Cheating detection using Item Response Theory - Guido Magnano Chiara Andrà Dipartimento di Matematica - Università di Torino
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Cheating detection using
Item Response Theory
Guido Magnano
Dipartimento di Matematica – Università di Torino
Chiara Andrà
Dipartimento di Matematica – Politecnico di Milano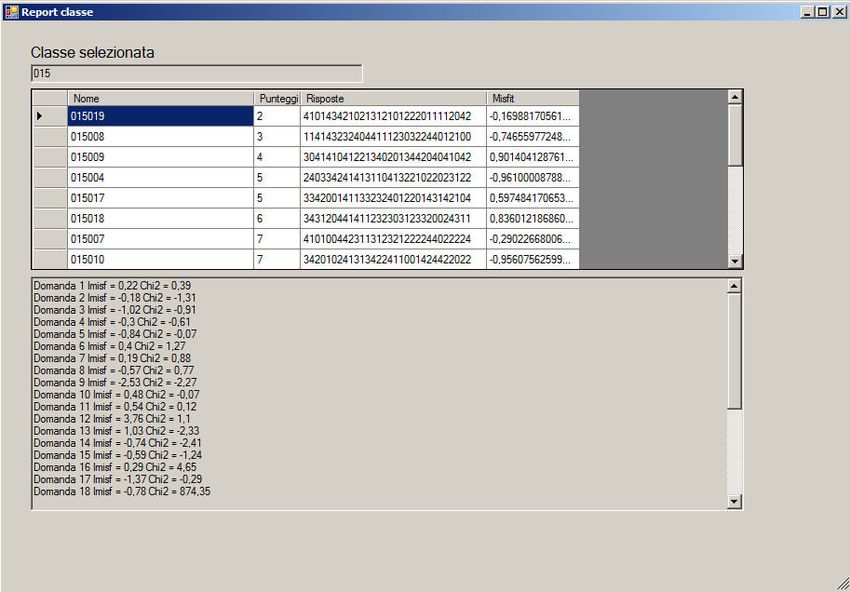
Obiettivi e risultati Obiettivi del progetto: • Costruire uno strumento, basato sulla sola analisi dei pattern di risposta, che individui le classi in cui si è verificata un’incidenza significativa del cheating. • Validare lo strumento su dati simulati. Risultati conseguiti: • Costruzione di un applicativo sensibile a diverse tipologie di cheating nelle classi (non solo copiatura fra studenti) con un tasso di falsi positivi intorno al 10% e un tasso di riconoscimento del cheating che varia fra il 40% e il 60% (a seconda del numero di item e della difficoltà media del questionario).
Perché uno studio su dati simulati? • La validazione di un algoritmo di cheating detection richiede una base di dati in cui si conosca con certezza quali fenomeni di cheating sono intervenuti. • A questo fine è necessario costruire un buon sistema di simulazione delle risposte e di simulazione del cheating.

Di quale cheating stiamo parlando? • Copiatura fra studenti (cheating di tipo A) • Diffusione di informazioni sulla risposta esatta a una o più domande (cheating di tipo B) • Manipolazione dei dati in fase di trasmissione (cheating di tipo C)

Simulare le risposte a un test
• θ abilità dello studente probabilità di
• β parametro dell’item risposta corretta
modello di Rasch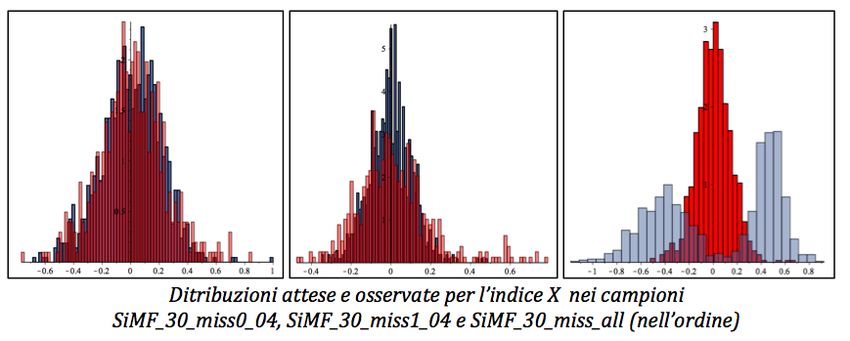
Simulare le risposte a un test
• θ abilità dello studente probabilità della
• (ak , ck) parametri dell’item risposta k
modello di Bock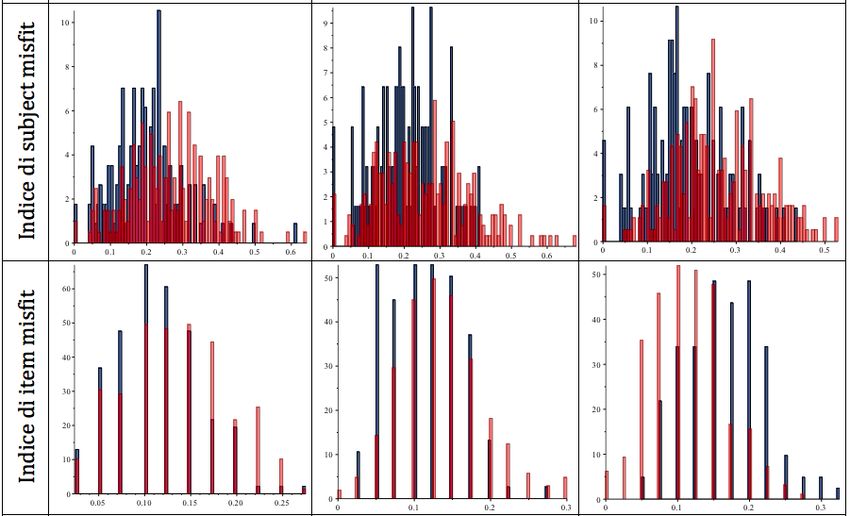
Simulare le risposte a un test
θ1 abilità degli x1 parametri
θ2 “studenti virtuali” x2 degli item
x3
θ3
.. ..
. .
xM
θN
pattern di risposte
ABAADBCC0CCADB00BC…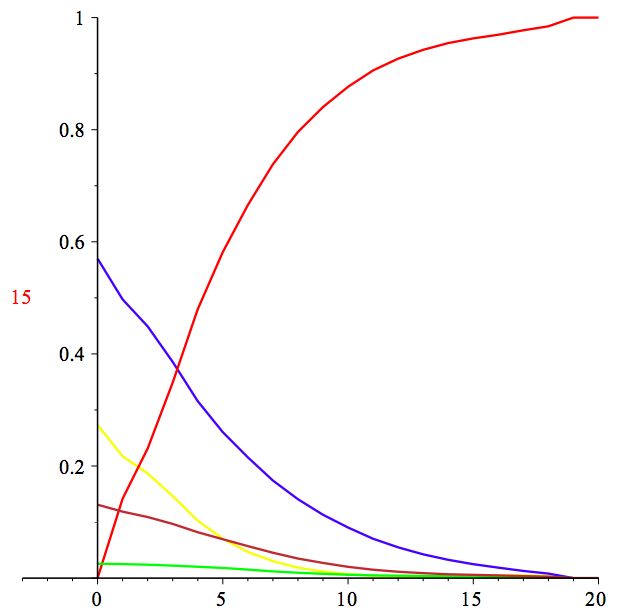
Simulare il cheating • I pattern generati dal simulatore di risposta sono ripartiti in “gruppi–classe” (in modo casuale: le classi hanno un numero variabile di studenti, in media 20). • Alcune classi sono selezionate come classi di controllo: ad esse non viene applicato alcun tipo di cheating.
Simulare il cheating • Cheating A: per ogni classe si seleziona un numero casuale di studenti, con score sotto la mediana • per ogni studente X in questo gruppo si estrae un secondo studente Y (sopra la mediana) da cui X “copia” un numero casuale di domande (fino a 1/3 di tutte, non in sequenza): nel pattern di risposte di X, le risposte corrispondenti sono sostituite con quelle di Y.
Simulare il cheating • Cheating B: per ogni classe si seleziona un numero casuale di studenti (da 5 a tutta la classe); • si estrae un numero casuale di domande (da 1 a 5); • per ognuno degli studenti estratti, le risposte alle domande selezionate (le stesse per tutti) sono sostituite con quelle corrette.
Simulare il cheating • Cheating C: per ogni classe si seleziona un numero casuale n di studenti (da 5 a tutta la classe); • si estrae un numero casuale q, che rappresenta il numero massimo di “correzioni” fatte per un singolo studente; • per tutti gli studenti estratti che hanno score minore di S/2 (S = punteggio massimo) fino a q risposte omesse sono sostituite con le risposte giuste.
Due questioni non banali: 1 La scelta della popolazione (spettro di abilità) • la distribuzione di abilità nella popolazione determina lo spettro dei punteggi del test. • ha senso estrarre tutte le classi da una sola popolazione?
Due questioni non banali: 1 si osservi la relazione che si ha in questo caso fra il punteggio medio della classe e l’aumento dovuto al cheating: (correlazione = 0.81)
Due questioni non banali: 1 se si estraggono le classi da popolazioni diverse, la correlazione sparisce. (correlazione = 0.23)
Due questioni non banali: 2 • come modellizzare la mancata risposta a una domanda? • I modelli IRT usuali (Rasch, 2PL, 3PL…) non contemplano la mancata risposta • in un modello politomico (Bock) si può considerare l’omessa risposta alla stregua di un distrattore • ma l’omissione di una risposta può dipendere solo dall’abilità del soggetto?
Due questioni non banali: 2
• congettura (Lord): ogni studente risponde alle
domande a cui crede di saper rispondere, e per le
altre:
– se le risposte errate non sono penalizzate, tira a
caso
– se le risposte errate sono penalizzate, evita di
rispondere
• questo comportamento in genere non
corrisponde a quanto avviene in realtàDue questioni non banali: 2 • vi sono evidenze che, nella medesima situazione, alcuni studenti rispondono comunque a tutte le domande, altri solo a quelle di cui si sentono sicuri. la decisione di non rispondere non dipende solo dall’abilità dello studente e dalla difficoltà della domanda.
Due questioni non banali: 2 abbiamo simulato le omesse risposte in due modi: 1. usando delle domande reali (conoscevamo le risposte date da studenti): in queste, le risposte omesse sono state trattate come distrattori. 2. implementando un modello di Rasch modificato con l’aggiunta di un parametro di propensione a rispondere alle domande difficili, indipendente dal parametro di abilità.
Individuare il cheating sui dati simulati Indici probabilistici di copiatura: • H (Angoff 1974) • g2 (Frary 1977) • K (Holland 1992) • ω (Wollack 1997) • …
Il problema delle statistiche di coincidenza
indice ω (Wollack 1997)
(a) 1441134324221131242133332144310211221141
(b) 1343104340034141333212224142420221321012
se b copia da a le prime 4
risposte, l’indice supera il
valore di soglia 1.28
ω = 0.905Il problema delle statistiche di coincidenza
indice ω (Wollack 1997)
(c) 1343112314421041142344134122441221321131
(d) 3113104144101140313313224141400030324223
se d copia da c le prime 10
risposte, l’indice non raggiunge
ω = –0.99 ancora il valore di sogliaIl problema delle statistiche di coincidenza
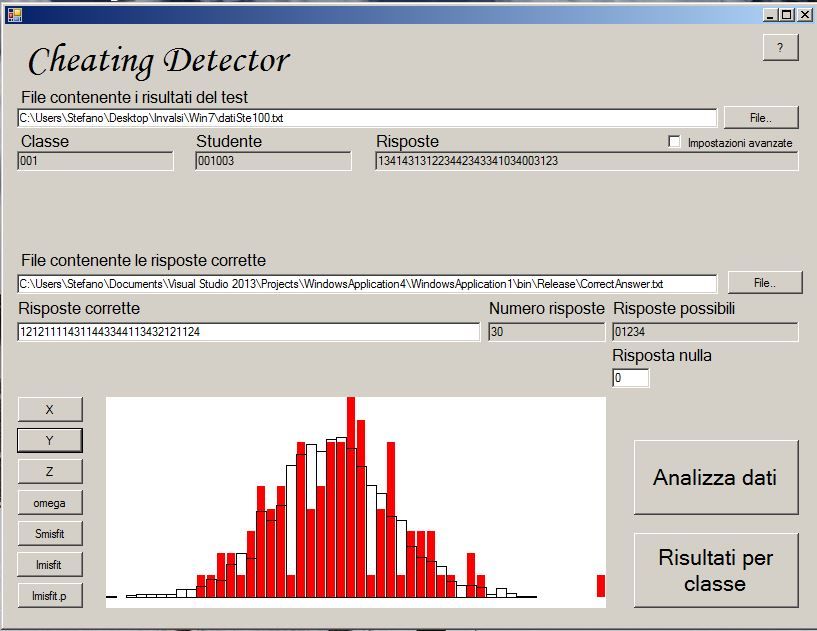
distribuzione dell’indice ω su una classe simulata
(senza cheating)Il problema delle statistiche di coincidenza
Il nostro cheating detector • Dato che lo scopo è individuare le classi in cui il punteggio medio potrebbe essere stato alterato dal cheating, accanto agli indici che misurano l’alterazione di singoli pattern di risposta o le coincidenze fra coppie di pattern abbiamo introdotto altri indici calcolati sull’intera classe. Nelle simulazioni, questi si sono rivelati particolarmente predittivi.
Il nostro cheating detector • Il criterio di individuazione del cheating è basato su sette indici che vengono calcolati sulla base dei dati forniti. • il sistema produce in primo luogo una stima delle probabilità di ciascuna risposta ad ogni item in funzione del punteggio complessivo del soggetto, sulla base delle frequenze osservate nell’intera popolazione studentesca sottoposta a test (senza suddividerla nelle classi di appartenenza)
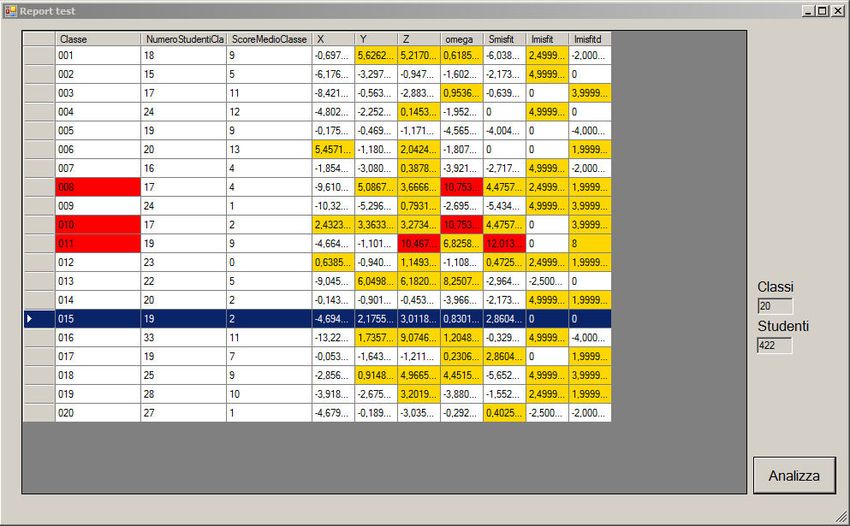
Il nostro cheating detector • con le probabilità calcolate, conoscendo I punteggio ottenuti dagli studenti il sistema simula la distribuzione che in ciascuna classe dovrebbero avere i sette indici in osservazione sotto l’ipotesi nulla (assenza di cheating), e per ciascuno di essi individua la mediana e il 99 centile. • a questo punto calcola il valore degli indici nella classe. Se per una classe uno di questi valori raggiunge il 99 centile, ovvero se tutti i valori (tranne al più uno) risultano sopra la mediana, il sistema segnala la classe come possibile sede di cheating.
risultati delle simulazioni
risultati delle simulazioni
funzionamento degli indici cheating di tipo A cheating di tipo B cheating di tipo C
cheating di tipo A cheating di tipo B cheating di tipo C
cheating di tipo A cheating di tipo B cheating di tipo C
cheating di tipo A cheating di tipo B cheating di tipo C
risultati delle simulazioni
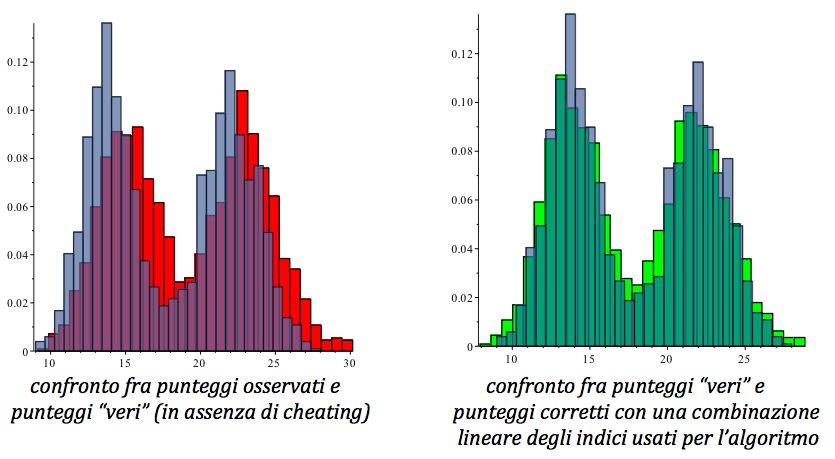
si può depurare il punteggio dal cheating?
si può depurare il punteggio dal cheating?
conclusioni • La potenza del test è apprezzabile, se confrontata con la performance degli indici noti in letteratura. • L’uso di più indici rende lo strumento sensibile a tipi diversi di cheating; inoltre, gli indici che possono generare un forte errore di tipo I in alcune situazioni (molte risposte omesse) si possono facilmente escludere dal criterio di decisione in questi casi. • La performance dello strumento è accettabile anche per dati dicotomici e per test non lunghi. La precisione è maggiore se il questionario è di livello medio/difficile in rapporto all’abilità della popolazione. • L’algoritmo può dunque essere usato a supporto di criteri basati su analisi statistiche che utilizzano altre informazioni relative al contesto/ classe, permettendo di focalizzare meglio le possibili relazioni fra cheating e caratteristiche del test (composizione e modalità di somministrazione).
Puoi anche leggere

















































