Utilizzo del servizio di bike sharing BikeMi in relazione a eventi significativi sul territorio - Corso di Laurea in Informatica per la ...
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Corso di Laurea in Informatica per la Comunicazione
Digitale
Utilizzo del servizio di bike
sharing BikeMi in relazione a
eventi significativi sul territorio
Relatore: Andrea Mario Trentini
Tesi di Laurea di: Lorenzo Ceo
Matr. 910319
Anno Accademico 2019/2020
Ringraziamenti
Vorrei ringraziare il Professor Andrea Mario Trentini, relatore di questa tesi,
per avermi proposto questo interessante progetto e per il supporto dedicatomi
per la sua realizzazione. Senza la sua guida e gli innumerevoli consigli, non
sarei stato in grado di completarlo in modo soddisfacente in ogni sua parte.
Desidero esprimere un ringraziamento particolare anche alla mia famiglia,
che mi ha continuamente supportato anche nei momenti piu ̀ difficili, senza
mai tirarsi indietro.
L’ultimo, ma non meno importante, ringraziamento ̀e dedicato ai miei
compagni di corso: senza di loro questi tre anni non sarebbero stati gli stessi.
1
Indice
1 Introduzione 4
1.1 Cos’è il bike sharing . . . . . . . . . . . . . . . . . . . . . . . 5
1.1.1 Storia del bike sharing . . . . . . . . . . . . . . . . . . 5
1.1.2 Vantaggi . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.1.3 Tipologie di servizi . . . . . . . . . . . . . . . . . . . . 7
1.2 Bike sharing a Milano . . . . . . . . . . . . . . . . . . . . . . 8
1.2.1 BikeMi . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2.2 Servizi alternativi . . . . . . . . . . . . . . . . . . . . . 14
2 Acquisizione ed elaborazione dei dati 18
2.1 Open Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2 Software utilizzati . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.3 Panoramica sui dati utilizzati . . . . . . . . . . . . . . . . . . 21
2.4 Elaborazione dei dati BikeMi . . . . . . . . . . . . . . . . . . 22
2.4.1 Preparazione dei file grezzi . . . . . . . . . . . . . . . . 23
2.4.2 Parsing . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.4.3 Verifica d’insieme dei dati . . . . . . . . . . . . . . . . 25
2.4.4 Verifica dei dati mancanti . . . . . . . . . . . . . . . . 26
2.4.5 Calcolo dei valori di utilizzo del servizio . . . . . . . . 26
2.4.6 Rimozione delle ore di non operatività . . . . . . . . . 27
2.4.7 Ricampionamento . . . . . . . . . . . . . . . . . . . . . 29
2.5 Elaborazione degli altri dataset . . . . . . . . . . . . . . . . . 29
2.5.1 Dataset ufficiale sulle stazioni BikeMi . . . . . . . . . . 29
2.5.2 Dataset relativi alle informazioni atmosferiche . . . . . 30
2.5.3 Dataset ufficiali relativi all’apertura dell’Area C . . . . 32
2.5.4 Informazioni di eventi sul territorio . . . . . . . . . . . 33
3 Analisi dei dati BikeMi 34
3.1 Crescita del servizio . . . . . . . . . . . . . . . . . . . . . . . . 34
3.1.1 Utilizzi annuali . . . . . . . . . . . . . . . . . . . . . . 34
3.1.2 Numero di veicoli . . . . . . . . . . . . . . . . . . . . . 35
2
3.1.3 Resa del servizio . . . . . . . . . . . . . . . . . . . . . 37
3.2 Andamento in relazione al periodo . . . . . . . . . . . . . . . . 38
3.2.1 Utilizzi stagionali . . . . . . . . . . . . . . . . . . . . . 38
3.2.2 Utilizzi mensili . . . . . . . . . . . . . . . . . . . . . . 40
3.2.3 Utilizzi giornalieri . . . . . . . . . . . . . . . . . . . . . 43
3.2.4 Utilizzi in base all’orario . . . . . . . . . . . . . . . . . 43
3.3 Andamento in relazione al luogo . . . . . . . . . . . . . . . . . 44
3.3.1 Numero di utilizzi . . . . . . . . . . . . . . . . . . . . . 44
3.3.2 Frequenza degli utilizzi . . . . . . . . . . . . . . . . . . 53
3.3.3 Pendolarismo . . . . . . . . . . . . . . . . . . . . . . . 57
3.4 Andamento in relazione a eventi . . . . . . . . . . . . . . . . . 60
3.4.1 Eventi meteorologici . . . . . . . . . . . . . . . . . . . 60
3.4.2 Area C . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
3.4.3 Eventi sul territorio . . . . . . . . . . . . . . . . . . . . 69
3.4.4 Coronavirus . . . . . . . . . . . . . . . . . . . . . . . . 70
4 Conclusioni e spunti futuri 82
4.1 Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
4.2 Spunti futuri . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
3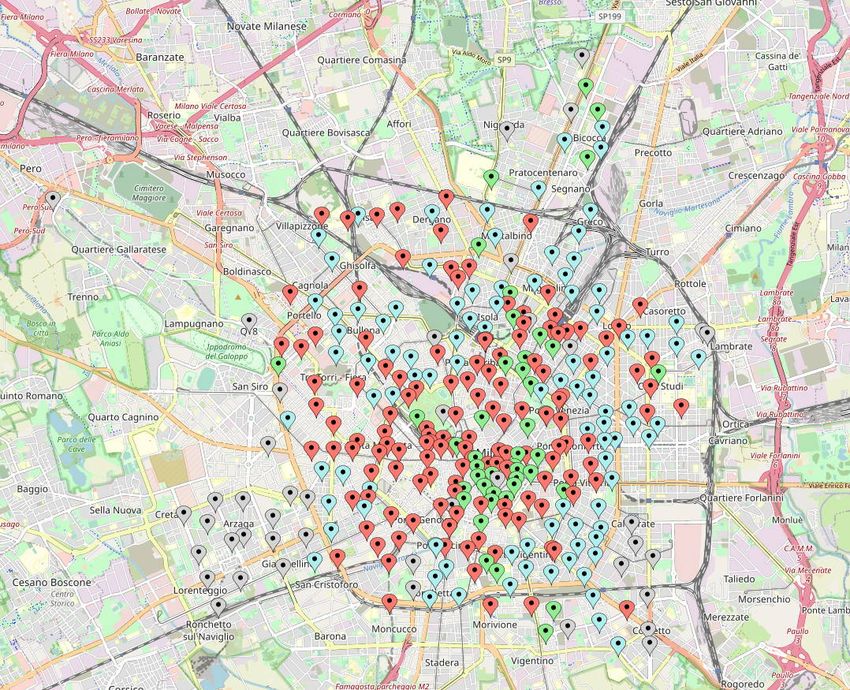
Capitolo 1
Introduzione
Con la crescente densificazione delle città, che si stima porterà la popolazione
urbana al 68% entro il 2050[11], si ̀e reso sempre piu ̀ necessario pensare a
nuovi sistemi di mobilità all’interno delle metropoli. Inoltre le recenti diret-
tive in termini di riduzione dell’inquinamento, che promettono di diminuire
almeno del 40% le emissioni di gas serra rispetto ai livelli del 1990 e aumenta-
re al 32% la quota di energia rinnovabile[3], hanno fatto sı̀ che in pochi anni
il business della mobilità sostenibile diventasse di fondamentale importanza
[2].
Grazie all’enorme e pervasiva crescita tecnologica sono nati numerosissimi
servizi che, in contrapposizione al paradigma della proprietà individuale del
mezzo da sempre utilizzato dall’invenzione delle automobili, prevedono un
sistema di noleggio dei veicoli. La mobilità sostenibile ha interessato ogni
settore dei trasporti: bike sharing, car sharing, car pooling, scooter sharing
e via dicendo sono termini ormai di utilizzo comune, nati per rispondere a
queste nuove necessità.
Questo progetto ha lo scopo di fornire una quanto piu ̀ completa analisi
del servizio di bike sharing BikeMi, il servizio pubblico di condivisione di
biciclette a Milano, partendo dalla scoperta di periodicità e pattern nell’an-
damento dell’utilizzo dei veicoli e cercando possibili correlazioni con eventi
significativi verificatisi sul territorio milanese. Obiettivo secondario ̀e inoltre
mostrare come tale analisi sia stata effettuata su dati non resi pubblici nella
loro interezza, ma raccolti nell’arco di anni.
Il documento ̀e diviso in quattro capitoli:
il primo capitolo introduce l’argomento dei servizi di bike sharing, dan-
done un panorama storico e passando poi al dettaglio della realtà mi-
lanese, in modo da presentare al lettore le conoscenze necessarie alla
corretta comprensione dell’analisi;
4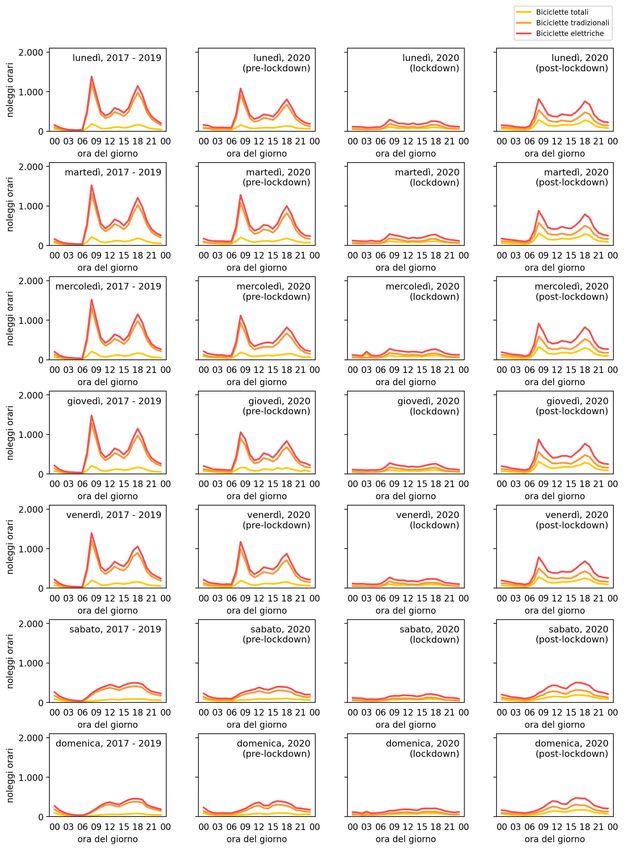
il secondo capitolo, dopo aver fornito una breve introduzione al concetto
di Open Data, descrive tutti i procedimenti e le modalità utilizzate per
ottenere ed elaborarare i dati grezzi, processo decisivo per estrarne
informazioni significative e procederne all’analisi;
il terzo capito ha lo scopo di mostrare, tramite visualizzazioni e metri-
che statistiche, tutte le analisi effettuate sui dati del servizio, illustran-
done i pattern emersi e le significative correlazioni trovate, passando
poi alla scoperta delle stazioni piu ̀ performanti sotto diversi punti di
vista e concludendo con la ricerca della correlazione con diversi eventi
avvenuti sul territorio milanese;
il quarto capitolo presenta in modo sintetico le conclusioni più rilevanti
ricavate dall’analisi precedente e diversi spunti per la continuazione del
progetto.
1.1 Cos’e
̀ il bike sharing
Il bike sharing ̀e uno degli strumenti di mobilità piu ̀ utilizzati nelle grandi
metropoli dalla popolazione locale e dai turisti 1 . Bike sharing significa “bici
condivisa” ed ̀e uno dei tanti servizi di mobilità sostenibile di cui si avvalgono
le amministrazioni pubbliche allo scopo di fornire una soluzione valida per
gli spostamenti a breve distanza, tramite l’uso di biciclette condivise anche
laddove i mezzi di trasporto comunali non arrivano o non possono arrivare.
Diversamente dal classico noleggio, i servizi di bike sharing prevedono una
flotta di veicoli utilizzabili per brevi periodi in diversi luoghi del territorio,
dietro un compenso stabilito all’attivazione del servizio.
1.1.1 Storia del bike sharing
La prima idea di bike sharing venne piu ̀ di mezzo secolo fa a un gruppo di
anarchici di Amsterdam, che il 28 luglio 1965 verniciarono di bianco alcune
biciclette nere e le lasciarono poi in giro per la città a disposizione di tutti.
L’esperimento fallı̀, non si sa se a causa di una vecchia legge che imponeva
che tutte le biciclette fossero dotate di un lucchetto, oppure perché la mag-
gior parte di esse venne rubata o danneggiata. Dopo questo primo fallimento
per quasi trent’anni nessuno ci riprovò, fino a quando, nel 1995, la città di
Copenhagen lanciò Bycykler, un servizio di bike sharing che funzionò, nono-
stante alcuni problemi iniziali come il furto, la vandalizzazione e la difficoltà
di rintracciare i mezzi per la manutenzione.
1
https://www.coopvoce.it/web/mag/blog/Bike_Sharing_nel_futuro
5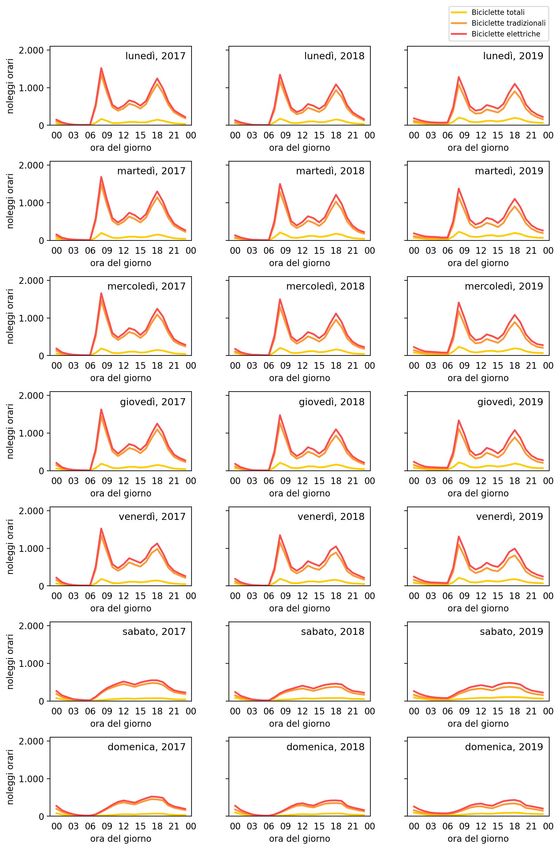
Figura 1.1: Veicoli del rivoluzionario servizio Vélib di Parigi
Negli anni seguenti questi servizi si diffusero poco a poco anche nel Re-
gno Unito, grazie all’invenzione di una sistema che prevedeva l’uso di tessere
magnetiche in appositi parcheggi e in Francia, nelle città di Rennes e Lione,
che ispirarono quello che oggi ̀e considerato uno dei servizi di bike sharing
piu
̀ ambiziosi mai realizzati: il Vélib di Parigi, lanciato nel 2007. Il Velib
introduceva alcune caratteristiche fondamentali dei servizi odierni: la trac-
ciabilità delle bici e l’iscrizione tramite carta di credito. Nonostante il primo
periodo caratterizzato da numerosi furti, il servizio possiede ad oggi circa
18mila bici. Un’immagine dei veicoli del servizio ̀e visibile alla figura 1.1.
Il 2007 ̀e stato un anno decisivo per il bike sharing in quanto nei dieci
anni successivi sono stati lanciati quasi 1.600 servizi contro i soli 75 degli anni
antecedenti. Fra i piu ̀ ambiziosi troviamo quelli attivi a Londra, New York,
Barcellona, ma soprattutto in Cina, che ha recentemente iniziato a esportare
i propri brand in occidente. La crescita dei servizi di bike sharing può essere
osservata nella figura 1.2. In Italia il bike sharing ha avuto negli ultimi
anni una notevole diffusione, specie al Nord, in cui il territorio e la cultura
cittadina meglio si ̀e approcciata all’uso delle bici in un sistema condiviso.
Particolarmente positive sono le esperienze di Milano, Alessandria, Parma,
Torino, Caserta 23 .
2
https://www.ilpost.it/2017/12/25/bike-sharing-storia/
3
https://www.halaesainbici.info/la-storia-del-bs/
6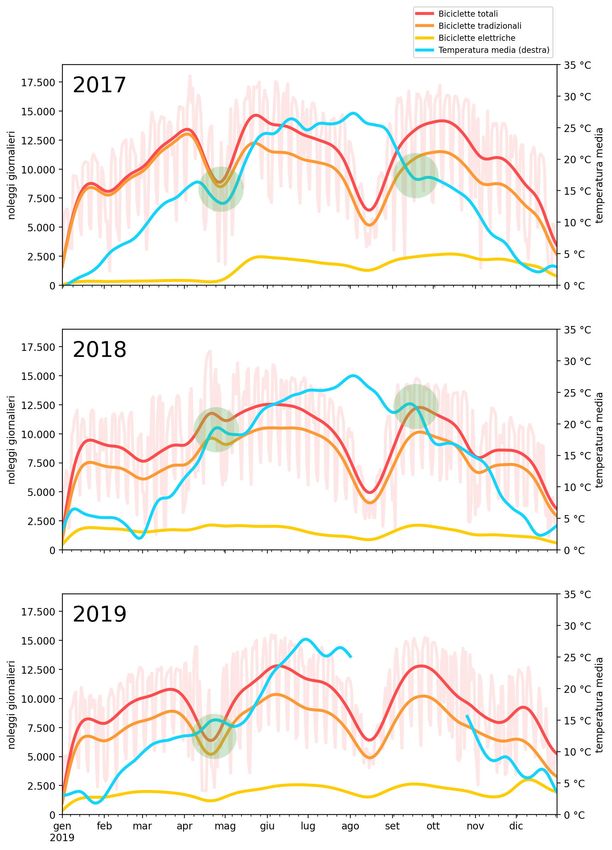
Figura 1.2: Crescita dei servizi di bike sharing nel mondo
1.1.2 Vantaggi
L’adozione di servizi di bike sharing, pur costando molto alla collettività,
fa sı̀ che gli utenti non siano vincolati ad acquistare un veicolo personale
e a portarlo con loro, eliminando anche la necessità di catene e lucchetti.
Per la pubblica amministrazione l’adozione del bike sharing si traduce in un
alleggerimento dell’uso dei mezzi pubblici nonché in un ulteriore passo verso
la mobilità sostenibile 4 .
1.1.3 Tipologie di servizi
I servizi di bike sharing si sviluppano secondo due filosofie: station-based
e free floating. La prima prevede il noleggio e la riconsegna dei veicoli in
apposite stazioni situate sul territorio locale, a seconda dell’utilizzo posso-
no esserci piani di riposizionamento dei veicoli, spesso negli orari in cui il
servizio non ̀e attivo. La seconda tipologia ̀e nata piu ̀ di recente grazie al-
lo sviluppo tecnologico, che permette di localizzare le biciclette tramite dei
dispositivi GNSS integrati e prevede il noleggio del mezzo tramite una map-
pa visualizzabile in mobilità tramite un’applicazione sul proprio smartphone.
La particolarità di questo tipo di servizio ̀e la possibilità di lasciare il mezzo
in qualsiasi punto del territorio, rendendo non piu ̀ necessaria la consegna in
un’apposita stazione.
4
https://www.focus.it/ambiente/ecologia/bike-sharing-traffico-
biciclette-e-salute-in-citta
7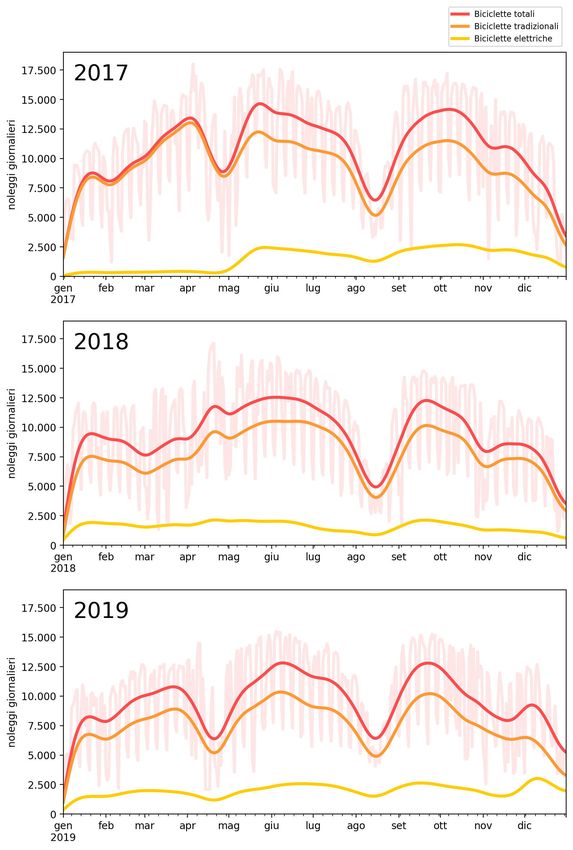
1.2 Bike sharing a Milano
Milano, grazie ai numerosi servizi offerti, si classifica tra le città pioniere nel
settore del bike sharing e, insieme al car sharing e allo scooter sharing, offre
un ampio servizio di mobilità sostenibile e complementare al trasporto pub-
blico. Sebbene nel capoluogo lombardo la mobilità privata ricopra ancora un
ruolo maggioritario, le proiezioni che ci portano al 2040 indicano un ribalta-
mento con il trasporto pubblico, che prende il sopravvento e in particolare
un raddoppio degli utilizzi del bike sharing 5 .
Sono entrate in vigore anche delle diverse regolamentazioni per quanto
riguarda le biciclette destinate al bike sharing: le bici si differenziano a se-
conda dell’operatore, ma in ogni caso devono per regolamento avere un peso
contenuto, essere resistenti alle intemperie e riconoscibili avendo ben visibile
il logo del Comune di Milano. Devono inoltre essere dotate di faro anteriore
e posteriore che si accende in automatico all’avvio del noleggio ed un siste-
ma di segnalazione acustica sul manubrio dove deve trovare posto anche un
cestino porta oggetti. In tema di sicurezza i cavi ed i componenti devono
essere incorporati nel telaio anche per minimizzare le manomissioni. I vei-
coli possono prevedere anche sistemi di pedalata assistita o a batteria con
la possibilità per l’utente di attivare e disattivare il motore elettrico quando
non lo desidera. La ricarica della batteria, a cura del gestore, deve avvenire
in luoghi predefiniti e le batterie devono essere al litio di alta qualità e senza
piombo 6 .
1.2.1 BikeMi
Il primo dei servizi di bike sharing presentato a Milano ̀e stato BikeMi, che,
attivo dal 2008 7 , ha avuto un rapido sviluppo. Nei primi dieci anni di vita
conta più di 650.000 iscritti e 23 milioni di utilizzi, per oltre 46 milioni di
chilometri percorsi 8 , che hanno permesso di risparmiare oltre 9,3 milioni di
chili di anidride carbonica in termini di mancate emissioni 9 , alle quali si
aggiunge il contributo di una centrale di ricarica elettrica con energia (75
khW/annui) prodotta da pannelli fotovoltaici 10 .
5
https://www.ilgiorno.it/milano/cronaca/bike-mi-1.4321609
6
https://www.primosito.it/blog/bike-sharing-milano/
7
https://bikemi.com/chi-siamo
8
https://www.ilgiorno.it/milano/cronaca/bike-mi-1.4321609
9
https://www.ansa.it/lombardia/notizie/2019/06/28/a-milano-in-arrivo-
altre-400-bikemi_55254097-b6ad-4b7a-8ffd-c0ede73cf389.html
10
https://www.clearchannel.it/clear-channel-italia-sponsor-della-3-
conferenza-nazionale-sulla-sharing-mobility/
8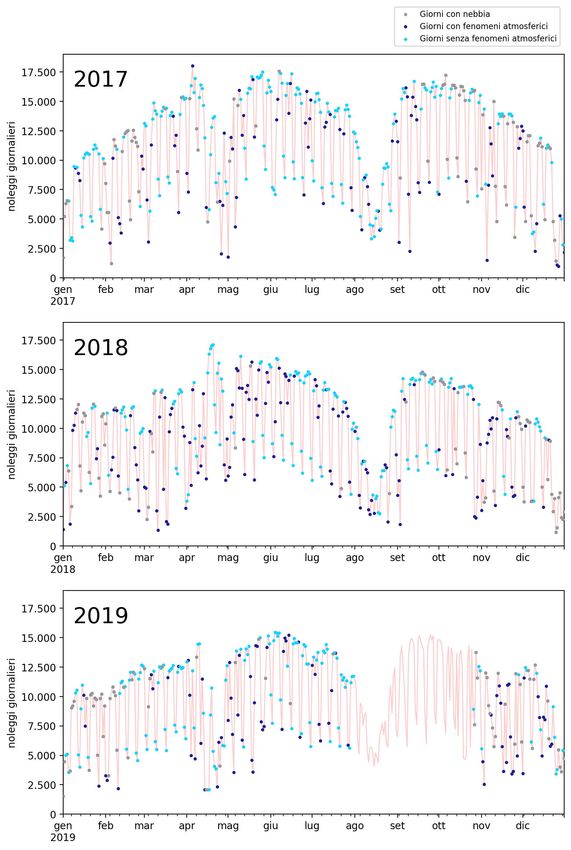
Figura 1.3: La stazione BikeMi numero 1: Duomo
Nel 2008 il servizio di tipo station-based ̀e iniziato con sole 66 stazioni per
la sosta di 850 mezzi 11 , per poi arrivare a fine 2020 con 317 postazioni attive
sull’intero territorio milanese e dintorni [10], con un numero di veicoli pari a
3.650 biciclette tradizionali e 1.150 elettriche a pedalata assistita, di cui 150
provviste di seggiolino per bambini 12 . La stazione numero 1, in prossimità
del Duomo di Milano, ̀e visibile alla figura 1.3. Il servizio ̀e operativo dalle 7
del mattino all’1 di notte. Durante il periodo estivo il servizio ̀e prolungato:
da domenica a giovedı̀ dalle 7:00 alle 2:00; nei giorni di venerdı̀ e sabato ̀e
disponibile 24 ore su 24 13 .
L’utilizzo di BikeMi
Le biciclette sono bloccate e sono prelevabili dalle stazioni sbloccandole con
un’apposita tessera contactless (tramite tecnologia RFID 14 ), tramite la tesse-
ra dell’abbonamento ATM oppure, grazie al recentissimo aggiornamento del
servizio di marzo 2021, tramite l’applicazione disponibile per smartphone.
11
https://milano.corriere.it/cronaca/cards/record-bikemi/nel-2008-
debutto.shtml
12
https://milano.corriere.it/19_maggio_16/flotta-nuove-stazioni-
ricambio-bike-sharing-bando-sostituire-ofo-ec40faae-77a8-11e9-bbe0-
f6f4647a7d08.shtml
13
https://www.comune.milano.it/servizi/bike-sharing
14
https://rfid.it/cos-e-la-tecnologia-rfid/
9Al termine della corsa la bicicletta deve essere obbligatoriamente riportata
in una stazione con almeno uno stallo disponibile.
Le tariffe sono a tempo: con le bici tradizionali la prima mezz’ora ̀e gratis,
ogni mezz’ora successiva costa 50 centesimi, dopo la quarta mezz’ora ogni ora
o frazione costa 2 euro. Con le bici a pedalata assistita la prima mezz’ora
costa 25 centesimi, la seconda 50 centesimi, la terza 1 euro, la quarta 2 euro.
Successivamente, ogni ora o frazione costa 4 euro. Il servizio prevede anche
degli abbonamenti: 4,5 euro per il giornaliero, 9 per il settimanale, 36 per
l’annuale 1516 . Da luglio 2019 l’abbonamento al servizio ̀e caricabile sulla
tessera ATM, la scheda relativa ai servizi offerti dall’azienda che gestisce i
trasporti pubblici milanesi, cosı̀ da consentire agli utenti di utilizzare un’unica
tessera per i mezzi pubblici e le bici in condivisione di BikeMi, con relativi
sconti per chi usufruisce dei diversi servizi. In alcune stazioni selezionate del
centro cittadino inoltre ̀e possibile usare l’abbonamento per prelevare anche
le biciclette da bambini del BikeMi Junior (1 euro per le prime due ore, 1
euro per ogni ora successiva o frazione) 17 .
Stazioni
Fin dalla sua nascita il servizio BikeMi ha vissuto una costante e uniforme
crescita, suddivisa in diverse fasi, a seconda dell’aumento del numero delle
stazioni, che si sono espanse lentamente nella periferia del capoluogo lom-
bardo. Nel dicembre 2008 BikeMi ha presentato 66 stazioni nel centro della
metropoli lombarda, scegliendo punti strategici per quanto riguarda il turi-
smo, i trasporti, le università e i parchi, tra cui Cadorna, Duomo, Centrale,
Garibaldi e Lambrate 18 . La maggior parte delle stazioni aperte al lancio
comprendeva 24 stalli, ma, in seguito, con l’introduzione delle bici elettriche
nel 2015, mostrate nella figura 1.6, il numero degli stalli ̀e aumentato a 36
[10].
Con la fase 1, terminata nel 2009, si ̀e raggiunto l’obiettivo di 100 stazioni
e 1.400 biciclette ed ̀e stato superato il record di 1milione e 500.000 bici
prelevate 1920 . Alla fine del 2010 sono stati registrati oltre 10.000 abbonati
15
https://bikemi.com/come-funziona
16
https://www.dueruote.it/news/attualita/2020/06/04/bike-sharing-
milano.html
17
https://www.atm.it/it/ViaggiaConNoi/Bici/Pagine/BikeMi.aspx
18
https://milano.corriere.it/cronaca/cards/record-bikemi/nel-2008-
debutto.shtml
19
https://www.atm.it/it/AtmNews/Comunicati/Pagine/
giornatanazionaledellabicicletta.aspx
20
https://www.atm.it/it/AtmNews/Comunicati/Pagine/BikeMi,
partelasecondafase.aspx
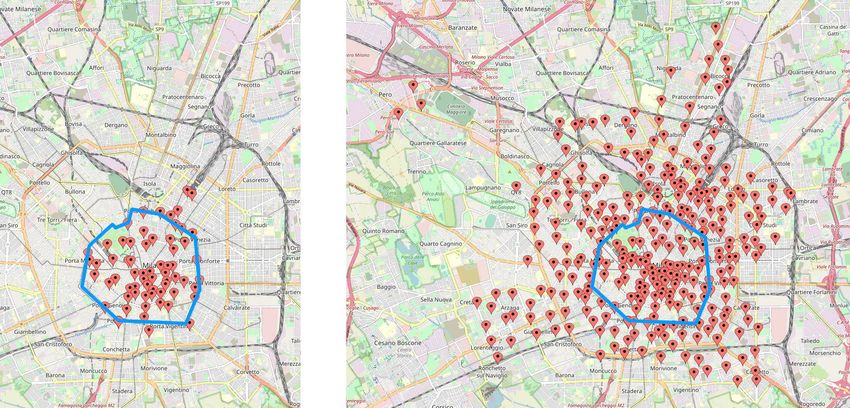
10Figura 1.4: Le originali 66 stazioni (a sinistra) contro le 317 disponibili a fine
2020 (a destra) mostrano l’espansione del servizio verso la periferia milanese.
L’area delimitata dal confine blu ̀e denominata “Area C”
annuali e 30.000 occasionali 21 . Nello stesso anno ̀e stata inaugurata la fase
2 del progetto di espansione del servizio, che si conclude con l’aumento delle
stazioni fino ad un totale di 200 e 3.650 biciclette 22 , confermando Milano al
primo posto in Italia e al quinto in Europa per il servizio di Bike Sharing 23 .
Il servizio ̀e scelto dai turisti, ma soprattutto dai lavoratori 24 : fin dalla
sua partenza, la stazione piu ̀ utilizzata ̀e quella di Cadorna, snodo centrale
di metropolitane e ferrovie e le fasce orarie di utilizzo mostrano il picco degli
spostamenti tra le ore 8.00 e le 9.00 e tra le ore 18.00 e le 19.00 25 .
“BikeMi - dichiara Elio Catania, presidente di ATM - ̀e a tutti gli effetti
un nuovo e importante tassello della piattaforma integrata di mobilità mila-
nese. Una rete d’eccezione per l’alta sostenibilità ambientale, oltre il 70% del
trasporto pubblico a energia elettrica e la pluralità di modalità di trasporto
offerte dalla metropolitana al tram, dal bus al filobus, al Radiobus di Quar-
tiere, fino al bike sharing e car sharing che si inseriscono e si integrano alla
21
https://www.atm.it/it/AtmNews/Comunicati/Pagine/autostradeperl%
27italia.aspx
22
http://www.officinadellambiente.com/it/articolo.php?idl1=1&idl2=21&id=
2416
23
http://bikesharing.gazzetta.it/2010/11/28/bikemi-fase-2-e-secondo-
compleanno-alle-porte/
24
https://www.bikeitalia.it/2011/11/10/bikemi-i-buoni-risultati-del-
bike-sharing-di-milano/
25
https://www.atm.it/it/AtmNews/Comunicati/Pagine/BikeMi,
partelasecondafase.aspx
11Figura 1.5: La crescita del numero di stazioni BikeMi
rete ‘tradizionale’ per rispondere sempre meglio alle esigenze di chi si muove”
26
.
Le prime due fasi dell’espansione del servizio hanno quindi visto la cresci-
ta delle stazioni fino a un totale di 200 postazioni nel capoluogo lombardo,
la maggior parte delle quali all’interno dell’area milanese denominata “Area
C”, che si estende per tutta la “Zona a traffico limitato (ZTL) Cerchia dei
Bastioni” e prevede il pagamento di un pedaggio nelle fasce in cui ̀e attiva
27
. In preparazione dell’Expo 2015, svoltosi dal 1 maggio al 31 ottobre 2015,
̀e iniziata la fase 3 di crescita del servizio, che prevedeva, per la prima volta
nel mondo, l’introduzione di veicoli a pedalata assistita. Questa nuova ti-
pologia di mezzi ̀e stata ospitata in ottanta-cento stazioni leggere, che in un
primo tempo sono state posizionate sulla via ciclabile per Expo, tra i Ba-
stioni e i padiglioni, e poi ricollocate sulla corona esterna della città alla fine
dell’evento, vicino a Bicocca, Città Studi e Bovisa 28 . La figura 1.4 mostra
su mappa l’aumento delle stazioni dalla nascita del servizio fino a fine 2020,
mentre la figura 1.5 mostra l’incremento del numero di stazioni negli anni.
Attualmente la stazione piu ̀ grande ̀e quella di S. Gioachimo, in via Galileo
Galilei, con 39 stalli, mentre quella piu ̀ piccola ̀e la Dante - San Tomaso con
sole 15 postazioni. La capacità media di tutte le stazioni ̀e di 29 bici [10].
26
https://www.atm.it/it/AtmNews/Comunicati/Pagine/BikeMi,
partelasecondafase.aspx
27
https://www.milanotoday.it/green/mobilita/bike-sharing-stazione-via-
pacini.html
28
https://www.blogo.it/post/47087/al-via-la-fase-3-del-bikemi-con-il-
primo-esperimento-al-mondo-di-bike-sharing-elettrico
12Figura 1.6: Le biciclette elettriche BikeMi
L’utente che vuole usufruire del servizio può conoscere lo stato di ogni
stazione, che comprende il numero di biciclette disponibili per ogni tipo e il
numero di stalli liberi per restituire un mezzo, sia dal sito web che dall’appli-
cazione per smartphone. Una volta scelta la stazione, l’utente può richiedere
lo sblocco del mezzo scelto tramite l’apposita colonnina oppure, grazie all’ag-
giornamento dell’applicazione di marzo 2021, dal proprio smartphone. Dopo
aver completato la corsa, il mezzo deve essere restituito alla stazione attiva
piu
̀ vicina con almeno uno stallo libero. Dato il costante utilizzo dei mezzi da
parte degli utenti, che riflette le dinamiche degli spostamenti cittadini, ̀e ne-
cessario riposizionare regolarmente i veicoli per andare incontro alle esigenze
degli utilizzatori.
Ribilanciamento
Ogni sistema di bike sharing di tipo location based deve affrontare il proble-
ma del ribilanciamento dei veicoli, in quanto gli utenti, una volta ritirato il
mezzo desiderato dall’apposita stazione, spesso lo riposizionano in un punto
di raccolta diverso. La disparità di veicoli disponibili in ogni stazione di-
venta un problema critico in quanto, nei casi estremi, potrebbe portare ad
una insoddisfacente risposta alla domanda di biciclette da parte degli utenti,
cosı̀ come l’impossibilità di riposizionare il mezzo nella stazione piu
̀ vicina,
con conseguente insoddisfazione da parte dell’utente, che potrebbe essere ri-
direzionato verso altri servizi di trasporto [12]. Per questo ogni servizio di
bike sharing location-based ha l’obbligo di effettuare un riposizionamento si-
13stematico dei veicoli in ogni stazione coperta, secondo le dinamiche rilevate
dall’attività dei mezzi.
La necessità di veicoli nelle diverse stazioni inoltre può essere prevista
sfruttando algoritmi di Machine Learning che, secondo studi recenti, eviden-
ziano risultati positivi, portando a un aumento degli abbonamenti. In ag-
giunta, lo spostamento delle biciclette diventa uno dei maggiori costi che un
servizio di bike sharing deve sostenere, oltre all’elettricità e alla manutenzione
dei mezzi. Ciò rende necessaria un’ottimizzazione del ribilanciamento, spes-
so denominato “Problema del Riposizionamento del Bike Sharing (BRP)”,
secondo due metodiche: ribilanciamento statico e ribilanciamento dinamico
[6, 5, 24].
La prima prevede, solitamente, un processo di riposizionamento durante
gli orari in cui il servizio non ̀e attivo, quando la domanda di veicoli ̀e molto
bassa. Questo, nel caso del serivio BikeMi, avviene di notte. La seconda,
invece, prevede un riposizionamento dei veicoli anche durante gli orari in cui
il servizio ̀e attivo. BikeMi prevede un riposizionamento dinamico, con 32
furgoni [1] attivi sia durante le ore di servizio che durante le ore notturne, in
cui il servizio non ̀e in funzione.
1.2.2 Servizi alternativi
Il 2017 ha visto due ulteriori servizi di bike sharing affiancarsi al quasi decen-
nale BikeMi, entrambi sono di tipologia free floating e provengono da aziende
cinesi: sono Mobike e Ofo [23].
Mobike
Mobike ̀e un’azienda fondata a Pechino nel 2015 operante nel settore del bike
sharing. Grazie ai numerosi paesi coperti dalla sua rete, Mobike ̀e diventata
il piu
̀ grande operatore al mondo in questo settore. Dal 2017 il servizio
ha raggiunto alcune città europee, tra cui, in Italia, Milano, Bologna Firenze
Torino e Venezia 29 . Mobike offre un servizio di free floating contrapponendosi
a quello offerto da BikeMi, in quanto i veicoli possono essere depositati, dopo
aver concluso il viaggio in qualunque luogo dell’area coperta, segnalando la
fine della corsa tramite l’apposita applicazione per smartphone.
A Milano Mobike ̀e arrivato nell’agosto del 2017 con 8.000 biciclette e
propone due modelli di veicoli tradizionali, entrambi riconoscibili per i loro
colori argento e arancione: il primo, denominato “Classic”, ha ruote piene
da 24”, trasmissione cardanica, cestino anteriore, campanello e luci, non
29
https://it.wikipedia.org/wiki/Mobike
14Figura 1.7: Il nuovo modello Mobike a pedalata assistita e il modello “Lite 3.0”,
prima revisione dell’originale
ha il cambio ed ̀e piuttosto pesante, la dimensione delle ruote e l’assenza
del cambio la rendono poco comoda e il secondo, denominato “Lite 3.0”,
arrivato a Milano nel 2018, ̀e dotato di ruote “classiche” da 26” e cambio
a 3 marce. Questo secondo modello ̀e stato concepito per risolvere alcune
problematiche sorte con l’utilizzo del primo, che risultava piuttosto pesante,
scomodo e non dotato di cambio. Inoltre per disincentivare possibili tentativi
di furti, il secondo modello ̀e stato dotato di componenti di materiali vari dal
magnesio all’alluminio costruiti non in serie 3031 . Nel settembre del 2020 ̀e
stato presentato a Milano il nuovo modello a pedalata assistita, caratterizzato
da una colorazione bianca, arancione e nera 32 . La figura 1.7 mostra gli ultimi
modelli resi disponibili al noleggio.
Il servizio di Mobike ̀e interamente gestibile tramite applicazione dispo-
nibile per smartphone: al primo avvio dell’app viene registrato un metodo
di pagamento elettronico tramite il quale ricaricare il proprio portafoglio. Il
servizio prevede anche un sistema a punteggio, destinato ad aumentare con
le “buone pratiche” e a diminuire a causa di “pratiche scorrette” segnalate
nelle condizioni comprese nei termini di utilizzo del servizio. Il punteggio
prevede un massimo di 1.000 punti e un limite minimo di 81 sotto il quale
30
https://www.milanotoday.it/green/mobilita/bike-sharing-flusso-
libero.html
31
http://urban.bicilive.it/bike-sharing-milano/
32
https://www.comune.milano.it/-/mobilita-sostenibile.-sharing-oggi-
alle-17-presentazione-della-bici-elettrica-movi-by-mobike
15Figura 1.8: Due veicoli dell’azienda cinese vandalizzati
verranno applicate delle tariffe maggiorate 33 .
Le quote vengono calcolate a tempo, ma esistono anche i “Mobike Pass”,
ovvero dei pacchetti di abbonamenti che permettono agli utenti di effettuare
un numero illimitato di corse gratuite durante periodi di: 30, 90, 180 e 360
giorni. La durata massima di una corsa gratuita effettuata con un Mobike
Pass ̀e di 2 ore, dopodiché verrà applicata la tariffa normale vigente nell’area
in questione 34 .
Ofo
Ofo ̀e un’azienda di bike sharing cinese fondata nel 2014 a Pechino da sei stu-
denti universitari. Pensata inizialmente come servizio interno al campus, in
pochi anni ̀e diventata una bici per tutti raggiungendo mercati internazionali
35
. Nel 2017, grazie all’espansione del suo servizio in molti Paesi come gli
Stati Uniti, Singapore, Thailandia e numerose capitali europee, ha raggiunto
20 milioni di utenti registrati.
A Milano il servizio ̀e rimasto attivo da settembre del 2017 fino a marzo
del 2019, quando, in seguito a diversi illeciti rispetto alle norme in materia
di bike sharing in vigore a Milano, il servizio ha cessato la sua attività 3637 .
33
https://www.milanotoday.it/cronaca/vandali-bike-sharing-floating.html
34
https://thebestrent.it/scopri-milano-citta/bike-sharing-milano/
35
ww.agi.it/economia/startup_ofo_bike_sharing_alibaba-3628566/news/2018-
03-15/
36
https://www.comune.milano.it/-/bike-sharing.-veicoli-abbandonati-
raccolte-372-bici-di-ofo
37
https://it.wikipedia.org/wiki/Ofo_(azienda)
16Hanno fatto scalpore le decine di veicoli che, ormai abbandonati dall’azienda,
sono stati rinvenuti nei luoghi piu
̀ disparati, come mostrato nella figura 1.8.
Ofo, come Mobike, offriva un servizio di free-floating. Al suo arrivo nel
capoluogo lombardo il servizio contava 4.000 veicoli, riconoscibili dal carat-
teristico colore giallo, dotati di una tradizionale trasmissione con catena,
cambio a 3 velocità, ruote da 26” piene, luci e campanello 38 . Anche OFO
non prevedeva canone, costi di prenotazione o depositi cauzionali, si paga-
vano solo i minuti di utilizzo. La tariffazione era unica e non erano previsti
abbonamenti 39 .
38
https://www.dday.it/redazione/24236/le-bici-gialle-di-ofo-a-milano-la-
sblocchi-con-lapp-e-la-lasci-dove-vuoi
39
http://urban.bicilive.it/bike-sharing-milano/
17Capitolo 2
Acquisizione ed elaborazione
dei dati
Questo capitolo della tesi fornisce una panoramica sui dati utilizzati per
il progetto di analisi. All’inizio verrà fornita una descrizione degli “Open
Data”, il paradigma secondo cui sono resi disponibili molti dei dati utilizzati
per il progetto. Successivamente verranno introdotti gli strumenti software
usati per l’analisi. Infine si darà un’esaustiva spiegazione di tutto il processo
di elaborazione che ha permesso un’efficace analisi.
2.1 Open Data
“Gli Open Data sono dati che possono essere liberamente utilizzati, riutilizza-
ti e ridistribuiti da chiunque, soggetti eventualmente alla necessità di citarne
la fonte e di condividerli con lo stesso tipo di licenza con cui sono stati ori-
ginariamente rilasciati” - Open Definition 1
Gli Open Data sono dati messi a disposizione da Pubbliche Amministra-
zioni o aziende private accessibili a tutti. Si ̀e iniziato a parlare di Open Data
a partire dal 2009, quando diversi governi, specialmente durante le elezioni
americane, si sono impegnati ad aumentare il grado di “openness” dell’in-
formazione pubblica. Nonostante gran parte dei dati prodotti da organismi
pubblici avrebbe dovuto essere già da allora pubblica per legge, molti non
erano disponibili al pubblico o, nel caso lo fossero, erano pubblicati in un
formato tale da non consentirne l’accesso.
L’utilità di questi dati ̀e varia: permettono sia di verificare l’effettiva
correttezza delle attività delle amministrazioni pubbliche, ma anche di svi-
1
https://opendatahandbook.org/
18luppare nuove applicazioni o soluzioni utili alla collettività, con un grado
di possibilità pressochè immenso. Il concetto di Open Data si basa su tre
fondamentali principi, specificati nella “full Open Definition”:
Disponibilità e accesso: i dati devono essere disponibili nel loro com-
plesso, per un prezzo non superiore ad un ragionevole costo di riprodu-
zione, preferibilmente mediante scaricamento da Internet. I dati devono
essere disponibili in un formato utile e modificabile;
Riutilizzo e ridistribuzione, i dati devono essere forniti a condizioni
tali da permetterne il riutilizzo e la ridistribuzione. Ciò comprende la
possibilità di combinarli con altre basi di dati;
Partecipazione universale: tutti devono essere in grado di usare, riuti-
lizzare e ridistribuire i dati. Non ci devono essere discriminazioni né di
ambito di iniziativa né contro soggetti o gruppi. Ad esempio, la clau-
sola “non commerciale”, che vieta l’uso a fini commerciali o restringe
l’utilizzo solo per determinati scopi, ad esempio quello educativo, non
̀e ammessa.
Particolare attenzione deve essere anche prestata al formato in cui verran-
no pubblicati i dati: le informazioni devono essere presentate in un formato
strutturato, cioè avente una struttura esplicitata e “machine-readable”, allo
scopo di essere letti ed elaborati in modo semplice da un computer. I for-
mati di file più utilizzati per questo scopo sono XML (eXtensible Markup
Language) e JSON (JavaScript Object Notation).
Un altro aspetto fondamentale relativo agli Open Data ̀e dove essi ver-
ranno pubblicati: parallelamente alla diffusione delle informazioni su siti web
preesistenti, che ̀e il caso di molti enti pubblici, esistono numerosi servizi on-
line, denominati repository, che consentono la pubblicazione di Open Data in
modo semplice e accessibile a tutti. Questi ultimi diventano, con l’aumento
delle informazioni caricate, dei punti di raccolta dei dati, contribuendo alla
loro diffusione 2 .
Gli Open Data sono inoltre classificabili con un punteggio che va da 1
a 5 stelle, dove ogni livello include anche le caratteristiche dei precedenti.
Questa catalogazione ̀e stata ideata da Tim Berners-Lee e richiede che un
dataset, per rientrare nella definizione di Open Data raggiunga il punteggio
di almeno 3 stelle 3 . I requisiti sono:
2
https://opendatahandbook.org/
3
https://docs.italia.it/italia/daf/lg-patrimonio-pubblico/it/stabile/
modellodati.html
19 essere disponibili sul Web con una licenza aperta;
essere disponibili in un formato strutturato, anche se proprietario;
essere disponibili in un formato strutturato non proprietario;
includere un Uniform Resource Identifier, in modo da poter essere
indirizzabili sulla rete per una facile consultazione ed elaborazione;
essere classificabili come Linked Open Data, cioè possedere dei col-
legamenti che puntano ad altri dataset cosı̀ da incrociare quante piu
̀
informazioni possibili.
2.2 Software utilizzati
L’intero progetto di analisi dei dati del servizio BikeMi, che comprende l’ot-
tenimento, l’elaborazione e lo studio delle informazioni, ̀e stato svolto uti-
lizzando il linguaggio Python 4 e alcune librerie aggiuntive nell’ambiente di
sviluppo Anaconda 5 , oltre che, in minima parte, con l’aiuto dell’editor di
testo libero Notepad++ 6 e l’editor grafico open source GIMP 7 , che ha
permesso di migliorare la comprensibilità di alcune visualizzazioni prodotte
appositamente per l’elaborato.
Python ̀e un linguaggio di programmazione ad alto livello orientato agli
oggetti che, fin dalla sua creazione nel 1991, ̀e cresciuto in maniera esponen-
ziale negli utilizzi e, grazie alle molte librerie rese disponibili gratuitamente
e al supporto moltipiattaforma, ̀e diventato uno dei linguaggi piu ̀ utilizzati
per molti scopi, che spaziano dallo sviluppo web fino all’elaborazione di dati
e la loro analisi.
Per questo progetto Python ̀e stato integrato con alcune librerie, descritte
qui di seguito:
Pandas 8 : ̀e la libreria piu
̀ utilizzata in Python per l’analisi e l’ela-
borazione di dati, grazie alla sua semplicità e flessibilità, nonché alla
possibilità di supportare dataset di grandi dimensioni;
Matplotlib 9 : ̀e la libreria di Python che integra diversi tool per visua-
lizzare grafici, statici o animati, di diversi tipi;
4
https://www.python.org/
5
https://www.anaconda.com/
6
https://notepad-plus-plus.org/
7
https://www.gimp.org/
8
https://pandas.pydata.org/
9
https://matplotlib.org/
20 Numpy 10 : ̀e una delle librerie piu
̀ utilizzate in Python, che fornisce
al linguaggio di programmazione il supporto a matrici e vettori mul-
tidimensionali, nonchè una serie esaustiva di tool per gestire queste
strutture dati;
Beautiful Soup 11 : ̀e una libreria disponibile per Python che consente
il parsing e la facile navigazione in documenti formattati nei linguaggi
di markup HTML (HyperText Markup Language) e XML;
SciPy 12 : ̀e una libreria che integra in Python una serie di pacchetti
utili per il calcolo scientifcio e l’elaborazione dei segnali;
Datetime 13
: ̀e una libreria che consente la facile gestione delle date;
Locale 14
: ̀e una libreria che integra la gestione dei fusi orari;
Csv 15 : ̀e la libreria che consente la lettura e la scrittura di dataset in
formato CSV (comma-separated values);
Glob 16 : ̀e una libreria che consente la facile navigazione nel File
System.
L’intero codice sorgente utilizzato per effettuare l’elaborazione e l’analisi
dei dati per questo progetto ̀e disponibile nella repository su GitHub 17 .
2.3 Panoramica sui dati utilizzati
Per realizzare il progetto di analisi del servizio BikeMi sono stati utilizzati
diversi dataset e informazioni reperibili in rete:
Collezione di file HTML riportanti informazioni sul servizio BikeMi:
questi file, ordinati per data e ora di ottenimento, si riferiscono alla
pagina del sito web del servizio BikeMi, che mostra lo stato di ogni
stazione in tempo reale e sono stati accuratamente salvati con la stessa
frequenza per un arco temporale che va dall’inizio del 2017 alla fine di
10
https://numpy.org/
11
https://www.crummy.com/software/BeautifulSoup/
12
https://www.scipy.org/
13
https://docs.python.org/3/library/datetime.html
14
https://docs.python.org/3/library/locale.html
15
https://docs.python.org/3/library/csv.html
16
https://docs.python.org/3/library/glob.html
17
https://github.com/SuppaMan150/BikeMI
21marzo 2021. Da essi sono state poi estratte le informazioni utili tramite
un processo di parsing, in modo da consentire la facile analisi dei dati.
I dataset divisi per anno sono inoltre già disponibili in formato CSV
sulla repository Zenodo 18 [13, 14, 15, 16, 17, 18, 19, 20, 21, 22];
Dataset ufficiale sulle stazioni del servizio BikeMi: questo dataset, reso
disponibile e costantemente aggiornato dal Comune di Milano, reca in-
formazioni per tutte le stazioni disponibili fin dall’apertura del servizio.
Il dataset ̀e disponibile in formato CSV [10];
Dataset relativi alle informazioni atmosferiche: un insieme di dataset
reso disponibile gratuitamente dal sito web “ilmeteo.it” che, organizza-
to per mese e con informazioni nell’arco della giornata, fornisce le in-
dicazioni sulle condizioni atmosferiche della città di Milano. Il dataset
̀e disponibile in formato CSV [4];
Dataset ufficiali relativi all’apertura dell’Area C: i dataset che, divisi
per mese e con una frequenza di 30 minuti, forniscono informazioni sul-
l’apertura dell’Area C di Milano, con relative indicazioni sul numero di
veicoli transitati. I dati, resi disponibili dal comune di Milano, partono
dalla fine del 2016 e sono disponibili in diversi formati, tra cui il CSV
[9];
Informazioni di eventi sul territorio: indicazioni riguardanti eventi svol-
tisi sul territorio milanese. Le informazioni, non strutturate in origine,
sono state recuperate da diverse fonti per poi essere organizzate tramite
l’editor di testo Notepad++ nel formato strutturato CSV 19202122 .
2.4 Elaborazione dei dati BikeMi
I dati relativi all’utilizzo del servizio BikeMi, non disponibili apertamente,
sono stati immagazzinati per il periodo che va dall’inizio del 2017 a fine
marzo 2021 e sono stati estratti dalla pagina del servizio che mostra la mappa
interattiva delle varie stazioni e lo stato di ognuna di esse.
L’estrazione di informazioni passa, per prima cosa, da un’iniziale analisi
dei file grezzi, per capire se ci sono file problematici o malformati. Successi-
vamente ̀e stata effettuata l’operazione di “parsing” dei file, cioè l’estrazione
18
https://zenodo.org/
19
https://www.ilgiornale.it/news/fiera-1343125.html
20
https://www.residencedesenzano.it/calendario-fiera-milano/
21
https://www.citydoormilano.it/calendario-fiere-milano-2018.html
22
https://www.fieramilano.it/calendario.html
22di informazioni utili partendo da file formattati in modo formale, in questo
caso in linguaggio HTML. Successivamente i dati strutturati sono stati ela-
borati principalmente tramite la libreria “Pandas” e visualizzati, sotto forma
di rappresentazioni grafiche, utilizzando la libreria “Matlibplot”, che ̀e anche
integrata in Pandas.
2.4.1 Preparazione dei file grezzi
Il primo passo per procedere all’analisi degli utilizzi del servizio ̀e stato quello
di ottenere le informazioni. Dato che il servizio non condivide dati utili allo
scopo, ̀e stato fondamentale aver avuto a disposizione una collezione di file
HTML memorizzati con la frequenza di 5 minuti l’uno dall’altro, relativi alla
pagina che mostra la mappa delle stazioni del servizio e il relativo stato, che
include il numero di biciclette disponibili dei tre tipi (tradizionale, elettriche
ed elettriche con seggiolino per bambini), nonchè il numero di stalli liberi
disponibili per restituire un veicolo. Nonostante la disponibilità dei dataset in
formato CSV sulla piattaforma Zenodo, si ̀e preferito ricavare le informazioni
direttamente dai file grezzi forniti dal Professor Andrea Mario Trentini per
estrarre le informazioni nella loro completezza.
Grazie a queste informazioni si ̀e potuto poi ricostruire l’andamento degli
utilizzi del servizio. Una prima analisi dei file ha permesso l’individuazione
di errori nel salvataggio o momenti in cui il sito web era in disservizio. Data
l’alta frequenza di cattura dei file, quelli risultati problematici sono stati
ritenuti inutili e di conseguenza scartati. La tabella 2.1 mostra il numero
totale di file per ogni anno e i relativi file problematici scartati. Il 2021
riporta un numero molto minore di file rispetto agli altri anni: questo perchè
i dati sono stati raccolti solo fino al 5 marzo 2021, data in cui il servizio ̀e stato
sospeso per tre giorni, per il rinnovamento dei sito web e delle applicazioni
BikeMi 23 .
Anno Numero file totali Numero file problematici
2017 104.500 8
2018 104.061 111
2019 103.278 8
2020 104.892 5
2021 18.043 0
Tabella 2.1: Numero di file HTML considerati nell’analisi
23
https://milano.notizie.it/trasporti-milano/2021/03/05/bikemi-sospeso-
aggiornamento-sistema/
23Figura 2.1: I dati sullo stato di ogni stazione visibili sul sito ufficiale del servizio
2.4.2 Parsing
Una volta effettuata una prima scrematura dei dati, si ̀e potuto procedere al
parsing, cioè all’estrazione di informazioni utili e strutturate a partire dai file
formattati in HTML relativi al sito web del servizio BikeMi. Le informazioni
utili visibili sul sito web sono evidenziate nella figura 2.1.
La libreria BeautifulSoup si ̀e rivelata preziosa a questo scopo, perchè ha
permesso di scorporare dalla formattazione HTML le informazioni rilevanti,
in questo caso, il numero di stalli e di veicoli disponibili. I dati estratti sono
stati poi salvati in formato CSV, il formato standard per la memorizzazione
di tabelle di dati. Ciascuna riga del file, oltre a recare la data e l’ora in
cui l’informazione ̀e stata salvata, descrive lo stato della singola stazione in
quel momento. Di seguito ̀e presentata una parte del codice utilizzato per il
parsing:
1 info = BeautifulSoup ( info , " html . parser " )
2 info . thead . decompose ()
3 # estrazione ulteriore nome della stazione
4 station_name = info . find ( " strong " ) . text
5 bike_row = []
6 # estrazione dati uso biciclette da sottotabella HTML
7 for row in info . find_all ( " tr " ) :
8 bici_disponibili = row . find_all ( " td " ) [1]. text
9 stal li _d is po ni bi li = row . find_all ( " td " ) [2]. text
24bici
bici
elettriche stalli
data ora nome stazione bici disponibili elettriche
seggiolino disponibili
disponibili
disponibili
2021-01-01 00:00 1 - Duomo 9 0 1 23
2021-01-01 00:00 3 - Cadorna 1 7 5 2 7
2021-01-01 00:00 4 - Lanza 19 3 0 2
2021-01-01 00:00 5 - Universita
̀ Cattolica 5 4 0 15
2021-01-01 00:00 6 - San Giorgio 2 5 0 17
2021-01-01 00:00 7 - Santa Maria Beltrade 12 1 0 8
Tabella 2.2: Righe di esempio di un file CSV ottenuto dopo il parsing (le colonne
meno rilevanti sono state omesse per ottenere una corretta visualizzazione)
10 bike_row . extend ([ bici_disponibili , s ta ll i_ dis po ni bi li ])
11
12 row = [ formatted_date , icon , latitude , longitude ,
station_name ]
13 row . extend ( bike_row )
Porzione di codice 2.1: Parte del codice utilizzato per il parsing
Ogni anno ̀e stato cosı̀ organizzato in un file CSV separato, per una
facile importazione ed elaborazione. Alcune colonne ottenute dal parsing
sono state poi analizzate e successivamente scartate perchè contenevano in-
formazioni ridondanti o non necessarie, riducendo le colonne finali a: “da-
ta ora”, “stato stazione”, “latitudine”, “longitudine”, “nome stazione”, “bi-
ci disponibili”, “bici elettriche disponibili” e “stalli disponibili”. A partire
dagli ultimi mesi del 2018 ̀e stata inoltre aggiunta l’informazione relativa ai
veicoli elettrici provvisti di seggiolino per bambini, memorizzata con il no-
me “bici elettriche seggiolino disponibili”. Una piccola porzione dei dataset
elaborati ̀e mostrata nella tabella 2.2.
2.4.3 Verifica d’insieme dei dati
Terminato il parsing, ̀e stato possibile analizzare i dati nella loro interezza.
In questa fase si ̀e reso necessario scrivere del codice Python apposito per
effettuare la ricerca e la sostituzione di determinati termini dai nomi delle
stazioni salvate, in quanto, molto spesso, l’informazione sullo stato delle sta-
zioni, che comprende ad esempio la loro temporanea rimozione dal servizio
o l’apertura di una nuova postazione, veniva inserita nel campo relativo al
nome. Un esempio dei nomi temporanei, con la loro correzione, ̀e visibile
nella figura 2.3. Questa ricerca e sostituzione sono importanti, in quanto,
successivamente, i dati relativi alla singola stazione saranno raggruppati e,
avendo nomi diversi che identitificano la stessa postazione semplicemente in
diverso stato, l’analisi sarebbe potuta risultare falsata.
251 - Duomo -CHIUSA PROVVISORIAMENTE-
1 - Duomo
11 - Castello Acquario civico -CHIUSA PER OH BEJ OH BEJ
11 - Castello Acquario civico
19 - Italia - Santa Sofia - PROSSIMA APERTURA
19 - Italia - Santa Sofia
Tabella 2.3: Alcuni dei nomi temporanei utilizzati per descrivere lo stato delle
stazioni e il relativo nome sostituito evidenziato
2.4.4 Verifica dei dati mancanti
Avendo raggruppato le informazioni in file CSV, ̀e stato possibile procedere
all’importazione dei dataset tramite la libreria Pandas di Python. Ogni ana-
lisi di un dataset inizia dalla verifica dei valori mancanti [7, 8]. L’analisi sui
dataset non ha rilevato valori mancanti in nessuno dei file dei diversi anni,
risultato probabilmente ottenuto grazie alla precedente rimozione di file cor-
rotti che avrebbero potuto dare risultati non corretti in seguito al parsing.
Parte del codice utilizzato per eseguire l’operazione ̀e presentato di seguito:
1 # totale valori mancanti per colonna per colonna
2 print ( df . isnull () . sum () )
Porzione di codice 2.2: Parte del codice utilizzato per verificare la presenza di
valori mancanti
2.4.5 Calcolo dei valori di utilizzo del servizio
Le informazioni ottenute dal parsing non forniscono direttamente il numero
di utilizzi delle biciclette nelle varie stazioni. Tuttavia, data l’alta frequenza
con cui sono state salvate le informazioni, ̀e possibile ottenere questo dato,
con una buona affidabilità, sottraendo al numero di biciclette disponibili in
un preciso istante il quantitativo di quelle disponibili in precedenza: se il
numero di veicoli diminuisce si sarà verificato un numero di prelievi pari alla
differenza tra i due istanti cambiata di segno. Nel caso il numero aumenti,
segno della restituzione di almeno un veicolo, non verrà conteggiata nessuna
operazione. Parte del codice relativo a questa operazione ̀e visibile di seguito:
1 # differenza nel tempo con la colonna precedente (
invertendola di segno per avere l ’ utilizzo effettivo )
262 df [ " bici_usate " ] = df . sort_values ([ ’ nome ’ , ’ data ’ ]) . groupby ( ’
nome ’) [ ’ bici_disponibili ’ ]. diff () * -1
3 df [ " b i c i _ e l e t t r i c h e _ u s a t e " ] = df . sort_values ([ ’ nome ’ , ’ data ’ ])
. groupby ( ’ nome ’) [ ’ b i c i _ e l e t t r i c h e _ d i s p o n i b i l i ’ ]. diff () * -1
4
5 # azzeramento delle restituzioni
6 df [ " bici_usate " ] = df [ " bici_usate " ]. mask ( df [ " bici_usate " ]pubblico. In queste ore, in cui i valori sugli utilizzi sono bassi ma non nulli,
avviene parte del ribilanciamento dei veicoli nelle varie stazioni. Un’altra
parte del ribilanciamento avviene durante le ore diurne, in cui il servizio
̀e attivo e, sebbene non si possa distinguere quali sono i ritiri reali dai ritiri
dovuti al riposizionamento, durante la notte ̀e possibile azzerare il valore degli
utilizzi in modo da non conteggiarli e ottenere un’analisi ancora piu ̀ accurata.
Il servizio BikeMi ̀e attivo tutti i giorni dalle 07:00 all’01:00 di notte, con delle
eccezioni nel periodo estivo, in cui, nelle giornate di venerdı̀ e sabato, ̀e attivo
24/24h. Il dataset ottenuto dal precedente passaggio, che riporta il numero
degli utilizzi tra l’istante precedente e attuale, ̀e stato quindi filtrato in modo
da riportare i soli valori compresi nelle ore di attività del servizio. Per fare ciò
̀e stato necessario estrarre i valori di ora e mese dall’informazione di istante
di salvataggio, già presente nel dataset, per poi filtrarli secondo le necessità.
Parte del codice scritto per questa elaborazione ̀e visibile di seguito:
1 # conversione del valore di istante da stringa a data , in
modo da poter eseguire le operazioni di estrazione di ora
e mese in modo facile
2 df [ ’ day_of_week ’] = pd . to_datetime ( df [ ’ data ’] , format = ’ \% Y -\%
m -\% d \% H :\% M ’) . dt . strftime ( ’ \% A ’)
3
4 # salvataggio dei valori di ora e mese in colonne separate ,
in modo da filtrare agilmente e in modo efficiente
5 df [ ’ hour ’] = pd . to_datetime ( df [ ’ data ’ ]) . dt . strftime ( ’ \% H ’)
6 df [ ’ month ’] = pd . to_datetime ( df [ ’ data ’ ]) . dt . strftime ( ’ \% m ’)
7
8 # conversione dei valori di ora e mese in tipo numerico , in
modo da poter eseguire le operazioni di comparazione tra
numeri
9 df [ ’ hour ’] = pd . to_numeric ( df [ ’ hour ’ ])
10 df [ ’ month ’] = pd . to_numeric ( df [ ’ month ’ ])
11
12 # filtraggio secondo le condizioni necessarie
13 df = ( df [(( df [ ’ hour ’ ] >=7) | ( df [ ’ hour ’ ]2.4.7 Ricampionamento
La maggior parte delle analisi svolte di seguito vedranno fornire risultati cam-
pionati diversamente dall’alta frequenza con cui sono stati catturati. L’ela-
borazione dei dati ̀e stata tuttavia finora eseguita nell’ambito della frequenza
con cui sono stati salvati in origine i file grezzi, cioè 5 minuti. Un primo
ricampionamento, comune a tutte le successive operazioni di analisi, ̀e stato
eseguito secondo il periodo di un’ora. I dati sono stati quindi raggruppati ad
ore e sommati, in modo da riportare i valori di utilizzo nell’ambito di un’ora.
Attraverso l’operazione di ricampionamento, disponibile nella libreria Pan-
das, ̀e stato possibile effettuare questo calcolo: tutti gli utilizzi nell’ambito
dei 5 minuti sono stati sommati e raggruppati per ogni ora. Questa opera-
zione ha permesso inoltre di ridurre notevolmente le dimensioni dei dataset.
Parte del codice utilizzato ̀e visibile di seguito:
1 # raggruppamento per stazione e ricampionamento con frequenza
di un ’ ora
2 df = df . groupby ([ pd . Grouper ( key = ’ data ’ , freq = ’ 60 T ’) , ’ nome ’
]) . sum () [[ " bici_usate " , " b i c i _ e l e t t r i c h e _ u s a t e " ]]
Porzione di codice 2.6: Parte del codice utilizzato per il ricampionamento ad ora
2.5 Elaborazione degli altri dataset
Gli altri dati utilizzati nell’analisi, cioè il dataset ufficiale sulle stazioni del
servizio BikeMi, il dataset relativo alle informazioni atmosferiche, il dataset
ufficiale relativo all’apertura dell’Area C e le informazioni riguardanti gli
eventi sul territorio sono stati elaborati in modo da risultare compatibili con
i dataset BikeMi e permettere l’incrocio dei dati.
2.5.1 Dataset ufficiale sulle stazioni BikeMi
Questo dataset, disponibile in formato CSV dal Comune di Milano secon-
do il paradigma Open Data, mostra alcune informazioni utili relativamente
alle singole stazioni del servizio BikeMi. Le informazioni contenute nel da-
taset sono state particolarmente utili per verificare la crescita del servizio
relativamente al numero totale di stazioni. Una volta scaricato il dataset,
l’unica elaborazione necessaria, dopo un’attenta verifica semantica, oltre che
alla detezione di dati mancanti, ̀e stata quella di sistemare i valori del campo
“anno” di alcune stazioni, che indica l’anno in cui la stazione ̀e entrata in ser-
vizio: determinate righe, infatti, presentavano un valore mancante per quel
campo. Per altre righe, invece, il campo includeva un valore inesatto. Dopo
29un’attenta ricerca i valori sono stati corretti, in modo da attribuire un’alta
affidabilità alle informazioni contenute nel dataset.
2.5.2 Dataset relativi alle informazioni atmosferiche
Si tratta di diversi dataset messi a disposizione dal sito web “ilmeteo.it”,
che consente, per ogni città italiana, di scaricare le informazioni giornaliere,
divise per mesi, sulle condizioni atmosferiche del luogo scelto. L’unica par-
ticolare elaborazione degna di nota ̀e stata, ancora una volta, la verifica dei
dati mancanti, che ha messo in luce l’assenza di informazioni per un periodo
di circa tre mesi consecutivi, oltre che per pochi giorni distributi negli anni.
Mentre l’analisi per il primo caso ̀e stata evitata, nel secondo si ̀e preferito
procedere con l’imputazione dei dati mancanti, dove il valore sostituito ̀e l’in-
terpolazione dei primi valori esterni non mancanti piu ̀ vicini al dato assente.
L’operazione di interpolazione ̀e inclusa nella libreria Pandas 2425 .
I dataset, scaricabili divisi per mensilità, sono stati uniti in modo da
racchiudere le informazioni per l’intero anno di interesse. Di seguito ̀e visibile
una parte del codice utilizzato per effettuare l’unione dei dati mensili in un
unico dataset annuale:
1 # preparazione di due liste contenenti rispettivamente gli
anni e i mesi presi in esame
2 anni = [ " 2014 " , " 2015 " , " 2016 " , " 2017 " , " 2018 " , " 2019 " , " 2020
"]
3 mesi = [ " Gennaio " , " Febbraio " , " Marzo " , " Aprile " , " Maggio " , "
Giugno " , " Luglio " , " Agosto " , " Settembre " , " Ottobre " , "
Novembre " , " Dicembre " ]
4
5 # preparazione dell ’ header dei dataset uniti
6 header = [ ’ data_formattata ’ , ’ LOCALITA ’ , ’ DATA ’ , ’ TMEDIA C ’ ,
’ TMIN C ’ , ’ TMAX C ’ , ’ PUNTORUGIADA C ’ , ’ UMIDITA \% ’ , ’
VISIBILITA km ’ , ’ VENTOMEDIA km / h ’ , ’ VENTOMAX km / h ’ , ’
RAFFICA km / h ’ , ’ PRESSIONESLM mb ’ , ’ PRESSIONEMEDIA mb ’ , ’
PIOGGIA mm ’ , ’ FENOMENI ’]
7
8 # ciclo per tutti gli anni
9 for anno in anni :
10
11 # preparazione di un file CSV per contenere le
informazioni annuali
12 csv_f = open ( " meteo_elab / meteo_ " + anno + " . csv " , ’w ’ ,
newline = ’ ’ , encoding = ’utf -8 ’)
24
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.
interpolate.html
25
https://www.geeksforgeeks.org/python-pandas-dataframe-interpolate/
30Puoi anche leggere

















































