Università degli Studi di Padova - SIAGAS
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù

Università degli Studi di Padova
Dipartimento di Matematica "Tullio Levi-Civita"
Corso di Laurea in Informatica
Sviluppo di una Proof of Concept per la
gestione di microservizi tramite API Gateway
Tesi di laurea triennale
Relatore
Prof.Luigi De Giovanni
Laureando
Damiano Cavazzana
Anno Accademico 2018-2019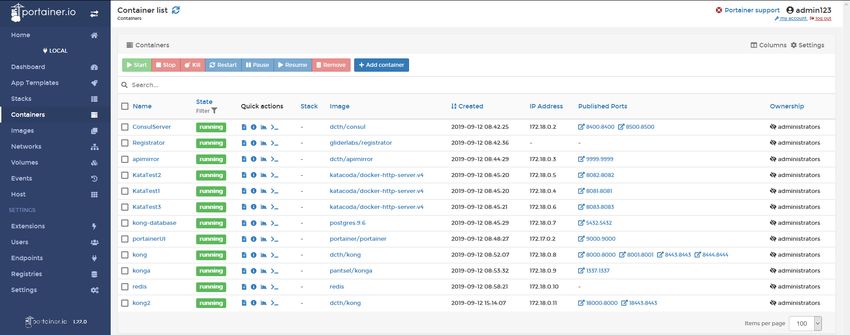
Damiano Cavazzana: Sviluppo di una Proof of Concept per la gestione di microservizi tramite API Gateway, Tesi di laurea triennale, c Dicembre 2019.
Sommario
Il presente documento descrive il lavoro svolto durante il periodo di stage, della durata
di trecentoventi ore, dal laureando Damiano Cavazzana presso l’azienda THRON S.p.A.
L’obiettivo principale era quello di sviluppare una POC che utilizzasse un software che
permettesse di gestire le richieste destinate a dei microservizi applicando rate limiting.
L’elaborato illustra:
∗ Il contesto aziendale nel quale si è svolto lo stage (Capitolo 1);
∗ La descrizione dello stage (Capitolo 2);
∗ Il contesto delle tecnologie utilizzate (Capitolo 3);
∗ La ricerca del software adatto (Capitolo 4);
∗ La soluzione sviluppata (Capitolo 5);
∗ La valutazione finale sull’esperienza e le competenze acquisite (Capitolo 6).
Organizzazione del testo
Riguardo la stesura del testo, relativamente al documento sono state adottate le
seguenti convenzioni tipografiche:
∗ gli acronimi, le abbreviazioni e i termini ambigui o di uso non comune menzionati
vengono definiti nel glossario e nella lista degli acronimi, situati alla fine del
presente documento;
∗ per la prima occorrenza dei termini riportati nel glossario viene utilizzata la
colorazione azzurra;
∗ i termini in lingua straniera o facenti parti del gergo tecnico sono evidenziati con
il carattere corsivo;
∗ i riferimenti alla bibliografia sono numerati ed evidenziati tra parentesi quadre.
iii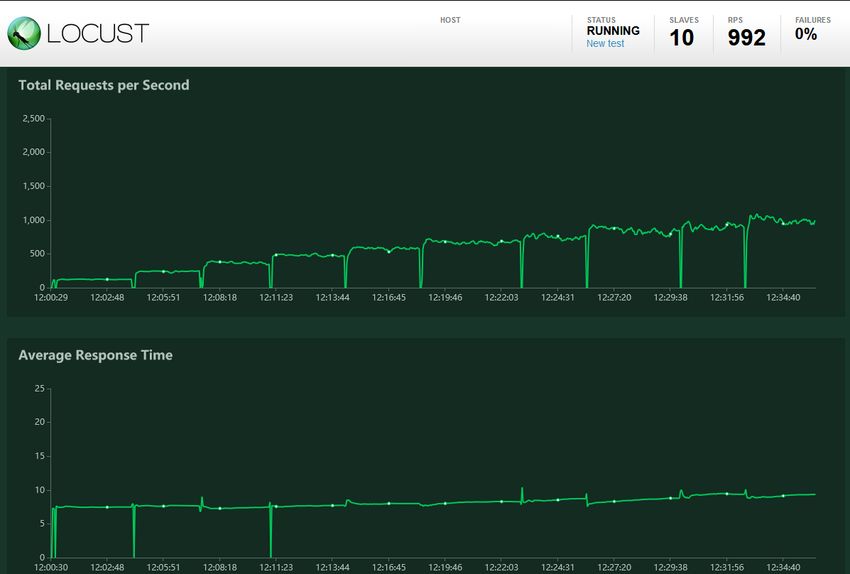
Ringraziamenti
Innanzitutto, vorrei esprimere la mia gratitudine al Prof. De Giovanni, relatore della
mia tesi, per l’aiuto e il sostegno fornitomi durante la stesura del lavoro.
Desidero ringraziare con affetto i miei genitori per il sostegno, il grande aiuto e per
essermi stati vicini in ogni momento durante gli anni di studio.
Ho desiderio di ringraziare poi i miei compagni studi Alberto, Davide, Fiorenza,
Tommaso e tutti i miei amici per tutti i bellissimi anni passati insieme e le mille
avventure vissute.
Padova, Dicembre 2019 Damiano Cavazzana
vIndice
1 L’azienda e il prodotto 1
2 Descrizione dello stage 3
2.1 Introduzione al progetto . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Obiettivi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.3 Vincoli temporali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.4 Ripartizione oraria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.5 Vincoli del software . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.6 Aspettative personali . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3 Introduzione alle tecnologie 7
3.1 Containerizzazione e Scaling del software . . . . . . . . . . . . . . . . . 7
3.2 Architettura a microservizi . . . . . . . . . . . . . . . . . . . . . . . . 8
4 Scouting del Software 11
4.1 Requisiti del Software . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
4.1.1 Rate Limiting condiviso nel Cluster . . . . . . . . . . . . . . . 11
4.1.2 Routing basato su Host . . . . . . . . . . . . . . . . . . . . . . 12
4.1.3 Service Discovery . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.1.4 Load Balancing . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4.1.5 Caching . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4.1.6 API di amministrazione . . . . . . . . . . . . . . . . . . . . . . 15
4.1.7 Autenticazione e Autorizzazione . . . . . . . . . . . . . . . . . 16
4.2 Soluzione individuata . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
5 Sviluppo della Proof of Concept 19
5.1 Software e Tecnologie utilizzati . . . . . . . . . . . . . . . . . . . . . . 19
5.1.1 Docker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.1.2 Portainer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.1.3 Amazon Web Services . . . . . . . . . . . . . . . . . . . . . . . 21
5.1.4 Kong . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.1.5 Konga . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.1.6 Locust . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.1.7 Python . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.1.8 Consul . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.1.9 Registrator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.1.10 PostgreSQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.1.11 Redis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5.2 Proof of Concept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
viiviii INDICE
5.2.1 Proof of Concept locale tramite Docker . . . . . . . . . . . . . 28
5.2.2 Proof of Concept tramite AWS . . . . . . . . . . . . . . . . . . 29
5.3 Requisiti Soddisfatti . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.3.1 Rate Limiting condiviso nel Cluster . . . . . . . . . . . . . . . 30
5.3.2 Routing basato su Host . . . . . . . . . . . . . . . . . . . . . . 31
5.3.3 Service Discovery . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.3.4 Load Balancing . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.3.5 Caching . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5.3.6 API di amministrazione . . . . . . . . . . . . . . . . . . . . . . 32
5.3.7 Autenticazione e Autorizzazione . . . . . . . . . . . . . . . . . 32
5.4 Test di Carico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
6 Conclusioni 35
6.1 Raggiungimento degli obiettivi . . . . . . . . . . . . . . . . . . . . . . 35
6.2 Consuntivo Finale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
6.3 Conoscenze acquisite . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
6.4 Valutazione personale . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Glossario 39
Acronimi 43
Riferimenti bibliografici 45Elenco delle figure
1.1 Logo THRON S.p.A. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
5.1 Logo Docker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.2 Logo Portainer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.3 Interfaccia di Portainer . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.4 Logo Amazon Web Services . . . . . . . . . . . . . . . . . . . . . . . . 21
5.5 Logo Kong . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.6 Dashboard di Konga . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.7 Logo Locust . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.8 Interfaccia di Locust . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.9 Logo Python . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.10 Logo Consul . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.11 Logo PostgreSQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.12 Logo Redis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5.13 POC in locale con Docker . . . . . . . . . . . . . . . . . . . . . . . . . 28
5.14 POC tramite servizio ECS . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.15 Risultati test di carico distribuiti . . . . . . . . . . . . . . . . . . . . . 34
Elenco delle tabelle
2.1 Tabella ripartizione oraria . . . . . . . . . . . . . . . . . . . . . . . . . 4
4.1 Tabella reverse proxy . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
5.1 Tabella dei test di carico sui plugin . . . . . . . . . . . . . . . . . . . . 33
6.1 Tabella del raggiungimento degli obiettivi . . . . . . . . . . . . . . . . 35
ixx ELENCO DELLE TABELLE
6.2 Tabella Consuntivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36Capitolo 1
L’azienda e il prodotto
Questo capitolo introduce l’azienda nella quale è stato svolto il progetto di stage.
THRON S.p.A. (vedi Figura 1.1) è un’azienda italiana nata dalla startup "New Vision"
che opera nell’ambito dello sviluppo software.
La sede principale è situata a Piazzola sul Brenta, davanti alla famosa villa Contarini,
le altre sedi si trovano a Londra, Milano e Shanghai. La fondazione dell’azienda risale
al 2000 da parte di Nicola Meneghello, l’attuale CEO, e Dario De Agostini, l’attuale
CTO.
Figura 1.1: Logo THRON S.p.A.
THRON S.p.A. sviluppa e offre un unico prodotto cloud secondo il modello Software as
a Service (SAAS) chiamato a sua volta THRON, che è un Digital Asset Management
(DAM), ovvero un software che ha lo scopo di archiviare e rendere facilmente accessibili
i contenuti digitali, come ad esempio immagini, video, audio e documenti.
Tra i competitor appaiono nomi del calibro di Adobe, Aprimo e Bynder, questo non ha
però impedito a THRON di ottenere la fiducia di aziende di rilievo come Valentino,
Whirlpool e Maserati.
THRON nasce dal desiderio delle aziende di raggruppare in un unico strumento
tutti i propri contenuti digitali, evitando ad esempio la duplicazione e favorendo il
ritrovamento, il versionamento, l’analisi, l’arricchimento dei dati e molto altro ancora.
I file vengono raggruppati in un’unica piattaforma che si occupa di analizzare il
contenuto ed arricchirlo con tag e metadati attraverso un sistema di analisi chiamato
content intelligence, il quale aggiunge e aggiorna automaticamente le informazioni nel
tempo. Rimane comunque possibile anche inserire manualmente i tag.
12 CAPITOLO 1. L’AZIENDA E IL PRODOTTO È possibile inoltre vedere lo storico dei contenuti, versionarli e impostare permessi sulla loro fruizione. THRON si occupa anche di analizzare gli interessi degli utenti in base ai contenuti consumati sui vari canali e di suggerirne automaticamente altri che seguano quelle preferenze attraverso algoritmi di machine learning.
Capitolo 2
Descrizione dello stage
In questo capitolo è descritto il progetto, i suoi vincoli e i suoi obiettivi.
2.1 Introduzione al progetto
L’obiettivo principale di questo stage è l’individuazione di un software centralizzato
e scalabile adatto alla gestione dei microservizi e che, tra le varie funzioni, applichi
rate limiting alle richieste ad essi indirizzate; una volta trovato tale software è richiesta
la realizzazione di una Proof of Concept (POC) che faccia uso di esso, in modo da
valutare la sua eventuale applicabilità all’interno dell’infrastruttura di THRON.
Il rate limiting è richiesto esplicitamente per via del fatto che THRON è un prodotto
cloud con architettura multi-tenant, ovvero più "clienti" operano contemporaneamente
sulla stessa infrastruttura, e c’è quindi interesse nell’evitare che un cliente che operi in
modo imprevisto possa creare disservizi agli altri clienti.
2.2 Obiettivi
Durante la stesura del piano di lavoro avvenuta prima dell’inizio dello stage, con la
collaborazione del tutor aziendale, sono stati individuati degli obiettivi che sono stati
suddivisi in obbligatori, desiderabili e facoltativi.
Obbligatori
∗ O01: Identificazione di una soluzione per la gestione centralizzata di un rate
limiter;
∗ O02: Rendere la soluzione identificata gestita tramite il sistema di containerizza-
zione Docker;
∗ O03: Apprendimento della tecnologia Docker;
∗ O04: Apprendimento di architetture di erogazione di servizi nel web.
34 CAPITOLO 2. DESCRIZIONE DELLO STAGE
Desiderabili
∗ D01: Apprendimento dei metodi di containerizzazione offerti da Amazon Web
Services (AWS);
∗ D02: Integrazione della soluzione identificata nell’architettura di THRON.
Facoltativi
∗ F01: Apprendimento di metodologie per lo sviluppo di test di carico distribuiti.
2.3 Vincoli temporali
La durata dello stage, come previsto dai vincoli imposti dal corso di laurea, deve
essere compresa tra le 300 e le 320 ore. Per questo motivo, è stato concordato assieme
all’azienda un piano di lavoro della durata di 320 ore, le quali sono state distribuite in
8 settimane. In particolare, l’orario di lavoro prevedeva 8 ore al giorno dal lunedì al
venerdì, dalle 8:30 del mattino alle ore 18:00, con una pausa di un’ora e mezza dalle
12:30 alle 14:00.
2.4 Ripartizione oraria
Durante la stesura del piano di lavoro, sono state preventivate le ore di lavoro distribuite
come riportato in Tabella 2.1.
Tabella 2.1: Tabella ripartizione oraria
Durata in ore Descrizione Attività
8 Apprendimento architetture web implementate in THRON
16 Analisi dei requisiti funzionali
24 Analisi dei requisiti non funzionali
24 Studio di Docker
32 Scouting delle soluzioni disponibili
40 Identificazione della POC da eseguire ed eventuale
sviluppo delle parti propedeutiche
104 Sviluppo POC con le soluzioni identificate
24 Esecuzione di test di carico e misura delle performance
con e senza rate limiter
32 Stesura documentazione
16 Sviluppo presentazione interna del lavoro svolto
320 Totale Ore
2.5 Vincoli del software
I vincoli imposti dal contesto dello stage per il software da individuare sono:2.6. ASPETTATIVE PERSONALI 5
∗ Soddisfare autonomamente tutti i requisiti in modo da limitare la complessità;
∗ Essere adatto alla containerizzazione in immagini Docker;
∗ Poter funzionare correttamente in un cluster ;
∗ Essere open source o quantomeno avere una versione gratuita che permetta di
testarlo nel corso dello stage senza costi aggiuntivi.
2.6 Aspettative personali
Per mettermi in contatto con le aziende e conoscere il panorama attuale del mondo
dell’IT ho scelto di partecipare all’evento StageIT organizzato dall’Università di Padova,
durante il quale ho avuto modo di conoscere varie aziende e le loro proposte di stage. Ho
successivamente scelto di effettuare il mio stage presso THRON S.p.A. per approfondire
degli argomenti che durante il corso di studi vengono toccati solo in ambito teorico: la
sicurezza delle reti e la containerizzazione di software.Capitolo 3
Introduzione alle tecnologie
In questo capitolo sono illustrati brevemente concetti necessari alla comprensione del
contesto del progetto.
3.1 Containerizzazione e Scaling del software
Nello sviluppo di un sistema complesso che deve eseguire più software differenti con-
temporaneamente, può accadere che ci siano dei conflitti nelle dipendenze, come ad
esempio la necessità di avere allo stesso tempo a disposizione più versioni della stessa
libreria.
Per evitare questi problemi una soluzione potrebbe essere quella di eseguire ogni
software in una macchina differente, tuttavia è facile accorgersi che avere hardware
specifico per ogni software da eseguire non è realizzabile per via dei costi che comporta.
Si può quindi pensare di utilizzare una sola macchina e eseguire ogni software in un
contesto separato, in una virtual machine, all’interno della quale è eseguito un sistema
operativo adatto con installate le dipendenze necessarie, il quale esegue a sua volta il
software di nostro interesse; sfortunatamente anche così, per via del fatto che un intero
sistema operativo è eseguito a supporto di ogni singolo software, molte risorse sono
utilizzate per i processi dei sistemi invece che per lo scopo prefissato.
Nel tempo sono state cercate soluzioni che permettano di utilizzare un unico sistema
ed eseguire comunque ogni singolo programma in ambienti virtualmente separati, così
che il malfunzionamento di un software non comprometta il funzionamento degli altri:
questo è stato inizialmente effettuato con modifiche ai sistemi operativi fino all’avvento
di Docker nel 2013 [10].
Un’immagine di Docker è un modello che contiene le istruzioni e i file necessari
per la creazione di un container : all’interno di un’immagine sono presenti i software e
il relativo ambiente (ad esempio le sue dipendenze, le sue configurazioni) già pronti
per l’esecuzione, senza bisogno di installare nulla.
Ogni immagine viene eseguita costruendo un container secondo le istruzioni indicate,
eseguito direttamente dal sistema nativo della macchina in modo isolato dal resto,
senza ulteriori strati di complessità nel mezzo, permettendo di eseguire grandi quantità
78 CAPITOLO 3. INTRODUZIONE ALLE TECNOLOGIE
di container utilizzando una sola macchina [2].
La semplicità con cui è possibile avviare un nuovo container senza dover riconfi-
gurare l’ambiente ha semplificato di molto lo sviluppo di sistemi complessi e la gestione
di carichi di richieste molto ampi.
Se un software si trova nella situazione di dover soddisfare molte richieste contem-
poraneamente, potrebbe essere necessario allocargli più risorse come ad esempio più
memoria o processori più potenti, ovvero scalarlo verticalmente. Non è però detto che
questa soluzione funzioni, in quanto il software stesso potrebbe non essere in grado di
sfruttare al meglio le risorse che gli vengono aggiunte, ad esempio la memoria extra
che gli viene allocata potrebbe non venire mai utilizzata.
Vista la facilità con cui è possibile avviare nuovi container grazie a Docker, risul-
ta più comodo scalare orizzontalmente, ovvero avviare nuove istanze dello stesso
software e distribuire il lavoro su ognuna di esse, andando a generare un cluster.
Così facendo anche software inadatti a eseguire più operazioni in contemporanea di-
ventano virtualmente adatti a farlo.
Per rendere ancora più efficace lo scaling orizzontale, si può variare nel tempo la
quantità di container in esecuzione in base al carico di lavoro, così da avere sempre
la quantità più adatta, risparmiando risorse nei momenti nei quali è possibile farlo e
avendo sempre a disposizione la potenza di elaborazione necessaria quando richiesto.
Questa possibilità è fornita dai servizi Elastic Container Service e Fargate di Amazon
ed è chiamata solitamente auto-scaling [1].
3.2 Architettura a microservizi
Fino ad alcuni anni fa molte applicazioni erano caratterizzate da un’architettura monoli-
tica [9], ovvero ognuna era composta da un unico grande software con tante componenti
che svolgevano le funzioni delle quali si aveva bisogno.
Col tempo e gli aggiornamenti, questo portava a dei problemi:
∗ ad ogni nuova funzionalità da implementare, occorreva adattare le nuove tecnolo-
gie al codice più datato già presente;
∗ il software diventava via via sempre più pesante, richiedendo risorse aggiuntive e
tempi di compilazione più lunghi;
∗ la complessità che si raggiungeva faceva sì che prima di poter lavorare corret-
tamente su un software, a un programmatore fosse richiesto diverso tempo per
conoscerne la struttura;
∗ rimuovere o riscrivere parti del software diventava via via un lavoro sempre più
lungo e costoso;
∗ a livello di affidabilità, un piccolo bug in una sola componente poteva causare il
crash dell’intero programma;
∗ tutti i difetti precedenti rallentavano l’innovazione perché aumentavano tempi e
costi dell’implementazione di nuove funzionalità;3.2. ARCHITETTURA A MICROSERVIZI 9
∗ se una sola componente era sovraccarica e richiedeva più risorse, occorreva scalare
l’intero software per poterne avere un’altra verso la quale reindirizzare parte del
traffico.
Per ovviare a questi problemi, con l’aumento del numero di utenti del web e della
velocità con la quale il software evolve, è stato necessario cambiare paradigma e passare
ad un’architettura a microservizi [5].
Con l’architettura a microservizi non si ha più un unico software molto grande (chiama-
to appunto monolite) che si occupa di tutto ma si hanno invece tanti piccoli software i
quali si occupano ciascuno di mettere a disposizione una sola o poche funzionalità.
Questi piccoli software, che da adesso chiameremo microservizi, non sono accoppiati
gli uni con gli altri ma comunicano invece tra loro solo tramite delle API (Application
Programming Interface) che ciascuno mette a disposizione, le quali permettono agli
altri software di comunicare senza bisogno di conoscere la struttura del microservizio
che le offre.
Questo disaccoppiamento genera vari vantaggi:
∗ ogni microservizio può essere facilmente scritto nel linguaggio più adatto a
eseguire il compito desiderato;
∗ se un programmatore deve sviluppare una nuova funzionalità non ha bisogno di
conoscere l’intera struttura del sistema ma gli basta solo conoscere il microservizio
sul quale lavora e le API messe a disposizione dagli altri, ciò gli permette di
dedicarsi di più all’ottimizzazione della funzionalità stessa piuttosto che a renderla
compatibile col software più datato;
∗ tecnologie nuove e datate possono coesistere senza modificare nulla;
∗ se si vogliono riscrivere parti di software o un intero microservizio, è possibile
farlo in modo invisibile al resto del sistema purché si continuino ad esporre le
stesse API;
∗ se occorrono più risorse, possono scalare solo i microservizi che effettivamente le
richiedono invece che tutto il monolite;
∗ se un microservizio ha dei problemi, il resto del sistema che non fa uso delle sue
API continua a funzionare;
∗ i microservizi possono essere installati in macchine in luoghi geografici diversi e
appartenere a proprietari diversi.
Questa "separazione dei software in più software" ha però creato la necessità di avere
ulteriori componenti della rete. In particolare è necessario avere un componente centrale
che rappresenti l’intera applicazione sulla rete esterna e che garantisca un accesso
sicuro alla rete interna ricevendo richieste e instradandole verso il microservizio corretto.
Questo componente è spesso rappresentato da un reverse proxy.
Un’altra funzionalità che diventa necessaria per via del fatto che i servizi sono separati
in più software e varia la quantità delle loro istanze è la possibilità di identificare quali
di questi sono disponibili in un determinato momento.Capitolo 4
Scouting del Software
In questo capitolo sono descritti i software testati, i requisiti da soddisfare e le decisioni
prese di conseguenza.
THRON, negli anni, ha adottato l’architettura a microservizi descritta nel Capi-
tolo 3, pertanto si è presentata la necessità di individuare un software adatto a gestire
l’accesso e quindi proteggere tali microservizi.
Nonostante il tema principale dello stage fosse il rate limiting, con la collaborazione
del tutor aziendale sono stati individuati vari altri requisiti da soddisfare così che il
software sia adatto ad essere integrato nell’architettura esistente.
Nel corso della prima metà dello stage è stata quindi individuata la famiglia dei
reverse proxy come software adatti a svolgere il compito richiesto e sono state testa-
te le funzionalità di alcuni di essi in modo da metterle in relazione ai requisiti individuati.
In questo periodo dello stage è anche stato approfondito il funzionamento di Docker e
dei servizi di Amazon, software richiesti per lo sviluppo della POC.
4.1 Requisiti del Software
Di seguito vengono descritti i requisiti individuati per i quali occorre identificare una
soluzione.
4.1.1 Rate Limiting condiviso nel Cluster
Il rate limiting è il mantenimento di un contatore e la conseguente limitazione del
numero di richieste accettate dall’applicazione, e può essere applicato in base a varie
condizioni e attraverso diversi algoritmi.
Le condizioni possono essere ad esempio la limitazione del numero di richieste to-
tali o ricevute da parte della stessa macchina o utente indirizzate ad un certo servizio
in un determinato lasso di tempo.
Il riconoscimento dei mittenti, necessario per applicare le limitazioni per utente e per
macchina, può essere effettuato basandosi su informazioni provenienti dalle richieste, e
sono ad esempio l’indirizzo IP dal quale la richiesta proviene o valori ricavati dall’header,
1112 CAPITOLO 4. SCOUTING DEL SOFTWARE
come un identificativo quale può essere la chiave API.
Nel caso di THRON, le condizioni da cercare di prendere in considerazione sono
quelle provocabili da comportamenti scorretti di clienti o di macchine di loro proprietà.
Gli algoritmi di rate limiting variano da soluzione a soluzione, per riassumerne alcuni
presenti nei software testati:
∗ semplice rifiuto delle richieste in eccesso entro il lasso di tempo scelto;
∗ algoritmo Sliding Window [8]: le richieste oltre il limite vengono rifiutate ri-
schiando di ripetersi nel tentativo di ottenere una risposta e di generare un burst
(un picco di richieste) all’inizio del lasso di tempo successivo; le richieste ripetute
andrebbero di conseguenza soddisfatte tutte contemporaneamente all’inizio del
nuovo lasso esaurendo subito tutta la disponibilità. Questo burst del lasso successi-
vo viene invece dosato mantenendo in considerazione una percentuale di chiamate
del lasso precedente come se fossero arrivate in quello nuovo; questa percentuale
decade poi nel tempo in modo da lasciare spazio alle nuove richieste, che vengono
così accettate in momenti differenti invece che tutte contemporaneamente;
∗ algoritmo Token Bucket [27]: permette di dosare meglio il carico di richieste e
di rifiutarne molte meno distribuendo il traffico nel tempo e accettando anche
burst dopo momenti particolarmente "calmi". Questo è reso possibile generando
un token ogni certo intervallo di tempo che viene consumato ad ogni richiesta
accettata. Le richieste che arrivano in mancanza di token vengono messe in
attesa fino alla generazione di un nuovo token. Se per molto tempo non arrivano
richieste, i token cominciano ad accumularsi (fino ad un limite massimo) ed è
quindi possibile accettare anche un piccolo burst che li consumi.
Il requisito specifica limiting "condiviso nel cluster " perché cercando una soluzione
scalabile è necessario che tutte le istanze nel cluster siano consapevoli delle richieste
ricevute dalle altre in modo da mantenere il contatore delle richieste al valore corretto.
Perché ciò sia possibile è necessario che le istanze comunichino tra loro o che si
appoggino ad una risorsa esterna centralizzata.
4.1.2 Routing basato su Host
Nel contesto dell’architettura a microservizi, il routing è il riconoscimento dello speci-
fico microservizio al quale una richiesta è destinata per effettuare un instradamento
corretto. Nei programmi testati, questo è solitamente effettuato basandosi sul path
della richiesta, sul campo host del suo header o sulla loro combinazione.
Nel caso di THRON però, per motivi dovuti all’infrastruttura esistente, è necessario
poter effettuare routing basandosi non solo sull’host nella sua interezza ma anche su
parte dei nomi di sottodominio dell’host indicato nelle richieste in modo da riconoscerne
interi gruppi con caratteristiche simili come se fossero lo stesso. Per poter soddisfare
questo requisito è necessario che il software da individuare sia in grado di identificare
gli host tramite espressioni regolari o sistemi simili, che permettono di riconoscere
interi gruppi di stringhe somiglianti invece che solamente stringhe specifiche.4.1. REQUISITI DEL SOFTWARE 13
4.1.3 Service Discovery
Il service discovery è il processo tramite il quale il reverse proxy viene a conoscenza delle
istanze dei microservizi disponibili nella rete. Questo processo può avvenire tramite
richieste al server DNS (Domain Name System) nel caso in cui la soluzione adottata sia
in grado di memorizzare i nomi DNS dei microservizi e di effettuare richieste di tipo
SRV (service), ovvero richieste la cui risposta fornisce non solo l’indirizzo IP effettivo
dei microservizi (memorizzato in un record DNS di tipo A, che sta per address) ma
anche i numeri delle porte che questi espongono (memorizzate in un record DNS di
tipo SRV).
La struttura tipica [13] di un record SRV è la seguente:
_service._proto.name. TTL class SRV priority weight port target.
∗ service: il nome simbolico del servizio desiderato.
∗ proto: il protocollo di trasporto adottato dal servizio desiderato; solitamente
(TCP o UDP).
∗ name: il nome di dominio entro il quale il record è valido, seguito da un punto.
∗ TTL: rappresenta il time to live, ovvero il tempo in secondi per il quale
l’informazione ottenuta è da considerarsi valida.
∗ class: classe standard DNS (corrisponde sempre a "IN").
∗ priority: la priorità dell’host indicato; valori minori rappresentano priorità più
alta.
∗ weight: il peso relativo per i record della stessa priorità; un valore maggiore
indica possibilità più alta di essere selezionato.
∗ port: la porta TCP o UDP attraverso la quale il servizio può essere contattato.
∗ target: l’hostname della macchina che mette a disposizione il servizio, seguito
da un punto.
L’indirizzo IP, mancante nel Record SRV, è restituito da un record di tipo A.
Nel caso le richieste DNS per questo tipo di record non siano supportate, alcune
soluzioni individuate durante lo stage si appoggiano invece ad un software aggiuntivo
come ad esempio Consul, il quale, popolato a sua volta da software terzi, espone delle
API tramite le quali molti reverse proxy sono in grado di venire a conoscenza dei servizi
disponili.
Nel caso di THRON, un DNS con record di tipo SRV è già messo a disposizione
tramite i servizi di Amazon e sono quindi state cercate delle soluzioni che permettessero
di utilizzarlo.14 CAPITOLO 4. SCOUTING DEL SOFTWARE
4.1.4 Load Balancing
Il Load Balancing è la distribuzione delle richieste tra più istanze dello stesso micro-
servizio, delle quali il software è venuto al corrente tramite il service discovery. Questa
operazione serve a evitare di affidare troppo lavoro a una singola istanza del cluster.
Per la scelta dell’istanza da contattare si utilizzano metodi che distribuiscono il carico,
in base al reverse proxy possono essere disponibili vari di questi:
∗ selezione casuale;
∗ Round Robin [14]: si seleziona via via ogni istanza dopo aver scelto una regola per
cui sono ordinate, generalmente in base al valore dell’hash generato da qualche
loro campo (come ad esempio l’indirizzo IP);
∗ Least Connections [7]: viene sempre selezionata una delle istanze che al momento
sta servendo meno richieste.
Nel caso sia inoltre possibile ottenere un valore weight (cosa vera nel caso di supporto
dei DNS SRV, dato che il campo weight è presente nei valori restituiti dai record) è
possibile anche applicare le versioni "pesate" dei precedenti algoritmi. Il valore weight
è tanto più alto quanto più l’istanza del microservizio è in grado di servire più richieste,
così facendo se due o più microservizi che svolgono la stessa funzione dovessero avere
prestazioni diverse è possibile bilanciare le richieste correttamente.
4.1.5 Caching
Il caching è una pratica che sfrutta il fatto che, in certi contesti, determinate informa-
zioni non hanno necessità di essere aggiornate in tempo reale ma rimangono valide per
un certo lasso di tempo, o comunque il loro mancato aggiornamento non crea criticità
rilevanti.
Queste informazioni, una volta ottenute dal microservizio di riferimento e restituite
al primo richiedente (con una risposta di tipo cache miss, ovvero il non ritrovamento
della risposta in cache), possono venire mantenute temporaneamente in uno spazio di
memorizzazione più velocemente accessibile ed essere fornite come risposta a richieste
dello stesso tipo successive (con una risposta di tipo cache hit), senza bisogno di
ricontattare il microservizio che le ha generate, così da alleggerire il lavoro dello stesso
e rendere più soddisfatti gli utenti che ottengono risposte più velocemente.
Nel caso di THRON, questo si può facilmente riconoscere nell’ambito della distri-
buzione di contenuti, ad esempio le immagini all’interno dei siti web, le quali anche se
aggiornate un paio di minuti in ritardo non creano particolari problemi.
Le due principali configurazioni da definire quando si sceglie di adottare la cache
in un sistema sono quelle relative alle condizioni che distinguono le risposte attese e al
tempo di validità.
Le condizioni che distinguono le risposte attese possono essere ad esempio i valo-
ri dei campi contenuti nell’header della richiesta: se si riceve una richiesta che specifica
un particolare tipo di risposta attesa, come può essere il formato dei dati di risposta, è
importante assicurarsi che a questa richiesta non venga fornita una risposta di tipo
diverso solo perché presente in cache. Lo stesso esempio può essere fatto nel caso in4.1. REQUISITI DEL SOFTWARE 15 cui siano fornite credenziali di un utente, le quali implicano che la risposta conterrà probabilmente dati riservati a quell’utente, che non si aspetta quindi di ricevere una risposta che era destinata ad un utente differente. Il tempo di validità della cache va scelto in base alla criticità dell’informazione restituita dal servizio alla quale questa è destinata. Quando è possibile farlo, torna utile anche diversificare questo tempo in base a condizioni come ad esempio il codice di stato della risposta HTTP (HyperText Transfer Protocol). Il codice di stato HTTP [4] è quello che indica come la richiesta è stata gestita; nella maggior parte dei casi ci si aspetta di ottenere un codice di risposta compreso tra il valore 200 e 299 (di tipo success), che indica che la richiesta è andata a buon fine, e viene quindi naturale pensare di memorizzare in cache questo tipo di risposte. Nel mondo reale però non sempre le cose vanno a buon fine, e capita quindi di ottenere risposte HTTP con codice compreso tra 400 e 499 (client error ) o tra 500 e 599 (server error ). Anche in questi casi, contrariamente a come si potrebbe credere, potrebbe tornare utile mantenere in cache la risposta contenente l’errore per pochi secondi, così da "concedere un attimo di pausa" al microservizio che ha generato quell’errore, il quale potrebbe essere semplicemente sovraccarico e non essere in grado di tornare operativo se venisse affollato di richieste in una situazione del genere. Ovviamente in contesti vari potrebbe risultare utile avere la possibilità di configurare la cache in base ad ancora differenti condizioni, e proprio questo è un problema per i software che se ne occupano, i quali non sempre prevedono di poter sfruttare ogni dettaglio per personalizzare la scelta. Occorre inoltre ricordare che nonostante tutti i lati positivi di questa tecnologia, non in tutti i casi risulta utile mantenere una cache. In contesti dove le richieste si aspettano sempre risposte differenti o dove semplicemente non viene attesa una risposta per utilizzarne le informazioni contenute ma solo per conferma dell’operazione andata a buon fine, come nel caso delle richieste HTTP POST, la cache non porta alcun beneficio. Alcuni software con cache più avanzate possono mettere inoltre a disposizione al- tre funzioni interessanti, ad esempio la request coalescing (o grace mode [3]), che fa sì che se più richieste dello stesso tipo che non trovano una risposta già pronta in cache arrivano quasi contemporaneamente in un brevissimo lasso di tempo, solo una venga inoltrata effettivamente al microservizio destinatario, mentre le altre vengono lasciate in attesa che la risposta della prima sia memorizzata per essere riutilizzata. Questa opzione aumenta ulteriormente la quantità di cache hit riducendo il carico di lavoro dei microservizi. 4.1.6 API di amministrazione Generalmente i reverse proxy ottengono le configurazioni tramite file che vanno riempiti con quanto definito dall’utente secondo la struttura attesa dal proxy scelto. Questi file, se possibile, vanno poi testati con i comandi forniti per evitare che contengano errori e solo poi integrati nel proxy stesso. Questa operazione, eseguita in tal modo, spesso richiede il riavvio del reverse proxy e la riapplicazione delle configurazioni su ogni singola istanza del cluster. Alcune soluzioni (ad esempio il servizio Elastic Container Service di Amazon [28]) semplificano questo processo permettendo di definire una nostra "nuova versione"
16 CAPITOLO 4. SCOUTING DEL SOFTWARE
(revisione) del proxy che contiene la nuova configurazione e occupandosi poi di termi-
nare autonomamente i proxy con la vecchia configurazione man mano che quelli nuovi
diventano operativi. Nonostante questa possibilità, l’operazione rimane scomoda, lenta
e pericolosa, provocando una situazione di inconsistenza durante la quale si hanno in
contemporanea alcune istanze con configurazione vecchia e altre con configurazione
nuova.
Per evitare questo, alcune soluzioni mettono a disposizione delle API da ammini-
stratore tramite le quali è possibile modificare rapidamente le configurazioni per
l’intero cluster senza downtime o inconsistenze, e prevengono così errori causati da
struttura del file scorretta.
4.1.7 Autenticazione e Autorizzazione
Ovviamente non tutti i microservizi sono sempre pensati per essere utilizzati da chiun-
que; alcuni, come nel caso di THRON, sono riservati ai clienti, che hanno permessi
e aspettative differenti. Da questo è facile intuire che è necessario avere modo di
riconoscere chi sta cercando di contattare un microservizio e di sapere se è autorizzato
a farlo.
Per l’autenticazione esistono vari sistemi, i quali coinvolgono tutti il passaggio di
un qualche identificativo tramite l’header delle richieste. I più famosi tra questi sono
l’uso di chiavi API, l’OAUTH [26] e il Json Web Token [6] (JWT).
4.2 Soluzione individuata
Come evidenziato nell’introduzione del Capitolo 4, nel corso dello stage i reverse proxy
sono stati identificati come i software che più si prestano a soddisfare questi requisiti.
Tra questi spicca la sottocategoria degli API Gateway [25], i quali generalmente offrono
funzioni aggiuntive specifiche per le API (come si può intuire dal nome) e configurazioni
molto meno complesse per l’utente perdendo però parte della personalizzazione.
In questo periodo sono state testate varie soluzioni, ad esempio gli API Gateway Kong,
KranenD e Gravitee e altri software che rientrano nella famiglia dei reverse proxy quali
Envoy, HAproxy e Traefik.
I problemi principali nell’individuare un software adatto sono apparsi proprio nel
soddisfare i requisiti principali:
∗ in tutti i casi è possibile applicare rate limiting, tuttavia solo alcuni software
permettono di farlo in modo condiviso nel cluster;
∗ il routing basato su host non è quasi mai presente nei software dichiarati come
API gateway; più in particolare questa funzione è apparsa mutualmente esclusiva
nei confronti della funzione di caching, la quale è invece presente in tutti gli API
gateway e mancante negli altri tipi di reverse proxy testati.
Unica eccezione a questa regola è Kong, il quale possiede entrambe le funzioni, ma
nel suo caso il routing basato su host non è abbastanza avanzato da riconoscere
gli host come richiesto nel caso di THRON.
Altro requisito critico è quello delle API di amministrazione: spesso queste non sono
presenti, mancanza compensata in parte da interfacce grafiche dalle quali è possibile4.2. SOLUZIONE INDIVIDUATA 17
vedere e solo in alcuni casi anche modificare le configurazioni.
Nel corso di questo periodo di scouting delle tecnologie sono stati anche identifi-
cati due software di supporto utili a completare o ad aggiungere le funzioni mancanti
necessarie per le soluzioni che non soddisfano autonomamente tutti i requisiti.
Il primo di questi è Consul, software che sarebbe servito a sostituire il service discovery
tramite DNS esponendo invece API che molti reverse proxy non in grado di effettuare
query di tipo SRV sono invece in grado di contattare nativamente; il secondo è Varnish
[24], un software per il caching HTTP veramente avanzato che possiede anche vari
moduli per funzioni aggiuntive, tra i tanti è particolarmente interessante il modulo
vsthrottle, che permette di applicare rate limiting.
L’adozione di Consul non avrebbe particolari problemi rispetto ai vincoli dello stage, in
quanto si sarebbe trattato solo di un componente aggiuntivo all’interno della rete che
avrebbe fatto le veci del DNS traducendone i record in API comprensibili. Varnish, al
contrario, si sarebbe dovuto posizionare frontalmente al reverse proxy scelto, violando
il vincolo di avere un unico software centralizzato e aggiungendo ulteriore complessità.
In Tabella 4.1 sono sintetizzati i risultati dello scouting per le soluzioni testate.
Tabella 4.1: Tabella reverse proxy
Nome e Rate Routing Service Load Cache Admin Autorizza-
Versione Limiting su Host Discovery Balancing API zione API
Envoy Software Completo Software Si No No Si
1.12.0 Aggiuntivo Aggiuntivo
Gravitee Condiviso No Consul Si Si No Si
1.28.0
HAproxy Non Completo DNS Si No No Si
2.1 Condiviso SRV
Kong Condiviso Parziale DNS Si Si Si Si
1.3 SRV
KrakenD Non No DNS Si Si No Si
0.9.0 Condiviso SRV
Traefik Non Completo Consul Si No No No
1.7 Condiviso
A seguito dello scouting, durante una riunione in presenza del tutor aziendale e del
CTO di THRON è stato deciso di utilizzare per la POC l’API gateway Kong.
Kong è l’unico software fra quelli testati che offre almeno una soluzione basilare per
ogni requisito, pertanto è risultato una scelta quasi obbligatoria.
Oltre a questo hanno influito nella scelta le seguenti motivazioni:
∗ Kong è la soluzione individuata con documentazione qualitativamente migliore,
più completa e ricca di esempi;
∗ Kong è un progetto maturo e ancora attivo, arrivato attualmente alla sua versione
1.3: anche in fase di scouting é stato possibile apprezzare le novità implementate,18 CAPITOLO 4. SCOUTING DEL SOFTWARE
prima tra tutte l’integrazione della cache anche per la versione community
(gratuita), che lo ha reso una scelta possibile;
∗ Kong è basato sul web server Nginx, tecnologia già utilizzata in THRON e nella
quale è posta particolare fiducia da parte dell’azienda.
Il problema del routing basato su gruppi di host non è risolvibile da Kong singolarmente,
ed è quindi stato deciso che, in caso di sua effettiva applicazione, la riscrittura dell’host
in un formato gestibile sarà affidata ad un altro componente della rete di THRON, la
CDN (Content Delivery Network). Tra le alternative sono presenti software in grado
di risolvere questo problema, tuttavia questi peccano tutti in maniera più grave nel
soddisfare altri requisiti.Capitolo 5
Sviluppo della Proof of Concept
In questo capitolo è descritto l’effettivo sviluppo della POC e i relativi software e le tecno-
logie impiegati.
5.1 Software e Tecnologie utilizzati
5.1.1 Docker
Docker [17] (vedi Figura 5.1) è un software open source che automatizza il deployment
di applicazioni all’interno di contenitori software, fornendo un’astrazione aggiuntiva
grazie alla virtualizzazione a livello di sistema operativo di Linux. Docker utilizza delle
funzionalità di isolamento delle risorse del kernel Linux per consentire a container
indipendenti di coesistere sulla stessa istanza di Linux, evitando l’installazione e la
manutenzione di un’intera macchina virtuale.
Figura 5.1: Logo Docker
Tramite Docker è possibile costruire (o scaricare da repository online) delle immagini
dei software, le quali sono pacchetti che contengono il software stesso, un ambiente già
pronto alla sua esecuzione (completo delle dipendenze e delle configurazioni necessarie)
e i comandi da eseguire per la generazione di un container.
I container, una volta generati, entrano a far parte delle network di Docker, attraverso
le quali viene associato loro un indirizzo IP e possono quindi comunicare tra loro come
se fossero macchine differenti all’interno di una stessa rete.
Nel progetto di stage, Docker è stato il software principale, ampiamente utilizza-
1920 CAPITOLO 5. SVILUPPO DELLA PROOF OF CONCEPT
to sia per testare le varie soluzioni in fase di scouting che per l’implementazione della
POC in locale.
Anche i servizi ECS e Fargate di AWS sono basati su Docker e utilizzano a loro volta
le stesse immagini.
5.1.2 Portainer
Portainer [20] (vedi Figura 5.2 e 5.3) è un set di strumenti che consente di creare,
gestire e mantenere facilmente ambienti Docker (ad esempio vedere quali container
sono in esecuzione e le loro informazioni, terminarli, riavviarli e accedere ad essi tramite
il terminale integrato nell’interfaccia).
È uno strumento che può essere a sua volta eseguito in un container Docker e fornisce
un’interfaccia grafica la quale permette di eseguire le principali operazioni in ambiente
Docker senza esecuzione di comandi da terminale.
Figura 5.2: Logo Portainer
Portainer non sostituisce interamente il classico controllo da terminale ma grazie alla
sua interfaccia rende lavorare con Docker molto più veloce e comprensibile, mantenendo
sempre tutto sotto controllo.
Nel progetto di stage è stato ampiamente utilizzato per monitorare la grande quantità
di container in esecuzione vista la centralità di Docker nello sviluppo della POC.
Figura 5.3: Interfaccia di Portainer5.1. SOFTWARE E TECNOLOGIE UTILIZZATI 21
5.1.3 Amazon Web Services
Amazon Web Services [15] (AWS, vedi Figura 5.4) è una piattaforma che fornisce
servizi di cloud computing on demand.
Figura 5.4: Logo Amazon Web Services
Nel contesto dello stage sono stati utilizzati i servizi seguenti.
Amazon Elastic Compute Cloud (EC2): è un servizio Web che fornisce capacità
di elaborazione sicura e scalabile nel cloud.
Nel progetto è stato utilizzato per avviare le macchine necessarie all’esecuzione
del servizio ECS. Quelle utilizzate nel corso dello stage appartengono al gruppo
delle macchine ad uso generale e sono quelle di tipo T2 ed M5.
Le macchine T2 sono a prestazioni espandibili, ovvero forniscono delle prestazione
di base garantite e la possibilità di superarle automaticamente per un certo periodo
di tempo se richiesto dal carico di lavoro. Per farlo, sono accumulati dei "crediti"
nei periodi di inattività o di attività ridotta che possono essere spesi per superare
il limite nei momenti nei quali risulta necessario.
La variazione di prestazioni delle macchine T2 renderebbe inconsistenti i test di
carico e pertanto per questa attività ne è stata usata una di tipo M5, a prestazioni
fisse.
Amazon Elastic Container Service (ECS): è un servizio di orchestrazione di con-
tenitori altamente dimensionabile ad elevate prestazioni che supporta i contenitori
Docker e consente di eseguire e ridimensionare facilmente le applicazioni suddivise
in contenitori su AWS.
Nel progetto ha consentito di eseguire container Docker sulle macchine fornite
dal servizio EC2.
Amazon Elastic Container Registry (ECR): è un registro di contenitori Docker
completamente gestito che semplifica agli sviluppatori la memorizzazione, la
gestione e la distribuzione di immagini di contenitori Docker.
Nel progetto è stato utilizzato per memorizzare e recuperare velocemente le
immagini Docker da eseguire tramite i servizi ECS e Fargate.
Elastic Load Balancing (ELB): è un servizio che instrada automaticamente il traf-
fico in entrata delle applicazioni tra molteplici destinazioni, quali istanze Amazon
EC2, container, indirizzi IP e funzioni Lambda. Può gestire i mutevoli carichi di
traffico di un’applicazione in una o più zone di disponibilità.
Nel progetto è stato utilizzato per avviare l’Application Load Balancer della POC
che si occupa di distribuire il carico di richieste tra le istanze dei reverse proxy
testati.
AWS Fargate: è un motore di elaborazione per Amazon ECS che permette di eseguire
contenitori senza dover gestire server o cluster.22 CAPITOLO 5. SVILUPPO DELLA PROOF OF CONCEPT
Nel progetto è stato utilizzato per eseguire piccoli container Docker che non
richiedono ingenti quantità di risorse per il loro funzionamento.
AWS Cloud Map: è un servizio di rilevamento delle risorse cloud. Con Cloud Map
è possibile definire i nomi personalizzati per le risorse dell’applicazione e gestire
la posizione aggiornata di queste risorse che cambiano in modo dinamico. Ciò
aumenta la disponibilità dell’applicazione poiché il servizio Web rileva sempre le
posizioni più aggiornate delle risorse.
Nel progetto è stato utilizzato per assegnare nomi DNS alle componenti della
POC.
Amazon Route 53: è un servizio Web di DNS (Domain Name System).
Nel progetto è stato utilizzato per il service discovery e load balancing grazie ai
record di tipo SRV messi a disposizione.
5.1.4 Kong
Kong [18] (vedi Figura 5.5) è un API Gateway Scalabile e open source sviluppato in
Lua ed eseguito sulla base del web server Nginx utilizzato come reverse proxy.
Ha nativamente poche funzioni basilari (routing, service discovery tramite DNS SRV,
load balancing) perché mette le altre a disposizione ufficialmente sottoforma di plugin.
Figura 5.5: Logo Kong
Le configurazioni di Kong si basano su quattro entità:
∗ i Consumer, che rappresentano utenti o macchine che contattano le API dei
microservizi;
∗ le Route, ovvero i metodi e le regole attraverso le quali i consumer possono
contattare i microservizi ;
∗ i Service, ovvero le entità che rappresentano i microservizi all’interno di Kong;
∗ i Plugin, ovvero le funzioni aggiuntive, i quali possono essere applicati globalmente,
per service e per route ed essere validi per tutti i consumer o specifici per uno
solo di essi.
Kong espone le sue funzionalità attraverso le seguenti porte di default, che possono
essere variate di numerazione:
∗ la porta 8000 è quella dove ci si aspetta di ricevere le richieste degli utenti che
vogliono contattare i microservizi ;
∗ la porta 8443 è per le richieste degli utenti attraverso il protocollo HTTPS;5.1. SOFTWARE E TECNOLOGIE UTILIZZATI 23
∗ la porta 8001 espone le API di amministrazione;
∗ la porta 8444 espone le API di amministrazione per il protocollo HTTPS.
Nel registrare un microservizio su Kong, si effettuano i seguenti step:
∗ si crea un service al quale viene associato il nome DNS del microservizio
rappresentato;
∗ si creano una o più route associate al service creato precedentemente per ogni
API che il microservizio corrispondente mette a disposizione, specificando quindi
host e/o path corrispondenti;
∗ si aggiungono i plugin necessari (ad esempio il rate limiter e la cache) sul service
stesso se si vuole che siano validi per tutte le API del microservizio, altrimenti
sulle singole route. Si specifica inoltre se il plugin ha una configurazione generica
per tutti o se è valido per un singolo consumer (distinto tramite un id ).
I plugin seguono le seguenti regole:
∗ non è possibile abilitare più di una volta lo stesso plugin per un’entità a meno
che questo non sia rivolto ad utenti differenti;
∗ se più plugin dello stesso tipo sono applicati allo stesso servizio su livelli diversi
(route, service e globale) e su più utenti (rispettando la regola precedente), per
una richiesta viene applicato sempre e solo il plugin più specifico prima rispetto
all’utente (quindi quello configurato per le credenziali del chiamante) e solo poi
per livello.
Se, ad esempio, è applicato un plugin di rate limiting su una route "X" che limita
le richieste a 3 al secondo per tutti gli utenti, ma a livello globale l’utente "Y" in
particolare ha un limite di 7 richieste al secondo, questo utente "Y", pur facendo
richiesta alla route "X" può comunque eseguire 7 richieste al secondo, anche se
la route è un livello più specifico rispetto al livello globale.
Per limitare le richieste a 3 anche all’utente "Y" sulla route "X", se non si vuole
modificare il limite globale, occorre quindi riapplicare rate limiting specifico per
l’utente "Y" nella route "X".24 CAPITOLO 5. SVILUPPO DELLA PROOF OF CONCEPT
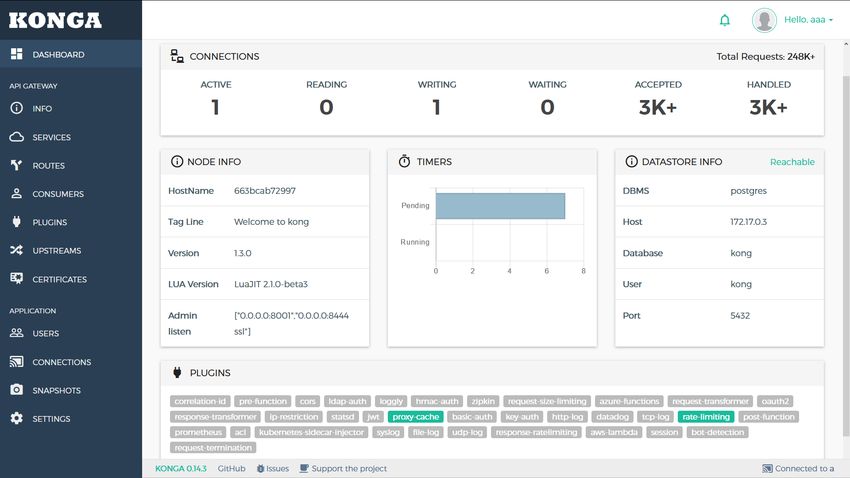
5.1.5 Konga
Konga [11] (vedi Figura 5.6) è un software open source che fornisce un’interfaccia
grafica pensata per visualizzare e modificare le configurazioni di Kong.
Nel contesto dello stage é stato utilizzato per modificare e monitorare le configurazioni
delle istanze di Kong presenti nella POC.
Figura 5.6: Dashboard di Konga
5.1.6 Locust
Locust [19] (vedi Figure 5.7 e 5.8) è uno strumento per l’esecuzione di test di carico
distribuiti il quale permette di simulare richieste da parte di utenti nel web.
È possibile programmare il comportamento dell’utente simulato in modo molto semplice
tramite uno script in Python che viene poi eseguito mentre si raccolgono dati sulle
prestazioni del servizio testato.
Figura 5.7: Logo Locust
Nel progetto di stage é stato utilizzato per soddisfare il requisito facoltativo dei test di
carico distribuiti.5.1. SOFTWARE E TECNOLOGIE UTILIZZATI 25
Figura 5.8: Interfaccia di Locust
5.1.7 Python
Python [22] (vedi Figura 5.9) è un linguaggio di programmazione ad alto livello,
orientato agli oggetti, adatto, tra gli altri usi, a sviluppare applicazioni distribuite,
scripting, computazione numerica e system testing.
Figura 5.9: Logo Python
Nel progetto di stage è stato utilizzato in modo marginale, in particolare per la scrittura
di piccoli servizi di test da containerizzare tramite Docker e per la configurazione di
Locust.
5.1.8 Consul
Consul [16] (vedi Figura 5.10) è una soluzione per implementare service discovery e
service mesh la quale offre tra le varie funzionalità quella di server DNS.
Con Consul è possibile creare una rete di istanze anche su macchine diverse che comu-
nicano tra loro, per essere sempre a conoscenza dei servizi scoperti da ogni istanza in26 CAPITOLO 5. SVILUPPO DELLA PROOF OF CONCEPT
ogni macchina.
Figura 5.10: Logo Consul
Nel contesto dello stage è stato utilizzato per fornire la funzionalità di service discovery
ai reverse proxy senza supporto a record SRV, e come DNS da utilizzare localmente su
Docker.
5.1.9 Registrator
Registrator [12] è un software che permette di registrare e deregistrare in tempo reale
su Consul i container in esecuzione su Docker e le relative porte esposte.
Nel progetto di stage è stato utilizzato in locale in accoppiata con Consul per fornire il
servizio DNS alla rete Docker.
5.1.10 PostgreSQL
Anche detto Postgres [21] (vedi Figura 5.11), è un RDBMS (Relational Database
Management System) open source che enfatizza l’estensibilità e la conformità agli
standard tecnici. È progettato per gestire una vasta gamma di carichi di lavoro.
Figura 5.11: Logo PostgreSQL
Nel contesto dello stage non ha avuto mai un ruolo principale, ma è stato utilizzato
soltanto containerizzato per conservare le configurazioni di Kong, in modo che queste
fossero unificate e condivise per l’intero cluster.5.1. SOFTWARE E TECNOLOGIE UTILIZZATI 27
5.1.11 Redis
Redis [23] (vedi Figura 5.12) è un archivio open source di strutture di dati in memoria,
utilizzato come database, cache e broker di messaggi.
Figura 5.12: Logo Redis
Nel contesto dello stage è stato utilizzato come cache per la sua velocità di accesso, in
particolare per conservare dati con accessi frequenti da condividere nei cluster, quali i
contatori richiesti per applicare rate limiting e le risposte dei servizi memorizzate in
cache.28 CAPITOLO 5. SVILUPPO DELLA PROOF OF CONCEPT
5.2 Proof of Concept
Sono state sviluppate due versioni della POC: la prima versione è eseguibile in locale con
il solo prerequisito di avere installato Docker; la seconda riprende la prima utilizzando
invece i servizi offerti da Amazon.
5.2.1 Proof of Concept locale tramite Docker
La struttura della POC locale è quella rappresentata in Figura 5.13.
Questa POC è composta da un gruppo di container Docker che riproducono un am-
biente con architettura a microservizi : sono presenti dei container necessari a fornire la
funzionalità DNS, dei container che fungono da microservizi di prova e le componenti
necessarie al funzionamento di Kong.
Figura 5.13: POC in locale con Docker
In particolare le componenti sono:
∗ il cluster di container che eseguono Kong, componente principale della POC;
∗ un container per l’interfaccia grafica di amministrazione Konga, utilizzata per
configurare Kong;
∗ un container Postgres, database nel quale sono contenute le configurazioni
condivise per l’intero cluster di istanze di Kong;
∗ un container Redis utilizzato per memorizzare i contatori delle richieste in modo
da effettuare rate limiting condiviso mantenendo buone prestazioni grazie alla
sua velocità di accesso;
∗ l’accoppiata di container Consul e Registrator:Puoi anche leggere

















































