Hack my iPhone7 LAB1 + LAB2 - Giorgio De Caro - Mauro Pelucchi
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

hack my iPhone7
Giorgio De Caro - Mauro Pelucchi
Progetto Fondamenti BI e Web Data Analytics
LAB1 + LAB2
hack my iPhone7
Link
http://www.hammer-project.com/labs/iphone7/index.html
Link to TreeMap ImageMap

Comunity & Super Mario Challenge
Link to Comunity
Super Mario Run
Super Mario Run has a very cool
comunity.
In yellow you can see the @TPindell
community (group by in-degree):
@TPindell is an actor, comedian,
producer and YouTube personality.
@HAL 9000 is the sentient on-board
computer of the spaceship Discovery.
@Mashable, @Time of India and
@Pete Pachal (and all the purple
cloud) are bid digital media
websites.
@Saint Chikna is an indian artist a
live in Dombivali (the most literate town
of India): he has 41,300 follower in
India.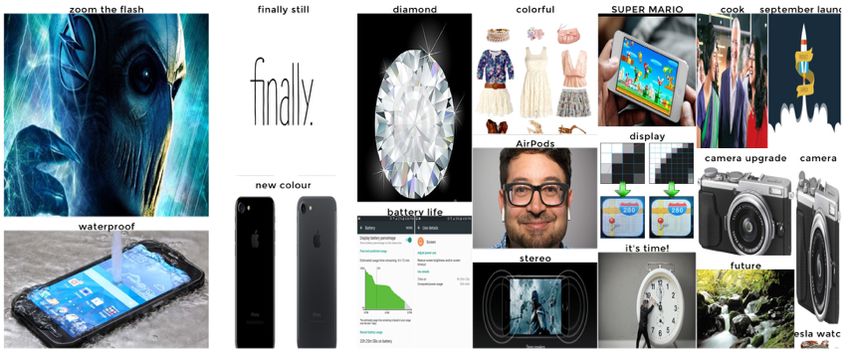
Story telling
Link to Big Data
Analytics
Sentiment Analysis Link to Sentiment Analysis

Indice 1. Obiettivi e destinatari 2. Fasi del progetto 3. Fonti e dati 4. Modello ER 5. Architettura 6. Strumenti e ciclo di vita dei dati 7. Features similarity e Jaro-Winkler 8. GraphDB e Neo4J 9. Comunity & Features 10. Text Mining e Clustering 11. ImageMap 12. Sentiment Analysis 13. Story telling 14. Problemi
Obiettivi e Destinatari
“hack my iPhone7” è un progetto di analisi e monitoring del lancio del
nuovo iPhone7 attraverso i tweet degli utenti
1 3
Analisi analitica dei tweet degli Marketing e Dipartimento di
Sintetizzare le aspettative degli
utenti prima, durante e dopo il Ricerca e Sviluppo sono i
utenti in modo da poterle
keynote del 7 Settembre 2016, destinatari principali di “hack my
facilmente individuare e
individuazione delle features e iPhone7”
visualizzare.
delle loro macro-classi.
L’analisi analitica dei tweet e delle
features permette di individuare le
aspettative degli utenti e di
visualizzarle in maniera sintetica e
Individuare ed analizzare sotto- veloce. Più di 160,000 tweet
Valutare il sentiment dei tweet
comunità di utenti che aspettano e verrano sintetizzati e visualizzati in
prima, durante e dopo il keynote
commentano la presenza o meno un’unica rappresentazione grafica
del 7 Settembre 2016.
di novità particolari. attraverso una story telling su
modello “Martini Glass”.
2 4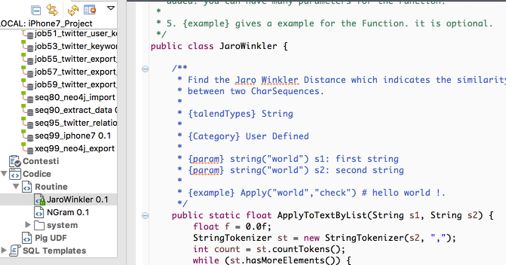
Fasi del Progetto
Comprensione del campo
Creazione di un insieme di dati
applicativo: ricerche su vari
per l’analisi: scraping da twitter
forum di settore e specialistici
dei tweet legati al lancio del nuovo
delle aspettative principali e delle
iPhone7, integrazione e pulizia dei
caratteristiche più importanti dei
dati.
prodotti competitor.
Scelta degli algoritmi di Esplorazione dei dati: valutazione
similarity, text mining e delle variabili più importanti, creazione
clustering: selezione degli del modello dati GraphDB ed
algoritmi e creazione dei data mart esplorazione delle features più
aggregati. Sentiment Analysis. importanti.
Analisi dei dati e ricerca di
Presentazione dei risultati: story
pattern: verifica dei risultati ottenuti
telling, commento ai risultati e
e selezione del modello di
creazione della pagina web.
visualizzazione migliore.
Fonti & Dati
FONTI NUMERI TESTO
Il testo è stato processato per
I tweet sono stati poter essere analizzato. Oltre alle
Utenti totali
scaricati da Twitter stop words abbiamo escluso
124.258
attraverso le parole tutte i termini molto frequenti
chiave “iphone”, all’interno del nostro dataset
Tweet
“iphone7”, “apple”, (“iphone”, “apple”, “keynote”) e
164.453
“appleevent”. quelli relativi a url web (“http”,
“https”)
DUPLICATE TWEET GEOLOCALIZZAZIONE UTENTI
Per costruire l’entità USER
Durante la procedura
Solo il 0,1271% dei abbiamo unito i dati dei mittenti
di scraping abbiamo
nostri tweet è (user_id, user_name e
aggiunto un controllo
georeferenziato. Non user_screen_name) con i dati
in Talend per gestire
possiamo fare analisi degli utenti menzionati (solo
le righe doppie (per
usando questo dato. user_id). Il 5,6% degli utenti ha
tweet_id).
solo il campo user_id valorizzato.Modello ER
Integrazione, orchestrazione e gestione del Architettura
File
CSV e JSON Vantaggi
bDW • Verifica veloce dei dati
Dati di • Flessibile
ciclo di vita dei dati
business • Veloce da
implementare
• Integrazione
• Consistente
Qualità, pulizia, business rules, aggregazione
Talend
Svantaggi
sDW • Poco agile
Dati grezzi • Complessa da gestire
(lungo periodo)
• Non funziona in tempo
reale
Scraping con Talend
TwitterStrumenti e ciclo di vita dei dati
Field Ingestions Manage Storage Mining Visualization
HTML single page per la
Java custom code per
presentazione dei risultati: la
algoritmo di Jaro-Winkler
pagina è il punto di inizio
e chiamate REST per
dell’analisi storytelling con
collegamento dei dati in Neo4J
metodologia “Martini Glass”Scraping e creazione del RAW-DWH
Scraping dei tweet
Attraverso l’utilizzo di Talend e del plugin per la
connessione a Twitter sono stati scaricati
160.000 tweet dal 31/8/2016 al 10/9/2016.
I tweet sono stati salvati in formato RAW su un
piccolo DWH Mysql.
I dati da twitter sono stati ricercati attraverso
parole chiave (selezione a priori) “iphone”,
“iphone7” e “ios10”.
Per coprire tutto l’evento (ed avere dati
confrontabili) abbiamo lavorato selezionando le
date di inizio/fine e il tweet id. Ogni tweet è stato
marcato con l’etichetta:
- prima dell’evento (before)
- durante il keynote (during)
- dopo l’evento (after)Features similarity con Jaro-Winkler
Features
Attraverso l’esplorazione dei siti web specializzati
e dei forum delle comunità abbiamo selezionato
una serie di caratteristiche desiderate dagli
utenti oppure presenti sugli smartphones di
fascia alta (competitors del nuovo iPhone7).
Ogni features è stata categorizzata attraverso
una macro-classe: design, hardware.
software e user-experience.
Per ogni features abbiamo indicato una serie di
sinonimi; l’obiettivo è quello di associare ad
ogni tweet le features di cui l’utente sta
parlando. Questo è stato possibile attraverso la
distanza di Jaro-Winkler implementata
attraverso codice Java richiamato in automatico
da Talend.Features similarity con Jaro-Winkler
Jaro-Winkler
“Thought the iPhone7 wasn't gone have Definiamo t e tq le due stringhe da confrontare.
no buttons on it just straight screen idk”
- |t’| —> numero di caratteri corrispondenti
fra t e tq (rispettivamente | t’q |)
- T(t’, t’q) —> numero di caratteri trasposti
Thought iPhone7, have
2-gram t
buttons, straight screen… Un carattere di t (posto alla posizione i) corrisponde
ad un carattere di tq se lo stesso carattere si trova in
tq alla posizione j, dove j dista da i a meno della
metà della lunghezza della stringa t.
Jaro-Winkler 0.439
Flat button
pressure-sensitive Variante Winkler —> la similarità di Jaro viene
synonyms tq
home button pesata attraverso il numero di caratteri in comune nel
touch home prefisso di t e tq.
features Home ButtonGraphDB - Aggregate model Neo4j Troppi dati per il nostro Neo4J!!! Abbiamo ridotto il modello creando un grafo per individuare le sotto- comunità di utenti. Attraverso un job Talend estraiamo i dati in formato CSV e chiamiamo direttamente le API Rest esposte da Ne4J per caricare i dati ed esplorare le elaborazioni.
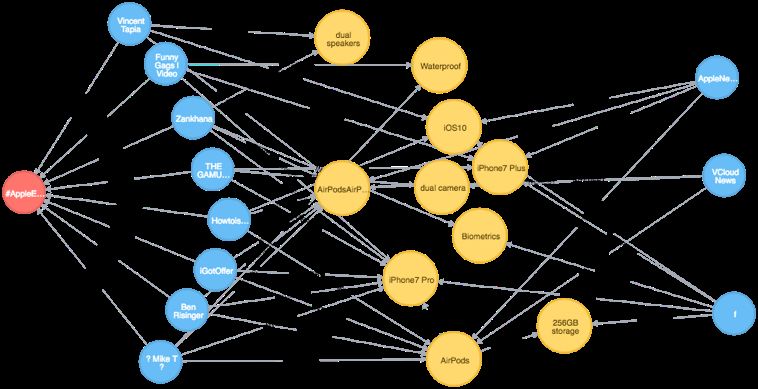
Comunity & Features
Il coefficiente di clustering locale di un nodo misura la sua possibilità di
formare una comunità (una cricca) con i suoi vicini.
Per ogni nodo andiamo a calcolare la misura in-degree: quanti nodi possono
raggiungere direttamente il nodo selezionato. Troviamo così i nodi (le persone) più
influenti, più “ascoltate”.
L’obiettivo è trovare sotto-comunità di utenti, cricche o comunità interessate a
particolari features.
La relazione IN_RELATION viene creata tra gli utenti che hanno almeno
2 interessi in comune (dove l’interesse viene misurato attraverso il
numero di tweet relativi ad una features).
match p1=(u1:user)-[r1:INTEREST]->(k:keyword) 3 and
toInt(r2.count_tweet) > 3 with u1, u2, count(distinct k) as score
where score > 2 CREATE (u1)-[:IN_RELATION {wt: score}]->(u2)
match (a:user)-[:IN_RELATION]-(b:user)
with a, collect(b) as sn, count(distinct b) as n, (count(distinct b)*(count(distinct b)-1))/2 as nk
match (a)-[:IN_RELATION]-(b1)-[rel:IN_RELATION]-(b2)-[:IN_RELATION]-(a)
WITH a, sn, n, nk, count(distinct rel) as r, toFloat(count(distinct rel))/toFloat(nk) as coef
where coef = 1
with a, sn
FOREACH(c in RANGE(0, size(sn)-1) |
FOREACH(n1 in [sn[c]] | Set n1.community= id(a), a.community = id(a) ))
return a, sn
CREATE INDEX ON :user(comunity)Comunity & Features Troviamo le comunità locali e i nodi che le mettono in connessione: match p=shortestPath((c1)-[:MENTIONS|RELATED|INTEREST|TWEET*..3 ]-(c2)) where EXISTS (c1.community) and EXISTS (c2.community) and (c1.community c2.community) with c1.community as a1, c2.community as a2, collect(p) as pmin where a1 < a2 return a1,a2,pmin[0] order by a1 asc, a2 asc
Comunity & Super Mario Challenge
Troviamo tutti i nodi in relazione alla features “Super Mario”
MATCH p=(u1:user)-[r:IN_RELATION]-
>(u2:user)-[t]->(k:keyword {keyword:'Super
Mario'}) RETURN u1.user_id, u2.user_id,
sum(toInt(t.count_tweet)) as num_tweet,
sum(r.wt) as rel_weightComunity & Super Mario Challenge
Troviamo tutti i nodi in relazione alla features “Super Mario” (e visualizziamoli attraverso un grafo)
MATCH p=(u1:user)-[r:IN_RELATION]->(u2:user)-
[t]->(k:keyword {keyword:'Super Mario'}) RETURN
u1.user_id, u2.user_id, sum(toInt(t.count_tweet))
as num_tweet, sum(r.wt) as rel_weight
• La nuvola viola rappresenta tutti gli
utenti relativi ai siti web e blog
tecnologici.
• La nuvola gialla è relativa alla comunità
di TPindell, un attore, produttore e
personalità YouTube.
• La nuvola azzurra è tutto ciò che ruota
attorno all’account HAL 9000
(principalmente studenti, accademici).
• La nuvola arancione è relativa all’artista
indiano Chikna e a tutti i suoi 41.000
followers (per la maggior parte indiani).Text Mining e Clustering
La fase di Text Mining o KDT (Knowledge Discovery Il document clustering è reso possibile dal calcolo
in Texts) ha l’obiettivo di estrarre informazioni dai testi delle somiglianze nel modello di spazio vettoriale.
non strutturati dei tweet. Ogni tweet è associato ai termini e agli n-grammi
In particolare ci siamo occupati di: attraverso al valore di tf-idf rispetto a tutto il catalogo
• Social Listening: cioè monitoraggio dell’evento con disponibile dai 160.000 testi.
l’obiettivo di rilevare il sentiment delle conversazioni;
• Social Analytics: analisi testuale per clustering e In questo modo ogni tweet è rappresentabile in un
creazione di gruppi omogenei di tweet in termini di modello di spazio vettoriale.
argomento trattato. I tweet di ogni fase (before, during e
after rispetto al keynote) sono stati
La fase di process documents ha seguito questi step: clusterizzati in 30 gruppi
- estrazione del contenuto e pulizia dai tag HTML
(abbiamo effettuato vari test a 20, 25
- lower case di tutto il testo;
e 30 gruppi scegliendo l’ultimo che
- tokenizzazione;
dava i risultati migliori) attraverso la
- filtro stop words (inglese);
metrica del coseno similare.
- filtro tokens (lunghezza > 2);
- generazione degli n-grammi (Come rappresentare 160.000 tweet?
ImageMap
Come rappresentare 160.000 tweet? I termini che costituisco il centroide sono stati
Come sintetizzare le aspettative di 124.000 raggruppati ed inviati alle API Rest esposte da:
persone (tra utenti e menzioni) e misurare • Flickr
l’outcome di marketing e la ricerca e sviluppo? • Europea
• DBPedia
• Google Custom Search
L’obiettivo è rappresentare il cluster attraverso
un’immagine in una TreeMap: la grandezza
dell’immagine è data dal numero di tweet del cluster
(abbiamo valutato anche il numero di utenti).
Mining Visualization Le performance migliori sono risultate quelle delle API di
Attraverso RapidMiner e il coseno similare abbiamo Google Custom Search: i termini della query sono stati
raggruppato i tweet di gruppi (30 gruppi per ogni fase). puliti dalle parole più comuni del dataset (“apple”,
“iphone”, …).
Di ogni cluster abbiamo estratto i termini che
rappresentano il centroide: ordinando i valori ed
escludendo le parole dopo un certo threshold.ImageMap
ImageMap
Before keynote During keynote
After keynoteImageMap > Before Le immagini trovate si riferiscono allo stato di interesse pre-annuncio (announcement, get involved) e ai rumors principali: le nuove AirPods (le cuffie) ed iOS 10.
ImageMap > During Durante l’evento le persone hanno visionato il prodotto presentato da Tim Cook: emergono le nuove caratteristiche già annunciate come gli AirPods, la nuova batteria e la resistenza all’acqua. Notiamo anche l’inatteso ZOOM OTTICO e la presenza dell’app Super Mario Run (integrata con iWatch).
ImageMap > After Dopo l’evento le persone hanno continuato a parlare e pensare agli AirPods e al nuovo display (abbinato al nuovo speaker sono un ottimo strumento per vedere film e video). Moltissime immagini richiamano all’acquisto, ma una delle figure più grandi richiama la serie televisiva LOST in relazione forse alla leardship tecnologica e innovativa che Apple ha perso nel settore degli smartphones.
Story telling L’approccio scelto è quello del Martini Glass: da un punto iniziale, impostato da noi attraverso la TreeMap e il grafo, portiamo l’utente verso la story telling in Tableau. Qui il nostro utente ha a disposizione tutti i dati in diverse serie temporali, TreeMap e nuvole di parole che può navigare a piacere. All’interno delle varie dashboard è possibile visionare le features principali (Super Mario, lo zoom ottico) e qualche innovazione presente sui prodotti competitor ma mancante sul nuovo iPhone7.
Sentiment Analysis
Per calcolare il sentiment di un tweet
abbiamo diviso il testo e filtrato le
WordNet è un database parole inutili. Ogni termine è stato
semantico-lessicale per la lingua cercato sul dizionario di WordNet: il
inglese. L'organizzazione del primo significato di una parola ha la
lessico si avvale di maggiore influenza su un sentimento
raggruppamenti di termini con (tutti gli altri un peso inferiore).
significato affine, chiamati
“synset”. All’interno dei synset le Il valore sentimento è nell'intervallo
differenze di significato sono [-1.0,1.0] dove -1 significa molto
numerate e definite. negativo e 1 molto positivo.
Il sentiment totale del tweet è dato dalla
media del sentiment di ogni termine.Puoi anche leggere

















































