Università degli Studi di Padova - Dipartimento di Matematica "Tullio Levi-Civita" - SIAGAS
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Università degli Studi di Padova
Dipartimento di Matematica "Tullio Levi-Civita"
Corso di Laurea in Informatica
Sviluppo di un algoritmo di
apprendimento automatico per il
confronto tra polizze assicurative
Tesi di laurea triennale
Relatore
Prof. Luigi De Giovanni
Laureando
Federico Bicciato
Anno Accademico 2018-2019
Federico Bicciato: Sviluppo di un algoritmo di apprendimento automatico per il confronto tra polizze assicurative, Tesi di laurea triennale, © Settembre 2019.

The master has failed more times than the beginner has even tried.
— Stephen McCranie

Sommario Il presente documento descrive il lavoro del laureando Federico Bicciato svolto durante lo stage presso RiskApp. Lo stage ha avuto luogo tra il 5 giugno 2019 e il 2 agosto 2019, per la durata di 312 ore. L’obiettivo dello stage è stato lo sviluppo di un algoritmo di apprendimen- to automatico per l’individuazione di tabelle nei documenti. In particolare, lo stage si è concentrato sull’allenamento di un modello di rete neurale. Questo documento tratta delle attività svolte per soddisfare l’obietti- vo: la formazione teorica, il rapporto con un progetto precedente, la configurazione dell’ambiente, lo sviluppo e i risultati ottenuti.

Ringraziamenti Per primo desidero ringraziare il Prof. Luigi De Giovanni che è stato relatore interno di questa tesi, per la sua attenzione e disponibilità. Ringrazio Federico Carturan e Luca Bizzaro di RiskApp, per avermi accolto in azienda e seguito durante lo stage. Grazie a tutti i docenti del Corso di Informatica. Ricordo con piacere alcuni dei concetti appresi dalle loro lezioni: come un problema sia scomponibile in sotto-problemi, come l’ordine delle operazioni sia determinante per i risultati, come ogni operazione venga al costo della propria complessità. Questi concetti sono piuttosto astratti, ma li ritrovo nella vita quotidiana. Grazie anche al Prof. Marco Zorzi e al dottorando Alberto Testolin, che mi hanno accompagnato nei primi passi del Deep Learning al corso di Intelligenza Artificiale, e ad Andrew Ng, che invece mi ha fatto correre parecchio durante lo stage. Molte delle conoscenze trasfuse in questa tesi vengono dai loro insegna- menti. Un grazie ai nuovi compagni che ho incontrato in questi anni, spesso molto diversi dalle persone che frequentavo abitualmente, e ai vecchi amici che sono rimasti con me. Infine ringrazio la mia famiglia, che mi ha trasmesso molti valori sani. In particolar modo ringrazio mio padre, ottimista e paziente, e mia madre, la cui tenacia è notevole. Non sarei la persona che sono oggi senza tutti loro. Padova, Settembre 2019 Federico Bicciato
Indice
Indice iii
Elenco delle figure v
Elenco delle tabelle vii
1 Scelta dello stage 1
2 L’azienda 2
2.1 Contesto organizzativo e produttivo . . . . . . . . . . . . . . 2
2.2 Clientela . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2.3 Innovazione . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.4 Tecnologie utilizzate . . . . . . . . . . . . . . . . . . . . . . . 3
2.5 Versionamento . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.6 Pianificazione . . . . . . . . . . . . . . . . . . . . . . . . . . 4
3 Descrizione dello stage 5
3.1 Il problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3.2 Il piano di lavoro . . . . . . . . . . . . . . . . . . . . . . . . . 5
3.2.1 Obiettivi . . . . . . . . . . . . . . . . . . . . . . . . . 5
3.2.2 Attività . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3.3 Il punto di partenza . . . . . . . . . . . . . . . . . . . . . . . 8
3.3.1 TableTrainNet . . . . . . . . . . . . . . . . . . . . . . 8
3.3.2 IntelligentOCR . . . . . . . . . . . . . . . . . . . . . . 9
4 Introduzione alle reti neurali 10
4.1 Deep Learning Specialization . . . . . . . . . . . . . . . . . 10
4.2 Cenni sul Deep Learning . . . . . . . . . . . . . . . . . . . . 10
4.2.1 La struttura di una rete neurale . . . . . . . . . . . . 11
4.2.2 Il dataset e le sue partizioni . . . . . . . . . . . . . . 12
4.2.3 Allenamento e inferenza . . . . . . . . . . . . . . . . 13
4.2.4 Miglioramento delle prestazioni della rete . . . . . . 15
4.3 Metriche per la valutazione dei modelli . . . . . . . . . . . . 17
4.3.1 Dati e predizioni . . . . . . . . . . . . . . . . . . . . . 17
4.3.2 Precision . . . . . . . . . . . . . . . . . . . . . . . . . 17
INDICE iv
4.3.3 Recall . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.3.4 F1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.3.5 Average Precision e Average Recall . . . . . . . . . . 18
4.3.6 Mean Average Precision . . . . . . . . . . . . . . . . . 18
4.3.7 Intersection over Union . . . . . . . . . . . . . . . . . 19
5 Tecnologie 20
5.1 Python . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.2 TensorFlow . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.3 TensorFlow Detection Model Zoo . . . . . . . . . . . . . . . 22
5.4 TensorBoard . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.5 Detectron . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
6 Sviluppo del progetto 26
6.1 Ambiente di lavoro . . . . . . . . . . . . . . . . . . . . . . . 26
6.2 Dataset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
6.2.1 Il dataset iniziale . . . . . . . . . . . . . . . . . . . . 26
6.2.2 Il dataset aumentato . . . . . . . . . . . . . . . . . . . 27
6.2.3 Il dataset definitivo . . . . . . . . . . . . . . . . . . . 28
6.3 Scelta del modello . . . . . . . . . . . . . . . . . . . . . . . . 28
6.4 Il modello adam2_tb . . . . . . . . . . . . . . . . . . . . . . . 29
6.4.1 Training . . . . . . . . . . . . . . . . . . . . . . . . . . 29
6.4.2 Tuning . . . . . . . . . . . . . . . . . . . . . . . . . . 29
6.4.3 Metriche . . . . . . . . . . . . . . . . . . . . . . . . . 31
6.5 Il modello ResNeXt-101 . . . . . . . . . . . . . . . . . . . . . 37
7 Risultati 38
7.1 Risultati di adam2_tb . . . . . . . . . . . . . . . . . . . . . . 38
7.2 Risultati di ResNeXt-101 . . . . . . . . . . . . . . . . . . . . 38
7.3 Osservazioni generali . . . . . . . . . . . . . . . . . . . . . . 39
8 Valutazione retrospettiva 40
8.1 Obiettivi raggiunti . . . . . . . . . . . . . . . . . . . . . . . . 40
8.2 Attività svolte . . . . . . . . . . . . . . . . . . . . . . . . . . 41
8.3 Valutazione personale . . . . . . . . . . . . . . . . . . . . . . 41
A Test sulle polizze 43
A.1 Test di adam2_tb . . . . . . . . . . . . . . . . . . . . . . . . . 43
A.2 Test di ResNeXt-101 . . . . . . . . . . . . . . . . . . . . . . . 56
Bibliografia 59
Articoli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
Lezioni universitarie . . . . . . . . . . . . . . . . . . . . . . . 60
Siti web . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
Video . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63Elenco delle figure
2.1 Logo di RiskApp. . . . . . . . . . . . . . . . . . . . . . . . . . . 2
4.1 Programmazione tradizionale vs. Machine Learning. Fonte: [4]. 11
4.2 Esempio di deep neural network. Fonte: [19]. . . . . . . . . . . 12
4.3 Discesa di gradiente su una funzione in tre dimensioni. Fonte:
[2]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4.4 Esempio di overfitting di curve. . . . . . . . . . . . . . . . . . . 15
4.5 Effetti sulla gradient descent al variare del learning rate. . . . . 16
4.6 Esempio di query. Fonte: [5]. . . . . . . . . . . . . . . . . . . . . 18
4.7 Esempio di IoU. Fonte: [5]. . . . . . . . . . . . . . . . . . . . . . 19
5.1 Logo di Python. . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.2 Logo di TensorFlow. . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.3 Esempio di modello con Keras. Fonte: [53]. . . . . . . . . . . . . 21
5.4 Esempio di applicazione di mask. Fonte: [7]. . . . . . . . . . . . 22
5.5 Modelli del TensorFlow Detection Model Zoo allenati sul data-
set COCO. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5.6 Avvio di TensorBoard su terminale. . . . . . . . . . . . . . . . . 24
5.7 Esempio di grafo su Tensorboard. Fonte: [53]. . . . . . . . . . . 25
6.1 Formato delle annotazioni in TableTrainNet. . . . . . . . . . . . 27
6.2 Comando per lanciare il training della rete neurale. . . . . . . . 29
6.3 Precisione di mAP di adam2_tb su TensorBoard. . . . . . . . . . 32
6.4 Recall di recall di adam2_tb su TensorBoard. . . . . . . . . . . . 34
6.5 Learning rate di adam2_tb su TensorBoard. . . . . . . . . . . . . 35
6.6 Loss function di adam2_tb su TensorBoard. . . . . . . . . . . . . 36
6.7 Esempio di overfitting su TensorBoard. . . . . . . . . . . . . . . 36
6.8 Metriche di ResNeXt-101 e ResNeXt-152. . . . . . . . . . . . . . 37
A.1 Test 1, immagine di partenza. . . . . . . . . . . . . . . . . . . . 44
A.2 Test 1, tabelle individuate per score = 0.2, versione filtered. . . 45
A.3 Test 1, tabelle individuate per score = 0.2, versione merged. . . 45
A.4 Test 1, tabelle individuate per score = 0.4, versione filtered. . . 45
A.5 Test 1, tabelle individuate per score = 0.4, versione merged. . . 45
A.6 Test 1, tabelle individuate per score = 0.6, versione filtered. . . 46A.7 Test 1, tabelle individuate per score = 0.6, versione merged. . . 46 A.8 Test 1, tabelle individuate per score = 0.8, versione filtered. . . 46 A.9 Test 1, tabelle individuate per score = 0.8, versione merged. . . 46 A.10 Test 2, immagine di partenza. . . . . . . . . . . . . . . . . . . . 47 A.11 Test 2, tabelle individuate per score = 0.2, versione filtered. . . 48 A.12 Test 2, tabelle individuate per score = 0.2, versione merged. . . 48 A.13 Test 2, tabelle individuate per score = 0.4, versione filtered. . . 48 A.14 Test 2, tabelle individuate per score = 0.4, versione merged. . . 48 A.15 Test 2, tabelle individuate per score = 0.6, versione filtered. . . 49 A.16 Test 2, tabelle individuate per score = 0.6, versione merged. . . 49 A.17 Test 2, tabelle individuate per score = 0.8, versione filtered. . . 49 A.18 Test 2, tabelle individuate per score = 0.8, versione merged. . . 49 A.19 Test 3, immagine di partenza. . . . . . . . . . . . . . . . . . . . 50 A.20 Test 3, tabelle individuate per score = 0.2, versione filtered. . . 51 A.21 Test 3, tabelle individuate per score = 0.2, versione merged. . . 51 A.22 Test 3, tabelle individuate per score = 0.4, versione filtered. . . 51 A.23 Test 3, tabelle individuate per score = 0.4, versione merged. . . 51 A.24 Test 3, tabelle individuate per score = 0.6, versione filtered. . . 52 A.25 Test 3, tabelle individuate per score = 0.6, versione merged. . . 52 A.26 Test 3, tabelle individuate per score = 0.8, versione filtered. . . 52 A.27 Test 3, tabelle individuate per score = 0.8, versione merged. . . 52 A.28 Test 4, immagine di partenza. . . . . . . . . . . . . . . . . . . . 53 A.29 Test 4, tabelle individuate per score = 0.2, versione filtered. . . 54 A.30 Test 4, tabelle individuate per score = 0.2, versione merged. . . 54 A.31 Test 4, tabelle individuate per score = 0.4, versione filtered. . . 54 A.32 Test 4, tabelle individuate per score = 0.4, versione merged. . . 54 A.33 Test 4, tabelle individuate per score = 0.6, versione filtered. . . 55 A.34 Test 4, tabelle individuate per score = 0.6, versione merged. . . 55 A.35 Test 4, tabelle individuate per score = 0.8, versione filtered. . . 55 A.36 Test 4, tabelle individuate per score = 0.8, versione merged. . . 55 A.37 Test 1, immagine di partenza. . . . . . . . . . . . . . . . . . . . 57 A.38 Test 1, tabelle individuate. . . . . . . . . . . . . . . . . . . . . . 57 A.39 Test 2, immagine di partenza. . . . . . . . . . . . . . . . . . . . 57 A.40 Test 2, tabelle individuate. . . . . . . . . . . . . . . . . . . . . . 57 A.41 Test 3, immagine di partenza. . . . . . . . . . . . . . . . . . . . 58 A.42 Test 3, tabelle individuate. . . . . . . . . . . . . . . . . . . . . . 58 A.43 Test 4, immagine di partenza. . . . . . . . . . . . . . . . . . . . 58
Elenco delle tabelle vii
A.44 Test 4, tabelle individuate. . . . . . . . . . . . . . . . . . . . . . 58
Elenco delle tabelle
3.1 Attività di stage pianificate. . . . . . . . . . . . . . . . . . . . . 7
8.1 Raggiungimento degli obiettivi. . . . . . . . . . . . . . . . . . . 40
8.2 Attività di stage svolte. . . . . . . . . . . . . . . . . . . . . . . . 42Scelta dello stage
1
Durante l’evento Stage It [48] tenutosi il 3 aprile 2019 presso la Fiera di
Padova, ho potuto incontrare varie aziende e parlare del possibile progetto
di stage. Quello che cercavo era uno stage stimolante e che mi mettesse
alla prova.
Da un lato volevo testare le mie conoscenze su argomenti diversi da quelli
affrontati nel corso di studi. Dall’altro volevo che anche le tecnologie da
usare fossero nuove rispetto a quelle che già conoscevo, almeno in par-
te. In particolare, durante il progetto di ingegneria del software mi sono
approcciato al linguaggio Python e sono rimasto positivamente colpito dal-
la sua sintesi e potenza espressiva: ero quindi interessato ad approfondirlo.
Tra le varie proposte delle aziende incontrate, una delle più interessanti
è stata quella di RiskApp. Il loro progetto prevedeva l’uso di Python
nell’ambito del Deep Learning, nonché la possibilità di usare le librerie in
JavaScript di React e Redux per integrare il progetto nell’interfaccia web
di RiskApp: ritenevo tali tecnologie attuali e spendibili sul mercato del la-
voro. Inoltre, lo stage ne prevedeva l’applicazione nel dominio della realtà
assicurativa, per me fresco e sconosciuto, e da cui avrei potuto imparare
molto.
Ma l’esperienza non sarebbe stata solamente uno spaventoso turbine di
novità. Ho visitato l’ufficio di Conselve in cui avrei lavorato, dove il clima
è tranquillo e informale. Ho incontrato Federico e Luca, futuri tutor e
collega di stage, e sono stato colpito positivamente dalla loro affabilità,
che mi avrebbe messo a mio agio, pensavo, nelle eventuali difficoltà future.
Dati gli ottimi presupposti, non ho potuto che intraprendere questo
percorso con RiskApp.2
L’azienda
Figura 2.1: Logo di RiskApp.
RiskApp [47] è un fornitore di tecnologia che possiede una piattaforma
di gestione del rischio a tutto tondo per il settore assicurativo. L’azienda
offre una soluzione software omonima atta a supportare e migliorare le
sottoscrizioni, i reclami, le vendite e le decisioni tecniche riguardanti le
coperture assicurative: lo fa offrendo dati, analisi dei rischi, consulenza e
svliuppo software.
RiskApp, il cui logo è mostrato in Figura 2.1, possiede un algoritmo
proprietario che stima il valore del rischio in base a dati raccolti da più
fonti ed esprime le perdite economiche che possono conseguire da tali
rischi, confrontando i risultati con le migliori pratiche del settore.
2.1 CONTESTO ORGANIZZATIVO E PRODUTTIVO
RiskApp è stata fondata dall’ing. Federico Carturan, attuale CEO del-
l’azienda, e da Pierpaolo Toniolo, ex CTO. L’azienda ha sede principale
in Conselve, in provincia di Padova, ma ha anche collaboratori a Milano.
Il core business, cioè l’attività principale dell’azienda, è la fornitura di
servizi ad agenti assicurativi e broker sulla piattaforma RiskApp, attra-
verso l’aggiunta di nuove funzionalità e il miglioramento dell’algoritmo
proprietario di calcolo dei rischi.
2.2 CLIENTELA
La piattaforma RiskApp viene principalmente utilizzata da professionisti
del rischio, broker e agenti assicurativi, che la utilizzano per reperireCAPITOLO 2. L’AZIENDA 3 informazioni dettagliate sui rischi assicurabili e per ricevere un preventivo in maniera istantanea di eventuali polizze. 2.3 INNOVAZIONE RiskApp è una startup che si dedica all’Insurtech. Il tutto è nato dalla selezione in Unipol Ideas, il percorso di Open Innovation del Gruppo Unipol: un canale di dialogo e contaminazione per promuovere l’innova- zione del core business aziendale e in ambiti collegati. Unipol è tra i soci fondatori della Fondazione ItaliaCamp [34]. RiskApp si è presentata in Expo Milano 2015 al Vivaio delle Idee, lo spazio dedicato all’innovazione ideato e gestito da Padiglione Italia, Ministero delle Politiche Agricole e Forestali e dalla Fondazione ItaliaCamp. Nel 2016 Unipol è diventata il primo cliente, inoltre sono state fatti altri programmi di accelerazione in Europa, tra i quali Deloitte Digital Disrup- tors [22] a Lisbona, MundiLab [38] a Madrid, Fintech Innovation Lab[28] a Londra che hanno portato alla collaborazione con Società di consulenza quali Deloitte e Accenture [13], riassicuratori Munich Re [39] e Swiss Re [49], e a nuovi clienti in Europa, come Fidelidade [27] e P&V [40]. 2.4 TECNOLOGIE UTILIZZATE Il software RiskApp si configura come un sito web. Il sito è modulare: è composto da un’insieme di servizi. A seconda della propria sottoscrizione, l’utente ha accesso a un sottoinsieme di questi servizi. Il backend di RiskApp è scritto in Python, supportato dal framework Djan- go [25] per un agevole sviluppo web. Il frontend è scritto in Javascript. L’uso delle librerie React [44] e Redux [45] consente il regolamento del flusso di esecuzione e l’organizzazione del codice in piccole componenti riusabili. Si utilizzano VirtualBox [59] e Vagrant [58] per consentire a tutti gli svi- luppatori di lavorare sullo stesso ambiente ed evitare la maggior parte degli errori dovuti alle proprie personali macchine. VirtualBox ospita l’immagine del sistema operativo desiderato comune a tutti gli sviluppato- ri, mentre Vagrant coordina il proprio sistema locale con quello presente sulla macchina virtuale. L’ambiente di sviluppo tipicamente usato per lavorare è PyCharm [42]. Strumento pensato appositamente per lavorare in Python, risulta comodo anche lato frontend con JavaScript; inoltre facilita l’utilizzo di Vagrant per il quale la configurazione risulta semplice. Questo IDE non è stato imposto in modo vincolante: infatti, al suo posto è stato possibile utilizzare Visual Studio Code [60], un pratico editor di testo che possiede un vasto parco di plugin per customizzarlo e renderlo pari a un IDE per funzionalità.
CAPITOLO 2. L’AZIENDA 4 2.5 VERSIONAMENTO Il codice di RiskApp si trova su GitHub [29], suddiviso in due repository: Ayako contiene il frontend, mentre su Noriko si trova il backend. Ogni sviluppatore lavora sul proprio ramo personale, derivato dal ramo comune develop. Dal proprio ramo, detto _develop, si deriva un nuovo ramo per ogni nuova feature da implementare. Una volta implementata la feature, viene inserita nel proprio ramo, se ne verifica il funzionamento, poi essa può essere integrata nel ramo develop comune: qui viene testata automaticamente con l’ausilio del tool di continuous integration CircleCI [20]. Se i test sono superati, la feature viene aggiunta al ramo master con una pull request. 2.6 PIANIFICAZIONE Per quanto riguarda la pianificazione, le milestone sono gestite attraverso i projects di GitHub, in cui sono presenti le feature da realizzare. A ogni feature è collegato un gruppo di compiti da eseguire per completare la feature. Su GitHub i compiti sono rappresentati dalle issue, e sono etichettati per priorità e assegnati a singole persone.
Descrizione dello stage
3
3.1 IL PROBLEMA
Il problema da affrontare è il confronto tra polizze assicurative. L’utente in
questione è un agente o un broker assicurativo, e si rivolge alle compagnie
di assicurazioni per ottenere le migliori polizze assicurative secondo le
richieste dei propri clienti, che sono aziende o liberi professionisti. Le
polizze assicurative sono diverse tra loro: contengono molti dati simili ma
esposti in modo diseguale, nonché una serie di clausole. La loro compren-
sione e comparazione non è immediata.
Dunque, è desiderabile per gli utenti avere uno strumento che confronti
le polizze in modo automatico ed esponga i risultati del confronto. Si
è ipotizzato che sia possibile costruire tale strumento. La piattaforma
RiskApp potrebbe esporlo come servizio, e l’utente potrebbe utilizzarlo
per facilitare il proprio lavoro di confronto e scelta.
Uno strumento del genere si baserebbe su un algoritmo capace di estrarre
alcuni dati di interesse dalle polizze. Le polizze sono composte principal-
mente da di due tipi di dato, testo e tabelle. Questi dati permettono di
mettere a confronto polizze diverse, e la macchina che li legge deve prima
distinguerli per poterli poi utilizzare correttamente. Una volta ottenuti e
letti, tali dati possono essere elaborati ed esposti all’utente.
3.2 IL PIANO DI LAVORO
L’azienda è interessata ad incorporare il sistema di confronto tra polizze
alla piattaforma, ma il modello di rete a loro disposizione non era sufficien-
temente preciso per essere utilizzato. Di conseguenza, il focus principale
del progetto descritto in questa tesi è stato di allenare un modello migliore
che produca risultati soddisfacenti utilizzando un progetto precedente,
TableTrainNet (vedi Sezione 3.3.1), come punto di partenza.
3.2.1 Obiettivi
Nel piano di lavoro sono stati stabiliti alcuni obiettivi di stage. Questi,
suddivisi in obbligatori (OB), desiderabili (DE) e opzionali (OP), sono:CAPITOLO 3. DESCRIZIONE DELLO STAGE 6
∗ 1-OB, comprensione del problema: lo studente ha una visione chiara
del problema da risolvere;
∗ 2-OB, comprensione delle tecnologie di backend: lo studente ha
studiato e conosce bene le tecnologie richieste per lo sviluppo dell’al-
goritmo e del modello che lo utilizza;
∗ 3-OB, comprensione delle tecnologie di frontend: lo studente ha
studiato e conosce bene le tecnologie richieste per lo sviluppo del-
l’interfaccia;
∗ 4-OB, sviluppo dell’algoritmo: l’algoritmo risolutivo è stato svilup-
pato, verificato ed è pronto all’uso;
∗ 5-OB, sviluppo dell’interfaccia: l’interfaccia dell’algoritmo è stata
sviluppata ed è pronta all’uso;
∗ 6-DE, sviluppo delle raccomandazioni: si tratta di implementare la
funzionalità di raccomandazione del miglioramento della polizza;
∗ 7-OB, validazione: si verifica la conformità del prodotto rispetto agli
obiettivi.
3.2.2 Attività
Per il completamento dello stage sono state identificate delle attività,
esposte in Tabella 3.1 con il loro processo di provenienza e la quantità di
ore da dedicare.CAPITOLO 3. DESCRIZIONE DELLO STAGE 7
Processo Attività Ore
Configurazione Setup dell’ambiente di lavoro 8
Acquisizione Comprensione approfondita del problema 16
Studio del tipo di documento (polizza) 8
Formazione Comprensione e pratica di Nltk 16
Comprensione e pratica di Spacy 16
Comprensione e pratica di TensorFlow 16
Comprensione e pratica di OpenCV 16
Comprensione e pratica di Tesseract 16
Comprensione e pratica di JavaScript 24
Comprensione e pratica di React 16
Sviluppo Ricerca di algoritmi simili applicabili 16
Progettazione dei componenti dell’architettura 16
Codifica dell’algoritmo 16
Sviluppo dell’interfaccia 32
Sviluppo del sistema di raccomandazioni 32
Verifica Verifica sugli errori del prodotto 24
Validazione Controllo sul raggiungimento degli obiettivi 8
Totali 320
Tabella 3.1: Attività di stage pianificate.CAPITOLO 3. DESCRIZIONE DELLO STAGE 8 3.3 IL PUNTO DI PARTENZA Il mio progetto riceve il testimone dal progetto di stage del 2018 di Gio- vanni Cavallin [1]. Il suo progetto aveva l’obiettivo di creare lo stesso algoritmo citato in Sezione 3.1, e ha posto le basi da cui proseguire nel mio. Questo progetto è scritto in Python 3.5 con l’ausilio di numerose librerie, tra le quali spicca TensorFlow (vedi Sezione 5.2) per implementare il machine learning. Il progetto è suddiviso in due parti distinte, ognuno dei quali ha la propria repository su GitHub. 3.3.1 TableTrainNet La prima repository contiene TableTrainNet [51] e rappresenta una strut- tura idonea per preparare ed allenare un modello di rete neurale. Questo progetto ha bisogno di un dataset composto da immagini contenen- ti testi e tabelle. Lo si importa nel progetto e lo si trasforma nel formato richiesto con alcuni script: le immagini colorate diventano in bianco e nero, e le annotazioni sono portate dal formato xml al formato record per poterle utilizzarle con TensorFlow. Si può quindi allenare un modello di rete neurale. La procedura con- sigliata è di scegliere un modello pre-allenato presente nel Tensorflow Detection Model Zoo [55], scaricarlo, importarlo nel proprio progetto e usare le Tensorflow Object Detection API [56] per allenarlo sul proprio dataset. Si può usare TensorBoard [52] per seguire in tempo reale l’andamento del training, monitorando su dei grafici le metriche disponibili, rilevando così tempestivamente le criticità e valutando l’efficacia dell’allenamento. Si possono anche allenare più modelli, confrontarli su TensorBoard, quindi utilizzarli o scegliere di allenarne uno migliore. Una volta soddisfatti del proprio modello, lo si può esportare, "congelan- dolo" in un formato che rimuove alcuni file generati durante il training e tiene quelli utili all’inferenza. Quindi si può testare il proprio modello, facendogli fare inferenza su delle immagini nuove, nel nostro caso di polizze. Il test verifica le capacità del modello su queste immagini. Tipicamente si userebbe lo stesso dataset per fare training, convalida e test, ma in questo caso non è possibile, visto che il dataset non contiene immagini di polizze: dunque si utilizza questa procedura più spartana ma funzionale. Il test restituisce in output le stesse immagini di partenza con sopra se- gnati i riquadri delle tabelle individuate: visionando gli output si può valutare se i riquadri sono posti correttamente o meno. È possibile fare inferenza in più varianti alterando i parametri del file di configurazione: si può ad esempio scegliere quali tabelle tenere a seconda dello score cioè della probabilità che queste siano presenti.
CAPITOLO 3. DESCRIZIONE DELLO STAGE 9 3.3.2 IntelligentOCR La seconda repository contiene IntelligentOCR [33] e utilizza il modello prodotto su TableTrainNet per estrarre i dati da testi e tabelle tramite computer vision. La sua architettura è organizzata come pipeline: per farla funzionare è suf- ficiente lanciare un singolo script. Gli unici file che è necessario modificare sono un file di configurazione, i file in input e il modello da importare. L’input richiesto è costituito da file in formato pdf: tipicamente si tratta di una polizza assicurativa ottenuta tramite scansione. Tale file viene proces- sato in modo bufferizzato tramite la libreria pdftoppm e viene scomposto in immagini singole. Le immagini ottenute sono fornite alla rete neurale che vi individua le tabelle presenti; quindi, l’algoritmo continua effettuando dei ritagli sulle immagini separando le tabelle e i testi in immagini distinte. Infine i ritagli vengono trattati con la libreria Tesseract [57], che riconosce i caratteri e permette di trascrivere i testi su file txt e le tabelle su file csv.
Introduzione alle reti neurali
4
4.1 DEEP LEARNING SPECIALIZATION
In generale, i progetti di deep learning sono impostati con una struttura
specifica che assume un significato preciso e contestualizzato nella disci-
plina. Per sviluppare tali progetti è tanto importante conoscere i concetti
di base e le pratiche migliori, quanto gli strumenti tecnici come linguaggi
e librerie.
La soluzione presa per la formazione su teoria e pratica del deep learning,
su proposta del tutor aziendale, è stato di seguire la Deep Learning Spe-
cialization [18] disponibile su Coursera e creata da deeplearning.ai [21].
Questa specializzazione è mirata all’apprendimento delle reti neurali e si
suddivide per argomenti in cinque corsi. I corsi consistono in videolezioni
ed esercizi da svolgere; di questi sono stati completati i tre più conformi
agli obiettivi dello stage:
∗ Neural Networks and Deep Learning: un corso introduttivo che spiega
le nozioni di base sulle reti neurali e spiega come implementarle;
∗ Improving Deep Neural Networks: Hyperparameter tuning, Regulari-
zation and Optimization: un corso sul tuning, ovvero l’insieme di
tecniche che si applicano alle reti per migliorarne le prestazioni,
l’efficienza, l’efficacia;
∗ Convolutional Neural Networks: un corso specifico sulla tipologia di
reti convoluzionali, adatte a lavorare con le immagini, in grado di
individuare oggetti e posizioni delle stesse, nonché di trasformarle.
4.2 CENNI SUL DEEP LEARNING
Il Deep Learning è una disciplina dove si creano e usano reti neurali per
risolvere problemi complessi che includono grandi quantità dati non strut-
turati, come audio, immagini e testo. Le reti neurali sono molto efficaci a
risolvere questo tipo di problemi: le loro performance migliorano all’au-
mentare della quantità di dati in input.
Come visibile in Figura 4.1, le reti neurali seguono un paradigma in con-
trasto con quello della programmazione tradizionale, dove si hanno a di-CAPITOLO 4. INTRODUZIONE ALLE RETI NEURALI 11 sposizione un’input e una forma di calcolo e si cerca di ottenere un’output. Nel deep learning (similmente a quanto avviene nel machine learning), invece, i dati hanno un ruolo primario: si hanno a disposizione input e output, e ciò che manca è la forma di calcolo in grado di associarli. Si tenta quindi di creare tale entità, che assume la forma di rete neurale. La sua particolarità è la capacità di auto-apprendere dall’esperienza senza conoscenza esplicita del problema. Imparano a generalizzare le proprie conoscenze rispetto a situazioni nuove, anche in presenza di rumore, senza che un umano le indichi esplicitamente come farlo [11]. Figura 4.1: Programmazione tradizionale vs. Machine Learning. Fonte: [4]. 4.2.1 La struttura di una rete neurale La struttura di una rete neurale è simile a quella del cervello umano: essa è composta da unità e da archi che le connettono. Le unità sono i cosiddetti neuroni artificiali, e hanno un valore reale soli- tamente compreso tra 0 e 1, o tra -1 e 1, a seconda dell’implementazione. A ciascuna delle unità si associa un bias, un piccolo valore casuale prossimo a zero che permette di inizializzare correttamente la rete. Gli archi, o connessioni, sono i pesi della rete, connettono le unità e per- mettono la propagazione del segnale e la modifica dei valori della rete. A ogni neurone è associata anche una funzione di attivazione, che ricava un valore binario (0 o 1) a partire dal neurone. Posti i dati seguenti: 1. x: valore del neurone in input; 2. y: valore del neurone in output; 3. w: peso tra i due neuroni; 4. σ : funzione di attivazione;
CAPITOLO 4. INTRODUZIONE ALLE RETI NEURALI 12
5. a: valore di attivazione;
6. b: bias.
Il valore di attivazione a si calcola usando l’Equazione 4.1:
ay = σ (w ∗ x + b) (4.1)
La funzione di attivazione determina l’attivarsi o meno del neurone. Quan-
do il neurone si attiva permette la trasmissione del segnale attraverso di
sè e la propaga alle proprie connessioni, mentre quando non è attivo la
inibisce.
Tipicamente i neuroni sono raggruppati in strati. Lo strato di input è
quello che riceve gli input dal dataset. Lo strato di output è quello su cui
sono memorizzati gli output prodotti dalla rete. Tutti gli strati intermedi
sono detti strati nascosti. Una rete neurale con 2 o più strati nascosti è
detta rete neurale profonda o DNN (Deep Neural Network): tale rete è
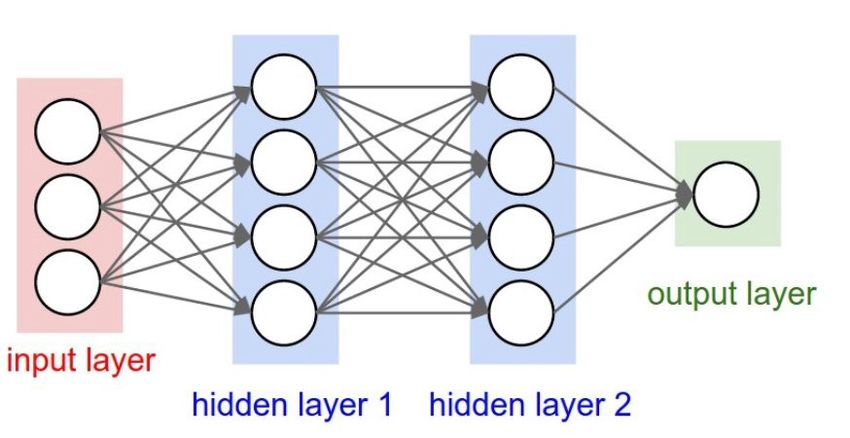
visibile in Figura 4.2.
Figura 4.2: Esempio di deep neural network. Fonte: [19].
L’architettura della rete è definita dal numero di strati, il numero di
neuroni per strato e le connessioni presenti tra i neuroni [12].
4.2.2 Il dataset e le sue partizioni
Una rete va allenata prima di poterla usare, e per allenarla serve un data-
set.
Un dataset è un insieme di dati composto da input e output. Gli input
possono essere immagini, audio, testi o altri tipi di file. Gli output rappre-
sentano ciò che vogliamo ottenere dal dato input: può essere un valore
binario (per dire se l’input appartiene a una categoria o meno), un valore
intero (per una serie di categorie) o altro ancora.
Un dataset viene solitamente partizionato in tre insiemi distinti [10]:CAPITOLO 4. INTRODUZIONE ALLE RETI NEURALI 13
∗ training set: la parte maggiore del dataset che viene usata per
allenare il modello;
∗ evaluation set: detto anche set di convalida o development set, è
una piccola parte del dataset che viene usata per controllare a in-
tervalli regolari le capacità del modello di fare predizioni durante
l’allenamento, e permette di fare il tuning degli iperparametri;
∗ test set: una piccola parte del dataset viene usata dopo l’allenamento
per controllare le capacità del modello su un nuovo insieme di dati.
Le proporzioni secondo cui partizionare il dataset variano a seconda del
numero di elementi totali.
Per dataset fino a 104 elementi, si è soliti partizionare il dataset secondo la
proporzione 70%|30% in training e test set rinunciando al’evaluation set,
oppure 60%|20%|20% se si usano tutti e tre i set.
Oggigiorno i dataset possono essere molto grandi, dell’ordine di 106 ele-
menti: per quest’ordine di grandezza si preferiscono distribuzioni come
98%|1%|1% oppure 99.5%|0.25%|0.25%. Infatti, usare più di 104 elementi
per dev o test set è considerato superfluo [63].
4.2.3 Allenamento e inferenza
L’allenamento della rete è un processo ciclico consistente in due fasi che si
ripetono continuamente per un certo numero predeterminato di iterazioni.
La prima fase è detta forward propagation. Ogni singolo elemento del
training set diventa un elemento di input per il modello, e prende il nome
di training example o training pattern. Durante la forward propagation
i training examples vengono letti dallo strato di input della rete e generano
un segnale che si propaga in avanti sulla rete attraverso i pesi e i neuroni
attivi fino allo strato di output. Il valore di output ottenuto è confronta-
to con l’output atteso, che può assumere vari nomi: label, annotazione,
ground truth. La differenza tra i due è calcolata da una funzione, detta
funzione di costo o funzione errore.
La seconda fase è la backward propagation, o back prop, e succede alla
prima a intervalli regolari, dopo un certo numero di esempi predefinito
detto batch size. In questa fase, il segnale torna indietro dall’output verso
l’input aggiornando i pesi della rete (questa è una fondamentale differen-
za dal cervello umano, le cui sinapsi permettono solo una trasmissione
monodirezionale del segnale). Questo fenomeno di aggiornamento dei
pesi è detto discesa di gradiente. Se la rete effettua la discesa corretta-
mente, diventa progressivamente più precisa nel calcolo degli output, e
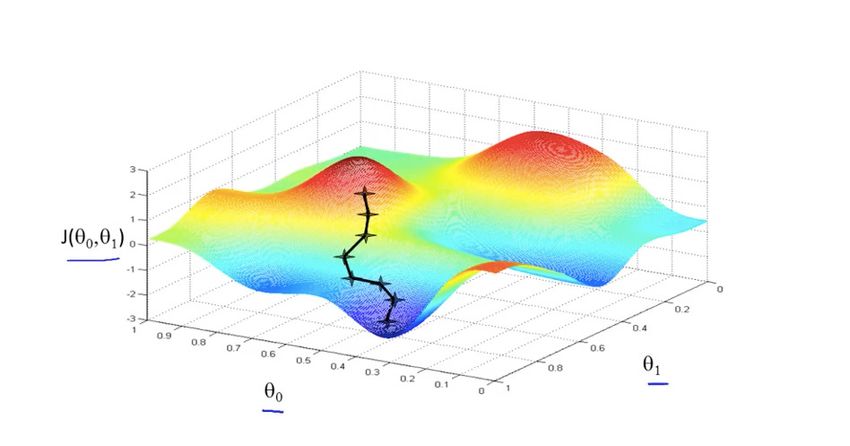
il valore ottenuto dalla funzione di costo tende a zero. Possiamo intuire
visivamente come avviene la discesa di gradiente in Figura 4.3.CAPITOLO 4. INTRODUZIONE ALLE RETI NEURALI 14
Figura 4.3: Discesa di gradiente su una funzione in tre dimensioni. Fonte: [2].
Estendiamo ora la funzione di costo a più dimensioni (cosa che effettiva-
mente accade nelle reti neurali). Per minimizzarla si calcolano le derivate
parziali lungo ogni dimensione, a ognuna delle quali corrisponde un peso
del modello.
Data la funzione di costo J e il peso w, la derivata parziale della funzione
rispetto a w si calcola secondo l’Equazione 4.2:
∂J
(4.2)
∂w
La sommatoria delle derivate parziali rispetto ciascun peso è il gradiente
della funzione (Equazione 4.3):
n
X ∂J
∇J = (4.3)
∂wi
i=0
Tuttavia, l’allenamento del modello non va sempre a buon fine. Ad esem-
pio, può essere che il modello sia troppo potente rispetto al compito che
deve risolvere. In questo caso il modello è in grado di riprodurre fedelmen-
te solo gli output del training set, mentre non è in grado di generalizzare lo
stesso compito sull’evaluation set o su un set diverso. In pratica il modello
non riesce più a distinguere il segnale, cioè le caratteristiche rilevanti
da apprendere dai dati, dal rumore, cioè quelle derivate dal caso e da
escludere.
Ecco un esempio in Figura 4.4: due funzioni devono distinguere due zone
del piano a partire dai dati che le popolano. La funzione rappresentata in
nero impara correttamente a distinguere le due aree, mentre quella in ver-
de è troppo complessa, e impara le posizioni dei dati specifici ignorando
le aree, che sono il vero obiettivo.CAPITOLO 4. INTRODUZIONE ALLE RETI NEURALI 15
Figura 4.4: Esempio di overfitting di curve.
Questo problema è noto come overfitting, ovvero l’adattamento eccessivo
del modello rispetto ai dati. Si verifica quando la prestazione sui training
continua a migliorare ma diminuisce la prestazione in termini di genera-
lizzazione [10].
Se la rete è stata allenata correttamente, gli output che si ottengono da
essa sono molto simili a quelli attesi: non è più necessario fare back prop
e ricalcolare i pesi. A questo punto la si può sfruttare unicamente per
calcolare gli output a un’unica passata di forward propagation: questo
procedimento è detto inferenza.
4.2.4 Miglioramento delle prestazioni della rete
Migliorare le prestazioni della rete spesso equivale a migliorare la discesa
di gradiente, rendendola più dolce: è possibile farlo fare in vari modi,
ad esempio intervenendo sugli iperparametri oppure utilizzando degli
algoritmi di ottimizzazione.
Learning rate
Oltre ai parametri usati nei calcoli dalla rete stessa, in una rete neurale ci
sono un’insieme di iperparametri che lo sviluppatore può settare esclusi-
vamente prima dell’allenamento, per influenzare le prestazioni e l’esito
dello stesso: questo processo è detto tuning degli iperparametri.
Tra i vari iperparametri, il più influente è il tasso di apprendimento, o
learning rate: esso determina quanto è grande la modifica dei pesi tra due
iterazioni successive. Il suo settaggio è sempre necessario per la buona
riuscita dell’allenamento.
Dati:
∗ i: neurone da cui parte il segnale;CAPITOLO 4. INTRODUZIONE ALLE RETI NEURALI 16
∗ j: neurone seguente;
∗ t: numero dell’iterazione;
∗ α: learning rate.
Vale la Formula 4.4 per il calcolo di un singolo peso:
t t−1 t
wi,j = wi,j + α ∗ ∆wi,j (4.4)
Il learning rate influenza la discesa di gradiente in modo determinante:
come si può notare nella Figura 4.5, un learning rate alto può velocizzarla,
ma anche andare in direzione opposta; un learning rate basso la può
rallentare (in alto a destra) ma è appropriato in prossimità del punto di
minimo.
Figura 4.5: Effetti sulla gradient descent al variare del learning rate.
Optimizers
Esistono una serie di algoritmi detti optimizers che applicano delle corre-
zioni matematiche ai parametri della rete neurale per migliorare la discesa
di gradiente. Uno di questi è Gradient Descent with Momentum [62],
che migliora l’equazione di update dei parametri aggiungendo un termine
che simula il momento fisico: dunque, previene bruschi cambiamenti di
direzione e intensità tra due iterazioni successive di discesa di gradiente.
Un suo successore è RMSProp [64], cioè Root Mean Square Propagation,
simile al precedente, ma più raffinato, che sfrutta l’estrazione di radice per
smorzare maggiormente i pesi più grandi, addolcendo quindi la discesa di
gradiente lungo le direzioni in cui le variazioni sono maggiori.
La combinazione delle migliori caratteristiche dei due ha portato all’algo-
ritmo Adam [61]. Grazie alla sua efficienza complessiva, e alla capacità di
convergere alla soluzione più rapidamente rispetto agli altri algoritmi, è
molto noto e utilizzato nella community del deep learning.CAPITOLO 4. INTRODUZIONE ALLE RETI NEURALI 17
4.3 METRICHE PER LA VALUTAZIONE DEI MODELLI
4.3.1 Dati e predizioni
Supponiamo di voler fare una predizione su dei dati: si vuole predire se
una determinata caratteristica è presente o meno in un dato. Rispetto alla
caratteristica suddetta, il dato può essere:
∗ Positive (P): caratteristica presente nel dato;
∗ Negative (N): caratteristica assente.
Una predizione può essere:
∗ True (T): corretta;
∗ False (F): non corretta.
Dalle combinazioni possibili di dati e predizioni si hanno le quattro
casistiche di predizione:
∗ True Positive (TP): predizione positiva e caratteristica presente;
∗ False Positive (FP): predizione positiva ma caratteristica assente;
∗ True Negative (TN): predizione negativa e caratteristica assente;
∗ False Negative (FN): predizione negativa ma caratteristica presente.
4.3.2 Precision
La precisione (Forumla 4.5) misura l’accuratezza di una predizione. Si
definisce:
TP
P recision = (4.5)
T P + FP
4.3.3 Recall
La Recall (Formula 4.6) misura la capacità di trovare i positivi. Si definisce
come il numero di positivi trovati sui positivi totali (trovati e non trovati):
TP
Recall = (4.6)
T P + FN
4.3.4 F1
Il punteggio F1 (Formula 4.7), o semplicemente F1, è la media armonica
[36] tra Precision e Recall. Si definisce:
precision ∗ recall
P recision = 2 ∗ (4.7)
precision + recall
F1 viene utilizzata in campi come information retrieval, machine learning
e natural language processing [26].CAPITOLO 4. INTRODUZIONE ALLE RETI NEURALI 18
4.3.5 Average Precision e Average Recall
Applichiamo le definizioni di Precision e Recall nel caso di una una query
su un piccolo dataset. La query, rappresentata in Figura 4.6, cerca una
determinata caratteristica in ogni immagine del dataset, e ritorna i risultati
positivi (P) in ordine (rank) dal più al meno probabile.
Figura 4.6: Esempio di query. Fonte: [5].
Si possono fare le seguenti affermazioni:
∗ tutte le predizioni ricadono nella categoria di dato Positive;
∗ non tutte le predizioni sono esatte.
Si può quindi notare come, scendendo nel ranking, la Precision, che di-
pende da FP, sia altalenante; al contrario la Recall, indipendente da FP,
non decresce mai.
Preso un intervallo da 1 a n nel ranking è possibile calcolare la Average
Precision (AP, 4.8) e la Average Recall (AR, 4.9) valutando Precision e
Recall di ogni posizionamento nello stesso intervallo.
n
X P recision i
AP = (4.8)
n
i=1
n
X Recall i
AR = (4.9)
n
i=1
4.3.6 Mean Average Precision
Nel campo dell’object detection si parla anche di Mean Average Precision
(mAP). Si tratta della media dell’AP rispetto a tutte le classi di oggetti. Nel
caso in cui si faccia object detection su una sola classe (caso della presente
tesi) AP e mAP sono equivalenti [8].CAPITOLO 4. INTRODUZIONE ALLE RETI NEURALI 19
4.3.7 Intersection over Union
Date due aree geometriche, la Intersection over Union (IoU) è la misura
della loro intersezione rispetto alla loro unione:
Intersezione delle aree
IoU = (4.10)
U nione delle aree
La IoU è sempre un numero compreso tra 0 e 1 inclusi (i casi limite si hanno
per intersezione pari a zero, e per intersezione e unione coincidenti). Nella
object detection, le due aree corrispondono a due porzioni rettangolari di
un’immagine: come visibile in Figura 4.7, una è l’area reale dell’oggetto
presente (ground truth), l’altra è l’area predetta. Tanto maggiore è la IoU,
tanto migliore è la predizione.
Figura 4.7: Esempio di IoU. Fonte: [5].
Si considera corretta una predizione se la sua IoU supera una certa soglia,
che solitamente è posta a 0.5 ma può essere scelta arbitrariamente [5].5
Tecnologie
Si riportano in questo capitolo alcune delle tecnologie più utilizzate nel
contesto dello stage.
5.1 PYTHON
Figura 5.1: Logo di Python.
Python, il cui logo è illustrato in Figura 5.1 è un noto linguaggio di pro-
grammazione ad alto livello a tipizzazione dinamica, interpretato. Viene
usato in vari contesti, tra cui scripting, programmazione ad oggetti, svi-
luppo mobile e web lato backend. Tra i punti forti di Python ci sono la
facilità di apprendimento iniziale, la velocità di sviluppo, i virtualenvs la
flessibilità, le numerosissime librerie e framework a supporto, di cui molte
in ambito machine e deep learning.
5.2 TENSORFLOW
Figura 5.2: Logo di TensorFlow.
TensorFlow [53] (logo in Figura 5.2) è una piattaforma open source di
machine learning sviluppata originariamente dal team Google Brain. L’og-
getto principale della piattaforma è la libreria omonima con la quale è
possibile allenare o usare i propri modelli di machine learning secondo le
proprie preferenze. Tale libreria supporta sia Python che JavaScript.CAPITOLO 5. TECNOLOGIE 21
La libreria si concede a vari livelli di dettaglio.
Si può scrivere con TensorFlow con costrutti di basso livello. I modelli
di machine learning sono rappresentati su TensorFlow da tf.Graph, che
sono grafi computazionali fatti di Operazioni (tf.Operation) e Tensori
(tf.Tensor). Nell’addestrare un modello per prima cosa si definisce la
struttura del grafo senza eseguire alcun calcolo, in modalità lazy. Successi-
vamente si avvia il calcolo al momento desiderato avviando una sessione
tf.Session con il comando run.
Giacché nel machine learning molti errori dipendono dalle errate dimen-
sioni degli strati, la modalità lazy appare vantaggiosa, permettendo di
avere un controllo sulle dimensioni in anticipo rispetto all’esecuzione dei
calcoli, spendendo così tempo e risorse inutilmente. Tuttavia, la versione
2.0 di TensorFlow sta prendendo una direzione diversa, favorendo la eager
execution, quindi eseguendo i calcoli immediatamente.
In alternativa si può utilizzare TensorFlow a un maggiore livello di astra-
zione, senza preoccuparsi troppo di come sia implementato. Questa è la
modalità di sviluppo suggerita per chi parte da zero, e il modulo prescelto
per attuarla è Keras (tf.keras). Si può notare la sintesi e semplicità di
Keras in Figura 5.3: la creazione del modello è affidata a models e layers,
e una volta compilato, il modello viene allenato con fit e valutato con
evaluate.
Figura 5.3: Esempio di modello con Keras. Fonte: [53].
Per uno sviluppo ancora più rapido si può usare un modello pre-allenatoCAPITOLO 5. TECNOLOGIE 22
scaricandolo dal Model Zoo di TensorFlow 5.3, configurandolo e utilizzan-
dolo tramite una raccolta di API [56].
Gli strumenti per lavorare con TensorFlow sono tanti, tra cui:
∗ CoLab, un’ambiente di sviluppo online;
∗ TensorBoard (vedi Sezione 5.4);
∗ TensorFlow Playground, una piattaforma di appredimento.
La vastità, buon supporto e documentazione di questa piattaforma ne
fanno una prima scelta per cimentarsi nel machine learning.
5.3 TENSORFLOW DETECTION MODEL ZOO
TensorFlow Detection Model Zoo [55] è una repository che raccoglie vari
modelli pre-allenati al compito dell’object detection sui dataset COCO [16],
Kitty [35], Open Images[41], AVAv2.1 [15] e iNaturalist Species Detection
[32].
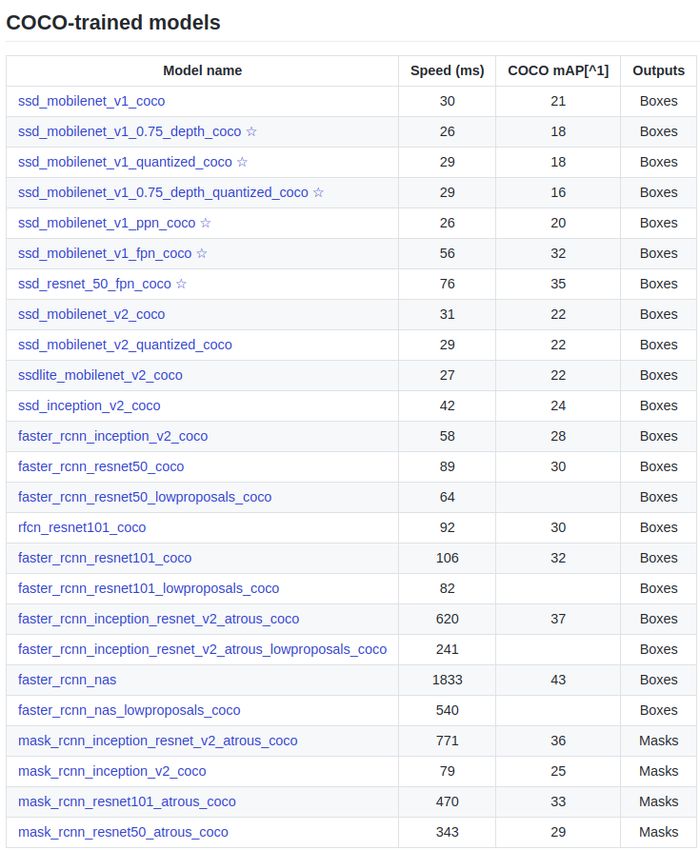
I modelli sono elencati in Figura 5.5 e differiscono principalmente per le
seguenti caratteristiche:
∗ architettura: leggibile nel nome del modello. Sono presenti architet-
ture tipiche di object detection, come la R-CNN e la ResNet;
∗ velocità: tempo in millisecondi per processare un’immagine di 600x600
pixel, da intendersi come indicativa, visto che dipende dall’hardware
usato;
∗ output: può essere una box, cioè un riquadro rettangolare dentro
il quale l’oggetto è presente (il nostro caso), o una mask, cioè una
precisa copertura dell’oggetto cercato, come quella in Figura 5.4;
Figura 5.4: Esempio di applicazione di mask. Fonte: [7].CAPITOLO 5. TECNOLOGIE 23
Per poter essere usato, ogni modello contiene al suo interno:
∗ un frozen graph per l’inferenza immediata;
∗ un file di configurazione per settare il modello;
∗ un checkpoint da cui far partire l’allenamento;
Figura 5.5: Modelli del TensorFlow Detection Model Zoo allenati sul dataset
COCO.
Per mantenere il corretto funzionamento dei modelli è presente un modulo
di export per aggiornarli automaticamente alla sotto-versione più recente
di TensorFlow v1.CAPITOLO 5. TECNOLOGIE 24
5.4 TENSORBOARD
TensorBoard è uno strumento facente parte della suite di TensorFlow. Con-
siste in un’interfaccia web dove è possibile avere un’introspezione del
proprio modello TensorFlow.
Vi si accede collegando il browser al proprio workspace, locale o remo-
to. Nel caso locale, si esegue TensorBoard da terminale con il comando
tensorboard -logdir (Figura 5.6).
Figura 5.6: Avvio di TensorBoard su terminale.
Tra le prime righe di output compare l’indirizzo a cui collegarsi sul browser
per aprire l’interfaccia di TensorBoard. Solitamente è localhost:6006.
Su TensorBoard sono presenti varie schermate.
Nella schermata principale scalars principale è possibile vedere l’evoluzio-
ne delle metriche del proprio modello, che possono essere customizzate
tramite il costrutto tf.summary all’interno del proprio script di training.
Particolarmente interessante è anche la schermata graphs (esempio in Fi-
gura 5.7). Questa permette di vedere tutti gli strati di cui è composto il
proprio modello a diverse granularità, e se usata correttamente previene
errori architetturali prima che il training cominci.CAPITOLO 5. TECNOLOGIE 25
Figura 5.7: Esempio di grafo su Tensorboard. Fonte: [53].
5.5 DETECTRON
Detectron [23] è un framework di machine learning sviluppato da Face-
book Research. Supporta un certo numero di algoritmi e architetture, e
dispone del proprio Model Zoo [24]. Questo framework è stato molto
usato in passato ma attualmente presenta alcuni limiti, deducibili dai
requisiti di installazione:
∗ funziona solo con Python2, linguaggio il cui supporto cesserà il 1°
gennaio 2020;
∗ dipende da un altro framework di machine learning, Caffe2, che a
sua volta è stato inglobato in un terzo framework, PyTorch [43];
∗ serve necessariamente una GPU per utilizzarlo, non può essere
eseguito da CPU: ciò limita i casi d’uso.
Pytorch e Detectron sono entrambi sviluppati da Facebook: tuttavia, il
primo riceve più supporto dagli sviluppatori e attenzione dai media rispet-
to al secondo, che appare una scelta percorribile se necessario, ma meno
conveniente oggigiorno.Sviluppo del progetto
6
6.1 AMBIENTE DI LAVORO
Il training delle reti neurali richiede notevoli risorse computazionali: in
particolar modo, si appoggia a schede video potenti e al calcolo parallelo.
Queste risorse non erano disponibili in partenza.
Per ottenere una macchina potente su cui allenare le mie reti ho scelto di
utilizzare Microsoft Azure [37]. Azure offre una suite di servizi, tra i quali
mette a disposizione delle macchine virtuali da utilizzare in remoto.
Tra le varie possibilità ho scelto la macchina NC6 Promo, la cui sche-
da video permette di utilizzare l’architettura Cuda con una capacità
computazionale indicata a 3.7. La macchina le seguenti caratteristiche:
∗ nome: NC6;
∗ sistema operativo: Linux 16.04 LTS;
∗ numero di core della CPU: 6;
∗ RAM: 56 GB;
∗ GPU: 1x NVIDIA Tesla K80.
La macchina remota è stata usata per il training delle reti neurali. Per le
altre attività ho preferito lavorare in locale.
6.2 DATASET
6.2.1 Il dataset iniziale
Nel progetto precedente era stato usato il dataset della ICDAR2017 POD
Competition [31], che contiene 2000 immagini di documenti di vari tipi
e layout più relative annotazioni. Le annotazioni sono in formato xml e
hanno la struttura riportata in Figura 6.1, che è stata adottata anche in
TableTrainNet.CAPITOLO 6. SVILUPPO DEL PROGETTO 27
Figura 6.1: Formato delle annotazioni in TableTrainNet.
I vertici della tabella sono indicati nell’ordine:
x0, y0 x1, y0 x0, y1 x1, y1
Questo dataset è stato individuato come punto di debolezza del progetto
precedente. La debolezza risiede in due aspetti:
∗ le dimensioni del dataset: nel campo dell’object detection si tende a
usare dataset molto grandi, sull’ordine di 105 o 106 elementi;
∗ la tipologia di documenti: il dataset di ICDAR2017 POD contiene
principalmente immagini tratte da paper scientifici; si ipotizza che
manchi di varietà e simiglianza rispetto alle polizze assicurative.
6.2.2 Il dataset aumentato
Inizialmente, si ha provveduto a ingrandire il dataset esistente.
Vi sono vari motori di ricerca, siti e cataloghi che offrono una moltitudine
di dataset. Tuttavia, il metodo più produttivo per trovarne è stato cercare
paper scientifici sulla table detection nei documenti ResearchGate [46], e
rintracciare i dataset citati al loro interno.
I dataset a disposizione differiscono per una serie di caratteristiche: quan-
tità e tipologia di immagini, formato delle annotazioni, disponibilità (gra-
tuiti o a pagamento), privatezza (disponibili pubblicamente o su richiesta),
documentazione.
Tenendo conto di tali caratteristiche, ho inizialmente individuato alcuni
dataset, di cui solamente due erano utilizzabili: il dataset della compe-
tizione ICDAR2019 sulla table detection e recognition [30], contenente
1000 immagini utili, e UNLV, contenente altre 400 immagini. Nonostante
i dubbi su ICDAR, si è fatto un tentativo: le annotazioni dei due dataset
sono state adattate, e i due sono stati aggiunti al precedente, ottenendo
così un dataset di 3400 elementi totali.
Questo nuovo dataset è stato usato per un breve periodo, ottenendo du-
rante il training risultati simili a quelli ottenuti con il modello precedente.CAPITOLO 6. SVILUPPO DEL PROGETTO 28 Infatti, il numero delle immagini era a malapena duplicato. 6.2.3 Il dataset definitivo Recentemente è stato pubblicato un’articolo su TableBank [6], un dataset per table detection e recognition. Questo non è disponibile pubblicamente perché contiene immagini protette da copyright, ma una volta accettata la richiesta di accesso è stato possibile utilizzarlo. Contiene un totale di 500.000 immagini, delle quali 350.000 adatte per la table detection, e 150.000 per la table recognition, ed è provvisto di annotazioni in formato json. Dopo aver adattato le annotazioni, si è sostituito il dataset precedente con questo, molto più ampio e promettente. Nella configurazione del progetto, il dataset va suddiviso in due parti: training set ed evaluation set. Il test set non è presente, e si utilizza al suo posto un’insieme di immagini senza label per fare inferenza e verificare i risultati. Le proporzioni in cui è stato diviso il dataset sono: ∗ 99.5% per il training; ∗ 0.5% per l’evaluation (1750 elementi). 6.3 SCELTA DEL MODELLO Come anticipato precedentemente, è conveniente utilizzare un modello pre-allenato a un compito simile ed allenarlo ulteriormente sul proprio dataset per specializzarlo. Questo consente di ottenere buone prestazioni più velocemente ed economicamente rispetto ad allenare un modello a partire da zero. Il modello utilizzato è stato scelto tra le proposte del TensorFlow Detection Model Zoo (vedi Sezione 5.3), visibili in Figura 5.5. Considerate le metriche e la modestia delle risorse a disposizione si è cercato un modello rapido ma sufficientemente preciso. Sono stati testati e testati alcuni modelli con velocità inferiore a 90ms e si è scento infine di tenere il modello faster_rcnn_v2_coco. Questo tipo di rete convoluzionale, la Faster R-CNN, vanta di velocità e prestazioni migliori rispetto ai suoi predecessori R-CNN e Fast R-CNN [3], e risulta essere un buon compromesso tra rapidità e precisione.
CAPITOLO 6. SVILUPPO DEL PROGETTO 29
6.4 IL MODELLO ADAM2_TB
6.4.1 Training
Una volta preparati dataset e modello dentro TableTrainNet, è possibile co-
minciare l’allenamento. Per avviare il training si sfruttano le API di object
detection offerte da TensorFlow [56]: è sufficiente scaricare la repository
corrispondente, svolgere una breve configurazione e lanciare il training
con il comando in Figura 6.2, che indica:
∗ la posizione del file d configurazione del modello;
∗ la posizione del modello;
∗ il numero di iterazioni per le quali allenarlo;
∗ un parametro preconfigurato;
∗ la richiesta di mostrare l’output sul terminale oltre che sul file di log.
Figura 6.2: Comando per lanciare il training della rete neurale.
L’allenamento avviene dentro un’apposita directory di TableTrainNet, e il
suo progresso è visibile in tempo reale sia all’interno del terminale che su
TensorBoard, e registrato su file di log.
Per ogni iterazione in forward propagation viene mostrato il numero di
iterazione, il tempo impiegato per farla e il valore della loss function ag-
giornato.
Dopo ogni batch_size elementi avviene l’evaluation: vengono stampate
tutte le metriche relative, e il risultato parziale viene salvato in un chec-
kpoint. In tale modo si può interrompere l’allenamento e riprenderlo
successivamente.
6.4.2 Tuning
La parte più delicata del training è il tuning, ovvero la modifica dei pa-
rametri della configurazione per regolare le prestazioni della rete. La
configurazione è nella forma di un dizionario Python e contiene le voci
seguenti:Puoi anche leggere

















































