettroni misurati, il secondo è dovuto al rumore
elettronico mentre il terzo è un contributo costante che domina ad alte energie
ed è dovuto alla calibrazione del calorimetro e ad altre incertezze sistematiche.
La risoluzione in energia di ECAL risulta essere:
2 1 !2 2
σE 2.8%GeV 12%GeV
2
= √ + + (0.3%)2 (2.7)
E E E
• Calorimetro adronico (HCAL): è un calorimetro a campionamento in cui
la parte assorbente è realizzata in acciaio e ottone mentre la parte attiva è2.2 Il rivelatore Compact Muon Solenoid (CMS) 17
composta da scintillatori plastici. La sua funzione è quella di identificare gli
adroni, misurarne l’energia ed inoltre ricostruire l’energia trasversa mancante.
E’ progettato per coprire un’area con |η| < 5 ed è diviso in quattro parti:
– Il Barrel Hadronic Calorimeter (HB) è posizionato tra ECAL e il
magnete solenoidale coprendo la regione con |η| < 1.3.
– L’ Endcap Hadronic Calorimeter (HE) è posizionato tra ECAL e il
magnete ma copre la regione con 1.3 < |η| < 3.
– L’ Outer Hadronic Calorimeter (HO) è posizionato esternamente
al magnete e serve a misurare l’energia degli adroni che non sono stati
contenuti nel HB, migliorando l’ermeticità.
– Il Forward Hadronic Calorimeter (HF) si trova anch’esso dopo il
magnete e misura l’energia degli adroni nella regione con 3 < |η| < 5.
Quest’ultimo è realizzato in maniera differente, parte assorbente in ferro
e parte attiva in fibre di quarzo.
La risoluzione in energia nel barrel e negli endcap risulta essere:
2 1 !2
σE 90%GeV
2
= √ + (4.5%)2 (2.8)
E E
mentre nel HF:
2 1 !2
σE 172%GeV
2
= √ + (9%)2 (2.9)
E E
• Magnete solenoidale: è realizzato in una lega di titanio e niobio, ha una
lunghezza di 12.5 metri e un diametro di 6 metri. Contiene sia il tracciatore
che i calorimetri, produce un campo magnetico di 3.8 T nella direzione del
fascio ed opera alla temperatura di 4.65 K. All’esterno è presente un giogo di
ritorno in ferro che consente di mantenere il campo il più uniforme possibile
internamente e di mantenere un campo di 1.8 T all’esterno del magnete.
• Camere per muoni: poiché i muoni sono le particelle cariche che rilasciano
meno energia nella materia per rivelarli è necessario realizzare nella parte più
esterna dell’esperimento dei rivelatori appositi. Nel caso di CMS sono presenti
3 tipi diversi di rivelatori a gas per identificare e misurare l’impulso dei muoni
con la possibilità di lavorare congiuntamente con il tracciatore per migliorare
le misure:2.2 Il rivelatore Compact Muon Solenoid (CMS) 18
– Camere a deriva: si trovano nella zona del barrel (|η| < 1.2) e al loro
interno contengono dodici tubi a deriva in grado di misurare la posizione
e il impulso dei muoni grazie alla presenza del campo magnetico.
– Cathode Strip Chambers: ne sono presenti 4 per ogni endcap (0.8 <
|η| < 2.4), sono separate da dischi in ferro che agiscono come giogo di
ritorno del magnete e forniscono misure di r e φ.
– Resistive Plate Chambers (RPC): sono presenti sia nel barrel che
negli endcap, nella regione con |η| < 2.4, e forniscono misure di posizione
e di tempo relative ai muoni.
• Trigger: il sistema di trigger di CMS si divide in due livelli: trigger di primo
livello (Level 1 (L1)) e trigger di alto livello (High Level Trigger (HLT)). Il
trigger di livello 1 è totalmente hardware ed ha una latenza fissa di 3.4 µs
per cui deve decidere in questo intervallo di tempo quali eventi selezionare,
riduce la frequenza dei dati a 100 kHz. Il trigger di alto livello è puramente
software e riduce la frequenza dei dati a 1 kHz in modo che possano essere
memorizzati.
2.2.1 Il dataset B-parking in CMS
Il B-parking è una tecnica innovativa per la raccolta di dati introdotta nel 2018 dal-
l’esperimento CMS che ha permesso la ricostruzione di 10 miliardi di decadimenti
di mesoni B[13]. Questo metodo di presa dati è stato progettato per contribuire
allo studio delle anomalie nel settore della fisica del mesone B a seguito di misu-
re che hanno riscontrato indicazioni di violazione dell’universalità leptonica in vari
esperimenti tra cui BaBar[9], Belle[10] e LHCb[11]. Per studiare il decadimento del
mesone B è stato necessario introdurre questa nuova tecnica poiché CMS è stato
progettato per misurare particelle ad alta energia mentre i prodotti di decadimento
dei mesoni B hanno energie di pochi GeV. Il sistema di trigger a due livelli discusso
nel paragrafo precedente consente di acquisire in modo efficiente decadimenti del
mesone B con muoni nello stato finale. L’elevato numero di eventi prodotti, com-
binato ad un alto rateo di misidentificazione di adroni in elettroni, obbliga però ad
applicare soglie in impulso trasverso alte (>10 GeV) nel caso di trigger per elettroni.
Questi trigger diventano pertanto altamente inefficienti nel caso degli elettroni di
basso impulso prodotti nel decadimento di mesoni B. Il B-parking sfrutta il fatto che
ad LHC, a seguito delle collisioni che avvengono tra i protoni, la luminosità istan-
tanea e il pile-up diminuiscono durante ogni singolo fill provocando la diminuzione2.2 Il rivelatore Compact Muon Solenoid (CMS) 19
del tasso di eventi selezionati dai trigger L1 e HLT e del tempo di processamento
degli eventi. Quindi è possibile attivare trigger con soglie di attivazione via via più
basse in modo da sfruttare a pieno il trigger rate e le risorse computazionali anche
quando la luminosità istantanea è bassa. L’enorme mole di dati così raccolta non
può essere processata immediatamente ma viene memorizzata e poi processata du-
rante i periodi in cui l’acceleratore è spento. In questo modo è possibile raccogliere
eventi con particelle a bassa energia senza compromettere la normale presa dati
dell’esperimento.
La tecnica del B-parking seleziona eventi bb usando il metodo tag and probe. Il
trigger sull’evento di tag si basa sulla presenza di un singolo muone proveniente da
un decadimento semileptonico del mesone B in un muone (b → (c →)µX, branching
ratio del 20%). La logica di trigger non pone alcun bias sull’evento di probe, che
quindi può essere usato anche per lo studio del decadimento del mesone B in elettro-
ni. Tra gli eventi probe possibili si cerca di ottimizzare l’identificazione dei processi
B ± → K ± l+ l− (branching ratio O(10−6 )) poiché questo tipo di eventi permette la
misura del valore di RK . Come accennato, durante il fill vengono attivati via via
nuovi trigger che richiedono la presenza di un muone con impulso trasverso sempre
più basso, come mostrato nella seguente tabella:
Figura 2.6. Trigger di livello 1 e di alto livello per selezionare gli eventi al diminuire della
luminosità istantanea.
Dalla tabella si nota come al variare della luminosità istantanea si aggiornano i
trigger L1 e HLT che selezionano gli eventi sulla base dell’impulso trasverso (L1 e
HLT) del muone e la significanza del parametro d’impatto (HLT). In Figura 2.7 è
mostrato il tasso di eventi selezionato dal trigger di livello 1 durante un fill prima
(2017) e dopo l’introduzione della tecnica del B-parking (2018). In particolare si
può notare come il tasso di eventi selezionato dal L1 trigger decrescesse nel tempo
mentre, con l’applicazione dei trigger mostrati in Figura 2.6, si nota che il tasso di
eventi selezionato dal trigger rimane circa costante tra 90 e 70 kHz.2.2 Il rivelatore Compact Muon Solenoid (CMS) 20
Figura 2.7. Rate del trigger di livello 1 prima (sinistra) e dopo (destra) l’introduzione del
B-parking.
In Figura 2.8 è invece riportato l’andamento del rate del trigger di alto livello. Si
può notare come aumenti il rate relativo ai dati B-parking mentre diminuisca quello
relativo alla normale presa dati di CMS.
Figura 2.8. Rate del trigger di alto livello dopo l’introduzione del B-parking.21 Capitolo 3 Ricostruzione e selezione degli elettroni in CMS Nel rivelatore CMS gli elettroni vengono identificati combinando le informazioni provenienti da ECAL e tracciatore. Infatti gli elettroni sono le uniche particelle, insieme ai fotoni, a rilasciare la maggior parte della propria energia nel calorimetro elettromagnetico e, a differenza dei fotoni, avendo carica non nulla lasciano anche una traccia nel tracciatore. Questo capitolo analizza i vari metodi di ricostruzione degli elettroni, studiandone l’efficienza per gli elettroni di basso impulso trasverso provenienti dai decadimenti del mesone B ± . 3.1 Algoritmi di ricostruzione degli elettroni in CMS La difficoltà principale nell’identificazione e nella misura delle proprietà degli elet- troni è il fatto che interagendo con il materiale del tracciatore possono emettere fotoni di bremsstrahlung che a loro volta possono produrre una coppia elettrone- positrone, per cui non sarà una sola particella ad impattare sul calorimetro e per misurare l’energia dell’elettrone originario occorre misurare quella dell’intero scia- me. Per riuscire a superare questa difficoltà è stato sviluppato un algoritmo di clustering per combinare i depositi energetici in ECAL (cluster) generati dalle sin- gole particelle, ottenendo un unico supercluster (SC) in modo da misurare l’energia dell’elettrone iniziale. Inoltre ogni volta che l’elettrone emette fotoni di brems- strahlung perde parte del suo impulso iniziale e la sua traiettoria varia, quindi per ricostruire correttamente le tracce degli elettroni, è stato sviluppato un algoritmo di tracciamento specifico basato sulla somma di filtri gaussiani (Gaussian Sum Filter, GSF)[14]. L’intera ricostruzione degli elettroni è integrata nell’algoritmo Particle
3.2 Ricostruzione di elettroni con l’algoritmo Particle Flow 22
Flow (PF)[15] ottimizzato per la ricostruzione di elettroni provenienti dai decadi-
menti dei bosoni W ± e Z e quindi con impulso trasverso maggiore di 15 GeV. Gli
elettroni prodotti nei decadimenti del mesone B hanno impulso trasverso di pochi
GeV, come mostrato in Figura 3.1 a sinistra. L’algoritmo PF, come si può vedere
dalla Figura 3.1 a destra, ha una bassa efficienza nella ricostruzione di elettroni con
impulso trasverso inferiore a 10 GeV ed in particolare efficienza nulla sotto i 2 GeV
di impulso trasverso. Per questo motivo è stato sviluppato un nuovo algoritmo,
chiamato low-pt (LP), per ottenere una maggiore efficienza e la possibilità di poter
ricostruire elettroni con impulso trasverso inferiore a 2 GeV (Figura 3.1 a destra).
Figura 3.1. A sinistra distribuzione del pt a livello di generatore dei prodotti di decadi-
mento del processo B + → K + l+ l− , mentre a destra l’efficienza di ricostruzione degli
elettroni PF, delle tracce GSF e degli elettroni low-pt in funzione del pt dell’elettrone
generato.
3.2 Ricostruzione di elettroni con l’algoritmo Particle
Flow
Nel caso dell’algoritmo PF i depositi di energia nel calorimetro vengono raggruppati
sotto l’ipotesi che ogni massimo locale di energia al di sopra di 1 GeV corrisponda
ad una particella arrivata sul rivelatore. La ricostruzione di elettroni comincia con
la ricerca di depositi di energia nel calorimetro con Et > 1 GeV , chiamati seed
cluster. Al fine di raccogliere tutta l’energia depositata da un elettrone (che per
quanto detto sopra si estende su una regione più o meno estesa) i cluster entro una3.3 Ricostruzione di elettroni con l’algoritmo low-pt 23
certa area geometrica vengono combinati in supercluster.
L’algoritmo GSF usato per la ricostruzione delle tracce è molto dispendioso dal
punto di vista computazionale, per cui viene utilizzato solo per tracce con un seed
(insieme di punti nella parte interna del tracciatore) compatibile con un elettrone.
Il seed della traiettoria dell’elettrone può essere ricostruito a partire dai depositi di
energia in ECAL (elettroni ECAL-driven) o dalla traccia (TRACKER-driven). Nel
primo caso vengono selezionati esclusivamente i supercluster con energia trasversa
maggiore di 4 GeV. Per ognuno dei SC individuati viene propagata la posizione
agli strati più interni del tracciatore assumendo traiettoria elicoidale e assenza di
perdita di energia per bremsstrahlung, quindi la posizione estrapolata viene con-
frontata con quella dei punti ricostruiti nei 2 o 3 strati piu’ interni del tracciatore.
Se le due posizioni sono compatibili entro una finestra predefinita (in φ e z nel
barrel, φ e r negli endcap) i punti nel tracciatore vengono usati come seed per la
traccia GSF. Nel caso degli elettroni TRACKER-driven si itera su tutte le tracce
ricostruite usando l’algoritmo di tracciamento standard di CMS, basato sul Kalman
Filter[16] e se una delle tracce è compatibile con un deposito di energia è utilizzata
come seed per la traccia GSF. La ricostruzione del seed della traccia partendo dal
calorimetro ha un’alta efficienza per elettroni ad alta energia trasversa (>95% per
ET > 10GeV ), mentre utilizzando la traccia si ottiene una buona efficienza anche a
basso impulso trasverso (' 50% per pT > 3GeV )[17]. Le tracce vengono costruite
in modo iterativo a partire dai seed ricostruiti, eliminando possibili sovrapposizioni.
Una volta che le tracce sono ricostruite si utilizza l’algoritmo GSF per stimarne i
parametri ed estrapolare la traiettoria dell’elettrone fino al calorimetro sotto l’ipo-
tesi di campo magnetico costante. I candidati elettroni vengono infine ricostruiti
associando traccia e supercluster e verificando che siano rispettati alcuni criteri di
compatibilità.
3.3 Ricostruzione di elettroni con l’algoritmo low-pt
L’algoritmo low-pt utilizza esclusivamente l’approccio TRACKER-driven poiché più
efficiente per elettroni a basso impulso trasverso. Dall’estrapolazione della traccia si
identifica il supercluster più vicino nel calorimetro che viene direttamente associato
alla traccia, l’assenza di criteri di compatibilità tra traccia e calorimetro permette
un aumento dell’efficienza ma anche del rateo di misidentificazione (mistag rate).
La scelta delle tracce adatte a fare da seed per l’algoritmo GSF si basa sull’output
di due Boosted Decision Tree (BDT) indipendenti. Entrambi selezionano le possibili3.4 Identificazione di elettroni 24 tracce elettroniche sfruttando le proprietà della traccia, in un caso includendo anche variabili cinematiche e nell’altro caso no. In Figura 3.2 è mostrato l’andamento dell’efficienza in funzione del mistag rate (curve ROC) per i due algoritmi su un campione di eventi simulati B ± → K ± e+ e− . Il punto di lavoro scelto corrisponde ad un mistag rate del 10% ed efficienza superiore al 90%. Per un confronto e’ mostrato anche il punto di lavoro per il seeding dell’algoritmo Particle Flow (baseline seeding). Figura 3.2. Curve di efficienza verso misidentificazione (ROC) dei due modelli (cinematico dipendente ed indipendente) con i due punti di lavoro individuati rispetto al punto di lavoro standard (in rosso). La linea tratteggiata mostra la performance che si avrebbe se la scelta tra elettrone e fondo fosse casuale[13]. 3.4 Identificazione di elettroni Affinché la ricostruzione degli elettroni sia efficiente le richieste di compatibilità tra traccia e deposito di energia nel calorimetro non possono essere troppo stringenti. Nel caso dell’algoritmo low-pt sono addirittura assenti, ciò ha come conseguenza un’alta probabilità di ricostruire come elettroni anche altre particelle (ad esempio adroni carichi o pioni neutri che decadono in due fotoni) ed è quindi necessario sviluppare dei criteri di identificazione. Le grandezze comunemente utilizzate per l’identificazione di elettroni possono essere suddivise in tre categorie: caratteristiche
3.4 Identificazione di elettroni 25
della traccia, caratteristiche del deposito di energia nel calorimetro e compatibilità
tra i due. Di seguito è riportato un elenco delle principali variabili relative agli
elettroni:
• Variabili relative alla traccia:
|ptrk−out |
– brem_f rac = 1− |ptrk−in | dove ptrk−in rappresenta il valore dell’impulso
nel punto di minimo approccio dal vertice primario e ptrk−out è il valore
dell’impulso sulla superficie di ECAL estrapolato tramite lo studio della
traccia dall’ultimo strato del tracciatore. Questa variabile dunque è un
indicatore della quantità di energia persa dall’elettrone a causa della
bremsstrahlung.
– numero di punti della traccia GSF nel tracciatore.
– valore del χ2 del fit alla traccia GSF.
• Variabili relative al deposito di energia nel calorimetro:
– rapporto tra l’energia depositata nella matrice 3x3 di cristalli del calori-
metro centrata nel cristallo più energetico e l’energia del supercluster[18].
– numero di cluster di cristalli presenti nel supercluster.
– ampiezza del supercluster nelle variabili φ ed η.
• Variabili confronto traccia-calorimetro:
– rapporto tra l’energia misurata dal calorimetro e l’impulso misurato
tramite la traccia.
– misura della differenza tra la posizione in φ ed η del superclsuter e della
traccia.
Per ridurre il mistag rate è necessario sviluppare criteri di identificazione
che sfruttano selezioni sequenziali sulle variabili oppure combinarle usando
tecniche multivariate.26 Capitolo 4 Algoritmo di identificazione con tecniche di Machine Learning Con il termine Machine Learning si indicano algoritmi che possono apprendere da un insieme di dati e fare predizioni su di essi. In particolare questo tipo di algoritmi apprende autonomamente per cui necessita di grandi quantità di dati per realizzare modelli predittivi da utilizzare su nuovi dati. Nell’ambito di questa tesi è stato usato un algoritmo di Machine Learning per mi- gliorare l’identificazione degli elettroni ricostruiti con l’algoritmo low-pt introdotto nel capitolo precedente. È stata utilizzata una simulazione Monte Carlo del pro- cesso B ± → J/ψ(e+ e− )K ± poiché i prodotti finali di questo decadimento sono gli stessi del canale elettronico per la misura del valore di RK . Per ogni candidato elettrone ricostruito nel campione simulato si conoscono diverse grandezze fisiche (feature), che possono essere anche misurate dall’esperimento, ed inoltre si conosce la classe del candidato, ossia se è effettivamente un elettrone. L’algoritmo viene quindi addestrato sulla simulazione Monte Carlo e ne vengono studiate le presta- zioni, fatto ciò può essere usato sui dati sperimentali per identificare gli elettroni e separarli da altre particelle (principalmente adroni carichi o neutri) che possono essere mis-ricostruite come tali. 4.1 Trattazione matematica dell’algoritmo XGBoost L’algoritmo di Machine Learning utilizzato in questa tesi si chiama XGBoost[19], sfrutta gruppi di alberi decisionali e fa parte della famiglia di algoritmi detti Boosted Decision Trees (BDT). L’albero decisionale (Figura 4.1) è uno degli algoritmi più semplici del Machine Learning in cui ogni nodo di input rappresenta una feature
4.1 Trattazione matematica dell’algoritmo XGBoost 27
diversa, ogni ramo identifica un intervallo di valori per la feature del nodo precedente
e le foglie rappresentano la classe scelta seguendo una determinata serie di rami e
nodi.
Figura 4.1. Esempio di albero decisionale.
L’algoritmo XGBoost utilizza gruppi di alberi decisionali con l’obiettivo di trovare i
migliori parametri per il fit dei dati xi con classe yi al fine di calcolare una predizione
yˆi . Per fare ciò è necessario definire una funzione obiettivo:
n
X t
X
Obj = l(yi , ŷi ) + Ω(fj ) (4.1)
i=1 j=1
dove l(yi , ŷi ) è una funzione che associa un costo alle decisioni prese dall’algoritmo,
Ω(fi ) è un termine che descrive la complessità dell’algoritmo, n è il numero di istan-
ze, ossia il numero di eventi, e t quello di alberi.
I parametri da imparare sono quindi le funzioni fj che contengono la struttura
dell’albero e i valori delle foglie. Poiché sarebbe impossibile imparare contempora-
neamente tutti gli alberi si usa una strategia additiva, ossia si costruisce un albero
alla volta fissando ciò che si è imparato:
(0)
ŷi =0
(1) (0)
ŷi = f1 (xi ) = ŷi + f1 (xi )
(2) (1) (4.2)
ŷi = f1 (xi ) + f2 (xi ) = ŷi + f2 (xi )
t
(t) X (t−1)
ŷi = fk (xi ) = ŷi + ft (xi )
k=1
Quindi la funzione precedentemente definita si può riscrivere come:4.1 Trattazione matematica dell’algoritmo XGBoost 28
n t
X (t) X
Obj (t) = l(yi , ŷi ) + Ω(fj )
i=1 j=1
n
(4.3)
X (t−1)
= l(yi , ŷi + ft (xi )) + Ω(ft ) + constant
i=1
Ad ogni passo si aggiungerà un albero da scegliere minimizzando la funzione obiet-
tivo per cui si effettua un’espansione di Taylor:
n
X (t−1) 1
Obj (t) ' [l(yi , ŷi ) + gi ft (xi ) + hi ft2 (xi )] + Ω(ft ) + constant (4.4)
i=1
2
dove gi e hi sono definite come:
(t−1)
gi = ∂ŷ(t−1) l(yi , ŷi )
i
(t−1)
(4.5)
hi = ∂ 2(t−1) l(yi , ŷi )
ŷi
rimuovendo tutti i termini costanti si rimane con:
n
X 1
Obj (t) ' [gi ft (xi ) + hi ft2 (xi )] + Ω(ft ) (4.6)
i=1
2
In questa equazione resta ancora da definire il termine che descrive la complessità
dell’algoritmo. Essa rappresenta una caratteristica fondamentale del modello, poi-
ché un algoritmo eccessivamente complesso può raggiungere ottime prestazioni sui
dati su cui viene addestrato ma ottenere risultati decisamente peggiori su nuovi dati
(overtraining). Per aggiungere il termine che descrive la complessità del modello si
ridefinisce la funzione ft che descrive l’albero nel seguente modo:
ft (x) = wq(x) w ∈ RT , q : Rd → {1, 2, ...T } (4.7)
dove w è il vettore contenente i risultati delle foglie, q è una funzione che assegna
ogni istanza alla foglia corrispondente e T è il numero di foglie. A questo punto si
può definire la funzione che tiene conto della complessità dell’algoritmo nel seguente
modo:
T
1 X
Ω(f ) = γT + λ w2 (4.8)
2 j=1 j
per cui la complessità dell’algoritmo XGBoost è proporzionale al numero di foglie e al
quadrato del vettore che contiene i risultati delle foglie. Il coefficiente λ, presente al4.1 Trattazione matematica dell’algoritmo XGBoost 29
secondo termine della formula (4.8), è un termine di regolarizzazione ed è definibile
tra zero ed uno. La sua funzione è quella di ridurre la possibilità di avere foglie
eccessivamente utilizzate nella classificazione con il rischio di un elevato overtraining.
Aggiungendo il termine relativo alla complessità la funzione obiettivo diventa:
n T
X 1 1 X
Obj (t) ' 2
[gi wq(xi ) + hi wq(x i)
)] + γT + λ wj2 =
i=1
2 2 j=1
T
(4.9)
X X 1 X
= [( gi )wj + ( hi + λ)wj2 )] + γT
j=1 i∈Ij
2 i∈I
j
dove Ij = i|q(xi = j) è l’insieme delle istanze assegnate alla j-esima foglia. A que-
sto punto si può trovare la miglior funzione wj ponendo la derivata della funzio-
ne obiettivo rispetto a wj pari a 0, ma prima si può semplificare la precedente
equazione:
T
X 1
Obj (t) ' [Gj wj + (Hj + λ)wj2 )] + γT (4.10)
j=1
2
P P ∂Obj
dove Gj = i∈Ij gi e Hj = i∈Ij hi per cui ponendo ∂wj = 0 si ottiene:
Gj
wj∗ = − (4.11)
Hj + λ
T
1X G2j
Obj ∗ = − + γT (4.12)
2 j=1 Hj + λ
quest’ultima equazione è una misura della qualità della struttura del tree q(x). In
questo modo è possibile calcolare la qualità di un albero quindi, ipoteticamente,
bisognerebbe costruire tutti gli alberi possibili e scegliere il migliore, ovviamente ciò
non è possibile per cui ciò che viene fatto è l’ottimizzazione di un albero alla volta
analizzando il guadagno che si otterrebbe dividendo una foglia in due rami:
" #
1 G2L G2R (GL + GR )2
Gain = + − −γ (4.13)
2 HL + λ HR + λ HL + HR + λ
i termini di questa equazione rappresentano rispettivamente il risultato sulla nuova
foglia di sinistra, quello sulla nuova foglia di destra, quello sulla foglia originale e il
termine γ utilizzato nella Formula (4.8). Quindi se il valore tra parentesi quadre è
minore di 2γ non è conveniente dividere la foglia.
La struttura di qualsiasi algoritmo di Machine Learning è definita tramite iperpa-
rametri, ossia parametri che restano immutati durante la fase di addestramento.4.2 Simulazione di eventi con decadimenti B ± → J/ψ(e+ e− )K ± 30
La peculiarità dell’algoritmo XGBoost è che il numero di alberi da utilizzare viene
scelto durante l’addestramento. Infatti, poiché gli alberi sono addestrati sequen-
zialmente, è possibile selezionare tramite due iperparametri il numero massimo di
alberi (n_estimators) da addestrare e il numero di alberi dopo il quale fermarsi
(early_stopping_rounds) se non ci sono stati miglioramenti della funzione che si
sta utilizzando per valutare le prestazioni dell’algoritmo.
4.2 Simulazione di eventi con decadimenti B ± → J/ψ(e+ e− )K ±
Per effettuare l’addestramento dell’algoritmo per l’identificazione degli elettroni
low-pt è stata utilizzata una simulazione Monte Carlo (MC) del processo B ± →
√
J/ψ(e+ e− )K ± . Per generare le interazioni protone-protone a s = 13 T eV è stato
utilizzato il generatore Pythia 8.230[20], mentre il generatore EvtGen[21] è stato
usato come libreria per simulare i decadimenti dei mesoni B. Una volta generati,
gli eventi sono stati processati con una simulazione del rivelatore CMS basata sul
software Geant4[22] e poi ricostruiti con lo stesso software (CMSSW) usato per la
ricostruzione dei dati.
I candidati elettroni ricostruiti con l’algoritmo low-pt nel campione MC di cui sopra
p
sono divisi in segnale e fondo basandosi sulla distanza ∆R = ∆η 2 + ∆φ2 tra elet-
trone ricostruito ed elettrone a livello di generatore che proviene dal decadimento
di una J/Ψ che a sua volta è prodotta dal decadimento di un mesone B:
• Segnale: se ∆R < 0.03 tra elettrone ricostruito e generato.
• Fondo: se ∆R > 0.1 tra elettrone ricostruito e generato.
In questo modo è possibile utilizzare questi due campioni per studiare l’algoritmo
di identificazione degli elettroni low-pt.
4.3 Scelta delle variabili discriminanti
La scelta delle feature, ossia delle grandezze da utilizzare per separare una classe
da un’altra, è un’operazione fondamentale poiché è necessario un compromesso tra
la ricerca di buone prestazioni e al contempo la creazione di un algoritmo non
eccessivamente complesso. Infatti, nei casi (come questo) in cui l’addestramento
viene effettuato sul MC e poi l’algoritmo è utilizzato sui dati, ogni differenza tra
dati e MC può portare ad un peggioramento delle prestazioni in output, quindi è
necessario trovare il giusto equilibrio tra la riduzione del numero di feature e laPuoi anche leggere

















































