Università degli Studi di Padova - SIAGAS
←
→
Trascrizione del contenuto della pagina
Se il tuo browser non visualizza correttamente la pagina, ti preghiamo di leggere il contenuto della pagina quaggiù
Università degli Studi di Padova
Dipartimento di Matematica "Tullio Levi-Civita"
Corso di Laurea in Informatica
Progettazione ed implementazione di
un’interfaccia di esplorazione di eventi in
ambito process mining
Tesi di laurea triennale
Relatore
Prof. Alessandro Sperduti
Laureando
Andrea Deidda
Anno Accademico 2019-2020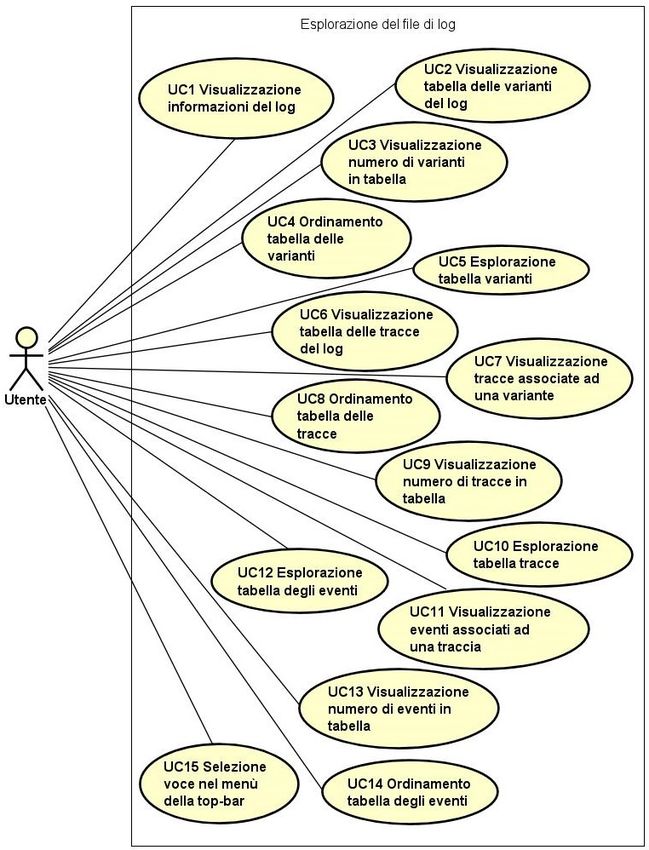
Andrea Deidda: Progettazione ed implementazione di un’interfaccia di esplorazione di eventi in ambito process mining, Tesi di laurea triennale, c Febbraio 2020.
Dedicato alla mia famiglia
Sommario
Il presente documento descrive il lavoro svolto durante il periodo di stage, della durata
di circa trecentonovanta ore, da parte del laureando Andrea Deidda, presso l’azienda
Siav S.p.a.
L’obiettivo principale era quello di implementare un software che realizzi delle fun-
zionalità di ispezione del log degli eventi e della rappresentazione visiva del modello
di processo sotteso dai dati in input. La soluzione integrerà anche delle funzionalità
di gestione di KPI di processo, permettendo anche di impostare soglie di guardia e
relative notifiche.
v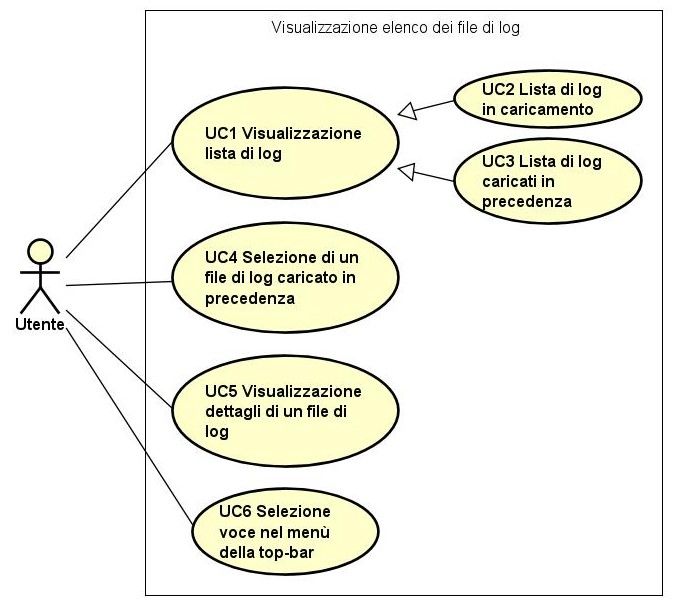
“Live a life you will remember”
— Avicii
Ringraziamenti
Innanzitutto, vorrei esprimere la mia gratitudine al mio tutor Daniele e al mio collega
Riccardo per avermi sopportato e supportato durante il periodo di stage.
Desidero ringraziare con affetto i miei genitori per avermi permesso di studiare in
questa università ed essermi stati vicini in ogni momento durante gli anni di studio.
Vorrei esprimere la mia gratitudine al Prof. Alessandro Sperduti, relatore della mia
tesi, per l’aiuto e il sostegno fornitomi durante la stesura del lavoro.
E per ultimi ma non meno importanti, ho desiderio di ringraziare tutte i miei amici
conosciuti durante gli anni universitari con cui ha passato dei bellissimi momenti.
Padova, Febbraio 2020 Andrea Deidda
vii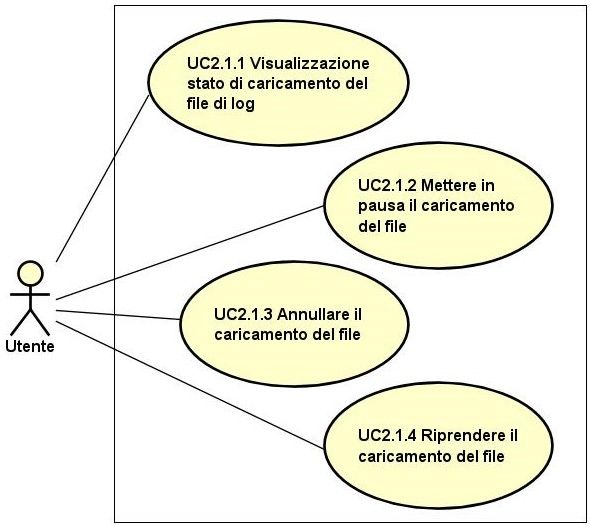
Indice
1 Introduzione 1
1.1 L’azienda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 L’idea . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.3 Pianificazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.4 Il prodotto ottenuto . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.5 Organizzazione del testo . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Descrizione dello stage 5
2.1 Introduzione al progetto . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Descrizione del prodotto . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Studio tecnologico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.1 Tecnologie utilizzate . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.2 Strumenti utilizzati . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3 Variazione degli obiettivi di stage . . . . . . . . . . . . . . . . . . . . . 7
3 Analisi dei requisiti 9
3.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.2 Casi d’uso . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.2.1 Attori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
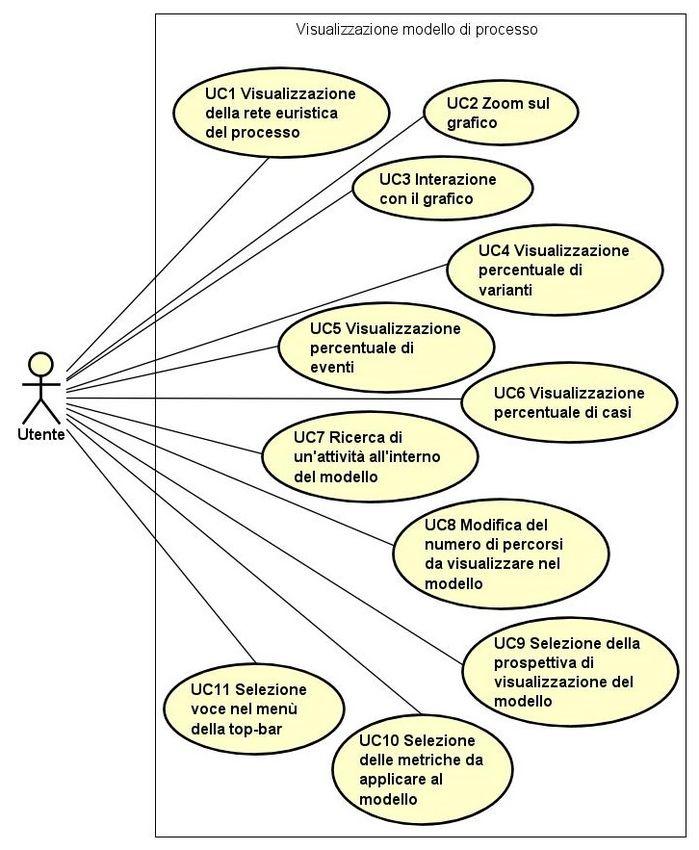
3.2.2 Pagina di visualizzazione del modello . . . . . . . . . . . . . . . 9
3.2.3 Pagina di visualizzazione elenco dei file di log . . . . . . . . . . 10
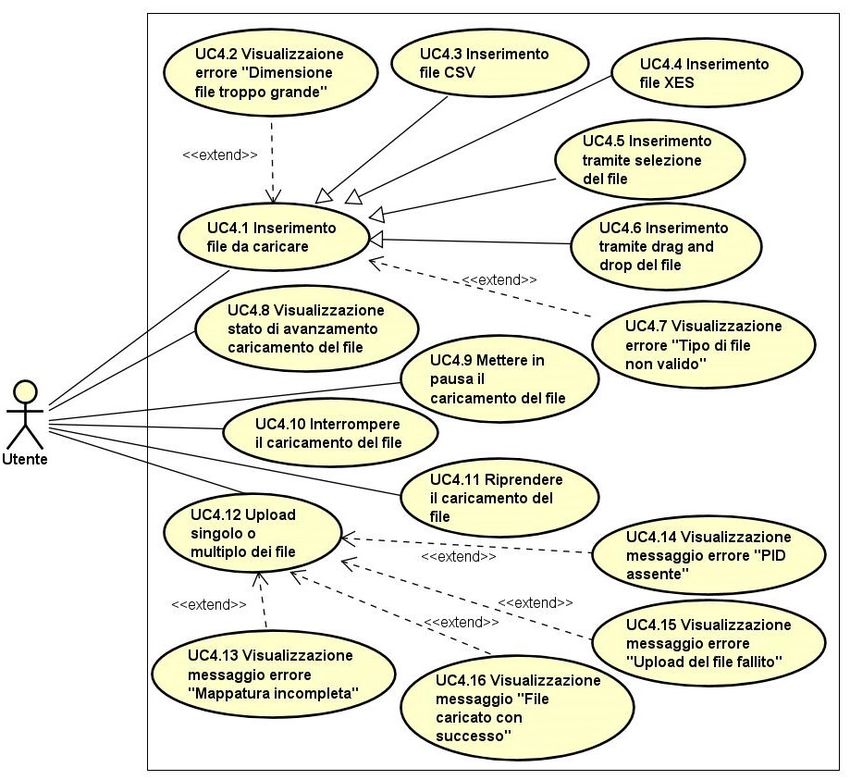
3.2.4 Pagina di caricamento dei file . . . . . . . . . . . . . . . . . . . 11
3.2.5 Pagina di esplorazione del file di log . . . . . . . . . . . . . . . 12
3.3 Classificazione dei requisiti . . . . . . . . . . . . . . . . . . . . . . . . 14
3.4 Tracciamento dei requisiti . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.4.1 Requisiti generali . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.4.2 Requisiti funzionali . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.4.3 Requisiti non funzionali . . . . . . . . . . . . . . . . . . . . . . 16
4 Progettazione 17
4.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.2 Architettura applicativo . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.2.1 Frontend . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.2.2 Backend . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.2.3 RESTful web services . . . . . . . . . . . . . . . . . . . . . . . 18
4.3 Pagina cases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.3.1 Informazioni del log . . . . . . . . . . . . . . . . . . . . . . . . 19
4.3.2 Ricerca tramite attributo . . . . . . . . . . . . . . . . . . . . . 19
ix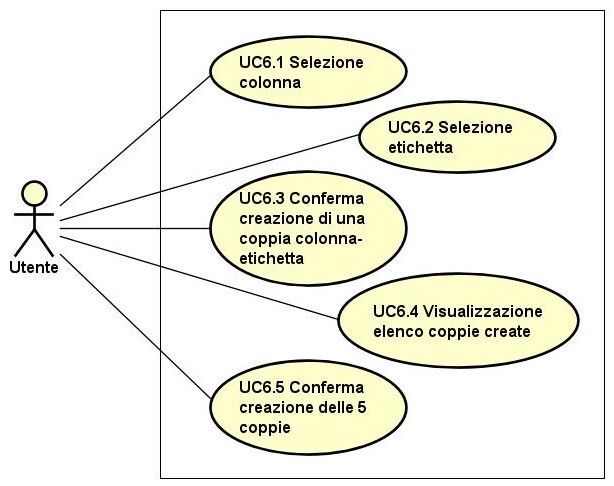
x INDICE
4.3.3 Tabella delle varianti . . . . . . . . . . . . . . . . . . . . . . . . 19
4.3.4 Tabella delle tracce . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.3.5 Tabella degli eventi . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.4 Pagina upload . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.4.1 Selezione producer id . . . . . . . . . . . . . . . . . . . . . . . . 20
4.4.2 Selezione dei file da caricare . . . . . . . . . . . . . . . . . . . . 20
4.4.3 Mappatura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.5 Lista dei servizi del backend . . . . . . . . . . . . . . . . . . . . . . . . 21
4.6 Documentazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5 Implementazione 25
5.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.2 Top-bar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.3 Pagina cases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.3.1 Servizio log . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.3.2 Tabelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5.3.3 Esplorazione delle tabelle . . . . . . . . . . . . . . . . . . . . . 27
5.3.4 Informazioni del file di log . . . . . . . . . . . . . . . . . . . . . 28
5.4 Pagina upload . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.4.1 Inserimento producer id . . . . . . . . . . . . . . . . . . . . . . 29
5.4.2 Form di caricamento dei file . . . . . . . . . . . . . . . . . . . . 30
5.4.3 Mappatura dei file . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.4.4 Gestione degli errori . . . . . . . . . . . . . . . . . . . . . . . . 31
5.5 Internazionalizzazione . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5.6 Diagramma delle classi . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
6 Verifica e validazione 35
6.1 Verifica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
6.2 Analisi dinamica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
6.2.1 Pagina di caricamento dei file . . . . . . . . . . . . . . . . . . . 36
6.2.2 Pagina di esplorazione del file di log . . . . . . . . . . . . . . . 36
6.3 Analisi statica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
6.4 Validazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
7 Conclusioni 39
7.1 Consuntivo finale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
7.2 SLOC dei metodi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
7.2.1 Classe UploadComponent . . . . . . . . . . . . . . . . . . . . . 40
7.2.2 Classe CasesComponent . . . . . . . . . . . . . . . . . . . . . . 40
7.2.3 Classe LogService . . . . . . . . . . . . . . . . . . . . . . . . . . 41
7.3 Copertura dei requisiti . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
7.3.1 Requisiti generali . . . . . . . . . . . . . . . . . . . . . . . . . . 41
7.3.2 Requisiti funzionali . . . . . . . . . . . . . . . . . . . . . . . . . 41
7.3.3 Requisiti non funzionali . . . . . . . . . . . . . . . . . . . . . . 42
7.4 Conoscenze acquisite . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
7.5 Valutazione personale . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
A Approfondimento dei casi d’uso 45
A.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
A.1.1 Attori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45INDICE xi
A.2 Elenco dei sottocasi d’uso . . . . . . . . . . . . . . . . . . . . . . . . . 45
A.2.1 Pagina di visualizzazione del modello . . . . . . . . . . . . . . . 46
A.2.2 Pagina di visualizzazione elenco dei file di log . . . . . . . . . . 48
A.2.3 Pagina di caricamento dei file . . . . . . . . . . . . . . . . . . . 53
A.2.4 Pagina di esplorazione del file di log . . . . . . . . . . . . . . . 59
B Guida per l’utilizzo di i18n 61
B.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
B.2 Aggiungere un nuovo termine . . . . . . . . . . . . . . . . . . . . . . . 61
B.3 Aggiungere un nuovo file di traduzione . . . . . . . . . . . . . . . . . . 62
B.4 Modificare una stringa con id autogenerato . . . . . . . . . . . . . . . 63
B.5 Modificare una stringa con id creato dall’utente . . . . . . . . . . . . . 63
Glossario 65Elenco delle figure
1.1 Funzionamento del process mining. . . . . . . . . . . . . . . . . . . . . 2
3.1 Use Case - Visualizzazione modello di processo. . . . . . . . . . . . . . 10
3.2 Use Case - Visualizzazione elenco dei file di log. . . . . . . . . . . . . . 11
3.3 Use Case - Caricamento dei file. . . . . . . . . . . . . . . . . . . . . . . 12
3.4 Use Case - Esplorazione del file di log. . . . . . . . . . . . . . . . . . . 13
4.1 Architettura applicativo. . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.2 Pagina di esplorazione del file di log. . . . . . . . . . . . . . . . . . . . 19
4.3 Pagina di caricamento dei file di log. . . . . . . . . . . . . . . . . . . . 20
5.1 Menù ad hamburger e titolo. . . . . . . . . . . . . . . . . . . . . . . . 25
5.2 Menù per la navigazione tra le pagine. . . . . . . . . . . . . . . . . . . 25
5.3 Nuova interfaccia di esplorazione dei file di log. . . . . . . . . . . . . . 26
5.4 Nuova interfaccia di caricamento dei file. . . . . . . . . . . . . . . . . . 29
5.5 Diagramma delle classi del frontend. . . . . . . . . . . . . . . . . . . . 33
A.1 Use Case 9 - Selezione della prospettiva di visualizzazione del modello. 46
A.2 Use Case 10 - Selezione delle metriche da applicare al modello. . . . . 47
A.3 Use Case 2 - Lista di log in caricamento. . . . . . . . . . . . . . . . . . 48
A.4 Use Case 2.1 - Visualizzazione file di log in caricamento. . . . . . . . . 49
A.5 Use Case 3 - Lista di log caricati in precedenza. . . . . . . . . . . . . . 50
A.6 Use Case 3.1 - Visualizzazione di un file di log caricato in precedenza. 51
A.7 Use Case 5 - Visualizzazione dettagli di un file di log. . . . . . . . . . . 52
A.8 Use Case 4 - Visualizzazione form di caricamento. . . . . . . . . . . . . 53
A.9 Use Case 6 - Mappatura sulle colonne. . . . . . . . . . . . . . . . . . . 56
A.10 Use Case 6.4 - Visualizzazione elenco coppie create. . . . . . . . . . . . 58
A.11 Use Case 1 - Visualizzazione informazioni del log. . . . . . . . . . . . . 59
xiiELENCO DELLE TABELLE xiii Elenco delle tabelle 3.1 Elenco dei requisiti generali. . . . . . . . . . . . . . . . . . . . . . . . . 14 3.2 Elenco dei requisiti funzionali. . . . . . . . . . . . . . . . . . . . . . . . 16 3.3 Elenco dei requisiti non funzionali. . . . . . . . . . . . . . . . . . . . . 16 4.1 Servizi nel backend. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 4.2 Descrizione dei servizi nel backend. . . . . . . . . . . . . . . . . . . . . 22 7.1 SLOC metodi della classe UploadComponent. . . . . . . . . . . . . . . 40 7.2 SLOC metodi della classe CasesComponent. . . . . . . . . . . . . . . . 41 7.3 SLOC metodi della classe LogService. . . . . . . . . . . . . . . . . . . . 41 7.4 Copertura dei requisiti generali. . . . . . . . . . . . . . . . . . . . . . . 41 7.5 Copertura dei requisiti funzionali. . . . . . . . . . . . . . . . . . . . . . 42 7.6 Copertura dei requisiti non funzionali. . . . . . . . . . . . . . . . . . . 42
Capitolo 1
Introduzione
1.1 L’azienda
Siav è una delle più importanti realtà italiane di sviluppo software e di servizi informatici
specializzata nella dematerializzazione e nella gestione documentale e nei processi
digitali. Si caratterizza per le competenze specialistiche maturate nella realizzazione
di progetti complessi e si distingue per la capacità di garantire con risorse proprie le
attività di analisi, implementazione, personalizzazione, formazione e supporto.
Con più del 20% di quota di mercato, oltre 3000 installazioni e un mercato trasversale
che comprende industria, servizi e Pubblica Amministrazione, Siav è la prima azienda
italiana nel settore dell’ECM (Enterprise Content Management) con soluzioni software
installate e utilizzate in oltre 70 paesi al mondo.
1.2 L’idea
L’informatizzazione delle attività produttive è in continuo sviluppo e ha raggiunto un
grado di diffusione tale che ogni azienda possiede almeno un sistema informativo a
supporto delle proprie attività, come sistemi CRM1 , con la conseguenza di registrare
una mole enorme di dati, che molto spesso sono sfruttati solo in minima parte.
Tali sistemi si basano sulla registrazione di una grande quantità di informazioni sia
descrittive (es. chi ha eseguito una certa azione) che temporali (es. timestamp
dell’azione eseguita) su basi di dati di varia natura.
Queste informazioni possono essere utilizzate, con adeguati algoritmi, per ricostruire
quali siano i processi che si svolgono all’interno dell’azienda.
Attraverso la loro rappresentazione, è possibile fornire dei modelli che possono essere
utilizzati per successive analisi ad alto livello, al fine di ottimizzare i processi aziendali.
Lo scopo del progetto è quello di implementare un tool di process mining che si occuperà
di estrarre informazioni a partire da una raccolta di registrazioni di eventi generati
da un sistema informativo, detto event log, e costruire il corrispondente modello di
processo. Questi file di event log possono essere in formato XES o CSV.
1 Customer Relationship Management
12 CAPITOLO 1. INTRODUZIONE
Figura 1.1: Funzionamento del process mining.
1.3 Pianificazione
Di seguito viene indicata la pianificazione inizialmente stabilita.
• Studio di fattibilità (48 ore): questa fase è suddivisa in due principali attività.
La prima attività consiste nello studio individuale del process mining con lo
scopo di acquisire delle conoscenze di base per poter iniziare il progetto di stage.
La seconda attività si concentrerà sullo studio vero e proprio della fattibilità di
realizzazione del frontend dell’applicativo;
• Analisi dei requisiti (30 ore): in questa attività verrà stilato un elenco di
requisiti che permettano il raggiungimento degli obiettivi prestabiliti.
Ogni requisito sarà identificato univocamente per evitare ambiguità;
• Progettazione architetturale (70 ore): durante questa attività verrà creata
una possibile architettura per poter realizzare le GUI (Graphic User Interface)
richieste;
• Implementazione del software (100 ore): in questa fase verrà scritto il codice
sulla base delle decisioni prese durante l’attività di progettazione. In particolare
verrà scritto il codice vero e proprio della GUI delle pagine web richieste;
• Verifica e validazione del software (24 ore): questa attività prevede la verifica
e la validazione del codice scritto tramite dei test. Ogni test verrà documentato
per tenere traccia dei risultati ottenuti;
• Documentazione (48 ore): in questa fase verrà scritta la documentazione di
supporto al progetto, nello specifico il manuale sviluppatore. Tale attività sarà
spalmata durante l’arco di tutto il progetto.1.4. IL PRODOTTO OTTENUTO 3
1.4 Il prodotto ottenuto
Le interfacce web realizzate consentono all’utente di effettuare il process mining su un
determinato event log al fine di migliorare i processi aziendali.
In particolare, la pagina upload consente di eseguire il caricamento di un file di log
in formato XES o CSV mentre la pagina cases ne consente l’esplorazione mostrando
all’utente i dati suddivisi per varianti, tracce ed eventi.
1.5 Organizzazione del testo
Il secondo capitolo descrive le tecnologie e gli strumenti utilizzati durante lo stage;
Il terzo capitolo descrive più in dettaglio il problema da risolvere e fornisce una
visione ad alto livello dei requisiti del progetto;
Il quarto capitolo descrive la progettazione dei vari componenti dell’applicativo;
Il quinto capitolo descrive l’implementazione dei vari componenti dell’applicativo;
Il sesto capitolo descrive le tecniche utilizzate per la verifica e la validazione del
prodotto con i relativi risultati;
Nel settimo capitolo viene scritta la conclusione;
L’appendice A contiene un approfondimento dei casi d’uso;
Nell’appendice B viene scritta una guida per l’utilizzo del tool i18n.
Riguardo la stesura del testo, relativamente al documento sono state adottate le
seguenti convenzioni tipografiche:
• Gli acronimi, le abbreviazioni e i termini ambigui o di uso non comune menzionati
vengono definiti nel glossario, situato alla fine del presente documento;
• Tutti i termini definiti nel glossario dei capitoli e degli appendici vengono
evidenziati come segue: API (Application Programming Interface);
• I termini in lingua straniera o facenti parti del gergo tecnico sono evidenziati con
il carattere corsivo.Capitolo 2
Descrizione dello stage
2.1 Introduzione al progetto
2.1.1 Descrizione del prodotto
A partire dal precedente prototipo Bipod, verrà realizzata l’interfaccia grafica di un
applicativo in grado di praticare il process mining a partire da un file di log caricato.
L’attività di stage ha come obiettivo la realizzazione dell’interfaccia grafica delle
seguenti pagine dell’applicativo:
• Pagina di esplorazione del log (../cases);
• Pagina di visualizzazione del modello di processo (../viewGraph);
• Pagina con l’elenco di tutti i log caricati in precedenza (../homepage);
• Pagina per il caricamento dei file di log (../upload).
2.2 Studio tecnologico
Di seguito viene data una panoramica delle tecnologie e degli strumenti utilizzati.
2.2.1 Tecnologie utilizzate
Framework Angular
Angular è una piattaforma open source per lo sviluppo di applicazioni web sviluppata
da Google. È scritto in typescript ed è considerato come l’evoluzione del framework
AngularJS.
Angular è fatto di componenti che possono interagire e scambiarsi dati tra loro. Un
componente è formato da tre file scritti con tre linguaggi diversi:
• Linguaggio HTML per creare la pagina web;
• Linguaggio CSS per lo stile della pagina web;
• Linguaggio typescript per gestire la logica del componente.
All’interno di un progetto scritto in Angular ogni componente viene identificato
univocamente tramite un selettore dichiarato all’interno del file typescript.
56 CAPITOLO 2. DESCRIZIONE DELLO STAGE Framework Material Design for Angular Material Design è un insieme di componenti pensati per essere usati con Angular. Ognuno di questi componenti possiede un proprio “stile” dichiarato all’interno del fra- mework e che può essere facilmente modificato utilizzando il linguaggio CSS all’interno di Angular. Bootstrap Boostrap è una raccolta di strumenti open source utilizzata per lo sviluppo di applica- zioni web basate su HTML, CSS e JS. Tale libreria mette a disposizione un sistema a griglia con cui è possibile posizionare i componenti di Angular nello schermo in modo da consentire la corretta visualizzazione delle pagina web su qualsiasi dispositivo. Git Software gratuito che effettua il versionamento del codice interagendo con un repository remoto situato su una determinata piattaforma web. Viene utilizzato per il versiona- mento del codice scritto durante la fase di implementazione per la comunicazione con il repository creato su GitLab. 2.2.2 Strumenti utilizzati ProM e Disco ProM e Disco sono dei software che offrono degli strumenti per effettuare il process mining su file di log visualizzando il rispettivo modello di processo. Inoltre a tale modello è possibile applicare dei filtri come ad esempio un filtro per visualizzare solo le attività eseguite in un determinato periodo di tempo oppure un filtro per visualizzare solo le attività eseguite da una determinata persona, etc. ProM, a differenza di Disco, consente anche di installare al suo interno dei plugin che gli consentono di svolgere altre operazioni con i file di log come ad esempio la conversione da file CSV in un file in XES. Questi software vengono entrambi utilizzati durante la fase di autoformazione, per comprendere meglio il funzionamento del process mining, e in fase di progettazione per avere un’idea di come implementare delle determinate funzionalità. Evernote Evernote è un’applicazione progettata per prendere appunti, organizzare, gestire le attività ed archiviarle. È suddiviso in note e all’interno di ciascuna nota è possibile scrivere del testo oppure inserire dei file multimediali (immagini, audio, video..). Viene utilizzato per la scrittura della documentazione durante tutto il periodo di stage. Visual Studio Code Editor open source per la scrittura del codice sviluppato da Microsoft. In questo editor è possibile integrare il software di versionamento Git ed effettuare il debug del proprio codice. Questo software verrà utilizzato per l’implementazione del codice in Angular per buona parte del periodo di stage.
2.3. VARIAZIONE DEGLI OBIETTIVI DI STAGE 7 IntelliJ IDEA Ambiente di sviluppo integrato utilizzato per il linguaggio di programmazione java sviluppato da JetBrains. Viene utilizzato per avviare il backend dell’applicativo e così verificare la correttezza del codice implementato. GitLab GitLab è una piattaforma web open source sviluppata da GitLab Inc che permette la gestione di un repository Git e di utilizzare il servizio di ticketing. Viene utilizzato in tutto l’arco di svolgimento dello stage per il versionamento del codice implementato. 2.3 Variazione degli obiettivi di stage Durante lo stage è stato constatato che gli obiettivi prestabiliti da raggiungere ri- chiedessero un effort maggiore rispetto a quello stimato all’inizio. Per questo motivo nella seconda metà del periodo di stage vengono eliminati alcuni obiettivi, ovvero la realizzazione dell’interfaccia grafica delle pagine homepage e viewGraph. All’interno di questo documento, nei capitoli §4, §5, §6 e §7 si parlerà solo della realizzazione e della verifica dell’interfaccia grafica delle pagine cases e upload.
Capitolo 3
Analisi dei requisiti
3.1 Introduzione
Nel presente capitolo verrà effettuata un’analisi dei requisiti ad alto livello descrivendo i
principali casi d’uso dell’applicazione ed illustrandone per ognuno il contesto di utilizzo,
gli attori coinvolti ed i requisiti principali.
3.2 Casi d’uso
Per lo studio dei casi di utilizzo del prodotto sono stati creati dei diagrammi.
I diagrammi dei casi d’uso sono diagrammi di tipo UML (Unified Modeling Language)
dedicati alla descrizione delle funzioni o servizi offerti da un sistema, così come sono
percepiti e utilizzati dagli attori che interagiscono col sistema stesso. Essendo il proget-
to finalizzato alla creazione di un tool per l’automazione di un processo, le interazioni
da parte dell’utilizzatore devono essere ovviamente ridotte allo stretto necessario.
Per questo motivo i diagrammi d’uso risultano semplici e in numero ridotto.
Per vedere un approfondimento sui casi d’uso si inviata il lettore ad andare nell’appen-
dice §A presente in questo documento.
3.2.1 Attori
Attori primari
• Utente: utente autenticato all’applicativo di process mining.
3.2.2 Pagina di visualizzazione del modello
Nella pagina di visualizzazione del modello, l’utente potrà visualizzare il modello
relativo ad uno specifico file di log. Nel menù posizionato nel lato destro dello schermo
l’utente potrà visualizzare i valori di varianti, eventi e casi in percentuale e selezionare
dei filtri da aggiungere al modello. Di seguito i filtri disponibili:
• Modifica del numero di percorsi da visualizzare;
• Modifica del livello di astrazione del grafico (Standard, Frequency o Performance);
910 CAPITOLO 3. ANALISI DEI REQUISITI
• Aggiunta di metriche al modello (media, mediana e somma).
Ogni volta che l’utente seleziona uno di questi filtri il grafico si aggiornerà automa-
ticamente. Inoltre sarà possibile fare zoom in e out nel grafico ed usufruire della
funzionalità di point-and-click per un’interazione con esso.
Figura 3.1: Use Case - Visualizzazione modello di processo.
3.2.3 Pagina di visualizzazione elenco dei file di log
In questa pagina l’utente potrà visualizzare i file di log caricati in precedenza e quelli
in fase di caricamento. Di questi ultimi si potrà interrompere, mettere in pausa e
riprendere il caricamento e visualizzarne lo stato di avanzamento.
Per quanto riguarda i log caricati in precedenza, l’utente avrà la possibilità di se-
lezionarne uno e visualizzarne i dettagli principali, una breve descrizione e vedere3.2. CASI D’USO 11
un’anteprima del modello di processo. Infine per i file già caricati c’è la possibilità di
aprirli, per visualizzare il modello associato, oppure di eliminarli.
Figura 3.2: Use Case - Visualizzazione elenco dei file di log.
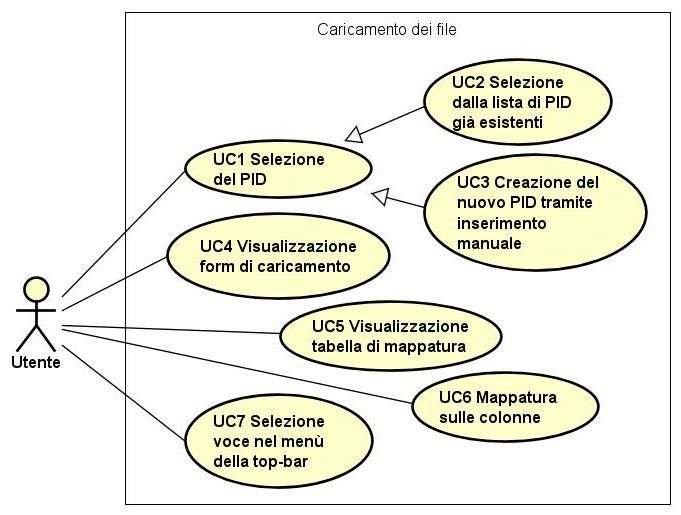
3.2.4 Pagina di caricamento dei file
L’utente per caricare un file, deve prima selezionare un PID (producer id) tra quelli già
esistenti o crearne uno nuovo che in automatico verrà aggiunto all’elenco dei PID già
esistenti. Alla selezione del PID compare un form che permette all’utente di scegliere
un file da caricare tramite selezione da file system o tramite drag and drop.
Viene consentito solo il caricamento di file in formato XES e CSV.
Nel momento in cui l’utente seleziona un file CSV da caricare, compare una tabella
che mostra un’anteprima dei dati che contiene il file e che da la possibilità all’utente di
mappare sulle colonne il file da caricare per una successiva conversione di quest’ultimo
in formato XES. Se non viene eseguita la mappatura del file, è presente una funzionalità
di auto-detect che si occupa di effettuare la mappatura in automatico.
Durante l’upload è possibile mettere in pausa, riprendere o interrompere il caricamento
del file.12 CAPITOLO 3. ANALISI DEI REQUISITI
Figura 3.3: Use Case - Caricamento dei file.
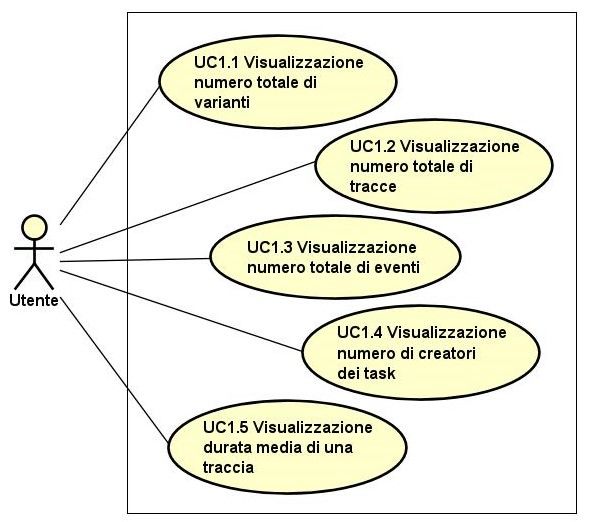
3.2.5 Pagina di esplorazione del file di log
La pagina di esplorazione del file di log permette all’utente di visualizzare i dati
contenuti all’interno di esso.
Questi dati vengono raggruppati in 3 tabelle: varianti, tracce ed eventi.
L’utente, selezionando una voce della tabella delle varianti, può vedere le tracce
associate a tale variante mentre selezionando una voce della tabella delle tracce si
possono vedere gli eventi associati a tale traccia. Inoltre l’utente può vedere, del log
corrente, le seguenti informazioni:
• Numero totale di varianti;
• Numero totale di tracce;
• Numero totale di eventi;
• Numero totale di persone che hanno creato un task;
• Tempo medio di esecuzione di una traccia.3.2. CASI D’USO 13
Figura 3.4: Use Case - Esplorazione del file di log.14 CAPITOLO 3. ANALISI DEI REQUISITI
3.3 Classificazione dei requisiti
Da un’attenta analisi dei requisiti e degli use case effettuata sul progetto è stata stilata
la lista dei requisiti in rapporto agli use case.
Sono stati individuati diversi tipi di requisiti e si è quindi fatto utilizzo di un codice
identificativo per distinguerli.
Il codice identificativo è così strutturato:
R[Ambito][Tipo][Priorità][Codice],
dove:
• [Ambito]: indica la pagina web del requisito. I possibili valori sono:
– U (Upload): il requisito è legato al funzionamento della pagina di caricamento
dei file di log;
– C (Cases): il requisito è legato al funzionamento della pagina di esplorazione
del log;
– H (Homepage): il requisito è legato al funzionamento della homepage;
– P (Process): il requisito è legato al funzionamento della pagina di visualiz-
zazione del modello di processo;
– G (Generale): il requisito è legato al funzionamento generale del sistema.
• [Tipo]: indica la tipologia di requisito. I tipi di requisito sono i seguenti:
– F (funzionale): indica che il requisito è inerente ad una funzionalità offerta
dal sistema;
– NF (non funzionale): il requisito si riferisce ad altre proprietà del sistema,
come vincoli, prestazioni o qualità.
• [Priorità]: indica l’importanza del requisito. I valori possibili sono i seguenti:
– O (obbligatorio): indica che il requisito è fondamentale e irrinunciabile per
la buona riuscita del progetto;
– D (desiderabile): indica che il soddisfacimento del requisito non è stretta-
mente necessario, ma comporterebbe un valore aggiunto riconoscibile;
– F (facoltativo): indica che l’implementazione del requisito non è vincolante
per la buona riuscita del progetto ed è negoziabile.
• [Codice]: numero progressivo ed univoco del requisito.
3.4 Tracciamento dei requisiti
Vengono di seguito riportati i requisiti che il sistema deve soddisfare.
3.4.1 Requisiti generali
Codice Descrizione
RGNFO1 Applicativo in inglese.
RGNFO2 Predisposizione dell’applicativo al multilingua.
Tabella 3.1: Elenco dei requisiti generali.3.4. TRACCIAMENTO DEI REQUISITI 15
3.4.2 Requisiti funzionali
Codice Descrizione
RHFO1 Visualizzazione elenco dei log già caricati.
RHFO2 Visualizzazione elenco dei log in caricamento.
RHFO3 Visualizzazione dettagli file di log selezionato.
Visualizzazione anteprima del modello di processo del file
RHFO4
di log selezionato.
RHFO5 Visualizzazione descrizione del file di log selezionato.
RHFO6 Visualizzazione stato di caricamento dei file.
RHFO7 Possibilità di annullare il caricamento di un file.
RHFO8 Possibilità di mettere in pausa il caricamento di un file.
RHFO9 Possibilità di riprendere il caricamento di un file.
RHFO10 Possibilità di aprire un file caricato.
RHFO11 Possibilità di eliminare un file caricato.
Possibilità di selezionare una voce presente nel menù della
RHFO12
top-bar.
RPFO1 Visualizzazione della rete euristica del processo.
Possibilità di modificare il numero di percorsi e di
RPFO2
visualizzare il nuovo modello.
RPFO3 Possibilità di fare l’export dello schema in un file XES.
Possibilità di selezionare la prospettiva di visualizzazione
RPFO4
del modello e di visualizzare il nuovo modello.
Possibilità di selezione delle metriche e di visualizzare il
RPFO5
nuovo modello.
RPFO6 Visualizzazione della percentuale di varianti.
RPFO7 Visualizzazione della percentuale dei casi.
RPFO8 Visualizzazione della percentuale di eventi.
RPFO9 Possibilità di ricercare un’attività all’interno del modello.
RPFO10 Possibilità di interazione con il grafico.
Possibilità di selezionare una voce presente nel menù della
RPFO11
top-bar.
Upload di un file CSV o XES salvato in locale tramite
RUFO1
form.
Upload multiplo di file CSV o XES salvati in locale tramite
RUFO2
form.
RUFO3 Selezione di un file XES o CSV da caricare.
Selezione di un file XES o CSV da caricare tramite drag
RUFD4
and drop.
Possibilità di selezionare un processo a cui aggiungere i
RUFO5 dati caricati e, nel caso in cui non esista, specificare il
nome.
RUFO6 Visualizzazione dello stato di caricamento dei file.
RUFO7 Possibilità di mettere in pausa il caricamento del file.
RUFO8 Possibilità di annullare il caricamento di un singolo file.
RUFO9 Possibilità di far riprendere il caricamento del file.
Visualizzazione dei dati del file CSV in forma tabellare
RUFO10
dopo la selezione.16 CAPITOLO 3. ANALISI DEI REQUISITI
Codice Descrizione
Visualizzazione dei dati del file CSV in forma tabellare
RUFO11
dopo la selezione tramite drag and drop.
Funzionalità di mappatura rispetto alle colonne della
RUFO12
tabella.
Possibilità di selezionare una voce presente nel menù della
RUFO13
top-bar.
Visualizzazione della lista di tutte le varianti e di alcune
RCFO1
statistiche ad esse relative.
Visualizzazione della lista di tutte le tracce e di alcune
RCFO2
statistiche ad esse relative.
Visualizzazione della lista delle tracce della variante
RCFO3
selezionata e di alcune statistiche ad esse relative.
Visualizzazione lista degli eventi che appartengono ad una
RCFO4
traccia selezionata e di alcune statistiche ad essi relativi.
RCFO5 Paginazione della tabella delle varianti.
RCFO6 Paginazione della tabella delle tracce.
RCFO7 Paginazione della tabella degli eventi.
RCFO8 Possibilità di ricerca per attributo nelle varie tabelle.
Visualizzazione delle informazioni generali relative al log
RCFO9
corrente.
Possibilità di cambiare pagina selezionando una voce
RCFO10
presente nel menù della top-bar.
Tabella 3.2: Elenco dei requisiti funzionali.
3.4.3 Requisiti non funzionali
Codice Descrizione
Visualizzazione messaggio di errore in caso di PID assente
RUNFD1
durante il caricamento.
Visualizzazione messaggio di errore nel caso in cui la
RUNFD2
mappatura del file sia incompleta.
Visualizzazione messaggio di errore se il file caricato non è
RUNFD3
in formato XES o CSV.
Visualizzazione messaggio di errore se il file caricato ha
RUNFD4
una dimensione troppo grande.
RUNFD5 Ordinamento della tabella sulle colonne.
RCNFO1 Visualizzazione del numero di varianti in tabella.
RCNFO2 Visualizzazione del numero di tracce in tabella.
RCNFO3 Visualizzazione del numero di eventi in tabella.
Possibilità di ordinamento su colonne nella tabella delle
RCNFO4
varianti.
Possibilità di ordinamento su colonne nella tabella delle
RCNFO5
tracce.
Possibilità di ordinamento su colonne nella tabella degli
RCNFO6
eventi.
Tabella 3.3: Elenco dei requisiti non funzionali.Capitolo 4
Progettazione
4.1 Introduzione
In questo capitolo verrà illustrata la fase di progettazione dell’applicativo, in particolare
delle pagine di esplorazione di un file di log (../cases) e di caricamento di un file di
log (../upload). La progettazione descritta in questo capitolo delle GUI (Graphic User
Interface) delle pagine web vene fatta basandosi sulle vecchie pagine (cases e upload)
del prototipo Bipod attualmente utilizzato dall’azienda.
Per la progettazione non sono stati imposti particolari vincoli da parte dell’azienda
quindi c’era un ampio margine di libertà nella scelta delle tecnologie da utilizzare.
Nonostante ciò tutte le scelte fatte, prima di passare alla fase successiva di codifica,
venivano discusse con il tutor aziendale.
4.2 Architettura applicativo
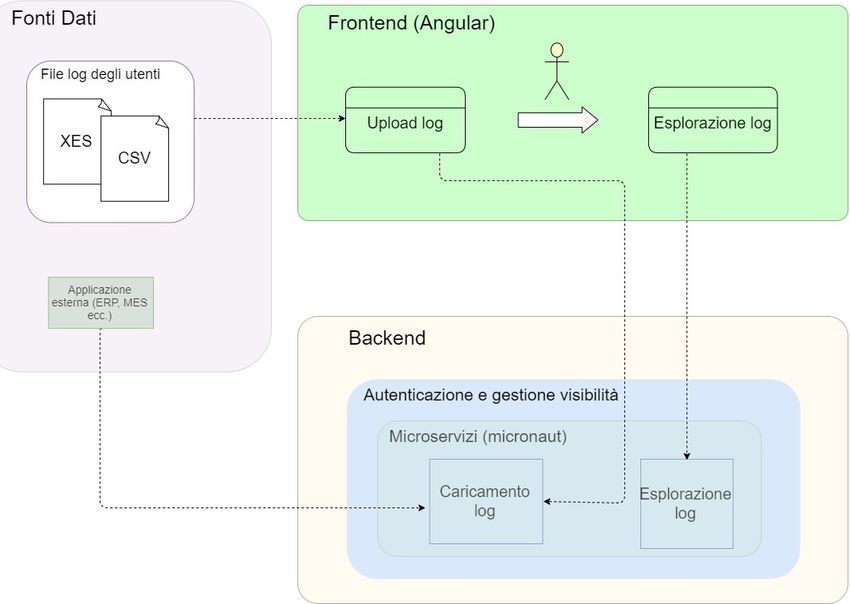
Prima di spiegare le tecniche di progettazione adottate è opportuno parlare dell’archi-
tettura che utilizza l’applicativo e alla quale l’interfaccia grafica da realizzare, dovrà
adattarsi.
4.2.1 Frontend
Come si può vedere dalla figura 4.1, tramite il frontend, l’utente potrà selezionare i file
da caricare e sarà possibile “esplorare” i file di log caricati e quindi visualizzare tutti i
dati contenuti in essi. Prima di poter usufruire di queste funzionalità è obbligatorio
effettuare l’autenticazione al sistema inserendo username e password.
4.2.2 Backend
In questo contesto il backend ha i seguenti compiti:
• Autenticare l’utente;
• Salvare i file di log caricati;
• Restituire al frontend i dati dei file di log per la sua esplorazione.
1718 CAPITOLO 4. PROGETTAZIONE
Figura 4.1: Architettura applicativo.
4.2.3 RESTful web services
Con RESTful si indica un insieme di servizi web che implementano l’architettura REST
(Representational State Transfer).
Quest’architettura viene utilizzata per la comunicazione tra frontend e backend per il
recupero delle informazioni (GET) e per la modifica (POST).
REST applica all’architettura client-server il paradigma Separation of Concerns (SoC)
che è un principio di progettazione che consiste nel separare il sistema in moduli distinti,
in modo tale che ognuno di essi si preoccupi di un certo compito.
I dati scambiati tra client e server sono contenuti all’interno di risorse rappresentate
in formato HTML, XML o JSON. La rappresentazione più utilizzata nelle implementa-
zioni REST è il JSON.
Di seguito possiamo vedere un esempio di file JSON:
{
" name ": " Francesco " ,
" surname ": " Bianchi " ,
" age ": 30
}
Listing 4.1: Esempio di file JSON.
4.3 Pagina cases
L’interfaccia di questa pagina permetterà di visualizzare il dato grezzo fornendo la
più fine granularità possibile (fino agli attributi del singolo evento). La funzionalità4.3. PAGINA CASES 19
prevede, dopo aver selezionato il log da analizzare, di esplorarlo visualizzando i suoi
dati nella pagina all’interno di 3 tabelle paginate come mostrato in figura 4.2.
Figura 4.2: Pagina di esplorazione del file di log.
4.3.1 Informazioni del log
All’inizio della pagina verranno mostrate le informazioni generali del log corrente, in
particolare:
• Numero delle tracce;
• Numero di eventi;
• Numero di creatori dei task;
• Durata media di una traccia;
• Numero totale di attività;
• Durata della deviazione standard di una traccia.
In questo stage verrà implementato solo il codice per visualizzare solo le prime quattro
voci del precedente elenco con l’aggiunta del numero totale di varianti come richiesto
dell’azienda.
4.3.2 Ricerca tramite attributo
Tramite il campo di ricerca per attributo, l’utente potrà ricercare e visualizzare tutte
quelle varianti, tracce ed eventi che hanno un determinato valore.
4.3.3 Tabella delle varianti
Conterrà tutte le possibili varianti del file di log selezionato più altre statistiche ad
esse relative. In questa tabella tutti i dati verranno paginati e sarà possibile effettuare
l’ordinamento degli elementi per colonna.20 CAPITOLO 4. PROGETTAZIONE
4.3.4 Tabella delle tracce
La tabella delle tracce conterrà, al primo caricamento della pagina, tutte le tracce del
file di log. Nel momento in cui l’utente seleziona una variante, tutte le tracce verranno
filtrate lasciando in tabella solo quelle relative alla variante selezionata.
In questa tabella tutti i dati verranno paginati e sarà possibile effettuare l’ordinamento
degli elementi per colonna.
4.3.5 Tabella degli eventi
La tabella degli eventi conterrà tutti gli eventi relativi ad una traccia selezionata.
In questa tabella tutti i dati verranno paginati e sarà possibile effettuare l’ordinamento
degli elementi per colonna.
4.4 Pagina upload
L’interfaccia di questa pagina permetterà di eseguire l’upload di un file di log sia in
formato XES che in formato CSV con dimensione massima all’ordine dei Gbyte.
Nel caso in cui il file da caricare fosse in formato CSV, sarà possibile effettuarne la
mappatura per poi convertirlo in formato XES a backend (figura 4.3).
Figura 4.3: Pagina di caricamento dei file di log.
4.4.1 Selezione producer id
Verrà data all’utente la possibilità di selezionare un producer id (PID) a cui aggiungere
il file caricato. In particolare si potrà sceglierne uno dalla lista dei PID già creati
oppure aggiungerne uno manualmente. Il file caricato verrà accodato automaticamente
agli altri file caricati in precedenza presenti all’interno del PID selezionato.
4.4.2 Selezione dei file da caricare
La funzionalità di upload può essere multipla ed ogni singolo processo di caricamento
potrà essere interrotto/ripreso e/o terminato nonché monitorato nella percentuale di4.5. LISTA DEI SERVIZI DEL BACKEND 21
avanzamento.
Verrà implementato in pagina un form che abbia queste funzionalità.
4.4.3 Mappatura
Nel caso di caricamento di file in formato CSV, sarà possibile vedere un’anteprima
del file visualizzando in forma tabellare i suoi dati e sarà possibile effettuare una
mappatura delle colonne per la creazione del log in formato standard XES.
Se l’utente decide di non effettuare la mappatura, il file potrà essere caricato ugualmente
in quanto esiste una funzionalità di auto-detect che si occupa di effettuare la mappatura
in automatico.
4.5 Lista dei servizi del backend
Di seguito verranno elencati i metodi presenti nel backend che le pagine dovranno
utilizzare per il recupero e l’invio dei dati.
Ad ogni metodo viene associato un codice univoco così strutturato:
M[Ambito][Codice],
dove:
• [Ambito]: indica la pagina web che dovrà utilizzare tale metodo. I possibili
valori sono:
– U (Upload): il metodo verrà utilizzato dalla pagina di caricamento dei file
di log;
– C (Cases): il metodo verrà utilizzato dalla pagina di esplorazione del log.
• [Codice]: numero progressivo ed univoco del metodo.
Codice Nome metodo Parametri di input
MU1 getPIDsFromHistoricalPath() String customer
MU2 upload() LinkedHashMap hashMap
String customer, String logId, int rangeMin, int
MC1 getVariantsByLog()
rangeMax, String sortColumn, String sortType
String customer, String logId, int rangeMin,
MC2 getTracesByLog()
int rangeMax
String variant, int rangeMin, int rangeMax,
MC3 getTracesByVariant()
String sortColumn, String sortType
String caseid, int rangeMin, int rangeMax,
MC4 getEventsByTrace()
String sortColumn, String sortType
MC5 getHeaderEventTable() String caseid
MC6 getLogInformation() String customer, String logId
MC7 getNumberOfVariantsByLog() String customer, String logId
MC8 getNumberOfTracesByLog() String customer, String logId
MC9 getNumberOfTracesByVariant() String variant
MC10 getNumberOfEventsByTrace() String caseid
Tabella 4.1: Servizi nel backend.22 CAPITOLO 4. PROGETTAZIONE
Codice Descrizione
MU1 Restituisce la lista di tutti i PID dell’utente.
Restituisce una risposta HttpResponse che indica
MU2
se l’upload è avvenuto con successo o meno.
Restituisce le varianti in ordine di occorrenza (o secondo
un certo ordine che può essere crescente o decrescente)
estraendo solo quelle del range incluso fra i due parametri
MC1 in input. Più in dettaglio, ritorna un file JSON contenente
una lista di dizionari dove ciascuno contiene come chiavi
ciascun attributo presente nel log e come valori i rispettivi
valori degli attributi.
Restituisce tutte le tracce del log in ordine di occorrenza
(o secondo un certo ordine che può essere crescente o
decrescente) estraendo solo quelle del range incluso fra
MC2 i due parametri in input. Più in dettaglio, ritorna un
file JSON contenente una lista di dizionari dove ciascuno
contiene come chiavi ciascun attributo presente nel log e
come valori i rispettivi valori degli attributi.
Restituisce le tracce della variante selezionata in ordine
di occorrenza (o secondo un certo ordine che può essere
crescente o decrescente) estraendo solo quelle del range
MC3 incluso fra i due parametri in input. Più in dettaglio,
ritorna un file JSON contenente una lista di dizionari dove
ciascuno contiene come chiavi ciascun attributo presente
nel log e come valori i rispettivi valori degli attributi.
Restituisce gli eventi della traccia selezionata in ordine
di occorrenza (o secondo un certo ordine che può essere
crescente o decrescente) estraendo solo quelle del range
MC4 incluso fra i due parametri in input. Più in dettaglio,
ritorna un file JSON contenente una lista di dizionari dove
ciascuno contiene come chiavi ciascun attributo presente
nel log e come valori i rispettivi valori degli attributi.
Restituisce una stringa che rappresenta l’intestazione per
la tabella degli eventi e delle impostazioni sulle funzionalità
MC5
delle colonne (ordinamento, ridimensionamento e larghezza
della colonna).
Restituisce un file JSON che contiene le informazioni
MC6
generali di un log.
MC7 Restituisce il numero totale di varianti del log.
MC8 Restituisce il numero totale di tracce del log.
MC9 Restituisce il numero di tracce della variante selezionata.
MC10 Restituisce il numero di eventi della traccia selezionata.
Tabella 4.2: Descrizione dei servizi nel backend.4.6. DOCUMENTAZIONE 23 4.6 Documentazione Nel corso di tutto lo stage verrà scritta la documentazione che spiegherà in maniera dettagliata lo svolgimento delle attività. Per la scrittura della documentazione verrà utilizzato il software Evernote come imposto dall’azienda.
Capitolo 5
Implementazione
5.1 Introduzione
In questo capitolo verrà spiegato il processo di implementazione delle interfacce grafiche
delle pagine web, dell’internazionalizzazione dell’applicativo e alla fine verrà mostrato
il diagramma delle classi finale.
5.2 Top-bar
Viene creata una top-bar da inserire all’inizio delle varie pagine per permettere all’utente
di spostarsi all’interno dell’applicativo di process mining.
Nella top-bar viene creato un menù ad hamburger, collocato a sinistra, con all’interno
un tasto per effettuare il logout dall’applicativo e a fianco viene scritto il titolo della
pagina corrente (figura 5.1). Nella parte destra della top-bar viene inserito un menù per
la navigazione tra le varie pagine dell’applicativo, composto da bottoni che contengono
delle icone realizzate usando il componente mat-icon di Angular Material (figura 5.2).
Per aiutare l’utente a capire a quali pagine sono collegate le varie voci del menù, viene
aggiunto un tooltip attivato al passaggio del cursore.
Per la scelta del colore da applicare alla top-bar e a tutte le pagine viene utilizzato
come riferimento un tool online.
Figura 5.1: Menù ad hamburger e titolo.
Figura 5.2: Menù per la navigazione tra le pagine.
2526 CAPITOLO 5. IMPLEMENTAZIONE
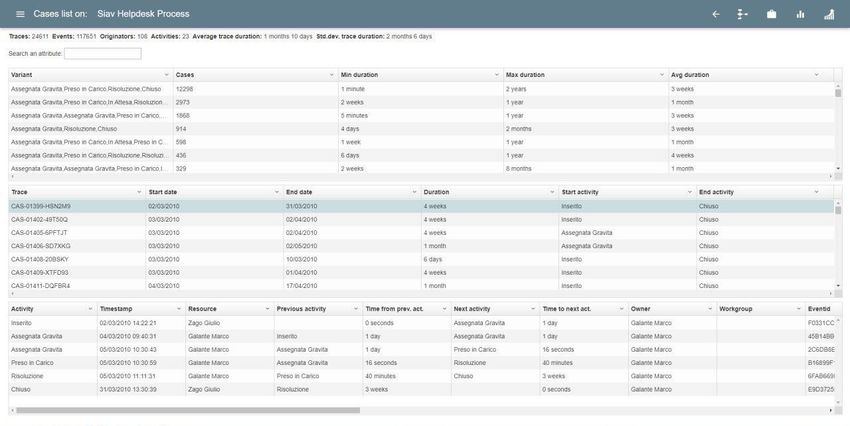
5.3 Pagina cases
Viene ora descritta in dettaglio la fase di implementazione della GUI (Graphic User
Interface) e delle funzionalità della pagina cases arrivando così ad ottenere un’interfaccia
grafica che permettesse all’utente l’esplorazione di un file di log (figura 5.3).
Per il posizionamento dei vari componenti nella pagina viene utilizzato il grid system
di Bootstrap.
Figura 5.3: Nuova interfaccia di esplorazione dei file di log.
5.3.1 Servizio log
Tutte le chiamate POST al server, necessarie alla pagina cases, vengono delegate ad un
servizio creato appositamente chiamato log. In questo modo la classe CasesComponent
si limita a chiamare i metodi del servizio creato che ritornano oggetti di tipo Observable
che contengono i dati richiesti.
Di seguito viene fatto un elenco dei metodi che troviamo nel servizio e del loro compito:
• getVariantsByLog(): questo metodo ritorna tutte le possibili varianti del log;
• getTracesByLog(): restituisce tutte tracce del log;
• getTracesByVariant(): questo metodo restituisce tutte le tracce del log di una
determinata variante;
• getEventsByTrace(): ritorna tutti gli eventi del log di una determinata traccia;
• getHeaderEventTable(): questo metodo ritorna l’intestazione della tabella degli
eventi;
• getLogInformation(): questo metodo ritorna le informazioni di un log;
• getNumberOfVariants(): questo metodo restituisce il numero di varianti del
log;
• getNumberOfTotalTraces(): ritorna il numero totale di tracce del log;5.3. PAGINA CASES 27
• getNumberOfTraces(): restituisce il numero di tracce del log che corrispondono
alla variante specificata;
• getNumberOfEvents(): questo metodo ritorna il numero di eventi del log che
corrispondono al case ID specificato.
Per i metodi getVariantsByLog(), getTracesByVariant(), getEventsByTrace() e
getTracesByLog(), l’oggetto restituito, contiene esattamente cento elementi dato che
ogni pagina delle tabelle può contenere al massimo cento elementi.
5.3.2 Tabelle
Per la creazione delle tre tabelle viene utilizzato il componente ag-Grid che permette
di disporre i dati in forma tabellare e fornisce molte funzionalità per la gestione dei
dati in essa contenuti.
Le tabelle delle varianti e delle tracce hanno una propria intestazione che è uguale per
tutti i file di log mentre l’intestazione della tabella degli eventi è formata da campi
fissi più dei campi aggiuntivi che variano in base al file da “esplorare”.
Per questo motivo, l’intestazione della terza tabella viene ricavata invocando il metodo
getHeaderTraceByLog(), del servizio log, che ritorna l’intestazione corretta da inserire
in tabella.
Al primo caricamento della pagina vengono inserite le intestazioni nelle prime due
tabelle e vengono invocati i metodi getVariantsByLog() e getTracesByLog(), del
servizio log, che ritornano rispettivamente tutte le varianti e tutte le tracce del file di
log che verranno poi inserite nelle corrispondenti tabelle. Quando l’utente seleziona
una voce della tabella delle varianti, le tracce vengono filtrate eliminando quelle non
inerenti alla variante selezionata. La stessa cosa accade se viene selezionata una traccia,
ovvero apparirà una terza tabella che conterrà solo gli eventi che compongono la traccia
selezionata.
Viene implementato l’ordinamento sulle colonne messo a disposizione dal componente
ag-Grid che effettua l’ordinamento di tutte le voci della pagina corrente della tabella
in base alla colonna selezionata.
5.3.3 Esplorazione delle tabelle
Ai lati delle tabelle vengono inseriti dei pulsanti per consentire all’utente l’esplorazione
delle tabelle. Nello specifico, quando l’utente clicca uno dei sei tasti, vengono svolte le
seguenti azioni:
1. Aggiornamento del numero attuale di pagina;
2. Calcolo dei nuovi range per recuperare il blocco di dati corretto;
3. Recupero dei nuovi dati da visualizzare invocando i metodi del servizio log come
segue:
• getVariantsByLog(): per ottenere i precedenti o successivi cento elementi,
rispetto alla pagina attuale, della tabella delle varianti;
• getTracesByLog(): per ottenere i precedenti o successivi cento elementi,
rispetto alla pagina attuale, della tabella delle tracce di tutto il file di log;28 CAPITOLO 5. IMPLEMENTAZIONE
• getTracesByVariant(): per ottenere i precedenti o successivi cento ele-
menti, rispetto alla pagina attuale, della tabella delle tracce di una variante
selezionata;
• getEventsByTrace(): per ottenere i precedenti o successivi cento elemen-
ti, rispetto alla pagina attuale, della tabella degli eventi di una traccia
selezionata.
4. Inserimento dei nuovi dati nella corrispondente tabella;
5. Calcolo del numero totale di pagine per decidere se abilitare o disabilitare i tasti
di esplorazione della tabella.
All’inizio di ogni tabella viene aggiunto il numero totale di voci presenti in tutte le
pagine di essa utilizzando i metodi getNumberOfVariants() e getNumberOfEvents()
rispettivamente per la tabella delle varianti e degli eventi.
Per ottenere il numero totale di voci della tabella delle tracce, vengono utilizzati i
metodi getNumberOfTotalTraces() e getNumberOfTraces() che restituiscono rispet-
tivamente il numero totale di tracce di un event log e il numero totale di tracce associate
ad una determinata variante.
Vengono implementati i controlli per abilitare e disabilitare i pulsanti per l’esplorazione
delle tabelle a seconda del numero di pagine della stessa:
• Se la tabella ha solo una pagina vengono disabilitati entrambi i pulsanti;
• Se la tabella ha un numero di pagine maggiore di 1 e l’utente si trova nella
prima pagina, il tasto di sinistra viene disabilitato mentre quello di destra viene
abilitato;
• Se l’utente è arrivato all’ultima pagina il pulsante di destra viene disabilitato
mentre quello di sinistra rimane abilitato.
Allo scopo di mantenere l’ordinamento delle voci delle tabelle anche durante la loro
esplorazione, vengono creati i metodi getSortModelVariantTable(),
getSortModelTraceTable() e getSortModelEventTable(), invocati nel momento in
cui l’utente applica l’ordinamento a una delle tre tabelle e che “catturano” il tipo di
ordinamento scelto e la colonna sulla quale viene fatto l’ordinamento.
Nel momento in cui l’utente cambia pagina e c’è un tipo di ordinamento impostato,
questo verrà applicato anche a quella nuova caricata.
L’ordinamento può essere di due tipi:
• asc: l’ordinamento è crescente;
• desc: l’ordinamento è decrescente.
5.3.4 Informazioni del file di log
All’inizio della pagina vengono mostrate le informazioni del file di log da esplorare, in
particolare:
• Numero di varianti;
• Numero di tracce;
• Numero di eventi;5.4. PAGINA UPLOAD 29
• Numero di creatori dei task;
• Durata media di una traccia.
Per ottenere tutte queste informazioni viene invocato il metodo getLogInformation(),
del servizio log, che recupera tutte le informazioni relative ad un determinato file di
log passato come parametro.
Per rendere più leggibile la durata media di una traccia viene creato il metodo
getFormatMillisecond() che riceve in input il tempo in millisecondi e restituisce una
stringa con il tempo rappresentato come segue: HHhr MMmin SSsec.
5.4 Pagina upload
Viene ora descritta in dettaglio la fase di implementazione della pagina upload arri-
vando ad ottenere un’interfaccia grafica che permettesse all’utente il caricamento e la
mappatura dei file di log (figura 5.4). Anche per questa pagina, per il posizionamento
dei componenti, viene utilizzato Bootstrap.
Figura 5.4: Nuova interfaccia di caricamento dei file.
5.4.1 Inserimento producer id
Per la scelta del producer id (PID) a cui aggiungere il file da caricare, abbiamo due
modalità:
• Selezione dall’elenco dei PID già esistenti;
• Creazione del nuovo PID tramite inserimento manuale.
Utilizzando il componente mat-select di Angular Material viene data la possibilità
all’utente di selezionare un PID. Il mat-select viene popolato con la lista di tutti i
PID, ottenuta effettuando una chiamata GET al backend ed invocando il metodo
getPIDsFromHistoricalPath() passandogli come parametro lo username dell’utente.
Per la seconda modalità di selezione viene creato un campo di input, a comparsa, in
cui l’utente può scrivere il nome del nuovo PID. Non appena l’utente seleziona un PID30 CAPITOLO 5. IMPLEMENTAZIONE
comparirà un form per consentire la selezione ed il caricamento dei file.
Dopo il caricamento, il file verrà accodato automaticamente ai log già esistenti nel file
system e verrà aggiornata la lista di PID contenuta nel mat-select.
5.4.2 Form di caricamento dei file
Per il form di caricamento dei file viene utilizzato il componente Essential JS 2
Uploader. Questo componente consente di effettuare anche il caricamento di più file
contemporaneamente ma in questo caso viene implementato solo il caricamento di file
singoli dato che sono stati riscontrati dei problemi durante i tentativi di caricamento
di file multipli. È possibile selezionare un event log da caricare cliccando sul tasto
“BROWSE” del form e scegliere il file da un determinato percorso oppure tramite drag
and drop (figura 5.4). Tutti i file da caricare devono avere una dimensione massima di
10GB e devono essere in formato XES o CSV.
Al momento dell’upload del file viene fatta una chiamata POST al server che invoca il
metodo upload() a cui vengono passati i seguenti dati addizionali:
• Nome utente;
• PID;
• Nome del file caricato;
• Formato del file caricato;
• Configurazione della mappatura dei file CSV.
Questi dati addizionali verranno utilizzati dal backend per inserire il file caricato nella
corretta cartella del PID e per la conversione del file da CSV a XES.
Vengono infine implementate le seguenti funzionalità offerte dal componente EJS 2
Uploader:
◦ Controllo del formato del file selezionato;
◦ Monitoraggio dello stato di avanzamento del caricamento del file;
◦ Messa in pausa del caricamento del file;
◦ Ripresa del caricamento del file;
◦ Interruzione del caricamento del file.
5.4.3 Mappatura dei file
Utilizzando il componente ag-Grid viene creata una tabella che contiene i dati del file
di log, che appare nel momento in cui si inserisce un file tramite selezione in formato
CSV nel form di caricamento. Si è tentato di implementare questa funzionalità anche
per l’inserimento tramite drag and drop purtroppo però si è scoperto che il componente
Essential JS possedeva un bug al proprio interno quindi si è deciso di permettere
all’utente la mappatura solo tramite selezione.
Per l’inserimento dei dati in tabella il componente ag-Grid richiedeva che questi fossero
inseriti sotto forma di elenco di array di dizionari come segue:Puoi anche leggere

















































