Analisi delle prestazioni di una piattaforma Open Source per Cloud Computing - Dessert
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica tesi di laurea specialistica Analisi delle prestazioni di una piattaforma Open Source per Cloud Computing Anno Accademico 2011-2012 Relatore: Ch.mo Prof. Domenico Cotroneo Correlatori: Ch.mo Ing. Flavio Frattini Ch.mo Ing. Vittorio Manetti Candidato: Danilo Maccariello matr. 885/498
Indice
Introduzione 5
Capitolo 1. Cloud Computing 8
1.1 Cos’è il Cloud Computing 8
1.2 Livelli del Cloud Computing 9
1.2.1 Modelli di Servizio Cloud Computing 11
1.2.2 Software as a Service 11
1.2.3 Platform as a Service 12
1.2.4 Infrastructure as a Service 13
1.3 Modelli di Deployment: Public, Private e Hybrid Clouds 14
Capitolo 2. CloudStack 17
2.1 Caratteristiche Generali 17
2.2 Architettura di CloudStack 18
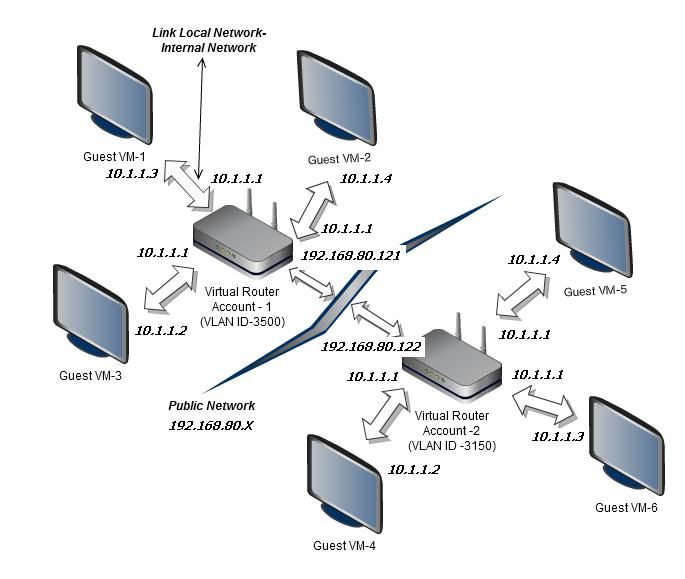
2.3 Network Overview 19
2.3.1 Basic Network 20
2.3.2 Advanced Network 21
2.4 System VM 23
2.5 Hypervisor Kernel-Based Virtual Machine (KVM) 24
2.6 CloudStack API 26
2.6.1 Come usare le API CloudStack 26
2.7 Installazione CloudStack 28
Capitolo 3. Design of Experiment 31
3.1 Identificazione e formulazione del problema 31
3.2 Testbed 32
3.3 Scelta dei fattori e dei livelli 33
3.4 Scelta del Piano Sperimentale 34
3.5 Esecuzione sperimentale 36
3.6 Regressione lineare 38
3.7 Allocazione della variazione 39
3.8 ANOVA 41
3.9 Analisi dei risultati 43
III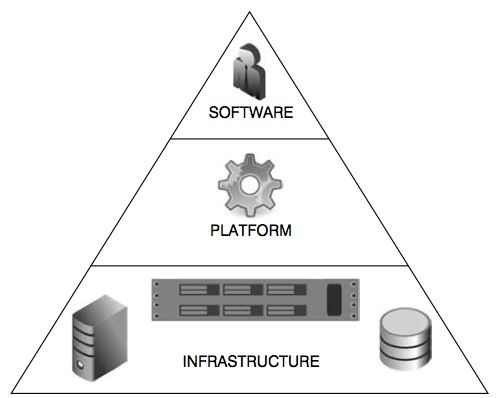
Conclusioni e sviluppi futuri 47
Appendice A. Dettagli installazione CloudStack 49
A.1 Requisiti di sistema 49
A.2 Preparazione sistema operativo 50
A.3 Installazione Management Server 51
A.4 Installazione e configurazione del DataBase 52
A.5 Preparazione NFS Shares 54
A.6 Installazione CloudStack Agent su un KVM Host 57
A.7 Provisioning Infrastructure 58
Appendice B. Derivazione partizione Sum of Square Total (SST) 62
Bibliografia 64
IV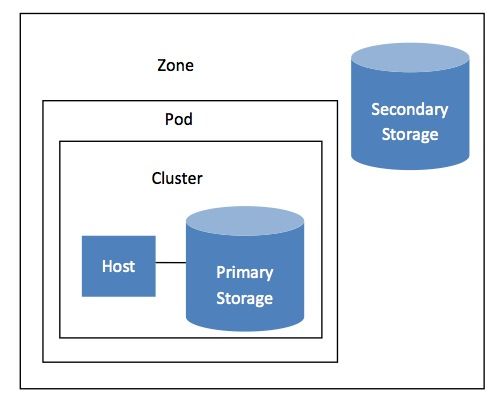
Introduzione
Nonostante la diffusione che ha avuto il Cloud Computing negli ultimi anni, darne una
definizione univoca è ancora difficile.
Fonti autorevoli considerano il termine privo di significato e sono stati fortemente contrari
al suo utilizzo [2]. Tuttavia, la mancanza di un preciso significato dell’espressione “Cloud
Computing” è significativa e ne costituisce un punto di forza, consentendo di includere in
essa sia gli aspetti tecnico-implementativi che di utilizzo.
Il Cloud Computing ha il potenziale per trasformare una grande parte del settore IT.
Infatti, si eliminano tutti i problemi delle aziende tradizionali le cui applicazioni sono da
sempre molto complicate e costose ed è necessario un intero team di esperti per installarle,
configurarle, testarle, eseguirle, proteggerle e aggiornarle. Con il Cloud Computing non si
richiede al cliente di gestire hardware e software, ma ad occuparsene è un fornitore
esperto. L'infrastruttura condivisa offre un funzionamento simile a quello dei servizi
pubblici: l'utente paga solo le funzionalità necessarie, gli aggiornamenti sono automatici e
la scalabilità verso l'alto o verso il basso è semplice.
Il calcolo scientifico richiede un numero sempre crescente di risorse per ottenere risultati
in un arco di tempo ragionevole. Negli ultimi dieci anni solo i più grandi progetti di
ricerca sono stati in grado di permettersi costosi supercomputer mentre altri progetti sono
stati costretti a optare per più economiche risorse. A tale scopo il Cloud Computing
propone un'alternativa in cui le risorse non sono più ospitate dalle strutture di calcolo del
ricercatore, ma in leasing da grandi centri dati solo quando necessario.
Il Cloud Computing si basa sui risultati di vari settori di ricerca, come la Service-Oriented-
Architecture (SOA), Grid Computing e la tecnologia di virtualizzazione. La
virtualizzazione delle risorse è al centro della maggior parte delle architetture Cloud e
5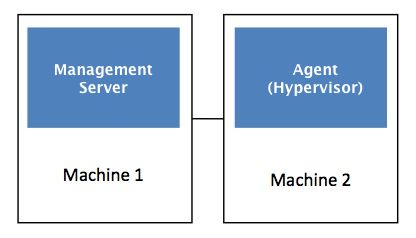
consente un’astrazione delle risorse fisiche, costituite da server, Data Stores e network.
Ad esempio è possibile generare dinamicamente una determinata piattaforma per una
specifica applicazione solo quando è necessario.
Le applicazioni basate sul Cloud sono operative in pochi giorni e sono accessibili da un
qualsiasi browser. Ecco perché Big Vendors e Users sono sempre più interessati alla
tecnologia del Cloud Computing e, quindi, diventa cruciale la valutazione delle prestazioni
e l’identificazione dei principali problemi di performance durante l’utilizzo di questa
tecnologia.
L’obiettivo di questo lavoro di tesi è la valutazione delle prestazioni di una piattaforma
open source per il Cloud Computing di tipo Infrastructure as a Service (si veda paragrafo
1.2.4). L’installazione della piattaforma è stata eseguita presso il SESM a Giugliano, un
centro di ricerca e sviluppo precompetitivo di aziende Finmeccanica SELEX Sistemi
Integrati e SELEX Galileo, attivo nel campo della difesa, gestione del traffico aereo e
logistica di grandi apparati. La sperimentazione è avvenuta sulla piattaforma Open Source
CloudStack utilizzata da un gran numero di Service Providers e da molte aziende dato che
offre servizi di Cloud Public, servizi di Cloud Privato e Ibrido. Le istanze di CloudStack
girano su una Infrastruttura fisica utilizzando il software Open Source di virtualizzazione
KVM (si veda paragrafo 2.5).
In questo elaborato focalizzeremo la valutazione delle prestazioni sui tempi necessari per
l’acquisizione delle risorse fisiche per ottenere il deploy di una Virtual Machine.
Effettueremo la rilevazione dei tempi attraverso un software scritto in JAVA,
prepareremo attraverso un Piano Fattoriale Completo con Replicazione dei dati consistenti
sui quali eseguiremo un’analisi statistica che ci permetterà di determinare se un fattore ha
un effetto significativo o se la differenza osservata è semplicemente dovuta a variazioni
causali causate da errori di misura e parametri che non sono stati controllati.
6Inserire il titolo della tesi di laurea come intestazione
7Capitolo 1
Cloud Computing
In questo capitolo viene introdotto il paradigma del Cloud Computing (paragrafo 1.1) e
illustrate le classificazioni dei servizi di Cloud in base al servizio offerto (paragrafo 1.2) e
dalla prospettiva amministrativa/organizzativa (paragrafo 1.3). La prima classificazione è
orientata verso le caratteristiche funzionali, mentre la prospettiva organizzativa opera una
distinzione in base al grado di separazione tra utenti e fornitori dei servizi.
1.1 Cos’è il Cloud Computing
Anche se non c'è una definizione standard di Cloud Computing, i suoi concetti di base così
come i suoi obiettivi generali sono indiscussi: il Cloud Computing utilizza la
virtualizzazione e il Web moderno per fornire dinamicamente le risorse e servizi di vario
genere. Questi servizi dovrebbero essere disponibili in modo affidabile e scalabile in modo
che i consumatori possano utilizzarli esplicitamente su richiesta o semplicemente come e
quando richiesto. Dal punto di vista del Provider Cloud, ciò implica di solito un multi-
tenant e un uso basato su modello di fatturazione. Quindi, possiamo asserire che il Cloud
Computing utilizza risorse virtualizzate di calcolo, di Storage e tecnologie web moderne,
inoltre offre network-centric, infrastrutture IT, piattaforme e applicazioni come servizi on-
demand. Questi servizi sono fatturati su base utilizzo e questa definizione non specifica se
i servizi sono forniti da un sistema distribuito o un singolo server ad alte prestazioni, ad
esempio un mainframe. Questo è in contrasto con il Grid Computing che utilizza sempre
un sistema distribuito.
Di solito, i servizi Cloud possono anche contare su una infrastruttura distribuita, ma la loro
8gestione è tipicamente determinata in una zona centrale (e di proprietà).
Questa è un'altra differenza tra Cloud Computing e Grid Computing in cui i nodi sono di
solito distribuiti e autonomi.
Un altro fattore determinante per il Cloud Computing è il suo impatto economico. Grazie
al suo stretto orientamento ai servizi e all'utilizzo di standard Web e Internet, il Cloud
Computing è ben posizionato per vari tipi di applicazioni.
Una definizione spesso citata del Cloud Computing è stata data dal National Institute of
Standards and Technology (NIST) negli Stati Uniti. Si specificano cinque caratteristiche
essenziali, tre modelli di servizio differenti, e quattro modelli di deployment diversi. Le
caratteristiche essenziali sono:
• On-demand self-service: i servizi possono essere forniti unilateralmente e su
richiesta per i consumatori senza richiedere l'interazione umana.
• Broad Network Access: i servizi sono disponibili in rete in tempo reale attraverso
meccanismi standard.
• Messa in comune delle risorse: le risorse sono messe in comune per consentire la
messa a disposizione di servizi a più utenti (modello multi-tenant).
• Elasticità: per il consumatore, le risorse sembrano essere illimitate.
• Servizio di misura: i servizi sfruttano una capacità di misurazione quantitativa e
qualitativa in modo che la fatturazione in base all'utilizzo e validazione della
qualità del servizio sia possibile.
1.2 Livelli del Cloud Computing
Nella descrizione di sistemi di calcolo locali (PS, workstation, server) si è soliti utilizzare
una rappresentazione a tre livelli. Più in basso, c’è il livello hardware “fisico” con i suoi
processori, chip di memoria, unità di disco, schede di rete ed altri components che
prendono il nome di Infrastruttura. In secondo luogo, nello strato intermedio, si dispone di
un sistema operativo (ad esempio Microsoft Windows) che interagisce con l'hardware e
fornisce un ambiente coerente per il software in esecuzione e in via di sviluppo
(utilizzando Visual Basic o Microsoft Access, per esempio), se lo si desidera possiamo
chiamare questo strato piattaforma. E, infine, in alto, ci sono applicazioni di terze parti che
è possibile utilizzare nel nostro lavoro e che possiamo chiamare software.
9Figura 1.1 – Un semplice modello di piramide a tre livelli.[2]
Questo modello a tre livelli può essere applicato anche al Cloud Computing, ma ci sono
alcune differenze fondamentali:
• Le applicazioni software non sono applicazioni desktop sono web-based in modo
che possano essere utilizzate in qualsiasi browser web e su qualsiasi sistema
operativo.
• Le piattaforme sono costruite appositamente su ambienti di sviluppo software che
sono ospitati su Internet piuttosto che sul vostro computer desktop in modo che per
creare, testare e distribuire applicazioni web tutto ciò che serve è un browser web.
• Elementi di infrastruttura (server, Storage, larghezza di banda, la potenza di
elaborazione, ecc.) sono forniti da un terzo, ma è possibile accedere e utilizzare
queste risorse di calcolo come se fossero installati sulla propria rete aziendale.
101.2.1 Modelli di Servizio Cloud Computing
Diversi tipi di Cloud Computing vengono forniti “come un servizio” (dall’inglese as a
Service) per i consumatori, e la maggior parte di essi rientrano in una o più delle tre
categorie: Software as a Service, Platform as a Service e Infrastructure as a Service.
Capacità di calcolo sono in affitto e le risorse hardware o software non sono acquistate a
titolo definitivo da parte del consumatore.
1.2.2 Software as a Service
Applicazioni software che rispondono direttamente all'utente finale appartengono al livello
della SaaS. Questo modello consente di liberare i clienti dalla necessità di installare il
software in locale e quindi di fornire le risorse necessarie agli stessi. Vista dal punto di
vista dell'architettura Cloud, l'offerta SaaS può essere sviluppata e gestita dal fornitore
sulla base di un PaaS o IaaS che offre.
Organizzazione Servizi Cloud Descrizione
Adobe Photoshop Express Online image processing
Google Google Docs OnLine office application
Google Google Maps API Servizio per l’integrazione di mappe
e geo-information
Google OpenSocial Interfaccia di programmazione
generica per l'integrazione dei social
network nelle applicazioni
OpenIDFoundation OpenID Sistema distribuito per la gestione
dell’user identity
Microsoft Windows Live Online office applications
Salesforce Salesforce.com Extensible CRM system
Tabella 1.1 – Software as a Service : offerte e tools
11Tra le offerte SaaS, si possono distinguere i servizi applicativi, le cui funzionalità si
basano principalmente su un unica, semplice applicazione, e vere e proprie, applicazioni
complesse. Gli utenti finali possono accedere direttamente ad alcuni dei servizi applicativi,
come ad esempio Google Maps.
Altri servizi sono forniti come componenti, per esempio, OpenID per l’user management o
OpenSocial per l’integrazione dei social network nelle applicazioni. Altre SaaS offerte e
tools in Tabella 1.1.
1.2.3 Platform as a Service
I servizi Cloud forniti sullo strato PaaS di solito non sono destinati ai semplici utenti, ma
piuttosto agli sviluppatori. Si tratta di ambienti di programmazione e di ambienti di
esecuzione in cui il software proprietario scritto in un linguaggio di programmazione
specifico può essere eseguito.
Esempi tipici di questi ambienti di programmazione sono Django Framework o Sun
Caroline. Si estendono linguaggi di programmazione esistenti, ad esempio, con l'aggiunta
di librerie e di classi. Ben noti esempi di ambienti di esecuzione cloud-based sono Google
App Engine, Azure di Microsoft o Smart Joyent. Google App Engine supporta la
creazione e l'esecuzione di applicazioni Web scritte in Python o Java.
Un esempio di come i servizi provenienti da diversi strati architetturali interagiscono o
sono costruiti uno sopra l'altro, è l’ambiente di programmazione AppScale, una re-
implementazione open source di Google App Engine. AppScale implementa le
funzionalità utilizzando il servizio di infrastruttura di Eucalypto.
L'intercambiabilità delle parti della pila sopra descritta, che è dovuta alla re-
implementazione in progetti open source, non solo favorisce alternative tecniche, ma
potrebbe, in alcuni casi, impedire agli utenti di diventare troppo dipendenti da un
particolare fornitore. Tabella 1.2 mostra e descrive ulteriori offerte e tools PaaS.
12Organizzazione Servizi Cloud Descrizione
Google App Engine Ambiente d’esecuzione scalabile
per le Web applications
Microsoft Azure Ambiente per Programmare e
Eseguire applicazioni Windows
Microsoft Windows SkyDrive Piattaforma per la sincronizzazione
dei dati tra terminali eterogenei
NetSuite SuiteFlex Business Process Development
Tool di NetSuite
Salesforce Force.com Sviluppo e gestione di Salesforce
“CRM extensions”
Sun Project Caroline Sviluppo e gestione di applicazioni
Web Distribuite
Zoho Zoho Creator Sviluppo e gestione di applicazioni
Web Database-Based
Facebook Facebook Platform Ambiente per applicazioni di
Facebook Social Network
Tabella 1.2 – Platform as a Service : offerte e tools.
1.2.4 Infrastructure as a Service
Lo strato IaaS offre agli utenti una visione astratta dell'hardware cioè computer, sistemi di
memoria di massa, reti, ecc. Questo è ottenuto fornendo un'interfaccia utente per la
gestione di un numero di risorse con il resource sun-layer (RS ). Esso consente agli utenti
di assegnare un sottoinsieme di risorse per il loro uso. Funzioni tipiche disponibili
dall'interfaccia utente includono la creazione o la rimozione di immagini del sistema
operativo, scalando capacità richieste, o definire le topologie di rete. Inoltre, l'interfaccia
13fornisce le funzionalità necessarie per le operazioni, quali l'avvio e l'arresto di istanze del
sistema operativo.
I sistemi IaaS includono tipicamente alcune o tutte le seguenti caratteristiche:
• una scelta di macchine virtuali già pronte con preinstallati i sistemi operativi, tra
cui numerose versioni di Windows, Linux e Solaris;
• una scelta di Appliance virtuali - macchine virtuali con gruppi specifici di software
preinstallato;
• possibilità di memorizzare copie di dati particolari in luoghi diversi in tutto il
mondo per effettuare il download dei dati il più velocemente possibile;
• strumenti software per eseguire calcoli complessi con grandi array di server
virtuali che lavorano in parallelo sullo stesso problema;
• capacità di aumentare o diminuire manualmente le risorse di calcolo assegnate
mediante un browser Web con le nuove esigenze;
• la capacità di scalare automaticamente le risorse di calcolo in risposta ad aumenti e
diminuzioni di utilizzo delle applicazioni.
La capacità elastica di sistemi IaaS rende possibile il Computing on-demand, ma sono i
bassi costi e il modello pay-per-use che li rendono attraenti per le imprese. La Tabella 1.3
mostra e descrive ulteriori offerte e tools IaaS.
1.3 Modelli di Deployment: Public, Private e Hybrid Clouds
Un Public Cloud (chiamato anche “Cloud esterno”) comprende tutte le offerte di Cloud in
cui i Providers e i potenziali utenti non fanno parte della stessa unità organizzativa. I
fornitori rendono la loro nuvola accessibile al pubblico e di solito offrono un portale Web
self-service in cui gli utenti possono specificare la portata desiderata dei servizi. I servizi
sono fatturati sulla base delle risorse effettivamente utilizzate nel periodo corrispondente.
In contrasto con questo modello, i Providers e gli utilizzatori di un cosiddetto Private
Cloud (indicato anche come “Cloud interno” o “IntraCloud”) appartengono alla stessa
unità organizzativa.
La ragione principale per cui un Private Cloud sarebbe preferibile ad un Public Cloud di
solito è la sicurezza infatti trattano informazioni sensibili, come ad esempio i piani di
progettazione o i dati di produzione, che si suppone, essere meglio protetti e le misure di
14regolamentazione, ad esempio per quanto riguarda i dati personali sulla salute, che in
questo modo possono essere meglio rispettate.
Quindi i servizi in un Private Cloud operano sulle risorse appartenenti all'organizzazione,
alcuni sviluppatori cercano di realizzare le interfacce utilizzando la stessa tecnologia del
Public Cloud.
Organizzazione Servizi Cloud Descrizione
Amazon Elastic Compute Cloud (EC2) Virtual servers
Cloud.com CloudStack Open source IaaS
University of Chicago Nimbus Open source IaaS
Openflow OpenFlow Local network simulation
OpenNebula Project OpenNebula Open source IaaS
Eucalyptus Systems Eucalyptus Open source IaaS
The Openstack Cloud OpenStack Open Source IaaS
Software
Joyent BingoDisk Mass storage
Amazon Simple Storage Service (S3) Mass storage
Tabella 1.3 – Infrastructure as a Service: offerte e tools.
L'obiettivo è assicurarsi che gli strumenti che sono disponibili nel Public Cloud possano
essere utilizzati anche nel Private Cloud, e inoltre mantenere la porta aperta per poter
scalare le applicazioni che sono state sviluppate per il Private Cloud per un uso successivo
nel Public Cloud.
Scenari in cui ci sono sia servizi del Public Cloud e sia servizi del Private Cloud, sono
15indicati come Hybrid Cloud. Con un Hybrid Cloud, alcune funzionalità sono di solito
trasferite al Public Cloud, mentre il normale funzionamento si basa su risorse private
dell'organizzazione. Secondo le considerazioni di sicurezza di cui sopra, i cambiamenti
devono essere tali che soltanto funzioni o dati non critici vengono trasferiti.
La Figura 1.2 mostra come i tre tipi, cioè Public Cloud, Private Cloud e Hybrid Cloud
sono posizionati l'uno rispetto all'altro.
Infine con il Community Cloud abbiamo un’infrastruttura per l'uso esclusivo da parte di
una determinata comunità di consumatori, da parte delle organizzazioni che hanno
condiviso ad esempio la missione, i requisiti di sicurezza, la politica e le misure di
regolamentazione. Esso può essere di proprietà, gestito da una o più delle organizzazioni
della comunità, da un terzo o da una combinazione di essi.
Figura 1.2 – Public Cloud, Private Cloud e Hybrid Cloud
16Capitolo 2
CloudStack
In questo capitolo descriveremo la piattaforma di Cloud Computing Open Source
CloudStack. Le caratteristiche generali della piattaforma sono descritte al paragrafo 2.1 e
l’architettura al 2.2. Sono quindi illustrati i tipi di rete che è possibile creare (Basic e
Advanced), che CloudStack mette a disposizione e descriveremo le Virtual Machine di
sistema che CloudStack utilizza per il Management interno.
Inoltre essendo una Piattaforma di tipo Cloud Computing utilizzerà un Hypervisor, quindi
alla fine del capitolo descriveremo KVM (Kernel-Based Virtual Machine) uno degli
Hypervisor supportati da CloudStack.
2.1 Caratteristiche Generali
CloudStack è una piattaforma software Open Source di tipo IaaS in gradi di creare
infrastrutture pubbliche, private e ibride. CloudStack gestisce la rete, lo Storage e i nodi di
calcolo che costituiscono un’infrastruttura Cloud.
Gli utenti tipici sono fornitori di servizi e le imprese.
Con CloudStack è possibile:
• configurare un servizio on-demand. I fornitori di servizi possono vendere istanze di
macchine virtuali, volumi di archiviazione e configurazioni di rete.
• creare un Cloud privato per l’utilizzo da parte dei dipendenti e la gestione delle
macchine virtuali come se fossero macchine fisiche.
17CloudStack lavora con una varietà di Hypervisor (KVM, VMware, vSphere e Citrix
XenServer) ed è in grado di gestire decine di migliaia di server installati in più data center
geograficamente distribuiti. CloudStack configura automaticamente la messa in rete di
ogni macchina virtuale Guest e le impostazioni di archiviazione, gestisce internamente un
pool di Appliance virtuali per sostenere la stessa nuvola e che offrono servizi come
firewall, Routing, DHCP, accesso VPN, desktop remoto e Storage. L'ampio uso di
Appliance virtuali semplifica notevolmente l'installazione, la configurazione e la gestione
continua di una distribuzione Cloud.
Offre un Administrator WEB-interface utilizzata per il Provisioning e la gestione del
Cloud e una User WEB-interface è utilizzata per l’esecuzione di macchine virtuali e
gestione dei Templates. La User WEB-interface può essere personalizzata in modo da
riflettere il fornitore del servizio.
Inoltre fornisce API che consentono l’accesso a tutte le funzionalità di gestione
disponibili.
2.2 Architettura di CloudStack
Un’installazione di CloudStack si compone di due parti il Management Server e la Cloud
Infrastructure che viene gestita. Un’installazione base consiste di una macchina dove
verrà installato il Management Server e una macchina dove verrà installato l’Agent e
l’Hypervisor.
Figura 2.1 – Installazione base CloudStack.
18Quando si imposta e gestisce un Cloud sono messe a disposizione delle risorse, come
Host, dispositivi di Storage, ed indirizzi IP. Il Management Server si occupa del
management di tali risorse.
Il Management Server:
• Fornisce le WEB-interface per l'amministratore e gli utenti finali.
• Fornisce le API per la piattaforma CloudStack.
• Gestisce l'assegnazione di indirizzi IP pubblici e privati.
• Gestisce Snapshot, Templates e immagini ISO, possibilmente replicandole sui
Data Center.
• Fornisce un unico punto di configurazione per il Cloud.
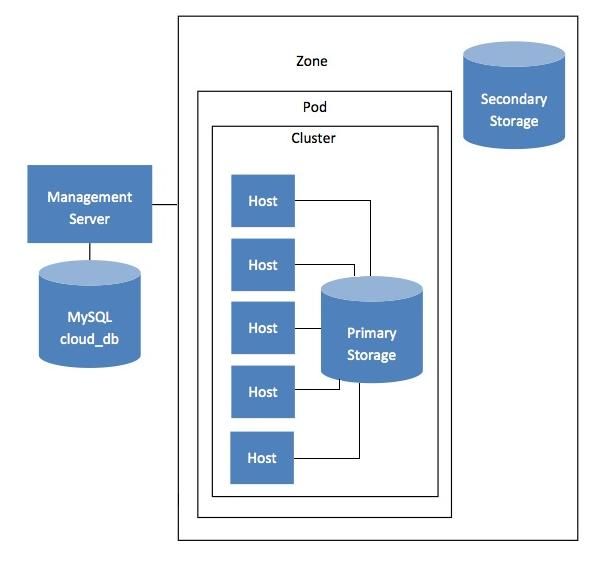
Come suggerisce il nome, il Management Server è lì per gestire qualcosa - una o più zone
(tipicamente, Data Center), contenenti i computer Host in cui macchine virtuali Guest
verranno eseguite. L'infrastruttura Cloud è organizzata come segue:
• Zona: In genere, una Zona è equivalente a un Data Center unico. Una Zona è
costituita da uno o più Pods e Storage secondario.
• Pod: un Pod di solito include un layer-2 switch e uno o più Cluster.
• Cluster: Un Cluster è costituito da uno o più Host e Storage Primario.
• Host: un singolo nodo di calcolo all'interno di un Cluster.
• Primary Storage: è associato ad un Cluster, e memorizza i volumi del disco per
tutte le macchine virtuali in esecuzione su Host nello stesso Cluster.
• Secondary Storage: è associato ad una Zona, memorizza i Templates, le immagini
ISO, e gli Snapshots del volume del disco.
Figura 2.2 – Organizzazione CloudStack. [4]
192.3 Network Overview
CloudStack offre due tipi di Network: Basic e Advanced. Basic Network prevede una rete
unica condivisa. L’isolamento è garantito attraverso i Security-Group (filtraggio indirizzi
IP). Tutti i Guests assegnati ad una zona condividono una singola rete.
L’Advanced Network offre invece la massima flessibilità ma richiede più passaggi di
configurazione.
Ciascuna Zona può essere Basic o Advanced, una volta che si effettua la scelta per una
zona questa resterà tale per l’intero ciclo di vita.
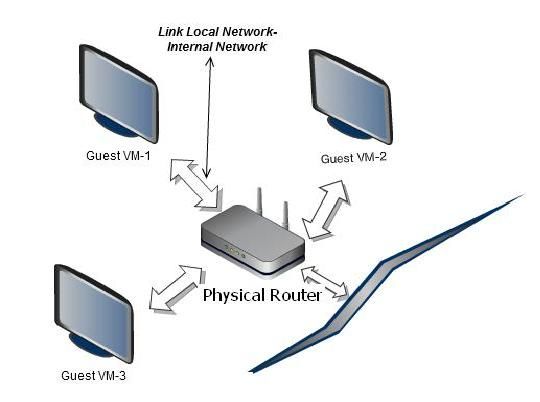
2.3.1 Basic Network
Quando la Basic Network viene utilizzata, ci può essere una sola rete fisica nella zona.
Tale rete fisica svolge tre tipi di traffico:
• Guest: quando gli utenti finali eseguono VMs, queste generano traffico guest. Ogni
Pod in una Zona di tipo Basic è un Broadcast Domain, e quindi ogni Pod ha un
diverso intervallo di indirizzi IP per la rete Guest. L’amministratore deve
configurare l’intervallo di indirizzi IP per ogni Pod.
• Management: quando le risorse interne di CloudStack comunicano tra loro, generano
Management Traffic. Ciò include la comunicazione tra Host, macchine virtuali (VM
di sistema utilizzate da CloudStack per diverse attività), e qualsiasi altro componente
che comunica direttamente con il Management Server di CloudStack. È necessario
configurare l'intervallo di indirizzi IP per le macchine virtuali di sistema.
• Storage: il traffico tra i server di Primary e Secondary Storage.
In una Basic Network, la configurazione della rete fisica è abbastanza semplice. Avremo
solo bisogno di configurare una rete ospite per trasportare il traffico generato da macchine
virtuali guest. Quando la Basic Network viene utilizzata, CloudStack assegnerà gli
indirizzi IP prendendoli dal CIDR del Pod. L’amministratore deve aggiungere un
intervallo di indirizzi IP nel Pod per tale scopo.
20Figura 2.3 – Basic Network.
2.3.2 Advanced Network
Quando viene utilizzata l’ Advanced Network, ci possono essere più reti fisiche nella
Zona. Ogni rete fisica può portare uno o più tipi di traffico. I tipi di traffico in una
Advanced Network sono:
• Guest: quando gli utenti eseguono macchine virtuali, generano traffico ospite. Le
Guest VM comunicano tra loro attraverso una rete che può essere definita come
guest network. Questa rete può essere isolata o condivisa. In una guest network
isolata, l'amministratore deve prenotare un range di VLAN per fornire l'isolamento
per la rete. In una guest network condivisa, tutte le macchine virtuali guest
condividono una singola rete. In questo caso, è possibile fornire l'isolamento
utilizzando tecniche di isolamento di tipo Layer-3, come ad esempio i Security
Group.
• Management: quando le risorse interne comunicano tra loro generano traffico di
tipo Management. Ciò include la comunicazione tra Host, macchine virtuali (VM
di sistema utilizzate da CloudStack per diverse attività nel Cloud), e qualsiasi altro
componente che comunica direttamente con il Management Server di CloudStack.
È necessario configurare l'intervallo di indirizzi IP per le macchine virtuali di
sistema da utilizzare.
• Public: Traffico pubblico viene generato quando le macchine virtuali nel Cloud
accedono a Internet. IPs accessibili al pubblico devono essere assegnati per questo
21scopo. Gli utenti finali possono utilizzare l'interfaccia utente CloudStack per
acquisire questi IP e per implementare NAT tra la rete ospite e la rete pubblica.
• Storage: Il traffico tra i server di Primary e Secondary Storage.
Quando viene utilizzata un’Advanced Network l'amministratore può creare reti aggiuntive
per l'utilizzo da parte degli ospiti. Queste reti possono estendersi nella zona e essere a
disposizione di tutti gli account, oppure possono essere definite nell'ambito di un unico
account, nel qual caso solo l'account denominato può creare gli ospiti che si attaccano a
queste reti.
CloudStack mette a disposizione un indirizzo IP pubblico per ogni account da utilizzare
come indirizzo IP sorgente NAT. Gli utenti possono richiedere ulteriori indirizzi IP
pubblici. L’amministratore deve configurare uno o più intervalli di indirizzi IP Pubblici
per tale scopo.
Figura 2.4 – Advanced Network.
222.4 System VM
CloudStack utilizza diversi tipi di macchine virtuali di sistema per eseguire le attività nel
Cloud. Tuttavia, l'amministratore dovrebbe essere a conoscenza di queste e del loro ruolo
per contribuire a problemi di debug. Le System VM sono:
Ø Console Proxy VM: è un tipo di macchina virtuale di sistema che ha il ruolo di
presentare tramite interfaccia utente web il Desktop remoto di una Guest VM.
Dall’User Interface cliccando sull'icona di una console viene visualizzata una nuova
finestra. Il codice AJAX viene scaricato da quella finestra dall'indirizzo IP pubblico
della Console Proxy VM. Infatti c'è esattamente un indirizzo IP pubblico assegnato
alla Console Proxy VM e quindi la Console Proxy si connette alla porta VNC della
VM richiesta. Quindi non c’è alcuna necessità di abilitare VNC all’interno di una
Guest VM.
Ø Virtual Router: è uno dei fornitori di servizi di uso più frequente in CloudStack.
L'utente finale non ha accesso diretto al router virtuale. Gli utenti possono eseguire
il ping del router virtuale e intraprendere azioni che incidono su di esso (ad esempio
impostando il Port Forwarding), ma gli utenti non hanno un accesso di tipo SSH.
Non esiste un meccanismo per l'amministratore per accedere al router virtuale, ma
possono essere riavviati dagli amministratori, questo interromperà l'accesso del
pubblico alla rete e ad altri servizi.
Un test fondamentale per il debug dei problemi di rete è quello di tentare di eseguire
il ping verso il router virtuale da una macchina virtuale Guest.
Ø Secondary Storage VM: fornisce un processo in Background che si occupa di una
serie di attività di archiviazione secondarie: il download di un nuovo template per
una Zona, la copia di template tra le zone, e lo snapshot backup.
L'amministratore può accedere alla Secondary Storage VM, se necessario.
232.5 Hypervisor Kernel-Based Virtual Machine (KVM)
Prima di aggiungere un Host alla configurazione CloudStack, è necessario installare un
Hypervisor sull'Host. CloudStack è in grado di gestire gli Host che eseguono macchine
virtuali su una varietà di Hypervisor tra cui KVM.
La virtualizzazione ha fatto molti progressi negli ultimi dieci anni, soprattutto a causa
dello sviluppo di una miriade di Open-Source Hypervisor. Questo progresso ha quasi
eliminato le barriere tra sistemi operativi e ha aumentato notevolmente l'utilizzo di server
potenti, portando un beneficio immediato alle aziende. Due degli approcci più comuni per
software di virtualizzazione sono Full Virtualization e Paravirtualization.
In Full-Virtualization, un livello, comunemente chiamato Hypervisor o Monitor della
macchina virtuale, esiste tra i sistemi operativi virtualizzati e l'Hardware. Questo strato fa
un Multiplexing delle risorse di sistema tra le concorrenti istanze del sistema operativo.
La Paravirtualization è diversa in quanto l'Hypervisor funziona in modo più cooperativo,
perché ogni sistema operativo Guest è consapevole del fatto che è in esecuzione in un
ambiente virtualizzato.
Entrambi gli approcci hanno vantaggi e svantaggi. Il vantaggio principale del metodo di
Paravirtualization è che permette la virtualizzazione più veloce possibile ed è basata su
Software, a costo di non supportare sistemi operativi proprietari. Approcci di Full-
Virtualization, ovviamente, non hanno questa limitazione, tuttavia, sistemi di Full-
Virtualization sono pezzi molto complessi di software.
VMware, una soluzione di virtualizzazione commerciale, è un esempio di Full-
Virtualization. La Paravirtualization è fornita da Xen, User-Mode Linux (UML) e altri.
Con l'introduzione di virtualizzazione basata su Hardware, queste linee sono sfocate. Con
l'avvento di Intel VT e AMD SVM, la scrittura di un Hypervisor è diventata molto più
facile, ed è ora possibile godere dei vantaggi della Full-Virtualization, mantenendo la
complessità dell'Hypervisor al minimo.
KVM è un relativamente nuovo e semplice, ma potente, Virtualization Engine, che ha
trovato la sua strada nel Kernel di Linux. Poiché utilizza la virtualizzazione basata su
Hardware non richiede modifiche ai sistemi operativi Guest, e, quindi, è in grado di
supportare qualsiasi piattaforma, dato che viene distribuito su un processore supportato.
Gli sviluppatori KVM hanno messo a punto un metodo che ha trasformato il Kernel di
Linux in un Hypervisor. Ciò è stato possibile attraverso un metodo minimamente invasivo
24attraverso lo sviluppo di KVM come modulo del Kernel. L'integrazione della funzionalità
di Hypervisor in un Linux Kernel come modulo caricabile è in grado di semplificare la
gestione e migliorare le prestazioni di ambienti virtualizzati.
Secondo questo modello, ogni macchina virtuale è un processo regolare Linux.
Tradizionalmente, un normale processo di Linux ha due modalità di esecuzione: Kernel e
utente. La modalità utente è la modalità di default per le applicazioni, e un'applicazione va
in modalità Kernel quando si richiede un servizio dal Kernel, come la scrittura sul disco
rigido. KVM aggiunge una terza modalità, la modalità Guest. Processi in modalità Guest
sono processi che vengono eseguiti all'interno della macchina virtuale. La modalità Guest,
proprio come la modalità normale (non virtualizzata), ha il suo Kernel e il suo spazio
utente.
KVM fa uso di virtualizzazione Hardware per virtualizzare gli stati del processore, e la
gestione della memoria per la macchina virtuale viene gestita all'interno del Kernel.
L’I/O nella versione corrente viene gestito nello spazio utente, principalmente attraverso
QEMU.
2.6 CloudStack API
Le API CloudStack sono API di basso livello che sono state utilizzate per implementare
l’interfaccia utente.
La maggior parte delle chiamate API CloudStack sono asincrone e la chiamata ritornerà
immediatamente un identificativo del processo (ID). Questo ID può essere utilizzato per
determinare in seguito lo stato del lavoro.
Le API sono basate su architettura REST e consentono agli sviluppatori di creare soluzioni
per la gestione e integrazioni di sistemi. Supportano Post/Get e restituiscono risposte sia in
XML che in JSON.
Le API di CloudStack supportano tre tipi di accesso:
• Root Admin. L’accesso a tutte le funzionalità del Cloud tra cui sia la gestione delle
risorse virtuali che fisiche.
• Domain Admin. L’accesso alle sole risorse virtuali del Cloud che appartengono al
dominio dell’amministratore.
• User. L’accesso alle sole funzioni che consentono la gestione di istanze virtuali
dell’utente come Storage e Network.
252.6.1 Come usare le API CloudStack
Descriveremo come usare le API di CloudStack con riferimento particolare all’API
deployVirtualMachine che crea e automaticamente avvia una Virtual Machine con un
Service Offering, un Disk Offering ed un Template.
La richiesta risulterà composta dai seguenti campi:
Ø CloudPlatform API URL: entry point del servizio WEB API.
Ø Command: Il comando del servizio Web che tu vuoi eseguire.
Ø Parameters: Si specificano i parametri per il comando.
Nel nostro caso avremo una GETRequest del tipo:
1. http://ManagementSeverIP:8080/client/api
2. ?command=deployVirtualMachine
3. &serviceOfferingId=1
4. &diskOfferingId=1
5. &templateId=2
6. &zoneId=4
7. &hostId=5
8. &apiKey=miVr6X7u6bN_sdahOBpjNejPgEsT35eXqjB8CG20YI3yaxX
cgpyuaIRmFI_EJTVwZ0nUkkJbPmY3y2bciKwFQ
9. &signature=Lxx1DM40AjcXU%2FcaiK8RAP0O1hU%3D
La prima riga è la CloudPlatform API URL. La seconda fa riferimento al Command che si
vuole eseguire, nel nostro caso stiamo lanciando un Deploy di una Virtual Machine,
preceduto da un (?) che serve a separarlo dalla CloudPlatform API URL. Le righe 3-7
rappresentano i Parameters per il dato Command. Ogni singolo Parameter è formato dalla
coppia (campo=valore) ed è preceduto da una (&). Alla riga 8 abbiamo la user API Key
che identifica univocamente l’account mentre alla riga 9 la signature che serve ad
autenticare l’user account per l’utilizzo delle API.
26Per ottenere la Signature occorre avere una API Key e una Secret Key fornita
dall’amministratore della CloudPlatform. Per capire meglio come otteniamo la Signature
dividiamo la nostra richiesta in:
• Base URL: URL del Management Server.
http://ManagementServerIP:8080
• API Path: Path all’API Servlet che processa la richiesta.
/client/api?
• Command String: comprende i Parameters e la API Key che identifica l’account.
La signature si ottiene:
1. Per ogni coppia campo-valore nel Command String effettuare una URL encode dato
che faranno parte di una GETRequest-HTTP.
2. Rendere minuscolo ciascun carattere della Command String e ordinare
alfabeticamente i campi in essa contenuti.
3. Con la Command String ottenuta eseguire HMAC SHA-1 hashing algorithm con la
Secret Key associata all’account e fornita dall’amministratore di CloudStack ed
effettuare sulla stringa ottenuta un Base 64 encoding.
Inviata la GetRequest, si ottiene una risposta in formato XML che salveremo in un file e
da cui tramite un parser otterremo il valore del tag JobId che identifica univocamente il
processo di deploy VM.
Con JobId, è possibile controllare periodicamente lo stato del processo di deploy
chiamando l’API queryAsyncJobResult. L’API restituirà nel tag JobStatus tre possibili
valori interi:
Ø 0 - Processo in corso. Quindi continueremo a interrogare periodicamente per
eventuali cambi di stato.
Ø 1 - Processo completato con successo.
Ø 2 – Processo non completato con successo e avremo un tag con il codice di errore.
272.7 Installazione CloudStack
L’installazione è stata eseguita presso il SESM a Giugliano, un centro di ricerca e sviluppo
precompetitivo di aziende Finmeccanica SELEX Sistemi Integrati e SELEX Galileo,
attivo nel campo della difesa, gestione del traffico aereo e logistica di grandi apparati.
La macchina su cui verrà eseguito il Management Server sarà utilizzata anche per fornire
Storage primario e secondario tramite NFS. Ciascun Host deve soddisfare determinati
requisiti di sistema (Appendice A.1). Il Sistema Operativo scelto è CentOS 6, ed è stato
opportunamente preparato ad ospitare il Management Server (Appandice A.2).
Effettueremo la procedura per l’installazione del Management Server e di MySQL sulla
stesso server, dopo aver scarico il Management Server di CloudStack sull’Host in cui
verrà eseguito (dettagli Appendice A.3).
CloudStack ha bisogno di un posto per ospitare Storage primario e secondario. Entrambi
possono essere NFS Shares, quindi imposteremo le NFS Shares prima di aggiungere
l'archiviazione di CloudStack. In genere si utilizza un server separato per NFS Shares, ma
è possibile utilizzare il nodo di Management Server anche come server NFS (Appendice
A.5).
Salveremo nel Secondary Storage un Template che viene utilizzato per le System VM di
CloudStack. Tenendo presente che il mio Hypervisor è KVM, quindi sul Management
Server lanceremo:
# /usr/lib64/cloud/agent/scripts/storage/secondary/cloud-install-sys-tmplt -m
/export/secondary -u http://download.cloud.com/templates/acton/acton-systemvm-
02062012.qcow2.bz2 -h kvm -F
Prima di poter aggiungere un host al Cloud, è necessario installare un software
Hypervisor. KVM è incluso con una varietà di sistemi operativi basati su Linux compreso
CentOS da noi scelto. All'interno di un cluster, tutti gli host KVM devono avere in
esecuzione lo stesso sistema operativo. Ogni host KVM deve avere il CloudStack Agent
installato su di esso.
Di default, CloudStack utilizzerà il dispositivo che viene utilizzato per la route predefinita.
Questo dispositivo viene collegato ad un Bridge creato da CloudStack. Visto che il nostro
28sistema dispone di più schede di rete creeremo un bridge e collegheremo la scheda di rete
prescelta al bridge.
L'Host Agent deve essere impostato per l'utilizzo di NTP. Tutti gli Host nello stesso Pod
devono avere lo stesso tempo. Per la configurazione di NTP seguiremo la stessa procedura
eseguita sul Management Server (Appendice A.2).
Dopo che il Management Server è installato e in esecuzione, è necessario aggiungere le
risorse di calcolo. Per fare questo bisogna accedere all’interfaccia utente di CloudStack e
eseguire una procedura per il Provisioning dell’infrastruttura.
Alla fine della procedura avremo la struttura in Figura 2.5. Abbiamo Scelto l’Advanced
Zone Configuration (Figura 2.6) quindi dopo aver effettuato il login sulla UI di
CloudStack e aver scelto Advanced nella sezione Add Zone eseguiremo tutti passi
descritti in Appendice A.7.
Figura 2.5 – Conceptual View of My Structure
29Figura 2.6 – Configurazione Advanced
30Capitolo 3
Design of Experiment
L’obiettivo di questo lavoro di tesi è la valutazione di una piattaforma di Cloud dal punto
di vista dei tempi necessari per eseguire le operazioni volte a fornire il servizio.
In altri termini, non ci preoccuperemo di analizzare i tempi per eseguire applicazioni
utente (come fatto in altri lavori quali [8][9]), bensì del tempo che la piattaforma open
source sotto esame impiega per elaborare una richiesta, individuare le risorse disponibili
per soddisfare la richiesta e, quindi, per rendere disponibile la risorsa al richiedente.
Tale studio è effettuato relativamente alla piattaforma CloudStack (Capitolo 2).
Per effettuare tali valutazioni, gli esperimenti sono stati pianificati secondo l’approccio
tipico del Design of Experiment (DoE) [7]. Il DoE è uno strumento estremamente potente
e trasversale, copre vari campi di indagine tecnico-scientifica, e comprende tecniche di
manipolazione dei risultati sperimentali nate per condurre ad un miglioramento del
sistema. Con il DoE cercheremo di dare un approccio statistico per ricavare conclusioni
sensate dai dati, dato che questi sono soggetti ad errori, quindi la metodologia statistica
rappresenta nel nostro caso di studio l’unico approccio oggettivo all’analisi.
3.1 Identificazione e formulazione del problema
Analizzeremo il Deployment Time di una Virtual Machine relativo alla piattaforma Open
Source CloudStack.
Il Deployment Time è il tempo che intercorre tra t0 e t3 (Figura 3.1), che indicano
rispettivamente l’istante “Arrivo Richiesta Utente” e l’istante finale “Risorsa Disponibile
31all’Utente”. Il Deployment Time comprende oltre al tempo di provisioning (Provisioning
Time, t3-t2) anche il tempo di scheduling (Scheduling Time, t2-t1) e il tempo di
elaborazione (Elaboration Time, t1-t0).
Il tempo di elaborazione è il tempo che impiega il Management Server per elaborare la
richiesta ed intercorre tra l’istante t0 “Arrivo Richiesta Utente” e l’istante t1 “Inizio
Scheduling”.
Il tempo di scheduling è il tempo che impiega il Management Server per scegliere l’Agent
con le risorse fisiche sufficienti a ospitare la VM Guest ed intercorre tra l’istante t1 “Inizio
Scheduling” e l’istante t2 “Arrivo Richiesta Deploy all’Agent”.
Mentre il tempo di provisioning è il tempo che intercorre tra l’istante t2 “Arrivo Richiesta
Deploy all’Agent” e l’istante t3 “Risorsa Disponibile all’Utente”.
Figura 3.1 – Deployment Time.
3.2 Testbed
L’installazione è stata eseguita presso il SESM a Giugliano, un centro di ricerca e sviluppo
precompetitivo di aziende Finmeccanica SELEX Sistemi Integrati e SELEX Galileo,
attivo nel campo della difesa, gestione del traffico aereo e logistica di grandi apparati.
La sperimentazione è avvenuta sulla piattaforma Open Source CloudStack installata su
alcuni nodi del cluster del SESM. I nodi a nostra disposizione sono 6, quindi la nostra
infrastruttura avrà un Management Server e cinque Agent.
Ø Management Server: il nodo che ospiterà il Management Server ha una CPU Intel
Core2 Duo 6300 1,86GHZ, 2GiB di RAM, un Hard Disk da 500GiB e come
sistema operativo CentOS 6 64 bit.
Ø Agent: i restanti cinque nodi hanno tutti 2 CPU QuadCore con una frequenza di
2,5 GHz, 8GiB di RAM, un HD da 32 GiB, come sistema operativo CentOS 6 64
bit e hypervisor KVM.
32Ø Primary Storage: che è associato ad un cluster e memorizza i volumi del disco per
tutte le macchine virtuali in esecuzione su host nello stesso cluster. Sarà
configurato sul Management Server.
Ø Secondary Storage: è associato ad una Zona, memorizza i templates, le immagini
ISO, e gli snapshots del volume del disco. Sarà configurato sul Management
Server.
Abbiamo effettuato un’installazione con un unico Management Server dato che abbiamo
solo 5 Agent da gestire e come scenario di Networking l’Advanced per avere una
maggiore flessibilità nella definizione delle reti Guest.
3.3 Scelta dei fattori e dei livelli
La scelta dei fattori e dei livelli ad essi associati è uno step fondamentale del Design of
Experiment. Nel nostro caso prenderemo in considerazione quattro fattori a ciascuno dei
quali sono associati due livelli.
Ø Service Offering – forniscono una scelta della CPU, numero di CPU, dimensione
della RAM e altre scelte. CloudStack mette a disposizione due Service Offering di
default Small Service Offering (CPU da 500MHz e 512Mb di RAM) e Medium
Service Offering (CPU da 1GHz e 1Gb di RAM) che noi prenderemo come livelli da
associare a questo fattore.
Ø Data Storage – in CloudStack abbiamo un Primary Storage che è associato con un
cluster e memorizza i Data Storage per tutte le macchine virtuali in esecuzione su
host del cluster. I due livelli associati a questo fattore saranno la presenza o meno
del Data Storage.
Ø VMs – molto importante e sicuramente da prendere in considerazione è anche il
numero di VM che sono già in esecuzione sull’Agent scelto per il deployment della
VM. I due livelli associati a questo fattore saranno agent senza VM in esecuzione (0
VM) e agent con 5 VM in esecuzione (5 VMs).
33Ø Scheduling –
con questo fattore si prende in considerazione lo Scheduling
dell’Agent sul quale fare il deploy della VM. I due livelli associati a questo fattore
saranno la presenza o meno dello Scheduling.
Fattori Livelli
Service Offering Small Medium
Data Storage No Si
VMs 0 VM 5 VM
Scheduling No Si
Tabella 3.1 – Fattori e Livelli.
3.4 Scelta del Piano Sperimentale
Come piano sperimentale si è scelto il Piano Fattoriale Completo con Replicazione. Sono
quindi considerate tutte le possibili combinazioni dei fattori a tutti i livelli, così da tenere
conto delle interazioni tra essi. Ripetendo ciascun esperimento r volte otterremo 2 4 r
osservazioni. Questa scelta è motivata dal fatto che tramite il Piano Fattoriale Completo
non è possibile quantificare l’errore dell’esperimento (errore associato alla combinazione
fattore-livello), cosa invece possibile replicando l’esperimento.
Introduciamo quattro variabili per indicare fattori e livelli: x A , xB , xC e xD :
Indicate con yij le riposte degli esperimenti, si ottiene il seguente modello di regressione
lineare:
34yij = q0 + qA x A + qB x B + qC xC + qD x D +
qAB x A x B + qAC x A xC + qAD x A x D + qBC x B xC + qBD x B x D + qCD xC x D +
qABC x A x B xC + qACD x A xC x D + qABD x A x B x D + qBCD x B xC x D +
[3.1]
qABCD x A x B xC x D +
eij
La corrispondenza tra fattori, livelli e risposte è mostrata in Tabella 3.1. Inoltre la [3.1] ci
mostra che il parametro q non è altro che la combinazione lineare delle risposte, questi
parametri sono detti contrasti, dividendo le q per 16 ottengo gli effetti di ciascun fattore e
delle interazioni tra essi.
La e rappresenta l’errore ed è dato dalla differenza tra la risposta media e il valore
misurato nell’esperimento i-esimo alla j-esima replicazione ( yij ). La somma degli errori
deve essere zero. Questo modello assume che gli effetti dei fattori, le loro interazioni e gli
errori sono additivi.
Num I Service Data VMs Scheduling AB AC AD BC BD CD ABC ACD ABD BCD ABCD
Offering Storage (C) (D)
(A) (B)
1 1 -1 -1 -1 -1 1 1 1 1 1 1 -1 -1 -1 -1 1
2 1 1 -1 -1 -1 -1 -1 -1 1 1 1 1 1 1 -1 -1
3 1 -1 1 -1 -1 -1 1 1 -1 -1 1 1 -1 1 1 -1
4 1 1 1 -1 -1 1 -1 -1 -1 -1 1 -1 1 -1 1 1
5 1 -1 -1 1 -1 1 -1 1 1 1 -1 1 1 -1 1 -1
6 1 1 -1 1 -1 -1 1 -1 1 1 -1 -1 -1 1 1 1
7 1 -1 1 1 -1 -1 -1 1 -1 -1 -1 -1 1 1 -1 1
8 1 1 1 1 -1 1 1 -1 -1 -1 -1 1 -1 -1 -1 -1
9 1 -1 -1 -1 1 1 1 -1 -1 -1 -1 -1 1 1 1 -1
10 1 1 -1 -1 1 -1 -1 1 -1 -1 -1 1 -1 -1 1 1
11 1 -1 1 -1 1 -1 1 -1 1 1 -1 1 1 -1 -1 1
12 1 1 1 -1 1 1 -1 1 1 1 -1 -1 -1 1 -1 -1
13 1 -1 -1 1 1 1 -1 -1 -1 -1 1 1 -1 1 -1 1
14 1 1 -1 1 1 -1 1 1 -1 -1 1 -1 1 -1 -1 -1
15 1 -1 1 1 1 -1 -1 -1 1 1 1 -1 -1 -1 1 -1
Tabella 3.2 – Piano Fattoriale Completo con Replicazione
35Per un Piano Fattoriale Completo con Replicazione 24 r abbiamo la tabella segno Tabella
3.2. La prima colonna della Tabella 3.2 viene etichettata “I” e consiste di tutti 1. Le
colonne successive A, B, C, D contengono tutte le combinazioni possibili di -1 e 1.
La colonna AB è il prodotto delle colonne A e B e allo stesso modo otteniamo le restanti
colonne (AC, AD,…,ABCD).
La Tabella 3.2 sarà completata con la colonna Media (Y) (Tabella 3.4), dove elenchiamo
le medie aritmetiche (essendo un Piano Fattoriale Completo con Replicazione) delle
replicazioni per ciascuna osservazione e la colonna Var (Varianza) che fornisce una
misura di quando siano vari i valori delle acquisizioni dei tempi.
3.5 Esecuzione sperimentale
Per la rilevazione dei tempi sfrutteremo le API di CloudStack in particolare l’API
deployVirtualMachine (vedi Paragrafo 2.6.1), scrivendo un’applicazione in Java che
sottometterà una richiesta GET-http con un associato Command e determinati Parameters
e attenderà una risposta in XML.
Avviando un timer nel momento in cui la GetRequest all’API deployVirtualMachine sarà
inviata e stoppandolo quando il tag jobStatus (vedi paragrafo 2.6.1) ci informerà che il
processo è completato otterremo il Deployment Time.
Il Provisionig Time verrà isolato aggiungendo opportuni parametri alla richiesta in modo
da rendere insignificante il tempo di elaborazione e specificando o meno hostid (agent di
destinazione per il deploy della VM) in modo da considerare o meno il tempo di
scheduling.
In Tabella 3.3 abbiamo la corrispondenza tra fattori-livelli del DoE e campo-valore dei
Parameters della GetRequest-http.
I tempi sono stati valutati seguendo il Piano Fattoriale Completo con Replicazioni e i
risultati degli esperimenti sono visibili in Tabella 3.4 nelle colonne Media e Var che
indicano rispettivamente la media aritmetica e la varianza che fornisce una misura di
quando siano vari i valori delle acquisizioni dei tempi.
36Fattori/Campi Livelli/Valori
Service Offering/ serviceOfferinId Small/ID Small Medium/ID Medium
Data Storage/ diskOfferingId No/Non specifico ID Si/Specifico ID Disk
Disk Offering Offering
VMs 0 VMs 5 VMs
Scheduling / hostId No/Specifico ID Host Si/Non specifico ID Host
Tabella 3.3 – Corrispondenza Fattori-Livelli/Campi-Valori
# I Service Data VMs Scheduling A A A B B C A A A B A Media Var
Offering Storage (C) (D) B C D C D D B C B C B
(A) (B) C D D D C (Y)
D
1 1 -1 -1 -1 -1 1 1 1 1 1 1 -1 -1 -1 -1 1 107,9441 0,1068
2 1 1 -1 -1 -1 -1 -1 -1 1 1 1 1 1 1 -1 -1 108,2159 0,1142
3 1 -1 1 -1 -1 -1 1 1 -1 -1 1 1 -1 1 1 -1 109,5562 0,4384
4 1 1 1 -1 -1 1 -1 -1 -1 -1 1 -1 1 -1 1 1 1098694 0,3336
5 1 -1 -1 1 -1 1 -1 1 1 1 -1 1 1 -1 1 -1 16,8016 0,1328
6 1 1 -1 1 -1 -1 1 -1 1 1 -1 -1 -1 1 1 1 16,8870 0,1523
7 1 -1 1 1 -1 -1 -1 1 -1 -1 -1 -1 1 1 -1 1 17,3560 0,0911
8 1 1 1 1 -1 1 1 -1 -1 -1 -1 1 -1 -1 -1 -1 17,5356 0,0854
9 1 -1 -1 -1 1 1 1 -1 -1 -1 -1 -1 1 1 1 -1 108,9044 0,3451
10 1 1 -1 -1 1 -1 -1 1 -1 -1 -1 1 -1 -1 1 1 109,5033 0,2001
11 1 -1 1 -1 1 -1 1 -1 1 1 -1 1 1 -1 -1 1 109,9153 0,2740
12 1 1 1 -1 1 1 -1 1 1 1 -1 -1 -1 1 -1 -1 110,2613 0,3983
13 1 -1 -1 1 1 1 -1 -1 -1 -1 1 1 -1 1 -1 1 16,9264 0,1066
14 1 1 -1 1 1 -1 1 1 -1 -1 1 -1 1 -1 -1 -1 16,9895 0,0728
15 1 -1 1 1 1 -1 -1 -1 1 1 1 -1 -1 -1 1 -1 17,4061 0,1515
16 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 17,5714 0,1260
Tabella 3.4 –Risultati (in secondi) del Piano Fattoriale Completo Con Replicazione
373.6 Regressione lineare
Un piano sperimentale 2 4 r (r=10) è stato utilizzato perché abbiamo 4 fattori, 2 livelli e
ciascuna delle 16 osservazioni è ripetuta r volte.
Il modello di regressione lineare è dato dall’equazione [3.1], dove e è l’errore sperimentale
e le q sono i contrasti. Per analizzare un piano sperimentale 2 4 r si utilizza la tabella segno
illustrata in Tabella 3.4, alla quale sono stati aggiunti i risultati delle osservazioni. In
Tabella 3.4 abbiamo le colonne segno l’elemento di ciascuna colonna è moltiplicato per il
corrispondente Media (Y) e poi sommati come in [3.2], dividendo poi il risultato ottenuto
per 16 otteniamo gli effetti.
A titolo esemplificativo, la seguente equazione [3.2] mostra il calcolo di qA :
q = −mediaY + mediaY − mediaY + mediaY − mediaY + mediaY − mediaY + mediaY −
A 1 2 3 4 5 6 7 8
[3.2]
mediaY + mediaY − mediaY + mediaY − mediaY + mediaY − mediaY + mediaY
9 10 11 12 13 14 15 16
Gli altri effetti si ottengono in modo analogo.
La e in [3.1] rappresenta l’errore ed è dato dalla differenza tra la risposta media e il valore
misurato nell’esperimento i-esimo alla j-esima replicazione ( yij ).
eij = yij − mediaYi [3.3]
La somma degli errori deve essere zero.
La Somma dei Quadrati degli Errori (SSE), che può essere utilizzata per stimare la
varianza degli errori, è data da:
24 r
SSE = ∑∑ eij2 = 22.5604 [3.4]
i=1 j=1
383.7 Allocazione della variazione
L’allocazione della variazione consente di determinare la percentuale di variazione
espressa da ciascun fattore, cosa utile per decidere se un fattore ha un impatto significativo
sulla risposta.
La Variazione Totale o Somma Totale dei Quadrati è data dall’equazione [3.5]. La
mediaYtot denota la media di tutte le repliche di tutti gli esperimenti.
La SST può essere divisa in più parti [3.6] (derivazione equazione [3.6] in Appendice B)
dove ogni SS (Somma dei Quadrati) sono le variazioni dei fattori e delle interazioni tra
essi mentre SSE è la variazione attribuita agli errori.
Nell’equazione [3.7] (derivazione Appendice B) la SS0 rappresenta la Somma dei
Quadrati delle medie ed è ottenuta elevando al quadrato entrambi i termini dell'equazione
[B.2] mentre SSY è la somma dei quadrati di tutte le risposte yij .
SST = ∑ (yij − mediaYtot )2 [3.5]
i, j
SST = 2 4 rqA2 + 2 4 rqB + 2 4 rqC ... + ∑ eij2 = SSA + SSB + SSC... + SSE [3.6]
i, j
SSY = SS0 + SSA + SSB + SSC +...SSABCD + SSE [3.7]
Avendo 16 osservazioni e 10 replicazioni, le Somme dei Quadrati sono calcolate come
segue:
SS0 = 160 * q 20 = 160 * 63,22772 =639639.1691
SSA = 160 * q 2A = 160 * 0.12652 =2.5594
SSB = 160 * q 2B = 160 * 0.4562 2 =33.2980
SSC = 160 * q C2 = 160 * (-46.0435)2 = 339201.0373
SSD = 160 * 0.2070 2 = 6.8551
SSAB = 160 * (-0.0009)2 = 0.0001
SSAC = 160 * (-0.0648)2 = 0.6714
SSAD = 160 * 0.0202 2 = 0.0653
39Puoi anche leggere

















































