Librerie per il Machine Learning: Core ML
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Università degli Studi di Napoli
Federico II
Scuola Politecnica e delle Scienze di Base
Corso di Laurea in Ingegneria Informatica
Tesi di Laurea Triennale
Librerie per il Machine Learning:
Core ML
Relatore Candidato
Prof. Vincenzo Moscato Salvatore Capuozzo
Matr. N46/2718
Anno Accademico 2017-2018
Indice
Premessa introduttiva e ringraziamenti 3
1 Una panoramica sul Machine Learning 4
1.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2 Reti Neurali Arti
ciali . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2.1 Reti Neurali Feedforward . . . . . . . . . . . . . . . . . . . . . 7
1.2.2 Algoritmo di Backpropagation . . . . . . . . . . . . . . . . . . 9
1.3 Deep Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3.1 Reti Neurali Convoluzionali . . . . . . . . . . . . . . . . . . . 11
1.4 Applicazioni principali delle reti neurali . . . . . . . . . . . . . . . . . 13
1.4.1 Riconoscimento e rilevamento di oggetti . . . . . . . . . . . . 13
1.4.2 Generazione di didascalie per immagini . . . . . . . . . . . . . 14
1.4.3 Riconoscimento e sintesi vocale . . . . . . . . . . . . . . . . . 15
1.4.4 Traduzione di testi . . . . . . . . . . . . . . . . . . . . . . . . 15
2 Librerie per il Machine Learning e Core ML 16
2.1 Librerie adottate nel Machine Learning . . . . . . . . . . . . . . . . . 16
2.1.1 TensorFlow . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.1.2 PyTorch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.1.3 Keras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2 Alcuni modelli signi
cativi . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2.1 Inception . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2.2 YOLO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.2.3 Watson Language Translator . . . . . . . . . . . . . . . . . . . 22
2.3 Una nuova libreria: Core ML . . . . . . . . . . . . . . . . . . . . . . 23
2.3.1 Struttura e vantaggi del framework . . . . . . . . . . . . . . . 23
2.3.2 Uno strumento intuitivo: Create ML . . . . . . . . . . . . . . 25
2.3.3 Ulteriori considerazioni su Core ML . . . . . . . . . . . . . . . 26
1
3 Reti neurali on-device: CoreL8 27
3.1 Approccio allo sviluppo . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.1.1 Modelli adottati . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2 Funzionalità ed analisi prestazionali . . . . . . . . . . . . . . . . . . . 30
3.2.1 Schermate adottanti YOLO . . . . . . . . . . . . . . . . . . . 30
3.2.2 Schermate adottanti Inception . . . . . . . . . . . . . . . . . . 31
3.2.3 Schermate adottanti Watson Language Translator . . . . . . . 31
3.3 Conclusioni sulle applicazioni di Core ML . . . . . . . . . . . . . . . . 33
2
Premessa introduttiva e
ringraziamenti
Il campo del Machine Learning, formatosi conseguentemente ai diversi studi mirati
nella disciplina dell'Intelligenza Arti
ciale e alla raccolta dei vari metodi di miglio-
ramento automatico degli algoritmi, mi ha sempre suscitato un particolare interesse,
sia dal punto di vista tecnico, dal momento che sfrutta le potenzialità dei linguaggi
di programmazione attuali per emulare o perlomeno imitare il comportamento della
nostra mente, sia dal punto di vista sociale, essendo questo un campo di ricerca che
sta portando notevole progresso nelle nostre vite, ma anche dibattiti e discussioni
di natura etica e
loso
ca. La mia fortuna è quella di vivere in un periodo in cui
questo campo ha già piantato le sue radici, ma è ancora in fase di evoluzione per
giungere a soluzioni de
nitive e concrete che portano alle macchine a poter ragionare
e migliorarsi autonomamente. Da fervido amante dell'innovazione tecnologica, dei
problemi da risolvere, dell'ingegnerizzazione di sistemi e della programmazione, non
posso che sentirmi coinvolto quando si parla di Machine Learning.
La fortuna di poter frequentare un'università che dia solide basi per arontare ed
apprendere i più svariati e moderni campi di studi, tra cui anche questo, assieme a
quella di poter partecipare dal vivo ai Worldwide Developers Conference di Apple
del 2017 e 2018 grazie a delle borse di studio, mi ha permesso di approfondire meglio
questo campo e di conoscere realtà in continua evoluzione che aprano le porte ai suoi
approcci. Ovviamente c'è ancora parecchia strada da fare, gli studi non hanno mai
ne, specie se si parla di questo nuovo campo in crescita esponenziale.
Il mio cammino
nora è stato pieno di alti e bassi, ma se ho ancora la forza di
proseguire e di puntare alle stelle lo devo soprattutto ai miei genitori, pilastri nei
miei momenti di crescita e ripari in quelli di crollo. Se mi è possibile esporre una
tesi in ciò che mi ha sempre aascinato, lo devo al prof. Vincenzo Moscato, che si è
reso disponibile a coronare questa mia utopia. In
ne voglio ringraziare Maria Luisa,
che mi ha dato lo sprint
nale per poter concludere questo primo percorso, e Gloria,
con la quale ho condiviso gioie e dolori del nostro cammino comune.
3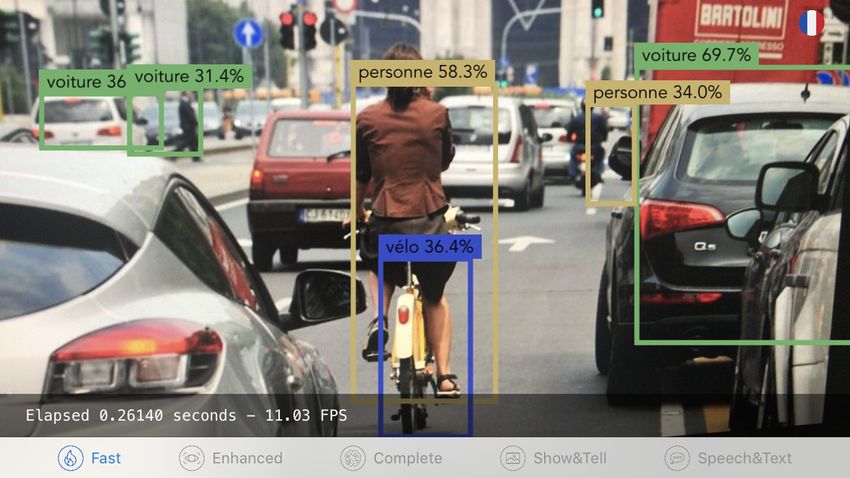
Capitolo 1
Una panoramica sul Machine
Learning
1.1 Introduzione
L'esponenziale evoluzione informatica, conseguente alla moltitudine di risultati del-
le ricerche compiute durante il XX secolo, ha portato allo sviluppo di un insieme
di metodi che permettono di fornire ai programmi la capacità dell'apprendimento
automatico.
Tali metodi fanno parte del campo denominato Machine Learning, una branca
dell'Intelligenza Arti
ciale che racchiude tutti gli studi sugli algoritmi in grado di
compiere un compito con migliori performance al crescere dell'esperienza.
Con il professor Tom M. Mitchell si ha una de
nizione più rigorosa di tale campo
[1], tuttavia, al momento della sua introduzione, non si avevano gli strumenti e l'e-
sperienza necessaria per poter sviluppare in maniera pragmatica algoritmi in grado
di rendere le macchine "pensanti", così come avrebbe proposto Alan Turing nel suo
articolo "Computing Machinery and Intelligence" [2].
Il Machine Learning vede
nalmente i suoi frutti negli anni '90 [3], periodo in cui
tale campo viene rivalutato in una chiave maggiormente problem-solving, al
ne di
risolvere problemi di natura pratica, e rinasce come una branca dalle potenzialità
in
nite e dalle soluzioni e
caci, grazie soprattutto alla tecnologia a disposizione e
all'avvento dell'Internet.
Ciò che rende estremamente innovativo questo campo è che si vuole rendere la mac-
china un'entità in grado di compiere ragionamenti induttivi in base all'esperienza,
in maniera del tutto analoga a come fa l'uomo stesso.
Quindi, basandosi su un training set di dati provenienti da una certa distribuzione
di probabilità, la macchina deve essere in grado di arontare problemi nuovi, non
4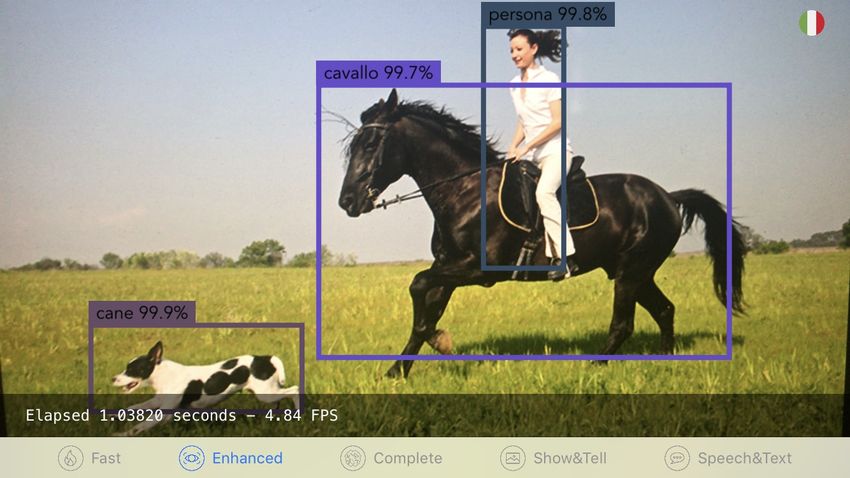
conosciuti quindi a priori, costruendo un modello probabilistico dello spazio delle
occorrenze.
L'analisi computazionale degli algoritmi di apprendimento automatico è uno dei la-
vori computi nella teoria dell'apprendimento, un campo di studi che si propone di
risolvere con vari approcci, seppur non potendo mai orire certezze in merito ai
risultati, sia per la quantità
nita di dati per l'addestramento sia per eventuali pro-
blemi di under
tting ed over
tting, dovuti essenzialmente ad una sproporzione tra
i parametri richiesti e numero di osservazioni.
Con l'avanzare degli studi e con il riconoscimento delle varie sfaccettature dei pro-
blemi arontati, si ha una suddivisione del campo del Machine Learning in vari
rami che dieriscono per l'approccio alla risoluzione dei problemi arontati, per la
tipologia dei dati elaborati e per il compito da svolgere dall'algoritmo.
Una classi
cazione per suddividere le tecniche di Machine Learning è la seguente:
• Apprendimento supervisionato: Il modello viene addestrato raccogliendo dati
in input, per poi ottenere degli output che permettano di formulare una regola
generale per associare correttamente input e output.
• Apprendimento non supervisionato: Il modello prende in ingresso degli in-
put non etichettati e cerca di generare una struttura comune a questi dati in
ingresso.
• Apprendimento per rinforzo: Il modello interagisce con un ambiente dinamico
e viene noti
cato o premiato solo nel caso in cui l'obiettivo da portare a termine
viene compiuto.
In questo campo vi sono numerosissimi approcci, che si basano sia sulla tipologia di
strategie adottate, sia sui modelli eettivamente generati. Passando dagli alberi di
decisione, gra
che permettono l'azione decisionale tramite cammini che portano al-
la predizione di una determinata variabile per classi
cazione, agli algoritmi genetici,
algoritmi che emulano il fenomeno della selezione naturale e dell'evoluzione genetica
mediante tecniche come mutazione e crossover, dalla programmazione logica indut-
tiva, approccio che lega la logica proposizionale all'apprendimento simbolico e che
fa ampio uso dell'entailment a partire dalle basi di conoscenza, alle reti bayesiane,
rappresentazioni gra
che delle relazioni di dipendenza tra le variabili di un sistema
che forniscono una speci
ca di qualsiasi distribuzione di probabilità congiunta com-
pleta. Tuttavia, l'approccio che si trova alla base di numerosissimi modelli generati
con librerie apposite, approccio che verrà approfondito in questa tesi, è quello delle
reti neurali arti
ciali.
5
1.2 Reti Neurali Arti
ciali
Una rete neurale arti
ciale, de
nita anche con l'acronimo ANN, derivante dal suo
nome inglese Arti
cial Neural Network, è un modello computazionale che è in gra-
do di riprodurre la struttura del cervello umano ed emularne il suo funzionamento.
Difatti anche la terminologia ricalca quella biologica, e abbiamo come unità elabo-
rativa di base il "neurone" arti
ciale.
I neuroni sono collegati tra loro tramite archi, che ricalcano le sinapsi cerebrali, e co-
municano tramite segnali che dipendono dai segnali di input e dal loro peso. Difatti
osserviamo che un neurone si attiva quando la somma pesata dei valori in ingresso
supera una data soglia. Questi neuroni sono la base di un modello computazionale
introdotto inizialmente nel 1943 da Warren McCulloch e Walter Pitts [4].
Figura 1.1: Struttura di un percettrone
Nella
gura riportata sopra vi è la struttura di base del neurone, come presentata
da Rosenblatt, ovvero del classi
catore binario alla base di questo modello denomi-
nato percettrone [5]. Questo riceve dei numeri dagli archi di input, ciascuno con
X
peso Wj,i , e la prima operazione eettuata è proprio una somma pesata: aj Wj,i .
j
Al valore ottenuto viene poi applicata la funzione di attivazione, indicata solitamen-
te con la lettera g , e il risultato di questa funzione viene propagato a tutti i neuroni
legati al neurone considerato. Questa funzione in origine era una semplice funzione
a gradino, sostituita poi dalla funzione sigmoide, anche detta funzione logistica.
Figura 1.2: Funzione gradino e funzione sigmoide
6
Il peso degli archi va a modi
care la soglia di attivazione delle funzioni.
Si tratta evidentemente di una grossa approssimazione del cervello umano, ma serve
per veri
care le capacità di una rete di elementi più semplici. Le reti neurali con
un unico layer sono molto limitate, non permettono l'implementazione neanche di
semplici funzioni logiche quali la XOR. Per questo motivo vengono implementante
reti neurali multilivello, dette anche Multilayer Perceptrons o MLP. La struttura
a singolo livello fornisce una funzione di tipo lineare e non permette di trattare non
linearità, mentre la struttura multilivello permette l'implementazione di funzioni
non lineari, e addirittura discontinue se si aumenta il numero di livelli.
Figura 1.3: Struttura di una rete neurale multilivello
La struttura di reti neurali maggiormente utilizzata è quella di tipo ricorrente
in cui, oltre a una strategia di feedforward, in cui l'informazione procede in avanti
attraverso i livelli neurali, è presente una strategia di feedback che permette ai
neuroni di conservare un determinato stato agendo come una memoria della rete
neurale.
1.2.1 Reti Neurali Feedforward
All'interno di queste strutture neurali, i neuroni ricevono degli stimoli in ingresso
che vengono elaborati. L'elaborazione può risultare molto so
sticata, ma si può im-
maginare banalmente che i singoli ingressi vengano moltiplicati per un determinato
valore, ovvero il peso, per poi andare a sommare il risultato di queste moltiplicazio-
ni: il neurone attiva la sua uscita solo se questa somma supera una data soglia. Il
peso indica l'e
cacia sinaptica dell'ingresso e ne quanti
ca l'importanza: un ingres-
so importante avrà peso maggiore, mentre un ingresso meno importante avrà peso
inferiore.
Tuttavia, le reti neurali non adottano percorsi preferenziali in base al confronto tra
i pesi dei percorsi, bensì, mediante contribuiti dall'importanza dierente determi-
7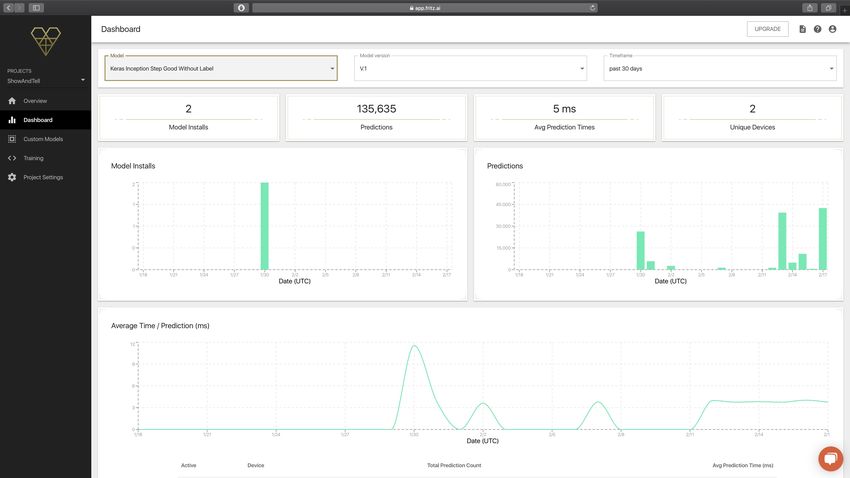
nata dal peso corrispettivo, tutti i neuroni nella rete contribuiscono al collegamento
ingresso/uscita.
Figura 1.4: Rete neurale pienamente connessa
Il collegamento dei neuroni non è casuale: difatti, ciascun neurone si collega a
quelli del livello successivo,
no a formare una rete complessa ma ben strutturata.
I neuroni quindi, come accennato, vengono solitamente posizionati in più livelli, che
possono essere di tre tipi:
• Livelli di ingresso (Input Layers): Livelli costruiti per ricevere dati provenienti
dall'esterno che vengono poi riconosciuti e processati.
• Livelli nascosti (Hidden Layers): Livelli che legano il livello di ingresso e quello
di uscita e che permettono alla rete neurale di imparare le relazioni complesse
elaborate dai dati.
• Livelli di uscita (Output Layers): Livelli
nali che mostrano il risultato di
quanto il programma è riuscito a imparare.
Queste reti possono essere anche molto complesse,
no ad avere migliaia di neu-
roni legati da innumerevoli connessioni.
Per costruire una rete neurale multistrato si possono inserire più strati nascosti, tut-
tavia all'aumentare degli strati nascosti aumenta pure la complessità della struttura.
L'e
cacia della generalizzazione di una rete neurale multilivello dipende dalle mo-
dalità di addestramento adottate e dall'aver individuato mediante questa un minimo
locale buono.
8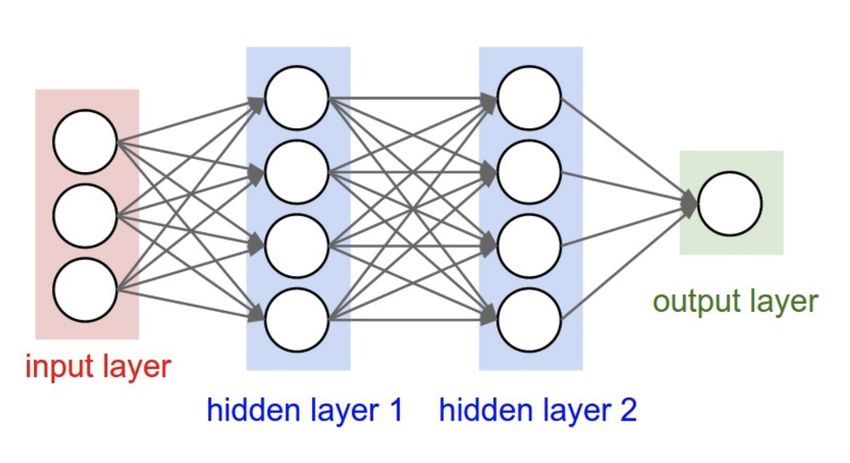
1.2.2 Algoritmo di Backpropagation
Per l'apprendimento si adotta l'algoritmo noto come algoritmo di Backpropaga-
tion, che consiste in pratica nel rimandare a ritroso attraverso la rete neurale errori
rispetto ai valori attesi, modi
cando il peso degli archi in modo da avvicinarsi al va-
lore corretto. Quindi si andrà ad osservare il gradiente nella funzione di attivazione.
L'algoritmo di retropropagazione dell'errore, come illustrato nel libro Arti
cial In-
telligence: A Modern Approach [6], viene costruito così:
Figura 1.5: Algoritmo di Backpropagation
Partendo da una rete di esempio, se in uscita viene generato un errore, l'errore
viene propagato a ritroso modi
cando i pesi sugli archi. In particolare, il peso
sull'ultimo livello wi,j viene aggiornato aggiungendo a se stesso il learning rate α
moltiplicato per il valore propagato ai e per la delta ottenuta da g 0 (inj ) e la dierenza
tra valore desiderato yj e ottenuto aj , mentre su quelli nascosti il procedimento è
analogo, con la sola dierenza che la delta si ottiene con g 0 (ini ) moltiplicato per la
sommatoria dei prodotti wi,j ∆ [j] precedenti.
Tale algoritmo presenta l'inconveniente di non riuscire ad evitare i minimi locali della
funzione, in quanto piccoli scostamenti dal minimo incrementano l'errore, mentre
grandi scostamenti portano al minimo globale e alla riduzione dell'errore, per questo
si utilizzano metodi come gli algoritmi genetici per ottimizzare questo algoritmo.
91.3 Deep Learning
Bisogna attendere
no al 2006 per poter assisitere all'introduzione del Deep Lear-
ning, difatti è quello il periodo in cui Georey Hinton, pioniere del campo delle
ANN, nonché coautore del libro che illustra il funzionamento dell'algoritmo di Bac-
kpropagation [7], insieme ai suoi colleghi si è approcciato alla costruzione di reti
neurali che, rapportate a quelle precedenti, presentavano molti più livelli. Però sol-
tanto nel 2009 fu sviluppata una prima reale applicazione di successo nata da questo
trend, ovvero il riconoscimento vocale. Possiamo aermare che il Deep Learning è
un campo di ricerca proveniente dal Machine Learning che si basa sulla complessità
incrementale delle reti neurali arti
ciali di vaste dimensioni.
Per essere più precisi, l'apprendimento profondo è de
nito come una classe di algorit-
mi di apprendimento automatico dotati di determinate caratteristiche ora elencate.
Difatti questi usano livelli di unità non lineari a cascata per poter svolgere lavori
di estrazione di caratteristiche e di trasformazione. Ogni livello prende in ingresso
le uscite provenienti dal livello precedente. Gli algoritmi di questo campo possono
essere di tipo supervisionato, come per la classi
cazione, oppure di tipo non super-
visionato, come per l'analisi di pattern. Questi ultimi si basano su livelli gerarchici
multipli di caratteristiche e rappresentazioni dei dati, difatti le caratteristiche di
più alto livello vengono ottenute da quelle di livello inferiore, formando quindi una
gerarchia, e inoltre apprendono multipli livelli di rappresentazione corrispondenti a
vari livelli di astrazione,
no a formare una gerarchia di concetti. La composizione
di ciascun livello dipende dal problema da risolvere. Le tecniche di Deep Learning
adottano principalmente molteplici livelli nascosti di una ANN, ma anche insiemi
di formule proposizionali. Le reti neurali arti
ciali in questo campo hanno almeno
2 livelli nascosti, ma in realtà le applicazioni del Deep Learning alle reti neurali
contengono molti più livelli, ad esempio 10 o 20 livelli nascosti.
Figura 1.6: Esempio di rete neurale profonda
10Lo sviluppo del Deep Learning in questo periodo è certamente dipeso dall'au-
mento esponenziale dei dati, con la conseguente introduzione dei Big Data, infatti
con questo aumento esponenziale dei dati si sono avute crescenti prestazioni dovute
al crescere del livello di apprendimento, soprattutto rispetto agli algoritmi già esi-
stenti. Inoltre, anche l'aumento delle performance dei computer hanno contribuito
al miglioramento dei risultati ottenibili e alla notevole riduzione dei tempi di calcolo.
Una conseguenza dell'applicazione degli algoritmi di Deep Learning alle reti neura-
li arti
ciali è lo sviluppo di un nuovo modello ben più complesso ma dai risultati
strabilianti, ovvero la rete neurale convoluzionale.
1.3.1 Reti Neurali Convoluzionali
Una rete neurale convoluzionale, detta anche CNN, acronimo di Convolutional Neu-
ral Network, è un particolare tipo di rete neurale arti
ciale feedforward in cui il
pattern di connettività tra i neuroni è ispirato dall'organizzazione della corteccia vi-
siva dell'occhio umano, in cui i singoli neuroni sono disposti in modo tale da dedicarsi
alle varie regioni che compongono complessivamente il campo visivo.
Figura 1.7: Esempio di rete neurale convoluzionale
Gli strati nascosti all'interno del livello nascosto di tale rete si classi
cano in
varie tipologie, a seconda del ruolo svolto. Questi infatti possono essere:
• Strati convoluzionali: Questo è lo strato principale di tale modello. Consiste
in un insieme di
ltri apprensivi, dal limitato campo di visione ma estesi lungo
tutta la super
cie dell'input. Qui si hanno le convoluzioni di ciascun
ltro
lungo le dimensioni della super
cie, facendo i prodotti scalari tra gli ingressi
del
ltro e l'immagine in input, generando quindi una funzione d'attivazione
bidimensionale che si attivi qualora la rete riconosca un determinato pattern.
• Strati di pooling: In questo strato vi è una decimazione non lineare che par-
tiziona l'immagine in input in un insieme di rettangoli non sovrapposti che
11vengono determinati a seconda della funzione non lineare. Per esempio, con il
max pooling si individua per ciascuna regione il massimo di un determinato
valore. L'idea dietro a questo strato è quella che la posizione esatta di una
caratteristica è meno importante della sua posizione rispetto alle altre, dunque
si omettono informazioni super
ue evitando anche l'over
tting.
• Strati ReLU: Lo strato di retti
cazione lineare (Recti
ed Linear Unit) permet-
te di linearizzare la funzione di attivazione bidimensionale e di porre a zero
tutti i valori negativi.
• Strati completamente connessi: Questo strato, posto generalmente al termine
della struttura, permette di eettuare i ragionamenti di alto livello della rete
neurale. Si chiama così in quanto i neuroni in questo strato hanno stati tutti
completamente connessi al livello precedente.
• Strati di perdita: Questo strato speci
ca quanto l'allenamento penalizzi la
deviazione tra le previsioni e i valori veri in uscita, quindi si trova sempre al
termine della struttura.
Figura 1.8: Esempio di max pooling
Per la maggior parte dei modelli più recenti, si adotta una versione avanzata
delle CNN denominata R-CNN, acronimo che sta per "Region Convolutional Neural
Network", ottimizzata appositamente per il problema del rilevamento degli oggetti
in un'immagine [8]. In questo caso vi è una ricerca selettiva delle regioni d'interesse,
tramite la segmentazione dell'immagine nelle varie regioni in base alla similitudine
dei pattern, seguita da un ridimensionamento di queste, così da renderle tutte di
dimensioni uguali ed adeguate per la rete neurale convoluzionale.
121.4 Applicazioni principali delle reti neurali
Abbiamo visto
nora quali sono le proprietà principali delle reti neurali arti
ciali,
introducendo anche le caratteristiche delle reti neurali convoluzionali, che saranno
per diverse volte protagonisti di ciò che verrà mostrato in seguito in questa tesi.
Difatti, vi sono innumerevoli implementazioni di soluzioni a problemi vari di natu-
ra pratica mediante l'approccio delle reti neurali, data la semplicità con la quale
si possono riprodurre funzioni non lineari e particolarmente complesse. Per que-
sta ragione, verranno analizzate alcune applicazioni in cui l'approccio illustrato ha
riscosso notevoli risultati.
1.4.1 Riconoscimento e rilevamento di oggetti
Le CNN risultano particolarmente adatte per il riconoscimento degli oggetti nelle
immagini. Esiste un intero campo di studi, ovvero quello che viene de
nito Com-
puter Vision, che si occupa di risolvere i problemi inerenti a tale ambito.
Per identi
care i contenuti di un'immagine, vengono utilizzate tecniche di riconosci-
mento delle caratteristiche delle immagini. Queste sono tecniche provenienti dagli
algoritmi di Computer Vision, in cui in fase iniziale di studio dell'immagine si com-
prendono parti speci
che dell'immagine con determinate caratteristiche ricercate.
Queste caratteristiche sono gli elementi necessari ad individuare informazioni più
dettagliate contenute nell'immagine. Inoltre, per facilitare il riconoscimento, l'algo-
ritmo utilizzato eettua un'analisi strutturale e la segmentazione dell'immagine per
comprendere la locazione delle regioni di interesse basandosi sulla disposizione dei
colori nello spazio o sulle distribuzioni di intensità di colore in un'immagine.
Per confrontare oggetti simili, o perlomeno per capire cosa essi rappresentino, è im-
portante che l'algoritmo di Computer Vision eettui esperimenti con dati eterogenei
e venga addestrato a dovere mediante le CNN. Tramite apprendimento non super-
visionato, questi algoritmi sono addestrati con enormi set di dati etichettati, così da
poter individuare con e
cacia gli oggetti analizzati in un'immagine.
Si ha avuto col tempo un progressivo miglioramento di tali algoritmi, permetten-
do di passare dalla classi
cazione delle immagini (Image Classi
cation), in cui
viene semplicemente riconosciuto un oggetto in un'immagine, al rilevamento degli
oggetti (Object Detection), in cui i vari oggetti presenti in un'immagine vengono
inquadrati, evidenziati e classi
cati, in genere mediante Faster R-CNN, un tipo di
rete neurale convoluzionale che permette di ottenere maggiore accuratezza e velocità
delle classiche R-CNN [9].
13Figura 1.9: Schermata di un rilevatore di oggetti
1.4.2 Generazione di didascalie per immagini
Le potenzialità delle CNN non si fermano qui, difatti grazie a queste è possibile
anche superare i limiti del rilevamento di oggetti in maniera individuale.
La nostra mente è abituata a contestualizzare ciascun oggetto nell'ambiente che lo
circonda, enfatizzandone eventuali legami di posizione, al
ne di ottenere una con-
sapevolezza spaziale e concreta di ciò che ci circonda. Per esempio, alla visione di
una tavola imbandita, diciamo che sono presenti piatti sul tavolo e bicchieri vicino ai
suddetti piatti, non ci limitiamo ad osservare gli oggetti singolarmente. Per quanto
ci risulti automatico ed estremamente semplice, questa è un'operazione parecchio
complessa da compiere per un agente intelligente.
La generazione di didascalie per immagini (Image Captioning) è ancora una vol-
ta un compito delle CNN, però con il supporto del Natural Language Proces-
sing, detto anche NLP, che permette il trattamento automatico delle informazioni in
linguaggio naturale mediante analisi lessicale, grammaticale, sintattica e semantica.
Figura 1.10: Generazione di didascalie per alcune immagini
141.4.3 Riconoscimento e sintesi vocale
Come accennato precedentemente, a stretto contatto con le CNN vi possono lavorare
anche le tecniche di NLP. Anche se di norma per il riconoscimento e la sintesi vocale
vengono utilizzati modelli statistici, come ad esempio il modello di Markov nascosto
[10], che è una catena di Markov in cui gli stati non sono osservabili direttamente,
esiste anche una strategia che utilizza reti neurali profonde.
Queste, rispetto al modello statistico, permettono di riconoscere parole singole e
fonemi in maniera e
ciente e naturale, a discapito tuttavia del fatto che siano meno
e
cienti per compiti a lungo termine, come traduzioni di testi lunghi, dal momento
che presenta una carenza di dipendenze temporali all'interno del modello. Adottan-
do invece reti neurali ricorrenti è possibile rimediare a tale difetto.
Le reti neurali per questa tipologia di problemi possono essere adottate anche per
operazioni di pre-processing per poi fornire i risultati al modello statistico.
Le continue ricerche sia sul campo del riconoscimento vocale (Speech Recognition)
sia su quello della sintesi vocale (Speech Synthesis), accompagnate dall'ingente
quantitativo di dati fornito da grandi aziende come Google [11] ed Apple [12], per-
mettono una rapida evoluzione di tali approcci, avvicinandoci sempre più ad una
soluzione che rendano gli agenti intelligenti capaci di comprendere ambiguità del
linguaggio e di parlare nella maniera più naturale possibile.
1.4.4 Traduzione di testi
In
ne giungiamo ad uno dei problemi più complessi da arontare per gli algoritmi
di Machine Learning, ovvero la traduzione dei testi. Tale problema viene arontato
anche in questo caso dalle reti neurali arti
ciali, per questa ragione l'approccio
utilizzato per tale problema è detto Neural Machine Translation, che si può
estendere anche alle reti neurali profonde con l'adozione di molteplici livelli nascosti
nella rete.
Le strutture formate da tale approccio risultano più semplici dei modelli statistici,
eppure risultano e
cienti, dal momento che si ottengono comunque risultati con
l'utilizzo di un singolo modello anziché di modelli per il linguaggio, la traduzione
e il riordinamento. Con l'adozione di reti neurali convoluzionali, accompagnati da
approcci attention-based, si hanno risultati migliori anche per lunghe frasi.
Per i notevoli vantaggi oerti, aziende come Google [13], Microsoft [14], Yandex [15]
e IBM hanno investito su tale approccio, producendo modelli resi disponibili a tutti
mediante servizi in cloud ed API.
15Capitolo 2
Librerie per il Machine Learning e
Core ML
2.1 Librerie adottate nel Machine Learning
Finora è stato discusso delle caratteristiche e dei vantaggi delle reti neurali classiche
e convoluzionali, nonché delle loro applicazioni pratiche. Adesso invece analizziamo
le basi a supporto degli algoritmi dettati da questi approcci.
A supporto di un tale campo di studi a così alto livello, bisogna utilizzare un lin-
guaggio di programmazione di altrettanto alto livello, che non ci ponga i problemi di
basso livello del linguaggio, bensì ci dia le potenzialità per poter costruire soluzioni
ai problemi da arontare. Per questa ragione, nel campo del Machine Learning non
si adottano linguaggi di programmazione con basi fortemente consolidate ma con
caratteristiche di basso livello, come per esempio il C, bensì si adottano linguaggi di
alto livello con notevoli livelli di astrazione, come ad esempio Python.
Python è un linguaggio di programmazione ad alto livello, object-oriented ed inter-
pretato avente origini relativamente recenti, tenendo conto di essere nato nel 1991.
Questo gode dei pregi di dinamicità, dovuta per esempio alla tipizzazione dinami-
ca, che lo rende comodissimo per la rappresentazione di dati, semplicità, potendo
raggiungere livelli di complessità elevati con poche righe di codice, e
essibilità, sup-
portando vari paradigmi come l'object oriented e la programmazione funzionale.
Non è un linguaggio consigliato per chi è alle prime armi in merito alla programma-
zione, data la sua non immediata intuitività, ma si rivela uno strumento eccellente
per la composizione di algoritmi come quelli di Machine Learning. Difatti, questo
linguaggio è fortemente supportato sia da innumerevoli interfacce verso altri lin-
guaggi, che quindi lo porta ad essere usufruibile in ogni ambiente, sia da librerie
dedicate che permettono lo sviluppo di codice per il Machine Learning.
16Tali librerie, anche quelle di recente uscita, sono già dei pilastri per chi si vuole
aacciare in questo campo, mantengono notevolissimi livelli di a
dabilità e sono
supportati e manutenuti sia da importanti aziende sia dagli utenti stessi, essendo
tali librerie open source.
Figura 2.1: Interesse nel tempo nelle migliori librerie di ML secondo Google Trends
2.1.1 TensorFlow
Il team di ricerca Google Brain, specializzato nella ricerca nel campo del Deep
Learning, rilasciò nel 2015 una nuova libreria in Python chiamata TensorFlow
[16]. Questa è una libreria open source dotata di funzionalità per calcoli di matrice
matematica e di strumenti per lavorare con le reti neurali arti
ciali. TensorFlow
utilizza gra
di
usso dei dati in cui i nodi rappresentano le operazioni matematiche,
mentre gli archi dei tensori, ovvero array di dati multidimensionali, che scorrono
tra i nodi, da cui l'origine del nome della libreria. A rimedio della sua natura
intrinsecamente complessa, il sito di riferimento tensor
ow.org permette di seguire
dei rapidi tutorial per gli utenti alle prime armi che permettono di utilizzare la
libreria partendo con dei progetti pronti e che mostrino immediatamente le in
nite
potenzialità oerte.
La community di TensorFlow, composta da ben più di 1800 sviluppatori in aggiunta
agli ingegneri e ricercatori di Google Brain, ha permesso l'esponenziale crescita di
questa libreria, con più di 48000 commit in soli 3 anni. I modelli sviluppati con
TensorFlow sono al servizio di innumerevoli aziende di alto prestigio, come Google
stessa, eBay, Coca-Cola, NVIDIA, Dropbox e Intel.
2.1.2 PyTorch
Nel 2002, una libreria open source di Machine Learning scritta in Lua fece il suo
esordio. Questa libreria, una delle prime promosse in questo campo, fu chiama-
ta Torch. Si strutturava essenzialmente in strumenti che fornissero la possibilità
di generare tensori, così come sono presenti nell'esempio precedente, e reti neurali
strutturati in maniera modulare attraverso il pattern Composite.
17Nel 2016, sulle basi della libreria Torch, il team di ricerca della FAIR, ovvero della
Facebook AI Research, rilascia una nuova libreria scritta in Python chiamata Py-
Torch [17]. Questa libreria fornisce funzionalità di computazione tramite tensori
con accelerazioni in GPU e di costruzione di reti neurali profonde con tecniche di
dierenziazione automatica, che permettono calcoli più veloci dei gradienti. In par-
ticolare, la tecnica adottata è chiamata Reverse-Mode Auto-Dierentiation:
grazie a questa tecnica, è possibile modi
care una rete neurale preesistente per ot-
tenere comportamenti dierenti senza dover ricostruire da zero il modello di base,
come descritto nel sito di riferimento pytorch.org.
Rispetto a TensorFlow, PyTorch risulta più semplice da utilizzare, essendo conce-
pito appositamente per fornire agli utenti un'esperienza di modellazione
essibile e
veloce. Anche se risulta meno maturo di TensorFlow, può contare sul supporto di
quasi 1000 utenti su GitHub con più di 16000 commit in poco più di 2 anni.
2.1.3 Keras
François Chollet, un ingegnere di Google, rilasciò nel 2015 una libreria open source
scritta in Python chiamata Keras, con il
ne di diondere uno strumento che fos-
se allo stesso tempo capace di eettuare sperimentazioni rapide con le reti neurali
profonde, ma anche user-friendly, modulare ed estensibile. Tale libreria presenta nu-
merosi vantaggi, come elencati nel sito di riferimento keras.io, tra i quali il supporto
di TensorFlow, tanto da essere preferita da parecchi utenti.
Keras supporta sia reti neurali classiche, sia reti neurali convoluzionali e ricorrenti,
con strumenti che permettono facilmente le operazioni degli strati nascosti, come per
esempio il pooling. Ore API intuitive, di più alto livello e con maggiore astrazione
rispetto a TensorFlow. Ciò nonostante, presenta una notevole
essibilità, grazie alla
possibilità di integrazione con librerie di più basso livello come TensorFlow.
Anche in questo caso vi è una vasta community di circa 250000 utenti contribuenti
al progressivo sviluppo di tale libreria. Ed anche per Keras vi è la
ducia da parti
di importanti aziende, come Net
ix, Uber e Yelp. Un vantaggio esclusivo di questa
libreria è la semplice portabilità verso piattaforme eterogenee, tra le quali il Rasp-
berry Pi, la Java Virtual Machine, il Google Cloud e le piattaforme iOS e Android.
I modelli in Keras possono essere sviluppati in vari ambienti di backend per il Deep
Learning, come quelli di Google e Microsoft, ma anche allenati con varie piattaforme
hardware come le GPU di NVIDIA o le TPU di Google. In
ne, tali ambienti sono
supportati e manutenuti da Google, Microsoft, NVIDIA, Amazon, Uber e Apple.
182.2 Alcuni modelli signi
cativi
Una volta dato uno sguardo alle librerie più gettonate per il Machine Learning,
si può passare ad alcuni modelli di spicco, sia per la loro utilità sia per la loro
e
cacia. Difatti, grazie agli studi condotti da appassionati, ricercatori, ingegneri e
sviluppatori, dopo poco tempo dal rilascio di tali librerie si aveva già a disposizione
un quantitativo ingente di modelli per ogni tipo di utilizzo, dalla classi
cazione di
immagini alla traduzione di testi.
2.2.1 Inception
Nel 2014, i ricercatori di Google rivelano al mondo il loro modello denominato Goo-
gLeNet, modello vincitore nell'ILSVRC 2014 [18], ovvero la "ImageNet Large
Scale Visual Recognition Competition", contest in cui si s
dano i migliori algoritmi
di rilevamento oggetti e classi
cazione immagini.
Figura 2.2: Struttura interna di GoogLeNet
Il segreto della potenza e del successo di tale modello è racchiuso nella volontà di
incrementare le qualità prestazionali del modello rendendo più complessi i
ltri, ov-
vero di fondere le basi delle CNN, i livelli convoluzionali, con quelle delle reti neurali
multilivello, i percettroni, in grado di sintetizzare funzioni non lineari. Difatti, ciò
è possibile in quanto i percettroni sono matematicamente equivalenti a convoluzioni
1x1. Insieme alla brillante intuizione dei ricercatori, che avevano constatato che
alcune zone vuote localizzate in determinate zone del modello avrebbero contribuito
all'incremento delle performance, si ha la costruzione dell'architettura di GoogLe-
Net, chiamato Inception.
Tale nome indica anche la presenza di moduli interni, detti appunto moduli di in-
ception, i quali servono per distribuire le convoluzioni lungo
ltri paralleli, che per-
mettono durante l'addestramento di far scegliere al modello stesso di scegliere la
dimensione di convoluzione più appropriata per l'occasione.
19(a) Modulo di inception base, detto (b) Modulo di inception con riduzio-
anche naïve ni dimensionali
Nel 2015, in particolare nell'edizione seguente dell'ILSVRC, venne presentato un
aggiornamento a tale modello, detto Inception v3, che presentava meno parametri
dei modelli concorrenti, grazie ad una fattorizzazione dei livelli di convoluzione, 42
livelli di rete neurale profonda e la normalizzazione degli output [19].
Figura 2.4: Struttura interna di Inception v3
2.2.2 YOLO
Joseph Redmon, supportato da Ali Farhadi, Professore Associato del Dipartimento
di Computer Science and Engineering dell'Università di Washington, nel 2016 pub-
blicò un articolo per il CVPR, ovvero la Conferenza su Computer Vision e Pattern
Recognition, in cui espose il suo modello per il rilevamento di oggetti. Gli diede il
nome "You Only Look Once", in forma abbreviata YOLO, si basa sulle reti neurali
profonde ma si presenta con un approccio dierente dai modelli concorrenti [20].
Innanzitutto, dierentemente da quanto detto in precedenza, questo modello è stato
sviluppato mediante un framework open source per le reti neurali in C e CUDA.
Ma la dierenza essenziale sta nel fatto che, diversamente dall'approccio standard
per il tracciamento di oggetti, ovvero la classi
cazione, l'approccio adottato è la
regressione. Mentre per la classi
cazione si ricavano output nel campo discreto
contrassegnati da etichette, per la regressione si ricavano output nel campo conti-
nuo che indicano i valori esatti in uno spazio di possibili valori. In questo caso,
20l'immagine viene separata in rettangoli delimitanti gli oggetti e probabilità per le
classi associative. Una singola rete neurale predice entrambe le cose direttamen-
te dalle immagini intere in una singola valutazione. Dal momento che è unica, si
possono eettuare delle ottimizzazioni dirette sulla performance. Questo modello è
estremamente veloce: può processare immagini in tempo reale a 45 frame al secondo,
superando in prestazioni anche i modelli avanzati come quello delle R-CNN.
Figura 2.5: Processo di rilevamento degli oggetti in YOLO
Il modello si struttura in 24 livelli convoluzionali, seguiti da 2 livelli completa-
mente connessi. È ispirato a GoogLeNet, tuttavia, al posto dei moduli di inception,
sono presenti livelli di riduzione 1x1 seguiti da livelli convoluzionali 3x3.
Figura 2.6: Struttura interna di YOLO
Nel 2018, dopo aver presentato il suo modello aggiornato all'edizione successiva
del CVPR e all'edizione del 2017 del TED1 , viene rilasciato l'aggiornamento deno-
minato YOLOv3, dove il modello risulta più pesante e lievemente meno performante,
ma più accurato e capace di riconoscere un numero maggiore di oggetti [21].
1
TED 2017, "How computers learn to recognize objects instantly":
https://www.ted.com/talks/joseph_redmon_how_a_computer_learns_to_recognize_objects_instantly
212.2.3 Watson Language Translator
IBM ore un servizio sulla sua piattaforma cloud che, mediante REST API, permet-
te agli utenti interessati di usufruire della traduzione di testi. Tale servizio è oerto
da Watson, un sistema di intelligenza arti
ciale della IBM, sviluppato da un team
di ricerca diretto da David Ferrucci, in grado di rispondere a domande poste in lin-
guaggio naturale [22]. Il suo nome è un omaggio al primo CEO dell'azienda Thomas
J. Watson. Tale sistema nasce dal progetto DeepQA, in cui si adottano tecniche di
NLP, Information Retrieval, ragionamento automatico e Machine Learning.
Tra i tanti servizi disponibili, reperibili dal sito di riferimento ibm.com/watson, vi è
Watson Language Translator2 , servizio che permette sia di adottare un modello
già allenato, sia di costruire modelli personalizzati mediante dati di addestramen-
to inclusi in
le di Translation Memory Exchange, quindi con estensione .tmx. In
genere i modelli personalizzati sono utili per domini speci
ci o industrie, e per la
generazione di questi si utilizzano due approcci dierenti:
• Forced Glossary Customization: in questo caso si utilizza un vocabolario for-
zato che traduca speci
ci termini e costrutti nella maniera desiderata, quindi
si ha un maggiore controllo sul comportamento di traduzione.
• Parallel Corpus Customization: in questo caso vengono include traduzioni ag-
giuntive nel modello base, pertanto è possibile adattarsi a determinati domini
speci
ci per tradurre nella maniera più appropriata.
Figura 2.7: Traduzione con modello base e con tecnica di Parallel Corpus
2
"Language Translator Service by IBM Watson": https://www.youtube.com/watch?v=bYtVaQxJ994
222.3 Una nuova libreria: Core ML
Durante l'edizione del 2017 della "Worldwide Developers Conference" di Apple
(WWDC 2017) tenutasi a San Jose in California venne mostrata una libreria che
ha suscitato particolare interesse. Questa venne introdotta col nome Core ML3 .
Tale libreria, difatti, permette di importare nei progetti sviluppati in Swift, linguag-
gio utilizzato per le applicazioni iOS, modelli allenati in maniera immediata, senza
eventuali conoscenze approfondite sul campo delle reti neurali e del Machine Lear-
ning in generale.
Grazie a questa inattesa libreria, gli sviluppatori da tutto il mondo potevano integra-
re i modelli costruiti con librerie per il Machine Learning, proprio come TensorFlow e
Keras, all'interno delle loro applicazioni. Questo signi
cava sia diondere con estre-
ma semplicità le potenzialità delle reti neurali anche ai neo
ti, sia rendere portatili
e facilmente usufruibili dei servizi che altrimenti sarebbero stati relegati e con
nati
nei computer dove venivano concepiti.
Al momento del rilascio di tale libreria, numerosi modelli di reti neurali erano già
stati sviluppati con le librerie prima citate, per questa ragione già si aveva una vasta
gamma di scelta di modelli da adottare, inclusi quelli elencati in precedenza.
Bisogna precisare però che Core ML non si limita a permettere agli utenti di im-
portare modelli per le proprie app, ma è un vero e proprio framework contenente
funzionalità di supporto per ulteriori framework e per la conversione di modelli
provenienti da altre librerie.
2.3.1 Struttura e vantaggi del framework
Core ML si presenta come una libreria dalle basi molto solide: infatti, questa
libreria poggia sulle primitive di basso livello di Accelerate, BNNS e del framework
dei Metal Performance Shaders. Il primo è la libreria di Swift contenente tutte
le funzionalità ad alta e
cienza della CPU di computazione di calcoli matematici
complessi e di immagini, il secondo è una collezione di funzioni di utilità per le reti
neurali e il terzo è una collezione di shader di computazione e gra
ca ottimizzati per
sfruttare a pieno le capacità della GPU del dispositivo.
Core ML supporta a sua volta librerie con compiti maggiormente speci
ci, ovvero
Vision, Natural Language e GameplayKit: il primo è specializzato per l'analisi delle
immagini, il secondo per il Natural Language Processing e il terzo per adottare gli
alberi di decisione.
3
WWDC 2017, "Introducing Core ML": https://developer.apple.com/videos/play/wwdc2017/703
23Figura 2.8: Strati
cazione delle dipendenze delle librerie in Swift
Uno dei principali vantaggi di Core ML è quello di adottare modelli non solo
semplici da utilizzare, ma anche di dimensioni su
cientemente ridotte da poter
essere portabili all'interno di una applicazione. Proprio per il fatto che tale libreria è
scritta in un linguaggio per lo sviluppo di applicazioni iOS, un altro grande vantaggio
che necessitava di essere introdotto è quello di essere ottimizzato per le performance
su device, ovvero che minimizza la memoria utilizzata e il consumo di batteria.
Inoltre, proprio perché le applicazioni vengono eseguite esclusivamente sui device e
non sui computer, vi è una garanzia di protezione della privacy. In
ne, c'è da
constatare che le applicazioni sviluppate con Core ML sono appositamente server-
independent, in quanto i modelli sono inclusi stesso nell'applicazione.
La conversione dei modelli già esistenti è stata resa semplice ed accessibile a tutti
grazie ai Core ML Tools, un insieme di strumenti in Python che permettono la
conversione di modelli da librerie preesistenti come Keras a Core ML.
Figura 2.9: Processo di costruzione del modello Core ML
Esponiamo un semplice esempio illustrativo. Si ha a disposizione un modello Ke-
ras chiamato MNIST.h5, modello che permette il riconoscimento di cifre all'interno
di un'immagine. Come per il modello Keras, anche per il modello Core ML l'input
24dovrà essere un'immagine e l'output una stringa contenente una cifra da 0 a 9.
Con poche righe di codice in Python si ha il modello Core ML desiderato:
Figura 2.10: Codice per la conversione tramite Core ML Tools
Durante il WWDC 2018, esattamente un anno dopo, viene presentato l'ag-
giornamento per la libreria Core ML, includendo notevoli novità ed aggiornamenti
rilevanti. In questa seconda versione, vi è un notevole incremento in velocità (circa
il 30%) e i modelli generati possono essere compressi del 75% grazie alla quantiz-
zazione. Inoltre, viene oerto un ulteriore framework che permette di rimediare ad
uno dei problemi di Core ML. Questo framework è stato chiamato Create ML4 .
2.3.2 Uno strumento intuitivo: Create ML
Create ML è ciò che mancava alla libreria di Core ML:
no a quella conferenza,
infatti, era possibile convertire modelli provenienti da TensorFlow, PyTorch o Keras
con gli strumenti oerti da Core ML, tuttavia non era possibile, senza una conoscen-
za approfondita di tali librerie e di come siano strutturate le reti neurali, costruire
un modello da zero direttamente in Swift dalla libreria Core ML.
Create ML è una novità introdotta nel WWDC 2018 che permette di costruire mo-
delli personalizzati mediante il semplice drag-and-drop delle immagini per il training
e il testing set, andando a generare modelli del calibro dei classi
catori di immagini.
Con l'aggiunta di questo framework si ha un nuovo approccio per la generazione
dei modelli Core ML, che porta a molti più sviluppatori, anche alle prime armi, a
provare le potenzialità delle reti neurali e quindi a diondere maggiormente questo
campo. Difatti, questo framework risulta tanto potente quanto semplice: attra-
verso l'esecuzione di un paio di righe di codice per l'avvio dell'interfaccia gra
ca di
Create ML, è possibile poi proseguire nell'atto di generazione dei modelli attraver-
so addestramento, che siano per classi
care immagini, testi in linguaggio naturale
oppure dati all'interno di tabelle. Inoltre è possibile modi
care alcune opzioni di
4
WWDC 2018, "Introducing Create ML": https://developer.apple.com/videos/play/wwdc2018/703
25addestramento, come le iterazioni, ed osservare i gradi di performance del modello
costruito.
Figura 2.11: Create ML supporta immagini, testi e dati strutturati come i
le .csv
2.3.3 Ulteriori considerazioni su Core ML
Core ML si presenta come una libreria di facile utilizzo e conveniente per gli svilup-
patori iOS, tuttavia non è esente da difetti. Innanzitutto, Core ML non permette
all'utente di costruire da zero con il linguaggio Swift una rete neurale, né di alle-
nare i modelli sui dispositivi iOS stessi, tant'è che è principalmente uno strumento
di conversione. Anche con l'introduzione di Create ML non si risolve del tutto
il primo problema, essendo possibile mediante quest'ultimo generare da zero solo
classi
catori di immagini. Poi vi è un problema di compromessi: se da un lato
è estremamente comodo avere il modello a portata di mano, senza la necessità di
una connessione ad un cloud, d'altro canto si ha una notevole pesantezza delle app
costruite con i modelli incorporati (si parla per esempio di poco più di 600 MB per
l'applicazione che verrà mostrata in seguito). In
ne, si può avere una tendenza alla
diusione dell'approccio tramite reti neurali senza una reale comprensione delle
strutture interne di cui sono composte, con la conseguenza di non saper agire in
maniera e
cace in presenza di comportamenti indesiderati, errori non riconosciuti
o casi particolari non previsti.
Ovviamente ciò non sminuisce il notevole lavoro di Apple nel voler diondere tale
tecnologia in pieno fermento a quante più persone entusiaste possibile, anzi, questo
intento rende la sua libreria un punto di svolta non solo per l'azienda stessa, ma
anche per i vari competitor, che potranno e dovranno senz'altro trarre i vantaggi
da Core ML, così come Apple deve trarne dalle loro librerie. Con l'introduzione di
strumenti intuitivi per la composizione modulare delle reti neurali, Core ML non
avrebbe nulla da invidiare alle altre librerie esistenti.
26Capitolo 3
Reti neurali on-device: CoreL8
3.1 Approccio allo sviluppo
L'entusiasmo portato da queste ultime novità ha portato allo scrittore di questa
tesi a sperimentare queste innovative funzionalità. Difatti, carico dell'esperienza del
primo anno di corso della Apple Developer Academy di Napoli e delle edizioni del
2017 e 2018 della WWDC, ho avuto modo di sviluppare una applicazione iOS che
permettesse allo stesso tempo di riconoscere oggetti in tempo reale e di conoscerli
in un set variegato di lingue. Così è nato CoreL8.
Per realizzarlo, era innanzitutto necessario cercare i modelli giusti e comprenderli
a fondo, per poi rivestire i modelli con le varie interfacce che caratterizzano l'app.
Distinguiamo tutto ciò che era necessario in base alle funzionalità richieste:
• Modello per il rilevamento di oggetti: YOLO
• Modello per il riconoscimento di oggetti e la generazione di didascalie per
immagini: Inception
• Libreria e framework per il riconoscimento e la sintesi vocale: Speech e Natural
Language
• Modello per la traduzione dei testi: Watson Language Translator
Come è possibile osservare, questi modelli servono proprio per risolvere i problemi
inerenti alle applicazioni principali delle reti neurali elencati in precedenza, per cui in
rete è già facilmente reperibile fonti performanti, anche se provenienti da autori dif-
ferenti, che siano di natura open source oppure servizi a sottoscrizione. Analizziamo
quindi con maggior dettaglio i modelli adottati.
273.1.1 Modelli adottati
In precedenza abbiamo descritto vari modelli signi
cativi presenti e reperibili in
rete, e proprio quei modelli rappresentano il punto di partenza dal quale iniziare
a progettare. Partendo proprio dal primo modello elencato, è palese riconoscere la
soluzione al problema nel modello pensato da Redmon, ovvero YOLO. In questo
caso, modelli in Core ML di questa soluzione erano già pronti per l'uso, per cui
bastava importare il modello all'interno del progetto e si aveva già una funzionalità
potenzialmente pronta. Osservando il procedimento di importazione del progetto,
difatti, ci si rende conto dell'estrema semplicità, dovuta sia all'intuitività di Core
ML sia alle facilitazioni introdotte nell'ambiente di sviluppo Xcode, tra le quali la
generazione automatica in Swift delle classi rappresentanti i modelli importati.
Figura 3.1: Conversione del modello in codice
Per quanto riguarda il secondo modello, si ha avuto un approccio lievemente
dierente. Ovviamente, per il secondo problema si adotta una soluzione che faccia
riferimento al modello Inception, date le sue prestazioni e la sua semplice reperi-
bilità. Tuttavia, mentre per il modello per il riconoscimento di oggetti è risultato
semplice reperire un modello già convertito in rete, per quello per la generazione di
didascalie è risultato lievemente più complesso, data la complessità intrinseca del
modello originale e del problema da risolvere, che possono facilmente portare ad
errori nella conversione. Come compromesso, si è individuato un modello perfor-
mante che però necessiti di continua manutenzione e limatura: difatti, si è adottato
una coppia di modelli, uno per la codi
ca delle immagini e uno per la sintesi delle
didascalie in linguaggio naturale, provenienti da un modello Keras di Inception, che
però si possono importare solo con l'ottenimento di un identi
cativo unico generato
al caricamento di tali modelli in Fritz (sito di riferimento: fritz.ai ), una piattaforma
che permette di ottimizzare e gestire modelli, seppur permetta anche l'utilizzo o ine
di tali modelli, prerogativa della libreria di Core ML.
28Figura 3.2: Interfaccia di gestione del modello in Fritz
Per il terzo problema da arontare, l'adozione di modelli esterni non risultava
necessario: ricordiamo infatti che Core ML supporta anche la libreria di Natural
Language, ed inoltre nelle librerie di base di Swift sono già presenti funzionalità per
gestire la sintesi vocale, per cui le potenzialità per risolvere tale problema erano già
sedimentate e solide. Considerando che tra le funzionalità della libreria chiamata
AVFoundation vi è una classe denominata AVSpeechSynthesizer, si intuisce che la
questione della sintesi vocale risulta già risolta. Per quanto riguarda il riconoscitore,
si utilizza un ulteriore framework di Swift chiamato Speech, contenente funzionali-
tà per la conversione dal parlato allo scritto (Speech-To-Text).
In
ne, per quanto riguarda l'ultimo problema, si deve adottare quello che risulterà
poi essere il modello più complesso di tutti. Difatti, parliamo di una delle applica-
zione più complesse portate a termine
nora nel mondo delle reti neurali profonde.
Tradurre un testo di un dato linguaggio in un linguaggio desiderato implica non
soltanto l'ingentissima mole di dati del training set dovuta al numero di parole
per lingua e al numero di lingue, ma anche una intelligenza tale da comprendere in
maniera corretta la semantica di un testo, trovare i costruttilessicali equivalenti
nel linguaggio desiderato e fare il tutto in un tempo ragionevole.
Al momento dello sviluppo dell'applicazione, non esistevano modelli open source che
potessero rimediare al problema della traduzione, tuttavia, come detto in preceden-
za, IBM ore la possibilità agli iscritti alla piattaforma online di usufruire dei suoi
servizi, tra cui quello perfetto per questa situazione: Watson Language Translator.
Una volta sottoscritto al servizio ed individuato una API in Swift per usufruire di
tale servizio, l'implementazione è risultata molto più semplice della ricerca.
29Puoi anche leggere

















































